
Efficient Self-Supervised Metric Information Retrieval: A Bibliography Based Method Applied to COVID Literature



Abstract
:1. Introduction
1.1. Overview of the Research
1.2. Organization of the Paper
1.3. Related Works
1.3.1. Neural Language Models
1.3.2. Information Retrieval
2. Materials and Methods
2.1. Hardware and Software
2.2. CORD-19 Dataset
2.3. The Language Model
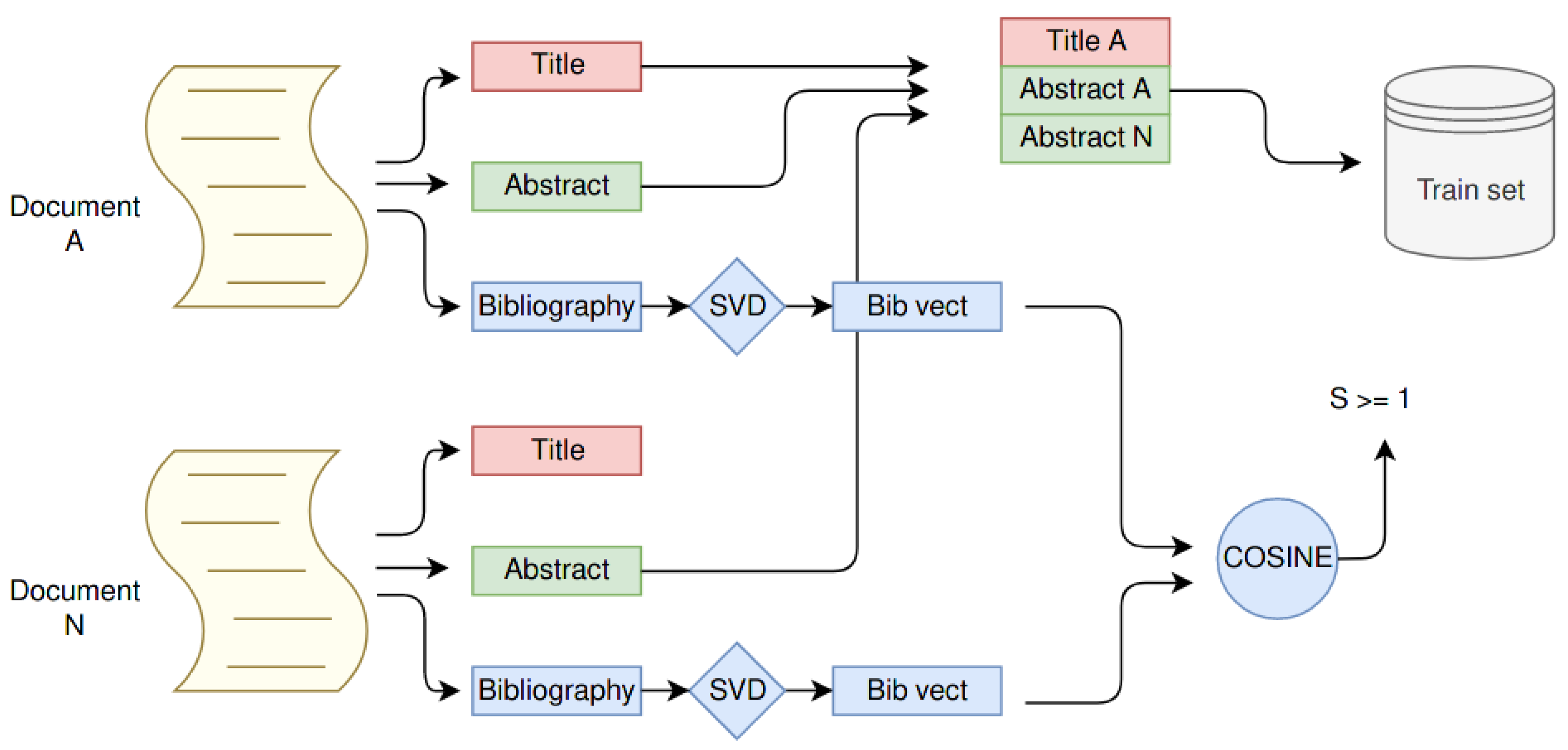
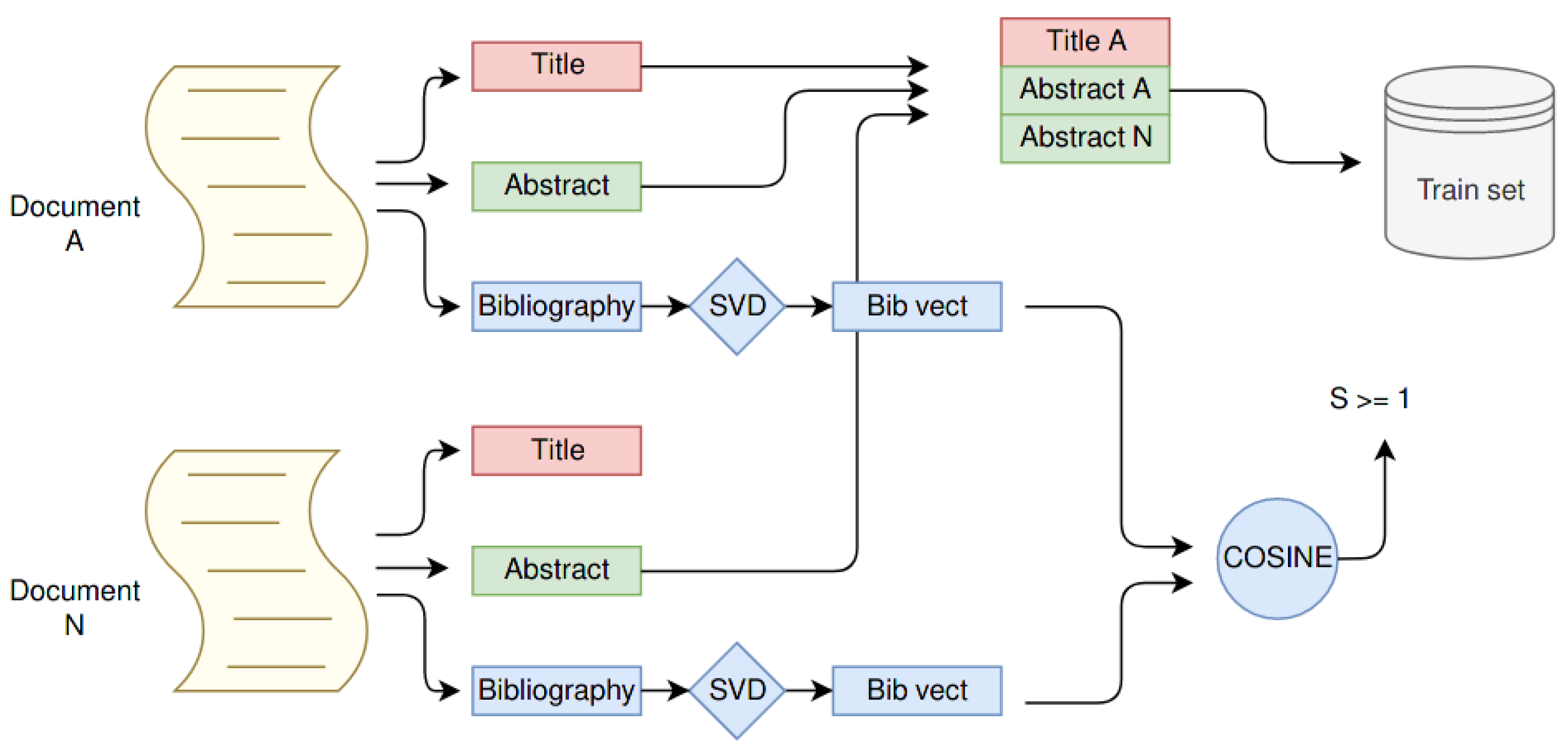
2.3.1. Bibliography Latent Information
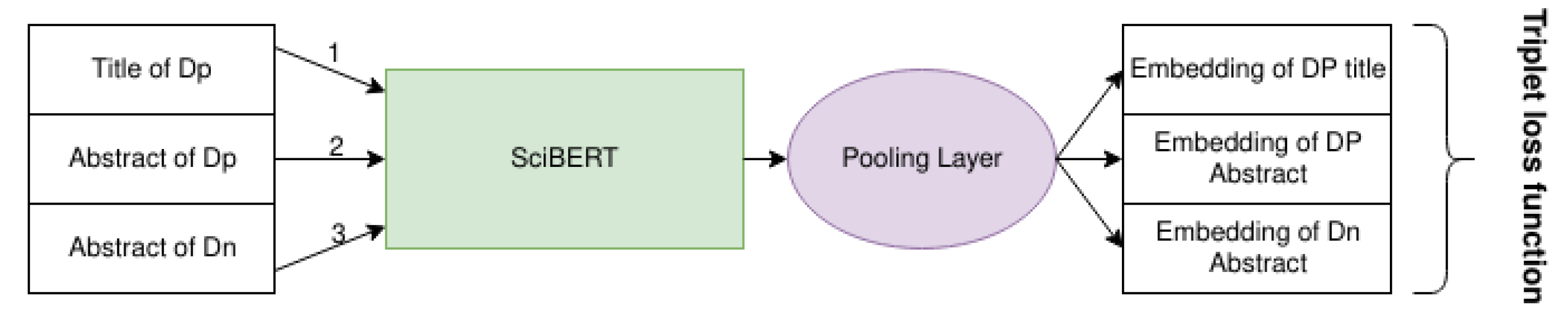
2.3.2. Training Set Creation
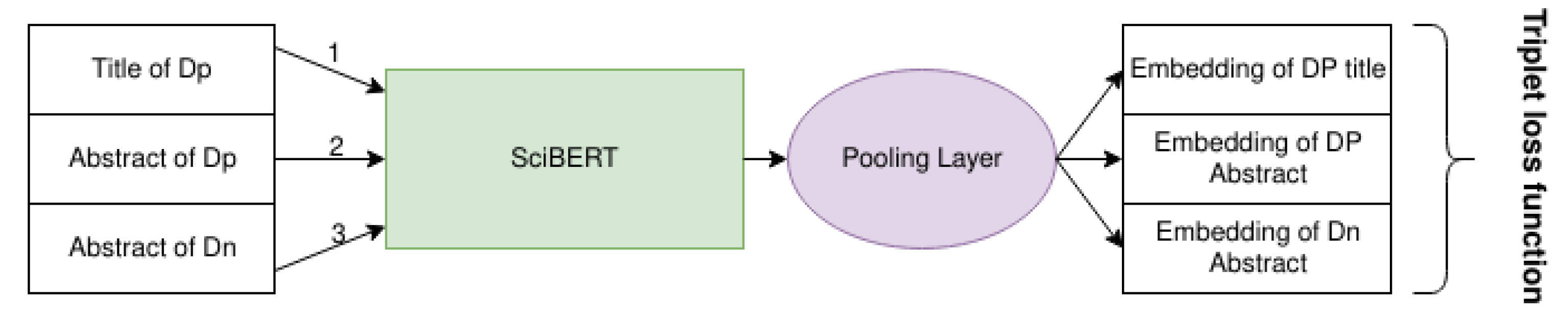
2.3.3. Loss Function
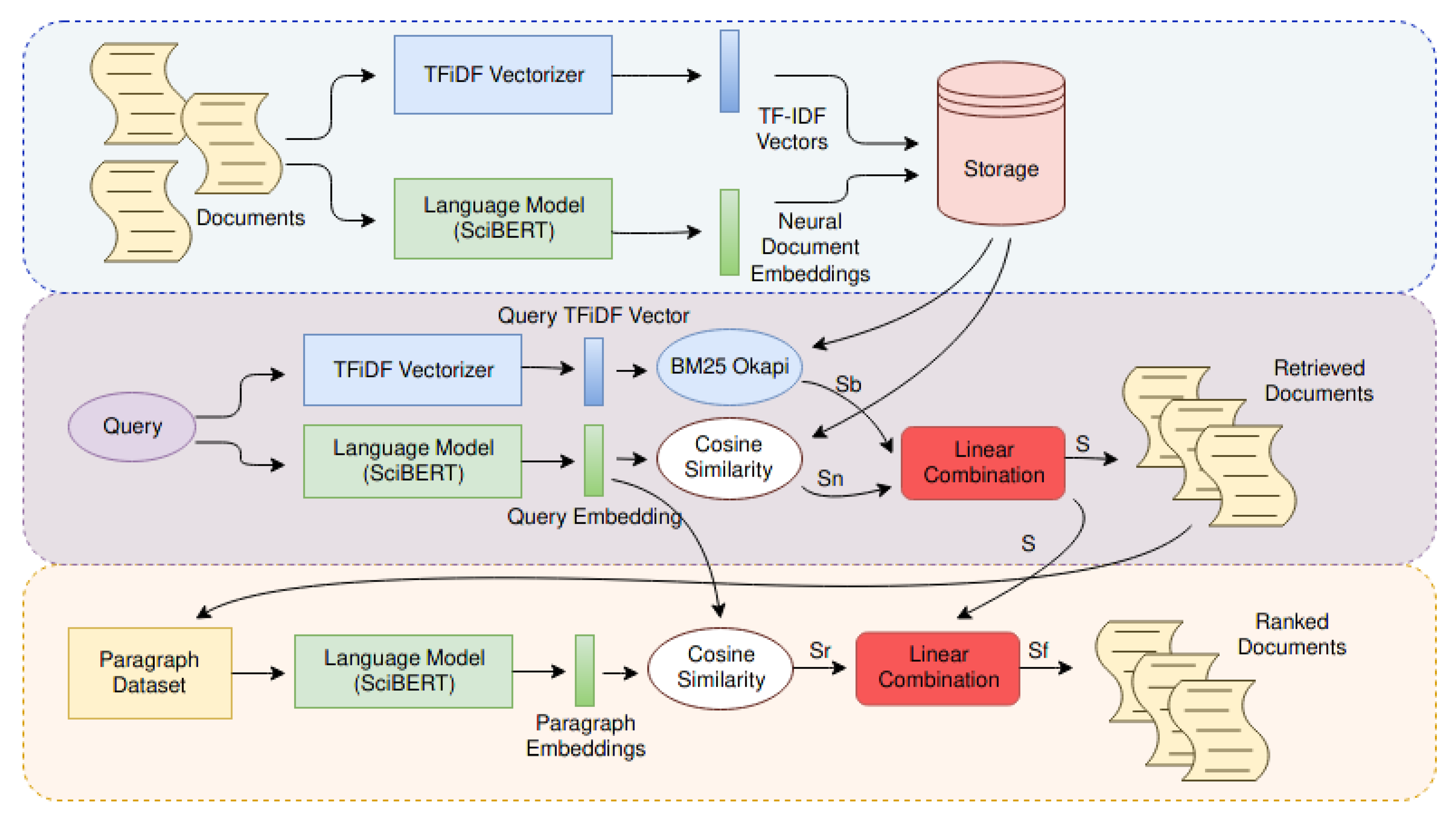
2.4. The IR System
- The indexer. It makes use of two embedding techniques to create different data structures useful for indexing: a real number vector representing the whole document (i.e., Neural Embedding), created by the language model, and the term frequency vector (i.e., TF-iDF) alongside with the bag of words of the entire domain used by the BM25 Okapi search algorithm [69].
- The retriever. It takes a query expressed by natural language, turns it into a vector using the neural network, and computes the TF-iDF. Then, the neural embedding is used to find the semantic related documents through cosine similarity, while BM25 Okapi algorithm leverages the tf-vector to assign to each document a score. Results from both the techniques are combined, and then all documents are sorted according to this new score.
- The reranker. The main idea behind this module is the title and the abstract used until this step to represent the entire document are not enough because some information remains unveiled in the full body. For this reason, this module considers all the inner paragraphs that compose the first K documents, in order to sort them according to their content. This task is performed by using a Neural Ranker Model, which is the same used by Retriever.
2.4.1. The Indexer
2.4.2. The Retriever
2.4.3. The Ranker
2.4.4. IR System Configuration
2.5. Language Model Fine-Tuning with Teacher
3. Results
3.1. TREC-COVID Test Set
3.2. Evaluation Metrics
3.2.1. Precision
3.2.2. nDCG
3.2.3. MAP
3.2.4. Bpref
3.3. IR Results
3.4. System Size Comparison
3.5. Bibliography Embeddings Evaluation
3.6. SUBLIMER: Web Information Retrieval Application
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| DL | Deep Learning |
| IR | Informational Retriever |
| NLP | Natural Language Processing |
| LM | Language Model |
| TF | Term Frequency |
| iDF | Inverse Document Frequency |
| TLF | Triplet Loss Function |
| MSL | Multi Similarity Loss |
| G.M. | Gianluca Moro |
| L.V. | Lorenzo Valgimigli |
References
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; Burstein, J., Doran, C., Solorio, T., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; Volume 1, pp. 4171–4186. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Beltagy, I.; Lo, K.; Cohan, A. SciBERT: A Pretrained Language Model for Scientific Text. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, 3–7 November 2019; Inui, K., Jiang, J., Ng, V., Wan, X., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 3613–3618. [Google Scholar] [CrossRef]
- Lee, J.; Yoon, W.; Kim, S.; Kim, D.; Kim, S.; So, C.H.; Kang, J. BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 2020, 36, 1234–1240. [Google Scholar] [CrossRef] [PubMed]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Esteva, A.; Kale, A.; Paulus, R.; Hashimoto, K.; Yin, W.; Radev, D.R.; Socher, R. CO-Search: COVID-19 Information Retrieval with Semantic Search, Question Answering, and Abstractive Summarization. NPJ Dig. Med. 2021, 4.1, 1–9. [Google Scholar]
- Rajpurkar, P.; Zhang, J.; Lopyrev, K.; Liang, P. Squad: 100,000+ questions for machine comprehension of text. arXiv 2016, arXiv:1606.05250. [Google Scholar]
- Yang, Z.; Qi, P.; Zhang, S.; Bengio, Y.; Cohen, W.W.; Salakhutdinov, R.; Manning, C.D. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. arXiv 2018, arXiv:1809.09600. [Google Scholar]
- Nguyen, T.; Rosenberg, M.; Song, X.; Gao, J.; Tiwary, S.; Majumder, R.; Deng, L. MS MARCO: A human generated machine reading comprehension dataset. arXiv 2016, arXiv:1611.09268. [Google Scholar]
- Domeniconi, G.; Moro, G.; Pagliarani, A.; Pasolini, R. On deep learning in cross-domain sentiment classification. In Proceedings of the 9th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management, IC3K 2017, Madeira, Portugal, 1–3 November 2017; Volume 1, pp. 50–60. [Google Scholar] [CrossRef]
- Domeniconi, G.; Semertzidis, K.; Lopez, V.; Daly, E.; Kotoulas, S.; Moro, G. A novel method for unsupervised and supervised conversational message thread detection. In Proceedings of the 5th International Conference on Data Management Technologies and Applications, DATA 2016, Lisbon, Portugal, 24–26 July 2016; pp. 43–54. [Google Scholar] [CrossRef]
- Domeniconi, G.; Moro, G.; Pasolini, R.; Sartori, C. Iterative refining of category profiles for nearest centroid cross-domain text classification. In Knowledge Discovery, Knowledge Engineering and Knowledge Management. Commun. Comput. Inf. Sci. 2015, 553, 50–67. [Google Scholar] [CrossRef]
- Moro, G.; Pagliarani, A.; Pasolini, R.; Sartori, C. Cross-domain & in-domain sentiment analysis with memory-based deep neural networks. In Proceedings of the 10th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management, IC3K 2018, Seville, Spain, 18–20 September 2018; Volume 1, pp. 127–138. [Google Scholar] [CrossRef]
- Domeniconi, G.; Moro, G.; Pagliarani, A.; Pasini, K.; Pasolini, R. Job Recommendation from Semantic Similarity of LinkedIn Users’ Skills. In Proceedings of the 5th International Conference on Pattern Recognition Applications and Methods, ICPRAM 2016, Rome, Italy, 24–26 February 2016; pp. 270–277. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of then Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.G.; Salakhutdinov, R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Johnson, K. OpenAI Releases Curtailed Version of GPT-2 Lnguage Model. Available online: https://venturebeat.com/2019/08/20/openai-releases-curtailed-version-of-gpt-2-language-model/ (accessed on 16 September 2021).
- Hern, A. New AI Fake Text Generator May Be Too Dangerous to Release, Say Creators. Available online: https://www.theguardian.com/technology/2019/feb/14/elon-musk-backed-ai-writes-convincing-news-fiction (accessed on 16 September 2021).
- Vincent, J. OpenAI Has Pblished the Text-Generating AI It Said Was Too Dangerous to Share. Available online: https://www.theverge.com/2019/11/7/20953040/openai-text-generation-ai-gpt-2-full-model-release-1-5b-parameters. (accessed on 16 September 2021).
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Proceedings of the Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, Virtual, 6–12 December 2020. [Google Scholar]
- Fedus, W.; Zoph, B.; Shazeer, N. Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. arXiv 2021, arXiv:2101.03961. [Google Scholar]
- Cohan, A.; Feldman, S.; Beltagy, I.; Downey, D.; Weld, D.S. SPECTER: Document-level Representation Learning using Citation-Informed Transformers. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, 5–10 July 2020; Jurafsky, D., Chai, J., Schluter, N., Tetreault, J.R., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 2270–2282. [Google Scholar]
- Schultz, M.; Joachims, T. Learning a Distance Metric from Relative Comparisons. In Proceedings of the Advances in Neural Information Processing Systems 16 Neural Information Processing Systems, NIPS 2003, Whistler, BC, Canada, 8–13 December 2003; Thrun, S., Saul, L.K., Schölkopf, B., Eds.; MIT Press: Cambridge, MA, USA, 2003; pp. 41–48. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, 3–7 November 2019; Inui, K., Jiang, J., Ng, V., Wan, X., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 3980–3990. [Google Scholar] [CrossRef] [Green Version]
- Dong, X.; Shen, J. Triplet Loss in Siamese Network for Object Tracking. In Proceedings of the Computer Vision—ECCV 2018-15th European Conference, Munich, Germany, 8–14 September 2018; Proceedings, Part XIII; Lecture Notes in Computer Science. Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; Volume 11217, pp. 472–488. [Google Scholar] [CrossRef]
- Gansbeke, W.V.; Vandenhende, S.; Georgoulis, S.; Proesmans, M.; Gool, L.V. SCAN: Learning to Classify Images Without Labels. In Proceedings of the Computer Vision—ECCV 2020-16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part X; Lecture Notes in Computer Science. Vedaldi, A., Bischof, H., Brox, T., Frahm, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12355, pp. 268–285. [Google Scholar] [CrossRef]
- Qian, Q.; Shang, L.; Sun, B.; Hu, J.; Tacoma, T.; Li, H.; Jin, R. SoftTriple Loss: Deep Metric Learning Without Triplet Sampling. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea, 27 October–2 November 2019; pp. 6449–6457. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Zhou, F.; Wen, S.; Liu, X.; Lin, Y. Deep Metric Learning with Angular Loss. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, 22–29 October 2017; pp. 2612–2620. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Han, X.; Huang, W.; Dong, D.; Scott, M.R. Multi-Similarity Loss With General Pair Weighting for Deep Metric Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; pp. 5022–5030. [Google Scholar] [CrossRef] [Green Version]
- Kaya, M.; Bilge, H.S. Deep Metric Learning: A Survey. Symmetry 2019, 11, 1066. [Google Scholar] [CrossRef] [Green Version]
- Jaiswal, A.; Babu, A.R.; Zadeh, M.Z.; Banerjee, D.; Makedon, F. A survey on contrastive self-supervised learning. Technologies 2021, 9, 2. [Google Scholar] [CrossRef]
- Jing, L.; Tian, Y. Self-supervised visual feature learning with deep neural networks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef] [PubMed]
- Komodakis, N.; Gidaris, S. Unsupervised representation learning by predicting image rotations. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3May 2018. [Google Scholar]
- Noroozi, M.; Favaro, P. Unsupervised learning of visual representations by solving jigsaw puzzles. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 69–84. [Google Scholar]
- Guo, J.; Fan, Y.; Pang, L.; Yang, L.; Ai, Q.; Zamani, H.; Wu, C.; Croft, W.B.; Cheng, X. A Deep Look into neural ranking models for information retrieval. Inf. Process. Manag. 2020, 57, 102067. [Google Scholar] [CrossRef] [Green Version]
- Yang, Z.; Lan, Q.; Guo, J.; Fan, Y.; Zhu, X.; Lan, Y.; Wang, Y.; Cheng, X. A Deep Top-K Relevance Matching Model for Ad-hoc Retrieval. In Information Retrieval, Proceedings of the 24th China Conference, CCIR 2018, Guilin, China, 27–29 September 2018; Lecture Notes in Computer Science; Zhang, S., Liu, T., Li, X., Guo, J., Li, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; Volume 11168, pp. 16–27. [Google Scholar] [CrossRef]
- Zheng, Y.; Fan, Z.; Liu, Y.; Luo, C.; Zhang, M.; Ma, S. Sogou-QCL: A New Dataset with Click Relevance Label. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, SIGIR 2018, Ann Arbor, MI, USA, 8–12 July 2018; Collins-Thompson, K., Mei, Q., Davison, B.D., Liu, Y., Yilmaz, E., Eds.; ACM: New York, NY, USA, 2018; pp. 1117–1120. [Google Scholar] [CrossRef]
- Moschitti, A.; Màrquez, L.; Nakov, P.; Agichtein, E.; Clarke, C.L.A.; Szpektor, I. SIGIR 2016 Workshop WebQA II: Web Question Answering Beyond Factoids. In Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval, SIGIR 2016, Pisa, Italy, 17–21 July 2016; Perego, R., Sebastiani, F., Aslam, J.A., Ruthven, I., Zobel, J., Eds.; ACM: New York, NY, USA, 2016; pp. 1251–1252. [Google Scholar] [CrossRef]
- Yang, L.; Ai, Q.; Guo, J.; Croft, W.B. aNMM: Ranking Short Answer Texts with Attention-Based Neural Matching Model. In Proceedings of the 25th ACM International on Conference on Information and Knowledge Management, Indianapolis, IN, USA, 24–28 October 2016. [Google Scholar]
- Qiu, X.; Huang, X. Convolutional Neural Tensor Network Architecture for Community-Based Question Answering. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, IJCAI 2015, Buenos Aires, Argentina, 25–31 July 2015; pp. 1305–1311. [Google Scholar]
- Yang, L.; Qiu, M.; Gottipati, S.; Zhu, F.; Jiang, J.; Sun, H.; Chen, Z. CQArank: Jointly model topics and expertise in community question answering. In Proceedings of the 22nd ACM International Conference on Information and Knowledge Management, CIKM’13, San Francisco, CA, USA, 27 October–1November 2013; He, Q., Iyengar, A., Nejdl, W., Pei, J., Rastogi, R., Eds.; ACM: New York, NY, USA, 2013; pp. 99–108. [Google Scholar] [CrossRef]
- Chen, L.; Lan, Y.; Pang, L.; Guo, J.; Xu, J.; Cheng, X. RI-Match: Integrating Both Representations and Interactions for Deep Semantic Matching. In Information Retrieval Technology, Proceedings of the 14th Asia Information Retrieval Societies Conference, AIRS 2018, Taipei, Taiwan, 28–30 November 2018; Lecture Notes in Computer Science; Tseng, Y., Sakai, T., Jiang, J., Ku, L., Park, D.H., Yeh, J., Yu, L., Lee, L., Chen, Z., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; Volume 11292, pp. 90–102. [Google Scholar] [CrossRef]
- Wan, S.; Lan, Y.; Xu, J.; Guo, J.; Pang, L.; Cheng, X. Match-SRNN: Modeling the Recursive Matching Structure with Spatial RNN. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, IJCAI 2016, New York, NY, USA, 9–15 July 2016. [Google Scholar]
- Gao, J.; Galley, M.; Li, L. Neural Approaches to Conversational AI. Found. Trends Inf. Retr. 2019, 13, 127–298. [Google Scholar] [CrossRef] [Green Version]
- Qu, C.; Yang, L.; Croft, W.B.; Zhang, Y.; Trippas, J.R.; Qiu, M. User Intent Prediction in Information-seeking Conversations. In Proceedings of the 2019 Conference on Human Information Interaction and Retrieval, CHIIR 2019, Glasgow, Scotland, UK, 10–14 March 2019; Azzopardi, L., Halvey, M., Ruthven, I., Joho, H., Murdock, V., Qvarfordt, P., Eds.; ACM: New York, NY, USA, 2019; pp. 25–33. [Google Scholar] [CrossRef] [Green Version]
- Pang, L.; Lan, Y.; Guo, J.; Xu, J.; Wan, S.; Cheng, X. Text Matching as Image Recognition. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 2793–2799. [Google Scholar]
- Palangi, H.; Deng, L.; Shen, Y.; Gao, J.; He, X.; Chen, J.; Song, X.; Ward, R.K. Deep Sentence Embedding Using Long Short-Term Memory Networks: Analysis and Application to Information Retrieval. IEEE ACM Trans. Audio Speech Lang. Process. 2016, 24, 694–707. [Google Scholar] [CrossRef] [Green Version]
- Fan, Y.; Guo, J.; Lan, Y.; Xu, J.; Zhai, C.; Cheng, X. Modeling Diverse Relevance Patterns in Ad-hoc Retrieval. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, SIGIR 2018, Ann Arbor, MI, USA, 8–12 July 2018; Collins-Thompson, K., Mei, Q., Davison, B.D., Liu, Y., Yilmaz, E., Eds.; ACM: New York, NY, USA, 2018; pp. 375–384. [Google Scholar] [CrossRef] [Green Version]
- Severyn, A.; Moschitti, A. Learning to Rank Short Text Pairs with Convolutional Deep Neural Networks. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; Baeza-Yates, R., Lalmas, M., Moffat, A., Ribeiro-Neto, B.A., Eds.; ACM: New York, NY, USA, 2015; pp. 373–382. [Google Scholar] [CrossRef]
- Xia, F.; Liu, T.; Wang, J.; Zhang, W.; Li, H. Listwise approach to learning to rank: Theory and algorithm. In Machine Learning, Proceedings of the Twenty-Fifth International Conference (ICML 2008), Helsinki, Finland, 5–9 June 2008; Cohen, W.W., McCallum, A., Roweis, S.T., Eds.; ACM International Conference Proceeding Series; ACM: New York, NY, USA, 2008; Volume 307, pp. 1192–1199. [Google Scholar] [CrossRef]
- Wang, L.L.; Lo, K.; Chandrasekhar, Y.; Reas, R.; Yang, J.; Eide, D.; Funk, K.; Kinney, R.M.; Liu, Z.; Merrill, W.; et al. CORD-19: The COVID-19 Open Research Dataset. arXiv 2020, arXiv:2004.10706. [Google Scholar]
- Zhang, E.; Gupta, N.; Tang, R.; Han, X.; Pradeep, R.; Lu, K.; Zhang, Y.; Nogueira, R.; Cho, K.; Fang, H.; et al. Covidex: Neural Ranking Models and Keyword Search Infrastructure for the COVID-19 Open Research Dataset. In Proceedings of the First Workshop on Scholarly Document Processing, SDP@EMNLP 2020, Online, 19 November 2020. [Google Scholar]
- Lin, J.; Ma, X.; Lin, S.C.; Yang, J.H.; Pradeep, R.; Nogueira, R. Pyserini: A Python Toolkit for Reproducible Information Retrieval Research with Sparse and Dense Representations. In Proceedings of the 44th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2021), Virtual, 11–15 July 2021. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv 2019, arXiv:1910.10683. [Google Scholar]
- Jin, Q.; Dhingra, B.; Liu, Z.; Cohen, W.W.; Lu, X. PubMedQA: A dataset for biomedical research question answering. arXiv 2019, arXiv:1909.06146. [Google Scholar]
- Ammar, W.; Groeneveld, D.; Bhagavatula, C.; Beltagy, I.; Crawford, M.; Downey, D.; Dunkelberger, J.; Elgohary, A.; Feldman, S.; Ha, V.; et al. Construction of the Literature Graph in Semantic Scholar. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2018, New Orleans, LA, USA, 1–6 June 2018; Industry Papers. Bangalore, S., Chu-Carroll, J., Li, Y., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; Volume 3, pp. 84–91. [Google Scholar] [CrossRef] [Green Version]
- Solawetz, J.; Larson, S. LSOIE: A Large-Scale Dataset for Supervised Open Information Extraction. arXiv 2021, arXiv:2101.11177. [Google Scholar]
- Agashe, R.; Iyer, S.; Zettlemoyer, L. JuICe: A Large Scale Distantly Supervised Dataset for Open Domain Context-based Code Generation. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, 3–7 November 2019; Inui, K., Jiang, J., Ng, V., Wan, X., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 5435–5445. [Google Scholar] [CrossRef]
- Minoguchi, M.; Okayama, K.; Satoh, Y.; Kataoka, H. Weakly Supervised Dataset Collection for Robust Person Detection. arXiv 2020, arXiv:2003.12263. [Google Scholar]
- Varadarajan, S.; Srivastava, M.M. Weakly Supervised Object Localization on grocery shelves using simple FCN and Synthetic Dataset. In Proceedings of the ICVGIP 2018: 11th Indian Conference on Computer Vision, Graphics and Image Processing, Hyderabad, India, 18–22 December 2018; ACM: New York, NY, USA, 2018; pp. 14:1–14:7. [Google Scholar] [CrossRef]
- Berthelot, D.; Carlini, N.; Goodfellow, I.J.; Papernot, N.; Oliver, A.; Raffel, C. MixMatch: A Holistic Approach to Semi-Supervised Learning. In Proceedings of the Advances in Neural Information, Processings of the Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; pp. 5050–5060. [Google Scholar]
- Misra, I.; van der Maaten, L. Self-Supervised Learning of Pretext-Invariant Representations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, 13–19 June 2020; pp. 6706–6716. [Google Scholar] [CrossRef]
- Hendrycks, D.; Mazeika, M.; Kadavath, S.; Song, D. Using Self-Supervised Learning Can Improve Model Robustness and Uncertainty. In Proceedings of the Advances in Neural Information, Processings of the Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- di Lena, P.; Domeniconi, G.; Margara, L.; Moro, G. GOTA: GO term annotation of biomedical literature. BMC Bioinform. 2015, 16, 346:1–346:13. [Google Scholar] [CrossRef] [Green Version]
- Lee, O.J.; Jeon, H.J.; Jung, J.J. Learning multi-resolution representations of research patterns in bibliographic networks. J. Inf. 2021, 15, 101126. [Google Scholar] [CrossRef]
- Frisoni, G.; Moro, G.; Carbonaro, A. Learning Interpretable and Statistically Significant Knowledge from Unlabeled Corpora of Social Text Messages: A Novel Methodology of Descriptive Text Mining. In Proceedings of the 9th International Conference on Data Science, Technology and Applications, DATA-2020, Setubal, Portugal, 7–9 July 2020; pp. 121–134. [Google Scholar]
- Frisoni, G.; Moro, G. Phenomena Explanation from Text: Unsupervised Learning of Interpretable and Statistically Significant Knowledge. Commun. Comput. Inf. Sci. 2021, 1446, 293–318. [Google Scholar] [CrossRef]
- Frisoni, G.; Moro, G.; Carbonaro, A. Unsupervised descriptive text mining for knowledge graph learning. In Proceedings of the 12th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management, IC3K 2020, Budapest, Hungary, 2–4 November 2020; Volume 1, pp. 316–324. [Google Scholar]
- Robertson, S.E.; Walker, S.; Jones, S.; Hancock-Beaulieu, M.; Gatford, M. Okapi at TREC-3. In Proceedings of the Third Text REtrieval Conference, TREC 1994, Gaithersburg, ML, USA, 2–4 November 1994. [Google Scholar]
- Voorhees, E.M.; Alam, T.; Bedrick, S.; Demner-Fushman, D.; Hersh, W.R.; Lo, K.; Roberts, K.; Soboroff, I.; Wang, L.L. TREC-COVID: Constructing a Pandemic Information Retrieval Test Collection. In ACM SIGIR Forum; ACM: New York, NY, USA, 2020; Volume 54, pp. 1–12. [Google Scholar]
- Craswell, N. Bpref. In Encyclopedia of Database Systems; Liu, L., Özsu, M.T., Eds.; Springer US: Boston, MA, USA, 2009; pp. 266–267. [Google Scholar] [CrossRef]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| P@5 | P@10 | nDCG@10 | MAP | Bpref | |
|---|---|---|---|---|---|
| LMrnbl | 0.0.69333 | 0.5868 | 0.6191 | 0.2716 | 0.5147 |
| SUBLIMERrnbl | 0.7867 | 0.69 | 0.6696 | 0.3272 | 0.5411 |
| LMtml | 0.74667 | 0.65333 | 0.6221 | 0.2776 | 0.5129 |
| SUBLIMERtml | 0.8333 | 0.71 | 0.6647 | 0.3238 | 0.5306 |
| LMmsl | 0.7000 | 0.64 | 0.6596 | 0.3040 | 0.5428 |
| SUBLIMERmsl | 0.8067 | 0.7067 | 0.7109 | 0.377 | 0.5662 |
| P@5 | P@10 | nDCG@10 | MAP | Bpref | |
|---|---|---|---|---|---|
| CoSearch | 0.8267 | 0.7933 | 0.7233 | 0.4870 | 0.5176 |
| Covidex | 0.6467 | 0.6032 | 0.2601 | ||
| LM | 0.74667 | 0.65333 | 0.6221 | 0.2776 | 0.5129 |
| SUBLIMER | 0.8333 | 0.71 | 0.6647 | 0.3238 | 0.5306 |
| SUBLIMERft | 0.84 | 0.7267 | 0.688501 | 0.362171 | 0.556162 |
| Alpha | P@5 | P@10 | nDCG@10 | MAP | Bpref |
|---|---|---|---|---|---|
| 1 | 0.74667 | 0.65333 | 0.6221 | 0.2776 | 0.5129 |
| 0.9 | 0.74667 | 0.69 | 0.64426 | 0.305501 | 0.52505 |
| 0.815 | 0.8067 | 0.71 | 0.6633 | 0.3232 | 0.5305 |
| 0.8 | 0.80 | 0.7067 | 0.6656 | 0.3251 | 0.5305 |
| 0.7 | 0.76 | 0.6933 | 0.6669 | 0.328096 | 0.5232 |
| 0.6 | 0.7333 | 0.6633 | 0.65996 | 0.3183 | 0.5041 |
| Beta | P@5 | P@10 | nDCG@10 | MAP | bpref |
| 0.8 | 0.8133 | 0.71 | 0.6638 | 0.3233 | 0.5306 |
| 0.77 | 0.8333 | 0.71 | 0.66471 | 0.323768 | 0.5306 |
| 0.7 | 0.7933 | 0.7067 | 0.6658 | 0.3233 | 0.5306 |
| K | Baseline | R1 | R2 |
|---|---|---|---|
| 2048 | 0.992 | 0.958 | 0.939 |
| 1024 | 0.991 | 0.943 | 0.922 |
| 512 | 0.989 | 0.939 | 0.913 |
| 256 | 0.981 | 0.906 | 0.871 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moro, G.; Valgimigli, L. Efficient Self-Supervised Metric Information Retrieval: A Bibliography Based Method Applied to COVID Literature. Sensors 2021, 21, 6430. https://doi.org/10.3390/s21196430
Moro G, Valgimigli L. Efficient Self-Supervised Metric Information Retrieval: A Bibliography Based Method Applied to COVID Literature. Sensors. 2021; 21(19):6430. https://doi.org/10.3390/s21196430
Chicago/Turabian StyleMoro, Gianluca, and Lorenzo Valgimigli. 2021. "Efficient Self-Supervised Metric Information Retrieval: A Bibliography Based Method Applied to COVID Literature" Sensors 21, no. 19: 6430. https://doi.org/10.3390/s21196430