1. Introduction
Coronary heart disease is a type of cardiovascular disease in which there is atherosclerotic plaque in the coronary arteries, resulting in myocardial infarction or sudden cardiac death [
1]. Coronary heart disease is a complex disease in which the genetic architecture and the influence of environmental factors both contribute to the disease’s development. Smoking, alcohol consumption, a lack of physical activity, a high-calorie diet high in fat, cholesterol and sugar, infections, environmental chemicals and pollutants, and stress are all ecological risk factors for heart disease. High blood pressure, high cholesterol, height, diabetes, overweight or obesity are all risk factors [
2]. Since this unexpected heart attack occurs without obvious symptoms, the early detection of the risk factors for coronary heart disease is required.
Heart disease detection depends on the variation chosen and the number of risk factor variables used. The clinical data that is uncertain and irregular will be challenging to use in the detection system. This detection system will later help doctors diagnose diseases. If the data processing is inadequate, the classification process will perform poorly. The selection of the features can be considered so that the detection system’s performance receives an accurate prediction. Irrelevant or redundant features can reduce the accuracy and increase the computational costs unnecessarily [
1].
Many studies have been conducted to improve the prediction accuracy by optimizing the classification process by removing irrelevant features. Verma et al. [
1] used a classification technique to build a predictive model for identifying coronary artery disease (CAD) cases, considering all aspects of the patient’s clinical data. The data from Indira Gandhi Medical College (IGMC) in Shimla, India, was used. There were 26 features in the data. However, not all the features were always significant. Some were irrelevant and redundant and contributed little to the prediction. The feature selection techniques typically reduced the feature space dimensions and eliminated the redundant, outside or noisy data. The reduction in the features impacted the modeling framework regarding the data mining algorithm speed, data quality, performance and understanding of the mining results. The best feature subset included at least a few features that contributed significantly to the accuracy and efficiency. As a result, Verma et al. proposed a hybrid model for detecting coronary heart disease that combined the correlation-based feature subset selection (CFS) algorithm with a particle swarm pptimization (PSO) as a search method and k-means clustering. The model was validated using a 10-fold cross-validation and employed a supervised learning classification algorithm such as MLP, MLG, FURIA and C4.5. The proposed method results were tested on the coronary heart disease dataset, specifically the Cleveland and Indira Gandhi Medical College (IMGC) datasets. The data achieved an accuracy of 0.92 and 0.88, respectively.
Tama et al. [
3] improved the model of detecting infectious diseases by employing a two-tiered classification algorithm. During this study, the features were chosen using the correlation-based feature subset selection (CFS) method and the particle swarm optimization technique (PSO). The dataset was obtained from the UCI machine learning repository. The datasets used were Z-Alizadeh Sani, Statlog, Cleveland and Hungary. According to the feature selection results, the PSO with 20 particles provided the best predictive performance on the Z-Alizadeh Sani dataset with an accuracy of 0.84 using a set of 27 features. The best classification accuracy was obtained using the same number of particles in the Statlog dataset, which produced a set of 8 elements with a prediction accuracy of 0.77. The following step was to create a two-level ensemble to build a classification model using random forest (RF), gradient boosting machine (GBM) and extreme gradient boosting machine (XGBoost). The proposed method’s accuracy on the z-Alizadeh Sani and Statlog datasets was 0.98% and 0.94, respectively.
According to Alqahtani et al. [
4], machine learning research aims for a classification model that can predict cardiovascular disease. An ensemble-based approach used machine learning and deep learning models with six classification algorithms for detecting cardiovascular disease. The random forest provided extracts of the essential features. The machine learning ensemble model obtained an accuracy score of 88.70%.
Many optimization algorithms, including genetic algorithms [
5,
6] and swarm intelligence algorithms such as particle swarm optimization (PSO) [
1,
3] and artificial bee colony (ABC) [
7], have been discovered to solve the relevant feature selection problems. However, the bee swarm optimization algorithm was successfully applied to various optimization problems [
8,
9]. The bee swarm optimization algorithm is an intelligent swarm algorithm inspired by the foraging behavior of natural bees. According to Sadeg et al. [
9], the bee swarm optimization algorithm outperformed other optimization algorithms. A swarm intelligence algorithm inspired by natural bee foraging behavior is used to find the best feature subset that maximizes the classification accuracy. A classification problem includes diagnosing diseases from many patients using data from different categories of a specific disease. The heart disease classification data will be significant, so the diagnosis will be able to be classified more accurately with the help of bee search optimization algorithms.
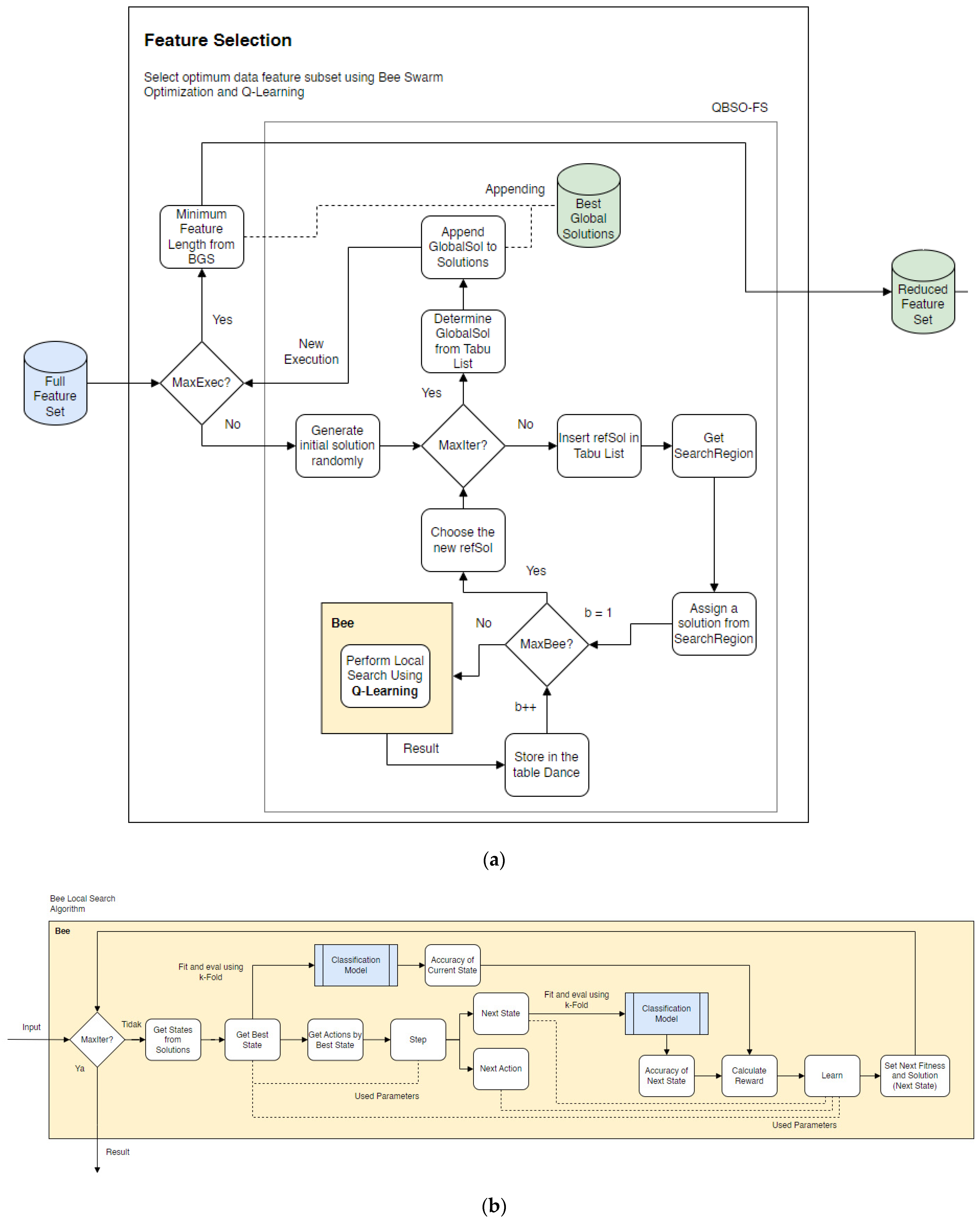
As the data increases, metaheuristic methods for solving the optimization problems become more complex. Sadeg et al. [
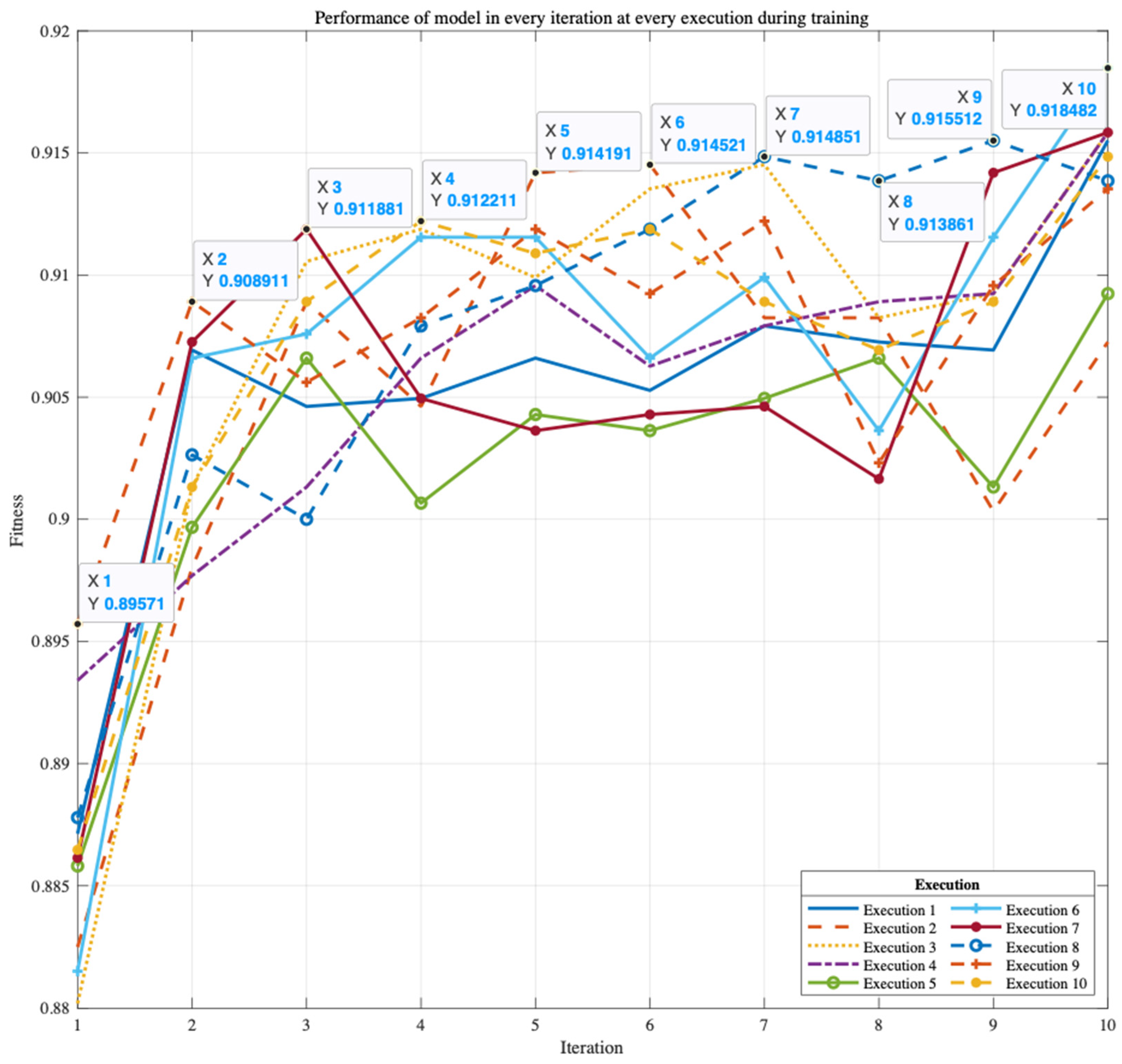
10] proposed a hybrid method to complete the feature selection by incorporating a reinforcement learning algorithm into bee swarm optimization (BSO). Q-learning was used during the search method process of the BSO to make the search process more adaptive and efficient. The integration of Q-learning into the bee swarm optimization algorithm helped improve the bee search performance. Q-learning is used to accelerate the convergence so that less execution time is required to achieve the same level of accuracy. On 20 well-known datasets, the bee swarm optimization and Q-learning (QBSO) performance were evaluated and compared to the BSO and other methods. The results show that the QBSO-feature selection outperformed the BSO-feature selection for large cases and produced outstanding results compared to recently published algorithms.
Based on the previous research, this study proposes for the bee swarm optimization algorithm to be combined with the Q-learning algorithm as a feature selection search algorithm. The Q-learning algorithm, also known as reinforcement learning, is used to improve the effectiveness of the feature search process. This feature selection model is intended to improve the classification process for detecting heart disease. This feature selection model is expected to produce results that identify the best subset of features for improving the classification accuracy in the detection of coronary heart disease.
Author Contributions
Conceptualization, Y.A.Z.A.F. and W.W.; methodology, Y.A.Z.A.F. and W.W.; writing—original draft preparation, Y.A.Z.A.F.; writing—review and editing, W.W. and E.S.; supervision, W.W. and E.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
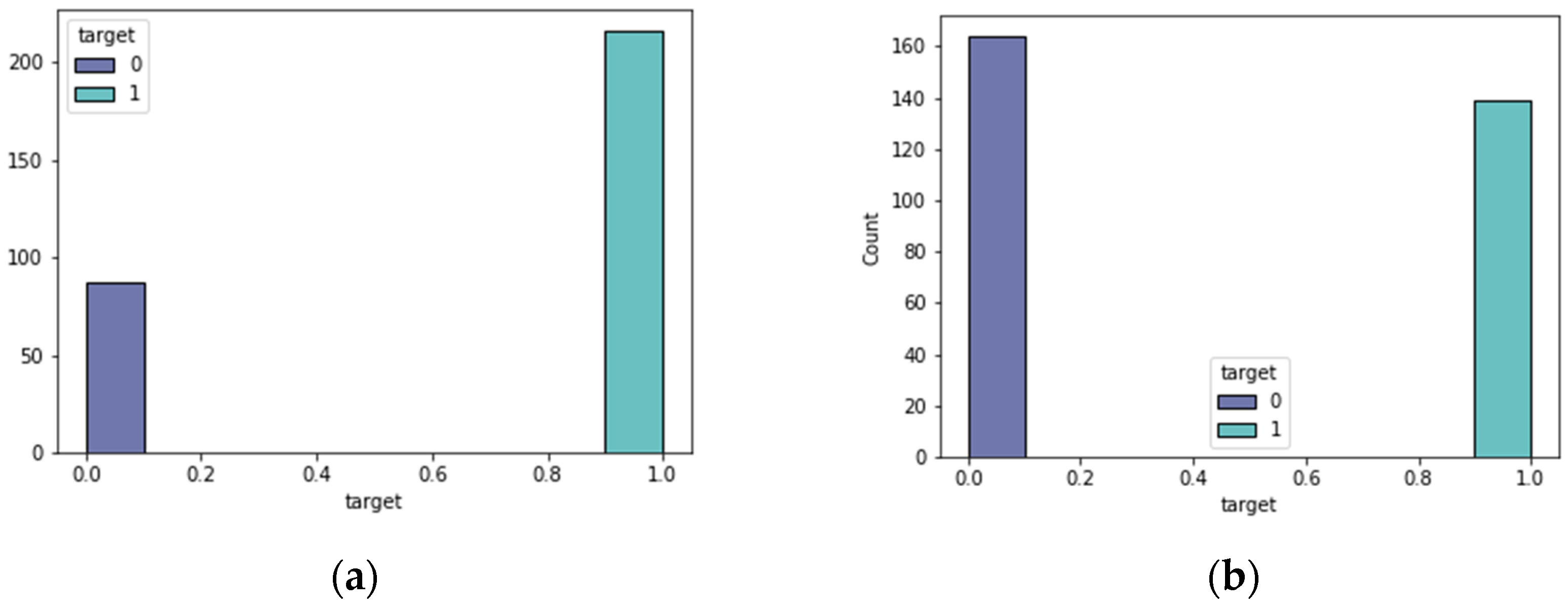
The data that support the findings of this study are available at UCI Machine Learning Repository.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Verma, L.; Srivastava, S.; Negi, P.C. A Hybrid Data Mining Model to Predict Coronary Artery Disease Cases Using Non-Invasive Clinical Data. J. Med. Syst. 2016, 40, 178. [Google Scholar] [CrossRef] [PubMed]
- Kolukisa, B.; Hacilar, H.; Goy, G.; Kus, M.; Bakir-Gungor, B.; Aral, A.; Gungor, V.C. Evaluation of Classification Algorithms, Linear Discriminant Analysis and a New Hybrid Feature Selection Methodology for the Diagnosis of Coronary Artery Disease. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; IEEE: Seattle, WA, USA, 2018; pp. 2232–2238. [Google Scholar]
- Tama, B.A.; Im, S.; Lee, S. Improving an Intelligent Detection System for Coronary Heart Disease Using a Two-Tier Classifier Ensemble. BioMed Res. Int. 2020, 2020, 9816142. [Google Scholar] [CrossRef] [PubMed]
- Alqahtani, A.; Alsubai, S.; Sha, M.; Vilcekova, L.; Javed, T. Cardiovascular Disease Detection using Ensemble Learning. Comput. Intell. Neurosci. 2022, 2022, 5267498. [Google Scholar] [CrossRef] [PubMed]
- Amin, S.U.; Agarwal, K.; Beg, R. Genetic neural network based data mining in prediction of heart disease using risk factors. In Proceedings of the 2013 IEEE Conference on Information and Communication Technologies, Thuckalay, India, 11–12 April 2013; IEEE: Thuckalay, India, 2013; pp. 1227–1231. [Google Scholar]
- Arabasadi, Z.; Alizadehsani, R.; Roshanzamir, M.; Moosaei, H.; Yarifard, A.A. Computer aided decision making for heart disease detection using hybrid neural network-Genetic algorithm. Comput. Methods Programs Biomed. 2017, 141, 19–26. [Google Scholar] [CrossRef] [PubMed]
- Subanya, B.; Rajalaxmi, R.R. Feature selection using Artificial Bee Colony for cardiovascular disease classification. In Proceedings of the 2014 International Conference on Electronics and Communication Systems (ICECS), Coimbatore, India, 13–14 February 2014; IEEE: Coimbatore, India, 2014; pp. 1–6. [Google Scholar]
- Sadeg, S.; Drias, H. A selective approach to parallelise Bees Swarm Optimisation metaheuristic: Application to MAX-W-SAT. IJICA 2007, 1, 146. [Google Scholar] [CrossRef]
- Sadeg, S.; Hamdad, L.; Benatchba, K.; Habbas, Z. BSO-FS: Bee Swarm Optimization for Feature Selection in Classification. In Advances in Computational Intelligence; Rojas, I., Joya, G., Catala, A., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2015; Volume 9094, pp. 387–399. ISBN 978-3-319-19257-4. [Google Scholar]
- Sadeg, S.; Hamdad, L.; Remache, A.R.; Karech, M.N.; Benatchba, K.; Habbas, Z. QBSO-FS: A Reinforcement Learning Based Bee Swarm Optimization Metaheuristic for Feature Selection. In Advances in Computational Intelligence; Rojas, I., Joya, G., Catala, A., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2019; Volume 11507, pp. 785–796. ISBN 978-3-030-20517-1. [Google Scholar]
- Dua, D.; Graff, C. UCI Machine Learning Repository. 2017. Available online: https://archive.ics.uci.edu/ml/index.php (accessed on 5 April 2022).
- Alizadehsani, R.; Habibi, J.; Hosseini, M.J.; Mashayekhi, H.; Boghrati, R.; Ghandeharioun, A.; Bahadorian, B.; Sani, Z.A. A data mining approach for diagnosis of coronary artery disease. Comput. Methods Programs Biomed. 2013, 111, 52–61. [Google Scholar] [CrossRef] [PubMed]
- Dipto, I.C.; Islam, T.; Rahman, H.M.M.; Rahman, M.A. Comparison of Different Machine Learning Algorithms for the Prediction of Coronary Artery Disease. JDAIP 2020, 08, 41–68. [Google Scholar] [CrossRef]
- Akbari, R.; Mohammadi, A.; Ziarati, K. A powerful bee swarm optimization algorithm. In Proceedings of the 2009 IEEE 13th International Multitopic Conference, Islamabad, Pakistan, 14–15 December 2009; IEEE: Islamabad, Pakistan, 2009; pp. 1–6. [Google Scholar]
- Ardiansyah, A.; Rainarli, E. Implementasi Q-Learning dan Backpropagation pada Agen yang Memainkan Permainan Flappy Bird. J. Nas. Tek. Elektro Dan Teknol. Inf. (JNTETI) 2017, 6, 1–7. [Google Scholar] [CrossRef][Green Version]
- Nugroho, A.S.; Witarto, A.B.; Handoko, D. Teori dan Aplikasinya dalam Bioinformatika1. 2003. Available online: http://asnugroho.net/papers/ikcsvm.pdf (accessed on 9 April 2022).
- Ali, J.; Khan, R.; Ahmad, N.; Maqsood, I. Random Forests and Decision Trees. Int. J. Comput. Sci. Issues (IJCSI) 2012, 9, 272. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling; Springer: New York, NY, USA, 2013; ISBN 978-1-4614-6848-6. [Google Scholar]
- Ali, S.A.; Raza, B.; Malik, A.K.; Shahid, A.R.; Faheem, M.; Alquhayz, H.; Kumar, Y.J. An Optimally Configured and Improved Deep Belief Network (OCI-DBN) Approach for Heart Disease Prediction Based on Ruzzo–Tompa and Stacked Genetic Algorithm. IEEE Access 2020, 8, 65947–65958. [Google Scholar] [CrossRef]
- Nandakumar, P.; Narayan, S. Cardiac disease detection using cuckoo search enabled deep belief network. Intell. Syst. Appl. 2022, 16, 200131. [Google Scholar]
- Shahid, A.H.; Singh, M.P. A Novel Approach for Coronary Artery Disease Diagnosis using Hybrid Particle Swarm Optimization based Emotional Neural Network. Biocybern. Biomed. Eng. 2020, 40, 1568–1585. [Google Scholar] [CrossRef]
- Gupta, A.; Arora, H.S.; Kumar, R.; Raman, B. DMHZ: A Decision Support System Based on Machine Computational Design for Heart Disease Diagnosis Using Z-Alizadeh Sani Dataset. In Proceedings of the 2021 International Conference on Information Networking (ICOIN), Jeju Island, Republic of Korea, 13–16 January 2021; IEEE: Jeju Island, Republic of Korea, 2021; pp. 818–823. [Google Scholar]
- Shah, S.M.S.; Shah, F.A.; Hussain, S.A.; Batool, S. Support Vector Machines-based Heart Disease Diagnosis using Feature Subset, Wrapping Selection and Extraction Methods. Comput. Electr. Eng. 2020, 84, 106628. [Google Scholar] [CrossRef]
- Sarra, R.R.; Dinar, A.M.; Mohammed, M.A.; Abdulkareem, K.H. Enhanced Heart Disease Prediction Based on Machine Learning and χ2 Statistical Optimal Feature Selection Model. Designs 2022, 6, 87. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).








{kind=link}
{kind=link}
{kind=link}
{kind=link}