1. Introduction
Currently pesticides are needed to produce sufficient and good quality food for the world′s constantly growing population [
1]. The pesticides are deliberately applied, and in most cases, their residues should remain in/on the target objects to deliver the desired functions. This raises food and environmental safety concerns. According to the survey conducted by the European Food Safety Authority (EFSA), pesticide residues in food (40%) and antibiotic, hormone or steroid residues in meat (39%) top the list of food safety-related concerns among Europeans [
2].
The experts of the FAO/WHO Joint Meeting on Pesticide Residues (JMPR) evaluate the experimental data and establish toxicological endpoints [e.g., no-effect levels, acceptable daily intake (ADI), acute reference dose (ARfD)] on the basis of all known facts at the time of the evaluation, perform initial exposure assessment and recommend maximum residue levels for consideration by the delegates of Codex Committee on Pesticide Residues (CCPR) [
3]. The JMPR recommendations are further evaluated within a stepwise procedure to establish CODEX MRLs by the Codex Alimentarius Commission (CAC) [
4,
5]. EFSA and some national authorities also evaluate the toxicological and residue data and derive the ADI, ARfD, MRL values that may be somewhat different from those established by the JMPR due to specific national circumstances.
To control the safe and efficient use of pesticides, their residues are regularly monitored in food and environmental samples in many countries. The samples are typically taken randomly based on the priorities reflecting the national risk assessment [
6,
7]. The monitoring programmes generally include raw and a limited number of processed commodities (e.g., wine and juice). Composite samples are usually taken according to the Codex sampling guidelines [
8] in food stores and food distribution centres [
6], while imported foods are collected at the point of entry in the country. Therefore, the monitoring data represent the actual residue that can be expected in the distributed foods. The evaluation of the results of monitoring programmes enables the national authorities, for instance, to:
- (i)
Identify the commodities with an incidence of high residues and initiate corrective actions;
- (ii)
Prevent the sale of food containing unacceptable residues;
- (iii)
Perform quantitative dietary exposure assessment; and
- (iv)
Manage the risk of chemical residues [
6].
The number and the scope of the analyses vary among countries. Likewise, the format and details reported are different. Some examples are given in
Table 1.
Specific studies covering selected crops and limited sampling targets have been reported in combination with modified sample preparation procedures in numerous publications, reflecting world-wide activities from Argentina to Vietnam. Some references are given as examples [
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31,
32,
33,
34,
35,
36,
37,
38,
39,
40,
41].
The objectives of our article are to show the internationally accepted methods for estimating of the consumers’ exposure to pesticide residues, testing compliance with national and export market MRLs and considering the level and frequency of residues for setting the priority of commodities in national monitoring programmes. However, we do not deal with the procedures used for estimation/establishing maximum residue limits because they are not based on monitoring data. Moreover, we present the data analysis system which we found useful for the evaluation of the very large number of monitoring results.
2. Methods and Results
The petitioners submit experimental data for supporting their claim for the registration of their pesticide products. The supervised trial data provided with the application can be used for the evaluation of international (IEDI) or national (NEDI) daily intake at the time or shortly after the registration of a pesticide when monitoring data are not yet available. Once a pesticide is regularly applied, the initial dietary intake estimate can be refined based on the results of the monitoring data. However, it should be noted that the monitoring data are normally obtained with multi-residue methods (MRM) determining the parent compound and/or its stable metabolite and do not cover all residues defined for risk assessment purposes [
42]. Therefore, an appropriate correction factor should be used that accounts for the ratio of total toxicologically significant residues and the analyte detected by the MRM [
43].
The daily intake can be estimated with deterministic and probabilistic methods. However, for the latter, a much larger database is required to obtain realistic results.
2.1. Deterministic Method for the Estimation of Long-Term (Chronic) Exposure
The daily intake is calculated as the product of the average food consumption (C
i, kg food/kg body weight, (bw) and the median or average pesticide residue concentration (R
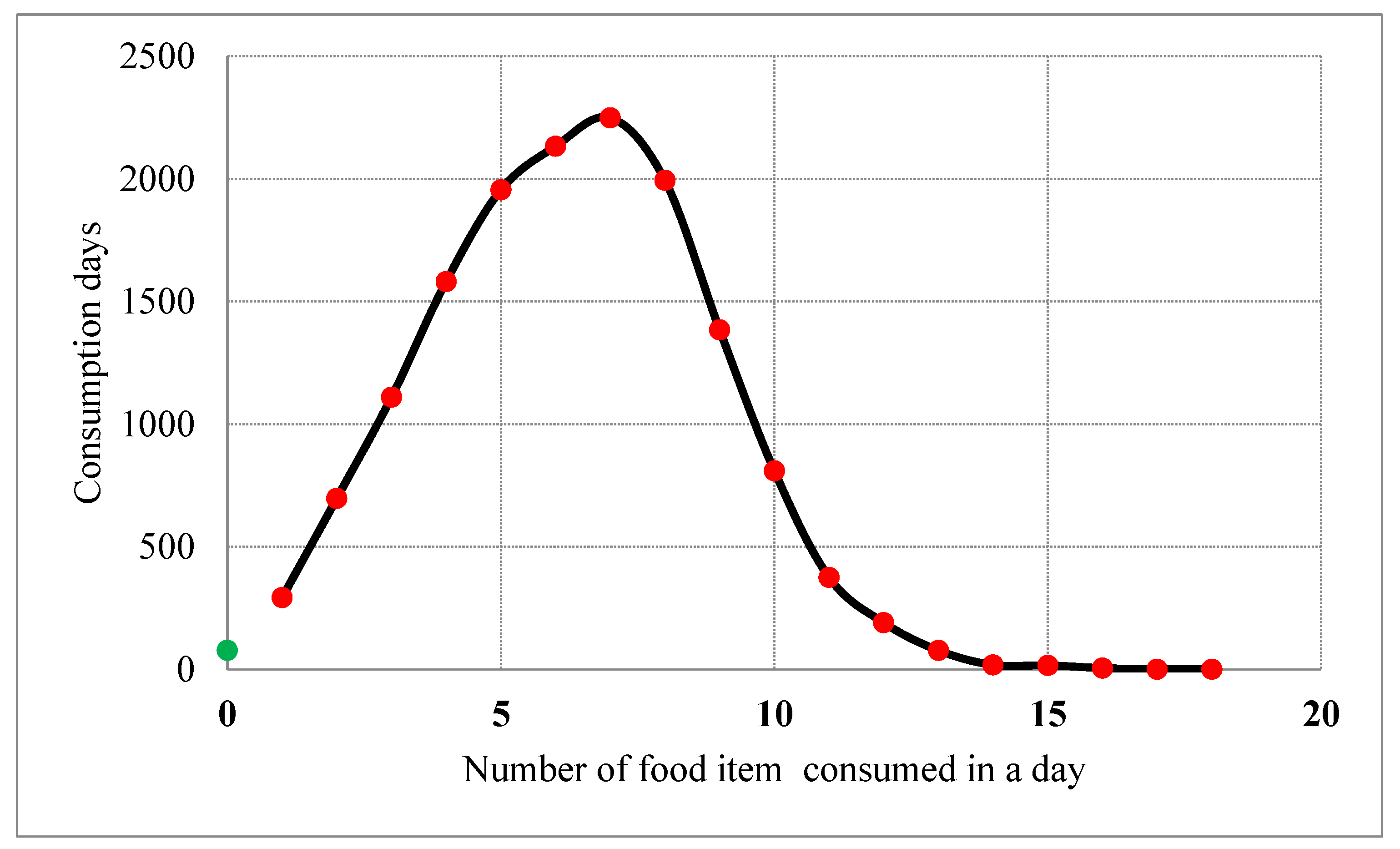
i, mg/kg). The total dietary exposure (estimated daily intake, EDI, in mg residue/kg bw) is obtained by adding up all intakes from ‘n’ food consumed on a given day for which residue data are available. For instance, the food consumption survey conducted in Hungary revealed (
Figure 1) that most frequently 5–8 different fruits and vegetable were eaten by a single person within a day [
44].
Applying the deterministic method, the EDI expressed in mg residue/kgbw is calculated as [
45,
46].
The median residue obtained from supervised trials (STMR) or the average residue concentration (R
i) from the monitoring programmes are expected to represent the long-term average of actual residue concentrations in the edible portion of the i
th food item. The average consumption (C
i) is obtained by taking into account consumers and non-consumers of a food by a given population cluster but does not account for the seasonal products or certain preferences for a food product group. The long-term dietary exposure reflects the average of eaters and possibly includes non-eaters over a lifetime [
47].
For the correct use of Equation (1), the following preconditions should be observed [
43]:
The R
i should include all metabolites and degradation products of toxicological concern according to the residue definition for risk assessment purposes. The definition of residues can be found for instance in the list of the Codex MRLs, EC Pesticide database, and USA Pesticide registration documents [
48,
49,
50];
In case of supervised trials, R
i is the median of residues in the edible portion of the crop [
51] obtained from all trials performed according to the maximum dosage and the shortest pre-harvest interval (PHI) registered (the so-called maximum GAP);
The median residue should be estimated with the reported LOQ values, except when evidence from trials and supporting studies suggests that the residues are essentially zero;
For evaluation of monitoring data, the nondetectable residues may be counted with LOQ, 0.5 LOQ or 0 leading to upper bound, middle bound and lower bound estimates that are used by EFSA to frame the boundaries of an exposure estimate to pesticide residues [
10];
Since a typically large proportion of samples contain non-detectable residues, the calculation of EDI with 0.5 LOQ values provides a conservative but not exaggerated estimate of the exposure of consumers. In the cases when a relatively large number of random monitoring residue data (>100) are available for a crop, the middle-bound calculation of the average residue can be best applied;
The residues should be measured in the edible portion of the tested food in contrast to the portion of commodity to which the MRL applies [
51];
Where data are available, the effect of processing and cooking practices should also be accounted for.
The NEDI should be based on the same factors as the IEDI, but the following additional aspects related to the national use pattern of the pesticides and food consumption data can also be considered [
46], which would allow a refinement of the NEDI:
Proportion of crop or food commodity treated;
Proportion of crop domestically produced and imported (they may contain different kinds of residues);
Total diet or market basket studies;
Food consumption data, including subgroups of the population.
The JMPR estimates the international daily intake (IEDI) [
52] based on the 17 GEMS/Food Consumption Cluster Diets [
53]. Despite many uncertainties and limitations [
42], they represent the best available source of data for predicting long-term intake of pesticides on an international level [
46]. This model is especially useful for countries where information about national food consumption data is rather meagre [
54]. If the national consumption figures are inserted into the template instead of the cluster diet, it will calculate the nation-specific dietary intake provided that no other alterations are made in the template. If consumer age group specific food consumption data are available at a national level, different EDI estimates can also be obtained for different age groups. EFSA developed the PRiMO model based on similar principles [
55], incorporating the national food consumption data of member and partner countries collected, applying the uniform methodology [
56].
2.2. Deterministic Estimation of Short-Term Intake (STI)
In addition to the average intake—the exposure of consumers occasionally eating large portions of food (LP) containing high residues—the STI should also be part of food safety risk assessment. The short-term intake may be estimated by multiplying the large portion of food consumption with the highest pesticide residue concentration in those foods. The estimated short-term intake (ESTI) is always expressed on a body weight basis for comparison with the ARfD [
45]. In the current IESTI-equations, the body weight is normally expressed as the arithmetic mean body weight of the target population. The large portion food consumption (LP, in kg edible portion of food/person) is obtained by taking the 97.5th percentile of a ‘consumer-only’ distribution of the food in question [
45,
46]. Each food commodity is assessed individually, because it is unlikely that one person consumes large portions from two or more different foods in one day.
During the pre-registration of a pesticide, the highest residue concentration from supervised field trials (HR, in mg/kg) is used to represent the actual high residue concentration. Where the results of monitoring programmes are used, the 97.5th percentile of residues can be applied to represent the HR provided that over 120 samples have been analysed [
47]. In this case the 97.5th percentile (the second highest residue value) can be estimated with 95% confidence level. If fewer results are available, the confidence level of the estimation would be lower.
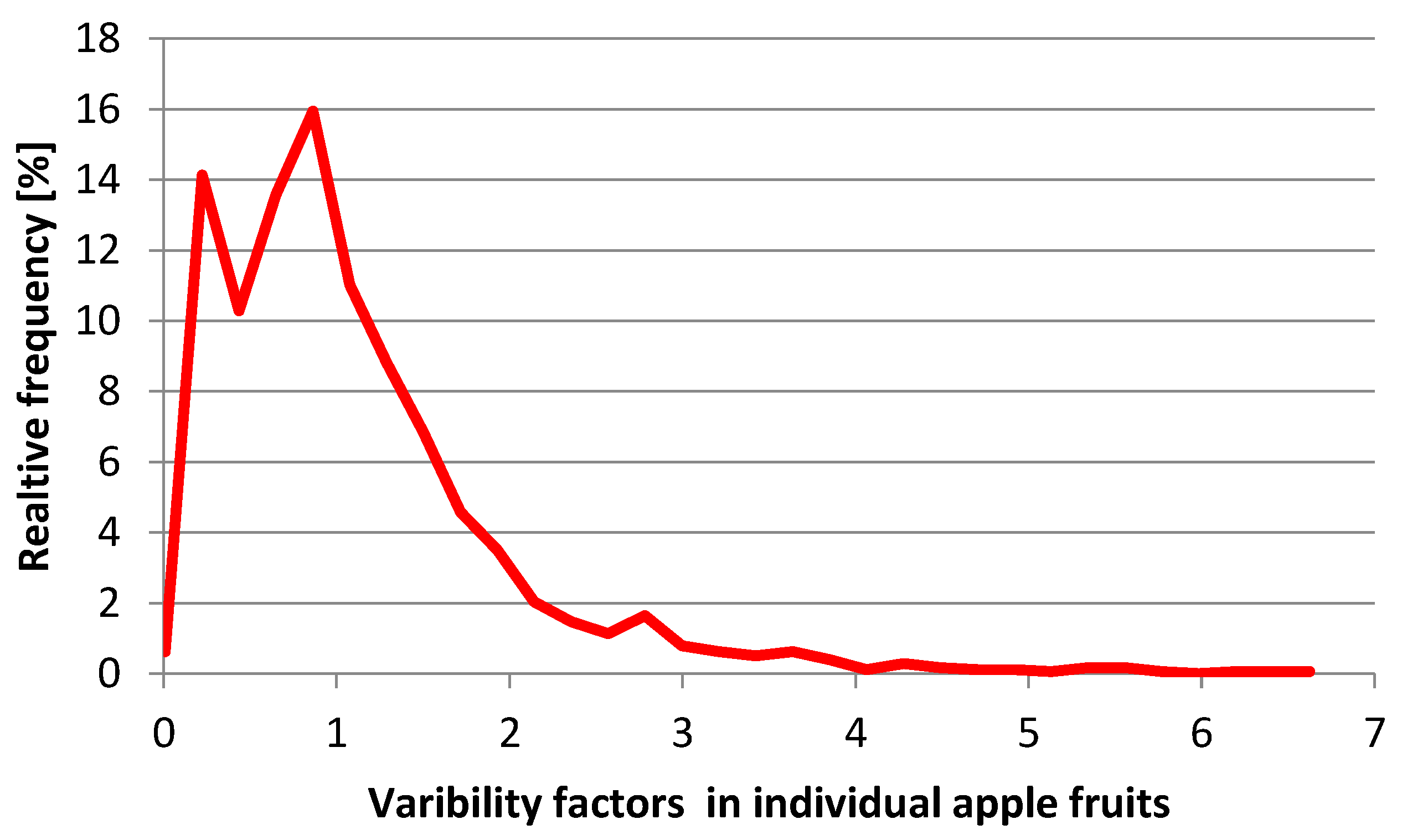
The concentration of residues in individual crop units derived from one lot may vary a hundred-fold, and it can be quite different from the average residue measured in the composite sample [
57,
58]. In the ESTI calculation, this variability is reflected by the so-called ‘variability’ factor (ν) that gives the ratio between the 97.5th percentile of the residues in crop units and the average residue in the sampled lot of the commodity represented by the average residue in the composite sample taken from that lot. The composite samples derived from supervised trials, usually consist of 12–25 individual units [
43] and therefore provide a robust estimate for the average residue concentration of the lot under investigation. An example of the distribution of residues in primary and composite samples is shown in
Figure 2. The distribution of residues in primary samples is obtained from random sampling the crop units or single increments from a single field [
57]. The composite samples are obtained from repeated random sampling with replacement from the primary residue population [
59,
60].
Based on over 20,000 residue data in various crop units, the JMPR decided to use the rounded average of 3 as the variability factor [
61]. EFSA evaluated a portion of the same residue dataset and concluded that the upper tail of the distribution of variability factors should be used [
62]. In the EFSA evaluations a variability factor of 5 is applied for food commodities with a unit weight (U
e) of more than 250 g (i.e., cauliflower). For mid-sized products (i.e., carrots, kiwi fruits (green, red, yellow), onions, orange, pears and potatoes) with a unit mass anywhere between 25 and 250 g, a variability factor of 7 is applied; no variability factor is used for commodities with unit masses less than 25 g and composite or animal products (i.e., dried beans, rice, rye, bovine fat or poultry fat) [
10,
62].
Considering the size of individual crop units, the IESTI is calculated for three different cases [
43,
45,
46].
In Case 1, the residue in a composite sample (raw or processed) reflects the residue level in a meal-sized portion of the commodity (unit weight of the raw agricultural commodity is below 25 g). It also applies to meat, edible offal and eggs, and for grains, oilseeds, and pulses treated post-harvest.
In Case 2a, the unit size of the edible portion, Ue, is less than the LP. The first unit contains the high residue (HR) multiplied by the variability factor, while the other units making up the LP contain the average residue measured in the composite sample.
In Case 2b, the mass of edible portion of the raw crop unit, Ue, exceeds the large portion weight. The variability factor (ν) is applied to the average residue in the composite sample to estimate the residue level in a high-residue unit.
Case 3 is used for processed commodities and those products that are likely bulked or blended before food portions are taken, such as flour, vegetable oils and fruit juices, milk and dairy products. It also applies to grains, oil seeds, and pulses treated pre-harvest. In such cases, the median residues obtained from the supervised trials or the average residues derived from monitoring programmes should be used.
Attention is drawn to the general limitations of the monitoring data that is normally obtained with multi residue methods determining the parent compound or its stable metabolite and not the residues defined for risk assessment purposes. Consequently, the estimated EDI or STI are lower than the real figures. For instance, the JMPR reports [
63], the list of Codex MRLs [
48] and some national regulatory agencies [
64,
65] provide the residue definitions for monitoring as well as for risk assessment purposes.
2.3. Probabilistic Modelling of Exposure of Consumers
In principle, the IEDI/NEDI concept for long-term dietary exposure could also address multiple compounds, but the variation in the co-occurrence of residues cannot be described by using only mean concentrations as the input parameter. Similarly, the IESTI-equation can be used for the assessment of multiple compounds found in one specific sample. However, the whole range of food items consumed within one day and the possible residue combinations exceeds the IESTI-concept dealing with the consumption of only one food commodity. Such situations can be addressed with probabilistic methods [
47]. The major advantage of probabilistic methodology is the consideration of all available data, including the full range of values and the variability of each parameter.
For the probabilistic calculation, random samples are taken with replacement from the whole datasets of food consumption [kg edible portion of food/kgbw], the residues detected in the given food [mg/kg], the mass of crop units and the distribution of variability factors (ESTI only). From each of the randomly selected values, an intake [mg residue/kg bw] is calculated. The random sampling is repeated many times to obtain the distribution of intakes. The upper percentile 97.5–99.9% of intakes [
66] are compared to the corresponding toxicological reference values (ADI, ARfD).
In the USA, the first probabilistic methods [
67] and guidance to assess the cumulative dietary risk were established in 2002 [
68]. In Europe, the Dutch National Institute for Public Health and the Environment (RIVM) developed the Monte-Carlo Risk Assessment tool (MCRA) [
69,
70,
71].
Zentai [
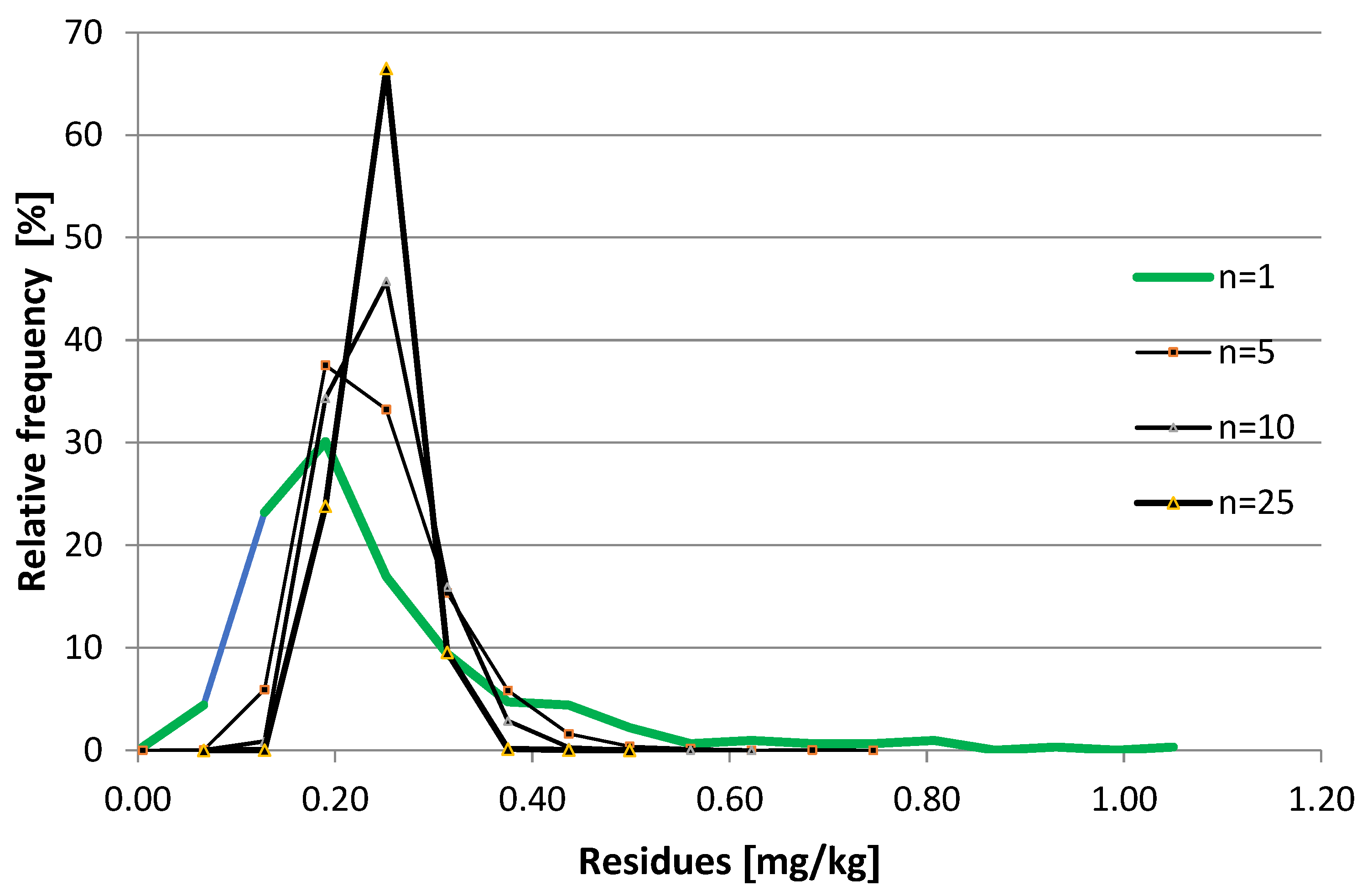
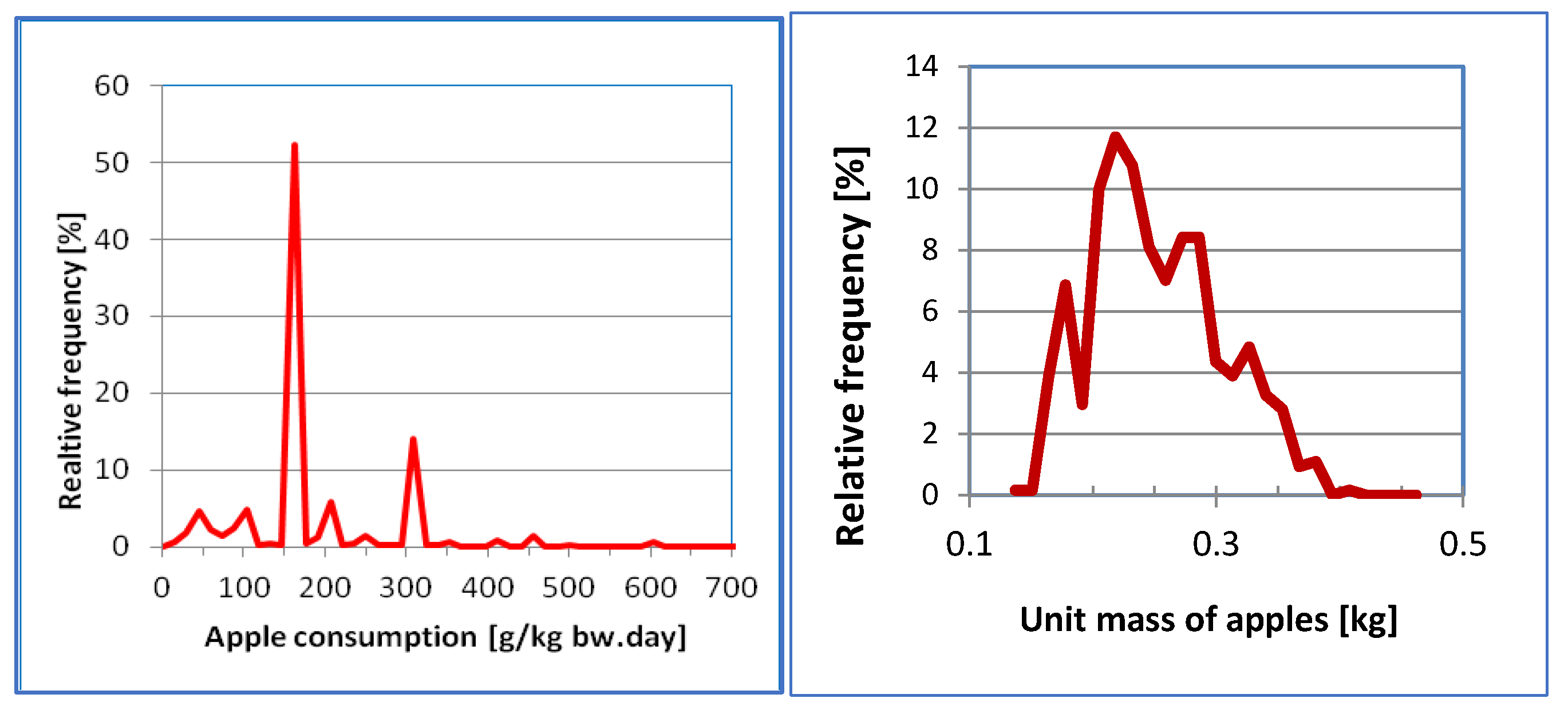
72] illustrated the procedure with the captan exposure resulted from apple consumption. The acute reference dose had been established for women of childbearing age, therefore the exposure calculation for this population was performed. The relative frequency distributions of input parameters are shown in
Figure 3,
Figure 4 and
Figure 5.
The apple consumption data were obtained from the national food consumption survey, including 3-day records of 4992 people [
73]. The individual mass of food items was measured in the central stores of large supermarket chains [
72,
74]. The captan residues were derived from the Hungarian monitoring programme during 2005–2011 (unpublished). The variability factors were calculated from the results of a targeted sampling programme [
57,
58].
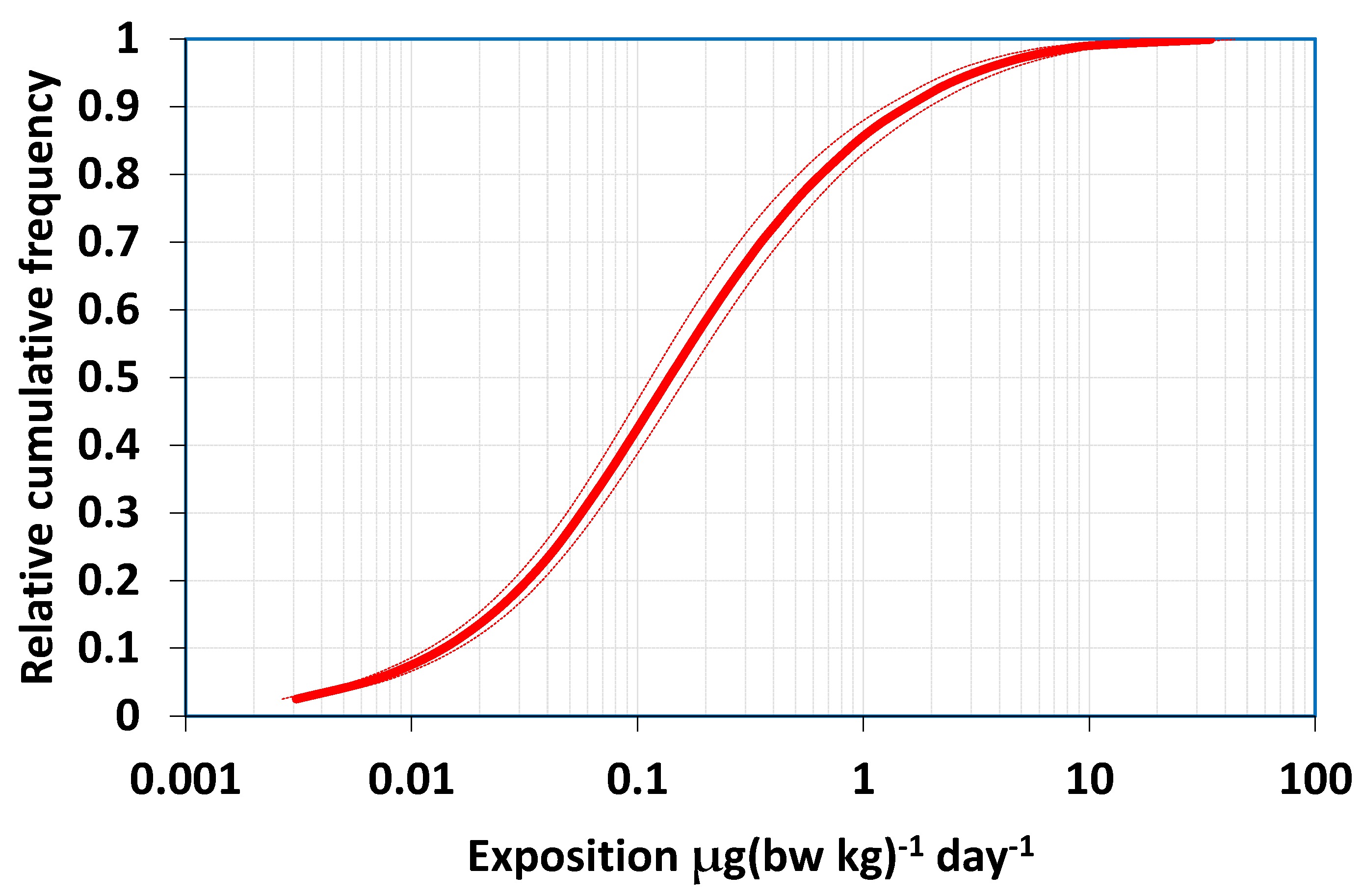
The estimated short term captan intake of the nth consumption day of a consumer eating an apple purchased at one time from the same lot was calculated according to Equation (6). Under this condition, the residue content of apples is represented by the mean residue in composite samples analysed:
In Equation (6), the R
k is the captan residue in the kth element of the apple composite samples consisting of K fruits, ν
i is the variability factor randomly selected from the 1769 variability values, and m
1 is the unit mass of the first apple that the nth consumer had eaten on the given day. The m
1 +…m
L is equal to the daily apple consumption on the nth consumption day. The last apple portion (m
L) can be a fraction of a whole apple for the calculation. The random sampling was carried out from the populations of the input parameters with replacement 500.000 times. Sampling with replacement is necessary to keep the size of the dataset constant. The cumulative frequency distribution of calculated intakes is presented in
Figure 6, which also shows the 95% confidence intervals around the intake.
The mathematical relationships are also given for the calculation of ‘refined’ probabilistic exposure estimation [
74], which can also take into consideration the raw material proportions of complex foods, the effect of processing operations on the pesticide residue concentrations in the raw product, and the pesticide residue concentrations in the portion of consumed produce.
2.4. Cumulative Exposure Assessment
The monitoring data reported by 30 countries within the coordinated and national monitoring programmes in 2020 [
10] revealed that multiple residues were detected in 27.2% of the samples, while 30%, 22.3%, 4.1%, 0.5%, 0.02% of samples contained 0, 1, 5, 10 and 15 different residues, respectively. In total, 18 and 31 residues were detected in 1 strawberry [
10] and honeysuckle sample [
75]. Multiple residues in one single sample may result from:
The application of different types of pesticides (e.g., application of fungicides or insecticides against different pests or diseases);
The use of different active substances for repeated treatments aiming at avoiding the development of resistant pests or diseases;
The uptake of persistent residues from soil treatments used in previous seasons;
Spray/dust drift to fields adjacent to the treated fields.
In addition to multiple residues resulting from agricultural practice, multiple residues may also occur because of mixing or blending of products with different treatment histories at different stages of the supply chain and contamination during food processing. It should be noted that when lots containing different residues are mixed prior to sampling and multiple residues are detected in a composite sample, it does not mean that every crop unit contains all detected pesticide residues. According to the present EU legislation, a sample containing multiple residues remains compliant if each individual residue concentration detected conforms to the corresponding MRL [
76].
Those pesticides that have the same mechanism of toxicological action may have a cumulative effect that should be accounted for in the correct evaluation of the exposure of pesticide residues. For addressing the mixture toxicity of multiple compounds, US-EPA started with an approach to group substances according to their chemical classes [
67]. EPA considered the 99.9th percentile of acute exposure from food, estimated by probabilistic analysis, as a threshold for a safety standard [
68]. EFSA applied a different concept by defining cumulative assessment groups (CAG) based on their toxicological effect, irrespective of chemical similarity. Altogether, 400 active substances were screened and organophosphates, N-methyl carbamates, organochlorines, macrocyclic lactones, pyrethroids, neonicotinoids or phenylpyrazoles were divided into 7 subgroups [
77]. The different toxicities of compounds are accounted for by their relative potency factors. The relative potency is defined as the ratio between the toxicological relevant dose of the index compounds (IC) and each compound within the group.
Due to the nature of the residue levels and food consumption data, probabilistic methods are generally used for the cumulative exposure assessment. The major advantage compared to the deterministic methodology is the consideration of all available data, including the full range of values and variability of each parameter. Caldas [
78] applied MCRA 3.6 system developed by RIKILT-Institute of Food Safety in The Netherlands [
69,
70,
71] for assessing the cumulative exposure of consumers. The relative potency factors were reported for 25 organophosphorus compounds. Zentai [
44] used the relative potency factors reported by Caldas et al. [
78] and Boon et al. [
79] for the exposure assessment of a Hungarian population. The residue values of the 24 organophosphorus pesticides were expressed in acephate equivalents as the reference compound. The cumulative residue content of a sample expressed as acephate equivalent (Equation (7)) was calculated by summing up the adjusted residue values of acephate, azinphos-methyl (am), chlorpyriphos (cp), etc…:
Up to 5 million residue food consumption combinations were calculated with an ordinary laptop, applying a self-developed random sampling programme. The findings of this study confirm that probabilistic modelling can also be performed with minimum hardware capacity [
74].
3. Risk Characterization
A hazard quotient (HQ) for a single chemical and the hazard index (HI) for a mixture of chemicals were first described as approaches for risk characterization by the EPA [
67]. The hazard quotient (HQ) is defined as the ratio of exposure to an appropriate reference dose, such as the ADI or ARfD.
The hazard index, HI, is defined as the sum of the hazard quotients of the individual components of an assessment group. Each of the hazard quotient is calculated as the ratio of the exposure to a chemical and the respective reference value (i.e., ADI, theoretical daily intake, TDI).
When the HQ or HI exceeds 1, a dietary risk may arise from a single substance or a mixture of compounds. When the results are interpreted, the inevitable uncertainties in the estimated EDI and ESTI values should always be considered [
42]. If reference values are not available for all components, the lowest available reference value (i.e., for the most potent chemical in the assessment group) can be used, assuming that all of the components with missing reference values are equally potent [
80]. HQ and HI have been used to characterize risk after various exposure scenarios [
30,
36,
37]. However, both approaches have a significant limitation in the way they are used. On the other hand, the advantages of the HI approach include its relatively easy and rapid application, its comparatively broad empirical foundation, and the fact that it often provides a conservative risk estimate for combined exposures [
81].
There are several limitations in the accurate estimation of the HQ and EDI:
If it is calculated from the residues measured in a single or a few food items, the calculated EDI may underestimate the real intake because the same pesticide can be applied in many crops;
During the monitoring programs the residues are usually measured in the specified portion of the commodity taken from the market or treated fields, while its edible portion may contain substantially lower residues;
If specific field treatments are carried out to generate residue data, the samples should always be taken at the authorized pre-harvest interval following the treatment with the maximum permitted dosage;
Summing up the HQ values of different pesticide residues measured in different samples can only be justified if they come from the same CAG and therefore they have the same toxic effects (e.g., cholinesterase inhibition, triazole group of pesticides, phthalates). In this case, their cumulative effect can be taken into account [
80,
81,
82,
83,
84], otherwise the sum of HQ-s would lead to wrong conclusions [
85];
When the number of and the locations of experimental plots are decided, the large inevitable field-to field variation of residues in/on crops should be considered [
86,
87]. In the latter cases, the median residue may be used in Equation (2);
To define the boundaries of the uncertainty of the estimated median residue, a minimum of eight trials should be performed [
42].
If any of the previously listed preconditions are not satisfied, the limitations of HQ or EDI calculations should be pointed out in the evaluation of the results.
4. Quality Assessment of Marketed Products
For the evaluation of the quality of a tested commodity considering the presence of multiple residues, the quality index (IqR) was introduced by Arienzo and co-workers [
88]. The quality index is calculated for one commodity as the sum of the ratios between the residue concentrations measured in the tested sample and the corresponding MRLs.
The authors suggested to use IqR to subdivide fruits, vegetables and cereals into four classes of quality: excellent (IqR: 0), good (0–0.6), adequate (0.6–1) and inadequate (>1). Moreover, they underlined that the IqR is not a toxicological criterion, but it must be related to the quality of the product with respect to pesticide residues. The quality index was used to characterize the tested vegetables for instance by Mac Loughlin et al. [
16], Ramadan [
18], Ngabirano [
40], and Gad Alla [
54].
5. Number of Samples Required for Food Safety Risk Assessment
There is no optimum number of samples to be taken. The frequency of violation rate of pesticide residues, the production volume and value/quantity of exported commodities can be primarily considered. There are several methods for the calculation of the number of samples to be taken. However, most of them are only applicable for (assumed) normal distribution. Extensive studies [
59,
86,
87] on the field-to-field variation of pesticide residues based on the analyses of composite samples revealed that it is strongly skewed and cannot be properly described with parametric functions. Therefore, the sample size calculation based on the principle of binominal distribution is the best choice, as it does not assume any distribution. The EU Coordinated monitoring programme [
89] specifies 642 samples for each commodity pesticide residue combination, which allows for the detection of a sample containing pesticide residues above the limit of determination (LOD), with a certainty of more than 99%, provided that not less than 1% of the products contain residues above that limit. The samples, divided among member states, should be analysed within 3 years. Sieke and co-workers [
90] applied the same principle and suggested analysing 188 samples, aiming for the 98% double-sided coverage of the 97.5th percentile with 95% confidence. The authors estimated a sample size of 94 to characterise a mean value with a ratio of 1:2 of mean and standard deviation and a certainty of 95% with a relative estimation error of 35%. The Codex Sampling Guideline [
8] and the USDA GLs [
91] provide a simpler calculation that can be more easily understood and applied. The principle is briefly described hereunder.
Let β
v be the probability that a random sample contains a residue above the allowed limit (e.g., MRL). Then, the proportion of samples at or below the selected limit, β
p, is 1-β
v. The number of random samples (n) required for finding at least one value above a selected percentile (β
p) of the parent population (e.g., residues in mango samples taken in packing houses) with a specified probability level (β
t) is calculated with the following equations:
It is important to note that Equation (11) provides correct information only if the following preconditions are satisfied:
The sampling target is accurately defined, and all of its elements can be the subject of sampling (e.g., all packing houses dealing with mango in the targeted area are accounted for in advance);
Before sampling starts at a given day, the available individual lots in the packing house can be accessed and counted;
The individual lots can be identified (lots are not mixed) and one composite sample represents one lot;
The lots to be sampled are selected by drawing random numbers without replacement, that is, one lot shall be sampled only once; it also means that the produce of the same farm shall not be sampled at the next sampling occasion but may be sampled during different sampling periods (main season, off-season);
The number of lots to be sampled (N) during the sampling period is much larger than the number of samples (n) calculated with Equation (10).
The violation rate (β
v) is equal to 1 − β
p. For example, the number of samples required for detecting a residue above a specified concentration at least in one sample at various violation rates is given in
Table 2 for large N.
Table 2 indicates, if we target verifying that 98% of our lots would comply with the MRLs of pesticide residues being in the samples with a 95% probability, we would need to analyse 149 samples. Moreover, if we would like to be 99% sure that no more than 2% of our lots contain residues above the MRL, we should analyse 228 samples and detect residues exceeding the MRL in only one sample.
The same principle can be applied [
92] for testing the presence of unauthorized pesticide residue. If we want to be sure that no more than 5% of the samples contain that substance above the LOD with 95% confidence, 59 samples must be analysed in a range of matrices, and detectable residue must not be any of them.
6. Testing Compliance with the MRLs
A correct assessment of compliance with legal limits can only be made if the uncertainty of the measured residue concentrations is taken into account. The uncertainty of measured residues shall be considered both in the cases of controlling the residues in marketed commodities and in products intended for export. However, the two situations are entirely different [
92,
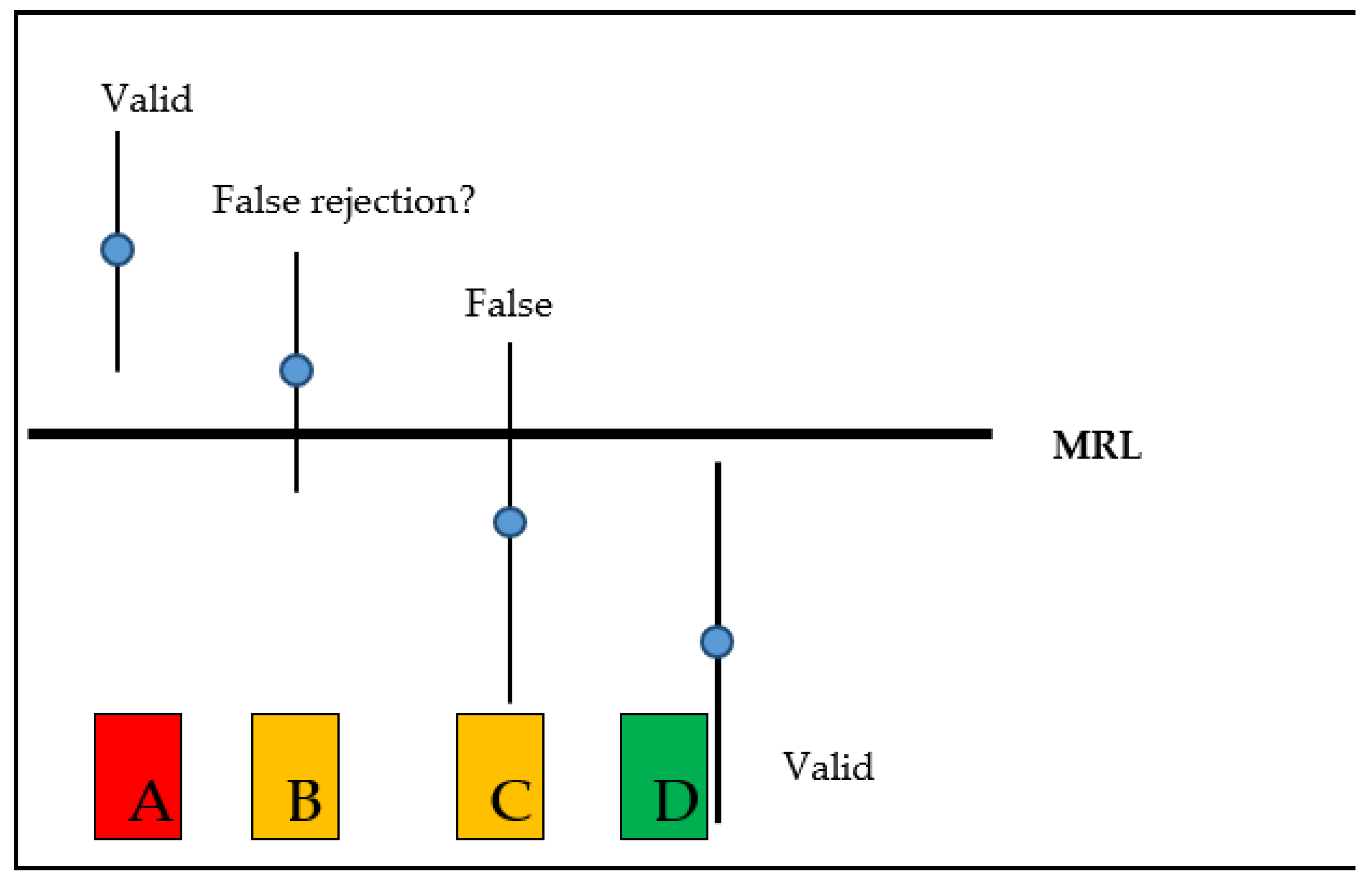
93]. The basic situations are illustrated in
Figure 7 [
94].
Case A: the measured residue and the lower limit of 95% uncertainty range are above the legal limit. The sampled product is non-compliant.
Case B: the measured residue is above the legal limit, but the lower limit of 95% uncertainty range is below the legal limit; the situation is uncertain.
Case C: the measured residue is below the legal limit, but the upper limit of 95% uncertainty range is above the legal limit; the situation is uncertain.
Case D: the measured residue and the upper limit of 95% uncertainty range are below the legal limit. The sampled product is clearly compliant.
For cases B and C, a decision can only be made if the decision rules are pre-defined. In the absence of a decision rule for such cases, the conclusion must be in doubt. In these cases, the acceptance or rejection depends on the national legislation because there is no Codex guidance values for such cases. The Codex Guidelines for settling disputes suggests that the trading partners should agree in advance on the acceptance criteria [
95,
96].
6.1. Testing Commodities in the Local Market Either Locally Produced or Imported
The same procedure is applied for both the locally produced and imported commodities. It should be noted that the maximum residue limit (MRL) [
97] refers to the average residue in the specified portion [
51] of the composite sample. The mass of the sample and the number of primary samples included in it should comply with the Codex Standard [
8] or Commission Directive 2002/63 [
97] (which is practically equal to the Codex Standard). The locally produced or imported product complies with the MRL if the following inequality stands:
where C
R is the residue measured in the composite sample taken from the inspected lot and MRL is the maximum residue limit for the given pesticide-commodity combination. Among laboratories, the reproducibility default CV
L in the EU is 25% (0.25) [
98]. It means that EU laboratories will reject a lot if the residue concentration is >2*MRL. This is a correct practical principle to consider the uncertainty of measurement results as it will lead to the rejection of a lot that contains residues at the EU MRL only in 2.5% of the cases. However, the laboratories monitoring the pesticide residues in the local market should apply their own inter-laboratory reproducibility, CV
L, value which should not be larger than 25% when deciding on the compliance of locally marketed products if they want to apply the R > 2*MRL criterion.
6.2. Testing Commodities before Export or Placing Them on the Local Market
Due to the large, often hundredfold [
57], within field (lot) variation of residues in crop units or primary samples, the measured residues will inevitably vary when composite samples complying with relevant standards [
8,
97] are taken repeatedly from a single lot. The detected residues would be similar in very rare cases in independently taken replicate samples.
When the compliance of residue content of commodities with MRLs shall be checked before they are placed on the local market or exported, it should be verified with acceptable certainty that any further sample taken from that given lot will not contain residues above the MRL. In such cases, the combined uncertainty of results including the sampling uncertainty should be considered. Farkas and co-workers published the best estimates of sampling uncertainty for 107 individual crops and 24 crop groups [
87,
97]. Since the sampling uncertainty is inversely proportional to the number of primary samples making up the composite sample, it is advisable to take composite samples containing up to 25 primary samples for checking compliance of commodities with MRLs before export or placing them on the market provided that the large sample can be effectively homogenized in the laboratory.
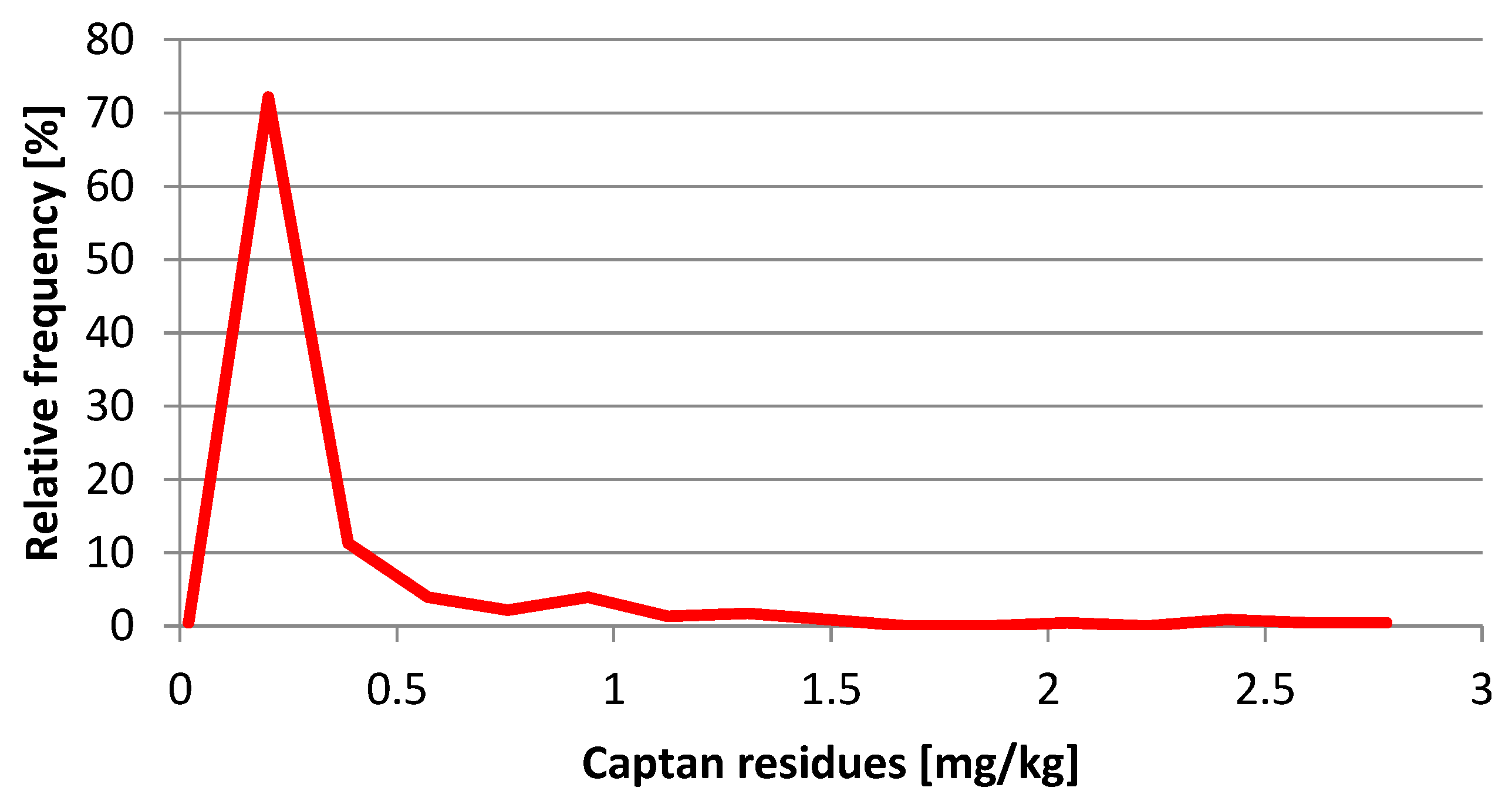
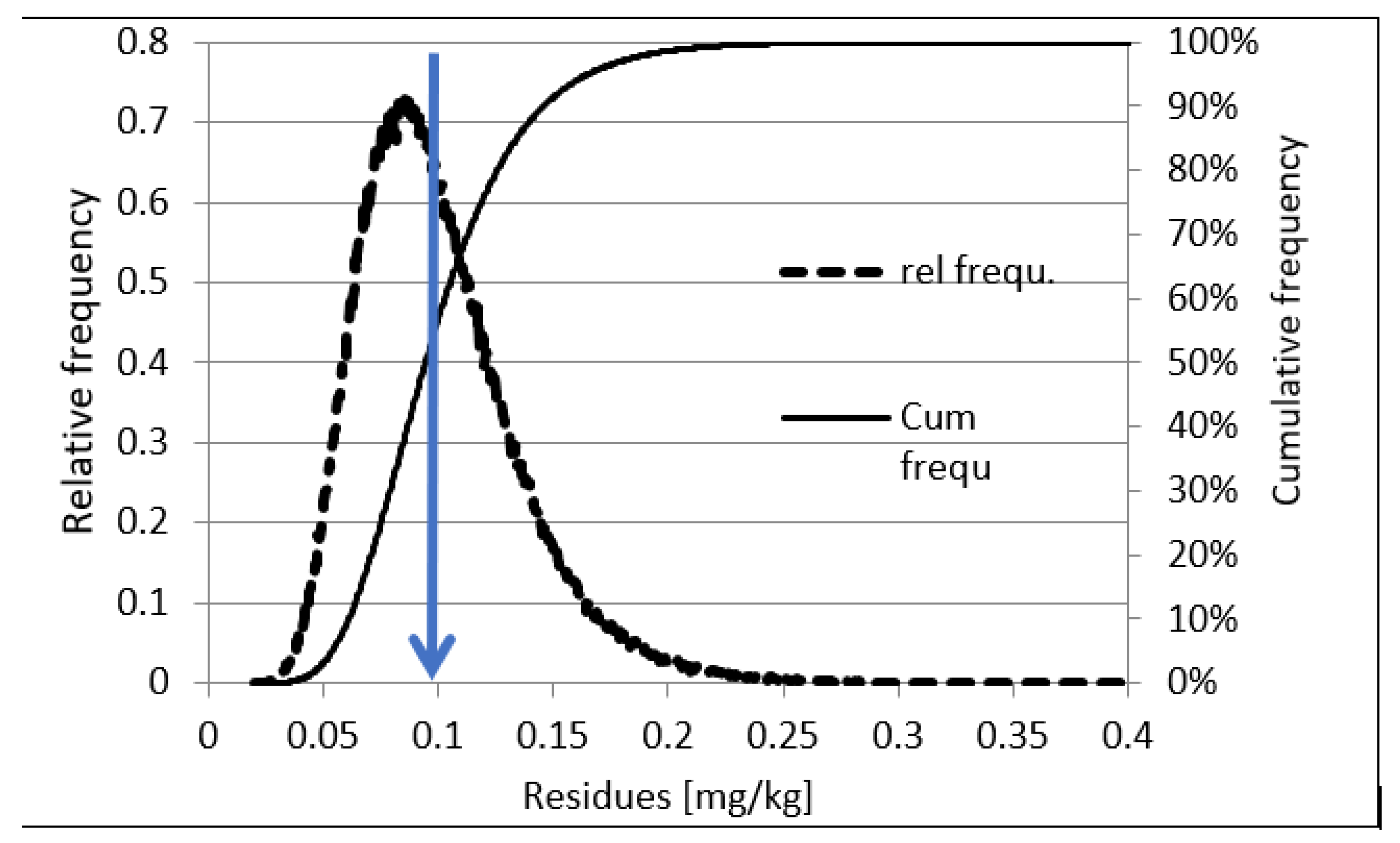
Figure 8 shows the typical relative frequency distribution of pesticide residues in composite samples taken from a single lot. The shape of the curves is very similar in fruits (shown for example in the case of apple) and vegetables irrespective of the pesticide residue present. The sampling distribution shown in the figure was obtained by drawing random composite samples of size 10 with replacement from the primary residue population in individual apples. The probability of taking a sample containing residue below the 0.1 mg/kg MRL is approximately 56% as shown by the cumulative distribution line. Moreover, finding a sample containing a given residue concentration is directly proportional to the corresponding relative frequency.
In this situation, if we compare the residue measured in the composite sample to the MRL value of 0.1 mg/kg, we would decide that the sampled product complies with the MRL in 56% of the cases, while the export partner may take another sample from the same lot containing residue above the MRL in 44% of the cases and can reject the lot. Making wrong decision in 44% of the cases is obviously too high to assure safe export. Therefore, the combined uncertainty (CV
R) of measurement results should always be used for deciding on the compliance of the residues measured in composite samples with the MRLs. Moreover, a residue concentration level lower than the MRL should be chosen as the action limit (AL) [
87]. The sampled lot should only be declared compliant if the residue measured does not exceed the calculated AL. The concept of action limit is relatively new. In addition to pesticide residues [
92,
93,
99], it was recently applied for mycotoxins [
100] and gluten in oat groats [
101]. Therefore, it is considered generally applicable for evaluation of results during pre-marketing control.
Considering the specific sampling uncertainty (CV
S) estimated from a large number of supervised trials, it was found [
87,
99,
102] that a default AL of 0.3–0.4*MRL would provide a safe starting point in most cases without the need for complicated calculations. Therefore, its application is recommended for the control of pesticide residues in commodities before their export or placing them on the local market. To save time, it is also advisable to take two independent replicate samples in case of pre-export control and to analyse the second sample if the residue concentration exceeds the action limit in the first. In this case, neither of the samples can contain residues above 0.5 MRL to have an approximately 95% probability that the lot would be accepted by the importing country based on a 3rd sample taken from the same lot.
Further on, it is pointed out that the correct utilization of this principle will require rigorous ongoing quality control in the testing laboratories especially in case of default MRLs of 0.01* mg/kg established in the EU, which means practically no detectable residue can be present in the tested crop.
7. Model for Ranking Commodities to Be Included in Monitoring Programmes
The national monitoring data are also used to estimate the frequency of occurrence and the level of pesticide residues in food items selected based on their consumption and/or importance for export [
6,
7]. The results are also used to initiate the necessary corrective actions. Details of the principles of ranking the importance of commodities and targeted pesticide residues are not given in the summary reports.
The number of samples that can be taken annually as part of the monitoring programmes depends on the laboratory testing capacity and the financial resources available. There is no need to test all commodities with equal frequency. Horváth and Ambrus elaborated a three-level tiered model to assist planning risk-based monitoring programmes considering the available information [
103]. The selection of commodity-pesticide combinations for freshly registered pesticides may be completed based on the supervised trial results in the first tier, the combination of supervised trials and limited monitoring data in the second and third tier depending on the number of monitoring data. In the latter case, the frequency of the occurrence and concentration levels (f
p) of the residues in a given commodity is calculated as:
where R
i–s are the measured (and not the reported) residues in samples derived from the monitoring programmes. MRL is the corresponding maximum residue limit of ‘i’ pesticide in the sampled commodity, and n is the number of samples taken during the period considered (normally one or two years). In Equation (13), if R
i< LOQ then R
i is counted with 0. We calculate the frequency of occurrence (f
p) of pesticide residues (Equation (13)) for a specified commodity and period of time with the built-in template (
Table A7) of the Hungarian residue data processing system.
The authors recommended selecting the number of samples to be taken, if sufficient resources are available, by considering the calculated fp. The pesticide-commodity combinations, which indicate the short-term intake problem or residues exceeding the MRL over 2% require special attention. In case of large-scale production, these commodities should preferably be included in the random monitoring programme and tested with an approximately 95% probability of finding defective lots.
Where the potential risk from pesticide residues is lower, then a lower probability of detection may be acceptable, which can be achieved with the analysis of fewer samples.
Table 3 contains the guidance values for the number of samples to be taken from a commodity according to the corresponding f
p values.
In view of the total number of samples that can be included in the monitoring programme, the final allocation of the number of samples for each commodity can be made proportionally to the corresponding fp values unless special reasons over-rule the ranked order. Where sufficient testing capacity or financial resources are not available, the most critical commodity-pesticide combinations should be given priority and the samples should be proportionally allocated to other commodities according to their importance.
To clarify high residue situations targeted field surveys are recommended by taking random samples from commodities with known pesticide treatment records, including the problematic pesticides. Since the pesticide treatment history is known in these cases, if limited laboratory testing capacity is available, a lower probability of detection of defective lots may be acceptable by taking a minimum of 40–60 samples.
8. Electronic Database for Evaluation of Monitoring Data
In view of the large number of samples, the wide scope of the analytical methods, and the supplementary information that should be attached to each sample, millions of data should be recorded for the multi-purpose evaluation of the monitoring data.
For instance, Australia [
7], EFSA [
10], EU member states [
10,
104,
105], US FDA [
9,
106,
107], and many other countries maintain certain electronic databases that serve as a central data repository. The records captured and stored in the databases include, for instance, sample collection and product information, residue concentrations for each sample analysed, and QA/QC records.
The EU Multiannual Control Programme (EU MACP) [
104] is complemented with the national annual monitoring programmes [
10]. The results of both programmes are electronically reported to EFSA. The information to be provided to EFSA for each sample is shown in
Table A1. The data processed by EFSA are available on a dedicated website [
105]. For the evaluation of national data, a less complex summary of the results can be sufficient.
The statistical analysis of the monitoring data can be used at the national level to decide which pesticides and food products should be targeted in risk-based monitoring programmes. The results can provide information for the necessary risk management measures, including but not limited to the review or adjustment of existing use recommendations and advisory actions for the farmers, etc. All of these actions have the aim of high-level consumer protection.
In the 1970s there were 20 small regional pesticide residue laboratories employing 3–5 analysts in Hungary. For the evaluation of their results an electronic data processing system was developed and introduced in 1978. The electronically stored results were used for the assessment of the performance of laboratories and the evaluation of the residue situation in the country. The residue data processing system was gradually updated and expanded, utilizing the development of personal computers. The current ‘Food Safety Information System (FSIS) was elaborated in 2004 and since then has been operated with minor changes and regular updates of the code dictionaries. It operates on the PostgreAQL (4 cpu core, 12 GB RAM, 500 GB) database server and the KFŐNIX (Wildfly 24 (4 cpu core, 12 GB RAM, 250 GB) application server. It consists of five main modules:
The sampling module is used to record the details of sampling and to directly transfer them to the laboratory module, eliminating double recording of data;
The laboratory module provides the platform for inputting and retrieving all sampling, analyses and quality control data;
The data storage module processes the data and prepares the reports in pre-defined formats that can be specified according to the main parameters (sample, residue, test period purpose of tests, etc.);
Master data and the bilingual code dictionary module;
The permission module for entry and recall data and to modify the content of code dictionary, etc.
The recorded data can be accessed and retrieved in specified formats by authorized persons except the quality control data which is only available for the selected staff of the laboratory. The access rights to FSIS are strictly regulated to assure protection of individual rights, data integrity and compliance with quality system provisions. For instance, sample administrators, laboratory analysts, responsible analyst, had or directors of the laboratory, programme coordinators, code directory administrators, system administrators, officials of National Food Chain Safety Office and Ministry of Agriculture have only access to specific parts of the data and the workflow.
The measurement results and supplementary data can only be entered by the authorized users in the laboratories applying specific unique codes, which are allocated by the system administrator. Keeping the code directories up-to-date is essential for the accurate operation of the system.
Table 4 provides an example of the date specific MRL records that makes it possible to retrieve and evaluate historical data by applying the MRLs which were valid for the examined period.
The expanded active substance, product and residue components code dictionaries are the basis of data entry. They provide information on the actual MRLs for commodity groups and individual commodities (
Table A2 and
Table A3).
Another code dictionary includes the mathematical expression of the calculation of the sum of residues included in the residue definition. The analysts enter the measured residue components. The programme automatically calculates the sum of residues and gives the residue value to be reported (
Table A4).
9. Conclusions
Monitoring programmes are implemented to various extents in many countries, for instance, with the aim of obtaining information on:
The pesticide residue distribution in raw agricultural commodities, their compliance to the MRLs specified in the national and major export countries’ legislations;
The potential problems concerning the registered or illegal use of pesticides;
The background data for calculation of percentiles of residue population to estimate the long and short-term intakes.
To obtain reliable and accurate information that fits to the purpose of the programme:
The number of samples to be taken from each commodity should be decided by considering the desired confidence level of the decision based on the results;
The sampling schedule should be carefully planned and prioritized based on the available laboratory capacity and resources;
The sampling target should be cautiously defined to cover all growing fields, growing seasons, commercialized lots, etc., for which information is sought;
Each unit of the sampling target should be accessible and have equal probability of being selected during sampling;
All stakeholders benefiting from the results can or should be involved in the planning and cost-sharing;
The laboratories should be equipped with suitable instruments (preferably LC-MS/MS and GC-MS/MS) and provided with well-trained analysts as well as an operational budget that is sufficient;
The management of the laboratory should put in place and implement the appropriate internal quality control;
The analysts should feel responsible for the results produced, continuously expand the scope of the methods applied and assure that the sensitivity of detection enables identifying the residues lower than the corresponding MRLs or action limits.
The monitoring programmes can only produce the expected benefits and justify the implementation cost if their results are systematically recorded in an easily retrievable form for which an electronic data storage and management system should be adapted and operated. The recorded data should be regularly evaluated together with the stakeholders and published, as it would increase trust in the results and facilitate the cooperation of all concerned parties. In addition, the periodic evaluation of the results obtained in previous years makes it possible to identify trends and helps to define future directions and actions.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







