


Deep Learning for Concrete Crack Detection and Measurement


Abstract
1. Introduction
- -
- development of an automatic image-based crack classification method that uses a CNN model to determine if cracks are present in an image, and does this by classifying them as cracked or not cracked;
- -
- development of a crack segmentation model, which is designed to segment the cracks identified in the images and classified as cracked;
- -
- crack width measurement of the segmented cracks masks in millimetres, which is achieved by using improved laser calibration;
- -
- evaluation and validation of the developed method, which is achieved by comparing the measured crack widths which are obtained through deep learning and image processing against manual measurements.
2. Materials and Methods
2.1. Overview of Developed Method
2.2. Data Acquisition
- -
- two concrete bridges in South Wales;
- -
- buildings around the University of South Wales (USW) Treforest Campus;
- -
- concrete beams, cubes and cylinders from laboratory experiments; and indoor and outdoor concrete slabs.
2.3. Data Pre-Processing
- 500 images captured, as described in Section 2.2.
- 150 images from SDNET2018
- 150 images from Concrete Crack Images for Classification
2.4. Algorithm Development
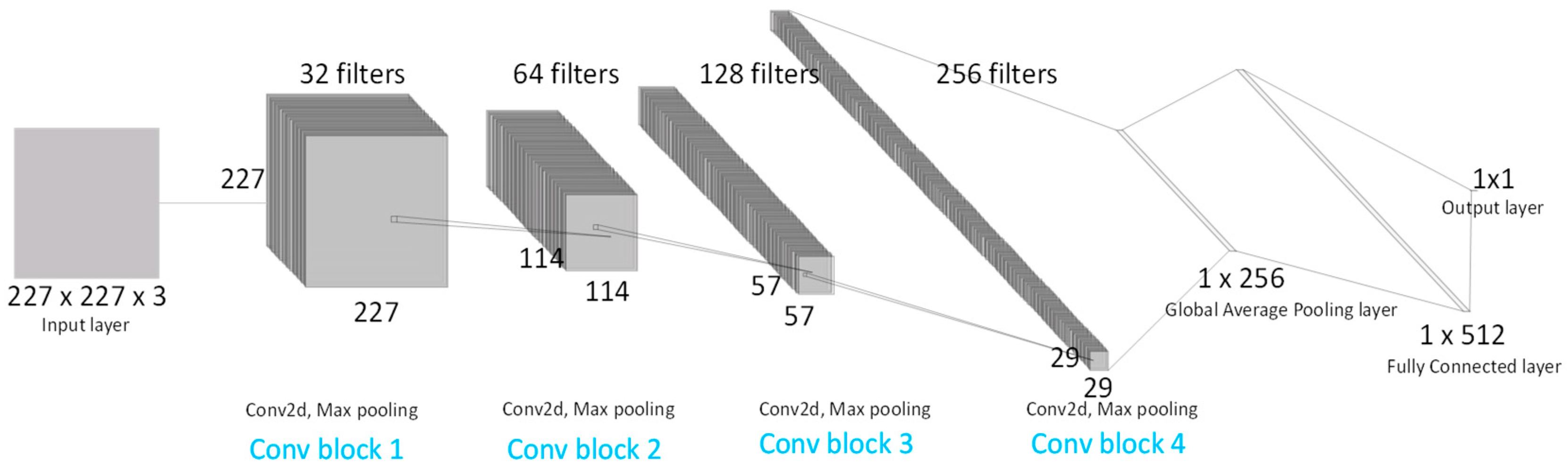
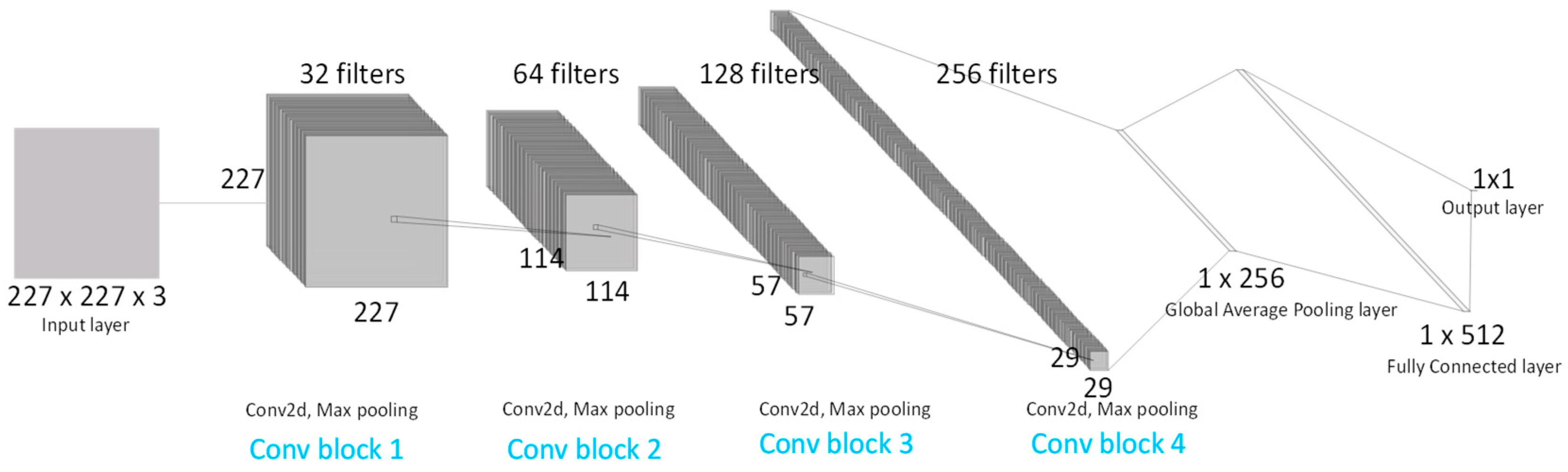
2.4.1. Crack Classification Model
2.4.2. Crack Segmentation Model
Custom U-Net Model
Custom FCN Model
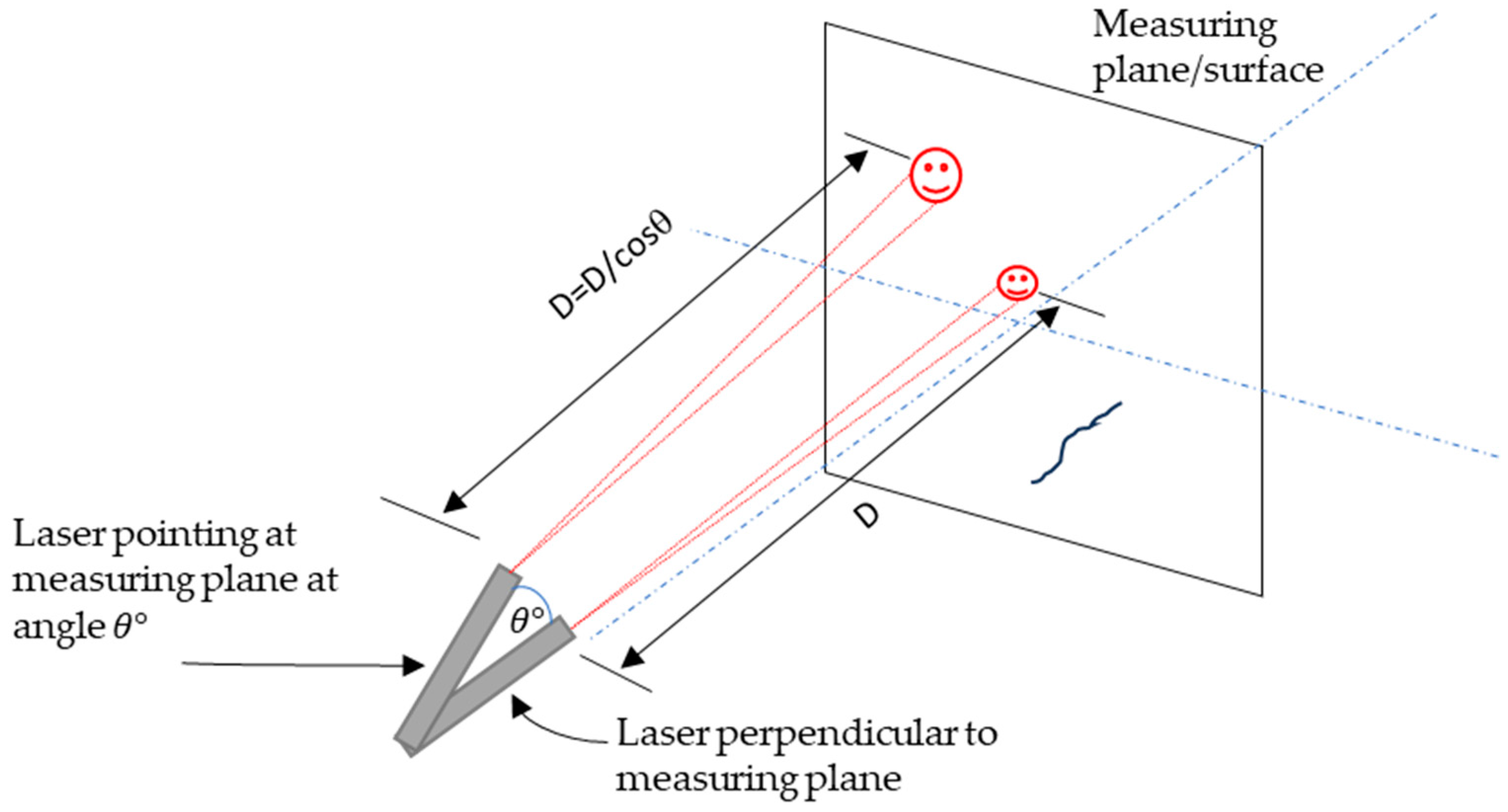
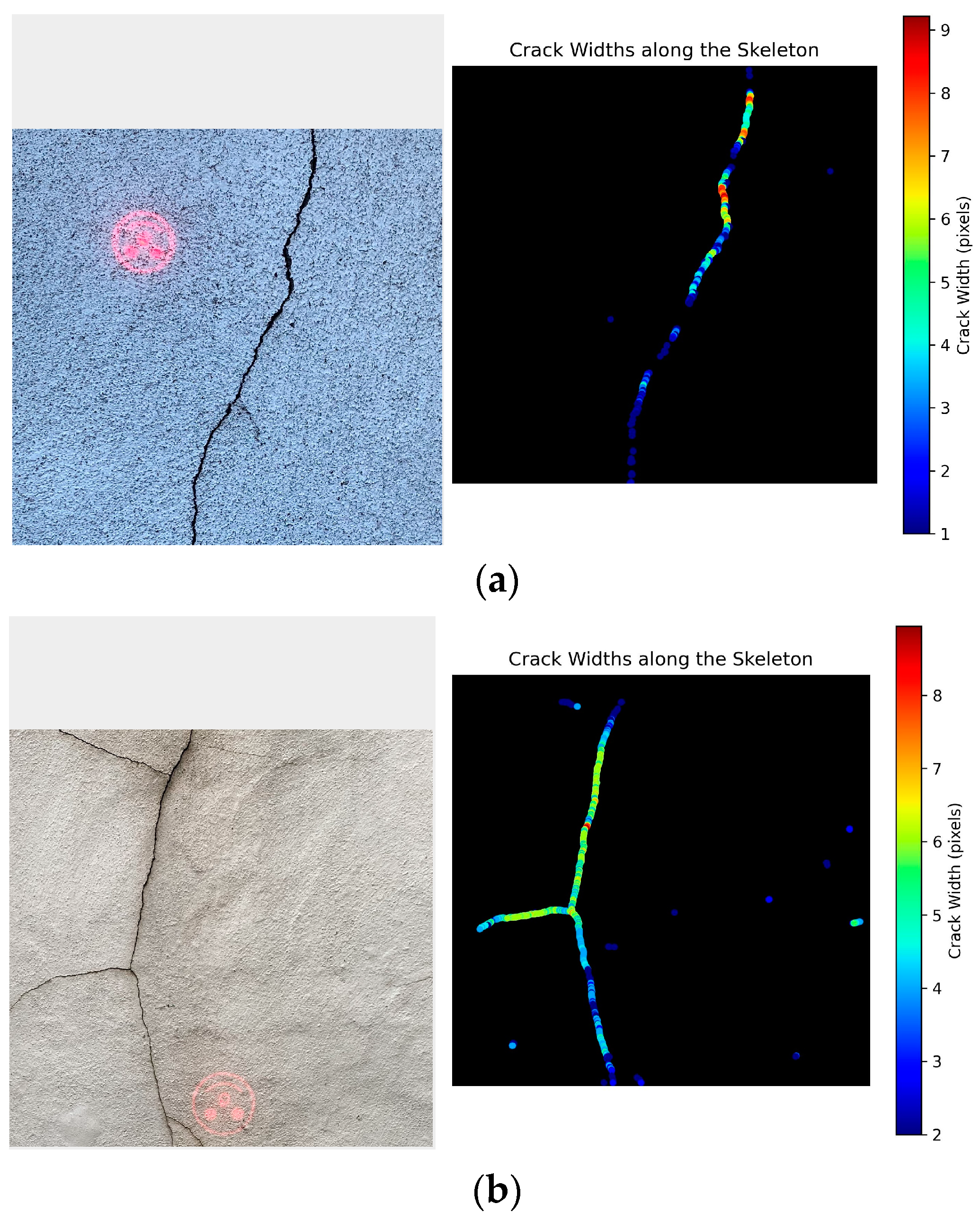
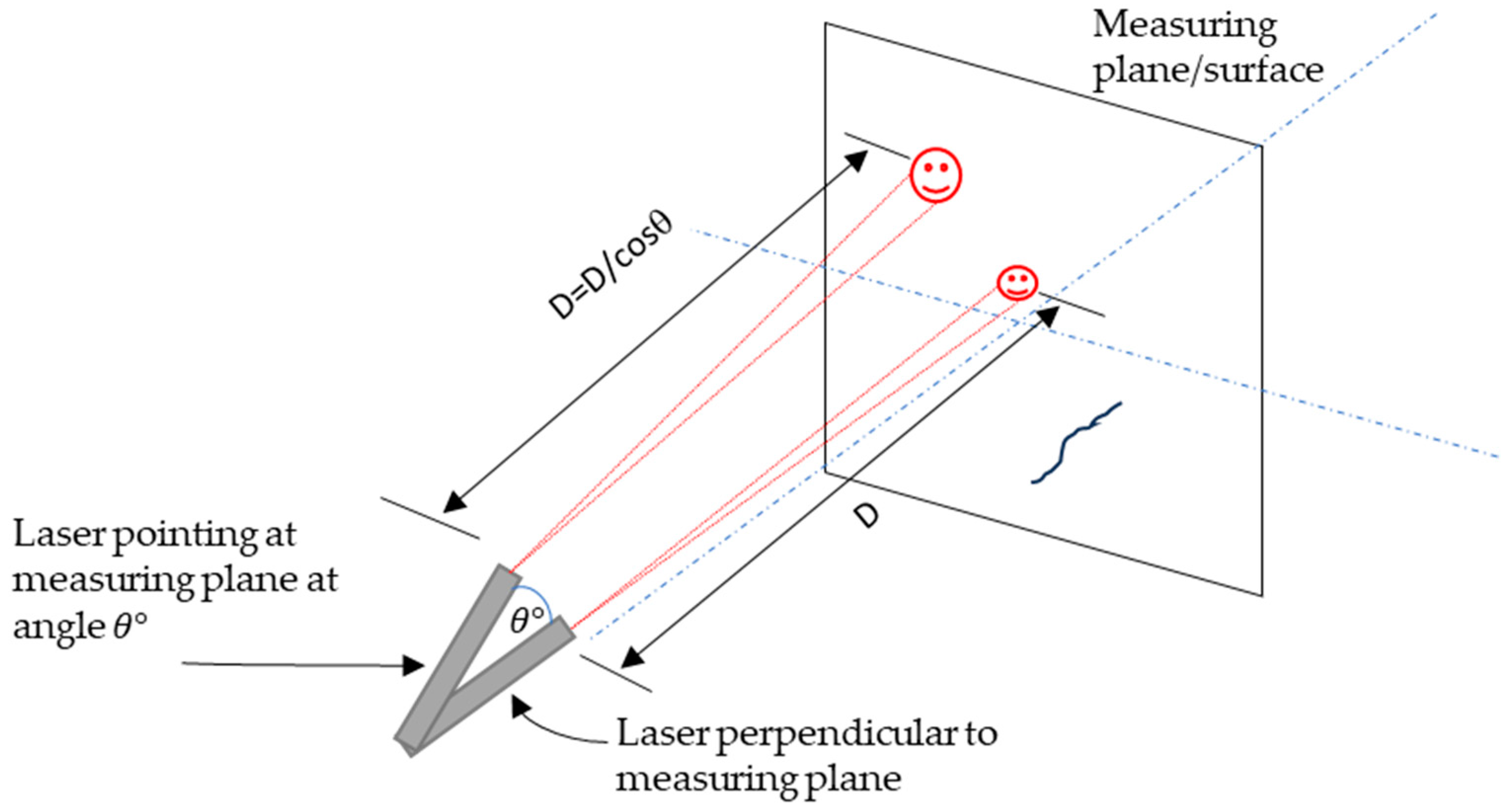
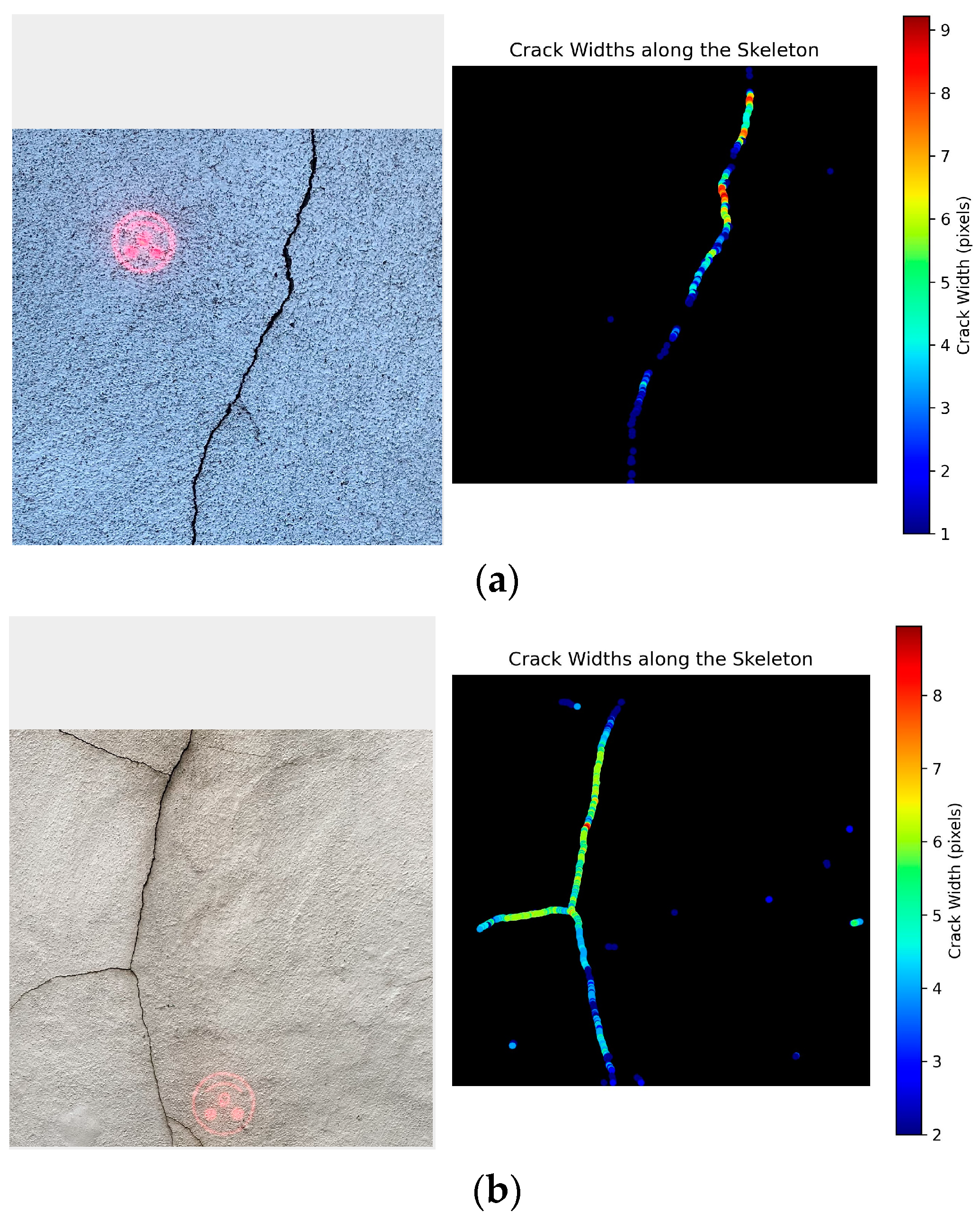
2.4.3. Crack Width Determination
2.5. Performance Evaluation
- Accuracy, defined by Equation (5), is the ratio of the correctly classified images to total number of images in the dataset.where TP represents True Positives; TN represents True Negatives; FP represents False Positives; and FN represents False Negatives; TP are correctly classified images with cracks; TN are correctly classified images with no cracks; FP are images with no cracks incorrectly classified as having cracks; and FN are images with cracks incorrectly classified as having no cracks.
- Precision, defined by Equation (6), is the ratio of positively classified crack images, true positives, over the total number of classified positives, both true and false.
- Recall, also referred to as sensitivity, is defined by Equation (7); it is the ratio of correctly classified cracks over the total number of crack observations.
- F1 score is used to calculate the weighted average of Precision and Recall and is defined by Equation (8). F1 scores range from 0 to 1, with values closer to one indicating a good balance between precision and recall.
- IOU, defined in Equation (9), is the measure of how much the predicted crack segmentation area overlaps (intersects) with the actual crack area, relative to the total area of predicted crack segmentation and actual crack.
2.6. Implementation
- Capture images or videos using the image acquisition device of choice.
- If videos were captured, pre-process them by converting the videos into image frames.
- Feed the collected images into the classification model, which will classify the images as ‘cracked’ or ‘uncracked’, and save in the relevant folder.
- Segment the images in the ‘cracked’ folder by passing them as an input to the segmentation model; this segments the images, producing a binary mask of the crack.
- Apply the measurement algorithm to binary masks to obtain a visual output, showing the crack width and location of maximum crack width.
- To convert the crack width from pixels to millimetres, detect the laser in the image and measure its pixel diameter. Use Equations (3) and (4) to convert the pixels to millimetres.
3. Results and Discussion
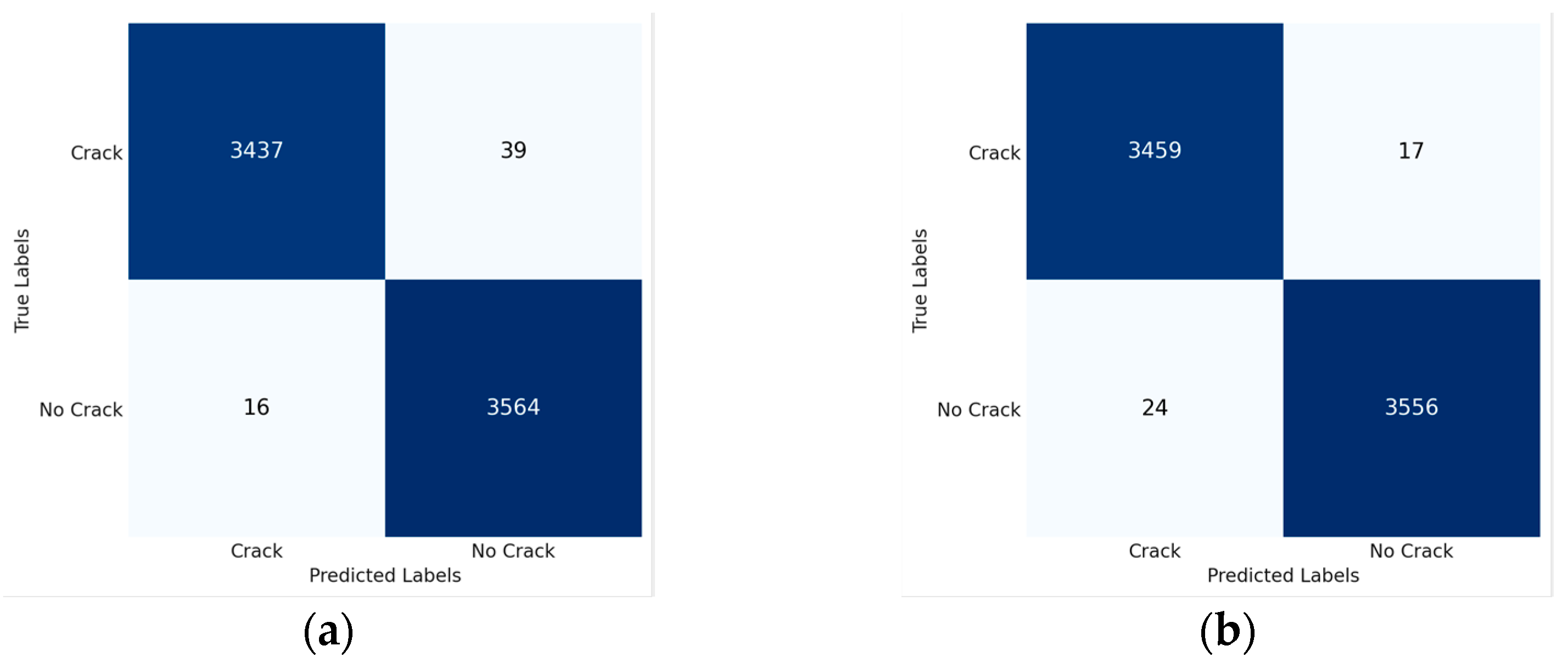
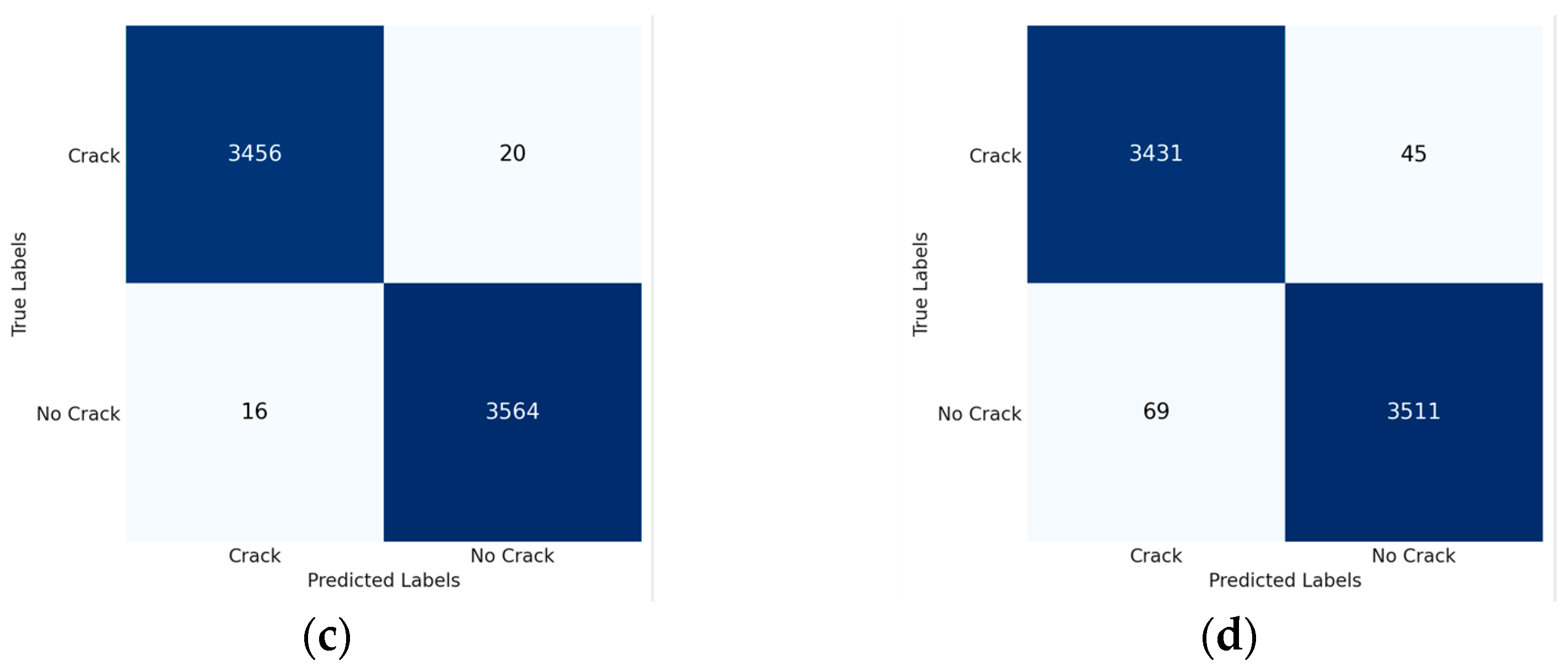
3.1. Classification
- improved efficiency by filtering out irrelevant images without cracks, ensuring the DL segmentation model only processes images with cracks;
- reduction in computational cost, due to only images with cracks being segmented;
- improved accuracy of the segmentation model, because only images known to have cracks are segmented, minimising the likelihood of false positive segmentations;
- lastly, the classification model is designed to save output in cracked or uncracked folders, thereby continuously expanding the dataset size.
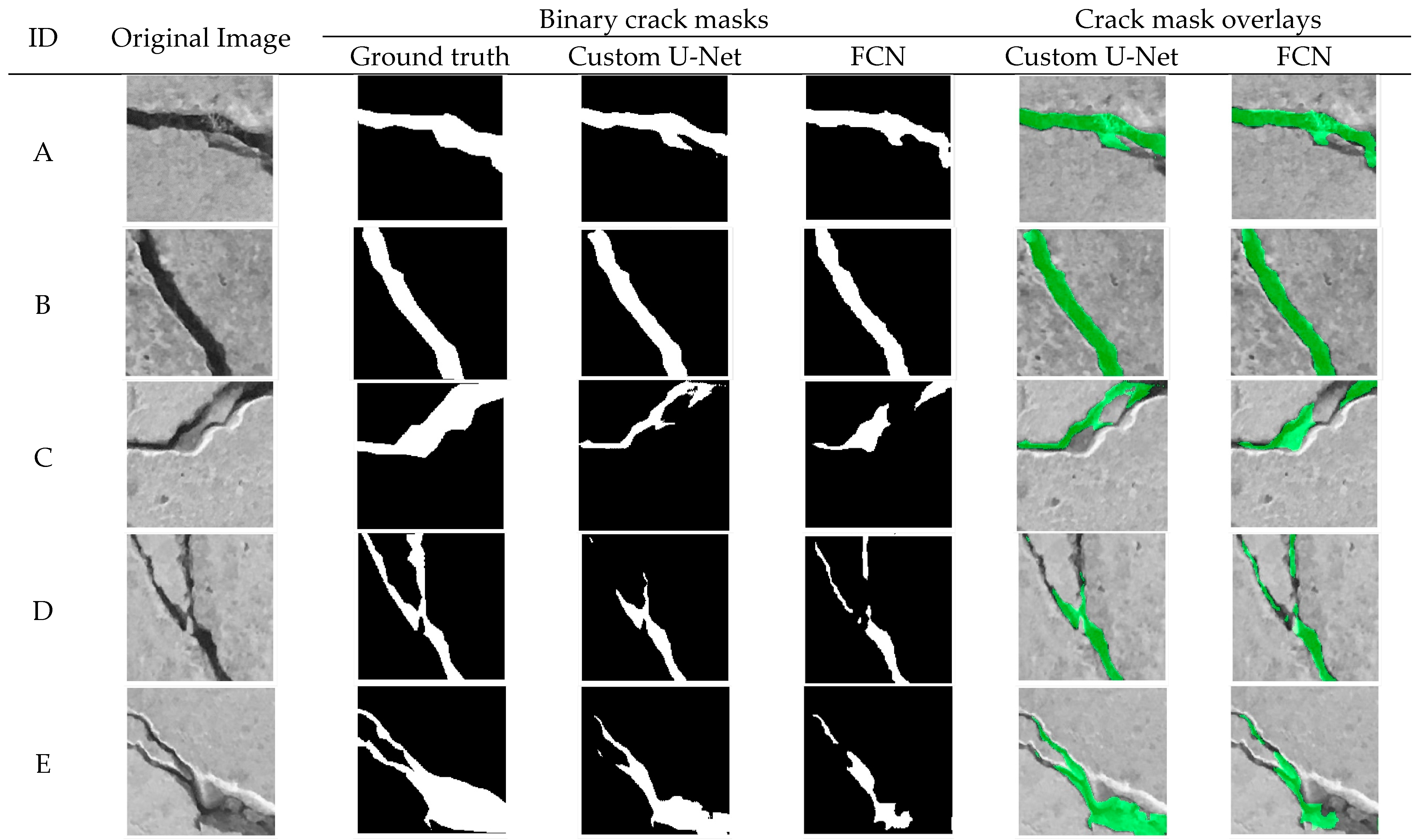
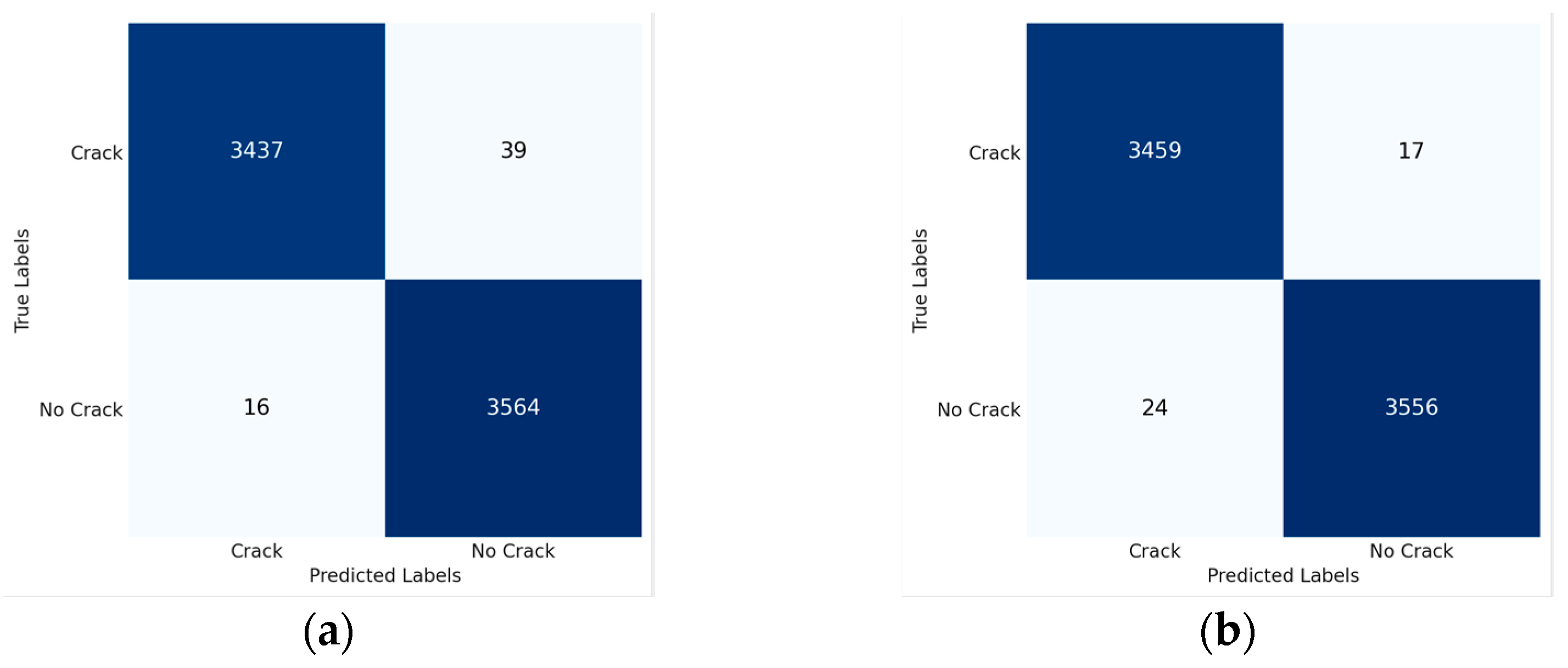
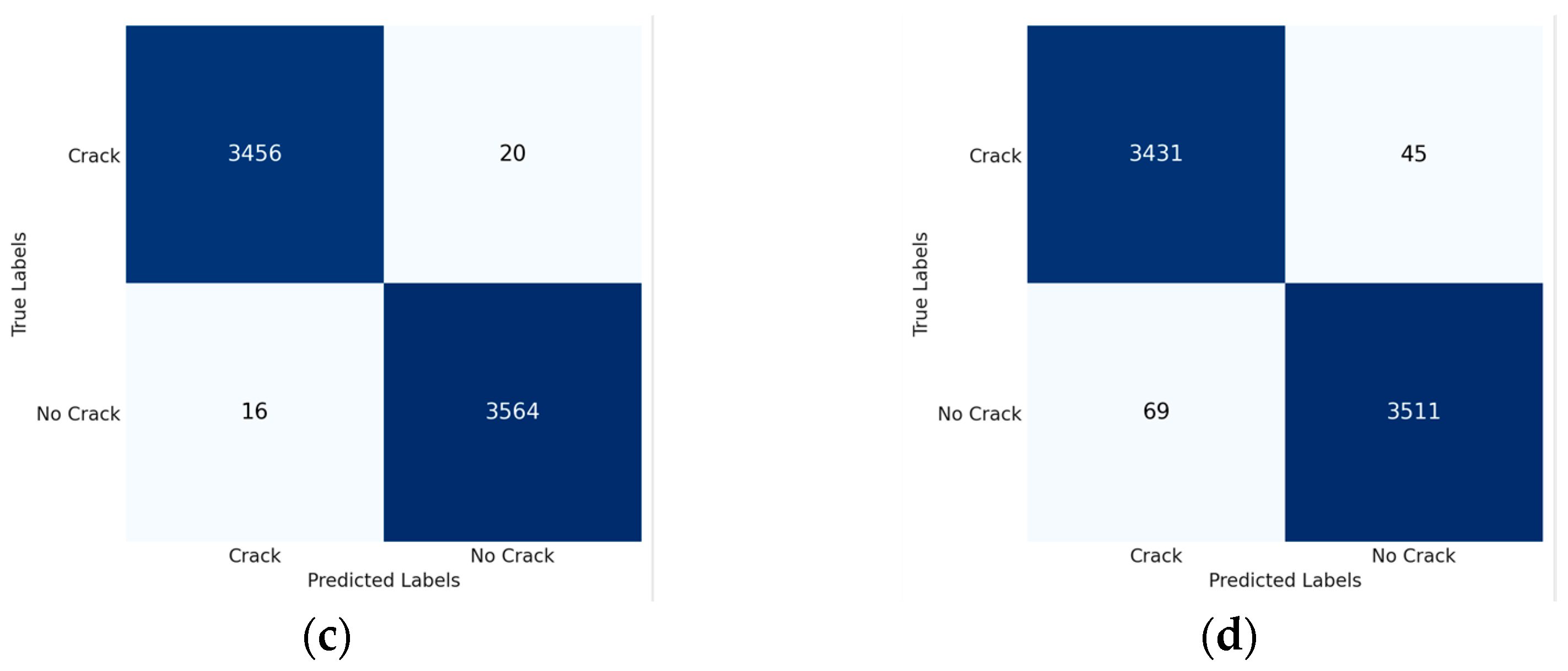
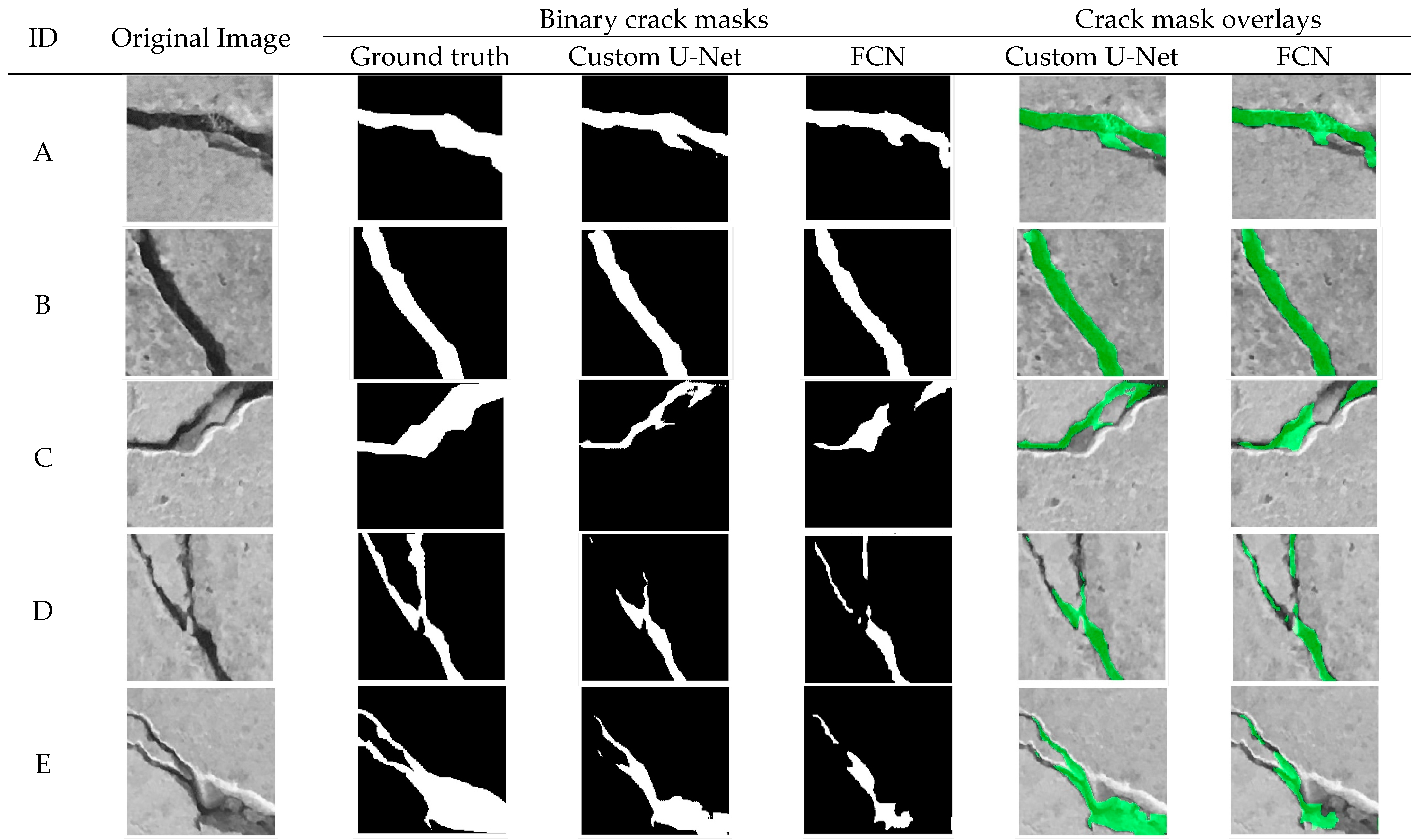
3.2. Segmentation
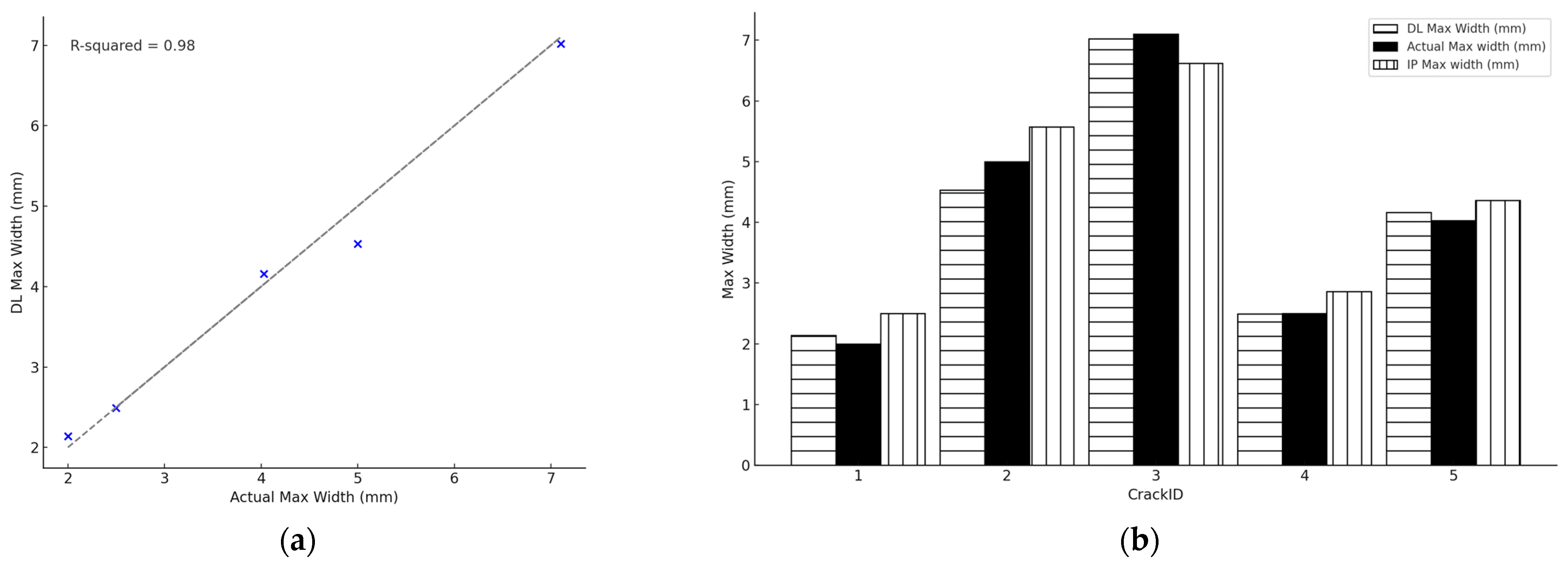
3.3. Crack Width Calculations
- (1)
- DL Max width: Maximum crack width measured from crack images segmented by using DL;
- (2)
- IP Max width: Maximum crack width measured from crack images segmented by using image processing (IP) algorithms;
- (3)
- Actual Max width: Maximum crack widths measured manually on site.
4. Conclusions
- A computationally effective approach that reduces false positives, which carries out crack segmentation by first passing images through a classification model has been proposed.
- DL segmentation yielded better results when compared to conventional image processing algorithms. In addition, DL offers better generalisation and quicker segmentation, and does not need an expert to carry out manual parameter selection.
- An enhanced laser calibration technique has been developed and applied successfully, meaning concrete crack width can be measured in millimetres.
- The use of the laser eliminates the need for physical markers to be attached to the surface being measured. This promotes safer inspections, which can be achieved by simply deploying a drone with the laser system, especially in hard-to-reach areas.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Choudhary, G.K.; Dey, S. Crack Detection in Concrete Surfaces Using Image Processing, Fuzzy Logic, and Neural Networks. In Proceedings of the 2012 IEEE 5th International Conference on Advanced Computational Intelligence, ICACI 2012, Nanjing, China, 18–20 October 2012; pp. 404–411. [Google Scholar] [CrossRef]
- Park, S.E.; Eem, S.H.; Jeon, H. Concrete Crack Detection and Quantification Using Deep Learning and Structured Light. Constr. Build. Mater. 2020, 252, 119096. [Google Scholar] [CrossRef]
- Frangopol, D.M.; Curley, J.P. Effects of Damage and Redundancy on Structural Reliability. J. Struct. Eng. 1987, 113, 1533–1549. [Google Scholar] [CrossRef]
- Avci, O.; Abdeljaber, O.; Kiranyaz, S.; Hussein, M.; Gabbouj, M.; Inman, D.J. A Review of Vibration-Based Damage Detection in Civil Structures: From Traditional Methods to Machine Learning and Deep Learning Applications. Mech. Syst. Signal Process. 2021, 147, 107077. [Google Scholar] [CrossRef]
- Nyathi, M.A.; Bai, J.; Wilson, I.D. Concrete Crack Width Measurement Using a Laser Beam and Image Processing Algorithms. Appl. Sci. 2023, 13, 4981. [Google Scholar] [CrossRef]
- Thagunna, G. Building Cracks—Causes and Remedies. Int. J. Adv. Struct. Geotech. Eng. 2015, 4, 16–20. [Google Scholar]
- Munawar, H.S.; Hammad, A.W.A.; Haddad, A.; Soares, C.A.P.; Waller, S.T. Image-Based Crack Detection Methods: A Review. Infrastructures 2021, 6, 115. [Google Scholar] [CrossRef]
- Golding, V.P.; Gharineiat, Z.; Munawar, H.S.; Ullah, F. Crack Detection in Concrete Structures Using Deep Learning. Sustainability 2022, 14, 8117. [Google Scholar] [CrossRef]
- Ai, D.; Jiang, G.; Lam, S.K.; He, P.; Li, C. Computer Vision Framework for Crack Detection of Civil Infrastructure—A Review. Eng. Appl. Artif. Intell. 2023, 117, 105478. [Google Scholar] [CrossRef]
- Fujita, Y.; Hamamoto, Y. A Robust Automatic Crack Detection Method from Noisy Concrete Surfaces. Mach. Vis. Appl. 2010, 22, 245–254. [Google Scholar] [CrossRef]
- Hoang, N.D. Detection of Surface Crack in Building Structures Using Image Processing Technique with an Improved Otsu Method for Image Thresholding. Adv. Civ. Eng. 2018, 2018, 3924120. [Google Scholar] [CrossRef]
- Canny, J. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar] [CrossRef]
- Zhao, H.; Qin, G.; Wang, X. Improvement of Canny Algorithm Based on Pavement Edge Detection. In Proceedings of the 2010 3rd International Congress on Image and Signal Processing, CISP 2010, Yantai, China, 16–18 October 2010; Volume 2, pp. 964–967. [Google Scholar] [CrossRef]
- Ioli, F.; Pinto, A.; Pinto, L. Uav Photogrammetry for Metric Evaluation of Concrete Bridge Cracks. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2022, XLIII-B2-2, 1025–1032. [Google Scholar] [CrossRef]
- Kim, H.; Ahn, E.; Cho, S.; Shin, M.; Sim, S.H. Comparative Analysis of Image Binarization Methods for Crack Identification in Concrete Structures. Cem. Concr. Res. 2017, 99, 53–61. [Google Scholar] [CrossRef]
- Kim, H.; Lee, J.; Ahn, E.; Cho, S.; Shin, M.; Sim, S.H. Concrete Crack Identification Using a UAV Incorporating Hybrid Image Processing. Sensors 2017, 17, 2052. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Li, H.; Yu, Y.; Luo, X.; Huang, T.; Yang, X. Automatic Pixel-Level Crack Detection and Measurement Using Fully Convolutional Network. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 1090–1109. [Google Scholar] [CrossRef]
- Silva, W.R.L.d.; Lucena, D.S.d. Concrete Cracks Detection Based on Deep Learning Image Classification. Proceedings 2018, 2, 489. [Google Scholar] [CrossRef]
- Kim, H.; Ahn, E.; Shin, M.; Sim, S.H. Crack and Noncrack Classification from Concrete Surface Images Using Machine Learning. Struct. Health Monit. 2018, 18, 725–738. [Google Scholar] [CrossRef]
- Liu, Y.; Yeoh, J.K.W. Automated Crack Pattern Recognition from Images for Condition Assessment of Concrete Structures. Autom. Constr. 2021, 128, 103765. [Google Scholar] [CrossRef]
- Uwanuakwa, I.D.; Idoko, J.B.; Mbadike, E.; Reşatoǧlu, R.; Alaneme, G. Application of Deep Learning in Structural Health Management of Concrete Structures. Proc. Inst. Civ. Eng.—Bridge Eng. 2022, 1–8. [Google Scholar] [CrossRef]
- Gao, Y.; Mosalam, K.M. Deep Transfer Learning for Image-Based Structural Damage Recognition. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 748–768. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Volume 9351, pp. 234–241. [Google Scholar] [CrossRef]
- Liu, Z.; Cao, Y.; Wang, Y.; Wang, W. Computer Vision-Based Concrete Crack Detection Using U-Net Fully Convolutional Networks. Autom. Constr. 2019, 104, 129–139. [Google Scholar] [CrossRef]
- Zhao, S.; Kang, F.; Li, J. Non-Contact Crack Visual Measurement System Combining Improved U-Net Algorithm and Canny Edge Detection Method with Laser Rangefinder and Camera. Appl. Sci. 2022, 12, 10651. [Google Scholar] [CrossRef]
- Mirzazade, A.; Popescu, C.; Gonzalez-Libreros, J.; Blanksvärd, T.; Täljsten, B.; Sas, G. Semi-Autonomous Inspection for Concrete Structures Using Digital Models and a Hybrid Approach Based on Deep Learning and Photogrammetry. J. Civ. Struct. Health Monit. 2023, 13, 1633–1652. [Google Scholar] [CrossRef]
- Zhao, W.; Liu, Y.; Zhang, J.; Shao, Y.; Shu, J. Automatic Pixel-Level Crack Detection and Evaluation of Concrete Structures Using Deep Learning. Struct. Control Health Monit. 2022, 29, e2981. [Google Scholar] [CrossRef]
- Chaiyasarn, K.; Buatik, A.; Mohamad, H.; Zhou, M.; Kongsilp, S.; Poovarodom, N. Integrated Pixel-Level CNN-FCN Crack Detection via Photogrammetric 3D Texture Mapping of Concrete Structures. Autom. Constr. 2022, 140, 104388. [Google Scholar] [CrossRef]
- Dung, C.V.; Anh, L.D. Autonomous Concrete Crack Detection Using Deep Fully Convolutional Neural Network. Autom. Constr. 2019, 99, 52–58. [Google Scholar] [CrossRef]
- Ye, X.W.; Jin, T.; Chen, P.Y. Structural Crack Detection Using Deep Learning–Based Fully Convolutional Networks. Adv. Struct. Eng. 2019, 22, 3412–3419. [Google Scholar] [CrossRef]
- Ren, Y.; Huang, J.; Hong, Z.; Lu, W.; Yin, J.; Zou, L.; Shen, X. Image-Based Concrete Crack Detection in Tunnels Using Deep Fully Convolutional Networks. Constr. Build. Mater. 2020, 234, 117367. [Google Scholar] [CrossRef]
- Kang, D.; Benipal, S.S.; Gopal, D.L.; Cha, Y.J. Hybrid Pixel-Level Concrete Crack Segmentation and Quantification across Complex Backgrounds Using Deep Learning. Autom. Constr. 2020, 118, 103291. [Google Scholar] [CrossRef]
- Yu, Z.; Shen, Y.; Sun, Z.; Chen, J.; Gang, W. Cracklab: A High-Precision and Efficient Concrete Crack Segmentation and Quantification Network. Dev. Built Environ. 2022, 12, 100088. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision 2018, Munich, Germany, 8–14 September 2018; Volume 11211, pp. 833–851. [Google Scholar] [CrossRef]
- Mishra, M.; Jain, V.; Saurabh, S.K.; Singh, K.; Damodar, M. Two-Stage Method Based on the You Only Look Once Framework and Image Segmentation for Crack Detection in Concrete Structures. Archit. Struct. Constr. 2022, 1, 429–446. [Google Scholar] [CrossRef]
- Tomczak, K.; Jakubowski, J.; Fiołek, P. Method for Assessment of Changes in the Width of Cracks in Cement Composites with Use of Computer Image Processing and Analysis. Stud. Geotech. Mech. 2017, 39, 73–80. [Google Scholar] [CrossRef]
- Ito, A.; Aoki, Y.; Hashimoto, S. Accurate Extraction and Measurement of Fine Cracks from Concrete Block Surface Image. In Proceedings of the IEEE 2002 28th Annual Conference of the Industrial Electronics Society, IECON 02, Seville, Spain, 5–8 November 2002; Volume 3, pp. 2202–2207. [Google Scholar] [CrossRef]
- Peng, X.; Zhong, X.; Zhao, C.; Chen, A.; Zhang, T. A UAV-Based Machine Vision Method for Bridge Crack Recognition and Width Quantification through Hybrid Feature Learning. Constr. Build. Mater. 2021, 299, 123896. [Google Scholar] [CrossRef]
- Li, S.; Zhao, X. Automatic Crack Detection and Measurement of Concrete Structure Using Convolutional Encoder-Decoder Network. IEEE Access 2020, 8, 134602–134618. [Google Scholar] [CrossRef]
- Kim, B.; Cho, S. Image-Based Concrete Crack Assessment Using Mask and Region-Based Convolutional Neural Network. Struct. Control Health Monit. 2019, 26, e2381. [Google Scholar] [CrossRef]
- Jeong, H.; Jeong, B.; Han, M.; Cho, D. Analysis of Fine Crack Images Using Image Processing Technique and High-Resolution Camera. Appl. Sci. 2021, 11, 9714. [Google Scholar] [CrossRef]
- Dorafshan, S.; Thomas, R.J.; Maguire, M. SDNET2018: An Annotated Image Dataset for Non-Contact Concrete Crack Detection Using Deep Convolutional Neural Networks. Data Brief 2018, 21, 1664–1668. [Google Scholar] [CrossRef] [PubMed]
- Özgenel, Ç.F.; Gönenç Sorguç, A. Performance Comparison of Pretrained Convolutional Neural Networks on Crack Detection in Buildings. In Proceedings of the 35th International Symposium on Automation and Robotics in Construction, Berlin, Germany, 20–25 July 2018; Volume 35, pp. 1–8. [Google Scholar]
- Roboflow Inc. Roboflow Annotate: Label Faster Than Ever. Available online: https://roboflow.com/annotate (accessed on 3 September 2023).
- Python Software Foundation the Python Language Reference. Available online: https://docs.python.org/3/reference/index.html (accessed on 1 August 2023).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Device | Specifications | Data Type | Location Used |
|---|---|---|---|
| DJI Mini 3 pro |
|
|
|
| iPhone 11 Pro Max |
|
|
|
| Nikon D3400 DSLR |
|
|
|
| Dataset | Crack Images | No Crack Images |
|---|---|---|
| Our data (NYA-Crack-Data) | 2167 | 2859 |
| SDNET2018 | 1000 | 1000 |
| Concrete Crack Images for Classification | 20,000 | 20,000 |
| Total (47,026) | 23,167 | 23,859 |
| Model | Testing | Precision | Recall | F1-Score | Training Time (min) | |
|---|---|---|---|---|---|---|
| Accuracy | Loss | |||||
| Custom CNN | 99.22 | 0.0340 | 0.9954 | 0.9888 | 0.9921 | 35.9 |
| Inception V4 | 99.87 | 0.0049 | 0.9931 | 0.9951 | 0.9941 | 66.5 |
| VGG16 | 99.89 | 0.0041 | 0.9954 | 0.9943 | 0.9949 | 46.2 |
| DenseNet121 | 98.21 | 0.0543 | 0.9803 | 0.9870 | 0.9836 | 60.5 |
| Model | Total Parameters | Trainable Parameters | Non-Trainable Parameters |
|---|---|---|---|
| Custom CNN | 409,442 | 409,314 | 128 |
| Inception V4 | 55,912,674 | 55,852,130 | 60,544 |
| VGG16 | 15,242,050 | 15,242,050 | 0 |
| DenseNet121 | 8,089,154 | 8,005,506 | 83,648 |
| Model | Accuracy | IoU | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| Custom U-Net | 96.54 | 0.6295 | 0.7174 | 0.8371 | 0.7726 |
| Custom FCN | 95.88 | 0.5900 | 0.6897 | 0.8031 | 0.7421 |
| Crack ID | Conversion Factor | Measured Max Width (Pixels) | Converted Max Width (mm) | Actual Max Width (mm) | Absolute Error (mm) |
|---|---|---|---|---|---|
| 1 | 0.357 | 6.00 | 2.14 | 2.00 | 0.14 |
| 2 | 0.507 | 8.94 | 4.53 | 5.00 | 0.47 |
| 3 | 0.351 | 20.0 | 7.02 | 7.10 | 0.08 |
| 4 | 0.275 | 9.06 | 2.49 | 2.50 | 0.01 |
| 5 | 0.205 | 20.3 | 4.16 | 4.03 | 0.13 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nyathi, M.A.; Bai, J.; Wilson, I.D. Deep Learning for Concrete Crack Detection and Measurement. Metrology 2024, 4, 66-81. https://doi.org/10.3390/metrology4010005
Nyathi MA, Bai J, Wilson ID. Deep Learning for Concrete Crack Detection and Measurement. Metrology. 2024; 4(1):66-81. https://doi.org/10.3390/metrology4010005
Chicago/Turabian StyleNyathi, Mthabisi Adriano, Jiping Bai, and Ian David Wilson. 2024. "Deep Learning for Concrete Crack Detection and Measurement" Metrology 4, no. 1: 66-81. https://doi.org/10.3390/metrology4010005
APA StyleNyathi, M. A., Bai, J., & Wilson, I. D. (2024). Deep Learning for Concrete Crack Detection and Measurement. Metrology, 4(1), 66-81. https://doi.org/10.3390/metrology4010005