Action Recognition Using Single-Pixel Time-of-Flight Detection

 , ,
, , 

Abstract
1. Introduction
- Introduce an unexplored data modality for action recognition scenarios. In contrast to other depth-based modalities, our single-pixel light pulses are not visually interpretable which makes it a more privacy preserving solution.
- Provide a manually annotated dataset of 550 robot action sequences, some of them containing obstacle objects.
- Apply multi-layer bi-directional recurrent neural networks for the recognition task as an initial machine learning benchmarking baseline.
- Present an extensive set of experiments on the recognition of several action classes. We demonstrate how the learning models are able to extract proper action features and generalise several action concepts from captured data.
2. Related Work
2.1. Depth Sensors
- Stereo cameras infer the 3D structure of a scene from two images from different viewpoints. The depth map is created using information about the camera setup (stereo triangulation) [37].
- A time-of-flight (ToF) camera estimates distance to an object surface using active light pulses from a single camera, whose time to reflect from the object give the distance. Such devices use a sinusoidally modulated infra-red light signal, and distance is estimated using the phase shift of the reflected signal on CMOS or CCD detector. The most commercially know device that uses this technology is Kinect 2 [38,39], which provides depth map of 512 × 424 pixels at 30 frames per second.
2.2. Sing-Pixel Single-Photon Acquisition
2.3. Action Recognition
2.4. Data Interpretability
3. Collected Data
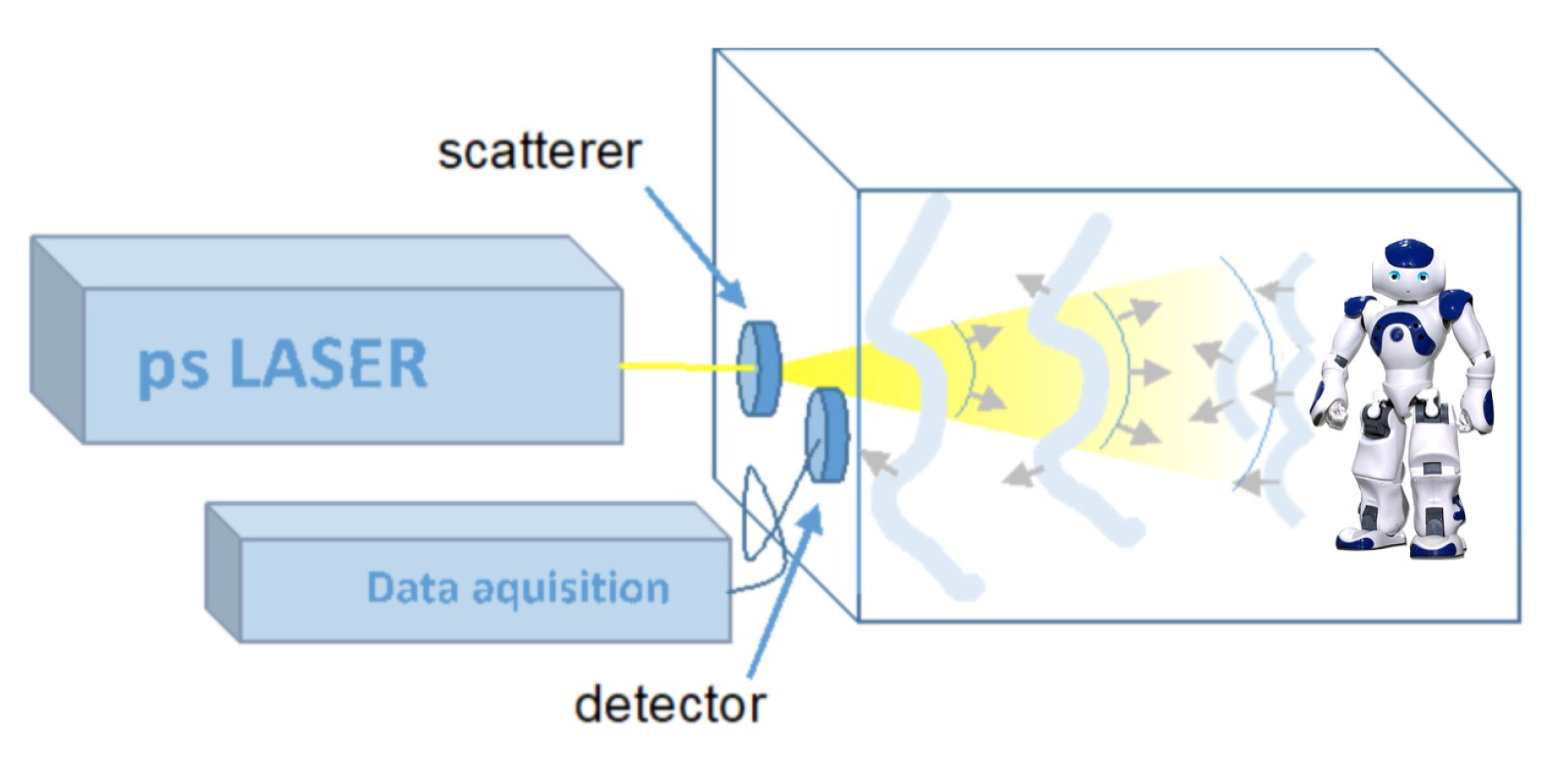
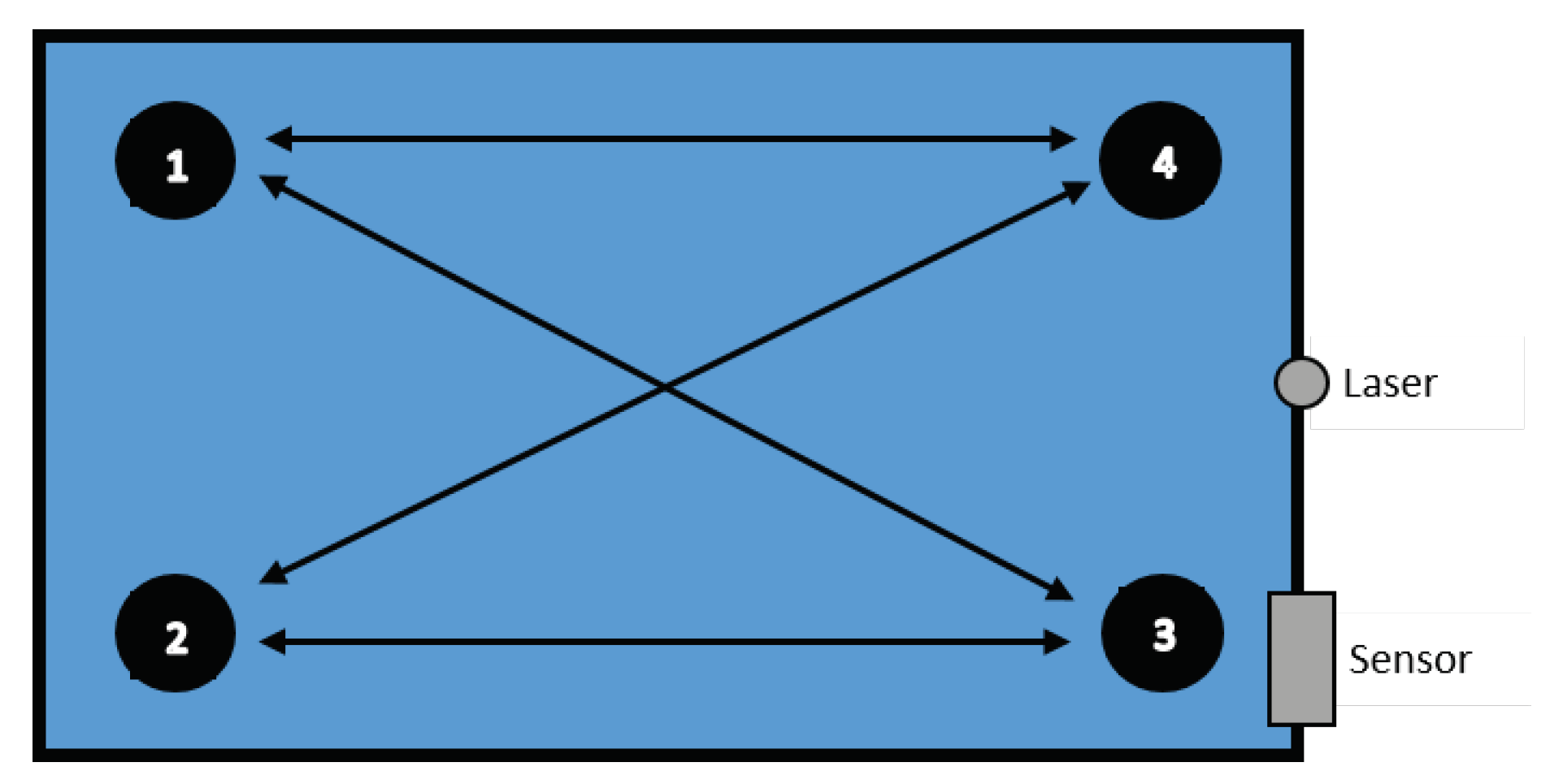
3.1. ONE-Robot Setup
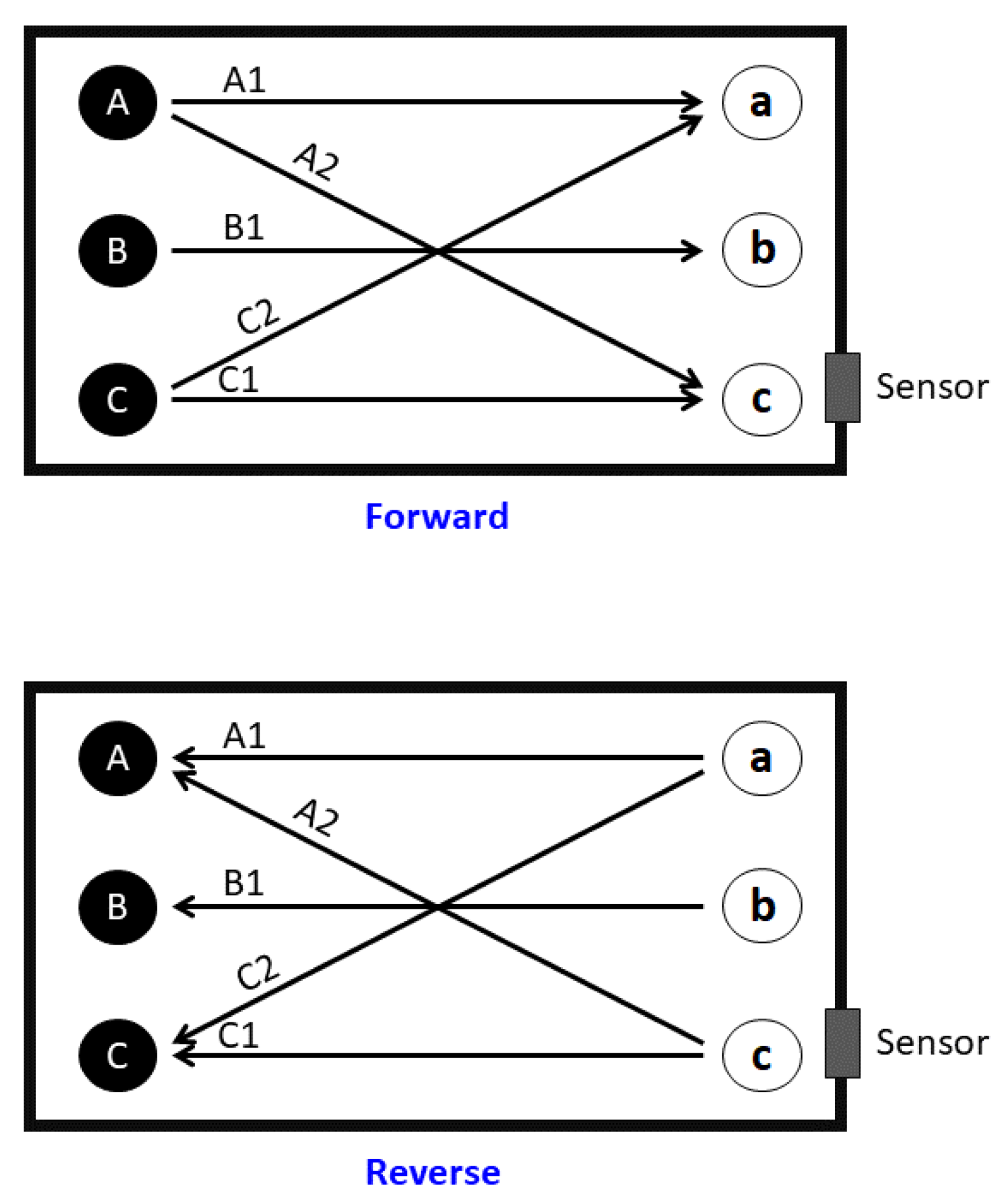
- Directional walk: We specified three starting points (A, B, and C) and three end points (a, b, and c) inside the box. The robot walked from starting points at 70 cm distance to corresponding end points, and vice versa. In addition, two diagonal directions, from Point A to Point c and from Point C to Point a, were travelled both forward and reverse, as illustrated in Figure 2. All action were repeated 25 times for each point per each direction. These walking actions are shown in Table 2 and Table 3.
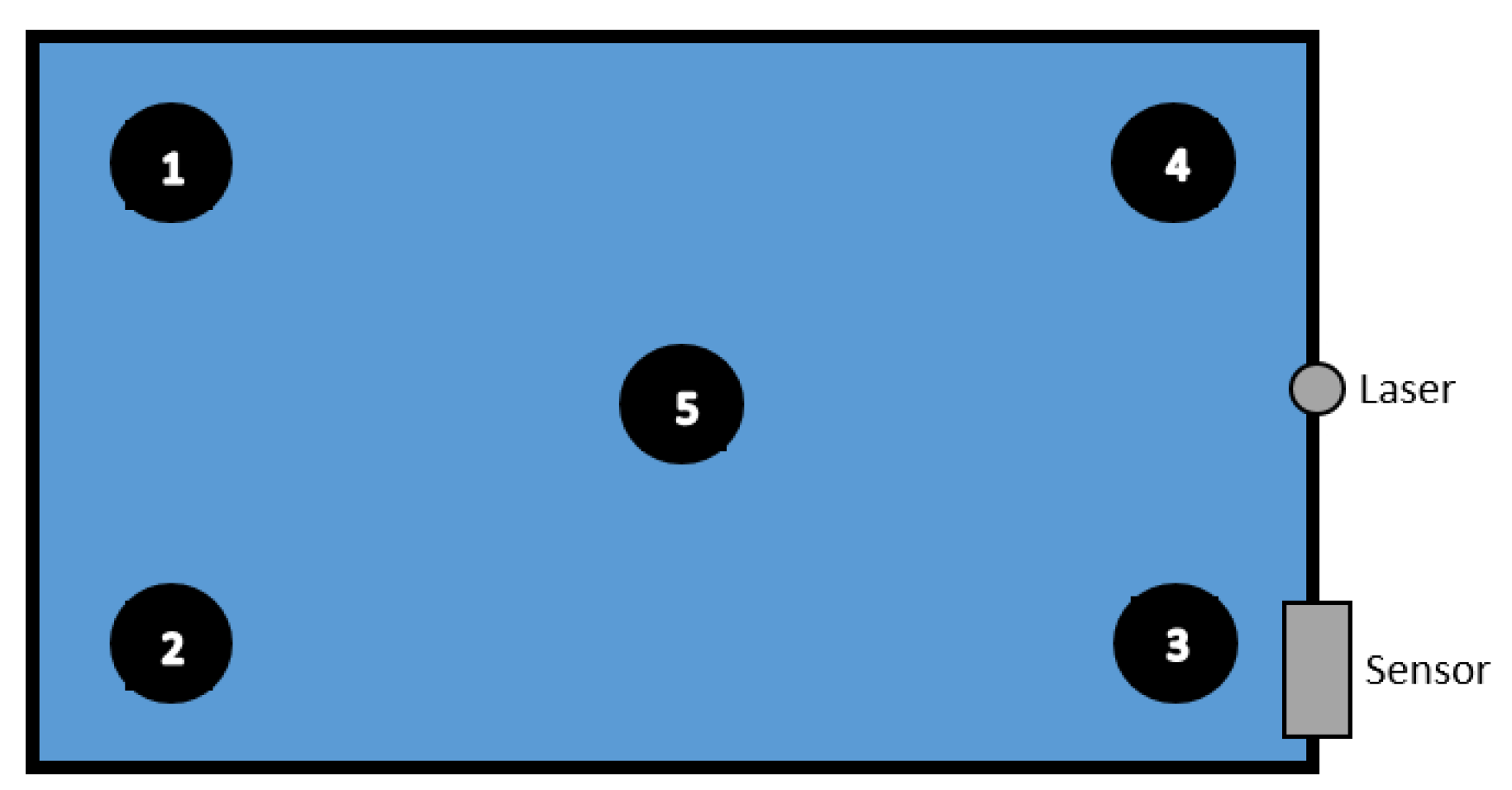
- Sitting down (sd) from standing up pose and Standing up (su) from sitting down pose: We specified five areas where the robot was located, as illustrated in Figure 3. These actions were repeated 10 times per area and in each repetition, the position of the robot was nearly the same. Summary of performed tasks is shown in Table 4.
- Waving right hand (hw) for 3 s: This action was repeated 25 times in Areas 2 and 5 (see Table 4).
3.2. Two-Robot Setup
4. Method
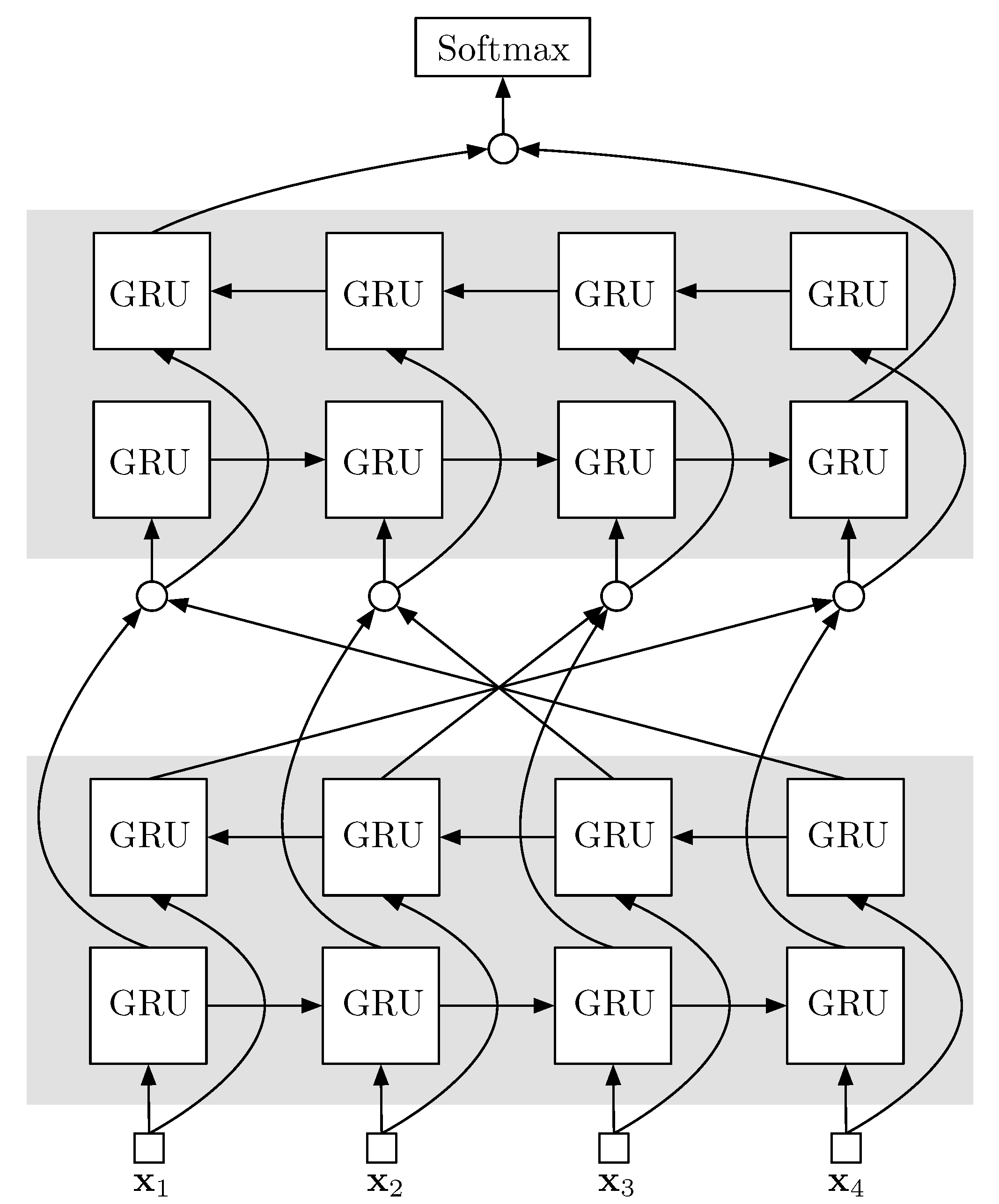
4.1. Gated-Recurrent Unit
4.2. Bidirectional GRU and Stacked Layers
4.3. Baseline
5. Experimental Results and Discussion
5.1. Learning Model Details and Code Implementation
5.2. Ablation Experiments on GRU Architectures
5.3. Final Experiments
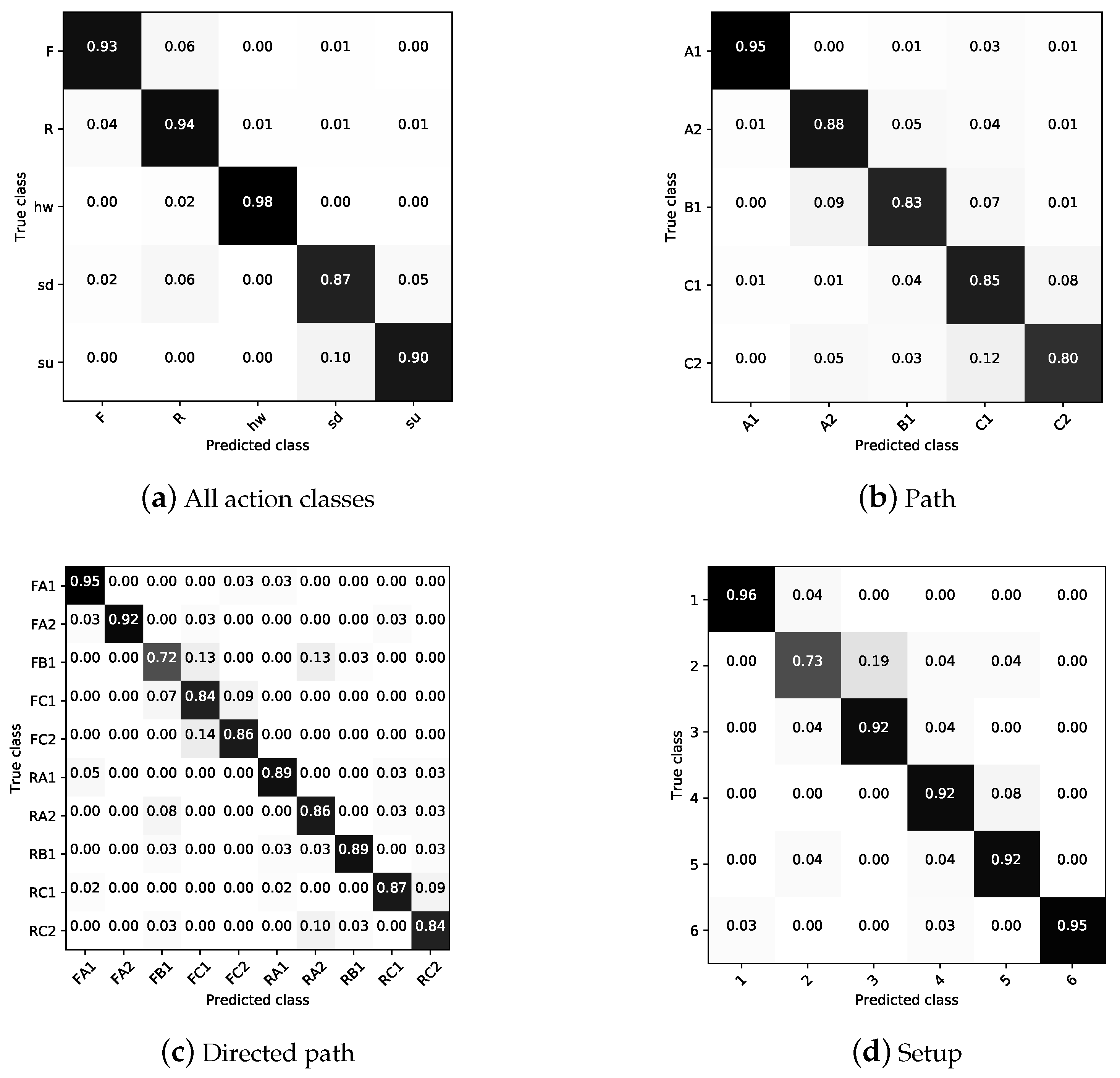
5.3.1. Multiclass Classification
5.3.2. Model Generalisation on Actions and Two Robots
5.4. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Fernando, B.; Gavves, E.; Oramas, J.M.; Ghodrati, A.; Tuytelaars, T. Modeling video evolution for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5378–5387. [Google Scholar]
- Nasrollahi, K.; Escalera, S.; Rasti, P.; Anbarjafari, G.; Baro, X.; Escalante, H.J.; Moeslund, T.B. Deep learning based super-resolution for improved action recognition. In Proceedings of the IEEE 2015 International Conference on Image Processing Theory, Tools and Applications (IPTA), Orleans, France, 10–13 November 2015; pp. 67–72. [Google Scholar]
- Haque, M.A.; Bautista, R.B.; Noroozi, F.; Kulkarni, K.; Laursen, C.B.; Irani, R.; Bellantonio, M.; Escalera, S.; Anbarjafari, G.; Nasrollahi, K.; et al. Deep Multimodal Pain Recognition: A Database and Comparison of Spatio-Temporal Visual Modalities. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 250–257. [Google Scholar]
- Ponce-López, V.; Escalante, H.J.; Escalera, S.; Baró, X. Gesture and Action Recognition by Evolved Dynamic Subgestures. In Proceedings of the BMVC, Swansea, UK, 7–10 September 2015; pp. 129.1–129.13. [Google Scholar]
- Wan, J.; Escalera, S.; Anbarjafari, G.; Escalante, H.J.; Baró, X.; Guyon, I.; Madadi, M.; Allik, J.; Gorbova, J.; Lin, C.; et al. Results and Analysis of ChaLearn LAP Multi-modal Isolated and Continuous Gesture Recognition, and Real Versus Fake Expressed Emotions Challenges. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3189–3197. [Google Scholar]
- Corneanu, C.; Noroozi, F.; Kaminska, D.; Sapinski, T.; Escalera, S.; Anbarjafari, G. Survey on Emotional Body Gesture Recognition. IEEE Trans. Affect. Comput. 2018. [Google Scholar] [CrossRef]
- Turaga, P.; Chellappa, R.; Subrahmanian, V.S.; Udrea, O. Machine recognition of human activities: A survey. IEEE Trans. Circuits Syst. Video Technol. 2008, 18, 1473. [Google Scholar] [CrossRef]
- Jahromi, M.N.; Bonderup, M.B.; Asadi-Aghbolaghi, M.; Avots, E.; Nasrollahi, K.; Escalera, S.; Kasaei, S.; Moeslund, T.B.; Anbarjafari, G. Automatic Access Control Based on Face and Hand Biometrics in a Non-Cooperative Context. In Proceedings of the 2018 IEEE Winter Applications of Computer Vision Workshops (WACVW), Lake Tahoe, NV, USA, 15 March 2018; pp. 28–36. [Google Scholar]
- Sapiński, T.; Kamińska, D.; Pelikant, A.; Ozcinar, C.; Avots, E.; Anbarjafari, G. Multimodal Database of Emotional Speech, Video and Gestures. In Proceedings of the International Conference on Pattern Recognition, Beijing, China, 20–24 August 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 153–163. [Google Scholar]
- Kim, Y.; Lee, H.; Provost, E.M. Deep learning for robust feature generation in audiovisual emotion recognition. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; pp. 3687–3691. [Google Scholar]
- Lusi, I.; Junior, J.C.J.; Gorbova, J.; Baró, X.; Escalera, S.; Demirel, H.; Allik, J.; Ozcinar, C.; Anbarjafari, G. Joint challenge on dominant and complementary emotion recognition using micro emotion features and head-pose estimation: Databases. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 809–813. [Google Scholar]
- Avots, E.; Sapiński, T.; Bachmann, M.; Kamińska, D. Audiovisual emotion recognition in wild. Mach. Vis. Appl. 2018, 1–11. [Google Scholar] [CrossRef]
- Noroozi, F.; Marjanovic, M.; Njegus, A.; Escalera, S.; Anbarjafari, G. Fusion of classifier predictions for audio-visual emotion recognition. In Proceedings of the IEEE 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 61–66. [Google Scholar]
- Guo, J.; Lei, Z.; Wan, J.; Avots, E.; Hajarolasvadi, N.; Knyazev, B.; Kuharenko, A.; Junior, J.C.S.J.; Baró, X.; Demirel, H.; et al. Dominant and Complementary Emotion Recognition From Still Images of Faces. IEEE Access 2018, 6, 26391–26403. [Google Scholar] [CrossRef]
- Grobova, J.; Colovic, M.; Marjanovic, M.; Njegus, A.; Demire, H.; Anbarjafari, G. Automatic hidden sadness detection using micro-expressions. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 828–832. [Google Scholar]
- Kulkarni, K.; Corneanu, C.; Ofodile, I.; Escalera, S.; Baró, X.; Hyniewska, S.; Allik, J.; Anbarjafari, G. Automatic recognition of facial displays of unfelt emotions. IEEE Trans. Affect. Comput. 2018. [Google Scholar] [CrossRef]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep face recognition. In Proceedings of the BMVC, Swansea, UK, 7–10 September 2015; Volume 1, p. 6. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Haamer, R.E.; Kulkarni, K.; Imanpour, N.; Haque, M.A.; Avots, E.; Breisch, M.; Nasrollahi, K.; Escalera, S.; Ozcinar, C.; Baro, X.; et al. Changes in facial expression as biometric: A database and benchmarks of identification. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 621–628. [Google Scholar]
- Tertychnyi, P.; Ozcinar, C.; Anbarjafari, G. Low-quality fingerprint classification using deep neural network. IET Biom. 2018, 7, 550–556. [Google Scholar] [CrossRef]
- Zhang, C.L.; Zhang, H.; Wei, X.S.; Wu, J. Deep bimodal regression for apparent personality analysis. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 August 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 311–324. [Google Scholar]
- Gorbova, J.; Avots, E.; Lüsi, I.; Fishel, M.; Escalera, S.; Anbarjafari, G. Integrating Vision and Language for First-Impression Personality Analysis. IEEE MultiMedia 2018, 25, 24–33. [Google Scholar] [CrossRef]
- Yang, J.; Nguyen, M.N.; San, P.P.; Li, X.; Krishnaswamy, S. Deep Convolutional Neural Networks on Multichannel Time Series for Human Activity Recognition. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; Volume 15, pp. 3995–4001. [Google Scholar]
- Ma, M.; Fan, H.; Kitani, K.M. Going deeper into first-person activity recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1894–1903. [Google Scholar]
- Ordóñez, F.J.; Roggen, D. Deep convolutional and lstm recurrent neural networks for multimodal wearable activity recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef]
- Ma, X.; Dai, Z.; He, Z.; Ma, J.; Wang, Y.; Wang, Y. Learning traffic as images: A deep convolutional neural network for large-scale transportation network speed prediction. Sensors 2017, 17, 818. [Google Scholar] [CrossRef]
- Kirmani, A.; Hutchison, T.; Davis, J.; Raskar, R. Looking around the corner using transient imaging. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 159–166. [Google Scholar]
- Velten, A.; Willwacher, T.; Gupta, O.; Veeraraghavan, A.; Bawendi, M.G.; Raskar, R. Recovering three-dimensional shape around a corner using ultrafast time-of-flight imaging. Nat. Commun. 2012, 3, 745. [Google Scholar] [CrossRef]
- Buttafava, M.; Zeman, J.; Tosi, A.; Eliceiri, K.; Velten, A. Non-line-of-sight imaging using a time-gated single photon avalanche diode. Opt. Express 2015, 23, 20997–21011. [Google Scholar] [CrossRef]
- Besl, P.J. Active optical range imaging sensors. In Advances in Machine Vision; Springer: Berlin/Heidelberg, Germany, 1989; pp. 1–63. [Google Scholar]
- Antipa, N.; Kuo, G.; Heckel, R.; Mildenhall, B.; Bostan, E.; Ng, R.; Waller, L. DiffuserCam: Lensless single-exposure 3D imaging. Optica 2018, 5, 1–9. [Google Scholar] [CrossRef]
- Gatti, A.; Brambilla, E.; Bache, M.; Lugiato, L.A. Ghost imaging with thermal light: Comparing entanglement and classicalcorrelation. Phys. Rev. Lett. 2004, 93, 093602. [Google Scholar] [CrossRef]
- Shapiro, J.H. Computational ghost imaging. Phys. Rev. 2008, 78, 061802. [Google Scholar] [CrossRef]
- Sun, M.J.; Edgar, M.P.; Gibson, G.M.; Sun, B.; Radwell, N.; Lamb, R.; Padgett, M.J. Single-pixel three-dimensional imaging with time-based depth resolution. Nat. Commun. 2016, 7, 12010. [Google Scholar] [CrossRef]
- Li, W.; Zhang, Z.; Liu, Z. Action recognition based on a bag of 3d points. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), San Francisco, CA, USA, 13–18 June 2010; pp. 9–14. [Google Scholar]
- Caramazza, P.; Boccolini, A.; Buschek, D.; Hullin, M.; Higham, C.; Henderson, R.; Murray-Smith, R.; Faccio, D. Neural network identification of people hidden from view with a single-pixel, single-photon detector. arXiv 2017, arXiv:1709.07244. [Google Scholar]
- Sanchez-Riera, J.; Čech, J.; Horaud, R. Action recognition robust to background clutter by using stereo vision. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 332–341. [Google Scholar]
- Zhang, Z. Microsoft kinect sensor and its effect. IEEE Multimed. 2012, 19, 4–10. [Google Scholar] [CrossRef]
- Papadopoulos, G.T.; Axenopoulos, A.; Daras, P. Real-time skeleton-tracking-based human action recognition using kinect data. In Proceedings of the International Conference on Multimedia Modeling, Dublin, Ireland, 6–10 January 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 473–483. [Google Scholar]
- Fofi, D.; Sliwa, T.; Voisin, Y. A comparative survey on invisible structured light. In Machine Vision Applications in Industrial Inspection XII; International Society for Optics and Photonics: San Diego, CA, USA, 2004; Volume 5303, pp. 90–99. [Google Scholar]
- Smisek, J.; Jancosek, M.; Pajdla, T. 3D with Kinect. In Consumer Depth Cameras for Computer Vision; Springer: Berlin/Heidelberg, Germany, 2013; pp. 3–25. [Google Scholar]
- Faccio, D.; Velten, A. A trillion frames per second: The techniques and applications of light-in-flight photography. Rep. Prog. Phys. 2018, 81, 105901. [Google Scholar] [CrossRef] [PubMed]
- Pandharkar, R.; Velten, A.; Bardagjy, A.; Lawson, E.; Bawendi, M.; Raskar, R. Estimating motion and size of moving non-line-of-sight objects in cluttered environments. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 265–272. [Google Scholar]
- Heide, F.; Hullin, M.B.; Gregson, J.; Heidrich, W. Low-budget transient imaging using photonic mixer devices. ACM Trans. Graph. (ToG) 2013, 32, 45. [Google Scholar] [CrossRef]
- Gariepy, G.; Tonolini, F.; Henderson, R.; Leach, J.; Faccio, D. Detection and tracking of moving objects hidden from view. Nat. Photonics 2016, 10, 23–26. [Google Scholar] [CrossRef]
- Warburton, R.E.; Chan, S.; Gariepy, G.; Altmann, Y.; McLaughlin, S.; Leach, J.; Faccio, D. Real-Time Tracking of Hidden Objects with Single-Pixel Detectors. In Imaging Systems and Applications; Optical Society of America: San Diego, CA, USA, 2016; p. IT4E–2. [Google Scholar]
- Chan, S.; Warburton, R.E.; Gariepy, G.; Leach, J.; Faccio, D. Non-line-of-sight tracking of people at long range. Opt. Express 2017, 25, 10109–10117. [Google Scholar] [CrossRef]
- Jia, L.; Radke, R.J. Using time-of-flight measurements for privacy-preserving tracking in a smart room. IEEE Trans. Ind. Inform. 2014, 10, 689–696. [Google Scholar] [CrossRef]
- Tao, S.; Kudo, M.; Nonaka, H. Privacy-preserved behavior analysis and fall detection by an infrared ceiling sensor network. Sensors 2012, 12, 16920–16936. [Google Scholar] [CrossRef] [PubMed]
- Kawashima, T.; Kawanishi, Y.; Ide, I.; Murase, H.; Deguchi, D.; Aizawa, T.; Kawade, M. Action recognition from extremely low-resolution thermal image sequence. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar]
- Dai, J.; Saghafi, B.; Wu, J.; Konrad, J.; Ishwar, P. Towards privacy-preserving recognition of human activities. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 4238–4242. [Google Scholar]
- Xu, M.; Sharghi, A.; Chen, X.; Crandall, D.J. Fully-Coupled Two-Stream Spatiotemporal Networks for Extremely Low Resolution Action Recognition. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1607–1615. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the properties of neural machine translation: Encoder-decoder approaches. arXiv 2014, arXiv:1409.1259. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Chollet, F. Keras. 2015. Available online: https://github.com/fchollet/keras (accessed on 4 February 2019).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| One-Robot | Two-Robot | |||||||
|---|---|---|---|---|---|---|---|---|
| Task | Walk Forward | Walk Reverse | Sit Down | Stand Up | Hand Wave | Object Setup | Same Action | Different Actions |
| Repetitions | 125 | 125 | 50 | 50 | 50 | 156 | 70 | 20 |
| Task | A1 | A2 | B1 | C1 | C2 |
|---|---|---|---|---|---|
| Repetitions | 25 | 25 | 25 | 25 | 25 |
| Start location | A | A | B | C | C |
| Stop location | a | c | b | c | a |
| Task | A1 | A2 | B1 | C1 | C2 |
|---|---|---|---|---|---|
| Repetitions | 25 | 25 | 25 | 25 | 25 |
| Start location | a | c | b | c | a |
| Stop location | A | A | B | C | C |
| Task | Sit Down | Stand Up | Hand-Wave | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Repetitions | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 25 | 25 |
| Location | 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | 5 | 2 | 5 |
| Action | sd | sd | sd | sd | sd | su | su | su | su | su | hw | hw |
| Task | 1 | 2 | 3 | 4 | 5 | 6 * |
|---|---|---|---|---|---|---|
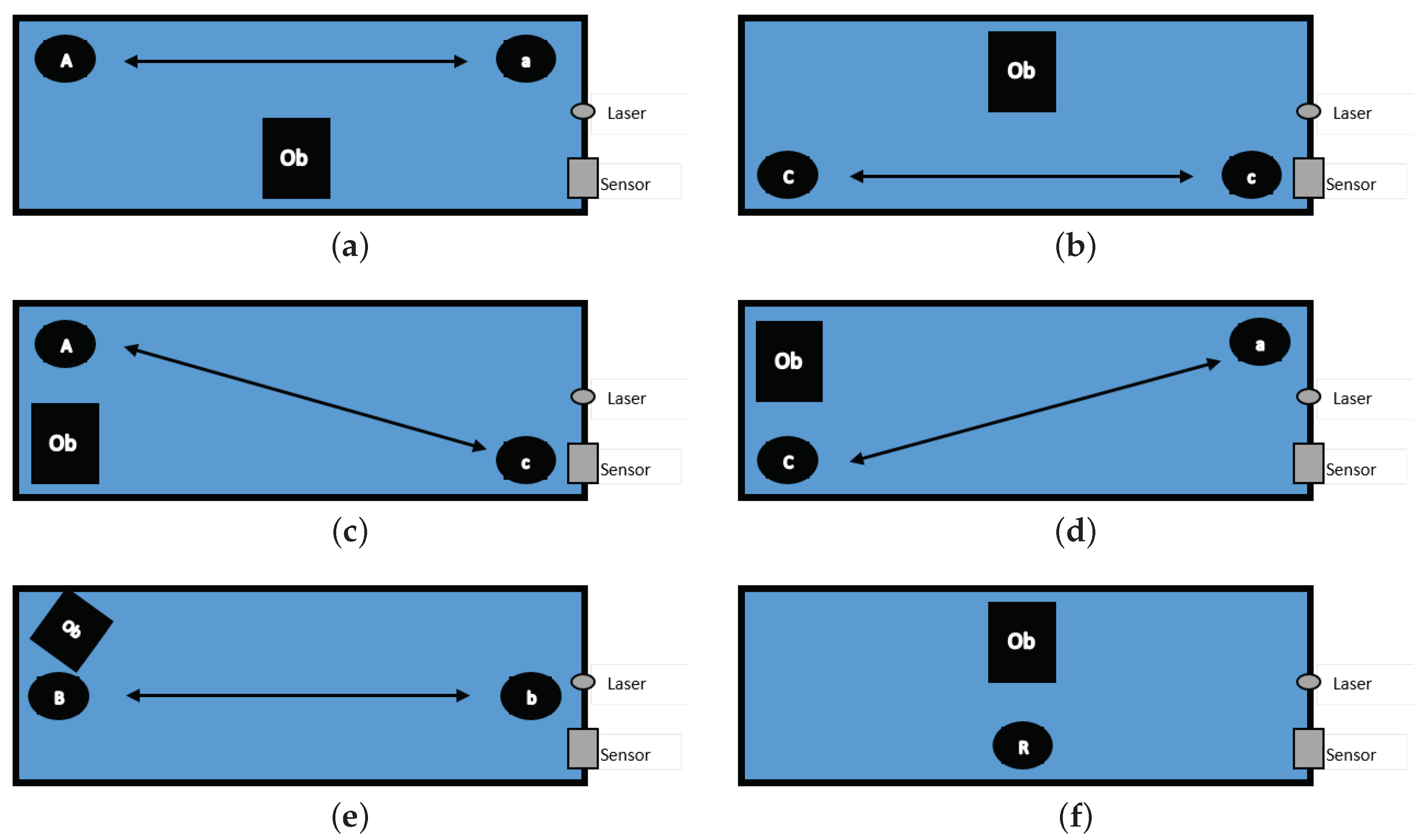
| Object location | Figure 4a | Figure 4b | Figure 4c | Figure 4d | Figure 4e | Figure 4f |
| Walk Forward | A to a | C to c | A to c | C to a | B to b | hw |
| Repetitions | 12 | 12 | 12 | 12 | 12 | 12 |
| Walk Reverse | a to A | c to C | a to C | c to A | b to B | su/sd |
| Repetitions | 12 | 12 | 12 | 12 | 12 | 12/12 |
| Repetition | Robot 1 Action | Position | Robot 2 Action | Position |
|---|---|---|---|---|
| 10 | Forward | 1 to 4 | Forward | 2 to 3 |
| 10 | Sit Down | 1 | Sit Down | 2 |
| 10 | Stand Up | 1 | Stand Up | 2 |
| 10 | Sit Down | 3 | Sit Down | 4 |
| 10 | Stand Up | 3 | Stand Up | 4 |
| 10 | Hand-Wave | 1 | Hand-Wave | 2 |
| 10 | Hand-Wave | 3 | Hand-Wave | 4 |
| 10 | Stand | 1 | Forward | 2 to 3 |
| 10 | Stand | 1 | Forward | 2 to 4 |
| Forward | Reverse | Sit-Down | Stand-Up | Handwave | Average | |
|---|---|---|---|---|---|---|
| GRU (1-layer, 64-hidden) | 87.28 | 83.85 | 76.48 | 78.15 | 0.945 | 84.05 |
| GRU (two-layer, 64-hidden) | 88.48 | 90.06 | 85.75 | 86.41 | 94.99 | 89.14 |
| biGRU (1-layer, 64-hidden) | 89.28 | 87.62 | 82.49 | 86.85 | 96.02 | 88.45 |
| biGRU (two-layer, 64-hidden) | 91.42 | 91.08 | 90.07 | 92.51 | 97.01 | 92.42 |
| Forward | Reverse | Sit-Down | Stand-Up | Handwave | Average | |
|---|---|---|---|---|---|---|
| biGRU (two-layer, 32-hidden) | 89.97 | 89.78 | 87.89 | 89.47 | 95.92 | 90.61 |
| biGRU (two-layer, 64-hidden) | 91.42 | 91.08 | 90.07 | 92.51 | 97.01 | 92.42 |
| biGRU (two-layer, 128-hidden) | 93.10 | 93.63 | 92.98 | 95.32 | 97.70 | 94.55 |
| biGRU (two-layer, 256-hidden) | 93.76 | 94.17 | 94.34 | 95.52 | 98.89 | 95.34 |
| biGRU (two-layer, 512-hidden) | 94.94 | 95.20 | 95.02 | 96.70 | 99.29 | 96.23 |
| Forward | Reverse | Sit-Down | Stand-Up | Handwave | Average | |
|---|---|---|---|---|---|---|
| biGRU (two-layer, 64-hidden) | 91.42 | 91.08 | 90.07 | 92.51 | 97.01 | 92.42 |
| biLSTM (two-layer, 64-hidden) | 91.56 | 96.91 | 92.02 | 89.84 | 94.58 | 92.98 |
| Actions | Path | Directed-Path | Setup |
|---|---|---|---|
| 92.67 | 86.23 | 86.65 | 90.00 |
| F | R | sd | su | hw | Average | |
|---|---|---|---|---|---|---|
| biGRU (two-layer, 512-hidden, 10fCV) | 94.94 | 95.20 | 95.02 | 96.70 | 99.29 | 96.23 |
| biGRU (two-layer, 512-hidden, LOROCV) | 96.77 | 95.14 | 93.36 | 97.11 | 100.0 | 96.47 |
| #{Examples} | F | R | sd | su | hw | |
|---|---|---|---|---|---|---|
| One robot standing up and sitting down | 100 | 80.00 | 88.00 | 95.00 | 15.00 | 100.00 |
| (50) | (50) | (0) | (100) | (0) | ||
| Same two actions | 70 | 25.00 | 72.86 | 75.00 | 54.00 | 50.00 |
| (10) | (10) | (20) | (20) | (20) | ||
| Two different actions | 20 | 50.00 | 100.00 | 95.00 | 55.00 | 55.00 |
| (10) | (0) | (10) | (10) | (10) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ofodile, I.; Helmi, A.; Clapés, A.; Avots, E.; Peensoo, K.M.; Valdma, S.-M.; Valdmann, A.; Valtna-Lukner, H.; Omelkov, S.; Escalera, S.; et al. Action Recognition Using Single-Pixel Time-of-Flight Detection. Entropy 2019, 21, 414. https://doi.org/10.3390/e21040414
Ofodile I, Helmi A, Clapés A, Avots E, Peensoo KM, Valdma S-M, Valdmann A, Valtna-Lukner H, Omelkov S, Escalera S, et al. Action Recognition Using Single-Pixel Time-of-Flight Detection. Entropy. 2019; 21(4):414. https://doi.org/10.3390/e21040414
Chicago/Turabian StyleOfodile, Ikechukwu, Ahmed Helmi, Albert Clapés, Egils Avots, Kerttu Maria Peensoo, Sandhra-Mirella Valdma, Andreas Valdmann, Heli Valtna-Lukner, Sergey Omelkov, Sergio Escalera, and et al. 2019. "Action Recognition Using Single-Pixel Time-of-Flight Detection" Entropy 21, no. 4: 414. https://doi.org/10.3390/e21040414
APA StyleOfodile, I., Helmi, A., Clapés, A., Avots, E., Peensoo, K. M., Valdma, S.-M., Valdmann, A., Valtna-Lukner, H., Omelkov, S., Escalera, S., Ozcinar, C., & Anbarjafari, G. (2019). Action Recognition Using Single-Pixel Time-of-Flight Detection. Entropy, 21(4), 414. https://doi.org/10.3390/e21040414