1. Introduction
Many concepts related to the treatment of information have ordinarily been used for centuries, but only rigorously defined within the context of information theory by the end of the 1940s [
1,
2]. Examples are information content, as quantified by the entropy, or communication load, as characterized by the channel capacity. In the same way, error is normally used as a binary concept that refers to either a correct or an incorrect transfer of a symbol. Writing, including the creation of original text in human languages or the generation of genes in biomolecular systems, transcription or translation of information, as well as any kind of evolution of an initial information chain, however, cannot be simply assessed as correct or wrong because many strings of characters may carry similar information. At the level of a single subunit, sometimes, the replacement of a particular symbol, as characterized by the value of a random variable, may be indifferent or simply may not alter the content or meaning of an information chain.
The appropriate introduction of operational rules to construct bit strings is linked to the use of the concept of proofreading and, more importantly, to the establishment of conditions for useful editing [
3]. These concepts appear together in biomolecular processes associated with information management [
4,
5,
6]. Monomers, either nucleotides or amino acids, are chained according to a template sequence. A replicated DNA strand or an RNA transcript thus represents a sequence of symbols that code for proteins; a protein, in turn, comprises a translated gene, an information chain that entails structural and functional fates in a cell. Physical interactions have been evolutionarily adapted in these natural systems generating a direct correspondence between the thermodynamic stability of a biopolymer chain and the transfer of its information [
7,
8].
Biomolecular engines that process genetic information work under non-equilibrium conditions [
9], but not in ensembles in the cell. These systems are one of the most important subjects of stochastic thermodynamics [
10], a relatively new extension of classical thermodynamics that deals with small systems [
11]. The relations between equilibrium thermodynamic potentials and non-equilibrium work or entropy production through fluctuation theorems [
12,
13] and the burst of single-molecule biophysics [
14], in which individual protein dynamics are experimentally followed [
15], demonstrate the importance of studying individual trajectories. In this regard, it is paradigmatic that writing, proofreading and editing of information involve the composition of individual strings of symbols, therefore making the statistical treatment in stochastic thermodynamics useful in this purely informational context [
16,
17].
We previously formulated a thermodynamic framework for physical systems that carry information in the presence of memory effects [
3] with general non-Markovian reach [
18]. In this paper, we expand this framework to general systems, both symbolic and physical, conveying information, that is to systems where information content is not determined by thermodynamic laws, but able to respond to ad hoc, imposed operational rules, as is the case for human languages. We then express conditions for both effective proofreading and editing. In the second part, we apply our formalism to the process of copying information. We adapt a toy model that was formulated in the context of DNA replication and transcription and test the universal conditions for effective revision. We end with concluding remarks on our theory, including an outlook toward its alternative exploitation.
2. Analysis
The probability distribution,
, of a random variable
X with alphabet
can be written as an exponential of an arbitrary real function, namely,
, with
. For convenience, and without loss of generality, we will introduce probability distributions as:
where
is a real function of the random variable
X and
is a parameter that modulates the weight of function
C in the exponent.
Q is a normalization factor, as determined from
. Function
C is recovered from the probability distribution by taking the logarithm to base
a, namely,
, and therefore,
can be considered a transform of the probability distribution
that maps the image interval
to
.
We next explain the convenience of expressing probabilities as in Equation (
1). In particular, we provide meaning to function
C in the context of a string of symbols, as characterized by a directional, stochastic chain with memory [
19]. Let
be a stochastic chain arranged
(say forward or from left to right) by a linear sequence of symbols and/or physical objects,
, as values of random variables
. We will extend the concept of energy to general linear, stochastic chains, so that it can be useful in information theory.
Definition (Correctness)
Let ν be a stochastic sequence of symbolic, random variables , . We associate with each a real function called the correctness
, , following Equation (1), which, within ν, depends on both the symbol and the sequence of previous symbols , as . We say that is the correctness of symbol provided that the previous symbols are . The correctness will be assigned to symbol on the basis of its precision within the chain ν. Specifically, the more correct symbol , the higher its correctness ; the more erroneous , the lower . Since the probability of a chain can be written as [
20]:
it is possible to define the total correctness of a sequence,
, as the sum over all the correctness of its symbols:
The correctness is therefore an additive property of the subunits within the chain.
The interactions, which determine a memory, between subunits in a material chain, as for example in polynucleotide biopolymers [
19], may be naturally imposed by the physics of the systems [
3]. In these chains, the energy plays the role of the correctness (
), and parameter
R is associated with the thermal energy level, namely
, where
k is the Boltzmann constant and
T the temperature. This suggests the modeling of function
C as a strategy to introduce ad hoc the operational rules in purely symbolic systems, like in human communication. In this case, each individual contributes differently to the correctness since his/her own capacity to assimilate the operational rules of a specific language entails different protocols for their application, as reflected in the probabilities of Equation (
1). The action of a human being in text composition is analogous to those of the DNA and RNA polymerases in replication and transcription, respectively. These nanomachines introduce non-equilibrium protocols with energy dissipation, which adds to the hybridization free energies of the resulting nucleic acids base-pairs [
3,
19].
Note that replacing C by , being a constant, affects the correctness, but not the probabilities. This arbitrariness is also present in Hamiltonian systems, where the reference for potential energies is not universal.
The individual outcomes of a multivariate stochastic process with memory or its time-evolution cannot be rated just as erroneous or correct because several degrees of accuracy may be possible. The correctness function allows extending the concepts of error and certainty (herein used as the opposite of error). Specifically, a stochastic sequence, , will be said to be erroneous when its associated correctness, , is low. The lower , the more erroneous . On the contrary, a chain will be said to be certain when its associated correctness, , is high. The higher , the more correct .
The fact that is low or high is then the result of a balance between the number of errors (wrong ) and certainties (correct ) and their impact, as measured by the individual correctness, . A high correctness is such that , and a low correctness, . In any case, it is necessary that for the concepts of both certainty and error to make sense. In the absence of randomness, which can be studied in the limit of very low R, the above formalism leads naturally to what is expected for probabilities, namely that and .
The probability of a particular configuration in directionally-constructed stochastic chains [
19] can now be written as:
where
stands for
,
is the sequence-dependent normalization,
N the number of sequences and
the two-sequence correctness defined as [
19]:
with
. Such chain-construction statistical treatment was shown to imply an irreversibility, which is inherent to the system as assessed by practical writing constraints (for example, when using a typewriting machine).
In contrast, if we do not restrict how to access each final configuration [
3,
19], the probability of a certain sequence reads:
being
Q the standard normalization. As with partition functions [
3,
19], the normalizations fulfill
and
, and the probabilities
and
, where
and
The formalism given by Equation (
6) involves a reversible process and therefore comprises the concept of revision, in which backward recognition of errors (proofreading) and their substitution by new objects (editing) take place [
3,
19] (as, for example, when using a word processor in a computer). Therefore, we will extend previous results, hence calling the process represented by Equation (
4) writing and that represented by Equation (
6) revision, thus justifying the use of superindices
w and
r, respectively.
We now introduce the edition potential, “
A”, and the entropy, “
H”, for single chains. Depending on whether we are writing or proofreading and editing, these functions read:
fulfilling:
which is the energy conservation analogue. It is noted that the edition potential does not depend on a particular chain,
, for the case of revision (Equation (
7), right). Besides, the correctness of a particular chain,
, does not depend on how it has been constructed (whether with or without revision). Functions “
A” and “
H” in Equations (
7) and (
8) characterize the generation of information and the information content, respectively, of an individual symbolic chain under the rules modeled through function
C.
Respective functionals can be constructed by taking ensemble-averages:
where
in Equation (11), right. Equations for writing (left) and revision (right) are formally analogous. Importantly, we recover the definition of entropy in information theory for
[
2]. These functionals characterize the average correctness, Equation (
10), the generation of information, Equation (
11), and information content, Equation (
12), of chains constructed under the rules modeled through function
C in the absence (superindex
w) or presence (
r) of revision.
The analogue of the energy conservation for ensemble-average phenomena yields:
which arise by formally taking expected values in Equations (
9). The demonstrations of Equations (
9)–(
13) are straightforward from their thermodynamic analogues [
3]. The following relations can also be deduced from their thermodynamic analogues [
3]:
where
. Since
and
, expressions on the left (writing), again, are formally analogous to those on the right (revision) in Equations (
14) and (
15).
The following inequalities hold [
3]:
In addition, it is straightforward to see that
and that
, which together with Inequality (
16), make
.
These expressions allow extending the conditions for effective revision that were found for thermodynamic systems carrying information [
3]:
Condition 1 (Effective editing necessary and sufficient condition).
Condition 2 (Effective proofreading necessary and sufficient condition).
The equalities take place when there exists no memory (see the independence limit theorem [
19]). Note that the introduction of an arbitrary constant in the definition of the correctness (say
; see above) does not affect the formulation of these conditions.
Corollary 1 (Effective editing necessary condition and effective proofreading sufficient condition).
Corollary 2 (Ineffective editing sufficient condition and ineffective proofreading necessary condition).
Corollaries 1 and 2 are consequences of Conditions 1 and 2 after the use of Equation (
17).
3. Application: Copying
We envision a system, either natural or artificial, that computes information by assembling characters in the same way as a so-called Turing machine and according to adopted rules, as characterized by the correctness. The characters are symbolic elements from an alphabet set, with the independence of the fact that they might have material reality, like atoms or molecules in a physical realization of the system. The alphabet, , is conformed by a number of characters correlated with symbolic operational rules, with independence of whether they might be implemented through existing interactions in a physical realization of the system. In the case of biomolecular systems in cells, intrinsic physical interactions have been accommodated to encode information through evolution. Under the action of protein motors, this information is transferred and subjected to mutations. In the case of human language, symbolic rules have been evolved throughout history, with persons interpreting them and managing information.
In the following, we model the copy of information in a binary-alphabet classical system (
,
). To this end, we adapt a toy model that was previously developed in the context of DNA replication and transcription [
3,
19,
21]. We propose that at each memory position, the introduction of a bit value (
) adds a contribution
(
, a real, positive parameter, which we will name stability contrast) to the correctness of the string and that this contribution is affected through the coupling with the previous bit values (memory), as modeled by a power law (see
Supplementary Materials). The coupling strength is controlled by parameter
in the exponent, which increases for decreasing memory effects. Memory effects specifically introduce either a positive or negative feedback, thus increasing or decreasing the amount
. For reference, when the feedback is positive or when it is negative, but the memory effects are not too strong, a bit value that contributes with
to the correctness is assimilated as a correct incorporation and a value with
as an error.
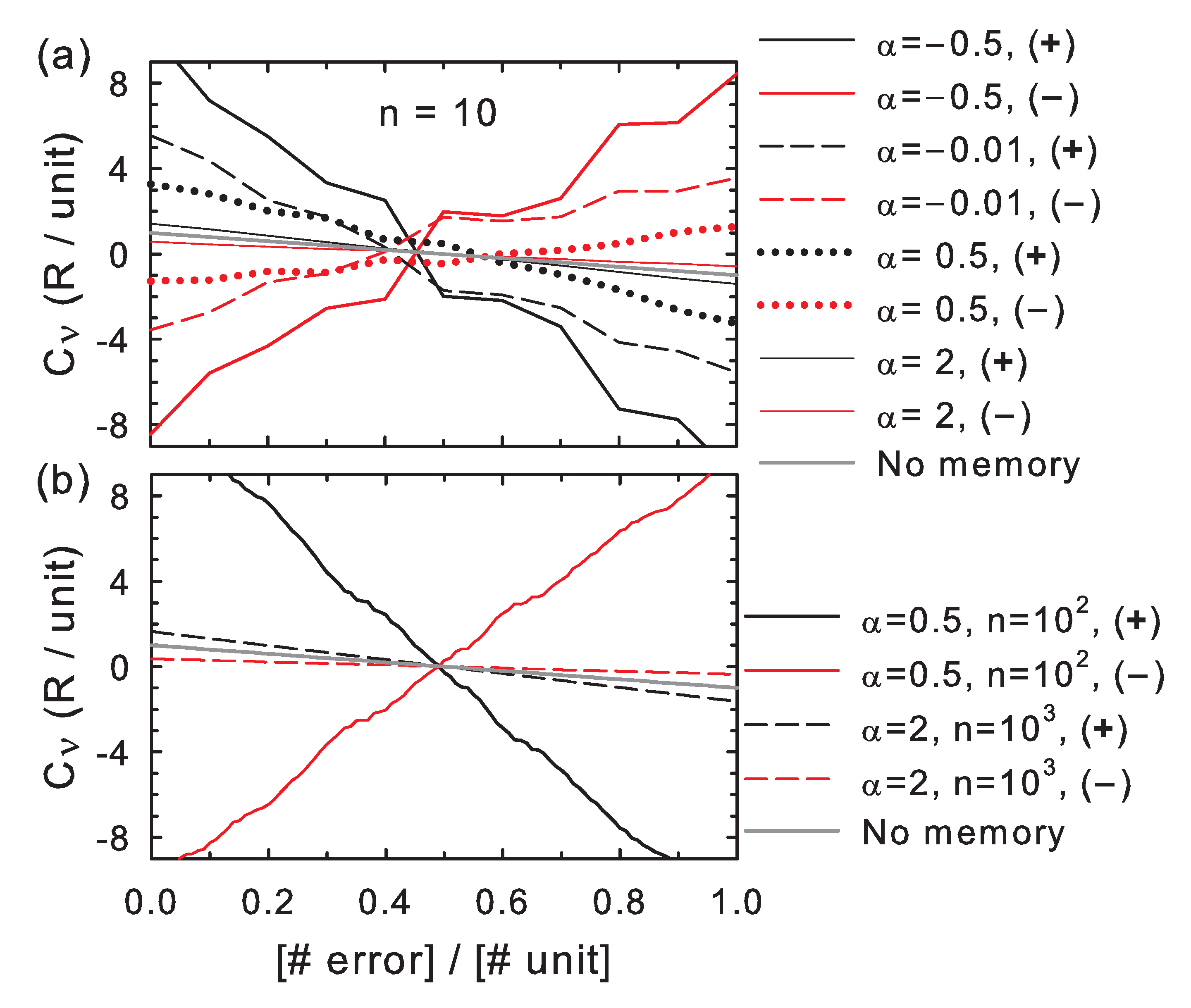
The correctness in individual bit strings decreases with the number of errors for positive feedback and for negative feedback under weak memory effects (high
), as shown in
Figure 1, which is expected for a rationally-designed copying system. When the feedback is negative and memory effects are sufficiently strong (low
), however, the correctness increases with the number of errors, which indicates that the correlations with the previous bit values reverse the effect of the a priori correct/incorrect bit values (
). In both positive and negative feedback cases, the correctness approaches the case of independent variables when memory effects become negligible (
). The curves further reveal that the correctness increases/decreases at each memory position,
i, in steps of size
swayed by the effect of the feedback from the previous bit values in the sequence.
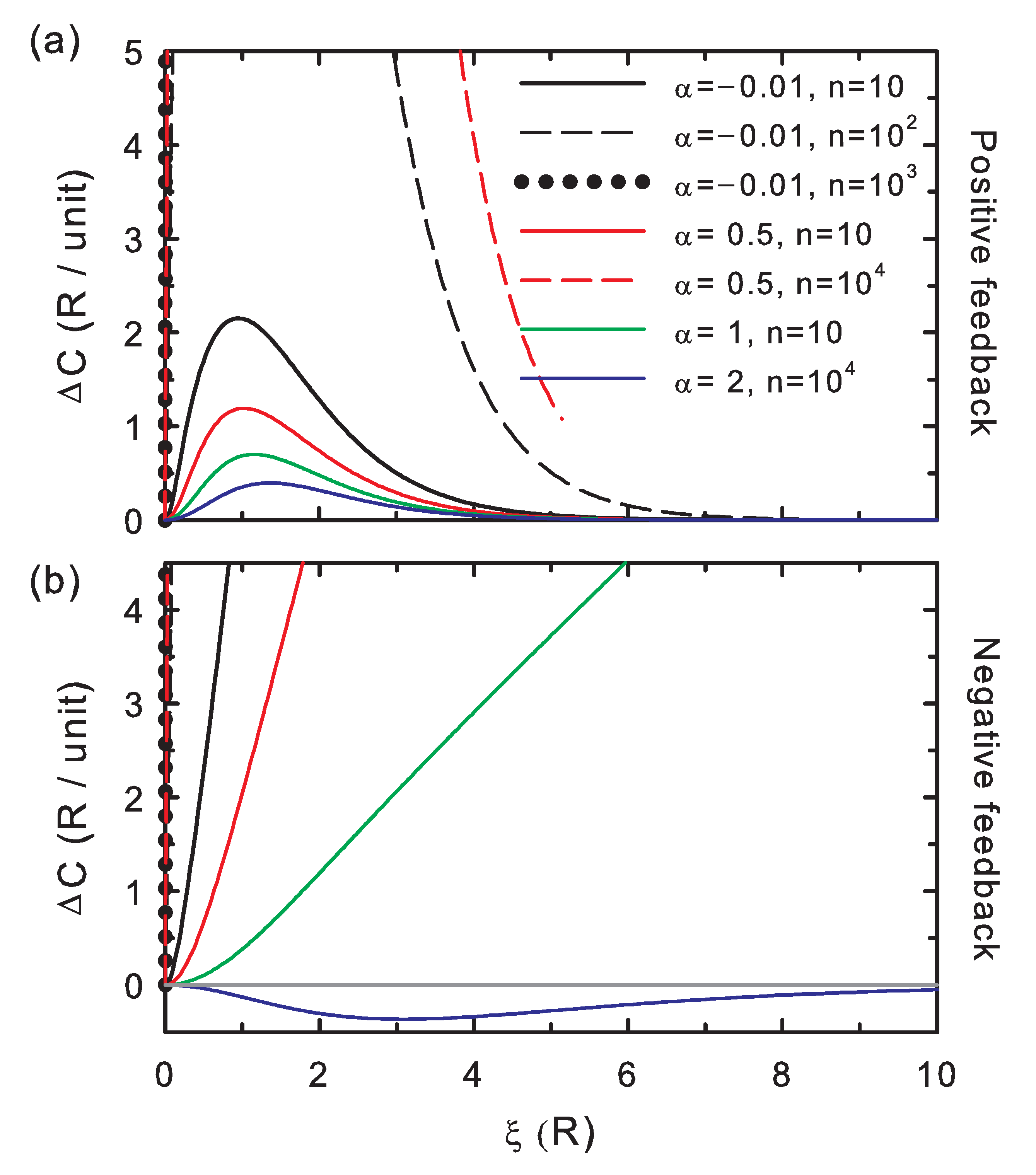
The entropy difference scaled to the number of memory positions, as shown in
Figure 2, ranges between
, as expected for a binary alphabet. This potential difference exhibits negative values for positive feedback, implying that revision improves the information content of the bit string (Condition 1). In the case of negative feedback,
becomes positive for weak memory effects, according to an ineffective revision (Condition 1). For strong negative feedback conditions (
), sufficiently long strings and low values of the stability contrast, this potential becomes again negative. In this case, information is generated (Condition 1) by opposites: a bit value that contributes with
to the correctness generates an overall negative contribution to the correctness due to the strong memory effects (and may be now assumed as an error) and that with
an overall negative contribution (and may be now considered as a correct incorporation). The information generation in this scenario is, however, of less quality than in the positive-feedback scheme: this strongly-correlated information system with negative feedback rewards the introduction of the above termed a priori errors.
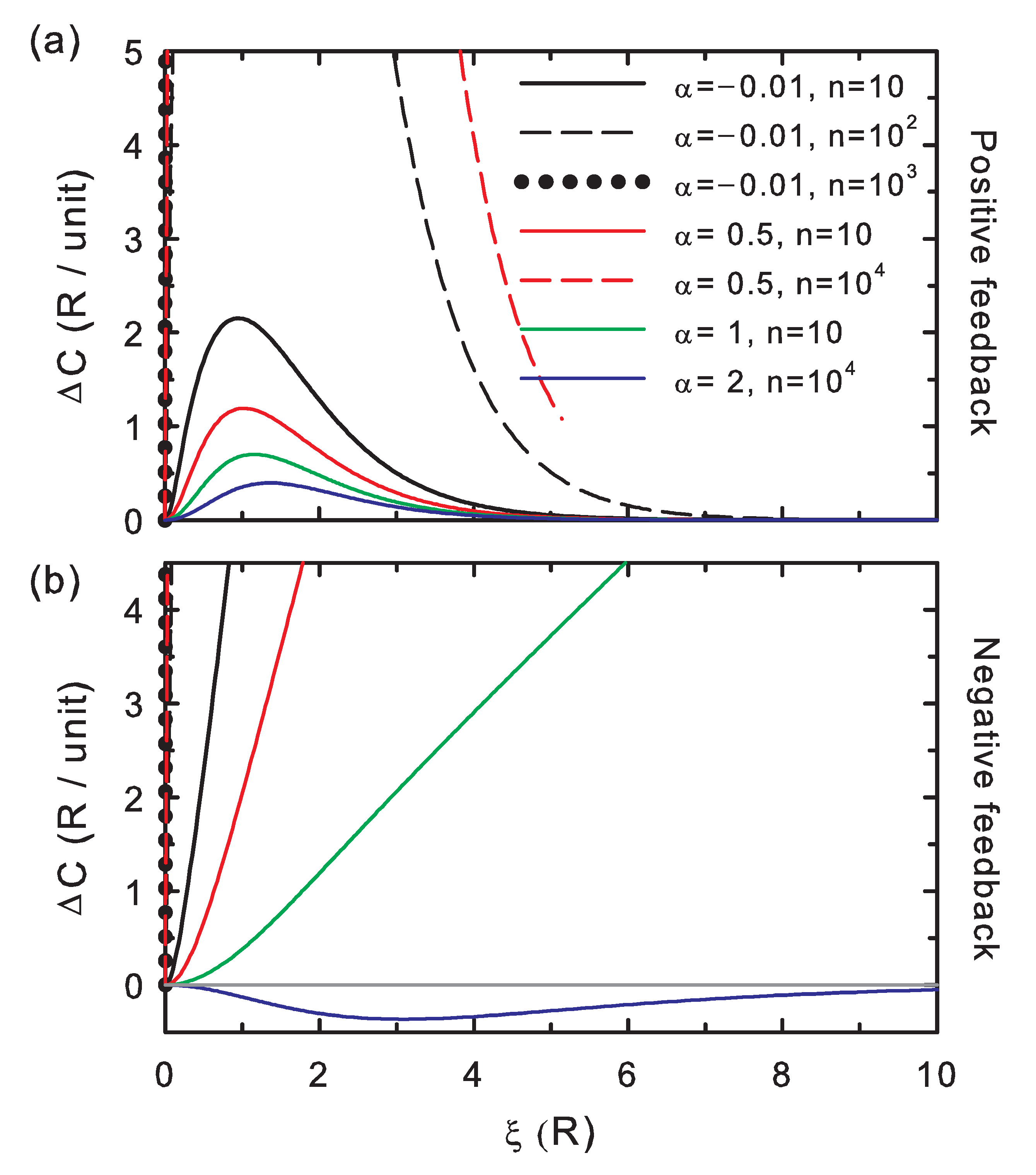
The correctness potential difference scaled to the number of memory positions, (
Figure 3) is positive for positive feedback, which indicates that the proofreading of the strings generated this way is effective (Condition 2). As explained above for
Figure 2, the fidelity of the copy increases (all in all, complying with Corollary 1). For negative feedback, there are again two regimes: for weak memory effects (high
), the correctness difference becomes negative, which indicates that proofreading is ineffective (Condition 2) and makes the editing ineffective, as well (Corollary 2). In the strongly-correlated limit (low
) and negative feedback, the correctness becomes again positive. This is compatible with revision being effective and ineffective, which, as explained for
Figure 2, depends on the string length and stability contrast regime. Information, as mentioned, is generated by a counter-balance effect of the memory. This is, again, coherent with the formulated revision Condition 1 and Corollary 1.
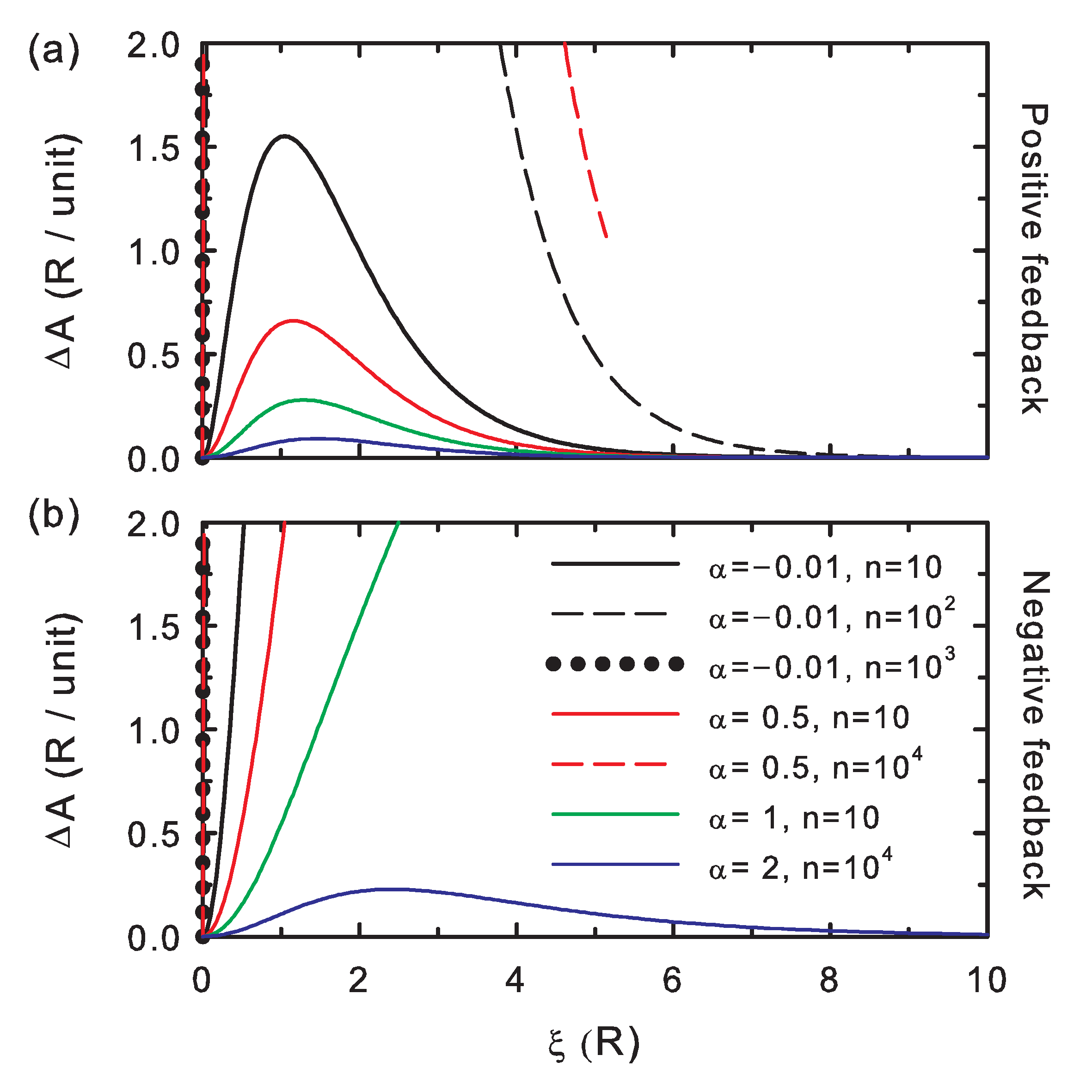
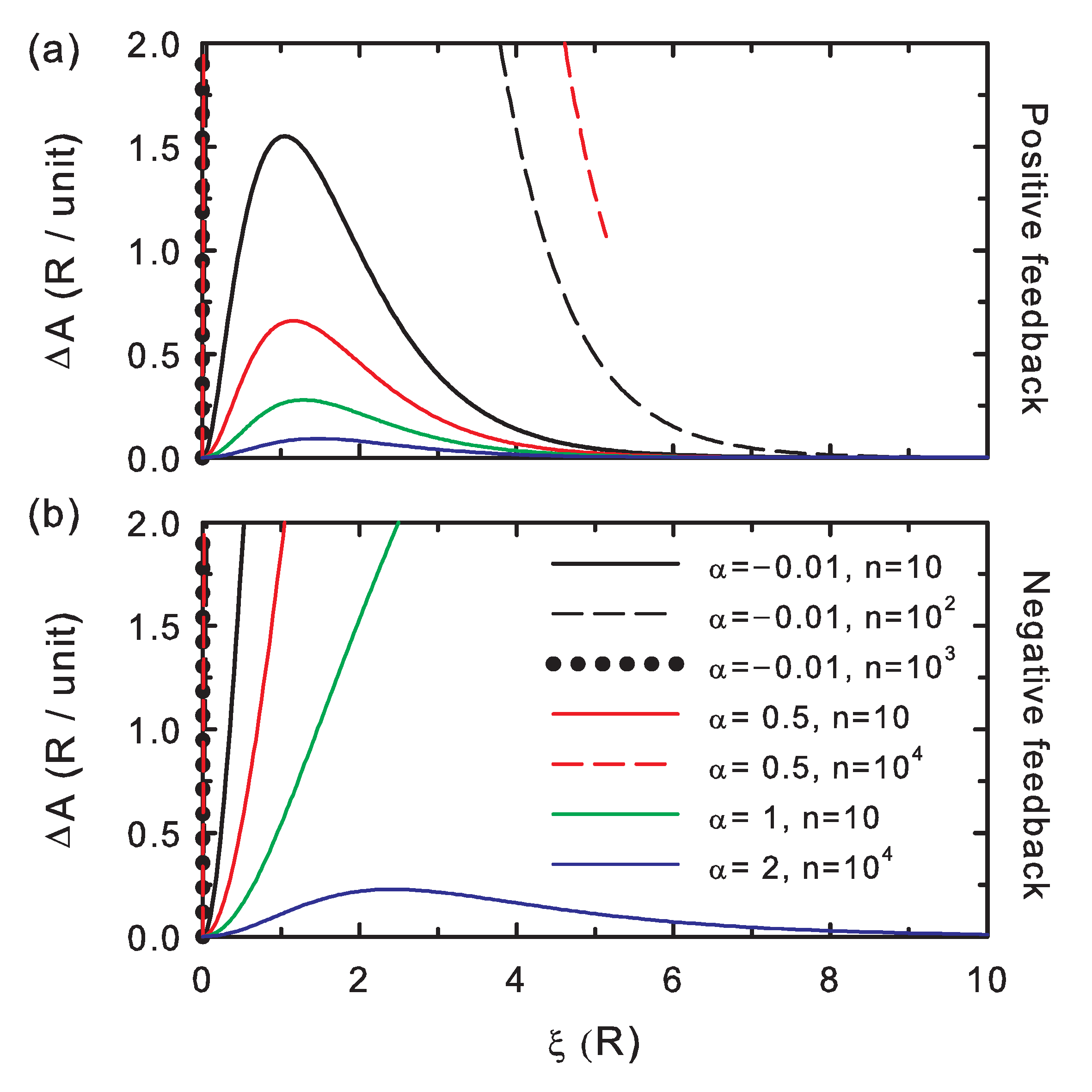
The edition potential difference (
Figure 4) is always positive, as described by Equation (
16); hence, it is also useful as a control check for the simulations. The larger its values, the more distinct the bit string after editing. The curves show that
increases for increasing interaction strength (i.e., decreasing coupling parameter,
) and for increasing chain length (
n).
These appear to be the general trends for the absolute value of the correctness potential difference:
overall increases for both increasing interactions (decreasing
) and chain length (
n),
Figure 3. Both trends are overall followed by the absolute value of the entropy potential difference (
Figure 2), although for the negative feedback regime,
must be analyzed with care along the stability contrast coordinate,
, for
, which separates the strong and weak coupling regimes.


{kind=link}
{kind=link}
{kind=link}
{kind=link}