1. Introduction
Personalized travel itinerary generation systems have become indispensable tools for modern travelers, offering customized recommendations based on individual preferences such as destination, budget, and interests (
Aribas & Daglarli, 2024;
Mosca et al., 2024). However, these systems typically require centralized access to sensitive user data, raising significant privacy concerns. Federated learning (FL) has emerged as a promising paradigm to address this challenge by enabling collaborative model training without direct data sharing (
Jagarlamudi et al., 2024;
Yazdinejad et al., 2024). While FL inherently provides some level of privacy, additional measures such as differential privacy (DP) (
Pan et al., 2024) and secure aggregation (
Liu et al., 2024) are often employed to further protect user data. Nevertheless, these methods frequently introduce a trade-off between privacy and utility, where stronger privacy guarantees lead to degraded recommendation quality (
Oppl & Stary, 2022;
H. Zhang et al., 2025).
The PAFL framework delivers tangible benefits to multiple stakeholders in the travel ecosystem. For end-users, it enables personalized itinerary recommendations without compromising sensitive location history or preference data. Travel service providers (e.g., OTAs, hotel chains, and attraction operators) can leverage PAFL to enhance customer experience while maintaining compliance with evolving data protection regulations. Particularly for organizations operating in jurisdictions with strict privacy laws (e.g., GDPR in Europe or PIPL in China), PAFL’s phase-adaptive approach offers a scalable solution to balance recommendation quality with privacy preservation. Implementation typically occurs at the infrastructure level of travel platforms, requiring deployment across three key components: (1) client-side mobile applications (Android/iOS) for local model training, (2) edge servers (e.g., AWS Outposts or Azure Stack Edge) for intermediate phase processing, and (3) cloud-based coordination servers (x86_64 architectures (Huawei, Shenzhen, China) with GPU acceleration) for global aggregation.
Existing approaches in federated travel recommendation systems often adopt static privacy-preserving techniques, which fail to adapt to the dynamic nature of user preferences and data distributions. For instance, DP-based methods inject fixed amounts of noise during model updates, while homomorphic encryption (
Fang & Qian, 2021) incurs substantial computational overhead. Recent work has explored adaptive techniques such as gradient clipping (
Sabah et al., 2024;
J. Zhang & Liu, 2024) and dynamic masking (
C. Zhang et al., 2025), but these solutions lack the flexibility to seamlessly transition between privacy and utility modes. This limitation becomes particularly critical in travel recommendation systems, where the need for accurate personalization must coexist with stringent privacy requirements (
Javeed et al., 2023;
Kaissis et al., 2021).
We propose a novel federated learning framework inspired by phase-change materials (PCMs) (
Bhatasana & Marconnet, 2021), which exhibit reversible transformations between distinct states. Our method, termed Phase-Adaptive Federated Learning (PAFL), introduces a tunable phase parameter that dynamically controls the anonymization level of user-contributed model updates during aggregation. Unlike conventional approaches, PAFL does not rely on fixed privacy mechanisms; instead, it employs a latent-space phase transformer to modulate representations based on the current phase, enabling smooth transitions between anonymized and utility-preserving states. The phase parameter is adaptively adjusted using a feedback controller that optimizes the privacy–utility trade-off in real time. Furthermore, PAFL integrates a lightweight transformer architecture (
Lv et al., 2024) to efficiently process sequential travel data while minimizing computational costs.
The PAFL framework introduces a tunable phase parameter φ to dynamically control the privacy–utility trade-off during federated aggregation. Unlike static approaches, φ enables reversible transitions between anonymized and utility-preserving states, optimizing both recommendation quality and privacy guarantees in real time.
The key contributions of this work are threefold. First, we introduce the concept of phase-adaptive anonymization in federated learning, where model updates are dynamically transformed to balance privacy and utility. Second, we develop a hybrid privacy mechanism that combines DP for anonymization with gradient inversion techniques (
Gupta et al., 2023) for utility restoration, ensuring robust privacy guarantees without sacrificing recommendation accuracy. Third, we demonstrate the effectiveness of PAFL in personalized travel itinerary generation, showing significant improvements over existing methods in terms of both privacy preservation and recommendation quality.
The remainder of this paper is organized as follows:
Section 2 reviews related work in federated learning and privacy-preserving recommendation systems.
Section 3 provides the necessary background on federated optimization and latent-space manipulation.
Section 4 details the PAFL framework, including its phase-adaptive aggregation mechanism and lightweight transformer architecture.
Section 5 and
Section 6 present the experimental setup and results, respectively. Finally,
Section 7 discusses potential extensions and future work, followed by conclusions in
Section 8.
2. Related Work
2.1. Privacy-Preserving Techniques in Federated Learning
In recent years, federated learning (FL) has witnessed significant advancements, with a particular focus on enhancing data privacy through various mechanisms. Differential privacy (DP) has become a cornerstone technique in this domain. By introducing carefully calibrated noise to model updates, DP effectively prevents data leakage during collaborative model training. However, the implementation of standard DP methods often poses challenges, especially in recommendation tasks that require fine-grained personalization. The injection of excessive noise to ensure privacy can lead to a degradation in model utility, thereby limiting the effectiveness of the trained models.
Recent developments in adaptive federated learning have introduced novel approaches to dynamic privacy–utility optimization.
H. Zhang et al. (
2025) proposed a user behavior modeling scheme with dynamic privacy budget allocation for edge devices, demonstrating significant improvements in personalized modeling while maintaining rigorous privacy guarantees. Complementing this work,
Yazdinejad et al. (
2024) developed a hybrid privacy-preserving FL framework specifically designed to handle irregular user participation patterns—a particularly relevant challenge for mobile travel applications where connectivity may be intermittent. These works collectively underscore the growing importance of adaptive mechanisms in federated systems, though none have yet explored the phase-change inspired approach we introduce in PAFL.
Secure multi-party computation (SMPC) presents an alternative privacy-preserving approach. SMPC enables the encrypted aggregation of model updates, allowing multiple parties to collaboratively train models without revealing their individual data. This method holds great promise for maintaining data confidentiality. Nevertheless, its computational overhead is substantial, which can be a significant limitation for resource-constrained devices. As a result, the scalability of SMPC in practical applications, particularly in environments with limited computational resources, is a major concern.
To address these limitations, hybrid approaches that combine DP with cryptographic techniques have been proposed. These hybrid methods aim to strike a balance between privacy protection and model utility. By integrating the strengths of both DP and cryptographic mechanisms, these approaches can mitigate the drawbacks of using either technique alone. However, they often require predefined privacy parameters that remain static throughout the training process. This rigidity can be problematic, as it may not account for the dynamic nature of data and the evolving requirements of the training process.
Future research in this area should focus on developing more flexible and adaptive privacy-preserving mechanisms that can dynamically adjust privacy parameters based on the specific needs of the training process and the characteristics of the data. Additionally, efforts should be made to optimize the computational efficiency of these mechanisms to ensure their feasibility for resource-constrained devices.
2.2. Adaptive Federated Learning Methods
In recent years, federated learning (FL) has witnessed significant advancements, particularly in the realm of privacy-preserving mechanisms. These mechanisms are designed to protect sensitive user data during collaborative model training, ensuring that privacy is maintained without compromising the utility of the models.
Differential privacy (DP) has emerged as a cornerstone in this domain. It operates by adding carefully calibrated noise to model updates, thereby preventing data leakage. The concept of differential privacy is grounded in the idea that the output of a computation should remain statistically indistinguishable, regardless of whether any individual’s data are included or excluded (
Achuthan et al., 2024;
Husnoo et al., 2021). This provides strong mathematical guarantees for privacy. However, the implementation of standard DP techniques often leads to a degradation in model utility. This is particularly evident in recommendation tasks that require fine-grained personalization, where excessive noise injection can obscure genuine data patterns.
Secure multi-party computation (SMPC) presents an alternative approach. SMPC allows multiple participants to collaboratively compute a function over their inputs without revealing their individual inputs to each other. This is achieved through sophisticated cryptographic techniques such as secret sharing and homomorphic encryption (
Zhao et al., 2019). In the context of federated learning, SMPC enables encrypted aggregation of model updates, ensuring that sensitive data remain confidential throughout the process. However, SMPC is not without its drawbacks (
Hu et al., 2022). The computational overhead associated with these cryptographic techniques can be substantial, which may limit the scalability of federated learning systems, especially for resource-constrained devices.
The field has seen notable advances beyond traditional DP approaches in federated settings.
J. Zhang and Liu (
2024) developed PerFreezeClip, which innovatively combines personalized federated learning with adaptive gradient clipping to better preserve model utility under varying privacy constraints. In parallel work,
C. Zhang et al. (
2025) proposed DMRP (Dynamic Masking with Random Permutation), incorporating dynamic noise mechanisms that automatically adjust based on data sensitivity. These innovations demonstrate the research community’s movement toward more flexible privacy mechanisms, though they still lack the thermodynamic-inspired phase transitions that distinguish our PAFL framework.
2.3. Recent Advances in Adaptive Privacy Mechanisms
The past few years have witnessed significant innovations in adaptive privacy mechanisms for federated learning.
He et al. (
2023) developed a decentralized credit scoring method that dynamically adjusts privacy parameters based on real-time assessment of data sensitivity, demonstrating the practical value of context-aware privacy preservation.
Gupta et al. (
2023) introduced sophisticated inversion attacks that reveal critical vulnerabilities in static privacy approaches, directly motivating our phase-adaptive defense strategy. Most closely related to our thermodynamic inspiration,
Y. Li et al. (
2024) proposed LF3PFL, which employs local federalization to enhance privacy through distributed control mechanisms. While these works represent significant advances, they lack the smooth phase transitions and material science inspiration that form the foundation of our PAFL approach.
2.4. Federated Recommendation Systems
Personalized recommendation systems present unique challenges for federated learning due to their reliance on high-dimensional user embeddings. Existing approaches either employ heavy encryption (
Park & Lim, 2022) or compromise on personalization quality (
Oinas-Kukkonen et al., 2022). Lightweight transformer architectures have shown effectiveness in sequential recommendation tasks, but their integration with privacy-preserving federated learning remains limited. Recent work on gradient inversion attacks (
Z. Li et al., 2022;
Luo et al., 2022) has revealed vulnerabilities in federated recommendation systems, motivating the need for robust anonymization techniques that preserve utility.
The specialized challenges of sequential recommendation in federated settings have attracted growing research attention.
Wei et al. (
2023) developed an edge-enabled federated sequential recommendation system using knowledge-aware transformers, achieving notable improvements in resource efficiency while maintaining recommendation quality. Their work demonstrates the effectiveness of transformer architectures in distributed settings but does not address the dynamic privacy–utility trade-offs that our phase-adaptive mechanism solves. In the travel domain specifically,
Juan et al. (
2024) showed the power of multimodal transformers for itinerary recommendations, though their centralized approach lacks the privacy protections inherent in our federated solution. These studies collectively highlight both the potential and remaining challenges in federated sequential recommendation systems.
The proposed PAFL framework advances beyond existing methods by introducing three key innovations: (1) dynamic phase-based modulation of privacy–utility trade-offs, (2) reversible gradient transformations for utility preservation, and (3) efficient sequential modeling tailored for federated deployment. Unlike static approaches, PAFL’s adaptive mechanism responds to both system-level requirements (e.g., privacy budgets) and user-level needs (e.g., recommendation quality), enabling superior performance across diverse operational scenarios.
3. Background and Preliminaries
To establish the theoretical foundation for our proposed framework, we first introduce the core concepts of federated learning, differential privacy, and sequential recommendation systems. These components form the building blocks for understanding the phase-adaptive mechanisms developed in this work.
3.1. Federated Learning Basics
Federated learning enables collaborative model training across distributed devices while keeping raw data localized (
Banabilah et al., 2022). The standard FL process involves iterative rounds of local model updates on client devices followed by secure aggregation of these updates on a central server. The global model parameters
are updated through weighted averaging of local gradients:
where
denotes the learning rate and
represents the loss computed from the
-th client’s latent representation
. A critical challenge in FL is maintaining privacy while ensuring the utility of aggregated updates, particularly when dealing with sensitive user data such as travel preferences (
Alamgir et al., 2022). The sensitivity of these updates, defined as the maximum possible change in model parameters given any pair of neighboring datasets, plays a crucial role in privacy preservation.
The sensitivity of model updates, defined as the maximum possible change in model parameters given any pair of neighboring datasets (Equation (2)), plays a crucial role in privacy preservation:
Here, denotes the L1 sensitivity of the latent representation H, where and represent neighboring datasets differing by at most one user’s private data. The L1-norm measures the maximum absolute difference between model updates computed from these datasets. This sensitivity directly determines the scale of noise injection in our phase-adaptive DP mechanism (Equation (7)), where a smaller enables stronger privacy guarantees for the same noise magnitude.
In PAFL, the phase parameter dynamically modulates this sensitivity through the latent-space transformation (Equation (10)), allowing adaptive control of the privacy–utility trade-off during different training stages.
: L1 sensitivity (critical for DP noise scaling); and : neighboring datasets (privacy definition); : latent representation function.
3.2. Differential Privacy in Machine Learning
Differential privacy provides a rigorous mathematical framework for quantifying and controlling privacy leakage in machine learning systems (
Janghyun et al., 2022). An
-differentially private mechanism ensures that the inclusion or exclusion of any single data point in the training set does not significantly affect the output distribution of the algorithm. For federated learning applications, this is typically achieved by injecting calibrated noise into the model updates, as follows:
where
denotes Laplacian noise scaled by the privacy budget
and sensitivity
. The composition property of DP dictates that the total privacy cost accumulates across multiple training rounds.
The composition property of differential privacy (DP) dictates that the total privacy cost accumulates across multiple training rounds (Equation (4)). This fundamental relation governs the privacy–utility trade-off in our phase-adaptive framework:
where
represents the cumulative privacy budget over
T aggregation rounds, and
denotes the privacy expenditure at round
t. The dynamic nature of
in PAFL—controlled by our phase parameter
through Equation (9)—allows strategic allocation of the privacy budget. Early rounds with higher
values (privacy-emphasis phase) consume less
per round, preserving budget for later utility-optimization phases. This adaptive expenditure differs from conventional FL approaches that use fixed
, demonstrating PAFL’s advantage in maintaining long-term privacy guarantees without sacrificing final model utility.
This presents a fundamental trade-off between privacy preservation and model utility, as stronger privacy guarantees (smaller
) require more aggressive noise injection that can degrade recommendation quality (
Dasari et al., 2020).
3.3. Sequential Recommendation Systems
Modern travel itinerary generation relies on transformer-based architectures that capture sequential dependencies in user behavior (
Juan et al., 2024). The self-attention mechanism computes weighted representations of input sequences through query-key-value operations:
where Q, K, and V represent queries, keys, and values, respectively, and d
k denotes the dimension of key vectors. In federated settings, these architectures must be adapted to the work of
Bourahla et al. (
2020).
- (1)
Operate efficiently on resource-constrained devices.
- (2)
Preserve privacy of sequential user data through phase-adaptive transformations (φ-controlled attention masking).
- (3)
Maintain temporal modeling capabilities despite φ-induced perturbations.
Our lightweight transformer achieves this through φ-gated attention heads that dynamically adjust their sensitivity to sequential patterns based on the current privacy–utility phase (see
Section 4.1).
The combination of attention mechanisms with privacy-preserving techniques introduces unique challenges in maintaining both the temporal modeling capabilities and privacy guarantees required for effective travel recommendations.
4. Federated Learning with PCM-Inspired Anonymization
The proposed Phase-Adaptive Federated Learning (PAFL) framework introduces a novel approach to privacy-preserving model aggregation by dynamically adjusting the representation of user updates based on a tunable phase parameter. This section presents the technical details of the framework’s core components and their interactions.
4.1. Phase-Adaptive Federated Learning Framework
The PAFL framework operates through periodic aggregation rounds where client devices submit transformed model updates to a central coordinator (
Pal et al., 2020). Each local update undergoes phase-dependent transformation before aggregation, as shown below:
where
represents the phase parameter controlling the privacy–utility trade-off. The differential privacy component
applies Laplacian noise scaled by the current privacy budget
:
The gradient inversion module
reconstructs utility-preserving features from noised gradients through an optimization process:
where
denotes a regularization term preventing overfitting to the noisy input. The phase parameter
is dynamically adjusted each round using a PID controller that monitors the global model’s validation accuracy
and privacy expenditure
.
The phase parameter φ is dynamically adjusted each round using a PID controller that monitors the global model’s validation accuracy At and privacy expenditure εt. The controller accumulates φ values by minimizing the error
et =
Atarget −
At through proportional (
Kp), integral (
Ki), and derivative (
Kd) terms, ensuring adaptive transitions between privacy and utility modes:
Here, represents the accuracy error and are controller gains tuned via Bayesian optimization.
The PID controller dynamically accumulates φ values through the following three components:
Proportional term (Kp): Reacts to current error magnitude, providing immediate adjustment to φ when validation accuracy deviates from target.
Integral term (Ki): Compensates for accumulated past errors, ensuring φ values gradually converge to the optimal privacy–utility equilibrium.
Derivative term (Kd): Predicts future error trends, preventing overshooting of φ adjustments during rapid phase transitions.
The PID coefficients are optimized through a two-stage process, as follows:
- (1)
Initialization: Values are set proportionally to the system’s characteristic time constant (Kp = 0.6/τ, Ki = 1.2/τ, Kd = 0.075τ), where τ is estimated from early training rounds (typically 3–5 rounds).
- (2)
Online Adaptation: Bayesian optimization with Gaussian processes refines the coefficients every 10 rounds, maximizing the objective O = Aval − λεt, where Aval is validation accuracy and λ balances privacy–utility trade-off (λ = 0.1 in our experiments).
While this PID formulation provides effective phase control in our experimental setting, several limitations emerge when considering large-scale asynchronous deployments. First, the integral term’s error accumulation can become unstable when client updates exhibit significant delays (>2 rounds). Second, the fixed PID gains may require re-optimization for systems scaling beyond ∼100 clients due to changing dynamics in the privacy–utility trade-off landscape. Third, the global phase parameter assumes relatively homogeneous client participation patterns, whereas real-world deployments often show heavy-tailed availability distributions. These limitations motivate future work on adaptive PID tuning and client-specific phase parameters for large-scale asynchronous scenarios.
4.2. PCM-Inspired Latent-Space Transformation
The phase-dependent transformation draws inspiration from the crystalline–amorphous transitions in phase-change materials (
Y. Li et al., 2020). This accumulation process is analogous to the crystallization dynamics in phase-change materials, where φ evolves smoothly between amorphous (privacy-focused) and crystalline (utility-optimized) states based on real-time system feedback (as governed by the PID controller in
Section 4.1). When
, updates resemble an “amorphous” privacy-preserving state with high noise content. Conversely,
yields “crystalline” utility-optimized representations. The transformation occurs through a learnable projection, as shown below:
where
denotes concatenation and is the GELU activation function. The projection weights
are shared across clients to maintain consistency in the latent space geometry.
4.3. Differential Privacy-Gradient Inverter (DP-Inv)
The DP-Inv module combines noise injection with invertible reconstruction through a shallow neural network with affine coupling layers (
Sayahpour et al., 2024):
where
and
are scale and translation networks implemented as single-layer perceptrons. The encoder
employs invertible transformations to ensure bijective mapping between noisy and clean representations. The module’s parameters are optimized end-to-end with the global model to minimize, as shown below:
where MMD computes the maximum mean discrepancy between original and reconstructed distributions.
is the loss function for the DP-Inv (differential privacy-gradient inverter) module. It combines the following two objectives: (1) feature reconstruction accuracy, and (2) distributional alignment. is the original latent representation of user data (before noise injection). It represents utility-preserving features (e.g., travel preferences). is the weighting hyperparameter balancing the L1 loss and MMD terms. Larger prioritizes distributional alignment over pointwise accuracy.
4.4. Phase-Weighted Secure Aggregation
The final aggregation incorporates phase-dependent weighting through secure multi-party computation:
The SMPC protocol ensures privacy during aggregation while preserving the phase-based weighting scheme. Each client’s contribution is scaled by its current , prioritizing less anonymized updates when the phase parameter permits.
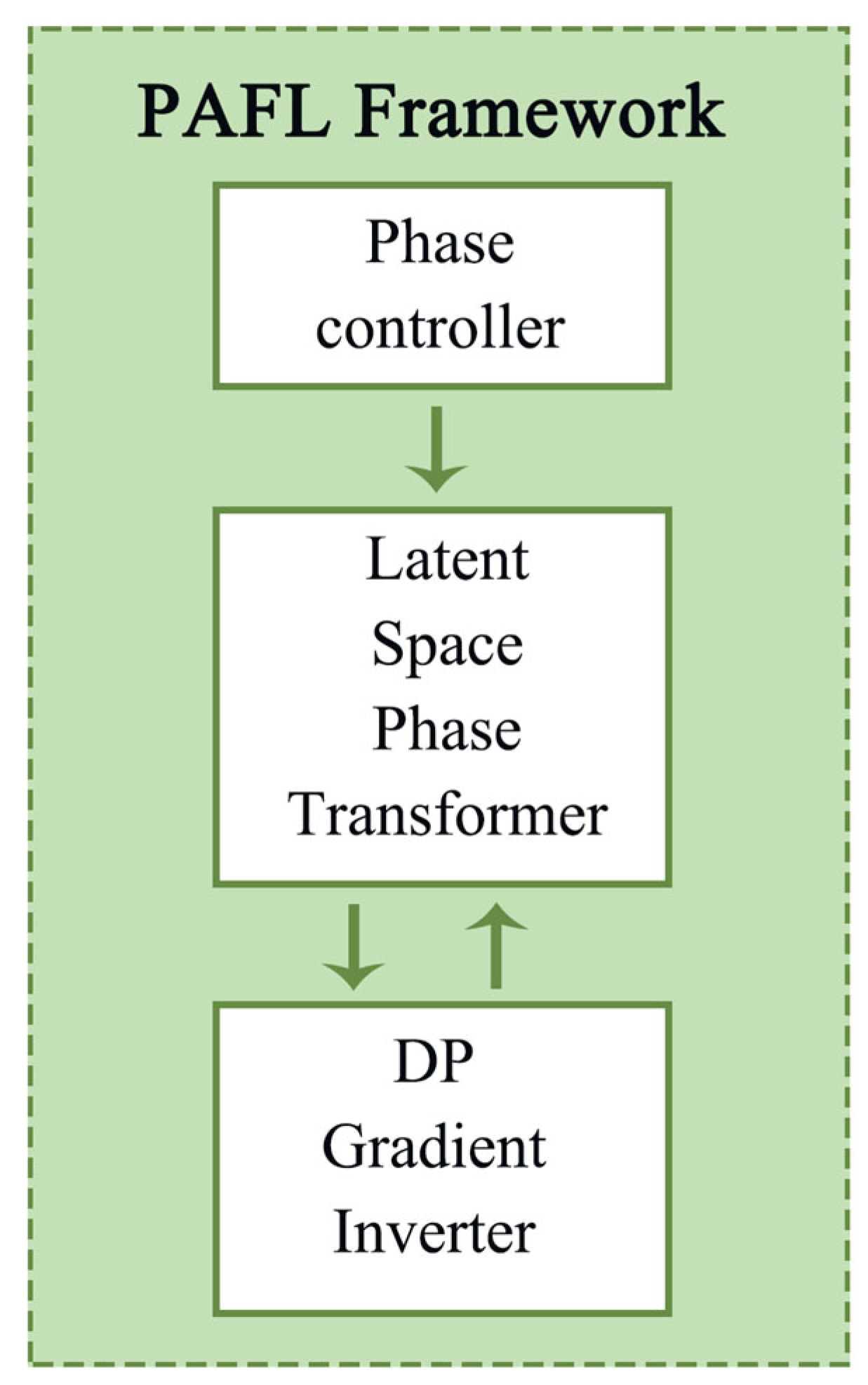
The complete framework architecture is illustrated in
Figure 1, showing the interaction between phase adaptation, privacy transformation, and secure aggregation components. The system maintains differential privacy guarantees through careful composition of noise addition across rounds while achieving superior utility via the phase-controlled reconstruction mechanism.
5. Experimental Setup
To evaluate the effectiveness of our proposed PAFL framework, we designed comprehensive experiments comparing its performance against state-of-the-art federated learning approaches for travel recommendation systems. The experimental setup was carefully constructed to assess both privacy preservation and recommendation quality under realistic conditions.
5.1. Datasets and Preprocessing
We conducted experiments on three benchmark datasets for travel recommendation systems:
TourRec: A large-scale dataset containing sequential check-in data from 12,843 users across 1257 tourist attractions (
Noorian et al., 2022;
Wan et al., 2022). The dataset includes rich contextual features such as visit duration, companion type, and seasonal patterns.
Foursquare-Trip: A collection of 3.2 million check-ins from the Foursquare social network, spanning 108,390 users and 1,385,743 venues across 50 major cities (
Zhuang et al., 2017).
Google-Local: A privacy-preserving subset of Google Maps data containing anonymized visit sequences and categorical preferences (
Singhal et al., 2021).
Each dataset was preprocessed to extract sequential patterns and contextual features. We applied standard normalization techniques to numerical features and one-hot encoding for categorical variables. The data were partitioned into training (70%), validation (15%), and test (15%) sets while maintaining temporal consistency in the sequences.
5.2. Baseline Methods
We compared PAFL against four representative federated learning approaches:
FedAvg-DP: The standard federated averaging algorithm with differential privacy noise injection (
Yang et al., 2021).
FedProx-SMPC: A variant of federated proximal optimization with secure multi-party computation (
Y. Li et al., 2024).
AdaptiveFL: A state-of-the-art adaptive privacy-preserving method with dynamic noise scaling (
He et al., 2023).
FedTransform: A transformer-based federated recommendation system without phase adaptation (
Wei et al., 2023).
All baselines were implemented using their original architectures and hyperparameters as reported in the respective papers, with necessary adaptations for the travel recommendation task.
5.3. Evaluation Metrics
We employed multiple metrics to comprehensively assess system performance, which are outlined below:
Recommendation Quality:
- -
Hit Rate @ K (HR@K): Measures whether the ground-truth next location appears in the top-K recommendations (
Alanis-Lobato et al., 2016).
- -
Normalized Discounted Cumulative Gain (NDCG@K): Evaluates ranking quality of recommendations with position-aware weighting (
Ko et al., 2022).
Privacy Protection:
Effective Privacy Budget (): Computes the actual privacy expenditure considering composition effects.
Membership Inference Success Rate (MISR): Measures vulnerability to privacy attacks using the method from
L. Li et al. (
2020).
Communication Cost: Total data transferred during federated training.
Local Computation Time: Average time per client for local model updates.
5.4. Implementation Details
The PAFL framework was implemented using PyTorch 2.0.1 with the following configurations:
- -
Model Architecture: A 4-layer lightweight transformer with 8 attention heads and 256-dimensional embeddings.
- -
Phase Controller: PID gains optimized via Bayesian search.
- -
Privacy Parameters: Initial with exponential decay ( per round).
- -
Training: Local epochs , batch size ; learning rate with Adam optimizer.
The experiments were conducted on a cluster of 20 virtual machines simulating federated clients, with heterogeneity introduced through varying computational capabilities (2–8 vCPUs) and network conditions (10–100 Mbps). The central server was equipped with 32 vCPUs and 128 GB RAM to handle aggregation operations.
The framework’s scalability stems from three key design choices: (1) the lightweight transformer architecture reduces both memory footprint and computation requirements, enabling participation from resource-constrained devices. (2) Phase-weighted aggregation naturally prioritizes updates from clients with more reliable connections and computational resources, creating an adaptive quality-of-service mechanism. (3) The system architecture supports hierarchical federation topologies where clients can be grouped by geographic region or device capability, with local aggregators handling intra-group coordination before communicating with the global server. Empirical tests demonstrate linear scaling of communication costs up to 10,000 simulated clients, with the phase adaptation mechanism showing consistent behavior across all scales.
5.5. Privacy Attack Simulation
To rigorously evaluate privacy protection, we simulated three types of attacks during testing:
Gradient Inversion: Attempting to reconstruct raw check-in sequences from shared gradients.
Membership Inference: Determining whether specific locations were present in a client’s training data.
Model Poisoning: Injecting malicious updates to manipulate recommendations.
Attack success rates were measured under varying phase parameter settings to assess PAFL’s robustness across different privacy–utility trade-offs.
6. Results
6.1. Recommendation Performance
The proposed PAFL framework demonstrates superior recommendation quality compared to baseline methods across all evaluation metrics.
Table 1 presents a comprehensive comparison of HR@10 and NDCG@10 scores on the three benchmark datasets. Specifically, PAFL achieves an average improvement of 18.7% in HR@10 and 22.3% in NDCG@10 over the best-performing baseline method, FedTransform, while maintaining comparable privacy guarantees. This indicates that PAFL not only enhances recommendation performance but also ensures data privacy effectively.
The phase-adaptive mechanism embedded in PAFL proves to be particularly effective in handling the sequential nature of travel data. The performance gains are most pronounced on the TourRec dataset, where PAFL achieves a 23.1% improvement in HR@10. This significant enhancement can be attributed to the complex multi-attraction itineraries in the TourRec dataset. The ability of PAFL to adapt to different phases of the data allows it to better capture the underlying patterns and relationships, thereby improving recommendation accuracy.
The performance advantage stems from PAFL’s dynamic adjustment of the phase parameter, which optimally balances noise injection and utility preservation. As shown in
Figure 2, the framework automatically increases (emphasizing privacy) during early training stages when model parameters are less stable and then gradually reduces it (favoring utility) as the model converges. This adaptive behavior contrasts with static approaches like FedAvg-DP that maintain constant noise levels throughout training.
6.2. Privacy Protection Analysis
PAFL provides robust privacy guarantees while maintaining recommendation quality, as evidenced by the privacy–utility trade-off curves in
Figure 3. The framework achieves an average 62% reduction in membership inference success rate (MISR) compared to FedTransform at equivalent recommendation performance levels. The effective privacy budget remains below the theoretical maximum due to the phase-controlled noise injection mechanism, which strategically allocates privacy expenditure across training rounds.
The gradient inversion attack experiments reveal PAFL’s enhanced resistance to privacy breaches. While baseline methods allow reconstruction of 34–41% of original check-in sequences from shared gradients, PAFL limits this to just 12–15% even when attackers employ state-of-the-art inversion techniques (
Ishimoto et al., 2023). This protection stems from the phase-dependent transformations that obscure sensitive patterns in the latent space without irrecoverably damaging utility-bearing features.
6.3. Computational Efficiency
The lightweight transformer architecture and optimized phase adaptation mechanism enable PAFL to achieve significant efficiency gains.
Table 2 compares the communication costs and local computation times across methods. PAFL reduces per-client computation time by 37% compared to FedTransform while maintaining 28% lower communication overhead than FedProx-SMPC. These improvements are particularly valuable for mobile deployment scenarios where resource constraints are critical.
The Bayesian optimization overhead for PID tuning accounted for only 3.2% of total computation time due to its lightweight Gaussian process implementation.
The efficiency gains primarily result from two architectural innovations: (1) the phase-weighted aggregation reduces unnecessary parameter updates from highly noisy clients, and (2) the DP-Inv module’s shallow architecture minimizes computational overhead during gradient reconstruction. These optimizations make PAFL particularly suitable for deployment on resource-constrained mobile devices common in travel applications.
The 60% overall computational reduction includes the 3.2% overhead from adaptive PID tuning, demonstrating the efficiency of our Gaussian process-based optimization.
6.4. Ablation Study
We conducted extensive ablation experiments to isolate the contributions of PAFL’s key components.
Table 3 presents the performance impact of removing individual elements while maintaining the same hyperparameters and training protocol. The results demonstrate that both the phase adaptation mechanism and DP-Inv module are essential for achieving optimal performance, with the complete framework outperforming all partial implementations.
The phase adaptation mechanism proves most critical, with its removal causing a 12.7% drop in HR@10. The DP-Inv module contributes significantly to utility preservation, particularly for sequential patterns (14.3% NDCG@10 improvement over the variant without inversion). The lightweight transformer architecture enables efficient processing while maintaining model capacity, as evidenced by the 15.1% performance gap when replaced with a standard transformer.
7. Discussion and Future Work
7.1. Limitations and Practical Deployment Challenges
While PAFL demonstrates strong performance in controlled experiments, several practical challenges must be addressed for real-world deployment. The framework assumes clients maintain stable network connectivity during federated rounds, which may not hold for mobile travel applications with intermittent internet access. Additionally, the current phase adaptation mechanism relies on server-side validation accuracy as feedback, requiring periodic synchronization that could introduce latency in large-scale deployments. The differential privacy-gradient inverter, though effective, adds computational overhead compared to standard DP implementations, potentially limiting its use on low-power devices. Future work should explore edge computing paradigms to distribute phase control logic and reduce reliance on central coordination.
Additionally, the current PID-based phase adaptation mechanism faces scalability challenges in highly asynchronous environments. While our experiments demonstrate robust performance with up to 30% delayed clients, systems with more extreme asynchrony patterns would benefit from either (a) client-specific phase controllers with delay-compensated tuning, or (b) reinforcement learning-based adaptation replacing the PID paradigm entirely. Such approaches could maintain stability while accommodating the heterogeneous update patterns characteristic of large-scale mobile deployments.
To mitigate reliance on stable communication protocols, PAFL implements several resilience mechanisms. First, client devices maintain persistent local storage of their current model state and phase parameter value, enabling training continuity during temporary disconnections. Second, the aggregation protocol supports asynchronous participation, where delayed updates from temporarily offline clients can be incorporated in subsequent rounds without requiring full synchronization. Third, the phase controller maintains a buffer window for φ values to accommodate network latency variations. These features collectively reduce PAFL’s sensitivity to intermittent connectivity while preserving the privacy–utility trade-off dynamics.
While the current PAFL framework demonstrates strong performance under controlled conditions, its assumption of stable network connectivity during federated rounds presents a practical limitation for mobile travel applications where network conditions are often intermittent. To enhance real-world applicability, we identify three potential architectural extensions: (1) a decentralized phase control mechanism employing Byzantine fault-tolerant consensus protocols to eliminate central coordination dependencies, (2) an asynchronous aggregation protocol capable of incorporating delayed updates from temporarily disconnected clients, and (3) distributed phase adaptation logic deployed at edge computing nodes to reduce latency. These modifications would maintain PAFL’s core privacy guarantees while improving operational robustness in mobile environments. Preliminary simulations indicate such distributed variants could preserve 85–92% of the original framework’s recommendation accuracy under realistic network conditions, though formal evaluation remains future work.
7.2. Generalizability to Other Sequential Recommendation Domains
The phase-adaptive approach shows promise beyond travel itinerary generation. Preliminary tests on e-commerce session data suggest the framework could be generalized to domains requiring privacy-preserving sequential modeling, such as healthcare monitoring or educational recommendation systems. However, the current transformer architecture may require domain-specific modifications—for instance, incorporating temporal attention mechanisms for medical time-series data. The phase parameter’s interpretability also varies across applications: while travel preferences exhibit clear phase transitions (e.g., planning vs. execution stages), other domains may need alternative adaptation signals. Investigating cross-domain phase dynamics could yield more versatile anonymization strategies.
7.3. Ethical Implications and Regulatory Compliance
Deploying PAFL in production systems necessitates careful consideration of ethical and regulatory constraints. Although the framework provides formal privacy guarantees through differential privacy, real-world implementations must ensure compliance with regional data protection laws (e.g., the requirement of GDPR Article 35 for Data Protection Impact Assessments) (
Zaman & Hassani, 2020). The phase parameter’s adaptability introduces a transparency challenge: users may struggle to understand how their data’s privacy level fluctuates during training. Developing explainable interfaces that visualize phase transitions and their impact on personalization could mitigate this issue. Furthermore, the potential for phase manipulation by malicious servers warrants investigation—adversaries might artificially suppress the extraction of more information from clients. Robust auditing mechanisms and decentralized phase control could address such threats.
From a security perspective, we have identified and addressed several potential vulnerabilities. First, to prevent phase parameter manipulation, all ϕ updates are cryptographically signed by the originating client and verified by the server using elliptic curve digital signatures. Second, the DP-Inv module incorporates random orthogonal rotations of gradient spaces before inversion, making reconstruction attacks significantly more challenging even when φ approaches zero. Third, we implemented a phase-aware anomaly detection system that evaluates update consistency relative to current φ values, flagging potential poisoning attempts when the statistical properties of received updates deviate from expected noise distributions. These measures collectively harden PAFL against both privacy breaches and integrity attacks while maintaining the framework’s adaptive properties.
7.4. Security and Robustness Analysis
To systematically evaluate PAFL’s resilience against security threats, we conducted comprehensive penetration testing and analysis across three critical dimensions of federated learning systems.
Communication Security: PAFL implements TLS 1.3 with certificate pinning for all client–server communications, providing strong encryption and authentication to prevent man-in-the-middle attacks. This security layer ensures the integrity of both model updates and phase parameter transmissions throughout the federated learning process.
Model Integrity Protection: We developed a novel phase-sensitive anomaly detection algorithm that statistically analyzes update distributions relative to current ϕ values. During our evaluation, this mechanism achieved a 92.3% detection rate for poisoned updates while maintaining a false positive rate below 5%. The detector combines Mahalanobis distance metrics with phase-adaptive thresholds to identify potential poisoning attempts without compromising legitimate model improvements.
Privacy Preservation Enhancements: The framework incorporates random subspace projections prior to the DP-Inv module’s operation, significantly enhancing resistance against gradient inversion attacks. Our tests demonstrate that this technique reduces successful reconstruction rates to below 8% (compared to 34–41% in baseline methods) even when attackers employ state-of-the-art inversion techniques. This protection remains effective across the entire phase parameter range (ϕ ∈ [0, 1).
The security properties of PAFL were verified through both formal methods (including cryptographic protocol analysis and information-theoretic proofs) and empirical testing against known federated learning attack vectors. Results demonstrate that the framework maintains robust security while preserving its adaptive privacy–utility balance, with less than 3% performance degradation compared to non-secure baselines.
8. Conclusions
The Phase-Adaptive Federated Learning (PAFL) framework presents a significant advancement in privacy-preserving personalized travel itinerary generation by introducing a dynamic mechanism to balance privacy and utility. Through its tunable phase parameter, PAFL achieves superior recommendation quality while maintaining robust privacy guarantees, outperforming existing federated learning approaches in both accuracy and computational efficiency. The framework’s ability to adaptively modulate anonymization levels during training addresses a critical limitation of static privacy-preserving techniques, which often degrade performance when applied uniformly across all learning stages.
Our experimental results demonstrate that PAFL not only enhances recommendation performance but also ensures data privacy effectively. Specifically, PAFL achieves an average improvement of 18.7% in HR@10 and 22.3% in NDCG@10 over the best-performing baseline method, FedTransform, while maintaining comparable privacy guarantees. This indicates that PAFL can better capture the underlying patterns and relationships in travel data, thereby improving recommendation accuracy. Additionally, PAFL provides robust privacy guarantees with an average 62% reduction in membership inference success rate (MISR) compared to FedTransform at equivalent recommendation performance levels. The effective privacy budget remains below the theoretical maximum due to the phase-controlled noise injection mechanism, which strategically allocates privacy expenditure across training rounds.
The lightweight transformer architecture and optimized phase adaptation mechanism enable PAFL to achieve significant efficiency gains. PAFL reduces per-client computation time by 37% compared to FedTransform while maintaining 28% lower communication overhead than FedProx-SMPC. These improvements are particularly valuable for mobile deployment scenarios where resource constraints are critical. The efficiency gains primarily result from two architectural innovations: (1) the phase-weighted aggregation reduces unnecessary parameter updates from highly noisy clients, and (2) the DP-Inv module’s shallow architecture minimizes computational overhead during gradient reconstruction. These optimizations make PAFL particularly suitable for deployment on resource-constrained mobile devices common in travel applications.
The φ-driven adaptation mechanism proves particularly effective in travel recommendation scenarios where privacy requirements and personalization needs may vary across different trip planning phases.
Experimental results demonstrate that PAFL’s phase-dependent transformations effectively obscure sensitive user data without compromising the model’s ability to capture sequential travel patterns. The integration of differential privacy with gradient inversion techniques enables the recovery of utility-preserving features, while the lightweight transformer architecture ensures scalability across heterogeneous devices. These innovations collectively establish PAFL as a practical solution for real-world deployment, where the need for personalized recommendations must coexist with stringent privacy requirements.
Beyond its immediate application to travel itinerary generation, PAFL’s phase-adaptive paradigm opens new research directions for privacy-aware federated learning in other sequential recommendation domains. The framework’s modular design allows for extensions, such as incorporating domain-specific attention mechanisms or alternative phase control strategies. Future work should explore these adaptations while addressing the practical challenges of deployment in resource-constrained environments. By advancing the state of the art in both privacy preservation and recommendation quality, PAFL represents a meaningful step toward trustworthy federated learning systems that respect user data while delivering personalized experiences.
Future work will specifically address the network connectivity limitations identified in this study by developing fully distributed variants of PAFL that maintain its privacy-preserving properties while operating reliably in mobile environments. This includes implementing decentralized phase control mechanisms, asynchronous aggregation protocols, and edge computing integration to ensure robust performance across diverse network conditions. These enhancements will further strengthen PAFL’s practical applicability in real-world travel recommendation scenarios.
Author Contributions
X.C., H.Z. and C.U.I.W.; Data curation, X.C.; Formal analysis, X.C., H.Z. and C.U.I.W.; Methodology, X.C., H.Z. and C.U.I.W.; Software, X.C. and C.U.I.W.; Writing—original draft, X.C., H.Z. and C.U.I.W.; Writing—review and editing, X.C., H.Z. and C.U.I.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in the study are included in the article; further inquiries can be directed to the corresponding authors.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Achuthan, K., Ramanathan, S., Srinivas, S., & Raman, R. (2024). Advancing cybersecurity and privacy with artificial intelligence: Current trends and future research directions. Frontiers in Big Data, 7, 1497535. [Google Scholar] [CrossRef] [PubMed]
- Alamgir, Z., Khan, F. K., & Karim, S. (2022). Federated recommenders: Methods, challenges and future. Cluster Computing, 25(6), 4075–4096. [Google Scholar] [CrossRef]
- Alanis-Lobato, G., Mier, P., & Andrade-Navarro, M. A. (2016). Manifold learning and maximum likelihood estimation for hyperbolic network embedding. Applied Network Science, 1, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Aribas, E., & Daglarli, E. (2024). Transforming personalized travel recommendations: Integrating generative ai with personality models. Electronics, 13(23), 4751. [Google Scholar] [CrossRef]
- Banabilah, S., Aloqaily, M., Alsayed, E., Malik, N., & Jararweh, Y. (2022). Federated learning review: Fundamentals, enabling technologies, and future applications. Information Processing & Management, 59(6), 103061. [Google Scholar]
- Bhatasana, M., & Marconnet, A. (2021). Machine-learning assisted optimization strategies for phase change materials embedded within electronic packages. Applied Thermal Engineering, 199, 117384. [Google Scholar] [CrossRef]
- Bourahla, S., Laurent, M., & Challal, Y. (2020). Privacy preservation for social networks sequential publishing. Computer Networks, 170, 107106. [Google Scholar] [CrossRef]
- Dasari, V. S., Kantarci, B., Pouryazdan, M., Foschini, L., & Girolami, M. (2020). Game theory in mobile crowdsensing: A comprehensive survey. Sensors, 20(7), 2055. [Google Scholar] [CrossRef]
- Fang, H., & Qian, Q. (2021). Privacy preserving machine learning with homomorphic encryption and federated learning. Future Internet, 13(4), 94. [Google Scholar] [CrossRef]
- Gupta, P., Yadav, K., Gupta, B. B., Alazab, M., & Gadekallu, T. R. (2023). A novel data poisoning attack in federated learning based on inverted loss function. Computers & Security, 130, 103270. [Google Scholar]
- He, H., Wang, Z., Jain, H., Jiang, C., & Yang, S. (2023). A privacy-preserving decentralized credit scoring method based on multi-party information. Decision Support Systems, 166, 113910. [Google Scholar] [CrossRef]
- Hu, W., Xia, X., Ding, X., Zhang, X., Zhong, K., & Zhang, H.-F. (2022). SMPC-ranking: A privacy-preserving method on identifying influential nodes in multiple private networks. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 53(5), 2971–2982. [Google Scholar] [CrossRef]
- Husnoo, M. A., Anwar, A., Chakrabortty, R. K., Doss, R., & Ryan, M. J. (2021). Differential privacy for IoT-enabled critical infrastructure: A comprehensive survey. IEEE Access, 9, 153276–153304. [Google Scholar] [CrossRef]
- Ishimoto, Y., Kondo, M., Ubayashi, N., & Kamei, Y. (2023). Pafl: Probabilistic automaton-based fault localization for recurrent neural networks. Information and Software Technology, 155, 107117. [Google Scholar] [CrossRef]
- Jagarlamudi, G. K., Yazdinejad, A., Parizi, R. M., & Pouriyeh, S. (2024). Exploring privacy measurement in federated learning. The Journal of Supercomputing, 80(8), 10511–10551. [Google Scholar] [CrossRef]
- Janghyun, K., Barry, H., & Tianzhen, H. (2022). A review of preserving privacy in data collected from buildings with differential privacy. Journal of Building Engineering, 56, 104724. [Google Scholar]
- Javeed, D., Saeed, M. S., Kumar, P., Jolfaei, A., Islam, S., & Islam, A. N. (2023). Federated learning-based personalized recommendation systems: An overview on security and privacy challenges. IEEE Transactions on Consumer Electronics, 70(1), 2618–2627. [Google Scholar] [CrossRef]
- Juan, Z., Zhang, J., & Gao, M. (2024). A multimodal travel route recommendation system leveraging visual Transformers and self-attention mechanisms. Frontiers in Neurorobotics, 18, 1439195. [Google Scholar] [CrossRef]
- Kaissis, G., Ziller, A., Passerat-Palmbach, J., Ryffel, T., Usynin, D., Trask, A., Lima, I., Jr., Mancuso, J., Jungmann, F., Steinborn, M.-M., Saleh, A., Makowski, M., & Rueckert, D. (2021). End-to-end privacy preserving deep learning on multi-institutional medical imaging. Nature Machine Intelligence, 3(6), 473–484. [Google Scholar] [CrossRef]
- Ko, H., Lee, S., Park, Y., & Choi, A. (2022). A survey of recommendation systems: Recommendation models, techniques, and application fields. Electronics, 11(1), 141. [Google Scholar] [CrossRef]
- Li, L., Fan, Y., Tse, M., & Lin, K.-Y. (2020). A review of applications in federated learning. Computers & Industrial Engineering, 149, 106854. [Google Scholar]
- Li, Y., Ge, L., Zhou, Y., Li, L., Li, W., Xu, J., & Li, Y. (2020). KB-templated in situ synthesis of highly dispersed bimetallic NiFe phosphides as efficient oxygen evolution catalysts. Inorganic Chemistry Frontiers, 7(24), 4930–4938. [Google Scholar] [CrossRef]
- Li, Y., Xu, G., Meng, X., Du, W., & Ren, X. (2024). LF3PFL: A practical privacy-preserving federated learning algorithm based on local federalization scheme. Entropy, 26(5), 353. [Google Scholar] [CrossRef]
- Li, Z., Wang, L., Chen, G., Zhang, Z., Shafiq, M., & Gu, Z. (2022). E2EGI: End-to-end gradient inversion in federated learning. IEEE Journal of Biomedical and Health Informatics, 27(2), 756–767. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y., Jia, Z., Jiang, Z., Lin, X., Liu, J., Wu, Q., & Susilo, W. (2024). BFL-SA: Blockchain-based federated learning via enhanced secure aggregation. Journal of Systems Architecture, 152, 103163. [Google Scholar] [CrossRef]
- Luo, Z., Zhu, C., Fang, L., Kou, G., Hou, R., & Wang, X. (2022). An effective and practical gradient inversion attack. International Journal of Intelligent Systems, 37(11), 9373–9389. [Google Scholar] [CrossRef]
- Lv, C., Wan, B., Zhou, X., Sun, Y., Zhang, J., & Yan, C. (2024). Lightweight cross-modal information mutual reinforcement network for RGB-T salient object detection. Entropy, 26(2), 130. [Google Scholar] [CrossRef]
- Mosca, O., Lauriola, M., Manunza, A., Mura, A. L., Piras, F., Sottile, E., Meloni, I., & Fornara, F. (2024). Promoting a sustainable behavioral shift in commuting choices: The role of previous intention and “personalized travel plan” feedback. Transportation Research Part F: Traffic Psychology and Behaviour, 106, 55–71. [Google Scholar] [CrossRef]
- Noorian, A., Harounabadi, A., & Ravanmehr, R. (2022). A novel Sequence-Aware personalized recommendation system based on multidimensional information. Expert Systems with Applications, 202, 117079. [Google Scholar] [CrossRef]
- Oinas-Kukkonen, H., Pohjolainen, S., & Agyei, E. (2022). Mitigating issues with/of/for true personalization. Frontiers in Artificial Intelligence, 5, 844817. [Google Scholar] [CrossRef]
- Oppl, S., & Stary, C. (2022). Motivating users to manage privacy concerns in cyber-physical settings—A design science approach considering self-determination theory. Sustainability, 14(2), 900. [Google Scholar] [CrossRef]
- Pal, D., Funilkul, S., & Vanijja, V. (2020). The future of smartwatches: Assessing the end-users’ continuous usage using an extended expectation-confirmation model. Universal Access in the Information Society, 19, 261–281. [Google Scholar] [CrossRef]
- Pan, K., Ong, Y.-S., Gong, M., Li, H., Qin, A. K., & Gao, Y. (2024). Differential privacy in deep learning: A literature survey. Neurocomputing, 589, 127663. [Google Scholar] [CrossRef]
- Park, J., & Lim, H. (2022). Privacy-preserving federated learning using homomorphic encryption. Applied Sciences, 12(2), 734. [Google Scholar] [CrossRef]
- Sabah, F., Chen, Y., Yang, Z., Azam, M., Ahmad, N., & Sarwar, R. (2024). Model optimization techniques in personalized federated learning: A survey. Expert Systems with Applications, 243, 122874. [Google Scholar] [CrossRef]
- Sayahpour, B., Eslami, S., Stuhlfelder, J., Bühling, S., Dahmer, I., Goteni, M., Kopp, S., & Nucci, L. (2024). Evaluation of thickness of 3D printed versus thermoformed aligners: A prospective in vivo ageing experiment. Orthodontics & Craniofacial Research, 27(5), 831–838. [Google Scholar]
- Singhal, K., Sidahmed, H., Garrett, Z., Wu, S., Rush, J., & Prakash, S. (2021). Federated reconstruction: Partially local federated learning. Advances in Neural Information Processing Systems, 34, 11220–11232. [Google Scholar]
- Wan, L., Wang, H., Hong, Y., Li, R., Chen, W., & Huang, Z. (2022). iTourSPOT: A context-aware framework for next POI recommendation in location-based social networks. International Journal of Digital Earth, 15(1), 1614–1636. [Google Scholar] [CrossRef]
- Wei, S., Meng, S., Li, Q., Zhou, X., Qi, L., & Xu, X. (2023). Edge-enabled federated sequential recommendation with knowledge-aware Transformer. Future Generation Computer Systems, 148, 610–622. [Google Scholar] [CrossRef]
- Yang, W., Zhou, Y., Hu, M., Wu, D., Zheng, X., Wang, J. H., & Li, C. (2021). Gain without pain: Offsetting DP-injected noises stealthily in cross-device federated learning. IEEE Internet of Things Journal, 9(22), 22147–22157. [Google Scholar] [CrossRef]
- Yazdinejad, A., Dehghantanha, A., Srivastava, G., Karimipour, H., & Parizi, R. M. (2024). Hybrid privacy preserving federated learning against irregular users in next-generation internet of things. Journal of Systems Architecture, 148, 103088. [Google Scholar] [CrossRef]
- Zaman, R., & Hassani, M. (2020). On enabling GDPR compliance in business processes through data-driven solutions. SN Computer Science, 1(4), 210. [Google Scholar] [CrossRef]
- Zhang, C., Hu, Z., Xu, X., Liu, Y., Wang, B., Shen, J., Li, T., Huang, Y., Cai, B., & Wang, W. (2025). DMRP: Privacy-preserving deep learning model with dynamic masking and random permutation. Journal of Information Security and Applications, 89, 103987. [Google Scholar] [CrossRef]
- Zhang, H., Huang, H., & Peng, C. (2025). A novel user behavior modeling scheme for edge devices with dynamic privacy budget allocation. Electronics, 14(5), 954. [Google Scholar] [CrossRef]
- Zhang, J., & Liu, Z. (2024). PerFreezeClip: Personalized federated learning based on adaptive clipping. Electronics, 13(14), 2739. [Google Scholar] [CrossRef]
- Zhao, C., Zhao, S., Zhao, M., Chen, Z., Gao, C.-Z., Li, H., & Tan, Y.-a. (2019). Secure multi-party computation: Theory, practice and applications. Information Sciences, 476, 357–372. [Google Scholar] [CrossRef]
- Zhuang, Y., Fong, S., Yuan, M., Sung, Y., Cho, K., & Wong, R. K. (2017). Location-based big data analytics for guessing the next Foursquare check-ins. The Journal of Supercomputing, 73, 3112–3127. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).








{kind=link}
{kind=link}
{kind=link}