
Improving Deep Segmentation of Abdominal Organs MRI by Post-Processing


Abstract
:1. Introduction
1.1. Background on Segmentation of Abdominal Organs in MRI
1.2. Contributions
2. Related Work
3. The Post-Processing Approach
3.1. Fencing (Expected Location Constraint)
| Algorithm 1: 3D Fencing | Comments |
| Input: training ground-truth sequences s as 3D array s{}, organ ids in ground-truth idx[] | |
| Output: 3D fence for each organ fence{organ}[] | |
| 1. fence={}; 2. for i = 1:length(idx) % for each organ a. fence{end+1}=zeros(maxX, maxY, maxZ); % create fence space b. for i = 1:length(s) % for each sequence i. fence{end}=fence{end} OR s{i}(idx organ) % OR the sequence c. end d. fence{end}=imdilate(fence{end}, δ); % add δ-dilation 3. end | |
3.2. Class Reassignments and Removal of Noise
- Define the largest continuous spatial region of a specific organ, O, as the main volume of that organ.
- For each region that is classified as another organ, O′, but is completely within the organ fence and which has a volume larger that a predefined threshold (the threshold was set to 500 pixels in our experiments), consider it as organ O (reclassify).
- For each region that is classified as another organ O’ but is completely within the organ fence and which has a volume smaller than the predefined threshold (the threshold was set to 500 pixels in our experiments), consider it as background (reclassify to background).
- Regions classified as organ O, but which are smaller than a certain threshold (i.e., “too small regions”) are considered noise and reclassified as background (the threshold was set to 500 pixels in our experiments).
| Algorithm 2: Class re-assignments and removal of noise | Comments |
| Input: segmentation outputs as sets of 3D arrays, each being one sequence s{sequence[]}, organ ids in ground-truth idx[], fences fence{organ} | |
| Output: cleaned segmentation outputs s{sequence[]} | |
| 1. sout={}; 2. for i = 1: length(s) % for each sequence a. sout{end+1}=zeroed 3D sequence volume; b. for j = i:length(idx) % for each organ i. O = zeroed 3D organ sequence volume; ii. volO=s{i} & fence{idx} % organ’s fence iii. bw=bwlabel(volO)=>regions % label differently each connected region iv. O = bw(bw=max(countEachLabel(bw))) % max volume region within fence v. bw(idx2:volO~=idx && countLabel(bw, idx2)>500)=idx=>volO % reclassify to organ vi. bw(idx2:volO~=idx && countLabel(bw, idx2)<=500)=idx=>volO % reclassify to bkgnd vii. bw(idx2:volO==idx && countLabel(bw, idx2)<=500)=background=>volO %remove noise viii. sout{end}= sout{end}|volO % add the organ volume to the sequence c. end 3. end | |
3.3. Computation and Filling of Organ Envelopes
3.4. Slice Smoothing and Filling
| Algorithm 3: Slice smoothing and filling | Comments |
| Input: sequence of 2D slices s[] | |
| Output: sequence of cleaned 2D slices s[] | |
| 1. For each slice si in s a. for each organ sio isolated from si i. apply 2D erode operator imerode [12] to sio (uses a structuring elem with size as parameter, we used square and size 3 empirically) ii. Keep the largest region by applying labeling of connected regions and counting the number of pixels of each region: 1. bw=bwlabel(sio)=>regions %label differently each connected region 2. R = bw(bw=max(countEachLabel(bw))) %max region in slice 3. Delete all but R iii. Apply a 2D dilate operator imdilate [12] to sio (structuring elem as well, we used square and size 3 empirically) iv. Fill holes inside sio using imfill morphological operator ([12,16]) v. Smooth contours of sio by blurring and re-thresholding (blur using 2-D average convolution, then keep intensities >0.5) b. End c. Reconstruct si from the modified sio for all organs as the union of all sio 2. end | |
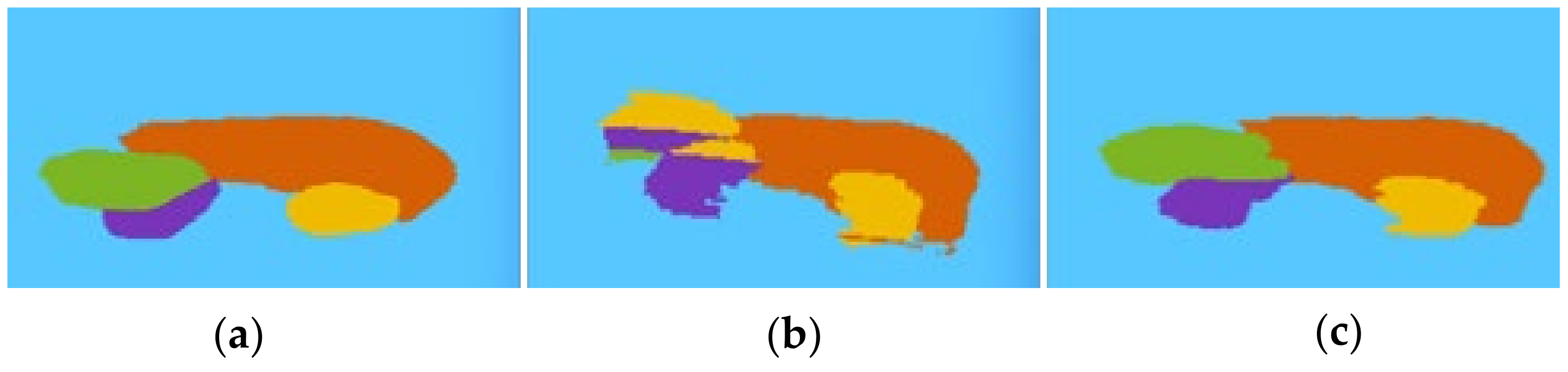
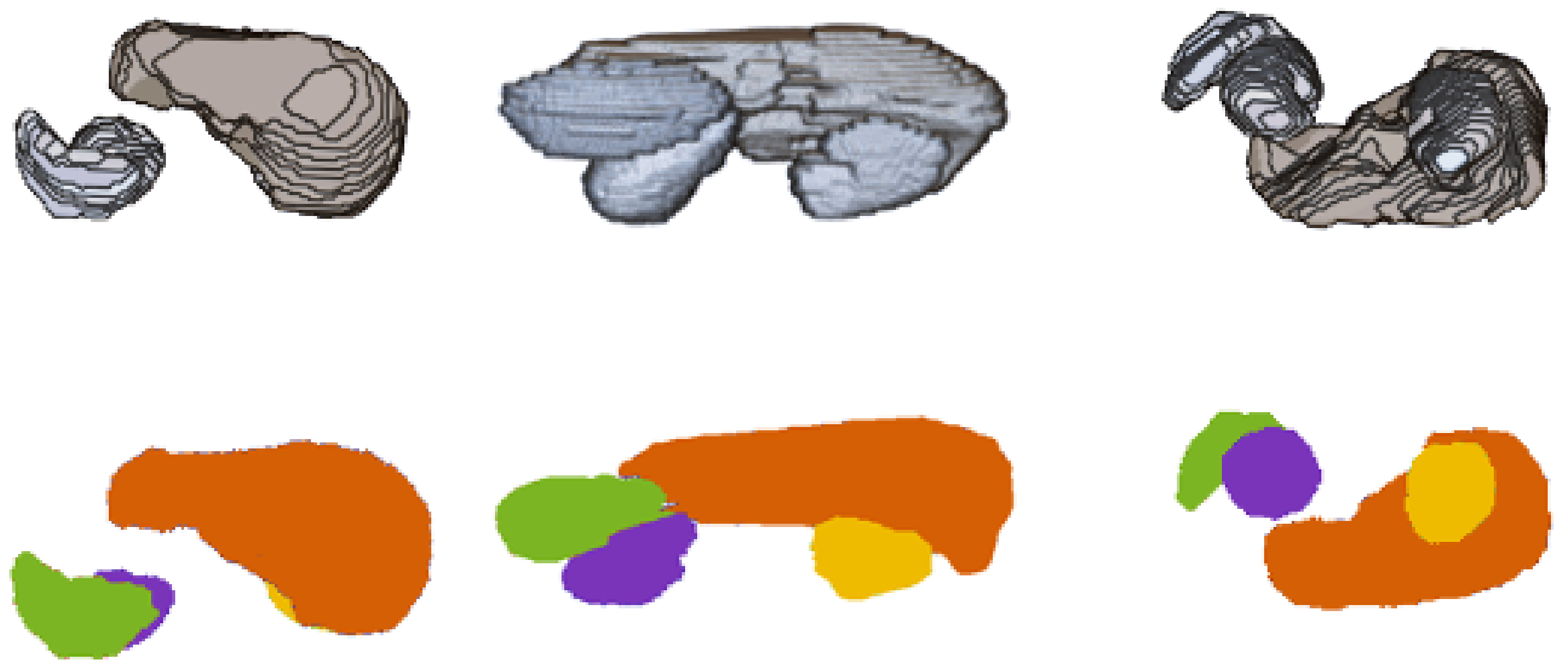
3.5. Illustrating Result of Post-Processing Transformations
4. Materials and Methods
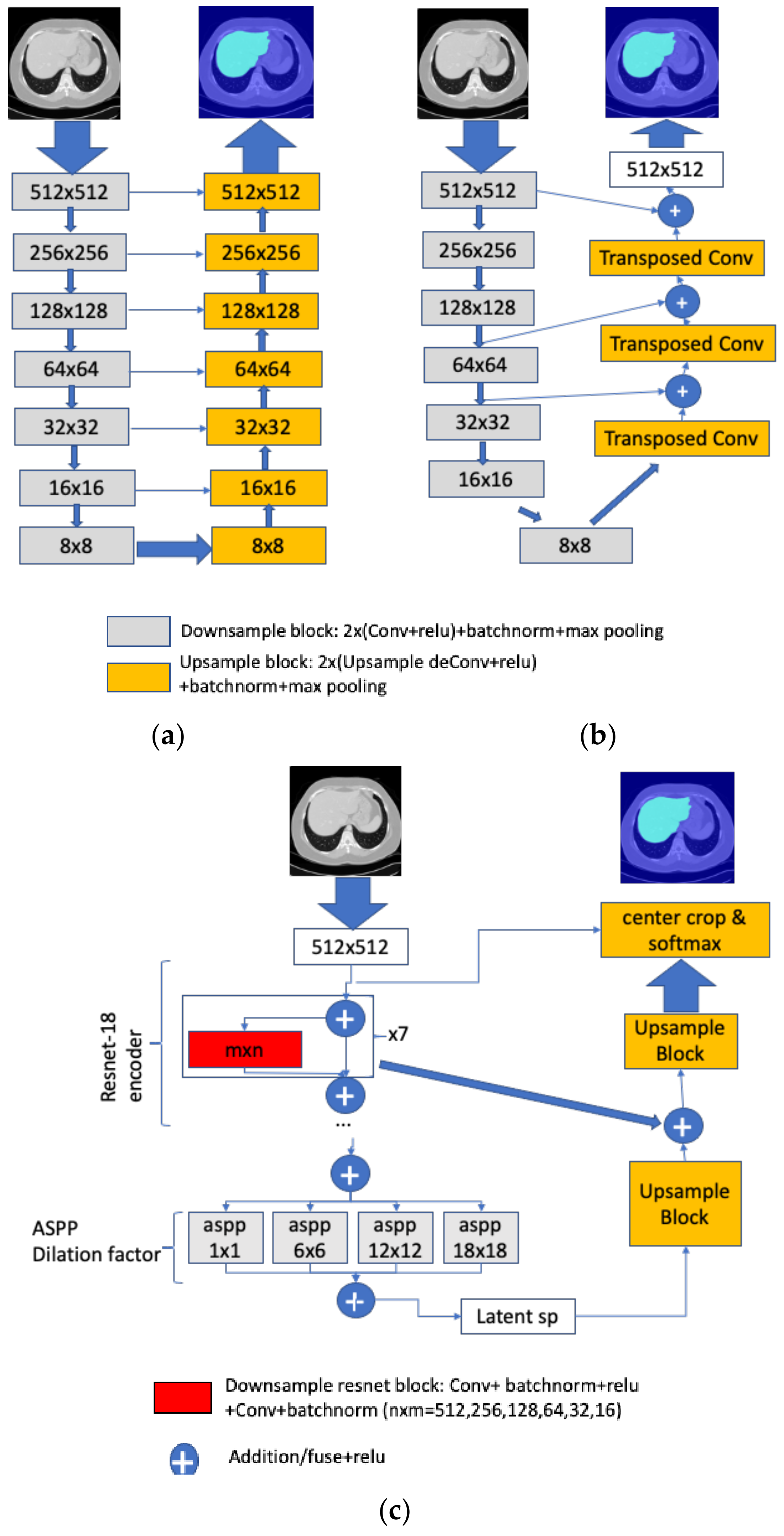
4.1. Segmentation Networks
4.2. Dataset
4.3. Training and Sequence of Experiments
4.4. Development Environment and Libraries Used
5. Experimental Results and Interpretation
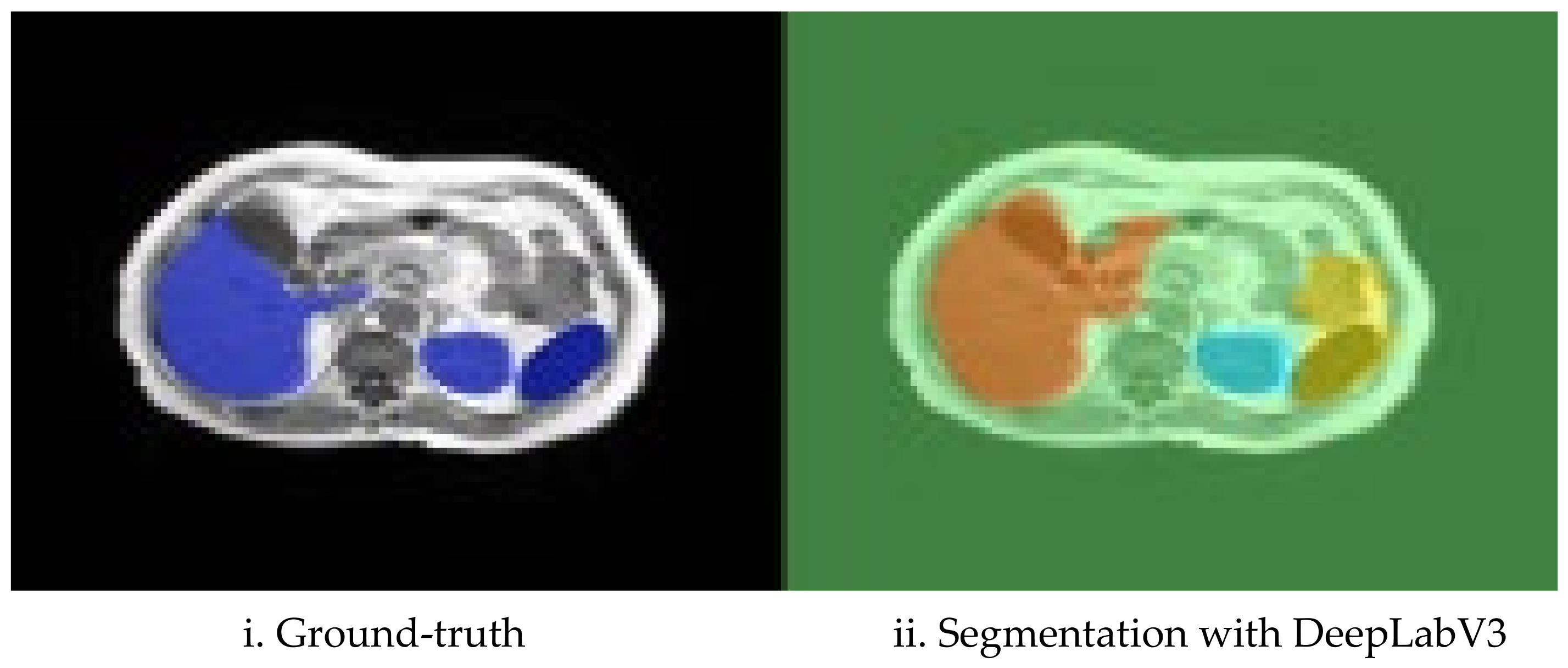
5.1. Choosing the Best-Performing Network
5.2. Post-Processing Results
5.3. Brief Comparison with Related Approaches
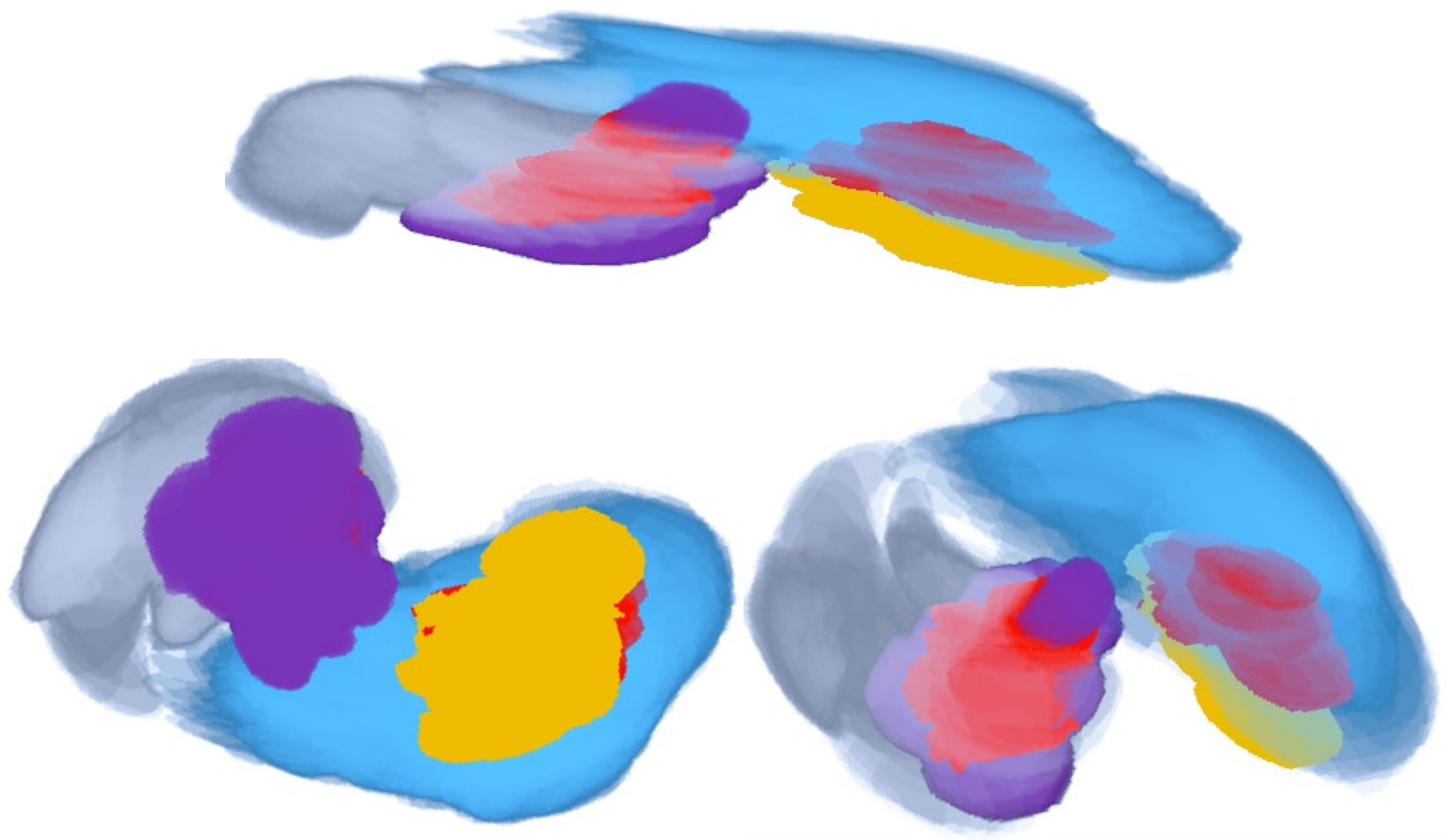
6. Post-Processing Extended Example
7. Conclusions and Future Work
Supplementary Materials
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Kavur, A.; Sinem, N.; Barıs, M.; Conze, P.; Groza, V.; Pham, D.; Chatterjee, S.; Ernst, P.; Ozkan, S.; Baydar, B.; et al. CHAOS Challenge—Combined (CT-MR) Healthy Abdominal Organ Segmentation. arXiv 2020, arXiv:2001.06535. [Google Scholar]
- Bereciartua, A.; Picon, A.; Galdran, A.; Iriondo, P. Automatic 3D model-based method for liver segmentation in MRI based on active contours and total variation minimization. Biomed. Signal Process. Control 2015, 20, 71–77. [Google Scholar] [CrossRef]
- Le, T.-N.; Bao, P.T.; Huynh, H.T. Fully automatic scheme for measuring liver volume in 3D MR images. Bio-Med. Mater. Eng. 2015, 26, S1361–S1369. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huynh, H.T.; Le, T.-N.; Bao, P.T.; Oto, A.; Suzuki, K. Fully automated MR liver volumetry using watershed segmentation coupled with active contouring. Int. J. Comput. Assist. Radiol. Surg. 2016, 12, 235–243. [Google Scholar] [CrossRef] [PubMed]
- Zhou, X.; Takayama, R.; Wang, S.; Zhou, X.; Hara, T.; Fujita, H. Automated segmentation of 3D anatomical structures on CT images by using a deep convolutional network based on end-to-end learning approach. In Medical Imaging 2017: Image Processing; International Society for Optics and Photonics: Bellingham, WA, USA, 2017; Volume 10133, p. 1013324. [Google Scholar] [CrossRef]
- Bobo, M.; Bao, S.; Huo, Y.; Yao, Y.; Virostko, J.; Plassard, A.; Landman, B. Fully convolutional neural networks improve abdominal organ segmentation. In Medical Imaging 2018: Image Processing; International Society for Optics and Photonics: Bellingham, WA, USA, 2018; Volume 10574, p. 105742V. [Google Scholar]
- Larsson, M.; Zhang, Y.; Kahl, F. Robust abdominal organ segmentation using regional convolutional neural networks. Appl. Soft Comput. 2018, 70, 465–471. [Google Scholar] [CrossRef] [Green Version]
- Groza, V.; Brosch, T.; Eschweiler, D.; Schulz, H.; Renisch, S.; Nickisch, H. Comparison of deep learning-based techniques for organ segmentation in abdominal CT images. In Proceedings of the 1st Conference on Medical Imaging with Deep Learning (MIDL 2018), Amsterdam, The Netherlands, 4–6 July 2018. [Google Scholar]
- Conze, P.; Kavur, A.; Gall, E.; Gezer, N.; Meur, Y.; Selver, M.; Rousseau, F. Abdominal multi-organ segmentation with cascaded convolutional and adversarial deep networks. arXiv 2020, arXiv:2001.09521. [Google Scholar]
- Chen, Y.; Ruan, D.; Xiao, J.; Wang, L.; Sun, B.; Saouaf, R.; Yang, W.; Li, D.; Fan, Z. Fully Automated Multi-Organ Segmentation in Abdominal Magnetic Resonance Imaging with Deep Neural Networks. arXiv 2019, arXiv:1912.11000. [Google Scholar]
- Gonzalez, R.C.; Woods, R.E.; Eddins, S.L. Digital Image Processing Using MATLAB; Gatesmark Publishing: Knoxville, TN, USA, 2009. [Google Scholar]
- Viergever, M.; Maintz, J.; Klein, S.; Murphy, K.; Staring, M.; Pluim, J. A Survey of Medical Image Registration—Under Review. Med. Image Anal. 2016, 33, 140–144. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Haralick, R.; Shapiro, L. Computer and Robot Vision; Addison-Wesley: Boston, MA, USA, 1992; Volume I, pp. 28–48. [Google Scholar]
- Boomgard, V.; van Balen, R. Methods for Fast Morphological Image Transforms Using Bitmapped Images. CVGIP Graph. Models Image Process. 1992, 54, 254–258. [Google Scholar]
- Soille, P. Morphological Image Analysis: Principles and Applications; Springer: Berlin/Heidelberg, Germany, 1999; pp. 173–174. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef] [Green Version]
- Fu, Y.; Mazur, T.R.; Wu, X.; Liu, S.; Chang, X.; Lu, Y.; Li, H.H.; Kim, H.; Roach, M.; Henke, L.; et al. A novel MRI segmentation method using CNN-based correction network for MRI-guided adaptive radiotherapy. Med. Phys. 2018, 45, 5129–5137. [Google Scholar] [CrossRef] [PubMed]
- Chlebus, G.; Meine, H.; Thoduka, S.; Abolmaali, N.; Van Ginneken, B.; Hahn, H.K.; Schenk, A. Reducing inter-observer varia-bility and interaction time of MR liver volumetry by combining automatic CNN-based liver segmentation and manual corrections. PLoS ONE 2019, 14, e0217228. [Google Scholar] [CrossRef] [PubMed]
- Hu, P.; Wu, F.; Peng, J.; Bao, Y.; Chen, F.; Kong, D. Automatic abdominal multi-organ segmentation using deep convolutional neural network and time-implicit level sets. Int. J. Comp. Assist. Radiol. Surg. 2016, 12, 399–411. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Zhou, Y.; Shen, W.; Park, S.; Fishman, E.; Yuille, A. Abdominal multi-organ segmentation with organ-attention networks and statistical fusion. Med. Image Anal. 2019, 55, 88–102. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, J.; Lee, J.-G. Deep-learning-based fast and fully automated segmentation on abdominal multiple organs from CT. In Proceedings of the International Forum on Medical Imaging in Asia, Singapore, 7–9 January 2019; SPIE: Bellingham, WA, USA, 2019; Volume 11050, p. 110500K. [Google Scholar]
- Gibson, E.; Giganti, F.; Hu, Y.; Bonmati, E.; Bandula, S.; Gurusamy, K.; Davidson, B.R.; Pereira, S.P.; Clarkson, M.J.; Barratt, D.C. Towards Image-Guided Pancreas and Biliary Endoscopy: Automatic Multi-organ Segmentation on Abdominal CT with Dense Dilated Networks. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2017, Quebec City, QC, Canada, 11–13 September 2017; pp. 728–736. [Google Scholar]
- Roth, R.; Shen, C.; Oda, H.; Sugino, T.; Oda, M.; Hayashi, H.; Misawa, K.; Mori, K. A multi-scale pyramid of 3D fully convo-lutional networks for abdominal multi-organ segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; pp. 417–425. [Google Scholar]
- Schlemper, J.; Oktay, O.; Schaap, M.; Heinrich, M.; Kainz, B.; Glocker, B.; Rueckert, D. Attention gated networks: Learning to leverage salient regions in medical images. Med. Image Anal. 2019, 53, 197–207. [Google Scholar] [CrossRef] [PubMed]
- Rundo, L.; Han, C.; Nagano, Y.; Zhang, J.; Hataya, R.; Militello, C.; Tangherloni, A.; Nobile, M.S.; Ferretti, C.; Besozzi, D.; et al. USE-Net: Incorporating Squeeze-and-Excitation blocks into U-Net for prostate zonal segmentation of multi-institutional MRI datasets. Neurocomputing 2019, 365, 31–43. [Google Scholar] [CrossRef] [Green Version]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kavur, A.E.; Gezer, N.S.; Barış, M.; Aslan, S.; Conze, P.-H.; Groza, V.; Pham, D.D.; Chatterjee, S.; Ernst, P.; Özkan, S.; et al. CHAOS Challenge—Combined (CT-MR) Healthy Abdominal Organ Segmentation. Med. Image Anal. 2021, 69, 101950. [Google Scholar] [CrossRef] [PubMed]
- Kavur, A.E.; Gezer, N.S.; Barış, M.; Şahin, Y.; Özkan, S.; Baydar, B.; Yüksel, U.; Kılıkçıer, Ç.; Olut, Ş.; Akar, G.B.; et al. Comparison of semi-automatic and deep learning-based automatic methods for liver segmentation in living liver transplant donors. Diagn. Interv. Radiol. 2020, 26, 11–21. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Machine | 1.5T Philips MRI |
| Acquisition protocol | T1-DUAL fat suppression |
| Image resolution | 12-bit DICOM images, resolution 256 × 256 |
| ISDs | 5.5–9 mm (average 7.84 mm) |
| x-y spacing | 1.36–1.89 mm (average 1.61 mm) |
| Number of sequences | 120 |
| Number of slices | 1594 |
| Number of slices per sequence | 26 to 50 (average 36) |
| Test data | 20% sequences, 5-fold cross-validation runs |
| IoU | Dice | |||||
|---|---|---|---|---|---|---|
| Class | DeepLabV3 | FCN | UNET | DeepLabV3 | FCN | UNET |
| Background | 99% | 99% | 98% | 99.5% | 99.5% | 99% |
| Liver | 86% | 86% | 74% | 93% | 93% | 85% |
| Spleen | 82% | 74% | 73% | 90% | 85% | 84% |
| rKidney | 77% | 78% | 75% | 87% | 87.6% | 86% |
| lKidney | 81% | 77% | 78% | 89.5% | 87% | 87.6% |
| Avg IoU | 85% | 83% | 80% | 92% | 91% | 89% |
| Step | Liver (IoU) | Spleen (IoU) | R Kidney (IoU) | L Kidney (IoU) | Pp Increase (Sum) |
|---|---|---|---|---|---|
| Base segmentation | 0.86 | 0.87 | 0.86 | 0.84 | - |
| Fencing | 0.86 | 0.87 | 0.87 | 0.85 | 2 |
| Re-assignments and noise redux | 0.88 | 0.89 | 0.87 | 0.87 | 6 |
| Enveloping, filling and slice filling and smoothing | 0.90 | 0.90 | 0.88 | 0.89 | 6 |
| Step | Liver (Dice) | Spleen (Dice) | R Kidney (Dice) | L Kidney (Dice) | Pp Increase (Sum) |
|---|---|---|---|---|---|
| Base segmentation | 0.925 | 0.93 | 0.925 | 0.91 | - |
| Fencing | 0.925 | 0.93 | 0.93 | 0.92 | 1.5 |
| Reassignments and noise redux | 0.936 | 0.94 | 0.93 | 0.93 | 3.6 |
| Enveloping, filling and slice filling and smoothing | 0.95 | 0.95 | 0.936 | 0.94 | 4 |
| Step | Liver (IoU) | Spleen (IoU) | R Kidney (IoU) | L Kidney (IoU) | Pp Increase (Sum) |
|---|---|---|---|---|---|
| Base segmentation | 0.86 | 0.82 | 0.77 | 0.81 | - |
| Fencing | 0.86 | 0.82 | 0.83 | 0.83 | 8 |
| Reassignments & noise redux | 0.88 | 0.85 | 0.84 | 0.86 | 9 |
| Enveloping, filling and slice filling and smoothing | 0.90 | 0.87 | 0.87 | 0.88 | 9 |
| Step | Liver (Dice) | Spleen (Dice) | R Kidney (Dice) | L Kidney (Dice) | Pp Increase (Sum) |
|---|---|---|---|---|---|
| Base segmentation | 0.925 | 0.9 | 0.87 | 0.895 | - |
| Fencing | 0.925 | 0.9 | 0.91 | 0.91 | 5 |
| Reassignments & noise redux | 0.936 | 0.92 | 0.913 | 0.925 | 5.3 |
| Enveloping, filling and slice filling and smoothing | 0.95 | 0.93 | 0.93 | 0.94 | 5.2 |
| MRI JI = IoU | Liver | Spleen | R Kidney | L Kidney |
|---|---|---|---|---|
| [10] teamPK | ||||
| U-Net | 0.73 | 0.76 | 0.79 | 0.83 |
| V19UNet | 0.76 | 0.79 | 0.84 | 0.85 |
| V19pUNet | 0.85 | 0.83 | 0.85 | 0.86 |
| V19pUnet1-1 | 0.86 | 0.83 | 0.86 | 0.87 |
| deeplabV3 post-processed | 0.90 | 0.90 | 0.88 | 0.89 |
| MRI JI = IoU | Liver | Spleen | R Kidney | L Kidney |
| [7] | 0.84 | 0.87 | 0.64 | 0.57 |
| [20] | 0.90 (LiverNet) | - | - | - |
| [21] | 0.91 | - | 0.87 | 0.87 |
| CT JI = IoU | Liver | Spleen | R Kidney | L Kidney |
| [23] | 0.938 | 0.945 | ||
| [24] | 0.85 | - | ||
| [6] | 0.88 | 0.77 | ||
| [19] | 0.92 | 0.89 | ||
| [20] | 0.96 | 0.94 | 0.96 | 0.94 |
| [25] | 0.9 | - | 0.84 | 0.80 |
| [9] | ||||
| F-net | 0.86 | 0.79 | 0.79 | 0.80 |
| BRIEF | 0.74 | 0.60 | 0.60 | 0.60 |
| U-Net | 0.89 | 0.80 | 0.77 | 0.78 |
| [8] | 0.90 | 0.87 | 0.76 | 0.84 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Furtado, P. Improving Deep Segmentation of Abdominal Organs MRI by Post-Processing. BioMedInformatics 2021, 1, 88-105. https://doi.org/10.3390/biomedinformatics1030007
Furtado P. Improving Deep Segmentation of Abdominal Organs MRI by Post-Processing. BioMedInformatics. 2021; 1(3):88-105. https://doi.org/10.3390/biomedinformatics1030007
Chicago/Turabian StyleFurtado, Pedro. 2021. "Improving Deep Segmentation of Abdominal Organs MRI by Post-Processing" BioMedInformatics 1, no. 3: 88-105. https://doi.org/10.3390/biomedinformatics1030007
APA StyleFurtado, P. (2021). Improving Deep Segmentation of Abdominal Organs MRI by Post-Processing. BioMedInformatics, 1(3), 88-105. https://doi.org/10.3390/biomedinformatics1030007