Abstract
Agents in financial networks can simultaneously be both creditors and debtors, creating the possibility that a default may cause a subsequent default cascade. Resolution of unpayable debts in these situations will have a distributional impact. Using a relative entropy-based measure of the distributional impact of the subsequent default resolution process, it is argued that minimum mutual information estimation of unknown cells in the matrix of funds originally owed by the network participants to each other does not introduce systematic biases when estimating that impact.
1. Introduction
The standard representation of a payments network starts with a snapshot of gross liabilities owed by each agent (bank, firm, trader, etc.) to each other agent, in the form of a matrix L
in which is an amount that agent i owes to agent j. These are gross rather than net liabilities, so that need not be ; in fact, all elements are nonnegative. The entries could represent outstanding loan balances, or loan payments that are due, or checks drawn on one bank that must be deposited in accounts at another bank, or payments owed as a result of mutual trading activities, etc. Total interagent liabilities (assets) of agent i are the row sum (column sum ), in L and their corresponding shares of the grand totals are and .
We will use the following numerical example for illustration throughout
Examining (1), we see that agent #2 owes to others but is owed only by others. Without some additional funds (a.k.a., collateral) available, it cannot pay all its liabilities, and hence will have to default on some of the debts owed. Agent #2 owes 20 to agent #3, who has no surplus available from its in assets to pay its in total liabilities, and hence will also have to default on some payments if it does not receive payment from the defaulting agent #2. In this way, default by one agent may trigger defaults by others. A cascade of defaults that is triggered by a single default is a type of financial contagion. Here, the contagion was triggered by some situation that resulted in agent #2 owing more in the aggregate than it was due to receive, without collateral that could be seized by its creditors. With other matrices, there may be more than one agent initially in default, and those may trigger subsequent defaults.
This aspect of credit/payment systems is not only relevant, it may have motivated the advent of bankruptcy law centuries ago. As noted in Kadens ([1], pp. 1237–1238):
The merchant or trader who relied on credit lived constantly on the edge. The still relatively primitive state of communication, travel, and production meant that he could not be sure when he would receive the next shipment or the next payment on which his ability to pay his own creditors depended. His goal was to “synchronize the payments being made to him as a creditor with those he had to make as a debtor”, and this he could never do with complete assurance. As all merchants and traders who depended on credit existed in this state of financial instability, the insolvency of one person who owed significant debts could lead to the failure of many others.
Because defaults prevent all the promised payments from being made, the severity and distributional impact of defaults also depends on the procedure for resolving them. Following Elimam et al. [2] and Eisenberg and Noe [3], the literature has focused on the following default resolution rule: after any default cascade has ended, an agent that can pay only of its total liabilities must pay exactly of the funds owed to each of its creditors. The resolution procedure is detailed Section 2, and used to formulate a relative entropy-based index of the interagent distributional impact of the default resolution process. In Section 3, we describe the use of minimum mutual information estimation when analysts are faced with the very practical need to estimate unknown cells in the interagent liabilities matrix L. This raises the issue of whether or not this estimator of unknown cells systematically biases estimation of the distributional impact index. That issue is investigated in Section 4, using simulations that failed to uncover a systematic bias. Section 5 provides a statistical rationale for this. Section 6 concludes.
2. The Proportional Payment Rule and the Entropic Index of Distributional Impact
In calculations concerning default, we first must consider the simultaneity problem in the liabilities network: an agent owes funds to others, but in turn is owed funds from them. Suppose we assume the proportional payment rule that requires each defaulting agent i to pay a maximal proportion of its separate liabilities to each of its creditors when it cannot fully pay all of them. In our example (1), suppose that . Then agent #2 must pay the same 15% of the amounts owed to each of its three creditors. Eisenberg and Noe (op. cit.) proved that it is possible to find a vector that implements the proportional payment rule and showed that a linear programming problem can be solved to find it.
We follow the lucid exposition of Demange [4] to define the linear programming problem and its solution. The proportional payment rule specifies that agent i pays agent j , so that the aggregate of payments from agent i will be , while the aggregate of payments to agent i will be . To focus sole attention on the role of the liabilities matrix, in what follows I assume that the agent has no collateral that can be seized to pay shortfalls in the event that the aggregate of payments made to agent i are insufficient to cover its aggregate liabilities. Letting agents have exogenous funds to cover defaults only complicates the issues addressed here. In actuality, rules or laws must be mutually or externally enacted and enforced to ensure that agents maintain fixed levels of collateral that can be assigned to cover defaults, so such analyses will be situation-dependent. Also, if such collateral requirements are high enough, there will be no initial bankruptcies, much less contagion. When collateral requirements are less than that, simulations of default and contagion would be dependent not just on the structure of L, but also on both the magnitudes and the distribution of the collateral, complicating our goal of understanding the relationships between the estimation of L and the distributional impact of the default resolution process. That understanding is enhanced by assuming situations in which default is not a rare event, as it will be when assumed collateral is high enough. Readers interested in estimates for a particular financial network can easily modify the analysis herein to incorporate that network’s distribution of assignable collateral. So the proportional payment rule requires that the vector satisfy the linear inequalities .
Now use these constraints to formulate the following linear programming problem
We see that the objective function in (2) is the aggregate amount paid in default resolution. Eisenberg and Noe (op. cit.) proved the existence of a solution to (2).
In our illustrative example (1), the solution to (2) is . Applying the proportional payment rule to (1), the default resolution payments are
We see that the defaulting agents #2, #3, and #4 all fully pay out the amounts they each receive, i.e., for each of them, so the corresponding constraints in (2) are binding. Thus the solution incorporates the common legal provision that receivables of defaulting agents are fully paid out to creditors. While ex-ante aggregate liabilities (and hence aggregate assets) owed both totaled 160, after default resolution, total liabilities paid are only 43.934. Because the latter is the objective function in (2), this is the maximum feasible aggregate that can be paid after resolution.
Comparing (3) to (1), note that the shares of liabilities paid in resolution by defaulting agents #2 and #4 fell from the fractions they owed ex-ante, while the opposite occurred for agents #1 and #3—despite default by the latter. The least distributional impact would arise if the distribution . Accordingly, we propose that the entropy of relative to be used to measure the distributional impact of the bankruptcy resolution. That is, our measure of distributional impact I is the Kullback–Leibler divergence (a.k.a., relative entropy) measure of directed distance between the distribution and the distribution
Index (4) is nonnegative, and has the value 0 only when A well-known alternative is the index which arises as a first-order approximation of (4) (see Cover and Thomas ([5], p. 333), and lacks the axiomatic rationalization of relative entropy derived by Shore and Johnson [6]. Plug the last columns of (1) and (3) into (4) to calculate I = 0.168.
We now turn to the practical problem of estimating unknown cells in the liabilities matrix L.
3. The Entropy of the Liabilities Matrix
Golan et al. [7] describe a now widely-used procedure to define the entropy of a nonnegative matrix L. One first normalizes it by dividing each of its cells by the grand total of all cells, i.e., define , and compute the Shannon entropy of the normalized matrix . By adopting the convention , cells containing zeros, e.g., those along the diagonal (no agent owes anything to itself), contribute nothing to entropy. Hence we calculate using the data in (1).
Now suppose that all cells in another interagent liabilities matrix L are unknown, but that its N row sums li (total liabilities of each agent i) and column sums aj (total assets of each agent j) are known. This situation is faced by researchers with access to financial reports that list total liabilities and assets of agents without breaking out the bilateral specifics. A researcher could estimate values for the unknown cells by maximizing this entropy subject to the constraints that row and column sums have their observed values. That is
where we recall that and . See Shore and Johnson [6] for a widely-used axiomatic rationale for this constrained maximum entropy estimation, or the constrained minimization of the cross-entropy (a.k.a., relative entropy) when the reference distribution is nonuniform, as we will soon do. The solution of (5) is , i.e., the constrained maximum entropy joint distribution is the product of the marginals defined by the distributions of row and column totals, as if we had assumed the distribution of agents’ total liabilities was independent of the distribution of their total assets. This is a consequence of Theorem 2.6.6 in Cover and Thomas ([5], p. 28). Using the solution to (5), the researcher estimates the amount owed by agent i to agent j by calculating . However, that would imply the counterfactual , i.e., that each agent owes something to itself. To remedy this problem, Upper and Worms [8] reformulate the problem to find the joint distribution that is as close to the product of the marginals as possible (measured by the relative entropy of the former relative to the latter) when . Formally, one minimizes the mutual information (see Cover and Thomas [op. cit., pp. 18–20] for the definition of “mutual information”) subject to the known row and column totals
We see that the objective function in (6), i.e., the mutual information, is the Kullback–Leibler divergence of the joint distribution with typical element from the distribution under independence, with corresponding element . Using the data in our illustrative example (1), numerically solve (6) for to find the following estimated liabilities , rounded to two decimal places below (causing some minor adding-up errors)
Comparing (7) to (1) illustrates how the minimum mutual information estimator (6) spreads the liabilities more evenly. Three off-diagonal cells in (1) were zeroes. None of them are zero in (7). In (1), agent #1 owed all liabilities to a single agent (#3). The (minimized) mutual information i.e., the value of the objective function in (6), is only 0.288. The necessarily higher mutual information in (1) is 0.466, reflecting the fact the actual (but from the researchers’ standpoint, unknown) joint distribution of L and A is not the product of its marginals.
If more information is known than just the row and column totals, e.g., some of the individual cells’ values in L are observed, we need only subtract them from their respective row and column totals, and then drop the corresponding probabilities from the estimation problem (6).
4. Will Entropic Estimation of L Bias Estimation of the Distributional Impact?
If minimization of the mutual information (6) is achieved by spreading an agent i’s estimated liabilities more evenly across the other agents, default by agent i may adversely affect more agents. However, perhaps each of those other agents can absorb relatively small losses better than in matrices in which the defaulting agent i’s liabilities are more concentrated. This suggests that the estimation procedure (6) might lead to underestimates of distributional impact. In other words, the lower the mutual information in a liabilities matrix L, the lower the impact might be, but suppose instead that the more evenly-spread liabilities are larger than what the other agents can absorb without also defaulting. This suggests that the estimation procedure might lead to overestimates of the distributional impact.
Which of these two occurred in our example? The mutual information in (1) is 0.466 vs. 0.288 for the minimal mutual information estimated matrix (7). We saw that the lower mutual information in (7) was indeed achieved by spreading liabilities in (1) more evenly across cells. We calculated that the impact index (4) is 0.168 when the liabilities matrix is (1). When the liabilities matrix is the minimal mutual information matrix (7), the impact index is 0.162. So in this case, we see that the tendency of the minimum mutual information estimator to more evenly spread liabilities across cells led to a slight underestimate of the impact.
To generate more evidence, a simple, easily replicable way to simulate liability matrices is now adopted. First, we permute the off-diagonal elements in (1), to produce other possible liabilities matrices with identical numbers in them. Note that permuting the off-diagonal elements will result in matrices with the same Shannon entropy, because permutation of matrix elements will permute the labels of the various , but will not change the sum of products defining the Shannon entropy. However, because the row and column totals will not be preserved by these permutations, the mutual information of these matrices will differ, and hence in principle can be related to the impact of contagion. In order to provide evidence based on comparisons to matrices with identical row and column totals, each matrix produced by permutation is considered as another matrix (1) and paired with the minimum mutual information matrix produced from its row and column totals, considered as matrix (7). Another advantage of this procedure is that it fixes the network’s total liabilities (and hence network total assets) in each pair to be the same as in the base example.
Specifically, our example (1) has total liabilities of 160. A simulated liabilities matrix was produced by permuting the off-diagonal cells in (1). The proportional payments rule solving (2) was used to derive the default resolution payments matrix analog of (3) from , and these two matrices are used to calculate the distributional impact index (4), with index value . If only the rows and columns of were known, the researcher would estimate the full liabilities matrix by solving (6) to produce the minimum mutual information estimated analog of matrix (7). The proportional payments rule solving (2) was then used to derive the default resolution payments analog of (3) from , and these two matrices were used to calculate the estimated distributional impact index (4), dubbed , resulting from resolution of . The estimation error is the difference between and the estimate . The process was repeated 500 times.
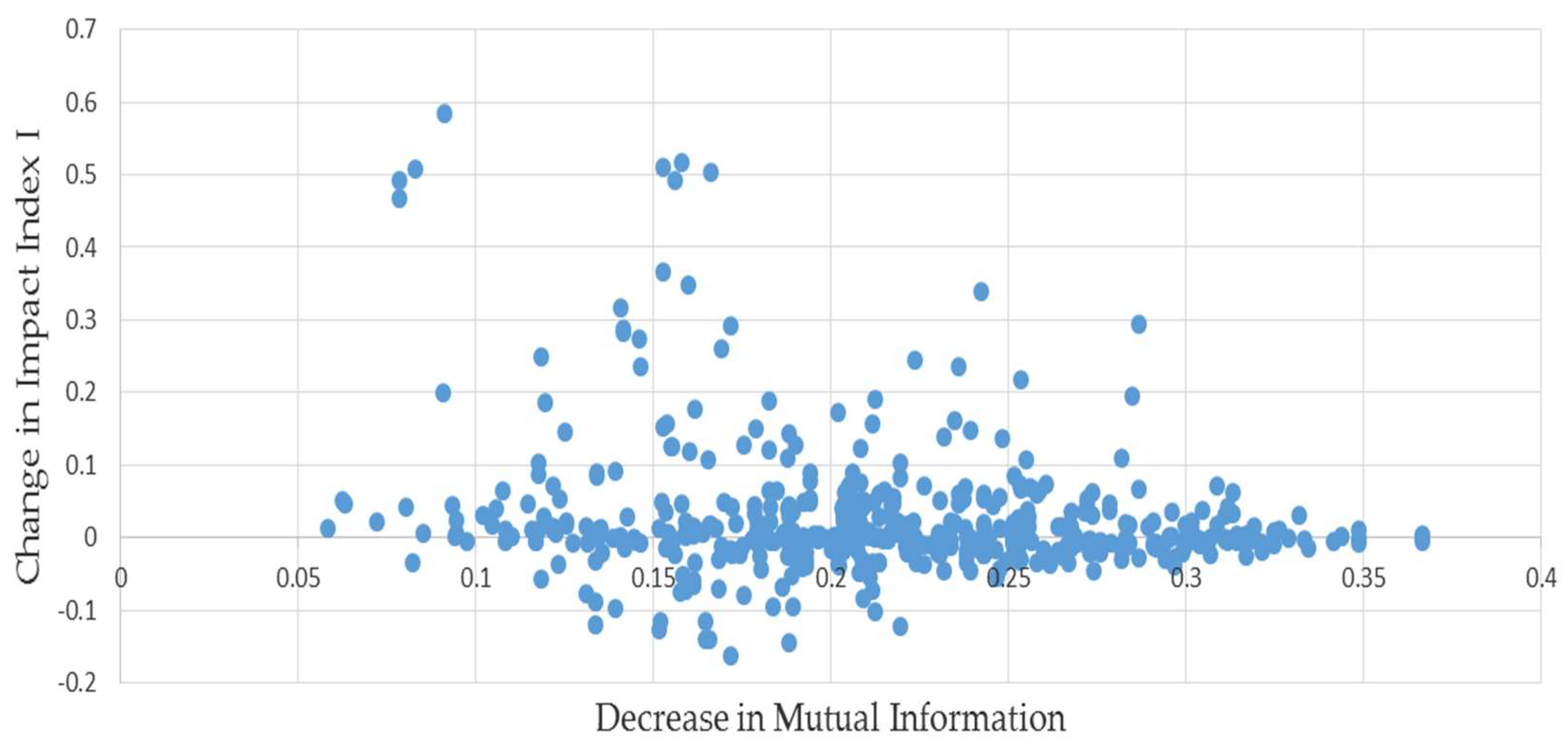
We examine whether or not the decrease in mutual information occurring when is estimated by results in a systematically higher or lower value of the estimate compared to . On average across the pairs, the estimated index was about 16% higher than its correct counterpart, but examining the relationship depicted in Figure 1 shows that there were some severe outliers among the 500 pairs. One way to help correct for them is to substitute the median change for the average. Doing so, we find that this bias is less than 2%, reflecting the concentration of points along the horizontal axis.
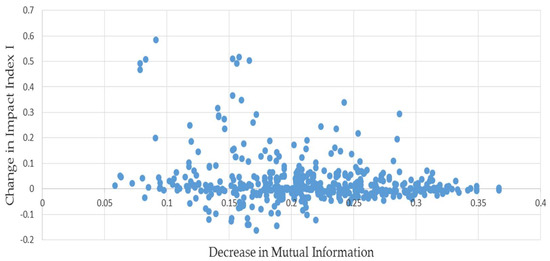
Figure 1.
L matrices paired with minimum mutual information estimates: results of permutations of example (1).
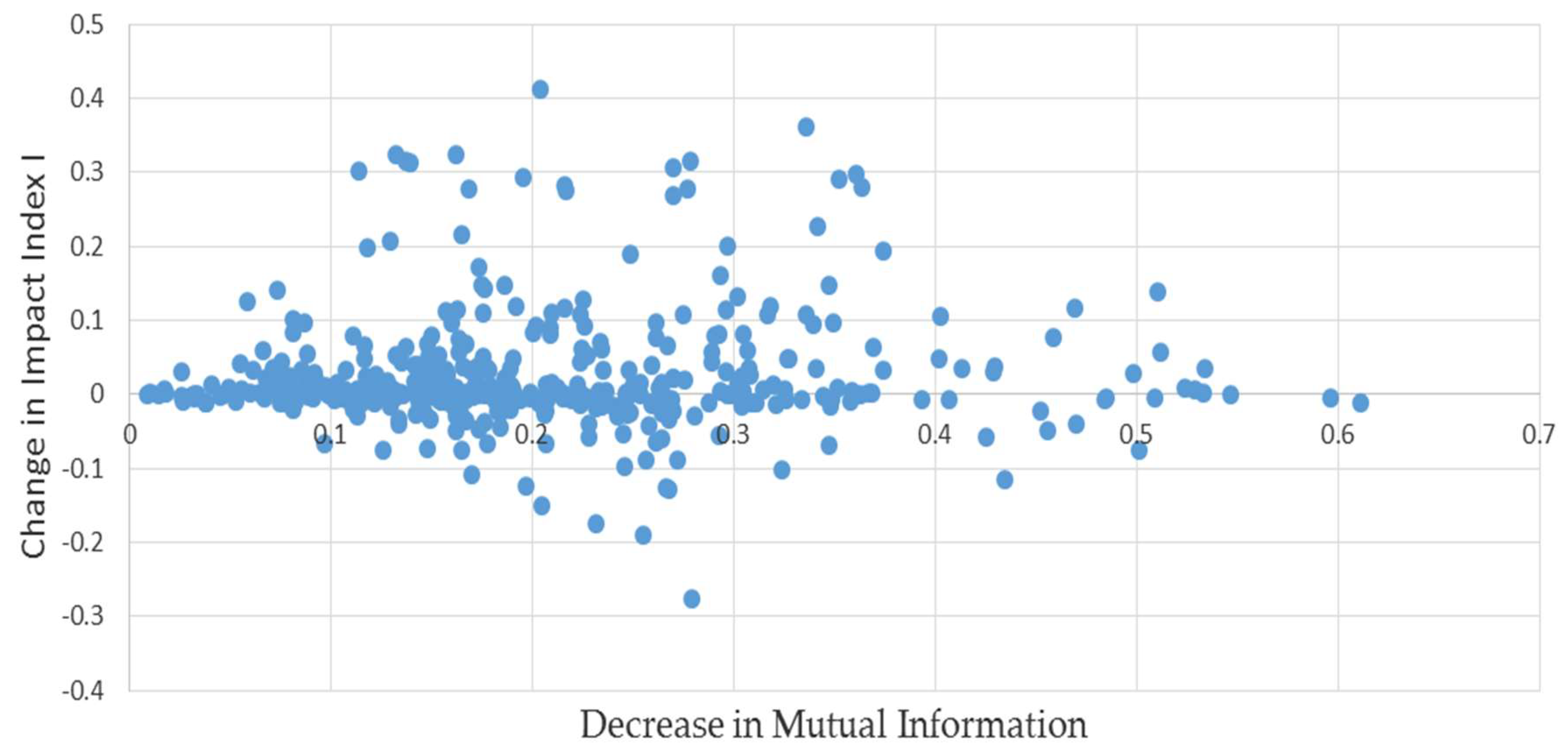
As an additional check, instead of permuting the elements in (1), a simulated liabilities matrix was produced bootstrapping the off-diagonal elements in (1). That is, we sampled the off-diagonal elements in (1) with replacement rather than without, and then proceeded as described above. In contrast to the permutations, this will produce simulated liabilities matrices with different total network liabilities. The results as depicted in Figure 2 are quite similar: the median bias is 3.5%, still quite small.
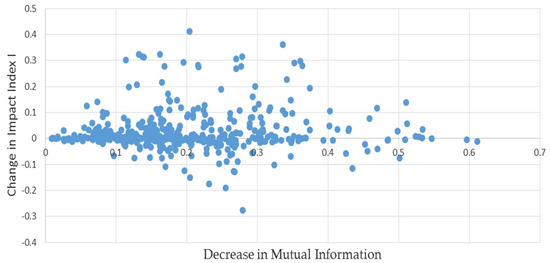
Figure 2.
L matrices paired with minimum mutual information estimates: results of bootstrapping example (1).
5. Why Doesn’t Mutual Information Estimation Systematically Bias Estimates of Distributional Impact?
The mutual information is an unsigned measure of the dependence between the row proportions vector and the column proportions vector considered as two probability distributions determined by a random liability matrix . While the mutual information is zero when the row and column proportions are independent, when there is dependence it is always positive regardless of whether the dependence is positive or negative. However, there is a signed dependency measure that is closely connected to the distributional impact index (4). That characteristic is the rank correlation between agent liabilities and agent assets. The (sound) intuition is that the distributional impact of default resolution will be more severe when agents with a relatively high share of total liabilities have relative low share of total assets that must be used to pay the liabilities. Because there is no reason to expect a linear correlation measured by the Pearson correlation, we accordingly surmise that the Kendall rank correlation between the agents’ respective shares of liabilities and assets will be negatively related to the distributional impact index (7). Moreover, the Pearson correlation is not as robust (i.e., insensitive to outliers) as the Kendall rank correlation or the Spearman rank correlation, as shown in Croux and Dehon ([9], p. 509), who further establish that “the Kendall correlation measure is more robust and slightly more efficient than Spearman’s rank correlation, making it the preferable estimator from both perspectives”. Evidence for that is now provided.
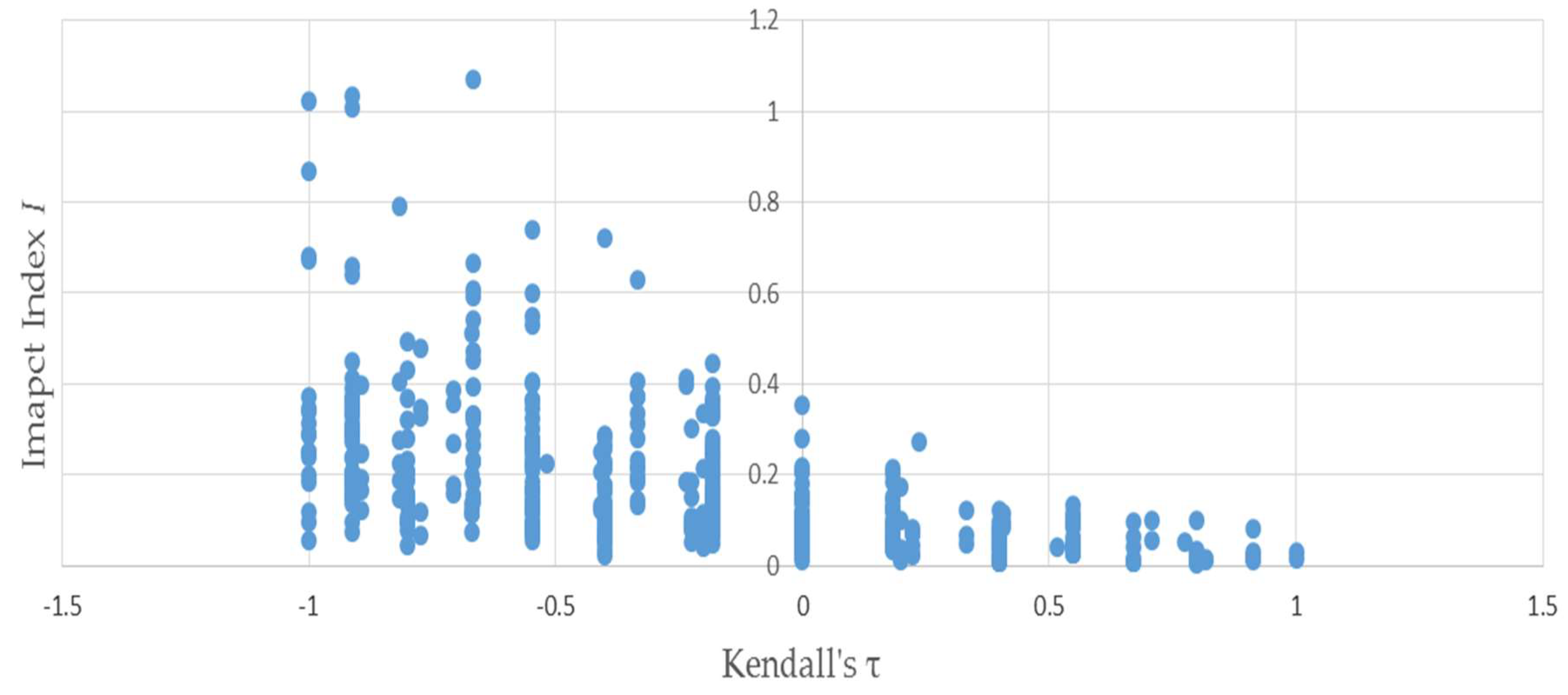
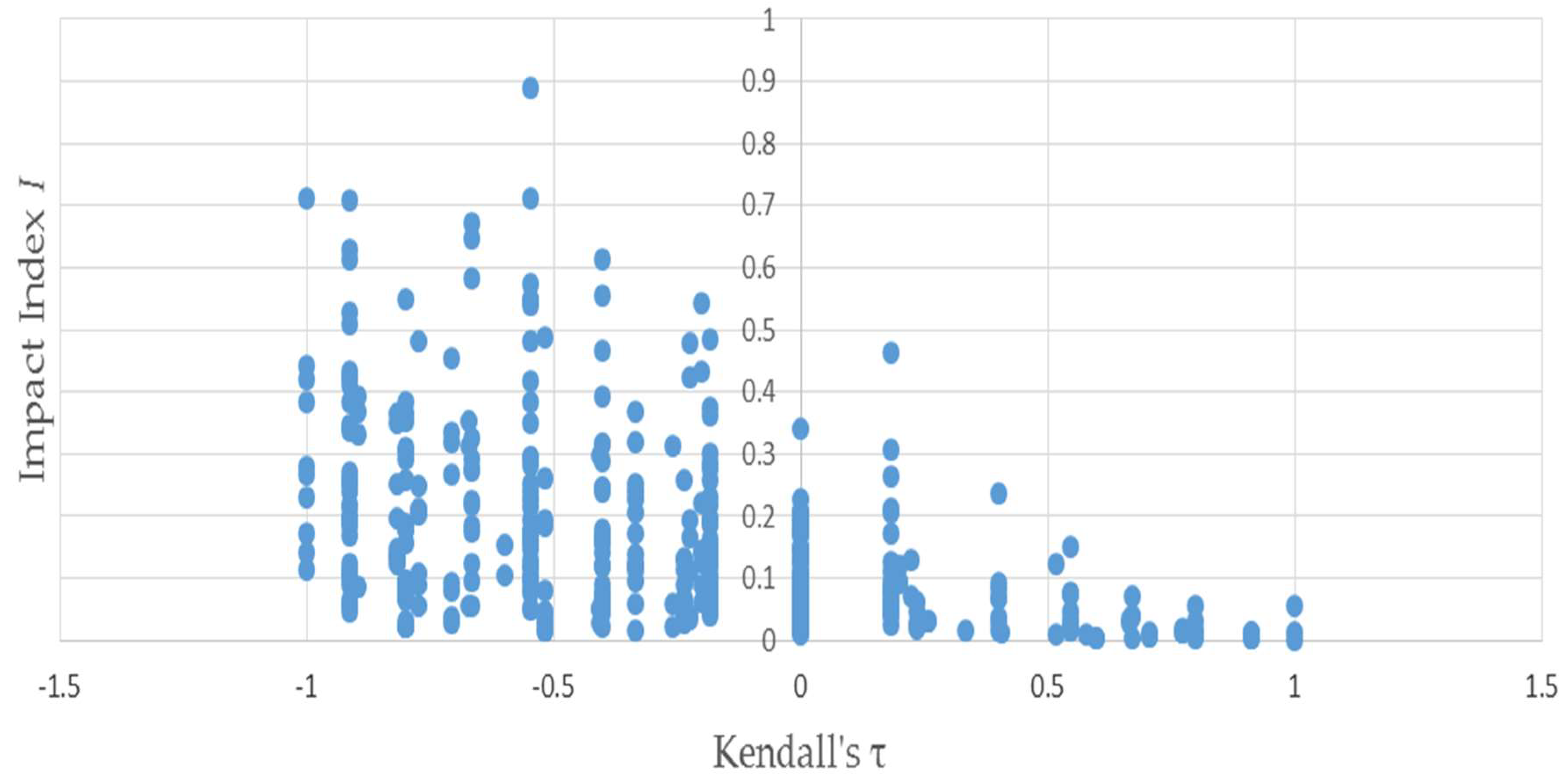
Figure 3 uses the same permutations used to produce Figure 1 to illustrate the negative relationship between the distributional impact index I and —because the two vectors and have only four elements apiece, Kendall’s can only assume a small number of values. This accounts for the discreteness of the horizontal axis values plotted in Figure 3 and Figure 4—evinced by the negative slope of the trend. Figure 4 depicts that the negative relationship also holds when bootstrapped matrices used to produce Figure 2 are substituted for the permutations.
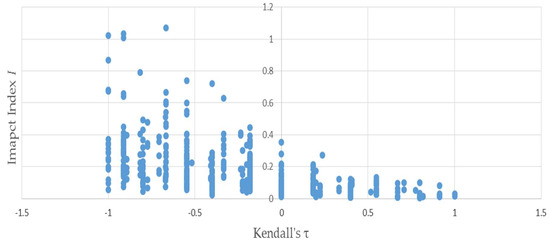
Figure 3.
Kendall’s τ is negatively related to the distributional impact index I: results of permutations of example (1).
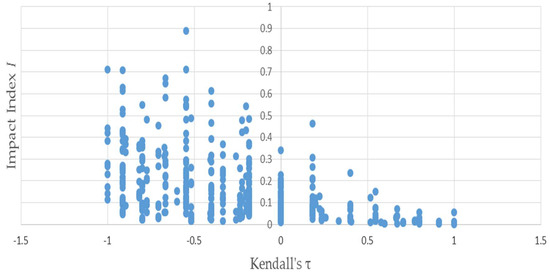
Figure 4.
Kendall’s τ is negatively related to the distributional impact index I: results of bootstrapping example (1).
6. Concluding Remarks
The minimum mutual information estimator has been used as an objective function in constrained minimization problems for estimating unknown cells in interagent liability matrices, and analogous matrices arising in the social sciences. Interagent liability matrices are important inputs for studies estimating the impact of default and possible subsequent default cascades (a.k.a., contagion) in financial payments networks. This raises the possibility that this estimator might systematically bias measures of the impacts that resolution of unpayable debts might have.
Using a relative entropy-based index of a default resolution’s impact, a simple simulation study did not evince systematic impact estimation bias resulting from minimum mutual information estimation of unknown cells in liability matrices. It was argued that negative dependence between the interagent distribution of money owed by them to the distribution of money owed to them should have a strong effect on the impact of default and any subsequent contagion. Measuring dependence by Kendall’s τ rank correlation statistic of signed dependence confirmed this intuition. Because the mutual information in the two distributions is an unsigned measure of such dependence, there is not as close a connection between it and the distributional impact of default and any subsequent contagion.
This paper’s modest contribution augments different, but foundationally similar, entropic statistical methods in finance. One of the more common uses is to select a probability distribution with minimum relative entropy, subject to moment constraints that are tailored to the particular application. A recent survey of this approach in finance is provided by Chen [10], who utilizes it to estimate distributions of the error term in GARCH models of stock returns. Another topic has been to produce asset pricing model error diagnostics that augment findings gleaned from the popular Hansen–Jagannathan [11] specification error diagnostic for pricing model’s implied stochastic discount factors. Most recently, Ghosh et al. [12] exploited the permanent vs. temporary component decomposition of stochastic discount factors to derive a new entropic diagnostic statistic, with enhanced ability to identify serious pricing errors in otherwise promising consumption-based asset pricing models. Finally, Golan [13] provides a comprehensive text that both develops the foundations as well as exposits other important entropic applications in economics and finance (e.g., option pricing).
Acknowledgments
The author acknowledges useful comments received from participants in the Conference on Systemic Risk (Singapore) and the Info-Metrics Institute Conference (Washington, DC).
Conflicts of Interest
The author declares no conflict of interest.
References
- Kadens, E. The last bankrupt hanged: Balancing incentives in the development of bankruptcy law. Duke Law J. 2010, 59, 1229–1319. [Google Scholar]
- Elimam, A.; Girgis, M.; Kotab, S. The use of linear programming in disentangling the bankruptcies of Al-Manakh stock market crash. Oper. Res. 1996, 44, 665–676. [Google Scholar] [CrossRef]
- Eisenberg, L.; Noe, T. Systemic risk in financial systems. Manag. Sci. 2001, 47, 236–249. [Google Scholar] [CrossRef]
- Demange, G. Contagion in Financial Networks: A Threat Index. Manag. Sci. 2016, 64, 955–970. [Google Scholar] [CrossRef]
- Cover, T.; Thomas, J. Elements of Information Theory; John Wiley: New York, NY, USA, 1991. [Google Scholar]
- Shore, J.E.; Johnson, R.W. Axiomatic derivation of the principle of maximum entropy and the principle of minimum cross-entropy. IEEE Trans. Inf. Theory 1980, 26, 26–37. [Google Scholar] [CrossRef]
- Golan, A.; Judge, G.; Robinson, S. Recovering information from incomplete or partial multisectoral economic data. Rev. Econ. Stat. 1994, 76, 541–549. [Google Scholar] [CrossRef]
- Upper, C.; Worms, A. Estimating bilateral exposures in the German Interbank market: Is there a danger of contagion? Eur. Econ. Rev. 2004, 48, 827–849. [Google Scholar] [CrossRef]
- Croux, C.; Dehon, C. Influence functions of the Spearman and Kendall correlation measures. Stat. Methods Appl. 2010, 19, 497–515. [Google Scholar] [CrossRef]
- Chen, Y. Modeling maximum entropy distributions for financial returns by moment combination and selection. J. Financ. Econ. 2015, 13, 414–455. [Google Scholar] [CrossRef]
- Hansen, L.; Jagannathan, R. Assessing specification errors in stochastic discount factor models. J. Financ. 1997, 52, 557–590. [Google Scholar] [CrossRef]
- Ghosh, A.; Juillard, C.; Taylor, A. What is the Consumption-CAPM missing? An information-theoretic framework for the analysis of asset pricing models. Rev. Financ. Stud. 2018, 30, 442–504. [Google Scholar] [CrossRef]
- Golan, A. Foundations of Info-Metrics: Modeling, Inference, and Imperfect Information; Oxford University Press: Oxford, UK, 2017. [Google Scholar]
© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).