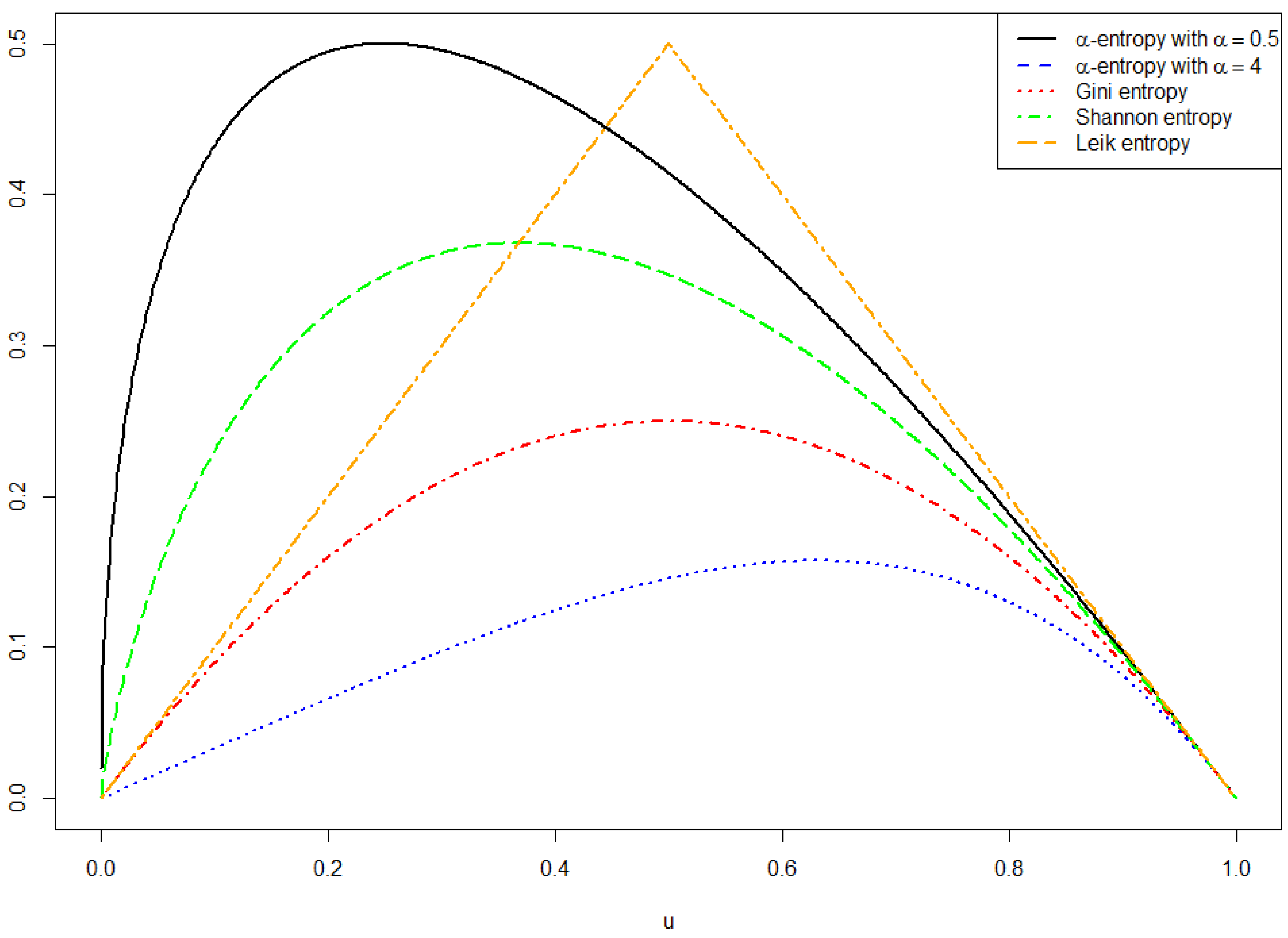
1. Introduction
The
φ-entropy
where
f is a probability density function and
φ is a strictly concave function, was introduced by [
1]. If we set
,
, we get Shannon’s differential entropy as the most prominent special case.
Shannon et al. [
2] derived the “entropy power fraction” and showed that there is a close relationship between Shannon entropy and variance. In [
3], it was demonstrated that Shannon’s differential entropy satisfies an ordering of scale and thus is a proper measure of scale (MOS). Recently, the discussion in [
4] has shown that entropies can be interpreted as a measure of dispersion. In the discrete case, minimal Shannon entropy means maximal certainty about the random outcome of an experiment. A degenerate distribution minimizes the Shannon entropy as well as the variance of a discrete quantitative random variable. For such a degenerate distribution, Shannon entropy and variance both take the value 0. However, there is an important difference between the differential entropy and the variance when discussing a discrete quantitative random variable with support
. The differential entropy is maximized by a uniform distribution over
, while the variance is maximal if both interval bounds
a and
b have the probability mass of
(cf. [
5]). A similar result holds for a discrete random variable with a finite number of realizations. Therefore, it is doubtful that Equation (
1) is a true measure of dispersion.
We propose to define the
φ-entropy for cumulative distribution functions (cdfs)
F and survivor functions (sf)
instead of for density functions
f. Throughout the paper, we define
. By applying this modification we get
where cdf
F is absolutely continuous,
means “cumulative paired entropy”, and
φ is the “entropy generating function” defined on
with
. We will assume that
φ is concave on
throughout most of this paper. In particular, we will show that Equation (
2) satisfies a popular ordering of scale and attains its maximum if the domain is an interval
, while
a,
b occur with a probability of
. This means that Equation (
2) behaves like a proper measure of dispersion.
In addition, we generalize results from the literature, focusing on the Shannon case with
,
(cf. [
6]), the cumulative residual entropy
(cf. [
7]), and the cumulative entropy
(cf. [
8,
9]). In the literature, this entropy is interpreted as a measure of information rather than dispersion without any clarification on what kind of information is considered.
A first general aim of this paper is to show that entropies can rather be interpreted as measures of dispersion than as measures of information. A second general aim is to demonstrate that the entropy generating function φ, the weight function J in L-estimation, the dispersion function d which serves as a criterion for minimization in robust rank regression, and the scores-generating function are closely related.
Specific aims of this paper are:
To show that the cdf-based entropy Equation (
2) originates in several distinct scientific areas.
To demonstrate the close relationship between Equation (
2) and the standard deviation.
To derive maximum entropy (ME) distributions under simple and more complex restrictions and to show that commonly known as well as new distributions solve the ME principle.
To derive the entropy maximized by a given distribution under certain restrictions.
To formally prove that Equation (
2) is a measure of dispersion.
To propose an
L-estimator for Equation (
2) and derive its asymptotic properties.
To use Equation (
2) in order to obtain new related concepts measuring the dependence of random variables (such as mutual
φ-information,
φ-correlation, and
φ-regression).
To apply Equation (
2) to get new linear rank tests for the comparison of scale.
The paper is structured in the same order as these aims. After this introduction, in the second section we give a short review of the literature that is concerned with Equation (
2) or related measures. The third section begins by summarizing reasons for defining entropies for cdfs and sfs instead of defining them for densities. Next, some equivalent characterizations of Equation (
2) are given, provided the derivative of
φ exists. In the fourth section, we use the Cauchy–Schwarz inequality to derive an upper bound for Equation (
2), which provides sufficient conditions for the existence of
. In addition, more stringent conditions for the existence are directly proven. In the fifth section, the Cauchy–Schwarz inequality allows to derive ME distributions if the variance is fixed. For more complicated restrictions we attain ME distributions by solving the Euler–Lagrange conditions. Following the generalized ME principle (cf. [
10]), we change the perspective and ask which entropy is maximized if the variance and the population’s distribution is fixed. The sixth section is of key importance because the properties of Equation (
2) as a measure of dispersion is analyzed in detail. We show that Equation (
2) satisfies an often applied ordering of scale by [
3], is invariant with respect to translations and equivariant with respect to scale transformations. Additionally, we provide certain results concerning the sum of independent random variables. In the seventh section, we propose an
L-estimator for
. Some basic properties of this estimator like influence function, consistency, and asymptotic normality are shown. In the eighth section, we introduce several new statistical concepts based on
, which are generalizing divergence, mutual information, Gini correlation, and Gini regression. Additionally, we show that new linear rank tests for dispersion can be based on
. The known linear rank tests like the Mood- or the Ansari-Bradley tests are special cases of this general approach. However, in this paper we exclude most of the technical details for they will be presented in several accompanying papers. In the last section we compute Equation (
2) for certain generating functions
φ and some selected families of distributions.
5. Maximum CPE Distributions
5.1. Maximum Distributions for Given Mean and Variance
Equality in the Cauchy–Schwarz inequality gives a condition under which the upper bound is attained. This is the case if an affine linear relation between respectively X and respectively exists with probability 1. Since the quantile function is monotonically increasing, such an affine linear function can only exist if is monotonic as well (de- or increasing). This implies that φ needs to be a concave function on . In order to derive a maximum distribution under the restriction that mean and variance are given, one may only consider concave generating functions φ.
We summarize this obvious but important result in the following Theorem:
Theorem 3. Let φ be a non-negative and differentiable function on the domain with derivative and . Then F is the maximum distribution with prespecified mean μ and variance of iff a constant exists such that Proof. The upper bound of the Cauchy–Schwarz inequality will be attained if there are constants
such that the first restriction equals
The property
leads to
such that
This means that there is a constant
with
The second restriction postulates that
φ is concave on
with
Therefore,
is monotonically increasing. The quantile function is also monotonically increasing such that
b has to be positive. This gives
☐
The quantile function of the Tukey’s
λ distribution is given by
Its mean and variance are
The domain is given by for .
By discussing the paired cumulative
α-entropy, one can prove the new result that the Tukey’s
λ distribution is the maximum
distribution for prespecified mean and variance. Tukey’s
λ distribution takes on the role of the Student-
t distribution if one changes from the differential entropy to
(cf. [
61]).
Corollary 5. The cdf F maximizes for under the restrictions of a given mean μ and given variance iff F is the cdf of the Tukey λ distribution with .
Proof. For
,
, we have
for
. As a consequence, the constant
b is given by
and the maximum
distribution results in
can easily be identified as the quantile function of a Tukey’s
λ distribution with
and
. ☐
For the Gini case (
), one obtains the quantile function of a uniform distribution
with domain
. This maximum
distribution corresponds essentially to the distribution derived by Dai et al. [
40].
The fact that the logistic distribution is the maximum
distribution, provided mean and variance are given, was derived by Chen et al. [
51] in the framework of uncertainty theory and by ([
50], p. 4) in the framework of reliability theory. Both proved this result using Euler–Lagrange equations. In the interest of completeness, we provide an alternative proof via the upper bound of the Cauchy–Schwarz inequality.
Corollary 6. The cdf F maximizes under the restrictions of a known mean μ and a known variance iff F is the cdf of a logistic distribution.
Inverting gives the distribution function of the logistic distribution with mean
μ and variance 1:
☐
As a last example we consider the cumulative paired Leik entropy .
Corollary 7. The cdf F maximizes under restrictions of a known mean μ and a known variance iff for F holds Proof. From
and
,
, follows that
☐
Therefore, the maximization of with given mean and variance leads to a distribution whose variance is maximal on the interval .
5.2. Maximum Distributions for General Moment Restrictions
Drissi et al. [
50] discuss general moment restrictions of the form
for which the existence of the moments is assumed. By using Euler–Lagrange equations they show that
maximizes the residual cumulative entropy
under constraints Equation (
31). Moreover, they demonstrated that the solution needs to be symmetric with respect to
μ. Here,
,
, are the Lagrange parameters which are determined by the moment restrictions, provided a solution exists. Rao et al. [
47] shows that for distributions with support
the ME distribution is given by
if the restrictions Equation (
31) are again required.
One can easily examine the shape of a distribution which maximizes the cumulative paired
φ-entropy under the constraints Equation (
31). This maximum
distribution can no longer be derived by the upper bound of the Cauchy–Schwarz inequality if
. One has to solve the Euler–Lagrange equations for the objective function
with Lagrange parameters
,
. The Euler–Lagrange equations lead to the optimization problem
for
. Once again there is a close relation between the derivative of the generating function and the quantile function, provided a solution of the optimization problem Equation (
32) exists.
The following example shows that the optimization problem Equation (
32) leads to a well-known distribution if constraints are chosen carefully in case of a Shannon-type entropy.
Example 1. The power logistic distribution is defined by the distribution functionfor . The corresponding quantile function is This quantile function is also solution of Equation (33) given , , under the constraint . The maximum of the cumulative paired Shannon entropy under the constraint is given by Setting leads to the familiar result for the upper bound of given the variance.
5.3. Generalized Principle of Maximum Entropy
Kesavan et al. [
19] introduced the generalized principle of an ME problem which describes the interplay of entropy, constraints, and distributions. A variation of this principle is the aim of finding an entropy that is maximized by a given distribution and some moment restrictions.
This problem can easily be solved for if mean and variance are given, due to the linear relationship between and the quantile function of the maximum distribution provided by the Cauchy–Schwarz inequality. However, it is a precondition for that is strictly monotonic on in order to be a quantile function. Therefore, the concavity of and the condition are of key importance.
We demonstrate the solution to the generalized principle of the maximum entropy problem for the Gaussian and the Student-t distribution.
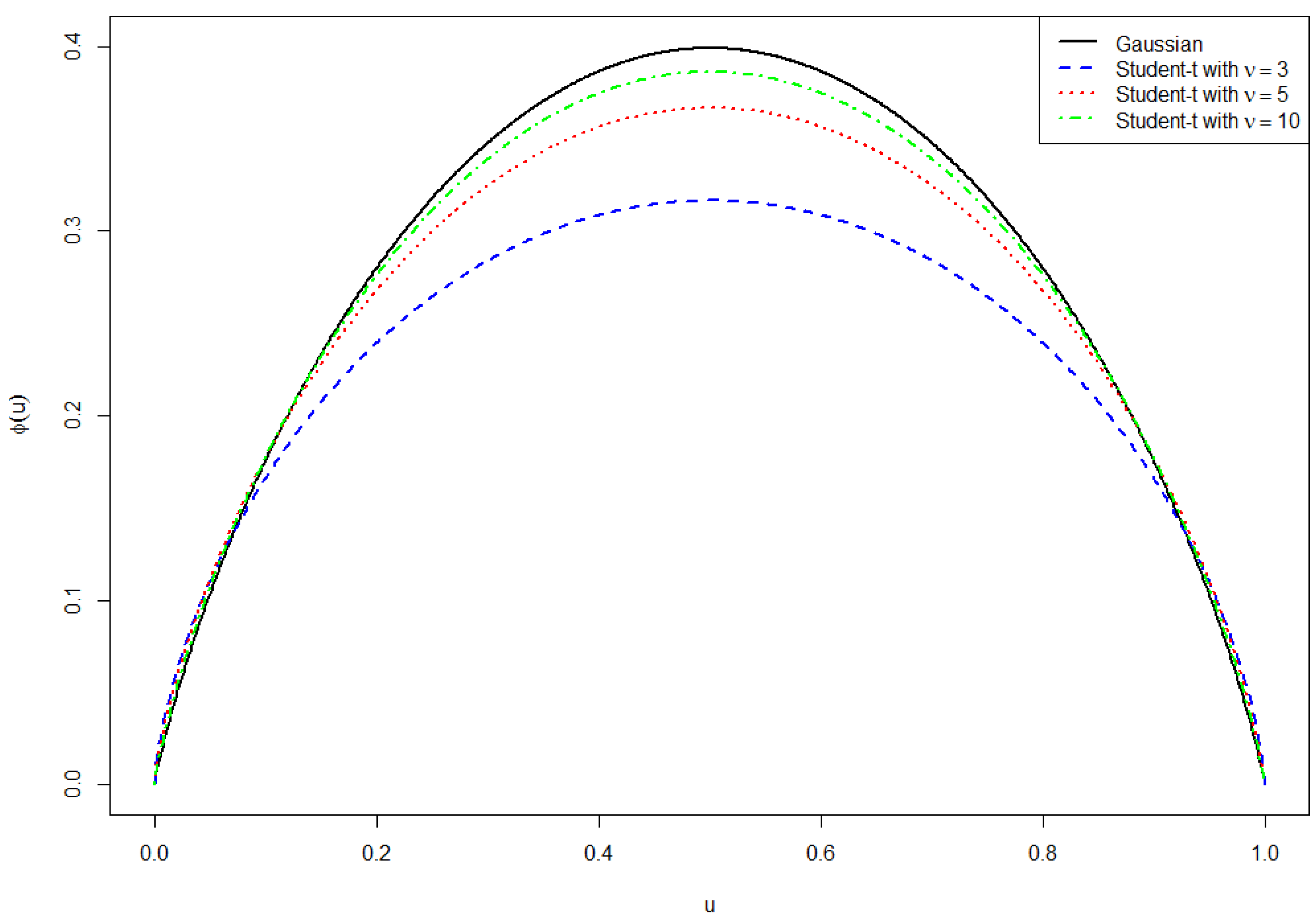
Proposition 3. Let φ, Φ
and be the density, the cdf and the quantile function of a standard Gaussian random variable. The Gaussian distribution is the maximum distribution for a given mean μ and variance for with entropy generating function Proof. With
the condition for the maximum
distribution with mean
μ and variance
becomes
By substituting
, it follows that
such that
is the quantile function of a Gaussian distribution with mean
μ and variance
. ☐
An analogue result holds for the Student-t distribution with k degrees of freedom. In this case, the main difference to the Gaussian distribution is the fact that the entropy generating function possesses no closed form but is obtained by numerical integration of the quantile function.
Corollary 8. Let respectively be the cdf respectively the quantile function of a Student-t distribution with k degrees of freedom for . is the maximum quantile function for a given mean μ and variance iff Proof. Starting with
and the symmetry of the
distribution around
μ, we get the condition
With
we get the quantile function of the
t distribution with
k degrees of freedom and mean
μ:
☐
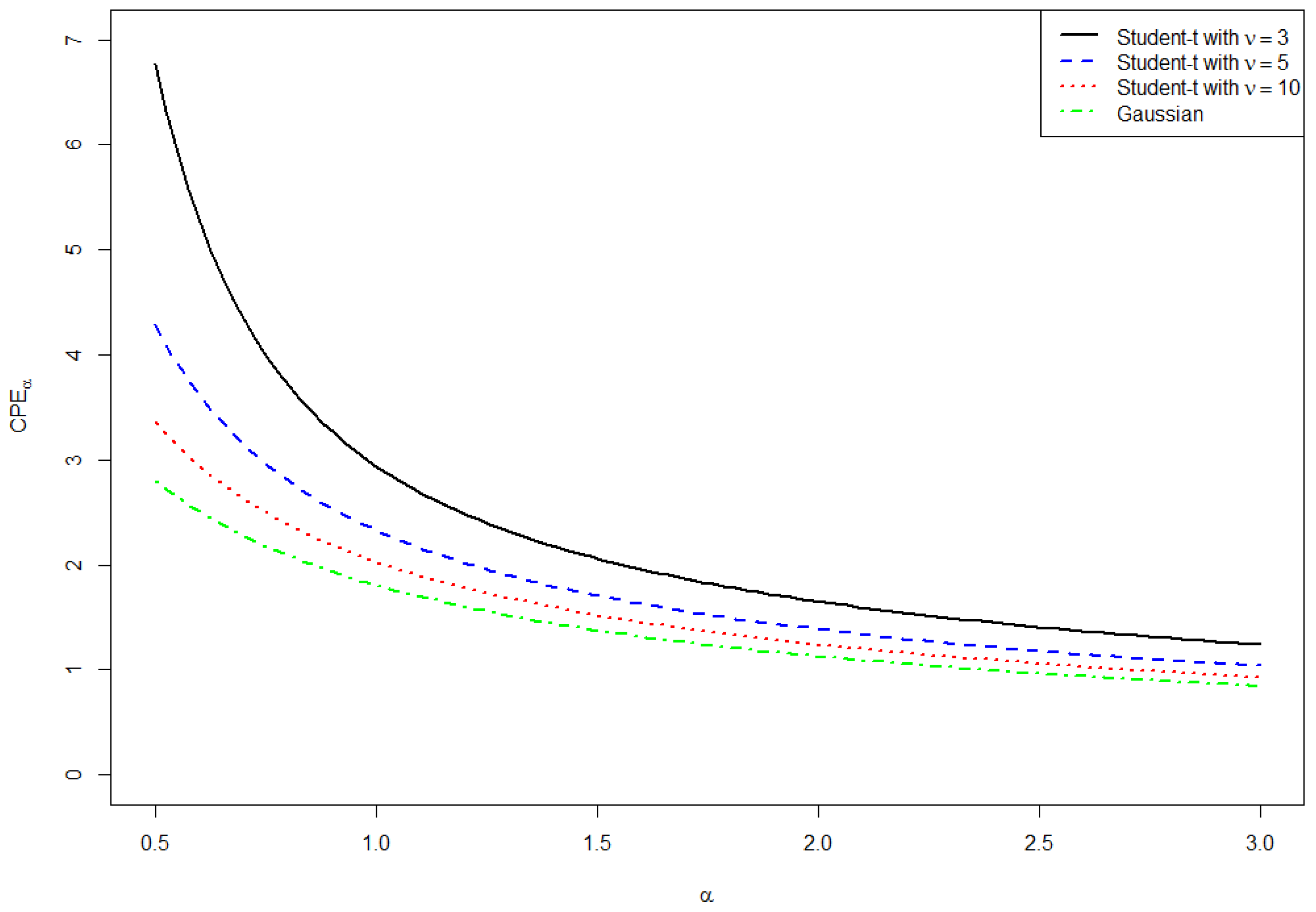
Figure 2 shows the shape of the entropy generating function
φ for several distributions generated by the generalized ME principle.
7. Estimation of CPE
Beirlant et al. [
67] presented an overview of differential entropy estimators. Essentially, all proposals are based on the estimation of a density function
f inheriting all typical problems of nonparametric estimation of a density function. Among others, the problems are biasedness, choice of a kernel, and optimal choice of the smoothing parameter (cf. [
68], p. 215ff.). However,
is based on cdf
F for which several natural estimators with desirable stochastic properties, derived from the Theorem of Glivenko and Cantelli (cf. [
69], p. 61), exist. For a simple random sample
, independently distributed random variables with identical distribution function
F, the authors of [
8,
9] estimated
F using the empirical distribution function
for
. Moreover, they showed for the cumulative entropy
that the estimator
is consistent for
(cf. [
8]). In particular, for
F being the distribution function of a uniform distribution, they provided the expected value of the estimator and demonstrated that the estimator is asymptotically normal. For
F being the cdf of an exponential distribution, they additionally derived the variance of the estimator.
In the following, we generalize the estimation approach of [
8] by embedding it into the well-established theory of
L-estimators (cf. [
70], p. 55ff.). If
φ is differentiable, then
can be represented as the covariance between the random variable
X and
:
An unbiased estimator for this covariance is
where
This results in an
L-estimator
with
,
. By applying known results for the influence functions of
L-estimators (cf. [
70]), we get for the influence function of
:
In particular, the derivative is
This means that the influence function will be completely determined by the antiderivative of . The following examples demonstrate that the influence function of can easily be calculated if the underlying distribution F is logistic. We consider the Shannon, the Gini, and the α-entropy cases.
Example 2. Beginning with the derivativewe arrive at The influence function is not bounded and proportional to the influence function of the variance, which implies that variance and have a similar asymptotic and robustness behavior. The integration constant C has to be determined such that Example 3. Using the Gini entropy and the logistic distribution function F we have Integration gives the influence function By applying numerical integration we get .
Example 4. For the derivative of the influence function is given byIntegration leads to the influence functionwhere Under certain conditions (cf. [
71], p. 143) concerning
J, or
φ and
F,
L- estimators are consistent and asymptotically normal. So, the cumulative paired
φ-entropy is
with asymptotic variance
The following examples consider the Shannon and the Gini case for which the condition that is sufficient to guarantee asymptotic normality can easily be checked. We consider again the cdf F of the logistic distribution.
Example 5. For the cumulative paired Shannon entropy it holds thatsince Example 6. In the Gini case we getsince by numerical integration It is known that
L-estimators have a remarkable small-sample bias. Following [
72], the bias can be reduced by applying the Jackknife method. It is well-known that asymptotical distributions can be used to construct approximate confidence intervals as well as that they can be applied for hypothesis tests in the one- or two-sample case. ([
70], p. 116ff.) discussed asymptotic efficient
L-estimators for a parameter of scale
θ. Klein et al. [
73] examine how the entropy generating function
φ will be determined by the requirement that
has to be asymptotically efficient.
8. Related Concepts
Several statistical concepts are closely related to cumulative paired
φ-entropies. These concepts generalize some results which are known from literature. We begin with the cumulative paired
φ-divergence that was discussed for the first time by [
41], who called it “generalized cross entropy”. Their focus was on uncertain variables, whereas ours is on random variables. The second concept generalizes mutual information, which is defined for Shannon’s differential entropy, to mutual
φ-information. We consider two random variables
X and
Y. The task is to decompose
into two kinds of variation such that the so-called external variation measures how much of
can be explained by
X. This procedure mimics the well-known decomposition of variance and allows to define directed measures of dependence for
X and
Y. The third concept deals with dependence. More precisely, we introduce a new family of correlation coefficients that measure the strength of a monotonic relationship between
X and
Y. Well-known coefficients like the Gini correlation can be embedded in this approach. The fourth concept treats the problem of linear regression.
can serve as general measure of dispersion that has to be minimized to estimate the regression coefficients. This approach will be identified as a special case of rank-based regression or
R regression. Here, the robustness properties of the rank-based estimator can directly be derived from the entropy generating function
φ . Moreover, asymptotics can be derived from theory of rank-based regression. The last concept we discuss applies
to linear rank tests for the difference of scale. Known results, especially concerning the asymptotics, can be transferred from the theory of linear rank tests to this new class of tests. In this paper, we only sketch the main results and focus on examples. For a detailed discussion including proofs we refer to a series of papers by Klein and Mangold ([
73,
74,
75]) , which are currently work in progress.
8.1. Cumulative Paired φ-Divergence
Let
φ be a concave function defined on
with
. Additionally, we need
. In the literature,
φ-divergences are defined for convex functions
φ (cf., e.g., [
76], p. 5). Consequently, we consider
with
φ concave.
The cumulative paired φ-divergence for two random variables is defined as follows.
Definition 4. Let X and Y be two random variables with cdfs and . Then the cumulative paired φ-divergence of X and Y is given by The following examples introduce cumulative paired φ-divergences for the Shannon, the α-entropy, the Gini, and the Leik cases:
Example 7. - 1.
Considering , , we obtain the cumulative paired Shannon divergence - 2.
Setting , , leads to the cumulative paired α-divergence - 3.
For we receive as a special case the cumulative paired Gini divergence - 4.
The choice , , leads to the cumulative paired Leik divergence
is equivalent to the Anderson-Darling functional (cf. [
77]) and has been used by [
78] for a goodness-of-fit test, where
represents the empirical distribution. Likewise,
serves as a goodness-of-fit test (cf. [
79]).
Further work in this area with similar concepts was done by [
80,
81], using the notation cumulative residual Kullback-Leiber (CRKL) information and cumulative Kullback-Leiber (CKL) information.
Based on work from [
82,
83,
84,
85] a general function
was discussed by [
86]:
Up to a multiplicative constant,
includes all of the aforementioned examples. In addition, the Hellinger distance is a special case for
that leads to the cumulative paired Hellinger divergence:
For a strictly concave function
φ, Chen et al. [
41] proved that
and
iff
X and
Y have identical distributions. Thus, the cumulative paired
φ-divergence can be interpreted as a kind of a distance between distribution functions. As an application, Chen et al. [
41] mentioned the “minimum cross-entropy principle”. They proved that
X follows a logistic distribution if
is minimized, given that
Y is exponentially distributed and the variance of
X is fixed. If
is an empirical distribution and
has an unknown vector of parameters
θ,
can be minimized to attain a point estimator for
θ (cf. [
87]). The large class of goodness-of-fit tests based on
, discussed by Jager et al. [
86], has already been mentioned.
8.2. Mutual Cumulative φ-Information
Let
X and
Y again be random variables with cdfs
,
, density functions
,
, and the conditional distribution function
.
and
denote the supports of
X and
Y. Then we have
which is the variation of
Y given
. Averaging with respect to
x leads to the internal variation
For a concave entropy generating function
φ, this internal variation cannot be greater than the total variation
. More precisely, it holds:
.
if X and Y are independent.
If φ is strictly concave and , X and Y are independent random variables.
We consider the non-negative difference
This expression measures the part of the variation of
Y that can be explained by the variable
X (= external variation) and shall be named “mutual cumulative paired
φ-information”
(cf. Rao et al. [
46] using the term “cross entropy”, (p. 3) in [
50]).
is equivalent to the transinformation that is defined for Shannon’s differential entropy (cf. [
60], p. 20f.). In contrast to transinformation,
is not symmetric, so
is not true in general.
Cumulative paired mutual
φ-information is the starting point for two directed measures of strength of
φ-dependence between
X and
Y, namely “directed (measure) of cumulative paired
φ-dependence”,
. The first one is
and the second one is
Both expressions measure the relative decrease in variation of Y if X is known. The domain is . The lower bound 0 is taken if Y and X are independent, while the upper bound 1 corresponds to . In this case, from for and , we can conclude that the conditional distribution has to be degenerated. Thus, for every there is exactly one with . Therefore, there is a perfect association between X and Y. The next example illustrates these concepts and demonstrates the advantage of considering both types of measures of dependence.
Example 8. Let follow a bivariate standard Gaussian distribution with , , and , . Note that X and Y follow univariate standard Gaussian distributions, whereas follows a univariate Gaussian distribution with mean 0
and variance . Considering this, one can conclude that By plugging this quantile function into the defining equation of the cumulative paired φ-entropy one yields For , the cumulative paired φ-entropy behaves like the variance or the standard deviation. All measures approach 0 for , such that can be used as a measure of risk since the risk can be completely eliminated in a portfolio with perfectly negative correlated returns of assets. To be more precise, it is to say that rather behaves like the standard deviation than the variance.
For , the variance of the sum equals the sum of the variances, but the standard deviation of the sum is equal to or smaller than the sum of the individual standard deviations. This is also true for .
In case of the bivariate standard Gaussian distribution, is Gaussian as well with mean and variance for and . Therefore, the quantile function of is Using this quantile function, the cumulative paired φ-entropy for the conditional random variable is Just like the variance of , does not depend on x in case of a bivariate Gaussian distribution. This implies that the internal variation is , as well.
For , the bivariate distribution becomes degenerated and the internal variation consequently approaches 0
. The mutual cumulative paired φ-information is given by takes the value 0 if and only if , in which case X and Y are independent.
The two measures of directed cumulative φ-dependence for this example areandρ completely determines the values for both measures of directed dependence. Provided the upper bound 1
will be attained, there is a perfect linear relation between Y and X. As a second example we consider the dependence structure of the Farlie-Gumbel-Morgenstern copula (FGM copula). For the sake of brevity, we define a copula
C as bivariate distribution function with uniform marginals for two random variables
U and
V with support
. For details concerning copulas see, e.g., [
88].
Example 9. Letbe the FGM copula (cf. [88], p. 68). Withit holds for the conditional cumulative φ-entropy of U given that To get expressions in closed form we consider the Gini case with , . After some simple calculations we have Averaging over the uniform distribution of V leads to the internal variation With , the mutual cumulative Gini information and the directed cumulative measure of Gini dependence are It is well-known that only a small range of dependence can be covered by the FGM copula (cf. [88], p. 129). Hall et al. [
89] discussed several methods for estimating a conditional distribution. The results can be used for estimating the mutual
φ-information and the two directed measures of dependence. This will be the task of future research.
8.3. φ-Correlation
Schechtman et al. [
90] introduced Gini correlations of two random variables
X and
Y with distribution functions
and
as
The numerator equals
of the Gini mean difference
where the expectation is calculated for two independent and with
identically distributed random variables
and
.
Gini’s mean difference coincides with the cumulative paired Gini entropy
in the following way:
Therefore, in the same way that Gini’s mean difference can be generalized to the Gini correlation, can be generalized to the φ-correlation.
Let
be two random variables and let
,
be the corresponding cumulative paired
φ-entropies, then
and
are called
φ-correlations of
X and
Y. Since
, the numerator is the covariance between
X and
.
The first example verifies that the Gini correlation is a proper special case of the φ-correlation.
Example 10. The setting , , leads to the Gini correlation, becauseand The second example considers the new Shannon correlation.
Example 11. Set , , then we get the Shannon correlation If Y follows a logistic distribution with , , then . Considering this, we get From Equation (30) we know that if X is logistically distributed. In this specific case we get In the following example we introduce the α-correlation.
Example 12. For , , we get the α-correlation For , , we get The authors of [
90,
91,
92] proved that Gini correlations possess many desirable properties. In the following we give an overview of all properties which can be transferred to
φ-correlations. For proofs and further details we refer to [
75].
We start with the fact that
φ-correlations also have a copula representation since for the covariance holds
The following examples demonstrate the copula representation for the Gini and the Shannon correlation.
Example 13. In the Gini case it is . This leads to Example 14. In the Shannon case, such that The following basic properties of
φ-correlations can easily be checked with the arguments applied by [
90]:
.
if there is a strictly increasing (decreasing) transformation g such that .
If g is monotonic, then .
If g is affin-linear, then .
If X and Y are independent, then .
If and are exchangeable for some constants with , then .
In the last subsection we have seen that two directed measures of φ-dependence do not rely on φ if a bivariate Gaussian distribution is considered. The same holds for φ-correlations as will be demonstrated in the following example.
Example 15. Let be a bivariate standard Gaussian random variable with Pearson correlation coefficient ρ. Thus, all φ-correlations coincide with ρ as the following consideration shows:
With it isDividing this by yields the result. Weighted sums of random variables appear for example in portfolio optimization. The diversification effect concerns negative correlations between the returns of assets. Thus, the risk of a portfolio can be significantly smaller than the sum of the individual risks. Now, we analyze whether cumulative paired φ-entropies can serve as a risk measure as well. Therefore, we have to examine the diversification effect for .
First, we display the total risk
as a weighted sum of individual risks. Essentially, the weights need to be the
φ-correlations of the individual returns with the portfolio return: Let
, then it holds that
For the diversification effect the total risk
has to be displayed as a function of the
φ-correlations between
and
,
. A similar result was provided by [
92] for the Gini correlation without proof. Let
and set
,
, then the following decomposition of the square of
holds:
This is similar to the representation for the variance of Y, where takes the role of the Pearson correlation and the role of the standard deviation for .
Schechtman et al. [
90] also introduced an estimator for the Gini correlation and derived its asymptotic distribution. For the proof it is useful to note that the numerator of the Gini correlation can be represented as a
U-statistic. For the general case of the
φ-correlation it is necessary to derive the influence function and to calculate its variance. This will be done in [
75].
8.4. φ-Regression
Based on the Gini correlation Olkin et al. [
93] considered the traditional ordinary least squares (OLS) approach in regression analysis
where
Y is the dependent variable and
x is the independent variable. They modified it by minimizing the covariance between the error term
ε in a linear regression model and the ranks of
ε with respect to
α and
β. Ranks are the sample analogue of the theoretical distribution function
, such that the Gini mean difference
is the center of this new approach for regression analysis. Olkin et al. [
93] noticed that this approach is already known as “rank based regression” or short “
R regression” in robust statistics. In robust regression analysis the more general optimization criteria
has been considered, where
φ denotes a strictly increasing score function (cf. [
94], p. 233). The choice
leads to the Gini mean difference, which is the scores generating function of the Wilcoxon scores. The rank based regression approach with general scores generating function
,
, is equivalent to the generalization of the Gini regression to a so-called
φ-regression based on the criteria function
which has to be minimized to obtain
α and
β. Therefore, cumulative paired
φ-entropies are special cases of the dispersion function that [
95,
96] proposed as optimization criteria for
R regression. More precisely,
R estimation proceeds in two steps. In the first step
has to be minimized with respect to
β. Let
denote this estimator. In the second step
α will be estimated separately by
The authors of [
97,
98] gave an overview of recent developments in rank based regression. We will apply their main results to
φ-regression. In [
99], the authors showed that the following property holds for the influence function of
:
where
represents an outlier.
determines the influence of an outlier in the dependent variable on the estimator
.
The scale parameter
is given by
The influence function shows that
is asymptotically normal:
For
bounded, Koul et al. [
100] proposed a consistent estimator
for the scale parameter
. This asymptotic property can again be used to construct approximate confidence limits for the regression coefficients, to derive a Wald test for the general linear hypothesis, to derive a goodness-of-fit test, and to define a measure of determination (cf. [
97])).
Gini regression corresponds to . In the same way we can derive from the new Shannon regression, from the α-regression, and from the Leik regression.
The R package “Rfit” has the option to include individual
φ-functions into rank based regression (cf. [
97]). Using this option and the dataset “telephone”, which is available with several outliers in “Rfit”, we compare the fit of the Shannon regression
), the Leik regression, and the
α-regression (for several values of
α) with the OLS regression.
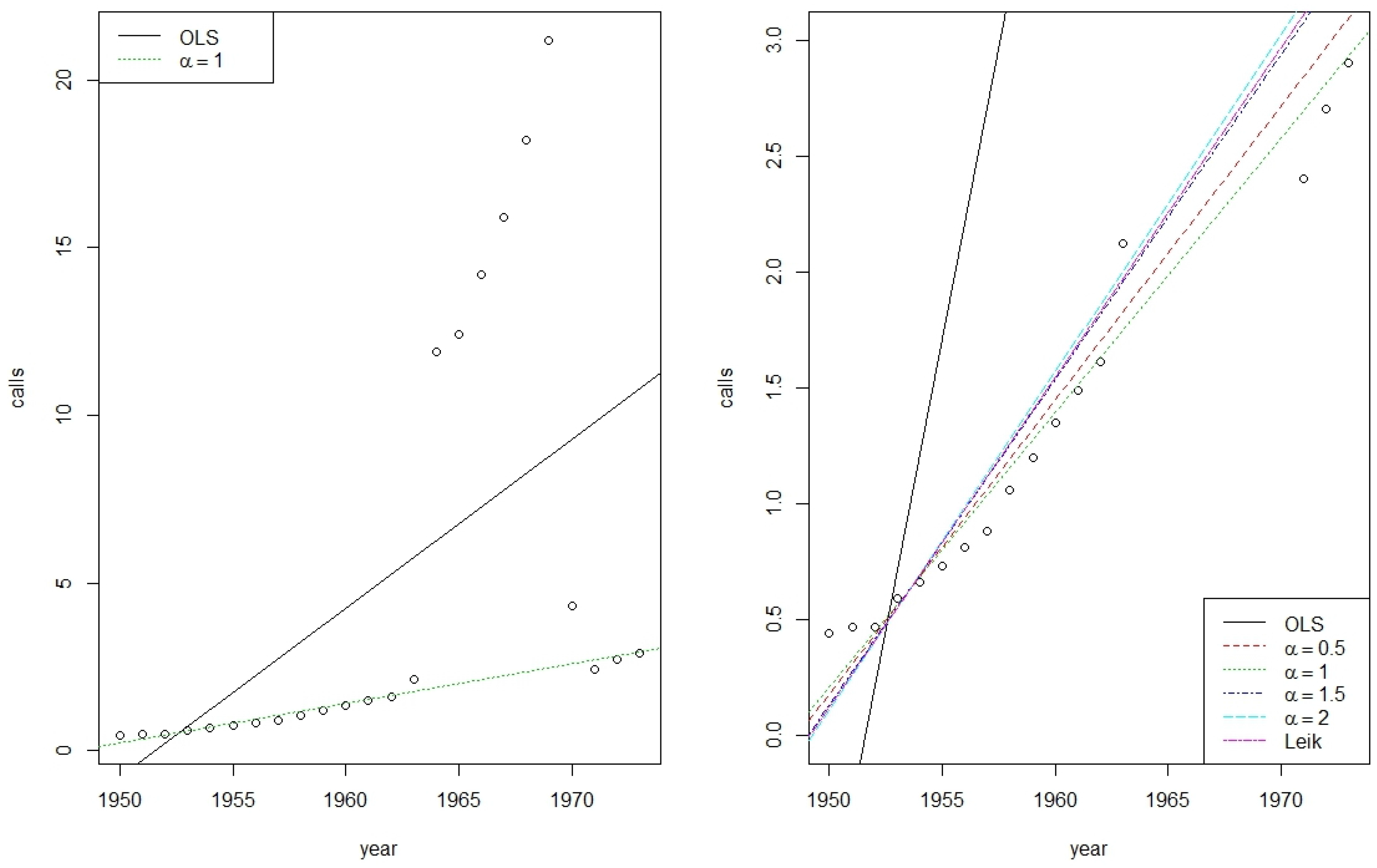
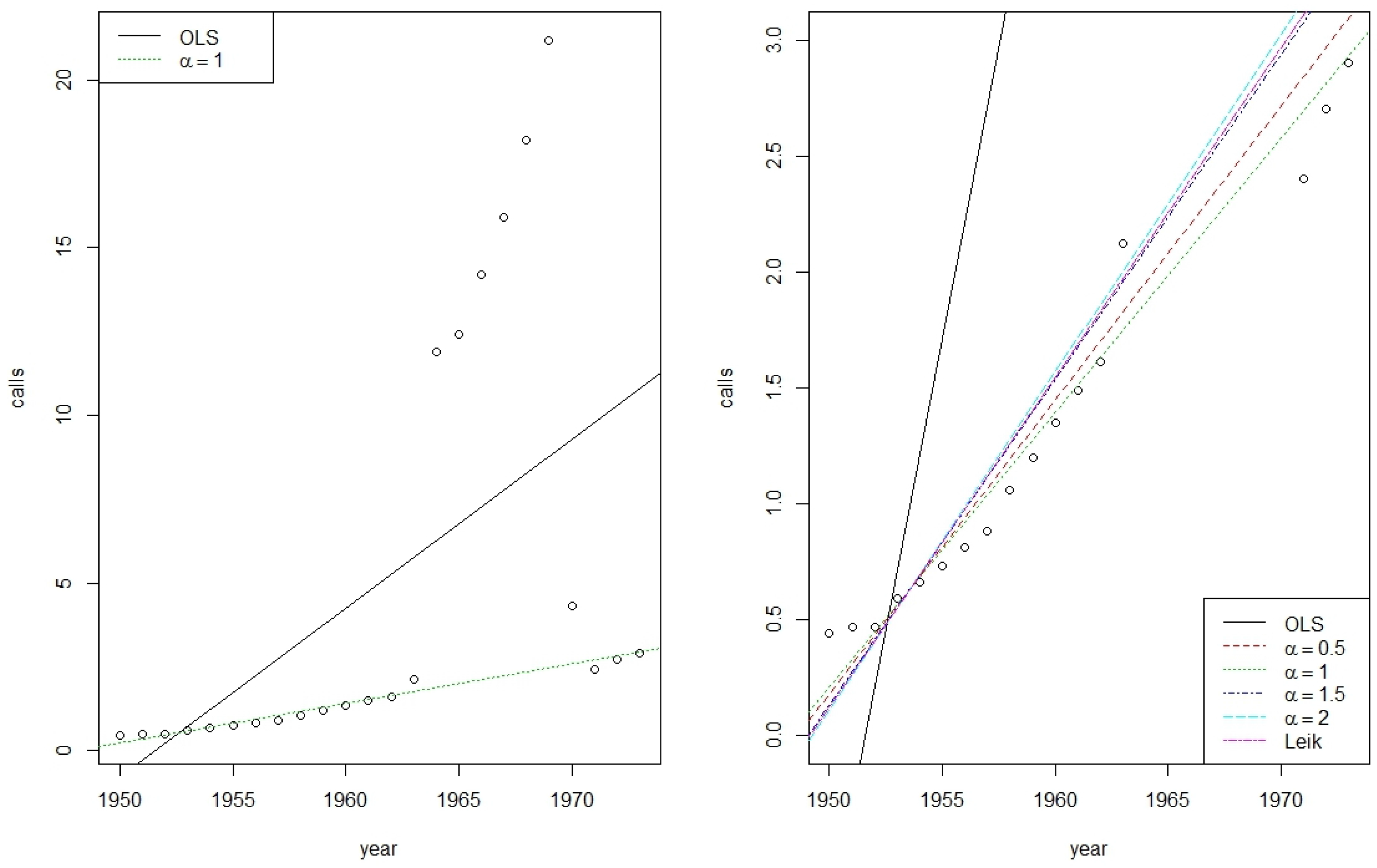
Figure 3 shows on the left the original data, the OLS, and the Shannon regression, while on its right side outliers were excluded to get a more detailed impression of the differences between the
φ-regressions.
In comparison with the very sensitive OLS regression all rank based regression techniques behave similarly. In case of a known error distribution, McKean et al. [
98] showed an asymptotically efficient estimator for
. This procedure also determines the entropy generating function
φ. In case of an unknown error distribution but some available information with respect to skewness and leptokurtosis, a data-driven (adaptive) procedure was proposed by them.
8.5. Two-Sample Rank Test on Dispersion
Based on
the linear rank statistics
can be used as a test statistic for alternatives of scale, where
are the ranks of
in the pooled sample
. All random variables are assumed to be independent.
Some of the linear rank statistics which are well-known from the literature are special cases of Equation (
56) as will be shown in the following examples:
Example 16. Let , , then we have Ansari et al. [101] suggest the statisticas a two-sample test for alternatives of scale (cf. [102], p. 104). Apparently, we have . Example 17. Let , . Consequently, we havewhich is identical to the test statistic suggested by [103] up to an affine linear relation (cf. [68], p. 149f.). This test statistic is given by , thus, the resulting relation is given by In the following, the scores of the Mood test will be generated by the generating function of .
Dropping the requirement of concavity of φ, one finds analogies to other well-known test statistics.
Example 18. Let , , which is not concave on the interval [0,1], we havewhich is identical to the quantile test statistic for alternatives of scale up to an affine linear relation ([102], p. 105). The asymptotic distribution of linear rank tests based on
can be derived from the theory of linear rank test, as discussed in [
102]. The asymptotic distribution under the null hypothesis is needed to be able to make an approximate test decision given a significance level
α. The asymptotic distribution under the alternative hypothesis is needed for an approximate evaluation of the test power and the choice of the required sample size in order to ensure a given effect size, respectively.
We consider the centered linear rank statistic
Under the null hypothesis of identical scale parameters and the assumption that
where
, the asymptotical distribution of
is given by
(cf. [
102], p. 194, Theorem 1 and p. 195, Lemma 1).
The property of asymptotic normality of the Ansari-Bradley test and the Mood test is well-known. Therefore, we provide a new linear rank test based on cumulative paired Shannon entropy (so-called “Shannon”-test) in the following example:
Example 19. With , , and we haveand Under the null hypothesis of identical scale, the centered linear rank statistic is asymptotically normal with variance If the alternative hypothesis
for a density function
is given by
for
and
, then set
and assume
. If
and
with
,
is asymptotically normal distributed with mean
and variance
This result follows immediately from [
102], p. 267, Theorem 1, together with the Remark on, p. 268.
If
is a symmetric distribution,
,
, holds such that
This simplifies the variance of the asymptotic normal distribution.
Since the asymptotic normality of the test statistic of the Ansari-Bradley test and the Mood test under the alternative hypothesis have been examined intensely (cf., e.g., [
103,
104]), we focus in the following example on the new Shannon test:
Example 20. Set , and let be the density function of a standard Gaussian distribution, such that and . As a consequence, we haveandwhere the integrals have been evaluated by numerical integration. Then under the alternative Equation (58): Hereafter, one can discuss the asymptotic efficiency of linear rank tests based on cumulative paired
φ-entropy. If
is the true density and
then
gives the desired asymptotic efficiency (cf. [
102], p. 317).
The asymptotic efficiency of the Ansari-Bradley test (and the asymptotic equivalent Siegel-Tukey test, respectively) and the Mood test have been analyzed by [
104,
105,
106]. The asymptotic relative efficiency (ARE) with respect to the traditional
F-test for differences in scale for two Gaussian distributions has been discussed by [
103]. This asymptotic relative efficiency between Mood test and
F-test for differences in scale has been derived by [
107]. Once more, we focus on the new Shannon-test.
Example 21. The Klotz test is asymptotically efficient for the Gaussian distribution. With ,gives the asymptotic efficiency of the new Shannon test. Using a distribution that ensures the asymptotic efficiency of the Ansari-Bradley test, we compare the asymptotic efficiency of the Shannon test to the one of the Ansari-Bradley test.
Example 22. The Ansari-Bradley test statistic is asymptotically efficient for the double log-logistic distribution with density function (cf. [102], p. 104). The Fisher information is given by Furthermore, we havesuch that the asymptotic efficiency of the Shannon-test for is These two examples show that the Shannon test has a rather good asymptotic efficiency, even if the underlying distribution has moderate tails similar to the Gaussian distribution or heavy tails like the double log-logistic distribution. Asymptotic efficient linear rank tests correspond to a distribution and a scores generating function
, from which we can derive an entropy generating function
φ and a cumulative paired
φ-entropy. This relationship will be further examined in [
74].
10. Conclusions
A new kind of entropy has been introduced that generalizes Shannon’s differential entropy. The main difference to the previous discussion of entropies is the fact that the new entropy is defined for distribution functions instead of density functions. This paper shows that this definition has a long tradition in several scientific disciplines like fuzzy set theory, reliability theory, and more recently in uncertainty theory. With only one exception within all the disciplines, the concepts had been discussed independently. Along with that, the theory of dispersion measures for ordered categorical variables refers to measures based on distribution functions, without realizing that implicitly some sort of entropies are applied. Using the Cauchy–Schwarz inequality, we were able to show the close relationship between the new kind of entropy named cumulative paired φ-entropy and the standard deviation. More precisely, the standard deviation yields an upper limit for the new entropy. Additionally, the Cauchy–Schwarz inequality can be used to derive maximum entropy distributions provided that there are constraints specifying values of mean and variance. Here, the logistic distribution takes on the same key role for the cumulative paired Shannon entropy which the Gaussian distribution takes by maximizing the differential entropy. As a new result we have demonstrated that Tukey’s λ distribution is a maximum entropy distribution if using the entropy generating function φ which is known from the Harvda and Charvát entropy. Moreover, some new distributions can be derived by considering more general constraints. A change in perspective allows to determine the entropy that will be maximized by a certain distribution if, e.g., mean and variance are known. In this context the Gaussian distribution gives a simple solution. Since cumulative paired φ-entropy and variance are closely related, we have investigated whether the cumulative paired φ-entropy is a proper measure of scale. We show that it satisfies the axioms which were introduced by Oja for measures of scale. Several further properties, concerning the behavior under transformations or the sum of independent random variables, have been proven. Consequently, we have given first insights on how to estimate the new entropy. In addition, based on cumulative paired φ-entropy we have introduced new concepts like φ-divergence, mutual φ-information, and φ-correlation. φ-regression and linear rank tests for scale alternatives were considered as well. Furthermore, formulas have been derived for some popular distributions with cdf or quantile function in closed form and for certain cumulative paired φ-entropies.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}