1. Introduction
In today’s fast-paced, data-driven business environment, the strategic adoption of technological advancements within business intelligence significantly influences organizational success. The Fourth Industrial Revolution, often referred to as the “Digital Era 4.0”, has led to a significant shift towards data-driven decision-making across various industries [
1,
2]. As companies harness the power of analytics to gain a competitive edge, recruiting individuals with strong analytical skills has become imperative, especially in sectors heavily reliant on business intelligence systems [
3].
Adapting and efficiently recruiting top talent is crucial for leveraging analytical capabilities. The traditional recruitment methods, often cumbersome and subjective, are increasingly inadequate given the rapidly expanding data volumes and the complexities of global talent markets [
4]. Recent advancements in big data analytics and predictive modeling present novel opportunities to enhance the recruitment processes [
5]. Predictive analytics, which uses historical data to forecast future outcomes, has become a focal point for organizations aiming to streamline recruitment and identify optimal candidates efficiently. However, integrating predictive analytics into recruitment processes poses challenges, including data privacy concerns, the complexity of model implementation, and the potential for bias in algorithmic decision-making [
6].
This study aims to address these challenges by rigorously evaluating various machine learning algorithms, including K-Nearest Neighbors (KNNs), Logistic Regression, Support Vector Machine (SVM), Naive Bayes, Decision Trees, Random Forest, Gradient Boost Classifier (GBC), AdaBoost, and Neural Networks. The research investigates their performance in enhancing the recruitment efficiency within business intelligence systems. By examining and comparing these models on key performance metrics such as accuracy, precision, recall, F1-score, and ROC-AUC score, this study tests the hypothesis that machine learning models, when properly tuned and applied, can significantly outperform the traditional methods in predicting the suitability of candidates for specific roles.
The main objectives of this research are to identify the most effective predictive model for talent recruitment in BI systems and to provide actionable insights for strategically integrating these technologies into business intelligence frameworks. These insights aim to help organizations optimize their recruitment processes and ensure the acquisition of top analytical talent, thereby enhancing their ability to innovate and achieve strategic objectives.
Through rigorous analysis and evaluation, this research concludes that certain models, notably Random Forest and Neural Networks, provide superior accuracy and efficiency in the candidate selection processes. These findings confirm the utility of machine learning in recruitment and highlight the practical steps that organizations can take to implement such technologies effectively.
The structure of the paper is organized as follows:
Section 1 represents the introduction; following this introduction,
Section 2 reviews the relevant literature, framing the technological advancements within the context of HR analytics and predictive modeling.
Section 3 details the research methodology employed to evaluate the different machine learning models.
Section 4 presents the findings of the study, while
Section 5 discusses the implications of these results. The paper concludes with
Section 6, summarizing the key findings, the limitations of the current research, and suggestions for future investigations in this area.
2. Literature Review
In reviewing the relevant literature, it is evident that predictive analytics and machine learning have emerged as powerful tools in the field of human resource management. These tools have the potential to revolutionize the talent recruitment and acquisition processes by leveraging big data and advanced algorithms. Through the analysis of large-scale talent and management-related data, organizations can gain valuable insights into organizational behaviors and make more informed decisions regarding talent management [
7]. Furthermore, machine learning models can enhance the accuracy and efficiency of the recruitment processes by identifying patterns and predicting the success of potential candidates [
8]. The use of machine learning and predictive analytics in the field of human resource management has gained significant attention in recent years [
9].
2.1. Big Data in Talent Recruitment in the BI
BI systems have become instrumental in managing the complexities of human capital within organizations. The ability to analyze vast datasets for patterns and insights is crucial for identifying the top talent and predicting their job performance [
10]. However, the traditional BI systems often fall short in terms of predictive accuracy and real-time analysis, necessitating the integration of advanced analytics and machine learning models to enhance the recruitment processes [
11]. Big data analytics has emerged as a powerful tool for HR management, offering the potential to revolutionize talent recruitment. The use of big data can lead to a more nuanced understanding of candidate profiles, thereby facilitating more informed and objective hiring decisions. Studies have shown that big data analytics can improve the efficiency of the recruitment processes and reduce the costs associated with hiring the wrong candidate [
12]. However, the implementation of big data in HR also presents challenges, such as ensuring data privacy and managing the complexity of algorithms [
13].
2.2. Predictive Modeling in Talent Recruitment
Predictive modeling, which involves the use of statistical algorithms and machine learning techniques to forecast future events based on historical data, has become increasingly popular in talent recruitment. These models can identify the characteristics of the top-performing candidates, thus streamlining the candidate selection process [
14]. Various studies have demonstrated the effectiveness of machine learning algorithms like KNNs, SVM, and Random Forest in predicting employee performance and turnover [
15,
16,
17]. However, the choice of the best predictive model often depends on the specific context and the nature of the data available. Ref. [
15] developed a model that accurately predicts employee turnover with an 87.43% success rate, highlighting the practical utility of machine learning in reducing turnover and enhancing retention strategies. Ref. [
18] explored the impact of big data analytics on business intelligence in China, emphasizing the significance of data quality and the challenges associated with data management and privacy concerns. Refs. [
19,
20] discussed the broad applications of big data analytics across various sectors, emphasizing its crucial role in strategic decision-making and operational improvements.
2.3. Machine Learning in Talent Recruitment
Machine learning algorithms have become increasingly integral to the recruitment process, enabling organizations to make data-driven decisions when evaluating potential candidates [
4]. These algorithms help to predict key outcomes such as employee performance, turnover rates, and the likelihood of an individual’s successful integration within an organization’s culture and structure.
KNNs: Recognized for its simplicity and effectiveness, the KNN approach has been effectively utilized in classification tasks within recruitment. The algorithm operates on the principle that similar cases with the same class labels tend to be located near each other in the feature space. This concept has been practically applied to sort candidates based on their skills and experiences in relation to those of previous successful employees [
16]. KNNs’ ability to classify job applicants based on their skills and experience makes the approach a valuable tool for initial candidate screenings and shortlisting [
21].
SVM: SVMs are particularly adept at handling high-dimensional datasets, which is often the case in recruitment, where numerous attributes must be considered. SVMs classify candidates by identifying a hyperplane that maximally separates different classes in the feature space, thereby determining the best fit for a job role based on a multitude of candidate attributes [
22]. The efficacy of SVMs in high-dimensional spaces makes them a preferred choice for complex recruitment analyses.
Random Forest: This ensemble method leverages multiple Decision Trees to enhance classification accuracy. Random Forest models are not only effective in handling large datasets with numerous features but are also less prone to overfitting, providing robust predictions on candidate success [
23]. The algorithm’s ensemble approach offers a comprehensive and less biased perspective on candidate evaluation.
AdaBoost Classifier: AdaBoost, an ensemble learning algorithm that combines multiple weak learners, has been applied in talent recruitment to predict employee success and identify key performance factors. Studies have shown that the AdaBoost Classifier can predict employee attrition with a notable degree of accuracy, precision, and recall [
24,
25]. The algorithm’s focus on iteratively improving the model performance makes it a strong contender in predictive analytics for recruitment.
Logistic Regression: Widely used in various fields, Logistic Regression models have found their way into recruitment for resume screening and predicting employee turnover [
4]. The algorithm’s ability to estimate the probability of a binary outcome makes it a useful tool for early-stage candidate evaluation.
Decision Trees: These models are favored for their simplicity and versatility in handling different data types. Their use in recruitment analysis enables a straightforward interpretation of the decision paths that lead to hiring choices [
26,
27].
Naive Bayes: Despite its simplicity, Naive Bayes has proven to be effective in classifying job candidates, particularly in scenarios where the dataset is less complex and the assumption of feature independence holds [
23].
GBC: Like AdaBoost, GBC is an ensemble algorithm that has been utilized to improve the prediction accuracy in recruitment. It focuses on reducing the errors of individual models by building successive models that address those errors [
24].
Neural Networks: Neural Networks, particularly deep learning models, offer a high degree of flexibility and accuracy in modeling the complex relationships within candidate data. While they require substantial computational resources and large datasets, their predictive power is unmatched. For instance, Ref. [
28] outlined a Neural Network model for talent recruitment and management, emphasizing its potential for employee growth and retention. Similarly, Ref. [
29] demonstrated the application of Neural Networks in predicting machine failures, showcasing the potential of these models in risk assessment and process improvement.
Comparative studies have been conducted to evaluate the performance of different ML models in the context of talent recruitment. These studies provide insights into the strengths and weaknesses of various models, offering guidance on model selection based on specific recruitment needs [
16,
30]. The literature suggests that ensemble methods and models capable of handling complex, non-linear relationships, such as Neural Networks, often perform well in predicting recruitment outcomes [
29]. The application of these algorithms within the context of business intelligence systems is particularly noteworthy. As organizations accumulate vast amounts of candidate data, the ability to leverage these machine learning models becomes increasingly valuable. The predictive insights gained from these models can significantly enhance the recruitment process, leading to better candidate selection and improved organizational outcomes.
Recent approaches have also utilized various data-centric techniques to optimize recruitment and team building. For instance, the work in [
31] explores calculating patterns to shape teams, providing a novel perspective on the data utilization in recruitment. Incorporating such approaches can further improve the effectiveness of machine learning models by leveraging pattern recognition to enhance the team composition and candidate selection.
The integration of predictive analytics in recruitment is not without challenges. Data quality, algorithmic complexity, and the potential for bias are significant concerns. Data privacy and the ethical use of personal information are also critical considerations that need to be addressed [
2]. Various ML models have been evaluated for their effectiveness in talent recruitment. A review of the literature shows that models such as SVM and Neural Networks have been employed with varying degrees of success [
17,
32]. The performance of these models is often contingent on the quality of the data, the selection of relevant features, and the specific context of the recruitment process [
2]. Studies have highlighted the need for transparency in algorithmic decision-making and the importance of high-quality, representative data for training predictive models [
33,
34]. Techniques such as data cleaning, feature engineering, and the use of synthetic data through methods like SMOTE are discussed to improve the data quality and model performance [
35].
2.4. Research Gaps and Contributions
This study addresses a significant gap in the literature by providing a comprehensive comparative analysis of various machine learning models within the context of BI systems for talent recruitment. By evaluating the performance of models such as KNNs, Logistic Regression, SVM, Naive Bayes, Decision Trees, Random Forest, GBC, AdaBoost, and Neural Networks, this research contributes to the academic discourse and offers practical insights for HR professionals. The study also examines the ethical considerations and challenges associated with the use of predictive analytics in recruitment, providing best practice insights for organizations seeking to enhance their recruitment processes through big data [
30,
36].
The literature review underscores the transformative potential of big data analytics and machine learning models in enhancing the talent recruitment in BI systems. It highlights the need for organizations to adopt data-driven approaches to recruitment while being mindful of the challenges and ethical considerations. This study aims to provide a robust comparative analysis of various machine learning models, contributing to the academic discourse and offering practical insights for HR professionals and decision-makers.
3. Materials and Methods
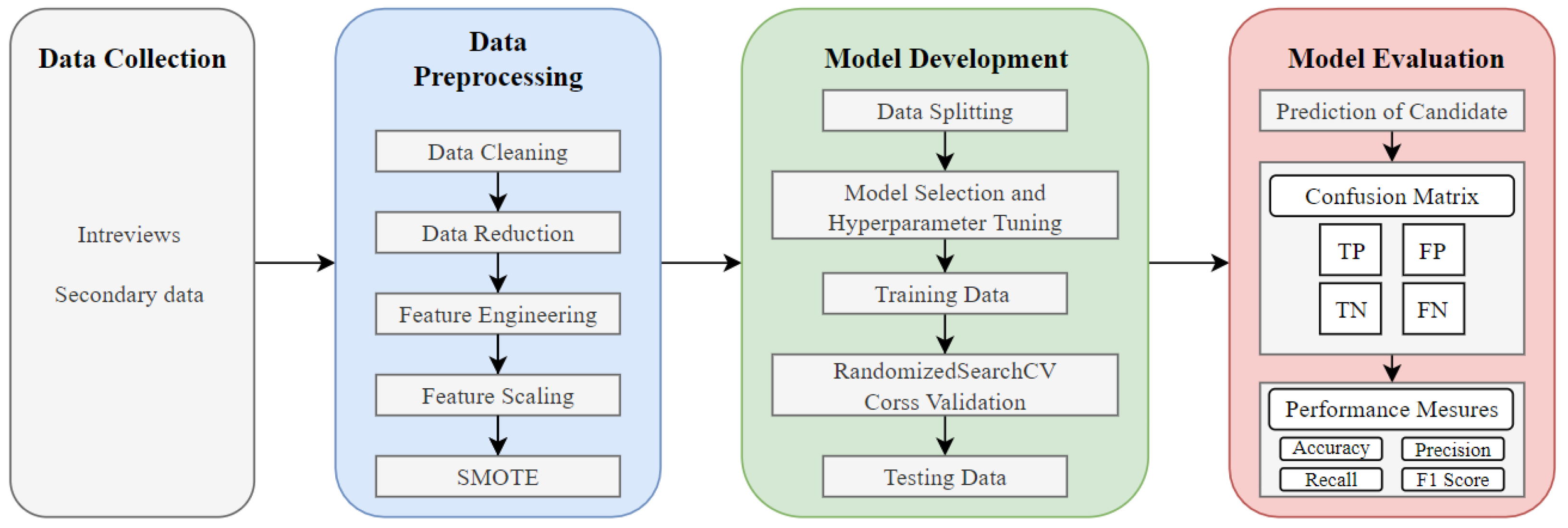
This research adopts a meticulous and systematic approach to optimize talent recruitment strategies within business intelligence systems through predictive analytics. Utilizing advanced machine learning algorithms, the study undertakes thorough data collection, preprocessing, model development, and evaluation stages, as shown in
Figure 1, to construct effective predictive models for talent acquisition. These methodological steps are intricately interlinked, fostering a coherent research flow that not only enhances the predictive model robustness but also upholds transparency and reproducibility in methodologies.
The approach detailed in this section encompasses the entire research process from data collection and preprocessing to advanced predictive model deployment and evaluation. By transparently describing each methodological facet, including the techniques and tools employed for extensive recruitment data analysis, this study ensures reproducibility and reliability in its findings. Through meticulous documentation of methodologies, this research contributes to the scientific rigor and verifiability of the study, providing a foundational framework for future studies exploring similar phenomena.
3.1. Data Collection
Data collection is a critical phase in any empirical study as it forms the basis for subsequent analysis and model development. For this research, the data were sourced from a leading recruitment organization in Yemen spanning the period from 2019 to 2022. The initial dataset, comprising 22,487 records, served as the primary material for our analysis and was extracted from the organization’s database and comprised a comprehensive collection of recruitment records.
The dataset includes both categorical and numerical features, such as educational background, work experience, employment test results, and candidate success metrics, as shown in
Table 1. The inclusion of these variables enables a robust analysis of the recruitment patterns and candidate performance, which are crucial for developing predictive models. The dataset was reduced to 20,245 candidates after data cleaning to ensure high-quality data for analysis. This reduction was due to the exclusion of records with missing or inconsistent information. The extensive size of the dataset and the organization’s significant market presence make it a representative sample of the recruitment landscape within the business intelligence sector in Yemen.
3.2. Data Preprocessing
The preprocessing phase was integral to preparing the dataset for machine learning analysis. It involved several steps to ensure the data were clean, consistent, and suitable for analysis:
3.2.1. Data Cleaning
The data cleaning process commenced with a meticulous review of the dataset to identify and rectify inaccuracies. The initial dataset, encompassing over 20,000 records, was subjected to a thorough examination to detect inconsistencies and address missing values. This rigorous cleaning process culminated in a refined dataset comprising 20,239 records following the elimination of duplicates and rectification of inaccuracies.
3.2.2. Dimensionality Reduction
This study employed Principal Component Analysis (PCA) and Exploratory Data Analysis (EDA) for dimensionality reduction. PCA is a method used to reduce the number of variables in a dataset while retaining its variability, thereby simplifying the model and enhancing its performance. EDA provides insights into the dataset, aiding in the discovery of valuable patterns. Univariate analysis was employed to analyze categorical and numerical data, while bivariate analysis helped to identify correlations between variables.
To address the dataset’s high dimensionality and enhance computational efficiency, dimensionality reduction techniques such as PCA and EDA were employed. These techniques facilitated the exploration of correlations between features, as illustrated in
Figure 2, aiding in the identification of the most significant features for predictive modeling. By transforming the original feature space into a lower-dimensional one, these methods preserved essential information, reduced noise, and revealed underlying patterns crucial for analysis.
3.2.3. Feature Selection and Engineering
We conducted a thorough feature selection process to identify the most relevant features that could potentially impact recruitment outcomes. This process involved statistical analysis and domain expertise to ensure that the selected features were both predictive and meaningful in the context of talent recruitment.
Feature engineering efforts included encoding categorical variables using techniques like one-hot encoding and label encoding, ensuring that these variables were represented in a format compatible with machine learning algorithms. The feature engineering process involved selecting relevant features that contribute significantly to the prediction models. Techniques such as one-hot encoding for categorical variables, normalization for numerical variables, and handling missing values through imputation were employed. Feature selection was guided by domain knowledge and statistical methods to retain the most informative features. We also created new features from existing ones to better capture the underlying patterns in the data.
Encoding Categorical Variables: One-hot encoding was used to convert categorical variables into binary vectors. This technique was particularly useful for handling non-ordinal categorical data. For ordinal data, label encoding was employed to maintain the inherent order in the data.
Creating New Features: New features were derived from existing ones to enhance the model’s predictive power. For instance, a composite feature combining years of experience and qualification levels was created to better represent a candidate’s suitability for advanced roles.
Handling Outliers: Outliers were identified using the Interquartile Range (IQR) method. These outliers were then treated by replacing them with the mean or median values of the corresponding feature to minimize their impact on the model.
The correlation between selected features is represented in
Figure 2, in which
qlf_w refers to the qualification weight feature,
workex_w refers to the work experience weight feature,
rel_workex_w refers to the related work experience weight feature,
TotalDegree refers to the degree of employment test feature, and
status refers to the status feature of the candidate whether they are placed or not.
3.2.4. Feature Scaling
Feature scaling was applied to ensure that all features contributed equally to the model’s performance. Numerical values were normalized using standard scaling methods, such as Min–Max scaling or Z-score normalization, to standardize the feature ranges and improve the convergence of learning algorithms.
3.2.5. Handling Imbalanced Data
To address the class imbalance in the dataset, particularly for underrepresented classes in the recruitment outcomes, we applied the Synthetic Minority Over-sampling Technique (SMOTE). This technique generates synthetic samples for the minority class by interpolating between existing minority class instances, thus providing a more balanced dataset for model training. By meticulously executing these preprocessing steps, we ensured that the dataset was clean, consistent, and optimal for developing robust predictive models for talent recruitment in business intelligence systems.
3.3. Model Development
Several predictive models were developed using a variety of machine learning algorithms known for their efficacy in classification tasks. The process involved several steps, including algorithm selection, hyperparameter tuning, and validation.
3.3.1. Algorithm Selection
We selected a set of nine machine learning algorithms based on their theoretical properties, empirical performance in similar contexts, and the specific requirements of our classification task. The chosen algorithms included KNNs, SVM, Random Forest, Neural Networks, Logistic Regression, Decision Trees, GBC, AdaBoost Classifier, and Naive Bayes. Each algorithm was selected based on its performance, as shown in
Table 2.
3.3.2. Hyperparameter Tuning
The specific hyperparameter tuning techniques used for each model and their impact on model performance are detailed in the subsequent sections.
For each of the nine models, we employed hyperparameter tuning techniques to optimize their performance. This process involved the following:
Grid Search: A technique where we define a grid of hyperparameter values and train a model for each combination to find the best-performing set.
Randomized Search: An alternative to grid search that samples a given hyperparameter space randomly, which can be more efficient when dealing with a large number of hyperparameters.
Hyperparameter tuning was conducted using RandomizedSearchCV and GridSearchCV to optimize model performance. The specific hyperparameters tuned for each model are as follows:
KNNs: Number of neighbors, weight function, distance metric, leaf size, and power parameter for the Minkowski metric.
Logistic Regression: Regularization parameter and penalty type.
SVM: Kernel function, regularization parameter, and penalty type.
Naive Bayes: Smoothing parameter, alpha value, vectorization method, and Gaussian variant.
Decision Tree: Criterion, maximum depth, minimum samples split, and minimum samples leaf.
Random Forest: Number of trees, criterion, maximum depth, minimum samples split, and minimum samples leaf.
AdaBoost Classifier: Number of estimators, learning rate, and loss function.
GBC: Number of estimators, learning rate, maximum depth, minimum samples split, and minimum samples leaf.
Neural Network (Binary Classification): Number of hidden layers, number of neurons, activation function, and regularization parameter.
3.3.3. Handling Overfitting
One potential issue with high-performing models like Random Forest and Neural Networks is overfitting, where the model performs well on the training data but poorly on unseen data. To mitigate this, several strategies were employed:
Cross-Validation: K-fold cross-validation was used to ensure that the model’s performance is consistent across different subsets of the data.
Regularization: Techniques such as L1 and L2 regularization were applied to penalize complex models.
Pruning: For tree-based models, pruning was used to limit the depth and complexity of the trees.
These strategies help in generalizing the model to new data and reduce the risk of overfitting. The optimal hyperparameters were selected based on cross-validated performance metrics to avoid overfitting. Each model was evaluated based on its performance metrics, including accuracy, precision, recall, F1-score, and AUC-ROC curve. The hyperparameters were fine-tuned to maximize these metrics, ensuring the models’ robustness and generalizability. The impact of these hyperparameters on model performance is summarized in
Table 3.
The criteria for evaluating the performance of each hyperparameter configuration included metrics such as accuracy, precision, recall, and F1-score. These metrics provided a comprehensive assessment of the models’ predictive capabilities, ensuring that the selected hyperparameters optimized both precision and recall.
3.3.4. Validation
The developed models were validated using a split-test method, where the dataset was divided into training and testing sets. This approach allowed us to assess the models’ ability to generalize to new, unseen data. The performance of each model was evaluated based on a set of metrics, as detailed in
Table 4.
These metrics were computed to provide a comprehensive evaluation of the model’s predictive capabilities. Additionally, we employed cross-validation techniques to further assess the models’ generalizability and robustness. The performance of each model was evaluated based on metrics such as accuracy, precision, recall, and F1-score. The results of the model evaluation will be discussed in the subsequent sections, where we will explore the performance of each model in detail.
3.4. Ethical Considerations
The research conducted in this study adhered to strict ethical guidelines to protect the rights and privacy of the individuals whose data were used in the analyses. Due to the sensitive nature of recruitment data, strict data privacy and ethical considerations have been implemented. Key ethical considerations included the following:
Data Processing Protocols: Robust data processing protocols have been put in place to ensure data confidentiality and integrity. All personal identifiers have been removed or encrypted to anonymize the data, ensuring that individuals cannot be traced. In addition, a Non-Disclosure Agreement (NDA) was implemented between the researcher and the company providing the dataset, ensuring that the data are treated with the highest level of confidentiality.
Informed Consent: Explicit consent has been obtained from the hiring organization, with assurances that candidates have consented to the use of their data in the research. They were provided with a clear explanation of the research objectives, the use of data, and the measures taken to protect their privacy.
Ethical Approval: Ethical approval has been obtained for data use, ensuring that all data processing, processing and analysis are conducted in accordance with ethical standards for research involving human subjects. The study protocol received ethical review and approval, ensuring compliance with guidelines and minimizing risk to participants.
Compliance with Guidelines: The research followed relevant ethical guidelines, including the principles set out in the Declaration of Helsinki and the General Data Protection Regulation (GDPR) for the protection of personal data. Efforts were made to analyze the data for inherent biases and take steps to mitigate their impact, ensuring that predictive models do not perpetuate or amplify existing hiring biases.
Implementing these measures, the study preserved the privacy and rights of the individuals whose data were used and also upheld the ethical standards necessary to conduct research in the field of talent recruitment.
4. Results
The analysis of various machine learning models has demonstrated their potential to revolutionize talent recruitment within business intelligence systems. This section presents a detailed analysis of the findings from the application of various machine learning algorithms to enhance the talent recruitment in business intelligence systems. The performance of each model was evaluated based on several key metrics, including accuracy, precision, recall, F1-score, and area under the ROC curve (AUC-ROC). The results are supported by the statistical analysis and visualizations derived from the processed data, enabling a clear comparison of the effectiveness of each predictive model.
4.1. Experimental Setup and Methodology
The experimental setup for this study involved leveraging a comprehensive dataset and preparing this dataset for analysis. A multi-step preprocessing phase was undertaken, including data cleaning to address missing values and inconsistencies, dimensionality reduction to focus on the most relevant features, and feature engineering to enhance the dataset’s predictive power. Specifically, the dataset was subjected to EDA to identify patterns and correlations, followed by the application of techniques such as SMOTE to address class imbalances.
The methodology encompassed the development and evaluation of nine distinct machine learning models, each chosen for its suitability in classification tasks. The models included KNNs, Logistic Regression, SVM, Naive Bayes, Decision Trees, Random Forest, GBC, AdaBoost Classifier, and Neural Networks. Each model was trained on the preprocessed dataset using a 75–25 split for training and testing, respectively.
Hyperparameter tuning played a critical role in optimizing the models’ performance. This was achieved through a combination of grid search and random search strategies, implemented using the RandomizedSearchCV function. The hyperparameters tuned for each model were selected based on their potential to enhance the model’s predictive accuracy, precision, recall, and F1-score.
The model evaluation was conducted using a range of performance metrics, including accuracy, precision, recall, F1-score, and the area under the receiver operating characteristic (ROC) curve (AUC-ROC). These metrics provided a comprehensive assessment of each model’s ability to predict successful recruitment outcomes.
The subsequent subsections delve into the performance metrics, comparative analysis, statistical validation, and discussion of the results, providing a thorough understanding of the models’ capabilities in the context of talent recruitment in business intelligence systems.
4.2. Overview of Model Performance
The performance of each predictive model was rigorously evaluated using a comprehensive set of metrics, including accuracy, precision, recall, F1-score, and AUC-ROC score. These metrics provide a multi-faceted view of the models’ predictive capabilities, capturing their overall correctness, ability to identify positive instances, balance between precision and recall, and discrimination threshold levels, respectively.
4.2.1. Random Forest Model
The Random Forest model emerged as the top performer, achieving an accuracy score of 92.8%. This model demonstrated a high precision of 91.2% and recall of 90.9%, indicating its effectiveness in correctly identifying positive instances without compromising on the breadth of detection. The F1-score of 91.0% further underscores the model’s balanced performance in precision and recall. The ROC-AUC score of 0.962 signifies the model’s excellent ability to distinguish between successful and unsuccessful recruitment outcomes. To mitigate the risk of overfitting, several strategies were employed. The Random Forest model utilized techniques such as limiting the maximum depth of the trees, setting a minimum number of samples required to split a node, and using cross-validation during the model training. These steps helped to ensure that the model generalized well to unseen data.
4.2.2. Neural Networks Model
The Neural Networks model also exhibited a remarkable performance, with an accuracy score of 92.6%. This model stood out with a precision score of 96%, suggesting its high reliability in identifying suitable candidates. The recall and F1-score of 88% and 92%, respectively, indicate that, while the model is slightly more conservative in its predictions, it maintains a strong balance between precision and recall. The ROC-AUC score of 0.962 is on par with the Random Forest model, reflecting its exceptional discriminative power. For the Neural Networks model, overfitting was mitigated by incorporating techniques such as dropout regularization, which randomly drops units from the Neural Network during training to prevent the co-adaptation of neurons. Additionally, early stopping was used to halt the training once the model’s performance on the validation set began to deteriorate, ensuring that the model did not learn noise from the training data.
4.2.3. Other Models
The GBC, Decision Trees, and KNNs models also performed commendably, with accuracy scores of 92.5%, 92.4%, and 92.2%, respectively. These models demonstrated strong predictive capabilities, although they were slightly behind the top performers in terms of precision, recall, and F1-score.
The SVM and AdaBoost Classifier models showed solid performance, with accuracy scores of 90.8% and 89.1%, respectively. However, they demonstrated lower precision and recall compared to the top models, suggesting that they may be less effective in identifying the best candidates without a higher risk of false negatives or positives.
The Naive Bayes and Logistic Regression models had the lowest accuracy scores at 86.2% and 78.3%, respectively. These models also had lower precision, recall, and F1-scores, indicating that they may not be as suitable for talent recruitment prediction in business intelligence systems.
The performance of each model was rigorously evaluated across several metrics, including accuracy, precision, recall, and F1-score. The detailed performance metrics for each model are summarized in
Table 5, providing a comprehensive overview of their predictive performance.
To provide a visual representation of the models’ performance,
Figure 3 presents a comparative analysis of the accuracy, precision, recall, and F1-score for each model. This visual aid enables a quick and clear comparison of the models’ predictive capabilities.
The performance metrics presented in this subsection provide detailed insight into the predictive capabilities of each model. The Random Forest and Neural Networks models stand out as the most effective in terms of accuracy, precision, recall, and F1-score, making them strong candidates for enhancing the talent recruitment in business intelligence systems. The other models, while showing varying degrees of performance, also contribute to the understanding of the different predictive behaviors in talent recruitment scenarios.
Two key figures provide deeper insights into the predictive performance of the models:
AUC-ROC Curves
Figure 4 illustrates the area under the receiver operating characteristic curve for each model. This figure is crucial for understanding how well each model distinguishes between classes under varying threshold settings, which is essential for fine-tuning the model parameters in practical applications.
Precision–Recall Curves
Figure 5 complements the AUC-ROC by focusing on the trade-off between precision and recall for different models. This is particularly useful for recruitment scenarios where the balance between identifying true positives and the precision of the selection process is critical.
4.3. Comparative Analysis
4.3.1. Random Forest
The Random Forest model excelled, with the highest accuracy (92.8%), indicating its strong predictive capability. It demonstrated high precision (91.2%) and recall (90.9%), suggesting the effective identification of positive recruitment outcomes without compromising on coverage. The F1-score of 91.0% and AUC-ROC score of 0.962 further substantiate its robust performance.
4.3.2. Neural Networks
The Neural Networks model was a close second, achieving an accuracy of 92.6%. It particularly stood out with a precision of 96%, highlighting its reliability in candidate selection. The F1-score of 92% and AUC-ROC score of 0.962 mirror the model’s effectiveness in balancing precision and recall.
4.3.3. Gradient Boosting Classifier (GBC)
The GBC model showed a competitive performance, particularly in terms of accuracy (92.5%) and AUC-ROC (95.5%). However, it fell slightly short in precision and recall compared to the Random Forest and Neural Networks models.
4.3.4. Decision Trees, KNNs, SVM, and AdaBoost
These models exhibited solid performances, with accuracy scores above 90%, but they were slightly less effective in precision and recall, which are crucial for talent recruitment applications.
4.3.5. Naive Bayes and Logistic Regression
These models had the lowest accuracy scores (86.2% and 78.3%, respectively), indicating potential limitations in their application for talent recruitment in business intelligence systems.
Interestingly, the trend across the models showed that ensemble methods like Random Forest and GBC, as well as complex models like Neural Networks, tend to perform better in this context. This could be attributed to their ability to capture the intricate patterns and interactions within the data. We have added a table summarizing the strengths, weaknesses, handling of different data sources, and handling of class imbalances for each model; these aspects are discussed in
Table 6.
4.4. Statistical Analysis
To statistically validate the performance differences among the models, a one-way ANOVA was conducted. The results revealed significant differences in the performance metrics across the models (p < 0.05). A post hoc analysis using Tukey’s Honest Significant Difference (HSD) test further confirmed that the Random Forest and Neural Networks models performed significantly better than the Naive Bayes and Logistic Regression models (p < 0.01).
The confidence intervals for the mean performance metrics provided additional insights into the reliability of the models’ rankings. For instance, the 95% confidence interval for the Random Forest model’s accuracy was (92.4%, 93.2%), indicating a high level of certainty in its superior performance.
The statistical validation of the models’ performance adds a layer of confidence to these insights, reinforcing the reliability of the findings. By leveraging these models, businesses can streamline their recruitment processes, reduce costs, and improve the overall efficiency of talent acquisition in business intelligence systems.
5. Discussion
This section explores the implications of the findings, situates them within the broader context of the existing research, and discusses their practical relevance to business intelligence systems’ recruitment strategies. The results show that the Random Forest model performs admirably in predicting recruitment outcomes, which encourages a closer look at its potential applications, restrictions, and future research directions.
5.1. Interpretation of Results
The primary objective of this study was to evaluate the performance of various machine learning models in enhancing the talent recruitment for business intelligence systems. The results from our analysis underscore the Random Forest and Neural Networks models as the most effective, with accuracy scores of 92.8% and 92.6%, respectively. These models demonstrated a remarkable balance between precision and recall, indicating their proficiency in identifying the top candidates without compromising on the breadth of selection.
An unexpected yet noteworthy outcome was the relatively lower performance of the Logistic Regression model, with an accuracy score of 78.3%. This divergence from the expectations may be attributed to the model’s assumptions not being fully met by the dataset’s characteristics.
The findings from this study have significant implications for the talent recruitment processes in business intelligence systems. The superior performance of the Random Forest and Neural Networks models suggests that these algorithms can effectively enhance the recruitment process by improving the quality of candidate selection.
The key takeaways from this analysis are the following:
- 1.
The ensemble methods and complex models outperform the traditional algorithms in predicting recruitment outcomes.
- 2.
Accuracy, precision, and recall are critical metrics for selecting models in talent recruitment tasks.
- 3.
The use of AUC-ROC scores provides a comprehensive view of a model’s ability to distinguish between successful and unsuccessful recruitments.
The actionable insights include the following:
- 1.
Organizations should consider implementing Random Forest or Neural Networks models to optimize their recruitment strategies.
- 2.
Further fine-tuning of hyperparameters and feature engineering could potentially enhance model performance.
- 3.
Ongoing monitoring and updating of models are essential to adapt to the evolving patterns in recruitment data.
5.2. Comparison with Existing Literature
Our findings align with numerous studies advocating for the use of ensemble methods and complex models in talent recruitment. For instance, Ref. [
17] developed an analytical prediction model using Random Forest and Naive Bayes classifiers, achieving significant improvements in recruitment prediction accuracy.
Similarly, Ref. [
16] found that the KNNs and SVM models performed well in predicting employee attrition, with accuracies of 94% and 96%, respectively. These studies support our results, where Random Forest and Neural Networks demonstrated superior performance with accuracy scores of 92.8% and 92.6%, respectively.
Additionally, Ref. [
37] used Logistic Regression, Random Forest, and GBC to predict the employee churn, reporting accuracy scores of 91.5%, 97.5%, and 97.9%, respectively. This aligns with our findings that ensemble methods like Random Forest can achieve high accuracy in recruitment predictions. However, our study observed a lower performance for Logistic Regression, with an accuracy of 78.3%, highlighting the importance of dataset characteristics in model performance.
The superior performance of the Random Forest and Neural Networks models in our study corroborates the findings from [
25,
38], which emphasized the robustness of Random Forest in handling the complex, high-dimensional data typical of recruitment processes. Furthermore, our findings are supported by the work of [
6], who highlighted the potential of machine learning models to enhance recruitment processes by reducing biases and improving efficiency.
Contrary to some studies that reported strong performance for Logistic Regression in similar contexts, our study found it less effective for recruitment prediction, possibly due to differences in the dataset composition and feature selection. This divergence underscores the necessity for careful model selection tailored to specific data characteristics.
Recent approaches have also utilized various data-centric techniques to optimize recruitment and team building. For instance, the work in [
31] explores calculating patterns to shape teams, providing a novel perspective on the data utilization in recruitment. Incorporating such approaches can further improve the effectiveness of machine learning models by leveraging pattern recognition to enhance the team composition and candidate selection.
These findings provide actionable insights for organizations aiming to optimize their talent recruitment strategies. The adoption of Random Forest and Neural Networks models can streamline the candidate selection processes, reduce the recruitment costs, and improve the hiring accuracy. Organizations are encouraged to integrate these models into their existing HR frameworks, leveraging their predictive capabilities to identify the most suitable candidates. Additionally, the continuous monitoring and updating of these models are essential to adapt to the evolving recruitment trends and data patterns.
5.3. Implications and Applications
The practical implications of our research are significant for organizations seeking to optimize their talent recruitment strategies. The identified models, particularly Random Forest and Neural Networks, offer a data-driven approach to candidate selection, potentially reducing biases and improving efficiency. By leveraging these models, organizations can enhance their recruitment processes in several ways:
Improving Candidate Selection: The high accuracy and precision of the Random Forest (92.8% accuracy, 91.2% precision) and Neural Networks (92.6% accuracy, 96% precision) models ensure the more reliable identification of the top candidates, reducing the risk of hiring mismatches.
Reducing Bias: Implementing machine learning models can help to mitigate unconscious biases in the recruitment process. By focusing on data-driven insights, organizations can ensure a fairer evaluation of candidates based on objective criteria.
Enhancing Efficiency: The automation of candidate screening through predictive models can significantly streamline the recruitment process, allowing HR professionals to focus on more strategic tasks. This can lead to cost savings and a more efficient allocation of resources.
Handling Large Volumes of Data: Both Random Forest and Neural Networks are adept at handling large datasets, making them suitable for organizations with extensive candidate pools. These models can process and analyze vast amounts of data quickly, providing actionable insights in a timely manner.
Continuous Improvement: The use of machine learning models enables continuous improvement and adaptation. Organizations can periodically retrain the models with new data to ensure that they remain effective and accurate over time.
Strategies for Implementation: Organizations should focus on ensuring high-quality data collection and preprocessing, performing hyperparameter tuning to optimize model performance, mitigating biases in the data and models, integrating predictive models with existing HR systems, ensuring compliance with ethical standards and data protection regulations, and training HR professionals to leverage machine learning models effectively. Our study contributes to the field by providing a comparative analysis of various ML models in the context of talent recruitment. The insights gained can guide future research and the development of more sophisticated models tailored to the nuances of recruitment data. Organizations that adopt these advanced analytics techniques can achieve a competitive advantage in attracting and retaining top talent, ultimately driving better organizational outcomes.
5.4. Limitations and Future Research Directions
This study is subject to certain limitations. The dataset, while extensive, is specific to a particular geographical region and may not be fully representative of the global recruitment patterns. Additionally, the reliance on historical data may not capture real-time dynamics effectively.
Future research could explore the integration of these models into real-world recruitment platforms, assess the impact of social media and behavioral data on model performance, and investigate the use of deep learning algorithms for talent recruitment.
6. Conclusions
This research systematically explored the efficacy of machine learning models in enhancing the talent recruitment processes within business intelligence systems. The primary objective was to enhance the recruitment accuracy and efficiency through the application of machine learning models.
Our findings indicate that the Random Forest and Neural Networks models outperformed the other algorithms, achieving accuracy scores of 92.8% and 92.6%, respectively. These models demonstrated exceptional precision, recall, and F1-scores, suggesting their effectiveness in identifying the top candidates and minimizing poor hiring decisions. Other models, such as GBC, Decision Trees, and KNNs, showed promising results but were slightly less effective. Conversely, Naive Bayes and Logistic Regression exhibited lower accuracy, indicating potential limitations in talent recruitment applications. The practical implications of our findings are significant for organizations seeking to optimize their recruitment processes. By leveraging the Random Forest and Neural Networks models, organizations can enhance their recruitment efficiency and effectiveness, leading to better hiring decisions and reduced costs. These models can identify the key variables contributing to successful recruitment outcomes, providing actionable insights for improving the candidate selection and retention rates.
Our study contributes to the existing body of knowledge by providing a comprehensive evaluation of various machine learning models in talent recruitment. It introduces a robust methodology for model selection and evaluation, which can be replicated in other contexts. Our findings highlight the importance of considering multiple performance metrics beyond accuracy, such as precision, recall, and F1-score, which are crucial for recruitment tasks. This study emphasizes the need for organizations to adopt a data-driven approach to talent recruitment, leveraging the power of machine learning algorithms to make informed decisions.
We recommend that organizations carefully select machine learning models based on their performance in recruitment tasks, focusing on models like Random Forest and Neural Networks. Implementing a rigorous model evaluation process that considers multiple performance metrics is essential to ensure that the selected model meets the specific recruitment needs. The continuous monitoring and updating of recruitment models are also crucial to adapt to the evolving patterns and trends in the job market.
For future research, we suggest investigating the integration of these models into real-world recruitment platforms and assessing their performance in dynamic, real-time settings. Exploring the use of hybrid models or ensemble methods could potentially improve the recruitment outcomes. Additionally, examining the impact of incorporating additional data sources, such as social media profiles and behavioral data, on model performance is another promising direction.
Author Contributions
Conceptualization, H.A.-Q.; methodology, H.A.-Q.; software, H.A.-Q.; validation, H.A.-Q., A.A. and A.M.; formal analysis, H.A.-Q.; investigation, H.A.-Q. and A.M.; resources, H.A.-Q.; data curation, H.A.-Q. and A.M.; writing—original draft preparation, H.A.-Q.; writing—review and editing, H.A.-Q. and A.A.; visualization, H.A.-Q.; supervision, J.S.; project administration, H.A.-Q.; funding acquisition, J.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research was conducted independently by the author, Hikmat Al-Quhfa, without external funding. Hikmat Al-Quhfa acknowledges the support received from the China Scholarship Council (CSC) scholarship during the study.
Data Availability Statement
The data used in this study were obtained from a leading hiring company in Yemen under a data privacy contract. Due to confidentiality agreements and ethical considerations, the data cannot be made publicly available. Access to the data is restricted to the researcher and authorized personnel only.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| BI | Business Intelligence |
| ML | Machine Learning |
| RF | Random Forest |
| SVM | Support Vector Machine |
| KNNs | K-Nearest Neighbors |
| GBC | Gradient Boosting Classifier |
| ROC-AUC | Receiver Operating Characteristic-Area Under Curve |
| HR | Human Resources |
| AI | Artificial Intelligence |
| ANOVA | Analysis of Variance |
| PCA | Principal Component Analysis |
| SMOTE | Synthetic Minority Over-sampling Technique |
| CV | Cross-Validation |
References
- Xu, M.; David, J.M.; Kim, S.H. The Fourth Industrial Revolution: Opportunities and Challenges. Int. J. Financ. Res. 2018, 9, 90. [Google Scholar] [CrossRef]
- Sarker, I.H.; Colman, A.; Han, J.; Khan, A.I.; Abushark, Y.B.; Salah, K. BehavDT: A Behavioral Decision Tree Learning to Build User-Centric Context-Aware Predictive Model. Mob. Networks Appl. 2019, 25, 1151–1161. [Google Scholar] [CrossRef]
- Nasir, M.; Dag, A.; Young II, W.A.; Delen, D. Determining Optimal Skillsets for Business Managers Based on Local and Global Job Markets: A Text Analytics Approach. Decis. Sci. J. Innov. Educ. 2020, 18, 374–408. [Google Scholar] [CrossRef]
- Ozdemir, F.; Coskun, M.; Gezer, C.; Gungor, V.C. Assessing Employee Attrition Using Classifications Algorithms. In Proceedings of the 2020 the 4th International Conference on Information System and Data Mining (ICISDM ’20), Hawaii, HI, USA, 15–17 May 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 118–122. [Google Scholar] [CrossRef]
- Zhang, Y.; Xu, S.; Zhang, L.; Yang, M. Big data and human resource management research: An integrative review and new directions for future research. J. Bus. Res. 2021, 133, 34–50. [Google Scholar] [CrossRef]
- Pessach, D.; Singer, G.; Avrahami, D.; Chalutz Ben-Gal, H.; Shmueli, E.; Ben-Gal, I. Employees recruitment: A prescriptive analytics approach via machine learning and mathematical programming. Decis. Support Syst. 2020, 134, 113290. [Google Scholar] [CrossRef] [PubMed]
- Qin, C.; Zhang, L.; Cheng, Y.; Zha, R.; Shen, D.; Zhang, Q.; Chen, X.; Sun, Y.; Zhu, C.; Zhu, H.; et al. A Comprehensive Survey of Artificial Intelligence Techniques for Talent Analytics. arXiv 2024, arXiv:2307.03195. [Google Scholar] [CrossRef]
- Koenig, N.; Tonidandel, S.; Thompson, I.; Albritton, B.; Koohifar, F.; Yankov, G.; Speer, A.; Hardy, J.H., III; Gibson, C.; Frost, C.; et al. Improving measurement and prediction in personnel selection through the application of machine learning. Pers. Psychol. 2023, 76, 1061–1123. [Google Scholar] [CrossRef]
- Manthena, S.R.L. Impact of Artificial Intelligence on Recruitment and its Benefits. IJIRMPS—Int. J. Innov. Res. Eng. Multidiscip. Phys. Sci. 2021, 9, 58–63. [Google Scholar] [CrossRef]
- Gomez-Mejia, L.R.; Balkin, D.B.; Cardy, R.L. Managing Human Resources, 7th ed.; OCLC: 706965973; Pearson: London, UK, 2012. [Google Scholar]
- Marr, B. Data-Driven HR: How to Use Analytics and Metrics to Drive Performance, 1st ed.; Kogan Page: London, UK, 2018; p. 264. [Google Scholar]
- Lohr, S. The age of Big Data. New York Times, 11 September 2012. [Google Scholar]
- Escobar, C.A.; McGovern, M.E.; Morales-Menendez, R. Quality 4.0: A review of big data challenges in manufacturing. J. Intell. Manuf. 2021, 32, 2319–2334. [Google Scholar] [CrossRef]
- Kelleher, J.D.; Tierney, B. Data Science; The MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Fang, M.; Su, J.; Liu, J.; Long, Y.; He, R.; Wang, T. A Model to Predict Employee Turnover Rate: Observing a Case Study of Chinese Enterprises. IEEE Syst. Man, Cybern. Mag. 2018, 4, 38–48. [Google Scholar] [CrossRef]
- R, V.R.; Doss, S.; K, A.K. Analytic Approach of Predicting Employee Attrition Using Data Science Techniques. Res. Sq. 2022. [Google Scholar] [CrossRef]
- Jantan, H.; Noh, M.; Yusoff, N. Towards Applying Support Vector Machine Algorithm in Employee Achievement Classification. In Proceedings of the International Conference on Data Mining, Internet Computing, and Big Data (BigData2014), Kuala Lumpur, Malaysia,, 17–19 November 2014; The Society of Digital Information and Wireless Communication: New Castle, DE, USA, 2014; pp. 12–21. [Google Scholar]
- Ram, J.; Zhang, C.; Koronios, A. The Implications of Big Data Analytics on Business Intelligence: A Qualitative Study in China. Procedia Comput. Sci. 2016, 87, 221–226. [Google Scholar] [CrossRef]
- Huang, S.C.; McIntosh, S.; Sobolevsky, S.; Hung, P.C.K. Big Data Analytics and Business Intelligence in Industry. Inf. Syst. Front. 2017, 19, 1229–1232. [Google Scholar] [CrossRef]
- Sun, Z.; Sun, L.; Strang, K. Big Data Analytics Services for Enhancing Business Intelligence. J. Comput. Inf. Syst. 2018, 58, 162–169. [Google Scholar] [CrossRef]
- Harrison, O. Machine Learning Basics with the K-Nearest Neighbors Algorithm; Towards Data Science Inc.: Toronto, ON, Canada, 2018. [Google Scholar]
- Li, Y.M.; Lai, C.Y.; Kao, J. Incorporate personality trait with support vector machine to acquire quality matching of personnel recruitment. In Proceedings of the 4th International Conference on Business and Information, Washington, DC, USA, 3–5 December 2008; pp. 1–11. [Google Scholar]
- Gao, X.; Wen, J.; Zhang, C. An Improved Random Forest Algorithm for Predicting Employee Turnover. Math. Probl. Eng. 2019, 2019, 4140707. [Google Scholar] [CrossRef]
- Pourkhodabakhsh, N.; Mamoudan, M.M.; Bozorgi-Amiri, A. Effective machine learning, Meta-heuristic algorithms and multi-criteria decision making to minimizing human resource turnover. Appl. Intell. 2023, 53, 16309–16331. [Google Scholar] [CrossRef]
- Qutub, A.; Al-Mehmadi, A.; Al-Hssan, M.; Aljohani, R.; Alghamdi, H.S. Prediction of Employee Attrition Using Machine Learning and Ensemble Methods. Int. J. Mach. Learn. Comput. 2021, 11, 110–114. [Google Scholar] [CrossRef]
- Hazra, S.; Sanyal, S. Recruitment Prediction Using ID3 Decision Tree. Int. J. Adv. Eng. Res. Dev. 2016, 3, 4–14. [Google Scholar] [CrossRef]
- Martinez-Gil, J.; Freudenthaler, B.; Natschläger, T. Recommendation of Job Offers Using Random Forests and Support Vector Machines. In Proceedings of the Data Analytics Solutions for Real-Life, Vienna, Austria, 26 March 2018. [Google Scholar]
- Mwaro, P.N.; Ogada, K.; Cheruiyot, W. Neural Network Model for Talent Recruitment and Management for Employee Development and Retention. In Proceedings of the 2021 IEEE AFRICON, Arusha, Tanzania, 13–15 September 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Ngwa, P.; Ngaruye, I. Big Data Analytics for Predictive System Maintenance Using Machine Learning Models. Adv. Data Sci. Adapt. Anal. 2023, 15, 2350001. [Google Scholar] [CrossRef]
- Jayanti, L.P.S.D.; Wasesa, M. Application of Predictive Analytics to Improve the Hiring Process in a Telecommunications Company. J. CoreIT J. Has. Penelit. Ilmu Komput. Dan Teknol. Inf. 2022, 8, 32–39. [Google Scholar] [CrossRef]
- Cauteruccio, F.; Terracina, G. Extended High-Utility Pattern Mining: An Answer Set Programming-Based Framework and Applications. Theory Pract. Log. Program. 2024, 24, 313–343. [Google Scholar] [CrossRef]
- Gaddam, L.; Lakshmi, S.; Kadali, H.; Abghari, S. Comparison of Machine Learning Algorithms on Predicting Churn within Music Streaming Service; Faculty of Computing, Blekinge Institute of Technology: Karlskrona, Sweden, 2022. [Google Scholar]
- Andariesta, D.T.; Wasesa, M. Machine learning models for predicting international tourist arrivals in Indonesia during the COVID-19 pandemic: A multisource Internet data approach. J. Tour. Futur. 2022. [Google Scholar] [CrossRef]
- Bergstra, J.; Ca, J.B.; Ca, Y.B. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Han, H.; Wang, W.Y.; Mao, B.H. Borderline-SMOTE: A New Over-Sampling Method in Imbalanced Data Sets Learning. In Proceedings of the Advances in Intelligent Computing, Hefei, China, 23–26 August 2005; Huang, D.S., Zhang, X.P., Huang, G.B., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 878–887. [Google Scholar]
- Kumar, V.; Garg, M.L. Predictive Analytics: A Review of Trends and Techniques. Int. J. Comput. Appl. 2018, 182, 31–37. [Google Scholar] [CrossRef]
- Jung, C. Predict Employee Churn with Machine Learning Using Python. 2020. Available online: https://towardsdatascience.com/will-your-employee-leave-a-machine-learning-model-8484c2a6663e (accessed on 7 June 2024).
- Rozario, S.D.; Venkatraman, S.; Abbas, A. Challenges in Recruitment and Selection Process: An Empirical Study. Challenges 2019, 10, 35. [Google Scholar] [CrossRef]
Figure 1.
This figure illustrates the methodological framework adopted for the study, devising prediction models through a process from data collection through preprocessing to model building and evaluation.
Figure 1.
This figure illustrates the methodological framework adopted for the study, devising prediction models through a process from data collection through preprocessing to model building and evaluation.
Figure 2.
Correlations between selected features.
Figure 2.
Correlations between selected features.
Figure 3.
Comparative analysis of model performance metrics: presents a bar chart comparing the performance metrics across the models, which emphasizes the higher performance efficiency of the Random Forest model over others.
Figure 3.
Comparative analysis of model performance metrics: presents a bar chart comparing the performance metrics across the models, which emphasizes the higher performance efficiency of the Random Forest model over others.
Figure 4.
AUC-ROC curves, produced by calculating and plotting the true positive rate against the false positive rate for classifiers at a variety of thresholds. The best value was 0.94 by the Random Forest model, which is considered excellent.
Figure 4.
AUC-ROC curves, produced by calculating and plotting the true positive rate against the false positive rate for classifiers at a variety of thresholds. The best value was 0.94 by the Random Forest model, which is considered excellent.
Figure 5.
Precision–recall curves for various models, demonstrating their ability to balance precision and recall effectively.
Figure 5.
Precision–recall curves for various models, demonstrating their ability to balance precision and recall effectively.
Table 1.
Data description.
Table 1.
Data description.
| Type of Data | Features | Data Type |
|---|
| Basic demographic information | ID Number | Numerical |
| | Gender | Categorical |
| | Qualification | Categorical |
| Educational Background | College | Categorical |
| | Specialization | Categorical |
| Work Experience | Work Experience | Numerical |
| | Related Work Experience | Numerical |
| Weights | Qualification weight | Numerical |
| | Work Experience weight | Numerical |
| | Related Work Experience weight | Numerical |
| Employment Test | Total Degree | Numerical |
| Year of Acceptance | Year | Categorical |
| Acceptance Status | Status | Numerical |
Table 2.
Summary of algorithms used. This table lists the machine learning algorithms employed in the study, along with their specific parameters and the rationale for their selection.
Table 2.
Summary of algorithms used. This table lists the machine learning algorithms employed in the study, along with their specific parameters and the rationale for their selection.
| Algorithm | Key Parameters | Rationale for Selection |
|---|
| KNNs | Number of neighbors, Metric (e.g., Euclidean, Manhattan) | Selected for its simplicity and effectiveness in classification tasks based on feature similarity. |
| SVM | Kernel type (e.g., linear, RBF), Regularization parameters | Chosen for its robustness in high-dimensional spaces and effectiveness in achieving clear margins of separation. |
| Random Forest | Number of trees, Max depth of trees, Criterion (e.g., Gini, Entropy) | Utilized for its ensemble learning approach, which provides high accuracy and handles overfitting well. |
| Neural Networks | Number of layers, Number of neurons per layer, Activation functions | Applied for their ability to model complex non-linear relationships through deep learning techniques. |
| Logistic Regression | Regularization strength, Type of regularization (e.g., L1, L2) | Selected for its effectiveness in binary classification tasks and its ability to estimate probabilities. |
| Decision Trees | Max depth, Min samples split, Min samples leaf | Chosen for its intuitive and interpretable decision-making process. |
| GBC | Number of estimators, Learning rate, Max depth | Utilized for its ability to build multiple weak models and combine them for improved predictions. |
| AdaBoost Classifier | Number of estimators, Learning rate | Selected for its adaptive boosting approach that focuses on misclassified instances. |
| Naive Bayes | Type of Naive Bayes classifier (e.g., Gaussian, Multinomial) | Chosen for its simplicity and effectiveness when strong independence assumptions between features hold. |
Table 3.
Hyperparameter tuning summary. This table lists the machine learning algorithms, their tuned hyperparameters, and the impact of these hyperparameters on model performance.
Table 3.
Hyperparameter tuning summary. This table lists the machine learning algorithms, their tuned hyperparameters, and the impact of these hyperparameters on model performance.
| Algorithm | Tuned Hyperparameters | Impact on Performance |
|---|
| KNNs | Number of neighbors, Metric (e.g., Euclidean, Manhattan) | Affects the model’s ability to capture local structures in the data. |
| SVM | Kernel type (e.g., linear, RBF), Regularization parameters (C) | Influences the decision boundary’s flexibility and complexity. |
| Random Forest | Number of trees, Max depth of trees, Criterion (e.g., Gini, Entropy) | Impacts accuracy and resistance to overfitting. |
| Neural Networks | Number of layers, Neurons per layer, Activation functions, Learning rate | Enhances the model’s ability to capture complex relationships. |
| Logistic Regression | Regularization strength, Type of regularization (e.g., L1, L2) | Prevents overfitting and improves generalization. |
| Decision Trees | Max depth, Min samples split, Min samples leaf | Balances tree’s complexity and ability to capture patterns. |
| GBC | Number of estimators, Learning rate, Max depth | Improves performance and prevents overfitting. |
| AdaBoost Classifier | Number of estimators, Learning rate | Enhances focus on misclassified instances. |
| Naive Bayes | Type of Naive Bayes classifier (e.g., Gaussian, Multinomial) | Suitability depends on the characteristics of the input data. |
Table 4.
Performance metrics summary. This table lists the performance metrics used to evaluate the predictive models.
Table 4.
Performance metrics summary. This table lists the performance metrics used to evaluate the predictive models.
| Metric | Description |
|---|
| Accuracy | Proportion of correct predictions out of the total number of instances. |
| Precision | Ratio of true positive predictions to the total number of positive predictions. |
| Recall (Sensitivity) | Ratio of true positive predictions to the total number of actual positive instances. |
| F1-Score | Harmonic mean of precision and recall, providing a balanced assessment of the model’s performance. |
| Area Under the Curve (AUC) | Performance measurement for classification problems at various threshold settings. |
Table 5.
Summary of model performance metrics.
Table 5.
Summary of model performance metrics.
| Model | Accuracy | Precision | Recall | F1-Score | AUC-ROC |
|---|
| KNNs | 92.2% | 57% | 65% | 61% | 95.1% |
| Logistic Regression | 78.3% | 27% | 78% | 40% | 85.2% |
| SVM | 90.8% | 50% | 58% | 54% | 93.3% |
| Naive Bayes | 86.2% | 25% | 25% | 25% | 88.6% |
| Decision Trees | 92.4% | 58% | 63% | 60% | 95.3% |
| Random Forest | 92.8% | 91.2% | 90.9% | 91.0% | 96.2% |
| GBC | 92.5% | 60% | 56% | 58% | 95.5% |
| AdaBoost Classifier | 89.1% | 42% | 48% | 45% | 91.9% |
| Neural Networks | 92.6% | 96% | 88% | 92% | 96.2% |
Table 6.
Summary of model strengths, weaknesses, and handling of data sources and class imbalances. This table lists the strengths, weaknesses, handling of different data sources, and handling of class imbalances for each model.
Table 6.
Summary of model strengths, weaknesses, and handling of data sources and class imbalances. This table lists the strengths, weaknesses, handling of different data sources, and handling of class imbalances for each model.
| Algorithm | Strengths | Weaknesses | Handling Different Data Sources | Handling Class Imbalances |
|---|
| Random Forest | High accuracy (92.8%), robust to overfitting | Computationally intensive, less interpretable | Handles various types of variables well | Mitigates class imbalances by sampling with replacement |
| Neural Networks | High precision (96%), models complex non-linear relationships | Requires large data, prone to overfitting | Adaptable to different data sources | Addressed with SMOTE or class weights |
| GBC | High accuracy (92.5%), handles complex data structures | Computationally expensive, sensitive to overfitting | Performs well with diverse datasets | Focuses on harder-to-classify instances |
| Decision Trees | Simple, interpretable | Prone to overfitting | Performs well with clean data | Can handle imbalances, but not as robustly |
| KNNs | Effective for small datasets, simple | Computationally intensive, sensitive to irrelevant features | Effective with clean data | Requires additional techniques |
| SVM | Effective in high-dimensional spaces | Requires careful tuning, inefficient with large datasets | Performs well with structured data | Requires additional techniques |
| AdaBoost | Enhances weak classifiers | Sensitive to noisy data | Performs well with preprocessed data | Focuses on misclassified instances |
| Naive Bayes | Simple, fast | Assumes feature independence | Effective with large, structured data | Requires resampling or class weights |
| Logistic Regression | Interpretable, easy to implement | Limited in capturing complex relationships | Performs adequately with structured data | Requires resampling or class weights |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}