Electricity Consumption Forecasting Scheme via Improved LSSVM with Maximum Correntropy Criterion


Abstract
:1. Introduction
2. Review of the LSSVM and MCC
2.1. Least Square Support Vector Machine
2.2. Maximum Correntropy Criterion
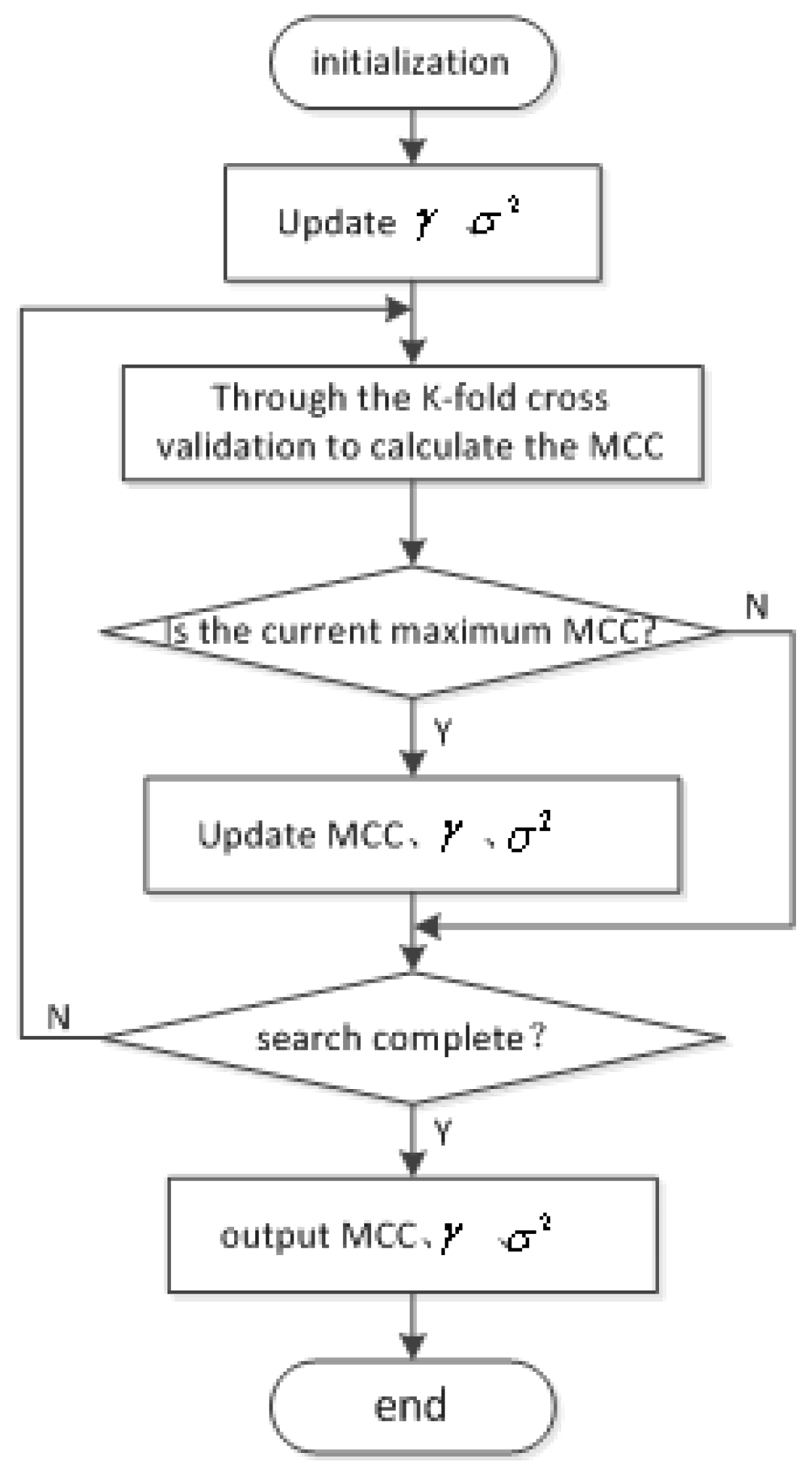
3. FoEC via LSSVM with MCC
- Step 1:
- Data preprocessing: Includes the processing of error data and data normalization.
- Step 2:
- Dataset constructing: The normalized data samples are divided into training and testing samples, which are used to train the LSSVM model and evaluate the performance of the trained model, respectively.
- Step 3:
- Parameter optimization: The parameters of the LSSVM model with the MCC are optimized by the grid search method.
- Step 4:
- Prediction: After training the LSSVM, the prediction accuracy and the generalization performance are demonstrated by the testing data.
- Step 5:
- Prediction result analysis: Applies certain evaluation criteria for performing evaluation tasks and analyzing the various elements that affect the result of such a forecast.
3.1. Data Preprocessing
- (1)
- Error data and missing data processing.
- (2)
- Normalization processing.
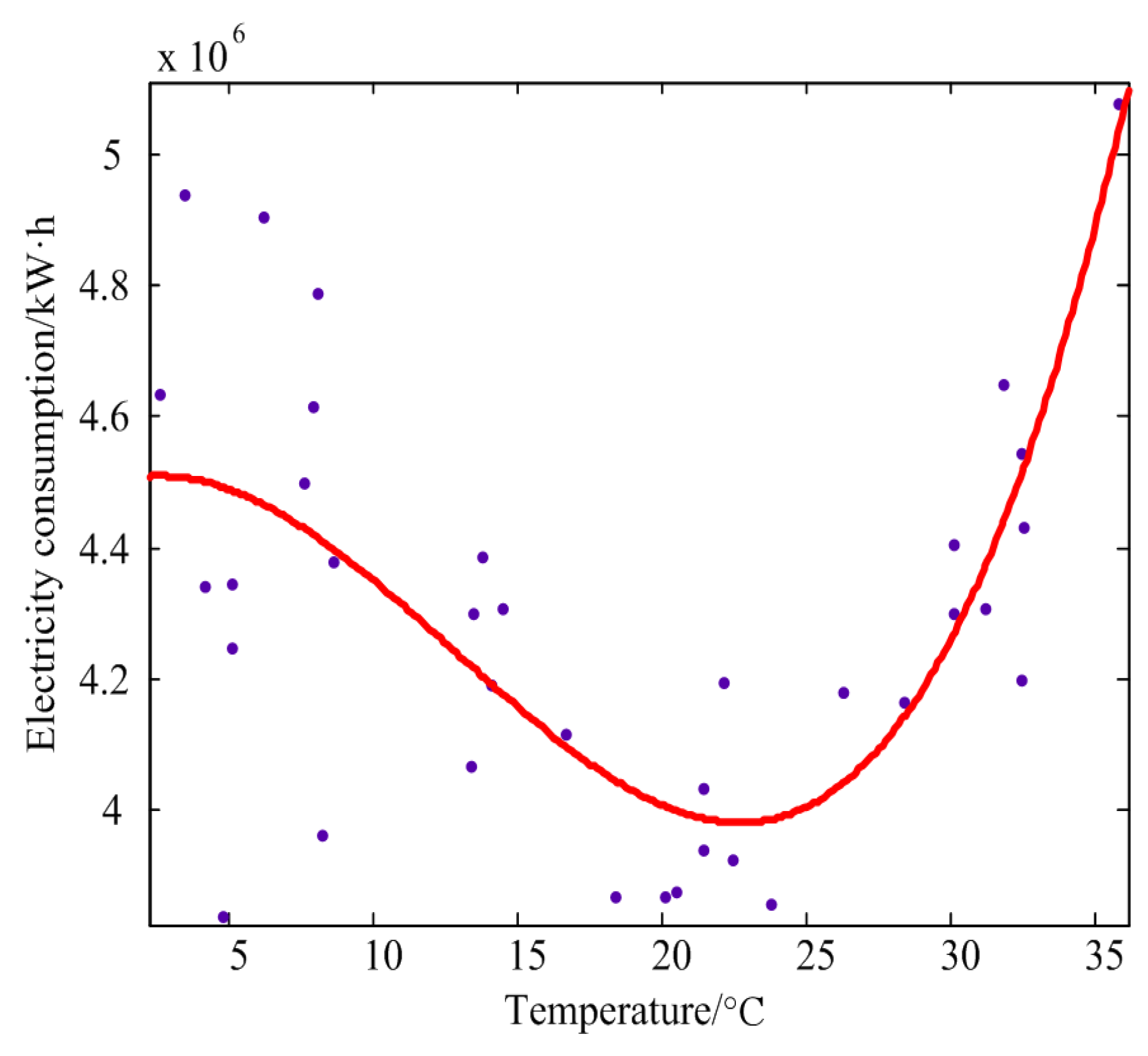
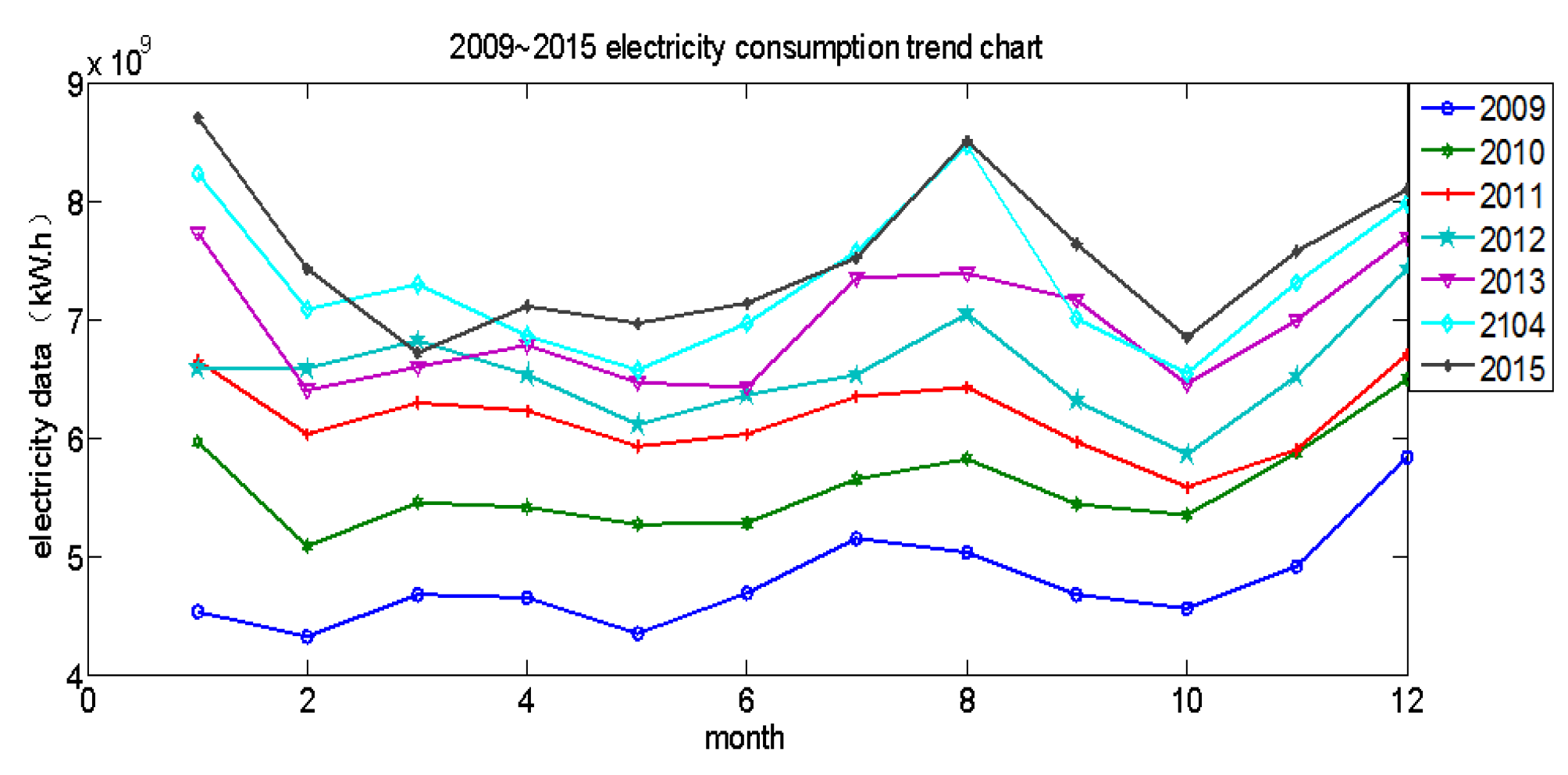
3.2. Selection of Influence Factors
- (1)
- The quantity of electricity data.
- (2)
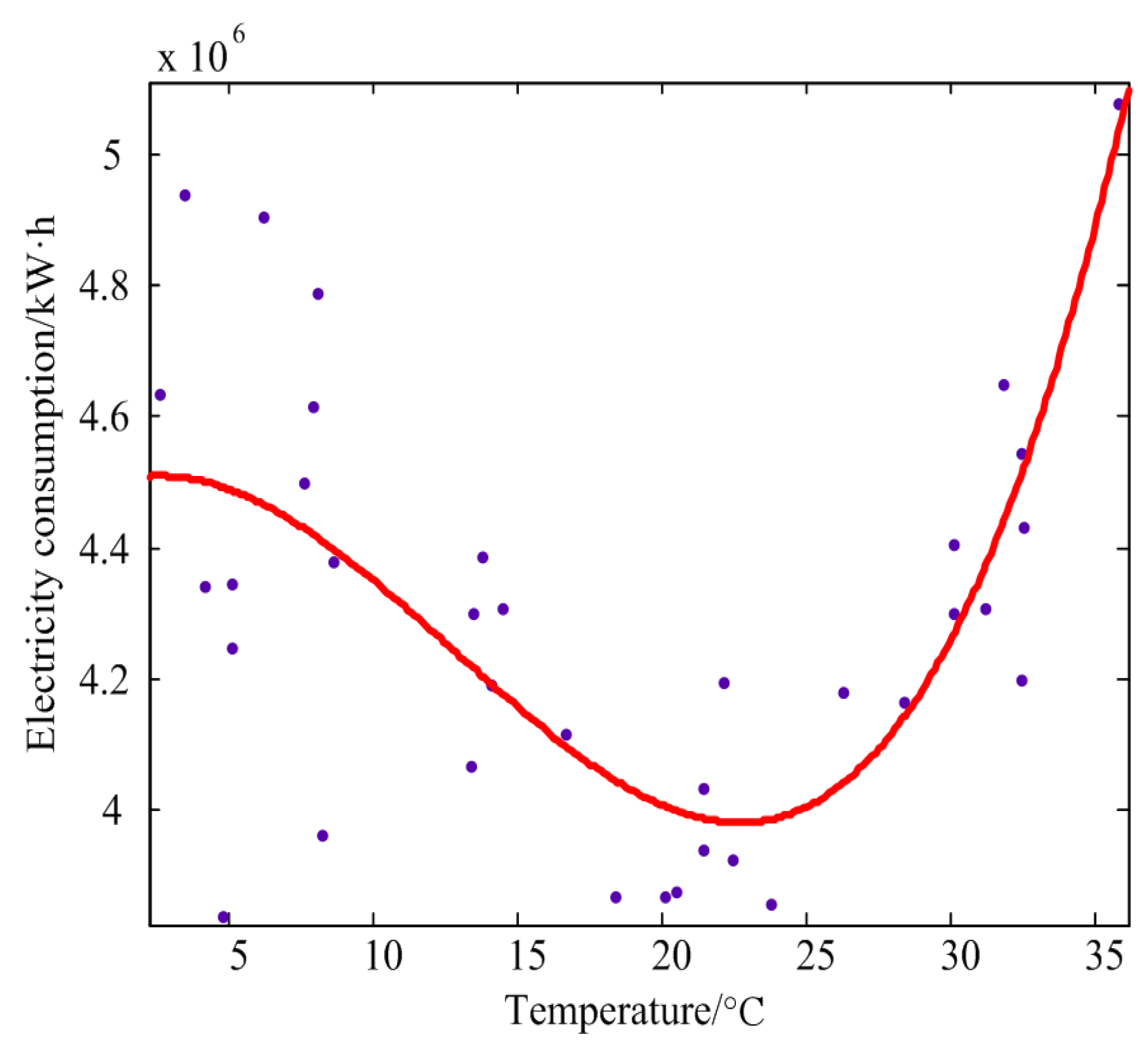
- Regional temperature.
- (3)
- GDP.
- (4)
- Number of holidays and types of holidays.
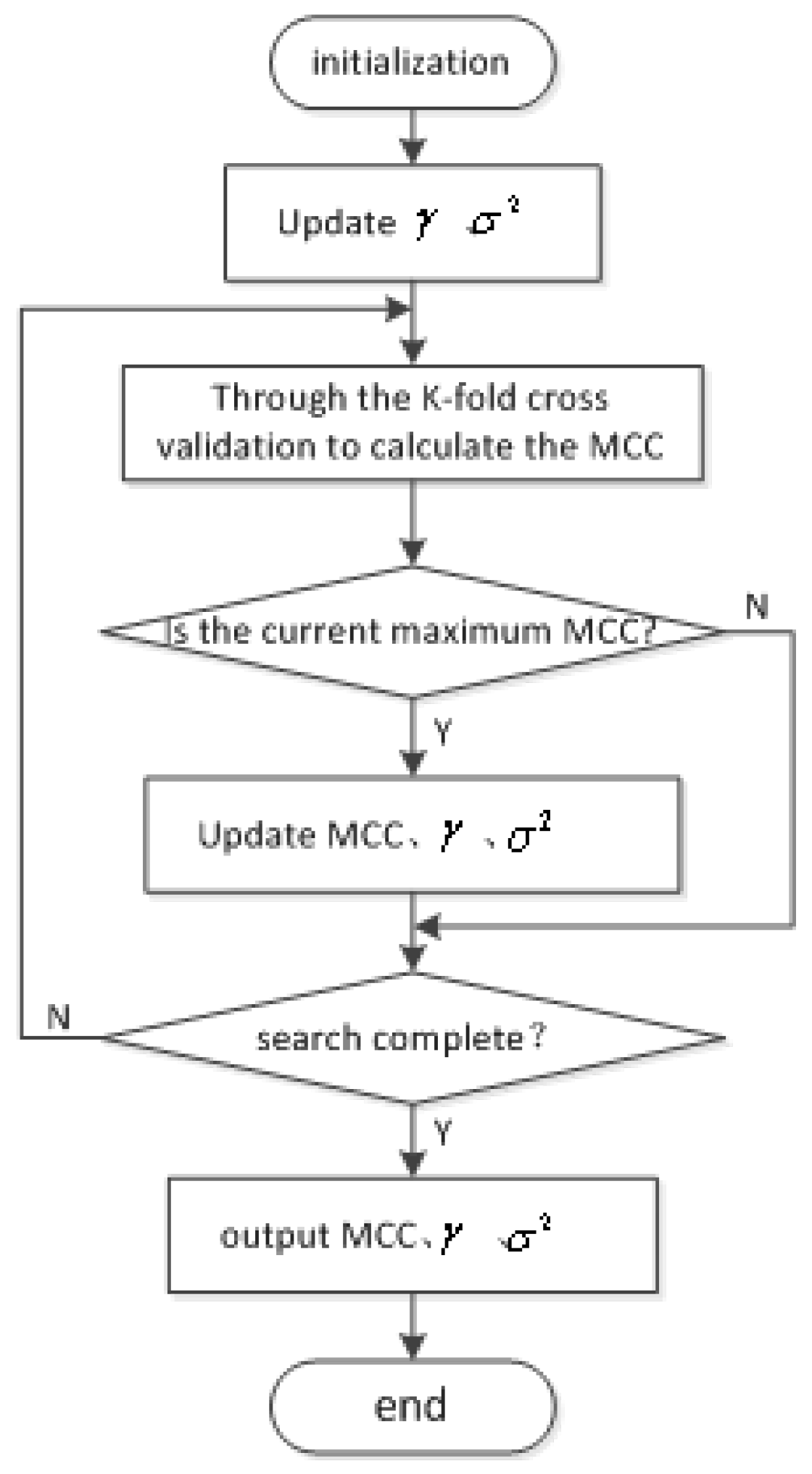
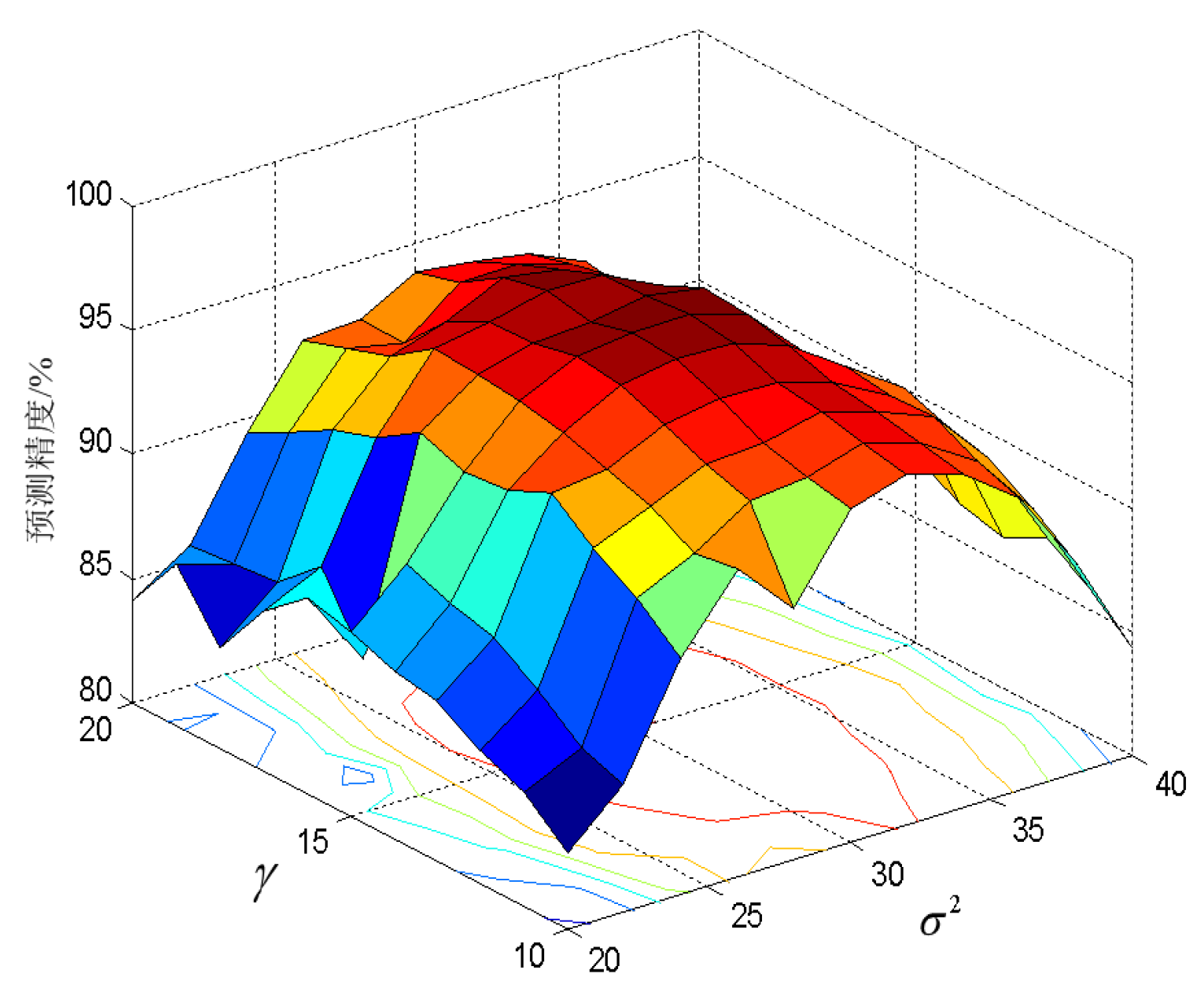
3.3. Parameter Optimization
3.4. Performance Evaluation Function (PEF)
4. Prediction Results and Analysis
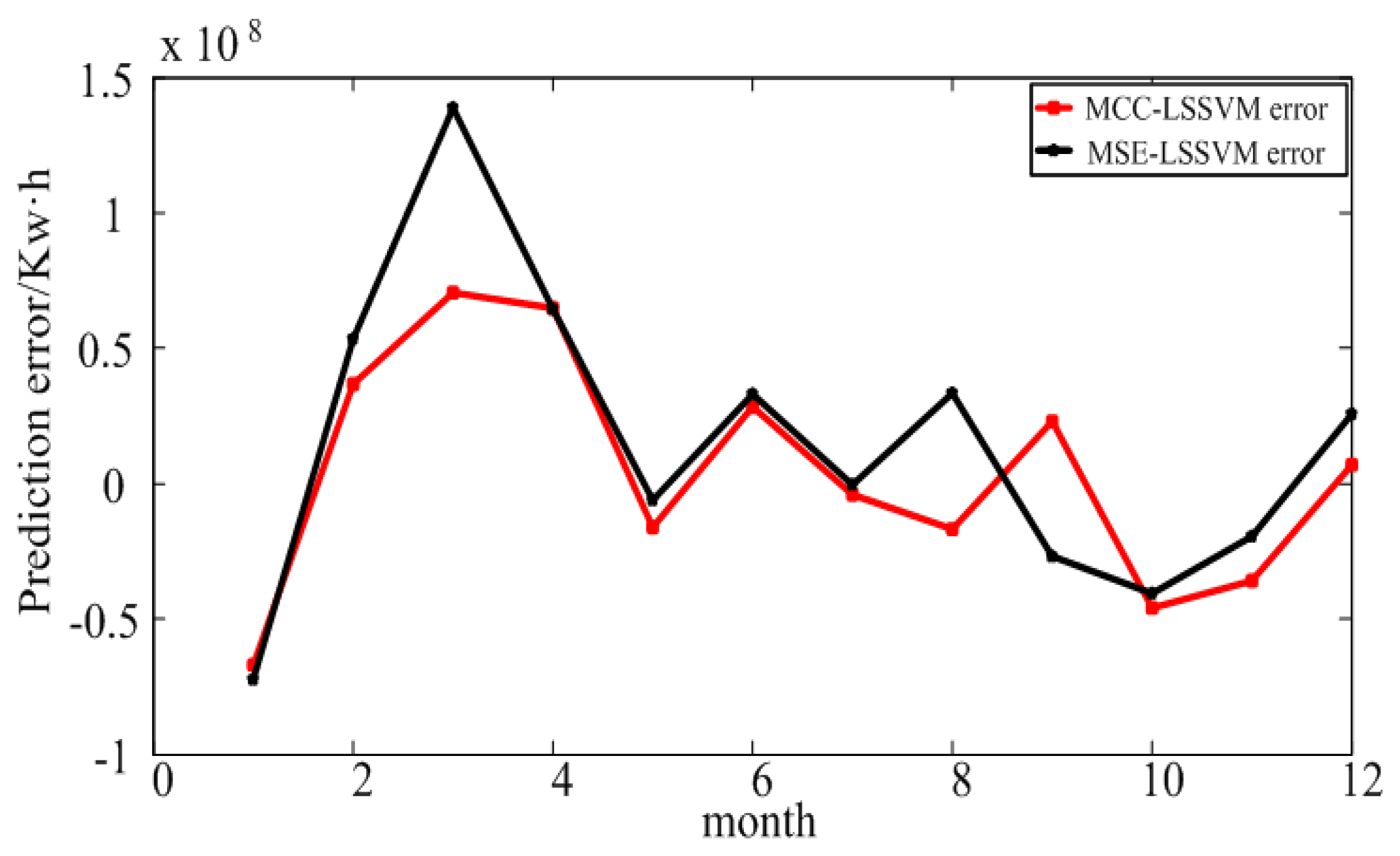
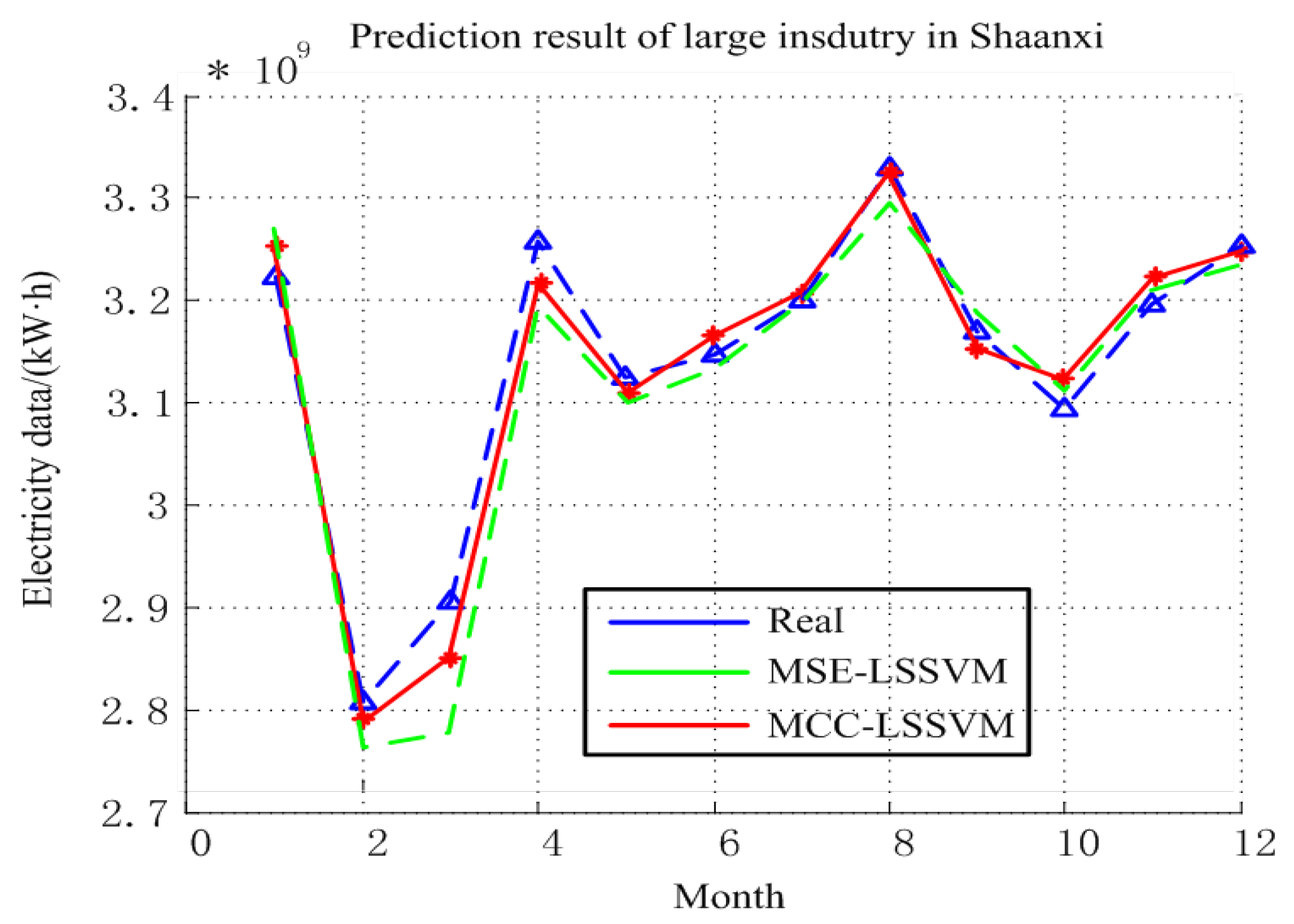
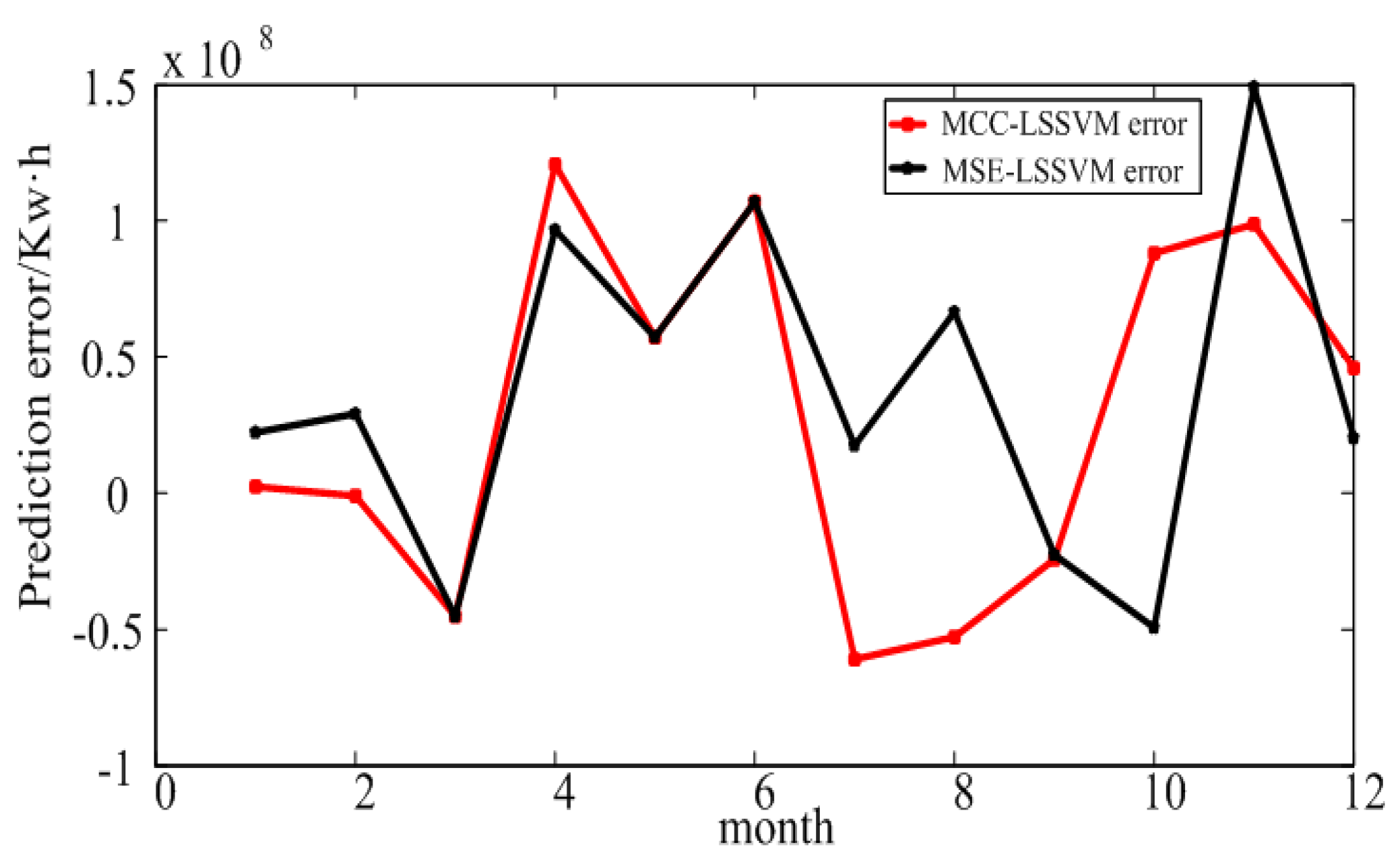
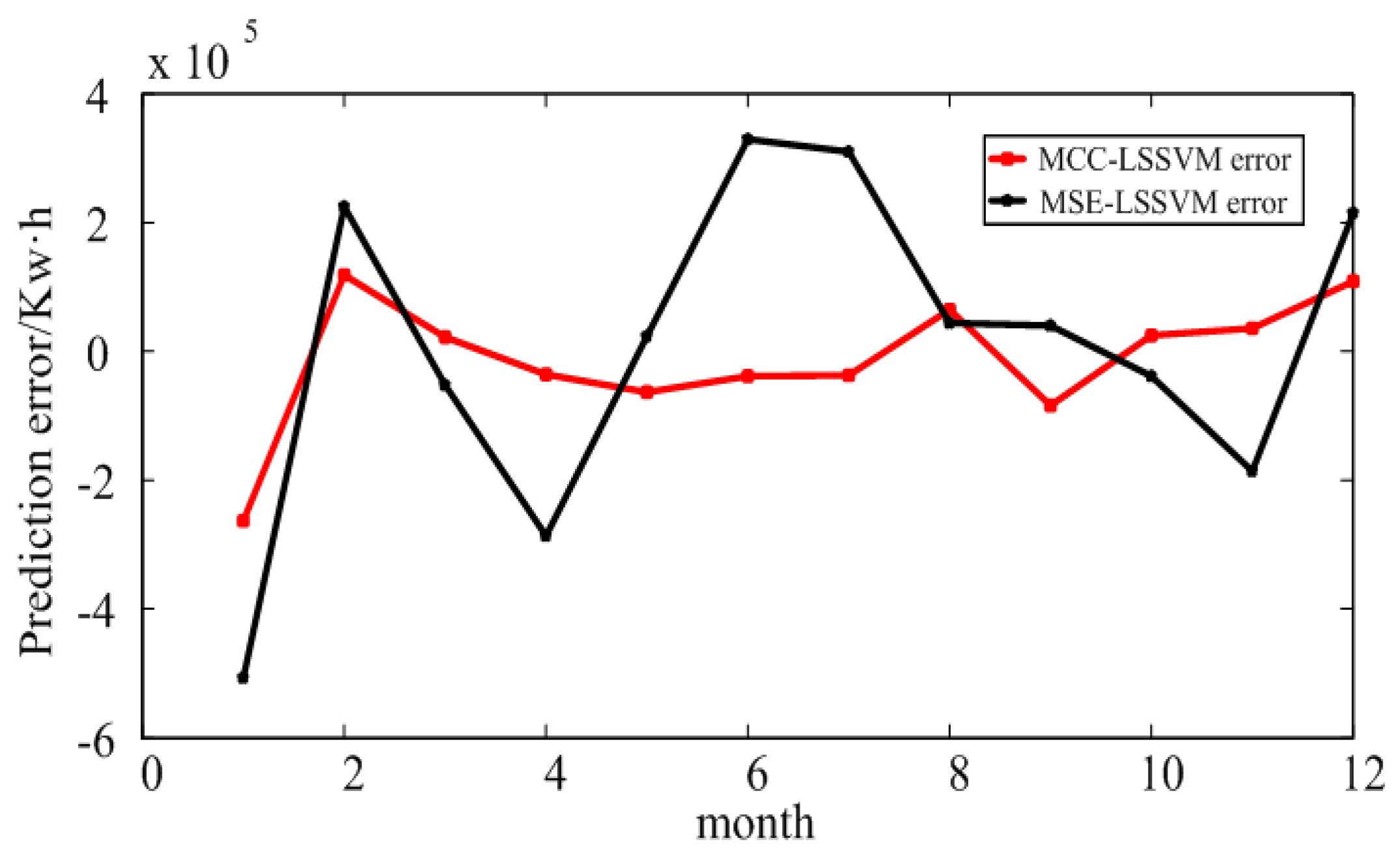
4.1. Prediction Results of Large Industry in Shaanxi Province
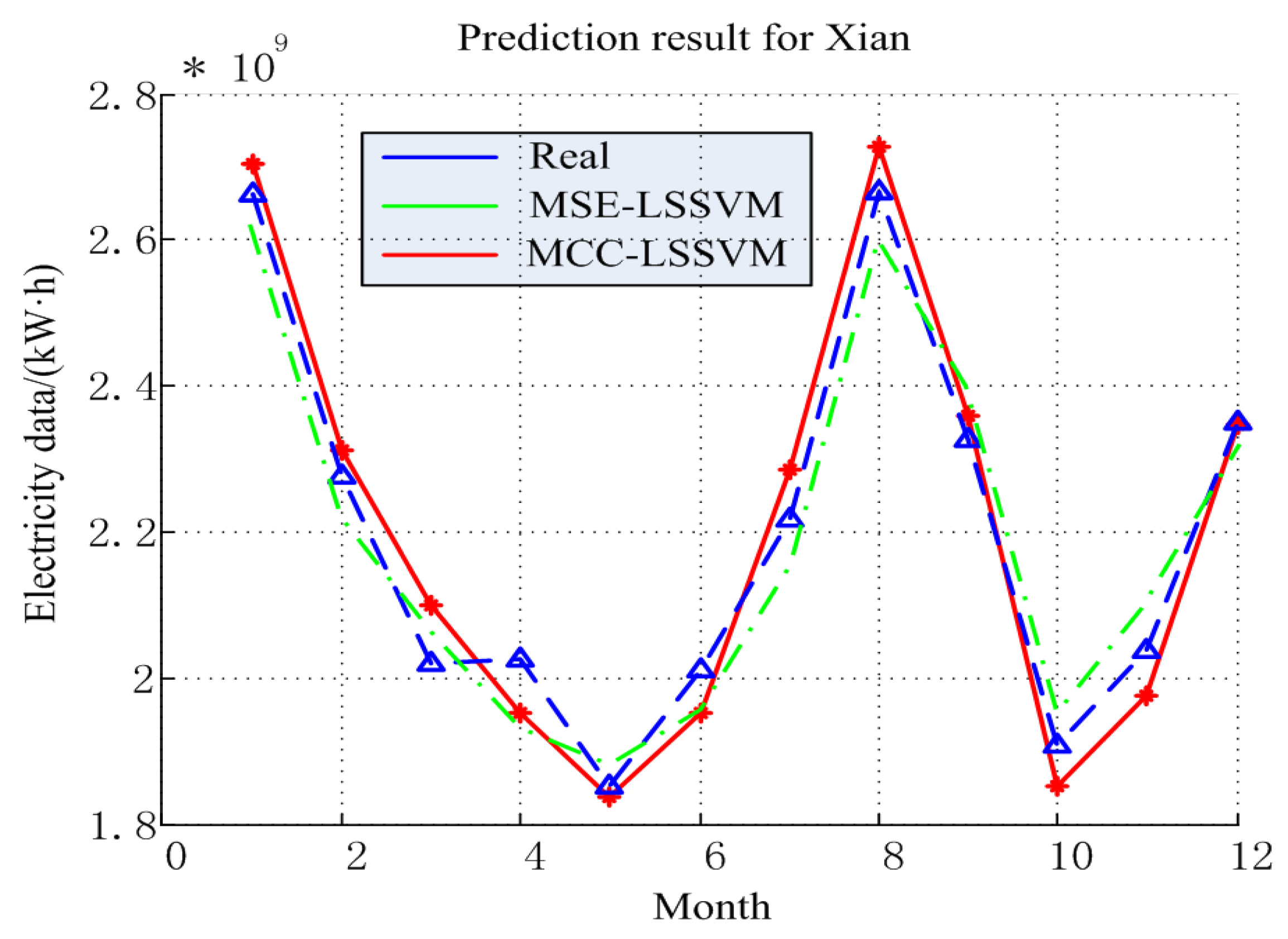
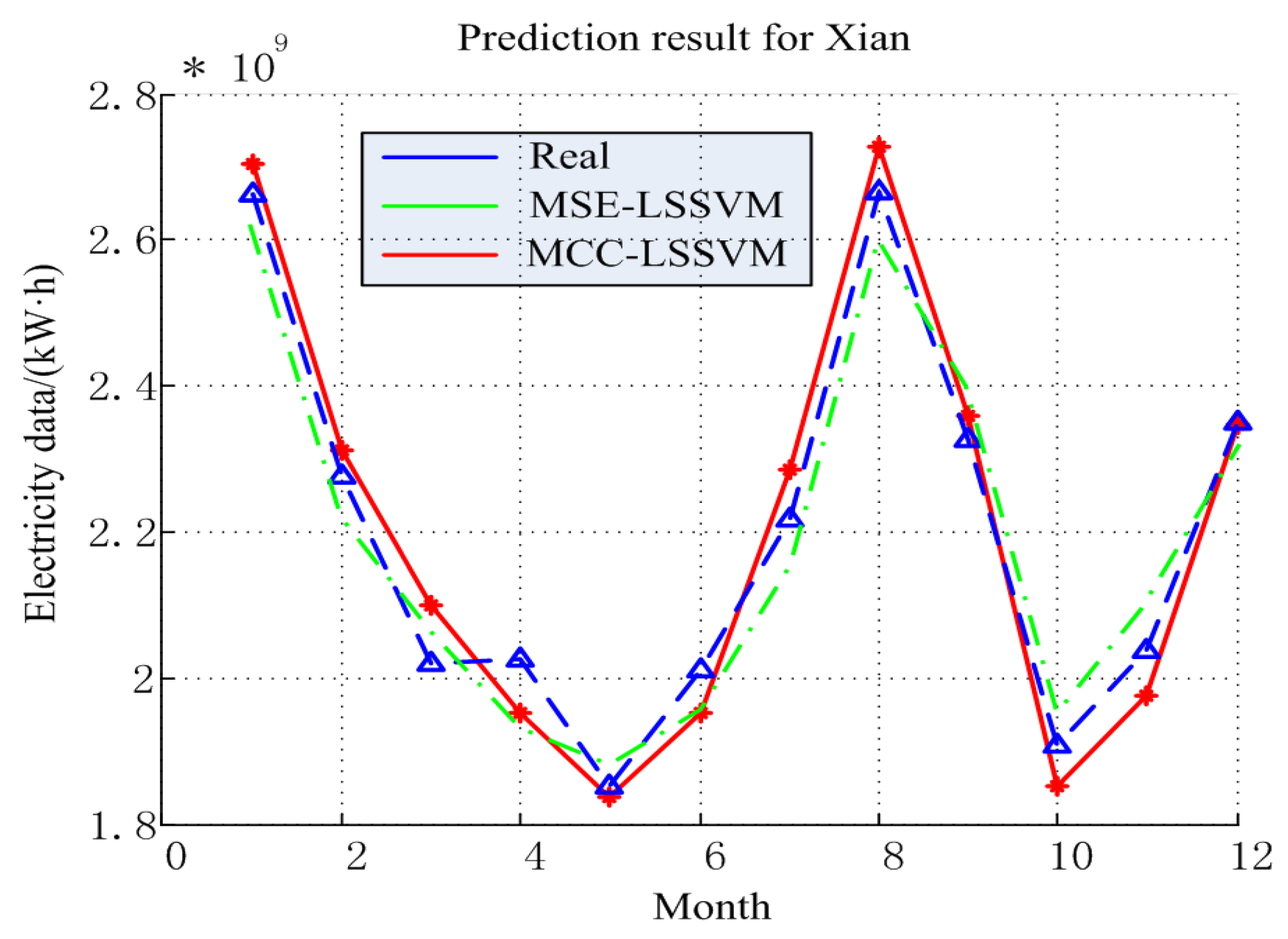
4.2. Prediction Result for Xi’an
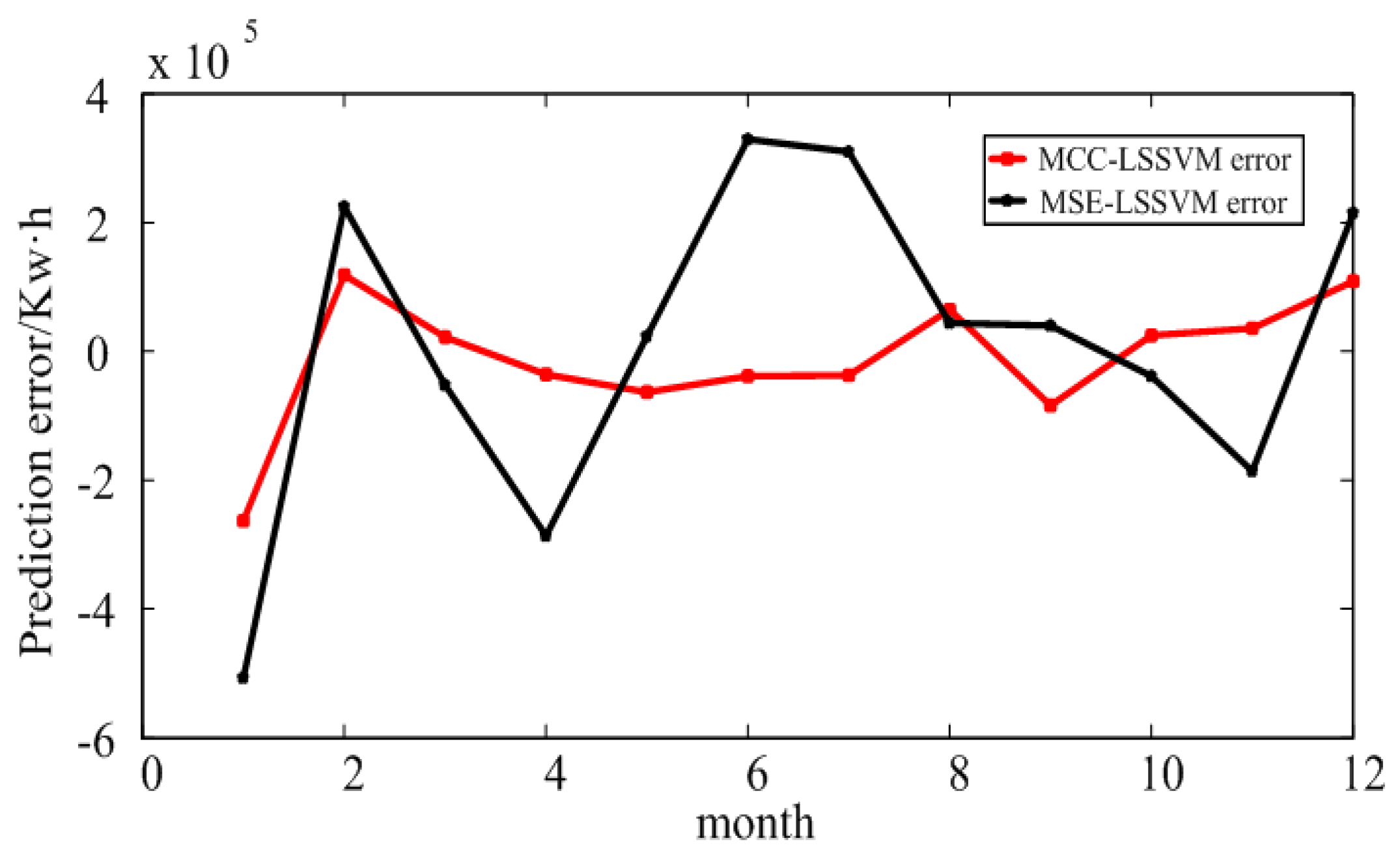
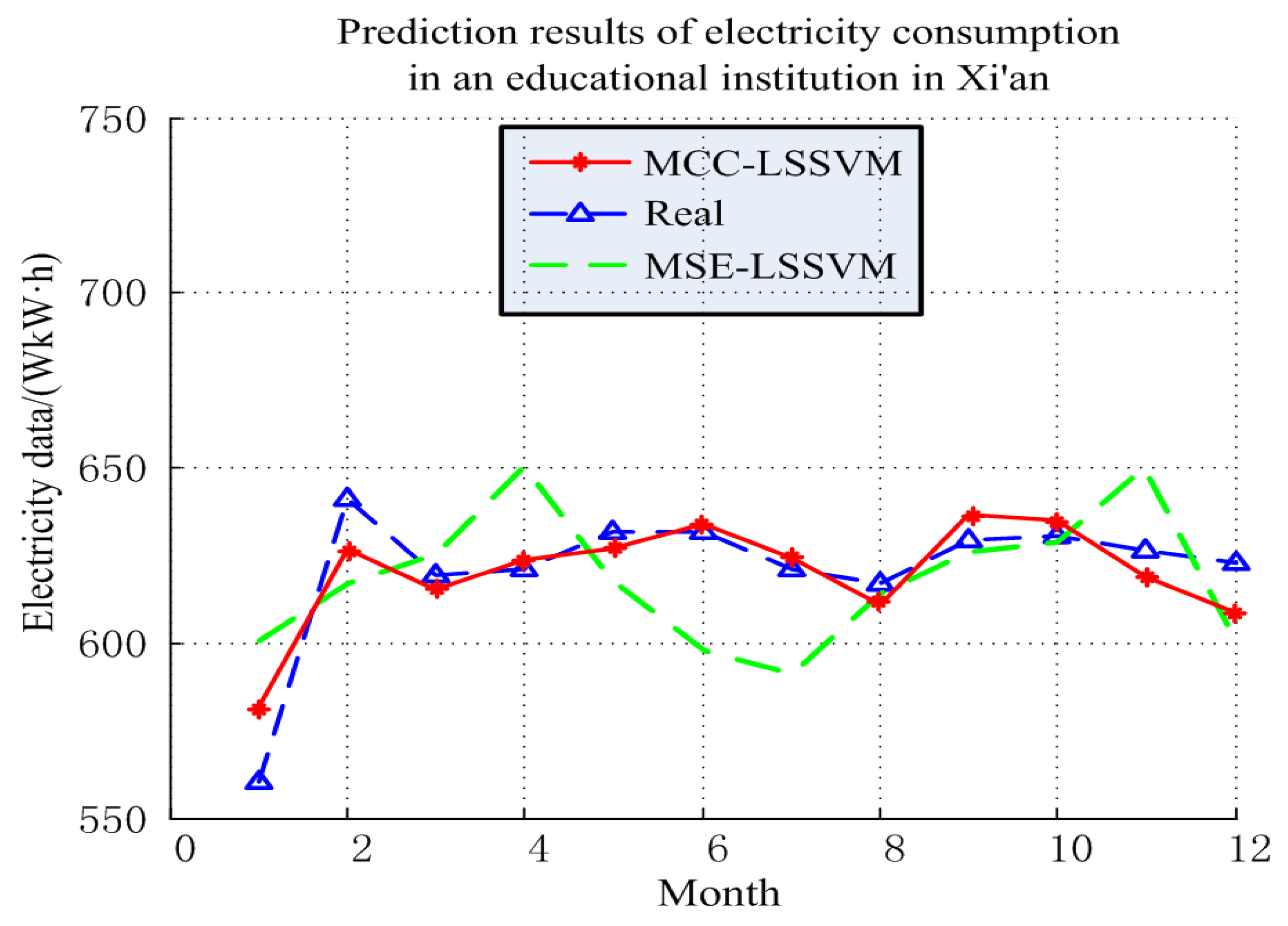
4.3. Prediction Results of Electricity Consumption in an Educational Institution in Xi’an
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Lu, B.; Zhao, S.; Tian, Y.; Yang, Y.; Li, B.; Chen, X.; Sun, L. Mid-long term electricity consumption forecasting based on improved NGM (1,1,k) gray model. power Syst. Prot. Control 2015, 43, 98–103. [Google Scholar]
- Xue, B.; Cheng, C.; Ou, S.; Liu, A.; Wang, S. A linear regression model for forecasting monthly electricity sales considering comfortable temperature range and sudden variable. power Syst. Prot. Control 2017, 45, 15–20. [Google Scholar]
- Cao, G.; Wu, L. Support vector regression with fruit fly optimization algorithm for seasonal electricity consumption forecasting. Energy 2016, 115, 734–745. [Google Scholar] [CrossRef]
- Chae, Y.T.; Horesh, R.; Hwang, Y.; Lee, Y.M. Artificial neural network model for forecasting sub-hourly electricity usage in commercial buildings. Energy Build. 2016, 111, 184–194. [Google Scholar] [CrossRef]
- Cabral, J.D.A.; Legey, L.F.L.; de Freitas Cabral, M. Electricity consumption forecasting in Brazil: A spatial econometrics approach. Energy 2017, 126, 124–131. [Google Scholar] [CrossRef]
- Gunay, M.E. Forecasting annual gross electricity demand by artificial neural networks using predicted values of socio-economic indicators and climatic conditions: Case of Turkey. Energy Policy 2016, 90, 92–101. [Google Scholar] [CrossRef]
- Amber, K.P.; Aslam, M.W.; Hussain, S.K. Electricity consumption forecasting models for administration buildings of the UK higher education sector. Energy Build. 2015, 90, 127–136. [Google Scholar] [CrossRef]
- Santamouris, M.; Cartalis, C.; Synnefa, A.; Kolokotsa, D. On the impact of urban heat island and global warming on the power demand and electricity consumption of buildings—A review. Energy Build. 2015, 98, 119–124. [Google Scholar] [CrossRef]
- Zhu, X.; Han, Z. Research on LS-SVM Wind Speed Prediction Method Based on PSO. Proc. CSEE 2016, 36, 6337–6342. [Google Scholar]
- Bessa, R.J.; Miranda, V.; Gama, J. Entropy and correntropy against minimum square error in offline and online three-day ahead wind power forecasting. IEEE Trans. Power Syst. 2009, 24, 1657–1666. [Google Scholar] [CrossRef]
- Chen, B.D.; Xing, L.; Zhao, H.; Zheng, N.; Principe, J.C. Generalized Correntropy for Robust Adaptive Filtering. IEEE Trans. Signal Proc. 2016, 64, 3376–3387. [Google Scholar] [CrossRef]
- Liu, W.F.; Pokharel, P.P.; Principe, J.C. Correntropy: Properties and applications in non-Gaussian signal processing. IEEE Trans. Signal Proc. 2007, 55, 5286–5298. [Google Scholar] [CrossRef]
- Chen, B.D.; Xing, L.; Liang, J.; Zheng, N.; Principe, J.C. Steady-State Mean-Square Error Analysis for Adaptive Filtering under the Maximum Correntropy Criterion. IEEE Signal Proc. Lett. 2014, 21, 880–884. [Google Scholar]
- Chen, B.D.; Principe, J.C. Maximum correntropy estimation is a smoothed MAP estimation. IEEE Signal Proc. Lett. 2012, 19, 491–494. [Google Scholar] [CrossRef]
- Chen, B.D.; Wang, J.; Zhao, H.; Zheng, N.; Príncipe, J.C. Convergence of a Fixed-Point Algorithm under Maximum Correntropy Criterion. IEEE Signal Proc. Lett. 2015, 22, 1723–1727. [Google Scholar] [CrossRef]
- Vapnik, V.N.; Chervonenkis, A.Y. On the uniform convergence of relative frequencies of events to their probabilities. In Measures of Complexity; Springer: Cham, Switzerland, 2015; pp. 11–30. [Google Scholar]
- Chen, X.; Yang, J.; Liang, J.; Ye, Q. Recursive robust least squares support vector regression based on maximum correntropy criterion. Neurocomputing 2012, 97, 63–73. [Google Scholar] [CrossRef]
- Nie, H.; Liu, G.; Liu, X.; Wang, Y. Hybrid of ARIMA and SVMs for Short-Term Load Forecasting. Energy Procedia 2012, 16, 1455–1460. [Google Scholar] [CrossRef]
- Sidorov, D. Integral dynamical models. Singularities, signals and control. World Sci. 2014, 87, 9–12. [Google Scholar]
- Chen, B.D.; Liang, J.; Zheng, N.; Principe, J.C. Kernel least mean square with adaptive kernel size. Neurocomputing 2016, 191, 95–106. [Google Scholar] [CrossRef]
- He, R.; Zheng, W.-S.; Hu, B.-G. Maximum Correntropy Criterion for Robust Face Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1561–1576. [Google Scholar] [PubMed]
- Ma, W.T.; Qua, H.; Gui, G.; Chen, B. Maximum correntropy criterion based sparse adaptive filtering algorithms for robust channel estimation under non-Gaussian environments. J. Frankl. Inst. 2015, 352, 2708–2727. [Google Scholar] [CrossRef]
- Chen, B.D.; Liu, X.; Zhao, H.; Principe, J.C. Maximum Correntropy Kalman Filter. Automatica 2017, 76, 70–77. [Google Scholar] [CrossRef]
- Izanloo, R.; Fakoorian, S.A.; Yazdi, H.S.; Simon, D. Kalman filtering based on the maximum correntropy criterion in the presence of non-Gaussian noise. Inf. Sci. Syst. 2016, 64, 500–505. [Google Scholar]
- Chen, B.D.; Xing, L.; Xu, B.; Zhao, H.; Zheng, N.; Príncipe, J.C. Kernel Risk-Sensitive Loss: Definition, Properties and Application to Robust Adaptive Filtering. IEEE Trans. Signal Proc. 2017, 65, 2888–2901. [Google Scholar] [CrossRef]
- Azadeh, A.; Ghaderi, S.F.; Sohrabkhani, S. Annual electricity consumption forecasting by neural network in high energy consuming industrial sectors. Energy Convers. Manag. 2008, 49, 2272–2278. [Google Scholar] [CrossRef]
- Zhang, Y.; Han, X.; Yang, Y.; Zhang, L.; Miao, X. A novel analysis and forecast method of electricity business expanding based on seasonal adjustment. In Proceedings of the 2016 IEEE PES Asia-Pacific Power and Energy Engineering Conference (APPEEC), Xi’an, China, 25–28 October 2016; pp. 707–711. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Month | Real/kWh | MCC–LSSVM/kWh | MSE–LSSVM/kWh |
|---|---|---|---|
| 1 | 3222141989 | 3289063235 | 3294523968 |
| 2 | 2807359588 | 2770660550 | 2753838956 |
| 3 | 2905625349 | 2835276855 | 2766953282 |
| 4 | 3258028408 | 3193065850 | 3193625474 |
| 5 | 3123940121 | 3140143741 | 3130143486 |
| 6 | 3146763568 | 3118571548 | 3113648647 |
| 7 | 3200783187 | 3204753934 | 3201236988 |
| 8 | 3330358001 | 3347137347 | 3297138647 |
| 9 | 3169671810 | 3146624356 | 3196624769 |
| 10 | 3094490648 | 3140563342 | 3134963398 |
| 11 | 3197240745 | 3233100710 | 3216824659 |
| 12 | 3253492846 | 3246565684 | 3227682398 |
| Evaluation Index | MRE (%) | /kWh | R |
|---|---|---|---|
| MCC–LSSVM | 0.9 | 73256684 | 0.9235 |
| MSE–LSSVM | 3.12 | 140348494 | 0.8952 |
| Month | Real/kWh | MCC–LSSVM/kWh | MSE–LSSVM/kWh |
|---|---|---|---|
| 1 | 2664166276 | 2661798254 | 2641798254 |
| 2 | 2275553927 | 2276537980 | 2246537980 |
| 3 | 2021181824 | 2066396013 | 2066396013 |
| 4 | 2025719576 | 1904917602 | 1928943561 |
| 5 | 1850231091 | 1792863625 | 1792863625 |
| 6 | 2011974726 | 1904917602 | 1872354896 |
| 7 | 2215976398 | 2276963182 | 2192662853 |
| 8 | 2664937423 | 2717665734 | 2596348624 |
| 9 | 2326022304 | 2350413608 | 2348629858 |
| 10 | 1906840712 | 1818905227 | 1956189345 |
| 11 | 2038734324 | 1940165576 | 1889654236 |
| 12 | 2350000000 | 2303946621 | 2329946654 |
| Evaluation Index | MRE (%) | /kWh | R |
|---|---|---|---|
| MCC–LSSVM | 2.77 | 120801974 | 0.9534 |
| MSE–LSSVM | 3.23 | 145653478 | 0.9316 |
| Month | Real/kWh | MCC–LSSVM/kWh | MSE–LSSVM/kWh |
|---|---|---|---|
| 1 | 5526468 | 5789523 | 6034028 |
| 2 | 6435286 | 6317452 | 6211205 |
| 3 | 6215832 | 6194268 | 6268253 |
| 4 | 6231532 | 6267145 | 6518210 |
| 5 | 6231102 | 6294423 | 6207253 |
| 6 | 6315468 | 6354652 | 5986242 |
| 7 | 6221536 | 6258553 | 5912131 |
| 8 | 6189358 | 6124125 | 6145128 |
| 9 | 6294825 | 6378632 | 6255368 |
| 10 | 6314653 | 6290058 | 6353895 |
| 11 | 6277436 | 6219389 | 6503896 |
| 12 | 6231862 | 6123568 | 6017658 |
| Evaluation Index | MRE (%) | /kWh | R |
|---|---|---|---|
| MCC–LSSVM | 3.98 | 2635648 | 0.9619 |
| MSE–LSSVM | 6.41 | 3296821 | 0.9106 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Duan, J.; Qiu, X.; Ma, W.; Tian, X.; Shang, D. Electricity Consumption Forecasting Scheme via Improved LSSVM with Maximum Correntropy Criterion. Entropy 2018, 20, 112. https://doi.org/10.3390/e20020112
Duan J, Qiu X, Ma W, Tian X, Shang D. Electricity Consumption Forecasting Scheme via Improved LSSVM with Maximum Correntropy Criterion. Entropy. 2018; 20(2):112. https://doi.org/10.3390/e20020112
Chicago/Turabian StyleDuan, Jiandong, Xinyu Qiu, Wentao Ma, Xuan Tian, and Di Shang. 2018. "Electricity Consumption Forecasting Scheme via Improved LSSVM with Maximum Correntropy Criterion" Entropy 20, no. 2: 112. https://doi.org/10.3390/e20020112
APA StyleDuan, J., Qiu, X., Ma, W., Tian, X., & Shang, D. (2018). Electricity Consumption Forecasting Scheme via Improved LSSVM with Maximum Correntropy Criterion. Entropy, 20(2), 112. https://doi.org/10.3390/e20020112