1. Introduction and Notation
Simulation is usually regarded as a powerful tool for producing forecasts, evaluating risk (see, e.g., [
1]), and animating and illustrating a system’s performance over time (see, e.g., [
2]). When a component of a simulation model has a certain degree of uncertainty, it is said to be a random component, and it is modeled by using a probability distribution and/or a stochastic process that is sampled throughout the simulation run to produce a stochastic simulation. A random component typically depends on the value of certain parameters; we denote by
a particular value for the vector of parameters of the random components of a stochastic simulation, and
denotes a random vector that corresponds to the parameter values when there is uncertainty in the values of these parameters.
Following the notation of [
1], the output of a stochastic (dynamic) simulation can be regarded as a stochastic process
, where
is a random vector (of arbitrary dimension
d) representing the state of the simulation at time
. The term transient simulation applies to a dynamic simulation that has a well-defined termination time, so the output of a transient simulation can be viewed as a stochastic process
, where
T is a stopping time (which may be deterministic); see, e.g., [
3] for a definition of stopping time.
A performance variable
W in a transient simulation is a real-valued random variable (r.v.) that depends on the simulation output up to time
T, i.e.,
, and the expectation of a performance variable
W is a performance measure that we usually estimate through experimentation with the simulation model. When there is no uncertainty in the parameters of the random components, the accepted technique for estimating a performance measure in transient simulation is the method of independent replications. This method consists of running experiments with the simulation model to produce
n replications
that can be regarded as independent and identically distributed (i.i.d.) random variables (see
Figure 1).
In the method of independent replications, a point estimator for the expectation
is the average
. If
, it follows from the classical Law of Large Numbers (LLN) that
is consistent, i.e., it satisfies
, as
(where ⇒ denotes weak convergence of random variables); see, e.g., [
3] for a proof. Consistency ensures that the estimator approaches the parameter as the number of replications
n increases, and an asymptotic confidence interval (ACI) for the parameter is often used to evaluate the accuracy of the simulation-based estimator. Typically, a Central Limit Theorem (CLT) for the estimator is used to derive the expression for an ACI (see, for example, chapter 3 of [
4]). For the case of the expectation
in the algorithm of
Figure 1, if
, the classical CLT implies that
as
, where
, and
denotes an r.v. distributed as normal with a mean of 0 and variance of 1. Then, if
, it follows from (
1) and Slutsky’s Theorem (see
Appendix A) that
as
, where
denotes the sample standard deviation, i.e.,
. This CLT implies that
for
, where
is the (
)-quantile of a
, so the CLT of Equation (
2) is sufficient to establish a
ACI for
with the following halfwidth:
The standard measurement used in simulation software (e.g., Simio; see [
2]) to evaluate the accuracy of
as an estimator of expectation
is a halfwidth in the form of (
2).
The parameters of the random input components of a simulation model are typically estimated from real-data observations (denoted by a real-valued vector
x), in contrast to an estimation of output performance measures that uses observations from simulation experiments. While the majority of applications covered in the related literature assume that there is no uncertainty in the value of input parameters, the uncertainty can be significant when these parameters are estimated by using small amounts of data. In these situations, Bayesian statistics can be used to incorporate this uncertainty in the output analysis of simulation experiments via the use of a posterior distribution
. A two-level nested simulation algorithm (see, e.g., [
5,
6,
7]) is a methodology that is currently proposed for the analysis of simulation experiments under parameter uncertainty. In the outer level, we simulate
n observations for the parameters from a posterior distribution
, while in the inner level, we simulate
m observations for the performance variable with the parameters fixed at the value
generated in the outer level. In this paper, we focus on the case where the observations at both levels of the algorithm are independent (as illustrated in
Figure 2). We first show how the variance of a simulated observation can be decomposed into parametric and stochastic variance components, and then we obtain CLTs for the estimator of the point forecast and the estimators of the variance components. Our CLTs allow us to compute an ACI for each estimator. Our results are validated through experiments with a forecast model for sporadic demand reported in [
8]. The main theoretical results reported in this paper were first stated in [
9] (although the proofs were omitted), and in this paper, we provide the missing proofs, a more comprehensive literature review, and a more complete set of experiments with different values for the parameters of our experiments.
The existing literature on quantifying the impact of uncertainty on the input components of a stochastic simulation is very extensive; detailed reviews can be found, e.g., in [
10,
11,
12] and the references therein. However, in order to situate our results within the framework of the bibliography related to the input analysis of simulation experiments, next, we present a brief discussion of the different approaches that have been proposed on this topic.
According to Barton et al. [
13], input analysis in the simulation literature has been addressed essentially in two ways: sensitivity analysis and the characterization of the impact of input uncertainty to provide an ACI (to evaluate the accuracy of a point estimator) that explicitly considers this uncertainty. A sensitivity analysis is performed by running simulation experiments under different distributions for the random components and/or different parameters in order to investigate and describe the changes in the main performance measures of the simulation experiments (see [
14,
15] for early proposals). Although formalization of this approach was initially proposed by using techniques (e.g., design of experiments and/or regression; see [
16]) that were previously proposed to analyze real-world experiments (see, e.g., [
17]), some other techniques were proposed for the special purpose of simulation; for example, Freimer and Schruben [
18] discussed methods for the design of experiments to search for the sample size of input data that ensured that the difference in the results of two simulation experiments was dominated by the stochastic variance (induced by the simulation experiments) so that the parametric variance (induced by input uncertainty) was not significant for decision making. As pointed out by Bruce Schmeiser in his discussion in [
19], sensitivity analysis has a wide range of applications, since it can handle model uncertainty, as well as situations where no real-world data exist; however, a significant drawback is that it does not provide a statistical characterization of input uncertainty. This characterization can be achieved through the construction of an ACI that explicitly considers input uncertainty based on sample data.
According to several authors (e.g., [
10,
13]), for the construction of an ACI that explicitly considers the impact of input uncertainty, there have been essentially three approaches: the delta method, resampling, and Bayesian methods. Let us denote by
the expectation of
(of
Figure 1) as a function of
, and let
be an estimator for parameter
(where
r is the sample size of real-world observations); in this notation, the main idea of the delta method is to consider a Taylor series expansion for
around
to investigate convergence properties (as
) of
as an estimator of
. Cheng and Holland ([
20,
21,
22]) introduced the use of the delta method to propose the construction of confidence intervals for the expectation of a performance variable of a stochastic simulation under uncertainty in the parameters of a proposed (known) parametric family of distributions for a random component. In [
20,
22], the authors did not formally prove the asymptotic validity of their proposed confidence intervals but justified them by appealing to the asymptotic normality (as
) of the estimator
(which is the case, under regularity conditions, when
is the maximum likelihood estimator). In a later publication ([
23]), Cheng and Holland provided proof of the asymptotic validity of their confidence intervals based on the delta method under regularity conditions as
and
. In [
20,
23], the authors also proposed the construction of asymptotic confidence intervals under parameter uncertainty based on a resampling technique known as parametric bootstrapping; this proposal basically consisted of using the algorithm of
Figure 1 but sampling the values for parameter
from the likelihood evaluated at the maximum likelihood estimator. Some other proposals for the construction of an ACI are based on resampling from the empirical distribution of real-data observations (see, e.g., [
13,
24,
25]). A drawback of proposed confidence intervals based on the delta method and resampling is that their asymptotic validity (see the Theorem of [
23] and Theorem 1 of [
13]) requires that the sample size of real observations be large (
), which is a condition that is probably true for big data, in which case parameter uncertainty may not be significant. Another drawback of techniques based on the delta method and parametric bootstrapping is that parameter
is assumed to be deterministic (although unknown) so that, at some point, the value of
is replaced by
, and this is one reason for why these methods are called frequentists in the statistics community. On the contrary, under a Bayesian approach, a parameter is regarded as a random variable
, and the uncertainty about
is assessed through a posterior distribution
that explicitly incorporates available information from sample data
x.
Bayesian methods have solid theoretical foundations (see, e.g., [
26]), and they have been proposed to assess not only parameter uncertainty, but also model uncertainty (see [
27]). Bayesian methods for input analysis in simulation experiments were introduced by Chick in [
28], and since then, there has been a fair number of publications on Bayesian methods for input simulation analysis (see, e.g., [
7,
29,
30,
31]). Bayesian methods require the specification of a prior distribution on the input parameters of the simulation model, and some users object to this requirement; however, there is a well-developed theory on objective priors (see, e.g., [
32]), and some authors (e.g., [
10,
33]) consider that this requirement is actually a strength of the approach. Another strength of Bayesian methods for input analysis in stochastic simulation is that some Bayesian methods have been developed to construct an ACI for parameters that are not the expectation—for example, the variance and quantiles for a consistent estimation of a credible interval for the performance variable
W (see [
34]). It is worth mentioning that some methods need the extra assumption that the simulation output satisfies a meta-model in order to justify the asymptotic validity of their proposed confidence intervals (e.g., [
13,
35]); as we will see, this extra assumption is not required to establish an ACI for the expectation and variance components of two-level simulation experiments in a Bayesian framework.
The organization of this article is as follows. After this introduction, our proposed methodologies for the computation of an ACI for the point forecast and the variance components in a two-level simulation experiment are then described, and the mathematical results that support the validity of the proposed ACIs are stated (the corresponding proofs are provided in
Appendix A). In the next section, we illustrate our notation by obtaining the analytical solutions for the point forecast and the variance components of a Bayesian model to forecast sporadic demand. This solution is used in the next section to illustrate and support, through simulation experiments, the validity of the ACIs proposed in this article. In the final section, we summarize our findings and suggestions for future research.
4. Empirical Results
To validate the ACIs proposed in (4), we conducted some experiments with the Bayesian model of
Section 3 to illustrate the estimation of
,
, and
. We considered the values
,
,
,
,
,
,
,
, and
. With these data, the point forecast is
, and the variance components are
and
. Note that
in this case, for which we also ran the same experiments with
, so
,
,
, and
in the latter case. The empirical results that we report below illustrate a typical behavior that we should experiment with for any other feasible dataset.
In each of the estimation experiments carried out for this research, we considered 1000 independent replications of the algorithm in
Figure 2 for different numbers of observations in the outer loop (
n) and in the inner loop (
m); in each replication, we computed the point estimators for
,
, and
, as well as the corresponding halfwidths of 90% ACIs according to Equation (
6). Because we are estimating parameters whose values we know a priori, we can report (for a given
n and
m) the empirical coverage (i.e., the proportion of independent replications in which the corresponding ACI covers the true value of the parameter), the average and the standard deviation of halfwidths, and the square root of the empirical mean squared error defined by
where
is the value obtained in replication
i for the point estimation of a parameter
(we set the number of replications to
).
In the first set of experiments, we considered
and
for each value of
to compare the effect of increasing the number of observations in the inner loop for a given value of
. The main results of this set of experiments are summarized in
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7 and
Figure 8. Note that we do not consider
in
Figure 5 and
Figure 6 to be able to construct an ACI for the stochastic variance
.
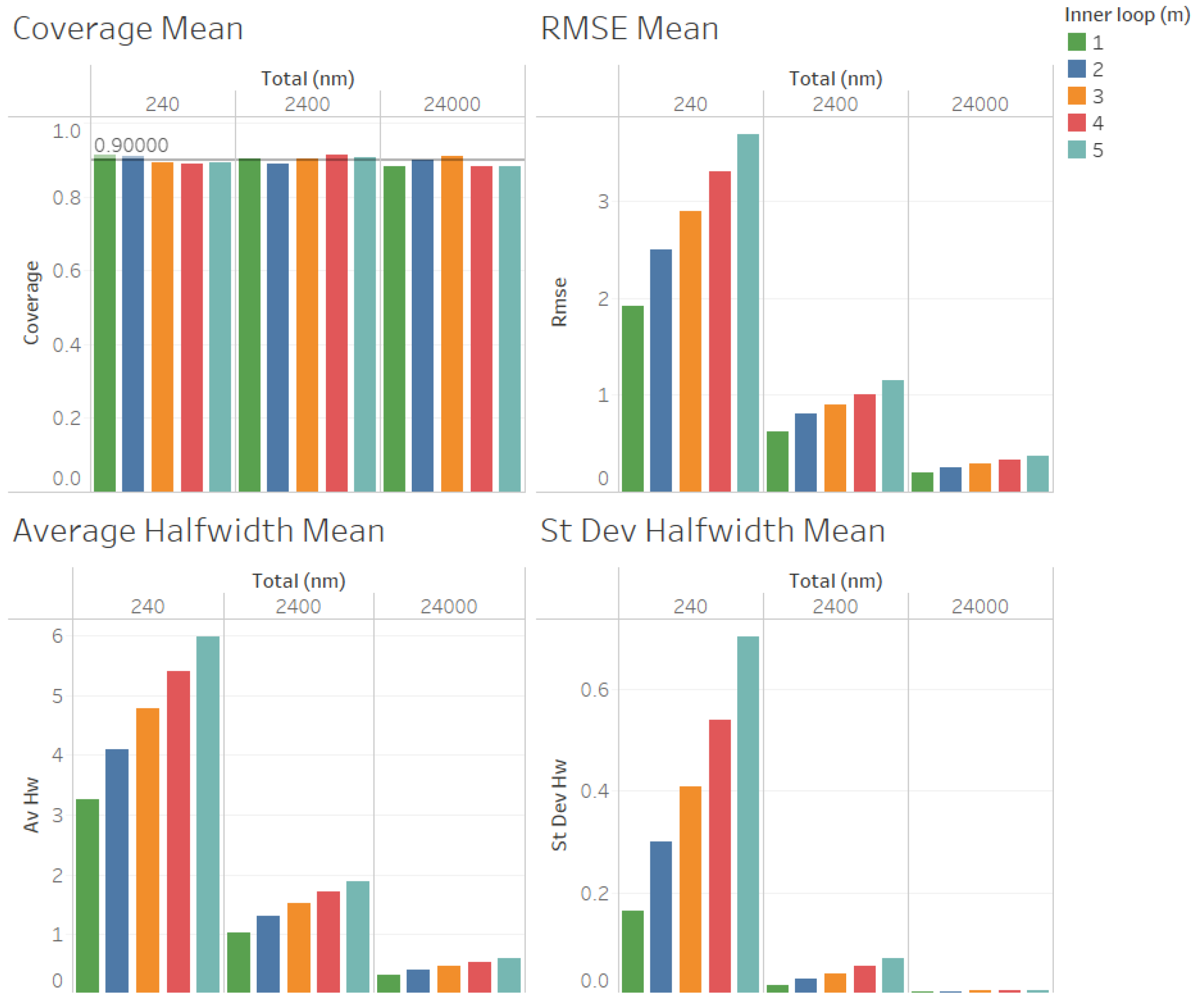
In
Figure 3, we illustrate the performance measures for the quality of the estimation procedure that we obtained for the estimation of the point forecast
when
. As we can observe in
Figure 3, the coverages are acceptable (very close to the nominal value of 0.9, even for
). These results validate the ACI defined in (
6) for the point forecast
. We also observe in
Figure 3 that the RMSE, average halfwidth, and standard deviation of the halfwidths improve (decrease) as the number of observations in the outer loop (
n) increases, as suggested by Corollary 1. Note also in
Figure 3 that a smaller value of
m provides smaller RMSEs, average halfwidths, and standard deviations of the halfwidths, thus validating our suggestion that
m should be as small as possible to improve the accuracy in the estimation of
. In
Figure 4, we illustrate the corresponding results for
, where we can observe that the same conclusions mentioned for
are fulfilled, and the main difference from the previous case is that the RMSE, average halfwidths, and standard deviation of halfwidths are smaller, which is consistent with the fact that the point forecast
is smaller than in the case in which
. Note that both in the case of
Figure 3 and in the case of
Figure 4, the RMSE, average halfwidth, and average standard deviation of the halfwidths seem to be a linear function of
m.
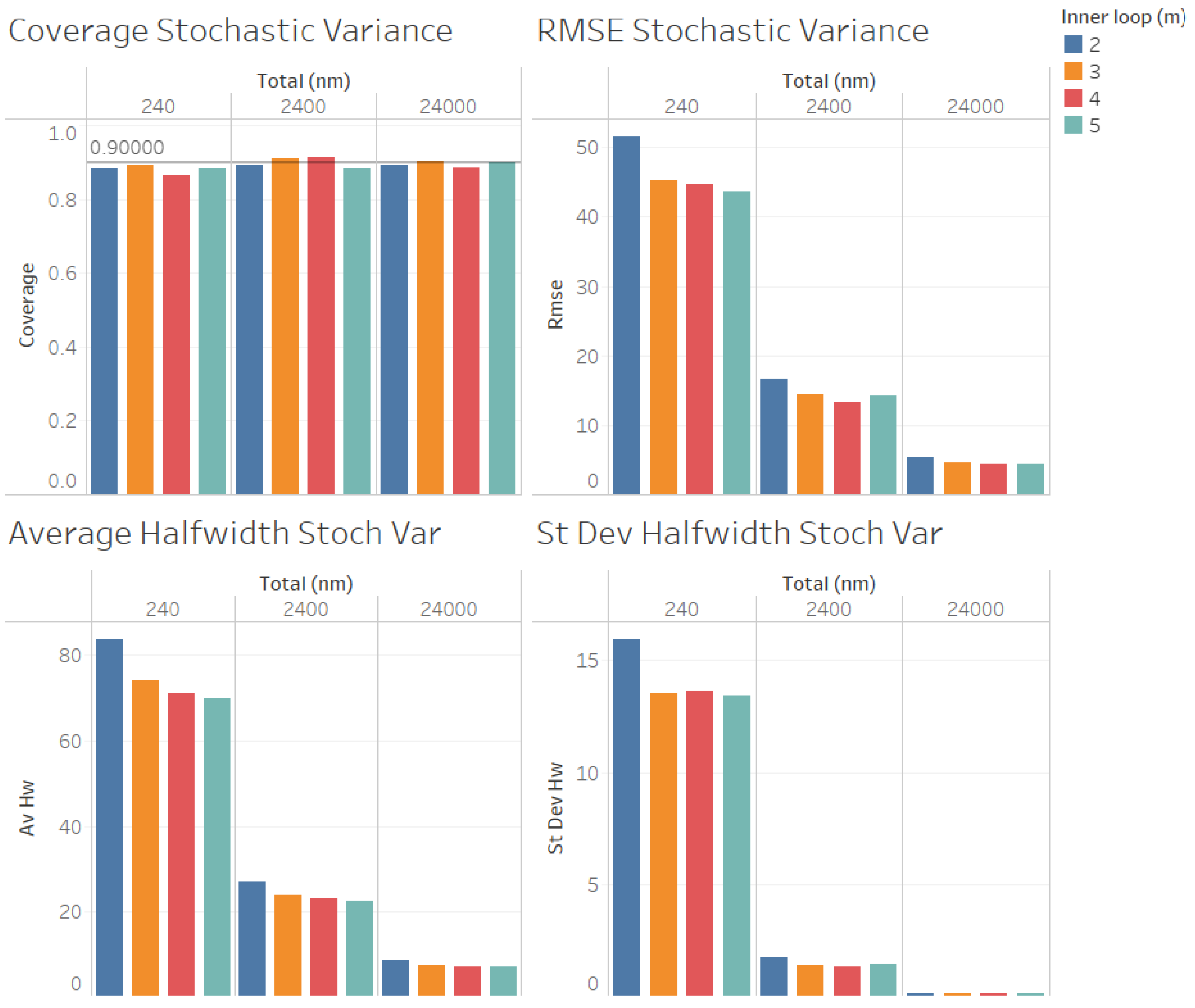
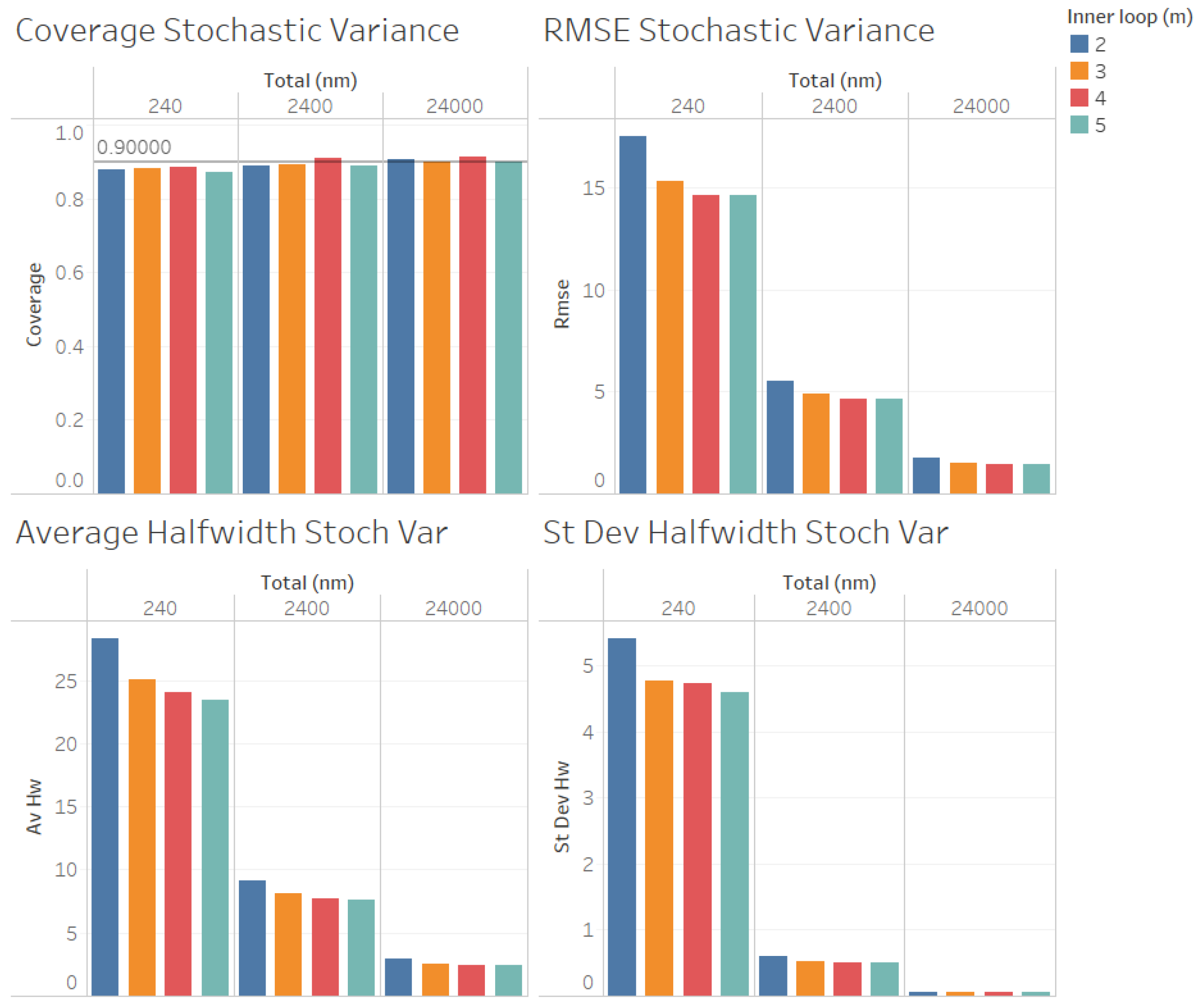
In
Figure 5, we illustrate the performance measures for the quality of the estimation procedure that we obtained for the estimation of the stochastic variance
when
. As we can observe in
Figure 5, the coverages are acceptable (very close to the nominal value of 0.9, even for
). These results validate the ACI defined in (
6) for the stochastic variance
. We also observe in
Figure 5 that the RMSE, average halfwidth, and standard deviation of halfwidths improve (decrease) as the number of observations in the outer level (
n) increases, as suggested by Corollary 2. However, contrary to what we observed for the estimation of
, a larger value of
m provides smaller RMSE, average halfwidths, and standard deviations of the halfwidths, suggesting that, for a fixed value of
, the quality of the estimation for the stochastic variance
improves as the number of the observations in the inner loop (
m) increases, although the values are very close for
. In
Figure 6, we illustrate the corresponding results for
, where we can observe that the same conclusions as those mentioned for
are fulfilled, and the main difference from the previous instance that we observed is that, now, the RMSE, average halfwidths, and standard deviation of halfwidths are smaller, which is consistent with the fact that the point forecast
is smaller than in the case
. Contrary to what we observed for the case of the estimation of
, note that both in the case of
Figure 5 and in the case of
Figure 6, the RMSE, average halfwidth, and average standard deviation of the halfwidth do not seem to be a linear function of
m. We emphasize that the case in which
is not considered in
Figure 5 and
Figure 6 because
cannot be estimated when
.
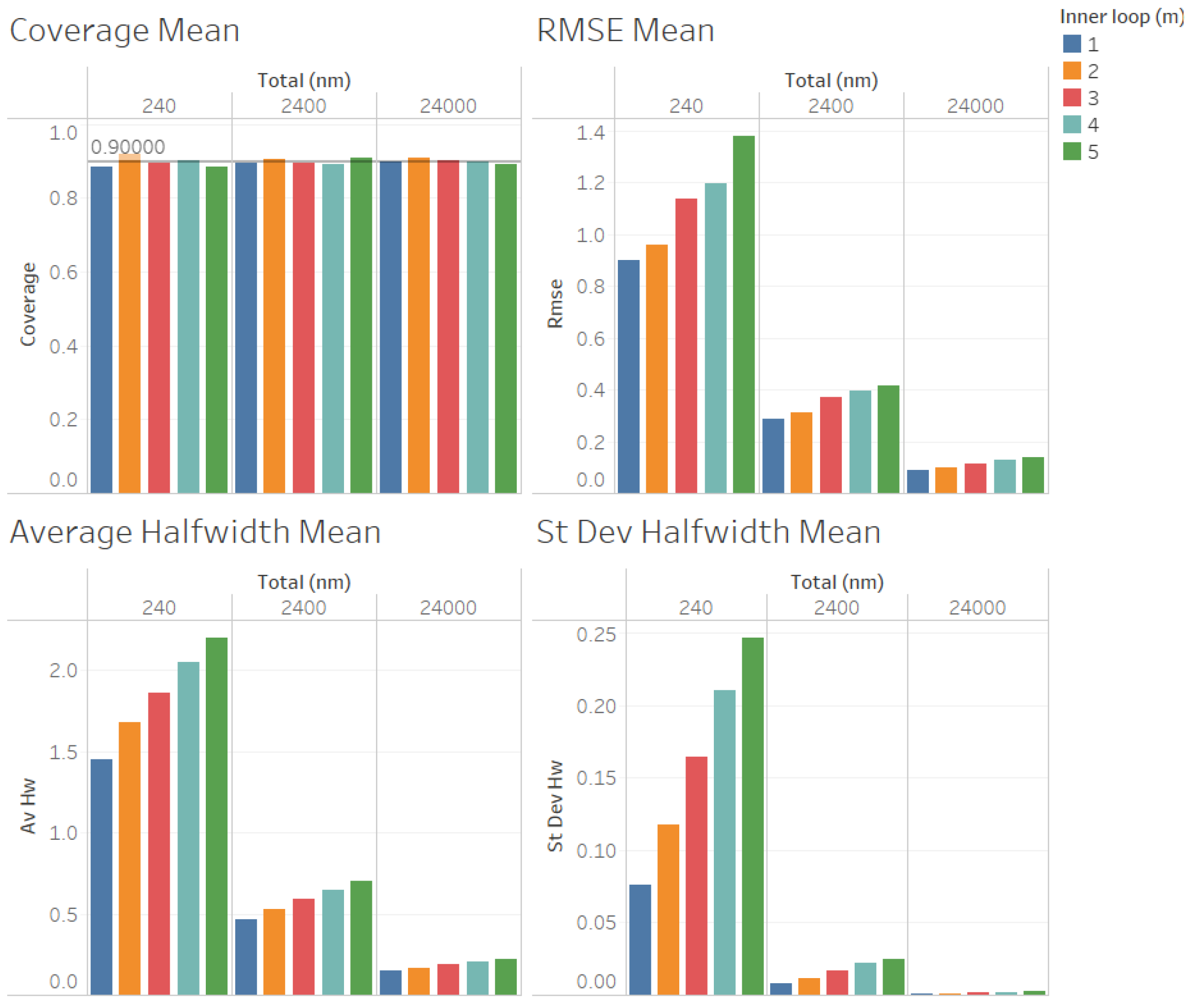
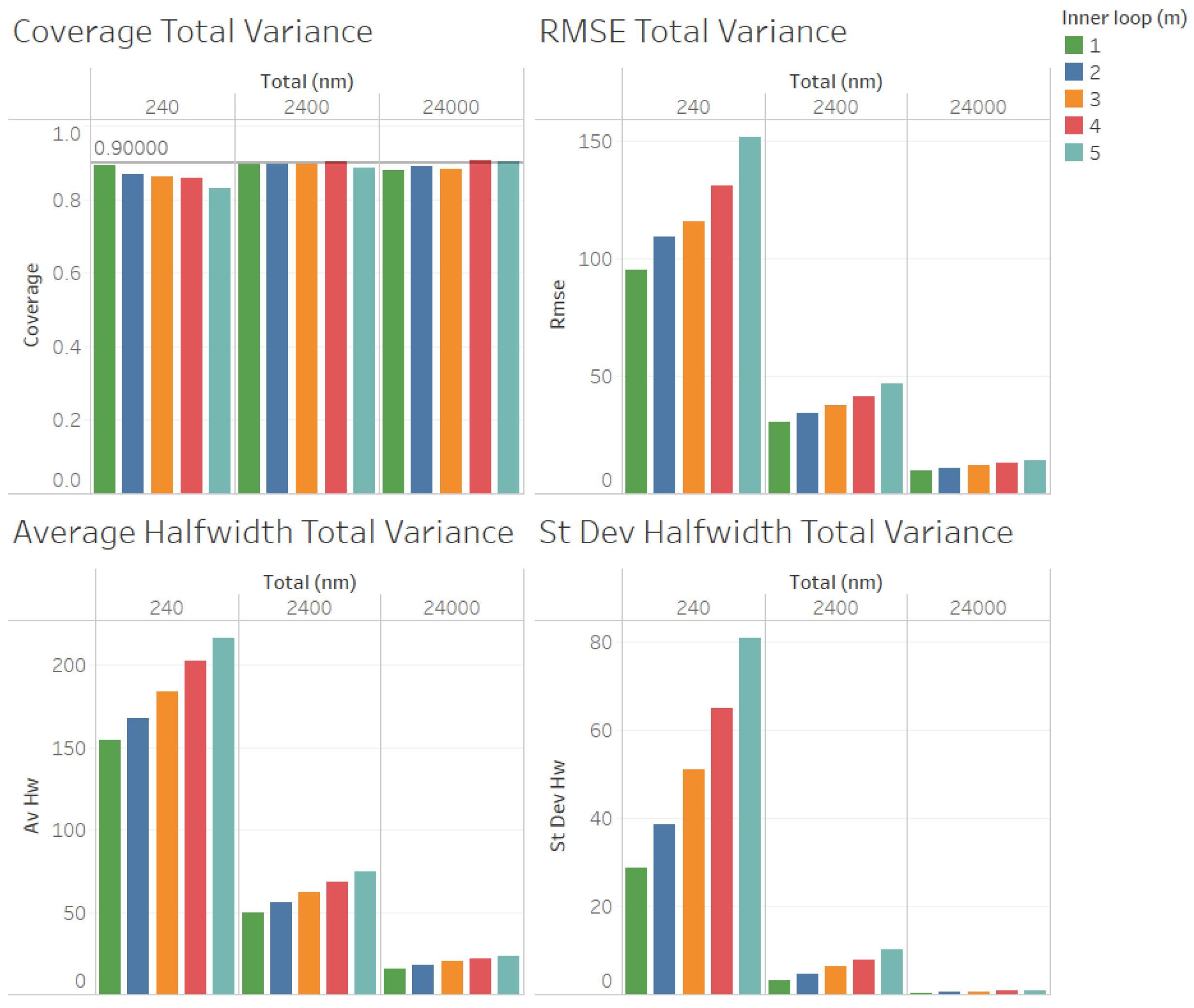
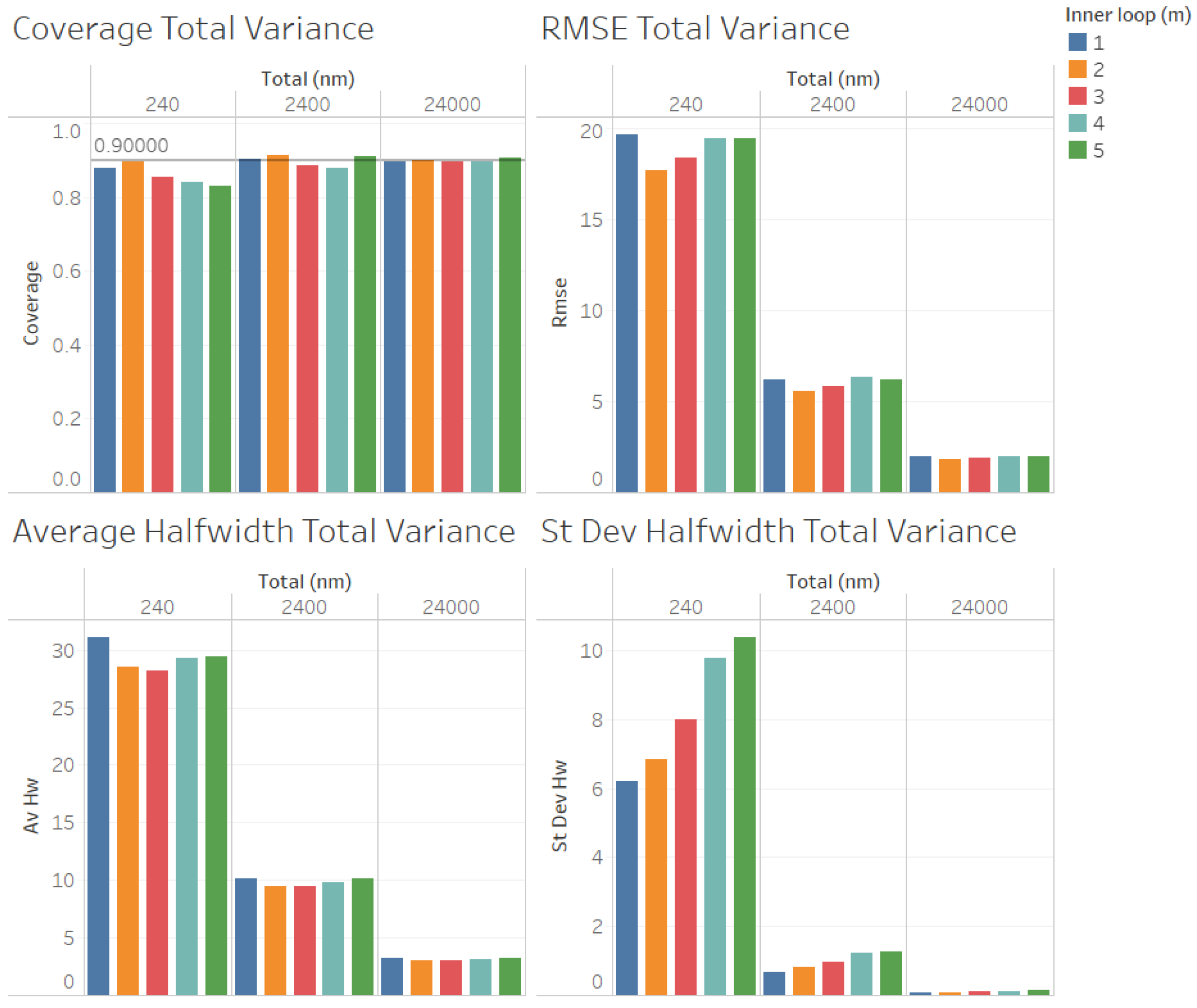
For the estimation of the total variance
(illustrated in
Figure 7 for
, and in
Figure 8 for
), we obtained results for the quality of the estimation that were similar to those for the estimation of the point forecast
, except that larger values of
n were required to obtain reliable coverages. As we can observe in
Figure 7 and
Figure 8, the coverages are acceptable (very close to the nominal value of 0.9, only for
and 24,000). These results validate the ACI defined in (
6) for the total variance
. We can also observe in
Figure 7 and
Figure 8 that the RMSE, average halfwidth, and standard deviation of the halfwidths improve (decrease) as the number of observations in the outer loop (
n) increases, as suggested by Corollary 3. Note also in
Figure 7 that a smaller value of
m provides smaller RMSEs, average halfwidths, and standard deviations of halfwidths. However, for the case in which
(illustrated in
Figure 8), where
, we observe that the RMSE and the average halfwidth decrease from
to
and then increase, showing that the best value of
m for the estimation of
depends on the value of the ratio of
.
In a second set of experiments, we considered , with , , and for each value of , to compare the quality of the estimation procedures by using the value of m that we suggested as appropriate for the estimation of the point forecast with other choices of p to illustrate the validity of Proposition 3.
Note that
is equivalent to
in Proposition 3, and
corresponds to
. Note also that
corresponds to the value of
m suggested in [
5], which is a good option for the case of biased estimation in the inner loop of the algorithm in
Figure 2. The results of this set of experiments are summarized in
Figure 9,
Figure 10,
Figure 11 and
Figure 12. Note that we do not consider the estimation of the stochastic variance
in this set of experiments because
is required to construct an ACI for the stochastic variance
. Note also that we consider
,
,
,
,
, and
, and we use the same color (red) for
, and
, as well as the same color (yellow) for
and
, to report our results in
Figure 9,
Figure 10,
Figure 11 and
Figure 12.
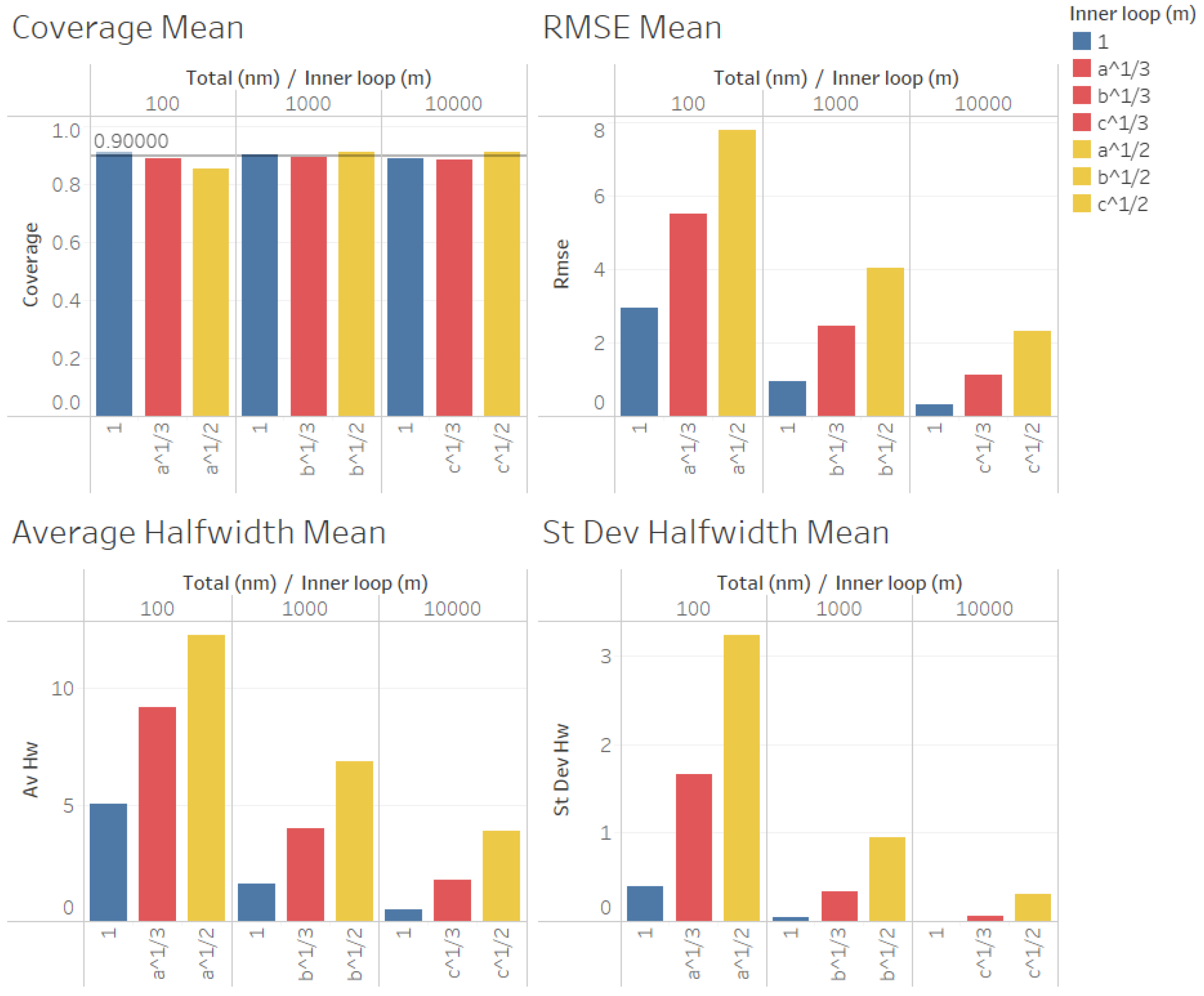
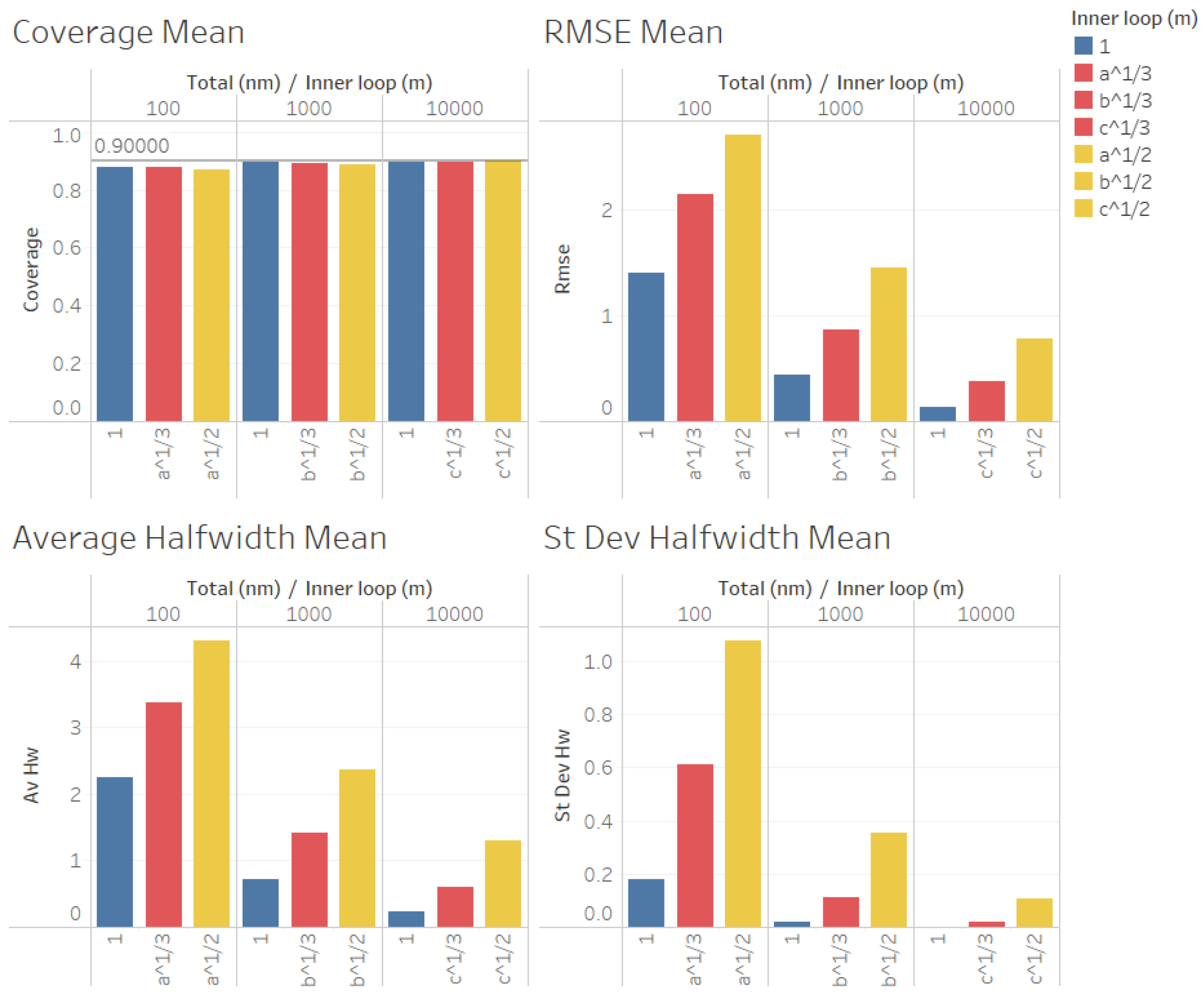
In
Figure 9 and
Figure 10, we illustrate the performance measures for the quality of the estimation procedure that we obtained for the estimation of the point forecast
in our second set of experiments. As we can observe in
Figure 9 and
Figure 10, the coverages are acceptable (very close to the nominal value of 0.9, even for
). These results validate the ACI defined in (
6) for the point forecast
and the ACI suggested by Proposition 3. We can also observe in
Figure 9 and
Figure 10 that the RMSE, average halfwidth, and standard deviation of the halfwidths are worse than
for
, and they are even worse for
, thus confirming our finding that, for a fixed number of simulated observations
, a smaller value of
m produces better point estimators for
, confirming the result of Proposition 3.
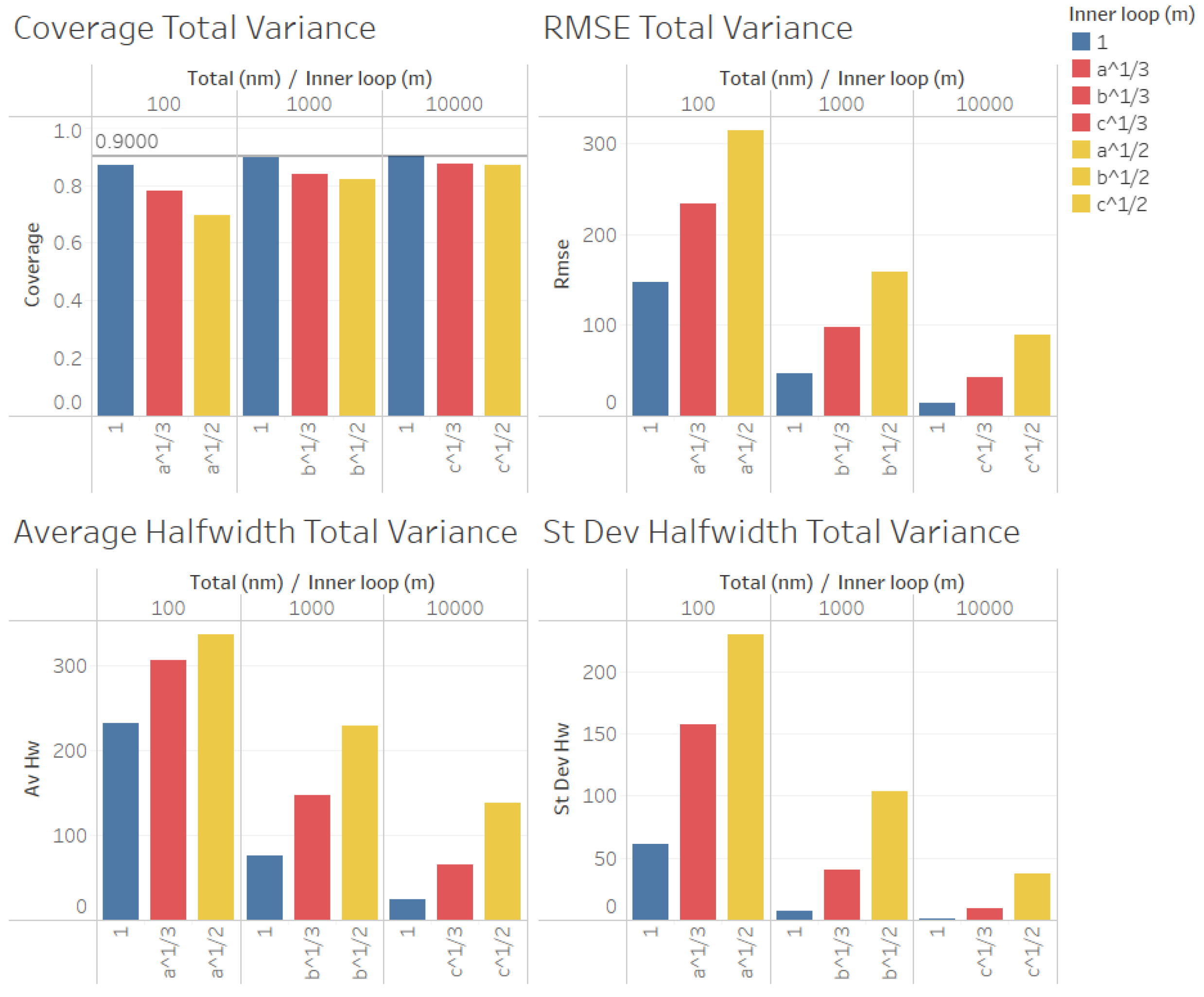
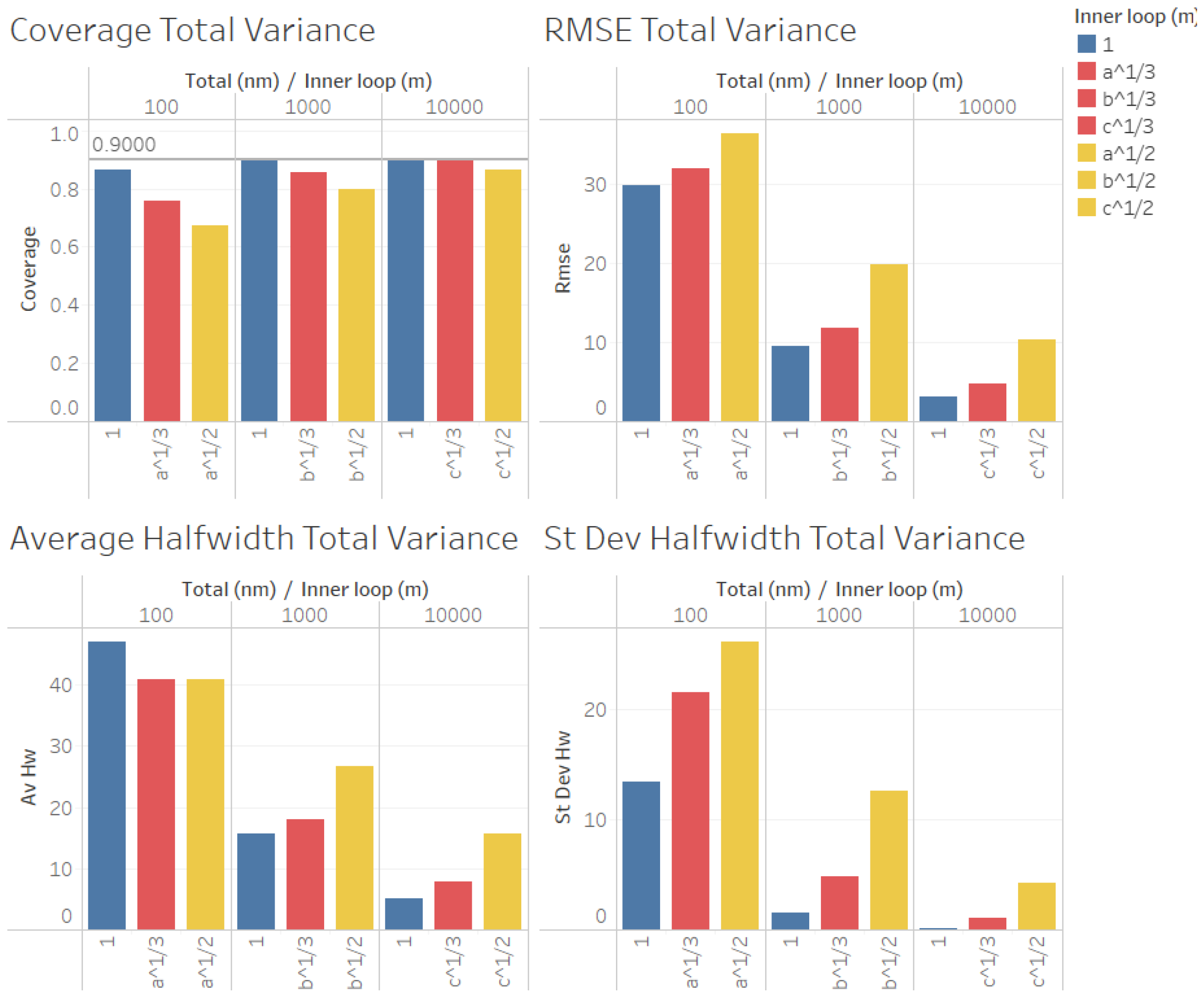
Finally, in
Figure 11 and
Figure 12, we show our results for the second set of experiments and the estimation of the total variance
.
In
Figure 11 and
Figure 12, we found similar results to those for the case of the estimation of the point forecast
, the coverages were very good (even for
n = 100), and all measures of the quality of the point estimation (RMSE, average and standard deviation of halfwidths) were worse than those in the case in which
for
, and they were even worse for
, suggesting that, as in the case of the estimation of
, a smaller value of
m produces better point estimators for
given a fixed number of replications
, with the only exception in
Figure 12 (
) being for the case of the average halfwidths and
, where the average halfwidth seems to decrease with the value of
m.



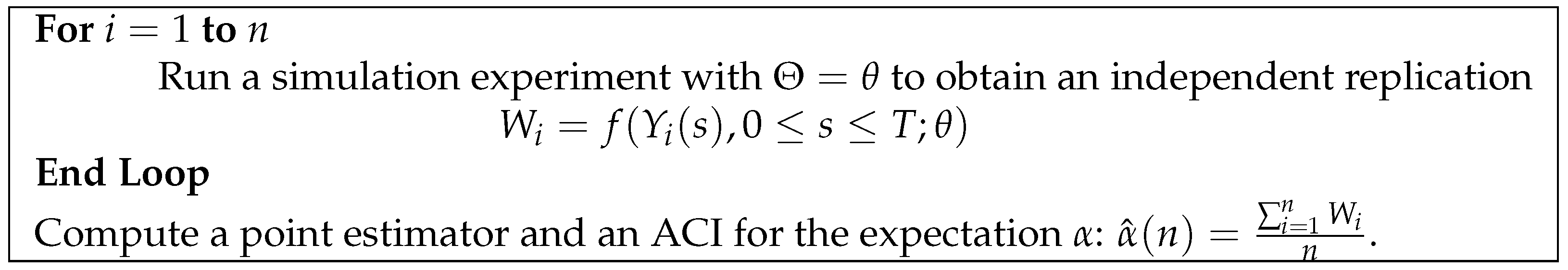{kind=link}
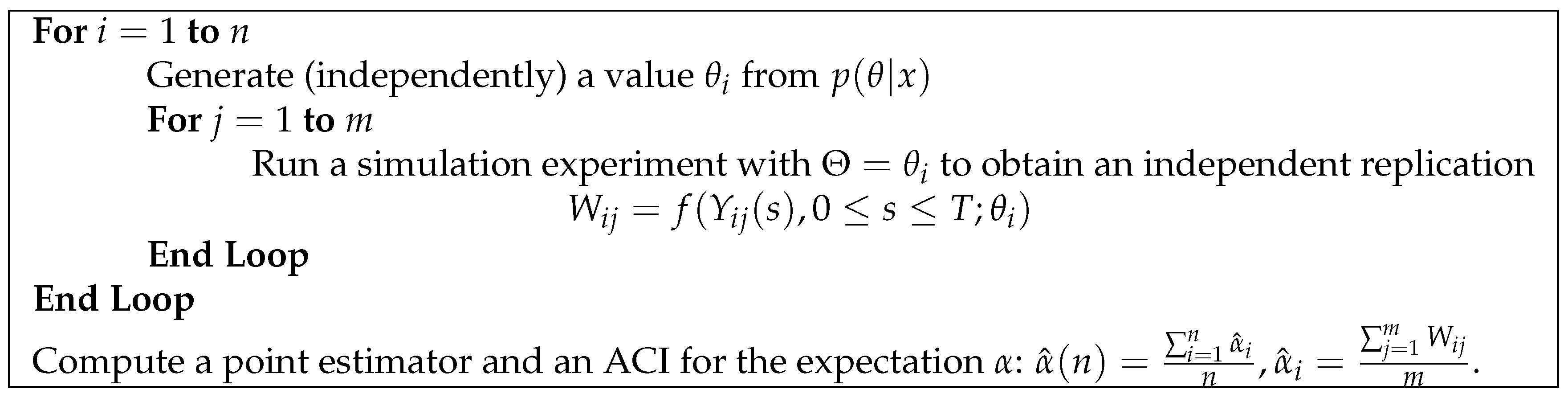{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











