1. Introduction
In this article, we present a novel methodology developed to address the retention challenges faced by life insurers in a French insurance portfolio consisting of equity-linked whole-life insurance policies (see [
1] for an extensive review of such insurance products). Lapse management refers to the strategies and processes employed by insurance companies to mitigate the risk of policy lapses, which occur when policyholders stop paying their premiums, leading to the termination of their insurance coverage. Understanding and managing lapses are crucial for maintaining the financial stability of insurers and ensuring continued protection for policyholders.
Several behaviours are leading to automatic lapses. First, if a policyholder fails to pay their premium by the due date, the policy may enter a grace period. If payment is not made during this period, the policy lapses, and coverage is terminated. Secondly, for policies with automatic payment setups, insufficient funds in the policyholder’s account can result in a missed payment and subsequent lapse. Eventually, some policies have specific requirements, such as maintaining a certain health status or providing periodic updates, non-compliance with these requirements can lead to a lapse. Apart from those behaviours, the policyholder can also unilaterally decide to lapse their policy to access their face amount and proceed to personal expenses. On those points, the respective obligations of the insured and the insurer are clear: on the one hand, the policyholder is obligated to pay premiums on time, maintain any conditions stipulated in the policy (e.g., health checks, notifications of changes in risk), and promptly communicate any issues or changes that might affect the policy. On the other hand, the insurance company must provide clear communication regarding premium due dates, grace periods, and consequences of non-payment. They are also responsible for offering reminders and support to help policyholders avoid lapses, such as flexible payment options or policy adjustments. Making these obligations clear from the beginning helps both parties understand their responsibilities and the importance of maintaining the policy. This proactive approach can significantly reduce the risk of automatic lapses and ensure continuous coverage.
Whole-life insurance provides coverage for the entire lifetime of the insured individual rather than a specified term, and when contracting such an insurance plan, policyholders can choose how the outstanding face amount of their policy is invested between “euro funds” and unit-linked funds. Understanding the fundamental differences between these investment vehicles is essential to comprehending the dynamics of the whole-life insurance market. For savings invested in euro funds, the coverage amount is determined by deducting the policy costs from the total premiums paid, the financial risk associated with these funds is borne by the insurance company itself. The underlying assets of euro funds primarily consist of government and corporate bonds, limiting the potential returns, and thus the performance of these funds is directly influenced by factors such as the composition of the euro fund, fluctuations in government bond yields, and the insurance company’s profit distribution policy. Additionally, early termination of the policy by the policyholder incurs exit penalties, as determined by the insurance company. In contrast, unit-linked insurance plans operate under a different framework. The coverage amount is determined by the number of units of accounts held by the policyholder, and the financial risk is assumed by the policyholders themselves. Unit-linked funds offer a wide range of underlying assets, among all types of financial instruments, enabling potentially unlimited performance based on the market performance of these assets. The investment strategy is tailored to the specific investment objectives of the policyholder and while certain limitations exist in terms of asset selection, policyholders generally face no exit penalties for their underlying investments.
Lapse is a critical risk for whole-life insurance products (see [
2] or [
3]), thus, policyholders represent a critical asset for life insurers. Therefore, the ability to retain profitable ones is a significant determinant of the insurer’s portfolio value (and more generally, a firm’s value; see [
4]). If some historical explanations for lapse are liquidity needs (see [
5]) and rise of interest rates, it also appears that individual characteristics are also insightful (see [
6] for a complete review). Consequently, policyholder retention is a strategic imperative, and lapse prediction models are a crucial tool for data-driven policyholder lapse management strategy in any company operating in a contractual setting such as a life insurer. In this paper, we build an extension of the framework of [
7], we recall that it originally defines an LMS with the following necessary hypothesis:
Definition 1 (Lapse management strategy (LMS)). A lapse management strategy for a life insurer is modelled by offering an incentive to policyholders . Their policies, at time t, yield a profitability ratio of . The incentive is accepted with probability , and contacting the targeted policyholder has a fixed cost c. A targeted subject who accepts the incentive, or any subject that will be predicted as a non-lapser, will be permanently considered as an “acceptant” who will never intend to lapse in the future, and their probability of being active at year is denoted . Conversely, a subject who refuses the incentive and prefers to lapse will be permanently considered as a “lapser”, and their probability of being active at year t is denoted . The parameters uniquely define a lapse management strategy, while and need to be estimated from the portfolio.
An advantage of this general framework is that it is designed with flexibility in mind, allowing for adaptation to any specific cultural and regulatory context.
The goal is not only to model the lapse behaviour but also to select which policyholder to target with a given retention strategy to generate an optimised profit for the insurer. Such a lapse management strategy requires estimating what can be considered as the future profit generated by a given policyholder: the individual customer lifetime value or CLV (see [
8]). The individual
over horizon
T, for the
i-th subject aims at capturing the expected profit or loss that will be generated in the next
T years and is expressed as follows, in the general time-continuous case:
with the profitability ratio
being represented as a proportion of the face amount,
, observed at time
t. The conditional individual retention probability,
, is the
i-th observation’s probability of still being active at time
t. In practice, the individual
is often discretised and computed as a sum of annual flows, thus with
, the time in years is,
Equation (
2) is primarily used in the marketing and actuarial literature (see [
9] or [
10]). If we only consider the future
T years of
, after time
t, the sum becomes
All the expected future financial flows are discounted, with representing the annual discount rate at year t. In definitive, represents the future T years of profit following observation at time t.
Given an LMS, a policyholder can either be likely to accept the offer of an incentive and behave with an “
acceptant” risk profile or they can be likely to reject the offer and thus behave with a “
lapser” risk profile. In this context,
acceptants and
lapsers will not generate the same CLV as their respective retention probabilities differ. The CLV of an
acceptant or a
lapser are estimated using, respectively,
and
as retention probabilities. The first way we contribute to this framework is by assuming that individuals with an active policy do not behave with risk profiles that are either “
100% acceptant" or “
100% lapsers", which was a simplifying assumption in the existing LMS frameworks. We assume here that each policyholder generates a future lifetime value calculated as a weighted mean of CLVs computed with “
acceptant” and “
lapser” risk profiles. The individual weights used to nuance behaviours are discussed in
Section 2.1.
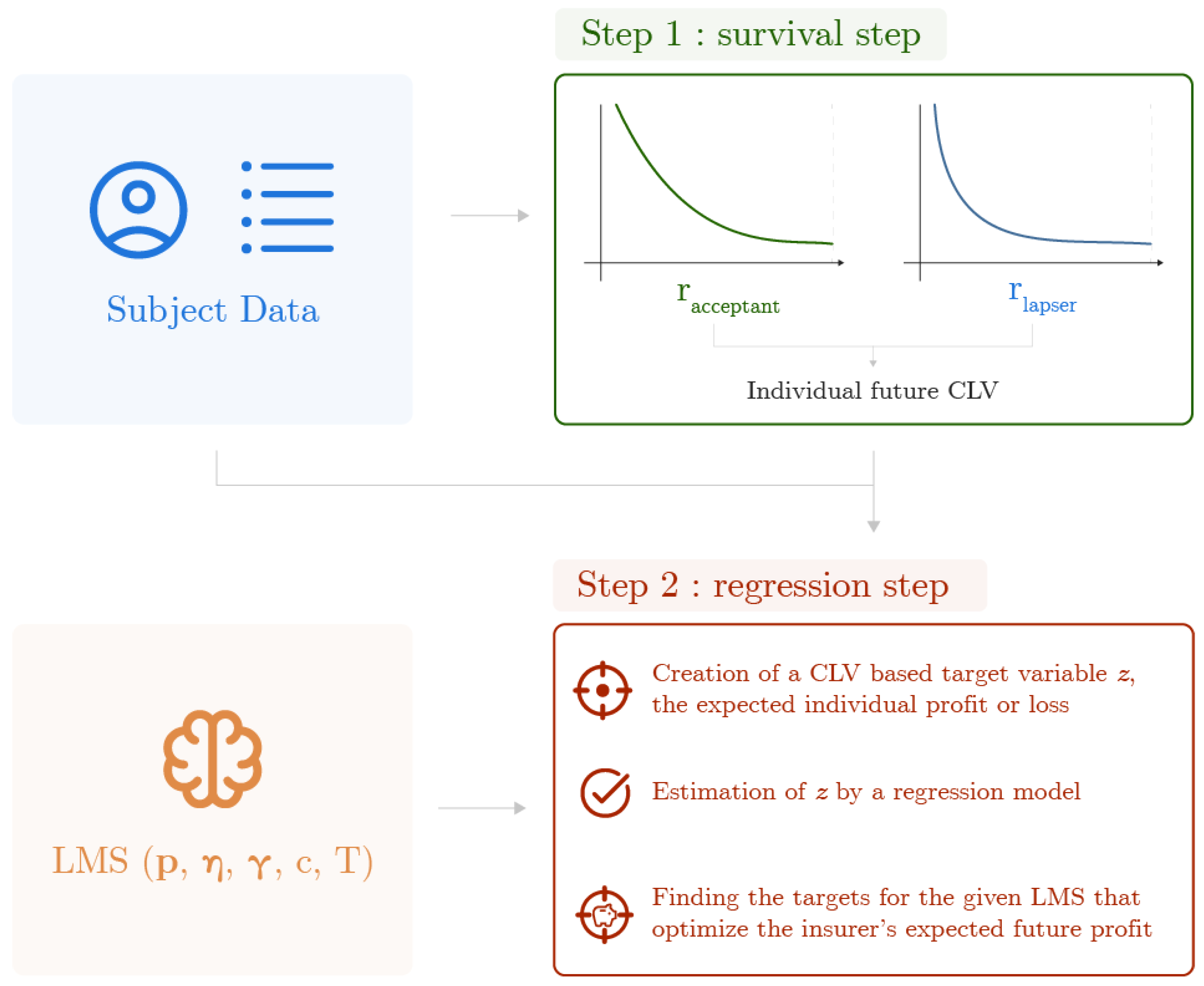
The analysis of a lapse management strategy, as described in [
10], then in [
7], is a two-step framework. The first step consists of using the insurer’s data to train survival models and predict yearly retention probabilities for any subject in the portfolio: we will refer to it as the
survival step. The retention probabilities are used to compute an individual CLV-based estimation of the profit generated from targeting any policyholder. This estimation is eventually used as a response variable to fit a model predicting which kind of subject is likely to generate profit for the insurer: we will refer to it as the
regression step. As in [
11] or [
12], the goal of such a CLV-based methodology is not only to model the lapse behaviour but rather to select which policyholder is worth targeting with a given retention strategy to generate an optimised profit for the insurer. This existing framework relies on the analysis of the time-to-death and time-to-lapse that can be updated regularly with new information from the policies. It is summarised in
Figure 1.
At least three limitations of that framework can be addressed. First, it does not consider that an acceptant can lapse in the future, which is at best a very optimistic assumption, and at worst a great oversimplification. Secondly, it does not give any information on whether the timing of the retention campaign is optimal or not. Thirdly, it does not allow tightening the criteria on which the targeting of each policyholder is decided, depending on the risk the insurer is willing to take on the uncertainty of the predictions. This work addresses these limitations.
Throughout the lifetime of such insurance policies, a series of significant time-dependent events shape the interactions between policyholders and insurers. Firstly, premium payments play a pivotal role in sustaining the policy: these payments are highly flexible, allowing policyholders to choose their amount and frequency, thus they can be adjusted according to the policyholder’s financial circumstances and preferences. Additionally, policyholders may decide to reduce their coverage by withdrawing a portion of their policy. We refer to these events as partial lapses: they involve a voluntary decrease in the face amount of the policy, enabling policyholders to adjust their coverage to better align with their changing needs. Such flexibility caters to policyholders’ evolving financial situations and offers them greater control over their insurance plans. Over the policy’s lifetime, other financial operations can occur, such as the payment of interest or profit sharing to the policyholder, and the payment of fees to the insurer. Insurance companies’ information systems are usually designed to keep track of those operations at the policy level, thus actuaries and life insurers often have access to the complete history of their policyholders, as the information system is updated in real-time.
In certain instances, a policyholder may choose to lapse their insurance policy entirely. Complete policy lapse typically occurs when the policyholder decides to terminate their policy and receives a surrender value, which represents the accumulated value of the premiums paid, adjusted for fees, expenses, and potential surrender charges. Moreover, the occurrence of a policyholder’s death also terminates the policy and triggers the payment of the policy’s value, often referred to as the death benefit or claim, to the designated beneficiaries.
In the context of our research, a policy can only terminate with a complete lapse or the death of the policyholder, which will be considered as competing risks in the following developments. If none of these events have happened to a policy, it is still active. The cumulated sum of all the financial flows occurring during one’s policy timeline, including premiums, claims, fees, interests, profit-sharing, and lapses, is commonly known as the face amount of the policy. This face amount represents the total value of the policy over its duration and serves as a measure of the policy’s coverage and financial benefits. By comprehensively understanding and analysing these events and their impact on the face amount of a life insurance policy, insurers can effectively develop lapse management strategies that align with policyholders’ preferences and financial goals. Through our research, we aim to shed light on these dynamics and provide insights to optimise the design of such strategies, ultimately enhancing customer retention and overall portfolio performance in the life insurance industry.
In practice, actuaries often have access to the complete trajectories of every policy and it seems that not using them in models is ignoring a significant part of the available information. A data structure where time-varying covariates are measured at different time points is called longitudinal and individual policyholders’ timelines, which can be illustrated as in
Figure 2. The dynamical aspects of covariates have an impact on the performance of lapse prediction models, and [
13] concludes in favour of the development of dynamic churn models. They showed how the predictive performance of different types of churn prediction models in the insurance market decays quickly over time: this conclusion arguably applies to life insurers and, in the case of lapse management strategy, we argue that using the complete longitudinal trajectories of every individual is also justified. Firstly, a change in financial behaviour—recent and frequent withdrawals for instance—can be an informative lapse predictor. As an illustration of this point, we can imagine making predictions for two individuals with the same characteristics at the time of study but completely different past longitudinal trajectories: one is consistently paying premiums, for instance, whereas the other stopped all payments for months and has been withdrawing part of their face amount lately. A prediction model ignoring longitudinal information would produce the same lapse prediction for both individuals. Conversely, an appropriate model, trained on longitudinal data is likely to seize the differences between the individuals over time and provide different predictions for the future. Secondly, a longitudinal lapse management framework allows for dynamic predictions with new information. It proves to be insightful in terms of decision-making for the insurer, as it shows how a change in the policy induces a change in the lapse behaviour. Eventually, the existing lapse management strategy approaches can only provide the insurer with information on whether targeting a given individual now is expected to yield profit, not on whether the timing of targeting is optimal. A longitudinal framework can help answer that last question.
In this paper, our goal is to account for the time-varying aspect of this problem in both steps of that framework. Firstly, we take advantage of the information contained in the historical data from the portfolio and obtain more accurate predictions for
and thus
: that is a gain of precision on the survival step. Secondly, we evaluate the expected individual retention gains over time to derive the optimal timing to offer the incentive: that is a gain of flexibility and expected profit on the regression step. For that purpose, we introduce tree-based models, which are, to the best of our knowledge, yet to be explored in the actuarial literature. Those models, such as left-truncated and right-censored (LTRC) survival trees and LTRC forests by [
14,
15] or mixed-effect tree-based regression models (see [
16,
17,
18,
19]) are considered state-of-the-art and have yet to be exploited in the actuarial literature. We propose an application of that framework with data-driven tree-based models but other types of models exist and could fit in this framework (see
Appendix A).
This extension is not trivial, as time-dependent features and time-dependent response variables are difficult to implement in parametric or tree-based models. Indeed, conventional statistical or machine learning models do not readily accommodate time-varying features. This is the case for most tree-based models as they assume that records are independently distributed. Of course, this is unrealistic as observations of any given individual are highly correlated. Moreover, time-varying features can generate bias if not dealt with carefully (see [
20] for instance). The use of longitudinal data is already a well-studied topic (see [
21]), with rare examples within the actuarial literature (see [
22] for instance) and, to the best of our knowledge, only a few actuarial uses of time-varying survival trees or mixed-effect tree-based models have been tried or suggested (see [
23], [
24] or [
25]) and no longitudinal lapse analysis framework based on CLV has been described.
In summary, this work presents a longitudinal lapse analysis framework with time-varying covariates and target variables. This framework accepts competing risks and relies on tree-based machine learning models. This work focuses on a lapse management strategy and retention targeting for life insurers and extends the existing lapse management framework proposed in [
7,
10]. It defers from the latter by taking advantage of time-varying features, introducing different tree-based models to the lapse management literature, including the possibility for an
acceptant to lapse in the future, yielding insights regarding individual targeting times, and adding the possibility to adjust the level of risk, which the insurer is willing to take in a retention campaign. The rest of this paper is structured as follows. We describe the specifics of longitudinal analysis and a new longitudinal and time-dynamic lapse management framework, which is the main contribution of this work in
Section 2. This section also includes a brief description of models that can fit in this framework. In
Section 3, we show a concrete application of our framework on a real-world life insurance portfolio with a discussion of our methodology and results. Eventually,
Section 4 concludes this paper.
Remark 1. While our primary focus is on the theoretical underpinnings, it is crucial to note that the LMS is adaptable and can be operationalised and adapted in different cultural environments, acknowledging the diversity of social factors that influence actuarial studies.
4. Conclusions, Limitations, and Future Work
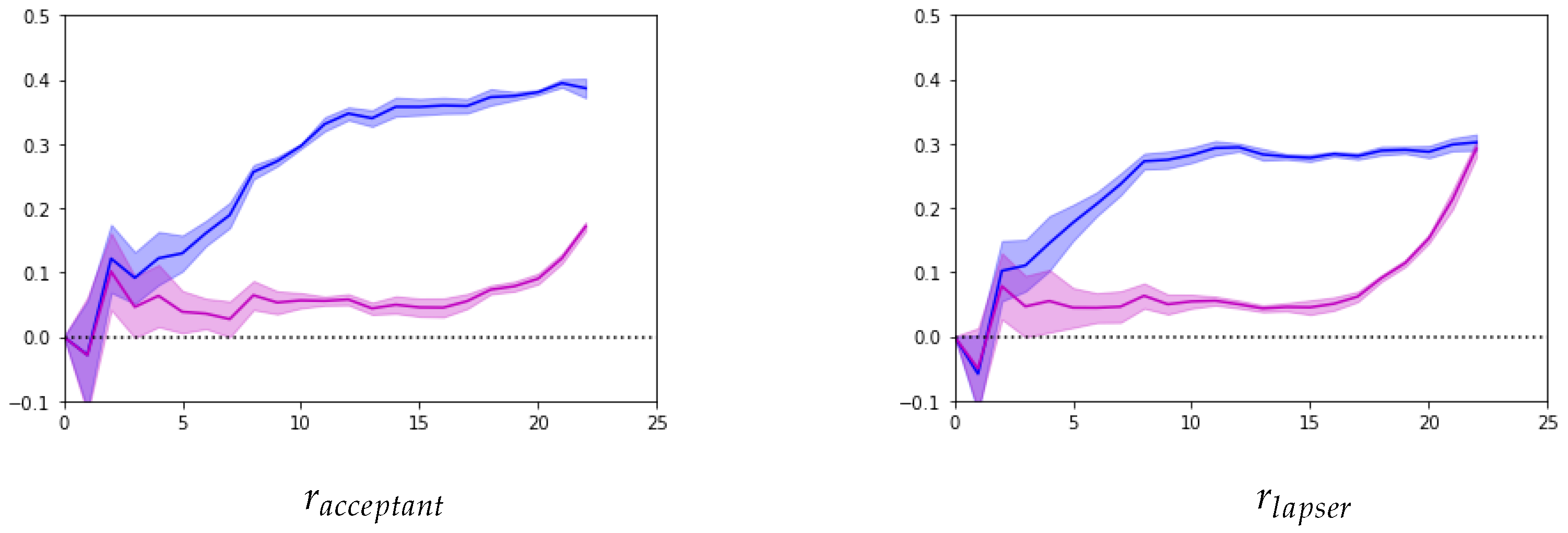
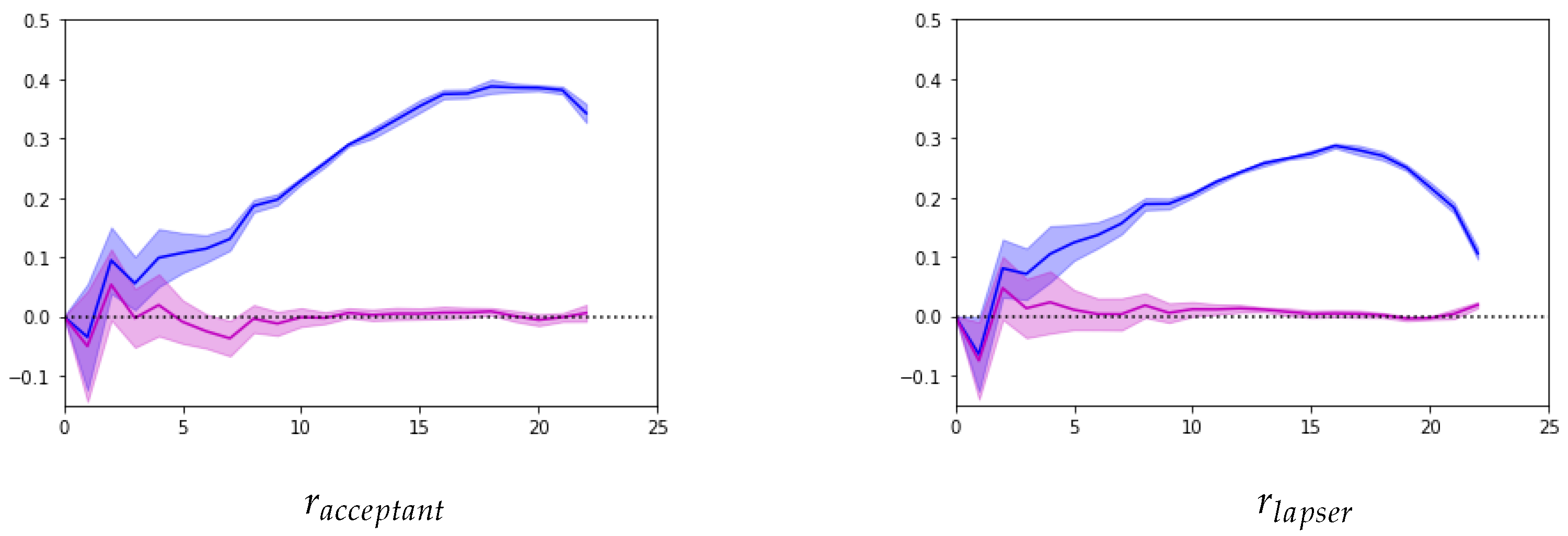
In conclusion, this paper presents a novel longitudinal lapse management framework tailored specifically for life insurers. The framework enhances the targeting stage of retention campaigns by selectively applying it to policyholders who are likely to generate long-term profits for the life insurer. Our key contribution is the adaptation of existing methodologies to a longitudinal setting using tree-based models. The results of our application demonstrate the advantages of approaching lapse management in a longitudinal context. The use of longitudinally structured data significantly improves the precision of the models in predicting lapse behaviour, estimating customer lifetime value, and evaluating individual retention gains. The implementation of mixed-effect random forests enables the production of time-varying predictions that are highly relevant for decision-making. The framework is designed to prevent the application of loss-inducing strategies and allows the life insurer to select the most profitable LMS, under constraints.
To effectively apply our longitudinal LMS framework in practice, we recommend discretising or aggregating the longitudinal data to an appropriate time grid to manage computational complexity without compromising the precision of the models. We also advise carefully considering realistic LMS scenarios to limit computationally intensive tasks; this involves selecting practical time intervals and retention strategies that align with the insurer’s operational capabilities. Eventually, we suggest, whenever possible, to include macro-economic longitudinal covariates (such as interest rates and unemployment rates), into the models. Although these features were not included in our application, they can provide additional context and improve the accuracy of lapse predictions.
By following these recommendations, insurers can enhance the practical implementation of our framework and achieve better outcomes in lapse management.
However, our work has several limitations that must be acknowledged:
First, regarding the framework: the longitudinal lapse management strategy is defined with fixed incentive, probability of acceptance, and cost of contact, regardless of the time in the future. Moreover, the parameter is constant for a given policyholder, but it could be seen as the realisation of a random variable following a chosen distribution. Those points may restrict the framework’s practical effectiveness. Moreover, we did not account for the interdependence between different LLMS parameters. In terms of interpretation of the results, accounting for this interdependence would allow the detection of unrealistic strategies. Additionally, the introduction of the confidence parameter could be discussed further as it could be linked with actuarial risk measures such as the value-at-risk. Eventually, the article describes a discrete-time longitudinal methodology, but in general, the insurer has access to the precise dates of any policy’s financial flows. Thus, a continuous-time framework could also be implemented.
Second, regarding the application: a lot of assumptions have been formulated in the application we propose, such as constant parameters, where the framework allows them to vary across time and policyholders, or the use of MERF, where more complex and completely non-linear models could be tried. It is also important to acknowledge that the longitudinal dataset used for the application does not contain any macroeconomic longitudinal covariate, which could lead to results that do not vary with the economic context. This is not reflective of real-world conditions, and including such features would enhance the results and allow the interpretation of the systemic effects of the economic context on lapse behaviour. The inclusion of such exogenous time-varying features would allow the merging of the economic-centred and micro-oriented literature and will be deferred as future research.
Finally, regarding longitudinal tree-based models: the use of LTRC and MERF requires the management of time-varying covariates with the pseudo-subject approach, which has practical limitations and prevents the longitudinal data from being predicted alongside the target variable. The pseudo-subject approach, which spreads observations across different leaves in the tree, does not produce a unique trajectory in the tree for a given subject. This does not affect the results but makes the models less interpretable, essentially turning them into black-box models. Improved interpretability would facilitate better understanding and application of the results in decision-making processes. Future works could address those remarks using joint models (see
Appendix A for references) or time-penalised trees (see [
27]).
The limitations of the general framework should be discussed and tackled in forthcoming research. Other use cases and applications, with sensitivity analysis over various sets of parameters, models, and datasets, could constitute an engaging following work. Pseudo-subject limitations are inherent in the current design of longitudinal tree-based models. Future work will involve developing innovative algorithms to address these issues. Overall, this article opens the field of lapse behaviour analysis to longitudinal models, and our framework has the potential to improve retention campaigns and increase long-term profitability for a life insurer.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}