A Review of Intelligent Fault Diagnosis for High-Speed Trains: Qualitative Approaches





Abstract
1. Introduction
- Gradation. The structure of high-speed trains has several levels, including train level, system level, subsystem level, and component level. Thus, referring to gradational structure of trains, their faults and symptoms have similar features [21].
- Confusion. Aiming at complex system with the high structure coupling, the relationship among different fault characteristics is complicated. When fault occurs, factors, like redundancy and relevance, reflecting on these characteristics should be considered [22].
- Propagation. When a fault appears in systems, it is a high probability with the phenomenon of causing other systems or subsystems to fail at the same time [23].
- Uncertainty. The occurrence of faults in high-speed trains is often random. Moreover, there are still several uncertainties under the following situations, such as monitoring process of measurement data, transformation in external operation environment, and so on [24].
- (1)
- The first aim of this paper is to deliver a report about the detailed structure of high-speed trains (including their common fault types and core systems) and then to provide researcher with the diagnostic objective suitable for the FD tasks of high-speed trains.
- (2)
- The second focus of this paper is to detail the extraction path of diagnostic knowledge, where extraction rules are significant for building the high-performing knowledge base (KB). It is preparation work for using qualitative IFD methods to achieve FD proposes for high-speed trains.
- (3)
- The third attempt of this paper is, by reviewing the research work of qualitative techniques and surveying the emerging techniques, to summarize qualitative IFD techniques from new perspectives.
- (4)
- The final attention of this paper is, by enumerating the limitations and future investigations of qualitative IFD techniques, to inspire new research ideas for researchers and engineers.
2. Background
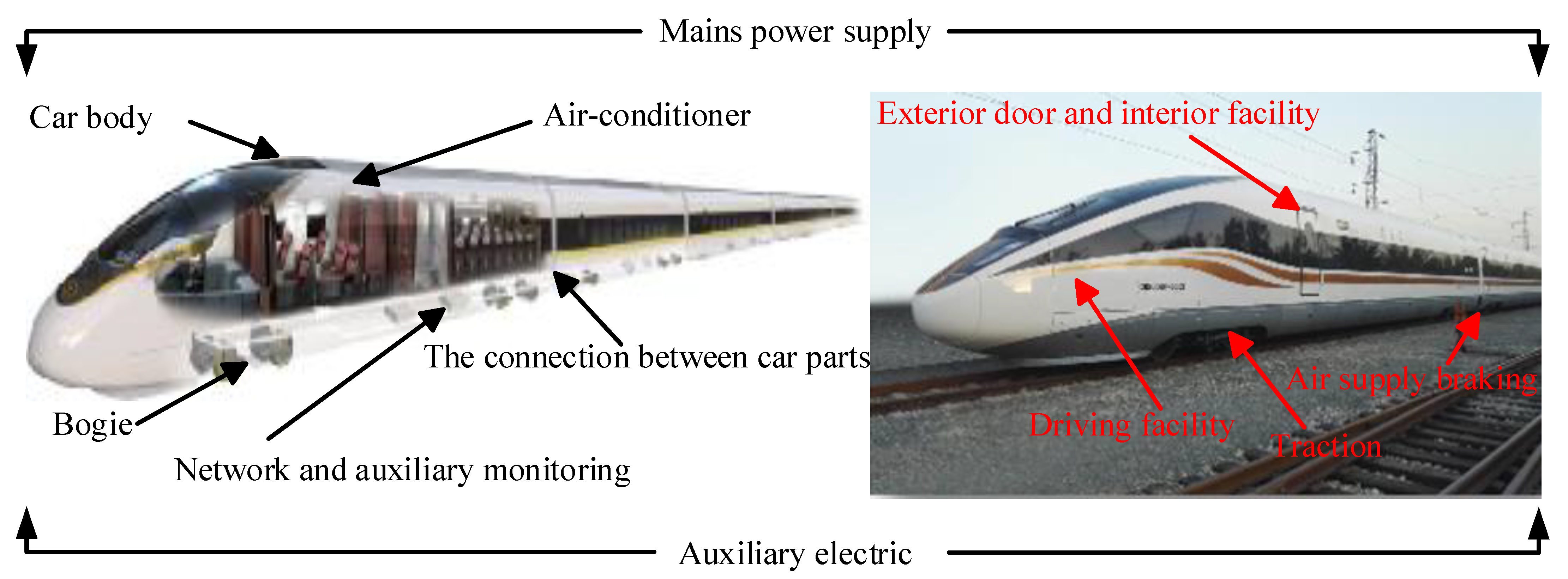
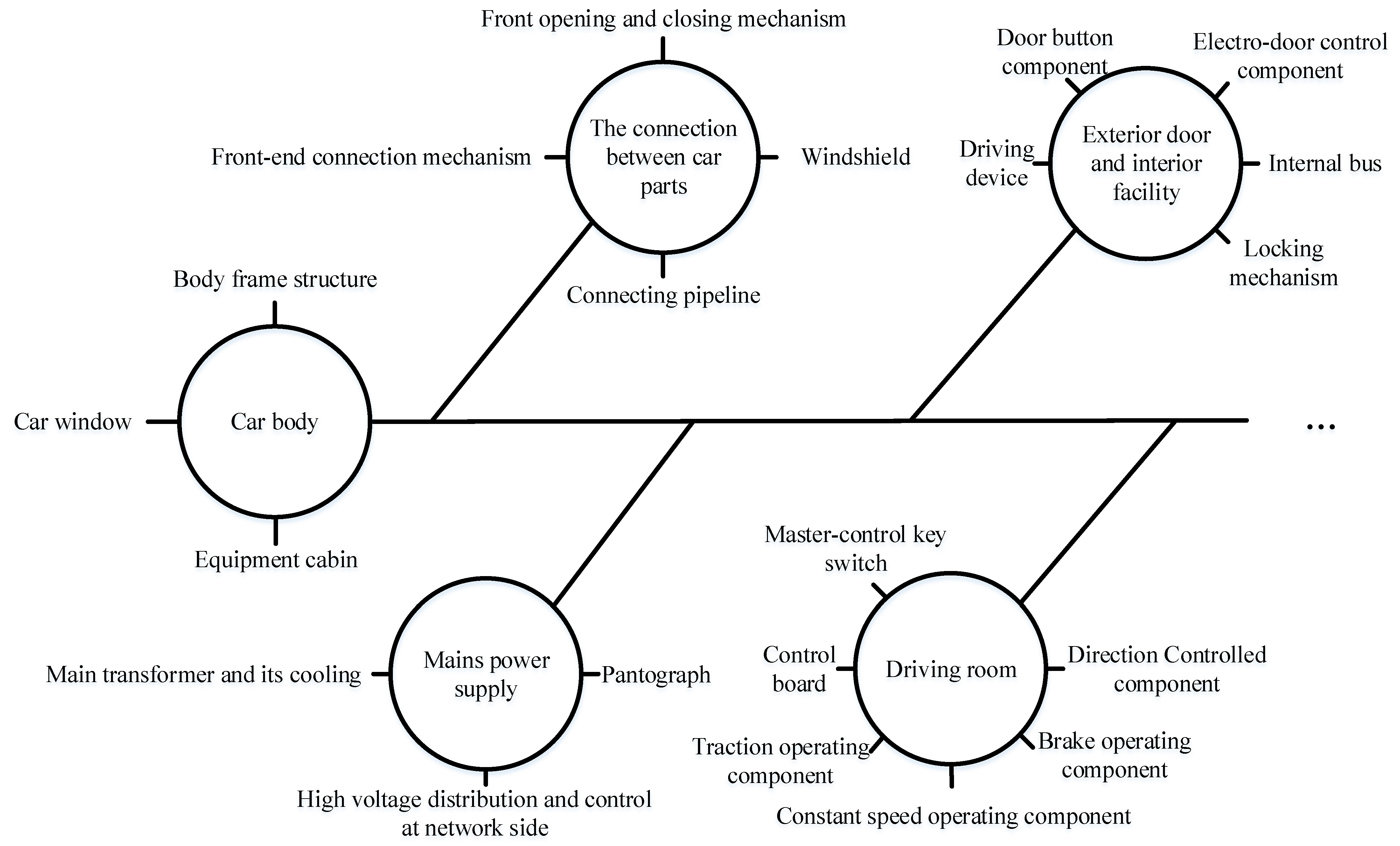
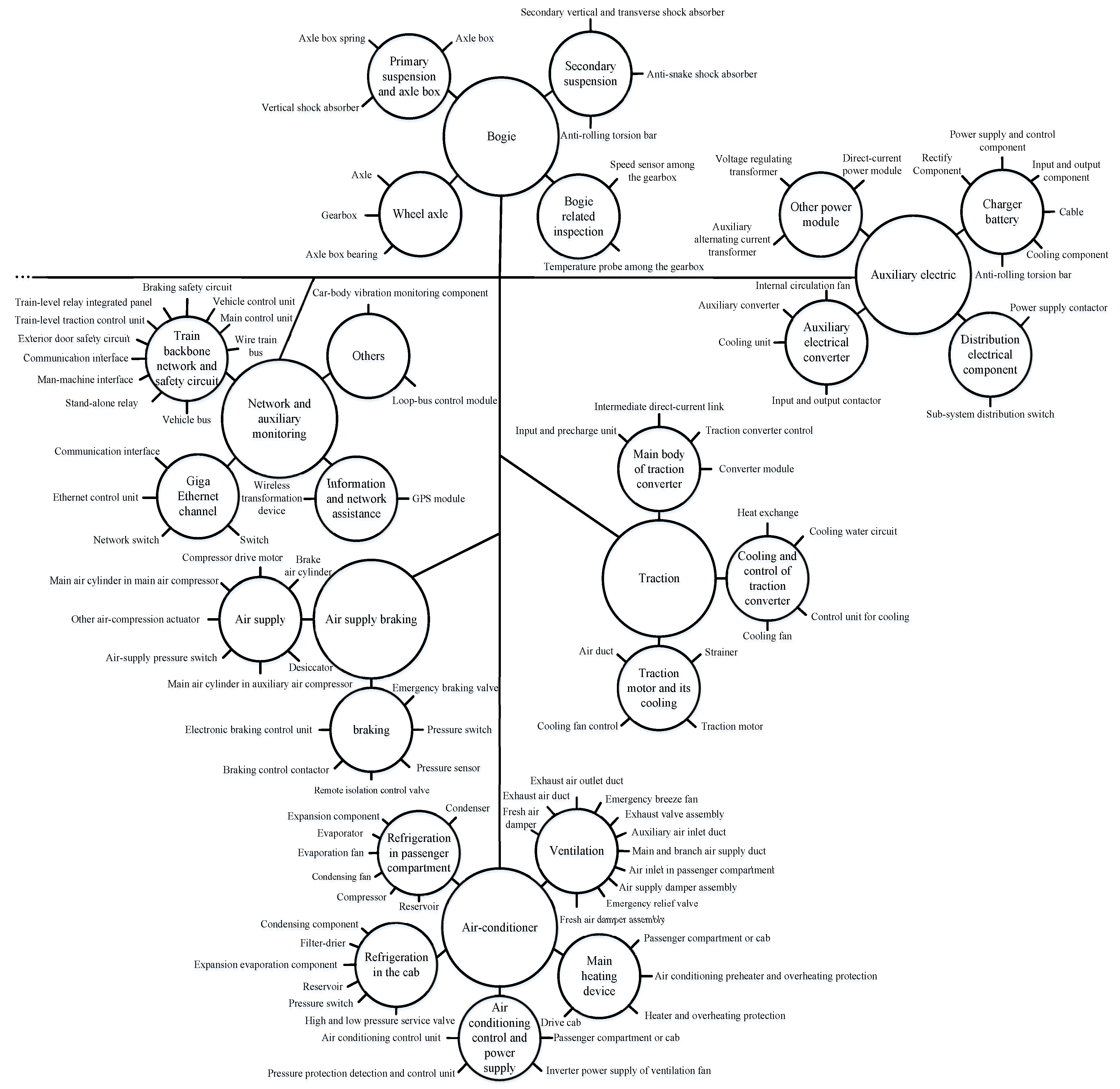
2.1. High-Speed Trains
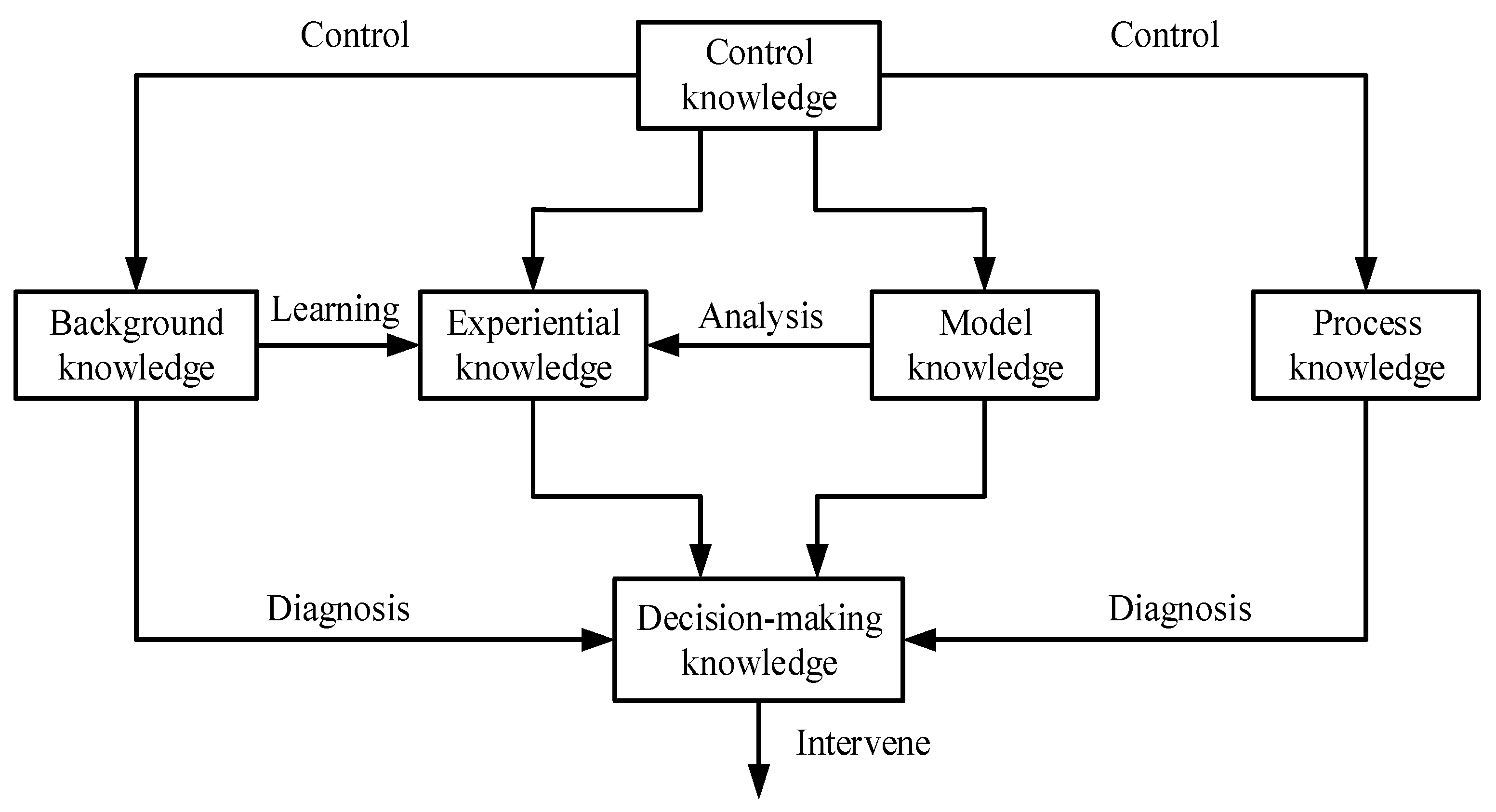
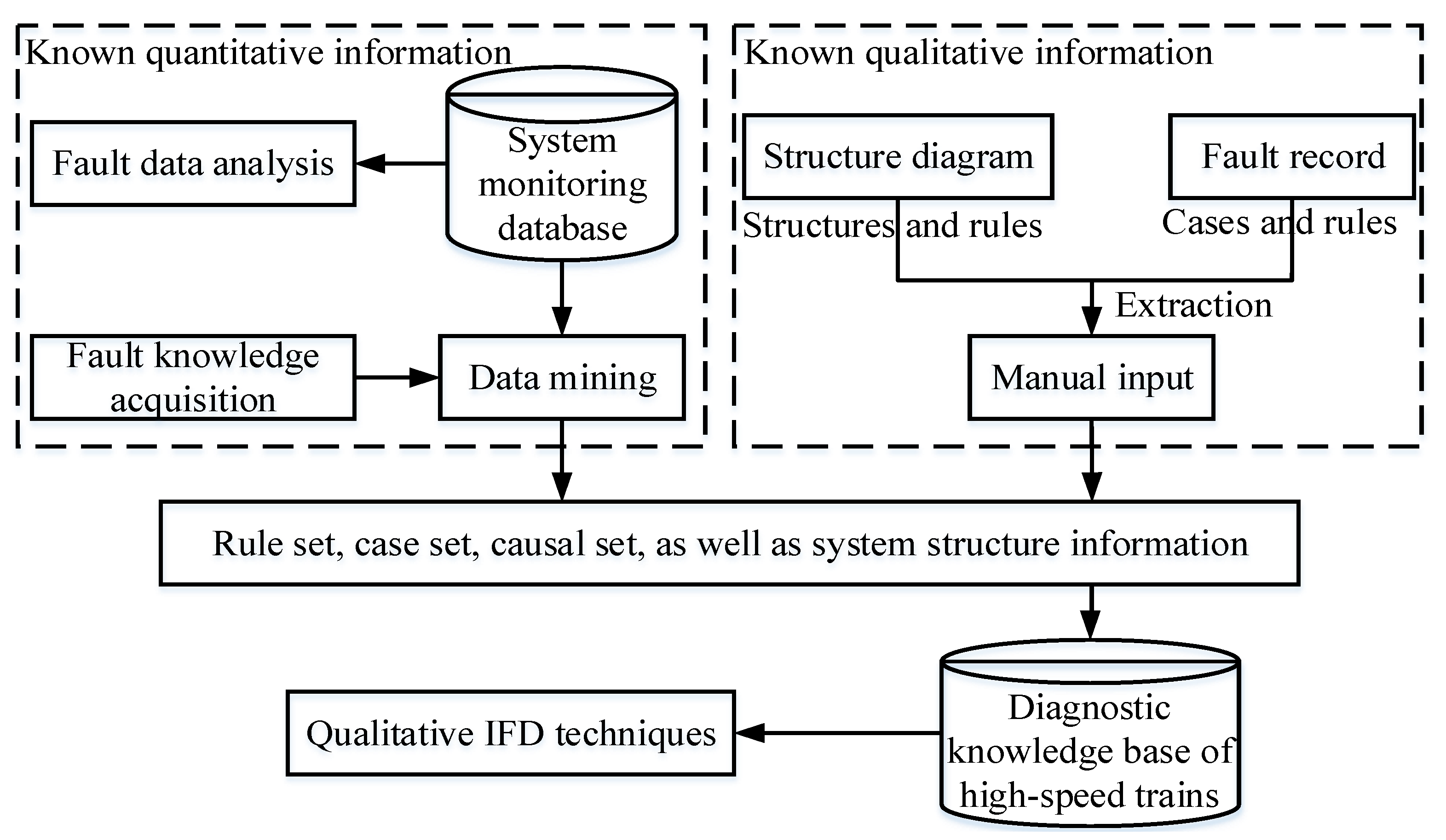
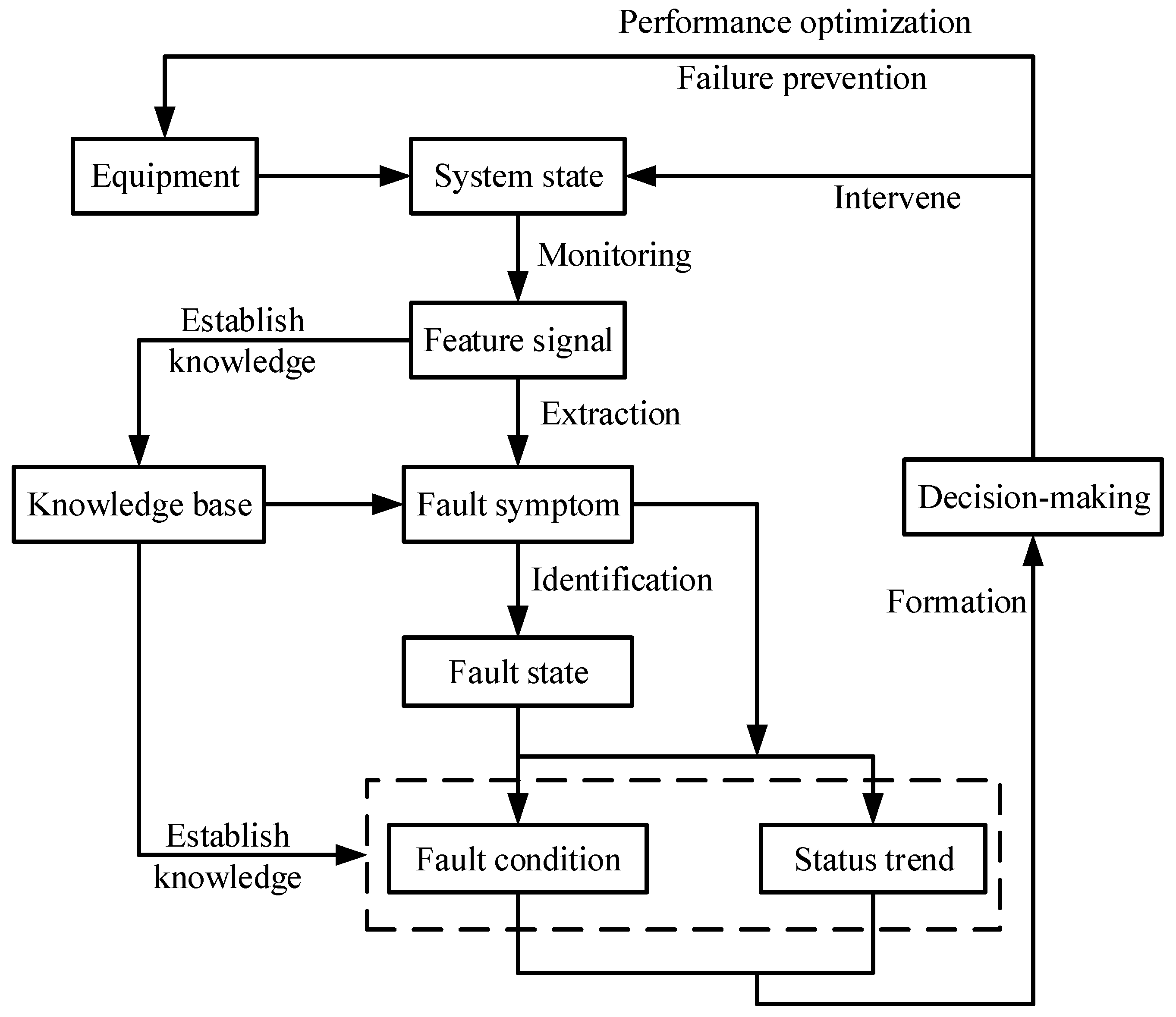
2.2. The Classification and Expression about Diagnostic Knowledge in High-Speed Trains
- Easy to be understood and implemented. Each means of expression should be consistent with the human logical thinking so that it can be easily described by the computer.
- Easy to use knowledge for reasoning. The objective of knowledge expression and knowledge storage is used for knowledge for reasoning, and further analyzing the fault causes. If the structure of knowledge expression is complex or the knowledge is difficult to understand, it will reduce the diagnostic efficiency.
- Beneficial to the management of KB. During the operation of the system, some knowledge will be increased or reduced according to the actual situation. Therefore, the selection of appropriate knowledge expressions could reduce the difficulty of knowledge management and improve the efficiency of knowledge maintenance.
2.3. Advantages of Qualitative IFD Methods
- It is easy to be designed and used.
- It is especially suitable for FD tasks with sufficient data.
- It can be implemented without accurate parameters.
- It can provide the basis for the diagnostic results (because a strong causal relationship exists among various fault modes and fault causes).
- It can make clear and transparent reasoning in uncertain situations.
3. Applications of Qualitative IFD Approach in High-Speed Trains
3.1. Symbol and Logical Reasoning in Qualitative IFD Approach of High-Speed Trains
3.1.1. Rule-Based Reasoning
3.1.2. Case-Based Reasoning
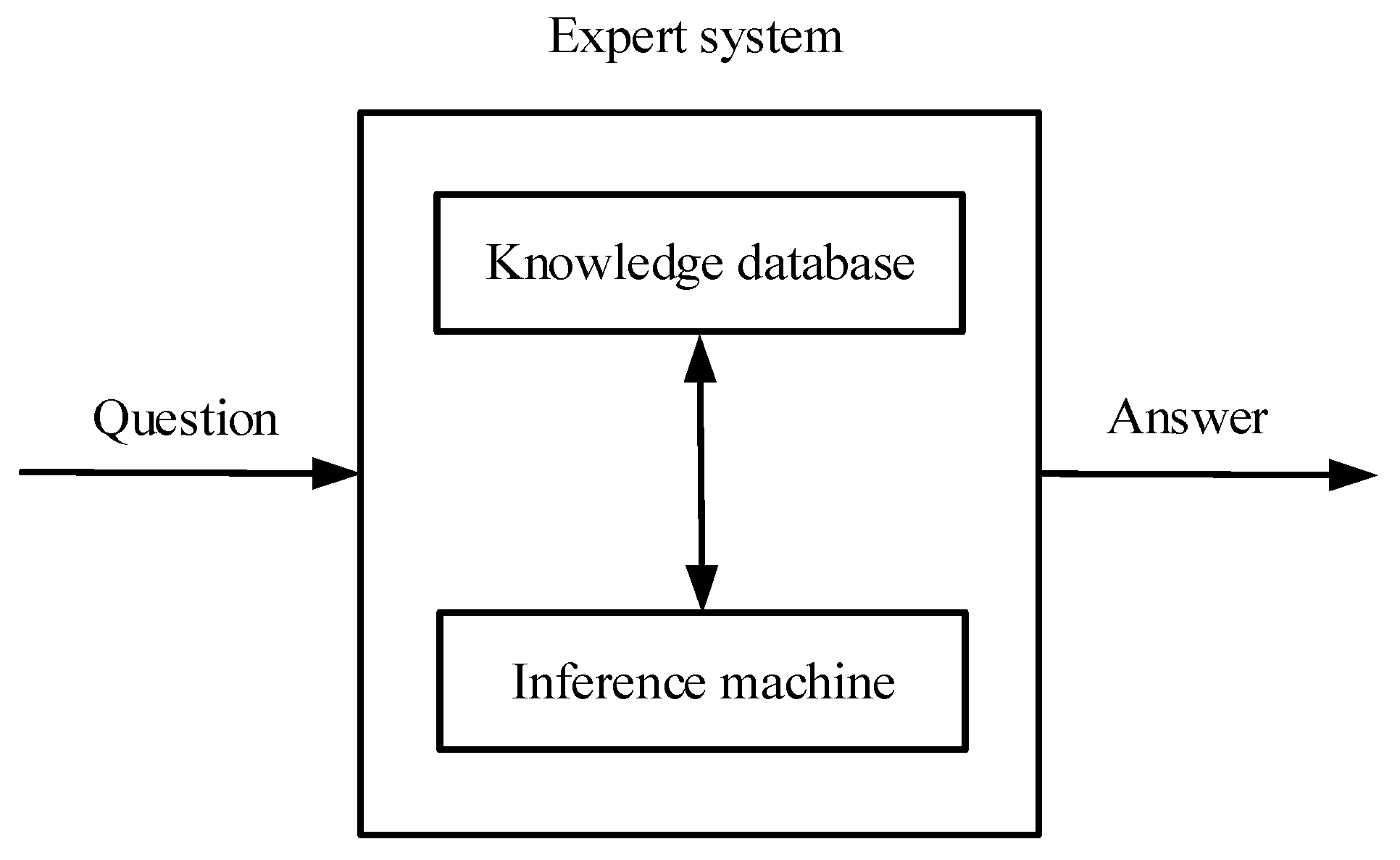
3.1.3. Expert System
3.2. Graph Theory in Qualitative IFD Approach of High-Speed Trains
3.2.1. Directed Graph
3.2.2. Undirected Graph
3.2.3. Clain Graph
- (1)
- If is an edge in G, and , then the form of an edge will be .
- (2)
- If is an edge in G, and , then the form of an edge will be .
3.2.4. Fault Tree Analysis
- (1)
- Fault types ought to be as extensive as possible.
- (2)
- The analysis of fault events should be as detailed as possible.
- (3)
- The principle of layer by layer transmission should be followed (please pay attention to the function of the gates in FTA methods).
- (4)
- Only gates in FTA approaches can be connected to events.
3.3. Fuzzy Theory in Qualitative IFD Approach of High-Speed Trains
- Step 1: Extract the fault characteristic fuzzy vector and fault cause fuzzy vector . There are n characteristics generated by faults of high-speed trains, in which the domain is . The variable describing the i-th characteristic is , and its membership function is . On this basis, is established as the fault characteristic fuzzy vector. Besides, there may be m fault causes when faults of systems occur, its domain is . The variable describing the j-th cause is , and its membership function is . On this basis, is established as the fault cause fuzzy vector.
- Step 2: Calculate the diagnostic matrix R. There is a connection among many facts in FD procedures, so the relationship among faults and fault symptoms is established through the diagnostic relation matrix R from U to V. In addition, the above relationship can be represented by an ordered pair , where the Cartesian product set of U domain and V domain is . Furthermore, R is a fuzzy set defined on , as follows:where the fuzzy set represents the causal relationship among causes and characteristics of fault.
- Step 3: Implement the fuzzy reasoning. Suppose R is a fuzzy relation from U to V. By means of fuzzy relation , the fuzzy set on V can be calculated. With the help of characteristic fuzzy vectors , the new domain of fault fuzzy vectors can be calculated via:where ∘ is the composition operator of fuzzy relation.
- Step 4: Perform the fuzzy FD. Faults can be matched with their causes by the maximum membership criterion. Specifically, if the element belongs to U domain and satisfies , then the fault characteristic will be matched with the fault cause .
4. Challenges and Future Trends
- Qualitative IFD techniques are useful for a specific system.
- In qualitative IFD techniques, it is difficult to ensure that all rules are applicable.
- The lower quality of knowledge results in worse FD performance in qualitative IFD techniques.
- With the complexity of system mechanism, knowledge becomes difficult to be extracted and stored.
- Qualitative IFD techniques are difficult to diagnose and detect incipient faults in high-speed trains.
- The diagnostic KB with complete fault knowledge, viewed as a prerequisite for using qualitative IFD techniques, is difficult to be constructed.
- (1)
- Management and maintenance of explicit diagnostic knowledge. It is well known that the construction of diagnostic KB about high-speed trains is a huge task. One of the difficulties lies in the need to expose invisible knowledge because most researchers or engineers only use existing technologies and explicit diagnostic knowledge to build a KB containing enough rich information. But, it is not even close to sufficient. Explicit knowledge usually contains the two types of known information discussed in Section 2.2. But, invisible knowledge, especially in the human brain of train maintenance engineers, is also an indispensable knowledge resource. At the moment, there have been many studies aiming at explicit knowledge extraction, but few reports consider invisible knowledge extraction. To overcome this difficulty, it is helpful to construct a complete diagnostic KB from the perspective of knowledge extraction.
- (2)
- Improvements in the quality of known quantitative information in high-speed trains. Based on the analysis in Section 2, a large amount of historical data is recorded during the operation of high-speed trains and then can be converted into fault knowledge through data mining methods. However, these data collected from the onboard information system in high-speed trains often suffer from missing data points. When extracting knowledge from missing data and building a diagnostic KB, it is easy to lose important knowledge. Thus, the selection of appropriate preprocessing techniques can improve the quality of knowledge discovery and monitoring data (will be used in data mining methods to extract fault knowledge), thereby improving the quality of the diagnostic KB and the result provided via qualitative IFD techniques.
- (3)
- Deep knowledge mining, extraction, and application. Shallow knowledge could be summarized from the massive historical data collected from high-speed trains. On the contrary, deep knowledge is helpful to explore relationships among subsystems in high-speed trains, providing the new solution for system level faults. It is expected that qualitative IFD techniques combining deep and shallow knowledge will be further developed in the future, so as to break the constraints of traditional qualitative methods for special applications in system level or component level FD.
- (4)
- The fusion of qualitative IFD and health management approaches. Under some special conditions (e.g., complete diagnostic KB, the transparent and interpretable FD procedure), qualitative IFD approaches can show accuracy results. These conditions are also necessary for health management techniques. One emerging solution for qualitative IFD approaches is to integrate into health management techniques, and the whole framework can be regarded as an autonomous and accurate comprehensive evaluation system for high-speed trains. With the critical advantages of health management, engineers can easily report the dynamic degradation of high-speed trains, providing effective suggestions for train maintenance. However, there are some challenges with the above technology, like system integration, sensor selection and optimal layout, and measurement data fusion. Fortunately, solutions to these challenges can improve the reliability of high-speed trains and reduce the operation cost of systems.
- (5)
- The research and application of integrated qualitative IFD techniques. Some critical systems in high-speed trains usually have complex nonlinear features, such as strong coupling and time-varying parameters. In addition, process uncertainties and external interferences also have negative effects on FD procedures. Therefore, different qualitative IFD approaches need to be integrated to improve the FD effect. However, there are still many problems to be further studied, such as combination principles of different methods, the fuzzy knowledge expression after fusion, etc.
- (6)
- The research and application of distributed qualitative IFD techniques. With the development of materials and technologies, high-speed trains are becoming systematic, continuous, and automated, many distributed frameworks, like distributed open-scale FD systems, are applied in FD procedures of trains. Distributed techniques provide a potential way for large-scale IFD. Through the description, decomposition and allocation of FD tasks, distributed qualitative IFD techniques can be designed for the decentralized and problem-oriented subsystems to overcome challenges in a parallel collaboration. Furthermore, FD schemes based on the fusion of multi-agent techniques and qualitative IFD techniques are also the advanced research topics in FD domains.
- (7)
- The research and application of remote cooperative qualitative IFD techniques. The premise is to integrate computer networks into qualitative IFD techniques, in which multicenter computers as servers work together. With the aid of computer remote monitoring, information transmission, remote IFD techniques are easy to realize the processing, transmission, storage, query, and display of monitoring information in high-speed trains. The successful implementation of remote cooperative qualitative IFD techniques will be helpful for online IFD in high-speed trains, providing real-time results for engineers in the operation center. Based on these results, engineers and experts can adjust maintenance plans of trains. The key to this technique includes remote signal analysis, remote transmission of real-time data, and open ES design.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, H.T.; Jiang, B. A review of fault detection and diagnosis for the traction system in high-Speed trains. IEEE Trans. Intell. Transp. Syst. 2020, 21, 450–465. [Google Scholar] [CrossRef]
- Yang, C.H.; Yang, C.; Peng, T.; Yang, X.Y.; Gui, W.H. A fault-injection strategy for traction drive control systems. IEEE Trans. Ind. Electron. 2017, 64, 5719–5727. [Google Scholar] [CrossRef]
- Tu, D.Y.; Zheng, J.D.; Jiang, Z.W.; Pan, H.Y. Multiscale distribution entropy and t-distributed stochastic neighbor embedding-based fault diagnosis of rolling bearings. Entropy 2018, 20, 360. [Google Scholar] [CrossRef]
- Chen, Z.W.; Ding, S.X.; Peng, T.; Yang, C.H.; Gui, W.H. Fault detection for non-gaussian processes using generalized canonical correlation analysis and randomized algorithms. IEEE Trans. Ind. Electron. 2018, 65, 1559–1567. [Google Scholar] [CrossRef]
- Chen, H.T.; Jiang, B.; Lu, N.Y. A newly robust fault detection and diagnosis method for high-speed trains. IEEE Trans. Intell. Transp. Syst. 2019, 20, 2198–2208. [Google Scholar] [CrossRef]
- Guo, L.; Lei, Y.G.; Xing, S.B.; Yan, T.; Li, N.P. Deep convolutional transfer learning network: A new method for intelligent fault diagnosis of machines with unlabeled data. IEEE Trans. Ind. Electron. 2019, 50, 92–111. [Google Scholar] [CrossRef]
- Cheng, C.; Wang, W.J.; Luo, H.; Zhang, B.C.; Cheng, G.L.; Teng, W.X. State-degradation-oriented fault diagnosis for high-speed train running gears system. Sensors 2020, 4, 1017. [Google Scholar] [CrossRef]
- Chen, H.T.; Jiang, B.; Zhang, T.Y.; Lu, N.Y. Data-driven and deep learning-based detection and diagnosis of incipient faults with application to electrical traction systems. Neurocomputing 2020, 396, 429–437. [Google Scholar] [CrossRef]
- Chen, H.T.; Jiang, B.; Ding, S.X.; Lu, N.Y.; Chen, W. Probability-relevant incipient fault detection and diagnosis methodology with applications to electric drive systems. IEEE Trans. Control Syst. Technol. 2019, 27, 2766–2773. [Google Scholar] [CrossRef]
- Cheng, C.; Wang, J.H.; Fu, C.X.; Zhang, B.C. A status assessment model for dynamic system based on cloud evidence reasoning. In Proceedings of the IECON 2019, Lisbon, Portugal, 14–17 October 2019. [Google Scholar]
- Chen, H.T.; Jiang, B.; Lu, N.Y.; Chen, W. Real-time incipient fault detection for electrical traction systems of CRH2. Neurocomputing 2018, 306, 119–129. [Google Scholar] [CrossRef]
- Chen, H.T.; Jiang, B.; Chen, W.; Li, Z.H. Edge computing-aided framework of fault detection for traction control systems in high-speed trains. IEEE Trans. Veh. Technol. 2020, 69, 1309–1318. [Google Scholar] [CrossRef]
- Lei, Y.G.; Lin, J.; He, Z.J.; Zuo, M.J. A review on empirical mode decomposition in fault diagnosis of rotating machinery. Mech. Syst. Signal Process 2013, 35, 108–126. [Google Scholar] [CrossRef]
- Liu, R.; Yang, B.; Zio, E.; Chen, X.F. Artificial intelligence for fault diagnosis of rotating machinery: A review. Mech. Syst. Signal Process 2018, 108, 33–47. [Google Scholar] [CrossRef]
- Liu, Z.G.; Liu, K.; Zhong, J.P.; Han, Z.W.; Zhang, W.X. A high-precision positioning approach for catenary support components with multi-scale difference. IEEE Trans. Instrum. Meas. 2020, 69, 700–711. [Google Scholar] [CrossRef]
- Wang, X.F.; Yang, G.H. Event-triggered fault detection observer design for T-S fuzzy systems. IEEE Trans. Fuzzy Syst. in press. [CrossRef]
- Chen, H.; Chai, Z.; Jiang, B.; Huang, B. Data-driven fault detection for dynamic systems with performance degradation: A unified transfer learning framework. IEEE Trans. Instrum. Meas. in press. [CrossRef]
- Chen, H.T.; Jiang, B.; Chen, W.; Yi, H. Data-driven detection and diagnosis of incipient faults in electrical drives of high-speed trains. IEEE Trans. Ind. Electron. 2019, 66, 4716–4725. [Google Scholar] [CrossRef]
- Shang, C.; Yang, F.; Gao, X.; Huang, X.; Suykens, J.A.K.; Huang, D. Concurrent monitoring of operating condition deviations and process dynamics anomalies with slow feature analysis. AIChE J. 2015, 61, 3666–3682. [Google Scholar] [CrossRef]
- Chen, H.T.; Jiang, B.; Lu, N.Y.; Mao, Z.H. Deep PCA based real-time incipient fault detection and diagnosis methodology for electrical drive in high-speed trains. IEEE Trans. Veh. Technol. 2018, 67, 4819–4830. [Google Scholar] [CrossRef]
- Cheng, C.; Wang, J.H.; Zhou, Z.J.; Teng, W.X.; Sun, Z.B.; Zhang, B.C. A BRB-based effective fault diagnosis model for high-speed trains running gear systems. IEEE Trans. Intell. Transp. Syst. in press. [CrossRef]
- Zhou, D.H.; Zhao, Y.H.; Wang, Z.D.; He, X.; Gao, M. Review on diagnosis techniques for intermittent faults in dynamic systems. IEEE Trans. Ind. Electron. 2020, 67, 2337–2347. [Google Scholar] [CrossRef]
- Song, L.L. Synthetically Intelligent Diagnosis Approach of High-Speed Trains Based on the Non-Canonical Knowledge Processing. Ph.D. Thesis, Beijing Jiaotong University, Beijing, China, 2016. [Google Scholar]
- Cheng, C.; Qiao, X.Y.; Luo, H.; Teng, W.X.; Gao, M.L.; Zhang, B.C.; Yin, X.J. A semi-quantitative information based fault diagnosis method for the running gears system of high-speed trains. IEEE Access 2019, 7, 38168–38178. [Google Scholar] [CrossRef]
- Lu, J.G.; Zhang, H.; Tang, X.H. A novel method for intelligent single fault detection of bearings using SAE and improved D-S evidence theory. Entropy 2019, 21, 687. [Google Scholar] [CrossRef] [PubMed]
- Glowacz, A.; Glowacz, W.; Kozik, J.; Piech, K.; Gutten, M.; Caesarendra, W.; Liu, H.; Brumercik, F.; Irfan, K.; Khan, Z. Detection of deterioration of three-phase induction motor using vibration signals, measurement science review. Meas. Sci. Rev. 2019, 19, 241–249. [Google Scholar] [CrossRef]
- Delpha, C.; Diallo, D.; Samrout, A.H.; Moubayed, N. Multiple incipient fault diagnosis in three-phase electrical systems using multivariate statistical signal processing. Eng. Appl. Artif. Intell. 2018, 73, 68–79. [Google Scholar] [CrossRef]
- Yuan, X.F.; Li, L.; Shardt, Y.; Wang, Y.L.; Yang, C.H. Deep learning with spatiotemporal attention-based LSTM for industrial soft sensor model development. IEEE Trans. Ind. Electron. in press. [CrossRef]
- Tian, E.G.; Wang, X.M.; Peng, C. Probabilistic-constrained distributed filtering for a class of nonlinear stochastic systems subject to periodic DOS attacks. IEEE Trans. Circuit. Syst.–I. in press. [CrossRef]
- Yu, W.K.; Zhao, C.H.; Huang, B. Stationary subspace analysis based hierarchical model for batch processes monitoring. IEEE Trans. Control Syst. Technol. in press. [CrossRef]
- Tian, E.G.; Peng, C. Memory-based event-triggering H-infinity load frequency control for power systems under deception attacks. IEEE Trans. Cybernetics. in press. [CrossRef]
- Delpha, C.; Chen, H.; Diallo, D. SVM based diagnosis of inverter fed induction machine drive: A new challenge. In Proceedings of the 38th Annual Conference on IEEE Industrial Electronics Society, Montreal, QC, Canada, 25–28 October 2012. [Google Scholar]
- Wan, S.T.; Peng, B. An integrated approach based on swarm decomposition, morphology envelope dispersion entropy, and random forest for multi-fault recognition of rolling bearing. Entropy 2019, 21, 354. [Google Scholar] [CrossRef]
- Frank, P.M. Fault diagnosis in dynamic systems using analytical and knowledge-based redundancy: A survey and some new results. Automatica 1990, 26, 459–474. [Google Scholar] [CrossRef]
- Zhou, D.H.; Hu, Y.Y. Fault diagnosis techniques for dynamic systems. Acta Autom. Sinica 2009, 35, 748–758. [Google Scholar] [CrossRef]
- Cheng, M.; Hang, J.; Zhang, J.Z. Overview of fault diagnosis theory and method for permanent magnet machine. Chin. J. Electr. Eng. 2015, 1. [Google Scholar]
- Zeng, J.; Chen, Y.F.; Yang, P.; Guo, H.X. Review of fault diagnosis methods of large-scale wind turbines. Power Syst. Technol. 2018, 42, 849–860. [Google Scholar]
- Xu, J.L.; Ge, Z.S.; Chen, Q. Summary fault diagnosis of wind turbines. Sci. Technol. Vision 2018, 36, 34–36. [Google Scholar]
- Yang, S. Application and prospect on electrical servo fault diagnosis technology in China. Henan Sci. Technol. 2019, 5, 67–71. [Google Scholar]
- Xue, G.H.; Wu, M. Research status and development trend of fault diagnosis methods for electromechanical equipment. Coal Eng. 2010, 5, 103–105. [Google Scholar]
- Lei, Y.G.; Lin, J.; Zuo, M.J.; He, Z.J. Condition monitoring and fault diagnosis of planetary gearboxes: A review. Measurement 2014, 48, 292–305. [Google Scholar] [CrossRef]
- Ma, J.P.; Jiang, J. Applications of fault detection and diagnosis methods in nuclear power plants: A review. Prog. Nucl. Energy 2011, 53, 255–266. [Google Scholar] [CrossRef]
- Dai, J.Y.; Tang, J.; Huang, S.Z.; Wang, Y.Y. Signal-based intelligent hydraulic fault diagnosis methods: Review and prospects. Chin. J. Mech. Eng. 2019, 75. [Google Scholar] [CrossRef]
- Shui, A.; Chen, W.M.; Zhang, P.; Hu, S.R.; Huang, X.W. Review of fault diagnosis in control systems. In Proceedings of the CCDC 2009, Guilin, China, 17–19 June 2009. [Google Scholar]
- Wang, Y.X.; Xiang, J.W.; Markert, R.; Liang, M. Spectral kurtosis for fault detection, diagnosis and prognostics of rotating machines: A review with applications. Mech. Syst. Signal Process 2016, 66–67, 679–698. [Google Scholar] [CrossRef]
- Mellit, A.; Tina, G.M.; Kalogirou, S.A. Fault detection and diagnosis methods for photovoltaic systems: A review. Renew. Sust. Energy Rev. 2018, 91, 1–17. [Google Scholar] [CrossRef]
- Liu, Y.Q.; Bazzi, A.M. A review and comparison of fault detection and diagnosis methods for squirrel-cage induction motors: State of the art. MISA Trans. 2017, 70, 400–409. [Google Scholar] [CrossRef] [PubMed]
- Fenton, W.G.; McGinnity, T.M.; Maguire, L.P. Fault diagnosis of electronic systems using intelligent techniques: A review. IEEE Trans. Syst. Man Cybern. C Appl. Rev. 2001, 31, 269–281. [Google Scholar] [CrossRef]
- Du, J.Q.; Zhao, M.; Yin, J.; Gu, W. Review of fault diagnosis methods for power plant. Yunnan Electr. Power 2018, 46, 88–96. [Google Scholar]
- Patton, R.J.; Chen, J. A review of parity space approaches to fault diagnosis. In Proceedings of the IFAC SAFEPROCESS Symptoms, Baden-Baden, Germany, 10–13 September 1991. [Google Scholar]
- Patton, R.J.; Chen, J. Review of parity space approaches to fault diagnosis for aerospace systems. Journal Guid. Control Dynam. 1994, 17, 278–285. [Google Scholar] [CrossRef]
- Lu, B.; Li, Y.Y.; Wu, X.; Yang, Z.Z. A review of recent advances in wind turbine condition monitoring and fault diagnosis. In Proceedings of the PEMWA 2009, Lincoln, NE, USA, 24–26 June 2009. [Google Scholar]
- Huang, L.M.; Zhang, Q. Review on fault diagnosis of converter based on data driven. Electr. Technol. 2019, 2, 1–7. [Google Scholar]
- Yang, H.F.; Jia, X.L.; Ren, S.W. Review of data-driven aeroengine fault diagnosis and prognosis methods. Aviat. Precis. Manuf. Technol. 2016, 52, 6–9. [Google Scholar]
- Henao, H.; Cabanas, M.; Filippetti, F.; Bruzzese, C.; Strangas, E.; Pusca, R.; Estima, J.; Riera-Guasp, M.; Kia, S.H. Trends in fault diagnosis for electrical machines: A review of diagnostic techniques. IEEE Ind. Electron. Mag. 2014, 8, 31–42. [Google Scholar] [CrossRef]
- Niu, G.; Xiong, L.J.; Qin, X.X.; Pecht, M. Fault detection isolation and diagnosis of multi-axle speed sensors for high-speed trains. Mech. Syst. Signal Process 2019, 131, 183–198. [Google Scholar] [CrossRef]
- Nor, N.M.; Hassan, C.R.C.; Hussain, M.A. A review of data-driven fault detection and diagnosis methods: Applications in chemical process systems. Rev. Chem. Eng. 2020, 36, 513–553. [Google Scholar] [CrossRef]
- Dai, X.W.; Gao, Z.W. From model, signal to knowledge: A data-driven perspective of fault detection and diagnosis. IEEE Trans. Ind. Inform. 2013, 9, 2226–2238. [Google Scholar] [CrossRef]
- Liu, Y.J.; Wang, Z.J. Overview of methods for rotating machinery fault diagnosis. J. Suzhou Vocat. Univ. 2010, 21, 6–8. [Google Scholar]
- Yan, Z.Q. Intelligent fault diagnosis and Simulation of servo system. Electromech. Eng. Technol. 2005, 34, 46–50. [Google Scholar]
- Wang, F.T.; Ma, X.J.; Zou, Y.K. An overview on intelligent technique of fault diagnosis. Mach. Tools Hydraul. 2003, 4, 6–8. [Google Scholar]
- Saufi, S.R.; Ahmad, Z.A.B.; Leong, M.S.; Lim, M.H. An intelligent bearing fault diagnosis system: A review. In Proceedings of the Engineering Application of Artificial Intelligence Conference 2018, Sabah, Malaysia, 3–5 December 2018. [Google Scholar]
- Jing, Y.W.; Li, L.F. Research overview on intelligent fault diagnosis technology of turbine. Appl. Mech. Mater. 2014, 556, 3191–3195. [Google Scholar] [CrossRef]
- Amiruddin, A.A.A.M.; Zabiri, H.; Taqvi, S.A.A.; Tufa, L.D. Neural network applications in fault diagnosis and detection: An overview of implementations in engineering-related systems. Neural Comput. Appl. 2018, 32, 447–472. [Google Scholar] [CrossRef]
- Hu, D.Q. Summary of rolling bearing fault diagnosis methods. Internal Combust. Engine Parts 2019, 9, 151–153. [Google Scholar]
- Li, B.Y.; Jiang, G.H.; Chen, B.W.; Wang, P.F. Overview of diesel engine fault diagnosis technology. Ship Mater. Market 2019, 1, 21–22. [Google Scholar]
- Li, X.M.; He, D.Q.; Deng, J.X.; Miao, J. Summary of fault diagnosis methods for bogies of urban rail transit vehicles. Eq. Manuf. Technol. 2015, 12s, 81–85. [Google Scholar]
- Chen, L.X.; Liu, F.J.; He, Y.L. An overview on the intelligent fault diagnosis research of automobile engineering. Manuf. Automat. 2010, 30, 54–57. [Google Scholar]
- Xie, C.L.; Dai, J.M. The research overview and prospects of gas turbine fault diagnosis technique. Turb. Technol. 2010, 52, 1–3. [Google Scholar]
- Duan, L.X.; Xie, M.Y.; Wang, J.J.; Bai, T.B. A Deep learning enabled intelligent fault diagnosis: Overview and applications. J. Intell. Fuzzy Syst. 2018, 35, 1–14. [Google Scholar] [CrossRef]
- Zhang, X.Y.; Luan, Z.Q.; Liu, X.L. Review on fault diagnosis of rolling bearing based on deep learning. Eq. Manage. Maintenance 2017, 18, 130–133. [Google Scholar]
- Nandi, S.; Toliyat, H.A.; Li, X.D. Condition monitoring and fault diagnosis of electrical motor-A review. IEEE Trans. Energy Conver. 2005, 20, 719–729. [Google Scholar] [CrossRef]
- Zaytoon, J.; Lafortune, S. Overview of fault diagnosis methods for Discrete Event Systems. Annu. Rev. Control 2013, 37, 308–320. [Google Scholar] [CrossRef]
- Wang, C.J.; Sun, G.Z. A review of intelligent models for fault diagnosis. Water Conservancy Electr. Power Mach. Water Conservancy Electr. Power Mach. 1998, 3, 9–12. [Google Scholar]
- Wang, R.C. Survey of knowledge based fault diagnosis methods for power systems. Sci. Technol. Innov. 2019, 5, 62–63. [Google Scholar]
- Liu, Z.L.; Wang, H.; Liu, J.J.; Qin, Y.; Peng, D.D. Multi-task learning based on lightweight 1DCNN for fault diagnosis of wheelset bearings. IEEE Trans. Instrum. Meas. in press. [CrossRef]
- Harmouche, J.; Delpha, C.; Diallo, D. Incipient fault detection and diagnosis based on Kullback-Leibler divergence using principal component analysis: Part I. Signal Process. 2014, 94, 278–287. [Google Scholar] [CrossRef]
- Chen, J.W.; Liu, Z.G.; Wang, H.R.; Núñez, A.; Han, Z.W. Automatic defect detection of fasteners on the catenary support device using deep convolutional neural network. IEEE Trans. Instrum. Meas. 2018, 67, 257–269. [Google Scholar] [CrossRef]
- Duan, A.; Guo, L.; Gao, H.; Wu, X.; Dong, X. Deep Focus Parallel Convolutional Neural Network for Imbalanced Classification of Machinery Fault Diagnostics. IEEE Trans. Instrum. Meas. in press. [CrossRef]
- Cheng, C.; Qiao, X.Y.; Teng, W.X.; Gao, M.L.; Luo, H. Principal component analysis and belief-rule-base aided health monitoring method for running gears of high-speed train. Sci. China Inform. Sci. 2020, 63. [Google Scholar] [CrossRef]
- Chen, H.T.; Jiang, B.; Ding, S.X. A broad learning aided data-driven framework of fast fault diagnosis for high-speed trains. IEEE Intell. Transp. Syst. Magazine. in press. [CrossRef]
- Zhao, H.Y.; Liang, J.Y.; Liu, C.Q. High-speed EMUs: Characteristics of technological development and trends. Engineering 2020, 6, 234–244. [Google Scholar] [CrossRef]
- Wang, J.F.; Wu, H.F.; Yang, T.Y.; Zhang, L.; Xing, Y. Bidirectional three-phase DC-AC converter with embedded DC-DC converter and carrier-based PWM strategy for wide voltage range applications. IEEE Trans. Ind. Electron. 2019, 66, 4144–4155. [Google Scholar] [CrossRef]
- Cheng, C.; Liu, M.; Zhang, B.C.; Yin, X.J.; Fu, C.X.; Teng, W.X. Health assessment of high-speed train running gear system under complex working conditions based on data-driven model. Math. Prob. Eng. in press. [CrossRef]
- Cheng, C.; Wang, J.H.; Teng, W.X.; Gao, M.L.; Zhang, B.C.; Yin, X.J.; Luo, H. Health status prediction based on belief rule base for high-speed train running gear system. IEEE Access 2018, 7, 4145–4159. [Google Scholar] [CrossRef]
- Chen, H.T.; Jiang, B.; Lu, N.Y.; Chen, W. Data-Driven Detection and Diagnosis of Faults in Traction Systems of High-Speed Trains; Springer Nature: Cham, Switzerland, 2020. [Google Scholar]
- Yang, F.; Habibullah, M.S.; Zhang, T.; Xu, Z.; Lim, P.; Nadarajan, S. Health index-based prognostics for remaining useful life predictions in electrical machines. IEEE Trans. Ind. Electron. 2016, 63, 2633–2644. [Google Scholar] [CrossRef]
- Delpha, C.; Diallo, D. Incipient fault detection and diagnosis: A hidden information detection problem. In Proceedings of the ISIE 2015, Janeiro, Brazil, 3–5 June 2015. [Google Scholar]
- Tai, L.G.; Guo, H.Y.; Zhong, Y.X.; Li, D.Q. Knowledge acquisition method for case-knowledge-based product family design. J. Harbin I Technol. 2007, 14, 623–628. [Google Scholar]
- Caceres, S.; Henley, E.J. Process failure analysis by block diagrams and fault trees. Ind. Eng. Chem. 1976, 15, 128–134. [Google Scholar] [CrossRef]
- Barrientos, F.; Sainz, G. Interpretable knowledge extraction from emergency call data based on fuzzy unsupervised decision tree. Knowl.-Based Syst. 2012, 25, 77–87. [Google Scholar] [CrossRef]
- Baysal, M.; Gunay, M.E.; Yildirim, R. Decision tree analysis of past publications on catalytic steam reforming to develop heuristics for high performance: A statistical review. Int. J. Hydrogen Energy 2017, 42, 243–254. [Google Scholar] [CrossRef]
- Thomas, M.C.; Zhu, W.; Romagnoli, J.A. Data mining and clustering in chemical process databases for monitoring and knowledge discovery. J. Process Control 2017, 67, 160–175. [Google Scholar] [CrossRef]
- Castro, A.R.G. Knowledge Extraction from Artificial Neural Networks: Application to Transformer Incipient Fault Diagnosis. Ph.D. Thesis, Universidade do Porto, Porto, Portugal, 2004. [Google Scholar]
- Shi, F.; Sun, S.; Xu, J. Employing rough sets and association rule mining in KANSEI knowledge extraction. Inform. Sci. 2012, 196, 118–128. [Google Scholar] [CrossRef]
- Feng, L.; Li, T.; Ruan, D.; Gou, S. A vague-rough set approach for uncertain knowledge acquisition. Knowl.-Based Syst. 2011, 24, 837–843. [Google Scholar] [CrossRef]
- Wang, H.; Kwong, S.; Jin, Y.; Wei, W.; Man, K.F. Multi-objective hierarchical genetic algorithm for interpretable fuzzy rule-based knowledge extraction. Fuzzy Sets Syst. 2005, 149, 149–186. [Google Scholar] [CrossRef]
- Tan, K.C.; Yu, Q.; Heng, C.M.; Lee, T.H. Evolutionary computing for knowledge discovery in medical diagnosis. Artif. Intell. Med. 2003, 27, 129–154. [Google Scholar] [CrossRef]
- Zhang, B.; Yang, C.; Zhu, H.; Shi, P.; Gui, W. Controllable-domain-based fuzzy rule extraction for copper removal process control. IEEE Trans. Fuzzy Syst. 2018, 26, 1744–1756. [Google Scholar] [CrossRef]
- Zhu, P.; Hu, Q. Rule extraction from support vector machines based on consistent region covering reduction. Knowl.-Based Syst. 2013, 42, 1–8. [Google Scholar] [CrossRef]
- Cintra, M.E.; Camargo, H.A.; Monard, M.C. Genetic generation of fuzzy systems with rule extraction using formal concept analysis. Inform. Sc. 2016, 349, 199–215. [Google Scholar] [CrossRef]
- Katipamula, S.; Brambley, M. Review article: Methods for fault detection, diagnostics, and prognostics for building systems—A review, Part I. HVAC R Res. 2005, 11, 3–25. [Google Scholar] [CrossRef]
- Venkatasubramanian, V.; Rengaswamy, R.; Kavuri, S.N. A review of process fault detection and diagnosis Part II: Qualitative models and search strategies. Comput. Chem. Eng. 2003, 27, 313–326. [Google Scholar] [CrossRef]
- Feng, Z.C.; Zhou, Z.J.; Hu, C.H.; Chang, L.L.; Hu, G.Y.; Zhao, F.J. A new belief rule base model with attribute reliability. IEEE Trans. Fuzzy Syst. 2018, 27, 903–916. [Google Scholar] [CrossRef]
- Isermann, R. Model base fault detection and diagnosis methods. In Proceedings of the 1995 American Control Conference, Seattle, WA, USA, 21–23 June 1995. [Google Scholar]
- Ishibuchi, H.; Nozaki, K.; Yamamoto, N.; Tanaka, H. Selecting fuzzy if-then rules for classification problems using genetic algorithms. IEEE Trans. Fuzzy Syst. 1995, 3, 260–270. [Google Scholar] [CrossRef]
- Wang, W.L.; Yang, M.; Seong, P.H. Development of a rule-based diagnostic platform on an object-oriented expert system shell. Ann. Nucl. Energy 2016, 88, 252–264. [Google Scholar] [CrossRef]
- Chen, H.T.; Jiang, B.; Ding, S.X.; Huang, B. Data-driven fault diagnosis for traction systems in high-speed trains: A survey, challenges, and perspectives. IEEE Trans. Intell. Transp. Syst. in press. [CrossRef]
- Fayyad, U.; Smyth, P. Image batabase exploration: Progress and challenges. Knowl. Discov. Databases Workshop 1993, AAAI-93, 14–27. [Google Scholar]
- Han, J.; Pei, J.; Mortazavi-Asl, B.; Chen, Q.; Dayal, U.; Hsu, M.C. Freespan: Frequent pattern-projected sequential pattern mining. In Proceedings of the International Conference on Knowledge Discovery and Data Mining (KDD00), Boston, MA, USA, 20–23 August 2000. [Google Scholar]
- Agrawal, R.; Imielienski, T.; Swami, A. Mining association rules between sets of items in large databases. In Proceedings of the Conf. on Management of Data, Washington, DC, USA, 26–28 May 1993. [Google Scholar]
- Hu, H.; Zhang, J.W. Research and application on algorithms of data mining for EMU malfunction’s data under cloud computing environment. In Proceedings of the New Network Technol. & Appl., Yunnan, China, 9 November 2014. [Google Scholar]
- Ren, J.H.; Liu, F.; Hu, H. Design and implementation of association rules in fault diagnosis of high-speed railway in China. In Proceedings of the AMEIT 2017, Shanghai, China, 23–24 April 2017. [Google Scholar]
- Zhao, H.; Chen, H.; Dong, W.; Sun, X.Y.; Ji, Y.D. Fault diagnosis of rail turnout system based on case-based reasoning with compound distance methods. In Proceedings of the CCDC 2017, Chongqing, China, 28–30 May 2017. [Google Scholar]
- Yang, B.S.; Jeong, S.K.; Oh, Y.M.; Tan, A.C.C. Case-based reasoning system with Petri nets for induction motor fault diagnosis. Expert Syst. Appl. 2004, 27, 301–311. [Google Scholar] [CrossRef]
- Zhong, Z.W.; Xu, T.H.; Wang, F.; Tang, T. Text case-based reasoning framework for fault diagnosis and predication by cloud computing. Math. Probl. Eng. 2018, 2018, 1–10. [Google Scholar] [CrossRef]
- Yang, L.B.; Xu, T.H.; Wang, Z.X. Agent based heterogeneous data integration and maintenance decision support for high-speed railway signal system. In Proceedings of the ITSC 2014, Qingdao, China, 1–8 October 2014. [Google Scholar]
- Park, Y.M.; Kim, G.W.; Sohn, J.M. A logic based expert system for fault diagnosis of power system. IEEE Trans. Power Syst. 1997, 12, 363–369. [Google Scholar] [CrossRef]
- Hernandez, C.; Arjona, M.A.; Dong, S.H. Object-oriented knowledge-based system for distribution transformer design. IEEE Trans. Magn. 2008, 44, 2332–2337. [Google Scholar] [CrossRef]
- Lee, H.J.; Ahn, B.S.; Park, Y.M. A fault diagnosis expert system for distribution substations. IEEE Trans. Power Deliver. 2000, 15, 92–97. [Google Scholar]
- Kumamoto, H.; Ikenchi, K.J.; Inoue, K.; Henley, E.J. Application of expert system techniques to fault diagnosis. The Chem. Eng. J. 1984, 29, 1–9. [Google Scholar] [CrossRef]
- Cardozo, E.; Talukdar, S.N. A distributed expert system for fault diagnosis. IEEE Trans. Power Syst. 1988, 3, 641–646. [Google Scholar] [CrossRef]
- Musgrave, J.L.; Guo, T.H.; Wong, E.; Duyar, A. Real-time accommodation of actuator faults on a reusable rocket engine. IEEE Trans. Control Syst. Technol. 1996, 5, 100–109. [Google Scholar] [CrossRef]
- Zhou, D.X.; Xie, X.M. Research of fault diagnosis expert system inference engine based on extension rule. Comput. Meas. Control 2011, 2, 266–272. [Google Scholar]
- Krishnamurthi, M.; Phillips, D.T. An expert system framework for machine fault diagnosis. Comput. Ind. Eng. 1992, 22, 67–84. [Google Scholar] [CrossRef]
- Bergman, S.; Astrom, K.J. Fault detection in boiling water reactors by noise analysis. In Proceedings of the Power Plant Dynamics, Control and Testing Symposium, Knoxville, TN, USA, 21–23 March 1983. [Google Scholar]
- Wu, J.L.; Li, H.Z. Hierachical structure analysis on knowledge representation in expert system. J. Decis. Making Decis. Support Syst. 1995, 2, 38–45. [Google Scholar]
- Yan, S.R. A kind of study program of fault diagnosis expert system for brake of high-speed train. Comput. Knowl. Technol. 2010, 6, 9097–9098. [Google Scholar]
- Wu, J.D.; Wang, Y.H.; Bai, M.R. Development of an expert system for fault diagnosis in scooter engine platform using fuzzy-logic inference. Expert Syst. Appl. 2007, 33, 1063–1075. [Google Scholar] [CrossRef]
- Shendy, M.E.; Alan, S.M. A fuzzy expert system for fault detection in statistical process control of industrial processes. IEEE Trans. Syst. Man Cybern. Part C 2000, 30, 281–289. [Google Scholar]
- Song, X.D.; Shao, W.; Qiu, Z.Z.; Chen, Y.X. Study on fuzzy inference method for fault diagnosis expert system. Adv. Mater. Res. 2013, 30, 639–642. [Google Scholar] [CrossRef]
- Yang, J.B.; Liu, J.; Wang, J.; Sii, H.S.; Wang, H.W. Belief rule-base inference methodology using the evidential reasoning approach-RIMER. IEEE Trans. Syst. Man Cybern. Part A 2006, 36, 266–285. [Google Scholar] [CrossRef]
- Xu, J.P.; Zhong, Z.Q.; Xu, L. ISHM-oriented adaptive fault diagnostics for avionics based on a distributed intelligent agent system. Int. J. Syst. Sci. 2015, 46, 2287–2302. [Google Scholar] [CrossRef]
- Spiegelhalter, J.D.; Lauritzen, S. Sequential updating of conditional probabilities on directed graphical structures. Networks 1990, 20, 579–605. [Google Scholar] [CrossRef]
- Pearl, J. Causal diagrams for empirical research. Biometrika 1995, 82, 669–688. [Google Scholar] [CrossRef]
- Lunn, J.D.; Thomas, A.; Best, N.; Spiegelhalter, D. WinBUGS-A Bayesian modelling framework: Concepts, structure, and extensibility. Stat. Comput. 2000, 10, 325–337. [Google Scholar] [CrossRef]
- Djeziri, M.A.; Bouamama, B.O.; Merzouki, R. Modelling and robust FDI of steam generator using uncertain bond graph model. J. Process Control 2009, 19, 149–162. [Google Scholar] [CrossRef]
- Ghosh, N.; Bhanu, B. Evolving bayesian graph for three-dimensional vehicle model building from video. IEEE Trans. Intell. Transp. Syst. 2014, 15, 563–578. [Google Scholar] [CrossRef]
- Richardson, T.; Spirtes, P. Ancestral graph Markov models. Ann. Statist. 2002, 30, 962–1030. [Google Scholar] [CrossRef]
- Liu, P.P.; Zuo, H.F.; Su, Y.; Sun, J.Z. Review of research progresses for graph-based models in fault diagnosis method. Chin. Mech. Eng. 2013, 24, 696–703. [Google Scholar]
- Xie, G.; Wang, X.; Xie, K.M. SDG-based fault diagnosis and application based on reasoning method of granular computing. In Proceedings of the Chinese Control & Decis. Conference, Xuzhou, China, 26–28 May 2010. [Google Scholar]
- Zuo, J.Y.; Chen, Z.K. Sensor configuration and test for fault diagnoses of subway braking system based on signed digraph method. Chin. J. Mech. Eng. 2014, 27, 475–482. [Google Scholar] [CrossRef]
- Nam, D.S.; Han, C.; Jeong, C.W.; Yoon, E. Automatic construction of extended symptom fault associations from the signed digraph. Comput. Chem. Eng. 1996, 20, S605–S610. [Google Scholar] [CrossRef]
- Togari, Y.; Yonezu, S.; Yongya, A.; Hashimoto, Y. Faults diagnosis utilizing a three-layer signed directed graph. Kagaku Kogaku Ronbun. 1991, 17, 810–815. [Google Scholar] [CrossRef][Green Version]
- Bouamama, B.O.; Biswas, G.; Loureiro, R.; Merzouki, R. Graphical methods for diagnosis of dynamic systems: Review. Annu. Rev. Control 2014, 38, 199–219. [Google Scholar] [CrossRef]
- Pearl, J. Bayesian networks: A model of self-activated memory for evidential reasoning. In Proceedings of the CogSci 1985, Irvine, CA, USA, 15–17 August 1985. [Google Scholar]
- Bobbio, A.; Portinale, L.; Minichino, M.; Ciancamerla, E. Improving the analysis of dependable systems by mapping fault trees into bayesian networks. Reliab. Eng. Syst. Saf. 2001, 71, 249–260. [Google Scholar] [CrossRef]
- Richardson, T.S.; Robins, J.M.; Wang, L.B. Discussion of “Data-driven confounder selection via Markov and Bayesian network” by Hggstrm. Biometrics 2018, 74, 403–406. [Google Scholar] [CrossRef]
- Pelc, A. Undirected graph models for system-level fault diagnosis. IEEE Trans. Comput. 1991, 40, 1271–1276. [Google Scholar] [CrossRef]
- Zhao, J.J.; Zheng, W. Study of fault diagnosis method based on fuzzy Bayesian network and application in CTCS-3 train control system. In Proceedings of the ICIRT2013, Beijing, China, 30 August–1 September 2013. [Google Scholar]
- Cai, B.P.; Liu, Y.; Xie, M. A dynamic-bayesian-network-based fault diagnosis methodology considering transient and intermittent faults. IEEE Trans. Autom. Sci. Eng. 2016, 14, 1–10. [Google Scholar]
- Wu, Y.K.; Jiang, B.; Lu, N.Y.; Zhou, Y. Bayesian network based fault prognosis via bond graph modeling of high-speed railway traction device. Math. Probl. Eng. 2015, a01, 1–11. [Google Scholar] [CrossRef]
- Cheng, Y.; Xu, T.H.; Yang, L.B. Bayesian network based fault diagnosis and maintenance for high-speed train control systems. In Proceedings of the QR2MSE 2013, Chengdu, China, 15–18 July 2013. [Google Scholar]
- Liu, J.W.; Li, H.E.; Luo, X.L. Representation theory of probabilistic graphical models. Comput. Sci. 2014, 41, 1–17. [Google Scholar]
- Maheshwari, S.N.; Hakimi, S.L. On models for diagnosable systems and probabilistic fault diagnosis. IEEE Trans. Comput. 1976, 25, 228–236. [Google Scholar] [CrossRef]
- Wang, T.; Lu, G.L.; Yan, P. Fault diagnosis of rolling bearings based on undirected weighted graph. In Proceedings of the PHM-PARIS 2019, Qingdao, China, 25–27 October 2019. [Google Scholar]
- Drton, M. Discrete chain graph models. Bernoulli 2009, 15, 736–753. [Google Scholar] [CrossRef]
- Lauritzen, S.L.; Wermuth, N. Graphical models for associations between variables, some of which are qualitative and some quantitative. Ann. Statist. 1989, 17, 31–57. [Google Scholar] [CrossRef]
- Lauritzen, S.L. Chain graph models and their causal interpretations. J. R. Statist. Soc. 2002, 64, 321–361. [Google Scholar] [CrossRef]
- Ma, Z.; Xie, X.; Geng, Z. Structural learning of chain graphs via decomposition. J. Mach. Learn. Res. 2008, 9, 2847–2880. [Google Scholar]
- Flaccadoro, D.; Cervellera, C.; Bosia, G.; Riccomagno, E. Modelling of fault detection and diagnostics for hybrid bus using Chain graph models. Qual. Reliab. Eng. Int. 2014, 30, 975–983. [Google Scholar] [CrossRef]
- Song, L.L.; Wang, T.Y.; Song, X.W.; Xu, L.; Song, D.G. Research and application of FTA and Petri nets in fault diagnosis in the pantograph-type current collector on CRH EMU trains. Math. Probl. Eng. 2015, 1–12. [Google Scholar] [CrossRef]
- Ku, B.H.; Cha, J.M. Reliability assessment of electric railway substation by using minimal cut sets algorithm. J. Int. Council Electr. Eng. 2011, 1, 135–139. [Google Scholar] [CrossRef]
- Liu, X.; Shahidehpour, M.; Cao, Y.J.; Li, Z.Y.; Tian, W. Reliability assessment of electric railway substation by using minimal cut sets algorithm. IEEE Trans. Smart Grid 2015, 6, 1073–1081. [Google Scholar] [CrossRef]
- Magott, J.; Skrobanek, P. Timing analysis of safety properties using fault trees with time dependencies and timed state-charts. Reliab. Eng. Syst. Saf. 2012, 97, 14–26. [Google Scholar] [CrossRef]
- Khanh Nguyen, T.P.; Beugin, J.; Marais, J. Method for evaluating an extended fault tree to analyze the dependability of complex systems: Application to a satellite-based railway system. Reliab. Eng. & Syst. Saf. 2015, 133, 300–313. [Google Scholar]
- Jiang, L.; Wang, X.M.; Liu, Y.L. Reliability evaluation of the Chinese train control system level 3 using a fuzzy approach. Proc. I Mech. 2018, 1–16. [Google Scholar] [CrossRef]
- Ouyang, C.D.; Zhang, J.; Zhao, H.M. The application of fuzzy control system model in bearing fault diagnosis. Eng. Eq. Mater. 2020, 10, 131–132. [Google Scholar]
- Zhang, L.L.; Wu, Y. An overview of fuzzy theory. Silicon Valley 2012, 17, 177–178. [Google Scholar]
- Zhang, N.Q.; Yang, S.W.; Xu, Z.Q.; Cui, Y. Fault diagnosis of choke adapter transformer based on rough set and fuzzy inference for high-speed railway. Res. Dev. 2017, 26, 1–5. [Google Scholar]
- Zuo, Z.H.; Wang, K.F.; Wei, Y.H.; Zhao, X. Wireless connection timeout fault diagnosis of Chinese train control system using adaptive neuro-fuzzy inference system. In Proceedings of the CAC 2017, Jinan, China, 20–22 October 2017. [Google Scholar]
- Wang, M.R.; Song, Y.D.; Song, Q.; Han, P. Fuzzy-adaptive fault-tolerant control of high speed train considering traction/braking faults and nonlinear resistive forces. In Proceedings of the ISNN 2011, Guilin, China, 29 May–1 June 2011. [Google Scholar]
- Zadeh, L.A. Fuzzy sets. Inform. Control 1965, 8, 338–353. [Google Scholar] [CrossRef]
- Caesarendra, W.; Pratama, M.; Kosasih, B.; Tjahjowidodo, T.; Glowacz, A. Parsimonious network based on a fuzzy inference system (PANFIS) for time series feature prediction of low speed slew bearing prognosis. Appl. Sci. 2018, 8, 2656. [Google Scholar] [CrossRef]
- Pan, J.; Desouza, G.N. FuzzyShell: A large-scale expert system shell using fuzzy logic for uncertainty reasoning. IEEE Trans. Fuzzy Syst. 1998, 6, 563–581. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method Classification | Reference | Application Scenarios |
|---|---|---|
| Quantitative technique [35] | ||
| Model-based | Cheng [36], Zeng [37], Xu [38], Yang [39], Xue [40], Lei [41], Ma [42], Dai [43], Shui [44], Wang [45], Mellit [46], Liu [47] | Permanent magnet machine [36], electronic systems [39,40,48], planetary gearbox [41], nuclear power plants [42], power generation equipment [49], dynamic systems [50], aerospace systems [51], wind turbine [52] |
| Data driven | Chen [1], Ma [42], Du [49], Huang [53], Yang [54], Henao [55], Niu [56], Norazwan [57], Dai [58] | Traction system [1], nuclear power plants [42], power generation equipment [49], converter [53], aeroengine [54], rotating electrical machines [55], multi-axle speed sensors [56], chemical process systems [57], industrial automation [58] |
| Signal-based | Chen [36], Zeng [37], Xu [38], Yang [39], Xue [40], Lei [41], Ma [42], Dai [43], Shui [44], Wang [45], Mellit [46], Liu [47] | Permanent magnet machine [36], wind turbines [37,38], electric systems [39,40], planetary gearbox [41], nuclear power plants [42], control systems [44], hydraulic systems [43], rotating machines [45], photovoltalic systems [46], squirrel-cage induction motors [47] |
| Neural Network | Liu [14,59], Yan [60], Wang [61,62], Wen [63], Amiruddin [64], Fenton [48], Hu [65], Li [66,67], Chen [68], Xie [69] | Rotating machinery [14,59], servo system [60], turbine [63], engineering-related systems [64], electric systems [48], rolling bearing [65], diesel engine [66], motor engine [68], gas turbine [69], running gear system [67] |
| Machine Learning | Liu [14], Zhang [61], Duan [70], Saufi [62], Hu [66], Li [67] | Rolling bearing [14,65,71], high-speed railway [67] |
| Artificial Intelligence | Mellit [46], Liu [47], Nandi [72], Wen [63] | Photovoltalic systems [46], squirrel-cage induction motors [47], electrical motors [72], turbine [63] |
| Petri Nets | Zaytoon [73], Niu [56] | Discrete event systems [73], multi-axle speed sensors [56] |
| Qualitative technique [35] | ||
| Expert System | Yan [60], Wang [61], Li [66], Chen [68], Xie [69], Lin [59] | Servo system [60], motor engine [68], gas turbine [69], rotating machinery [59], high-speed railway [67] |
| Fuzzy Theory | Wang [61,74], Li [66], Chen [68], Xie [69], Lin [59] | Diesel engine [66], motor engine [68], rotating machinery [59] |
| Knowledge-based | Cheng [36], Yang [39], Xue [40], Du [49], Wang [75] | Permanent magnet machine [36], electric systems [39,40,75], power generation equipment [49] |
| Rule and Case-based | Wang [47], Fenton [48] | Electrical systems [48] |
| Fault Tree | Wang [61], Zaytoon [73], Chen [68] | Discrete event systems [73], motor engine [68] |
| Method | Advantage | Limitation |
|---|---|---|
| RBR | 1. Easy-to-understand forms of reasoning 2. Expression of uncertain knowledge 3. Easy interpretation | 1. Hard to grasp the overall structure of knowledge 2. Unclear relationships among the rules 3. Lack of flexibility in reasoning |
| CBR | 1. The extended coverage of case bases with the continuous use of systems 2. No rule extraction | 1. A complicated knowledge extraction process 2. The low retrieval efficiency in large case base 3. Consistency test of difficult case correction |
| ES | 1. Transparent and interpretable FD procedures 2. No requirements of mathematical equations 3. Easy to determine the fault cause | 1. Lack of the self-learning and self-adaptive ability 2. The slow reasoning speed and low efficiency 3. Not ideal for the real-time performance |
| DG | 1. Processing of various uncertainties via graphs 2. More forms of knowledge expressions 3. No need for other reasoning methods | 1. Easy to lose vital variables in fault propagations 2. Dependent on the experience and simulation 3. Further simplification of the model |
| UG | 1. The expression from global graphic forms | 1. Difficult to accurately locate faults |
| CG | 1. No requirements of mathematical equations 2. Simple and easy to be operated | 1. Complex search procedure 2. Easy to lose information |
| FTA | 1. Good logic performance 2. Easy modeling | 1. High requirements for failure mechanism 2. Weak real-time processing ability |
| Fuzzy Theory | 1. More solutions with different priorities 2. The ability to analyze uncertainty issues | 1. With subjective factors 2. No self-learning ability |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, C.; Wang, J.; Chen, H.; Chen, Z.; Luo, H.; Xie, P. A Review of Intelligent Fault Diagnosis for High-Speed Trains: Qualitative Approaches. Entropy 2021, 23, 1. https://doi.org/10.3390/e23010001
Cheng C, Wang J, Chen H, Chen Z, Luo H, Xie P. A Review of Intelligent Fault Diagnosis for High-Speed Trains: Qualitative Approaches. Entropy. 2021; 23(1):1. https://doi.org/10.3390/e23010001
Chicago/Turabian StyleCheng, Chao, Jiuhe Wang, Hongtian Chen, Zhiwen Chen, Hao Luo, and Pu Xie. 2021. "A Review of Intelligent Fault Diagnosis for High-Speed Trains: Qualitative Approaches" Entropy 23, no. 1: 1. https://doi.org/10.3390/e23010001
APA StyleCheng, C., Wang, J., Chen, H., Chen, Z., Luo, H., & Xie, P. (2021). A Review of Intelligent Fault Diagnosis for High-Speed Trains: Qualitative Approaches. Entropy, 23(1), 1. https://doi.org/10.3390/e23010001