1. Introduction
Maximum likelihood is one of the most used tools of modern statistics. As a result of its attractive properties, it is useful and suited for a wide class of statistical problems, including modeling, testing, and parameters estimation [
1,
2]. In the case of regular and correctly-specified models, maximum likelihood provides a simple and elegant means of choosing the best asymptotically normal estimators. Generally, the maximum likelihood workflow proceeds by first defining the statistical model which is thought to generate the sample data and the associated likelihood function. Then, the likelihood is differentiated around the parameters of interest by getting the likelihood equations (score), which are solved at zero to find the final estimates. In most simple cases, the maximum likelihood solutions are expressed in closed-form. However, analytic expressions are not always available for most complex problems and researchers need to solve likelihood equations numerically. A broad class of these procedures include Newton-like algorithms, such as the Newton–Raphson, Fisher-scoring, and quasi Newton–Raphson algorithms [
3]. However, when the sample size is small, or when the optimization is no longer convex as in the case of more sophisticated statistical models, the standard version of Newton–Raphson may not be optimal. In this case, robust versions should instead be used [
4]. A typical example of such a situation is the logistic regression for binary data, where maximum likelihood estimates may no longer be available, for instance, when the binary outcome variable can be perfectly or partially separated by a linear combination of the covariates [
5]. As a result, the Newton–Raphson is unstable with inconsistent or infinite estimates. Other examples include small sample sizes, large numbers of covariates, and multicollinearity among the regressor variables [
6]. Different proposals have been made to solve these drawbacks, many of which are based on iterative adjustments of the Newton–Raphson algorithm (e.g., see [
7,
8]), penalized maximum likelihood (e.g., see [
9]), or the homotopy-based method (e.g., see [
10]). Among them, bias-corrected methods guarantee the existence of finite maximum likelihood estimates by removing first-order bias [
11], whereas homotopy Newton–Raphson algorithms, which are mostly based on Adomian’s decomposition, ensure more robust numerical convergences in finding roots of the score function (e.g., see [
12]).
Maximum entropy (ME)-based methods have a long history in statistical modeling and inference (e.g., for a recent review see [
13]). Since the seminal work by Golan et al. [
14], there have been many applications of maximum entropy to the problem of parameter estimation in statistics, including autoregressive models [
15], multinomial models [
16], spatial autoregressive models [
17], structural equation models [
18], the co-clustering problem [
19], and fuzzy linear regressions [
20]. What all these works share in common is an elegant estimation method that avoids strong parametric assumptions on the model being used (e.g., error distribution). Differently, maximum entropy has also been widely adopted in many optimization problems, including queueing systems, transportation, portfolio optimization, image reconstruction, and spectral analysis (for a comprehensive review see [
21,
22]). In all these cases, maximum entropy is instead used as a pure mathematical solver engine for complex or ill-posed problems, such as those encountered when dealing with differential equations [
23], oversampled data [
24], and data decomposition [
25].
The aim of this article is to introduce a maximum entropy-based technique to solve likelihood equations as they appear in many standard statistical models. The idea relies upon the use of Jaynes’ classical ME principle as a mathematical optimization tool [
22,
23,
26]. In particular, instead of maximizing the likelihood function and solving the corresponding score, we propose a solution where the score is used as the data constraint to the estimation problem. The solution involves two steps: (i) reparametrizing the parameters as discrete probability distributions and (ii) maximizing the Shannon’s entropy function w.r.t. to the unknown probability mass points constrained by the score equation. Thus, parameter estimation is reformulated as recovering probabilities in a (hyper) symplex space, with the searching surface being always regular and convex. In this context, the score equation represents all the available information about the statistical problem and is used to identify a feasible region for estimating the model parameters. In this sense, our proposal differs from other ME-based procedures for statistical estimation (e.g., see [
27]). Instead, our intent is to offer an alternative technique to solve score functions of parametric, regular, and correctly specified statistical models, where inference is still based on maximum likelihood theory.
The reminder of this article is organized as follows.
Section 2 presents our proposal and describes its main characteristics by means of simple numerical examples.
Section 3 describes the results of a simulation study where the ME method is assessed in the typical case of logistic regression under separation. Finally,
Section 4 provides a general discussion of findings, comments, and suggestions for further investigations. Complementary materials like datasets and scripts used throughout the article are available to download at
https://github.com/antcalcagni/ME-score, whereas the list of symbols and abbreviations adopted hereafter is available in
Table 1.
2. A Maximum Entropy Solution to Score Equations
Let
be a random sample of independent observations from the parametric model
, with
being a density function parameterized over
,
the parameter space with
J being the number of parameters, and
the sample space. Let
be the log-likelihood of the model and
the score equation. In the regular case, the maximum likelihood estimate (MLE)
of the unknown vector of parameters
is the solution of the score
. In simple cases,
has closed-form expression but, more often, a numerical solution is required for
, for instance by using iterative algorithms like Newton–Raphson and expectation-maximization.
In the maximum likelihood setting, our proposal is instead to solve
by means of a maximum entropy approach (for a brief introduction, see [
28]). This involves a two step formulation of the problem, where
is first reparameterized as a convex combination of a numerical support with some predefined points and probabilities. Next, a non-linear programming (NLP) problem is set with the objective of maximizing the entropy of the unknown probabilities subject to some feasible constraints. More formally, let
be the reparameterized
vector of parameters of the model
, where
is a user-defined vector of
(finite) points, whereas
is a
vector unknown probabilities obeying to
. Note that the arrays
must be chosen to cover the natural range of the model parameters. Thus, for instance, in the case of estimating the population mean
for a normal model
with
known,
with
d as large as possible. In practice, as observations
are available, the support vector can be defined using sample information, i.e.,
. Similarly, in the case of estimating the parameter
of the Binomial model
, the support vector is
. The choice of the number of points
K of
can be made via sensitivity analysis although it has been shown that
is usually enough for many regular problems (e.g., see [
27,
29]). Readers may refer to [
27,
30] for further details.
Under the reparameterization in Equation (
1),
is solved via the following NLP problem:
where
is the Shannon’s entropy function, whereas the score equation
has been rewritten using the reparameterized parameters
. The problem needs to recover
quantities which are defined in a (convex) hyper-simplex region with
J (non-) linear equality constraints
(consistency constraints) and linear equality constraints
(normalization constraints). The latter ensure that the recovered quantities
are still probabilities. Note that closed-form solutions for the ME-score problem do not exist and solutions need to be attained numerically.
In the following examples, we will show how the ME-score problem can be formulated in the most simple cases of estimating a mean from normal, Poisson, and gamma models (Examples 1–3) as well as in more complex cases of estimating parameters for logistic regression (Example 4).
2.1. Example 1: The Normal Case
Consider the case of estimating the location parameter
of a Normal density function with
known. In particular, let
be a sample of
drawn from a population with Normal density
with
known. Our objective is to estimate
using the information of
. Let
be the log-likelihood of the model where constant terms have been dropped and
be the corresponding score w.r.t.
. To define the associated ME-score problem to solve
, first let
with
and
being
vector of supports and unknown probabilities. In this example,
with
,
, and
. Given the optimization problem in (
2), in this case
can be recovered via the Lagrangean method, as follows. Let
be the Lagrangean function, with
and
being the usual Lagrangean multipliers. The Lagrangean system of the problem is
Solving
in Equation (
4), by using Equation (
6), we get the general solutions for the ME-score problem:
where the quantity in the denominator is the normalization constant. Note that solutions in Equation (
7) depend on the Lagrangean multiplier
, which needs to be determined numerically [
31]. In this particular example, we estimate the unknown Lagrangean multiplier using a grid-search approach, yielding to
. The final solutions are
with
, which corresponds to the maximum likelihood estimate of
, as expected.
2.2. Example 2: The Poisson Case
Consider the simple case of estimating
of a Poisson density function. Let
be a sample of
drawn from a Poisson density
and
be the score of the model. The reparameterized Poisson parameter is
, with support being defined as follows:
where
and
. Note that, since the Poisson parameter
is bounded below by zero, we can set
. Unlike the previous case, we cannot determine
analytically. For this reason, we need to solve the ME-score problem:
via the augmented Lagrangean adaptive barrier algorithm as implemented in the function
constrOptim.nl of the
R package
alabama [
32]. The algorithm converged successfully in few iterations. The recovered probabilities are as follows:
with
, which is equal to the maximum likelihood solution
, as expected.
2.3. Example 3: The Gamma Case
Consider the following random sample
drawn from a Gamma density
with
being the scale parameter and
the rate parameter. The log-likelihood of the model is as follows:
where
is the well-known gamma function. The corresponding score function equals to
with
being the digamma function, i.e., the derivative of the logarithm of the gamma function evaluated in
. The re-parameterized gamma parameters are defined as usual
and
whereas the supports can be determined as
and
, with
being a positive constant. Note that the upper limits of the support can be chosen according to the following approximations:
and
, with
and
[
33]. In the current example, the supports for the parameters are:
where
,
,
, and
. The ME-score problem for the gamma case is
which is solved via an augmented Lagrangean adaptive barrier algorithm. The algorithm required few iterations to converge and the recovered probabilities are as follows:
The estimated parameters under the ME-score formulation are and which equal to the maximum likelihood solutions and .
2.4. Example 4: Logistic Regression
In what follows, we show the ME-score formulation for logistic regression. We will consider both the cases of simple situations involving no separation—where maximum likelihood estimates can be easily computed—and those unfortunate situations in which separation occur. Note that in the latter case, maximum likelihood estimates are no longer available without resorting to the use of a bias reduction iterative procedure [
7]. Formally, the logistic regression model with
p continuous predictors is as follows:
where
is an
matrix containing predictors,
is a
vector of model parameters, and
is an
vector of observed responses. Here, the standard maximum likelihood solutions
are usually attained numerically, e.g., using Newton–Raphson like algorithms [
5].
No separation case. As an illustration of the ME-score problem in the optimal situation where no separation occurs, we consider the traditional Finney’s data on vasoconstriction in the skin of the digits (see
Table 2) [
34].
In the Finney’s case, the goal is to predict the vasoconstriction responses as a function of volume and rate, according to the following linear term [
34]:
with
being the inverse of the logistic function. In the maximum entropy framework, the model parameters can be reformulated as follows:
where
is a
vector of support points,
is an identity matrix of order
(including the intercept term),
is a
matrix of probabilities associated to the
p parameters plus the intercept, ⊗ is the Kronecker product, whereas
is a linear operator that transforms a matrix into a column vector. Note that in this example
and
, whereas the support
is defined to be the same for both predictors and the intercept (the bounds of the support have been chosen to reflect the maximal variation allowed by the logistic function). Finally, the ME-score problem for the Finney’s logistic regression is:
where
is the
matrix containing the variables rate, volume, and a column of all ones for the intercept term, and
, with
being defined as in Equation (
12). Solutions for
were obtained via the augmented Lagrangean adaptive barrier algorithm, which yielded the following estimates:
where the third line of
refers to the intercept term. The final estimated coefficients are
which are the same as those obtained in the original paper of Pregibon et al. [
34].
Separation case. As a typical example of data under separation, we consider the classical Fisher iris dataset [
35]. As generally known, the dataset contains fifty measurements of length and width (in centimeters) of sepal and petal variables for three species of iris, namely setosa, versicolor, and virginica [
36]. For the sake of simplicity, we keep a subset of the whole dataset containing two species of iris (i.e., setosa and virginica) with sepal length and width variables only. Inspired by the work of Lesaffre and Albert [
35], we study a model where the response variable is a binary classification of iris, with
indicating the class virginica and
the class setosa, whereas petal length and width are predictors of
Y. The logistic regression for the iris data assumes the following linear term:
where model parameters can be reformulated as in Equation (
12), with
,
, and
being centered around zero with bounds
and
. The ME-score problem for the iris dataset is the same as in (
13) and it is solved using the augmented Lagrangean adaptive barrier algorithm. The recovered
is
where the intercept term is reported in the third line of the matrix. The estimates for the model coefficients are reported in
Table 3 (ME, first column). For the sake of comparison,
Table 3 also reports the estimates obtained by solving the score of the model via bias-corrected Newton–Raphson (NRF, second column) and Newton–Raphson (NR, third column). The NRF algorithm uses the Firth’s correction for the score function [
7] as implemented in the
R package
logistf [
37]. As expected, the NR algorithm fails to converge reporting divergent estimates. By contrast, the NRF procedure converges to non-divergent solutions. Interestingly, the maximum entropy solutions are more close to NRF estimates although they differ in magnitude.
3. Simulation Study
Having examined the ME-score problem with numerical examples for both simple and more complex cases, in this section, we will numerically investigate the behavior of the maximum entropy solutions for the most critical case of logistic regression under separation.
Design. Two factors were systematically varied in a complete two-factorial design:
- (i)
the sample size n at three levels: 15, 20, 200;
- (ii)
the number of predictors p (excluding the intercept) at three levels: 1, 5, 10.
The levels of n and p were chosen to represent the most common cases of simple, medium, and complex models, as those usually encountered in many social research studies.
Procedure. Consider the logistic regression model as represented in Equation (
10) and let
and
be distinct elements of sets
n and
p. The following procedure was repeated
Q = 10,000 times for each of the
combinations of the simulation design:
Generate the matrix of predictors , where is drawn from the multivariate standard normal distribution , whereas the column vector of all ones stands for the intercept term;
Generate the vector of predictors from the multivariate centered normal distribution , where was chosen to cover the natural range of variability allowed by the logistic equation;
Compute the vector
via Equation (
10) using
and
;
For , generate the vectors of response variables from the binomial distribution , with being fixed;
For , estimate the vectors of parameters by means of Newton–Raphson (NR), bias-corrected Newton–Raphson (NRF), and ME-score (ME) algorithms.
The entire procedure involves a total of 10,000 × 3 × 3 = 90,000 new datasets as well as an equivalent number of model parameters. For the NR and NRF algorithms, we used the
glm and
logistf routines of the
R packages
stats [
38] and
logistf [
37]. By contrast, the ME-score problem was solved via the augmented Lagrangean adaptive barrier algorithm implemented in
constrOptim.nl routine of the
R package
alabama [
32]. Convergences of the algorithms were checked using the built-in criteria of
glm,
logistf, and
constrOptim.nl. For each of the generated data
, the occurrence of separation was checked using a linear programming-based routine to find infinite estimates in the maximum likelihood solution [
39,
40]. The whole simulation procedure was performed on a (remote) HPC machine based on 16 cpu Intel Xeon CPU E5-2630L v3 1.80 GHz, 16 × 4 GB Ram.
Measures. The simulation results were evaluated considering the averaged bias of the parameters , its squared version (the square here is element-wise), and the averaged variance of the estimates . They were then combined together to form the mean square error (MSE) of the estimates . The relative bias was also computed for each predictor , ( indicates the population parameter). The measures were computed for each of the three algorithms and for all the combinations of the simulation design.
Results.
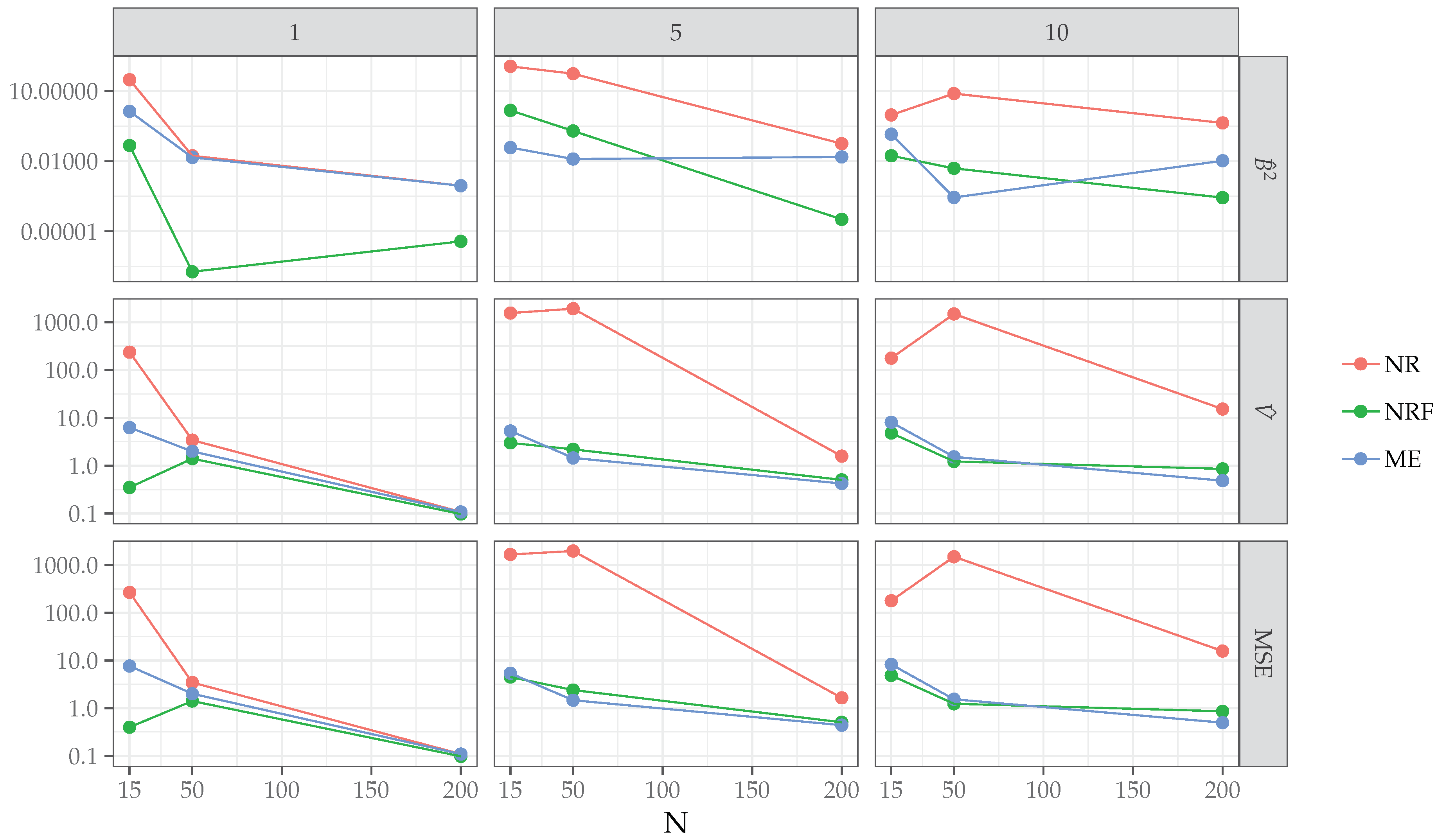
Table 4 reports the proportions of separation present in the data for each level of the simulation design along with the proportions of non-convergence for the three algorithms. As expected, NR failed to converge when severe separation occurred, for instance, in the case of small samples and large number of predictors. By contrast, for NRF and ME algorithms, the convergence criteria were always met. The results of the simulation study with regards to bias, variance, and mean square error (MSE) are reported in
Table 5 and
Figure 1. In general, MSE for the three algorithms decreased almost linearly with increasing sample sizes and number of predictors. As expected, the NR algorithm showed higher MSE than NRF and ME, except in the simplest case of
and
. Unlike for the NR algorithm, with increasing model complexity (
), ME showed a similar performances of NRF both for medium (
) and large (
) sample sizes. Interestingly, for the most complex scenario, involving a large sample (
) and higher model complexity (
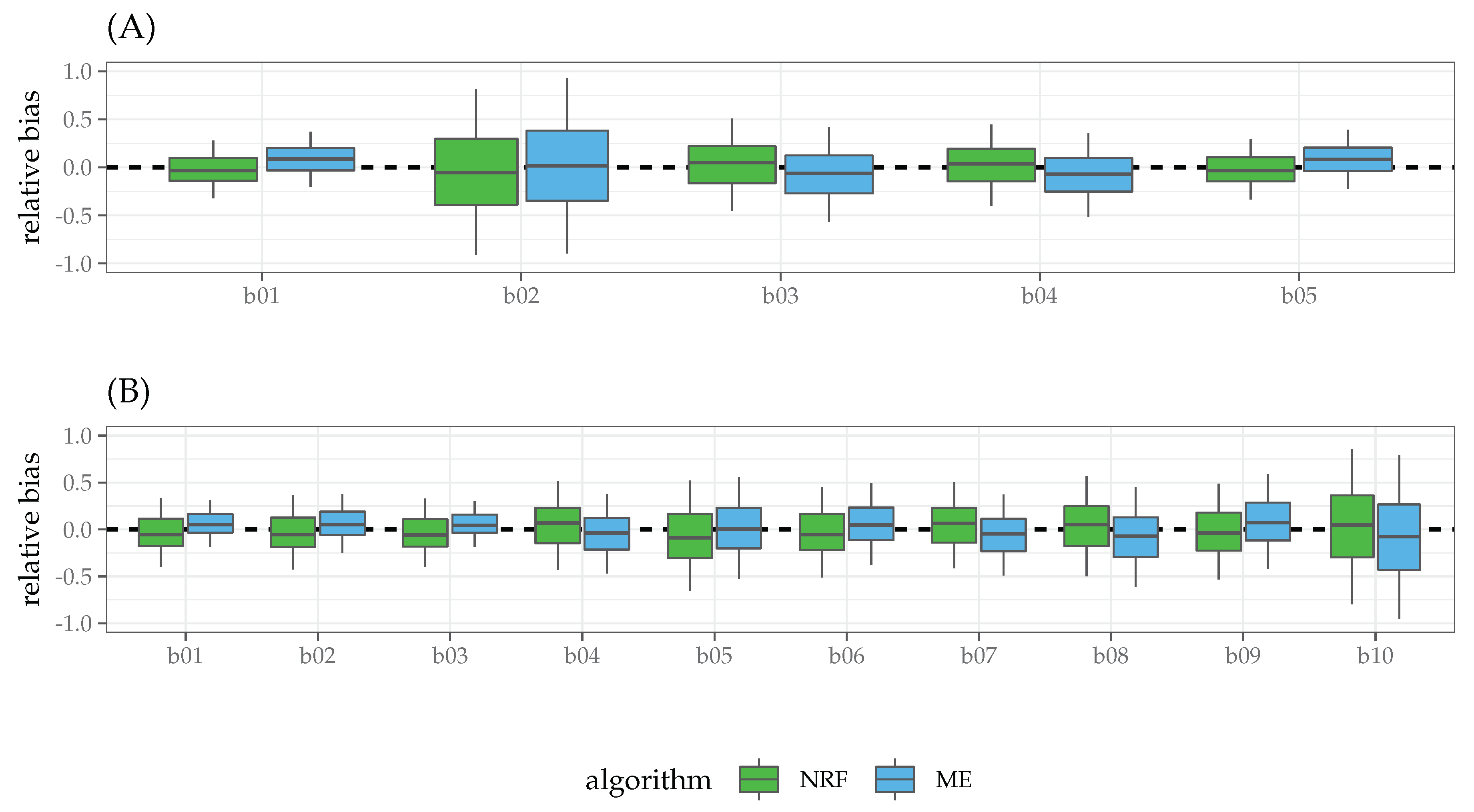
), the ME algorithm outperformed NRF in terms of MSE. To further investigate the relationship between NRF and ME, we focused on the latter conditions and analyzed the behavior of ME and NRF in terms of relative bias (RB, see
Figure 2). Both the ME and NRF algorithms showed RB distributions centered about 0. Except for the condition
, where ME showed smaller variance than NRF, both the algorithms showed similar variance in the estimates of the parameters. Finally, we also computed the ratio of over- and under-estimation
r as the ratio between the number of positive RB and negative RB, getting the following results:
(over-estimation: 54%),
(over-estimation: 49%) for the case
and
(over-estimation: 53%),
(over-estimation: 47%) for the case
.
Overall, the results suggest the following points:
In the simplest cases with no separation (i.e.,
,
,
), the ME solutions to the maximum likelihood equations were the same as those provided by standard Newton–Raphson (NR) and the bias-corrected version (NRF). In all these cases, the bias of the estimates approximated zero (see
Table 5);
In the cases of separation, ME showed comparable performances to NRF, which is known to provide the most efficient estimates in the case of logistic model under separation: Bias and MSE decreased as a function of sample size and predictors, with MSE being lower for ME than NRF in the case of and ;
In the most complex scenario with a large sample and higher model complexity (, ), ME and NRF algorithms showed similar relative bias, with ME estimates being less variable than NRF in condition. The ME algorithm tended to over-estimate the population parameters, by contrast NRF tended to under-estimate the true model parameters.
4. Discussion and Conclusions
We have described a new approach to solve the problem in order to get in the context of maximum likelihood theory. Our proposal took the advantages of using the maximum entropy principle to set a non-linear programming problem where was not solved directly, but it was used as informative constraint to maximize the Shannon’s entropy. Thus, the parameter was not searched over the parameter space , rather it was reparameterized as a convex combination of a known vector , which indicated the finite set of possible values for , and a vector of unknown probabilities , which instead needed to be estimated. In so doing, we converted the problem from one of numerical mathematics to one of inference, where was treated as one of the many pieces of (external) information we may have had. As a result, the maximum entropy solution did not require either the computation of the Hessian of second-order derivatives of (or the expectation of the Fisher information matrix) or the definition of initial values, as is required by Newton-like algorithms . In contrast, the maximum entropy solution revolved around the reduction of the initial uncertainty: as one adds pieces of external information (constraints), a departure from the initial uniform distribution results, implying a reduction of the uncertainty about ; a solution is found when no further reduction can be enforced given the set of constraints. We used a set of empirical cases and a simulation study to assess the maximum entropy solution to the score problem. In cases where the Newton–Raphson is no longer correct for (e.g., logistic regression under separation), the ME-score formulation showed results (numerically) comparable with those obtained using the Bias-corrected Newton–Raphson, in the sense of having the same or even smaller mean square errors (MSE). Broadly speaking, these first findings suggest that the ME-score formulation can be considered as a valid alternative to solve , although further in-depth investigations need to be conducted to formally evaluate the statistical properties of the ME-score solution.
Nevertheless, we would like to say that the maximum entropy approach has been used to build a solver for maximum likelihood equations [
22,
23,
26]. In this sense, standard errors, confidence levels, and other likelihood based quantities can be computed using the usual asymptotic properties of maximum likelihood theory. However, attention should be directed at the definition of the support points
since they need to be sufficiently large to include the true (hypothesized) parameters we are looking for. Relatedly, our proposal differs from other methods, such as generalized maximum entropy (GME) or generalized cross entropy (GCE) [
20,
27], in two important respects. First, the ME-score formulation does not provide a class of estimators for the parameters of statistical models. By contrast, GME and GCE are estimators belonging to the exponential family, which can be used in many cases as alternatives to maximum likelihood estimators [
28]. Secondly, the ME-score formulation does not provide an inferential framework for
. While GME and GCE use information theory to provide the basis for inference and model evaluation (e.g., using Lagrangean multipliers and normalized entropy indices), the ME-score formulation focuses on the problem of finding roots for
. Finally, an open issue which deserves greater consideration in future investigations is the examination of how the ME-score solution can be considered in light of the well-known maximum entropy likelihood duality [
41].
Some advantages of the ME-score solution over Newton-like algorithms may include the following: (i) model parameters are searched in a smaller and simpler space because of the convex reparameterization required for ; (ii) the function to be maximized does not require either the computation of second-order derivatives of , or searching for good initial values ; (iii) additional information on the parameters, such as dominance relations among the parameters, can be added to the ME-score formulation in terms of inequality constraints (e.g., , ). Furthermore, the ME-score formulation may be extended to include a priori probability distributions on . While in the current proposal, the elements of have the same probability to occur, the Kullback–Leibler entropy might be used to form a Kullback–Leibler-score problem, where are adequately weighted by known vectors of probability . This would offer, for instance, another opportunity to deal with cases involving penalized likelihood estimations.
In conclusion, we think that this work yielded initial findings in the solution of likelihood equations from a maximum entropy perspective. To our knowledge, this is the first time that maximum entropy is used to define a solver to the score function. We believe this contribution will be of interest to all researchers working at the intersection of information theory, data mining, and applied statistics.




{kind=link}
{kind=link}