
Learning Analytics in the Era of Large Language Models




{kind=link}
Abstract
:1. Introduction
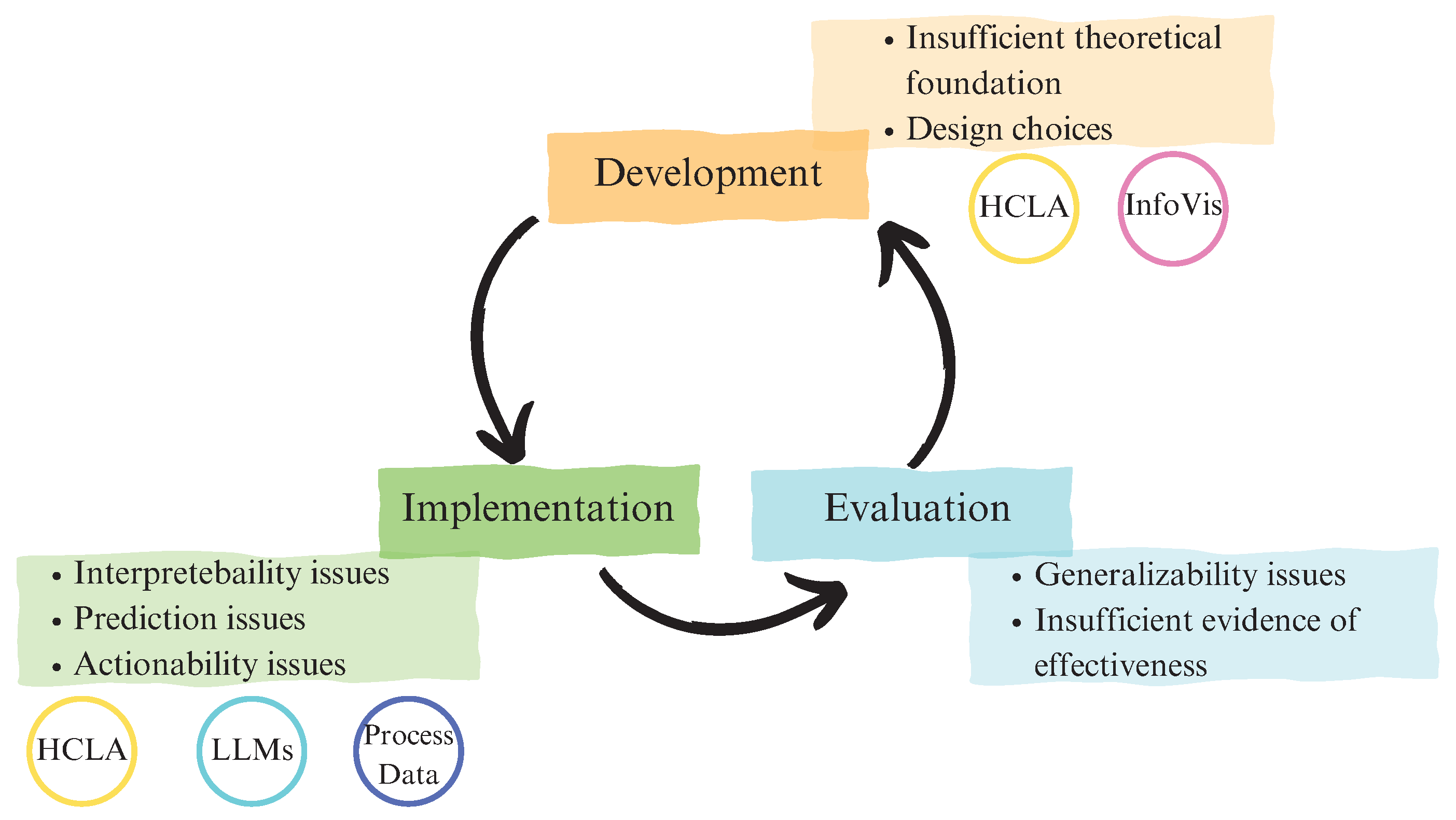
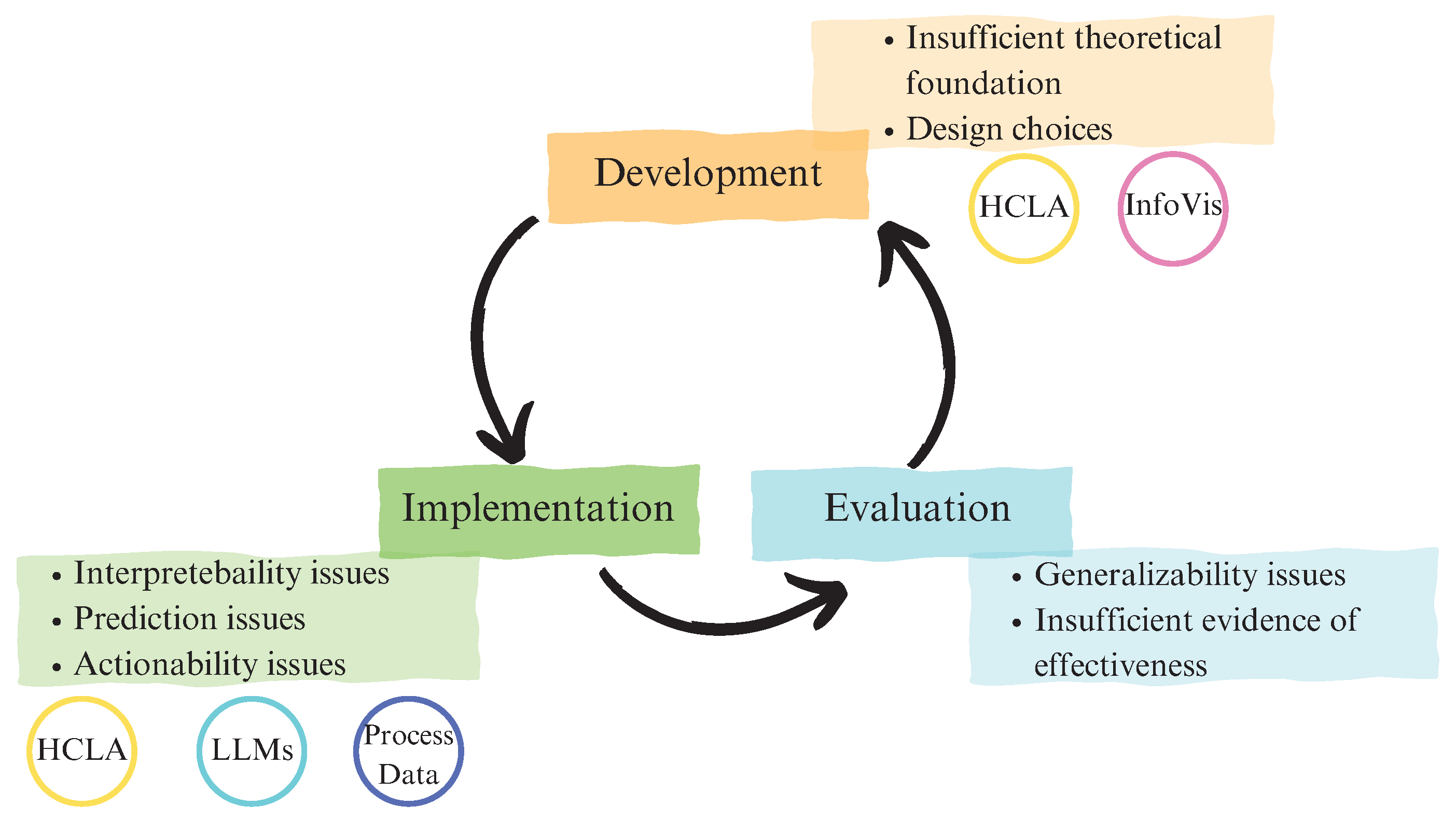
2. LA: Limitations and Ongoing Challenges
2.1. Descriptive, Predictive, and Prescriptive LA
2.2. Insufficient Grounding in Learning Sciences
2.3. Interpretability Challenges
2.4. Prediction Issues
2.5. Beyond Prediction: Actionability Issue for Automatically Generated Feedback
2.6. Generalizability Issue
2.7. Insufficient Evidence of Effectiveness
2.8. Insufficient Teacher Involvement
3. Moving Forward in LA
3.1. Involving Teachers as Co-Designers in LA
3.2. Using Natural Language to Increase Interpretability
3.3. Using Process Data to Increase Interpretability
3.4. Using Language Models to Increase Personalization
3.5. Using Language Models to Support Teachers
4. Discussion
Limitations and Directions for Future Research
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Society for Learning Analytics Research [SoLAR]. What Is Learning Analytics? 2021. Available online: https://www.solaresearch.org/about/what-is-learning-analytics/ (accessed on 31 May 2023).
- Siemens, G. Learning analytics: Envisioning a research discipline and a domain of practice. In Proceedings of the 2nd International Conference on Learning Analytics and Knowledge, Vancouver, BC, Canada, 29 April–2 May 2012; LAK ’12. pp. 4–8. [Google Scholar] [CrossRef]
- Lee, L.K.; Cheung, S.K.S.; Kwok, L.F. Learning analytics: Current trends and innovative practices. J. Comput. Educ. 2020, 7, 1–6. [Google Scholar] [CrossRef]
- El Alfy, S.; Marx Gómez, J.; Dani, A. Exploring the benefits and challenges of learning analytics in higher education institutions: A systematic literature review. Inf. Discov. Deliv. 2019, 47, 25–34. [Google Scholar] [CrossRef]
- Banihashem, S.K.; Aliabadi, K.; Pourroostaei Ardakani, S.; Delaver, A.; Nili Ahmadabadi, M. Learning Analytics: A Systematic Literature Review. Interdiscip. J. Virtual Learn. Med. Sci. 2018, 9. [Google Scholar] [CrossRef]
- Avella, J.T.; Kebritchi, M.; Nunn, S.G.; Kanai, T. Learning Analytics Methods, Benefits, and Challenges in Higher Education: A Systematic Literature Review. Online Learn. 2016, 20, 13–29. [Google Scholar]
- Matcha, W.; Uzir, N.A.; Gašević, D.; Pardo, A. A Systematic Review of Empirical Studies on Learning Analytics Dashboards: A Self-Regulated Learning Perspective. IEEE Trans. Learn. Technol. 2020, 13, 226–245. [Google Scholar] [CrossRef]
- Wang, Q.; Mousavi, A.; Lu, C. A scoping review of empirical studies on theory-driven learning analytics. Distance Educ. 2022, 43, 6–29. [Google Scholar] [CrossRef]
- Alhadad, S.S.J. Visualizing Data to Support Judgement, Inference, and Decision Making in Learning Analytics: Insights from Cognitive Psychology and Visualization Science. J. Learn. Anal. 2018, 5, 60–85. [Google Scholar] [CrossRef]
- Wong, B.T.M.; Li, K.C. A review of learning analytics intervention in higher education (2011–2018). J. Comput. Educ. 2020, 7, 7–28. [Google Scholar] [CrossRef]
- Bodily, R.; Ikahihifo, T.K.; Mackley, B.; Graham, C.R. The design, development, and implementation of student-facing learning analytics dashboards. J. Comput. High. Educ. 2018, 30, 572–598. [Google Scholar] [CrossRef]
- Jivet, I.; Scheffel, M.; Specht, M.; Drachsler, H. License to evaluate: Preparing learning analytics dashboards for educational practice. In Proceedings of the 8th International Conference on Learning Analytics and Knowledge, Sydney, NSW, Australia, 7–9 March 2018; pp. 31–40. [Google Scholar] [CrossRef]
- Buckingham Shum, S.; Ferguson, R.; Martinez-Maldonado, R. Human-Centred Learning Analytics. J. Learn. Anal. 2019, 6, 1–9. [Google Scholar] [CrossRef]
- UNESCO. Section 2: Preparing learners to thrive in the future with AI. In Artificial Intelligence in Education: Challenges and Opportunities for Sustainable Development; Working Papers on Education Policy; The United Nations Educational, Scientific and Cultural Organization: Paris, France, 2019; pp. 17–24. [Google Scholar]
- Schwendimann, B.A.; Rodríguez-Triana, M.J.; Vozniuk, A.; Prieto, L.P.; Boroujeni, M.S.; Holzer, A.; Gillet, D.; Dillenbourg, P. Perceiving Learning at a Glance: A Systematic Literature Review of Learning Dashboard Research. IEEE Trans. Learn. Technol. 2017, 10, 30–41. [Google Scholar] [CrossRef]
- Sedrakyan, G.; Malmberg, J.; Verbert, K.; Järvelä, S.; Kirschner, P.A. Linking learning behavior analytics and learning science concepts: Designing a learning analytics dashboard for feedback to support learning regulation. Comput. Hum. Behav. 2020, 107, 105512. [Google Scholar] [CrossRef]
- Rets, I.; Herodotou, C.; Bayer, V.; Hlosta, M.; Rienties, B. Exploring critical factors of the perceived usefulness of a learning analytics dashboard for distance university students. Int. J. Educ. Technol. High. Educ. 2021, 18, 46. [Google Scholar] [CrossRef] [PubMed]
- Susnjak, T.; Ramaswami, G.S.; Mathrani, A. Learning analytics dashboard: A tool for providing actionable insights to learners. Int. J. Educ. Technol. High. Educ. 2022, 19, 12. [Google Scholar] [CrossRef]
- Valle, N.; Antonenko, P.; Valle, D.; Sommer, M.; Huggins-Manley, A.C.; Dawson, K.; Kim, D.; Baiser, B. Predict or describe? How learning analytics dashboard design influences motivation and statistics anxiety in an online statistics course. Educ. Technol. Res. Dev. 2021, 69, 1405–1431. [Google Scholar] [CrossRef]
- Iraj, H.; Fudge, A.; Khan, H.; Faulkner, M.; Pardo, A.; Kovanović, V. Narrowing the Feedback Gap: Examining Student Engagement with Personalized and Actionable Feedback Messages. J. Learn. Anal. 2021, 8, 101–116. [Google Scholar] [CrossRef]
- Wagner, E.; Ice, P. Data changes everything: Delivering on the promise of learning analytics in higher education. Educ. Rev. 2012, 47, 32. [Google Scholar]
- Algayres, M.G.; Triantafyllou, E. Learning Analytics in Flipped Classrooms: A Scoping Review. Electron. J. E-Learn. 2020, 18, 397–409. [Google Scholar] [CrossRef]
- Wise, A.F.; Shaffer, D.W. Why Theory Matters More than Ever in the Age of Big Data. J. Learn. Anal. 2015, 2, 5–13. [Google Scholar] [CrossRef]
- You, J.W. Identifying significant indicators using LMS data to predict course achievement in online learning. Internet High. Educ. 2016, 29, 23–30. [Google Scholar] [CrossRef]
- Caspari-Sadeghi, S. Applying Learning Analytics in Online Environments: Measuring Learners’ Engagement Unobtrusively. Front. Educ. 2022, 7, 840947. [Google Scholar] [CrossRef]
- Few, S. Dashboard Design: Taking a Metaphor Too Far. DM Rev. 2005, 15, 18. [Google Scholar]
- McKenney, S.; Mor, Y. Supporting teachers in data-informed educational design. Br. J. Educ. Technol. 2015, 46, 265–279. [Google Scholar] [CrossRef]
- van Leeuwen, A. Teachers’ perceptions of the usability of learning analytics reports in a flipped university course: When and how does information become actionable knowledge? Educ. Technol. Res. Dev. 2019, 67, 1043–1064. [Google Scholar] [CrossRef]
- Davis, F.D.; Bagozzi, R.P.; Warshaw, P.R. User Acceptance of Computer Technology: A Comparison of Two Theoretical Models. Manag. Sci. 1989, 35, 982–1003. [Google Scholar] [CrossRef]
- van Leeuwen, A.; Janssen, J.; Erkens, G.; Brekelmans, M. Supporting teachers in guiding collaborating students: Effects of learning analytics in CSCL. Comput. Educ. 2014, 79, 28–39. [Google Scholar] [CrossRef]
- van Leeuwen, A.; Janssen, J.; Erkens, G.; Brekelmans, M. Teacher regulation of cognitive activities during student collaboration: Effects of learning analytics. Comput. Educ. 2015, 90, 80–94. [Google Scholar] [CrossRef]
- Ramaswami, G.; Susnjak, T.; Mathrani, A.; Umer, R. Use of Predictive Analytics within Learning Analytics Dashboards: A Review of Case Studies. Technol. Knowl. Learn. 2022, 28, 959–980. [Google Scholar] [CrossRef]
- Liu, R.; Koedinger, K.R. Closing the Loop: Automated Data-Driven Cognitive Model Discoveries Lead to Improved Instruction and Learning Gains. J. Educ. Data Min. 2017, 9, 25–41. [Google Scholar] [CrossRef]
- Bañeres, D.; Rodríguez, M.E.; Guerrero-Roldán, A.E.; Karadeniz, A. An Early Warning System to Detect At-Risk Students in Online Higher Education. Appl. Sci. 2020, 10, 4427. [Google Scholar] [CrossRef]
- Namoun, A.; Alshanqiti, A. Predicting Student Performance Using Data Mining and Learning Analytics Techniques: A Systematic Literature Review. Appl. Sci. 2021, 11, 237. [Google Scholar] [CrossRef]
- Jayaprakash, S.M.; Moody, E.W.; Lauría, E.J.M.; Regan, J.R.; Baron, J.D. Early Alert of Academically At-Risk Students: An Open Source Analytics Initiative. J. Learn. Anal. 2014, 1, 6–47. [Google Scholar] [CrossRef]
- Gray, G.; Bergner, Y. A Practitioner’s Guide to Measurement in Learning Analytics: Decisions, Opportunities, and Challenges. In The Handbook of Learning Analytics, 2nd ed.; Lang, C., Siemens, G., Wise, A.F., Gasevic, D., Merceron, A., Eds.; SoLAR: Vancouver, BC, Canada, 2022; pp. 20–28. [Google Scholar]
- Hattie, J.; Timperley, H. The power of feedback. Rev. Educ. Res. 2007, 77, 81–112. [Google Scholar] [CrossRef]
- Carless, D.; Boud, D. The development of student feedback literacy: Enabling uptake of feedback. Assess. Eval. High. Educ. 2018, 43, 1315–1325. [Google Scholar] [CrossRef]
- Sutton, P. Conceptualizing feedback literacy: Knowing, being, and acting. Innov. Educ. Teach. Int. 2012, 49, 31–40. [Google Scholar] [CrossRef]
- Irons, A. Enhancing Learning through Formative Assessment and Feedback; Routledge: London, UK, 2007. [Google Scholar] [CrossRef]
- Karaoglan Yilmaz, F.G.; Yilmaz, R. Learning analytics as a metacognitive tool to influence learner transactional distance and motivation in online learning environments. Innov. Educ. Teach. Int. 2021, 58, 575–585. [Google Scholar] [CrossRef]
- Butler, D.L.; Winne, P.H. Feedback and Self-Regulated Learning: A Theoretical Synthesis. Rev. Educ. Res. 1995, 65, 245–281. [Google Scholar] [CrossRef]
- Dawson, P.; Henderson, M.; Ryan, T.; Mahoney, P.; Boud, D.; Phillips, M.; Molloy, E. Technology and Feedback Design. In Learning, Design, and Technology: An International Compendium of Theory, Research, Practice, and Policy; Spector, M.J., Lockee, B.B., Childress, M.D., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 1–45. [Google Scholar] [CrossRef]
- Pardo, A.; Jovanovic, J.; Dawson, S.; Gašević, D.; Mirriahi, N. Using learning analytics to scale the provision of personalised feedback. Br. J. Educ. Technol. 2019, 50, 128–138. [Google Scholar] [CrossRef]
- Evans, C. Making Sense of Assessment Feedback in Higher Education. Rev. Educ. Res. 2013, 83, 70–120. [Google Scholar] [CrossRef]
- Wilson, A.; Watson, C.; Thompson, T.L.; Drew, V.; Doyle, S. Learning analytics: Challenges and limitations. Teach. High. Educ. 2017, 22, 991–1007. [Google Scholar] [CrossRef]
- Gašević, D.; Dawson, S.; Rogers, T.; Gasevic, D. Learning analytics should not promote one size fits all: The effects of instructional conditions in predicting academic success. Internet High. Educ. 2016, 28, 68–84. [Google Scholar] [CrossRef]
- Joksimović, S.; Poquet, O.; Kovanović, V.; Dowell, N.; Mills, C.; Gašević, D.; Dawson, S.; Graesser, A.C.; Brooks, C. How Do We Model Learning at Scale? A Systematic Review of Research on MOOCs. Rev. Educ. Res. 2018, 88, 43–86. [Google Scholar] [CrossRef]
- Bodily, R.; Verbert, K. Review of Research on Student-Facing Learning Analytics Dashboards and Educational Recommender Systems. IEEE Trans. Learn. Technol. 2017, 10, 405–418. [Google Scholar] [CrossRef]
- Greer, J.; Mark, M. Evaluation methods for intelligent tutoring systems revisited. Int. J. Artif. Intell. Educ. 2016, 26, 387–392. [Google Scholar] [CrossRef]
- Islahi, F.; Nasrin. Exploring Teacher Attitude towards Information Technology with a Gender Perspective. Contemp. Educ. Technol. 2019, 10, 37–54. [Google Scholar] [CrossRef]
- Herodotou, C.; Hlosta, M.; Boroowa, A.; Rienties, B.; Zdrahal, Z.; Mangafa, C. Empowering online teachers through predictive learning analytics. Br. J. Educ. Technol. 2019, 50, 3064–3079. [Google Scholar] [CrossRef]
- Herodotou, C.; Rienties, B.; Boroowa, A.; Zdrahal, Z.; Hlosta, M. A large-scale implementation of predictive learning analytics in higher education: The teachers’ role and perspective. Educ. Technol. Res. Dev. 2019, 67, 1273–1306. [Google Scholar] [CrossRef]
- Sabraz Nawaz, S.; Thowfeek, M.H.; Rashida, M.F. School Teachers’ intention to use E-Learning systems in Sri Lanka: A modified TAM approach. Inf. Knowl. Manag. 2015, 5, 54–59. [Google Scholar]
- Dimitriadis, Y.; Martínez-Maldonado, R.; Wiley, K. Human-Centered Design Principles for Actionable Learning Analytics. In Research on E-Learning and ICT in Education: Technological, Pedagogical and Instructional Perspectives; Tsiatsos, T., Demetriadis, S., Mikropoulos, A., Dagdilelis, V., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 277–296. [Google Scholar] [CrossRef]
- Prestigiacomo, R.; Hadgraft, R.; Hunter, J.; Locker, L.; Knight, S.; Van Den Hoven, E.; Martinez-Maldonado, R. Learning-centred translucence: An approach to understand how teachers talk about classroom data. In Proceedings of the LAK ’20: 10th International Conference on Learning Analytics & Knowledge, Frankfurt, Germany, 23–27 March 2020; pp. 100–105. [Google Scholar] [CrossRef]
- Herodotou, C.; Rienties, B.; Hlosta, M.; Boroowa, A.; Mangafa, C.; Zdrahal, Z. The scalable implementation of predictive learning analytics at a distance learning university: Insights from a longitudinal case study. Internet High. Educ. 2020, 45, 100725. [Google Scholar] [CrossRef]
- Cardona, M.A.; Rodríguez, R.J.; Ishmael, K. Artificial Intelligence and Future of Teaching and Learning: Insights and Recommendations; Technical Report; US Department of ti Education, Office of Educational Technology: Washington, DC, USA, 2023.
- Sarmiento, J.P.; Wise, A.F. Participatory and co-design of learning analytics: An initial review of the literature. In Proceedings of the LAK22: 12th International Learning Analytics and Knowledge Conference, Online, 21–25 March 2022; pp. 535–541. [Google Scholar]
- Pardo, A.; Bartimote, K.; Shum, S.B.; Dawson, S.; Gao, J.; Gašević, D.; Leichtweis, S.; Liu, D.; Martínez-Maldonado, R.; Mirriahi, N.; et al. OnTask: Delivering Data-Informed, Personalized Learning Support Actions. J. Learn. Anal. 2018, 5, 235–249. [Google Scholar] [CrossRef]
- Martinez-Maldonado, R.; Echeverria, V.; Fernandez Nieto, G.; Buckingham Shum, S. From Data to Insights: A Layered Storytelling Approach for Multimodal Learning Analytics. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; pp. 1–15. [Google Scholar] [CrossRef]
- Conijn, R.; Van Waes, L.; van Zaanen, M. Human-Centered Design of a Dashboard on Students’ Revisions During Writing. In Addressing Global Challenges and Quality Education; Lecture Notes in Computer Science; Alario-Hoyos, C., Rodríguez-Triana, M.J., Scheffel, M., Arnedillo-Sánchez, I., Dennerlein, S.M., Eds.; Springer: Cham, Switzerland, 2020; pp. 30–44. [Google Scholar] [CrossRef]
- Echeverria, V.; Martinez-Maldonado, R.; Shum, S.B.; Chiluiza, K.; Granda, R.; Conati, C. Exploratory versus Explanatory Visual Learning Analytics: Driving Teachers’ Attention through Educational Data Storytelling. J. Learn. Anal. 2018, 5, 73–97. [Google Scholar] [CrossRef]
- Fernandez Nieto, G.M.; Kitto, K.; Buckingham Shum, S.; Martinez-Maldonado, R. Beyond the Learning Analytics Dashboard: Alternative Ways to Communicate Student Data Insights Combining Visualisation, Narrative and Storytelling. In Proceedings of the LAK22: 12th International Learning Analytics and Knowledge Conference, New York, NY, USA, 21–25 March 2022; pp. 219–229. [Google Scholar] [CrossRef]
- Ramos-Soto, A.; Vazquez-Barreiros, B.; Bugarín, A.; Gewerc, A.; Barro, S. Evaluation of a Data-To-Text System for Verbalizing a Learning Analytics Dashboard. Int. J. Intell. Syst. 2017, 32, 177–193. [Google Scholar] [CrossRef]
- Sultanum, N.; Srinivasan, A. DataTales: Investigating the use of Large Language Models for Authoring Data-Driven Articles. arXiv 2023, arXiv:2308.04076. [Google Scholar] [CrossRef]
- He, Q.; von Davier, M. Identifying Feature Sequences from Process Data in Problem-Solving Items with N-Grams. In Quantitative Psychology Research; Springer Proceedings in Mathematics & Statistics; van der Ark, L.A., Bolt, D.M., Wang, W.C., Douglas, J.A., Chow, S.M., Eds.; Springer: Cham, Switzerland, 2015; pp. 173–190. [Google Scholar] [CrossRef]
- Reis Costa, D.; Leoncio Netto, W. Process Data Analysis in ILSAs. In International Handbook of Comparative Large-Scale Studies in Education: Perspectives, Methods and Findings; Springer International Handbooks of Education; Nilsen, T., Stancel-Piątak, A., Gustafsson, J.E., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 1–27. [Google Scholar] [CrossRef]
- Wise, S.L.; Ma, L. Setting response time thresholds for a CAT item pool: The normative threshold method. In Proceedings of the Annual Meeting of the National Council on Measurement in Education, Vancouver, BC, Canada, 13–17 April 2012; pp. 163–183. [Google Scholar]
- Rios, J.A.; Guo, H. Can Culture Be a Salient Predictor of Test-Taking Engagement? An Analysis of Differential Noneffortful Responding on an International College-Level Assessment of Critical Thinking. Appl. Meas. Educ. 2020, 33, 263–279. [Google Scholar] [CrossRef]
- Wise, S.L.; Kong, X. Response Time Effort: A New Measure of Examinee Motivation in Computer-Based Tests. Appl. Meas. Educ. 2005, 18, 163–183. [Google Scholar] [CrossRef]
- Su, Q.; Chen, L. A method for discovering clusters of e-commerce interest patterns using click-stream data. Electron. Commer. Res. Appl. 2015, 14, 1–13. [Google Scholar] [CrossRef]
- Ulitzsch, E.; He, Q.; Ulitzsch, V.; Molter, H.; Nichterlein, A.; Niedermeier, R.; Pohl, S. Combining Clickstream Analyses and Graph-Modeled Data Clustering for Identifying Common Response Processes. Psychometrika 2021, 86, 190–214. [Google Scholar] [CrossRef]
- Tang, S.; Samuel, S.; Li, Z. Detecting atypical test-taking behaviors with behavior prediction using LSTM. Psychol. Test Assess. Model. 2023, 65, 76–124. [Google Scholar]
- Gao, G.; Marwan, S.; Price, T.W. Early Performance Prediction using Interpretable Patterns in Programming Process Data. In Proceedings of the 52nd ACM Technical Symposium on Computer Science Education, Virtual Event, 13–20 March 2021; pp. 342–348. [Google Scholar] [CrossRef]
- Rayner, K. Eye movements in reading and information processing: 20 years of research. Psychol. Bull. 1998, 124, 372. [Google Scholar] [CrossRef]
- Morad, Y.; Lemberg, H.; Yofe, N.; Dagan, Y. Pupillography as an objective indicator of fatigue. Curr. Eye Res. 2000, 21, 535–542. [Google Scholar] [CrossRef]
- Benedetto, S.; Pedrotti, M.; Minin, L.; Baccino, T.; Re, A.; Montanari, R. Driver workload and eye blink duration. Transp. Res. Part Traffic Psychol. Behav. 2011, 14, 199–208. [Google Scholar] [CrossRef]
- Booth, R.W.; Weger, U.W. The function of regressions in reading: Backward eye movements allow rereading. Mem. Cogn. 2013, 41, 82–97. [Google Scholar] [CrossRef]
- Inhoff, A.W.; Greenberg, S.N.; Solomon, M.; Wang, C.A. Word integration and regression programming during reading: A test of the E-Z reader 10 model. J. Exp. Psychol. Hum. Percept. Perform. 2009, 35, 1571–1584. [Google Scholar] [CrossRef]
- Coëffé, C.; O’regan, J.K. Reducing the influence of non-target stimuli on saccade accuracy: Predictability and latency effects. Vis. Res. 1987, 27, 227–240. [Google Scholar] [CrossRef] [PubMed]
- Adhikari, B. Thinking beyond chatbots’ threat to education: Visualizations to elucidate the writing and coding process. arXiv 2023, arXiv:2304.14342. [Google Scholar] [CrossRef]
- Allen, L.K.; Mills, C.; Jacovina, M.E.; Crossley, S.; D’Mello, S.; McNamara, D.S. Investigating boredom and engagement during writing using multiple sources of information: The essay, the writer, and keystrokes. In Proceedings of the Sixth International Conference on Learning Analytics & Knowledge, Edinburgh, UK, 25–29 April 2016; LAK ’16. pp. 114–123. [Google Scholar] [CrossRef]
- Bixler, R.; D’Mello, S. Detecting boredom and engagement during writing with keystroke analysis, task appraisals, and stable traits. In Proceedings of the 2013 International Conference on Intelligent User Interfaces, Santa Monica, CA, USA, 19–22 March 2013; IUI ’13. pp. 225–234. [Google Scholar] [CrossRef]
- Allen, L.; Creer, S.; Oncel, P. Chapter 5: Natural Language Processing as a Tool for Learning Analytics—Towards a Multi-Dimensional View of the Learning Process. In The Handbook of Learning Analytics; Society of Learning Analytics Research: Vancouver, BC, Canada, 2022. [Google Scholar] [CrossRef]
- He, Q.; von Davier, M. Analyzing process data from problem-solving items with n-grams: Insights from a computer-based large-scale assessment. In Handbook of Research on Technology Tools for Real-World Skill Development; IGI Global: Hershey, PA, UAS, 2016; pp. 750–777. [Google Scholar] [CrossRef]
- Ulitzsch, E.; He, Q.; Pohl, S. Using sequence mining techniques for understanding incorrect behavioral patterns on interactive tasks. J. Educ. Behav. Stat. 2022, 47, 3–35. [Google Scholar] [CrossRef]
- Guthrie, M.; Chen, Z. Adding duration-based quality labels to learning events for improved description of students’ online learning behavior. In Proceedings of the 12th International Conference on Educational Data Mining, Montreal, QC, Canada, 2–5 July 2019. [Google Scholar]
- Chhabra, A. A System for Automatic Information Extraction from Log Files. Ph.D. Thesis, University of Ottawa, Ottawa, ON, Canada, 2022. [Google Scholar]
- Roberts, L.D.; Howell, J.A.; Seaman, K. Give Me a Customizable Dashboard: Personalized Learning Analytics Dashboards in Higher Education. Technol. Knowl. Learn. 2017, 22, 317–333. [Google Scholar] [CrossRef]
- Cavalcanti, A.P.; Barbosa, A.; Carvalho, R.; Freitas, F.; Tsai, Y.S.; Gašević, D.; Mello, R.F. Automatic feedback in online learning environments: A systematic literature review. Comput. Educ. Artif. Intell. 2021, 2, 100027. [Google Scholar] [CrossRef]
- McGee, R.W. Is ESG a Bad Idea? The Chatgpt Response. SSRN 2023. [Google Scholar] [CrossRef]
- Kaddour, J.; Harris, J.; Mozes, M.; Bradley, H.; Raileanu, R.; McHardy, R. Challenges and Applications of Large Language Models. arXiv 2023, arXiv:2307.10169. [Google Scholar] [CrossRef]
- Frieder, S.; Pinchetti, L.; Griffiths, R.R.; Salvatori, T.; Lukasiewicz, T.; Petersen, P.C.; Chevalier, A.; Berner, J. Mathematical Capabilities of ChatGPT. arXiv 2023, arXiv:2301.13867. [Google Scholar] [CrossRef]
- Lim, L.A.; Dawson, S.; Gašević, D.; Joksimović, S.; Fudge, A.; Pardo, A.; Gentili, S. Students’ sense-making of personalised feedback based on learning analytics. Australas. J. Educ. Technol. 2020, 36, 15–33. [Google Scholar] [CrossRef]
- Dai, W.; Lin, J.; Jin, F.; Li, T.; Tsai, Y.S.; Gasevic, D.; Chen, G. Can Large Language Models Provide Feedback to Students? Case Study on ChatGPT. EdArXiv 2023. [Google Scholar] [CrossRef]
- Matelsky, J.K.; Parodi, F.; Liu, T.; Lange, R.D.; Kording, K.P. A large language model-assisted education tool to provide feedback on open-ended responses. arXiv 2023, arXiv:2308.02439. [Google Scholar]
- Yildirim-Erbasli, S.N.; Bulut, O. Conversation-based assessment: A novel approach to boosting test-taking effort in digital formative assessment. Comput. Educ. Artif. Intell. 2023, 4, 100135. [Google Scholar] [CrossRef]
- Hasan, M.; Ozel, C.; Potter, S.; Hoque, E. SAPIEN: Affective Virtual Agents Powered by Large Language Models. arXiv 2023, arXiv:2308.03022. [Google Scholar]
- Bulut, O.; Yildirim-Erbasli, S.N. Automatic story and item generation for reading comprehension assessments with transformers. Int. J. Assess. Tools Educ. 2022, 9, 72–87. [Google Scholar] [CrossRef]
- Attali, Y.; Runge, A.; LaFlair, G.T.; Yancey, K.; Goodwin, S.; Park, Y.; von Davier, A.A. The interactive reading task: Transformer-based automatic item generation. Front. Artif. Intell. 2022, 5, 903077. [Google Scholar] [CrossRef]
- Sarsa, S.; Denny, P.; Hellas, A.; Leinonen, J. Automatic generation of programming exercises and code explanations using large language models. In Proceedings of the 2022 ACM Conference on International Computing Education Research, Virtual Event, 7–11 August 2022; Volume 1, pp. 27–43. [Google Scholar]
- Tsai, D.; Chang, W.; Yang, S. Short Answer Questions Generation by Fine-Tuning BERT and GPT-2. In Proceedings of the 29th International Conference on Computers in Education Conference, ICCE 2021—Proceedings; Rodrigo, M., Iyer, S., Mitrovic, A., Cheng, H., Kohen-Vacs, D., Matuk, C., Palalas, A., Rajenran, R., Seta, K., Wang, J., Eds.; Asia-Pacific Society for Computers in Education: Taoyuan, Taiwan, 2021; pp. 509–515. [Google Scholar]
- Shan, J.; Nishihara, Y.; Yamanishi, R.; Maeda, A. Question Generation for Reading Comprehension of Language Learning Test: -A Method using Seq2Seq Approach with Transformer Model-. In Proceedings of the 2019 International Conference on Technologies and Applications of Artificial Intelligence (TAAI), Kaohsiung, Taiwan, 21–23 November 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Offerijns, J.; Verberne, S.; Verhoef, T. Better Distractions: Transformer-based Distractor Generation and Multiple Choice Question Filtering. arXiv 2020, arXiv:2010.09598. [Google Scholar] [CrossRef]
- Zu, J.; Choi, I.; Hao, J. Automated distractor generation for fill-in-the-blank items using a prompt-based learning approach. Psychol. Test. Assess. Model. 2023, 65, 55–75. [Google Scholar]
- Wainer, H.; Dorans, N.J.; Flaugher, R.; Green, B.F.; Mislevy, R.J. Computerized Adaptive Testing: A Primer; Routledge: Oxfordshire, UK, 2000. [Google Scholar]
- Woolf, B.P. Building Intelligent Interactive Tutors: Student-Centered Strategies for Revolutionizing E-Learning; Morgan Kaufmann: Cambridge, MA, USA, 2010. [Google Scholar]
- Friedman, L.; Ahuja, S.; Allen, D.; Tan, T.; Sidahmed, H.; Long, C.; Xie, J.; Schubiner, G.; Patel, A.; Lara, H.; et al. Leveraging Large Language Models in Conversational Recommender Systems. arXiv 2023, arXiv:2305.07961. [Google Scholar]
- Patel, N.; Nagpal, P.; Shah, T.; Sharma, A.; Malvi, S.; Lomas, D. Improving mathematics assessment readability: Do large language models help? J. Comput. Assist. Learn. 2023, 39, 804–822. [Google Scholar] [CrossRef]
- Zhang, Y.; Ding, H.; Shui, Z.; Ma, Y.; Zou, J.; Deoras, A.; Wang, H. Language models as recommender systems: Evaluations and limitations. In Proceedings of the NeurIPS 2021 Workshop on I (Still) Can’t Believe It’s Not Better, Virtual, 13 December 2021. [Google Scholar]
- Lim, L.A.; Dawson, S.; Gašević, D.; Joksimović, S.; Pardo, A.; Fudge, A.; Gentili, S. Students’ perceptions of, and emotional responses to, personalised learning analytics-based feedback: An exploratory study of four courses. Assess. Eval. High. Educ. 2021, 46, 339–359. [Google Scholar] [CrossRef]
- Bonner, E.; Lege, R.; Frazier, E. Large Language Model-Based Artificial Intelligence in the Language Classroom: Practical Ideas For Teaching. J. Teach. Engl. Technol. 2023, 2023. [Google Scholar] [CrossRef]
- DiCerbo, K. Building AI Applications Based on Learning Research [Webinar]. 2023. Available online: https://www.youtube.com/watch?v=ugyfdjI9NEk (accessed on 14 July 2023).
- Kasneci, E.; Seßler, K.; Küchemann, S.; Bannert, M.; Dementieva, D.; Fischer, F.; Gasser, U.; Groh, G.; Günnemann, S.; Hüllermeier, E.; et al. ChatGPT for good? On opportunities and challenges of large language models for education. Learn. Individ. Differ. 2023, 103, 102274. [Google Scholar] [CrossRef]
- Tlili, A.; Shehata, B.; Adarkwah, M.A.; Bozkurt, A.; Hickey, D.T.; Huang, R.; Agyemang, B. What if the devil is my guardian angel: ChatGPT as a case study of using chatbots in education. Smart Learn. Environ. 2023, 10, 15. [Google Scholar] [CrossRef]
- Mathrani, A.; Susnjak, T.; Ramaswami, G.; Barczak, A. Perspectives on the challenges of generalizability, transparency and ethics in predictive learning analytics. Comput. Educ. Open 2021, 2, 100060. [Google Scholar] [CrossRef]
- Barros, T.M.; Souza Neto, P.A.; Silva, I.; Guedes, L.A. Predictive models for imbalanced data: A school dropout perspective. Educ. Sci. 2019, 9, 275. [Google Scholar] [CrossRef]
- Yan, L.; Sha, L.; Zhao, L.; Li, Y.; Martinez-Maldonado, R.; Chen, G.; Li, X.; Jin, Y.; Gašević, D. Practical and Ethical Challenges of Large Language Models in Education: A Systematic Literature Review. arXiv 2023, arXiv:2303.13379. [Google Scholar]
- Truong, T.L.; Le, H.L.; Le-Dang, T.P. Sentiment analysis implementing BERT-based pre-trained language model for Vietnamese. In Proceedings of the 2020 7th NAFOSTED Conference on Information and Computer Science (NICS), Ho Chi Minh City, Vietnam, 26–27 November 2020; pp. 362–367. [Google Scholar] [CrossRef]
- Khosravi, H.; Shum, S.B.; Chen, G.; Conati, C.; Tsai, Y.S.; Kay, J.; Knight, S.; Martinez-Maldonado, R.; Sadiq, S.; Gašević, D. Explainable artificial intelligence in education. Comput. Educ. Artif. Intell. 2022, 3, 100074. [Google Scholar] [CrossRef]
- Huang, L. Ethics of Artificial Intelligence in Education: Student Privacy and Data Protection. Sci. Insights Educ. Front. 2023, 16, 2577–2587. [Google Scholar] [CrossRef]
- Remian, D. Augmenting Education: Ethical Considerations for Incorporating Artificial Intelligence in Education. In Instructional Design Capstones Collection; University of Massachusetts Boston: Boston, MA, USA, 2019. [Google Scholar]
- Akgun, S.; Greenhow, C. Artificial intelligence in education: Addressing ethical challenges in K-12 settings. AI Ethics 2022, 2, 431–440. [Google Scholar] [CrossRef] [PubMed]
- Knight, S.; Shibani, A.; Abel, S.; Gibson, A.; Ryan, P.; Sutton, N.; Wight, R.; Lucas, C.; Sandor, A.; Kitto, K.; et al. AcaWriter: A learning analytics tool for formative feedback on academic writing. J. Writ. Res. 2020, 12, 141–186. [Google Scholar] [CrossRef]
- Kochmar, E.; Vu, D.D.; Belfer, R.; Gupta, V.; Serban, I.V.; Pineau, J. Automated personalized feedback improves learning gains in an intelligent tutoring system. In Proceedings of the Artificial Intelligence in Education: 21st International Conference, AIED 2020, Proceedings, Part II, Ifrane, Morocco, 6–10 July 2020; pp. 140–146. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mazzullo, E.; Bulut, O.; Wongvorachan, T.; Tan, B. Learning Analytics in the Era of Large Language Models. Analytics 2023, 2, 877-898. https://doi.org/10.3390/analytics2040046
Mazzullo E, Bulut O, Wongvorachan T, Tan B. Learning Analytics in the Era of Large Language Models. Analytics. 2023; 2(4):877-898. https://doi.org/10.3390/analytics2040046
Chicago/Turabian StyleMazzullo, Elisabetta, Okan Bulut, Tarid Wongvorachan, and Bin Tan. 2023. "Learning Analytics in the Era of Large Language Models" Analytics 2, no. 4: 877-898. https://doi.org/10.3390/analytics2040046
APA StyleMazzullo, E., Bulut, O., Wongvorachan, T., & Tan, B. (2023). Learning Analytics in the Era of Large Language Models. Analytics, 2(4), 877-898. https://doi.org/10.3390/analytics2040046