1. Introduction
Tomography concerns reconstructing a probability density by synthesizing data collected along sections (or slices) of that density and is a problem of great significance in applied mathematics. Some popular applications of tomography in the field of medical imaging are computed tomography (CT), magnetic resonance imaging (MRI) and positron emission tomography (PET). In each of these, sectional data is obtained in a non-invasive manner using penetrating waves and images are generated using tomographic reconstruction algorithms.
Geometric tomography is a term coined by Gardner [
1] to describe an area of mathematics that deals with the retrieval of information about a geometric object from data about its sections, projections or both. Gardner notes that the term
geometric is deliberately vague, since it may be used to study convex sets or polytopes as well as more general shapes such as star-shaped bodies, compact sets or even Borel sets.
An important problem in geometric tomography is estimating the size of a set using lower dimensional sections or projections. Here, projection of a geometric object refers to its shadow or orthogonal projection, as opposed to the marginal of a probability density. As detailed in Campi and Gronchi [
2], this problem is relevant in a variety of settings ranging from the microscopic study of biological tissues [
3,
4], to the study of fluid inclusions in minerals [
5,
6] and to reconstructing the shapes of celestial bodies [
7,
8]. Various geometric inequalities provide bounds on the sizes of sets using lower dimensional data pertaining to their projections and slices of sets. The “size” of a set often refers to its volume but it may also refer to other geometric properties such as its surface area or its mean width. A canonical example of an inequality that bounds the volume of set using its orthogonal projections is the Loomis-Whitney inequality [
9]. This inequality states that for any Borel measurable set
,
Equality holds in (
1) if and only if
K is a box with sides parallel to the coordinate axes. The Loomis-Whitney inequality has been generalized and strengthened in a number of ways. Burago and Zalgaller [
10] proved a version of (
1) that considers projections of
K on to all
m-dimensional spaces spanned by
. Bollobas and Thomason [
11] proved the Box Theorem which states that for every Borel set
, there exists a box
B such that
and
for every
m-dimensional coordinate subspace
S. Ball [
12] showed that the Loomis-Whitney inequality is closely related to the Brascamp-Lieb inequality [
13,
14] from functional analysis and generalized it to projections along subspaces that satisfy a certain geometric condition. Inequality (
1) also has deep connections to additive combinatorics and information theory. Some of these connections have been explored in Balister and Bollobas [
15], Gyarmati et al. [
16] and Madiman and Tetali [
17].
A number of geometric inequalities also provide upper bounds for the surface area of a set using projections. Naturally, it is necessary to make some assumptions for such results, since one can easily conjure sets that have small projections while having a large surface area. Betke and McMullen [
2,
18] proved that, for compact convex bodies,
Motivated by inequalities (
1) and (
2), Campi and Gronchi [
2] investigated upper bounds for
intrinsic volumes [
19] of compact convex sets.
Inequalities (
1) and (
2) provide upper bounds and a natural question of interest is developing analogous lower bounds. Lower bounds are obtained via
reverse Loomis-Whitney inequalities or
dual Loomis-Whitney inequalities. The former uses projection information whereas the latter uses slice information, often along the coordinate axes. A canonical example of a dual Loomis-Whitney inequality is Meyer’s inequality [
20], which states that for a compact convex set
, the following lower bound holds:
with equality if and only if
K is a regular crosspolytope. Generalizations of Meyer’s inequality have also been recently obtained in Li and Huang [
21] and Liakopoulos [
22]. Betke and McMullen [
2,
18] established a reverse Loomis-Whitney type inequality for surface areas of compact convex sets:
Campi et al. [
23] extended inequalities (
3) and (
4) for intrinsic volumes of certain convex sets.
Our goal in this paper is to develop lower bounds on volumes and surface areas of geometric bodies that are most closely related to dual Loomis-Whitney inequalities; that is, inequalities that use slice-based information. The primary mathematical tools we use are entropy and information inequalities; namely, the Brascamp-Lieb inequality, entropy bounds for log-concave random variables and superadditivity properties of a suitable notion of Fisher information. Using information theoretic tools allows our results to be quite general. For example, our volume bounds rely on maximal slices parallel to a set of subspaces and are valid for very general choices of subspaces. Our surface area bounds are valid for polyconvex sets, which are finite unions of compact convex sets. The drawback of using information theoretic strategies is that the resulting bounds are not always tight; that is, equality may not achieved by any geometric body. However, we show that in some cases our bounds are asymptotically tight as the dimension n tends to infinity, thus partly mitigating the drawbacks. Our main contributions are as follows:
Volume lower bounds: In Theorem 3, we establish a new lower bound on the volume of a compact convex set in terms of the size of its slices. Just as Ball [
12] extended the Loomis-Whitney inequality to projections in more general subspaces, our inequality also allows for slices parallel to subspaces that are not necessarily
. Another distinguishing feature of this bound is that unlike classical dual Loomis-Whitney inequalities, the lower bound is in terms of
maximal slices; that is, the largest slice parallel to a given subspace. The key ideas we use are the Brascamp-Lieb inequality and entropy bounds for log-concave random variables.
Surface area lower bounds: Theorem 7 contains our main result that provides lower bounds for surface areas. Unlike the volume bounds, the surface area bounds are valid for the larger class of polyconvex sets, which consists of finite unions of compact, convex sets. Moreover, the surface area lower bound is not simply in terms of the maximal slice; instead, this bound uses all available slices along a particular hyperplane. As in the volume bounds, the slices used may be parallel to general
-dimensional subspaces and not just
. The key idea is motivated by a superadditivity property of Fisher information established in Carlen [
24]. Instead of classical Fisher information, we develop superadditivity properties for a new notion of Fisher information which we call the
-Fisher information. This superadditivity property when restricted to uniform distributions over convex bodies yields the lower bound in Theorem 7.
In
Section 2 we state and prove our volume lower bound and in
Section 3 we state and prove our surface area bound. We conclude with some open problems and discussions in
Section 4.
Notation: For
, let
denote the set
. For
and any subspace
, the orthogonal projection of
K on
E is denoted by
. The standard basis vectors in
are denoted by
. We use the notation
to denote the volume functional in
. The boundary of
K is denoted by
and its surface area is denoted by
. For a random variable
X taking values in
, the marginal of
X along a subspace
E is denoted by
. In this paper, we shall consider random variables with bounded variances and whose densities lie in the convex set
. The differential entropy of such random variables is well-defined and is given by
where
is an
-valued random variable. The Fisher information of a random variable
X with a differentiable density
is given by
3. Surface Area Bounds
The information theoretic quantities of entropy and Fisher information are closely connected to the geometric quantities of volume and surface area, respectively. Surface area of
is defined as
where
is the Euclidean ball in
with unit radius and ⊕ refers to the Minkowski sum. The Fisher information of a random variable
X satisfies a similar relation,
where
Z is a standard Gaussian random variable that is independent of
X. Other well-known connections include the relation between the entropy of a random variable and the volume of its typical set [
29,
30], isoperimetric inequalities concerning Euclidean balls and Gaussian distributions and the observed similarity between the Brunn-Minkowski inequality and the entropy power inequality [
31]. In
Section 2, we used subadditivity of entropy as given by the Brascamp-Lieb inequality to develop volume bounds. To develop surface area bounds, it seems natural to use Fisher information inequalities and adapt them to geometric problems. In the following subsection, we discuss relevant Fisher-information inequalities.
3.1. Superadditivity of Fisher Information
The Brascamp-Lieb subadditivity of entropy has a direct analog noted in Reference [
25]. We focus on the case when
and constants
for
satisfy John’s condition. The authors of Reference [
25] provide an alternate proof to the Brascamp-Lieb inequality in this case by first showing a superadditive property of Fisher information, which states that
The Brascamp-Lieb inequality follows by integrating inequality (
15) using the following identity that holds for all random variables
X taking values in
[
32]:
where
for a standard normal random variable
Z that is independent of
X. In particular, using this formula for inequality (
15) yields the geometric Brascamp-Lieb inequality of Ball [
33]:
If
and
for
, then inequality (
15) reduces to the standard superadditivity of Fisher information:
where
.
In
Section 2, we directly used the entropic Brascamp-Lieb inequality on random variables uniformly distributed over suitable sets
. It is tempting to use inequality (
15) to derive surface area bounds for geometric bodies. Unfortunately, directly substituting
X to be uniform over
in inequality (
15) does not lead to any useful bounds. This is because the left hand side, namely
, is
since the density of
X is not differentiable. Thus, it is necessary to modify inequality (
15) before we can apply it to geometric problems. A classical result concerning superadditivity of Fisher information-like quantities is provided in Carlen [
24]:
Theorem 4 (Theorem 2, [
24])
. For , let be a function in . Define the marginal map M asdenoted by . Then the following inequality holds: Carlen [
24] also established the (weak) differentiability of
G and the continuity of
M prior to proving Theorem 4, so the derivatives in its statement are well-defined. The notion of Fisher information we wish to use is essentially identical to the case of
in Theorem 4. However, since our goal is to use this result for uniform densities over compact sets, we cannot directly use Theorem 4, since such densities do not satisfy the required assumptions. In particular, the (weak) partial derivatives of conditional densities are defined in terms of Dirac delta distributions and so the densities do not lie in the Sobolev space
. To get around this, we redefine the
case as follows:
Definition 1. Let be a random vector on and be its density function. For any unit vector , definegiven that the limit exists. Define the -Fisher information of X asgiven that the right hand side is well-defined. In particular, when X is a real-valued random variable, Our new definition is motivated by observing that Theorem 4 is essentially a data processing result for
-divergences and specializing it to the total variation divergence yields our definition. To see this, consider real-valued random variables
X and
Y with a joint density
. Let the marginal of
Y on
be
. For
, consider the perturbed random variable
. Let the joint density of this perturbed random variable be
and the marginal of
by
. Recall that for every convex function
satisfying
, it is possible to define the divergence
for two probability densities
p and
q. It is well-known that such divergences satisfy the data-processing inequality [
34]; that is, if
is a Markov chain, then
. Using this fact, we obtain
Choosing
and using Taylor’s expansion, it is easy to see that
And similarly,
Substituting in inequality (
20), dividing by
and taking the limit as
yields
The above inequality is exactly equivalent to that in Theorem 4 using the substitution
and
. Although we focused on joint densities over
, the same argument also goes through for random variables on
.
Recall that Definition 1 redefines the case of in Theorem 4. Such redefinitions could indeed be done for as well. However, the perturbation argument presented above makes it clear that if , the -divergence between a random variable (taking uniform values on some compact set) and its perturbation will be , since their respective supports are mismatched. Thus, analogous definitions for will not yield useful bounds for such distributions. Using Definition 1, we now establish superadditivity results for the -Fisher information.
Lemma 1. Let X be an -valued random variable with a smooth density . Let be any unit vector. Define to be the projection of X along u. Then the following inequality holds when both sides are well-defined: Proof. Define the random variable
. Then the distribution of
satisfies
and is therefore a translation of
along the direction
u by a distance
. Using the data-processing inequality for total-variation distance, we obtain
where
is the total variation divergence. Notice that
and thus
. Dividing the left hand side of inequality (
24) by
and taking the limit as
, we obtain
Here, equality
follows by the definition of
and the assumption that it is well-defined. Doing a similar calculation for the right hand side of inequality (
24) leads to
The equality in
follows from the definition of
and the assumption that it is well-defined. □
Our next result is a counterpart to the superadditivity property of Fisher information as in inequality (
17).
Theorem 5. Let be an -valued random variable. Then the following superadditivity property holds: Proof. Applying Lemma 1 for the unit vectors
, we obtain
□
3.2. Surface Integral Form of the -Fisher Information
If we consider a random variable X that takes values uniformly over a set , then the -Fisher information superaddivity from Theorem 5 allows us to derive surface area inequalities once we observe two facts:
- (a)
The -Fisher information is well-defined for X and is given by a surface integral over and
- (b)
The quantity may be calculated exactly given the sizes of all slices parallel to or may be lower-bounded by using any finite number of slices parallel to .
Establishing the surface integral result in part (a) requires making some assumptions on the shape of the geometric body. We focus on the class of polyconvex sets [
19,
35], which are defined as follows:
Definition 2. A set is called a polyconvex set if it can be written as , where and each is a compact, convex set in that has positive volume. Denote the set of polyconvex sets in by .
In order to make our analysis tractable and rigorous, we first focus on polytopes and prove the polyconvex case by taking a limiting sequence of polytopes. Recall that convex polytope is the convex hull of a set of points. A precise definition of a polytope is as follows:
Definition 3. Define the set of polytopes, denoted by to be all subsets of such that every admits a representation where and is a compact, convex polytope in with positive volume for each .
In what follows, we make observations and precise.
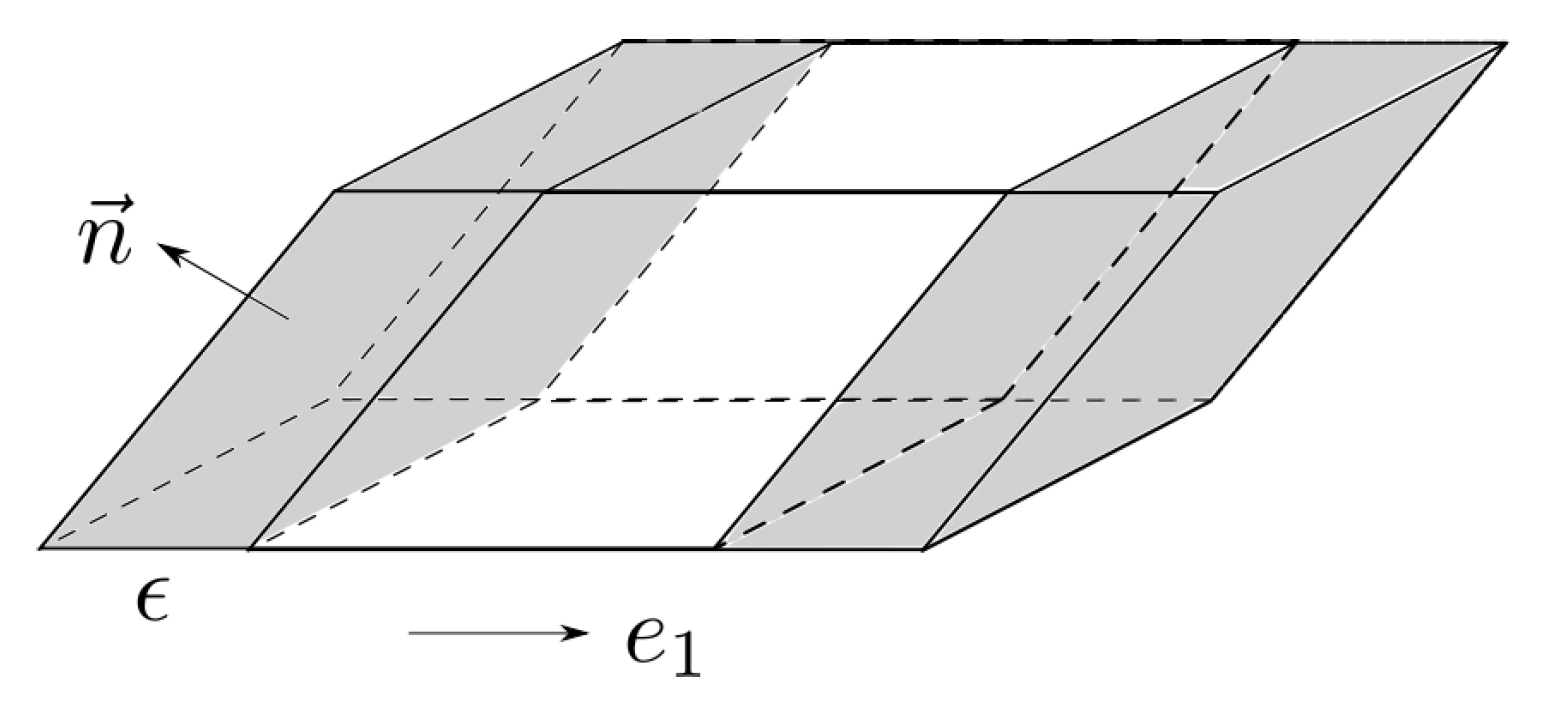
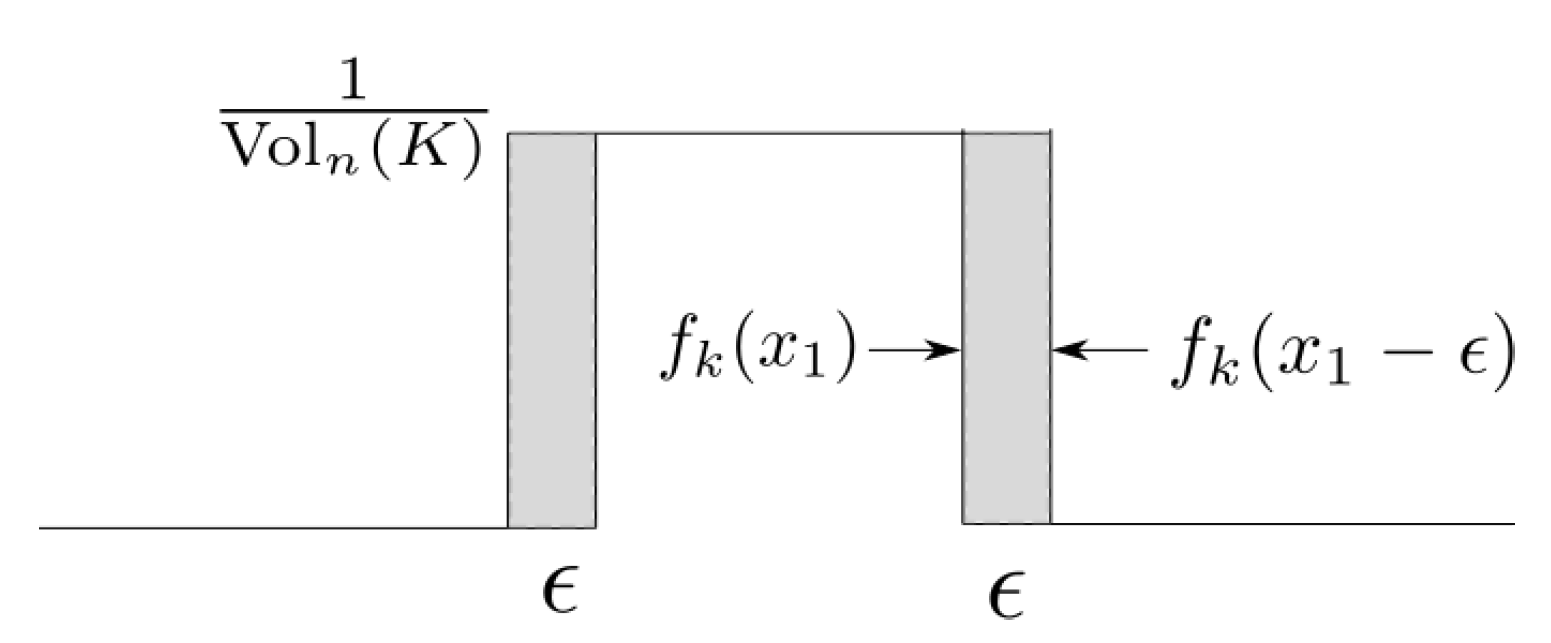
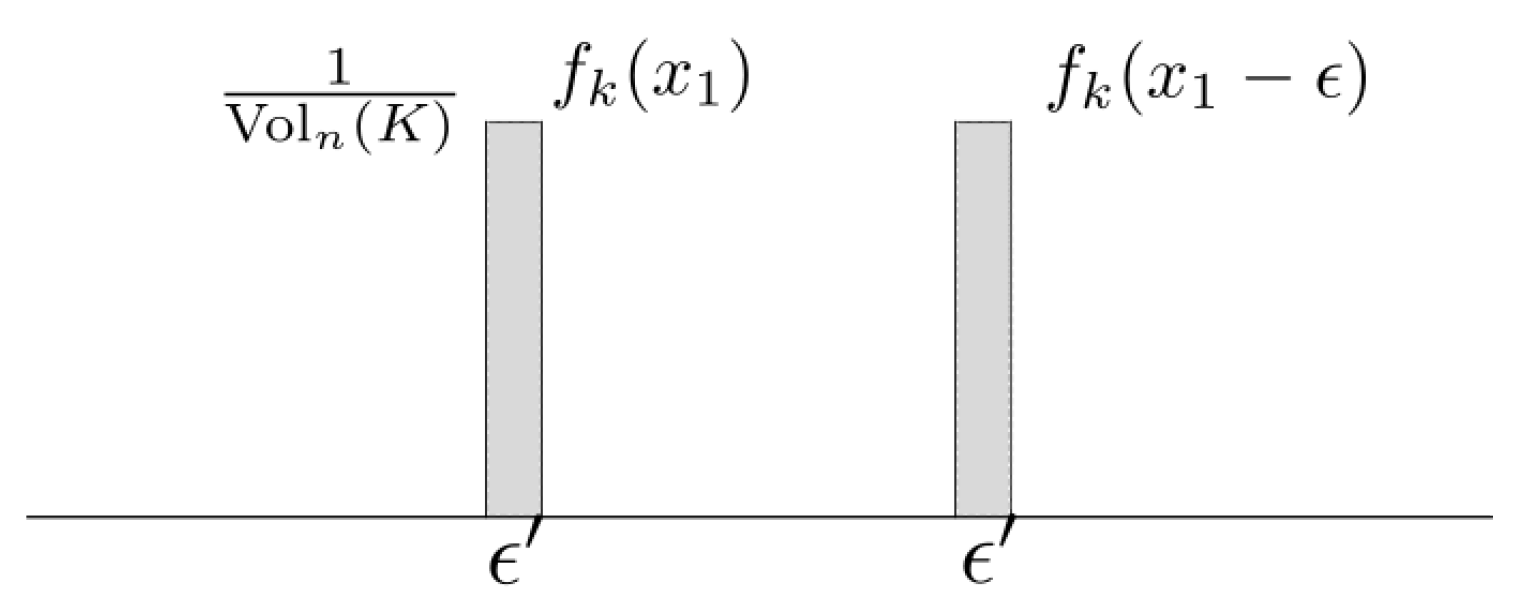
Theorem 6. Let X be uniformly distributed over a polytope K. Then the following equality holds:where is a unit normal vector at x on . Proof of Theorem 6. The equality in (
25) is not hard to see intuitively. Consider the set
K and its perturbed version
that is obtained by translating
K in the direction of
by
. The
distance between the uniform distributions on
K and
is easily seen to be
As shown in
Figure 1, each small patch
contributes
volume to
, where
is the normal to the surface at
. Summing up over all such patches
yields the desired conclusion. We make this proof rigorous with the aid of two lemmas:
Lemma 2 (Proof in
Appendix A)
. Let X be uniformly distributed over a compact measurable set . If there exists an integer L such that the intersection between K and any straight line can be divided into at most L disjoint closed intervals, thenHere stands for removing from the expression. The function is the number of disjoint closed invervals of the intersection of K and line . The above lemma does not require K to be a polytope. However, the surface integral Lemma 3 below uses this assumption.
Lemma 3 (Proof in
Appendix B)
. Let X be uniform over a polytope . ThenHere is the normal vector at point and is the element for surface area. Lemmas 2 and 3 immediately yield the desired conclusion, since and □
Our goal now is to connect to the size of the slices of K along .
3.3. -Fisher Information via Slices
Consider the marginal density of
, which we denote by
. It is easy to see that for each
, we have
Thus, the distribution of
is determined by the slices of
K by hyperplanes parallel to
. Since Theorem 5 is expressed in terms of
, where each
is a real-valued random variable, we establish a closed form expression for real-valued random variables in terms of their densities as follows:
Lemma 4 (Proof in
Appendix C)
. Let X be a continuous real-valued random variable with density . If we can find such that (a) is continuous and monotonic on each open interval ; (b) For , the limitsexist and are finite. Then We can see that the first sum in (
28) captures the change of function values on each monotonic interval and the second term captures the difference of the one-sided limits at end points. The following two corollaries are immediate.
Corollary 1. Let X be uniformly distributed on finitely many disjoint closed intervals; that is, there exist disjoint intervals for and such thatthen Corollary 2. Let X be a real-valued random variable with unimodal piecewise continuous density function . Then the following equality holds: Lemma 4 gives an explicit expression to compute when we know the whole profile of . When is only known for certain values x, we are able to establish a lower bound for . Note that knowing for only certain values corresponds to knowing the sizes of slices along a certain directions.
Corollary 3. Let where is as in Lemma 4. If there exists a setsuch that is continuous at each for , then Proof. We can find
where
,
such that they satisfy the conditions in Lemma 4 and
Consider the set
, which divides
into subintervals
We claim that
For the second term, note that
since
is assumed to be continuous at
for
. The points in
subdivide each of the intervals
; that is, for each interval
we can find an index
such that
and the monotonicity of the function over
gives
Summing up over all intervals yields equality (
31). To conclude the proof, note that
is not necessarily monotonic in the interval
. Thus, if we have indices
, the triangle inequality yields
Here, equality
follows from the continuity of
at the points in
S. Performing the above summation over all intervals
for
and using equality (
31), we may conclude the inequality
□
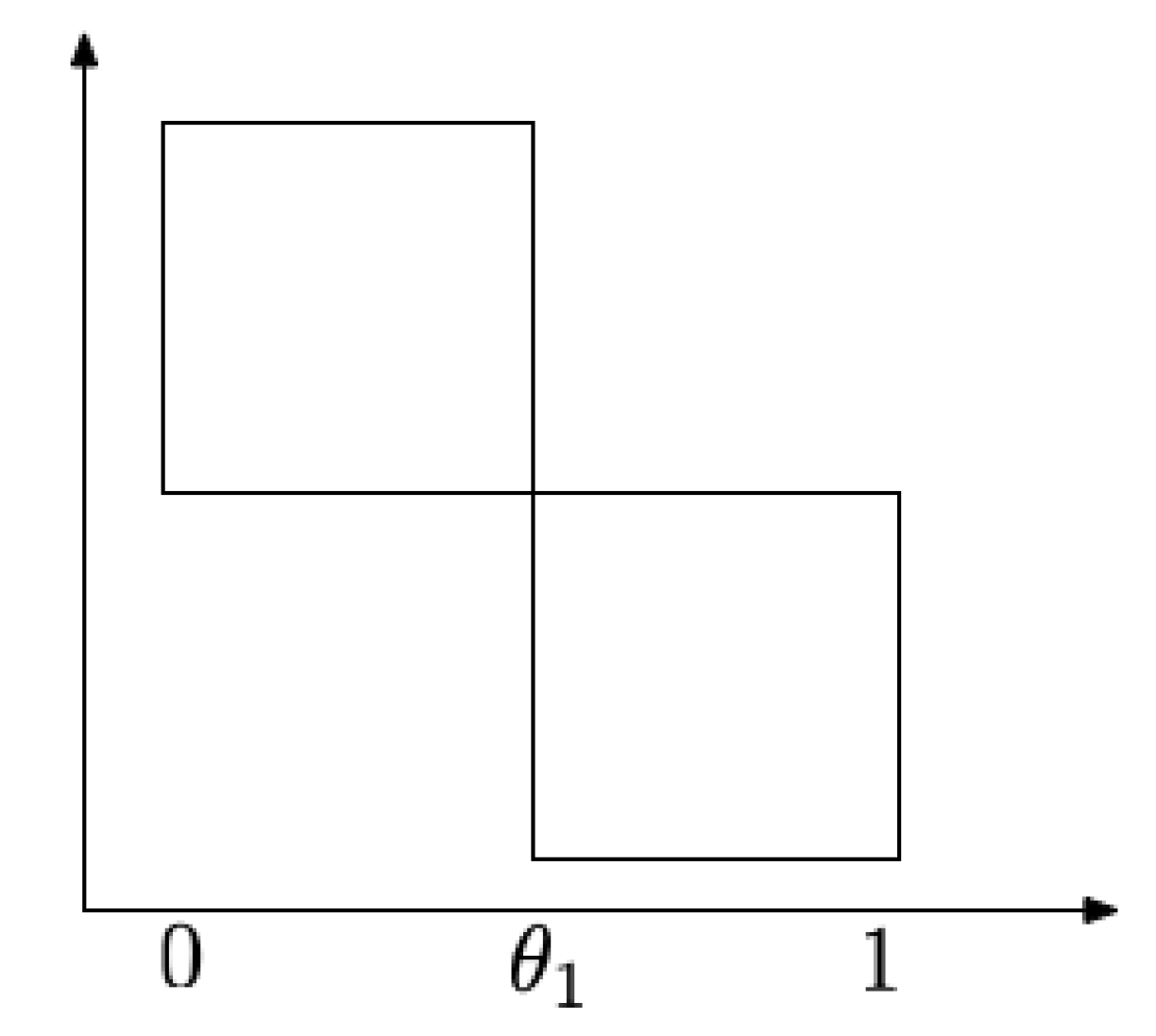
Remark 1. Suppose K is the union of two squares joined at the corner as shown in Figure 2. Let X be uniformly distributed on K. Suppose also that the slice of K is known only at . By direct calculation, we have , since is uniform over . Notice that and thus the bound from Corollary 3 is 4, which is larger
than . This reversal is due to the discontinuity of at the sampled location — equals neither the left limit or the right limit at . To avoid such scenarios, we require continuity of the density at sampled points. Corollary 3 shows that under mild conditions, we can estimate when only limited information is known about its density function.
3.4. Procedure to Obtain Lower Bounds on the Surface Area
We first verify that the assumptions required by Lemma 4 are satisfied by the marginals of uniform densities over polytopes.
Lemma 5 (Proof in
Appendix D)
. Suppose is uniformly distributed over a polytope . Let u be any unit vector and let be the marginal density of . Then satisfies the conditions in Lemma 4. Now suppose
is uniformly distributed over a polytope
K. Since
K is a polytope, we may write
where each
is a compact, convex polytope. Theorem 5 provides the lower bound:
To derive surface area bounds, notice that
and thus
Suppose we know the sizes of some finite number of slices by hyperplanes parallel to
for
. We may use Corollary 3 to obtain lower bounds
on
for each
using the available slice information. This leads to the lower bound
and thereby we may conclude the lower bound
This is made rigorous in the following result, which may be considered to be our main result concerning surface areas.
Theorem 7. Let K be a polyconvex set. For , suppose that we have slices of K obtained by hyperplanes , with sizes . Then the surface area of K is lower-bounded bywhere for all . Proof. Let
K be a polyconvex set with a representation
where
are compact, convex sets. For each
, we construct a sequence of convex polytopes
which approximate
from the outside. This means that
for all
and
, where
d is the Hausdorff metric. (This is easily achieved, for instance by sampling the support function of
uniformly at random and constructing the corresponding polytope.) Consider the sequence of polytopes
. For each
k, we would like to assert that inequality (
35) holds for the polytope
; that is, we would like to lower bound
using the slices of
at
for
and
. The only difficulty in applying Corollary 3 to obtain such a lower bound on
is the continuity assumption, which states that the marginal of the uniform density of
on
, denoted by
, should be continuous at
for all
and all
. However, this is easily ensured by choosing an outer approximating polytope for
that has no face parallel to
for all
.
To complete the proof for
K, we need to show that
and
for any
and any
. To show this, we use the following lemma [
36]:
Lemma 6 (Lemma 1 [
36])
. Let be compact sets. Let , be a sequence of compact approximations converging to in Hausdorff distance, such that for all and for . Then it holds that Using Lemma 6, we observe that for any collection of indices
, we must have
as
. Since surface area is convex continuous with respect to the Hausdorff measure [
19,
35], we have the limit
Moreover, surface area is a valuation on polyconvex sets [
19,
35] and thus the surface area of a union of convex sets is obtained using the inclusion exclusion principle. In particular, the surface area of
K is
and the surface area of
is given by
Using the limit in equation (
37), we may conclude that every single term in (
39) converges to the corresponding term in (
38) and so
We now show that each slice of
converges in size to the corresponding slice of
K. Let
H be some fixed hyperplane that is orthogonal to one of the coordinate axes. Since each
can be replaced by a polytope
, we can assume without loss of generality that for each
, the sequence of polytopes that approximate
from outside is monotonically decreasing; that is,
for all
. For any fixed compact convex set
, Lemma 6 yields
and thus the
-dimensional volume of the two sets also converges. Picking
L to be
, we see that
and
is
and thus equation (
41) yields
The sequence of set
for
is an outer approximation to
that converges in the Hausdorff metric. Therefore, using Lemma 6,
Using the continuity of the volume functional,
Now an identical argument as above says that the
-dimensional volume of
is obtained via an inclusion exclusion principle applied to the convex sets
for
. Applying Equation (
44) to all the terms in the inclusion exclusion expression, we conclude that
This concludes the proof. □
Note that there is nothing restricting us to hyperplanes parallel to
. For example, suppose we have slice information available via hyperplanes parallel to
for some unit vectors
for
. In this case, we have the inequality
Using the slice information, we may lower bound
via Corollary 3. Suppose this bound is
. To arrive at a lower bound for the surface area, all we need is the best possible constant
such that
for all unit vectors
. (This constant happened to be
when
’s were the coordinate vectors.) With such a constant, we may conclude
In
Appendix E, we work out the surface area lower bound from Theorem 7 for a particular example of a nonconvex (yet polyconvex) set.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




