1. Introduction
What is thermodynamics? The question, so central to physics, has been asked numerous times and has been given nearly as many different answers. To quote just a few: thermodynamics is “the branch of science concerned with the relations between heat and other forms of energy involved in physical and chemical processes” [
1]; “the study of the restrictions on the possible properties of matter that follow from the symmetry properties of the fundamental laws of physics” [
2]; “concerned with the relationships between certain macroscopic properties of a system in equilibrium” [
3]; “a phenomenological theory of matter” [
4]. Such statements, while strictly true, focus on aspects that are far too narrow to converge to a definition of sufficient generality as to
what to call thermodynamics or
how to carry it outside physics. And yet, since Gibbs [
5], Shannon [
6] and Jaynes [
7] drew quantitative connections between entropy and probability distributions, thermodynamics has been spreading to new fields. The tools of statistical thermodynamics are now used in network theory [
8], ecology [
9], epidemics [
10], neuroscience [
11], financial markets [
12], and in the study of complexity in general. What motivates the impulse to apply thermodynamics to such vastly diverse problems? Is thermodynamics even applicable outside classical or quantum mechanical systems? And if so, what is the scope of its applicability?
Here we answer these fundamental questions: Statistical thermodynamics is variational calculus applied to probability distributions and by extension to stochastic processes in general; it is independent of physical hypotheses but provides the means to incorporate our knowledge and model assumptions about the particular problem. The fundamental ensemble is a space of probability distributions sampled via a bias functional. The maximization of this functional expresses a distribution—any distribution—via a set of parameters (microcanonical partition function, canonical partition function and generalized temperature) that are connected through a set of mathematical relationships that we recognize as the familiar equations of thermodynamic. Entropy and the second law have simple interpretations in this theory. We obtain statistical mechanics as a special case and make contact with Information Theory and Bayesian inference.
2. The Calculus of Statistical Thermodynamics
Before we derive a theory of generalized thermodynamics we review the key elements of the standard thermodynamic calculus. The central quantity of interest in statistical thermodynamics is the probability of microstate. For a system of
N particles in volume
V and temperature
T this probability is given by the exponential (canonical) distribution,
where
Q is the canonical partition function,
is the energy of microstate,
and
is Boltzmann’s constant. The corresponding probability to find the system in a microstate with energy
E is obtained by summing all microstates with fixed energy
E and is given by
where
is the microcanonical partition function, also equal to the number of microstates with energy
E, volume
V and number of particles
N. The mean energy
and the parameters
,
Q and
that appear in Equation (
2) are interrelated:
Equations (
3) and (
4) establish that
and
are Legendre pairs; Equation (
6) states that
is concave. In addition, any probability distribution
that could be assigned to microstate
i under fixed
satisfies the inequality,
with the equal sign only for the canonical distribution in Equation (
1). This inequality is the statistical expression of the second law. If we identify
with entropy and
with free energy Equations (
3)–(
6) represent the familiar relationships of classical thermodynamics. Along with Equations (
2) and (
7), which provide the probabilistic context, the above set comprises the core relationships of statistical thermodynamics. The physical assumptions and postulates that produce these results can be found in any standard textbook (for example [
3]). We will now show that this network of mathematical relationships arises naturally via a probabilistic construction that makes no reference to physics and endows any probability distribution
,
with the thermodynamic relationships shown here.
4. Generalized Statistical Thermodynamics
These results can be summarized in the form of the following theorem:
Theorem 1. Given normalized distribution , , with mean , it is possible to construct a functional W such that:
(a) All distributions , , with mean satisfy the inequalitywith the equal sign only for , a condition that defines ω; (b) f can be expressed in canonical form aswhere is the variational derivative of ; and (c) parameters , β, q and ω satisfy The existence of
W is established by the fact that the functional
satisfies the theorem. This is a linear functional whose derivative is
for all
h. More generally, any homogeneous functional
of degree 1, linear or non-linear, whose derivative at
is given by
where
and
satisfy
but are otherwise arbitrary, also satisfies the theorem. The inequality in Equation (
39) follows from the concave requirement that ensures the maximization of Equation (
34).
We recognize Equation (
35) as the canonical distribution of statistical mechanics, Equations (
36)–(
38) and (
33), which relate its parameters, as the core set of thermodynamic relationships, and Equation (
34) as the inequality of the second law. The probabilistic interpretation is that any distribution
f may be obtained as the most probable distribution under a probability measure defined via a suitable functional
W. Whereas in statistical mechanics the central stochastic variable is the mechanical microstate, in generalized thermodynamics it is the probability distribution itself. Thermodynamics may be condensed into the microcanonical inequality in Equation (
34), a generalized expression of the second law that defines the most probable distribution in the microcanonical space. All relationships between
(microcanonical partition function),
q (canonical partition function),
(generalized inverse temperature) and
follow from the maximization of this inequality and have equivalents in familiar thermodynamics. The derivatives
and
in Equations (
36) and (
37) may be viewed as equations of change along a path (“process”) in the space of distributions under fixed bias
W. This path is described parametrically in terms of
and represents a nonstationary stochastic process. We call this process
quasistatic—a continuous path of distributions that maximize locally the thermodynamic functional.
4.1. Contact with Statistical Mechanics
The obvious way to make contact with statistical mechanics is to take
f to be the probability of microstate at fixed temperature, volume and number of particles. The postulate of equal a priori probabilities fixes the selection functional and its derivative to
; if we identify
x as the energy
of microstate
i,
as
,
q as the thermodynamic canonical partition function,
as the thermodynamic microcanonical partition function, Equations (
24)–(
33) map to standard thermodynamic relationships. From Equation (
29) we obtain
: the canonical probability
f maximizes entropy and thus we obtain the second law.
This is not the only way to establish contact with statistical mechanics. We may choose
f to be some other probability distribution, for example, the probability to find a
macroscopic system of fixed
at energy
E. We write the energy distribution in the form of Equation (
24) with
w,
and
q to be determined. From Equations (
25), (
31) and (
32) with
we make the identifications
,
(free energy),
thermodynamic entropy. To identify
w we require input from physics and this comes via the observation that the probability density of macroscopic energy
E is asymptotically a Dirac delta function at
. Then
(this is the entropy of the energy distribution, not to be confused with thermodynamic entropy). From Equations (
14) and (
29) we find
, and conclude that
is the thermodynamic entropy. This establishes correspondence between generalized thermodynamics and macroscopic (classical) thermodynamics. If we further postulate, again motivated by physics, that
is the number of microstates under fixed volume and number of particles, we establish the microscopic connection. Since
is proportional to the number of microstates with energy
E and individual microstates are unobservable, we may as well ascribe equal probability to all microstates. Thus we recover the postulate of equal a priori probabilities (statistical thermodynamics). Finally, by adopting a physical model of microstate, classical, quantum or other, we obtain classical statistical mechanics, quantum statistical mechanics or yet-to-be-discovered statistical mechanics, depending on the model. In all cases the thermodynamic calculus is the same, only the enumeration of microstates—that is,
W— depends on the physical model.
4.2. What is W?
Once the selection functional
W is specified the most probable distribution is fixed and all canonical variables become known functions of
. But what
is W? The selection functional is a placeholder for our knowledge, hypotheses and model assumptions about the stochastic processes that gives rise to the probability distribution of interest. This knowledge fully specifies the distribution. The opposite is not true: given distribution
f there is an infinite number of functionals
W that produce that distribution as the most probable distribution in their probability space. This nonuniquness is a feature, not a bug: it allows models that are quite different in their details to produce the same final distribution. Here is an example. The unbiased functional
produces the exponential distribution
with canonical parameters
Now consider the nonlinear selection functional
whose logarithm is equal to entropy. The corresponding microcanonical probability functional is obtained by inserting this into Equation (
27),
and is maximized by (see
Supplementary Information)
with
We have arrived at the exponential distribution, the same distribution that is obtained by the unbiased functional , but with different canonical parameters because the probability space from which it arises is now different. If all we know is that the probability distribution in a stochastic process is exponential, it is not possible to determine whether it was obtained using , , or any other functionals that is capable of reproducing the exponential distribution. While the selection bias identifies the most probable distribution uniquely, the opposite is not true.
The selection functional represents external input to thermodynamics and is fixed by the rules that govern the stochastic process that produces the distribution in question. In the case of statistical mechanics it is fixed by the postulate of equal a priori probabilities. In another example, recently given for stochastic binary clustering, it is fixed by the aggregation kernel, a function that determines the aggregation probability between clusters of different sizes [
17]. The selection functional is the contact point between generalized statistical thermodynamics—a mathematical theory for generic distributions—and
physics, i.e., our knowledge in the form of model assumptions and postulates about the process that gives rise to the observed distribution. It is interesting to point out that the variational derivative
w in Equation (
27) appears in the form of Bayesian prior [
18]. In the context of generalized thermodynamics
w is not a prior distribution—although it might if
in Equation (
41). In general,
w is a non normalizable derivative of the functional that represents our knowledge about the process, an improper prior that points nonetheless to a proper distribution.
5. Thermodynamic Sampling of Distributions
We have shown that any distribution
defined in
can be viewed as the most probable distribution in an appropriately constructed probability space. Here we will show that any distribution
f in this domain can be obtained as the equilibrium distribution of reacting clusters under an appropriately constructed equilibrium constant. Consider a population of
M identical particles (“monomers”) distributed into
N clusters and let
be an ordered list of
N cluster masses with total mass
M such that
is the mass of the
kth cluster in the list (“configuration”). The complete set of configurations with
N clusters and total mass
M comprises the cluster ensemble
. Let
be the size distribution of the clusters in configuration
such that
is the number of clusters with
i monomers. With
at fixed
, the cluster ensemble contains every discrete distribution
with mean
. We now construct the following stochastic process: given a configuration
, pick two clusters at random, merge them, then split them back into two clusters at random. This amounts to an exchange of mass between two clusters that is represented schematically by the reaction
and transforms the parent configuration
into an new configuration
with the same number of clusters
N and total mass
M. This process may also be represented as a reaction that transforms a parent configuration into an offspring,
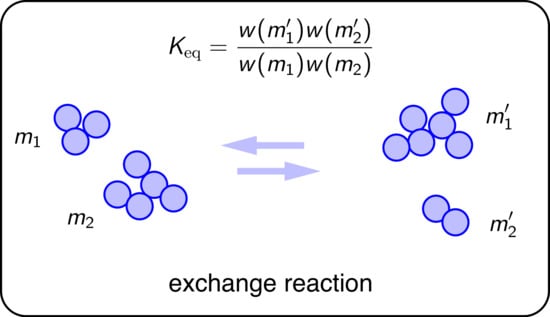
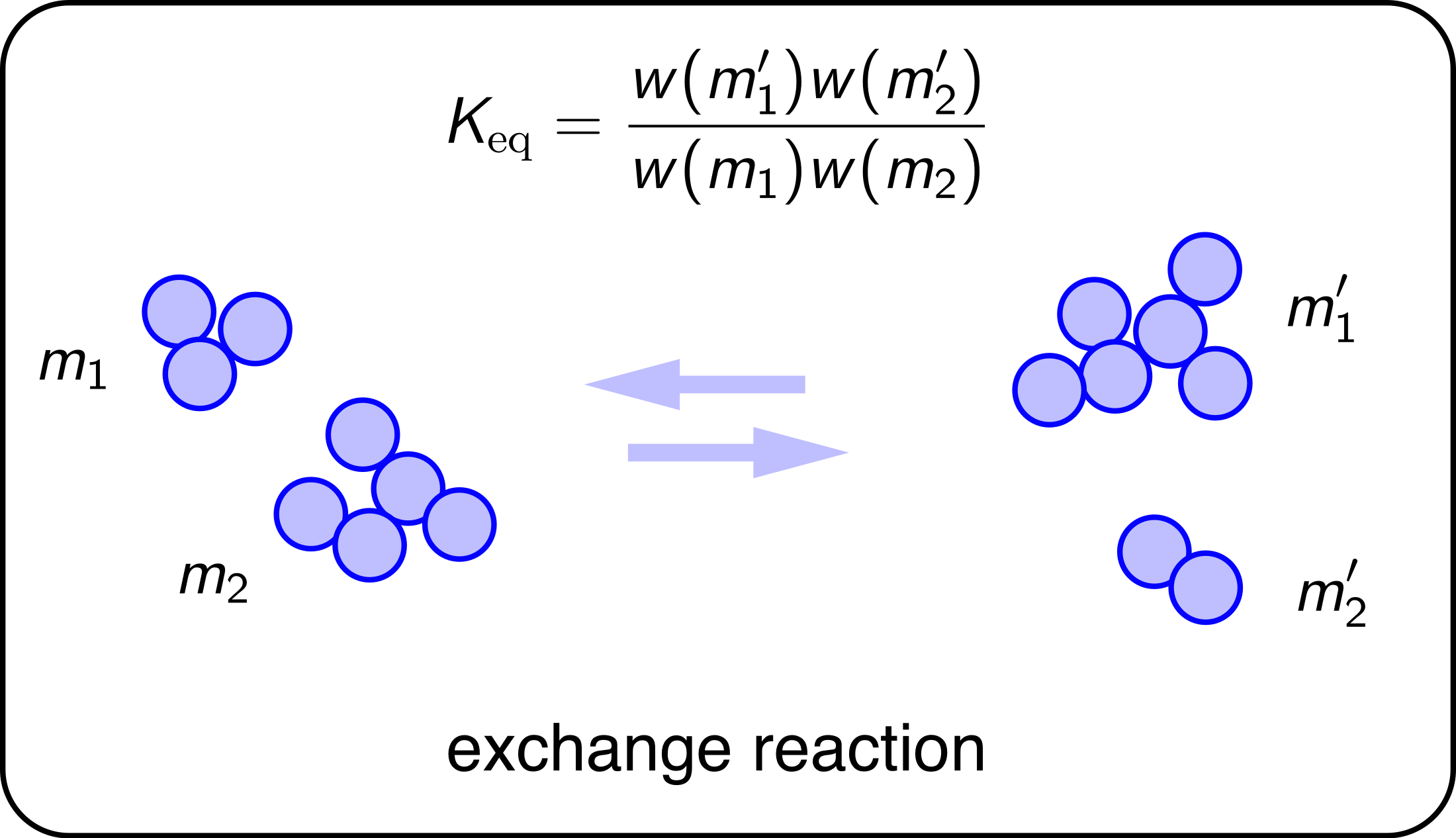
We define the equilibrium constant of this reaction as
where
and
are the cluster size distributions of the product and reactant configurations, respectively, and
is the selection functional applied to distribution
. The change
of the corresponding distributions upon the exchange reaction is a change of
in the number of cluster masses
and
on the reactant side, and
for cluster masses on the product side. By virtue of the homogeneous property of
, its change for large
M and
N is a differential that can be expressed in terms of the derivatives of
where
is the functional derivative of
evaluated in distribution
. Using this result the equilibrium constant becomes
This has the standard form of an equilibrium constant for the reaction in Equation (
49). We may identify
as the “fugacity” of species
x and “species” as a cluster with mass
x. The reaction can be simulated by Monte Carlo using the Metropolis transition probabilities
where
is a uniform random number in
. This forms a reducible Markov process that samples the microcanonical space of distribution
with fixed zeroth order moment
N and first moment
M. Its stationary distribution is [
19]
where
is the functional derivative of
evaluated at
and the parameters
and
q are obtained by solving the set of equations
With we obtain the exponential distribution, which implies that the exchange reaction with equilibrium constant for all transitions is equivalent to unbiased sampling from an exponential distribution with fixed mean .
Once the selection functional
W is given the most probable distribution is fixed and may be obtained either by simulation or in many cases analytically. We will now construct
W such that the most probable distribution is any distribution
f defined in
. We construct the linearized selection functional
with
w from Equation (
41), which we write in the form
and
and
arbitrary constants. It is easy to show that the selection of
and
is immaterial because both constants drop out of Equation (
53). If we choose
, then
; alternatively, we may choose these constants so as to obtain simpler forms for
. We demonstrate the construction of
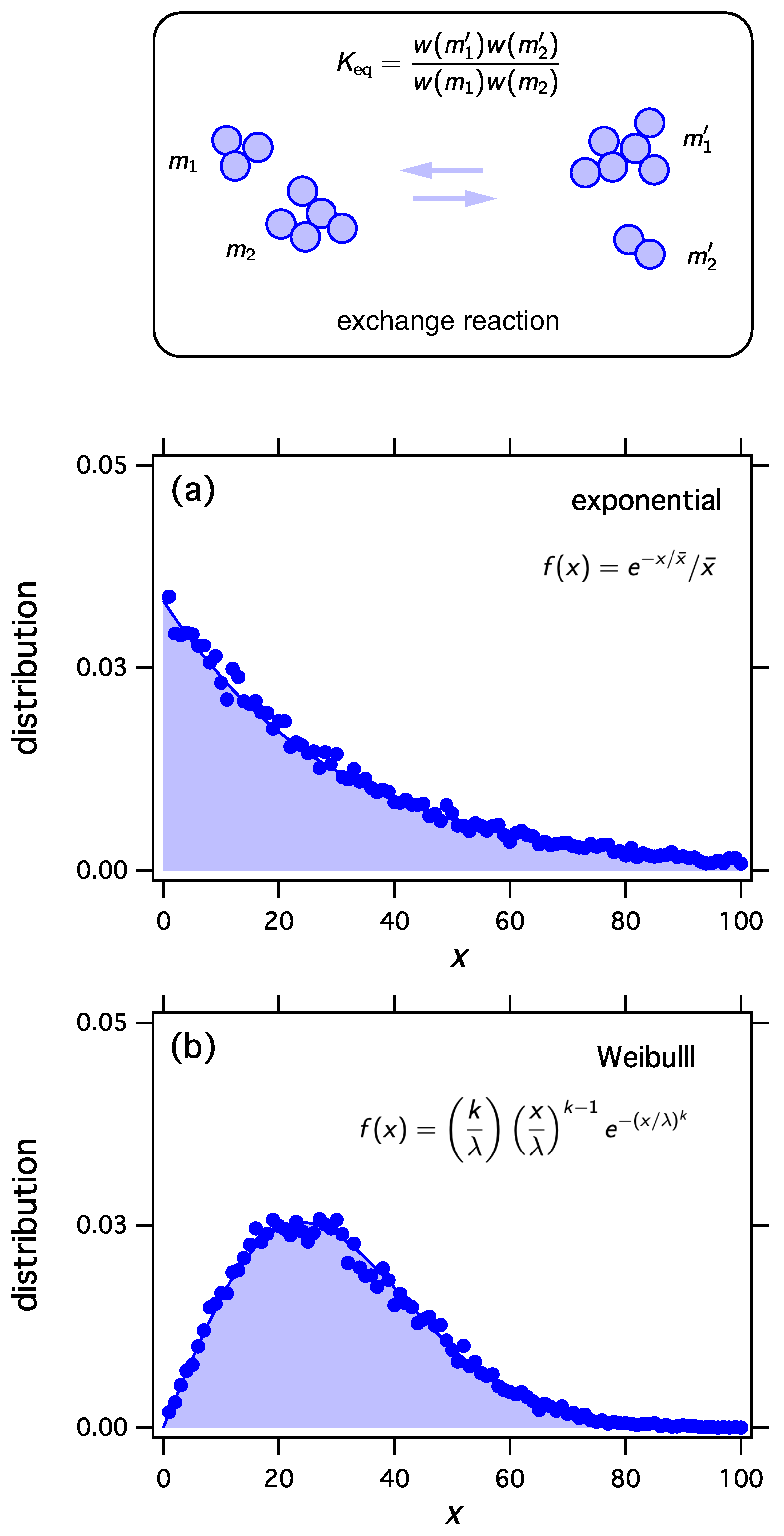
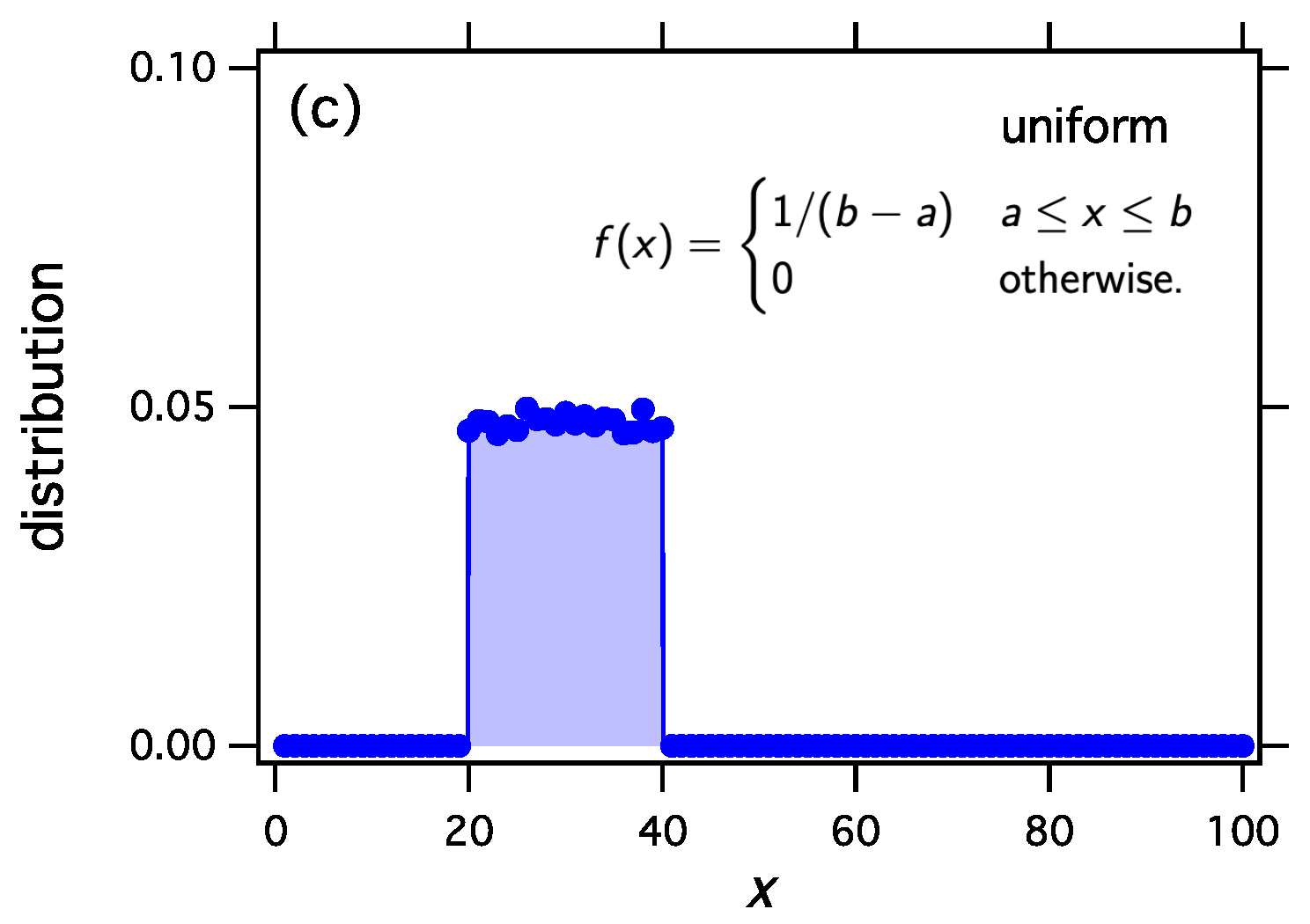
w with three examples using the exponential, the Weibull, and the uniform distribution.
We implement thermodynamic sampling using Monte Carlo. We begin with an ordered list of
N integers
whose sum is
M. We then pick two numbers at random and implement a random exchange reaction to produce a new pair of integers with the same combined sum. The new pair replaces the old with acceptance probability computed according to Equation (
54) using
from Equation (
53) and the function
obtained above. Following a successful trial we calculate the distribution of the current configuration. The mean distribution is obtained by averaging over a large number of trials. For these simulations
,
,
, and the mean distribution is calculated over 20,000 trials. As we discuss elsewhere, the mean distribution and the most probable distribution converge to each other unless the system exhibits phase separation [
17,
19,
20]. The results in
Figure 1 make it clear that thermodynamic sampling converges indeed to the distribution for which the
w function was derived. Any discrete distribution
, and with proper scaling, any continuous distribution
, may be associated with the equilibrium distribution of reacting clusters under a suitable equilibrium constant.
The selection functionals constructed by the procedure discussed here apply the variational derivative at
f to all distributions
h, i.e., they are linearized at the most probable distribution. Any nonlinear functional
with the same derivative at
will produce the same distribution as the stationary distribution under exchange reactions. One example is the entropic functional in Equation (
45), a nonlinear functional that produces the exponential distribution. Even though the entropic and unbiased functionals both produce the same distribution (
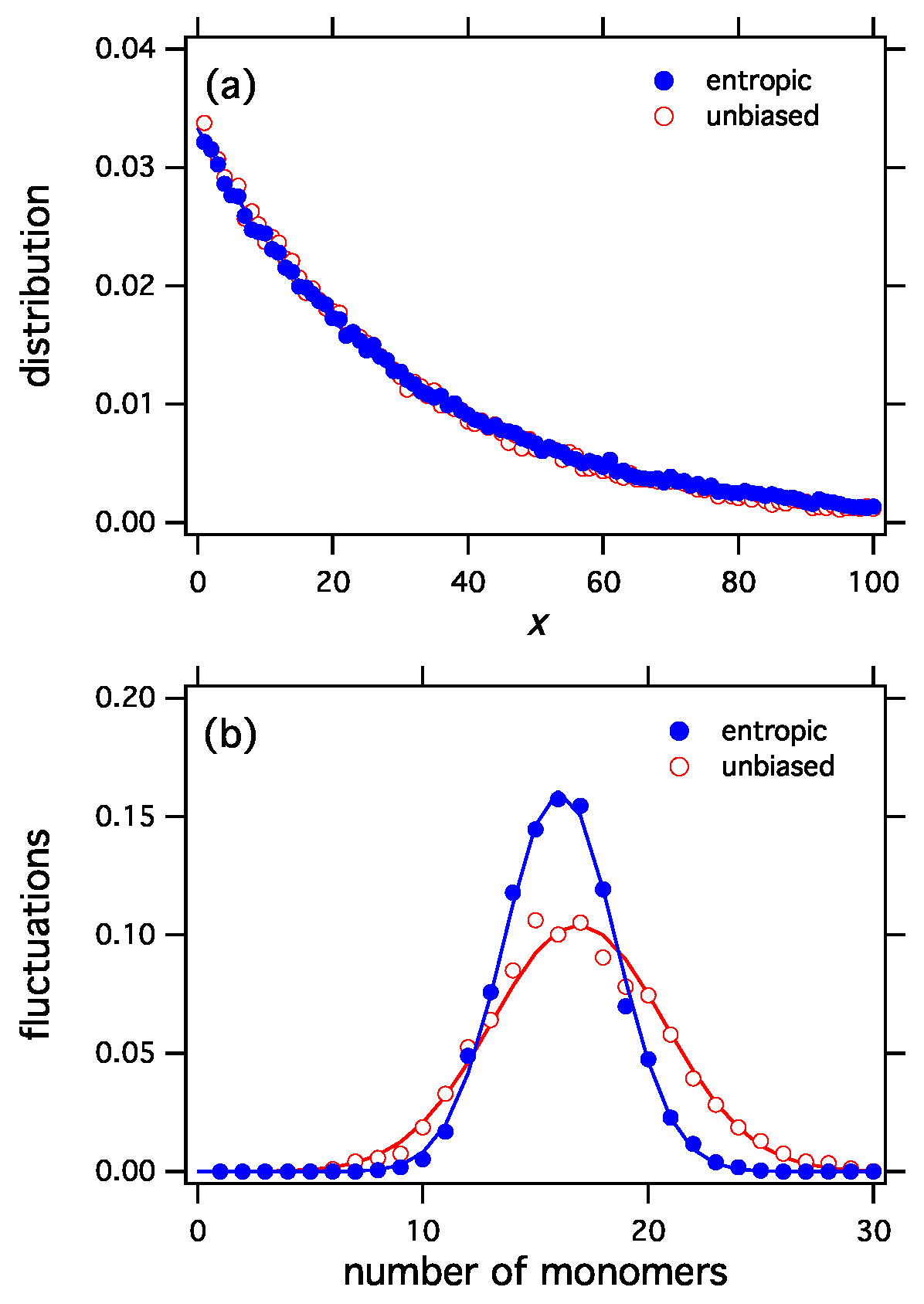
Figure 2a), their corresponding ensembles are distinctly different because each functional assigns different probabilities to the distributions of the ensemble. This difference can be seen in the fluctuations (
Figure 2b). The entropic functional is more selective than the unbiased, which picks configurations with equal probability. Accordingly, fluctuations in the entropic ensemble have narrower distribution. This can be clearly seen in
Figure 2b that shows the fluctuations in the number of monomers for the entropic and the unbiased functionals.


{kind=link}
{kind=link}
{kind=link}
{kind=link}


