A Convolution Neural Network-Based Seed Classification System
by
 , , and
, , and
Yonis Gulzar
1,* ,
,
Yasir Hamid
2,*, 
Arjumand Bano Soomro
1,*,
Ali A. Alwan
3 and
and
Ludovic Journaux
4 1
Department of Management Information Systems, College of Business Administration, King Faisal University, Al-Ahsa 31982, Saudi Arabia
2
Information Security and Engineering Technology, AbuDhabi Polytechnic College, Abu Dhabi 111499, UAE
3
Department of Computer Science, Faculty of Information and Communication Technology, International Islamic University Malaysia, Gombak, Selangor 53100, Malaysia
4
AgroSup Informatic Laboratory, Burgundy University, 21078 Dijon, France
*
Authors to whom correspondence should be addressed.
Symmetry 2020, 12(12), 2018; https://doi.org/10.3390/sym12122018
Submission received: 6 November 2020
/
Revised: 1 December 2020
/
Accepted: 4 December 2020
/
Published: 7 December 2020
(This article belongs to the Section Computer)
Abstract
:Over the last few years, the research into agriculture has gained momentum, showing signs of rapid growth. The latest to appear on the scene is bringing convenience in how agriculture can be done by employing various computational technologies. There are lots of factors that affect agricultural production, with seed quality topping the list. Seed classification can provide additional knowledge about quality production, seed quality control and impurity identification. The process of categorising seeds has been traditionally done based on characteristics like colour, shape and texture. Generally, this is performed by specialists by visually inspecting each sample, which is a very tedious and time-consuming task. This procedure can be easily automated, providing a significantly more efficient method for seed sorting than having them be inspected using human labour. In related areas, computer vision technology based on machine learning (ML), symmetry and, more particularly, convolutional neural networks (CNNs) have been generously applied, often resulting in increased work efficiency. Considering the success of the computational intelligence methods in other image classification problems, this research proposes a classification system for seeds by employing CNN and transfer learning. The proposed system contains a model that classifies 14 commonly known seeds with the implication of advanced deep learning techniques. The techniques applied in this research include decayed learning rate, model checkpointing and hybrid weight adjustment. This research applies symmetry when sampling the images of the seeds during data formation. The application of symmetry generates homogeneity with regards to resizing and labelling the images to extract their features. This resulted in 99% classification accuracy during the training set. The proposed model produced results with an accuracy of 99% for the test set, which contained 234 images. These results were much higher than the results reported in related research.
1. Introduction
A large portion of the world’s population is associated with the agriculture sector. Many developing and underdeveloped countries’ economies rely on agriculture. This sector has experienced multiple transformations with the increase in the world’s population [1]. The growth in the human population is directly related to the need to increase the world’s agricultural productivity and its sustainability. Technology was introduced to agriculture more than one century ago, and, to improve production efficiency, several studies have been conducted since the 1990s [1]. In recent times, advanced industrial technologies based on artificial intelligence (AI) have been applied in the field of agriculture to improve productivity, environmental impact, food security and sustainability. Before addressing any problems in this area, one is required to understand the basic ecosystem of agriculture and the fundamental requirements of farming. This field is considered one of the most challenging research fields, and technology has massive potential to be incorporated into it to increase the mass and quality of agricultural products. The incorporation of AI, particularly deep learning perceptions, can be used to make advances in the agricultural sector [2].
In the agriculture sector, the farming of crops relies heavily on seeds. Without seeds, there is no chance of producing or harvesting any crops. The human population has been increasing rapidly for many years. Due to this population growth, agricultural land is reducing day by day, which causes a decline in the production of food. To balance consumption rate with production rate, crop production must be increased. In this regard, people have started growing crops and vegetables in their homes. However, not everyone possessed the knowledge needed to do this. Only a person who has expertise in identifying seeds can cultivate them. To eliminate this dependency, there is the need for an automated system that can assist in identifying and classifying the different types of seeds. Several studies have been conducted in which various issues related to seeds have been addressed by using AI techniques, ranging from simple object identification-based techniques to complex texture and pattern identification. In recent studies, machine learning techniques have been observed more frequently to perform seed classification of various crops, fruits and vegetables. Most of these studies have been conducted on a single genre of seed (e.g., weed seeds [3], cottonseeds [4], rice seeds [5,6], oat seeds [7], sunflower seeds [8], tomato seeds [9] and corn [10,11]) with varying purposes. These included observing germination and vigour detection, purification and growth stages.
There are hardly any studies that apply convolutional neural networks (CNNs) [12] in their models to address seed identification/classification problems. CNNs are deep learning models consisting of several layers: convolutional, pooling and fully connected layers. The convolutional layers perform feature extractions, the pooling layers perform compression and fully connected layers are for classification. Their main use is image recognition and classification. A general representation of CNNs model can be seen in Figure 1. CNN can bring efficiency and accuracy in visual imagery analysis using precise feature extractions [12,13].
To the best of our knowledge, there is no study that has addressed subject heterogeneity problems with regards to various kinds of seeds. Also, most of the studies incorporated only traditional machine learning techniques for feature extraction and classification. Hence, an approach that is capable of solving the problem of subject heterogeneity by incorporating deep learning techniques to bring efficiency and accuracy in identifying and classifying seeds is needed. Previously, many researchers reported their successful results by using traditional machine learning techniques. Although these traditional techniques/approaches have been successfully applied in many practical studies, they still have many limitations in certain real-world scenarios [14].
This research proposed an efficient approach for seed identification and classification based on a deep learning CNN model and the application of symmetry. The model is trained by implementing transfer learning, which focuses on transferring knowledge across domains and is considered a promising machine learning methodology. It is an important machine learning (ML) tool in solving problems related to insufficient training data, which can encourage the idea of not training the model from scratch and significantly reducing the training time [15]. In this research, a dataset comprised of symmetric images of various seeds was used to carry out the seed classification process. Many symmetric images from each seed class were captured and then augmented to train the proposed model. Further details pertaining to the dataset are presented in Section 3. This research work adopted a VGG16-trained model in order to accomplish successful seed identification and classification [16]. However, the model was modified by adding new layers, which aimed to increase accuracy and reduce the error rate of the classification process. This modification in the VGG16 model leads to the optimisation of the classification process and eventually assists the common man in identifying and classifying the different type of seeds.
The following points summarise the contributions of this paper:
We conduct a detailed review examining the most notable work in the area of seed classification via machine learning and deep learning.
We re-introduce the problem of seed classification using pre-trained VGG16 convolutional neural network architecture, where variant seeds have been classified, unlike in previously proposed models, which focused only on one kind of seed.
We propose a new model for seed identification and classification by using advanced deep learning techniques. Furthermore, dropout and data augmentation techniques have been incorporated to minimise the chances of overfitting.
We fine-tune our model by applying an adjustable learning rate to make sure that our model performs equally well on the dataset and does not miss the global minimum.
We develop an optimisation technique that monitors any positive change in the validation accuracy and validation error rate. In case of change, it takes the backup of an optimal model at the end of the iteration to make sure that the proposed model is at its highest level of accuracy with the least validation loss.
The remainder of the paper is organised as follows. In Section 2, the previous work related to this research are reported and discussed. The proposed model is explained and illustrated in Section 3, and the results and discussion are illustrated and explained in Section 4. Our conclusions are described in Section 5.
2. Related Work
AI has made many contributions to agriculture, as it brings flexibility, high performance, accuracy and cost-effective solutions to solve various problems [17]. Image processing aligned with computer vision has remained the main area of interest for many researchers. Image processing was introduced in agriculture less than a decade ago to address seed sorting and classification for the quality of crop production. Image processing involves feature extraction, which is considered a complex task and helps in object identification and classification. In AI, traditional ML techniques have been widely applied in object identification and classification.
Jamuna et al. [4] employed machine learning techniques (e.g. Naïve Bayes classifier, a decision tree classifier and MLP) to train the model in feature extraction using a sample of 900 cotton seeds. They reported that the decision tree classifier and MLP gave the same accuracy in classifying the seed cotton, with a rate of 98.7%, and Naïve Bayes classifier had an accuracy rate of 94.22%. Their results show that Naïve Bayes classifier had the highest error rate, as it made incorrect classification 52 times, whereas the decision tree classifier and MLP made 11 incorrect classifications each.
Feature extraction in traditional ML techniques mainly relies on user-specified features that may cause the loss of some important information, due to which researchers are then faced with difficulty in getting accurate results. Deep learning techniques determine the features of the images in different layers instead of relying on the self-made features of the images [2]. For example, in a study by Rozman and Stajnko [9], the quality of tomato seeds was reported in terms of their vigour and germination. In their study, they proposed a computer vision system and reported a detailed procedure for image processing and feature extraction by incorporating a Gaussian filter, segmentation, and Region of Interest (ROI). This study incorporated machine learning classification algorithms including Naïve Bayes classifiers (NBC), k-nearest neighbours (k-NN), decision tree classifiers, support vector machines (SVM) and artificial neural networks (ANN) to sort a sample of 700 seeds. Among these algorithms, the ANN (MLP architecture) showed the best performance in seed classification, with an accuracy of 95.44%. Other accuracy rates were NBC at 87.89%, k-NN at 91.66%, DT at 93.66% and SVM at 93.09% [9].
A comparative study conducted by Agrawal and Dahiya [18] on ML algorithms aimed to classify various grain seeds by using logistic regression (LR), Linear Discriminant Analysis (LDA), k-Nearest Neighbors classifier (kNN), a decision tree classifier (CART), Gaussian Naïve Bayes (NB) and support vector machine (SVM). This study reported performance rates for both linear (LR and LDA) and non-linear (kNN, CART, NB and SVM) algorithms. The accuracy rates for these six algorithms were as follows: the rate of LR was 91.6%, the rate of LDA was 95.8%, the rate of kNN was 87.5%, the rate of CART was 88%, the rate of NB was 88.05% and the rate of SVM was 88.71%. From these results, it can be seen that LDA had the superior performance [18].
Another classification study conducted on corn seeds incorporated a probabilistic neural network (PNN). This analysis has been done on waveform data and aligned the terahertz time-domain spectroscopy (THz-TDS) with the machine learning algorithm PNN. The result of their classification rate showed 75% accuracy with 5-fold cross-validation [10].
Moreover, on feature extraction, research carried out by Vlasov and Fadeev [19] on grain crop seeds by used a machine learning approach over mechanical methods. They elaborated the details of feature extraction by using traditional machine learning, which included image feature extraction, descriptors retrieval, clustering and finishing with a vocabulary of visual words. Although their major focus was on the traditional ML approach, they also reported deep learning as a second method for seed classification and purification. Their results showed that the deep learning approach reached 95% classification accuracy, where traditional learning had a rate of around 75% [19].
In another study, the feature extraction of rice, which was based on physical properties like shape, colour and texture, was done for classification. The researchers used four methods (LR, LDA, k-NN and SVM) of statistical machine learning techniques, and five pre-trained models (VGG16, VGG19, Xception, InceptionV3 and InceptionResNetV2) with deep learning techniques were used for the classification performance comparison. The best accuracy rate was obtained from the SVM method (83.9%), while the best accuracy from the deep learning techniques was obtained from the InceptionResNetV2 model (95.15%) [6].
In a study conducted on corn seed purification, a hybrid dataset preparation was reported. The authors performed a tedious procedure to extract features from corn seeds. The hybrid feature dataset was comprised of a histogram, texture features and spectral features. The classification models used in their study included random forest (RF), BayesNet (BN), LogitBoost (LB) and multilayer perceptron (MLP), along with optimised multi-feature using the (10-fold) cross-validation approach. Among these classifiers, MLP reported outstanding classification accuracy (98.93%) on ROIs size (150 × 150) [11].
With regards to traditional AI-based algorithms, they involve detailed steps in the feature extraction technique. They also need assistance from experts, which has a negative impact on the efficiency of the algorithms. Deep learning (DL), unlike traditional classification learning methods, is not limited to shallow structure algorithms. It can perform complex functions with limited samples, extracting the most essential features from only a small number of training samples. A study conducted by Xinshao [3], based on a sample of weed seeds, used the deep learning technique principal component analysis network (PCANet). This study minimised the limitation of manual feature extraction by learning features from the dataset.
DL, which mainly focuses on machine learning, has brought advancements to the producing of results within various data analysis tasks, especially in computer vision [5]. DL is capable of representing data by automatically learning abstract deep features of a deep network. It is widely applied in various visual tasks. A study conducted on oat seed variety implemented a deep convolutional neural network (DCNN) in combination with some traditional classifiers, namely logistic regression (LR), support vector machine with RBF kernel (RBF_SVM) and linear kernel (LINEAR_SVM) [7].
Another study [5] compared the performance of k-nearest neighbours (kNN), a support vector machine (SVM) and CNN models on spectral data of rice. They reported that CNN outperformed the other two models with 89.6% and 87% accuracy rates on a training set and testing set, respectively.
The complexity of sunflower seed features was addressed in a study with a core focus on CNN. The authors claim that the impurities in sunflower seeds are difficult to recognise due to their texture. They reported that, among all available methods, CNN achieved great success in object detection and identification. Therefore, they used it to address their research problem. They developed an eight-layer CNN model to extract image features. The results of their extensive experiments affirmed the model’s accuracy to be much higher than any other traditional model [8].
There are not many studies found that incorporated CNN to identify and classify varieties of seeds. In their study, Maeda-Gutiérrez et al. [20] reported comparisons among CNN-based architectures, including AlexNet [21], GoogleNet [22], Inception V3 [23] and Residual Network (ResNet 18 and 50) [24]. The data set used in their research contained a single genre (tomato plant seeds), whereas, in our research, we have proposed an efficient model for seed identification and classification based on CNN, which is a deep learning model that possesses a high precision level in image features extraction. Unlike most of the relevant studies, the dataset of this research contains 14 types of seed. The training of this model was carried out through transfer learning, which made the focus of this research more about validation and the testing of the model.
3. The Proposed Model
We proposed a new model based on CNN [12], which provides an efficient approach for seed identification and classification. The whole process consists of three phases: dataset formation, training and testing (as demonstrated in Figure 2). These three phases are further explained in the following subsections.
3.1. Data Set Formation
This subsection explains the formation of the dataset for this research. In this work, 14 different types of commonly known seeds have been selected for the preparation of the dataset. The chosen seeds were black-eyed pea, black pepper, chickpea, coriander, corn, cumin, fennel, fenugreek, flax, kidney beans, mustard, onion, pumpkin and sunflower, as listed in Table 1. For experimentation purposes, the weight of each seed type was around 100 gm. Table 1 and Figure 3 show the frequency distribution of the dataset.
A smartphone (Samsung Galaxy Note 8) was used to capture digital images of these seeds. The resolution of the camera was set at 12-megapixels (4032 × 3024). A tripod mobile stand with a ring light was used to capture images, as illustrated in Figure 4. It is important to note that the number of captured images for each type of seed was around 200 to avoid any imbalance in classification. If one set of the seeds has a high number of images than others, there will be biased results in favour of the dominating set.
All digital images were captured from a distance of one foot away. The digital imaging process was performed during the day to avoid any change in the texture of the seeds. Furthermore, a white ring light was used to avoid shadow effects. A sample of captured images of each seed is depicted in Figure 5. Images were rescaled (224 × 223 × 3), labelled and arranged in separate folders after being captured.
3.2. Training
This subsection reports the training of the proposed model based on the dataset created, as mentioned in the previous subsection. In order to train the model, the dataset was split into training and validation sets. The training of the model was accomplished in many steps, starting with the selection of the pre-trained model, followed by the modification of the model. The process started by adapting the VGG16 architecture [16]. This architecture contains 1000 nodes in its last layer, where each one refers to one of the 1000 objects. We removed the final classification layer of the VGG16 in order to adjust it to the dataset of our research, which consisted of 14 classes. The main reason for choosing VGG16 architecture is that it uses 3 × 3 kernels, which assists in generalising the classification problems outside of the originally trained network. Most importantly, the VGG16 architecture creates a deeper neural network by using a stacked representation of convolution and pooling layers. This makes VGG16 deeper and wider than the former CNN structure. It has five batches of convolution operations, with each batch consisting of 2–3 adjacent convolution layers. Furthermore, a modified version of the CNN model with five additional layers (average pooling layer, flatten layer, dense layer, dropout layer and softmax layer) was incorporated. In the average pooling layer, the pool size was set to (7, 7). In flatten layer, neurons are flattened before being fed to the dense layer, with the activation function being ReLu. After that, a dropout layer with a probability of 0.5 and a classification layer with 14 nodes are added to the model. The softmax function is elucidated in Figure 6. This results in an updated version of VGG16 architecture with 14 classification nodes, which is better suited to investigating our problem and more convenient for transfer learning.
Traditional machine learning technology has achieved great success and has been successfully applied in many practical studies. However, it still has some limitations in certain real-world scenarios [14]. Transfer learning aims to improve the performance of target learners on target domains by transferring knowledge. In this way, constructing target learners’ dependence on a large number of target domain data can be reduced and problems of insufficient training data can be solved [14,15]. There are two popular approaches to transfer learning. In the first approach, the initial weights of the trained model are simply discarded, and the whole of the network is trained afresh on a new dataset. In the second approach, the layers of the existing model are left unchanged, but the newly added layers are trained on the new dataset. In our proposed work, we adopted a hybrid approach in which the actual layers of the model were initially frozen, and only the newly added layers were trained on our seed dataset. This process continued until the 20th iteration. After the 20th iteration, we unfroze the stalled layers in order to make slight weight adjustments to the trained layers for our dataset.
The process of model training has three distinct characteristics: image augmentation, decayed learning rate and model checkpointing. In general, the trained models result in a good classification rate on the training set but fail miserably once exposed to the test set. One of the major reasons for this is overfitting. To avoid overfitting and improve the generalisation capability of machine learning models, an image augmentation technique was implemented [25]. During image augmentation, various images were artificially created through different ways of processing or a combination of multiple processing methods, such as random rotation, shifts, shear and flips. In this proposed work, an inbuilt function in Keras’ library [26] was used to generate the augmented images. From each image, we randomly generated 10 images by randomly rotating images by 30%, zooming by 20%, adjusting height and shifting width by 10%. To speed up the calculations, ADAM optimizer [27] was employed. Figure 7 presents the sample of augmented images of all seed classes considered in this work.
Furthermore, a decaying learning rate with an initial weight of 0.001 mg was used to adjust the model learning rate, as it had almost reached the global optimum. The reason for doing this was to make sure that the model did not take bigger jumps and miss the global optimum. Since the problem we are addressing is a multiclass classification problem, the loss function is set to categorical cross-entropy. The loss function calculates the loss of an example by computing the following sum:
where is the actual value and is the observed value.
It is important to note that in our proposed work we make sure that we have the best possible trained model. In this regard, we implemented a technique called model checkpointing. This model checkpoint observes changes during the training. If there are any positive changes in validation loss, the model checkpoint replaces the existing retained model with the new one, where the validation loss is better than the existing one. At the end of the model training process, the best possible model will be retained with minimum validation loss.
3.3. Testing
This subsection reports the testing of the model. This phase was initiated by loading the best-trained model from the previous phase for testing. To test the trained model, a test dataset was prepared. The test dataset contained 15 images of each selected seed, which were mentioned in Table 1. Unlike in the training dataset, the images were captured randomly by varying light levels and adjusting distance and angle. This test dataset helped in generalising the model for unseen data in a real-life scenario. The image size was resized to (224 × 224 × 3), similar to the training set, to make it compatible with the proposed model. After resizing, these images are fed to the proposed model to predict the test dataset. The result values obtained during the testing phase and training phase were compared. This comparison is done to validate the proposed model.
It is important to mention that, during the training and testing phases, the Class Activation Maps (CAMs) technique was employed with the intention of extracting features from the seed images. Therefore, the effect of each of the layers can be visualised to show how the CNN model handled the images during the training process. This assists in providing deeper insight into the user to validate the usability and lifecycle of the model. Figure 8 demonstrates a sample of the visual representation of the features extracted by our trained model using the provided images of black-eyed peas, black pepper, coriander and corn. The figure illustrates the selected regions in the images that were to be used to generate certain class labels.
4. Experimentation and Result Analysis
To fairly evaluate the performance and prove the efficiency of our proposed solution to processing seed identification and classification over a broad range of seeds, several extensive experiments were designed. The proposed work is implemented in Python, a scientific programming language on the Windows 10 operating system. The system configuration includes an i7 processor with 16GB RAM. It took 67 h to train the proposed model with the specified configurations. To capture images, an android device running on android Pi with 6GB RAM and a camera resolution of 12-megapixels was used. With regards to lighting, white light was used, and seeds were placed on a white background.
To assess the performance of the classification model, a range of performance metrics were employed, derived from a 2 × 2 confusion matrix. By definition, a confusion matrix (C) is such that Ci,j is equal to the number of observations known to be in group (i) and predicted to be in group (j), as described in Figure 9.
There are four different cases in the confusion matrix, from which more advanced metrics are obtained:
- True positive: a presented image is of a mustard seed and the model classifies it as a mustard seed image.
- True negative: a presented image is not of mustard seed and the model does not classify it as a mustard seed image.
- False positive: a presented image is not of mustard seed; however, the model incorrectly classifies it as the mustard seed image.
- False negative: a presented image is actually of mustard seed; however, the model incorrectly classifies it as something else.
In machine learning, life cycle model evaluation is an important phase used to check its performance. To check the performance of our proposed model, the following metrics have been measured:
- Accuracy: the proportion of the total number of correct predictions, which is a sum of the total correct positive instances and total correct negative instances over the total number of instances.
- Precision: a calculation of correct positive prediction over the total number of positively predicted instances, which is calculated as true positive over the sum true positive and false positive.
- Recall: a calculation of correct positive predictions over the total number of actual positive classes, which is computed as true positive over the sum of true positive and false negative.
We have also assessed the trained model for validation accuracy and validation loss. Furthermore, the model is being continuously monitored in terms of validation accuracy and validation loss to spot any noticeable deviation in training and validation performance.
Figure 10 depicts the training accuracy and loss of the model. In Figure 10a, it can be seen that the model started with a training accuracy of 0.81 in the first epoch. The model performance continues to improve from iterations 1 to 5, and reaches a maximum accuracy of 0.93. Thereafter, accuracy plunges in the successive iteration, and by the end of the 10th iteration, it drops to the initial starting accuracy.
In these 10 iterations, we could see both high and low accuracy rates, which indicates that the model is not yet best fit for the data. The performance of the model appreciably improves from the 10th to the 40th iteration, reaching a maximum value of 0.996. In between, it can be seen that there are some cases where accuracy reduces. However, this does not have any impact on the performance of the model. From the 40th iteration onwards, there is a small reduction in the accuracy up to the next 60 iterations by keeping the performance steady. This indicates that the optimal model has been obtained for the training data.
Figure 10b illustrates the training loss of the model. In the beginning, the model lost value, which is normal at the initial stage of the training process, as a model has not been exposed to many examples of the data. Figure 10b also depicts that the training loss drops with each successive epoch, which is considered to be a characteristic of a good model. From the figure, it can be seen that the model’s loss oscillates between noticeable highs and lows up to the 40th iteration. However, after the 40th iteration, the model maintains its smallest loss value. The steadiness in the results shown is due to the quality of the dataset and the implementation of dense architecture with multiple layers.
It is evident from the literature that, during the training of the model, the performance can be made desirable. However, this process can be misleading and may fail on the validation dataset. This is because the model has only seen supervised data and is not well-learned. To consider a model as the best fit, it should not only perform well on the training dataset, but also the validation dataset. Figure 11 elucidates the validation accuracy and loss of the proposed model.
From Figure 11a, it can be seen that the model initially performs poorly with an accuracy rate of around 0.22. This is because the model is not trained enough. The performance of the model stays more or less the same for the first 20 iterations. From the 20th to the 30th iteration, there is a gradual improvement in the performance of the model. It reaches its peak value at the 40th iteration. From there onwards, the performance of the model remains steady. This is due to the fact that we implemented dense architecture with multiple layers. Figure 11b shows the validation loss of the model. It can be seen that the model had a very high validation loss at the initial stage during the validation process, which was not even close to the acceptable range. The figure also shows that the loss oscillates between highs and lows for the first 40 iterations. From the 40th iteration onwards, the loss starts to reduce monotonously and eventually reaches the minimum value in the 55th iteration, remaining unchanged from there.
The model showed stability in its performance during the training and validation processes, which was due to the pre-processing techniques employed in the model. This started with the collection of data, within which an effort was made to have a balanced distribution of data across all of the classes. In addition, the image augmentation technique also helped to make sure that the system was exposed to the most variations of the dataset. The dropout technique played a major role in the model’s validation performance by making sure that the model did not deviate much from its training performance.
Table 2 outlines the performance of each seed class mentioned in the proposed model in terms of precision, recall, F1-score and support. Support represents the number of instances of each class that was performed during model training. It is important to note that, with the help of image augmentation for each class, around 1700 to 1800 random instances were synthetically created. From the table, it can be noticed that the model showed the maximum possible values for each seed class except the chickpea and pumpkin seed classes. This is because the model mixed up these two classes due to the similarities in their texture. This may have been caused by the light settings of the camera. From the table, it can also be seen that the aggregate accuracy value of the proposed model is equal to 1, which is considered the maximum value. This high performance of the model was due to the implementation of the pre-processing techniques, as well as other hyperparameters. A visual representation of the model training performance can be seen in Figure 12.
It is important to test the proposed model and check its performance on unseen real-world data. In this regard, a new dataset was prepared in which images were captured randomly in different light settings and angles. This newly prepared dataset was used by the trained model to predict the images. Table 3 presents the test results of the proposed model. It can be seen from the table that the model reported a precision value of 1 for most of the classes. However, the cumin seeds had the lowest precision value (0.89). This is because the textures of the cumin and fennel seeds are alike. From the table, it is obvious that the precision value of the mustard seed is second lowest (0.94). This is because, while zooming, the images of mustard seeds show similar features to those seen in the images of black pepper seeds. Similarly, in the recall, the model reports maximum values for most of the classes, except black pepper, fenugreek and flax seeds, all with a value of 0.94. F1-scores are also reported in the table.
Figure 13 depicts a heat map of the performance of the proposed model on the testing set. It also shows the steady performance given for most of the classes in the model in terms of precision, recall and F1-score. A visual representation of the model testing performance can be seen in Figure 14. The test results of the proposed model are encouraging and can be used in the industry for sorting seeds in conveyor systems and for packaging.
Since this study is the first attempt to investigate the issues of seed identification and classification with a large variety of different seed types (up to 14 types), we compare our proposed solution to other well-known existing strategies that are the closest to this work, namely kNN, a decision tree classifier, Gaussian Naïve Bayes, random forest classifier, AdaBoost classifier and logistic regression. Table 4 presents the precision, recall and F1-score results produced using the training data by kNN, decision tree classifier, Gaussian Naïve Bayes, random forest classifier, AdaBoost classifier, logistic regression and our proposed model, respectively. From these results, it can be seen that our proposed model outperforms all other models by achieving the highest values for precision, recall and F1-score. Also, the table depicts that the decision tree classifier was the worst, while the random forest classifier achieved the most acceptable precision results compared to other models except our proposed model. The results also indicate that kNN, Gaussian Naïve Bayes and AdaBoost classifiers were slightly better than the decision tree classifier in terms of precision. The results described in Table 4 illustrate that our proposed model is superior to the other models considered in this research work with regards to recall and F1-score. Lastly, the results demonstrate that AdaBoost classifier was the worst in terms of recall and F1-score. The random forest classifier steadily outperformed the other models by achieving the second-highest recall and F1-score values, after our proposed model. The main reason that our proposed approach achieved the highest precision, recall, and F1-score was the application of the CNN strategy and the incorporation of five new layers in the VGG16 model. This helped in generating more accurate classifications of seed based on provided images.
5. Conclusions and Future Work
This paper proposed an efficient model for seed identification and classification. The model is trained on a dataset containing images of 14 variants of seed. The image augmentation technique was used to produce more training images artificially by using an inbuilt API ImageDataGenerator in Keras’ library. The augmented images were rescaled to 224 × 224 × 3. The proposed model adopted existing VGG16 architecture for classification, in which the last layer was replaced with five newly implemented layers: the average pooling layer, the flatten layer, the dense layer, the dropout layer and the softmax layer. To improve classification performance, the model was fine-tuned. To increase the accuracy rate and reduce the error rate, the model was optimised and validated. The results from the proposed model show an accuracy of up to 99.9%. In future work, we are planning to develop a mobile-based application using a larger number of different seeds (more than the 14 types that were considered in this research), which aims to lead to a wider range of seed classification. This application would help people with limited knowledge about seeds, as it is not easy to seek suitable advice from agriculture experts or experienced farmers to identify, sort or classify the seeds manually.
Author Contributions
Conceptualization, Y.G. and Y.H.; methodology, Y.G. and Y.H.; software, Y.H.; validation, Y.G., Y.H. and A.A.A.; formal analysis, A.B.S. and A.A.A; investigation, Y.G. and Y.H.; resources, L.J. and A.B.S.; data curation, Y.H. and Y.G.; writing—original draft preparation, Y.G. and A.A.A.; writing—review and editing, A.B.S. and L.J.; visualization, Y.G.; supervision, Y.G.; project administration, Y.G. and Y.H.; funding acquisition, Y.G. All authors have read and agreed to the published version of the manuscript.
Funding
This research study has been funded by Deputyship for Research & Innovation, Ministry of Education in Saudi Arabia: Project number IFT20056.
Acknowledgments
The authors extend their appreciation to the Deputyship for Research & Innovation, Ministry of Education in Saudi Arabia, for funding this research work through the project number IFT20056.
Conflicts of Interest
The authors declare no conflict of interest. The funder had no role in the design of the study and in the writing of the manuscript, or in the decision to publish the results.
References
- Santos, L.; Santos, F.N.; Dos Oliveira, P.M.; Shinde, P. Deep Learning Applications in Agriculture: A Short Review. In Iberian Robotics Conference; Springer: Cham, Switzerland, 2020; pp. 139–151. ISBN 9783030359898. [Google Scholar]
- Barman, U.; Choudhury, R.D.; Sahu, D.; Barman, G.G. Comparison of convolution neural networks for smartphone image based real time classification of citrus leaf disease. Comput. Electron. Agric. 2020, 177, 105661. [Google Scholar] [CrossRef]
- Xinshao, W. Weed Seeds Classification Based on PCANet Deep Learning Baseline. In Proceedings of the 2015 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference APSIPA ASC, Hong Kong, China, 16–19 December 2015; pp. 408–415. [Google Scholar]
- Jamuna, K.S.; Karpagavalli, S.; Vijaya, M.S.; Revathi, P.; Gokilavani, S.; Madhiya, E. Classification of Seed Cotton Yield Based on the Growth Stages of Cotton Crop Using Machine Learning Techniques. In Proceedings of the ACE 2010–2010 International Conference on Advances in Computer Engineering, Bangalore, India, 20–21 June 2010; pp. 312–315. [Google Scholar]
- Qiu, Z.; Chen, J.; Zhao, Y.; Zhu, S.; He, Y.; Zhang, C. Variety identification of single rice seed using hyperspectral imaging combined with convolutional neural network. Appl. Sci. 2018, 8, 212. [Google Scholar] [CrossRef] [Green Version]
- Kiratiratanapruk, K.; Temniranrat, P.; Sinthupinyo, W.; Prempree, P.; Chaitavon, K.; Porntheeraphat, S.; Prasertsak, A. Development of Paddy Rice Seed Classification Process using Machine Learning Techniques for Automatic Grading Machine. J. Sens. 2020, 2020, 7041310. [Google Scholar] [CrossRef]
- Wu, N.; Zhang, Y.; Na, R.; Mi, C.; Zhu, S.; He, Y.; Zhang, C. Variety identification of oat seeds using hyperspectral imaging: Investigating the representation ability of deep convolutional neural network. RSC Adv. 2019, 9, 12635–12644. [Google Scholar] [CrossRef] [Green Version]
- Luan, Z.; Li, C.; Ding, S.; Wei, M.; Yang, Y. Sunflower Seed Sorting Based on Convolutional Neural Network. In Proceedings of the ICGIP 2019 Eleventh International Conference on Graphics and Image Processing, Hangzhou, China, 12–14 October 2019; Pan, Z., Wang, X., Eds.; SPIE: Bellingham, WA, USA, 2020; Volume 11373, p. 129. [Google Scholar]
- Rozman, Č. Denis Stajnko Assessment of germination rate of the tomato seeds using image processing and machine learning. Eur. J. Hortic. Sci. 2015, 80, 68–75. [Google Scholar]
- Taylor, J.; Chiou, C.P.; Bond, L.J. A methodology for sorting haploid and diploid corn seed using terahertz time domain spectroscopy and machine learning. AIP Conf. Proc. 2019, 2102. [Google Scholar] [CrossRef] [Green Version]
- Ali, A.; Qadri, S.; Mashwani, W.K.; Brahim Belhaouari, S.; Naeem, S.; Rafique, S.; Jamal, F.; Chesneau, C.; Anam, S. Machine learning approach for the classification of corn seed using hybrid features. Int. J. Food Prop. 2020, 23, 1097–1111. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. Handb. Brain Theory Neural Netw. 1995, 3361, 1995. [Google Scholar]
- Schmidhuber, J. Deep Learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. Proc. IEEE 2020, 1–31. [Google Scholar] [CrossRef]
- Tan, C.; Sun, F.; Kong, T.; Zhang, W.; Yang, C.; Liu, C. A Survey on Deep Transfer Learning. In Proceedings of the International Conference on Artificial Neural Networks, Rhodes, Greece, 4–7 October 2018; pp. 270–279. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Eli-Chukwu, N. Applications of Artificial Intelligence in Agriculture: A Review. Eng. Technol. Appl. Sci. Res. 2019, 9, 4377–4383. [Google Scholar] [CrossRef]
- Agrawal, D.; Dahiya, P. Comparisons of classification algorithms on seeds dataset using machine learning algorithm. Compusoft 2018, 7, 2760–2765. [Google Scholar]
- Vlasov, A.V.; Fadeev, A.S. A machine learning approach for grain crop’s seed classification in purifying separation. J. Phys. Conf. Ser. 2017, 803, 012177. [Google Scholar] [CrossRef] [Green Version]
- Maeda-Gutiérrez, V.; Galván-Tejada, C.E.; Zanella-Calzada, L.A.; Celaya-Padilla, J.M.; Galván-Tejada, J.I.; Gamboa-Rosales, H.; Luna-García, H.; Magallanes-Quintanar, R.; Guerrero Méndez, C.A.; Olvera-Olvera, C.A. Comparison of convolutional neural network architectures for classification of tomato plant diseases. Appl. Sci. 2020, 10, 1245. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 25 (NIPS 2012), Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hawkins, D.M. The Problem of Overfitting. J. Chem. Inf. Comput. Sci. 2004, 44, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Arnold, T.B. kerasR: R Interface to the Keras Deep Learning Library. J. Open Source Softw. 2017, 2, 296. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J.L. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—C, San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
Figure 1.
General Representation of CNN Model.
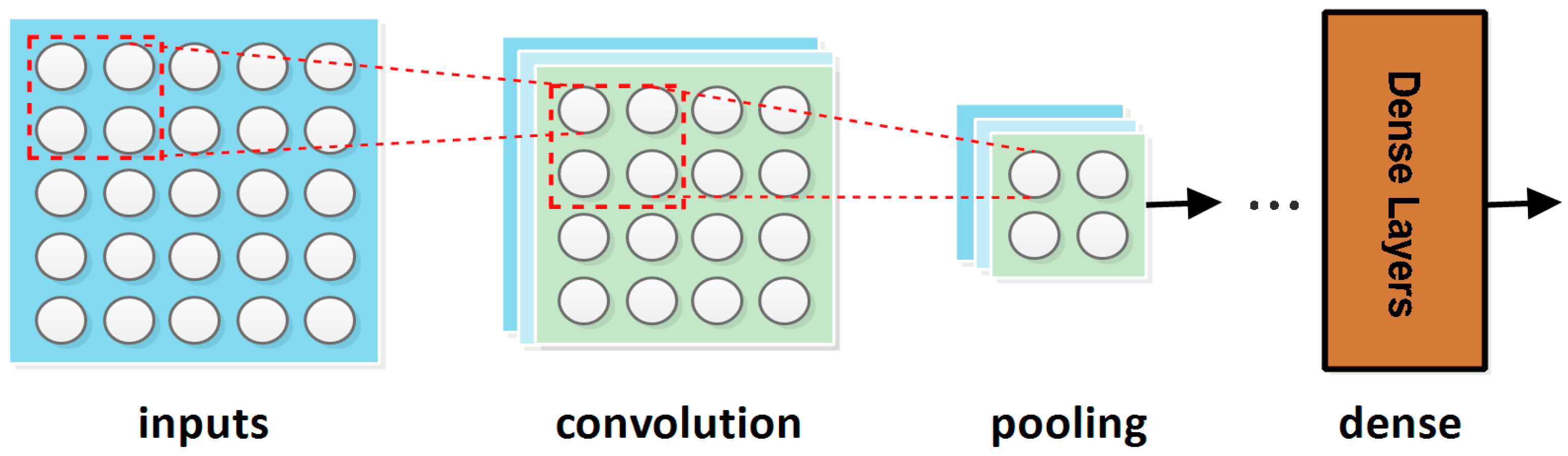
Figure 2.
Research flow diagram.
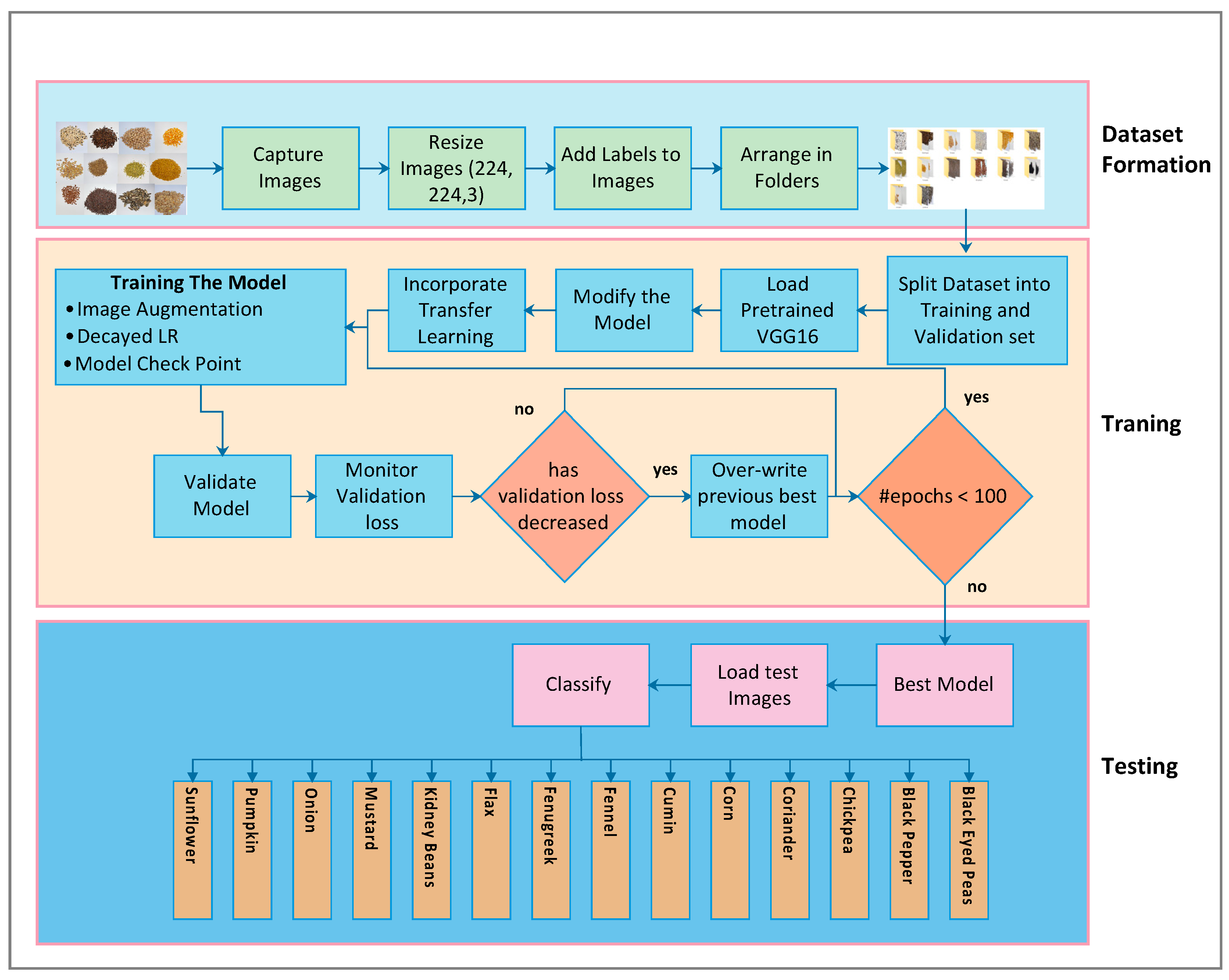
Figure 3.
Frequency distribution of dataset (seeds).
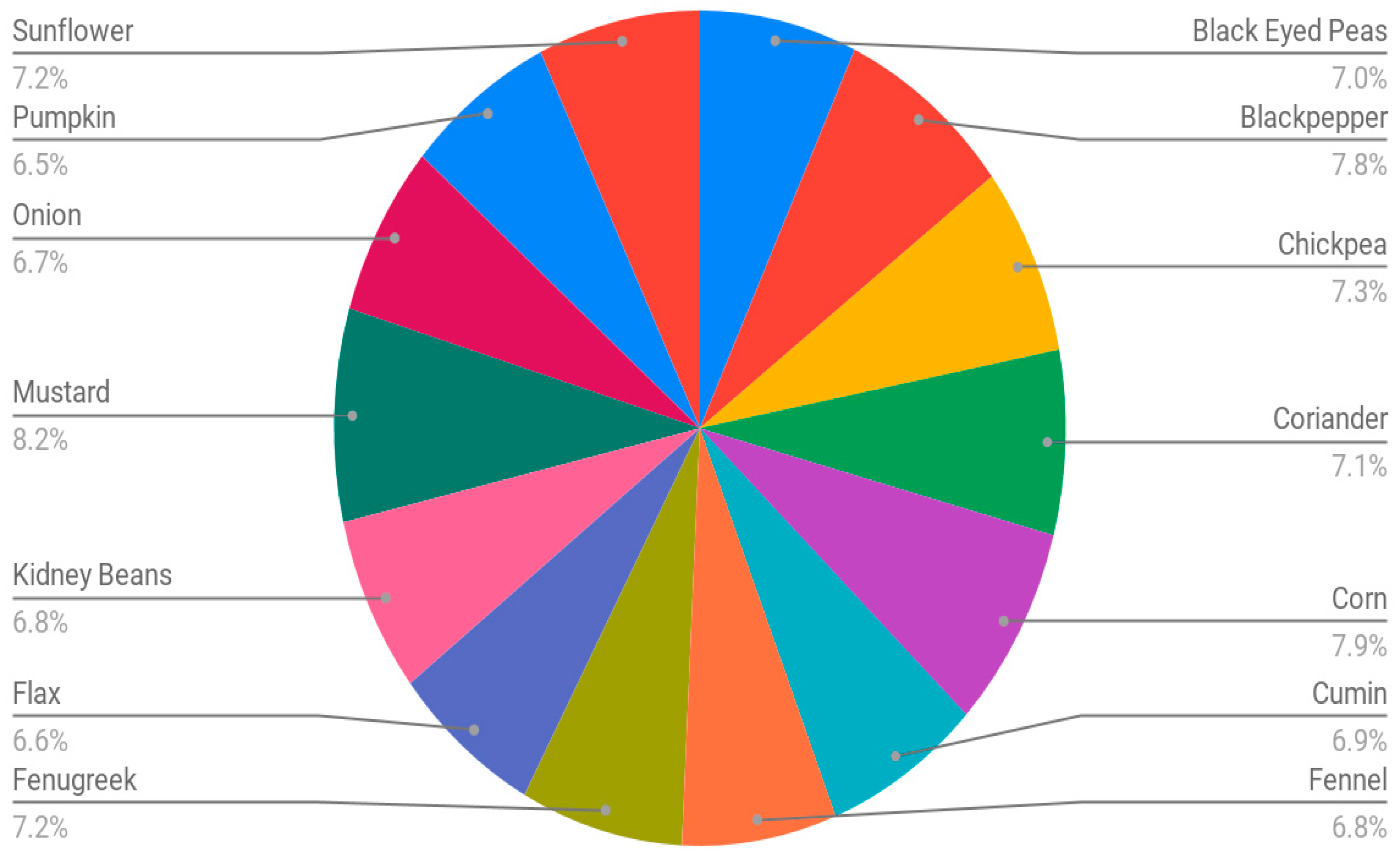
Figure 4.
Setup for capturing images of seeds.

Figure 5.
Sample images of 14 different seeds.

Figure 6.
Proposed CNN model for seed classification.
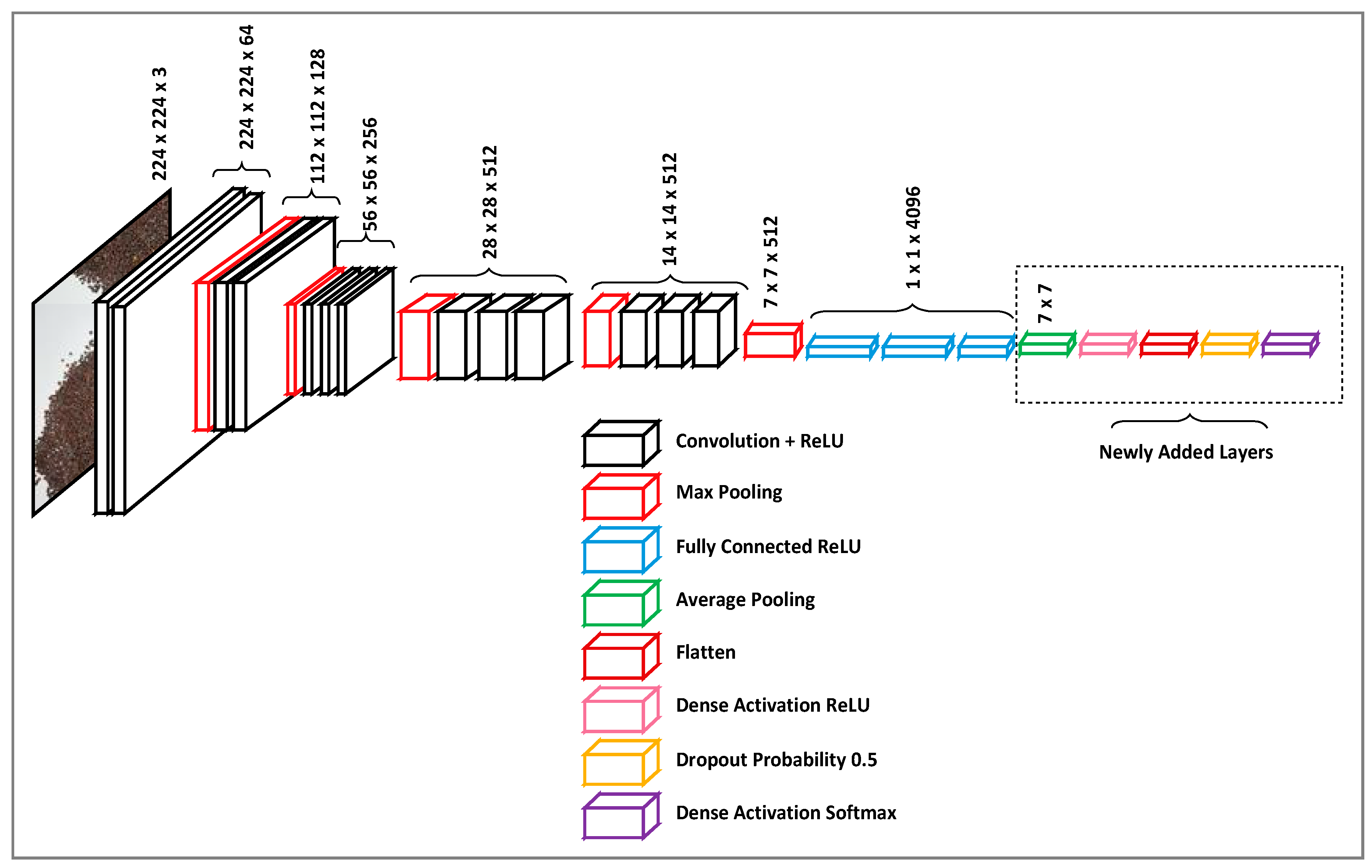
Figure 7.
Sample of augmented images of seed classes.

Figure 8.
Sample of visual representation of CNN features of seed images.
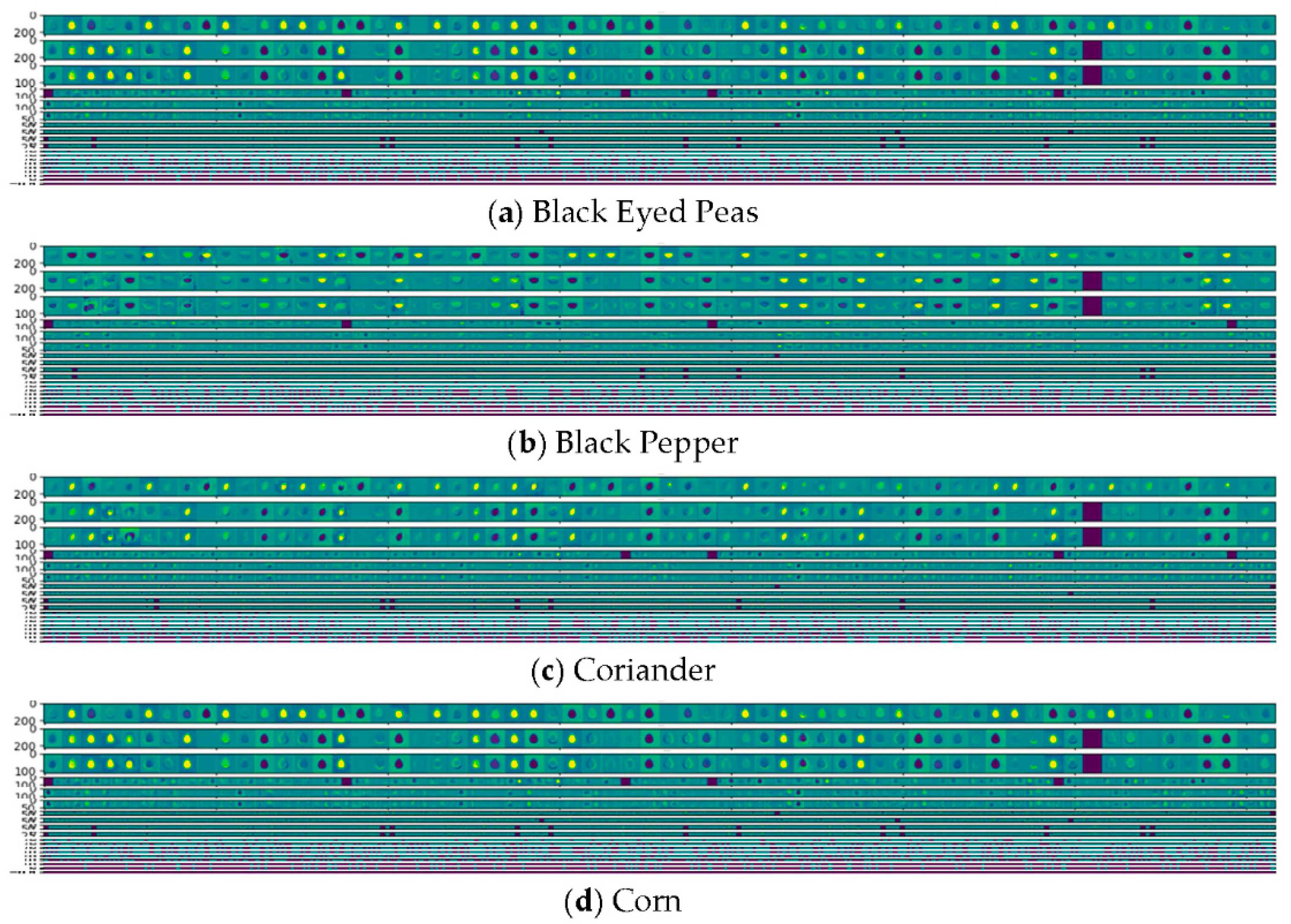
Figure 9.
Confusion matrix (Ci, j).

Figure 10.
Training accuracy and loss of the model.
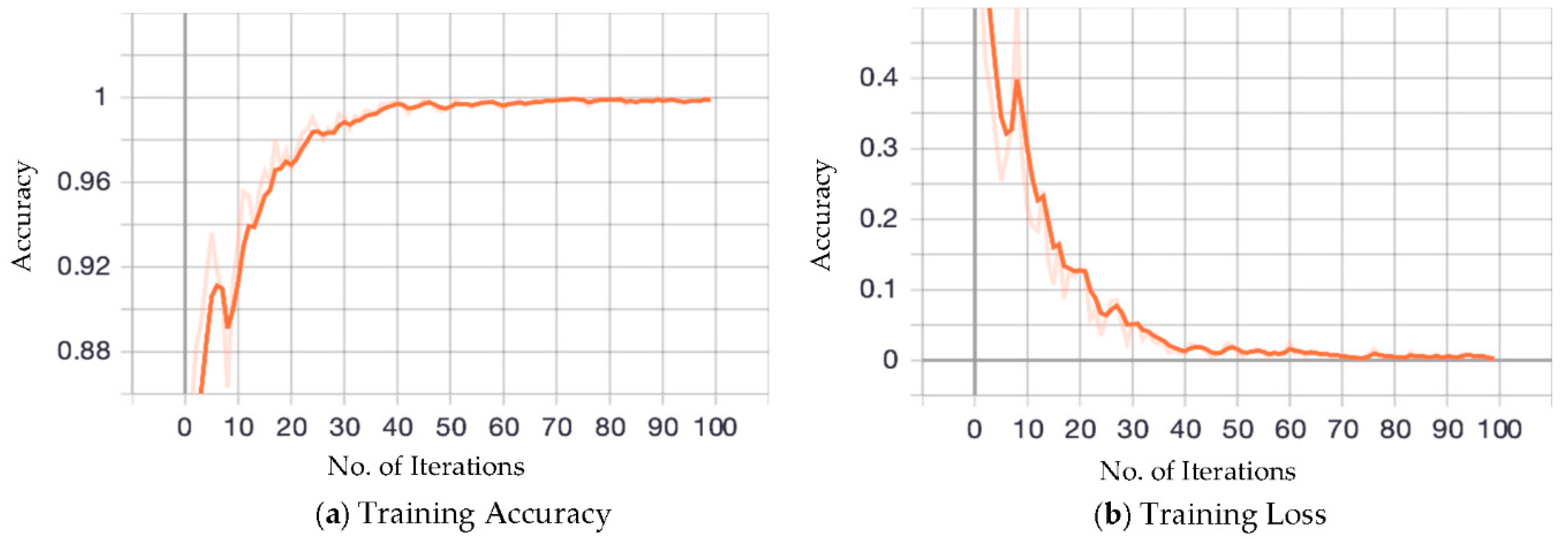
Figure 11.
Validation accuracy and loss of the model.
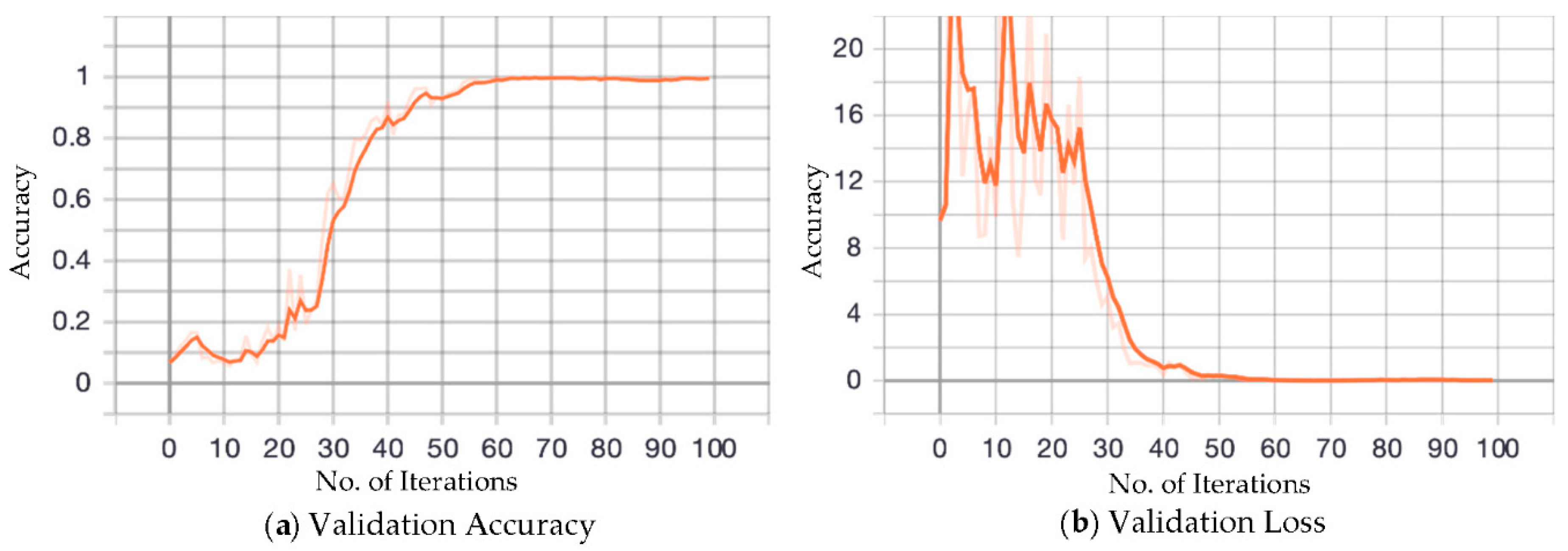
Figure 12.
The training results of the proposed model.
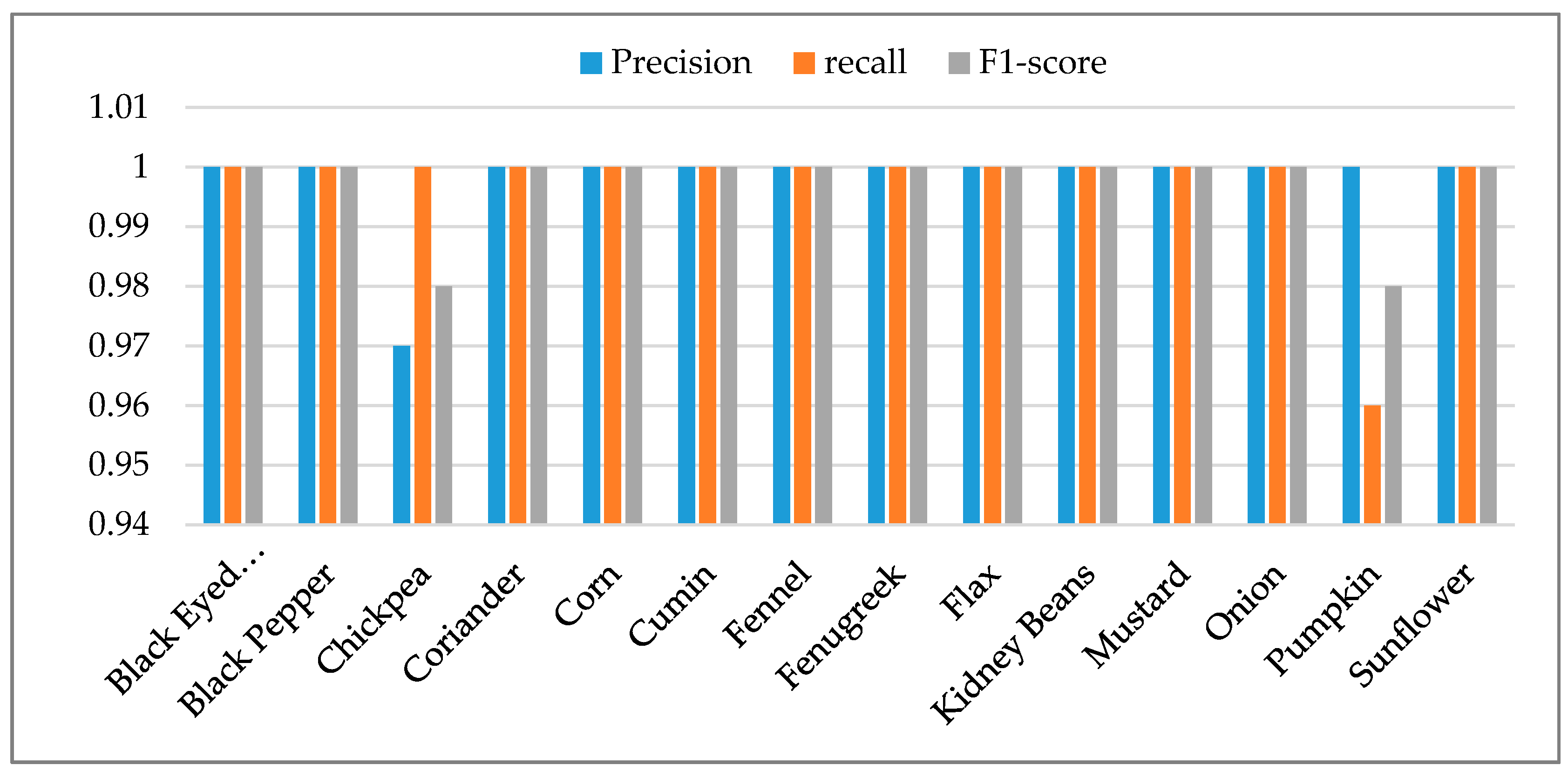
Figure 13.
Heatmap of the proposed model.
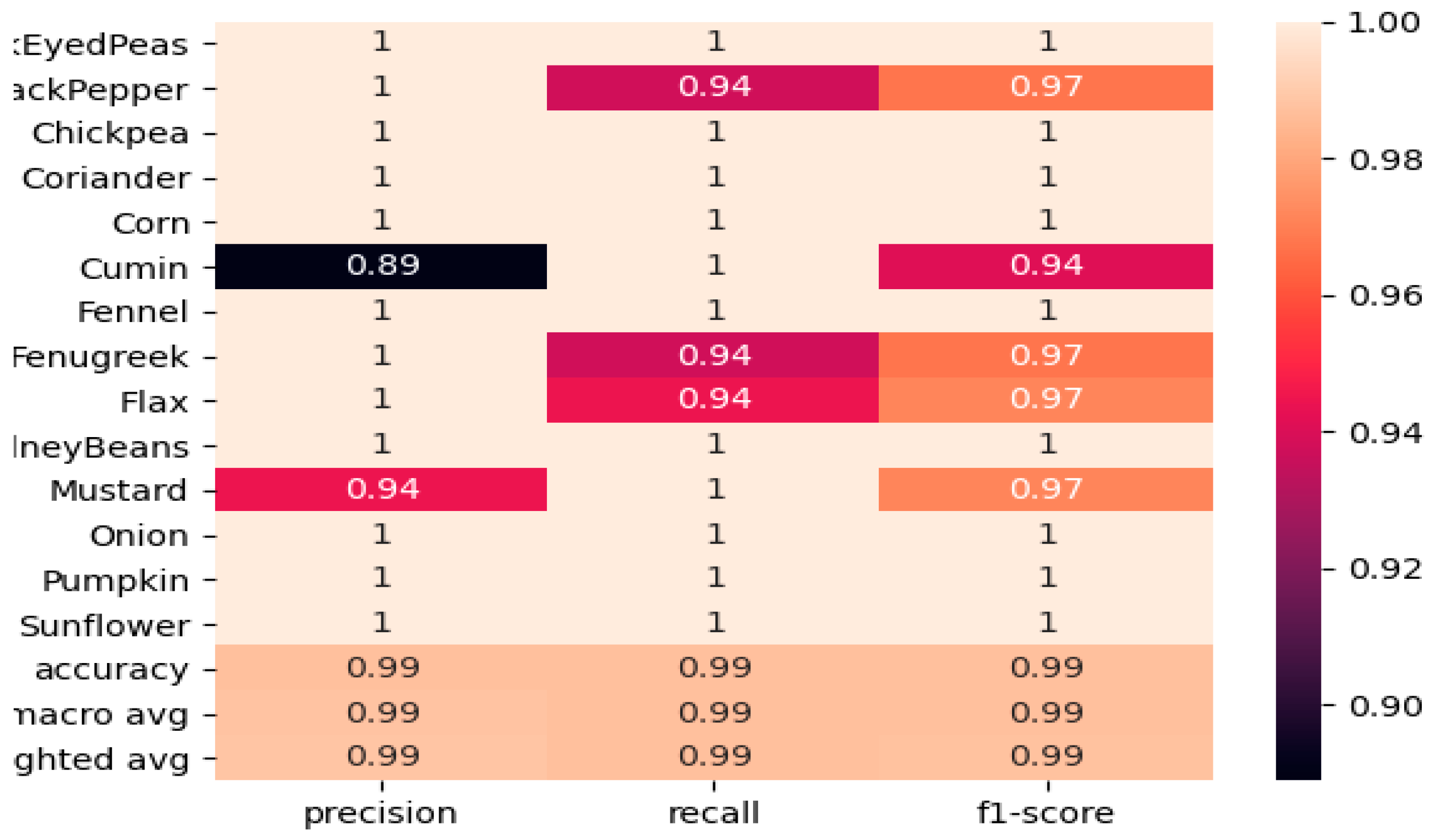
Figure 14.
The testing results of the proposed model.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Details of 14 different seeds and their image count.
| S.No. | Seed | # | S.No. | Seed | # |
|---|---|---|---|---|---|
| 1 | Black-Eyed Peas | 190 | 2 | Black Pepper | 212 |
| 3 | Chickpea | 199 | 4 | Coriander | 195 |
| 5 | Corn | 216 | 6 | Cumin | 189 |
| 7 | Fennel | 187 | 8 | Fenugreek | 196 |
| 9 | Flax | 180 | 10 | Kidney Beans | 187 |
| 11 | Mustard | 225 | 12 | Onion | 182 |
| 13 | Pumpkin | 179 | 14 | Sunflower | 196 |
Table 2.
Model training results.
| Seeds | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| Black Eyed Peas | 1 | 1 | 1 | 440 |
| Black Pepper | 1 | 1 | 1 | 510 |
| Chickpea | 0.97 | 1 | 0.98 | 620 |
| Coriander | 1 | 1 | 1 | 460 |
| Corn | 1 | 1 | 1 | 470 |
| Cumin | 1 | 1 | 1 | 450 |
| Fennel | 1 | 1 | 1 | 530 |
| Fenugreek | 1 | 1 | 1 | 530 |
| Flax | 1 | 1 | 1 | 450 |
| Kidney Beans | 1 | 1 | 1 | 520 |
| Mustard | 1 | 1 | 1 | 530 |
| Onion | 1 | 1 | 1 | 460 |
| Pumpkin | 1 | 0.96 | 0.98 | 480 |
| Sunflower | 1 | 1 | 1 | 390 |
| Accuracy | 1 | 6840 | ||
| Macro Avg | 1 | 1 | 1 | 6840 |
| Weighted Avg | 1 | 1 | 1 | 6840 |
Table 3.
Model test results.
| Seeds | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| Black Eyed Peas | 1 | 1 | 1 | 16 |
| Black Pepper | 1 | 0.94 | 0.97 | 16 |
| Chickpea | 1 | 1 | 1 | 16 |
| Coriander | 1 | 1 | 1 | 16 |
| Corn | 1 | 1 | 1 | 17 |
| Cumin | 0.89 | 1 | 0.94 | 16 |
| Fennel | 1 | 1 | 1 | 18 |
| Fenugreek | 1 | 0.94 | 0.97 | 16 |
| Flax | 1 | 0.94 | 0.97 | 18 |
| Kidney Beans | 1 | 1 | 1 | 17 |
| Mustard | 0.94 | 1 | 0.97 | 17 |
| Onion | 1 | 1 | 1 | 18 |
| Pumpkin | 1 | 1 | 1 | 18 |
| Sunflower | 1 | 1 | 1 | 18 |
| Accuracy | 0.99 | 237 | ||
| Macro Avg | 0.99 | 0.99 | 0.99 | 237 |
| Weighted Avg | 0.99 | 0.99 | 0.99 | 237 |
Table 4.
Comparison between proposed model with traditional algorithms.
| Models | Precision | Recall | F1-Score |
|---|---|---|---|
| KNN Algorithms | 0.58 | 0.47 | 0.48 |
| Decision Tree | 0.50 | 0.49 | 0.49 |
| Gaussian Naïve Bayes | 0.54 | 0.40 | 0.41 |
| Random Forest Classifier | 0.84 | 0.83 | 0.83 |
| AdaBoost Classifier | 0.61 | 0.24 | 0.28 |
| Logistic Regression | 0.64 | 0.63 | 0.63 |
| Proposed Model | 0.99 | 0.99 | 0.99 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Gulzar, Y.; Hamid, Y.; Soomro, A.B.; Alwan, A.A.; Journaux, L. A Convolution Neural Network-Based Seed Classification System. Symmetry 2020, 12, 2018. https://doi.org/10.3390/sym12122018
AMA Style
Gulzar Y, Hamid Y, Soomro AB, Alwan AA, Journaux L. A Convolution Neural Network-Based Seed Classification System. Symmetry. 2020; 12(12):2018. https://doi.org/10.3390/sym12122018
Chicago/Turabian StyleGulzar, Yonis, Yasir Hamid, Arjumand Bano Soomro, Ali A. Alwan, and Ludovic Journaux. 2020. "A Convolution Neural Network-Based Seed Classification System" Symmetry 12, no. 12: 2018. https://doi.org/10.3390/sym12122018
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.