1. Introduction
Forecasting stock prices is an attractive pursuit for investors and researchers who want to beat the stock market. The benefits of having a good estimation of the stock market behavior are well-known, minimizing the risk of investment and maximizing profits. Recently, the stock market has become an easily accessible investment tool, not only for strategic investors, but also for ordinary people. Over the years, investors and researchers have been interested in developing and testing models of stock price behavior. However, analyzing stock market movements and price behaviors is extremely challenging because of the market’s dynamic, nonlinear, non–stationary, nonparametric, noisy, and chaotic nature [
1]. Stock markets are affected by many highly interrelated uncertain factors that include economic, political, psychological, and company-specific variables. These uncertain factors are undesirable for the stock investor and make stock price prediction very difficult, but at the same time, they are also unavoidable whenever stock trading is preferred as an investment tool [
1,
2]. To invest in stocks and achieve high profits with low risks, investors have used technical and fundamental analysis as two major approaches in decision-making in financial markets [
2].
Fundamental analysis studies all of the factors that have an impact on the stock price of the company in the future such as financial statements, management processes, industry, etc. It analyzes the intrinsic value of the firm to identify whether the stock is underpriced or overpriced. On the other hand, technical analysis uses past charts, patterns, and trends to forecast the price movements of the entity in the coming time [
2,
3]. The main weakness of fundamental analysis is that it is time-consuming as people cannot quickly locate and absorb the information needed to make thoughtful stock picks. People’s judgments are subjective, as is their definition of fair value. The second drawback of a fundamental analysis is in relation to the efficient market hypothesis. Since all information about stocks is public knowledge—barring illegal insider information—stock prices reflect that knowledge.
A major advantage of technical analysis is its simple logic and application. It is seen in the fact that it ignores all economic, market, technological, and any other factors that may have an impact on the company and the industry and only focuses on the data on prices and the volume traded to estimate future prices. The second advantage of technical analysis is that it excludes the subjective aspects of certain companies such as the analyst’s personal expectations [
4]. However, technical analysis may get an investor trapped: when price movements are artificially created to lure an investor into the stock and once enough investors are entered, they start selling, and you may be trapped. Furthermore, it is too reliant on mathematics and patterns in the chart of the stock and ignores the underlying reasons or causes of price movements. As a result, the stock movements are too wild to handle or predict through technical analysis.
There exist two types of forecasting techniques to be implemented [
5,
6]: (a) qualitative forecasting models; and (b) quantitative forecasting models. The qualitative forecasting models are generally subjective in nature and are mostly based on the opinions and judgments of experts. Such types of methods are generally used when there is little or no past data available that can be used to base the forecast. Hence, the outcome of the forecast is based upon the knowledge of the experts regarding the problem. On the other hand, quantitative forecasting models make use of the data available to make predictions into the future. The model basically sums up the interesting patterns in the data and presents a statistical association between the past and current values of the variable. Management can use qualitative inputs in conjunction with quantitative forecasts and economic data to forecast sales trends. Qualitative forecasting is useful when there is ambiguous or inadequate data. The qualitative method of forecasting has certain disadvantages such as anchoring events and selective perception. Qualitative forecasts enable a manager to decrease some of this uncertainty to develop plans that are fairly accurate, but still inexact. However, the lack of precision in the development of a qualitative forecast versus a quantitative forecast ensures that no single qualitative technique produces an accurate forecast every time [
2,
4,
7,
8,
9,
10].
In nearly two decades, the fuzzy time series approach has been widely used for its superiorities in dealing with imprecise knowledge (like linguistic) variables in decision making. In the process of forecasting with fuzzy time series models, the fuzzy logical relationship is one of the most critical factors that influence the forecasting accuracy. Many studies seek to deploy neuro-fuzzy inference to the stock market in order to deal with probability. Fuzzy logic is known to be useful for decision-making where there is a great deal of uncertainty as well as vague phenomena, but lacks the learning capability; on the other hand, neural networks are useful in constructing an adaptive system that can learn from historical data, but are not able to process ambiguous rules and probabilistic datasets. It is tedious to develop fuzzy rules and membership functions and fuzzy outputs can be interpreted in a number of ways, making analysis difficult. In addition, it requires a lot of data and expertise to develop a fuzzy system.
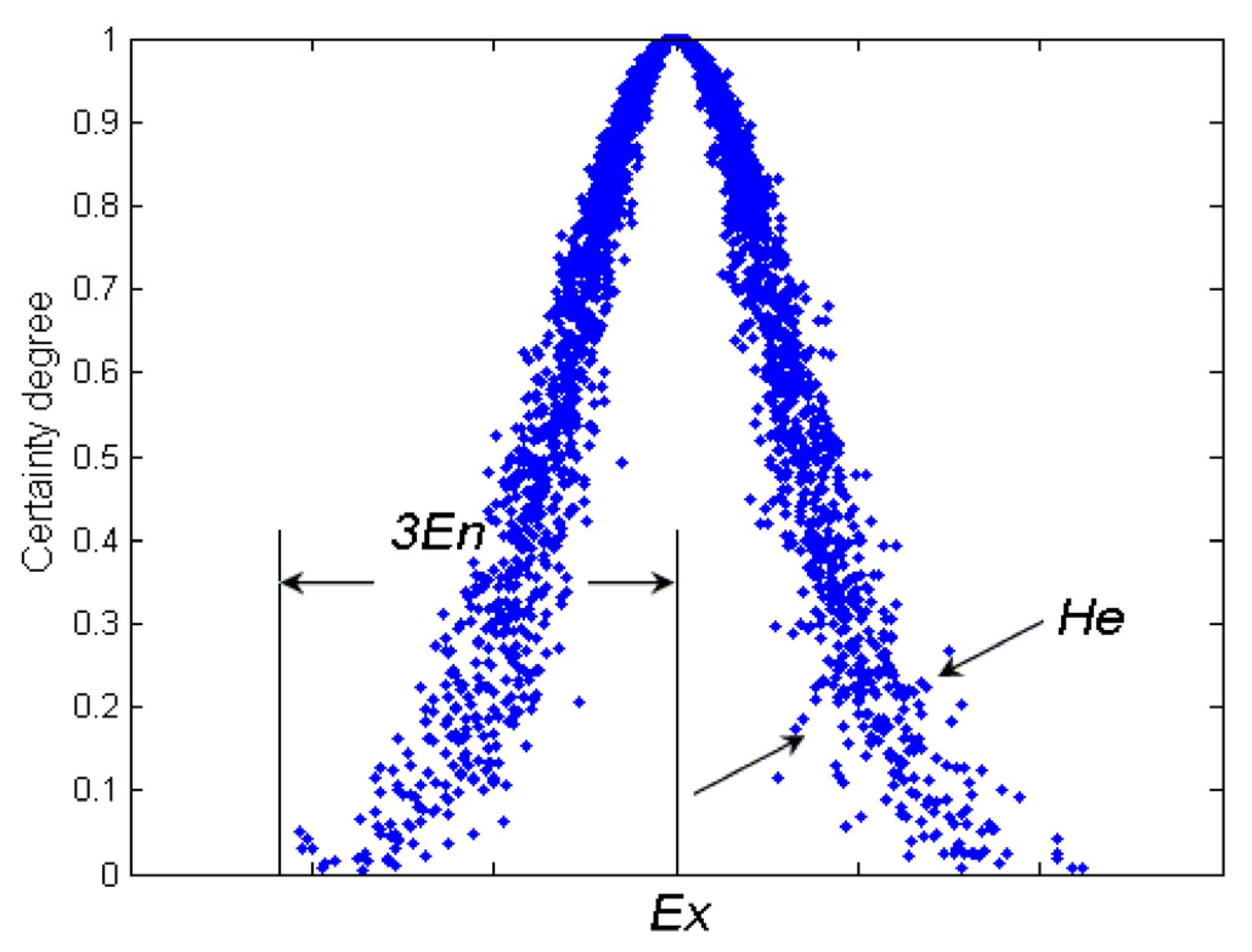
Recently, a probabilistic fuzzy set was suggested for forecasting by introducing probability theory into a fuzzy set framework. It changes the secondary MF of type 2 fuzzy into the probability density function (PDF), so it is able to capture the random uncertainties in membership degree. It has the ability to capture uncertainties with fuzzy and random nature. However, the membership functions are difficult to obtain for existing fuzzy approaches of measurement uncertainty. In order to conquer this disadvantage, the cloud model was used to calculate the measurement uncertainty. A cloud is a new, easily visualized concept for uncertainty with well-defined semantics, mediating between the concept of a fuzzy set and that of a probability distribution [
11,
12,
13,
14,
15,
16]. A cloud model is an effective tool in transforming qualitative concepts and their quantitative expressions. The digital characteristics of cloud, expect value (
Ex), entropy (
En), and hyper–entropy (He), well integrate the fuzziness and randomness of linguistic concepts in a unified way. Cloud is combined with several cloud drops in which the shape of the cloud reflects the important characters of the quantity concept [
17]. The essential difference between the cloud model and the fuzzy probability concept lies in the used method to calculate a random membership degree. Basically, with the three numerical characteristics, the cloud model can randomly generate a degree of membership of an element and implement the uncertain transformation between linguistic concepts and its quantitative instantiations.
Candlestick patterns provide a way to understand which buyer and seller groups currently control the price action. This information is visually represented in the form of different colors on these charts. Recently, several traders and investors have used the traditional Japanese candlestick chart pattern and analyzed the pattern visually for both quantitative and qualitative forecasting [
6,
7,
8,
9,
10]. Heikin–Ashi candlesticks are an offshoot from Japanese candlesticks. Heikin–Ashi candlesticks use the open–close data from the prior period and the open–high–low–close data from the current period to create a combo candlestick. The resulting candlestick filters out some noise in an effort to better capture the trend.
1.1. Problem Statement
The price variation of the stock market is a non–linear dynamic system that deals with non–stationary and volatile data. This is the reason why its modeling is not a simple task. In fact, it is regarded as one of the most challenging modeling problems due to the fact that prices are stochastic. Hence, the best way to predict the stock price is to reduce the level of uncertainty by analyzing the movement of the stock price. The main motivation of our work was the successful prediction of stock future value that can yield enormous capital profits and can avoid potential market risk. Several classical approaches have been evolved based on linear time series models, but the patterns of the stock market are not linear. These approaches lead to inaccurate results, which may be susceptible to highly dynamic factors such as macroeconomic conditions and political events. Moreover, the existing qualitative based methods developed based on fuzzy reasoning techniques cannot describe the data comprehensively, which has greatly limited the objectivity of fuzzy time series in uncertain data forecasting. The most important disadvantage of the fuzzy time series approach is that it needs subjective decisions, especially in the fuzzification stage.
1.2. Contribution and Novelty
The objective of the work presented in this paper is to construct an accurate stock trend prediction model through utilizing a combination of the cloud model, Heikin–Ashi candlesticks, and fuzzy time series (FTS) in a unified model. The purpose of the cloud model is to add the randomness and uncertainty to the fuzziness linguistic definition of Heikin–Ashi candlesticks. FTS is utilized to abstract linguistic values from historical data, instead of numerical ones, to find internal relationship rules. Heikin–Ashi candlesticks were employed to give easier readability of the candle’s features through the reduction of noise, eliminates the gaps between candles, and smoothens the movement of the market.
As far as the authors know, this is the first time that the cloud model has been used in forecasting stock market trends that is unlike the current methods that adopt a fuzzy probability approach for forecasting that requires an expert to define the extra parameters of the probabilistic fuzzy system such as output probability vector in probabilistic fuzzy rules and variance factor. These selected statistical parameters specify the degree of randomness. The cloud model not only focuses on the studies regarding the distribution of samples in the universe, but also try to generalize the point–based membership to a random variable on the interval [0, 1], which can give a brand new method to study the relationship between the randomness of samples and uncertainty of membership degree. More practically speaking, the degree with the aid of three numeric characteristics, by which the transformation between linguistic concepts and numeric values will become possible.
The outline of the remainder of this paper is as follows.
Section 2 presents the background and summary of the state-of-the-art approaches.
Section 3 describes the proposed model. The test results and discussion of the meaning are shown in
Section 4. The conclusion of this work is given in
Section 5.
3. Proposed Model
The purpose of the study is to predict and confirm accurate stock future trends due to a lack of insufficient levels of accuracy and certainty. However, there are many problems in previous studies. The main problems in data are uncertainty, noise, non-linearity, non-stationary, and dynamic process of stock prices in time series. In the prediction model, many models are used. The statistical method like the ARMA family is achieved with the trial and error basis iterations. Traders also have problems that include predicting the stock price every day, finding the reversal patterns of the stock price, the difficulty in model parameter tuning, and finally, the gap exists between prediction results and investment decision. Additionally, traditional candlestick patterns have problems such as the definition of the patterns itself being ambiguous and the largest number of patterns.
In order to deal with the above problems, the suggested prediction model uses both cloud model and Heikin–Ashi (HA) candlestick patterns.
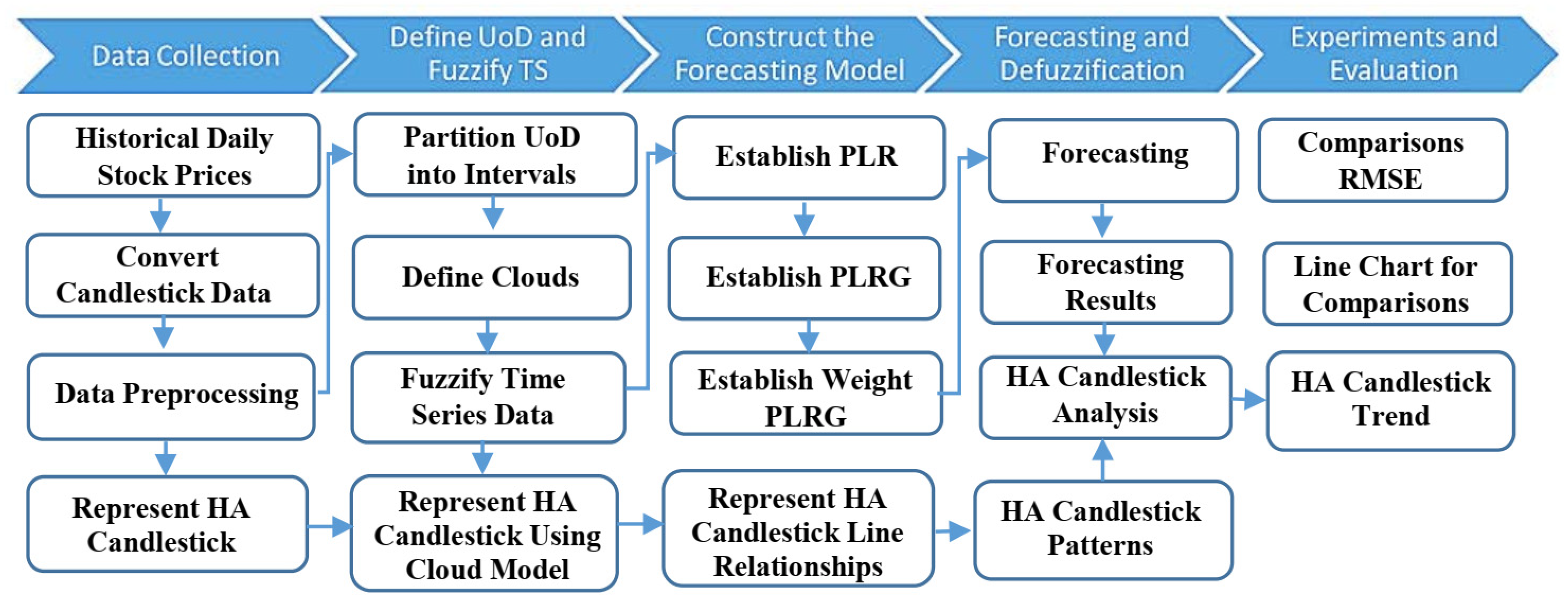
Figure 5 illustrates the main steps of the suggested model that include preparing historical data, HA candlestick processing, representing the HA candlestick using the cloud model, forecasting the next day price (open, high, low, close) using cloud–based time series prediction, formalizing the next day HA candlestick features, and finally, forecasting the trend and its strong patterns. The following subsection discusses each step in detail [
9].
3.1. Step 1: Preparing the Historical Data
The publicly available stock market datasets contain historical data on the four price time series for several companies were collected from Yahoo (
http://finance.yahoo.com). The dataset specifies the “opening price, lowest price, closing price, highest price, adjusted closing price, and volume” against each date. The data were divided into two parts: the training part and the testing part. The training part from the time series data was used for the formulation of the model while the testing part was used for the validation of the proposed model.
3.2. Step 2: Candlestick Data
The first stage in stock market forecasting is the selection of input variables. The two most common types of features that are widely used for predicting the stock market are fundamental indicators and technical indicators. The suggested model used technical indicators that are determined by employing candlestick patterns such as open price, close price, low price, and high price to try to find future stock prices [
5,
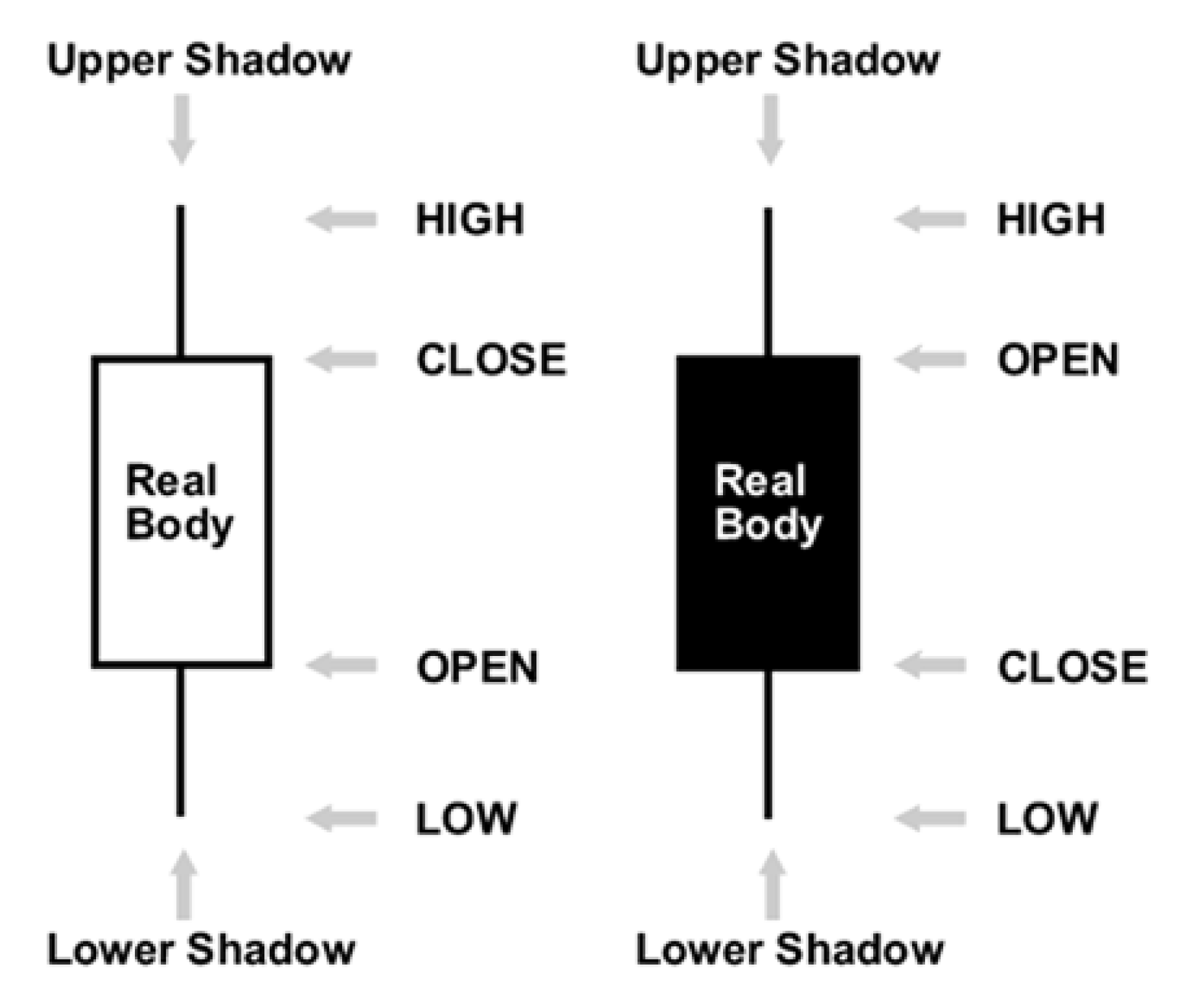
6]. A standard candlestick pattern is composed of one or more candlestick lines. However, the extended candlestick (Heikin–Ashi) patterns have one candlestick line. The HA candlestick uses the modified OHLC values as candlesticks that are calculated using [
5]:
Herein, each candlestick line has the following parameters: length of the upper shadow, length of the lower shadow, length of the body, color, open style, and close style. The open style and close style are formed by the relationship between a candlestick line and its previous candlestick line. The crisp value of the length of the upper shadow, length of the lower shadow, length of the body, and color play an important role in identifying a candlestick pattern and determining the efficiency of the candlestick pattern. The candlestick parameters are directly calculated using [
9,
10].
where
HaL indicates the length of the body, upper shadow, or lower shadow of the HA candlestick. The
HaCOLOR parameter represents the mean body color of the HA candlestick. Heikin–Ashi candlesticks are similar to conventional ones, but rather than using opens, closes, highs, and lows, they use average values for these four price metrics.
In stock market prediction, the quality of data is the main factor because the accuracy and the reliability of the prediction model depends upon the quality of data. Any unwanted anomalies in the dataset are known as noise. Outliers are the set of observations that do not obey the general behavior of the dataset. The presence of noise and outliers may result in poor prediction accuracy of forecasting models. The data must be prepared so that it covers the range of inputs for which the network is going to be used. Data pre-processing techniques attempt to reduce errors and remove outliers, hence improving the accuracy of prediction models. The purpose of HA charts is to filter noise and provide a clearer visual representation of the trend. Heikin–Ashi has a smoother look, as it is essentially taking an average of the movement [
9,
10].
3.3. Step 3: Cloud Model-Based Candlestick Representation
There is no crisp value to define the length of body and shadow in the HA candlestick; these variables are usually described as imprecise and vague. Herrin, to transform crisp candlestick parameters (HA quantitative values) to linguistic variables to define the candlestick (qualitative value), the cloud model was used. To achieve this goal, fuzzy HA candlestick pattern ontology was built that contains [
4,
8]:
- -
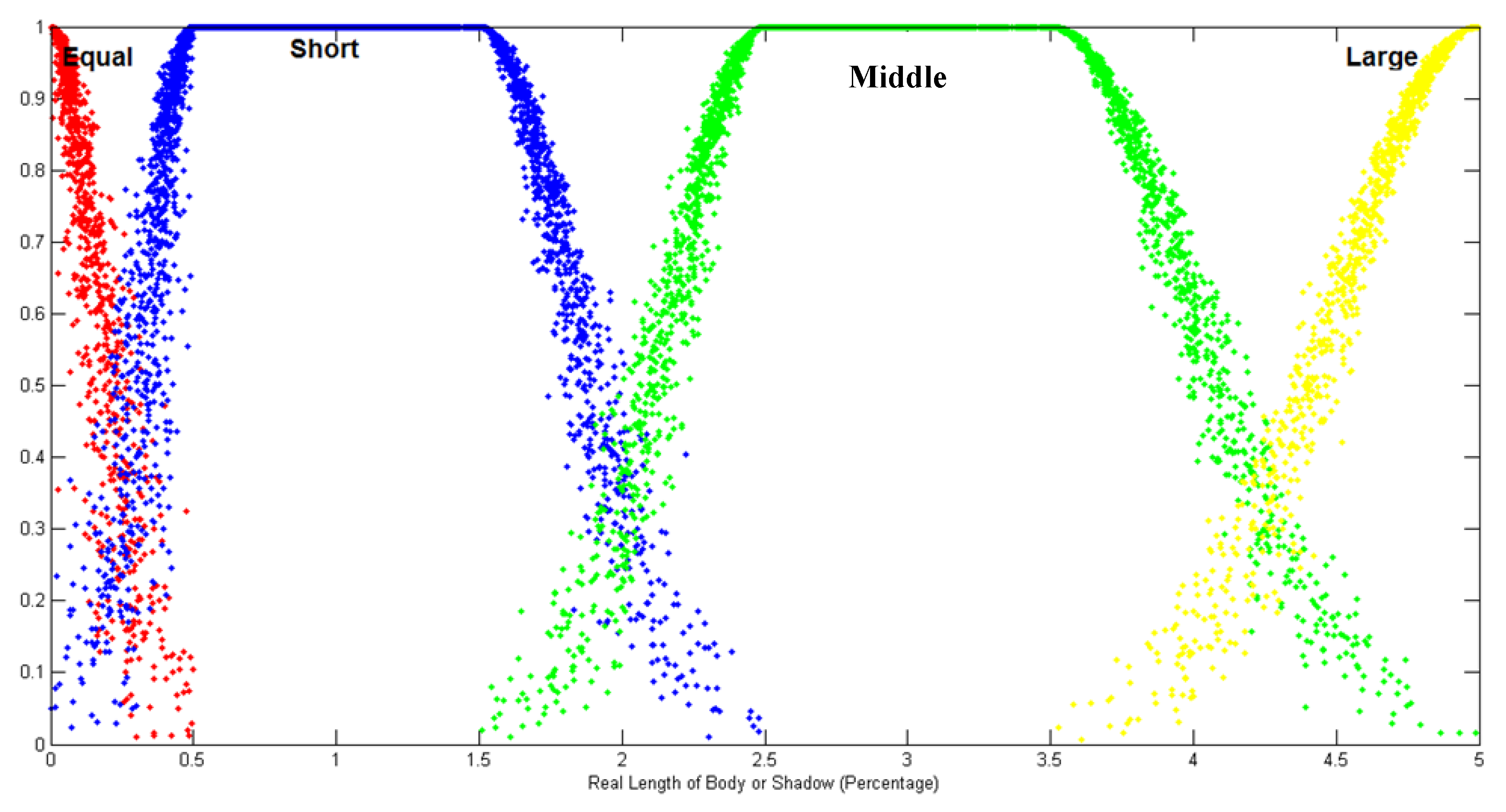
Candlestick Lines: Four fuzzy linguistic variables, equal, short, middle, and long, were defined to indicate the cloud model of the shadows and the body length.
Figure 6 shows the membership function of the linguistic variables based on the cloud model, then used the maximum μ(x) to determine its linguistic variable. The ranges of body and shadow length were set to (0, p) to represent the percentage of the fluctuation of stock price. The parameter value of each fuzzy linguistic variable was set as stated in [
8]. See [
8] for more details regarding the rationale of using these values. These fuzzy linguistic variables are defined as:
The body color
is also an import feature of a candlestick line. It is defined by three terms Black, White, and Doji. A Doji term is defined to describe the situation where the open price equals the close price. In this case, the height of the body is 0, and the shape is represented by a horizontal bar. The definition of body color is defined as [
10]:
- -
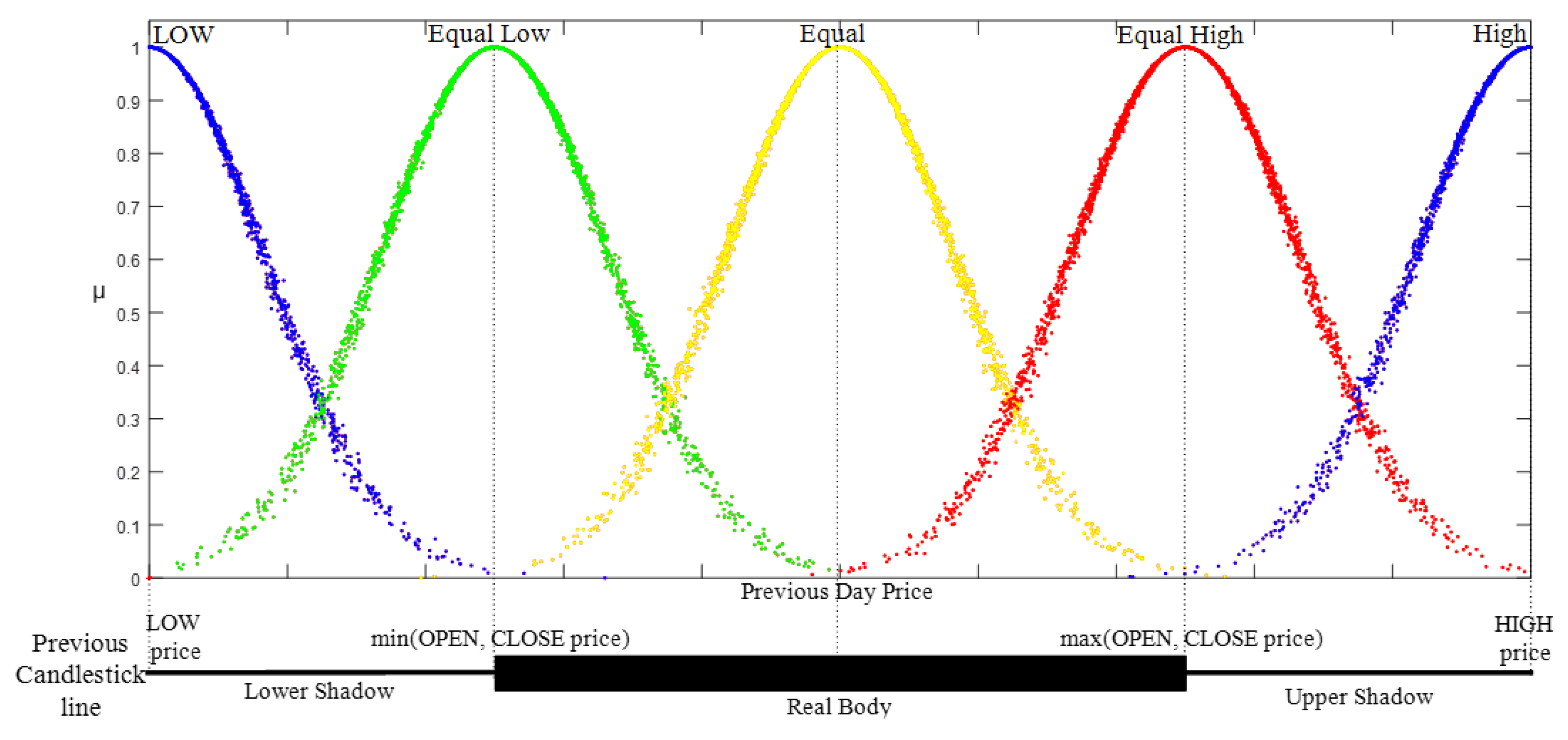
Candlestick Lines Relationships: This defines the place of the HA candlestick with the previous one to form open style and close style linguistic variables. In general, merging the description of the candlestick line and HA candlestick line relationship can create a HA candlestick pattern that is completely defined. Herein, five linguistic variables were defined to represent the relationship style (X style): low, equal low, equal, equal high, and high. Their membership function follows half bell cloud defined in Equation (7). Additionally, the parameter value of each fuzzy linguistic variable was set as stated in [
8].
Figure 7 shows the membership function of the linguistic variable based on the cloud model:
In our case, membership cloud function (forward normal cloud generator) converts the statistic results to fuzzy numbers, and constructs the one–to–many mapping model. The input of the forward normal cloud generator is three numerical characteristics of a linguistic term, (Ex, En, He), and the number of cloud drops to be generated, N, while the output is the quantitative positions of N cloud drops in the data space and the certain degree that each cloud drop can represent the linguistic term. The algorithm in detail is:
- -
Produce a normally distributed random number En’ with mean En and standard deviation He;
- -
Produce a normally distributed random number x with mean Ex and standard deviation En’;
- -
Calculate Y =
- -
Drop (x,y) is a cloud drop in the universe of discourse; and
- -
Repeat step 1–4 until N cloud drops are generated.
Expectation value (
Ex) at the center-of-gravity positions of cloud drops is the central value of distribution. Entropy (
En) is the fuzzy measure of qualitative concept that describes the uncertainty and the randomness. The larger the entropy, the larger the acceptable interval of this qualitative concept, which represents that this conception is more fuzzy. Hyper entropy (He) is the uncertain measure of qualitative concept that describes the dispersion. The larger the hyper entropy, the thicker the shape of the cloud, which shows that this conception is more discrete [
20,
21].
– Forecast the next day price (open, high, low, close)
In the fuzzy candlestick pattern approach, the measured values are the open, close, high, and low price of trading targets in a specific time period. The features of the trading target price fluctuation are represented by the fuzzy candlestick pattern. The classification rules of fuzzy candlestick patterns can be determined by the investors or the computer system. In general, using a candlestick pattern approach for financial time series prediction consists of the following steps [
21]:
- -
Partitioning the universe of discourse into intervals: In this case, after preparing the historical data and defining the range of the universe of discourse (UoD), open, high, low, and close prices should be established as a data price set for each one. Then, for each data price set, the variation percentage between two prices on time and time is calculated to partition the universe of discourse dataset into intervals. Based on the variation, the minimum variation and the maximum variation are determined that define , where and are suitable positive numbers.
- -
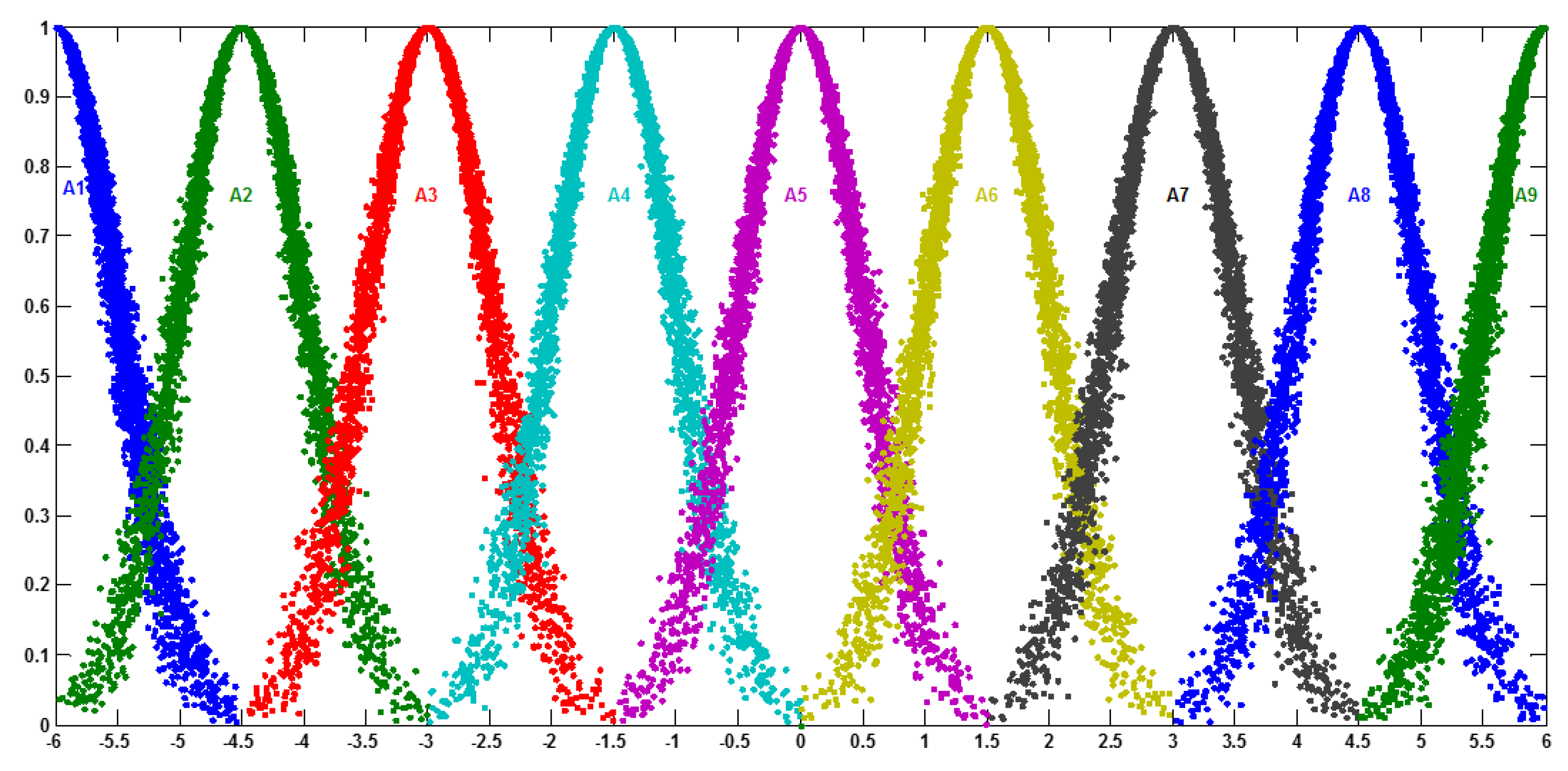
Classifying the historical data to its cloud: The next step determines the linguistic variables represented by clouds (see
Figure 8) to describe the degree of variation between data of time
and time
and defined it as a set of linguistic terms.
Table 1 shows the digital characteristics of the cloud member function (
Ex,
En,
He) for each linguistic term.
- -
Building the predictive logical relationships (PLR): The model builds the PLR to carry on the soft inference , where and are clouds representing linguistic concepts, by searching all clouds in time series with the pattern ().
- -
Building of predictive linguistic relationship groups (PLRG): In the training dataset, all PLRs with the same “current state” will be grouped into the same PLRG. If , ,⋯, is the “current state” of one PLR in the training dataset and there are r PLRs in the training dataset as; ; …. ;, the r PLRs can be grouped into the same PLRG, as . Then, assign the weight elements for each PLRG. Assume has relationships with , relationships with , and so on. The weight values (w) can be assigned as wi = (number of recurrence of Ai)/(total number of PLRs).
- -
Calculating the predicted value via defuzzification: Then the model forecasts the next day (open, high, low, close) prices through defuzzification and calculates the predicted value at time t P(t) by following the rule:
- ✔
Rule 1: If there is only one PLR in the PLRG, (
) then,
- ✔
Rule 2: If there is
r PLR in the PLRG, (
) then,
- ✔
Rule 3: If there is no PLR in the PLRG, () where the symbol “#” denotes an unknown value; then apply Equation (8). is the expectation of the Gaussian cloud corresponding to, is the number of appearing in the PLRG, 1 ≤ i ≤ r, and S(t − 1) denotes the observed value at time t – 1.
- -
Transforming the forecasting results (open, high, low, and close) to the next HA candlestick. through the following rules [
9]:
- ✔
Rule 1: If is White and is Long Then, UP Trend.
- ✔
Rule 2: If is Black and is Long Then, Down Trend.
- ✔
Rule 3: If is White and is Long and is Equal Then, Strong UP Trend.
- ✔
Rule 4: If is Black and is Long and is Equal Then, Strong Down Trend.
- ✔
Rule 5: If ( is Equal) and ( & ) is Long Then Change of Trend.
- ✔
Rule 6: If ( is Short) and ( & ) is not Equal Then, Consolidation Trend.
- ✔
Rule 7: If ( is Short or Equal) and (_Style and _Style) is (Low_Style or EqualLow_Style) and is Equal Then Weaker Trend.
4. Experimental Results
In order to test the efficiency and validity of the proposed model, the model was implemented in MATLAB language. The prototype verification technique was built in a modular fashion and has been implemented and tested in a Dell™ Inspiron™ N5110 Laptop machine, Dell computer Corporation, Texas, which had the following features: Intel(R) Core(TM) i5–2410M CPU@ 2.30GHz, and 4.00 GB of RAM, 64–bit Windows 7. A dataset composed of real-time stocks series of the NYSE (New York Stock Exchange) was used in the experimentation. The dataset had 13 time series of NYSE companies, each one with the four prices (open, high, low, and close). Time series were downloaded from the Yahoo finance website (
http://finance.yahoo.com),
Table 2 shows the companies’ names, symbol, and starting date and ending date for the selected dataset. The dataset was divided into 2/3 for training and the other 1/3 for testing.
In the proposed forecasting model, the parameters were set as follows: the ranges of body (p) and shadow length were set to (0, 14) to represent the percentage of the fluctuation of stock price because the varying percentages of the stock prices are limited to 14 percent in the Taiwanese stock market, for example. It should be noted that although we limited the fluctuation of body and shadow length to 14 percent, in other applications, the designer can change the range of the fluctuation length to any number [
4]. The four parameters (a–d) of the function to describe the linguistic variables SHORT and MIDDLE were (0, 0.5, 1.5, 2.5) and (1.5, 2.5, 3.5, 5). The parameters (a, b) that were used to model the EQUAL fuzzy set were equal to (0, 0.5). Regarding the two parameters
and
, which are used to determine the UOD, we can set
= 0:17 and
= 0:34, so the UoD can be represented as [
6,
8]. Finally, the number of drops in the cloud model used to build the membership function is usually equal to the number of samples in the dataset to describe the data efficiently. The mean squared error (MSE) and mean absolute percentage error (MAPE) that are used by academicians and practitioners [
4,
21] were used to evaluate the accuracy of the proposed method.
Table 3,
Table 4,
Table 5 and
Table 6 show the output of applying each model step for the Yahoo dataset.
The suggested model was verified with respect to the RMS on both the training and testing data. The predicted prices of the model were found to be correct and close to the actual prices. There was a clear difference between the MSE values for the training and testing data, showing that the model was overfitting the training data as the error on the training dataset was minimized. The reason for this is that the model was not as generalized and was specialized to the structure in the training dataset. Using cross validation represents one possible way to handle overfitting, and using multiple runs of cross validation is better again. The model RMS is summarized in
Table 7.
Table 8 shows the comparison results between our two versions of the suggested model: the first one uses open, high, low, and close price as the initial price in the cloud FTS model (Cloud FTS) and the second method uses HaOpen, HaHigh, HaLow, and HaClose prices as the initial price in the cloud FTS model (HA Cloud FTS), and other two standard Song fuzzy time series (FTS) [
13,
14] and Yu weighted fuzzy time series (WFTS) models [
23]. In Song’s studies, the fuzzy relationships were treated as if they were equally important, which might not have properly reflected the importance of each individual fuzzy relationship in forecasting. In Yu’s study, it is recommended that different weights be assigned to various fuzzy relationships. From
Table 8, the MSE of the forecasting results of the proposed model was smaller than that of the other methods for all datasets. That is, the proposed model could obtain a higher forecasting accuracy rate for forecasting stock prices than the Song FTS and Yu WFTS models. In general, the MSE values changed according to the nature of each dataset. It can be noted from the table that the Wells Fargo dataset yielded the best results in terms of RMS for both the training and testing data. In general, the Wells Fargo dataset is a small dataset (2,313 row and 12 column) that is probably linearly separable, so it produced high accuracy. This is a bit difficult to accomplish with larger data, so the algorithm produced lower accuracy.
One possible explanation of these results is that, compared with standard models that use FTS only, utilizing FTS with the cloud model helps to automatically produces random membership grades of a concept through a cloud generator. In this way, the membership functions are built based on the characteristics of the data instead of traditional fuzzy–based forecasting methods that depend on the expert. From the point of view of the importance of using HA candlesticks with the cloud model for forecasting, utilizing the HA candlesticks showed significant features that could identify market turning points and also the direction of the trend that helps improve prediction accuracy.
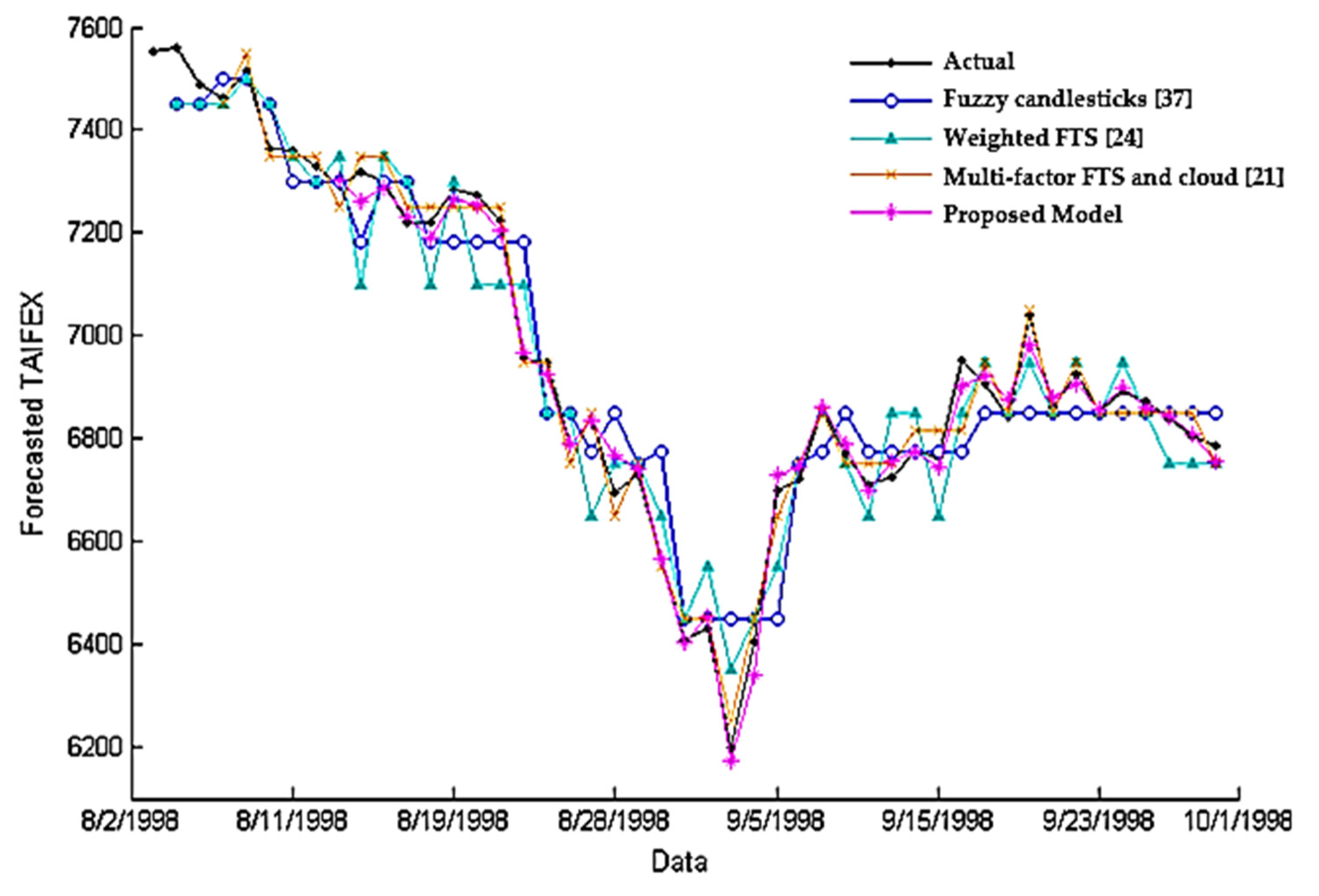
The last set of experiments was fulfilled to validate the efficiency of the suggested model compared to state-of-the-art models listed in
Figure 9 using the Taiwan Capitalization Weighted Stock Index (TAIEX). The data used for comparison were obtained from a website
https://www.twse.com.tw/ that provided the stock prices prevailing at the NASDAQ stock quotes. As shown in
Figure 9, the proposed model can perform effective prediction where the predicted stock price closely resembles the actual price in the stock market. The MSE of the suggested model was 665.40 compared with 1254.90, 4530.45, and 4698.78 for the other methods, respectively. Clearly, the suggested model had a smaller MSE than the previous methods. One of the reasons for this result is due to the merging between the cloud model and HA candlesticks, which makes it possible to account for the vagueness and uncertainty of the pattern features based on data characteristics.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}