1. Introduction
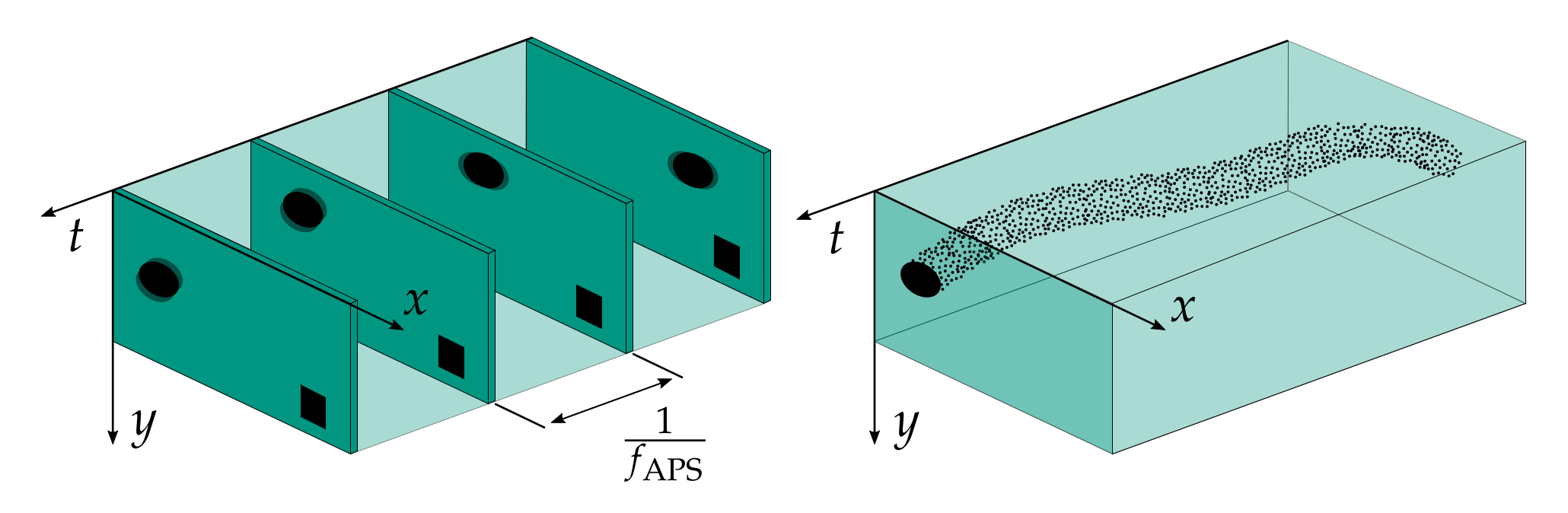
In recent years, a new type of image sensor principle has undergone a rapid development. So-called Dynamic Vision Sensors (DVS) merely perceive changes in intensity and encode this information as events in an asynchronous stream. The approach is further illustrated in
Figure 1. DVS promises high time resolution in the order of microseconds, low latency, and a low data rate by omitting transmission of redundant information, i.e., static regions of the image plane. If there is no moving object in the visual scope, no events are triggered. Although theoretical advantages of the sensor principle have been discussed thoroughly [
1], their fields of application still remain somewhat unclear. In previous works, DVS are mainly investigated in the field of autonomous driving, for monitoring, and gesture recognition. Additionally, it has recently been shown that the strength of the concept is particularly evident in sparsely populated scenes [
2]. However, this does match very well to the fields of application considered so far.
Automatic visual inspection is a widely spread form of automatic quality control. It is vital to a variety of processing and manufacturing industries and serves the purpose of inspecting wrought materials and end products, among others. In contrast to manual inspection performed by human personnel, machine vision-based approaches promise objective and reproducible results, fast inspection execution, and less expensive solutions. By “looking”, it is evaluated whether components have been correctly assembled, containers are fully loaded, or individual objects meet the quality requirements in terms of dimensions, shape, surface finish, or color [
3], to name a few examples. The process of “looking” is performed by one or multiple imaging sensors. According to the state-of-the-art, those are typically either line-scanning or frame-based.
In this paper, application of DVS in the so far unconsidered field of automatic visual inspection is investigated. Machine vision applications are often characterized by a highly controlled environment. This is reflected, among other things, in a static sensor position, control over the design and parameterization of the illumination, and the feeding or presentation of test objects. This in turn enables the realization of data acquisition conditions in which the potential of DVS can fully unfold, for instance, sparsely populated scenes. A resulting advantage lies in increasing the processing speed of “looking”.
Main contributions of this paper are threefold. First, the most recent classification algorithms are evaluated in the context of the new application domain of automatic visual inspection in a unitized, modular machine vision pipeline. Second, a novel algorithmic module is proposed, included and evaluated using the pipeline in order to meet common challenges in automated visual inspection, such as arbitrary object rotations. We refer to this algorithmic contribution as contrast-based windowing and demonstrate how it enhances classification accuracy distinctly. Third, two novel event-based datasets for challenging scenarios in automatic visual inspection are introduced. By publishing the datasets alongside this paper, we intend to further stimulate research on DVS in the context of machine vision.
This paper is organized as follows. Following this brief introduction, related work is reviewed in
Section 2. A modular pipeline for event processing in the context of machine vision is presented in
Section 3. Here, the new concept of contrast-based windowing is also introduced. Following, two novel datasets containing event-streams from typical visual inspection scenarios are introduced in
Section 4. Results from utilizing the presented pipeline with these datasets are presented in
Section 5.
Section 6 concludes the paper.
3. Event-Based Vision Pipeline
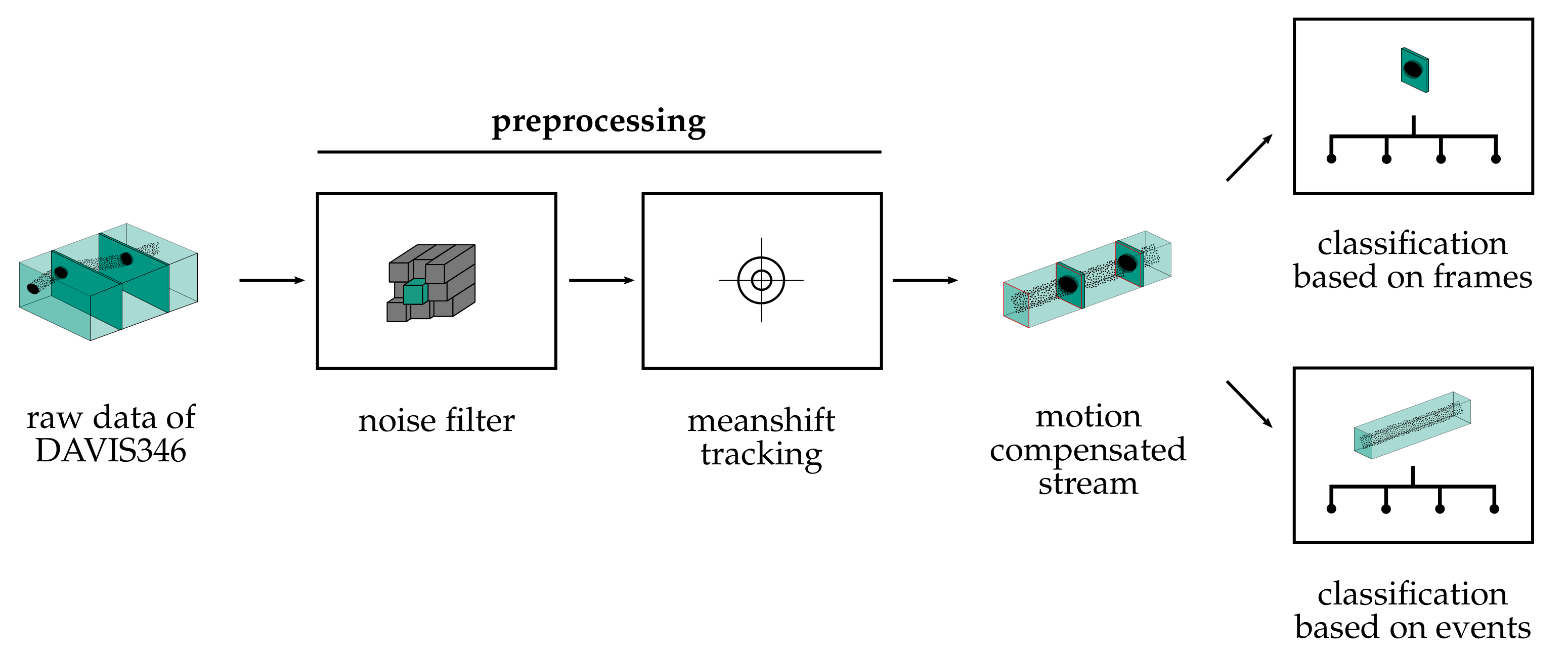
We propose a modular processing pipeline for object classification using DAVIS cameras. A general overview of the processing steps is provided in
Figure 2. The procedure is divided into two stages. The first stage addresses the tasks of preprocessing and object tracking. First, noisy events are filtered out of the stream. Then, a tracking algorithm clusters events of an object and tracks the object center in the image plane. This results in motion-compensated event streams, conventional frames of the DAVIS camera within a region of interest (ROI), and information about the object’s position and velocity. In the second stage, the classification of the detected objects is performed. For this purpose, we consider classification based on frames with conventional methods and also classification utilizing the motion compensated event streams. For the latter, four different approaches are considered. One method is the reconstruction of an intensity image and application of a classical image classifier. Furthermore, HATS [
18] and MatrixLSTM [
19], two recently proposed methods, are implemented to transform events into a suitable feature space. Based on this, a convolutional neural network with ResNet [
25] architecture is used as a classifier. Finally, a SNN is considered that can process the event stream directly, thus completing the neuromorphic approach of event-based cameras. In the following, all components of the pipeline are explained, starting with the format of raw event data.
3.1. Event Representation
The pixels of an event camera detect changes in the logarithmic intensity signal independently and emit an asynchronous event stream. According to the address-event representation [
4], events are described as tuples
where
defines the horizontal and
the vertical position in the image plane,
the polarity, and
the timestamp of an event, commonly expressed in microseconds.
Assuming the brightness constancy assumption and a constant illumination, it can be derived that events occur at moving edges [
1]. If the edge is aligned parallel to the direction of movement, no events are generated, but if it is aligned perpendicular to it, a maximum number of events are generated. Consequently, only partial areas of a pattern can be perceived that do not have a parallel orientation.
3.2. Noise Filtering and Tracking
Pixels with strong activity, so-called hot pixels, are detected and eliminated from the stream during a learning phase while viewing a rigid scene. This learning process only needs to be performed once during the initial camera calibration. To reduce background noise, the well-established spatio-temporal correlation filter from in [
9] is used. Partitioning events in packets of
μs has been empirically determined to yield a good trade-off between processing quality and speed. Based on the filtered event packets, the tracking algorithm of Barranco et al. [
11] is used to determine and track the center of the object. The method is based on a meanshift approach with multivariate Gaussian kernel according to
The variable is composed of the event position and a weighted temporal difference between the timestamp t of the event and the end time of the time interval under consideration and is a suitable weighting matrix. The clustering result provides the cluster centroid in the image plane and the allocation of the events to the objects. In general, this also allows for multi-object tracking, but in this work we restrict ourselves to tracking one object. The detected object center point is then estimated using a Kalman filter, which includes the position as well as the velocity of the object as part of the state variable. A square ROI of constant size is formed around the object center, which encloses the entire object. To compress information, all events associated with the object are represented relative to this ROI, and the entire stream is limited to the time range in which the object is fully visible. In addition, all conventional frames of the DAVIS camera are also extracted within the ROI. These data form the basis for the subsequent procedures.
3.3. Contrast-Based Windowing (CBW)
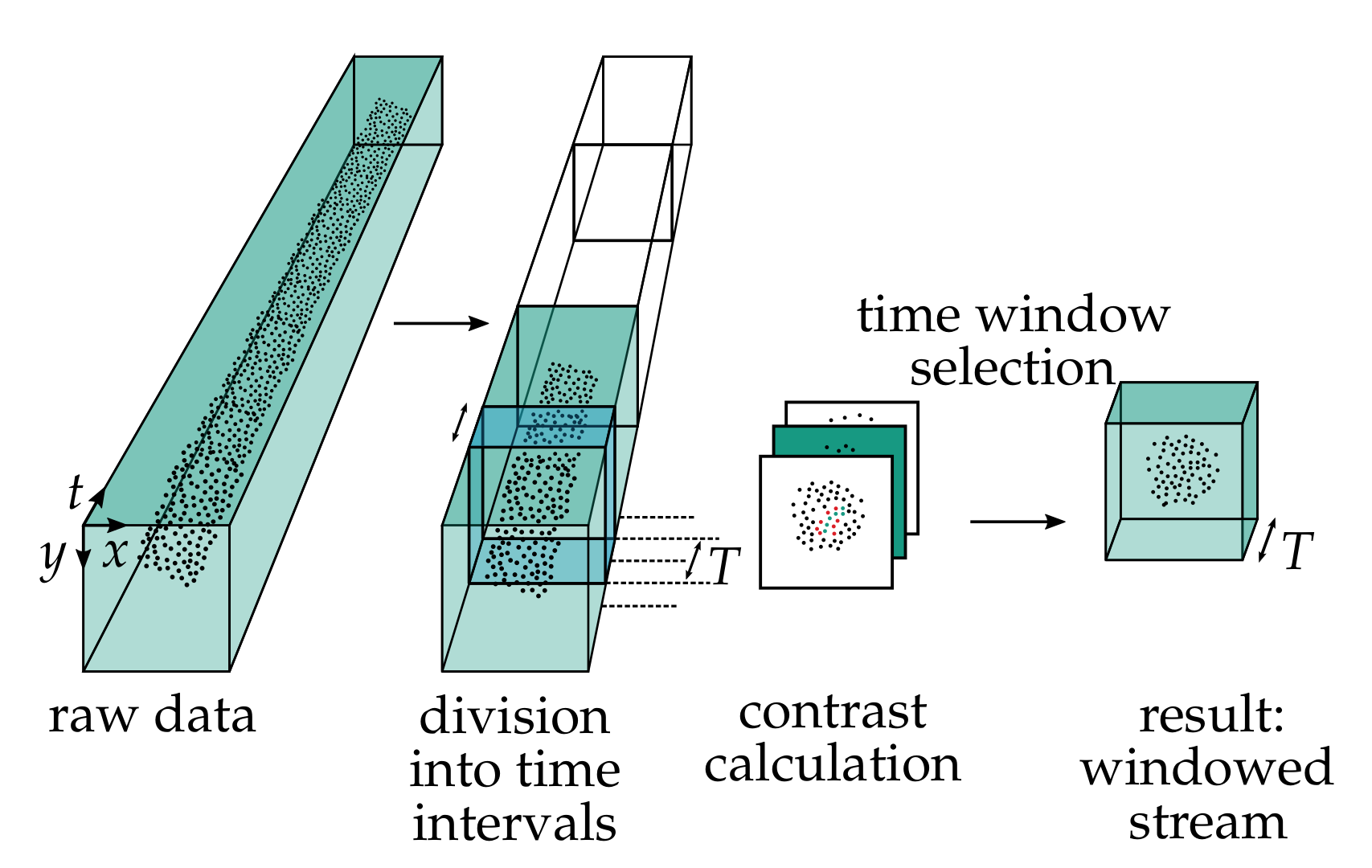
For both datasets presented in
Section 4, the objects are only completely visible in the camera’s field of view for a certain time interval. During this time, the objects can rotate strongly and thus the texture is not constant for all samples at all times in the stream. This challenge distinguishes our dataset strongly from already published ones, as, due to the fields of application yet considered in the literature, rotation of objects rarely occurs and lateral motion is typically much slower. Previously developed classifiers for event streams hardly include this additional degree of freedom.
In the context of this study, we observe that a classifier provides higher classification accuracy when the stream is limited to a short time interval. For this reason, this paper presents a method to determine an optimal time interval for classifying an event stream as shown in
Figure 3. The basic idea is to detect the time point with maximum contrast. The event stream is divided into
N time intervals similar to the work in [
18,
19]. The time of maximum contrast is determined separately for each time interval. For this purpose, a sliding time window of length
T is applied to the time interval. Within this window, a neighborhood defined by
of an event
is considered, where
defines the size of this neighborhood and
describes the position of
. Using this neighborhood, a contrast value
c is determined according to
Here, c is the sum of all events with at least one event of opposite polarity in the neighborhood of . Over all time windows considered, the window that has the largest contrast c is chosen. The algorithm splits the original event stream and returns only events within the optimal time window for each time interval. This data is now used as the input signal for the classification algorithms described below.
3.4. Classification Framework
To obtain a broad analysis of the suitability of event-based cameras for automatic visual inspection, different classification approaches are tested. We implement a unified framework that allows easy adaptation of the processing pipeline, for example, switching classification methods comparable to the work in [
19]. Besides conventional intensity frames that serve as a reference, we consider four approaches. These are described in the following in more detail. A basic distinction is made between frame-based and event-based methods.
3.4.1. Frame-Based Methods
The group of frame-based methods includes all methods in which a frame represents the data basis for the subsequent classification. This frame can be interpreted as a gray scale image of the scene. First, this category includes the conventional images of the DAVIS camera. This approach only serves as a baseline and comparison to a conventional camera with 25 frames per second (fps). Second, the method of Scheerlinck et al. [
15] as formalized in Equations (5) and (6) is used to reconstruct an intensity image from the event stream. Although this approach originally applies a complementary filter to fuse event and frame information, it also allows a reconstruction based on events only. To estimate the brightness
at a location
, Scheerlinck’s approach reduces to a differential equation as given by
where
is an accumulated event image and
defines the cut-off frequency. The tuning parameters
and
are used to ensure the visibility of the object’s texture during a chosen interval length. The initial gray value gradient is chosen to be 128, which corresponds to half of the 8-bit coded value range. As we are focusing on event-based approaches, no information from conventional frames is considered in our work. Reconstructed frames are normalized and then classified with a ResNet-18 [
25].
3.4.2. HATS
In addition to frame-based methods, this work applies two approaches that do not reconstruct a grayscale image, but instead transform the events into a feature map. The HATS algorithm [
18] divides the image plane into
K cells of equal size. Incoming events are uniquely assigned to a cell based on their position and polarity. Within the cell, a
Local Memory Time Surface as defined by
is calculated for each event, where
denotes the neighborhood of an event
over a time interval of length
T and
is a time weight. Then, all
Local Memory Time Surfaces are accumulated and normalized by the number of events within the cell. Due to the superposition of time surfaces, the influence of noisy events can be reduced and the normalization provides additional independence from the number of events and thus the contrast conditions of the scene. Finally, the histograms of the individual cells are combined to form a feature map. In the original publication, a linear support vector machine (SVM) is used for classification. However, in this work it is shown that better results can be obtained using deep neural networks. A ResNet-18 is used for the classification of the time surfaces, which also ensures comparability to the other considered methods.
3.4.3. MatrixLSTM
In addition to HATS, another algorithm that has a similar basic principle is evaluated. Instead of clustering the image plane into cells, MatrixLSTM [
19] represents each pixel with its own LSTM cell. For an incoming event in the time interval
, a feature vector
is computed based on polarity, other events in a local neighborhood, and several temporal information. All computed features of a pixel are processed with an LSTM cell that combines event dynamics into an output vector
. After the last event of the pixel has been processed in the time interval
, the last outputs of the LSTM cell
map the complete event sequence dynamics at the pixel under consideration. The final feature map
is subsequently composed of all outputs of cells
at their original pixel position. In their paper, Cannici et al. [
19] present different configurations that define the structure of the classifier and the selection of features. In the context of our work, we evaluate these different configurations and conclude that the configuration referred to as
ResNet18-Ev2Vid outperforms the other ones. Thus, we focus on this configuration, by which MatrixLSTM is configured to provide three channels at the output and processes the entire stream as one time interval. The normalized timestamp difference between successive events at a pixel is chosen as the temporal feature. In addition, the polarity of the events is added as a feature.
3.4.4. Multi-Level SNN
Last, a direct end-to-end classification procedure that retains the event character from generation to classification is evaluated. The approach of Liu et al. [
20] is used, which is based on a multi-level SNN. Incoming events are convolved in the input layer with Gabor filters that detect patterns of different orientation and scaling. The pulses are integrated with
Leaky Integrate-and-Fire (LIF) neurons and passed on as a pulse to the next layer as soon as the activity of a cell’s neurons exceeds a threshold. The subsequent layer receives the pulses, and the assignment of cells to neurons is unique. Subsequently, a layer of fully linked synapses enables the learning of different classes based on the detected features.
As a learning algorithm, the authors present a new method called Segmented Probability-Maximization (SPA). The algorithm is based on a Noisy Softplus feature that is biologically inspired and tailored to the LIF neurons used. The learning algorithm adjusts the weights based on the output neuron potentials and the impulse behavior of the middle layer. The procedure can be summarized in two steps. In the first step, the time point with maximum activity within a specified search radius is determined for each output neuron. Subsequently, the individual weights are adjusted by taking the firing rate of each output neuron into account. The goal is to adjust the weights in a way that the output neuron shows the highest activity compared to the other output neurons when viewing an object of class j.
As the original source code is not available at the time of this research, the algorithm itself is implemented based on
BindsNet [
26] and integrated into the modular pipeline. Compared to the original release, a few changes are made. The size of the Gabor filter bank is reduced such as there are only four filters of different orientations. A separate consideration of the scaling is not necessary in our use case, because the objects are almost the same size in the image. Reducing the number of filters decreases the computational effort and thus significantly reduces the time for a training run. The filter bank is implemented using a combination of two layers in
BindsNet. The number of output neurons is adjusted to the number of classes in the dataset. The learning algorithm now adjusts the connection weights between the middle and the output layer.
3.5. Summary of the Resulting Pipeline
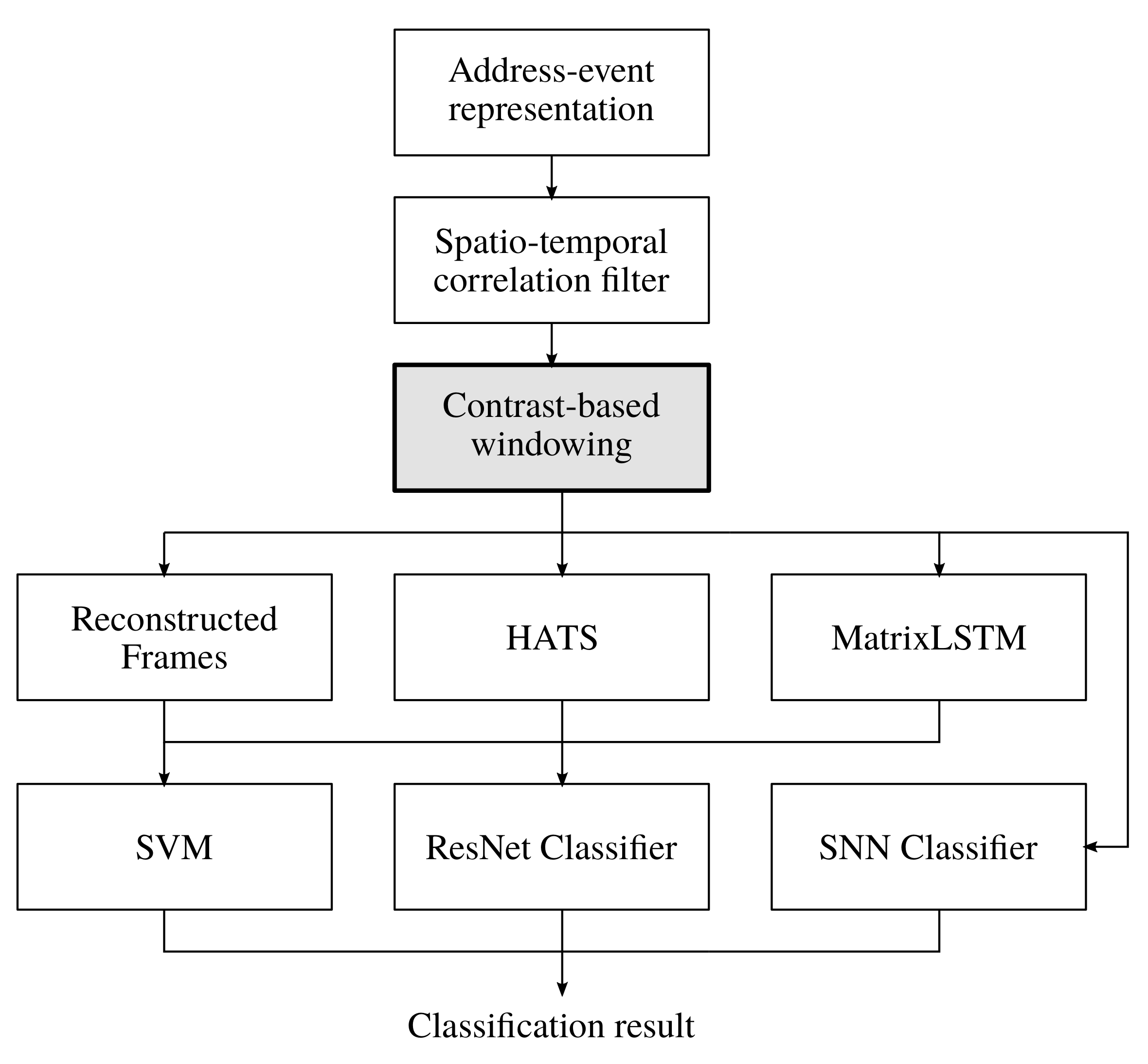
A visual summary of the proposed pipeline is provided in
Figure 4. Regarding the input format, the address-event representation [
4] is chosen. Noise filtering is implemented using the spatio-temporal correlation filter from in [
9]. For object tracking, we use the algorithm from in [
11] in order to determine the center of an object together with a Kalman filter. Subsequently, the proposed CBW approach is applied. With respect to classification, two paths exist. For the first path, we integrate the image reconstruction approach from in [
15], HATS [
18] and MatrixLSTM [
19] to calculate feature maps which are then used in conjunction with a SVM or ResNet classifier. For the second path, data are directly classified by a SNN [
20].
4. Datasets for Visual Inspection
As described in
Section 2.2, existing datasets mainly address the fields of autonomous driving, robotics, and surveillance. In order to test an application of the pipeline described above in the application field of automatic visual inspection, novel datasets are generated in this work. Some preliminary considerations are made when selecting suitable scenes for the generation of event-based datasets. In general, scenes of automatic visual inspection are characterized by high dynamics of objects in a controlled environment. The illumination and the distance between camera and object can be assumed to be constant. Especially suitable scenarios that are often found in automatic visual inspection include the inspection of objects during free fall in front of a static background or on a conveyor belt with constant speed. An advantage of the event-based technology is directly shown by the fact that only dynamic and high-contrast image areas are perceived. This greatly simplifies the detection of the objects and computations only need to be made at relevant time intervals. In order to cover a wide range of applications, two different datasets are generated.
The first dataset contains recordings of wooden balls with a diameter of
that differ in their texture by means of a varying number of stripes. We use four balls that are marked by hand with stripes that extend around the complete circumference. The number of stripes varies between none and three, resulting in four different classes to be distinguished. These four test objects are fed repeatedly to the system for data recording.
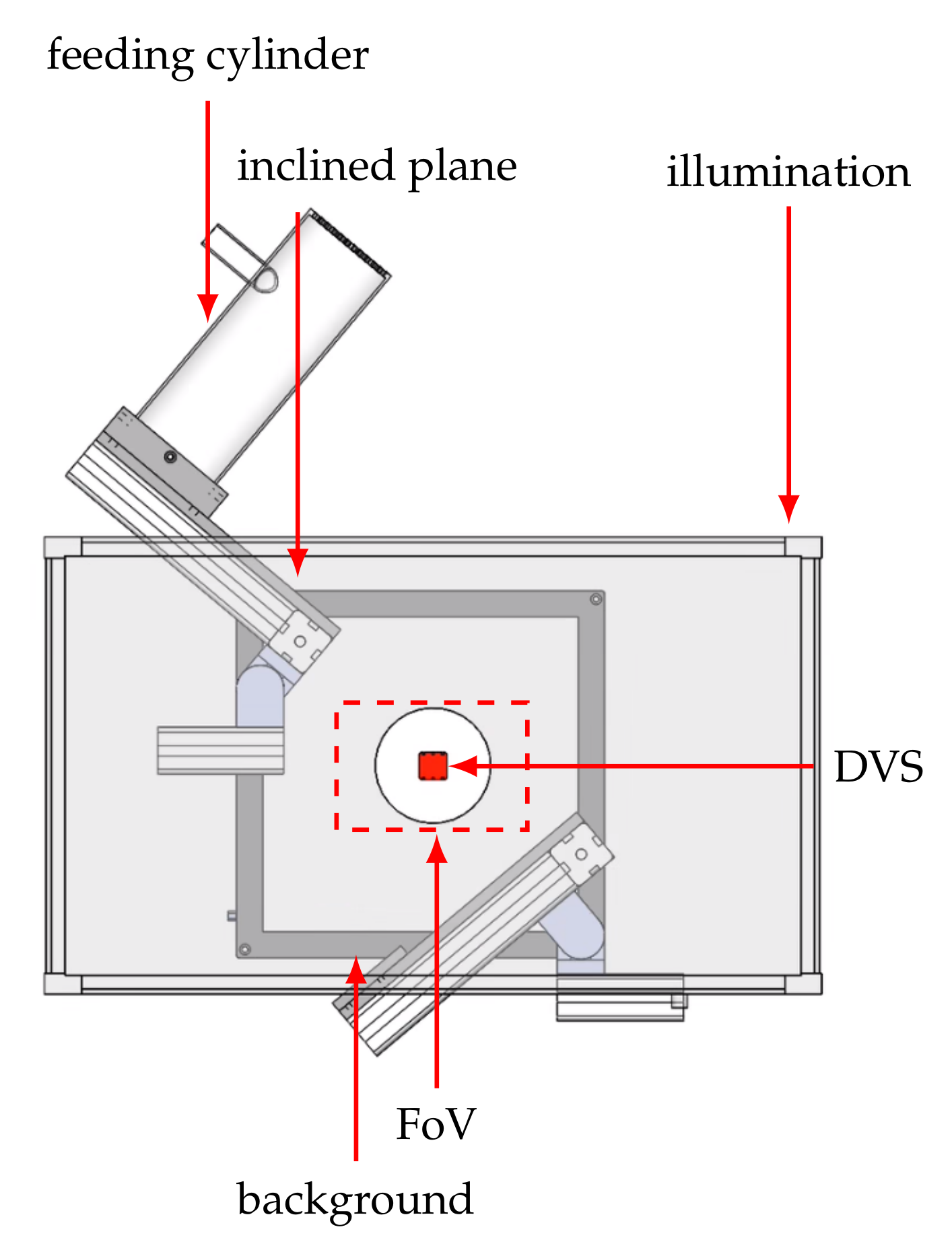
Figure 5 shows the experimental setup which is used to record the balls in free fall. The setup is inspired by the authors of [
27]. Starting from the upper cylinder, the balls pass through a small opening onto an inclined plane. There they are accelerated and pass diagonally through the camera’s field of view, see
Figure 6. A funnel catches the ball at the bottom and a pneumatic conveying system transports it back into the upper cylinder. The scene is diffusely illuminated using a LED flat dome and the black background ensures that the object is shown with a high contrast. The balls are on average
completely visible in the image and have an approximate velocity of 1.3
at the time of disappearance. The particular challenge of the dataset is the strong rotation of the objects, which means that the stripes can only be seen completely at short time intervals.
As a result of the rotation of the balls, the texture may not be fully visible. In order to ensure a distinct database, samples of balls with one, two, or three stripes that do not contain the relevant texture are removed manually. Due to the time-consuming manual process, we restrict ourselves to selecting 2000 samples per class. For the balls without a stripe, we randomly select 2000 samples. The final dataset hence includes 8000 samples.
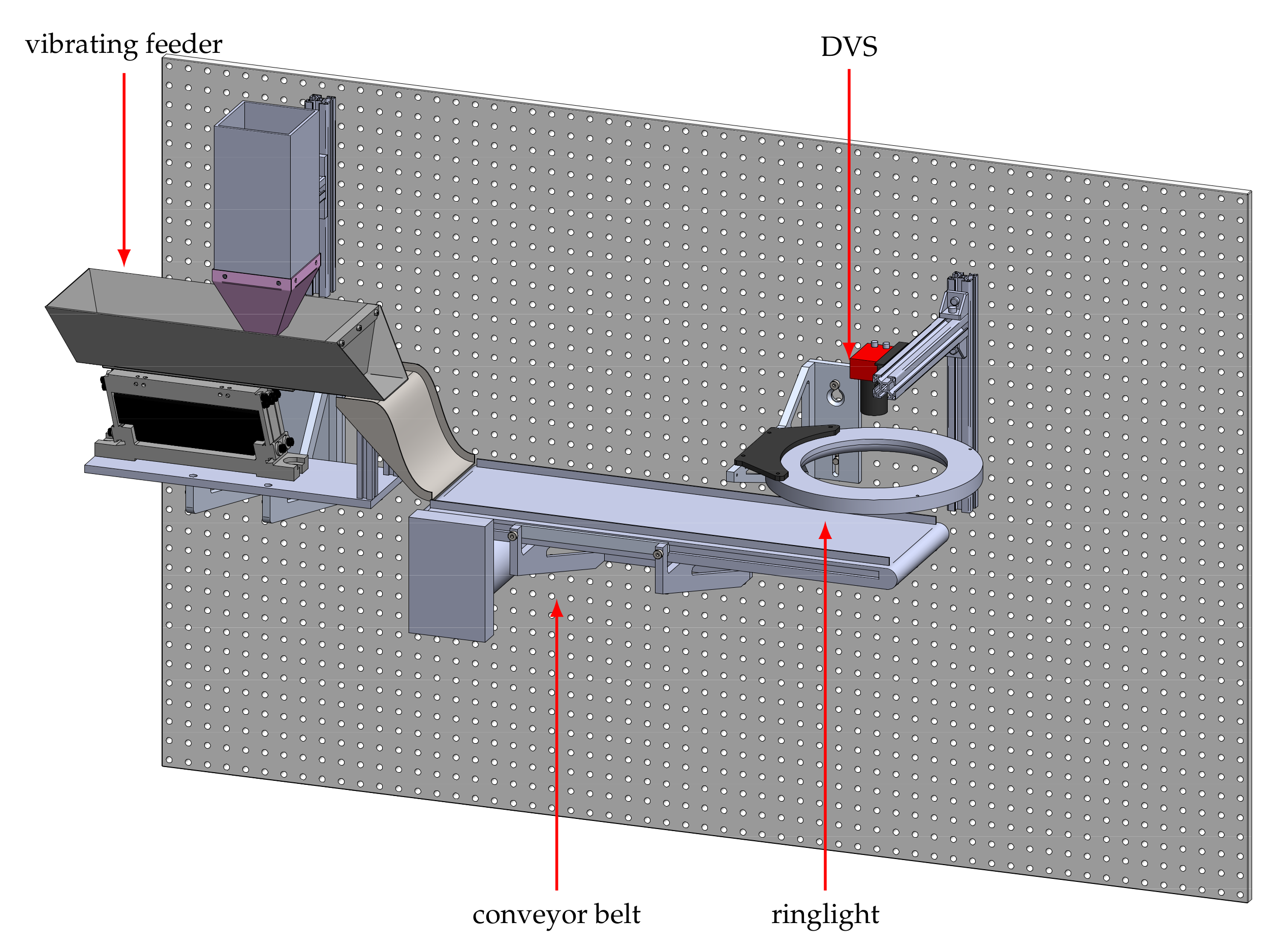
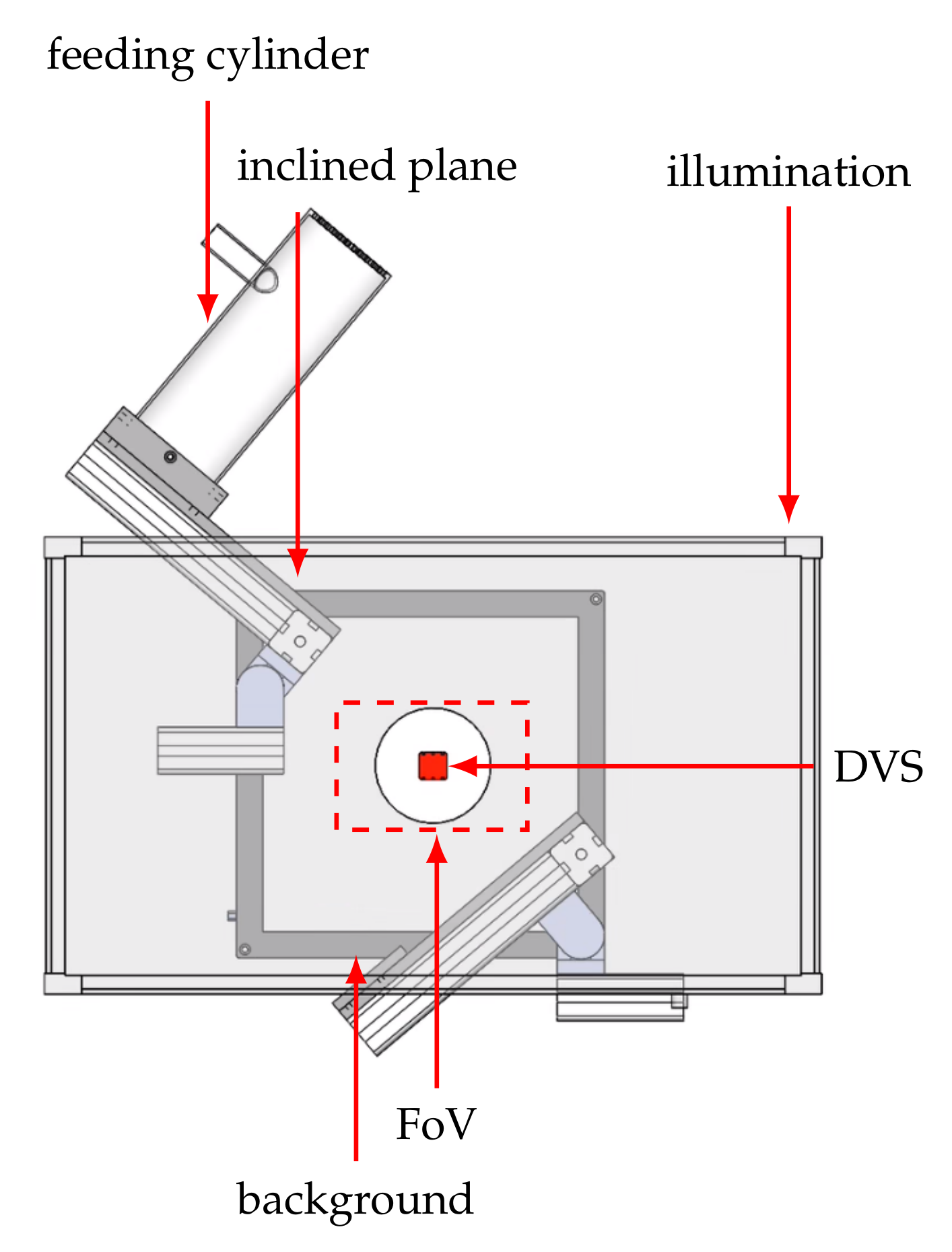
The second dataset contains recordings of two bean varieties that differ in texture. The aim is to distinguish white beans from Borlotti beans, which have a cream base color with a random pattern of red dots and stripes. We use approximately 9500 beans of each class for recording data, with each bean passing through the system only once. The second experimental setup is shown in
Figure 7. It is adapted from an experimental platform for sensor-based sorting and is described in detail in [
28]. The beans are fed into the system by a vibrating feeder onto a conveyor belt via a connecting feeding chute. As soon as a bean enters the belt, it is transported through the field of view of the event-based camera at a speed of
, see
Figure 8. One major challenge of the setup is the moving background. Due to the high dynamic range of event-based cameras, even low contrasts of the black belt can lead to background noise. The scene is illuminated with a diffuse LED ring light. The final dataset includes 18,804 samples, 9353 of Borlotti and 9451 of white beans.
Both scenes are recorded with the event-based camera DAVIS346 by iniVation. Properties of this model can be found in [
1]. The parameters of the photoreceptor amplification (PrBp) and source follower (PrSfPb) are tuned manually beforehand such that the object’s texture and outline is clearly visible. Besides the event information, conventional frames are recorded at a rate of
.
All raw data are then preprocessed using the event-based pipeline presented in
Section 3. In order to filter out background activity noise, we require an event to have at least 2 supporting events in its direct neighborhood during a time horizon of
μs for the ball and
μs for the bean dataset. The tracker detects an object as soon as a minimum of 50 events form a valid cluster in case of the ball dataset and 250 events that are validated at least five times in case of the bean dataset. The events and conventional frames of all tracked balls are then reduced to an ROI of size
pixels and the beans’ data to a window of size
pixels. A sample of preprocessed events and frames for each class is shown in
Figure 9. Beside the frames and events, information about the object’s velocity and actual position is recorded as well. The datasets with all relevant parameter configurations are made publicly available alongside this publication.
5. Results
In the following, the performance of the presented data processing methods and the impact of the proposed CBW approach are comparatively evaluated on the basis of the two datasets from
Section 4. For our analysis, we split the datasets into a training and a test set with a ratio of
%. As a figure of merit, we use
accuracy which is calculated on the basis of the resulting confusion matrices as discussed below. It is defined as the ratio of number of samples along the main diagonal of the matrix to the overall number of samples.
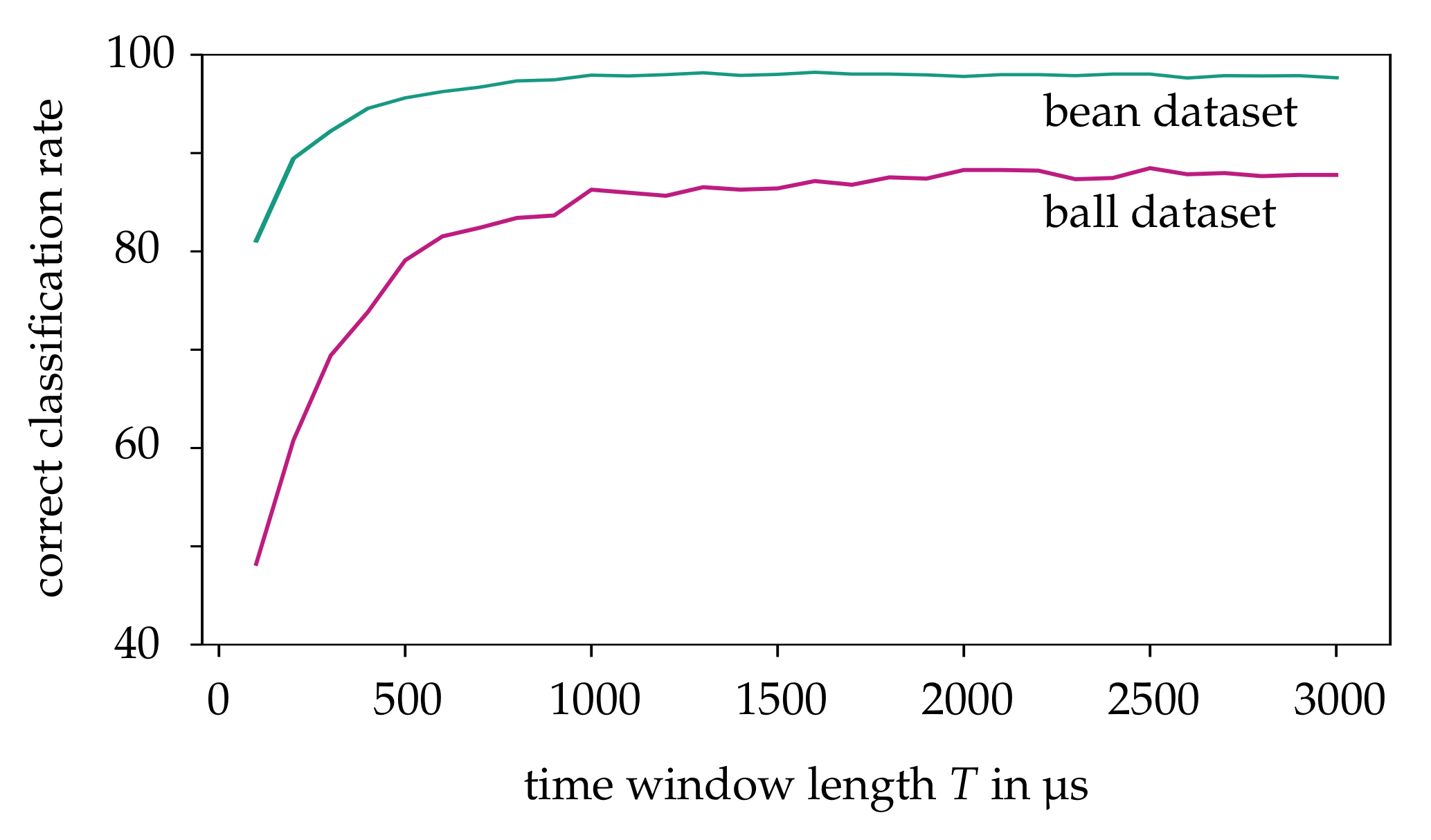
We start by elaborating the impact of our CBW approach in more detail. For this purpose, the HATS algorithm with a SVM as proposed in [
18] is used as a proven classification method. Due to the low local resolution of the event data, the size of the cells
and the neighborhood
is chosen as small as possible. The CBW approach requires two design parameters to be specified, namely, the number of time intervals
N and the time window length
T. Empirically,
N has been shown to have little effect on the correct classification rate and is therefore set to
. The resulting classification quality is shown for increasing time window lengths
T in
Figure 10. The purpose of this consideration is to find an optimal
T that satisfies the trade-off between a high correct classification rate and low observation time. For the following analysis,
μs for the ball dataset and
μs for the bean dataset is identified as a reasonable choice. We now compare the classification accuracy of CBW with a randomly selected time window of same length within the stream as shown in
Table 1. For the ball dataset, the CBW approach achieves a correct classification rate of
%, which is a significant improvement over a random time window with a rate of
%. Thus, selection based on contrast represents a suitable method to reduce streams with highly rotating objects to the essential time interval. A small improvement of
on average can also be achieved for the bean dataset. Hence, we conclude that the CBW approach achieves a general benefit.
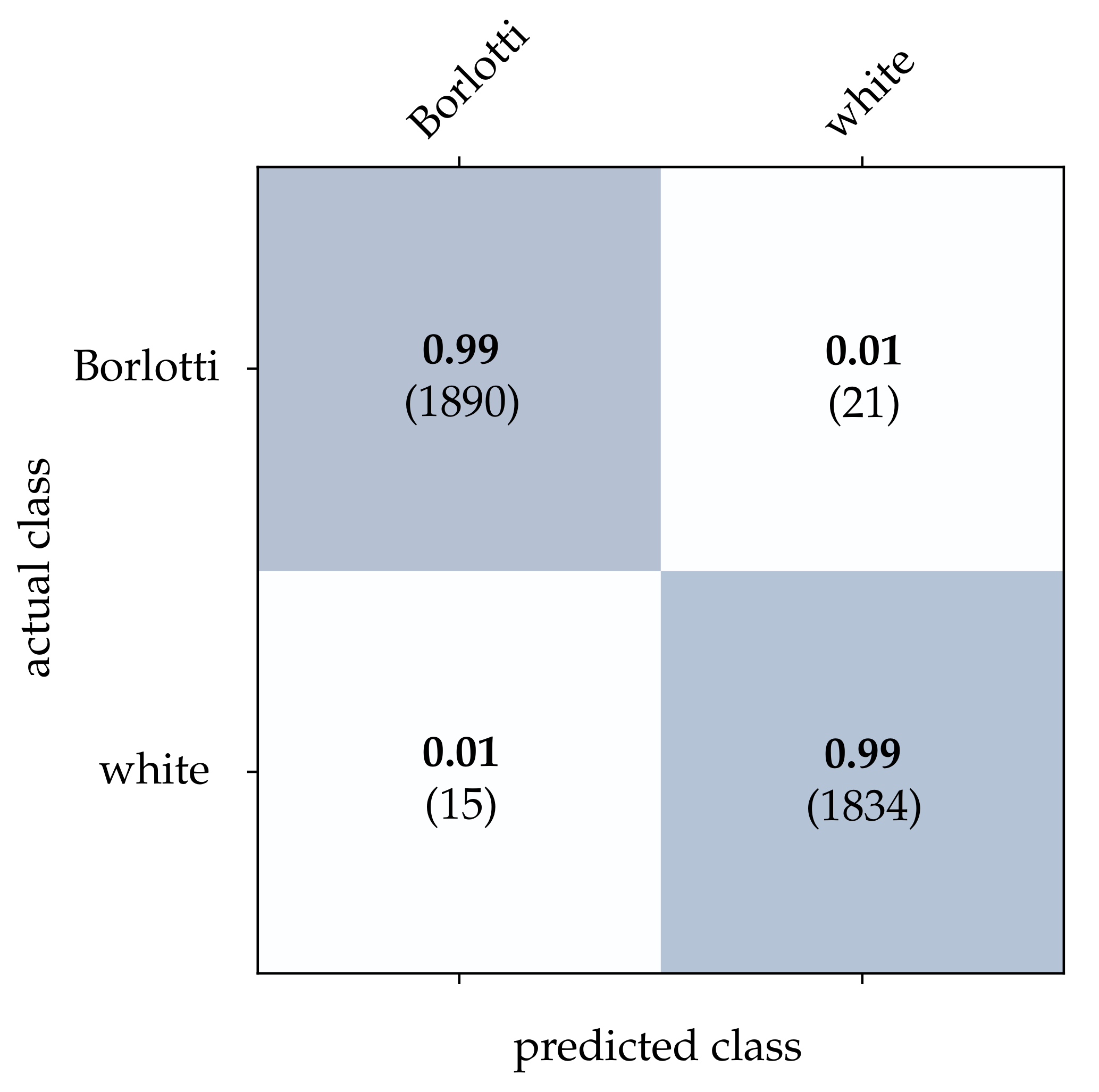
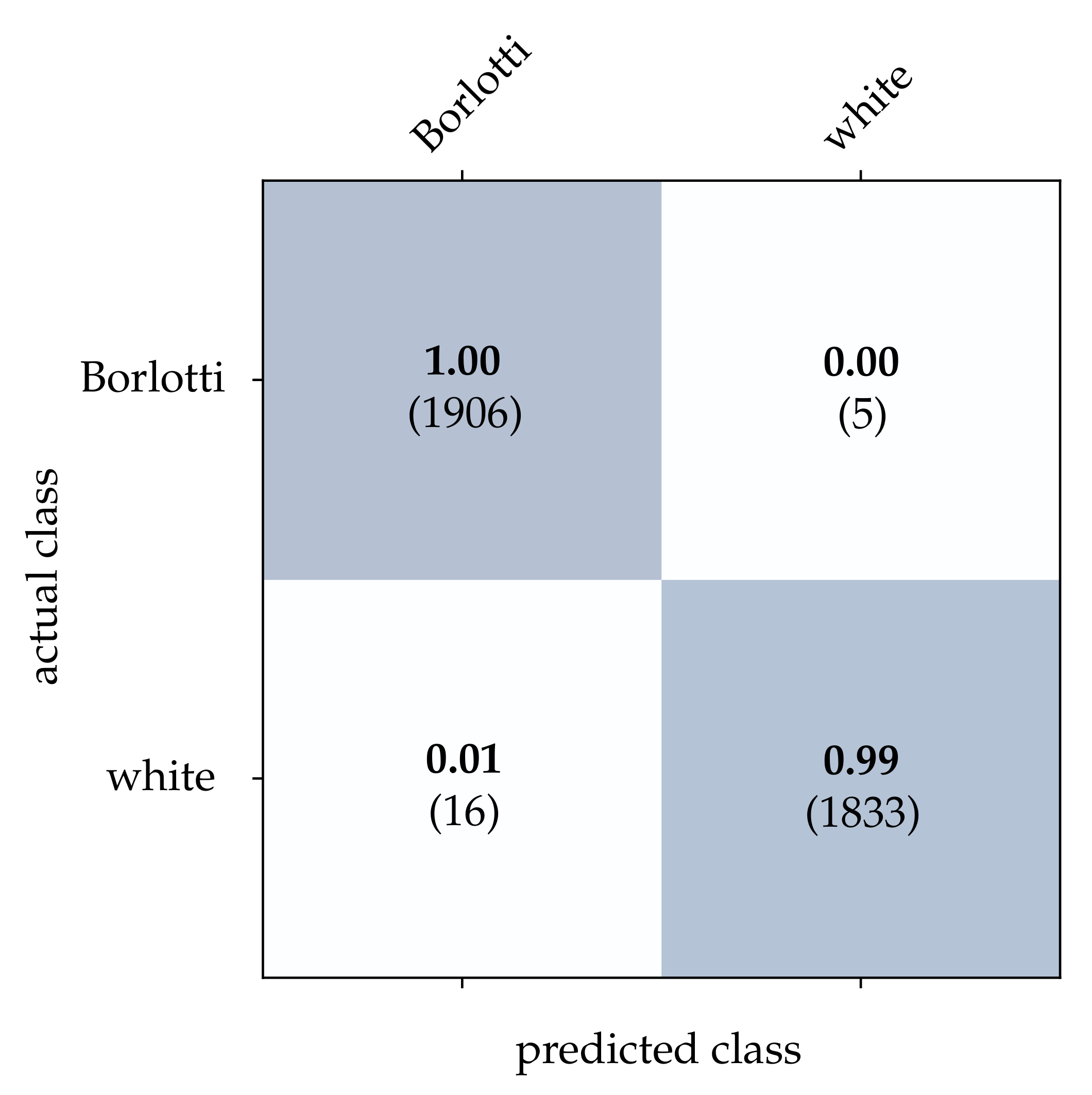
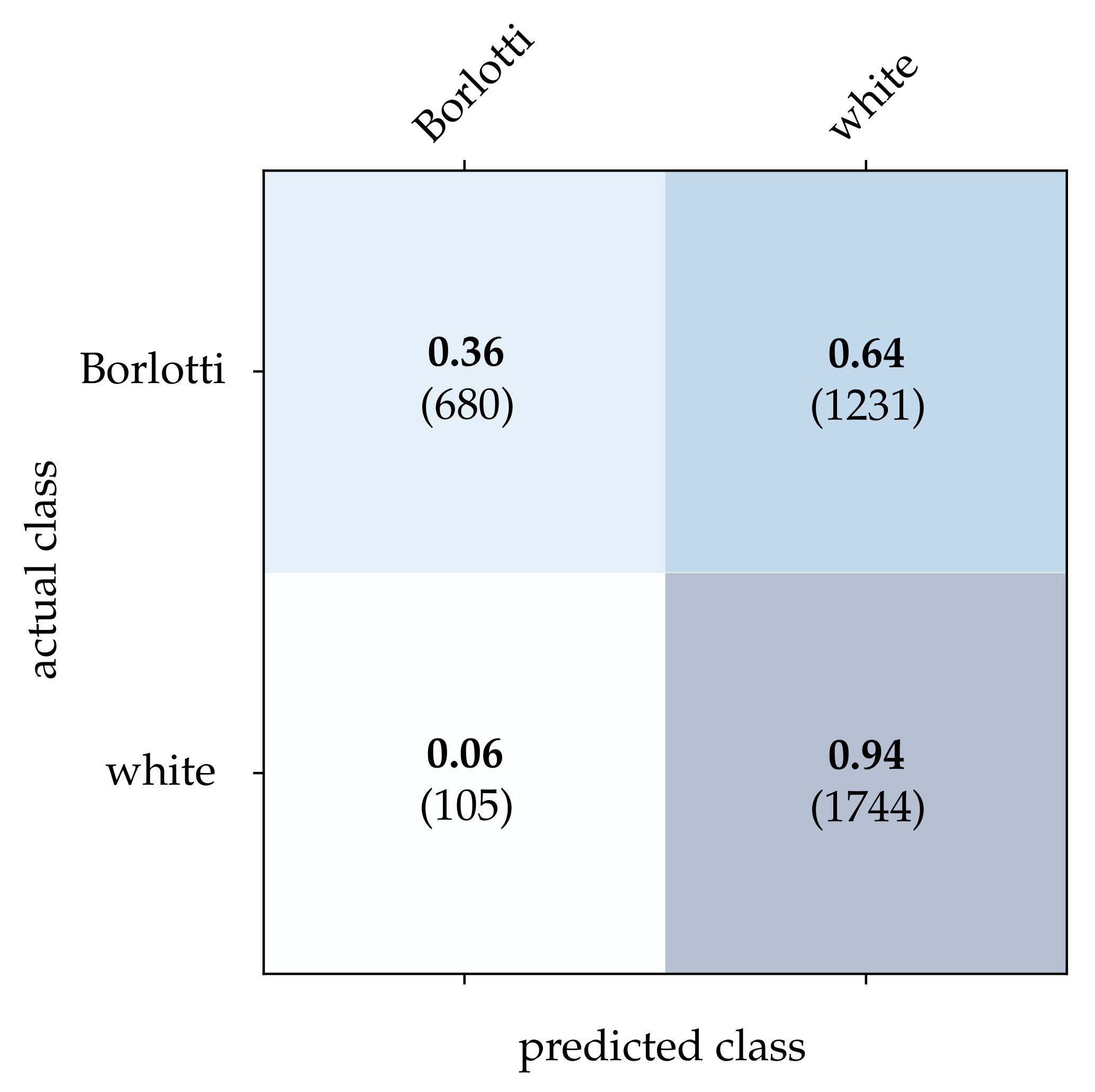
Following that, the performance of each classification method extended by the CBW approach is determined. The obtained results are summarized in
Table 2. The first three methods—intensity frames, reconstructed frames, and HATS—were implemented by ourselves during this work and use a ResNet-18 classifier. To avoid under- and overfitting, an early stopping procedure is used that takes
% of the training data as the validation dataset. The training is terminated as soon as the classification performance does not increase over 5 epochs or the maximum number of 50 epochs is reached. An Adam optimizer with a learning rate of
and a cross entropy error function is used to optimize the network. In case of MatrixLSTM, the original implementation as provided by Cannici et al. [
19] is applied to the full event streams. The CBW method is not used because MatrixLSTM already takes different time intervals and a learning of the time horizon with LSTM cells into account. When using SNN as a classifier, the stream is first reduced using the CBW method and then transformed into a three-dimensional matrix of size
. The time constant
of the LIF neurons and the search range
is fixed to the length of the time window
T. As described in [
20], the neuron threshold of the output layer is chosen to be 2 in the training and 1 in the testing phase.
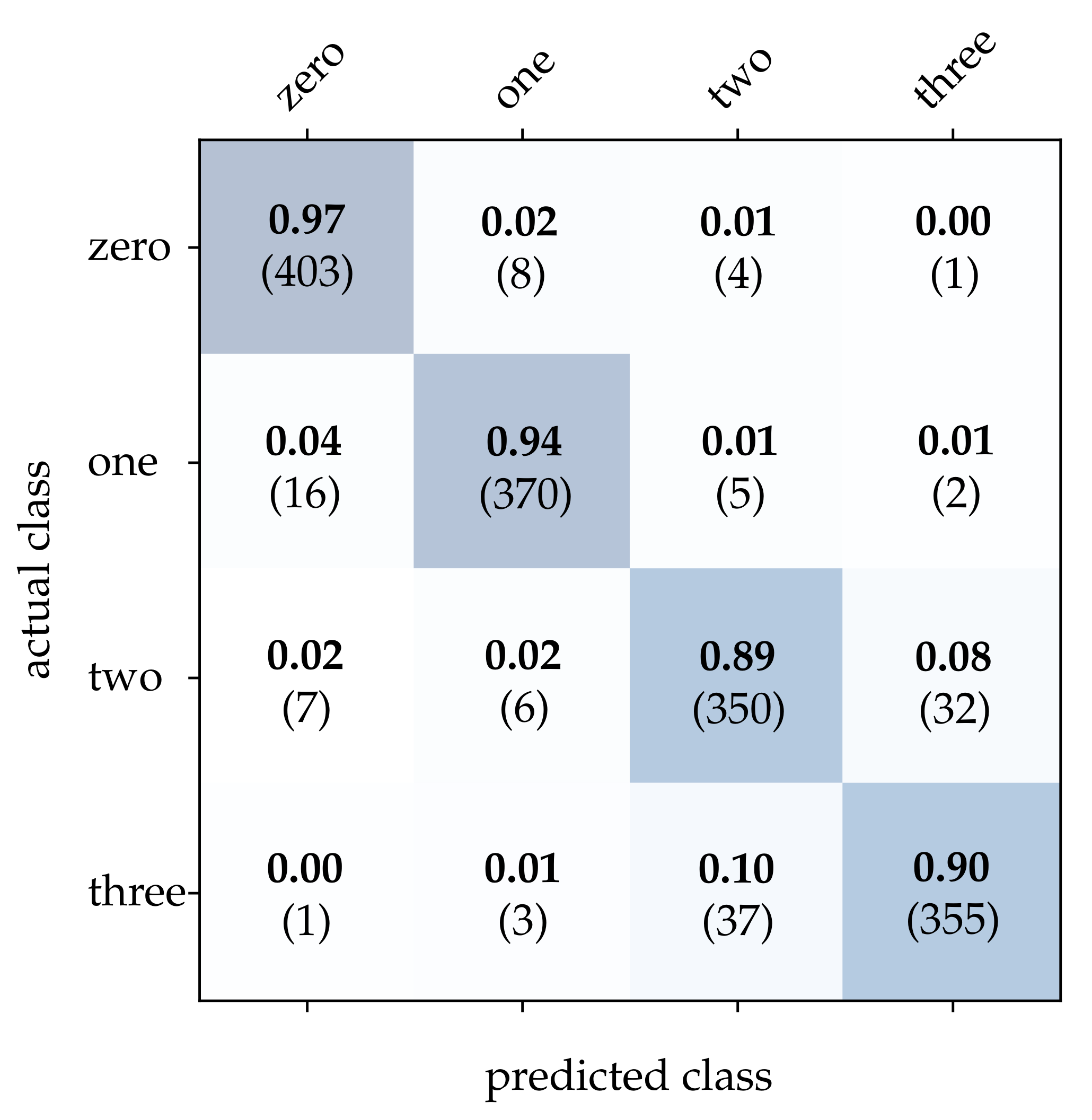
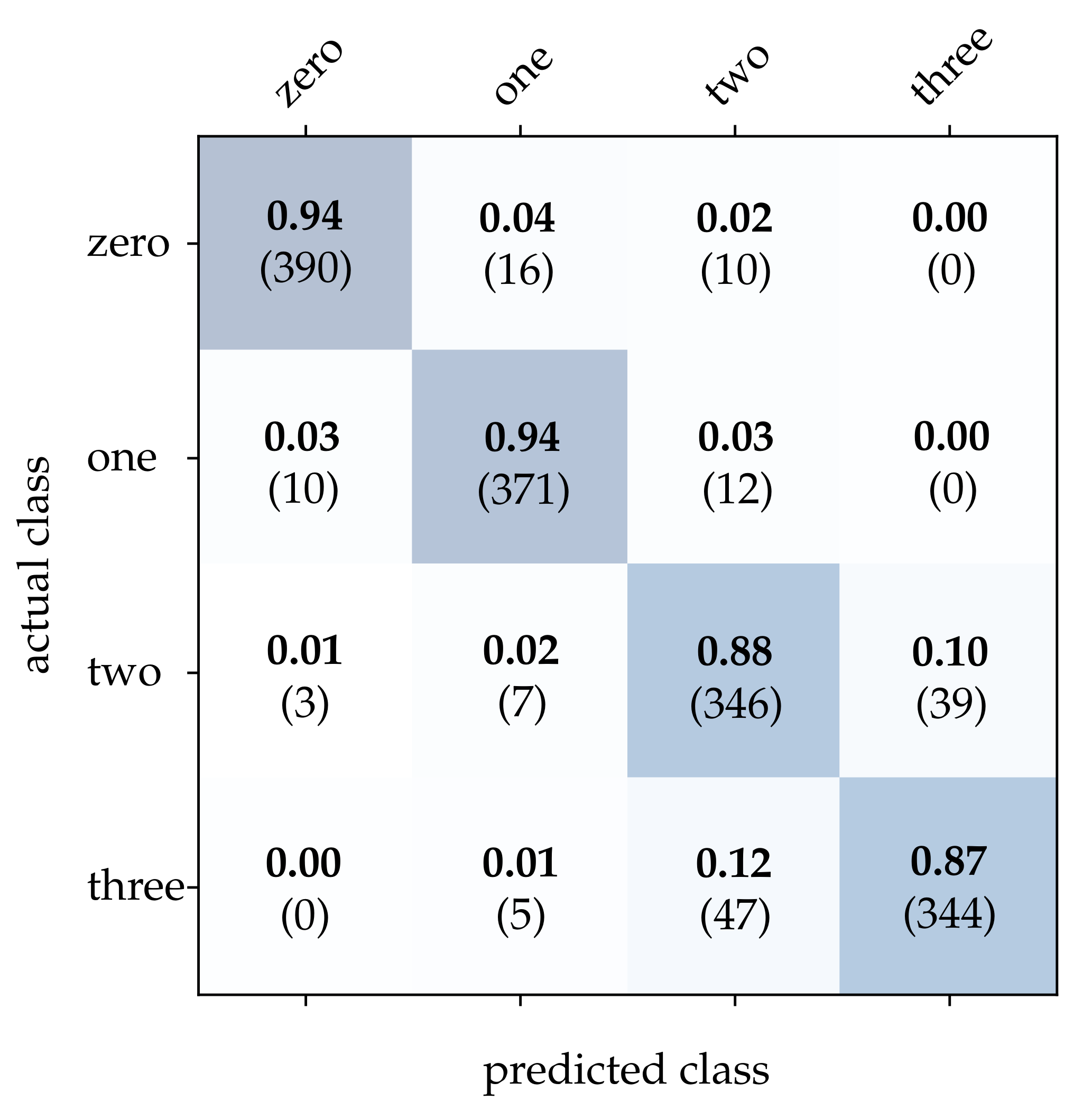
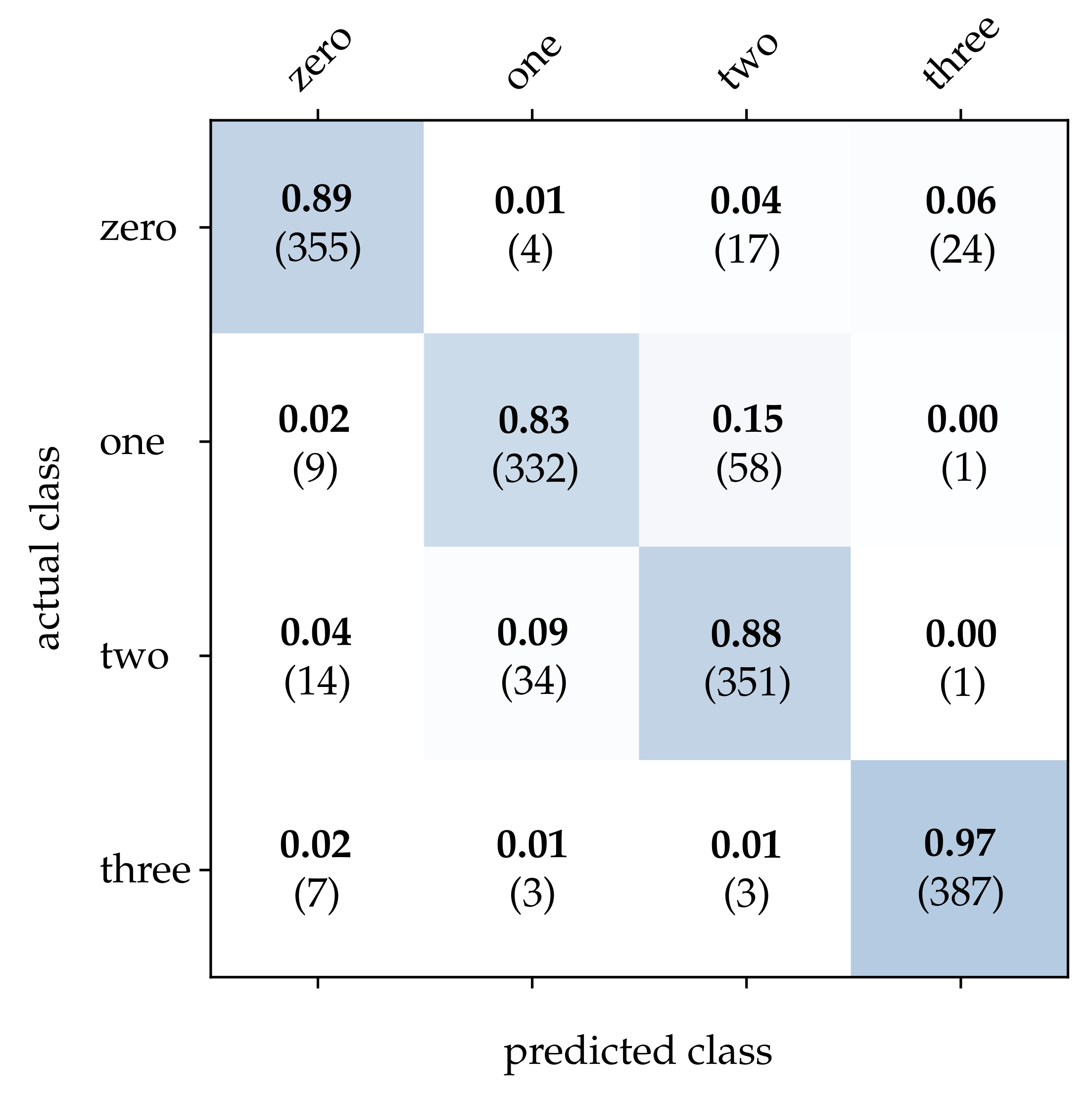
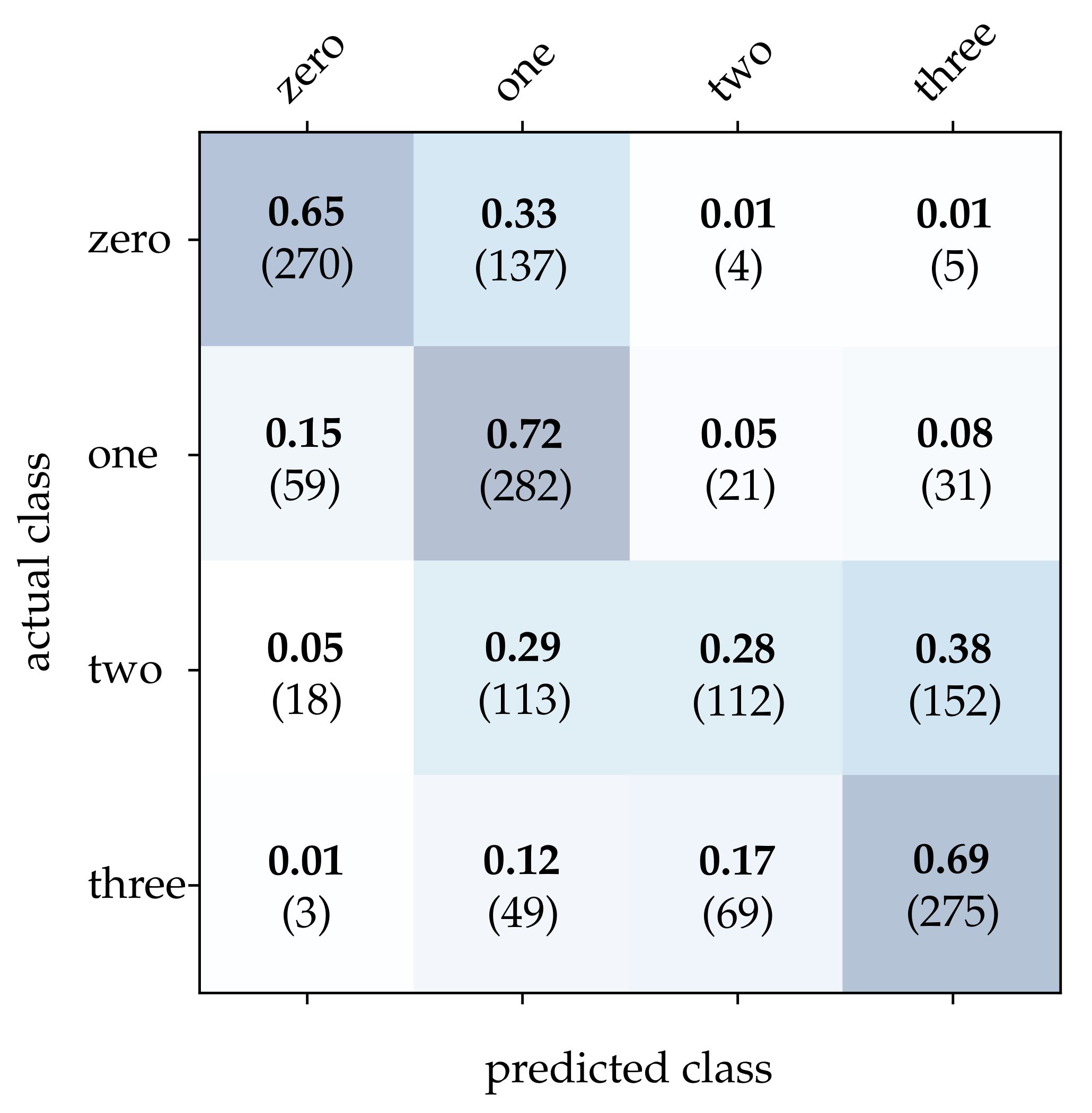
First, we take a closer look at the wooden ball dataset. As can be seen from
Table 2, conventional frames achieve a mediocre correct classification rate compared to the other approaches, which can be attributed to a frame rate that is too low for the task. It can be expected that a higher sampling rate of the scene will improve the result significantly. Detailed results for image reconstruction [
15] and HATS [
18] are provided in
Figure 11 and
Figure 12. As can be seen, using these methods results in particularly high accuracy for the detection of balls with no or only one stripe. However, MatrixLSTM [
19] achieves the highest accuracy for the detection of balls with four stripes, see
Figure 13. The result of the SNN [
20] is clearly overshadowed by the other methods, see
Figure 14. This is due to a low network depth and the performance of the SPA learning algorithm. Due to the high event activity at the contour of the balls, the SNN obtains a large amount of irrelevant data for the classification and fails to extract the essential information.
Both the image reconstruction and the HATS method use the proposed approach for selecting the time interval with maximum contrast. These methods also achieve the highest accuracy for this dataset. This further demonstrates that CBW is a suitable method to increase the quality of the classifier significantly. A determinant difference between the image reconstruction and the HATS method is the local averaging of the events. As the resolution of pixels is low for the detection of the stripes, the local averaging of the HATS algorithm additionally decreases the visibility of the stripes. However, this can also be observed with MatrixLSTM, which leads to the conclusion that a higher local resolution would achieve a better result over the two methods.
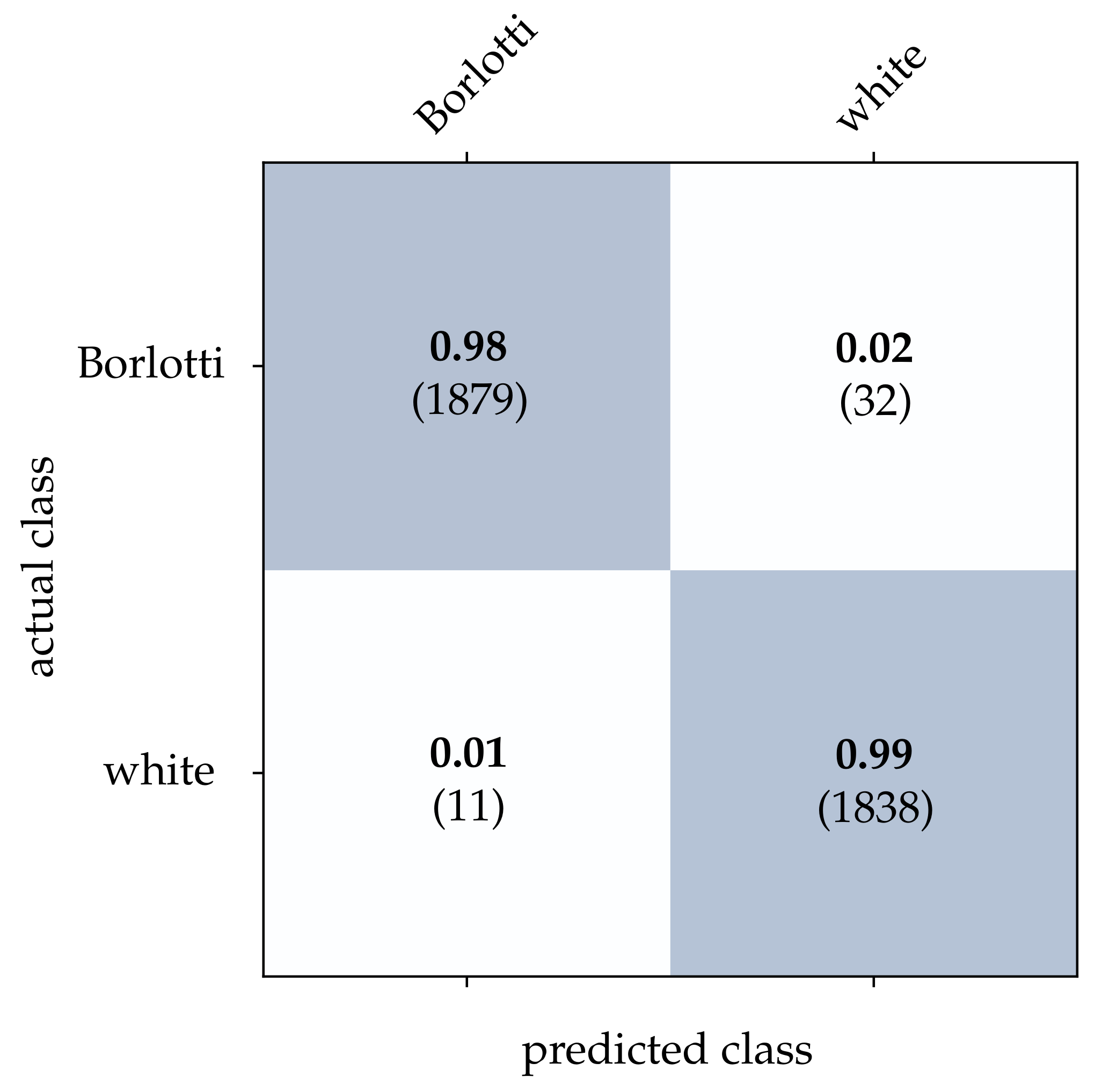
For the bean dataset, it can be seen from
Table 2 that a correct classification based on the conventional images is clearly possible. However, HATS [
18] and MatrixLSTM [
19], which both transfer the event stream into a feature space, come very close to this result. Due to the higher resolution of
pixels, the advantage of methods that accumulate events in a local neighborhood becomes apparent at this point. The reconstruction method [
15] only considers the event rate for each pixel independently, and thus it is more prone to noise which leads to a slightly lower correct classification rate. From
Figure 15,
Figure 16 and
Figure 17, it can be seen that all three methods detect both kinds of beans with comparable accuracy. The SNN [
20] also achieves comparatively low correct classification rates for the bean dataset, see
Figure 18. Due to the larger ROI, significantly more neurons are required per layer, which further complicates the learning algorithm requirements.
Overall, it can be summarized that conventional frames can be used to achieve the best classification results given sufficient sampling of the scene. These methods are already established and well researched. However, feature-based algorithms for processing the events come very close to the conventional frames and offer the benefit to improve the processing speed significantly while reducing the amount of data. Regarding the current state of research, the results of event-based methods such as SNNs cannot keep up with feature-based ones. However, due to the constantly growing research field, further developments for SNN architectures and learning algorithms are to be expected in the near future.
6. Conclusions
In this paper, we presented a modular pipeline including the common processing steps in machine vision for the new DVS principle. For the evaluation of state-of-the-art processing algorithms as well as a newly introduced algorithmic approach, we introduced two novel datasets for the so far unconsidered field of application of automatic visual inspection. The first dataset includes samples of four types of wooden balls and contains 8000 samples. The wooden balls feature one, two, three, or four stripes, resulting in a four-class discrimination problem. The second dataset consists of two types of beans that differ in texture and contains approximately 18,804 samples. Data were acquired in typical visual inspection settings, i.e., on a conveyor belt and during free fall. For this purpose, we considered two different experimental setups, each of which with its own special characteristics. By making these datasets publicly available, we provide a basis for further research on the application of DVS in the context of machine vision.
We introduced a novel algorithmic approach for selecting an ideal time window for object classification within an event stream. This approach provides a solution for dealing with typical challenges in this field of application, for instance object rotations. Based on the introduced datasets, it was shown that this extension can significantly increase the accuracy of proven classification methods. Using HATS [
18] in conjunction with a SVM classifier, it was shown that classification accuracy can be increased from
to
for the wooden balls dataset and from
to
for the beans dataset.
We extended classification methods based on reconstructed frames [
15], HATS [
18], MatrixLST [
19] and a SNN [
20] by our novel approach and evaluated their performance on the basis of the new datasets. For the wooden balls dataset, it was shown that reconstructed frames and HATS achieved particularly high classification accuracy of up to
. For the beans dataset, none of the approaches outperformed classification based on conventional intensity frames. However, using MatrixLSTM, a high accuracy of
was also obtained. Results obtained with the SNN were not able to keep up with the other considered approaches. However, further developments for SNN architectures and learning algorithms could change that.
In the future, we are interested in investigating DVS technology for deriving mechanical properties of test objects. Approaches as considered in visual vibrometry might be exploited in DVS due to the high temporal resolution. However, we consider further advances in sensor technology, especially regarding the spatial resolution, as a necessity for such kinds of tasks. Furthermore, advances in SNN are required in order to design systems according to the neuromorphic concept of the sensors.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}