1. Introduction
In recent years, there have been many technical advances in the remote sensing field. Several thousand Earth observation (EO) satellites are currently orbiting the planet and provide a considerable number of images. With the short revisit time of satellites over an area, it will likely soon be possible to get free daily images of any surface on the world [
1]. Since 2014, for instance, the Copernicus program, launched by the European Union and the European Space Agency (ESA), has provided data from a constellation of six satellites called the Sentinel mission (Sentinel-1 to Sentinel-6). The first mission of this series, Sentinel-1 (S1), operates in active mode and supplies images every six days, regardless of the weather or the time of day (e.g., night, cloud cover, fog). Compared to optical Sentinel-2 (S2) images, S1 radar images have the advantage of being cloud-free. This quality allows them the ability to perform better in many applications; however, before use, raw satellite data must be preprocessed. In practice, the processing operations for S1 images are more complex and diverse than those of S2 images, which often limits their uses.
Consecutive data of an area, acquired from several dates, are called satellite image time series (SITS) [
2,
3,
4,
5]. Satellite image time series applications are varied and include agricultural resources monitoring, environment management, forest mapping, anomaly detection, and SITS prediction [
6,
7]. For the case of SITS prediction tasks, deep learning (DL) techniques are more and more mentioned in the literature. In particular, long-short-term memory (LSTM) architectures such as ConvLSTM, CNN-LSTM, and Stack-LSTM are used for their ability to deal with image sequences [
8].
LSTM networks are a particular type of recurrent neural network (RNN) introduced by Hochreiter and Schmidhuber in [
9]. The LSTM architectures are generally used with data organized in sequences and have cells that store the state from previous layers [
2].
DL algorithms for time series prediction typically require datasets made of long image sequences [
10,
11,
12]; however, the complexity of SITS preprocessing tasks and the lack of training datasets are some limitations related to the use of DL techniques, as mentioned in [
2]. Indeed, for works on the prediction of land cover classes using DL algorithms, for example, it is not easy to find datasets with SITS already preprocessed. Starting from scratch to build a long series can also be difficult for non-experts in the remote sensing domain. To resolve this, it has been suggested to reveal methods for automatic image batch processing and increase the number of available training datasets. In this way, the number of works using DL algorithms for SITS prediction could considerably increase. An interesting application in this field is for example the prediction of deforestation from SITS with DL approaches.
There are several publicly available remote sensing databases to use with DL algorithms [
13,
14,
15,
16]; however, these datasets are mostly used for image classification tasks [
17,
18]. For example, the authors in [
16] proposed a georeferenced dataset for training and validation of deep learning algorithms for flood detection for Sentinel-1 images. In [
13], an image dataset for ecological investigations of birds in wind farms was constructed. The authors in [
14] also proposed OpenSARUrban, a Sentinel-1 dataset dedicated to the content-related interpretation of urban SAR images.
Moreover, although some studies have explored the problem of a lack of datasets [
19,
20,
21,
22,
23,
24,
25], there are few studies that have addressed the constitution of datasets suitable for SITS forecasting problems. For ship detection, for example, the authors in [
25] carried out a study in which ship positions have been automatically extracted in batch from Sentinel-1A images, and in [
15], the Large-Scale SAR Ship Detection Dataset-v1.0 from Sentinel-1 have been proposed. In [
20], a workflow allowing the production of a set of preprocessed Sentinel-1 GRD data was presented. However, the proposed scripts allow the preprocessing of the images one by one.
Within this scope, the goal of this paper is to propose a complete workflow with scripts for collecting and batch processing S1 images. Then, a method to prepare the datasets to use with the DL algorithms is presented. The purpose of this experiment is to build public datasets of SITS that can be used for multiple other purposes. The code used to collect images in bulk was generated from NASA’s Vertex platform. For preprocessing, the scripts were based on the graph processing tool (GPT), proposed by the engine part of the Sentinel application platform (SNAP) software, Version 8.0 [
26]. This special command based on the SNAP graph processing framework (GPF) is used to process raster data in batches, through extensible markup language (XML) files containing graph operators.
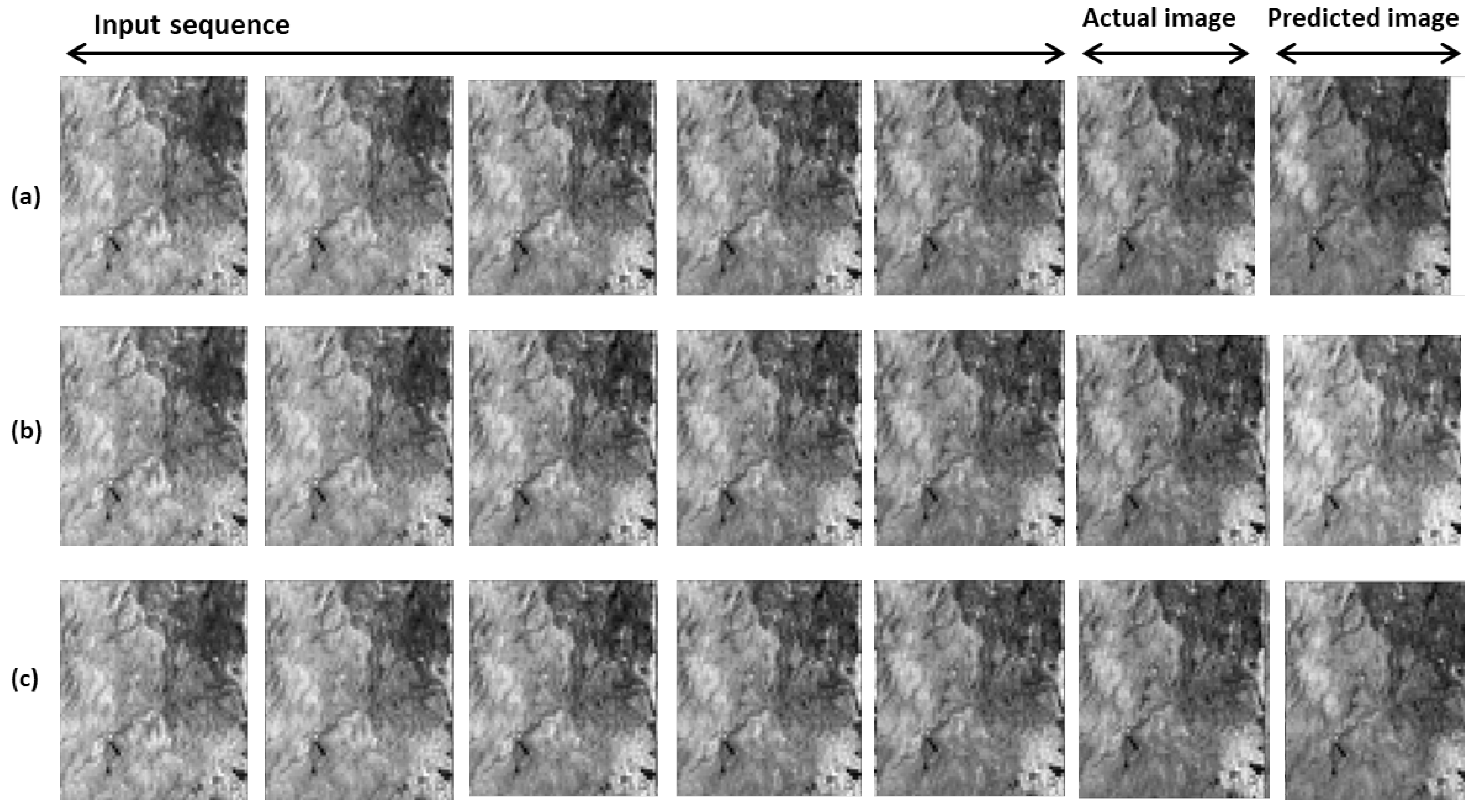
To test the effectiveness of the proposed methodology and demonstrate the practicality of the built datasets, the CNN-LSTM, ConvLSTM, and Stack-LSTM architectures were used to design DL models for the next frame forecasting in S1 image sequences. Experiments have shown that longer time series provide better performance than shorter ones.
Compared to similar works in the literature, the methodology proposed in this study has the following particularities: (1) the process described in this paper allows us to easily build datasets of SITS suitable for prediction tasks with DL algorithms. The images of each series allow us to represent the different states of the land cover classes thanks to the data acquired over time. Contrary to the dataset used mainly for classification tasks, the data collected here are more adequate for forecasting problems; (2) the procedure is complete, going from data collection to data preparation; (3) the proposed preprocessing chains allow us to execute operations in batch and not individually; (4) the VV and VH bands of images are separated during the process to allow a better analysis; (5) the preprocessed datasets and all the scripts used in this study are available to users.
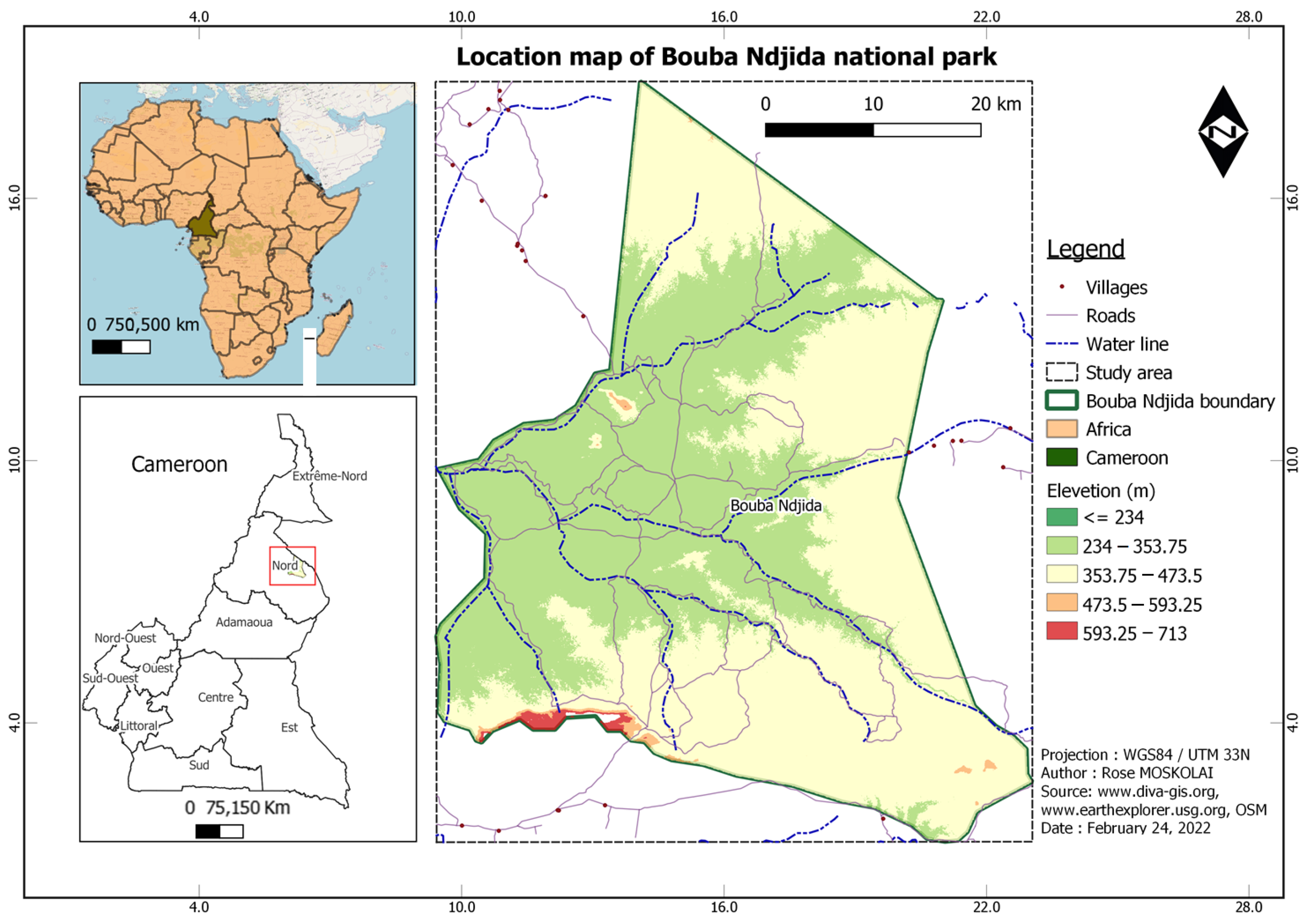
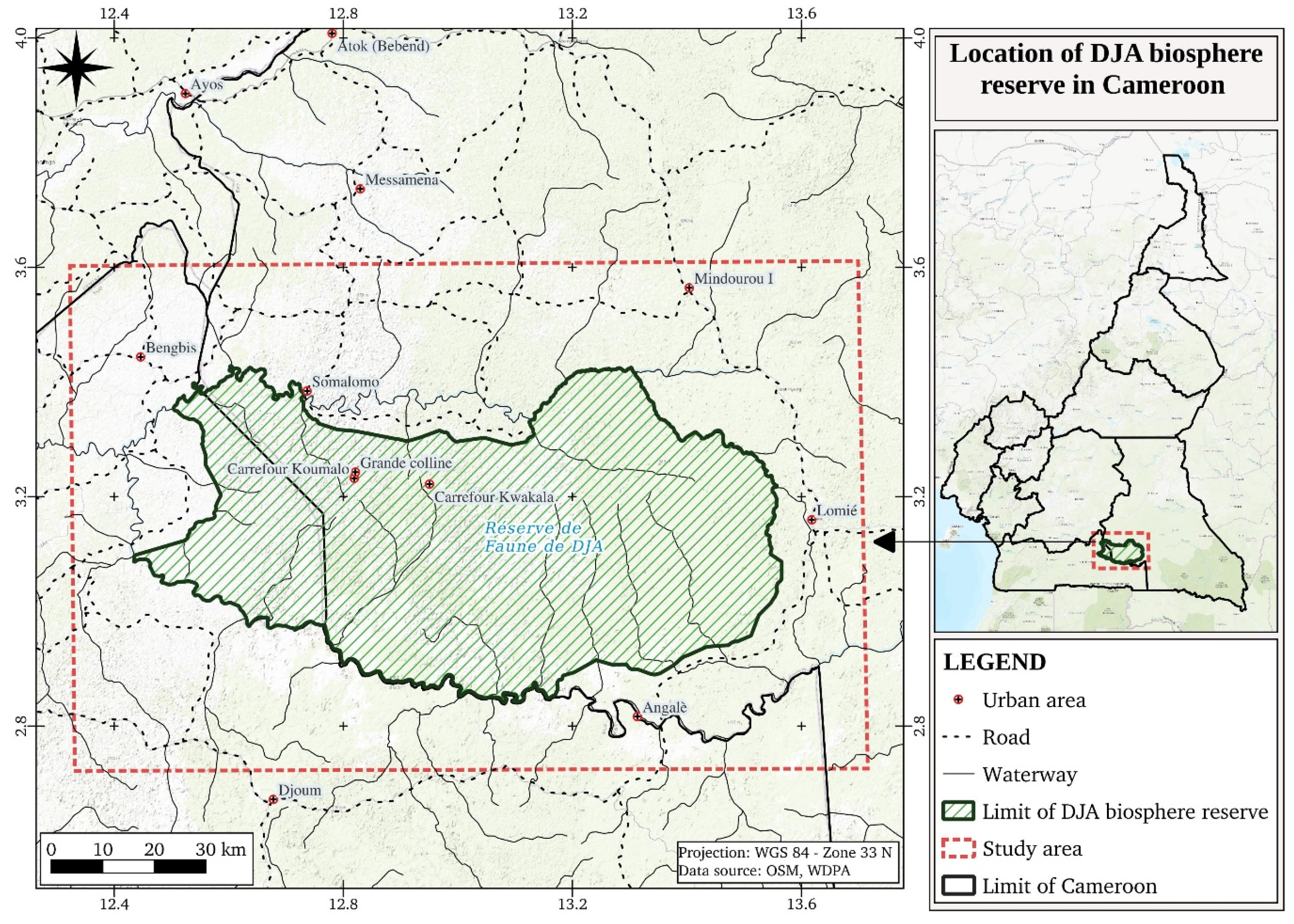
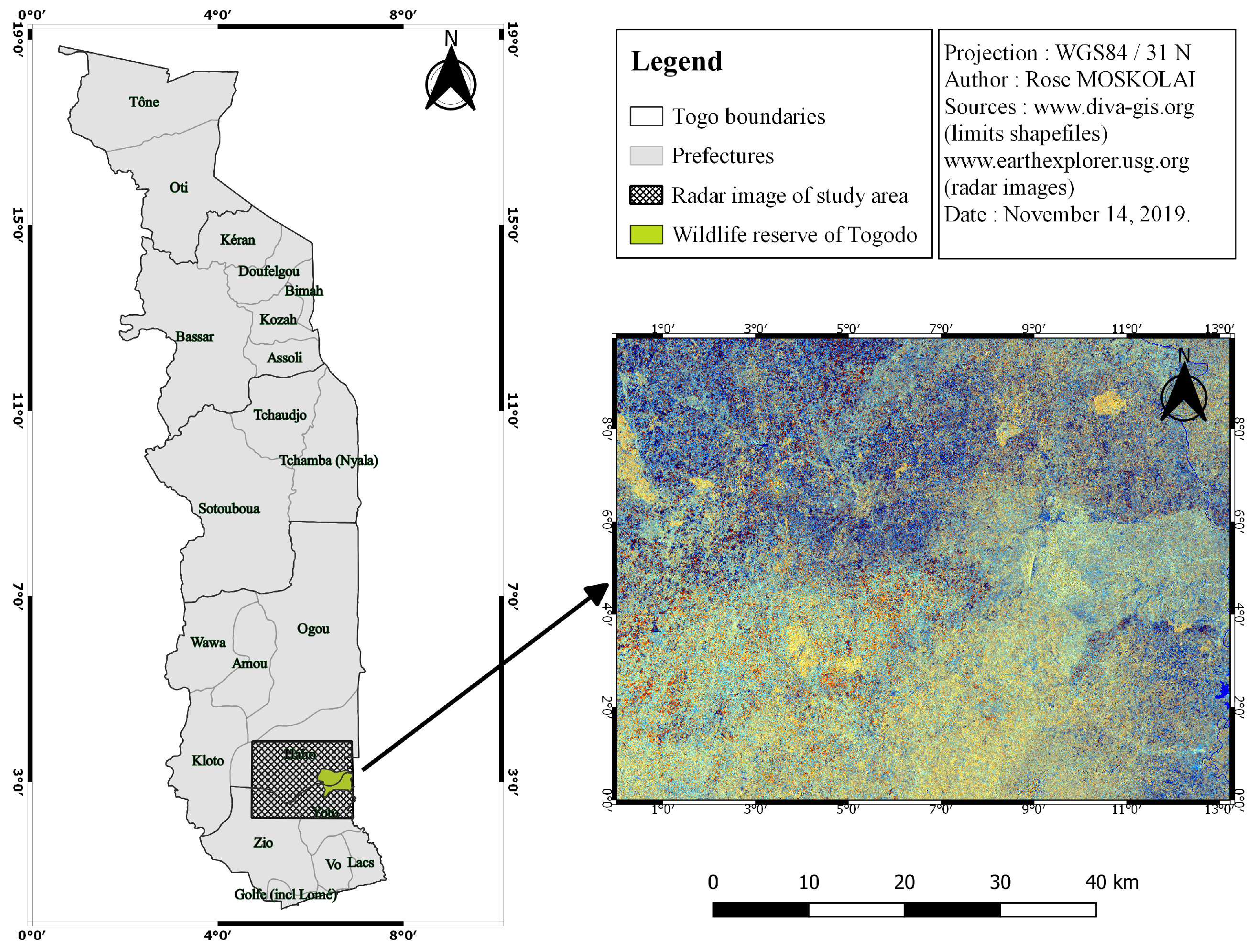
The experiments conducted on three study areas, namely the Bouba Ndjida National Park (BNP), the Dja Biosphere Reserve (DBR), and the Wildlife Reserve of Togodo (WRT) provided the preprocessed datasets for time series applications. The land cover classes on the selected AOI are diverse. This will allow us to create several types of DL models for many applications.
In sum, the contributions of this paper are as follows:
Proposal of a complete workflow for S1 image time series collection and preprocessing;
Development of a GPT-based script for S1 images batch processing that can be easily modified by users;
Construction of a public database made of three SITS;
Presentation of a method for preparing image time series to use with DL algorithms.
The rest of this paper is organized as follows:
Section 2 describes the data used for this study.
Section 3 presents the methodology and the tools used in this paper.
Section 4 depicts the results obtained from the study areas. Finally,
Section 5 concludes the paper.
3. Methodology
The estimation of future values in a time series is always based on the observation of previous values. The time series prediction task is more difficult than classification and regression problems because of the complexity added by the order and temporal dependence between the data.
Several prediction methods exist and allow us to obtain very good results for some problems. For linear time series, the main methods are regression models (such as the auto-regressive integrated moving average), exponential smoothing models, and the other linear models that have been very popular for the last thirty years [
35]. However, these classical methods have some limitations. For example, they require the use of complete sets (missing or corrupted data usually degrade the performance of the model). These methods are also suitable for linear series or series with a constant time step, focus on one-step prediction problems, and concentrate on the use of uni-variate data [
6].
For problems such as the prediction of land use and land cover changes using satellite imagery, classical models are not very suitable because SITS are non-linear and sometimes, there are missing or corrupted data in the series. CA-Markov methods are widely used in the literature for this kind of problem, but these methods require an important step of features engineering and the use of auxiliary data which strongly influence the prediction results [
36]. Moreover, DL models can automatically learn complex mappings between inputs and outputs. Feature extraction is a very laborious and time-consuming step; this step is done automatically with DL algorithms, unlike classical machine learning methods where the users have to be extremely accurate in the supervised learning process. The authors in [
37] have compared classical methods and DL algorithms for time series prediction problems and have shown for example that DL methods are effective and easier to apply than classical methods.
The powerful deep learning capabilities hold great promise for time series forecasting, especially for problems with complex and non-linear dependencies such as in SITS. The abilities of neural networks such as multi-layer perceptrons (MLP), CNN, or LSTM networks allow reaching performances that surpass those of classical methods: (1) neural networks are robust to noise in the data and can produce good results even with non-linear series or with missing or corrupted data; (2) the capabilities of CNNs to automatically extract important features from the raw input data can be applied to time series prediction problems; (3) LSTM networks can store temporal dependencies between data [
38,
39,
40].
So, for complex tasks such as SITS forecasting, the capabilities of DL models seem well suited, provided that a dataset with a long time series is available. In fact, the volume of historical available data representing the same area is important for the DL model to better capture the relationships between past and present images. Some events may occur, for example, only after a long period of time; it is important for the model to have a long enough series to capture the behavior of that event over time. The longer the series, the more training data the model can access; this leads to greater prediction accuracy. Having a long time series also avoids the phenomenon of overfitting that occurs in DL models when it focuses on the training data and fails to make good predictions on new data [
41].
Since collecting and preprocessing satellite images is not always a straightforward task, we present in the following subsections methods to facilitate batch collection and preprocessing of Sentinel-1 image time series that are suitable for time series prediction with DL algorithms. In addition, the process of preparing preprocessed data for use with DL models is also described.
3.1. Bulk Collection
All types of S1A images can be downloaded for free from several platforms. Each platform has its own particularities. The most widely used platforms are as follows:
The Copernicus Open Access Center (
https://scihub.copernicus.eu/ (accessed on 10 May 2022)) provides users with full access to Sentinel products. Images are available online as soon as satellite images are received; however, older images are generally not immediately downloadable and must be specifically requested. About six months after the registration of an image, the image is put in offline mode on the official Copernicus website, and a request must be sent to the server to put the product back online, for a determined period.
The Copernicus Dedicated Access Center (
https://cophub.copernicus.eu/ (accessed on 10 May 2022)) is for project services such as the provision of image archives that are no longer available on the main server.
The NASA Vertex platform or Alaska Satellite Facility (ASF) (
https://search.asf.alaska.edu/#/ (accessed on 10 May 2022)) provides the whole image time series of an area online. In other words, there are no offline products in this data center. Another advantage of this platform is the fact that the area of interest (AOI) can be imported as a shapefile or in well-known text format (WKT).
The Copernicus Access Center mirrors
https://peps.cnes.fr (accessed on 10 May 2022) (PEPS) and
https://code-de.org (accessed on 10 May 2022) (code-de) proposed by the National Center of Space Studies, known as Centre d’Etude Spatiale (CNES), and the German Space Agency, respectively.
In most platforms, images are generally downloaded individually; however, when a series of images must be collected, it is preferable to automate the downloading of the data using scripts, and, one way to do this is using dhusget program, a download command line based on the cURL and Wget programs and initiated by the Sentinel Data Center. The use of dhusget is completed by a command line query, which has the following structure:
dhusget.sh [LOGIN] [SEARCH_QUERY] [SEARCH_RESULTS] [DOWNLOAD_OPTIONS]
Another simple way to automatically download S1 images is using aria2c, which is the download manager on the official Copernicus website. With this tool, the user specifies the search criteria related to the AOI, and the validation of the selected products generates a file named products.meta4. The command used to start the batch download is listed below. Note that a valid Copernicus Open Access Center user account is required to run these command lines.
aria2c --http-user=’username’ --http-passwd=’password’
--check-certificate=false
--max-concurrent-downloads=2
-M products.meta4
A major drawback with the two methods is when a product is offline, the command is not able to immediately download it; however, there is a way to configure the script to send a request to the server when a product is offline, and check its availability after a certain time.
For the data used in this study, the researchers downloaded images from the ASF platform and selected all the available images for each study area. The corresponding Python scripts were executed in command lines on a local machine to start the recording of all images. For more information about the bulk collection from the Vertex platform, please navigate to the ASF website. (Online (Available):
https://asf.alaska.edu/how-to/data-tools/data-tools/ (accessed on 3 July 2022).)
The files containing the source code used to download the images from the three study areas are available at
http://w-abdou.fr/sits/ (accessed on 10 August 2022).
Table 1 presents the search parameters used for each study area and all available data from 15 June 2014 to 3 July 2022 were selected to be downloaded.
The AOI to be downloaded are delimited using the WKT coordinate; thus, to download the images corresponding to a new location, one needs to know the geographical coordinates and enter them on the platform to generate a corresponding Python file. The command to execute the download file (on a Unix console) is the following:
Python name_of_python_file.py
3.2. Preprocessing
3.2.1. SNAP Software
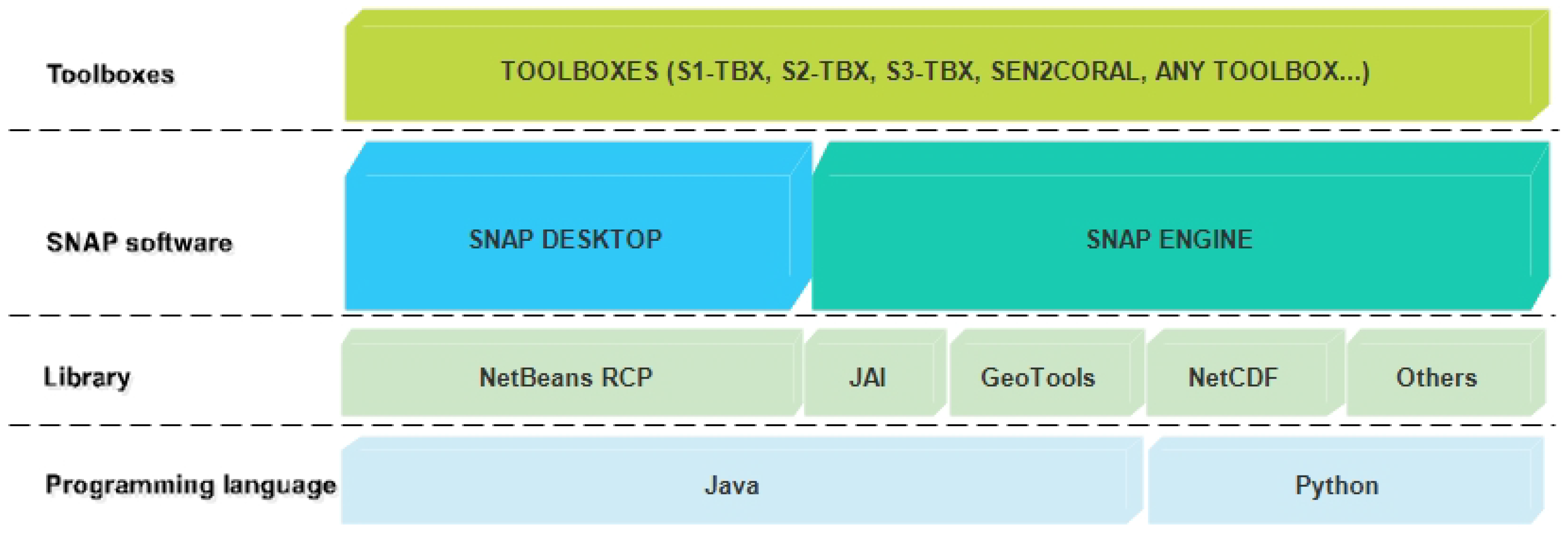
For the processing of Sentinel data, the ESA has developed a powerful application called the Sentinel Application Platform (SNAP). The SNAP software was jointly developed by Brockmann Consult, SkyWatch, and C-S for the visualization, processing, and analysis of EO data in general and Sentinel products in particular. As
Figure 4 displays, SNAP uses several technologies such as the Geospatial Data Abstraction Library, NetBeans Platform, Install4J, GeoTolls, and Java Advanced Imaging (JAI). The processing can be done using the SNAP Desktop graphical interface or command line in the SNAP Engine.
Within the SNAP software, there is a flexible processing framework called GPF [
26]. The GPF is based on JAI and allows users to implement custom batch processing chains.
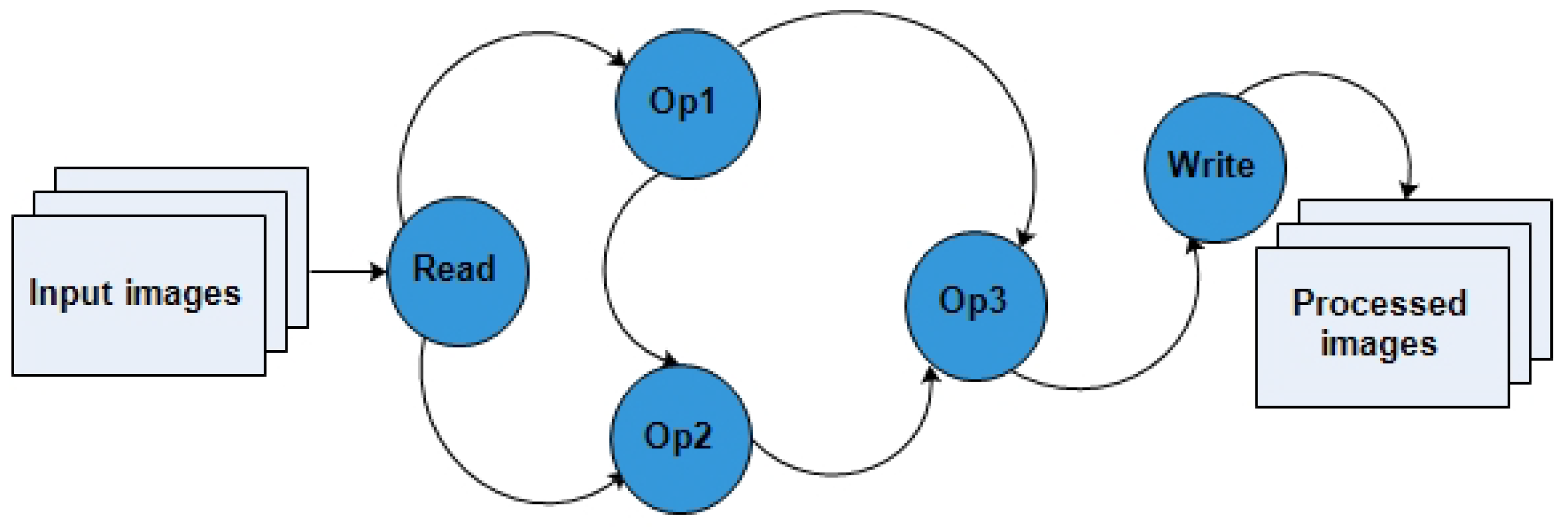
Figure 5 highlights how the GPF works using assembled graphs from a list of available operators. It is a directed acyclic graph (without loops or cycles) where nodes represent the processing steps called operators, and edges indicate the direction in which data is transferred between the nodes. The data source is the images received as inputs from the read operator, and the output can be either an image recorded by the write operator or a displayed image. Each data passes through an operator, which transforms the image, and the resulting image is sent to the next node until it reaches the output. No intermediate files are recorded during the process unless a write operation has been intentionally introduced into the graph.
In sum, the GPF architecture offers the following advantages:
No overloading of input/output operations;
Efficient use of storage memory (no writing of intermediate files);
Re-usability of the processing chains;
Ability to reuse operator configurations;
Parallel processing of graphs according to the number of available cores.
3.2.2. Preprocessing Workflow
Prior to the development of the batch script, a processing workflow was built using the SNAP graph builder tool. The designed graph representing the operators applied to the study’s data is schematized in
Figure 6.
Read: The “read’’ operator is used to load the data. This operator accepts not only S1 images but also other types of data.
Apply orbit file (AOF): The default metadata provided when SAR data are downloaded is generally not very accurate. In SNAP, the updated orbit file, with more accurate information to help improve geocoding and other processing results, is automatically downloaded by the AOF operator. This operation should be performed as a priority before all other preprocessing steps for better results.
Border noise removal (BNR): Because of irregularities on the Earth’s surface, deformations can appear on the Level-1 images during their generation. The BNR operation allows one to correct and remove noises present on the edges of images.
Calibration: The calibration step (calibrate) aims to correct the signal intensity according to the sensor characteristics and the local incidence angle. The metadata of the input products allows SNAP to automatically determine the corrections to be applied. In this work, the operation is performed for both VV and VH polarizations.
Terrain correction: The initially downloaded S1 images are devoid of geographic coordinates, which makes them unusable for most applications. The ortho-rectification step is performed to geo-reference images in order to project them into the Universal Transverse Mercator system or World Geodetic System 1984. This process also allows one to correct the distortion effects that occurred during the acquisition (overlay, shading). The terrain correction operation is based on a digital elevation model (DEM) automatically downloaded by SNAP or provided by the user.
Image clipping (subset): Each downloaded S1 image covers an area of 250 km × 250 km (swath). For smaller AIO, it is often not necessary to use the whole image but to extract a region. This can be done in SNAP using the subset operator, which slices the image according to a specific area. Moreover, cutting an image before performing other processing reduces memory consumption, processing time, and storage. The geographic coordinates of the AOI in WKT format may be required for this step.
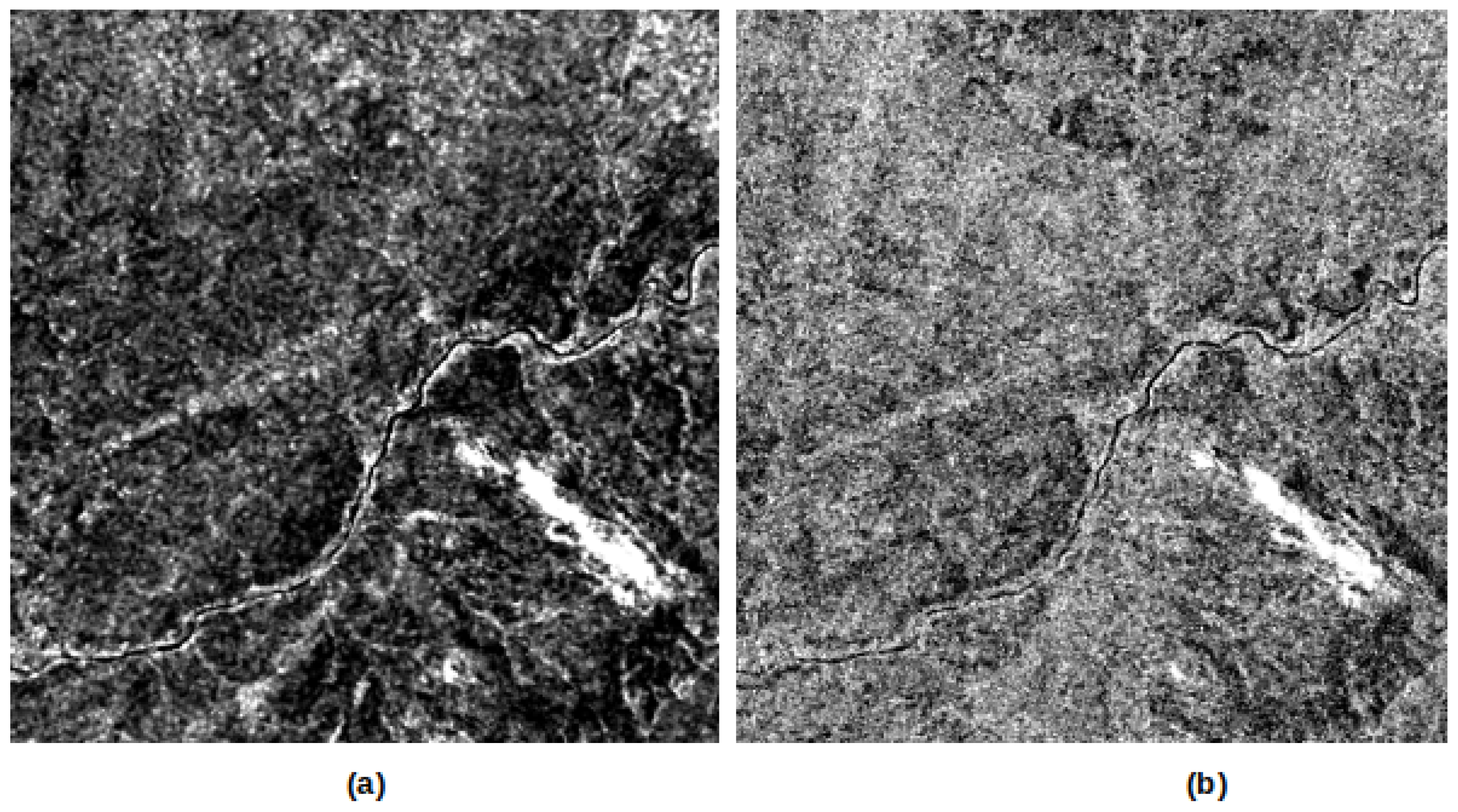
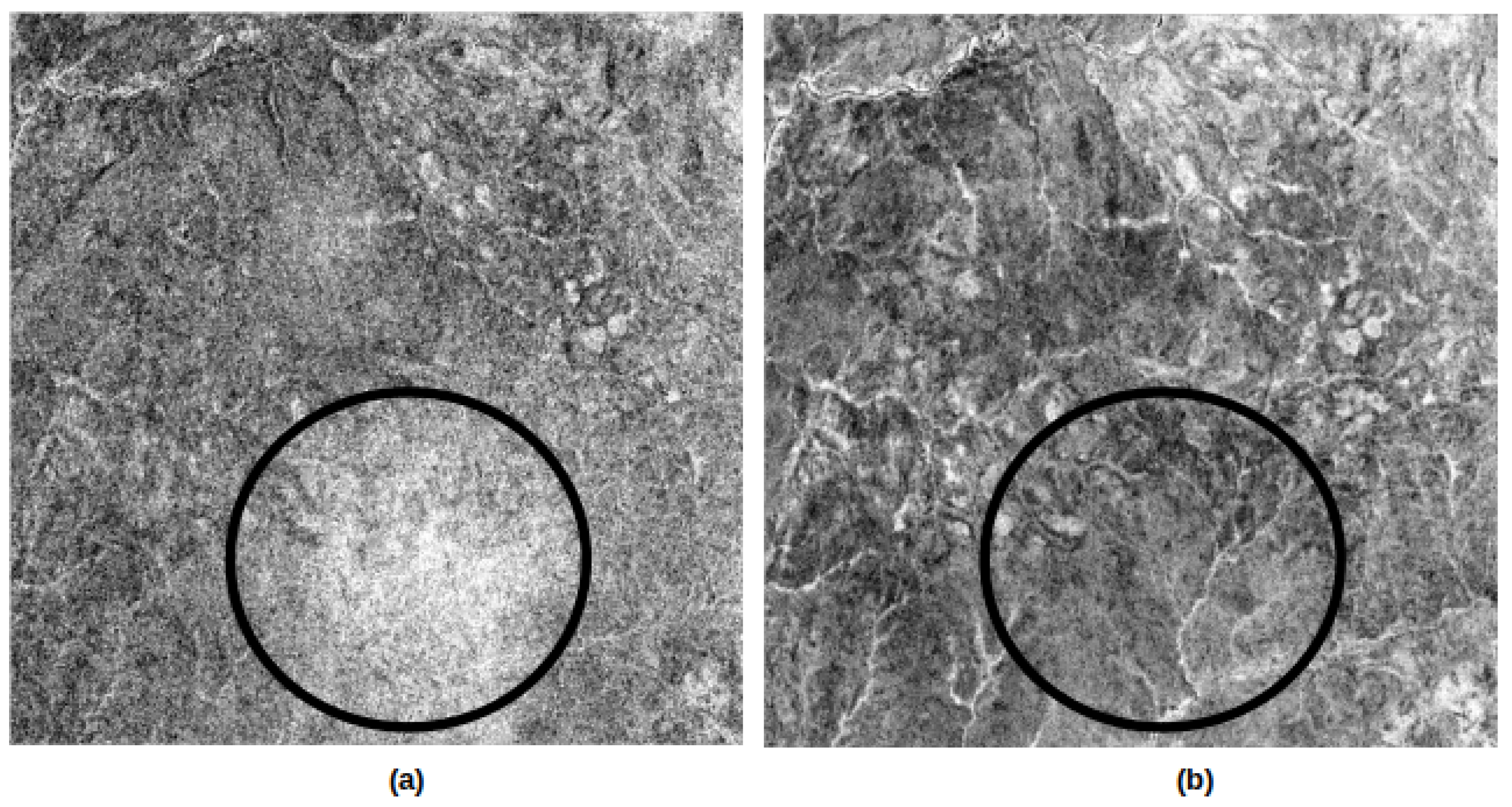
Filtering: Radar images contain some noise called speckle, which degrades them and makes them unusable in most cases. To improve the quality of the data and their analysis, it is useful, in some cases, to reduce the speckle effect using filtering. The speckle filtering operation allows one to remove as much noise as possible and improve the readability of the images. There are several filtering algorithms and methods such as simple spatial filtering, spatio-temporal filtering, or multi-temporal filtering.
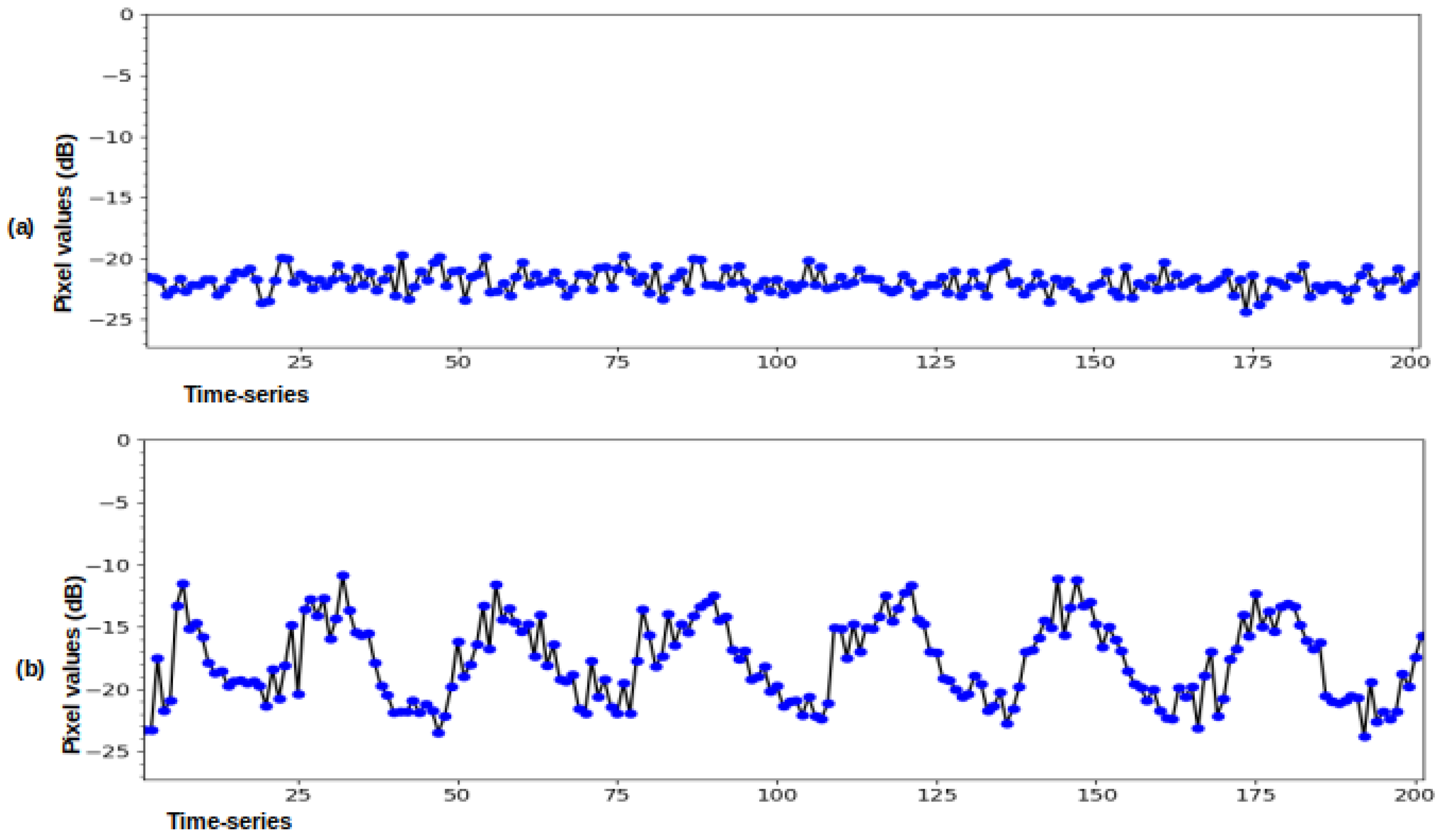
Converting values to decibels: Before writing the data to disk, the last step in the processing chain is the conversion to decibel scale to convert the initial pixel values to decibels (dB). In fact, SAR imagery has a high value range, and the decibel transformation is made to improve data visualization and analysis. Typically, this is done using a logarithmic transformation that stretches the radar backscatter over a more usable range that has a nearly Gaussian distribution.
Write: The last operation of the process is the writing of the resulting data to the disk.
Each of the used operators are presented below and the corresponding parameters are described in
Table 2.
3.2.3. Batch Processing Using GPT
Each graph designed with the SNAP graph builder can be exported as an XML file to automate the process. Even though it is possible to run batch processing from SNAP software, it is recommended to execute operators via the SNAP GPT tool for greater flexibility. The GPT tool is the command-line interface of SNAP that is used to execute raster data operators in batch mode. This is another way to perform batch processing without using the graphical user interface mode within the SNAP software. To use the gpt command, the operations can be processed individually, or they can be processed in a defined workflow.
Instead of specifying operator parameters separately in the processing stream, it is possible to use the XML-encoded file as a parameter of the gpt command. The general syntax used to execute the command for one image is offered below.
gpt <GraphFile.xml> [ options ] [<sourcefile1> <sourcefile2> ...]
All the XML files used to process images corresponding to the three study areas have almost the same content. The main difference lies in the geographical coordinates used to clip the images (subset operator) and the map projection system (terrain correction operator).
To simultaneously execute the processing of all the raw images, the researchers proposed a bash script. The code lines were written to be executed in a Unix environment. This script browses the whole directory and applies the processing chain to each found image. The advantage of having each file name written according to a particular naming convention (Online (Available):
https://sentinels.copernicus.eu/web/sentinel/user-guides/sentinel-1-sar (accessed on 10 May 2022)) is that it allows one to receive the acquisition date of each image and rename the processed image. For instance, a raw image name is renamed after processing into
20150409_VH.dim for the VH band and
20150409_VV.dim for the VV band. This change facilitates the subsequent use and manipulation of the processed images.
S1A_IW_GRDH_1SDV_20150409T171237_20150409T171302_005410_006E19_7760.zip
The XML files defining all the preprocessing operations and the scripts to execute data in the batch are available at
http://w-abdou.fr/sits/ (accessed on 10 August 2022).
At this stage of the preprocessing workflow, the images can be used for many other applications such as classification, segmentation, spatio-temporal analysis, and so on. For each use case, specific operations must be performed on the preprocessed data. For the specific case of using datasets for SITS prediction, the operations described in the following section prepare the data so that it can be provided to DL networks.
3.2.4. Data Preparation for Use with DL Algorithms
Once the SITS are available, the next step is to prepare the data for use with DL algorithms. Indeed, time series data must be transformed before it can be used in a supervised learning model.
In a univariate supervised learning problem, there are input variables
, output variables
, and a model that uses an algorithm to learn the mapping function from the input to the output:
[
8]. In this paper, the researchers present a method used to transform univariate time series (univariate time series are sequences of data consisting of a single set of observations with a temporal order (such as SITS)) to solve sequence-to-one forecasting problems where the inputs are a sequence of data and only one occurrence of data is offered as an output.
First, to simplify the use of the DL algorithms, all the images are transformed into JPG files, normalized, and reshaped to smaller sizes before the preparation step. Each image of the series has the shape , where W, H, and N denote the number of rows, columns, and channels for each image, respectively. Note that chronological order of images must be kept in each data since the researchers were studying forecasting tasks, and 80% of the data was selected for model training with the remaining 20% for testing.
Next, the DL model to design requires that data are provided as a collection of samples, where each sample has an input component
and an output component
, as presented in
Table 3. This transformation allows one to know what the model will learn and how the model can be used to make predictions. After transforming the data into a suitable form, they are represented as rows and columns.
For two-dimensional data using DL networks, such as convolutional neural networks (CNN) or long-short term memory (LSTM) for prediction, additional transformations are required to prepare the data before fitting models. Thus, the data are transformed to the form of , where are the sequences, is the number of occurrences in each sample, and correspond to the number of variables to predict.
In sum, to prepare the time series data for fitting predictive DL models, the following actions are necessary:
Resize the data;
Organize data into a training set and test set (80% and 20%);
Split the univariate sequence into samples (generate and samples);
Reshape data from into .
5. Conclusions
In this study, the researchers propose processes for automatic downloading and batch processing of S1 images. The presented processing workflow was designed based on the GPF of SNAP software. The study resulted in three time series made of preprocessed Sentinel-1A (Level-1 GRD) images in VV and VH polarizations. The researchers considered three study areas: the BNP, the DBR, and the WRT. A seven-year long-term series (1256 processed images), along with the source codes used, were made available to the public. The resulting datasets which are diverse can be used for multiple purposes, including time series prediction problems with DL algorithms such as deforestation forecasting. Moreover, the time series can help other applications such as multi-temporal speckle filtering, classification, and time series analysis for the considered areas. To validate the proposed workflow, the CNN-LSTM, ConvLSTM, and Stack-LSTM architectures were used for the next occurrence prediction in Sentinel-1 image sequences. For each of the series, missing data were found, likely due to sensor failures. Yet, having a complete series is an essential element that influences the quality of the predictions. It would, therefore, be relevant to propose algorithms to reconstruct the missing data in the Sentinel-1 image time series to have complete sequences in future works.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}