
Approximating a Function with a Jump Discontinuity—The High-Noise Case

Abstract
1. Introduction
2. Our Approach
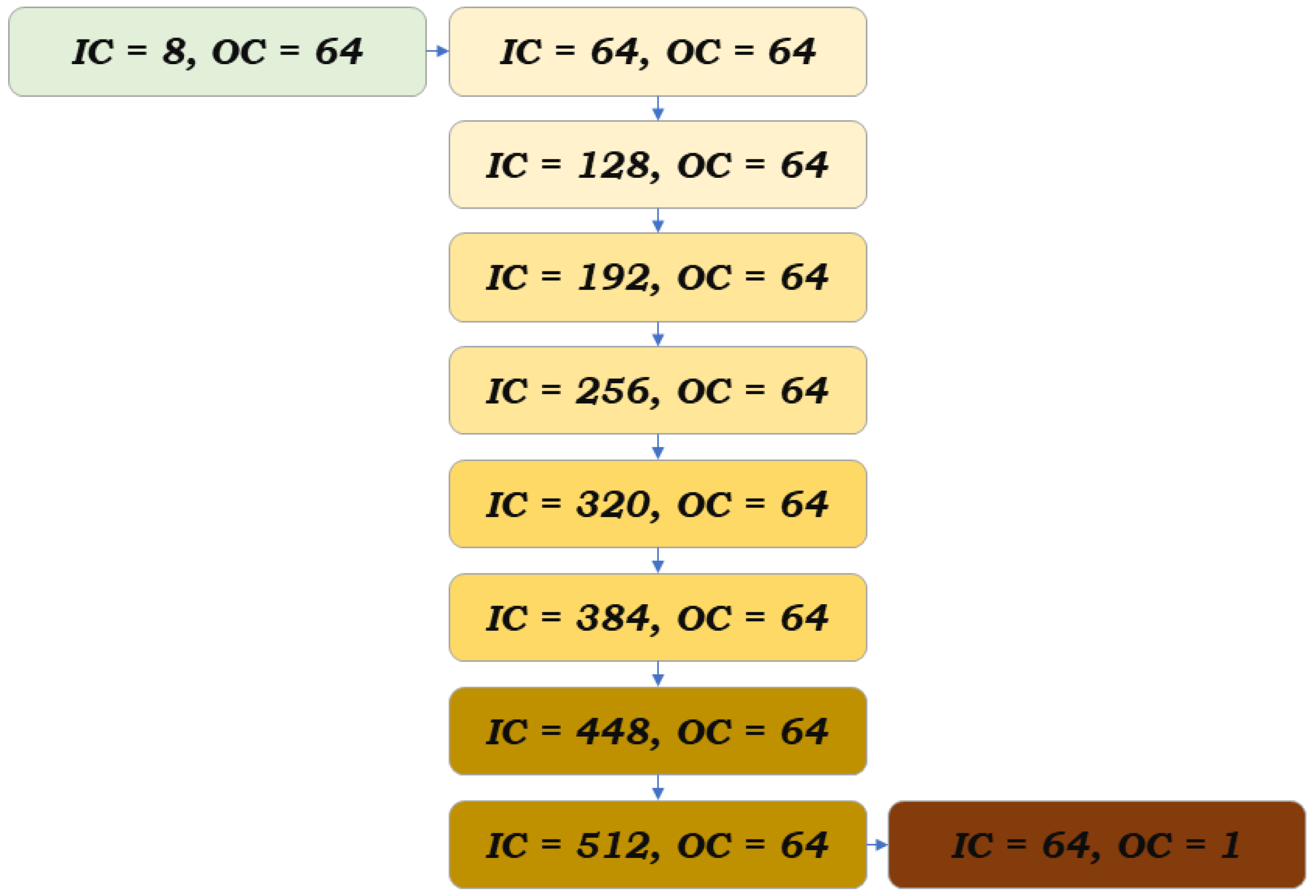
2.1. The Model
2.2. Training Data
2.3. Approximating the Function from Its Samples
3. Numerical Results
3.1. Detecting the Interval of the Discontinuity and Approximating the Function
3.2. Comparing Our Approach with Two Other Approaches
3.3. Error Measurement of Approximations of Functions
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ageev, A.L.; Antonova, T.V. On a new class of ill-posed problems. Izv. Ural. Gos. Univ. Mat. Mekh. Inform. 2008, 58, 24–42. [Google Scholar]
- Cherepashchuk, A.M.; Goncharskii, A.V.; Yagola, A.G. Inverse problems of astrophysics. In Ill-Posed Problems in Natural Sciences, Proceedings of the International Conference Held in Moscow, August 19–25, 1991; De Gruyter: Berlin, Germany, 1992; pp. 472–481. [Google Scholar]
- Terebizh, V.Y. Introduction to the Statistical Theory of Inverse Problems; Fimzmatlit: Moscow, Russia, 2005. [Google Scholar]
- Aràndiga, F.; Donat, R. Nonlinear multiscale decompositions: The approach of A. Harten. Numer. Algorithm 2000, 23, 175–216. [Google Scholar] [CrossRef]
- Shu, C.-W. Essentially non-oscillatory and weighted essentially non-oscillatory schemes for hyperbolic conservation laws. In Advanced Numerical Approximation of Nonlinear Hyperbolic Equations: Lectures Given at the 2nd Session of the Centro Internazionale Matematico Estivo (C.I.M.E.) Held in Cetraro, Italy, June 23–28, 1997; Springer: Berlin/Heidelberg, Germany, 1998; pp. 325–432. [Google Scholar]
- Amat, S.; Levin, D.; Ruiz-Álvarez, J. A two-stage approximation strategy for piecewise smooth functions in two and three dimensions. IMA J. Numer. Anal. 2021, 42, 3330–3359. [Google Scholar] [CrossRef]
- Antonova, T.V. New methods for localizing discontinuities of a noisy function. Numer. Anal. Appl. 2010, 3, 306–316. [Google Scholar]
- Mbakop, E. Reconstruction of Discontinuities in Noisy Data; Citeseer: Pennsylvania, USA. Available online: https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=0c1b69c38e1df16c7c939ad07705ee6bb53a6bd2 (accessed on 31 March 2024).
- Lee, D. Detection, Classification, and Measurement of Discontinuities. SIAM J. Sci. Stat. Comput. 1991, 12, 311–341. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Chapra, S.C.; Canale, R.P. Numerical Methods for Engineers, 8th ed.; McGraw-Hill Education: New York, NY, USA, 2021. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 0.30 | 0.60 | 0.90 | 1.20 | 1.50 | 1.80 | 2.10 | 2.40 | |
| 0.00 | 0.38 | 0.47 | 0.50 | 0.49 | 0.48 | 0.49 | 0.48 | 0.49 |
| 0.10 | 0.10 | 0.28 | 0.45 | 0.50 | 0.50 | 0.53 | 0.48 | 0.51 |
| 0.20 | 0.10 | 0.21 | 0.29 | 0.42 | 0.46 | 0.46 | 0.50 | |
| 0.30 | 0.12 | 0.14 | 0.24 | 0.29 | 0.37 | 0.42 | ||
| 0.40 | 0.11 | 0.14 | 0.19 | 0.25 | 0.31 | |||
| 0.50 | 0.11 | 0.13 | 0.17 | 0.22 | ||||
| 0.60 | 0.11 | 0.13 | 0.17 | |||||
| 0.70 | 0.10 | 0.12 | ||||||
| 0.80 | 0.12 |
| 0.30 | 0.60 | 0.90 | 1.20 | 1.50 | 1.80 | 2.10 | 2.40 | |
| 0.00 | 0.24 | 0.24 | 0.28 | 0.24 | 0.26 | 0.25 | 0.24 | 0.23 |
| 0.10 | 0.30 | 0.27 | 0.25 | 0.25 | 0.27 | 0.24 | 0.25 | 0.27 |
| 0.20 | 0.30 | 0.26 | 0.28 | 0.24 | 0.25 | 0.28 | 0.25 | |
| 0.30 | 0.33 | 0.28 | 0.29 | 0.26 | 0.28 | 0.28 | ||
| 0.40 | 0.34 | 0.30 | 0.30 | 0.26 | 0.30 | |||
| 0.50 | 0.34 | 0.32 | 0.30 | 0.28 | ||||
| 0.60 | 0.32 | 0.29 | 0.33 | |||||
| 0.70 | 0.34 | 0.31 | ||||||
| 0.80 | 0.33 |
| 0.30 | 0.60 | 0.90 | 1.20 | 1.50 | 1.80 | 2.10 | 2.40 | |
| 0.00 | 0.89 | 0.99 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| 0.10 | 0.53 | 0.93 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| 0.20 | 0.67 | 0.92 | 0.98 | 1.00 | 1.00 | 1.00 | 1.00 | |
| 0.30 | 0.73 | 0.92 | 0.97 | 0.99 | 1.00 | 1.00 | ||
| 0.40 | 0.76 | 0.90 | 0.95 | 0.98 | 0.99 | |||
| 0.50 | 0.79 | 0.89 | 0.94 | 0.97 | ||||
| 0.60 | 0.79 | 0.88 | 0.95 | |||||
| 0.70 | 0.79 | 0.88 | ||||||
| 0.80 | 0.79 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Muzaffar, Q.; Levin, D.; Werman, M. Approximating a Function with a Jump Discontinuity—The High-Noise Case. AppliedMath 2024, 4, 561-569. https://doi.org/10.3390/appliedmath4020030
Muzaffar Q, Levin D, Werman M. Approximating a Function with a Jump Discontinuity—The High-Noise Case. AppliedMath. 2024; 4(2):561-569. https://doi.org/10.3390/appliedmath4020030
Chicago/Turabian StyleMuzaffar, Qusay, David Levin, and Michael Werman. 2024. "Approximating a Function with a Jump Discontinuity—The High-Noise Case" AppliedMath 4, no. 2: 561-569. https://doi.org/10.3390/appliedmath4020030
APA StyleMuzaffar, Q., Levin, D., & Werman, M. (2024). Approximating a Function with a Jump Discontinuity—The High-Noise Case. AppliedMath, 4(2), 561-569. https://doi.org/10.3390/appliedmath4020030