

Code Plagiarism Checking Function and Its Application for Code Writing Problem in Java Programming Learning Assistant System †


Abstract
1. Introduction
2. Literature Review
2.1. Programming Education Learning Tools
2.2. Plagiarism Detection and Assessment Tools
2.3. Discussion and Implications
2.3.1. Comparative Analysis
2.3.2. Theoretical Implications
2.3.3. Practical Implications
3. Previous Works of Code Writing Problem
3.1. Code Writing Problem
- Create the problem statement with specifications for the assignment.
- Make or collect the model source code for the assignment and prepare the input data.
- Run the model source code to obtain the expected output data for the prepared input data.
- Make the test code that has proper test cases using the input and output data, and add messages there to help implement the source code.
- Register the test code and the problem statement as the new assignment.
3.2. JUnit for Unit Testing
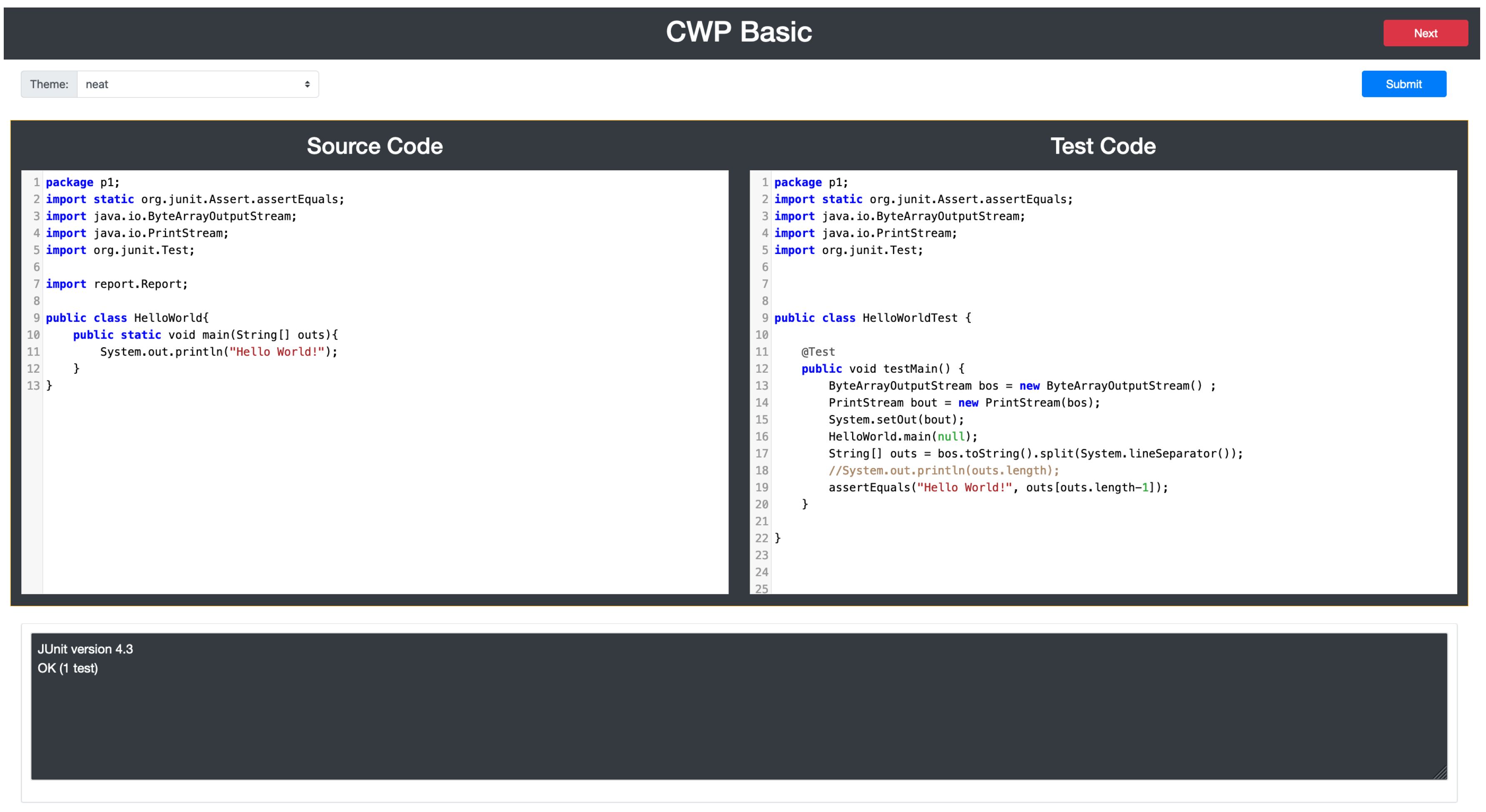
3.3. Example Test Code
| Listing 1. Source Code 1. | |
| 1 | package CWP; |
| 2 | public class BubbleSort { |
| 3 | public static int[] sort(int[] a) { |
| 4 | int n = a.length; |
| 5 | int temp = 0; |
| 6 | for(int i=0; i < n; i++){ |
| 7 | for(int j=1; j < (n-i); j++){ |
| 8 | if(a[j-1] > arr[j]){ |
| 9 | temp = a[j-1]; |
| 10 | a[j-1] = a[j]; |
| 11 | a[j] = temp; |
| 12 | } |
| 13 | } |
| 14 | } |
| 15 | return a; |
| 16 | } |
| 17 | } |
| Listing 2. Test Code 1. | |
| 1 | package CWP; |
| 2 | import static org.junit.Assert.*; |
| 3 | import org.junit.Test; |
| 4 | import java.util.Arrays; |
| 5 | public class BubbleSortTest { |
| 6 | @Test |
| 7 | public void testSort() { |
| 8 | BubbleSort bubbleSort = new BubbleSort(); |
| 9 | int[] codeInput1 = {7,5,0,4,1,3}; |
| 10 | int[] codeOutput = bubbleSort.sort(codeInput1); |
| 11 | int[] expOutput = {0,1,3,4,5,7}; |
| 12 | try { |
| 13 | assertEquals("1:One input case:",Arrays.toString(expOutput)); |
| 14 | } catch (AssertionError ae) { |
| 15 | System.out.println(ae.getMessage()); |
| 16 | } |
| 17 | } |
| 18 | } |
- Generate the bubbleSort object of the BubbleSort class in the source code.
- Call the sort method of the bubbleSort object with the arguments for the input data.
- Compare the output codeOutput of the sort method with the expected one expOutput using the assertEquals method.
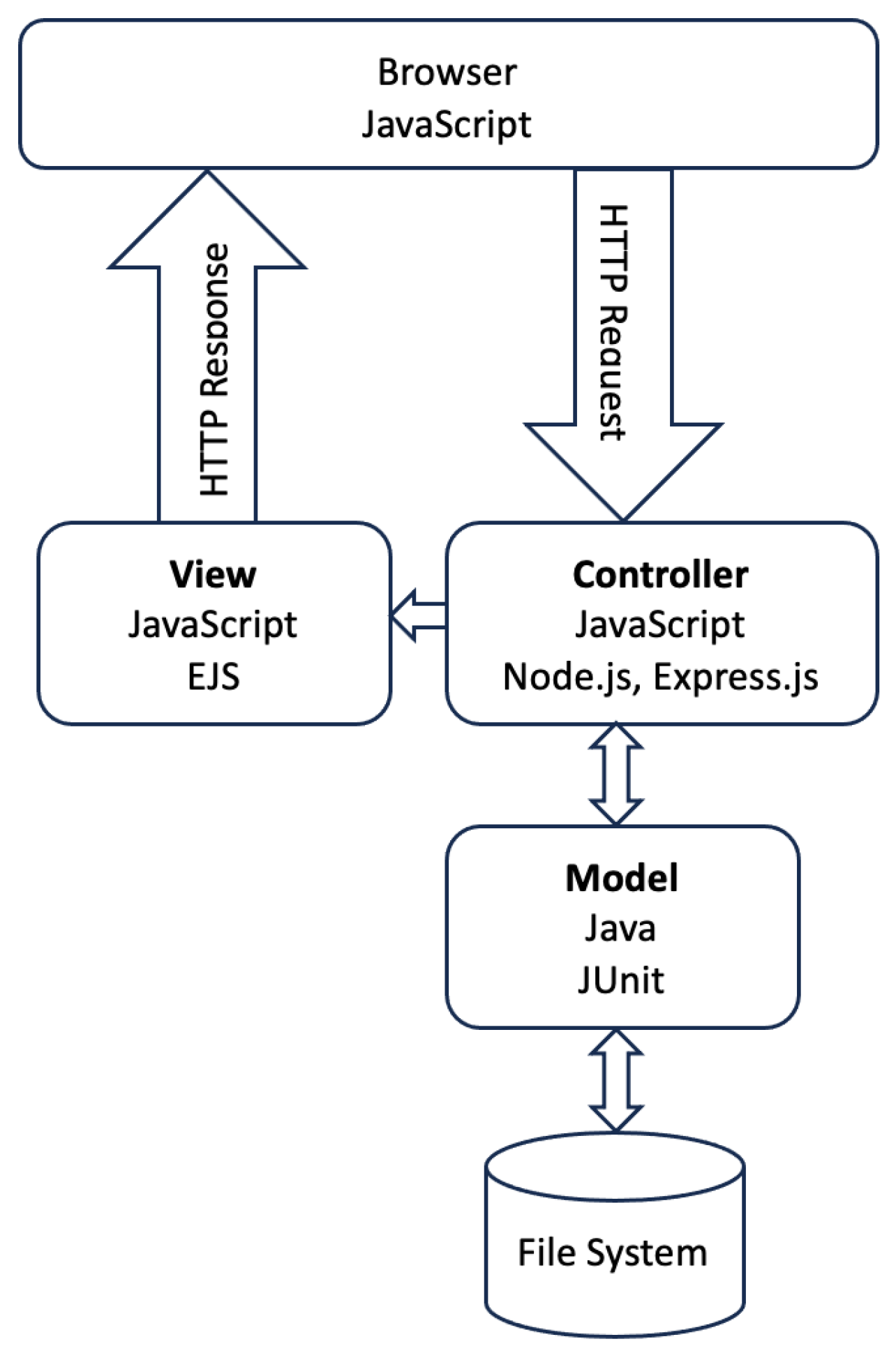
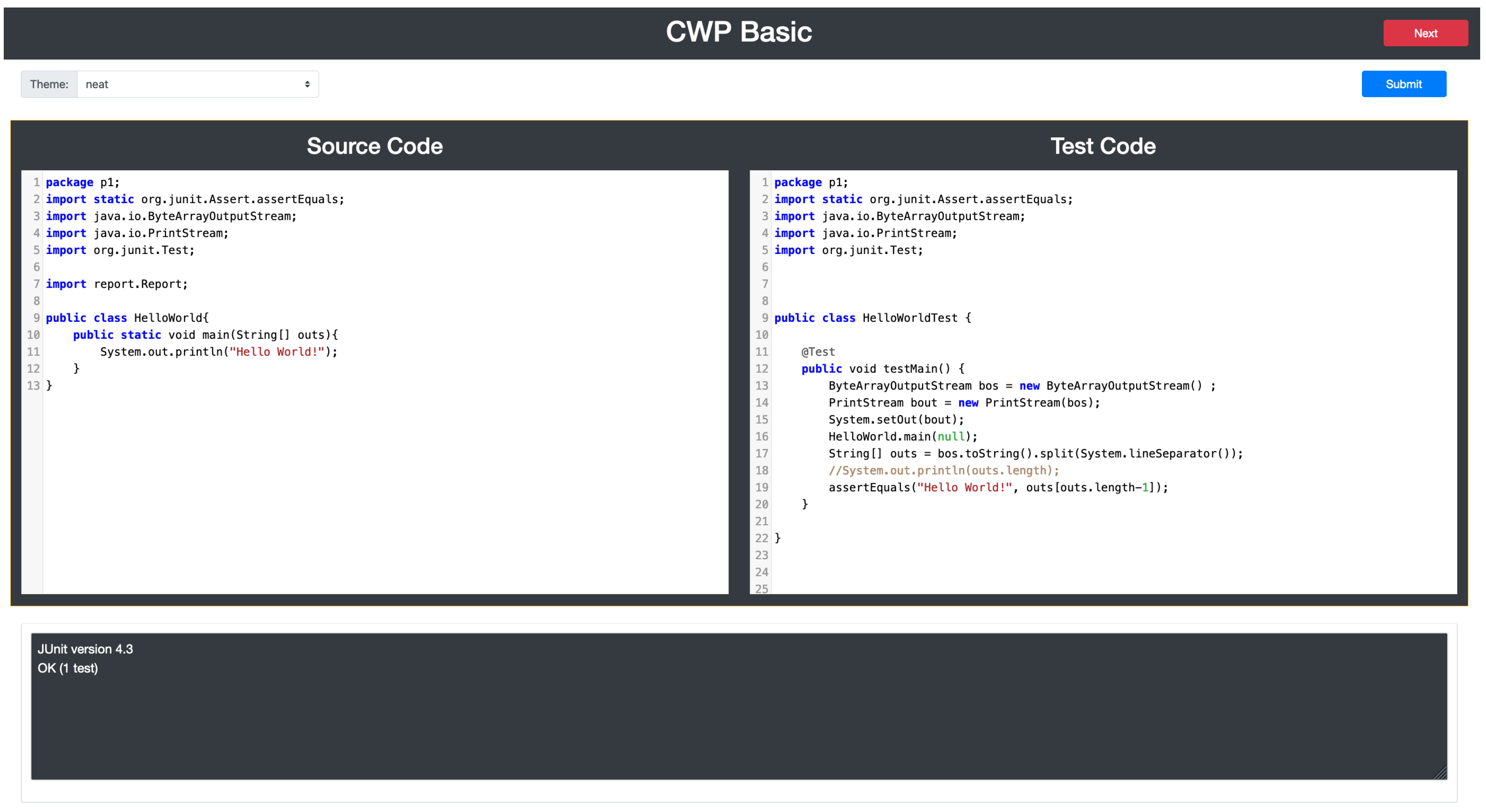
3.4. CWP Answer Platform for Students
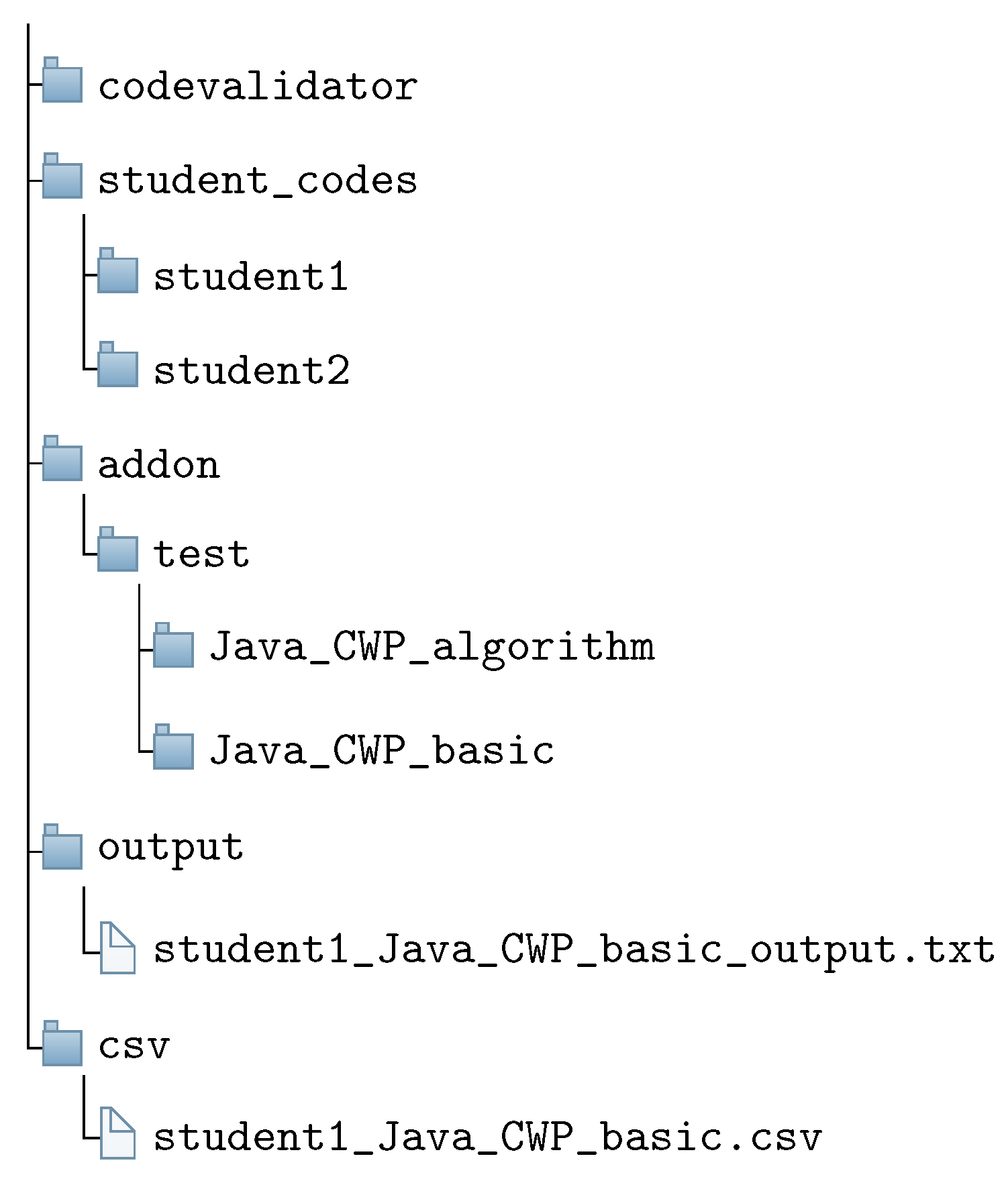
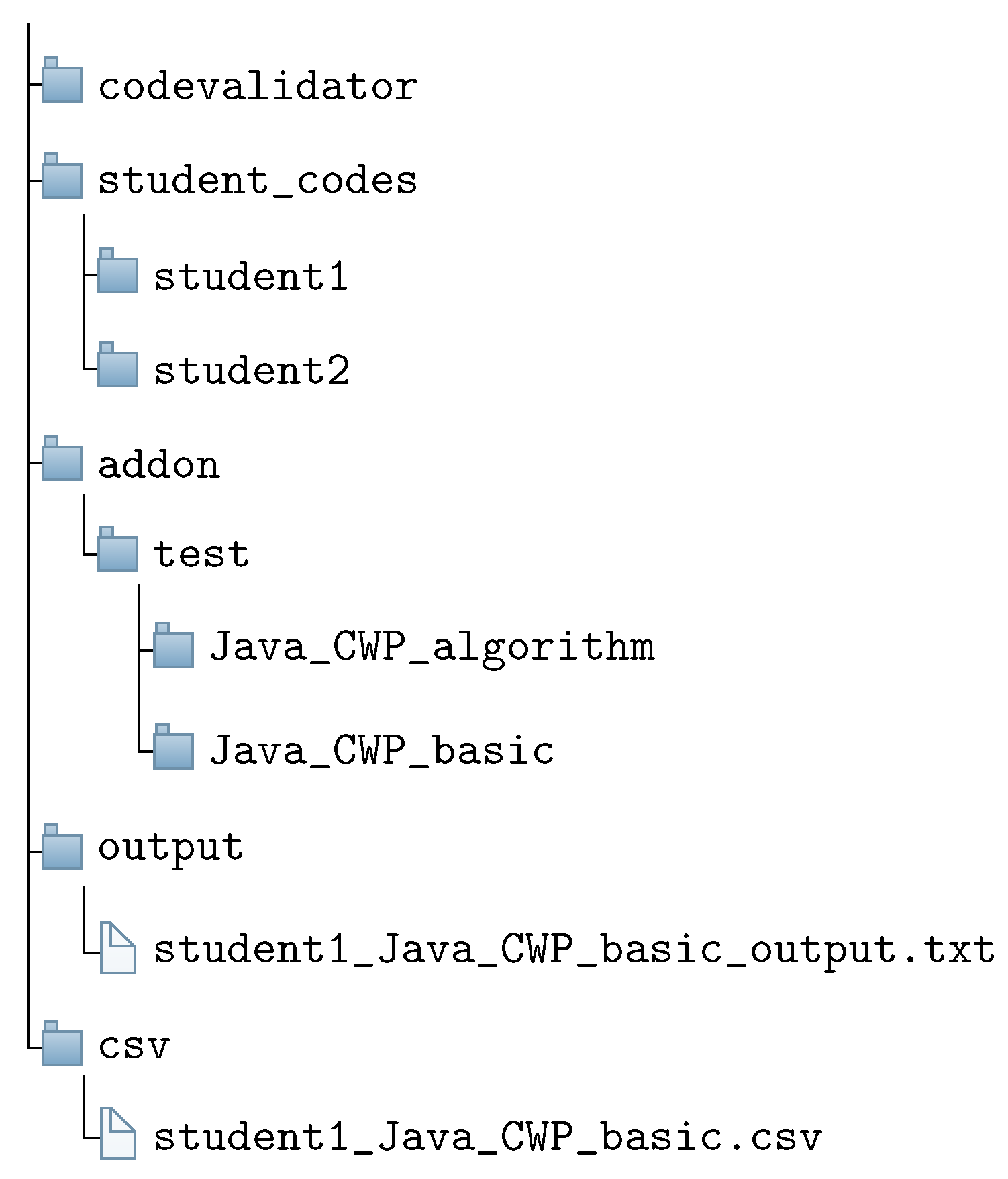
3.5. Answer Code Validation Program for Teachers
- Download the zip file containing the source codes for each assignment using one test code. It is noted that a teacher usually uses an e-learning system such as Moodle in the programming course.
- Unzip the zip file and store the source code files in the appropriate folder under the “student_codes” folder within the project path.
- Store the corresponding test code in the “addon/test” folder within the project directory.
- Read each source code in the “student_codes” folder, run the test code with the source code on JUnit, and save the test result in the text file within the “output” folder. This process is repeated until all the source codes in the folder are tested.
4. Code Plagiarism Checking Function
4.1. Levenshtein Distance
4.2. Procedure of Code Plagiarism Checking Function
- Import the necessary Python libraries to calculate the Levenshtein distance, CSV output, and regular expressions.
- Read the two files for source codes, and remove the whitespace characters such as spaces and tabs and the comment lines using the regular expression to make one string.
- Calculate the Levenshtein distance using the editops function.
- Compute the similarity score from the Levenshtein distance.
- Repeat Steps 2–4 for all the source codes in the folder.
- Sort the pairs in descending order of similarity scores using the sorted function and output the results in the CSV file.
4.3. Example Result
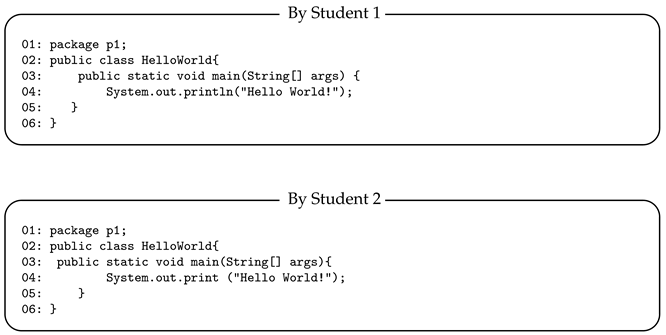 |
4.4. Computational Complexity Analysis of Code Plagiarism Checking Function
5. Analysis of Application Results
5.1. CWP Assignments
5.2. Analysis Results of Individual Assignments
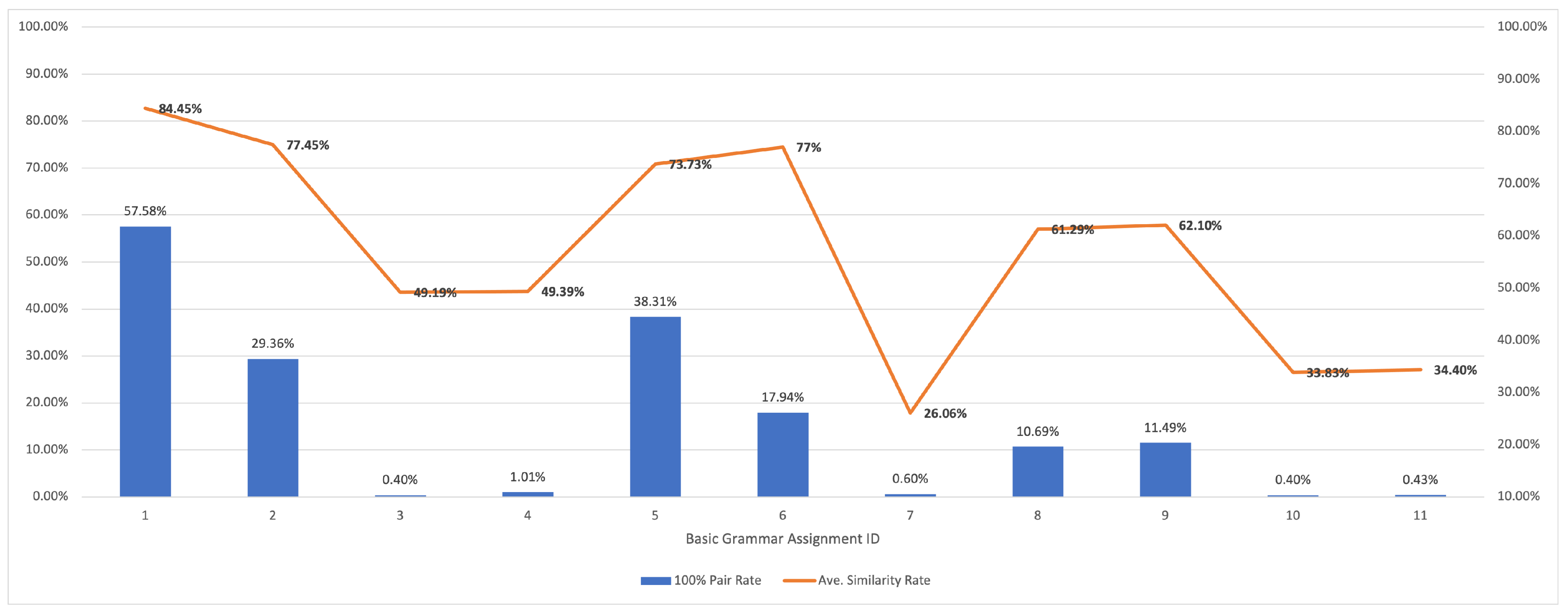
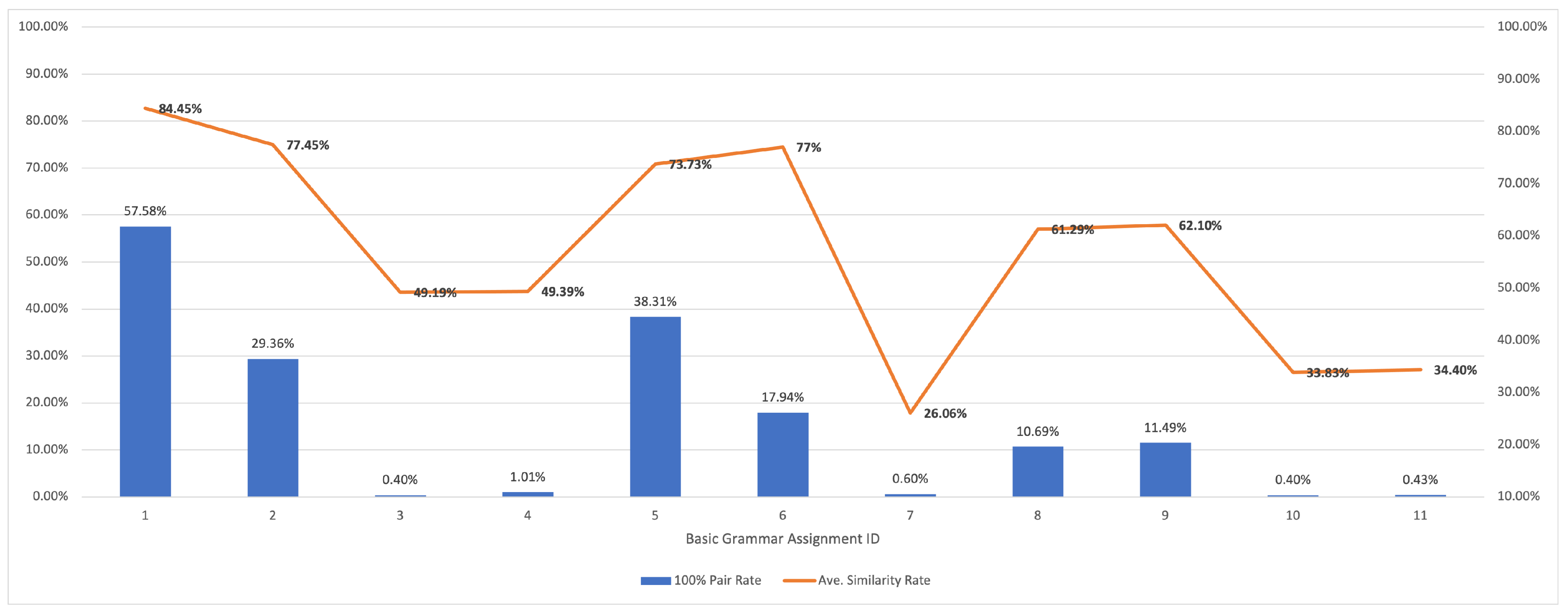
5.2.1. Results for Basic Grammar
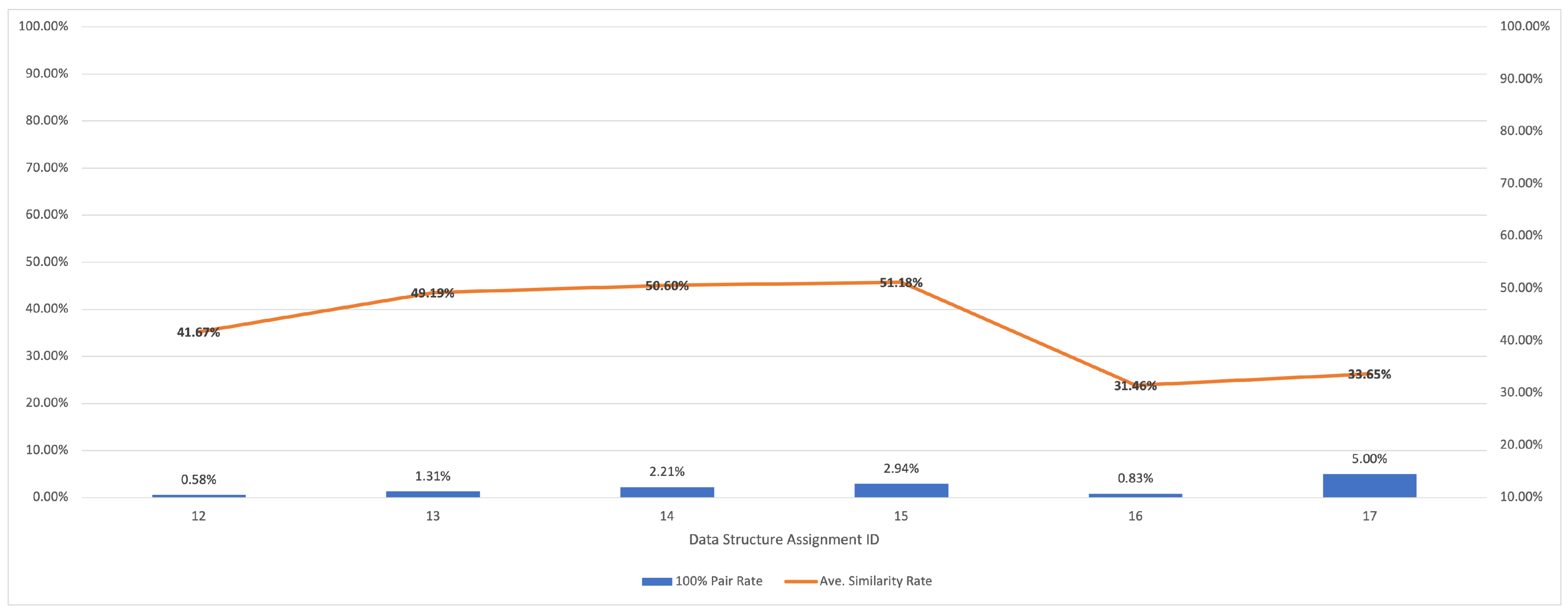
5.2.2. Results for Data Structure
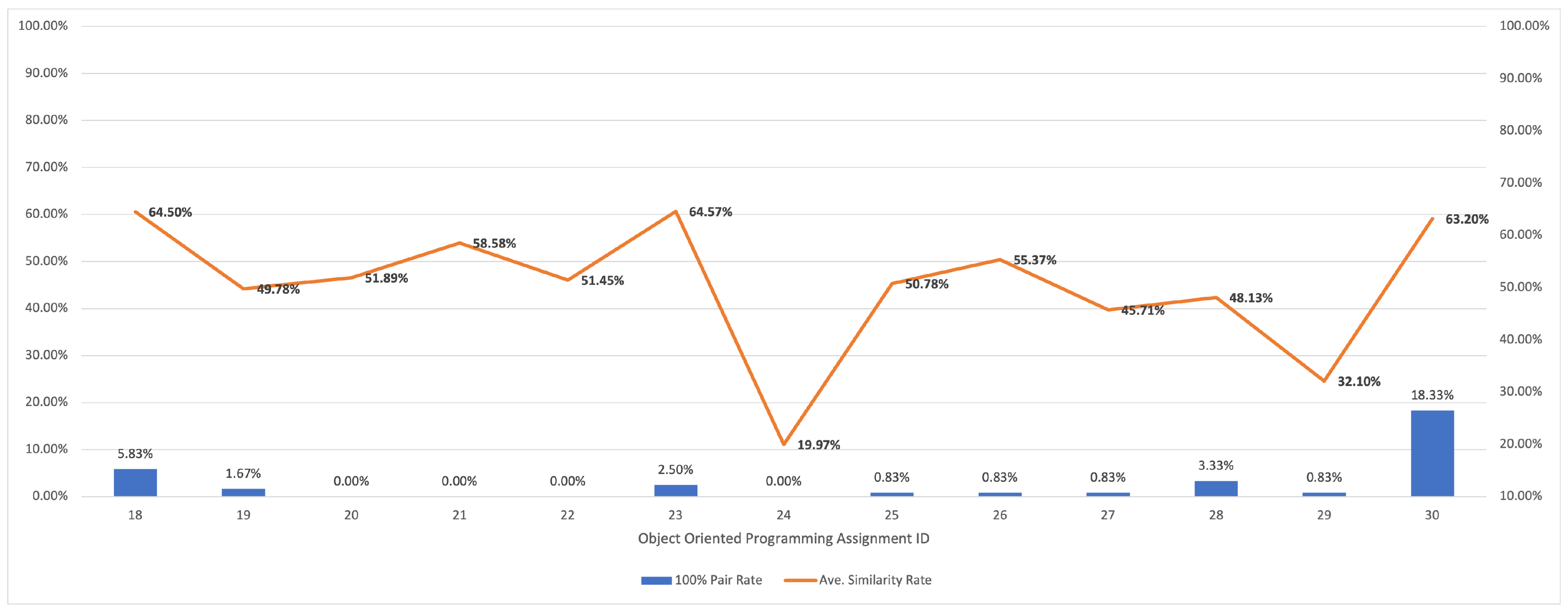
5.2.3. Results for Object-Oriented Programming
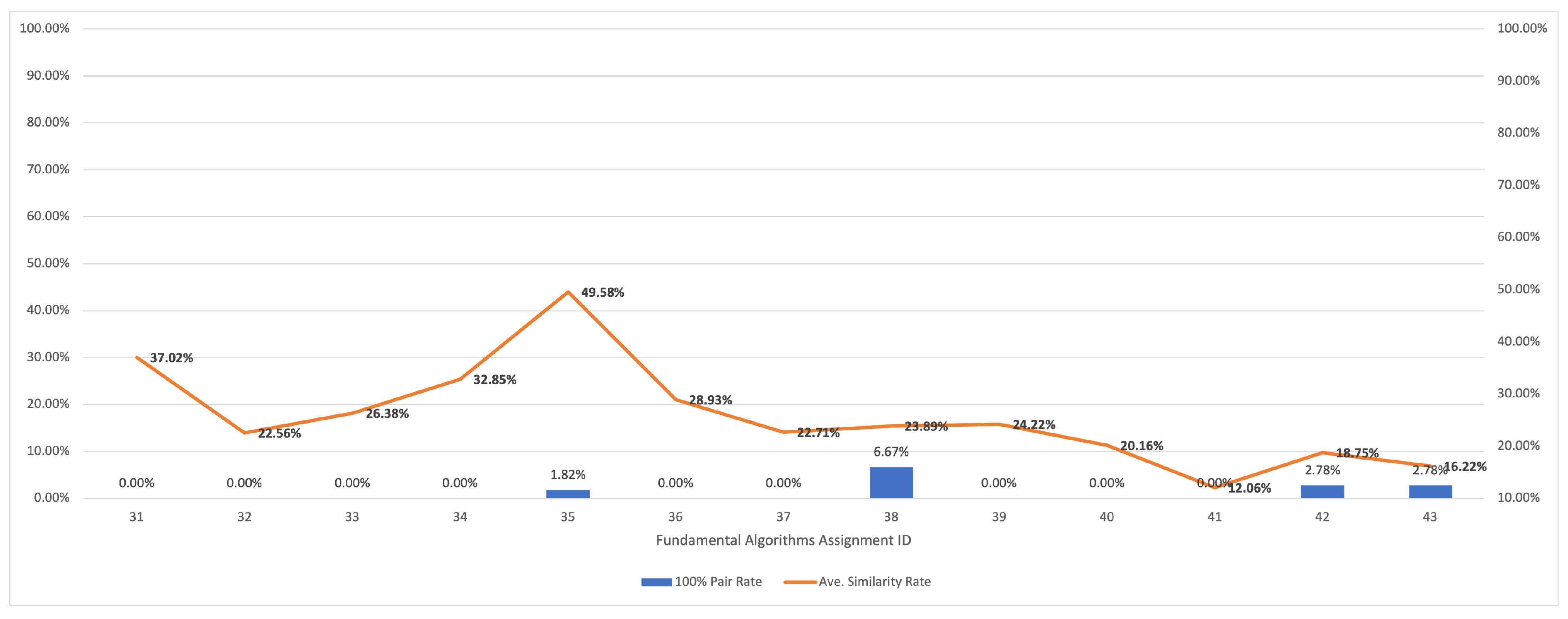
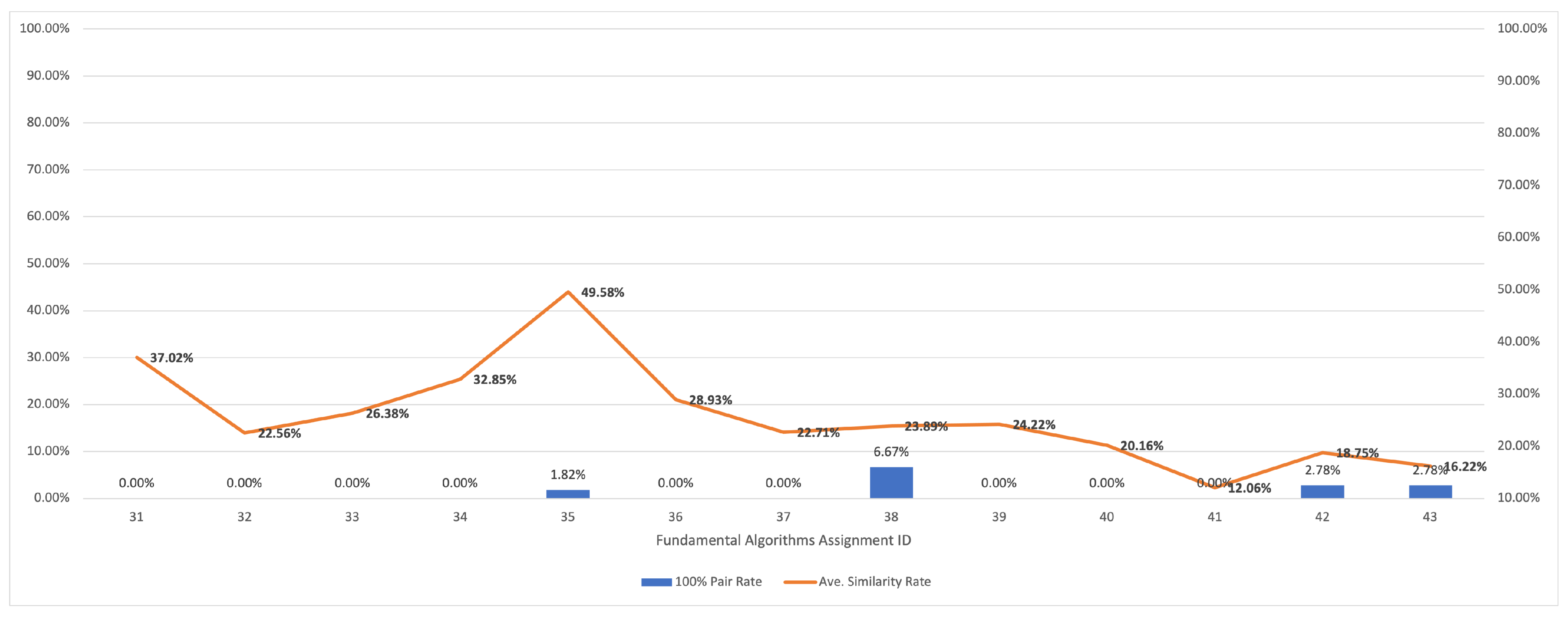
5.2.4. Results for Fundamental Algorithms
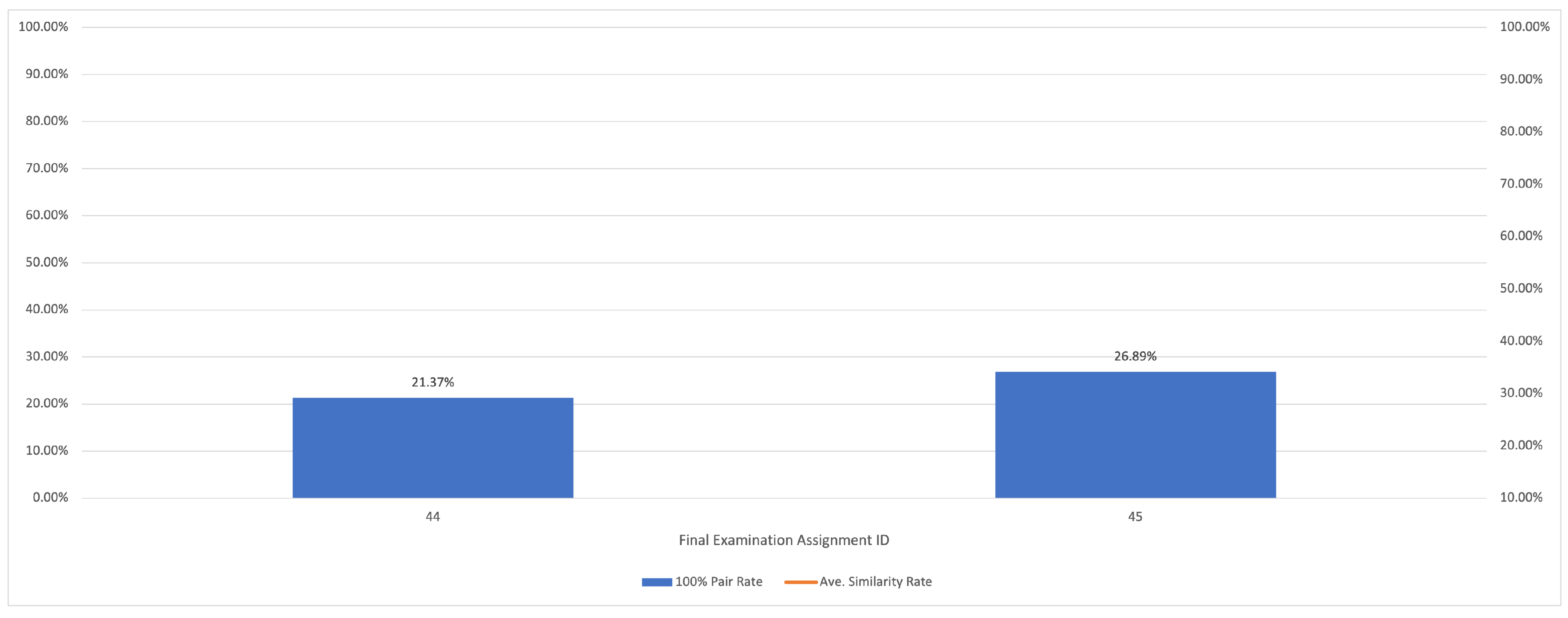
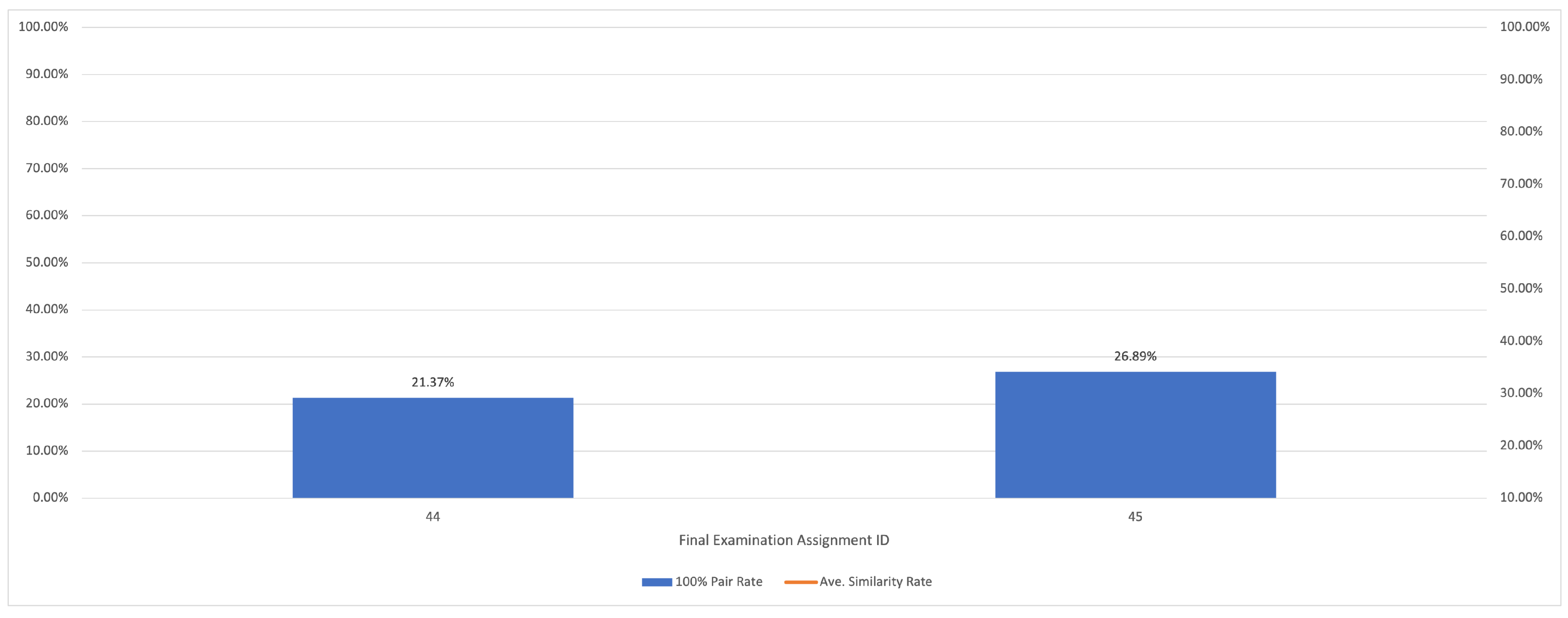
5.2.5. Results for Final Examination
5.3. Analysis Results of Assignment Group
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Aung, S.T.; Funabiki, N.; Aung, L.H.; Htet, H.; Kyaw, H.H.S.; Sugawara, S. An implementation of Java programming learning assistant system platform using Node.js. In Proceedings of the International Conference on Information and Education Technology, Matsue, Japan, 9–11 April 2022; pp. 47–52. [Google Scholar]
- Node.js. Available online: https://nodejs.org/en (accessed on 4 November 2023).
- Docker. Available online: https://www.docker.com/ (accessed on 4 November 2023).
- Wai, K.H.; Funabiki, N.; Aung, S.T.; Mon, K.T.; Kyaw, H.H.S.; Kao, W.-C. An implementation of answer code validation program for code writing problem in java programming learning assistant system. In Proceedings of the International Conference on Information and Education Technology, Fujisawa, Japan, 18–20 March 2023; pp. 193–198. [Google Scholar]
- Ala-Mutka, K. Problems in Learning and Teaching Programming. A Literature Study for Developing Visualizations in the Codewitz-Minerva Project; Tampere University of Technology: Tampere, Finland, 2004; pp. 1–13. [Google Scholar]
- Konecki, M. Problems in programming education and means of their improvement. In DAAAM International Scientific Book; DAAAM International: Vianna, Austria, 2014; pp. 459–470. [Google Scholar]
- Queiros, R.A.; Peixoto, L.; Paulo, J. PETCHA—A programming exercises teaching assistant. In Proceedings of the ACM Annual Conference on Innovation and Technology in Computer Science Education, Haifa, Israel, 3–5 July 2012; pp. 192–197. [Google Scholar]
- Li, F.W.-B.; Watson, C. Game-based concept visualization for learning programming. In Proceedings of the ACM Workshop on Multimedia Technologies for Distance Learning, Scottsdale, AZ, USA, 1 December 2011; pp. 37–42. [Google Scholar]
- Ünal, E.; Çakir, H. Students’ views about the problem based collaborative learning environment supported by dynamic web technologies. Malays. Online J. Edu. Tech. 2017, 5, 1–19. [Google Scholar]
- Zinovieva, I.S.; Artemchuk, V.O.; Iatsyshyn, A.V.; Popov, O.O.; Kovach, V.O.; Iatsyshyn, A.V.; Romanenko, Y.O.; Radchenko, O.V. The use of online coding platforms as additional distance tools in programming education. J. Phys. Conf. Ser. 2021, 1840, 012029. [Google Scholar] [CrossRef]
- Denny, P.; Luxton-Reilly, A.; Tempero, E.; Hendrickx, J. CodeWrite: Supporting student-driven practice of Java. In Proceedings of the ACM Technical Symposium on Computer Science Education, Dallas, TX, USA, 9–12 March 2011; pp. 471–476. [Google Scholar]
- Shamsi, F.A.; Elnagar, A. An intelligent assessment tool for student’s Java submission in introductory programming courses. J. Intelli. Learn. Syst. Appl. 2012, 4, 59–69. [Google Scholar]
- Edwards, S.H.; Pérez-Quiñones, M.A. Experiences using test-driven development with an automated grader. J. Comput. Sci. Coll. 2007, 22, 44–50. [Google Scholar]
- Tung, S.H.; Lin, T.T.; Lin, Y.H. An exercise management system for teaching programming. J. Softw. 2013, 8, 1718–1725. [Google Scholar] [CrossRef]
- Rani, S.; Singh, J. Enhancing Levenshtein’s edit distance algorithm for evaluating document similarity. In Proceedings of the International Conference on Computing, Analytics and Networks, Singapore, 27–28 October 2018; pp. 72–80. [Google Scholar]
- Ihantola, P.; Ahoniemi, T.; Karavirta, V.; Seppälä, O. Review of recent systems for automatic assessment of programming assignments. In Proceedings of the 10th Koli Calling International Conference on Computing Education Research, New York, NY, USA, 28 October 2010; pp. 86–93. [Google Scholar]
- Duric, Z.; Gasevic, D. A source code similarity system for plagiarism detection. Comput. J. 2013, 56, 70–86. [Google Scholar] [CrossRef]
- Ahadi, A.; Mathieson, L. A comparison of three popular source code similarity detecting student plagiarism. In Proceedings of the Twenty-First Australasian Computing Education Conference, Sydney, Australia, 29–31 January 2019; pp. 112–117. [Google Scholar]
- Novak, M.; Joy, M.; Keremek, D. Source-code similarity detection and detection tools used in academia: A systematic review. ACM Trans. Comp. Educ. 2019, 19, 1–37. [Google Scholar] [CrossRef]
- Karnalim, S.O.; Sheard, J.; Dema, I.; Karkare, A.; Leinonen, J.; Liut, M.; McCauley, R. Choosing code segments to exclude from code similarity detection. In Proceedings of the Working Group Reports on Innovation and Technology in Computer Science Education, Trondheim, Norway, 17–18 June 2020; pp. 1–19. [Google Scholar]
- Kustanto, C.; Liem, I. Automatic source code plagiarism detection. In Proceedings of the 10th ACIS International Conference on Software Engineering, Artificial Intelligences, Networking and Parallel/Distributed Computing, Daegu, Republic of Korea, 27–29 May 2009; pp. 481–486. [Google Scholar]
- JUnit. Available online: https://en.wikipedia.org/wiki/JUnit (accessed on 4 November 2023).
- Bubble Sort. Available online: https://en.wikipedia.org/wiki/Bubble_sort (accessed on 4 November 2023).
- Levenshtein Distance. Available online: https://en.wikipedia.org/wiki/Levenshtein_distance (accessed on 4 November 2023).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Group Topic | ID | Assignment Title | Number of Students | LOC | CPU Time (s) |
|---|---|---|---|---|---|
| basic grammar | 1 | helloworld | 33 | 6 | 1.13 |
| 2 | messagedisplay | 33 | 8 | 0.27 | |
| 3 | codecorrection1 | 32 | 11 | 0.23 | |
| 4 | codecorrection2 | 32 | 12 | 0.25 | |
| 5 | ifandswitch | 32 | 27 | 0.25 | |
| 6 | escapeusage | 32 | 6 | 0.23 | |
| 7 | returnandbreak | 32 | 18 | 0.25 | |
| 8 | octalnumber | 32 | 8 | 0.23 | |
| 9 | hexadecimal | 32 | 9 | 1.38 | |
| 10 | maxitem | 32 | 11 | 1.02 | |
| 11 | minitem | 31 | 11 | 1.05 | |
| data structure | 12 | arraylistimport | 19 | 35 | 0.20 |
| 13 | linkedlistdemo | 18 | 28 | 0.19 | |
| 14 | hashmapdemo | 17 | 26 | 0.22 | |
| 15 | treesetdemo | 17 | 32 | 0.11 | |
| 16 | que | 16 | 17 | 0.06 | |
| 17 | stack | 16 | 17 | 0.06 | |
| object-oriented programming | 18 | animal | 16 | 18 | 0.06 |
| 19 | animal1 | 16 | 20 | 0.08 | |
| 20 | animalinterfaceusage | 16 | 29 | 0.41 | |
| 21 | author | 16 | 34 | 0.13 | |
| 22 | book | 16 | 43 | 0.55 | |
| 23 | book1 | 16 | 24 | 0.08 | |
| 24 | bookdata | 16 | 40 | 0.11 | |
| 25 | car | 16 | 21 | 0.09 | |
| 26 | circle | 16 | 22 | 0.09 | |
| 27 | gameplayer | 16 | 13 | 0.27 | |
| 28 | methodoverloading | 16 | 13 | 0.31 | |
| 29 | physicsteacher | 16 | 25 | 0.08 | |
| 30 | student | 16 | 17 | 0.27 | |
| fundamental algorithms | 31 | binarysearch | 12 | 12 | 0.16 |
| 32 | binsort | 11 | 20 | 0.19 | |
| 33 | bubblesort | 11 | 21 | 0.22 | |
| 34 | bubblesort1 | 11 | 16 | 0.17 | |
| 35 | divide | 11 | 8 | 0.09 | |
| 36 | GCD | 11 | 19 | 0.13 | |
| 37 | LCM | 11 | 18 | 0.16 | |
| 38 | heapsort | 10 | 38 | 0.14 | |
| 39 | insertionsort | 10 | 23 | 0.16 | |
| 40 | shellsort | 10 | 28 | 0.19 | |
| 41 | quicksort1 | 9 | 38 | 0.28 | |
| 42 | quicksort2 | 9 | 25 | 0.11 | |
| 43 | quicksort3 | 9 | 30 | 0.13 | |
| final examination | 44 | makearray | 39 | 25 | 0.34 |
| 45 | primenumber | 39 | 20 | 0.27 |
| Number of Assignments with Identical Codes | Number of Student Pairs |
|---|---|
| 11 | 1 |
| 10 | 1 |
| 6 | 3 |
| 5 | 8 |
| 4 | 31 |
| 3 | 71 |
| 2 | 132 |
| 1 | 182 |
| Number of Assignment with Identical Codes | Number of Student Pairs |
|---|---|
| 5 | 1 |
| 4 | 1 |
| 1 | 8 |
| Group Topic | Number of Source Codes | Number of Assignments | Ave. Similarity Score | 100% Pair Rate | CPU Time (s) |
|---|---|---|---|---|---|
| basic grammar | 353 | 11 | 57.17 | 15.29 | 6.29 |
| data structure | 103 | 6 | 42.96 | 2.15 | 0.84 |
| object-oriented | 208 | 13 | 50.46 | 2.69 | 2.53 |
| programming | |||||
| fundamental | 135 | 13 | 25.79 | 1.08 | 2.13 |
| algorithms | |||||
| final exam | 78 | 2 | 24.13 | 0.00 | 0.61 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Htet, E.E.; Wai, K.H.; Aung, S.T.; Funabiki, N.; Lu, X.; Kyaw, H.H.S.; Kao, W.-C. Code Plagiarism Checking Function and Its Application for Code Writing Problem in Java Programming Learning Assistant System. Analytics 2024, 3, 46-62. https://doi.org/10.3390/analytics3010004
Htet EE, Wai KH, Aung ST, Funabiki N, Lu X, Kyaw HHS, Kao W-C. Code Plagiarism Checking Function and Its Application for Code Writing Problem in Java Programming Learning Assistant System. Analytics. 2024; 3(1):46-62. https://doi.org/10.3390/analytics3010004
Chicago/Turabian StyleHtet, Ei Ei, Khaing Hsu Wai, Soe Thandar Aung, Nobuo Funabiki, Xiqin Lu, Htoo Htoo Sandi Kyaw, and Wen-Chung Kao. 2024. "Code Plagiarism Checking Function and Its Application for Code Writing Problem in Java Programming Learning Assistant System" Analytics 3, no. 1: 46-62. https://doi.org/10.3390/analytics3010004
APA StyleHtet, E. E., Wai, K. H., Aung, S. T., Funabiki, N., Lu, X., Kyaw, H. H. S., & Kao, W.-C. (2024). Code Plagiarism Checking Function and Its Application for Code Writing Problem in Java Programming Learning Assistant System. Analytics, 3(1), 46-62. https://doi.org/10.3390/analytics3010004