1. Introduction
Protein disorder, where whole proteins or protein segments are either unstable or meta-stable, has proven to be a critical property to understand function in biological systems [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31,
32,
33]. Such disordered proteins and regions have been demonstrated to become more abundant as organism complexity increases [
23,
29,
34,
35,
36,
37]. This increase in disorder with organism complexity likely results from the key roles played by disorder in the signaling and regulatory processes underlying cellular differentiation, cell cycle control, gene regulation, and protein–protein interactions, especially enabling the existence of hubs [
10,
13,
38,
39,
40,
41,
42,
43,
44]. The origin of these effects arises because disordered proteins enable more diverse function, yet are still able to maintain a high degree of specialization in their specific interactions.
Understanding entropic effects in protein systems is usually difficult, and understanding molecular stability is arguably one of the most important problems in molecular biology, particularly of interest for proteins. This problem is clearly important for understanding the relationship between protein function, structure, and sequence. The full knowledge of protein stabilities requires the reliable evaluation of energies and entropies. This would also aid in the evaluation of structural models of the large number of genes with unknown protein structures. Even a partial understanding of the relationship between entropic sequence effects and structure has already yielded significant success [
45,
46,
47], and will most likely lead to further success in the future.
Entropy and disorder are intimately related. The aim here was to explore this relationship for proteins. In this work, we analyzed datasets of related proteins with known sequences and structures. We split each cluster of related proteins into two sets, one having a greater sequence similarity than the other. We do this as a way to further explore the relationship to sequence variability. We analyzed the variations in sequence and structure among these sets and quantify their entropies.
Entropy is a global variable. It is the logarithm of the number of phase space states accessible to a system. In very large systems, such that they appear continuous, the number of states is estimated from the phase space volume. Since velocity coordinates in a protein system are related to thermal degrees of freedom and we assumed a constant temperature, the momentum distribution of different conformational states will be similar and, to a good approximation, the difference in the entropy of two states will depend only on the difference between their configuration space volumes.
A previous study of entropy in protein systems by Franzosa and Xia [
48] investigated the constraints that structure imposes upon protein evolution. They found that solvent exposure is the most significant structural determinant of residue evolution and also identified a weak effect from the packing density. The relationship between solvent exposure and entropy they found was “strong, positive, and linear”. We investigated these relationships.
2. Materials and Methods
To obtain a dataset of both sequence and structure of related proteins, we clustered PDB [
49,
50,
51] structures with resolution better than 3 Angstrom, at 25% or greater sequence identity (SID). This was done by first clustering the PDB at 99% SID, to remove redundancies, and then clustering at 25% SID. We used BLASTClust [
52] with default parameters to do the clustering. We selected the largest clusters and divided each cluster into two separate sets having SID values in the range of 30–50% SID for one set (A types) and 60–80% for the second set (B types). These collections represent more diverse A sets and less diverse B sets, respectively.
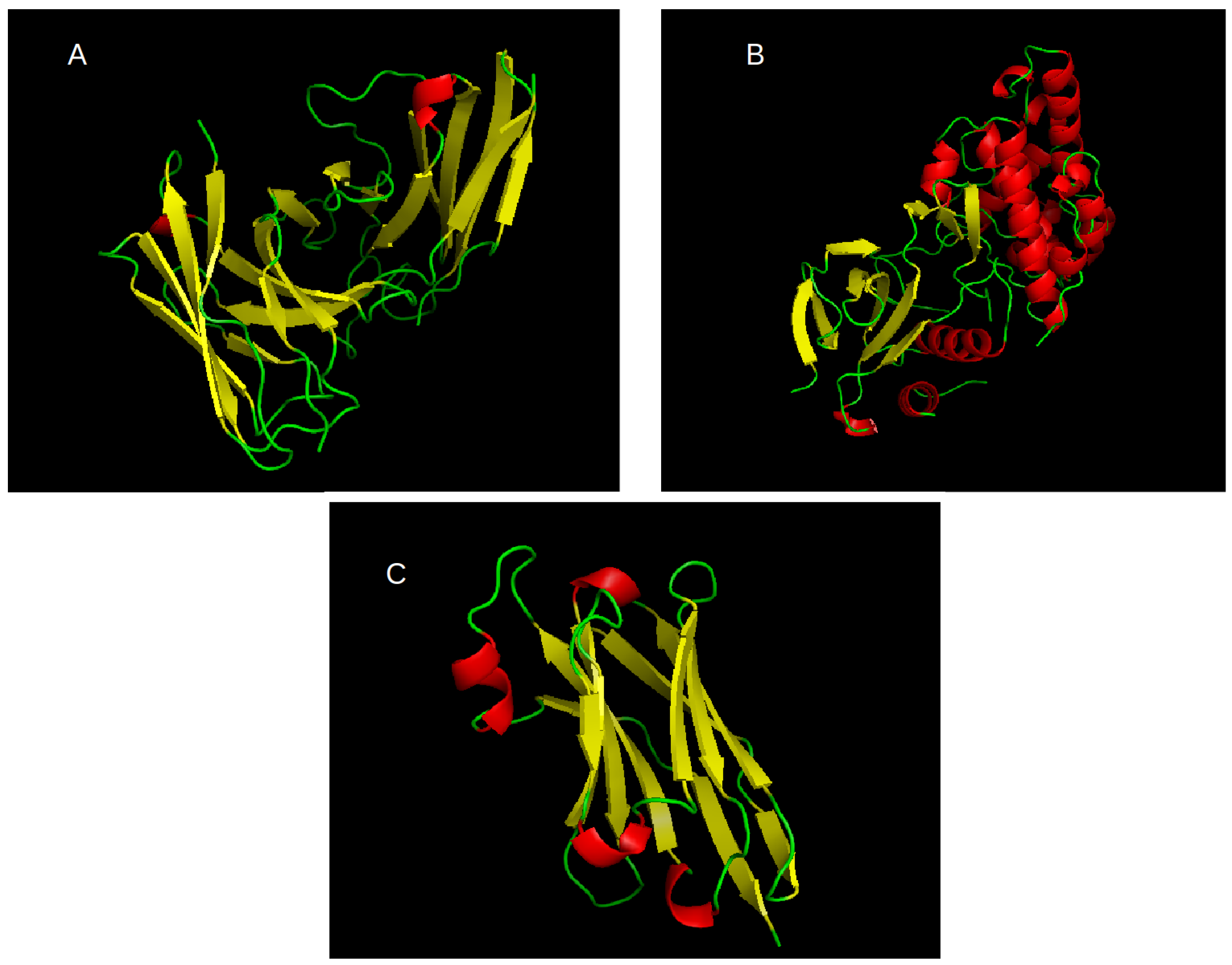
The most abundant cluster of related proteins we found is that of antibodies. We use the notation of L1 to refer to this set. The PDB ID for the structural seed of this set is 5U68E, where the fifth character gives the chain ID. The second most abundant cluster is for kinases. We use the notation of L2 to refer to this set. The PDB ID for the structural seed of this set is 3TTIA. Per review request, we included the third largest cluster as an additional test for some of our results as described in the text. The PDB seed for this cluster is 5F1OB and it is labeled L3. Cartoon representations of the seed structures for L1, L2, and L3, are given in
Figure 1. In total, we have 6 sets of proteins: L1, L2, and L3, each split into two sets as described above. The number of proteins in each set and the corresponding descriptors are given in
Table 1.
For each of these sets, we collected their sequences and executed a multiple sequence alignment (MSA) using CLUSTALW [
53,
54] with default parameters. The length of the alignment obtained for each set is also given in
Table 1. We observed that, the more varied is the set, the longer is the length of the alignment, as expected. In addition, we found that the more distant are the proteins (lower SID), the longer is the alignment. That is also to be expected since aligning more distant proteins would require inserting more gaps to accommodate the larger sequence variations. We refer to a given column in the MSA as an MSA site. To avoid cases of sparseness in the data, we only used MSA sites having a count of at least 20 amino acids. The number of MSA sites obeying this condition is also given in
Table 1. Finally, we give the means, medians, and standard deviations, for the TM-scores [
55] between the seed structure and all the rest of the structures in the corresponding set. The Template Modeling score (TM-score) is a parameter to measure protein structure similarity. It is calculated from the distances between the residues of two aligned proteins:
where the maximum is taken over all possible alignments.
is the length of the target protein,
is the length of the protein that is aligned to it,
is the distance between the residues at alignment location
i, and
is a scaling distance, optimized to
. With such calibration, the TM-score does not depend on the protein length, and varies between 0 and 1, with 1 indicating a perfect match. A TM-score below 0.2 indicates structurally unrelated proteins, while a TM-score greater than 0.5 indicates the two proteins belong to the same fold.
We observed that the largest set L1 is distributed around relatively distinct structures with some similarity, having a TM-score of just below 0.5. All three sets have TM-scores with means ranging between 0.37 and 0.67. We also observed an appropriate increase in mean and median TM-score for the more similar structures (the B sets - SID 60–80%). We note that the set L2B with SID 60–80% is composed of two overlapping structure clusters. This is exhibited in the range of TM-score and also somewhat skews the results for this set.
To evaluate the amount of disorder at a given MSA site, we introduce the parameter
that counts the excess number of disordered residues:
Here,
is the number of residues at an MSA site classified as disordered, i.e., their coordinates appear in the missing coordinates section of the corresponding PDB file (remark 465), and
is the number of residues classified as ordered, i.e., with coordinates in the corresponding PDB file.
is the total number of residues per MSA site, i.e., the total number of sequences that have a residue at this site in the MSA. Note that in a few instances there is a discrepancy between the residue type as it appears in the Uniprot [
56] sequence information and that in the PDB file. We discarded these cases and did not classify them as either ordered or disordered, however, they appear in
. Hence, in general
, and
. At a given MSA site,
indicates all residues at that site are classified as disordered, while
indicates that all residues at that site are classified as ordered. Using this approach, for any specific mutation site, we established linked measures of both disorder and structural order. Note that, for a given MSA site, with a number of proteins having a residue at that location, those residues with missing coordinates in the PDB file are labeled disordered. For those residues with coordinates in the PDB, we calculated the structural features. Hence, for a given MSA site, we have both structural and disorder information and we investigated the relationship between them. To ensure that we have some sampling points per MSA site we restricted our attention only to those MSA sites that have at least 20 proteins contributing a residue to the alignment. Note that, since the protein sequences were obtained from Uniprot, residues without PDB coordinates can still contribute to the alignment.
To characterize the structure and fluctuations at a given MSA site, we proceeded as follows. We started by finding the closest long-range contact (CLRC), that is, the closest residue in space which has a sequence separation of more than 5 residues from the MSA site. The distances between the C (C for GLY) atoms was used to measure the distance between residues. For all MSA sites, we calculated the average of these distances, , and their standard deviations, . We quantified the rotational relationship by calculating the cosines of the angles between the N-C, C-C, and C-C (0.0 for GLY) bonds for the residue pair identified by a given MSA site and its CLRC site. The cosine of the angle was obtained by taking the dot product of the bond vectors and normalizing by their lengths. The average values of these were identified as , , , respectively, and the standard deviations of the cosines of these angles are denoted as , , and , respectively.
We also calculated the Shannon entropy for the original MSA site with respect to residue type fluctuations, i.e., from those aligned sequences at a given MSA site we created a probability distribution for residue type and then used
to calculate the sequence entropy. We performed a similar procedure on the probability distribution for residue types of the CLRC. The Shannon entropy parameter for the original MSA site is denoted
, and that for the CLRC
. In
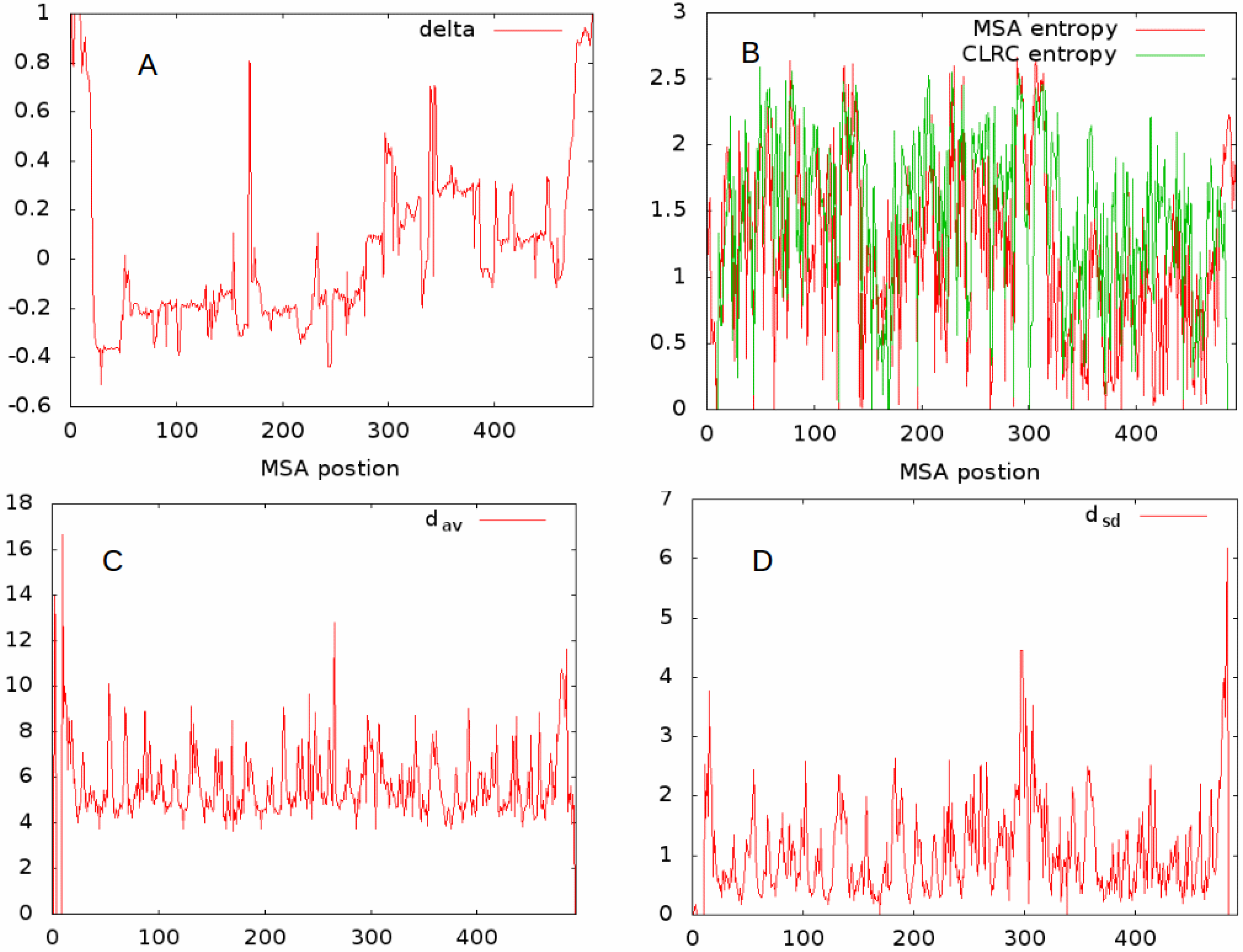
Figure 2, we give example plots of
(
Figure 2A), the two entropies
and
(
Figure 2B),
(
Figure 2C), and
(
Figure 2D), for all MSA sites having at least 20 residues contributing to the alignment for the set L1A. The relationships even between this limited set seem complex. In what follows, we try to further characterize the features of a given MSA site, and as a first approach determine the correlations between these different features.
In addition, we calculated the average and standard-deviations for the accessible surface area, relative accessible surface area (RSA), and the
and
dihedral angles for both the MSA site and the CLRC site. For the MSA site, we identify these parameters as
,
,
,
,
,
,
, and
, respectively. For the CLRC, we identify these as
,
,
,
,
,
,
, and
, respectively. We also calculated the propensity of secondary structure types at the MSA and CLRC sites. In general, we use the index 1 for the MSA site and the index 2 for the CLRC site. The letters
h, c, and e refer to the helix, coil, and, sheet secondary structure types, respectively. We use the same secondary structure assignment scheme as in SPINE-X [
57,
58,
59]. From these propensities, we calculate a probability distribution for secondary structure states and from that we calculate the Shannon entropy for secondary structure. We use the notation
for this entropy for the MSA site and
for this entropy at the CLRC.
3. Results and Discussion
To estimate the relationships between the various parameters and the disorder propensity of an alignment site,
, we calculated Pearson correlation coefficients (correlations) between them. In
Table 2,
Table 3,
Table 4,
Table 5,
Table 6 and
Table 7, we give the correlations between the various sequence and structure parameters we calculated. Correlations to entropic parameters are given in
Table 2. We found that there is a consistent negative correlation between
and
. The only exception is a marginal positive correlation for L3B. Since L3B is a smaller set, this result may be due to not enough statistics. The positive correlation between
and
seems to indicate a significant average residue conservation for residues proximate to disordered sites. This can be an indication of their importance for function, and this will be further explored in future work. The correlation values between
and the entropy of the disordered site are weaker. This indicates that the residue type substitution rate is not significantly different between ordered and disordered residues in this case. This behavior of the correlation could come about because disordered sites form structure with protein or nucleic acid partners, with the resulting structure imparting increased conservation for the amino acids involved in the formation of the complex. Some disordered regions have high conservation throughout [
60], possibly because they form multiple partnerships such that nearly all of their residues are important for at least one critical structure.
In
Table 3, we give the correlations between the different entropic parameters. Overall, there is a positive correlation between them. In addition, as expected, correlations within the more similar set L2B appear larger than those of the less similar sets L2A. For set L1, the situation is less clear and may be an indication that set L1 carries more noise.
Correlations between
and spatial parameters are given in
Table 4. We found significant positive correlations between
and
. This is to be expected from the definition of disorder. It is interesting to note that the correlations to the fluctuations of the rotational degrees of freedom (
,
,
) are all negative. This is a puzzle since it seems to associate larger rotational fluctuations with less disorder. It may be an indication that disorder fluctuations are more abundant in the radial directions than in the rotational ones.
To further test the correlation between
and
and
, we performed a similar analysis on the third most abundant cluster of related sequences of structures deposited in the PDB. The general properties for this cluster are labeled under L3 in
Table 1. The seed PDB structure for this protein chain is 5F1OB; a representative cartoon of it is given in
Figure 1. For the more diverse subgroup of L3 (30–50% SID), we found correlations of 0.219 and 0.195 for
and
, respectively. For the less diverse subgroup of L3 (60–80% SID), we found correlations of 0.361 and 0.225 for
and
, respectively. These trends are in line with the results for clusters L1 and L2. To estimate the statistical significance of the observed positive correlations between
and
and
, we performed the following analysis for the set L1A. We started by selecting a random subset of 200 points and calculated the correlation for this subset. We then repeated this process 15 times and use a majority vote to determine the sign of the correlation. Hence, we can consider such a round a flip of a coin, with two possible outcomes. We conducted 10 such rounds and obtained a positive correlation for all of them. In analogy with coins, this would correspond to a
p-value of
, indicating confident rejection of the null hypothesis that the correlations are random.
Correlations between
and accessible surface area parameters are given in
Table 5. They are mostly significantly positive, and similarly for the RSA. This is in agreement with the general observation that disordered residues occur in exposed regions of proteins. The negative correlations with fluctuations in accessible surface area may be due to the same observation, as disordered residues would tend to remain exposed, and hence have reduced fluctuations. We could not identify any consistent trend from the correlations with the dihedral angles values (
Table 6). However, we did find one for the fluctuations in the dihedral angles. Fluctuations of the dihedral angles are positively correlated with disorder propensity for the original residues, and negatively correlated for the CLRC residues. This is in agreement with the results for the Shannon entropy at these sites, indicating allowed variability at the disordered site, and increased rigidity in the parts of the protein where this disordered site interacts. This may be another indication that disordered residues are involved in protein function.
Correlations between
and probabilities of secondary structure types are given in
Table 7. As expected, we found a significant negative correlation. We found the strongest negative correlation with the propensity of
-sheets. This is also expected. We also found a negative correlation between the entropy of secondary structure and
for both the original site and its CLRC. This indicates that as disorder is increased at a given MSA site, it becomes more probable for the secondary structure to be of a particular type. This results is consistent with our previous observations for the CLRC. It is difficult to evaluate their significance for the original site since, we have a mixture of disorder and order information.
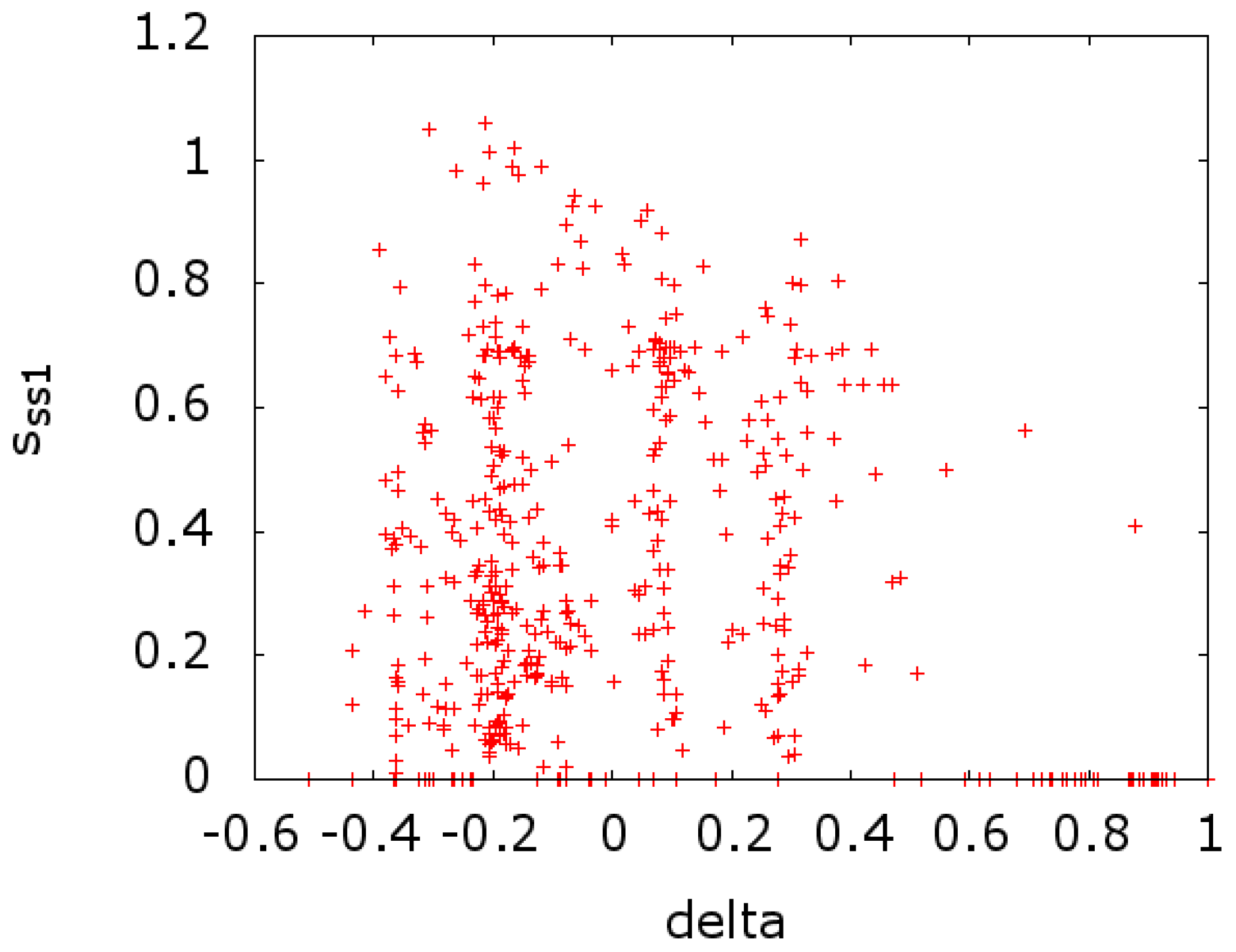
In
Figure 3, we plot the entropy of secondary structure at a given MSA site (
) versus the value of
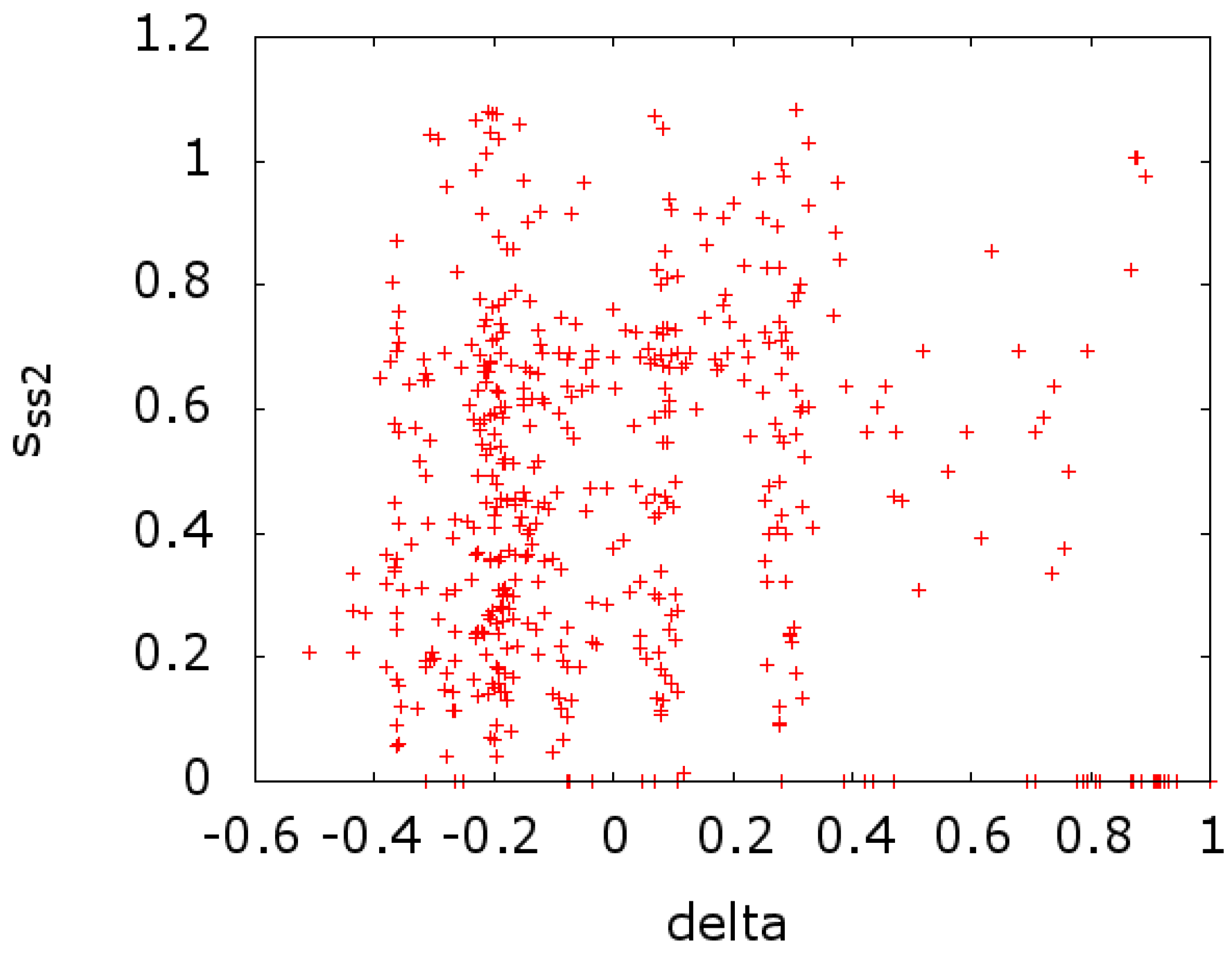
at that site. In
Figure 4, we plot the same at the CLRC site (
versus
). In both cases, we see a scatter of points on the
x-axis. This indicates a strong effect that is due to conserved sites with zero entropy. If we remove these sites from the calculations of the entropy, we get a reversal in the sign of the correlation, going from −0.213 and −0.141 to 0.139 and 0.247 for
Figure 3 and
Figure 4, respectively.
We also calculated the correlations between secondary structure type probabilities of the original site and the CLRC. Our aim here was to study the relationship between the structure at the MSA and CLRC sites. Specifically, if there is a difference in that relationship between sites that tend to be more or less disordered. In
Table 8, we give these values. We also calculated these correlation values separately for MSA sites with
(more disordered) and with
(more ordered). There is a clear positive correlation for secondary structure types regardless of the state of disorder. One should note that for set L1 there is very little helix conformation, as observed in
Figure 1A. This is the reason for the low correlation for this case in
Table 8 as there are not enough data.
Finally, part of our aim in the research was to find differences in behavior between two sets of proteins, one with more related proteins, and the other a more diverse set of proteins. Unfortunately, we do not feel confident in drawing conclusions from the data regarding that question. However, future studies may find the data presented here useful.
4. Conclusions
We investigated the relationship between entropy and disorder using native protein structures found in the PDB. By finding clusters of related proteins and studying the MSA of the sequences of these clusters, we were able to establish a link between sequence, structure, and disorder information. We introduced several parameters as measures of fluctuations at a given MSA site and used these as plausible representative of the sequence and structure entropy at that site. We then defined a disorder propensity of an MSA site, , and calculated the Pearson correlations between it and our fluctuation parameters. Overall, we found a tendency for negative correlations between disorder and structure. We also found evidence for residue-type conservation for those residues in close proximity to potentially disordered sites. Mutations at the disordered site itself appear to be allowed.
We found significant positive correlations between and the fluctuations in the system. This is to be expected from the definition of disorder. It is interesting to note that the correlations to the fluctuations of the rotational degrees of freedom (, , and ) are all negative. This may be an indication that disorder fluctuations are more abundant in the radial direction than in rotational directions but this result will be investigated in future studies.
As expected, we found positive correlations for disorder and accessible surface area, indicating that disordered residues occur in exposed regions of proteins. We found a negative correlations for disorder with fluctuations in accessible surface area. This seems to indicate that disordered residues would tend to remain exposed, and hence with reduced RSA fluctuations. We also found that fluctuations in the dihedral angles at the original mutated residue and disorder are positively correlated while dihedral angle fluctuations in the CLRC residue are negatively correlated with disorder. This agrees with the results for the Shannon entropy at these sites, indicating permissible variability in the disordered site, but greater rigidity in the parts of the protein with which the disordered site interacts. This is another indication that disordered residues are involved in protein function. We also found indications that, as disorder is increased at a given MSA site, it becomes more probable for the secondary structure to be of a particular type.










{kind=link}
{kind=link}
{kind=link}
{kind=link}