Efficient Multi-Object Detection and Smart Navigation Using Artificial Intelligence for Visually Impaired People

 ,
, 


Abstract
1. Introduction
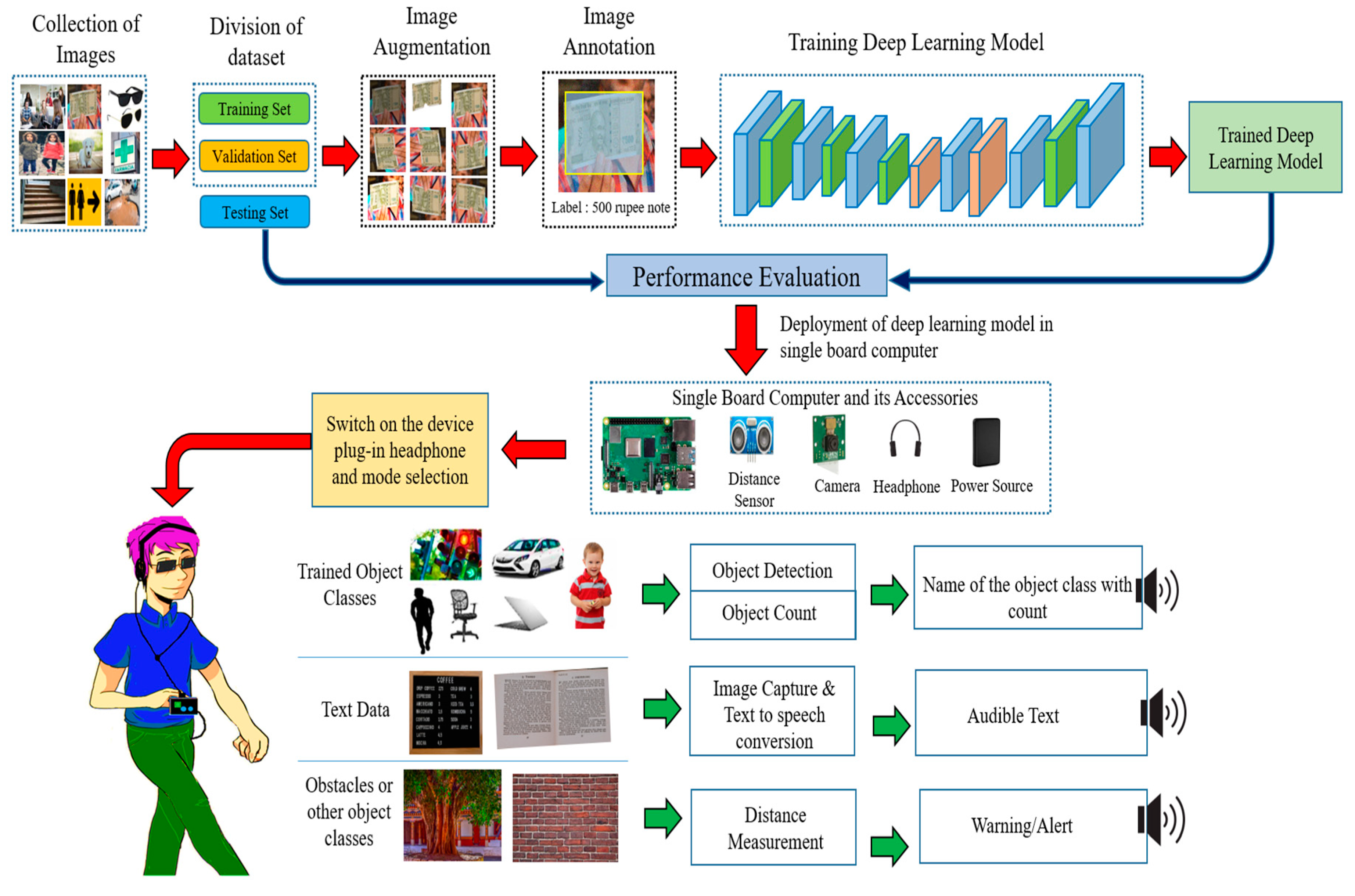
2. Methodology
2.1. Dataset for Visual Impaired People
2.2. Image Augmentation
2.3. Image Annotation
2.4. Dataset Training on Deep-Learning Model
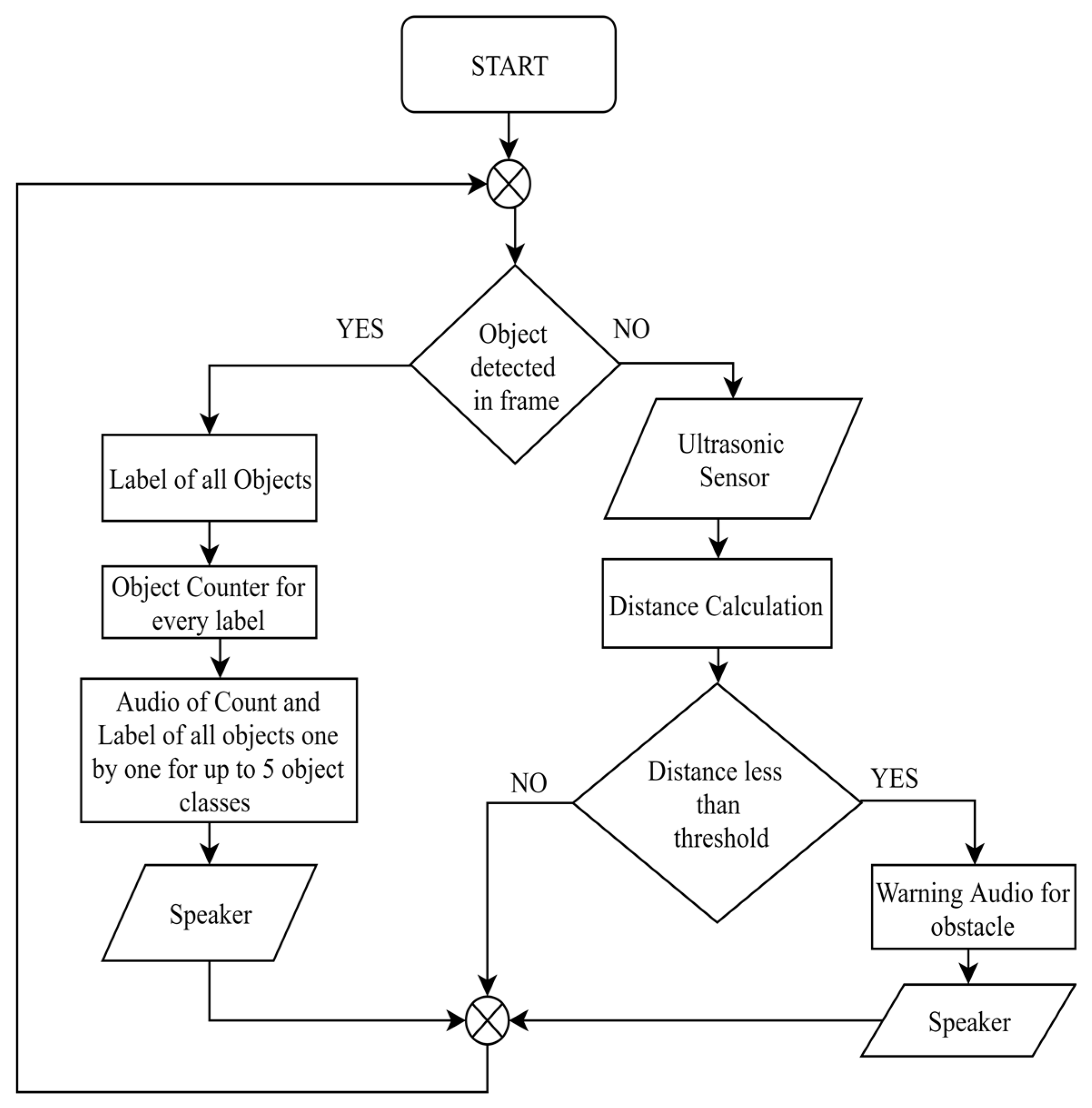
| Algorithm 1. Object detection for visually impaired person after training of dataset. |
| Input: Captured image from the Camera Output: Audio for the label of the detected object Step 1:Save the captured image, I Step 2:Pre-processing of the image Resize the image in dimensions w*h where, w = number of pixels in the x-axis h = number of pixels in the y-axis Increase the contrast value for I Step 3:Load the trained deep-learning model and its parameters Step 4:Image I is processed with the deep-learning model detections = detectObjectsFromImage(input_image = I) Step 5:Save processed output image, O fordetections Bounding Box prediction (bx, by, bw, bh) Percentage probability of the object Label, l = name of the detected object Text to speech conversion for l end |
3. Experiments and Results
4. Conclusions and Future Scope
Author Contributions
Funding
Conflicts of Interest
References
- Bourne, R.R.A.; Flaxman, S.R.; Braithwaite, T.; Cicinelli, M.V.; Das, A.; Jonas, J.B.; Keeffe, J.; Kempen, J.H.; Leasher, J.; Limburg, H.; et al. Magnitude, temporal trends, and projections of the global prevalence of blindness and distance and near vision impairment: A systematic review and meta-analysis. Lancet Glob. Health 2017, 5, e888–e897. [Google Scholar] [CrossRef]
- Global Trends in the Magnitude of Blindness and Visual Impairment. Available online: https://www.who.int/blindness/causes/trends/en/ (accessed on 12 June 2020).
- Blindness and Vision Impairment. Available online: https://www.who.int/news-room/fact-sheets/detail/blindness-andvisual-impairment (accessed on 12 June 2020).
- Thaler, L.; Arnott, S.R.; Goodale, M.A. Neural Correlates of Natural Human Echolocation in Early and Late Blind Echolocation Experts. PLoS ONE 2011, 6, e20162. [Google Scholar] [CrossRef] [PubMed]
- Van Lam, P.; Fujimoto, Y.; Van Phi, L. A Robotic Cane for Balance Maintenance Assistance. IEEE Trans. Ind. Inform. 2019, 15, 3998–4009. [Google Scholar] [CrossRef]
- Bhatlawande, S.; Mahadevappa, M.; Mukherjee, J.; Biswas, M.; Das, D.; Gupta, S. Design, Development, and Clinical Evaluation of the Electronic Mobility Cane for Vision Rehabilitation. IEEE Trans. Neural Syst. Rehabil. Eng. 2014, 22, 1148–1159. [Google Scholar] [CrossRef] [PubMed]
- Ando, B.; Baglio, S.; Marletta, V.; Valastro, A. A Haptic Solution to Assist Visually Impaired in Mobility Tasks. IEEE Trans. Hum. Mach. Syst. 2015, 45, 641–646. [Google Scholar] [CrossRef]
- Bai, J.; Lian, S.; Liu, Z.; Wang, K.; Liu, D. Smart guiding glasses for visually impaired people in indoor environment. IEEE Trans. Consum. Electron. 2017, 63, 258–266. [Google Scholar] [CrossRef]
- Di, P.; Hasegawa, Y.; Nakagawa, S.; Sekiyama, K.; Fukuda, T.; Huang, J.; Huang, Q. Fall Detection and Prevention Control Using Walking-Aid Cane Robot. IEEE/ASME Trans. Mechatron. 2015, 21, 625–637. [Google Scholar] [CrossRef]
- López-De-Ipiña, D.; Lorido, T.; López, U. BlindShopping: Enabling Accessible Shopping for Visually Impaired People through Mobile Technologies. In Proceedings of the 9th International Conference on Smart Homes and Health Telematics, Montreal, QC, Canada, 20–22 June 2011; LNCS 6719. pp. 266–270. [Google Scholar]
- Tekin, E.; Coughlan, J.M. An algorithm enabling blind users to find and read barcodes. In Proceedings of the 2009 Workshop on Applications of Computer Vision (WACV), Snowbird, UT, USA, 7–8 December 2009; pp. 1–8. [Google Scholar] [CrossRef]
- Ahmad, N.S.; Boon, N.L.; Goh, P. Multi-Sensor Obstacle Detection System Via Model-Based State-Feedback Control in Smart Cane Design for the Visually Challenged. IEEE Access 2018, 6, 64182–64192. [Google Scholar] [CrossRef]
- Takatori, N.; Nojima, K.; Matsumoto, M.; Yanashima, K.; Magatani, K. Development of voice navigation system for the visually impaired by using IC tags. In Proceedings of the 2006 International Conference of the IEEE Engineering in Medicine and Biology Society, New York, NY, USA, 30 August–3 September 2006; pp. 5181–5184. [Google Scholar]
- Fukasawa, A.J.; Magatani, K. A navigation system for the visually impaired an intelligent white cane. In Proceedings of the 2012 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, San Diego, CA, USA, 28 August–1 September 2012; pp. 4760–4763. [Google Scholar]
- Rastogi, R.; Pawluk, T.V.D.; Ketchum, J.M. Intuitive Tactile Zooming for Graphics Accessed by Individuals Who are Blind and Visually Impaired. IEEE Trans. Neural Syst. Rehabil. Eng. 2013, 21, 655–663. [Google Scholar] [CrossRef]
- Aladrén, A.; Lopez-Nicolas, G.; Puig, L.; Guerrero, J.J. Navigation Assistance for the Visually Impaired Using RGB-D Sensor with Range Expansion. IEEE Syst. J. 2014, 10, 922–932. [Google Scholar] [CrossRef]
- Yang, X.; Yuan, S.; Tian, Y. Assistive Clothing Pattern Recognition for Visually Impaired People. IEEE Trans. Hum. Mach. Syst. 2014, 44, 234–243. [Google Scholar] [CrossRef]
- Katzschmann, R.K.; Araki, B.; Rus, D. Safe Local Navigation for Visually Impaired Users with a Time-of-Flight and Haptic Feedback Device. IEEE Trans. Neural Syst. Rehabil. Eng. 2018, 26, 583–593. [Google Scholar] [CrossRef] [PubMed]
- Kang, M.-C.; Chae, S.-H.; Sun, J.-Y.; Yoo, J.-W.; Ko, S.-J. A novel obstacle detection method based on deformable grid for the visually impaired. IEEE Trans. Consum. Electron. 2015, 61, 376–383. [Google Scholar] [CrossRef]
- Chen, X.; Xu, J.; Yu, Z. A 68-mw 2.2 Tops/w Low Bit Width and Multiplierless DCNN Object Detection Processor for Visually Impaired People. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 3444–3453. [Google Scholar] [CrossRef]
- Hassaballah, M.; Awad, A.I. Deep Learning in Computer Vision; Informa UK Limited: London, UK, 2020. [Google Scholar]
- Mocanu, B.; Tapu, R.; Zaharia, T. DEEP-SEE FACE: A Mobile Face Recognition System Dedicated to Visually Impaired People. IEEE Access 2018, 6, 51975–51985. [Google Scholar] [CrossRef]
- Ton, C.; Omar, A.; Szedenko, V.; Tran, V.H.; Aftab, A.; Perla, F.; Bernstein, M.J.; Yang, Y. LIDAR Assist Spatial Sensing for the Visually Impaired and Performance Analysis. IEEE Trans. Neural Syst. Rehabil. Eng. 2018, 26, 1727–1734. [Google Scholar] [CrossRef]
- Croce, D.; Giarre’, L.; Pascucci, F.; Tinnirello, I.; Galioto, G.E.; Garlisi, D.; Valvo, A.L. An Indoor and Outdoor Navigation System for Visually Impaired People. IEEE Access 2019, 7, 170406–170418. [Google Scholar] [CrossRef]
- Meshram, V.V.; Patil, K.; Meshram, V.A.; Shu, C. An Astute Assistive Device for Mobility and Object Recognition for Visually Impaired People. IEEE Trans. Hum. Mach. Syst. 2019, 49, 449–460. [Google Scholar] [CrossRef]
- Goyal, S.; Bhavsar, S.; Patel, S.; Chattopadhyay, C.; Bhatnagar, G. SUGAMAN: Describing floor plans for visually impaired by annotation learning and proximity-based grammar. IET Image Process. 2019, 13, 2623–2635. [Google Scholar] [CrossRef]
- Chang, W.-J.; Chen, L.-B.; Hsu, C.-H.; Chen, J.-H.; Yang, T.-C.; Lin, C.-P. MedGlasses: A Wearable Smart-Glasses-Based Drug Pill Recognition System Using Deep Learning for Visually Impaired Chronic Patients. IEEE Access 2020, 8, 17013–17024. [Google Scholar] [CrossRef]
- Jarraya, S.K.; Al-Shehri, W.S.; Ali, M.S. Deep Multi-Layer Perceptron-Based Obstacle Classification Method from Partial Visual Information: Application to the Assistance of Visually Impaired People. IEEE Access 2020, 8, 26612–26622. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2009, 88, 303–338. [Google Scholar] [CrossRef]
- Calik, R.C.; Demirci, M.F. Cifar-10 Image Classification with Convolutional Neural Networks for Embedded Systems. In Proceedings of the 2018 IEEE/ACS 15th International Conference on Computer Systems and Applications (AICCSA), Aqaba, Jordan, 28 October–1 November 2018; pp. 1–2. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei, L.-F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef]
- Xiao, J.; Hays, J.; Ehinger, K.A.; Oliva, A.; Torralba, A. SUN database: Large-scale scene recognition from abbey to zoo. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3485–3492. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Bioinformatics Research and Applications; Springer Science and Business Media LLC: Berlin, Germany, 2014; Volume 8693, pp. 740–755. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO-v3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Qiu, X.; Yuan, C. Improving Object Detection with Convolutional Neural Network via Iterative Mechanism. Bioinform. Res. Appl. 2017, 10636, 141–150. [Google Scholar]
- Günther, J.; Pilarski, P.M.; Helfrich, G.; Shen, H.; Diepold, K. First Steps towards an Intelligent Laser Welding Architecture Using Deep Neural Networks and Reinforcement Learning. Procedia Technol. 2014, 15, 474–483. [Google Scholar] [CrossRef]
- Guerra, E.; De Lara, J.; Malizia, A.; Díaz, P. Supporting user-oriented analysis for multi-view domain-specific visual languages. Inf. Softw. Technol. 2009, 51, 769–784. [Google Scholar] [CrossRef]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate Image Super-Resolution Using Very Deep Convolutional Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1646–1654. [Google Scholar]
- Hoang, V.-N.; Nguyen, T.-H.; Le, T.-L.; Tran, T.-H.; Vuong, T.-P.; Vuillerme, N. Obstacle detection and warning system for visually impaired people based on electrode matrix and mobile Kinect. Vietnam. J. Comput. Sci. 2016, 4, 71–83. [Google Scholar] [CrossRef]
- Yang, K.; Bergasa, L.M.; Romera, E.; Cheng, R.; Chen, T.; Wang, K. Unifying terrain awareness through real-time semantic segmentation. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1033–1038. [Google Scholar] [CrossRef]
- Mancini, A.; Frontoni, E.; Zingaretti, P. Mechatronic System to Help Visually Impaired Users during Walking and Running. IEEE Trans. Intell. Transp. Syst. 2018, 19, 649–660. [Google Scholar] [CrossRef]
- Bauer, Z.; Dominguez, A.; Cruz, E.; Gomez-Donoso, F.; Orts-Escolano, S.; Cazorla, M. Enhancing perception for the visually impaired with deep learning techniques and low-cost wearable sensors. Pattern Recognit. Lett. 2019. [Google Scholar] [CrossRef]
- Patil, K.; Jawadwala, Q.; Shu, F.C. Design and Construction of Electronic Aid for Visually Impaired People. IEEE Trans. Hum. Mach. Syst. 2018, 48, 172–182. [Google Scholar] [CrossRef]
- Eckert, M.; Blex, M.; Friedrich, C.M. Object Detection Featuring 3D Audio Localization for Microsoft HoloLens—A Deep Learning based Sensor Substitution Approach for the Blind. In Proceedings of the 11th International Joint Conference on Biomedical Engineering Systems and Technologies, Funchal, Portugal, 19–21 January 2018; pp. 555–561. [Google Scholar]
- Parikh, N.; Shah, I.; Vahora, S. Android Smartphone Based Visual Object Recognition for Visually Impaired Using Deep Learning. In Proceedings of the 2018 International Conference on Communication and Signal Processing (ICCSP), Chennai, India, 3–5 April 2018; pp. 420–425. [Google Scholar]
- Al-Madani, B.; Orujov, F.; Maskeliunas, R.; Damaševičius, R.; Venckauskas, A. Fuzzy Logic Type-2 Based Wireless Indoor Localization System for Navigation of Visually Impaired People in Buildings. Sensors 2019, 19, 2114. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Total Images in Each Object Class | Original Dataset | After Augmentation | Test Set | ||
|---|---|---|---|---|---|
| Training Set | Validation Set | Training Set | Validation Set | ||
| 650 | 350 | 150 | 3500 | 1500 | 150 |
| Objects | Total Testing Images | Correctly Detected | Detection Accuracy (%) | Correctly Recognized | Recognition Accuracy (%) |
|---|---|---|---|---|---|
| Person | 150 | 148 | 98.67 | 148 | 100.00 |
| Car | 150 | 146 | 97.33 | 145 | 99.32 |
| Bus | 150 | 144 | 96.00 | 144 | 100.00 |
| Truck | 150 | 143 | 95.33 | 141 | 98.60 |
| Chair | 150 | 147 | 98.00 | 146 | 99.32 |
| TV | 150 | 140 | 93.33 | 140 | 100.00 |
| Bottle | 150 | 148 | 98.67 | 148 | 100.00 |
| Dog | 150 | 145 | 96.67 | 144 | 99.31 |
| Fire hydrant | 150 | 146 | 97.33 | 146 | 100.00 |
| Stop Sign | 150 | 149 | 99.33 | 147 | 98.66 |
| Socket | 150 | 143 | 95.33 | 143 | 100.00 |
| Pothole | 150 | 129 | 86.00 | 128 | 99.22 |
| Pharmacy | 150 | 141 | 94.00 | 139 | 98.58 |
| Stairs | 150 | 139 | 92.67 | 139 | 100.00 |
| Washroom | 150 | 145 | 96.67 | 145 | 100.00 |
| Wrist Watch | 150 | 140 | 93.33 | 139 | 99.29 |
| Eye glasses | 150 | 141 | 94.00 | 141 | 100.00 |
| Cylinder | 150 | 131 | 87.33 | 131 | 100.00 |
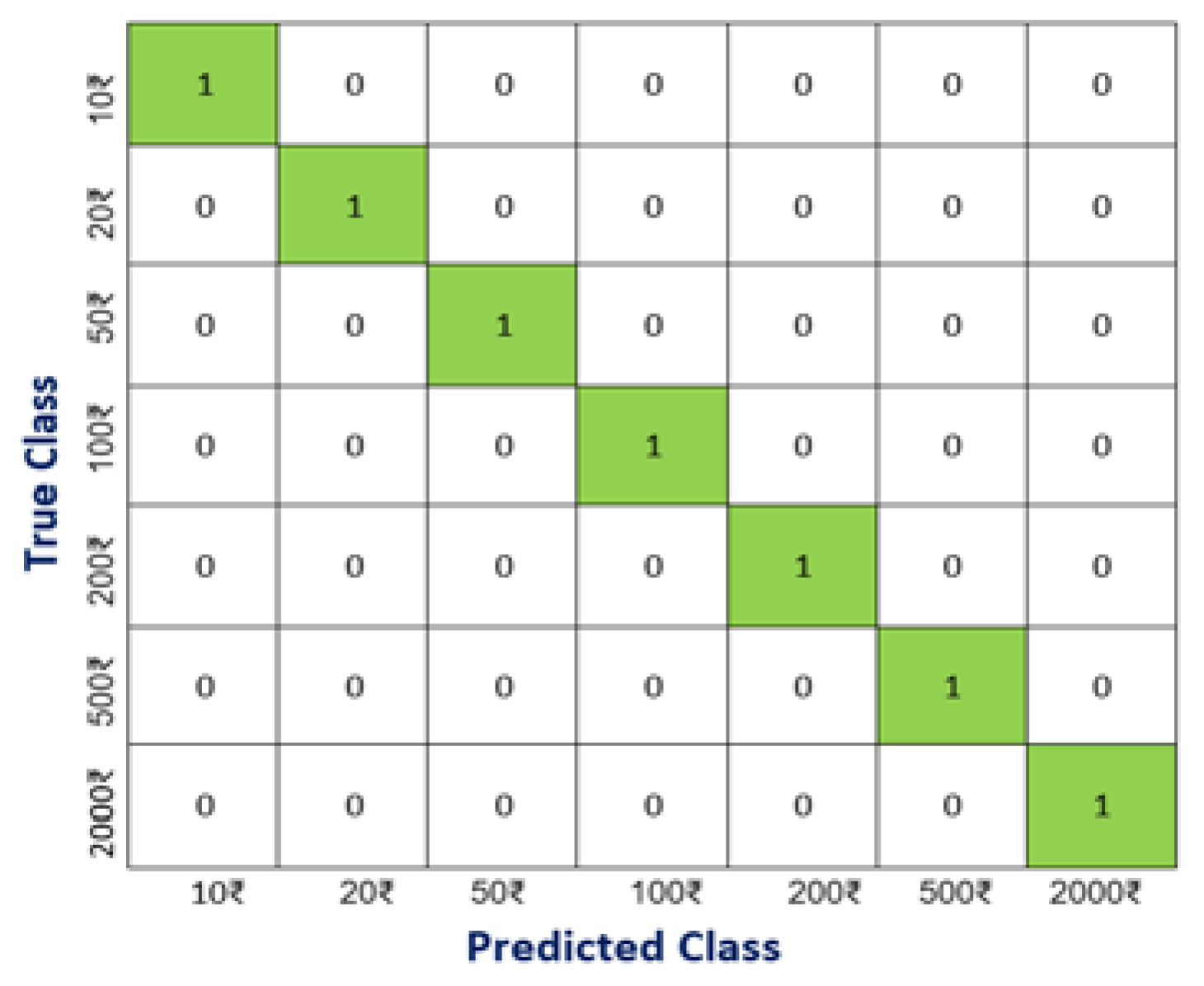
| 10 ₹ Note | 150 | 141 | 94.00 | 141 | 100.00 |
| 20 ₹ Note | 150 | 148 | 98.67 | 148 | 100.00 |
| 50 ₹ Note | 150 | 143 | 95.33 | 143 | 100.00 |
| 100 ₹ Note | 150 | 140 | 93.33 | 140 | 100.00 |
| 200 ₹ Note | 150 | 144 | 96.00 | 144 | 100.00 |
| 500 ₹ Note | 150 | 140 | 93.33 | 140 | 100.00 |
| 2000 ₹ Note | 150 | 149 | 99.33 | 149 | 100.00 |
| Average | 95.19% | 99.69% |
| Methods | Testing Accuracy | Frame Processing Time |
|---|---|---|
| AlexNet [38] | 83.39 | 0.275 s |
| VGG-16 [39] | 86.80 | 0.53 s |
| VGG-19 [40] | 90.21 | 0.39 s |
| YOLO-v3 | 95.19 | 0.1 s |
| Parameters | Average Time Taken (s) |
|---|---|
| Object Detection in single frame with GPU | 0.1 |
| Object Detection in single frame in single board DSP processor without GPU | 0.3 |
| Average time of Audio for name of object | 0.4 |
| Average time of Audio for count of object | 0.2 |
| Average time of Audio for name of object with count | 0.6 |
| Number of Object Class | Number of Instances of Each Object | Total Number of Objects in Frame | Average Time Taken for Object Detection (s) | Average Time of Audio Prompt (s) | Total Time to Process Single Frame (s) |
|---|---|---|---|---|---|
| 0 | 0 | 0 | 0.3 | 0 | 0.3 |
| 1 | 1 | 1 | 0.3 | 0.4 | 0.7 |
| 1 | 2 | 2 | 0.3 | 0.6 | 0.9 |
| 1 | 5 | 5 | 0.3 | 0.6 | 0.9 |
| 2 | 1 | 2 | 0.3 | 0.4 + 0.4 | 1.1 |
| 2 | 2 | 4 | 0.3 | 0.6 + 0.6 | 1.5 |
| 3 | 5 | 15 | 0.3 | 0.6 + 0.6 + 0.6 | 2.1 |
| 4 | 1 | 4 | 0.3 | 0.4 + 0.4 + 0.4 + 0.4 | 1.9 |
| 4 | 5 | 20 | 0.3 | 0.6 + 0.6 + 0.6 + 0.6 | 2.7 |
| 5 | 1 | 5 | 0.3 | 0.4 + 0.4 + 0.4 + 0.4 + 0.4 | 2.3 |
| 5 | 3 | 15 | 0.3 | 0.6 + 0.6 + 0.6 | 2.1 |
| 5 | 5 | 25 | 0.3 | 0.6 + 0.6 + 0.6 + 0.6 + 0.6 | 3.3 |
| 5 | 10 | 50 | 0.3 | 0.6 + 0.6 + 0.6 + 0.6 + 0.6 | 3.3 |
| Method | Components | Dataset | Result | Coverage Area | Connection | Cost |
|---|---|---|---|---|---|---|
| Hoang et al. [41] | Mobile Kinect, laptop Electrode matrix, headphone and RF transmitter | Local dataset | Detect obstacle and generate audio warning | Indoor | Offline | High |
| Bai et al. [8] | Depth camera, glasses, CPU, headphone and ultrasonic sensor | Not included | Obstacle Recognition and audio output | Indoor | Offline | High |
| Yang et al. [42] | Depth Camera on Smart glass, Laptop, and headphone | ADE20, PASCAL, and COCO | Obstacle Recognition and generate clarinet sound as warning | Indoor, Outdoor | Internet Required | High |
| Mancini et al. [43] | Camera, PCB, and vibration motor | Not included | Obstacle recognition and vibration feedback for the direction | Outdoor | Offline | Low |
| Bauer et al. [44] | Camera, smartwatch, and smartphone | PASCAL VOC Dataset | Object detection with direction of object into audio output | Outdoor | Internet Required | High |
| Patil et al. [45] | Sensors, vibration motors, | No Dataset | Obstacle detection with audio output | Indoor, Outdoor | Offline | Low |
| Eckert et al. [46] | RGB-D camera and IMU sensors | PASCAL VOC dataset | Object detection with audio output | Indoor | Internet Required | High |
| Parikh et al. [47] | Smartphone, server, and headphone | Local dataset of 11 objects | Object detection with audio output | Outdoor | Internet Required | High |
| AL-Madani et al. [48] | BLE fingerprint, fuzzy logic | Not included | Localization of the person in the building | Indoor | Offline (Choice Wi-Fi or BLE) | Low |
| Proposed Method | RGB Camera, Distance Sensor, DSP processor, Headphone | Local dataset of highly relevant objects for VIP | Object detection, Count of objects, obstacle warnings, read text, and works in different modes | Indoor, Outdoor | Offline | Low |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Joshi, R.C.; Yadav, S.; Dutta, M.K.; Travieso-Gonzalez, C.M. Efficient Multi-Object Detection and Smart Navigation Using Artificial Intelligence for Visually Impaired People. Entropy 2020, 22, 941. https://doi.org/10.3390/e22090941
Joshi RC, Yadav S, Dutta MK, Travieso-Gonzalez CM. Efficient Multi-Object Detection and Smart Navigation Using Artificial Intelligence for Visually Impaired People. Entropy. 2020; 22(9):941. https://doi.org/10.3390/e22090941
Chicago/Turabian StyleJoshi, Rakesh Chandra, Saumya Yadav, Malay Kishore Dutta, and Carlos M. Travieso-Gonzalez. 2020. "Efficient Multi-Object Detection and Smart Navigation Using Artificial Intelligence for Visually Impaired People" Entropy 22, no. 9: 941. https://doi.org/10.3390/e22090941
APA StyleJoshi, R. C., Yadav, S., Dutta, M. K., & Travieso-Gonzalez, C. M. (2020). Efficient Multi-Object Detection and Smart Navigation Using Artificial Intelligence for Visually Impaired People. Entropy, 22(9), 941. https://doi.org/10.3390/e22090941