Exploring Evolutionary Fitness in Biological Systems Using Machine Learning Methods



Abstract
1. Introduction
2. Materials and Methods
2.1. Generic Framework to Estimate Evolutionary Fitness
- signifies the absence of v in the system at time
- signifies the presence of v in the system at time
- is a continuous function of v in
- is a continuous function of time;
- approaching zero by over time means the extinction of the strategy
- if at some time , then for all and
- is uniformly bounded by a constant, i.e., .
2.2. Predicting Patterns of Optimal DVM via Machine Learning
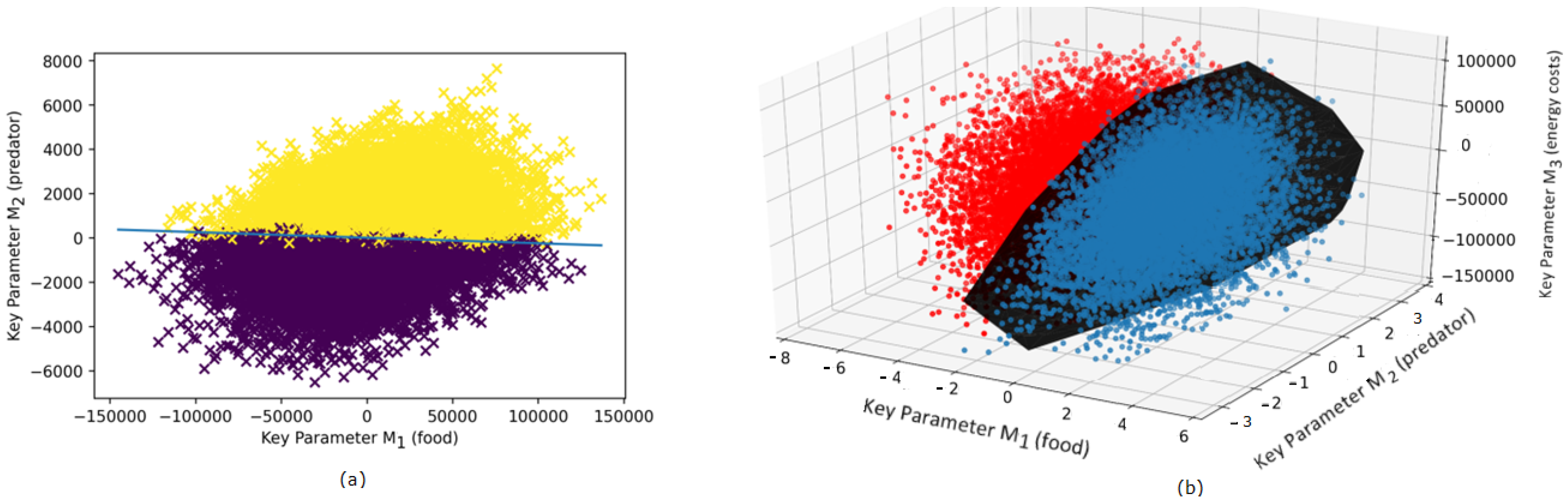
3. Results
3.1. Revealing Fitness in a Non-Structured Population
3.2. Revealing Evolutionary Fitness in a Structured Population
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
- Input box. Input two vectors v and w of vertical locations of zooplankton measured every 3 h (determining two different strategies of DVM). The components of these vectors are denoted by , with .
- Evaluation of values of the functions E, S, G as well as the velocity for both strategies v and w at the considered discrete points , with . We calculate the values of , , , , , , , .
- Computation of the key parameters via summation of components obtained in step 2 with appropriate signs: ; ; ; (for w the corresponding expressions will be similar).
- Calculation of the difference between the key parameters , .
- Computation of convolution of the differences with the corresponding weighting coefficients as .
- Implementation of a sigmoid function to the convolution found in step 5. Comparison with a fixed threshold value.
- Output box: interpretation of the obtained result as comparison of strategies by concluding if or .

Appendix B
References
- Darwin, C. On the Origin of Species by Means of Natural Selection, or Preservation of Favoured Races in the Struggle for Life; Harvard University Press: Cambridge, MA, USA, 1964. [Google Scholar]
- Birch, J. Natural selection and the maximization of fitness. Biol. Rev. 2016, 91, 712–727. [Google Scholar] [CrossRef] [PubMed]
- Dieckmann, U.; Heino, M.; Parvinen, K. The adaptive dynamics of function-valued traits. J. Theor. Biol. 2006, 241, 370–389. [Google Scholar] [CrossRef]
- Gabriel, W.; Thomas, B. Vertical migration of zooplankton as an evolutionarily stable strategy. Am. Nat. 1988, 132, 199–216. [Google Scholar] [CrossRef]
- Sandhu, S.K.; Morozov, A.; Kuzenkov, O. Revealing Evolutionarily Optimal Strategies in Self-Reproducing Systems via a New Computational ApproachJournal. Bull. Math. Biol. 2019, 81, 4701–4725. [Google Scholar] [CrossRef]
- Fisher, R.A. The General Theory of Natural Selection; Oxford University Press: Oxford, UK, 1999. [Google Scholar]
- Wright, S. Surfaces of selective value revisited. Am. Nat. 1988, 131, 115–123. [Google Scholar] [CrossRef]
- Gavrilets, S. Fitness Landscapes and the Origin of Species (MPB-41); Princeton University Press: Princeton, NJ, USA, 2004; Volume 41, p. 476. [Google Scholar]
- Sainmont, J.; Andersen, K.H.; Thygesen, U.H.; Fiksen, O.; Visser, A.W. An effective algorithm for approximating adaptive behavior in seasonal environments. Ecol. Model. 2015, 311, 20–30. [Google Scholar] [CrossRef]
- Clark, C.W.; Mangel, M. Dynamic State Variable Models in Ecology: Methods and Applications; Oxford University Press: Oxford, UK, 2000. [Google Scholar]
- Liu, S.H.; Sun, S.; Han, B.P. Viewing DVM via general behaviors of zooplankton: A way bridging the success of individual and population. J. Theor. Biol. 2006, 238, 435–448. [Google Scholar] [CrossRef] [PubMed]
- Han, B.P.; Strakraba, M. Control mechanisms of diel vertical migration: Theoretical assumptions. J. Theor. Biol. 2001, 210, 305–318. [Google Scholar] [CrossRef]
- Gyllenberg, M.; Metz, J.H.; Service, R. When do optimisation arguments make evolutionary sense? In The Mathematics of Darwin’s Legacy; Springer: Berlin/Heidelberger, Germany, 2011. [Google Scholar]
- Parvinen, K.; Dieckmann, U.; Heino, M. Function-valued adaptive dynamics and the calculus of variations. J. Math. Biol. 2006, 52, 1–26. [Google Scholar] [CrossRef]
- Klimenko, A.Y. Entropy and equilibria in competitive systems. Entropy 2014, 16, 1–22. [Google Scholar] [CrossRef]
- Fiksen, O.; Giske, J. Vertical distribution and population dynamics of copepods by dynamic optimization ICES. J. Mar. Sci. 1995, 52, 483–503. [Google Scholar]
- Kuzenkov, O.; Ryabova, E. Variational Principle for Self-replicating Systems. Math. Model. Nat. Phenom 2015, 10, 115–128. [Google Scholar] [CrossRef]
- Kuzenkov, O.A.; Kuzenkova, G.V. Optimal control of self-reproduction systems. J. Comput. Syst. Sci. Int. 2012, 51, 500–511. [Google Scholar] [CrossRef]
- Morozov, A.Y.; Kuzenkov, O.A. Towards developing a general framework for modelling vertical migration in zooplankton. J. Theor. Biol. 2016, 405, 17–28. [Google Scholar] [CrossRef]
- Gorban, A.N. Selection Theorem for Systems with Inheritance. Math. Model. Nat. Phenom. 2007, 2, 1–45. [Google Scholar] [CrossRef]
- Kuzenkov, O.A.; Ryabova, E.A. Limit possibilities of solution a hereditary control system. Diff. Equ. 2015, 51, 523–532. [Google Scholar] [CrossRef]
- Kuzenkov, O.; Morozov, A. Towards the construction of a mathematically rigorous framework for the modelling of evolutionary fitness. Bull. Math. Biol. 2019, 81, 1–22. [Google Scholar] [CrossRef]
- Karev, G.P.; Kareva, I.G. Replicator equations and models of biological populations and communities. Math. Model. Nat. Phenom. 2014, 9, 68–95. [Google Scholar] [CrossRef]
- Mohri, M.; Rostamizadehm, A.; Talwalkar, A. Foundations of Machine Learning; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Tax, N.; Bockting, S.; Hiemstra, D. A cross-benchmark comparison of 87 learning to rank methods. Inf. Process. Manag. 2015, 51, 757–772. [Google Scholar] [CrossRef]
- Liu, T.-Y. Learning to Rank for Information Retrieval. Found. Trends Inf. Retr. 2009, 3, 225–331. [Google Scholar] [CrossRef]
- Kuzenkov, O.; Kuzenkova, G. Identification of the fitness function using neural networks. Procedia Comput. Sci. 2020, 169, 692–697. [Google Scholar] [CrossRef]
- Kuzenkov, O.; Morozov, A.; Kuzenkova, G. Machine learning evaluating evolutionary fitness in complex biological systems. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; IEEE: Piscataway, NJ, USA, 2020; p. 1. [Google Scholar]
- Duh, K.K. Learning to Rank with Partially-Labeled Data; University of Washington: Seattle, WA, USA, 2009. [Google Scholar]
- Abiodun, O.I.; Jantan, A.; Omolara, A.E.; Dada, K.V.; Mohamed, N.A.; Arshad, H. State-of-the-art in artificial neural network applications: A survey. Heliyon 2018, 4, e00938. [Google Scholar] [CrossRef] [PubMed]
- Hays, G. A review of the adaptive significance and ecosystem consequences of zooplankton diel vertical migrations. Hydrobiologia 2003, 503, 163–170. [Google Scholar] [CrossRef]
- Buesseler1, K.; Lamborg, C.; Boyd, P.; Lam, P.; Trull, T.; Bidigare, R.; Bishop, J.; Casciotti1, K.; Dehairs, K.; Elskens, M.; et al. Revisiting carbon flux through the oceans twilight zone. Science 2007, 316, 567–570. [Google Scholar] [CrossRef] [PubMed]
- De Robertis, A. Size-dependent visual predation risk and the timing of vertical migration: An optimization model. Limnol. Oceanogr. 2002, 47, 925–933. [Google Scholar] [CrossRef]
- Klimenko, A.Y. Intransitivity in theory and in the real world. Entropy 2015, 17, 4364–4412. [Google Scholar] [CrossRef]
- Debreu, G. Continuity properties of Paretian utility. Int. Econ. Rev. 1964, 3, 285–293. [Google Scholar] [CrossRef]
- Jain, A.K.; Duin, R.P.W.; Mao, J. Statistical pattern recognition: A review. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 4–37. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberger, Germany, 2006. [Google Scholar]
- Kudo, M.; Sklansky, J. Comparison of algorithms that select features for pattern classifiers. Pattern Recognit. 2000, 33, 25–41. [Google Scholar] [CrossRef]
- Fuhr, N. Optimum polynomial retrieval functions based on the probability ranking principle. ACM Trans. Inf. Syst. 1989, 7, 183–204. [Google Scholar] [CrossRef]
- Kuzenkov, O.; Morozov, A.; Kuzenkova, G. Recognition of patterns of optimal diel vertical migration of zooplankton using neural networks. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar] [CrossRef]
- Kuzenkov, O. Information technologies of evolutionarily stable behavior recognition. In Proceedings of the International Conference on Modern Information Technology and IT Education, Moscow, Russia, 29 November–2 December 2018; Springer: Berlin/Heidelberger, Germany, 2018. [Google Scholar]
- Morozov, A.; Kuzenkov, O.; Arashkevich, E. Modelling optimal behavioural strategies in structured populations using a novel theoretical framework. Sci. Rep. 2019, 9, 15020. [Google Scholar] [CrossRef] [PubMed]
- Gorban, A.N. Equilibrium Encircling (Chemical Kinetics Equations and Their Thermodynamic Analysis); Nauka: Moscow, Russia, 1984; p. 226. (In Russian) [Google Scholar]
- Kuzenkov, O. The Cauchy problem for a class of nonlinear differential equations in a Banach space. Diff. Equ. 2004, 40, 23–32. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Coefficient | Analytical Model | Recognition of Pairs |
|---|---|---|
| 1.00 | 1.00 | |
| 0.6478 | 0.6332 | |
| −1.3472 | −1.3692 | |
| −1.4809 | −2.4853 | |
| −2.1204 | −2.0251 | |
| 0.1417 | 0.1436 | |
| −0.1417 | −0.1589 | |
| 4.1073 | 3.8467 | |
| 4.2301 | 4.0135 | |
| −4.2301 | −4.7115 | |
| −3.9474 | −3.3190 | |
| 4.2301 | 4.8529 | |
| 3.9474 | −3.9102 | |
| −4.7742 | −5.4857 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kuzenkov, O.; Morozov, A.; Kuzenkova, G. Exploring Evolutionary Fitness in Biological Systems Using Machine Learning Methods. Entropy 2021, 23, 35. https://doi.org/10.3390/e23010035
Kuzenkov O, Morozov A, Kuzenkova G. Exploring Evolutionary Fitness in Biological Systems Using Machine Learning Methods. Entropy. 2021; 23(1):35. https://doi.org/10.3390/e23010035
Chicago/Turabian StyleKuzenkov, Oleg, Andrew Morozov, and Galina Kuzenkova. 2021. "Exploring Evolutionary Fitness in Biological Systems Using Machine Learning Methods" Entropy 23, no. 1: 35. https://doi.org/10.3390/e23010035
APA StyleKuzenkov, O., Morozov, A., & Kuzenkova, G. (2021). Exploring Evolutionary Fitness in Biological Systems Using Machine Learning Methods. Entropy, 23(1), 35. https://doi.org/10.3390/e23010035