1. Introduction
In the context of Bayesian probability theory, a proper assignment of prior probabilities is crucial. Depending on the domain, quite different prior information can be available. It may be in the form of point estimates provided by domain experts (see, e.g., [
1] for prior distribution elicitation) or in the form of invariances (of the prior knowledge) of the system of interest, which should be reflected in the prior probability density [
2]. However, especially for the ubiquitous case of the estimation of parameters of linear equation systems (like a straight line or hyperplane fitting), the latter requirement is often violated. Consider, for concreteness, the simple case of
y =
ax, a straight line through the origin, with
a the parameter of interest. Here, the commonly-applied prior is constant,
p (
a|I) = const., often accompanied by statements like “Since we do not have specific prior information, we chose a uniform prior on
a…”. In
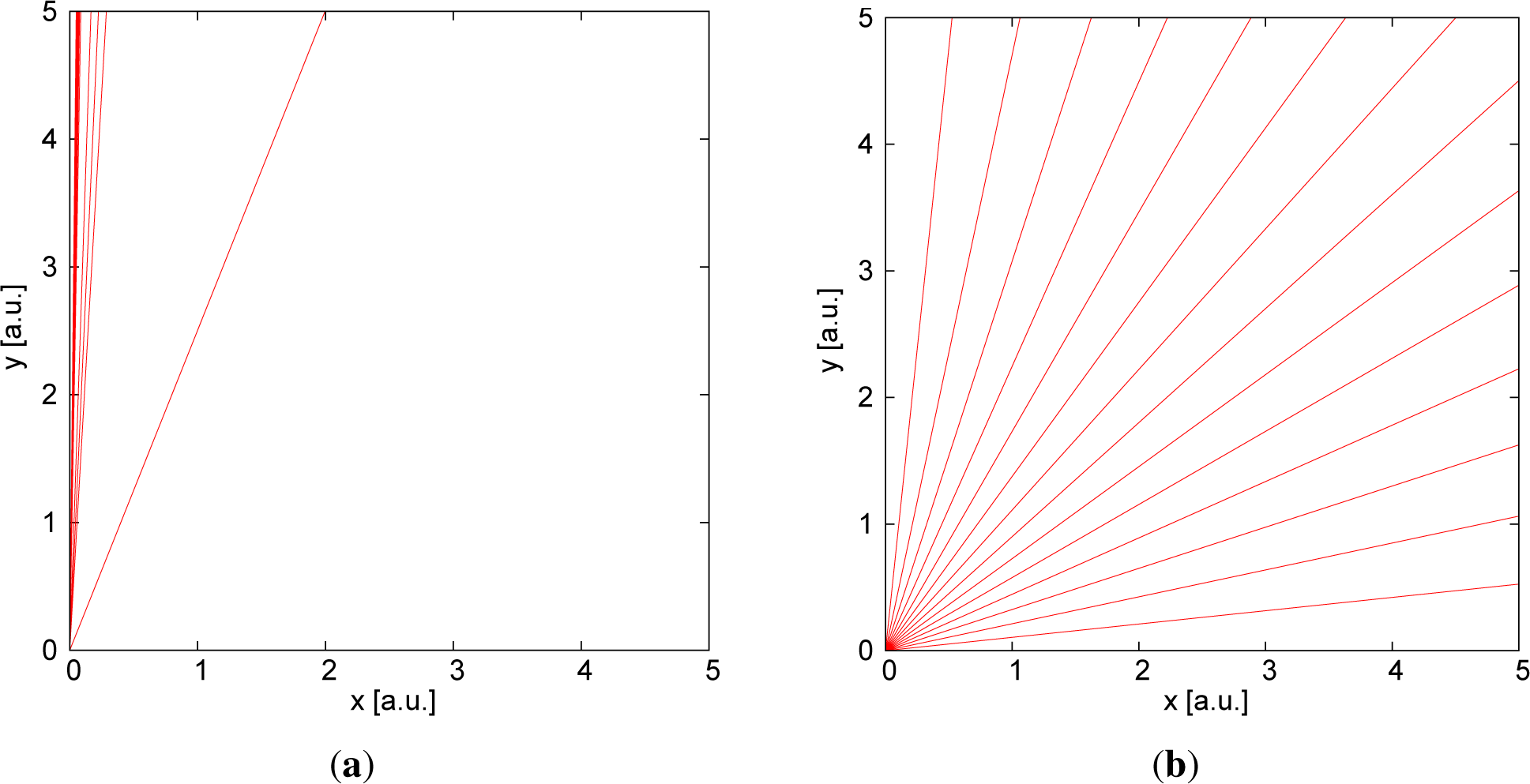
Figure 1 on the left-hand side, 15 random samples generated from this prior distribution with
a ∈ [0, 50] are displayed. Confronted with this result, the typical response is (at least in the experience of the author) that instead, a more “uniform” prior distribution of the slopes was intended, which is often depicted like in
Figure 1 on the right-hand side. This plot was generated from a prior distribution that has an equal probability density for the angle of the line to the abscissa, corresponding to
Additionally, in fact, in practice, the units of the axes are commonly chosen in such a way that extreme values of the slopes are not
a priori overrepresented. If we generalize this requirement to more than one independent or dependent variable, then the desired prior probability should be invariant under arbitrary rotations in this parameter space. Some important special cases have been given already in [
3], e.g., for a 1D line in two dimensions or a 2D plane in three dimensions. There also, the governing transformation invariance equation underlying invariant priors is derived. These special cases have since then been generalized to invariant priors for (
N − 1)-dimensional hyperplanes in
N-dimensional space; see, e.g., [
4]. These hyperplane priors proved to be valuable for Bayesian neural networks [
5], where the specific properties of the prior density favored node-pruning instead of simple edge pruning of standard (quadratic) weight regularizers. This is especially helpful for a Bayesian approach to fully-connected deep convolutional networks; see e.g., [
6,
7].
Nevertheless, the general case of prior probability densities for
L-dimensional hyperplanes in
N-dimensions (
N > L) in a suitable parameterization has not been available so far. It has even been conjectured that it is impossible to derive a general solution [
8]. Luckily, this conjecture has been too pessimistic, and an explicit formula for the prior density, which can directly be applied to linear regression problems, is derived below.
It should be pointed out that multivariate regression is of course a longstanding topic in Bayesian inference. with classical contributions, e.g., by Box and Tiao [
9], Zellner [
10] or West [
11]. However, the standard approach is based on the use of conjugate priors (instead of invariance priors), mostly for computational convenience [
12]. In contrast, the subsequently derived prior distribution is determined by the basic desideratum of consistency if the available prior information is invariant under the considered transformations (
i.e., rotations). Whether this invariance holds depends on the considered problem and must not be assumed without further consideration (similar to the case of flat priors for the coefficients). For example, the assumption of rotation invariance may not be suitable for covariates with different underlying units (e.g., m
2, kg).
2. Problem Statement
In standard notation, a multivariate regression model is notated as follows:
with:
where
zi is the response vector,
yi the model value vector,
xi the vector of the
L covariates for observation
i,
t the intercept vector and
A the
M × L-dimensional matrix of adjacent regression coefficients. The observation noise
ϵi of each data point is often considered as Gaussian distributed,
. This regression model can also be considered as estimating the “best”
L-dimensional hyperplane in an
N-dimensional space, because in an
N-dimensional space, an
L-dimensional hyperplane is given by:
with
M =
N − L.
The quantity of interest is the prior probability density F (A) = F (a11, ⋯, aML, t1, ⋯, tM|I) for the coefficients a11, ⋯, aML, t1, ⋯, tM, which remains invariant under translations and rotations of the coordinate system.
5. Solution
This system of PDEs (
Equations (28),
(29) and
(33)) can be tackled with the theory of Lie groups, which provides a systematic, though algebraically-intensive solution strategy, which is implemented in contemporary computer algebra systems. The solutions of several test cases computed by the Maple computer algebra system (
http://www.maplesoft.com/) (it proved to be superior to MATHEMATICA (
www.http://www.wolfram.com/mathematica/) for the present PDE-systems) led to the conjecture that a general solution to this PDE system is given by the sum of the squares of all possible minors of the coefficient matrix:
where
An denotes a submatrix (minor) of size
n × n (this notation is used at various places throughout the paper and should not be confused with the power of a matrix, which does not occur in this paper) and
P = Min (
M, L).
Equation (34) does not appear unreasonable from the onset as prior density, because it preserves the underlying symmetry of the problem (permutation invariance of the parameters) and it is non-negative.
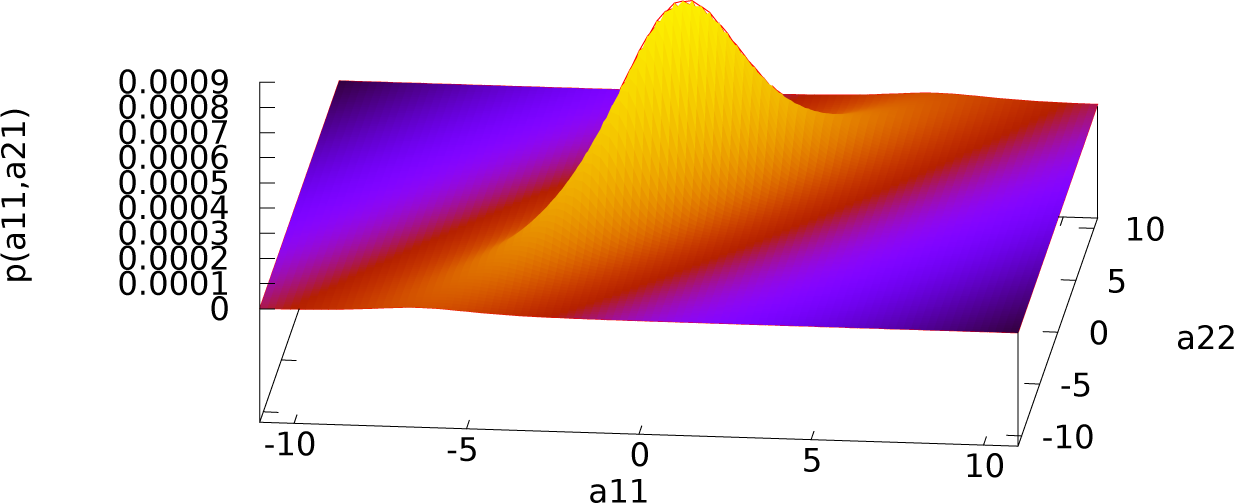
An explicit example for the case
N = 4,
L = 2 is:
A two-dimensional slice of this probability density is given in
Figure 2. The high symmetry of the prior distribution with respect to parameter permutations results in similar, “Cauchy”-like shapes if slices along other parameter axis are displayed.
For the case
N = 6,
L = 3, the solution is given by:
7. Relation to Previously-Derived Special Cases
The underlying equation systems of the special case of an (
n−1)-dimensional hyperplane in an
n-dim space used in [
8] and in this paper differ slightly due to a different parameterization, and therefore, the derived priors appear on first glance to be different, although they are identical, as will be shown below.
For probability density functions in different coordinate systems, the following equation holds:
where |⋯| denotes the absolute value of the Jacobi determinant:
The equation describing the (n-1)-dim hyperplane in an n-dim space in this paper is given by:
and results in the following prior:
In [
8], the corresponding hyperplane equation reads:
with prior distribution:
The latter constraints yield a proper (normalizable) prior. The relation of the two different parameterizations is given by:
which yields the Jacobian:
Using this result and
Equation (65), we can write:
which shows the equivalence of the two priors (
Equations (62) and
(64)). The requirement of
leads to:
In the case of all
a1i = 0, we obtain:
which means that the lower limit
corresponds to an upper limit of
.
8. Practical Hints
In the worst case, the hyperplane prior has an exponentially-increasing number of determinants with increasing dimension. The total number of individual determinants for an
N-dimensional plane in a 2
N-dimensional space is given by:
which is already 70 for a 4D hyperplane in an 8D space. Therefore, it is advantageous to compute the determinants using iteratively the Laplace expansion, starting from small determinants, storing the determinants of the previous step. This requires the storage of at most
terms. As a proposal density for Markov chain Monte Carlo (MCMC) sampling methods (e.g., rejection sampling), the dominating multivariate Cauchy distribution is a good candidate. Source code for the set up of the PDE system and for the solution, together with a Maple script for the verification of the solution, can be obtained from the author.



{kind=link}
{kind=link}