
Does AutoML Outperform Naive Forecasting? †




Abstract
:1. Introduction
- A description of several state-of-the-art AutoML frameworks;
- The comparison between several state-of-the-art AutoML frameworks on univariate and multivariate time series forecasting on different horizons;
- The assessment of their effectiveness against conventional forecasting strategies such as naive and exponential smoothing on comparable scale times.
2. Machine Learning and Forecasting
- Preprocessing: the observations are cleaned, normalized and rescaled. Missing data can be removed or replaced. New features may be produced by means of feature engineering [11].
- Dimensionality reduction: this step aims at reducing the input dimension, to diminish the computational burden and avoid numerical and statistical issues [12].
- Model estimation: this step estimates from the available data the input-output relationship.
- Performance assessment: the model performances are validated by means of a validation set, a subsample of the observed data that is kept aside to verify the ability of the model previously trained to correctly predict new unseen samples. This is followed by an analysis of the distribution of performance measures.
2.1. Conventional Statistical Approaches
3. AutoML Frameworks
4. Experimental Benchmark
- Electricity consumption: the original dataset (https://archive.ics.uci.edu/ml/datasets/ElectricityLoadDiagrams20112014, accessed on 30 March 2021) contains electricity consumption of 370 clients recorded every 15 min from 2011 to 2014. The preprocessed dataset contains hourly consumption (in kWh) of 321 clients from 2012 to 2014.
- Exchange rate: the dataset (possible source: https://fred.stlouisfed.org/series/EXUSEU, accessed on 3 March 2021) is a collection of the daily exchange rates of eight foreign countries, including Australia, Great Britain, Canada, Switzerland, China, Japan, New Zealand and Singapore. The considered time ranges from 1990 to 2016.
Experimental Results
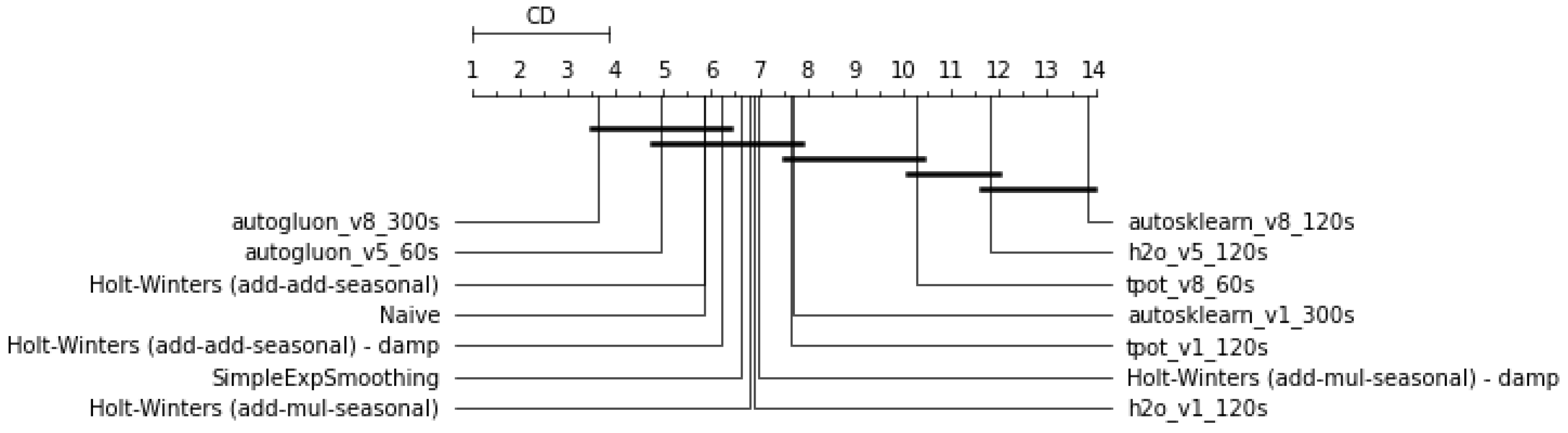
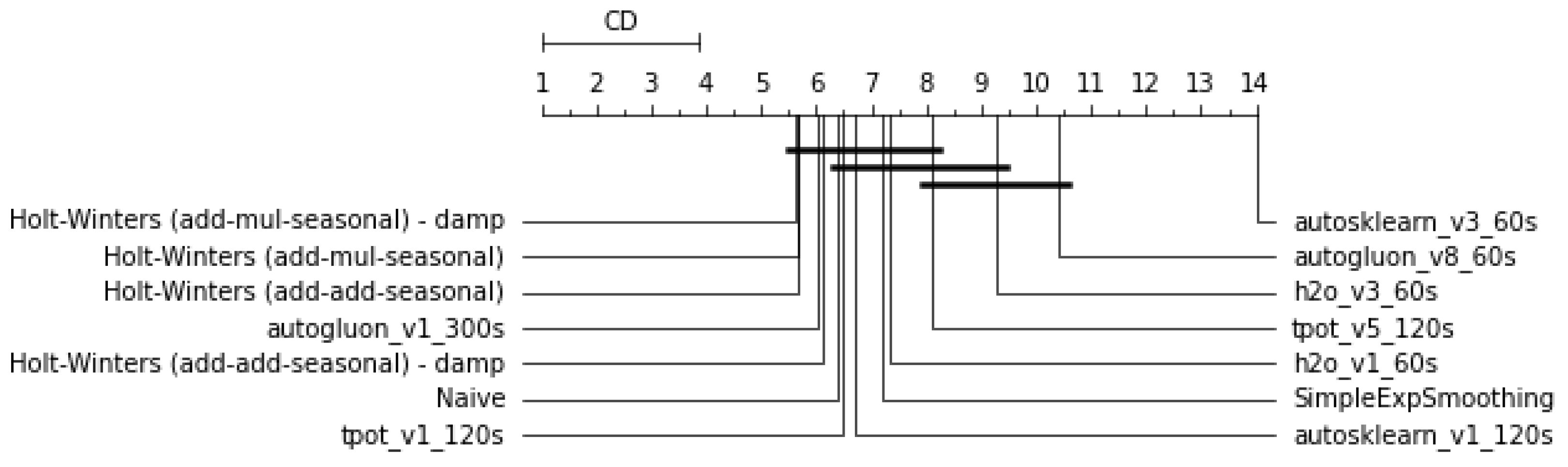
- Short-range training times (in the order of few minutes) are not sufficient for the AutoML frameworks considered to significantly outperform conventional methods (Figure 3). For short-horizons quick forecasting, it might therefore be convenient to rely on the latter.
- In terms of training time, 120 s seems to allow slightly better generalization ability than 60 or 300 s (Table 2). This might indicate that with 60 s, the models tend to underfit and with 300 s to overfit the observations.
- All traditional methods dominate every AutoML method in terms of wins count with respect to the naive (Table 2), which reflects the strong forecasting ability of the exponential smoothing family of methods. It could be appropriate to consider those methods as a baseline.
- Moving from a univariate SISO to multivariate MISO approach does not improve the performances of any method despite that the variables are added by maximizing correlation. This seems to suggest a lack of effectiveness in the feature selection approaches of the AutoML frameworks, when implemented.
5. Conclusions, Recommendations and Future Work
Acknowledgments
References
- He, X.; Zhao, K.; Chu, X. AutoML: A Survey of the State-of-the-Art. Knowl. Based Syst. 2021, 212, 106622. [Google Scholar] [CrossRef]
- Bontempi, G. A blocking strategy to improve gene selection for classification of gene expression data. IEEE/ACM Trans. Comput. Biol. Bioinform. 2007, 4, 293–300. [Google Scholar] [CrossRef] [PubMed]
- Balaji, A.; Allen, A. Benchmarking automatic machine learning frameworks. arXiv 2018, arXiv:1808.06492. [Google Scholar]
- Gijsbers, P.; LeDell, E.; Thomas, J.; Poirier, S.; Bischl, B.; Vanschoren, J. An open source automl benchmark. arXiv 2019, arXiv:1907.00909. [Google Scholar]
- Hanussek, M.; Blohm, M.; Kintz, M. Can AutoML outperform humans? An evaluation on popular OpenML datasets using AutoML Benchmark. arXiv 2020, arXiv:2009.01564. [Google Scholar]
- Guyon, I.; Sun-Hosoya, L.; Boullé, M.; Escalante, H.J.; Escalera, S.; Liu, Z.; Jajetic, D.; Ray, B.; Saeed, M.; Sebag, M.; et al. Analysis of the AutoML Challenge Series 2015–2018. In Automated Machine Learning; Hutter, F., Kotthoff, L., Vanschoren, J., Eds.; The Springer Series on Challenges in Machine Learning; Springer: Cham, Switzerland, 2019. [Google Scholar] [CrossRef] [Green Version]
- Zöller, M.A.; Huber, M.F. Benchmark and survey of automated machine learning frameworks. arXiv 2019, arXiv:1904.12054. [Google Scholar]
- Erickson, N.; Mueller, J.; Shirkov, A.; Zhang, H.; Larroy, P.; Li, M.; Smola, A. Autogluon-tabular: Robust and accurate automl for structured data. arXiv 2020, arXiv:2003.06505. [Google Scholar]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. Statistical and Machine Learning forecasting methods: Concerns and ways forward. PLoS ONE 2018, 13, e0194889. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bontempi, G.; Taieb, S.B.; Le Borgne, Y.A. Machine learning strategies for time series forecasting. In European Business Intelligence Summer School; Springer: Berlin, Germany, 2012; pp. 62–77. [Google Scholar]
- Christ, M.; Braun, N.; Neuffer, J.; Kempa-Liehr, A.W. Time series feature extraction on basis of scalable hypothesis tests (tsfresh—A python package). Neurocomputing 2018, 307, 72–77. [Google Scholar] [CrossRef]
- Bermingham, M.L.; Pong-Wong, R.; Spiliopoulou, A.; Hayward, C.; Rudan, I.; Campbell, H.; Wright, A.F.; Wilson, J.F.; Agakov, F.; Navarro, P.; et al. Application of high-dimensional feature selection: Evaluation for genomic prediction in man. Sci. Rep. 2015, 5, 1–12. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brown, R.G. Statistical Forecasting for Inventory Control; McGraw/Hill: New York, NY, USA, 1959. [Google Scholar]
- Holt, C.C. Forecasting seasonals and trends by exponentially weighted moving averages. Int. J. Forecast. 2004, 20, 5–10. [Google Scholar] [CrossRef]
- Goodwin, P. The holt-winters approach to exponential smoothing: 50 years old and going strong. Foresight 2010, 19, 30–33. [Google Scholar]
- Hyndman, R.; Koehler, A.B.; Ord, J.K.; Snyder, R.D. Forecasting with Exponential Smoothing: The State Space Approach; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Pegels, C.C. Exponential forecasting: Some new variations. Manag. Sci. 1969, 15, 311–315. [Google Scholar]
- Gardner, E.S., Jr. Exponential smoothing: The state of the art. J. Forecast. 1985, 4, 1–28. [Google Scholar] [CrossRef]
- Taylor, J.W. Exponential smoothing with a damped multiplicative trend. Int. J. Forecast. 2003, 19, 715–725. [Google Scholar] [CrossRef] [Green Version]
- LeDell, E.; Poirier, S. H2O AutoML: Scalable Automatic Machine Learning. In Proceedings of the 7th ICML Workshop on Automated Machine Learning (AutoML), Online, 18 July 2020. [Google Scholar]
- Feurer, M.; Klein, A.; Eggensperger, K.; Springenberg, J.; Blum, M.; Hutter, F. Efficient and Robust Automated Machine Learning. 2015. Available online: http://papers.nips.cc/paper/5872-efficient-and-robust-automated-machine-learning (accessed on 30 March 2021).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. CoRR 2012, abs/1201.0490. [Google Scholar]
- Olson, R.S.; Bartley, N.; Urbanowicz, R.J.; Moore, J.H. Evaluation of a Tree-based Pipeline Optimization Tool for Automating Data Science. In Proceedings of the Genetic and Evolutionary Computation Conference (GECCO ’16), Denver, CO, USA, 20–24 July 2016; ACM: New York, NY, USA, 2016; pp. 485–492. [Google Scholar] [CrossRef] [Green Version]
- Banzhaf, W.; Nordin, P.; Keller, R.E.; Francone, F.D. Genetic Programming: An Introduction; Morgan Kaufmann Publishers: San Francisco, CA, USA, 1998; Volume 1. [Google Scholar]
- Lai, G.; Chang, W.C.; Yang, Y.; Liu, H. Modeling long-and short-term temporal patterns with deep neural networks. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 95–104. [Google Scholar]
- Demšar, J. Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Trend Comp. | Seasonal Comp. |
|---|---|---|
| Simple exponential smoothing | None | None |
| Additive Holt-Winters’ method | Additive | Additive |
| Multiplicative Holt-Winters’ method | Additive | Multiplicative |
| Additive Holt-Winters’ damped method | Additive damped | Additive |
| Multiplicative Holt-Winters’ damped method | Additive damped | Multiplicative |
| Model | Wins | Losses | Model | Wins | Losses |
|---|---|---|---|---|---|
| Holt-Winters (add-add) | 146 | 46 | h2o_v3_300s | 66 | 126 |
| Holt-Winters (add-add) | 146 | 46 | autogluon_v3_300s | 65 | 127 |
| SimpleExpSmoothing | 139 | 53 | tpot_v3_60s | 65 | 127 |
| Holt-Winters (add-mul) | 138 | 54 | h2o_v5_60s | 65 | 127 |
| Holt-Winters (add-mul) | 138 | 54 | h2o_v3_60s | 63 | 129 |
| h2o_v1_120s | 80 | 112 | h2o_v8_60s | 62 | 130 |
| h2o_v1_300s | 79 | 113 | tpot_v5_60s | 62 | 130 |
| autosklearn_v1_300s | 75 | 117 | autosklearn_v1_60s | 61 | 131 |
| h2o_v1_60s | 75 | 117 | tpot_v8_60s | 60 | 132 |
| h2o_v8_120s | 74 | 118 | autogluon_v5_300s | 60 | 132 |
| autogluon_v1_300s | 74 | 118 | tpot_v8_120s | 60 | 132 |
| tpot_v1_120s | 74 | 118 | autogluon_v8_300s | 59 | 133 |
| tpot_v8_300s | 74 | 118 | autogluon_v8_120s | 59 | 133 |
| autogluon_v1_60s | 73 | 119 | autogluon_v5_120s | 59 | 133 |
| tpot_v1_60s | 72 | 120 | autogluon_v8_60s | 57 | 135 |
| tpot_v1_300s | 71 | 121 | autogluon_v5_60s | 53 | 139 |
| h2o_v5_300s | 69 | 123 | autosklearn_v3_300s | 51 | 141 |
| autogluon_v1_120s | 69 | 123 | h2o_v5_120s | 50 | 142 |
| autogluon_v3_120s | 69 | 123 | autosklearn_v5_300s | 36 | 156 |
| h2o_v8_300s | 68 | 124 | autosklearn_v3_120s | 18 | 174 |
| tpot_v5_120s | 67 | 125 | autosklearn_v5_120s | 17 | 175 |
| autogluon_v3_60s | 67 | 125 | autosklearn_v5_60s | 14 | 178 |
| autosklearn_v1_120s | 67 | 125 | autosklearn_v8_300s | 14 | 178 |
| tpot_v5_300s | 66 | 126 | autosklearn_v8_60s | 9 | 183 |
| tpot_v3_300s | 66 | 126 | autosklearn_v8_120s | 5 | 187 |
| tpot_v3_120s | 66 | 126 | autosklearn_v3_60s | 2 | 190 |
| h2o_v3_120s | 66 | 126 | Naive | Base | Base |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Paldino, G.M.; De Stefani, J.; De Caro, F.; Bontempi, G. Does AutoML Outperform Naive Forecasting? Eng. Proc. 2021, 5, 36. https://doi.org/10.3390/engproc2021005036
Paldino GM, De Stefani J, De Caro F, Bontempi G. Does AutoML Outperform Naive Forecasting? Engineering Proceedings. 2021; 5(1):36. https://doi.org/10.3390/engproc2021005036
Chicago/Turabian StylePaldino, Gian Marco, Jacopo De Stefani, Fabrizio De Caro, and Gianluca Bontempi. 2021. "Does AutoML Outperform Naive Forecasting?" Engineering Proceedings 5, no. 1: 36. https://doi.org/10.3390/engproc2021005036
APA StylePaldino, G. M., De Stefani, J., De Caro, F., & Bontempi, G. (2021). Does AutoML Outperform Naive Forecasting? Engineering Proceedings, 5(1), 36. https://doi.org/10.3390/engproc2021005036