
Detection and Quantification of Visual Tablet Surface Defects by Combining Convolutional Neural Network-Based Object Detection and Deterministic Computer Vision Approaches



Abstract

1. Introduction
2. Materials and Methods
2.1. Materials
2.2. Background Suppression
2.3. Tablet Support
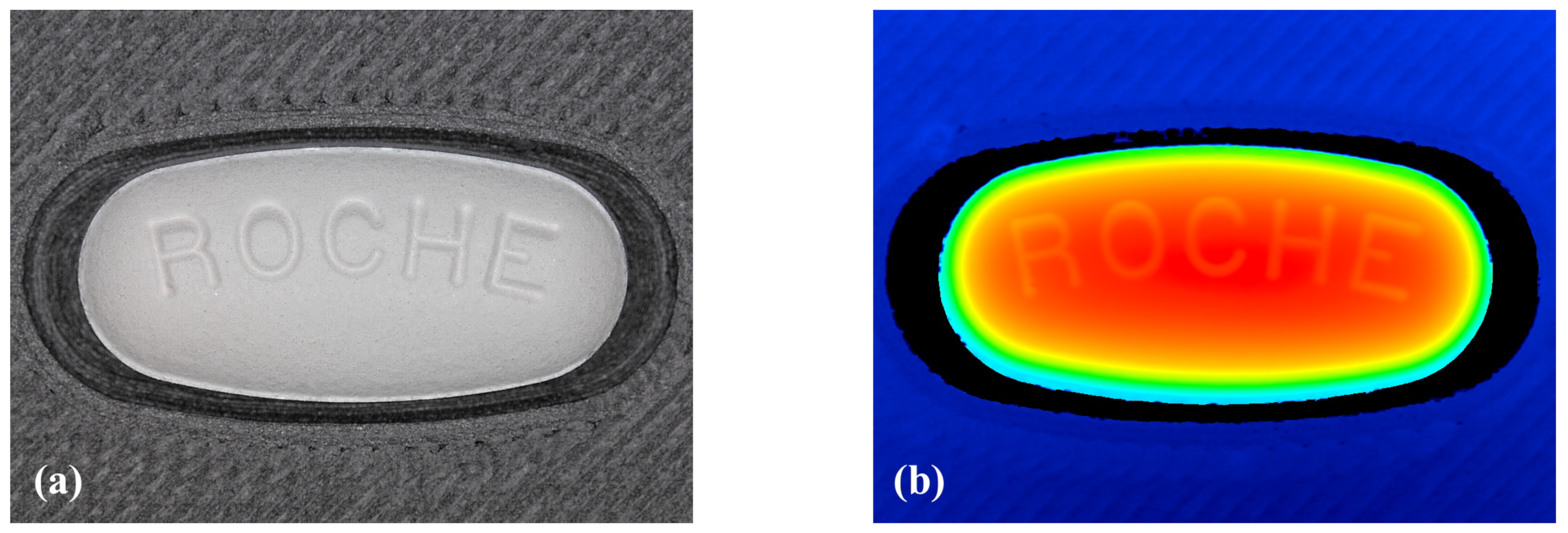
2.4. Flattening and Normalization
2.5. Segmentation and Classification
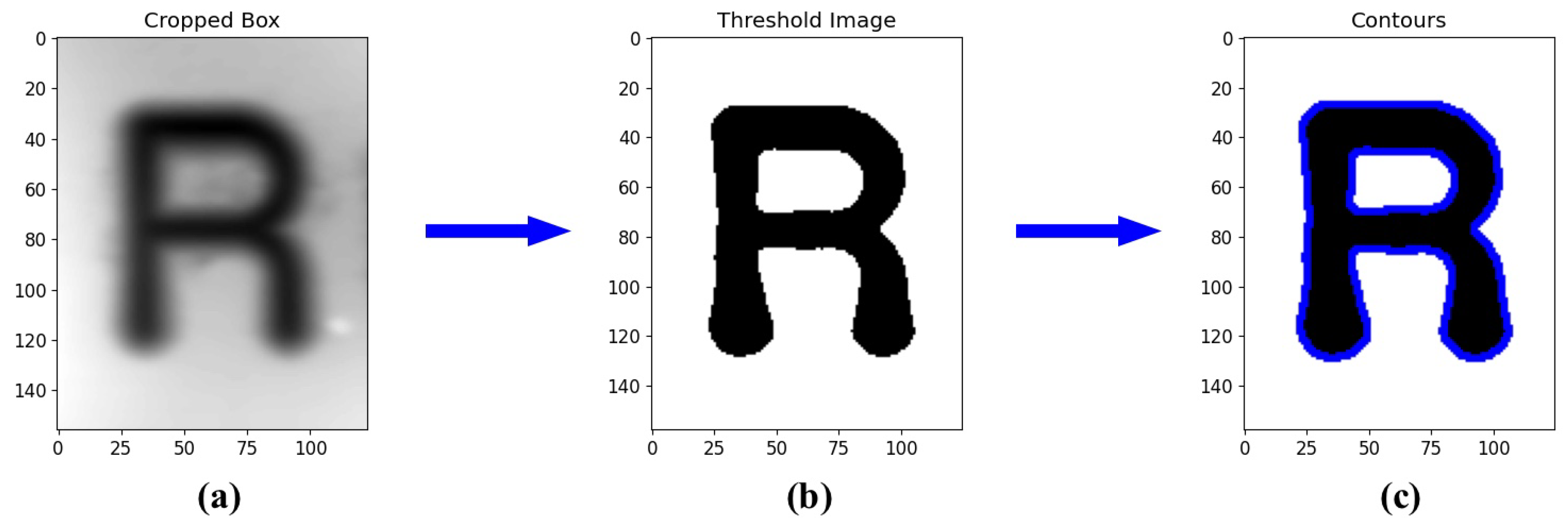
2.6. Quantification
2.7. Tolerance Interval
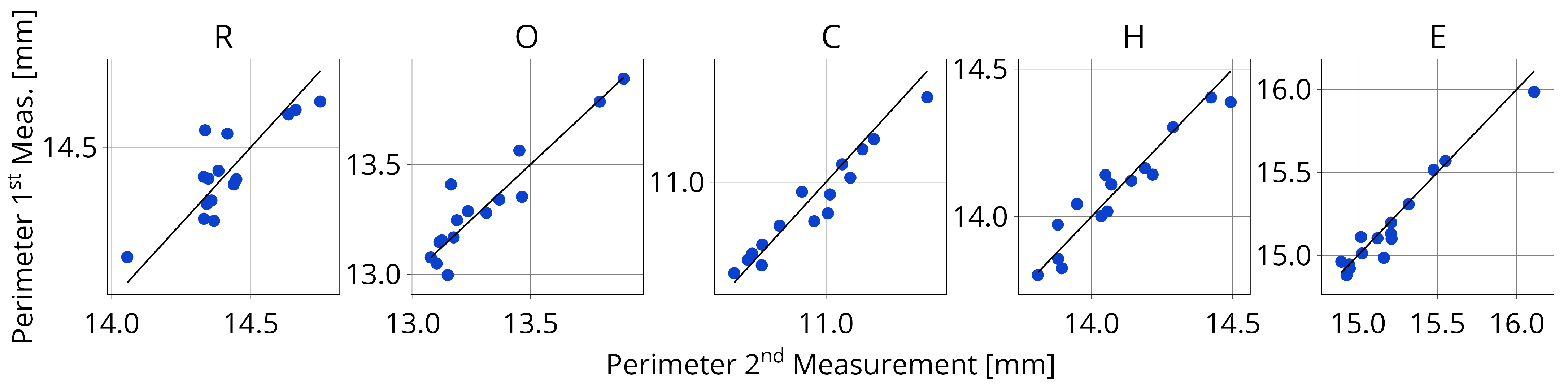
2.7.1. Tolerance Interval for Tablet Characters
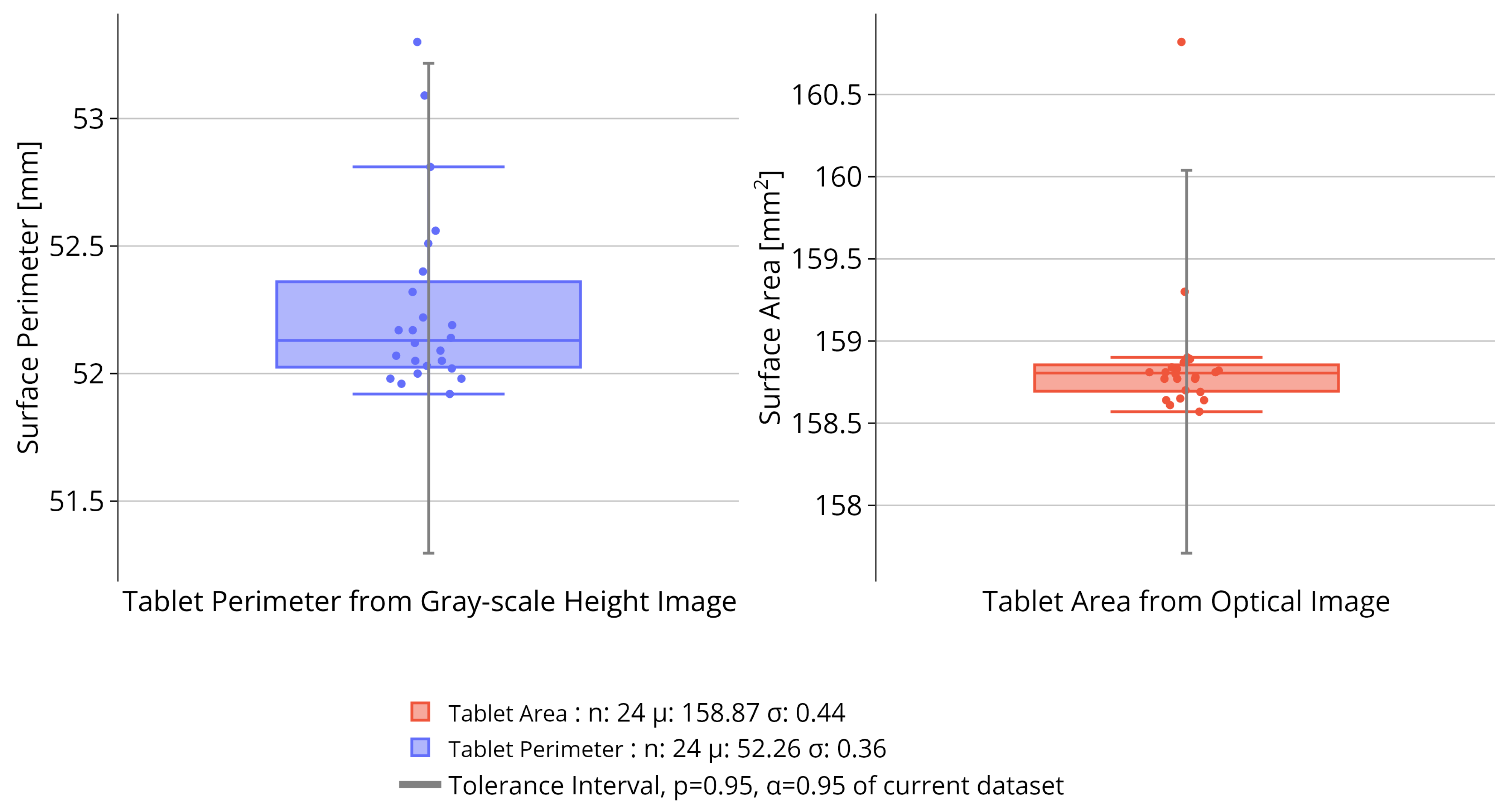
2.7.2. Tolerance Interval for Tablet Body
2.8. Process Flowchart
3. Results and Discussion
3.1. Precision
3.2. Case Studies
3.2.1. Defect Identification
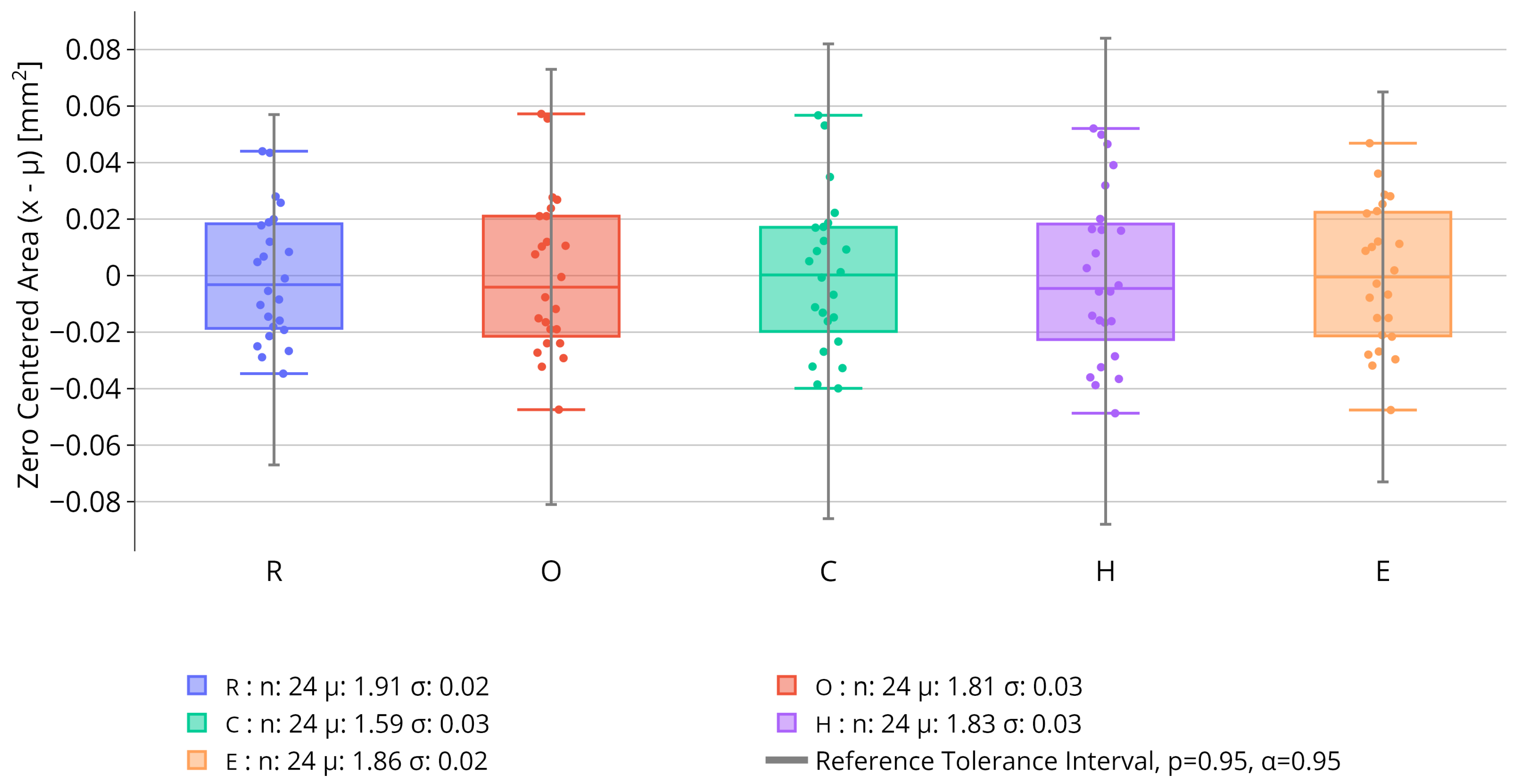
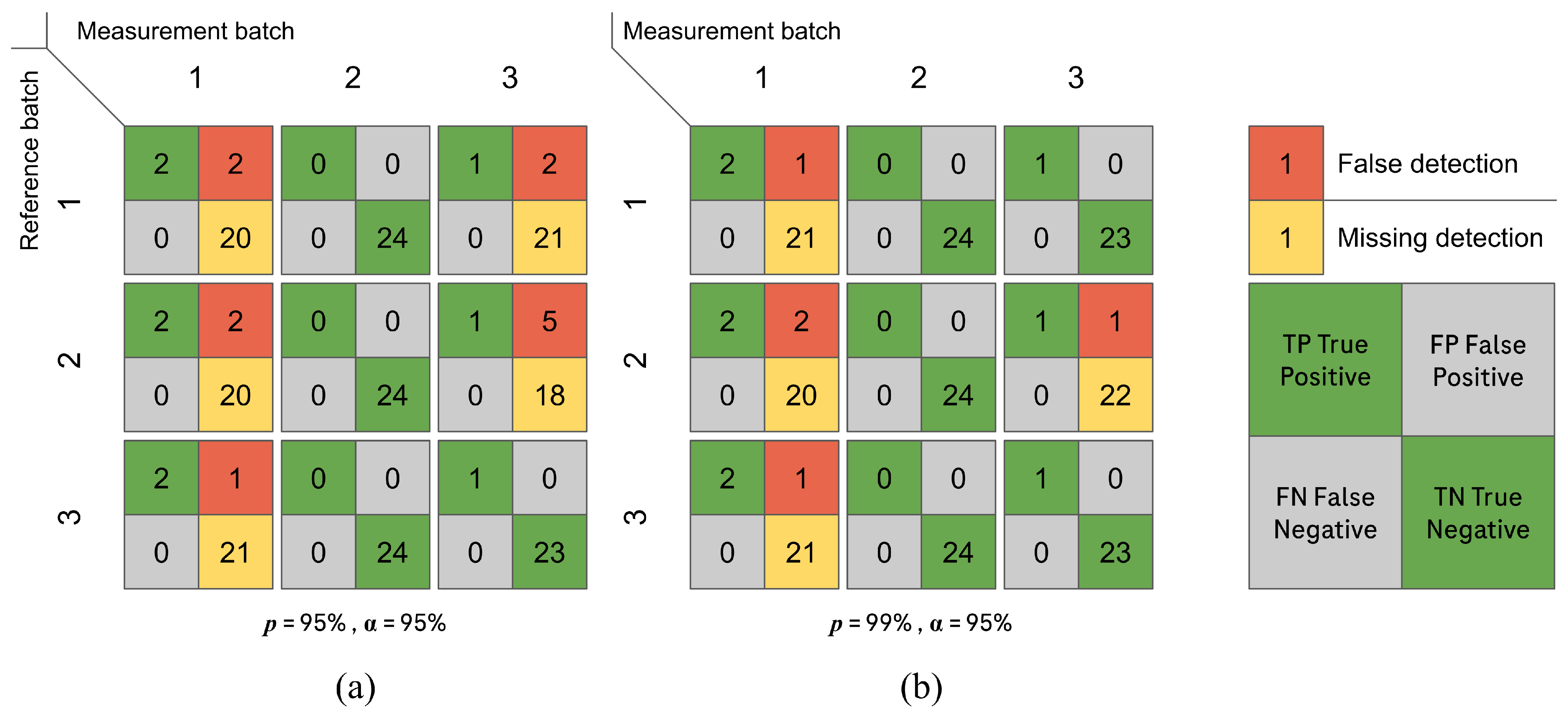
3.2.2. Inter-Batch Assessment
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Qiu, Y.; Chen, Y.; Zhang, G.G.Z.; Liu, L.; Porter, W. Developing Solid Oral Dosage Forms: Pharmaceutical Theory and Practice, 2nd ed.; Academic Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Zhong, H.; Chan, G.; Hu, Y.; Hu, H.; Ouyang, D. A Comprehensive Map of FDA-Approved Pharmaceutical Products. Pharmaceutics 2018, 10, 263. [Google Scholar] [CrossRef] [PubMed]
- Pekari, K.; Fürst, T.; Gössl, R.; Dudhedia, M.S.; Segretario, J.; Sommer, F.; Watson, P. The Score Card Approach: A First Step Toward an Evidence-based Differentiation Assessment for Tablets. Ther. Innov. Regul. Sci. 2016, 50, 204–212. [Google Scholar] [CrossRef] [PubMed]
- Food and Drug Administration. Safety Considerations for Product Design to Minimize Medication Errors Guidance for Industry; Food and Drug Administration, Center for Drug Evaluation and Research: Silver Spring, MD, USA, 2016.
- Chattoraj, S.; Daugherity, P.; McDermott, T.; Olsofsky, A.; Roth, W.J.; Tobyn, M. Sticking and Picking in Pharmaceutical Tablet Compression: An IQ Consortium Review. J. Pharm. Sci. 2018, 107, 2267–2282. [Google Scholar] [CrossRef] [PubMed]
- Špiclin, Z.; Bukovec, M.; Pernuš, F.; Likar, B. Image registration for visual inspection of imprinted pharmaceutical tablets. Mach. Vis. Appl. 2011, 22, 197–206. [Google Scholar] [CrossRef]
- Barimani, S.; Šibanc, R.; Tomaževič, D.; Meier, R.; Kleinebudde, P. 100% visual inspection of tablets produced with continuous direct compression and coating. Int. J. Pharm. 2022, 614, 121465. [Google Scholar] [CrossRef] [PubMed]
- Podrekar, G.; Tomaževič, D.; Likar, B.; Usenik, P. Model based visual inspection of pharmaceutical tablets with photometric stereo. In Proceedings of the 2017 Fifteenth IAPR International Conference on Machine Vision Applications (MVA), Nagoya, Japan, 8–12 May 2017. [Google Scholar] [CrossRef]
- Pharmatec—Tablet & Capsule Visual Inspection System. Available online: https://pharmatec.be/products/t-cvis-nsr-tablet-capsule-visual-inspection-system/ (accessed on 27 September 2024).
- Sensum—Computer Vision Systems. Available online: https://www.sensum.eu/ (accessed on 27 September 2024).
- Cognex—Machine Vision and Barcode Readers. Available online: https://www.cognex.com/ (accessed on 27 September 2024).
- Jung, C.R.; Ortiz, R.S.; Limberger, R.; Mayorga, P. A new methodology for detection of counterfeit Viagra® and Cialis® tablets by image processing and statistical analysis. Forensic Sci. Int. 2012, 216, 92–96. [Google Scholar] [CrossRef] [PubMed]
- Hirschberg, C.; Edinger, M.; Holmfred, E.; Rantanen, J.; Boetker, J. Image-Based Artificial Intelligence Methods for Product Control of Tablet Coating Quality. Pharmaceutics 2020, 12, 877. [Google Scholar] [CrossRef] [PubMed]
- Pathak, K.A.; Kafle, P.; Vikram, A. Deep learning-based defect detection in film-coated tablets using a convolutional neural network. Int. J. Pharm. 2025, 671, 125220. [Google Scholar] [CrossRef] [PubMed]
- Qin, X.; Zhang, Z.; Huang, C.; Dehghan, M.; Zaiane, O.R.; Jagersand, M. U2-Net: Going Deeper with Nested U-Structure for Salient Object Detection. arXiv 2022, arXiv:2005.09007. [Google Scholar] [CrossRef]
- Smith, R. An Overview of the Tesseract OCR Engine. In Proceedings of the Ninth International Conference on Document Analysis and Recognition (ICDAR 2007), Paraná, Brazil, 23–26 September 2007; Volume 2. [Google Scholar] [CrossRef]
- Bhavya Sree, B.; Yashwanth Bharadwaj, V.; Neelima, N. An Inter-Comparative Survey on State-of-the-Art Detectors—R-CNN, YOLO, and SSD. In Intelligent Manufacturing and Energy Sustainability; Reddy, A., Marla, D., Favorskaya, M.N., Satapathy, S.C., Eds.; Springer: Singapore, 2021. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2016, arXiv:1506.01497. [Google Scholar] [CrossRef] [PubMed]
- Suzuki, S.; Be, K. Topological structural analysis of digitized binary images by border following. Comput. Vis. Graph. Image Process. 1985, 30, 32–46. [Google Scholar] [CrossRef]
- Witkovský, V. On the Exact Two-Sided Tolerance Intervals for Univariate Normal Distribution and Linear Regression. Austrian J. Stat. 2014, 43, 279–292. [Google Scholar] [CrossRef]
- Howe, W.G. Two-Sided Tolerance Limits for Normal Populations—Some Improvements. J. Am. Stat. Assoc. 1969, 64, 610–620. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characters | Tablets | |||||
|---|---|---|---|---|---|---|
| R | O | C | H | E | ||
| NRMSE Perimeter () | 12.78 | 10.99 | 7.89 | 8.74 | 6.16 | 34.60 |
| NRMSE Area () | 2.39 | 2.15 | 3.60 | 3.63 | 2.98 | 8.88 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Freiermuth, E.; Kohler, D.; Hofstetter, A.; Thun, J.; Juhnke, M. Detection and Quantification of Visual Tablet Surface Defects by Combining Convolutional Neural Network-Based Object Detection and Deterministic Computer Vision Approaches. J. Pharm. BioTech Ind. 2025, 2, 9. https://doi.org/10.3390/jpbi2020009
Freiermuth E, Kohler D, Hofstetter A, Thun J, Juhnke M. Detection and Quantification of Visual Tablet Surface Defects by Combining Convolutional Neural Network-Based Object Detection and Deterministic Computer Vision Approaches. Journal of Pharmaceutical and BioTech Industry. 2025; 2(2):9. https://doi.org/10.3390/jpbi2020009
Chicago/Turabian StyleFreiermuth, Eric, David Kohler, Albert Hofstetter, Juergen Thun, and Michael Juhnke. 2025. "Detection and Quantification of Visual Tablet Surface Defects by Combining Convolutional Neural Network-Based Object Detection and Deterministic Computer Vision Approaches" Journal of Pharmaceutical and BioTech Industry 2, no. 2: 9. https://doi.org/10.3390/jpbi2020009
APA StyleFreiermuth, E., Kohler, D., Hofstetter, A., Thun, J., & Juhnke, M. (2025). Detection and Quantification of Visual Tablet Surface Defects by Combining Convolutional Neural Network-Based Object Detection and Deterministic Computer Vision Approaches. Journal of Pharmaceutical and BioTech Industry, 2(2), 9. https://doi.org/10.3390/jpbi2020009