
An Approach to Data Analysis in 5G Networks




Abstract
:1. Introduction
2. Background
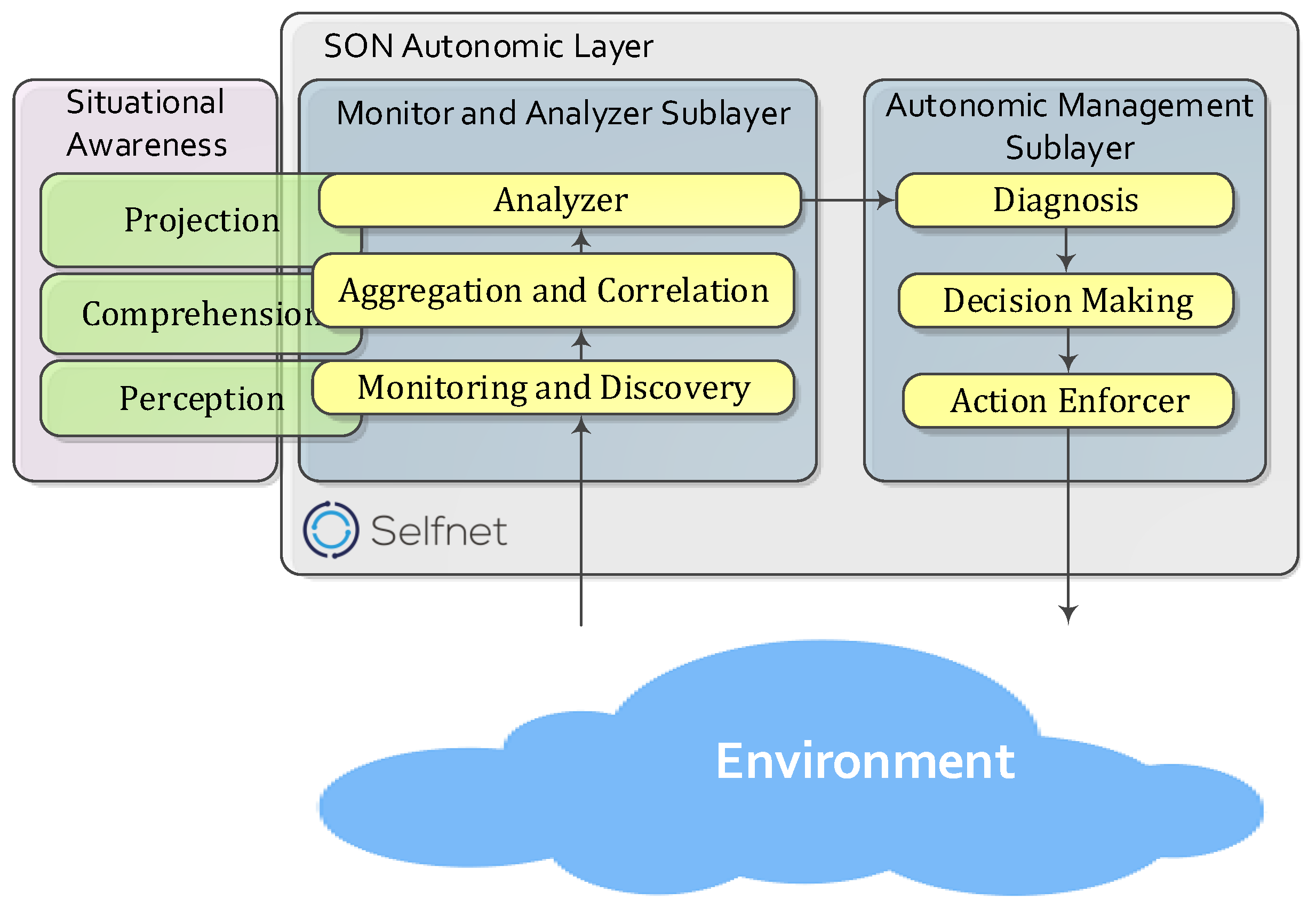
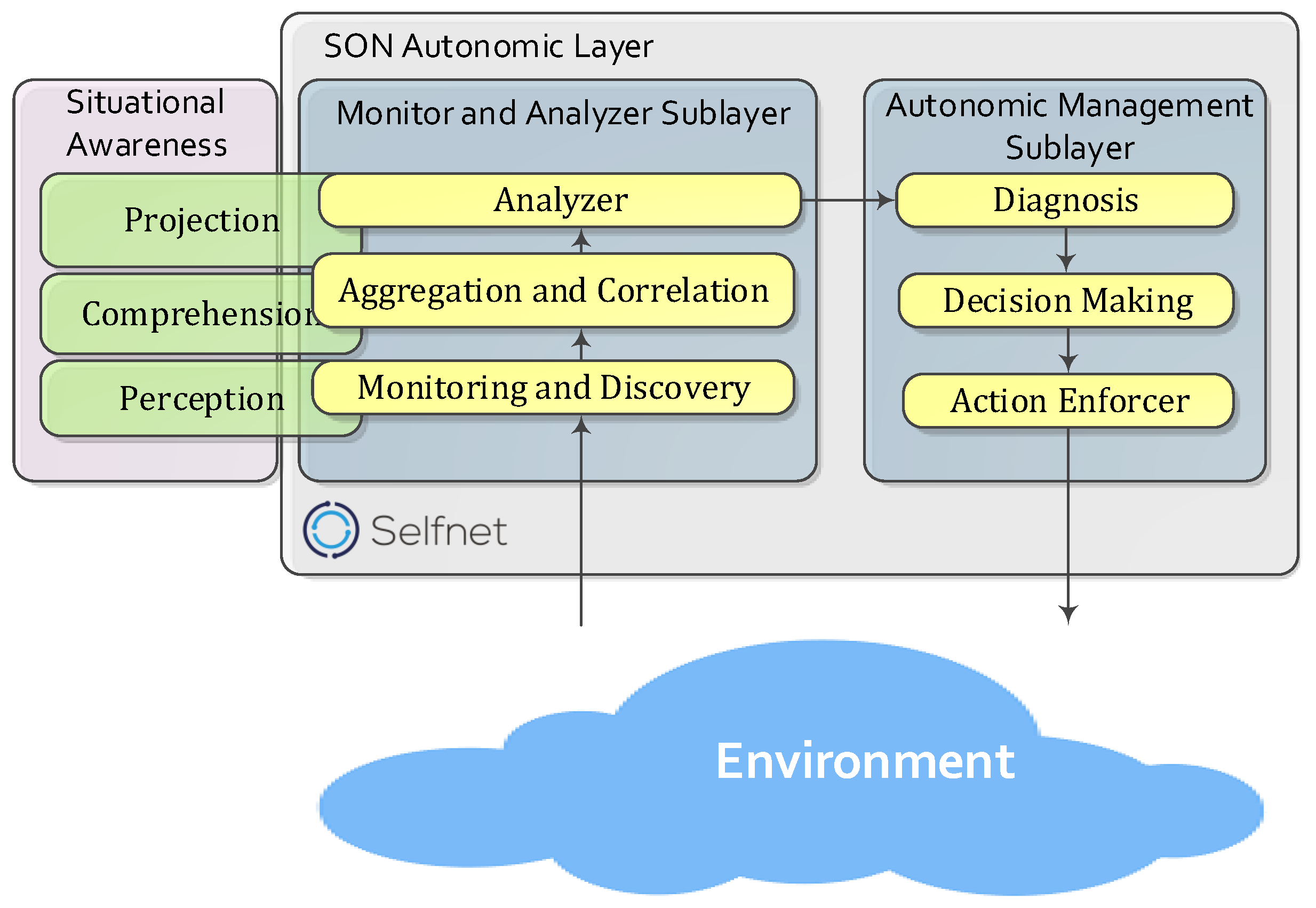
2.1. Diagnosis Capabilities in 5G Networks
2.2. SELFNET Project
3. SELFNET Analyzer Module Design
3.1. Initial Assumption and Requirements
- Scalability. The approach must be allowed to add new capabilities (extensibility), according to SELFNET design principles. For this reason, the integration of additional analytic functionalities are done via plugins.
- Use Case Driven. Given the heavy reliance of the tasks performed with the characteristics of use cases, the basic definition of the observations to be studied (Knowledge-based objects, rules, prediction metrics, etc.) are provided by the use case operator, thus being the Analyzer Module scalable to alternative contexts.
- Knowledge Acquisition. It is well known that the most common disadvantage of the expert systems is the initial knowledge acquisition problem. Hence, to have skilled operators in novel use cases with the ability to properly specify rules is not always straightforward. This document does not address the issue of the innate knowledge acquisition. Our approach assumes that the use case knowledge-bases are provided by skilled operators or by accurate machine learning algorithms.
- User-Friendly Symptom Definition Rules. The definition of proper rule-sets is a tricky business. Thus, even the skilled operators often do coherence/ambiguity mistakes. In order to mitigate these problems, the configuration and definition of new use cases should be user-friendly, as well as the scheme for building new rule-sets.
- Uncertainly. Classical logic permits only exact reasoning. It assumes that perfect knowledge always exists, but this remains far from the SELFNET reality. In order to improve the quality of the conclusions, the Analyzer Module manages the knowledge bearing in mind uncertainty. This is particularly appropriate for certain analytic features, such as studying observations based on decision thresholds or confidence intervals. In addition, closing the door on possible stochastic dependent definitions is against the SELFNET design principles, as these could be the keys to properly specify future use cases.
- Filtering. Initially, the filtering of symptom reports is not considered. Because of this, every inferred symptom, regardless of nature or uncertainty, is transmitted to the diagnosis/decision-making stages, where their impact and relevance are properly assessed.
3.2. Design Principles
- Big Data. In order to deal with huge and homogeneous datasets, Big Data provides predictive algorithms, user behaviour analytics, and aggregation/correlation functionalities [39]. These capabilities are mainly taken into account in monitoring and aggregation tasks. The Analyzer Module deals with aggregated and correlated metrics, hence reducing the amount of information to be analysed. In our approach, the implementation of Big Data technologies to handle all this information is optional, leaving the decision of integrate these tools at the mercy of the SELFNET administrators, which driven by a better awareness of the use cases and the monitoring environment are more able to decide whether they are counterproductive or beneficial [40]. Because of this, our contribution is compatible with both Big Data and conventional techniques.
- Stationary Monitoring Environment. According to Holte et al. [41], in a stationary monitoring environment, the characteristics and distribution of the normal observations to be analysed match the reference sample population considered in the Analyzer learning processes. If the monitoring environment distribution is able to change representatively, it is considered non-stationary. Another problem that may reduce the quality of the analytics is the presence of gradual changes over time in the statistical characteristics of the class to which an observation belongs. In the literature this fluctuation is known as concept-drift. These problems are discussed at length in [42]. The assumption that the Analyzer Module operates on a stationary environment brings a simple and efficient solution, but prone to slight failures when the changes occur. On the other hand, to consider a non-stationary monitoring environment improves accuracy, but entails new challenges, among them: detection of changes, implementation of model/regression updating techniques, identifying when the calibration must be completed or selection of the samples that will be taken into account in new trainings. Given the complexity that this implies, the Analyzer Module assumes a stationary monitoring environment. The non-stationary approach will be part of future work.
- High Dimensional Data. The analysis of high dimensional data implies to bear in mind data whose dimension is larger than dimensions considered in classical multivariate analysis. As indicated by Bouveyron et al. [43], when conventional methods deal with high dimensional data they are susceptible to suffer the well-known curse of dimensionality, where considering a large number of irrelevant, redundant and noisy attributes leads to important prediction errors. Hence operate with this data implies the need for more specific and complex algorithms. In terms of SELFNET this means that the vector of Health of Network Metrics (HoN) is large enough to consider the implementation of specific methods adapted to optimize the processing tasks of this kind of information. A priori there are no signs of SELFNET requiring processing an important amount of High Dimensional Data. Therefore, this paper does not take into account differences between conventional and High Dimensional data, assuming that the aggregation tasks will be able to optimize the amount of attributes to be analysed.
- Supervision. SELFNET training mode. The analytical methods based on modeling/regression assume that new knowledge can be inferred from observations, by a prior learning stage. The learning process often requires reference data which allows identifying the most characteristic features of the monitoring environment, such as rules, boundaries, incidence matrices, direction vectors or basic statistics. Given the complexity involved in designing a SELFNET training mode, this approach describes how the information needed for the construction of new models is obtained.
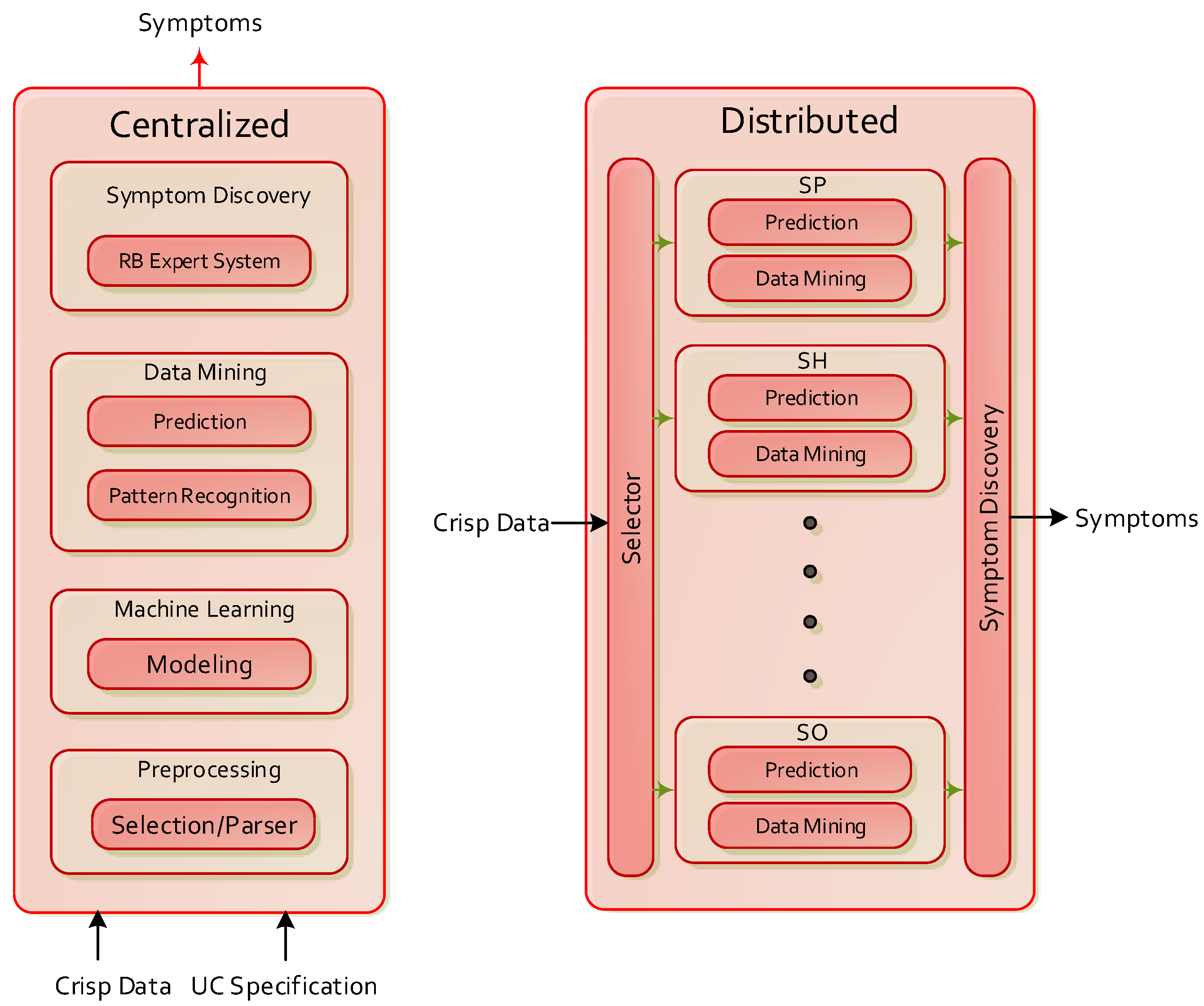
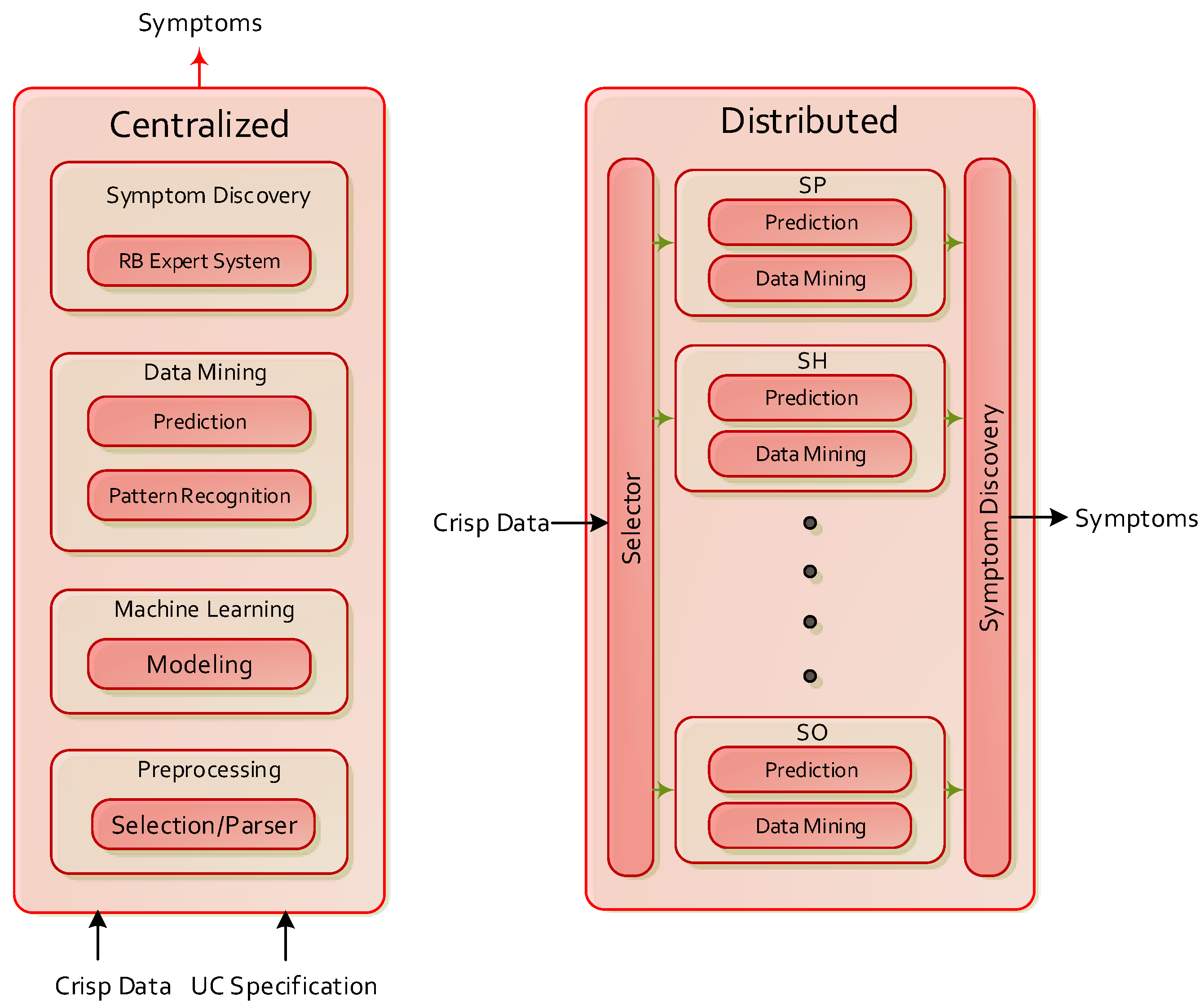
- Centralized Design. To assume a centralized approach lead us to pose a general purpose scheme where the onboarding of new use cases is completely configurable by specification, and which does not requires updating the implementation (see Figure 2). Therefore the centralized approach is not dependent on the characteristics of the use case, so it is highly scalable and allows performing tasks efficiently (avoiding redundancy). However, its design and the description of use cases is complex. On the other hand, the distributed approach includes an additional component for each use case in which specific pattern recognition and prediction methods are implemented via plugin. The preprocessing, selection and symptom discovery mechanisms have general purpose. In essence, this second approach is easy of design, but completely use case dependent; each time a new use case is onboarded, the Analyzer implementation must be updated. Due to the large impact on the scalability that this entails, the centralized approach is considered hereinafter.
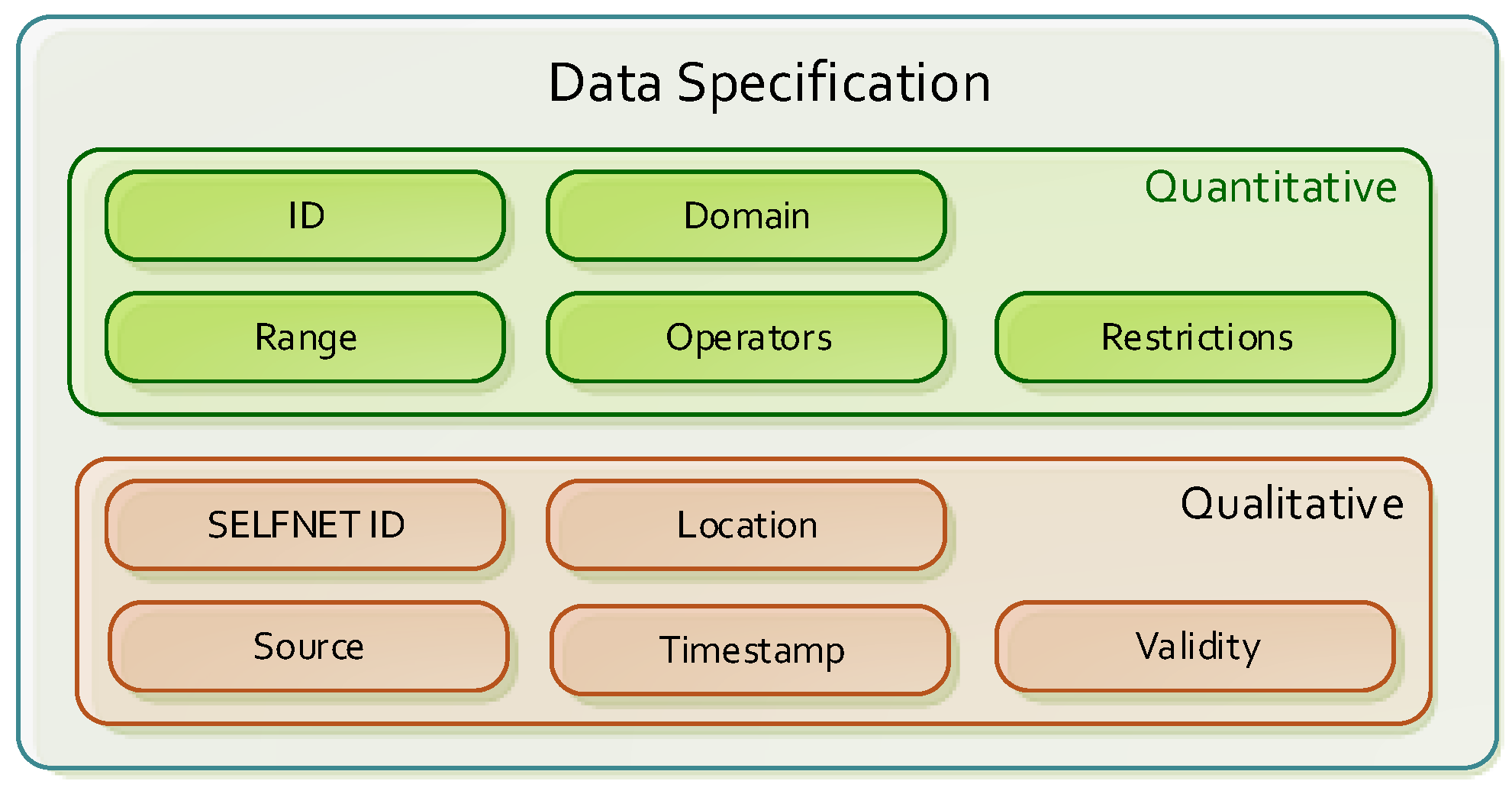
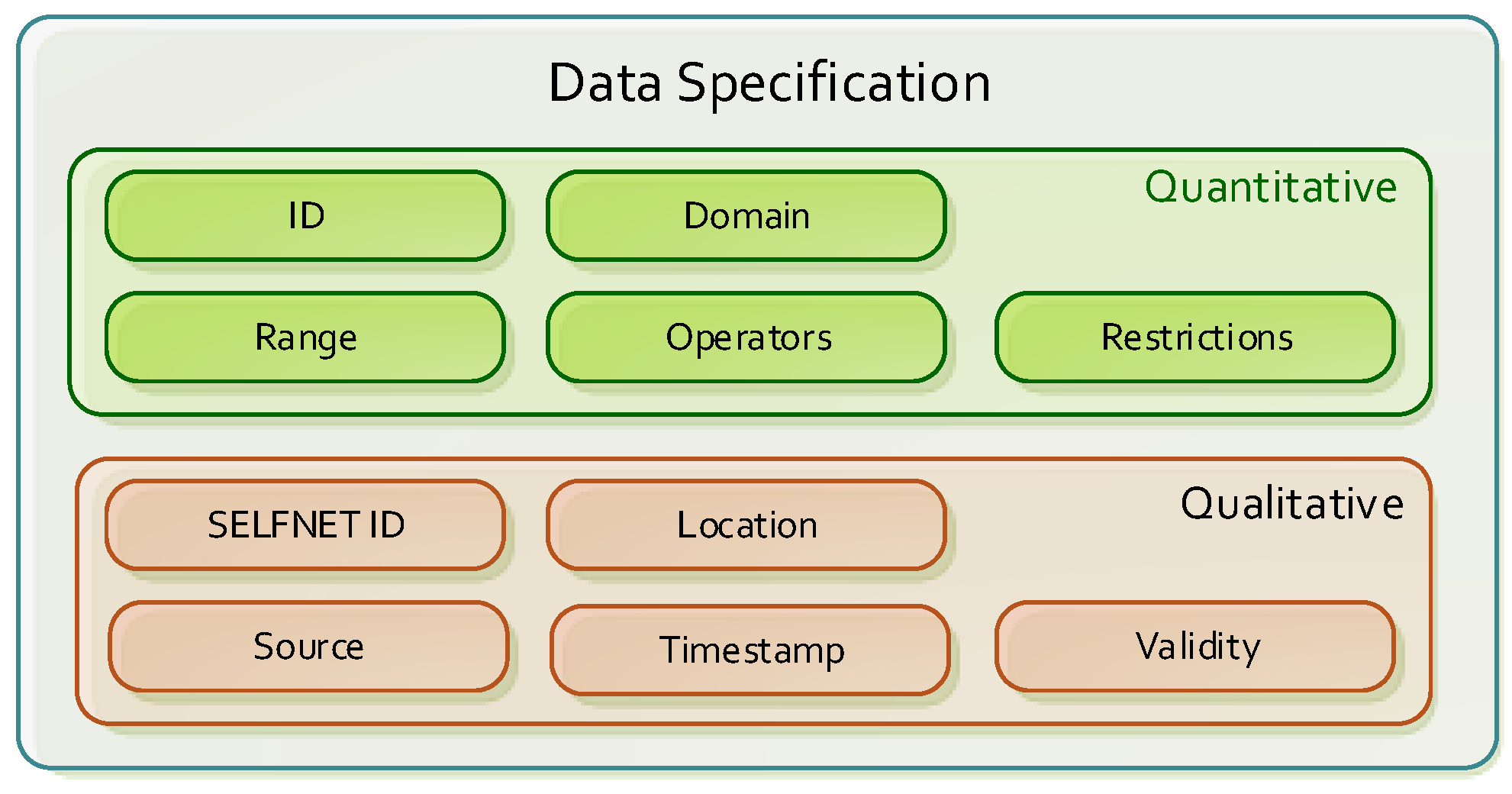
- Data Encapsulation. The greatest challenge in designing the SELFNET Analyzer approach is the requirement of dealing with unknown data. It is possible to assume that use cases do not provide clear enough information about the characteristics of the information to be analyzed (in fact, several future use cases are completely unknown). At the specification stage, use cases operators tend to provide good qualitative information about the metrics to consider, but may overlook details about their quantitative nature: data type, domain, range, restrictions, etc., which is what in the first instance, will be considered in the analysis tasks. Furthermore, quantitative information is much use case dependent. In order to subtract relevance to quantitative details (which are the backbone of the aggregation/correlation tasks), and thus facilitate the incorporation of new use cases by definition of general purpose descriptors, the SELFNET Analyzer is driven by data encapsulated in two levels of abstraction: quantitative and qualitative parameters (see Figure 3). The first one is independent of the use cases, and allows designing a centralized analysis framework valid for any type of data specification. On the other hand the qualitative parameters gather information directly related with SELFNET and the use case to which they belong (metric name, source, location, tenant, etc.). This data is mainly required for aggregation/correlation, diagnosis and decision making.
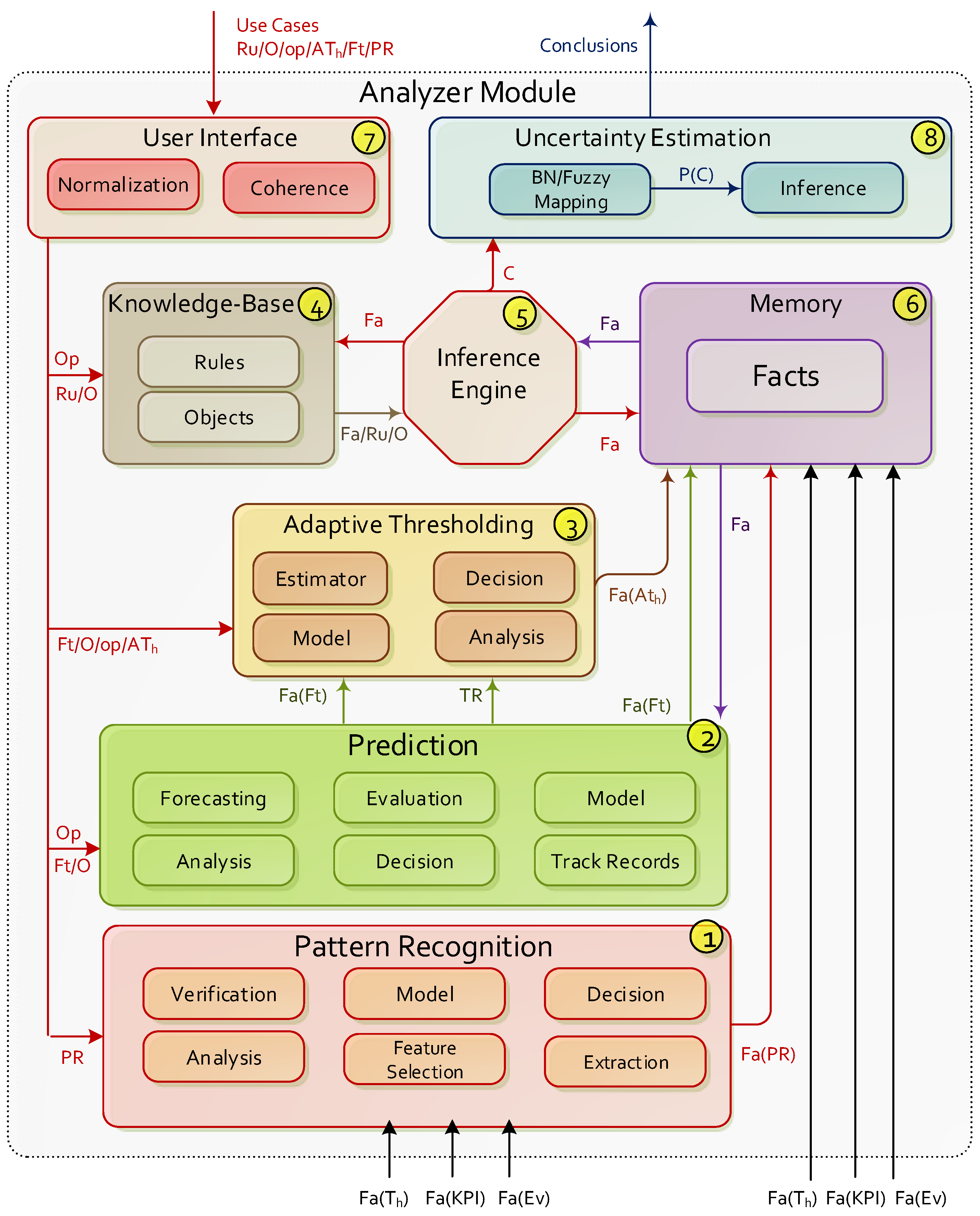
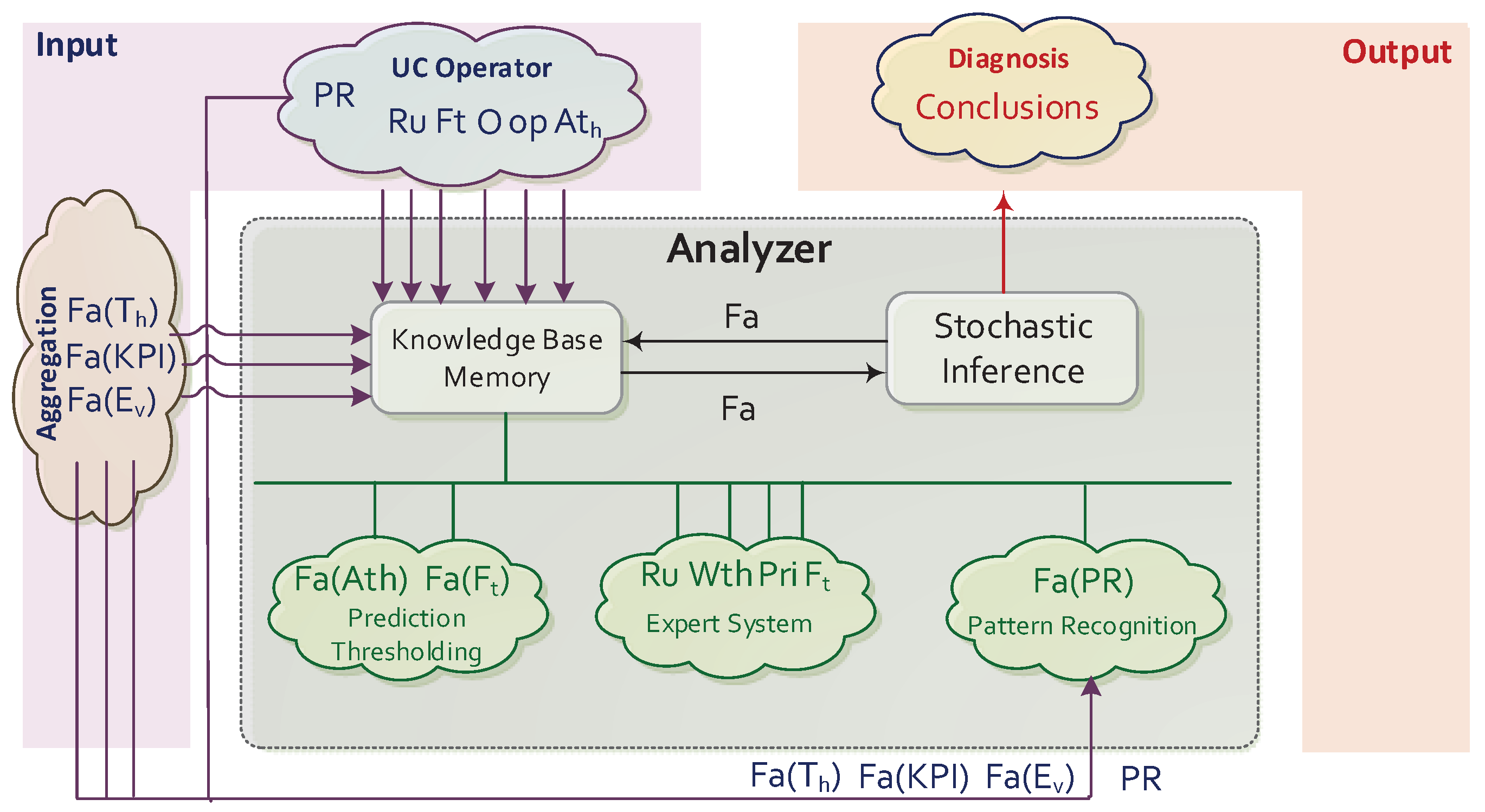
3.3. Analyzer Module Architecture
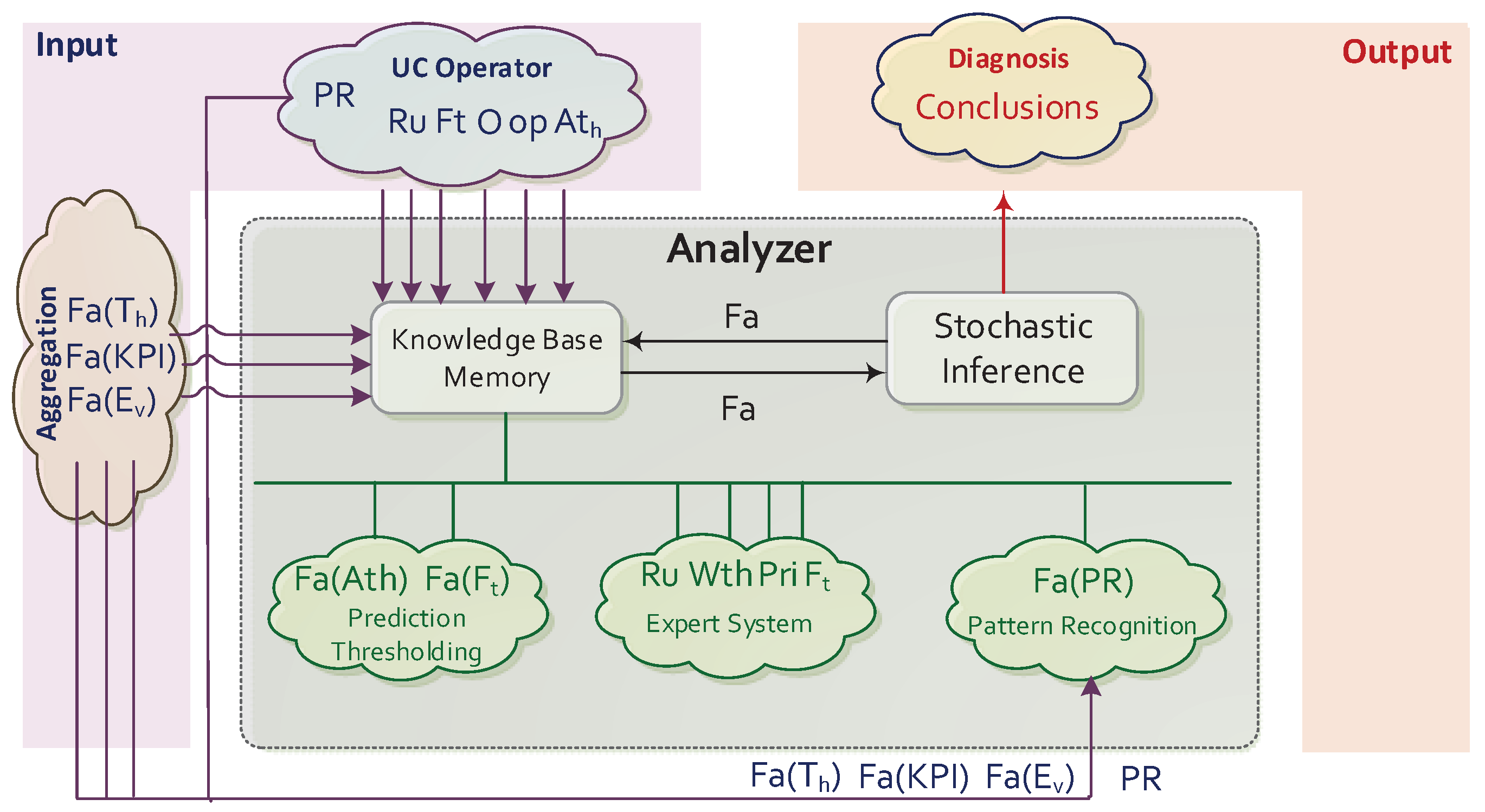
- Pattern Recognition: identifies previously known or acquired patterns and regularities in facts related with aggregate data (i.e., ), and returns Facts with the results of their study. With this purpose, different internal tasks may be executed: study of the input data (both training data and samples to be analysed), decision of the best suited data mining strategies for each context, feature extraction, construction of models/regressions, analysis of facts related with aggregate data in order to find and labeling verification. Note that the bibliography collects a plethora of pattern recognition methods, which are adapted to the needs of the use cases and to the characteristics of the different monitoring environments [44]. The SELFNET Analyzer focuses on two fundamental actions: the identification of signatures of previously known events [45] and the detection of anomalies [46].
- Prediction Component: calculates the prediction metrics (as Facts ) associated to each use case from the observations provided by the aggregation stage (Thresholds , Key Performance Indicators and Events ). This implies different processing steps: management of a track record with the data required to build forecasting models, analysis of the data characteristics which are relevant for deciding the best suited prediction algorithms, construction of forecasting models, decision of prediction algorithms, forecasting and evaluation of the results in order to learn from the previous decisions. Note that as stated in [47], the prediction of network events enhances the optimization of resources, allows the deployment of proactive actions and anticipates risk identification. The SELFNET Analyzer focuses primarily on infer predictions from two data structures: time series and graphs. The first one aims to determine the evolution of the HoN metrics, hence it mainly implements exponential smoothing algorithms [48] and autoregressive models [49]. On the other hand, the evolution of graphs is predicted in order to anticipate the discovery of new elements [50] and facilitate the management of resources [51].
- Adaptive Thresholding: establishes measures to approximate when the forecast errors must be taken into account when identifying symptoms. Therefore it receives as input parameters the values related with the prediction metrics (Track Record and Forecasts ), and returns adaptive thresholds . Their construction involves different steps, such as analyzing and extracting the main features from the input data, decision of the best suited thresholding algorithms, modeling and estimation of thresholds. The SELFNET Analyzer build adaptive thresholds from data represented as time series or graph, which allows inferring more accurate conclusions from every forecast generated by the prediction component. The main applicability of the adaptive thresholds is considering the context of the monitoring environment in the inference of new facts related with filtering [52], and decreasing the false positives rates [53].
- Knowledge-Base: stores specific information about each use case. This data is represented by objects and rules. The objects O are the basic units of information (ex. temperature, congestion, latency, etc.). The rules Ru are the guidelines for reasoning that enable the inference of facts and conclusions. Facts, objects, and their values are interrelated through operations Op. A priori, in this approach online machine learning is not considered in order to acquire knowledge about the use cases in real-time [54], such as definition of new rules, prioritization, metric weighting, etc. (i.e., all information to be considered part of the original training and the specification of the use cases and their symptoms provided by operators).
- Inference Engine: applies rules Ru to the knowledge base in order to deduce new knowledge. This process would iterate as each new fact Fa in the knowledge base could trigger additional rules. Traditionally, inference engines operate in one of two modes: forward chaining and backward chaining [55]. The first initially considers previously known facts and infers new facts. On the other hand, backward chaining initially considers facts and tries to infer the causes that have led to them. Because the SELFNET Analyzer infers conclusions from discovered facts, the first approach is implemented. In addition, it is important to bear in mind that the easier implementation of the inference engine considers basic implication elimination rules (i.e., modus ponens rules) driven by propositional logic [56]. They can be adapted to different representations of uncertainty, such as fuzzy logic [57], rough sets [58] or Bayesian networks [26]. But in order to facilitate the understanding of this proposal, the current specification of rules on the SELFNET Analyzer applies only basic propositional logic rules (as described in Section 5), hence postponing for future works a most complex but generic definition.
- Memory: stores all the known facts Fa concerning with the use cases (ex. Temperature , Latency >200 ms, etc.) considering those predicted/inferred and those provided by the SELFNET Monitoring/Aggregation stages . Metadata related with qualitative additional information about the nature of the discovered facts is also stored.
- User Interface: configures Patter Recognition PR for each use case and allows updating the knowledge-base by inserting, modifying or deleting data associated with every use case, such as objects O, rules Ru operations Op or prediction metrics Ft. The information is preprocessed aiming to ensure compatibility and coherence [59]. The latter is particularly important, as it tries to avoid contradictions and ambiguity between rules, prior to their incorporation into the SELFNET intelligence.
- Uncertainly Estimation: complements the inference engine and facilitates the study of the conclusions bearing in mind their uncertainty. Its outputs are the acquired conclusions as potential symptoms of relevant incidences, their uncertainty and the information associated with their inference (facts, triggering rules, etc.). This is the only optional element of the architecture, since its use is only required when the SELFNET Diagnostic task [60] need to disambiguate conclusions, filter those of greater uncertainty or convert the logic on the Analyzer to data specified for upper layers of SELFNET. For example, when the inference engine operates on fuzzy logic rules, the element of Uncertainly Estimation generates a quantifiable result use-friendly for Diagnosis as crisp logic, given fuzzy sets and the corresponding membership degrees (i.e., defuzzification) [61].
4. Analyzer Inputs/Outputs
- Aggregation. Observations in SELFNET come to the Analyzer through the Aggregation Layer (Perception capabilities within the Endsley’s model). The information provided by this source contains facts concerning Events , Thresholds and Key Performance Indicators related to the current network status.
- Use Case Operators. The knowledge-base is specified from data acquired from the use case definitions. Because of this, use case operator may provide inference rules Ru (1), and declare the objects O (2), operations Op (3) and prediction metrics Ft (4) to be taken into account (i.e., what observations should be taken into account (2), how (3)what data must be forecasted (4) and how are they considered in order to acquire knowledge about the specific use case (1)). Optionally, the use case operator may describe the adaptive thresholds to be calculated, and if pattern recognition PR is required, then configuring how it must be addressed.
- Analyzer. An important part of the information necessary for proper Reasoning is generated by the Analyzer Module itself. It is gathered into a pair of groups: Perception and Machine Learning. The first block is imperative, and establishes facts Fa from pattern recognition , forecasts and adaptive thresholds . On the other hand, machine learning may provide additional data to that provided by use case operators (definition of new rules Ru and description of prediction metrics Ft). Furthermore, it could generate information to improve the knowledge management (weight, prioritizations, fusion, smoothing, etc.).
- Diagnosis. the final conclusions and symptoms that compose the SELFNET Situational Awareness are sent to Intelligent Diagnostic Module (Autonomic Management Sublayer) [60], via reports Re.
5. Use Case Descriptors
5.1. Object O
5.2. Operations
5.3. Facts
5.4. Rules
5.5. Forecast
5.6. Thresholds
5.7. Adaptive Thresholds
5.8. Pattern Recognition
5.9. Datasets D
5.10. Conclusions C
6. Examples of Specification and Workflows
6.1. UC 1: Device Temperature Analysis
6.1.1. Description
6.1.2. Initial Status
6.1.3. Use Case Specification
6.1.4. Workflow
6.2. UC 2: Network Congestion Analysis
6.2.1. Description
6.2.2. Initial Status
6.2.3. Use Case Specification
6.2.4. Workflow
6.3. UC 3: Payload Analysis
6.3.1. Description
6.3.2. Initial Status
6.3.3. Use Case Specification
6.3.4. Workflow
7. Discussion
8. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- NGMN Alliance. NMGN 5G White Paper 2015. Available online: https://www.ngmn.org/uploads/media/NGMN_5G_White_Paper_V1_0.pdf (accessed on 9 January 2017).
- Agyapong, P.K.; Iwamura, M.; Staehle, D.; Kiess, W.; Benjebbour, A. Design Considerations for a 5G Network Architecture. IEEE Commun. Mag. 2014, 52, 65–75. [Google Scholar] [CrossRef]
- Kreutz, D.; Ramos, F.M.V.; Verissimo, P.E.; Rothenberg, C.E.; Azodolmolky, S.; Uhlig, S. Software-defined Networking: A Comprehensive Survey. Proc. IEEE 2015, 103, 14–76. [Google Scholar] [CrossRef]
- Hu, F.; Hao, Q.; Bao, K. A Survey on Software-Defined Network and OpenFlow: From Concept to Implementation. IEEE Commun. Surv. Tutor. 2014, 16, 1–27. [Google Scholar] [CrossRef]
- ETSI Industry Specification Group (ISG). Network Function Virtualization (NFV) Architectural Framework. Available online: http://www.etsi.org/technologies-clusters/technologies/nfv (accessed on 9 January 2017).
- Mijumbi, R.; Serrat, J.; Gorricho, J.L.; Bouten, N.; Turck, F.; Boutaba, R. Network Function Virtualization: State-of-the-art and Research Challenges. IEEE Commun. Surv. Tutor. 2015, 18, 236–262. [Google Scholar] [CrossRef]
- Zhang, Q.; Cheng, L.; Boutaba, R. Cloud Computing: State-of-the-art and Research Challenges. J. Int. Serv. Appl. 2010, 1, 7–18. [Google Scholar] [CrossRef]
- Baldo, N.; Giupponi, L.; Mangues-Bafalluy, J. Big Data Empowered Self Organized Networks. In Proceedings of the 20th European Wireless Conference, Barcelona, Spain, 14–16 May 2014.
- Aliu, O.G.; Imran, A.; Imran, M.A.; and Evans, B. A Survey of Self Organisation in Future Cellular Networks. IEEE Commun. Surv. Tutor. 2013, 15, 336–361. [Google Scholar] [CrossRef]
- Imran, A.; Zoha, A.; Abu-Dayya, A. Challenges in 5G: How to Empower SON with Big Data for enabling 5G. IEEE Netw. 2014, 28, 27–33. [Google Scholar] [CrossRef]
- Quick, D.; Choo, K.K.R. Digital forensic Intelligence: Data Subsets and Open Source Intelligence (DFINT + OSINT): A timely and Cohesive Mix. Future Gener. Comput. Syst. 2016. [Google Scholar] [CrossRef]
- Quick, D.; Choo, K.K.R. Big Forensic Data Management in Heterogeneous Distributed Systems: Quick Analysis of Multimedia Forensic Data. Software: Practice and Experience. J. Netw. Comput. Appl. 2016. [Google Scholar] [CrossRef]
- Demestichas, P.; Georgakopoulos, A.; Karvounas, D.; Tsagkaris, K.; Stavroulaki, V. 5G on the horizon: Key Challenges for the Radio-Access Network. IEEE Veh. Technol. Mag. 2013, 8, 47–53. [Google Scholar] [CrossRef]
- Boccardi, F.; Heath, R.W.; Lozano, A.; Marzetta, T.L.; Popovski, P. Five Disruptive Technology directions for 5G. IEEE Commun. Mag. 2014, 52, 74–80. [Google Scholar] [CrossRef]
- Akyildiz, I.F.; Lin, S.C.; Wang, P. Wireless Software-Defined Networks (W-SDNs) and Network Function Virtualization (NFV) for 5G Cellular Systems: An Overview and Qualitative Evaluation. Comput. Netw. 2015, 93, 66–79. [Google Scholar] [CrossRef]
- Abdelwahab, S.; Hamdaoui, B.; Guizani, M.; Znati, T. Network Function Virtualization in 5G. IEEE Commun. Mag. 2016, 54, 84–91. [Google Scholar] [CrossRef]
- Lin, X.; Choo, K.K.R.; Lin, Y.D.; Mueller, P. Guest Editorial: Network Forensics and Surveillance for Emerging Networks. IEEE Netw. 2016, 30, 4–5. [Google Scholar] [CrossRef]
- 5G Infrastructure Public Private Partnership—5G PPP. Available online: https://5g-ppp.eu (accessed on 16 December 2016).
- 5G Americas, 2016. Available online: http://www.5gamericas.org/es/ (accessed on 16 December 2016).
- Barona López, L.I.; Valdivieso Caraguay, Á.L.; Maestre Vidal, J.; Sotelo Monge, M.A.; García Villalba, L.J. Towards Incidence Management in 5G based on Situational Awareness. Future Internet 2017, 9, 1–15. [Google Scholar] [CrossRef]
- 5G Ensure. Deliverable D 2.3, Risk Assessment, Mitigation and Requirements (Draft). Available online: http://www.5gensure.eu/deliverables (accessed on 19 December 2016).
- SELFNET Project. Framework for Self-Organized Network Management in Virtualized and Software Defined Networks. Available online: https://selfnet-5g.eu/ (accessed on 15 February 2017).
- Tahaei, H.; Salleh, R.; Khan, S.; Izard, R.; Choo, K.K.R.; Anuar, N.B. A multi-objective Software Defined Network Traffic Measurement. Measurement 2016, 95, 317–327. [Google Scholar] [CrossRef]
- Agiwal, M.; Roy, A.; Saxena, N. Next Generation 5G Wireless Networks: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2016, 18, 1617–1655. [Google Scholar] [CrossRef]
- Liu, D.; Wang, L.; Chen, Y.; Elkashlan, M.; Wong, K.K.; Schober, R. User association in 5G networks: A survey and an outlook. IEEE Commun. Surv. Tutor. 2016, 18, 1018–1044. [Google Scholar] [CrossRef]
- Fenton, N.; Neil, M. Making decisions: Using Bayesian Nets and MCDA. Knowl. Syst. 2001, 14, 307–325. [Google Scholar] [CrossRef]
- Marquezan, C.C.; Mahmood, K.; Zafeiropoulos, A.; Krishna, R.; Huang, X.; An, X.; Corujo, D. Context Awareness in Next Generation of Mobile Core Networks. Available online: https://arxiv.org/ftp/arxiv/papers/1611/1611.05353.pdf (accessed on 9 January 2017).
- Tullberg, H.; Popovski, P.; Li, Z.; Uusitalo, M.A. The METIS 5G System Concept–Meeting the 5G Requirements. IEEE Commun. Mag. 2016, 54, 132–139. [Google Scholar] [CrossRef]
- CONTENT Project. Convergence of Wireless Optical Network and iT rEsources iN SupporT of Cloud Services. FP7-ICT. Project Reference: 318514, Funded under: FP7-ICT. Available online: http://cordis.europa.eu/fp7/ict/future-networks/documents/call8-projects/content-factsheet.pdf (accessed on 9 January 2017).
- Kuruvatti, N.P.; Schotten, H.D. Framework to Support Mobility Context Awareness in Cellular Networks. In Proceedings of the IEEE 83rd Vehicular Technology Conference (VTC Spring), Nanjing, China, 15–18 May 2016.
- Apajalahti, K.; Eero, H.; Juha, N.; Vilho, R. StaRe: Statistical Reasoning Tool for 5G Network Management. In Proceedings of the 2016 Semantic Web-ESWC, Heraklion, Greece, 29 May–2 June 2016.
- Martin, B.A.; Marinos, L.; Rekleitis, E.; Spanoudakis, G.; Petroulakis, N.E. Threat Landscape and Good Practice Guide for Software Defined Networks/5G. Available online: http://openaccess.city.ac.uk/15504/7/SDN%20Threat%20Landscape.pdf (accessed on 9 January 2017).
- You, I.; Sharma, V.; Atiquzzaman, M.; Choo, K.K.R. GDTN: Genome-Based Delay Tolerant Network Formation in Heterogeneous 5G Using Inter-UA Collaboration. PLoS ONE 2016, 11, 1–37. [Google Scholar] [CrossRef] [PubMed]
- Neves, P.; Calé, R.; Costa, M.R.; Parada, C.; Parreira, B.; Alcaraz-Calero, J.; Wang, Q.; Nightingale, J.; Chirivella-Perez, E.; Jiang, W.; et al. The SELFNET Approach for Autonomic Management in an NFV/SDN Networking Paradigm. Int. J. Distrib. Sens. Net. 2016, 2016, 1–17. [Google Scholar] [CrossRef]
- 5G-NORMA Project. 5G NOvel Radio Multiservice Adaptive Network Architecture. Project Reference: 671584. Funded under: H2020-ICT-2014-2. Available online: https://5gnorma.5g-ppp.eu/ (accessed on 9 January 2017).
- CHARISMA Project. Converged Heterogeneous Advanced 5G Cloud-RAN Architecture for Intelligent and Secure Media Access. Project Reference: 671704. Funded under: H2020-ICT-2014-2. Available online: http://www.charisma5g.eu// (accessed on 9 January 2017).
- Xu, L.; Assem, H.; Yahia, I.G.B.; Buda, T.S. CogNet: A Network Management Architecture Featuring Cognitive Capabilities. In Proceedings of the 2016 European Conference on Networks and Communications (EuCNC), Athens, Greece, 27–30 June 2016.
- Endsley, N.R. Design and Evaluation for Situation Awareness Enhancement. In Proceedings of the 32nd Annual Meeting on Human Factors and Ergonomics Society, Anaheim, CA, USA, 24–28 October 1988; Volume 32, pp. 97–101.
- Sivarajah, U.; Kamal, M.M.; Irani, Z.; Weerakkody, V. Critical analysis of Big Data Challenges and Analytical Methods. J. Bus. Res. 2017, 70, 263–286. [Google Scholar] [CrossRef]
- Heijungs, R.; Henriksson, P.J.; Guinée, J.B. Measures of Difference and Significance in the Era of Computer Simulations, Meta-Analysis, and Big Data. Entropy 2016, 18, 361. [Google Scholar] [CrossRef]
- Holte, R.C. Very Simple Classification Rules Perform well on most commonly used Datasets. Mach. Learn. 1993, 11, 63–90. [Google Scholar] [CrossRef]
- Ditzler, G.; Roveri, M.; Alippi, C.; Polikar, R. Learning in Nonstationary Environments: A Survey. IEEE Comput. Intell. Mag. 2015, 10, 12–25. [Google Scholar] [CrossRef]
- Bouveyron, C.; Brunet-Saumard, C. Model-based Clustering of high-dimensional Data: A Review. Comput. Stat. Data Anal. 2014, 71, 52–78. [Google Scholar] [CrossRef]
- De Sanctis, M.; Bisio, I.; Araniti, G. Data Mining Algorithms for Communication Networks Control: Concepts, Survey and Guidelines. IEEE Netw. 2016, 30, 24–29. [Google Scholar] [CrossRef]
- Meng, W.; Li, W.; Kwok, L.F. EFM: Enhancing the Performance of signature-based Network Intrusion Detection Systems using enhanced Filter Mechanism. Comput. Secur. 2014, 43, 189–204. [Google Scholar] [CrossRef]
- Aggarwal, C.C. Outlier Analysis. Available online: http://www.charuaggarwal.net/outlierbook.pdf (accessed on 15 January 2017).
- Katris, C.; Daskalaki, S. Comparing Forecasting Approaches for Internet Traffic. Expert Systems with Applications. Expert Syst. Appl. 2015, 42, 8172–8183. [Google Scholar] [CrossRef]
- Gardner, E.S.; Dannenbring, D.G. Forecasting with Exponential Smoothing: Some Guidelines for Model Selection. Decis. Sci. 1980, 11, 370–383. [Google Scholar] [CrossRef]
- Kadri, F.; Harrou, F.; Chaabane, S.; Sun, Y.; Tahon, C. Seasonal ARMA-based SPC Charts for Anomaly Detection: Application to Emergency Department Systems. Neurocomputing 2016, 173, 2102–2114. [Google Scholar] [CrossRef]
- Berlingerio, M.; Pinelli, F.; Calabrese, F. Abacus: Apriori-based Community Discovery in Multidimensional Networks. Data Min. Knowl. Discov. 2013, 27, 294–320. [Google Scholar] [CrossRef]
- Radenkovic, M.; Grundy, A. Efficient and Adaptive Congestion Control for Heterogeneous delay-Tolerant Networks. Ad Hoc Netw. 2012, 10, 1322–1345. [Google Scholar] [CrossRef]
- Zhang, T.; Wang, J.; Huang, J.; Huang, Y. Adaptive Marking Threshold Method for delay-sensitive TCP in Data Center Network. J. Netw. Comput. Appl. 2016, 61, 222–234. [Google Scholar] [CrossRef]
- Boem, F.; Ferrari, R.M.; Keliris, C.; Parisini, T.; Polycarpou, M.M. A Distributed Networked Approach for Fault Detection of Large-Scale Systems. IEEE Trans. Autom. Control 2017, 62, 18–33. [Google Scholar] [CrossRef]
- Venkatesan, R.; Er, M.J. A Novel Progressive Learning Technique for Multi-class Classification. Neurocomputing 2016, 207, 310–321. [Google Scholar] [CrossRef]
- Hayes-Roth, F.; Waterman, D.A.; Lenat, D.B. Building Expert Systems; Addison-Wesley: Boston, MA, USA, 1983. [Google Scholar]
- Mas, M.; Monserrat, M.; Ruiz-Aguilera, D.; Torrens, J. RU and (U,N)-implications Satisfying Modus Ponens. Int. J. Approx. Reason. 2016, 73, 123–137. [Google Scholar] [CrossRef]
- Morsi, N.N.; Fahmy, A.A. On Generalized Modus Ponens with Multiple Rules and a Residuated Implication. Fuzzy Sets Syst. 2002, 129, 267–274. [Google Scholar] [CrossRef]
- Chen, H.; Li, T.; Luo, C.; Horng, S.J.; Wang, G. A Decision-Theoretic Rough Set Approach for Dynamic Data Mining. IEEE Trans. Fuzzy Syst. 2015, 23, 1958–1970. [Google Scholar] [CrossRef]
- Gilio, A. Generalizing Inference Rules in a Coherence-based Probabilistic default Reasoning. Int. J. Approx. Reason. 2012, 53, 413–434. [Google Scholar] [CrossRef]
- SELFNET Consortium. Deliverable 5.3: Report and Prototypical Implementation of the Integration of the Algorithms and Techniques Used to Provide Intelligence to the Decision-Making Framework. Available online: https://selfnet-5g.eu/2016/12/15/deliverables-online/ (accessed on 9 January 2017).
- Talon, A.; Curt, C. Selection of Appropriate Defuzzification Methods: Application to the Assessment of Dam Performance. Expert Syst. Appl. 2017, 70, 160–174. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | Category | Provider | Destination | Format |
|---|---|---|---|---|
| Object (simple) O | Specification | Use Case | Analyzer | |
| Object (mult) O | Specification | Use Case | Analyzer | |
| Operation | Specification | Use Case | Analyzer | |
| Facts | Assessment | Agg-Ana | Analyzer | |
| Rule | Specification | Use Case | Analyzer | |
| Forecast (ts) | Specification | Use Case | Analyzer | |
| Forecast (G) | Specification | Use Case | Analyzer | |
| Threshold | Specification | Use Case | Analyzer | |
| A. Threshold | Specification | Use Case | Analyzer | |
| Datasets D | Specification | Use Case | Analyzer | |
| Pattern Recognition | Specification | Use Case | Analyzer | |
| Conclusion C | Specification | Use Case | Analyzer | |
| Report | Report | Analyzer | Diagnosis |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Barona López, L.I.; Maestre Vidal, J.; García Villalba, L.J. An Approach to Data Analysis in 5G Networks. Entropy 2017, 19, 74. https://doi.org/10.3390/e19020074
Barona López LI, Maestre Vidal J, García Villalba LJ. An Approach to Data Analysis in 5G Networks. Entropy. 2017; 19(2):74. https://doi.org/10.3390/e19020074
Chicago/Turabian StyleBarona López, Lorena Isabel, Jorge Maestre Vidal, and Luis Javier García Villalba. 2017. "An Approach to Data Analysis in 5G Networks" Entropy 19, no. 2: 74. https://doi.org/10.3390/e19020074
APA StyleBarona López, L. I., Maestre Vidal, J., & García Villalba, L. J. (2017). An Approach to Data Analysis in 5G Networks. Entropy, 19(2), 74. https://doi.org/10.3390/e19020074