1. Introduction
The deep supervised classifiers demonstrate an impressive performance when the amount of labeled data is large. However, their performance significantly deteriorates with the decrease of labeled samples. Recently, semi-supervised classifiers based on deep generative models such as VAE (M1 + M2) [
1], AAE [
2], CatGAN [
3], etc., along with several other approaches based on multi-view and contrastive metrics just to mention the most recent ones [
4,
5], are considered to be a solution to the above problem. Besides the remarkable reported results, the information theoretic analysis of semi-supervised classifiers based on generative models and the role of different priors aiming to fulfil the gap in the lack of labeled data remain little studied. Therefore, in this paper we will try to address these issues using IB principle [
6] and practically compare different priors on the same architecture of classifier.
Instead of considering the latent space of generative models such as VAE (M1 + M2) [
1] and AAE [
2] trained in the unsupervised way as suitable features for the classification, we will depart from the IB formulation of supervised classification, where we consider an encoder-decoder formulation of classifier and impose priors on its latent space. Thus, we study an approach to semi-supervised classification based on an IB formulation with a variational decomposition of IB compression and classification mutual information terms. To deeper understand the role and impact of different elements of variational IB on the classification accuracy, we consider two types of priors on the latent space of classifier: (i) hand-crafted and (ii) learnable priors.
Hand-crafted latent space priors impose constraints on a distribution of latent space by fitting it to some targeted distribution according to the variational decomposition of the compression term of the IB. This type of latent space priors is well known as an information dropout [
7]. One can also apply the same variational decomposition to the classification term of the IB, where the distribution of labels is supposed to follow some targeted class distribution to maximize the mutual information between inferred labels and targeted ones. This type of class label space regularization reflects an adversarial classification used in AAE [
2] and CatGAN [
3]. In contrast,
learnable latent space priors aim at minimizing the need in human expertise in imposing priors on the latent space. Instead, the learnable priors are learned directly from unlabeled data using auto-encoding (AE) principle. In this way, the learnable priors are supposed to compensate the lack of labeled data in the semi-supervised learning yet minimizing the need in the hand-crafted control of the latent space distribution.
We demonstrate that several state-of-the-art models such as AAE [
2], CatGAN [
3], VAE (M1 + M2) [
1], etc., can be considered to be instances of the variational IB with the learnable priors. At the same time, the role of different regularizers in the hand-crafted semi-supervised learning is generalized and linked to known frameworks such as information dropout [
7].
We evaluate our model using standard dataset MNIST on both hand-crafted and learnable features. Besides revealing the impact of different components of variational IB factorization, we demonstrate that the proposed model outperforms prior works on this dataset.
Our main contribution is three-fold: (i) We propose a new formulation of IB for the semi-supervised classification and use a variational decomposition to convert it into a practically tractable setup with learnable parameters. (ii) We develop the variational IB for two classes of hand-crafted and learnable priors on the latent space of classifier and show its link to the state-of-the-art semi-supervised methods. (iii) We investigate the role of these priors and different regularizers in the classification, latent and reconstruction spaces for the same fixed architecture under the different amount of training data.
2. Related Work
Regularization techniques in semi-supervised learning: Semi-supervised learning tries to find a way to benefit from a large number of unlabeled samples available for training. The most common way to leverage unlabeled data is to add a special regularization term or some mechanism to better generalize to unseen data. The recent work [
8] identifies three ways to construct such a regularization: (i) entropy minimization, (ii) consistency regularization and (iii) generic regularization. The entropy minimization [
9,
10] encourages the model to output confident predictions on unlabeled data. In addition, more recent work [
3] extends this concept to adversarially generated samples or fakes for which the entropy of class label distribution was suggested to be maximized. Finally, the adversarial regularization of label space was considered in [
2], where the discriminator was trained to ensure the labels produced by the classifier follow a prior distribution, which was defined to be a categorical one. The consistency regularization [
11,
12] encourages the model to produce the same output distribution when its inputs are perturbed. Finally, the generic regularization encourages the model to generalize well and avoid overfitting the training data. It can be achieved by imposing regularizers and corresponding priors on the model parameters or feature vectors.
In this work, we implicitly use the concepts of all three forms of considered regularization frameworks. However, instead of adding additional regularizers to the baseline classifier as suggested by the framework in [
8], we will try to derive the corresponding counterparts from a semi-supervised IB framework. In this way, we will try to justify their origin and investigate their impact on overall classification accuracy for the same system architecture.
Information bottleneck: In the recent years, the IB framework [
6] is considered to be a theoretical framework for analysis and explanation of supervised deep learning systems. However, as shown in [
13], the original IB framework faces several practical issues: (i) for the deterministic deep networks, either the IB functional is infinite for network parameters, that leads to the ill-posed optimization problem, or it is piecewise constant, hence not admitting gradient-based optimization methods, and (ii) the invariance of the IB functional under bijections prevents it from capturing properties of the learned representation that are desirable for classification. In the same work, the authors demonstrate that these issues can be partly resolved for stochastic deep networks, networks that include a (hard or soft) decision rule, or by replacing the IB functional with related, but more well-behaved cost functions. It is important to mention that the same authors also note that rather than trying to repair the inherent problems in the IB functional, a better approach may be to design regularizers on latent representation enforcing the desired properties directly.
In our work, we extend these ideas using variational approximation approach suggested in [
14] and that was also applied to unsupervised models in the previous work [
15,
16]. More particularly, we extend the IB framework to the semi-supervised classification and as discussed above we will consider two different ways of regularization of the latent space of classifier, i.e., either using traditional hand-crafted priors or suggested learnable priors. Although we do not consider the semi-supervised clustering and conditional generation in this work, the proposed findings can be extended to these problems in a way similar to prior works such as AAE [
2], ADGM [
17] and SeGMA [
18].
The closest works: The proposed framework is closely related to several families of semi-supervised classifiers based on generative models. VAE (M1 + M2) [
1] combines latent-feature discriminative model M1 and generative semi-supervised model M2. A new latent representation is learned using the generative model from M1 and subsequently a generative semi-supervised model M2 is trained using embeddings from the first latent representation instead of the raw data. Semi-supervised AAE classifier [
2] is based on the AE architecture, where the encoder of AE outputs two latent representations: one representing class and another style. The latent class representation is regularized by an adversarial loss forcing it to follow categorical distribution. It is claimed that it plays an essential role for the overall classification performance. The latent style representation is regularized to follow Gaussian distribution. In both cases of VAE and AAE, the mean square error (MSE) metric is used for the reconstruction space loss. CatGAN [
3] is an extension of GAN and is based on an objective function that trades-off mutual information between observed examples and their predicted categorical class distribution, against robustness of the classifier to an adversarial generative model.
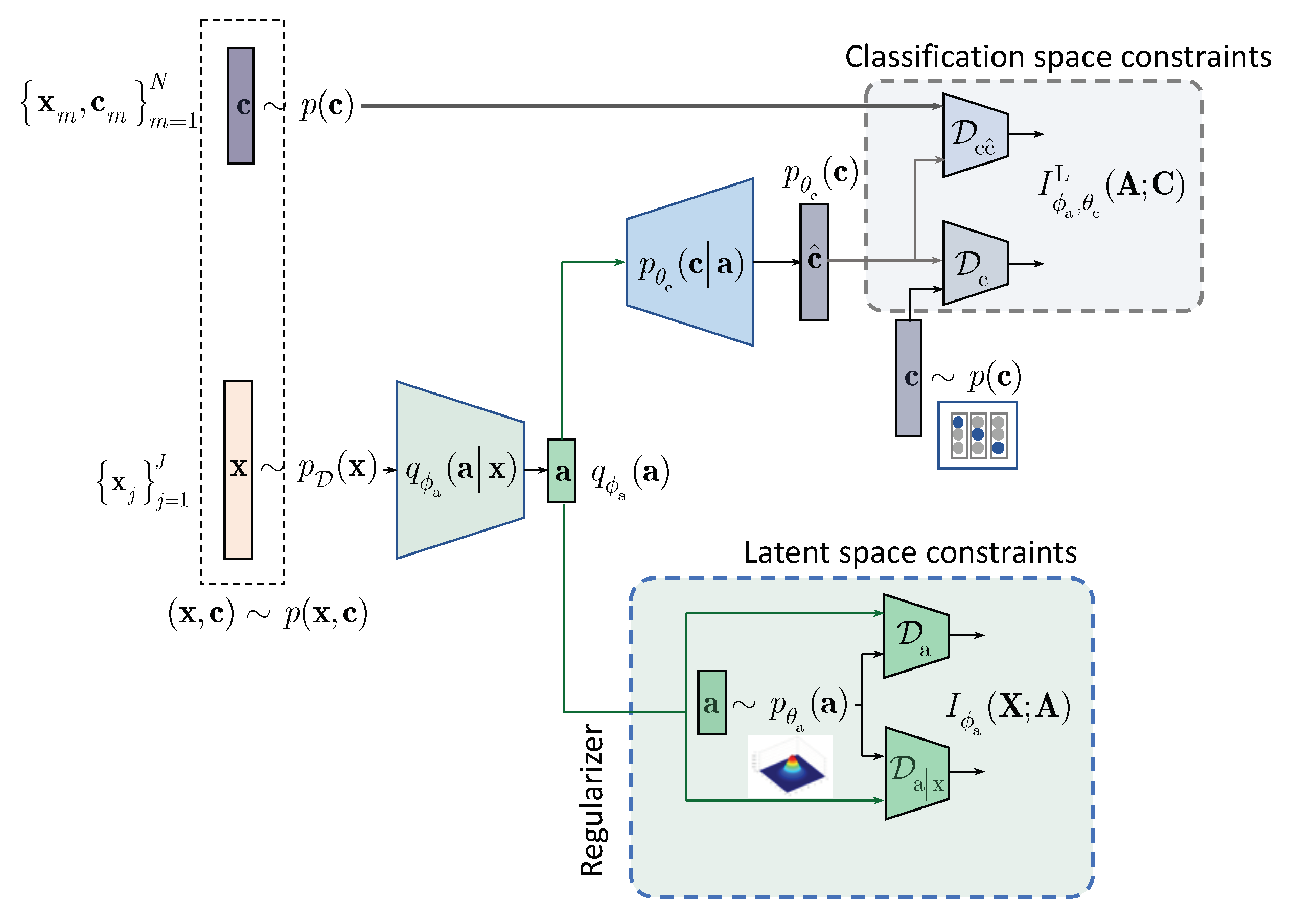
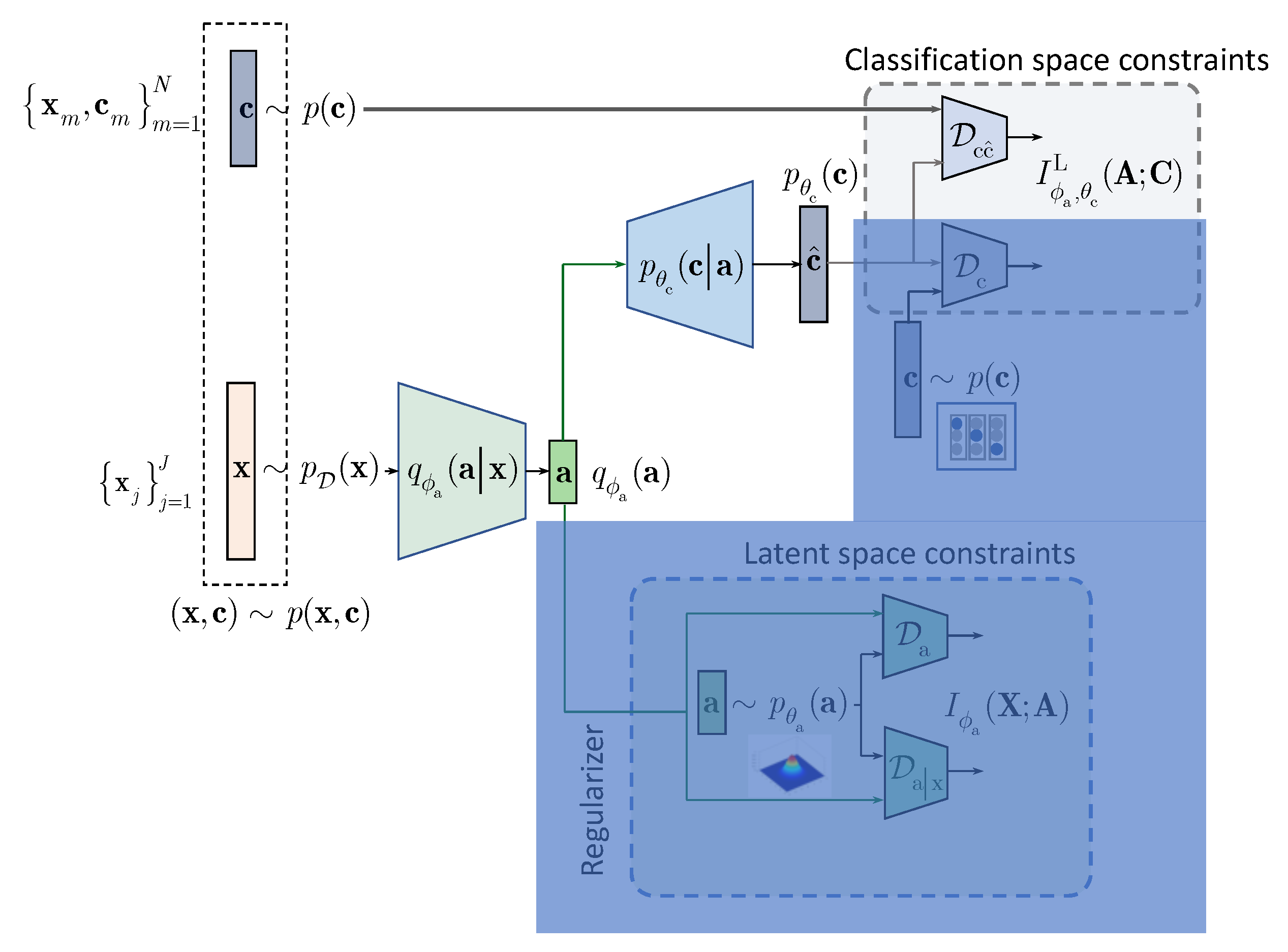
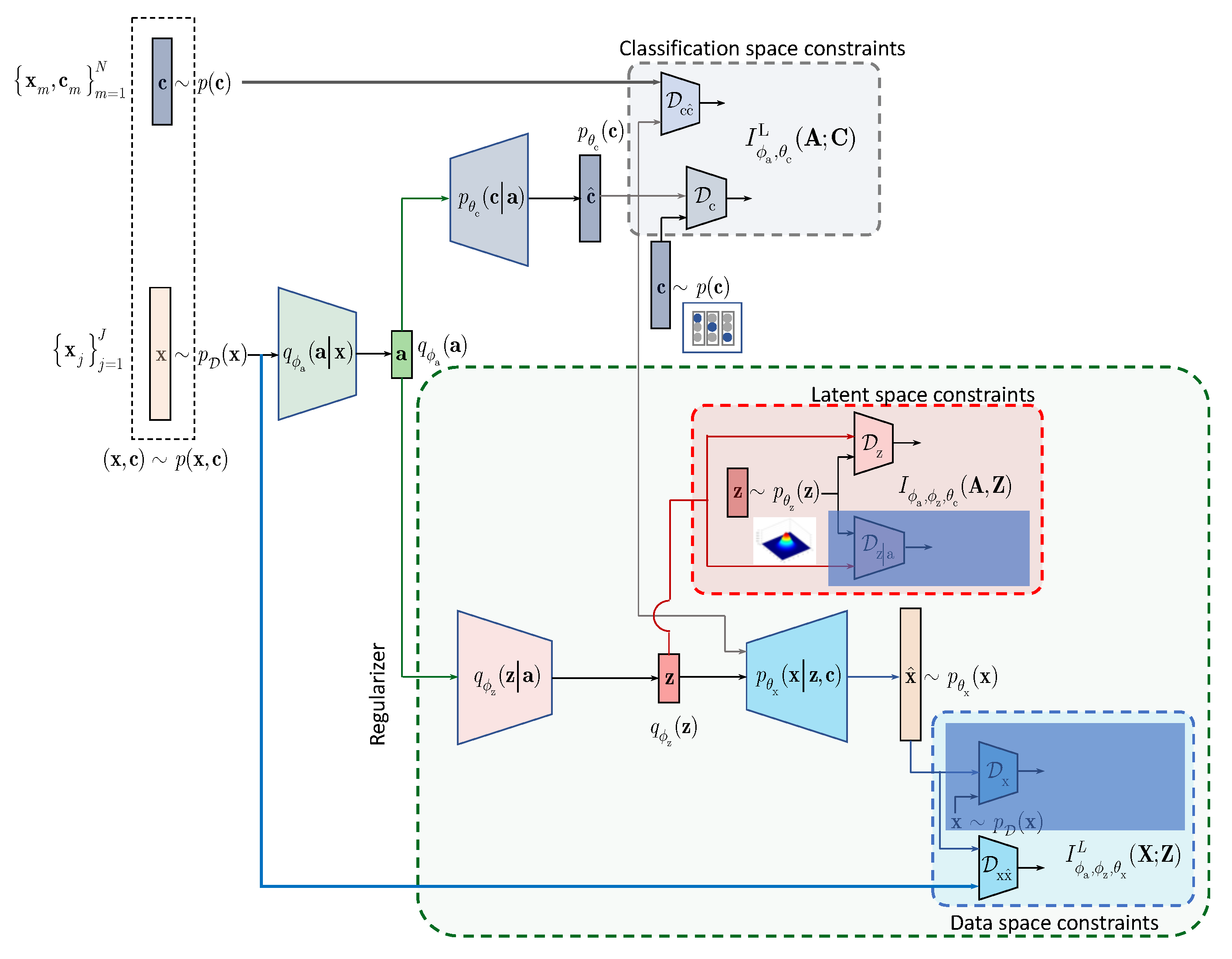
In contrast to the above approaches and following the IB framework, we formulate the semi-supervised classification problem as a training of classifier that aims at compressing the input
to some latent data
via an encoding that is supposed to retain only class relevant information that is controlled by a decoder as shown in
Figure 1. If the amount of labeled data is sufficiently large, the supervised classifier can achieve this goal. However, when the amount of labeled examples is small such an encoder-decoder pair representing an IB-driven classifier is regularized by a latent space and adversarial label space regularizers to fill the gap in training data. The adversarial label space regularization was already used in AAE and CatGAN. The latent space regularization in the scope of IB framework was reported in [
7]. In this paper, we demonstrate that both label and latent space regularizations are instances of the generalized IB formulation developed in
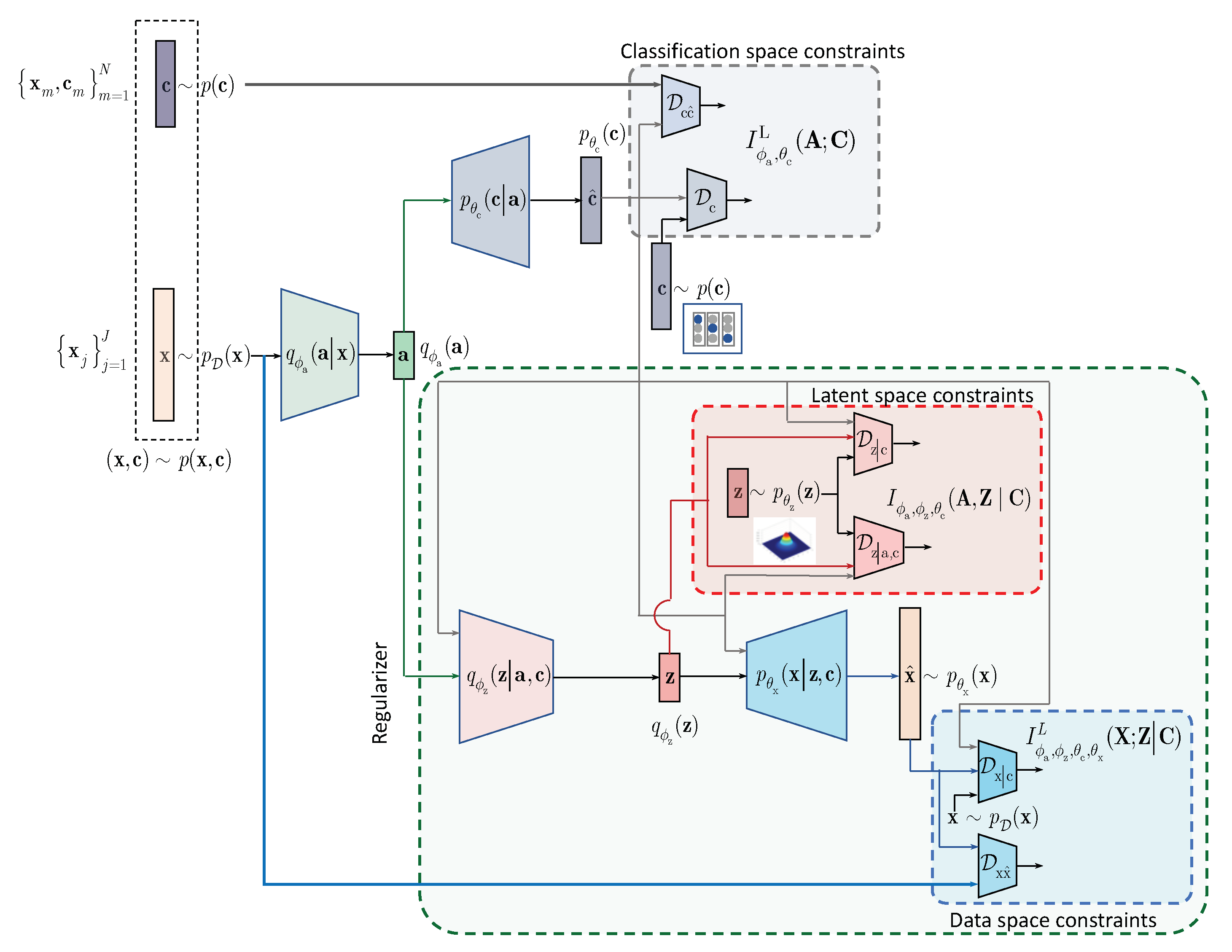
Section 3. At the same time, in contrast to the hypothesis that the considered label space and latent space regularizations are the driving factors behind the success of semi-supervised classifiers, we demonstrate that the hand-crafted priors considered in these models cannot completely fulfil the lack of labelled data and lead to relatively poor performance in comparison to a fully supervised system based on a sole cross-entropy metric. For these reasons, we analyze another mechanism of regularization of latent space based on learnable priors as shown in
Figure 2 and developed in
Section 4. Along this line, we provide an IB formulation of AAE and explain the driving mechanisms behind its success as an instance of IB with learnable priors. Finally, we present several extensions that explain the IB origin and role of adversarial regularization in the reconstruction space.
Summary: The considered methods of semi-supervised learning can be differentiated based on: (i) the targeted tasks (auto-encoding, clustering, generation or classification that can be accomplished depending on available labeled data); (ii) the architecture in terms of the latent space representation (with a single representation vector or with multiple representation vectors); (iii) the usage of IB or other underlying frameworks (methods derived from the IB directly or using regularization techniques); (iv) the label space regularization (based on available unlabeled data, augmented labeled data, synthetically generated labeled and unlabeled data, especially designed adversarial examples); (v) the latent space regularization (hand-crafted regularizers and priors or learnable priors under the reconstruction and constrastive setups) and (vi) the reconstruction space regularization in case of reconstruction setup (based on unlabeled and labeled data, augmented data under certain perturbations, synthetically generated examples).
In this work, our main focus is the latent space regularization for the hand-crafted and learnable priors under the reconstruction setup within the IB framework. Our main task is the semi-supervised classification. We will not consider any augmentation and adversarial techniques besides a simple stochastic encoding based on the addition of data independent noise at the system input or even deterministic encoding without any form of augmentation. The regularization of the label space and reconstruction space is solely based on the terms derived from the IB framework and only includes available labeled and unlabeled data without any form of augmentation. In this way, we want to investigate the role and impact of the latent space regularization as such in the IB-based semi-supervised classification. The usage of the above mentioned techniques of augmentation should be further investigated and will likely provide an additional performance improvement.
3. IB with Hand-Crafted Priors (HCP)
We assume that a semi-supervised classifier has an access to
training labeled samples, where
denotes
data sample and
corresponding encoded class label from the set
, generated from the joint distribution
, and non-labeled data samples
with
. To integrate the knowledge about the labeled and non-labeled data at training, one can formulate the IB as:
where
denotes the latent representation,
is a Lagrangian multiplier and the IB terms are defined as
and
.
According to the above IB formulation the encoder is trained to minimize the mutual information between and while ensuring that the decoder can reliably decide on labels from the compressed representation . The trade-off between the compression and recognition terms is controlled by . Thus, it is assumed that the information retained in the latent representation represents the sufficient statistics for the class labels .
However, since optimal
is unknown, the second term
is lower bounded by
using a variational approximation
:
where
and the inequality follows from the fact that
. We denote the term
. Thus,
.
Thus, the IB (
1) can be reformulated as:
The considered IB is schematically shown in
Figure 1 and we will proceed next with the detailed development of each component of the IB formulation.
3.1. Decomposition of the First Term: Hand-Crafted Regularization
The first mutual information term
in (
3) can be decomposed using a factorization by a parametric marginal distribution
that represents a prior on the latent representation
:
where the first term denotes the KL-divergence
and the term denotes the KL-divergence
.
It should be pointed out that the encoding
can be both stochastic or deterministic.
Stochastic encoding can be implemented via: (a)
multiplicative encoding applied to the input
as
or in the latent space
, where
is the output of the encoder, ⊙ denotes the element-wise product and
follows some data independent or data dependent distribution as in information dropout [
7]; (b)
additive encoding applied to the input
as
with the data independent perturbations, e.g., such as in PixelGAN [
19], or in the latent space with generally data-dependent perturbations of form
, where
and
are outputs of the encoder and
is assumed to be a zero mean unit variance vector such as in VAE [
1] or (c)
concatenative/mixing encoding that is generally applied at the input of encoder. Deterministic encoding is based on the mapping
, i.e., no randomization is introduced, e.g., such as one of encoding modalities of AAE [
2].
3.2. Decomposition of the Second Term
In this section, we factorize the second term in (
3) to address the semi-supervised training, i.e., to integrate the knowledge of both non-labeled and labeled data available at training:
with
denoting a cross-entropy between
and
, and
to be a KL-divergence between the prior class label distribution
and the estimated one
. One can assume different forms of labels’
encoding but one of the most often used forms is one-hot-label encoding that leads to the categorical distribution
.
Finally, the conditional entropy is defined as .
Since
, one can lower bound (
5) as
where:
3.3. Supervised and Semi-Supervised Models with/without Hand-Crafted Priors
Summarizing the above variational decomposition of (
3) with the terms (
4) and (
6), we will proceed with four practical scenarios.
Supervised training without latent space regularization (baseline): is based on term
in (
6)
Semi-supervised training without latent space regularization is based on terms
and
in (
6):
Supervised training with latent space regularization is based on term
in (
6) and either term
or
or jointly
and
in (
4):
Semi-supervised training with latent space regularization deploys all terms in (
4) and (
6):
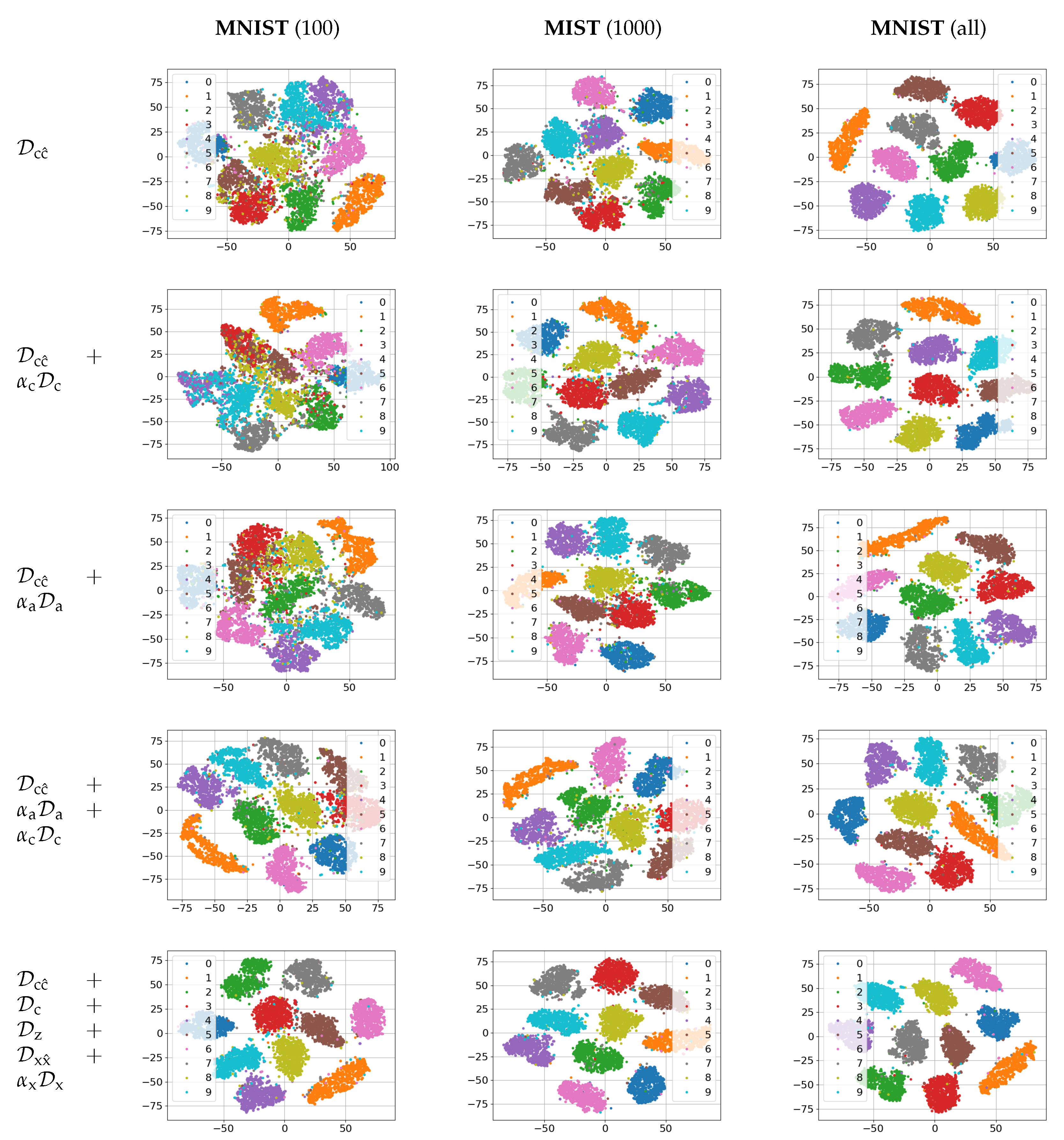
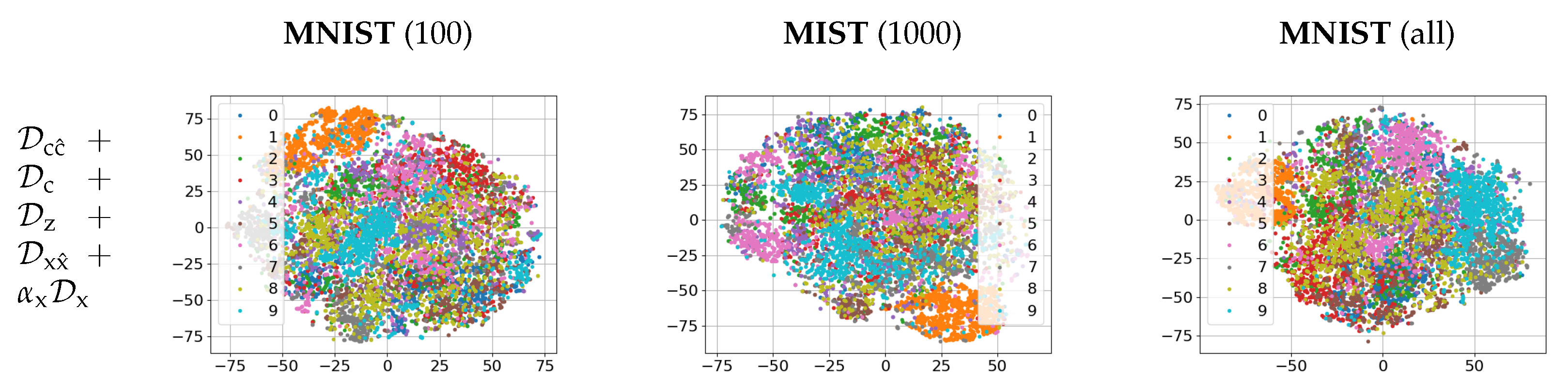
The empirical evaluation of these setups on MNIST dataset is given in
Section 5. The same architecture of encoder and decoder was used to establish the impact of each term in a function of available labeled data.
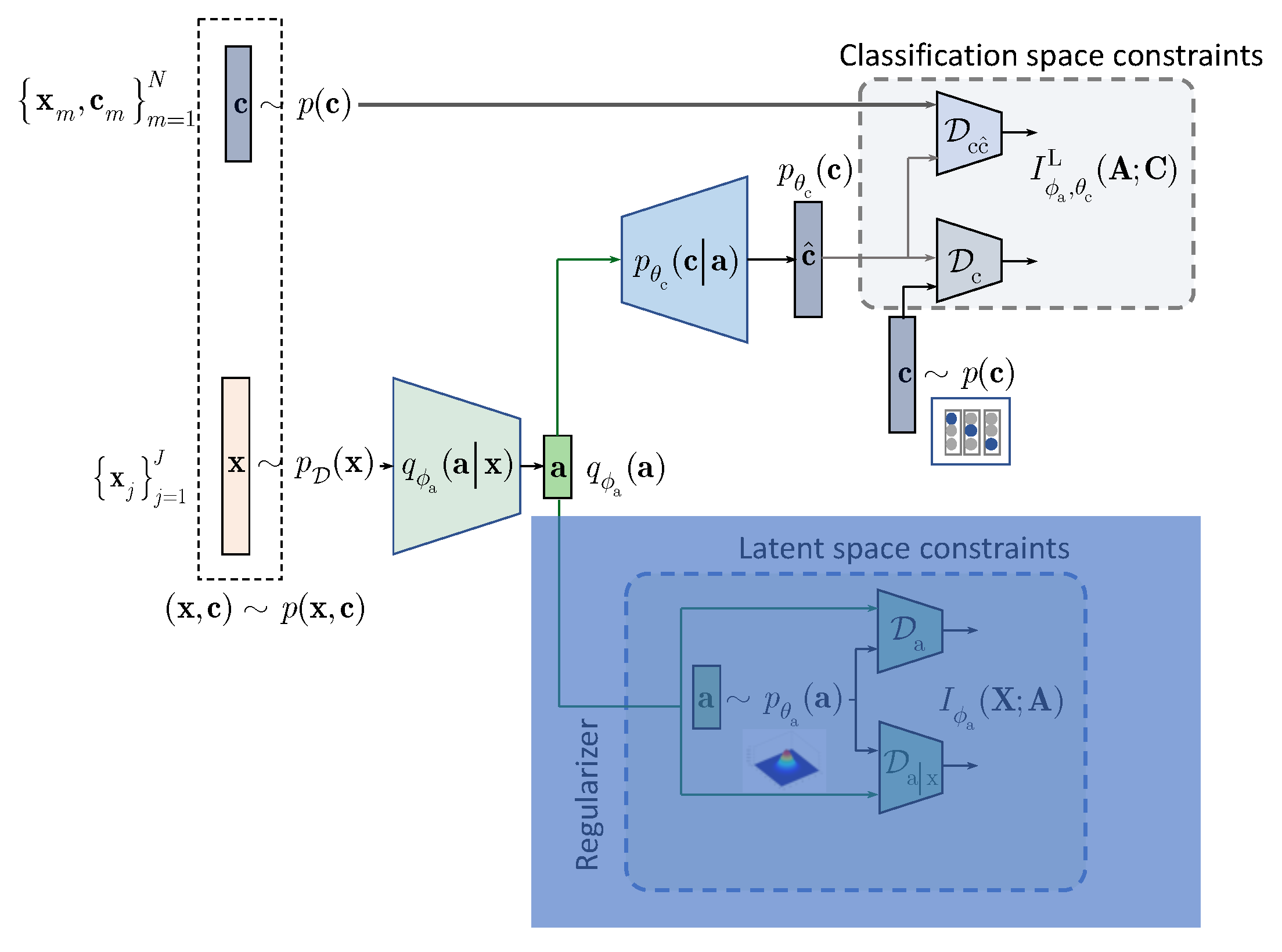
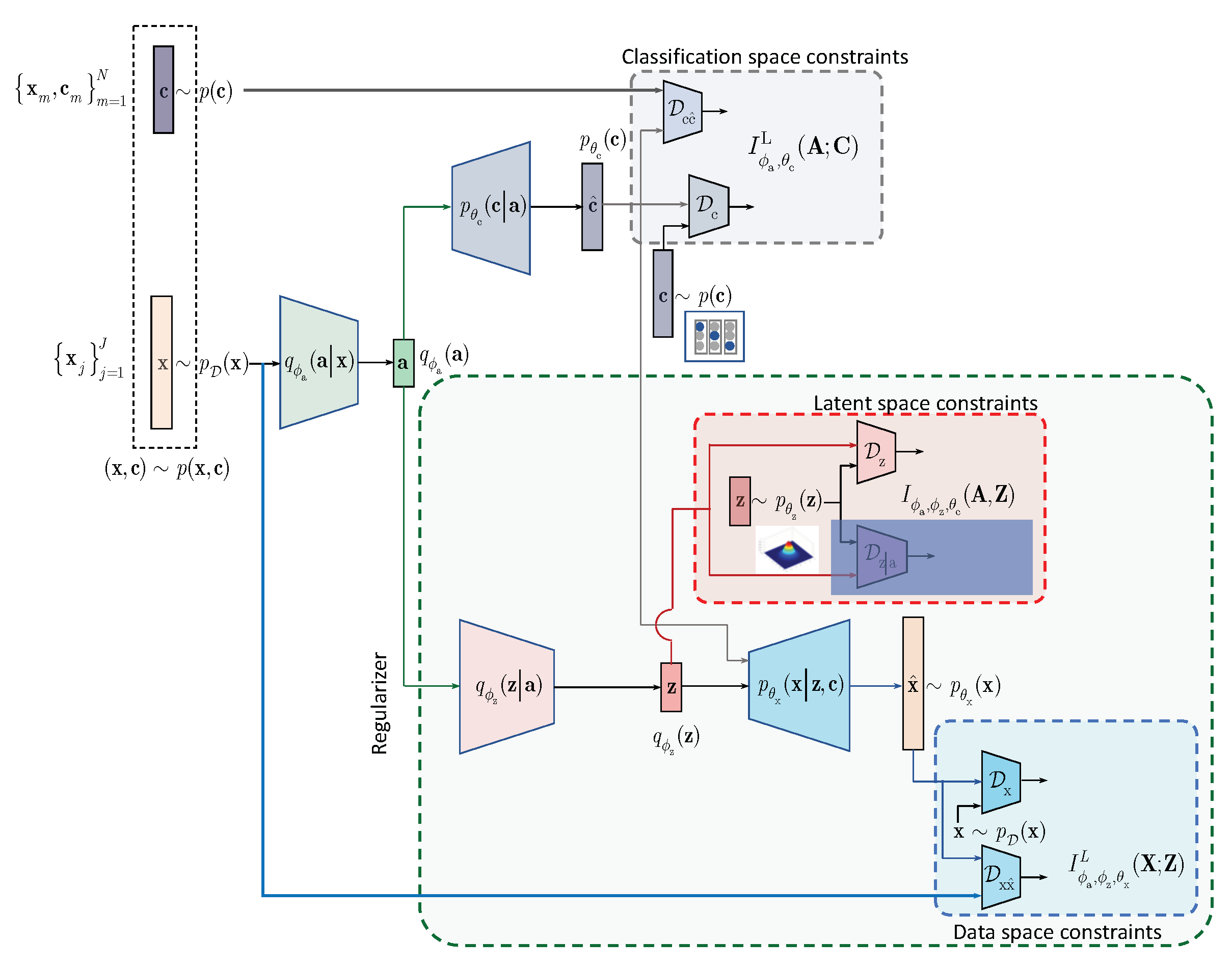
4. IB with Learnable Priors (LP)
In this section, we extend the results obtained for the hand-crafted priors to the learnable priors. Instead of applying the hand-crafted regularization of the latent representation
as suggested by the IB (
3) and shown in
Figure 1, we will assume that the latent representation
is regularized by an especially designed AE as shown in
Figure 2. The AE-based regularization has two components: (i) the latent space
regularization and (ii) the observation space regularization. The design and training of this latent space regularizer in a form of the AE is guided by its own IB. In the general case, all elements of AE, i.e., its encoder-decoder pair, latent and observation space regularizers are conditioned by the learned class label
. The resulting Lagrangian with the learnable prior is (formally one should consider
for the term A. However, since
due to the Markovianity of considered architecture, we consider the decomposition starting from
[
20], Data Processing Inequality, Theorem 2.8.1):
where
is a Lagrangian multiplier controlling the reconstruction of
at the decoder and
is the same as in (
1).
The terms A and B, conditioned by the class
, play a role of the latent space regularizer by imposing the learnable constrains on the vector
. These two terms correspond to the hand-crafted counterpart
in (
3). The term C in the learnable IB formulation corresponds to the classification part of hand-crafted IB in (
3) and can be factorized along the same lines as in (
6). Therefore, we will proceed with the factorization of terms A and B.
One can also consider the following IB formulation with the learnable priors with no conditioning on
in term A in (
11) leading to an unconditional counterpart D below that can be viewed as an IB generalization of semi-supervised AAE [
2]:
4.1. Decomposition of Latent Space Regularizer
We will denote
and decompose the term A in (
11) using variational factorization as:
where
and
denote the KL-divergence terms and
.
4.2. Decomposition of Reconstruction Space Regularizer
Denoting
, we decompose the term B in (
11) as:
where
. The terms are defined as
,
and
. Since
, we can lower bound
.
4.3. Semi-Supervised Models with Learnable Priors
Summarizing the above variational decomposition of (
11) with the terms (
13) and (
14), we will consider semi-supervised training with latent space regularization as:
To create a link to the semi-supervised AAE [
2], we also consider (
12), where all latent and reconstruction space regularizers are independent of
, i.e., do not contain conditioning on
.
Semi-supervised training with latent space regularization and MSE reconstruction based on (
12):
where
.
Semi-supervised training with latent space regularization and with MSE and adversarial reconstruction based on (
12) deploys all terms:
where
.
4.4. Links to State-Of-The-Art Models
The considered HCP and LP models can be linked with several state-of-the-art unsupervised models such VAE [
21,
22],
-VAE [
23], AAE [
2] and BIB-AE [
15] and semi-supervised models such as AAE [
2], CatGAN [
3], VAE (M1 + M2) [
1] and SeGMA [
18].
4.4.1. Links to Unsupervised Models
The proposed LP model (
11) generalizes unsupervised models without the categorical latent representation. In addition, the unsupervised models in a form of the auto-encoder are used as a latent space regularizer in the LP setup. For these reasons, we will briefly consider four models of interest, namely VAE,
-VAE, AAE, and BIB-AE.
Before we proceed with the analysis, we will define an unsupervised IB for these models. We will assume the fused encoders
and
without conditioning on
in the inference model according to
Figure 2. We also assume no conditionally on
in the generative model.
The Lagrangian of unsupervised IB is defined according to [
15]:
where similarly to the supervised counterpart (
4), we define the first term as:
and similarly to (
14) the second term is defined as:
where the definition of all terms should follow from the above equations. Since
, we can lower bound
.
Having defined the unsupervised IB variational bounded decomposition, we can proceed with an analysis of the related state-of-the-art methods along the lines of analysis introduced in Summary part of
Section 2.
The targeted tasks: auto-encoding and generation.
The architecture in terms of the latent space representation: the encoder outputs two vectors representing the mean and standard deviation vectors that control a new latent representation , where and are outputs of the encoder and is assumed to be a zero mean unit variance Gaussian vector.
The usage of IB or other underlying frameworks: both VAE and
-VAE use evidence lower bound (ELBO) and are not derived from the IB framework. However, it can be shown [
15] that the Lagrangian (
18) can be reformulated for VAE and
VAE as:
where
for VAE. It can be noted that the VAE and
-VAE are based on an upper bound on the mutual information term
, since
. Similar considerations apply to the second term since
.
The label space regularization: does not apply here due to the unsupervised setting.
The latent space regularization: is based on the hand-crafted prior with Gaussian pdf.
The reconstruction space regularization in case of reconstruction loss: is based on the mean square error (MSE) counterpart of that corresponds to the Guassian likelihood assumption.
The targeted tasks: auto-encoding and generation.
The architecture in terms of the latent space representation: the encoder outputs one vector in stochastic or deterministic way as .
The usage of IB or other underlying frameworks: AAE is not derived from the IB framework. As shown in [
15], the AAE equivalent Lagrangian (
18) can be linked with the IB formulation and defined as:
where
in the original AAE formulation. It should be pointed out that the IB formulation of AAE contains the term
, whose origin can be explained in the same way as for the VAE. Despite the fact that the term
indeed appears in (
22) with the opposite sign, it cannot be interpreted either as an upper bound on
similarly to the VAE or as a lower bound. The goal of AAE is to minimize the reconstruction loss or to maximize the log-likelihood by ensuring that the latent space marginal distribution
matches the prior
. The latter corresponds to the minimization of
, i.e.,
term.
The label space regularization: does not apply here due to the unsupervised setting.
The latent space regularization: is based on the hand-crafted prior with zero mean unit variance Gaussian pdf for each dimension.
The reconstruction space regularization in case of reconstruction loss: is based on the MSE.
The targeted tasks: auto-encoding and generation.
The architecture in terms of the latent space representation: the encoder outputs one vector using any form of stochastic or deterministic encoding.
The usage of IB or other underlying frameworks: the BIB-AE is derived from the unsupervised IB (
18) and its Lagrangian is defined as:
The label space regularization: does not apply here due to the unsupervised setting.
The latent space regularization: is based on the hand-crafted prior with Gaussian pdf applied to both conditional and unconditional terms. In fact, the prior for can be any but requires analytical parametrisation.
The reconstruction space regularization in case of reconstruction loss: is based on the MSE counterpart of and the discriminator . This is a disctintive feature in comparison to VAE and AAE.
In summary, BIB-AE includes VAE and AAE as two particular cases. In turns, it should be clear that the regularizer of semi-supervised model considered in this paper resembles the BIB-AE model and extends it to the conditional case that will be considered below.
4.4.2. Links to Semi-Supervised Models
The proposed LP model (
11) is also related to several state-of-the-art semi-supervised models used for the classification. As pointed out in the introduction, we only consider available labeled and unlabeled samples in our analysis. The extension to the augmented samples, i.e., permutations, syntehtically generated samples, i.e., fakes, and the adversarial examples for both latent space and label space regularizations can be performed along the line of analysis but it goes beyond the scope and focus of this paper.
The targeted tasks: auto-encoding, clustering, (conditional) generation and classification.
The architecture in terms of the latent space representation: the encoder outputs two vectors representing the discrete class and continuous type of style. The class distribution is assumed to follow categorical distribution and style Gaussian one. Both constraints on the prior distributions are ensured using adversarial framework with two corresponding discriminators. In its original setting, AAE does not use any augmented samples or adversarial examples.
Remark: It should be pointed out that in our architecture we consider the latent space to be represented by the vector , which is fed to the classifier and regularizer that gives a natural consideration of IB and corresponding regularization and priors. In the case of semi-supervised AAE, the latent space is considered by the class and style representations directly. Therefore, to make it coherent with our case, one should assume that the class vector of semi-supervised AAE corresponds to the vector and the style vector to the vector .
The usage of IB or other underlying frameworks: AAE is not derived from the IB framework. However, as shown in our analysis the semi-supervised AAE represents the learnable prior case in part of latent space regularization. The corresponding Lagrangian of semi-supervised AAE is given by (
16) and considered in
Section 4.3.
The label space regularization: is based on the adversarial discriminator in assumption that the class labels follow categorical distribution. This is applied to both labeled and unlabeled samples.
The latent space regularization: is based on the learnable prior with Gaussian pdf of AE.
The reconstruction space regularization in case of reconstruction loss: is only based on the MSE.
CatGAN [
3]: is based on an extension of classical GAN binary discriminator designed to distinguish between the original images and fake images generated from the latent space distribution to a multi-class discriminator. The author assumes the one-hot-vector encoding of class labels. The system is considered for the unsupervised and semi-supervised modes. For both modes the one-hot-vector encoding is used to encoded class labels. For the unsupervised mode, the system has an access only to the unlabeled data and the output of the classifier is considered to be a clustering to a predefined number of clusters/classes. The main idea behind the unsupervised training consists of a training of the discriminator that any sample from the set of original images is assigned to one of the classes with high fidelity whereas any fake or adversarial sample is assigned to all classes almost equiprobably. This corresponds to the fake samples and the regularization in the label space is based on the considered and extended framework of entropy minimization-based regularization. In the case of absence of fakes, this regularization coincides with the semi-supervised AAE label space regularization under the categorical distribution and adversarial discriminator that is equivalent to enforcing the minimum entropy of label space. However, the encoding of fake samples is equivalent to a sort of rejection option expressed via the activation of classes that have maximum entropy or uniform distribution over the classes. Equivalently, the above types of encoding can be considered to be the maximization of mutual information between the original data and encoded class labels and minimization of mutual information between the fakes/adversarial samples and the class labels. Semi-supevised CatGAN model adds a cross-entropy term computed for the true labeled samples.
Therefore, in summary:
The targeted tasks: auto-encoding, clustering, generation and classification.
The architecture in terms of the latent space representation: there is no encoder as such and instead the system has a generator/decoder that generates samples from a random latent space following some hand-crafted prior. The second element of architecture is a classifier with the min/max entropy optimization for the original and fake samples. The encoding of classes is assumed to be a one-hot-vector encoding.
The usage of IB or other underlying frameworks: CatGAN is not derived from the IB framework. However, as shown in [
15], one can apply the IB formulation to the adversarial generative models as in the case of CatGAN assuming that the term
in (
3) due to the absence of encoder as such. The minimization problem (
3) reduces to the maximization of the second term
expressed via its lower bound of variational decomposition (
6). The first term
enforces that the class labels of unlabeled samples follow the defined prior distribution
with the above property of entropy minimization under one-hot-vector encoding whereas the second term
reflects the supervised part for labeled samples. In the original CatGAN formulation, the author does not use the expression for the mutual information for the decoder/generator training as it is shown above but instead uses the decomposition of mutual information via the difference of corresponding entropies (see, first two terms in (9) in [
3]). As we have pointed out, we do not include in our analysis the term corresponding to the fake samples as in original CatGAN. However, we do believe that this form of regularization does play an important role for the semi-supervised classification. The impact of this terms requires additional studies.
The label space regularization: is based on the above assumptions for labeled samples, which are included into the cross-entropy term, unlabeled samples included into the entropy minimization term and fake samples included into the entropy maximization term in the original CatGAN method.
The latent space regularization: is based on the hand-crafted prior.
The reconstruction space regularization in case of reconstruction loss: is based on the adversarial discriminator only.
SeGMA [
18]: is a semi-supervised clustering and generative system with a single latent vector representation auto-encoder similar in spirit to the unsupervised version of AAE that can be also used for the classification. The latent space of SeGMA is assumed to follow a mixture of Gaussians. Using a small labeled data set, classes are assigned to components of this mixture of Gaussians by minimizing the cross-entropy loss induced by the class posterior distribution of a simple Gaussian classifier. The resulting mixture describes the distribution of the whole data, and representatives of individual classes are generated by sampling from its components. In the classification setup, SeGMA uses the latent space clustering scheme for the classification.
Therefore, in summary:
The targeted tasks: auto-encoding, clustering, generation and classification.
The architecture in terms of the latent space representation: a single vector representation following mixture of Gaussians distribution.
The usage of IB or other underlying frameworks: SeGMA is not derived from the IB framework but a link to the regularized ELBO an other related auto-encoders with interpretable latent space is demonstrated. However, as in previous methods it can be linked to the considered IB interpretation of the semi-supervised methods with hand-crafted priors (
16). An equivalent Lagrangian of SeGMA is:
where the latent space discriminator
is assumed to be the maximum mean discrepancy (MMD) penalty that is analytically defined for the mixture of Gaussians pdf,
is represented by the MSE and
represents the cross-entropy for the labeled data defined over class labels deduced from the latent space representation.
The label space regularization: is based on the above assumptions for labeled samples, which are included into the cross-entropy term as discussed above.
The latent space regularization: is based on the hand-crafted mixture of Gaussians pdf.
The reconstruction space regularization in case of reconstruction loss: is based on the MSE.
VAE (M1 + M2) [
1]: is based on the combination of several models. The model M1 represents a vanilla VAE considered in
Section 4.4.1. Therefore, model M1 is a particular case of considered unsupervised IB. The model M2 is a combination of encoder producing a continuous latent representation and following Gaussian distribution and a classifier that takes as an input original data in parallel to the model M1. The class labels are encoded using the one-hot-vector representations and follow categorical distribution with a hyper-parameter following the symmetric Dirichlet distribution. The decoder of model M2 takes as an input the continuous latent representation and output of classifier. The decoder is trained under the MSE distortion metric. It is important to point out that the classifier works with the input data directly but not with the common latent space such as in the considered LP model. For this reason, it is an obvious analogy with the considered LP model (
11) under the assumption that
and all performed IB analysis directly applies to. However, as pointed by the authors, the performance of model M2 in the semi-supervised classification for the limited number of labeled samples is relatively poor. That is why the third hybrid model M1 + M2 is considered when the models M1 and M2 and used in a stacked way. At the first stage, the model M1 is learned as the usual VAE. Then the latent space of model M1 is used as an input to the model M2 trained in a semi-supervised way. Such a two-stage approach closely resembles the learnable prior architecture presented in
Figure 2. However, our model is end-to-end trained with the explainable common latent space and IB origin, while the model M1 + M2 is trained in two stages with the use of regularized ELBO for the derivation of model M2.
The targeted tasks: auto-encoding, clustering, (conditional) generation and classification.
The architecture in terms of the latent space representation: the stacked combination of models M1 and M2 is used as discussed above.
The usage of IB or other underlying frameworks: VAE M1 + M2 is not derived from the IB framework but it is linked to the regularized ELBO with the cross-entropy for the labeled samples. The corresponding IB Lagrangian of semi-supervised VAE M1 + M2 under the assumption of end-to-end training can be defined as:
The label space regularization: is based on the assumption of categorical distribution of labels.
The reconstruction space regularization in case of reconstruction loss: is only based on the MSE.
6. Conclusions and Future Work
We have introduced a novel formulation of variational information bottleneck for semi-supervised classification. To overcome the problem of original bottleneck and to compensate the lack of labeled data in the semi-supervised setting, we considered two models of latent space regularization via hand-crafted and learnable priors. On a toy example of MNIST dataset we investigated how the parameters of proposed framework influence the performance of classifier. By end-to-end training, we demonstrate how the proposed framework compares to the state-of-the-art methods and approaches the performance of fully supervised classifier.
The envisioned future work is along the lines of providing a stronger compression yet preserving only classification task relevant information since retaining more task irrelevant information does not provide distinguishable classification features, i.e., it only ensures reliable data reconstruction. In this work, we have considered IB for the predictive latent space model. We think that the contrastive multi-view IB formulation would be an interesting candidate for the regularization of latent space. Additionally, we did not use the adversarially generated examples to impose the constraint on the minimization of mutual information between them and class labels or equivalently to maximize the entropy of class label distribution for these adversarial examples according to the framework of entropy minimization. This line of “adversarial” regularization seems to be a very interesting complement to the considered variational bottleneck. In this work, we considered a particular form of stochastic encoding by the addition of data independent noise to the input with the preservation of the same class labels. This also corresponds to the consistency regularization when samples can be more generally permuted including the geometrical transformations. It is also interesting to point out that the same form of generic permutations is used in the unsupervised constrastive loss-based multi-view formulations for the continual latent space representation as opposed to the categorical one in the consistency regularization. Finally, the conditional generation can be an interesting line of research considering the generation from discrete labels and continuous latent space of the autoencoder.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






