Evaluation of Feature Selection Techniques in a Multifrequency Large Amplitude Pulse Voltammetric Electronic Tongue †

 ,
,  , and
, and 
Abstract
:1. Introduction
2. Materials and Methods
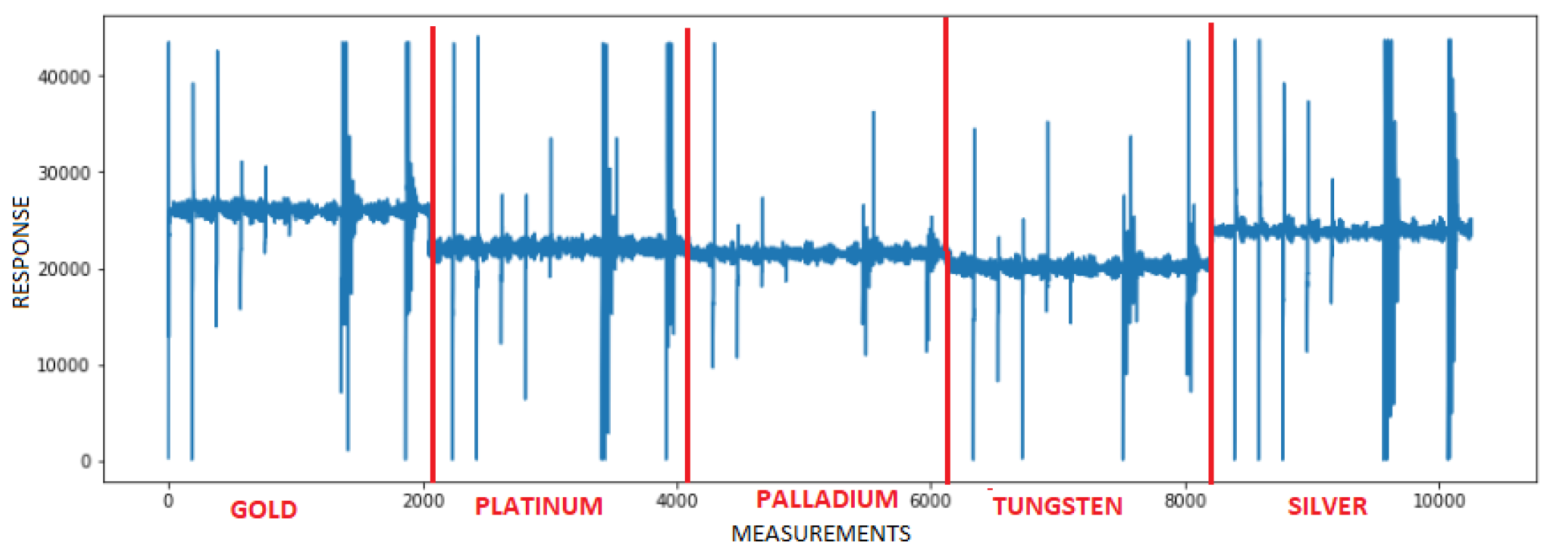
2.1. MLAPV Electronic Tongue Dataset
2.2. Feature Selection
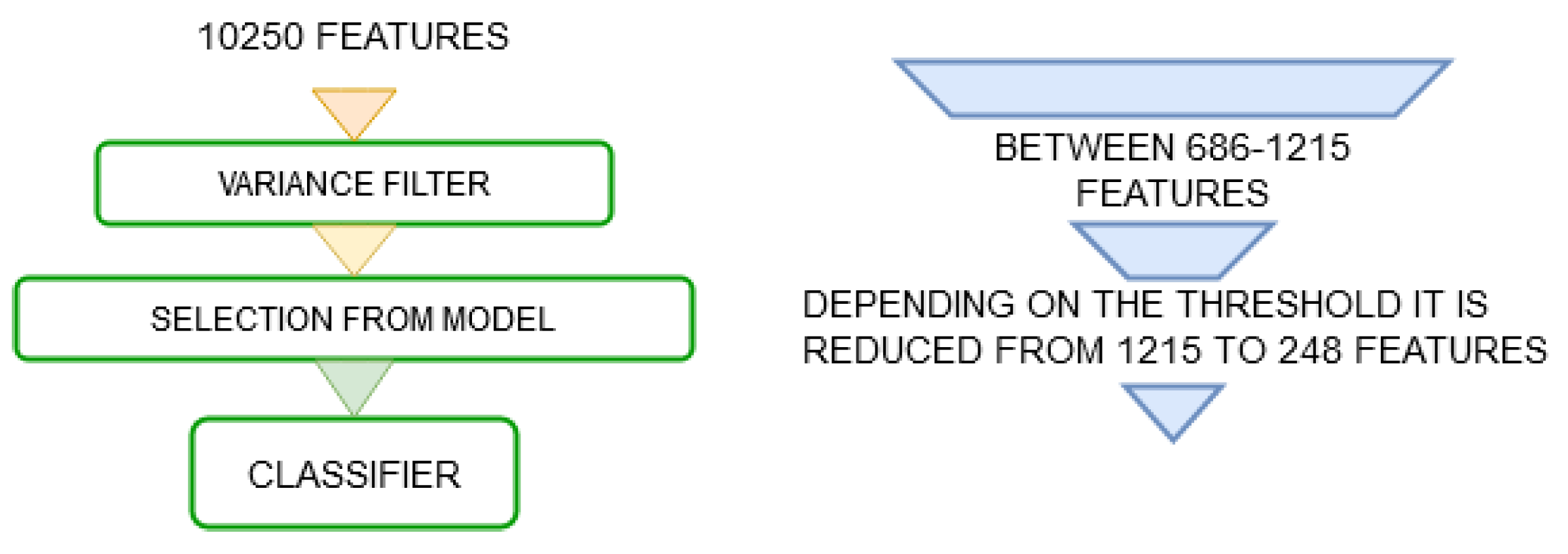
- Variance filter: It is used in order to examine each feature present in the data set and eliminate those least differentiating columns, that is, those that may be very common between classes. In this algorithm, the variance present is calculated between the samples for a certain feature. If this value turns out to be zero, it means that all the samples for that analyzed variable have the same value. In this sense, if the probability of obtaining a value is greater than 0.8, 0.9 or similar, this feature is eliminated because it is evidently a trait that will be present in several classes and most likely will not contribute to the classification.
- ANOVA F-value: The ANOVA test is used to study the difference between the means of various data groups [8,9]. This test allows searching for a similarity between features. If the difference between means of two variables is very small, it is most likely that the difference between the data of both variables is also small, which makes them very similar.
- Recursive Feature Elimination (RFE): It is an embedded type of feature selection, whose main objective is to reduce the dimension of the data by choosing a subgroup of variables with greater differentiating capacity [10]. An optimal subgroup for the classification is selected from the score given by the chosen estimator. To find this subgroup, successive trainings of the selected classifier are used. In each training, a score is given to the variables, so that after each iteration the weaker or less relevant variable or group of variables is eliminated. Finally, the last deleted variables turn out to be the most relevant [11].
- Selection from model: Some classifiers have coded techniques of punctuation that are able to deliver the respective coefficients for each feature, after the construction of a model. These coefficients can be used to form a threshold, taking the more relevant ones according to specific estimator. This method takes the coefficients obtained and organized by importance in order to select a group N of optimal features.
2.3. Combined Methods
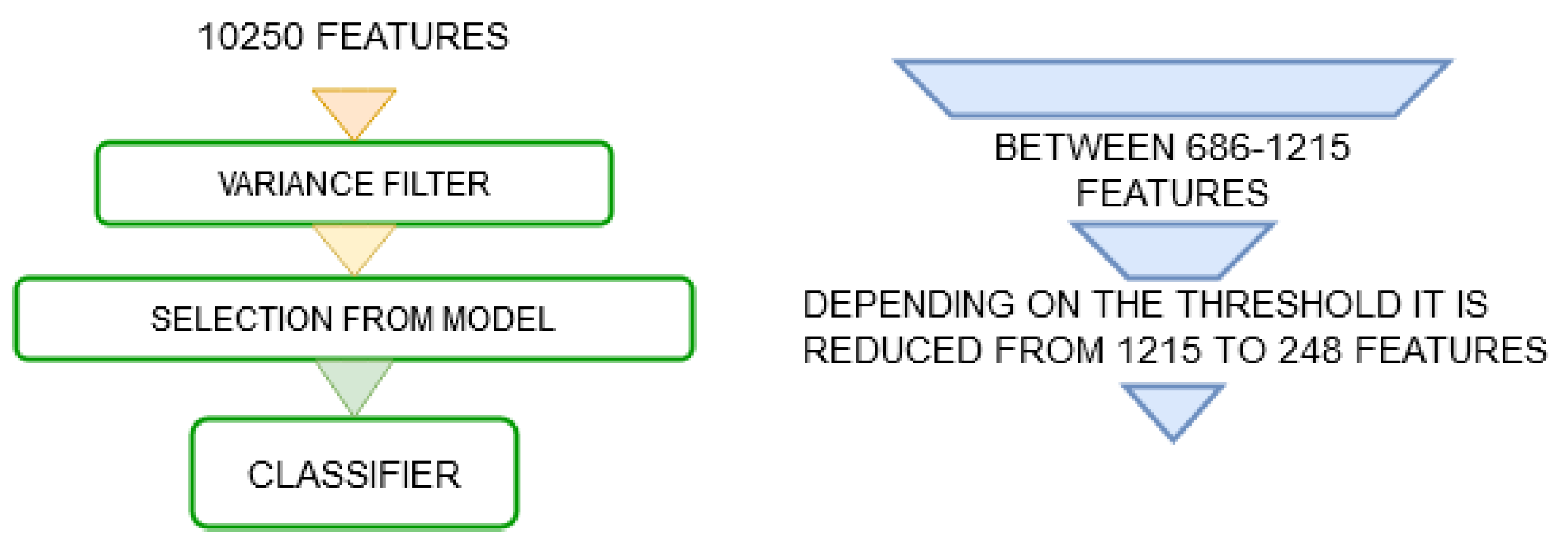
- Combination between the variance filter and selection from model: A combined method is proposed. First, it uses a variance filter in order to eliminate features with the same value in almost all samples and reduce the size of the initial group. Then, it applies selection from the model in a more agile and effective way. This process is illustrated in Figure 3.
- Combination between variance filter, ANOVA filter and selection from model: A similar technique to the previous one is proposed using another intermediate feature selection method, the ANOVA technique as shown in Figure 4.
- Combination between variance filter, ANOVA filter and RFE technique: In this case, the recursive RFE elimination method will be used after applying the variance and ANOVA filters as it is show in Figure 5. It is expected to reduce the number of features at the RFE input and in this way reduce the processing time and use a small step size, which can help to improve the final performance of the algorithm.
3. Results
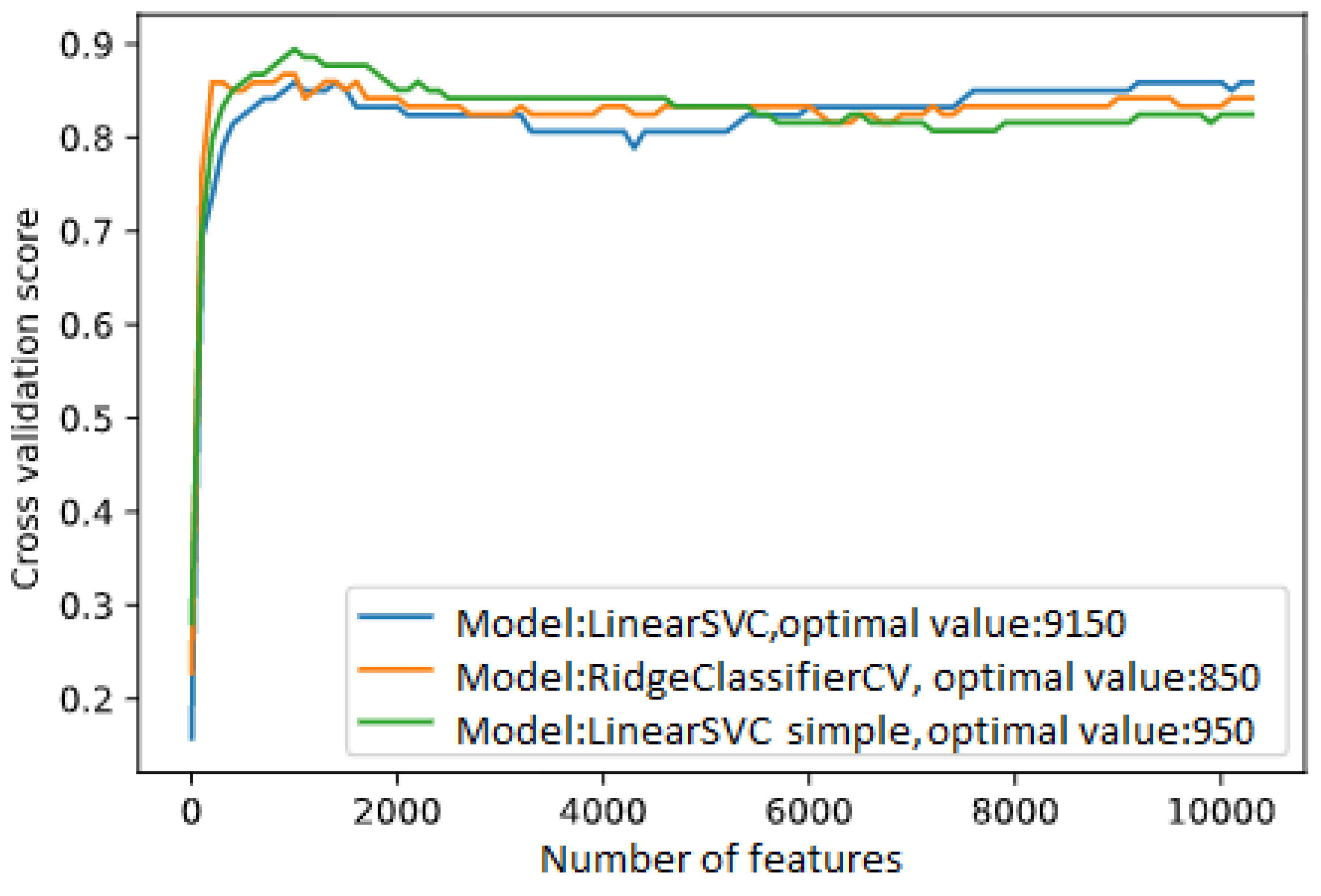
3.1. Combination between the Variance Filter and Selection from Model
3.2. Combination between Variance Filter, ANOVA Filter and Selection from Model
3.3. Combination between Variance Filter, ANOVA Filter and RFE Technique
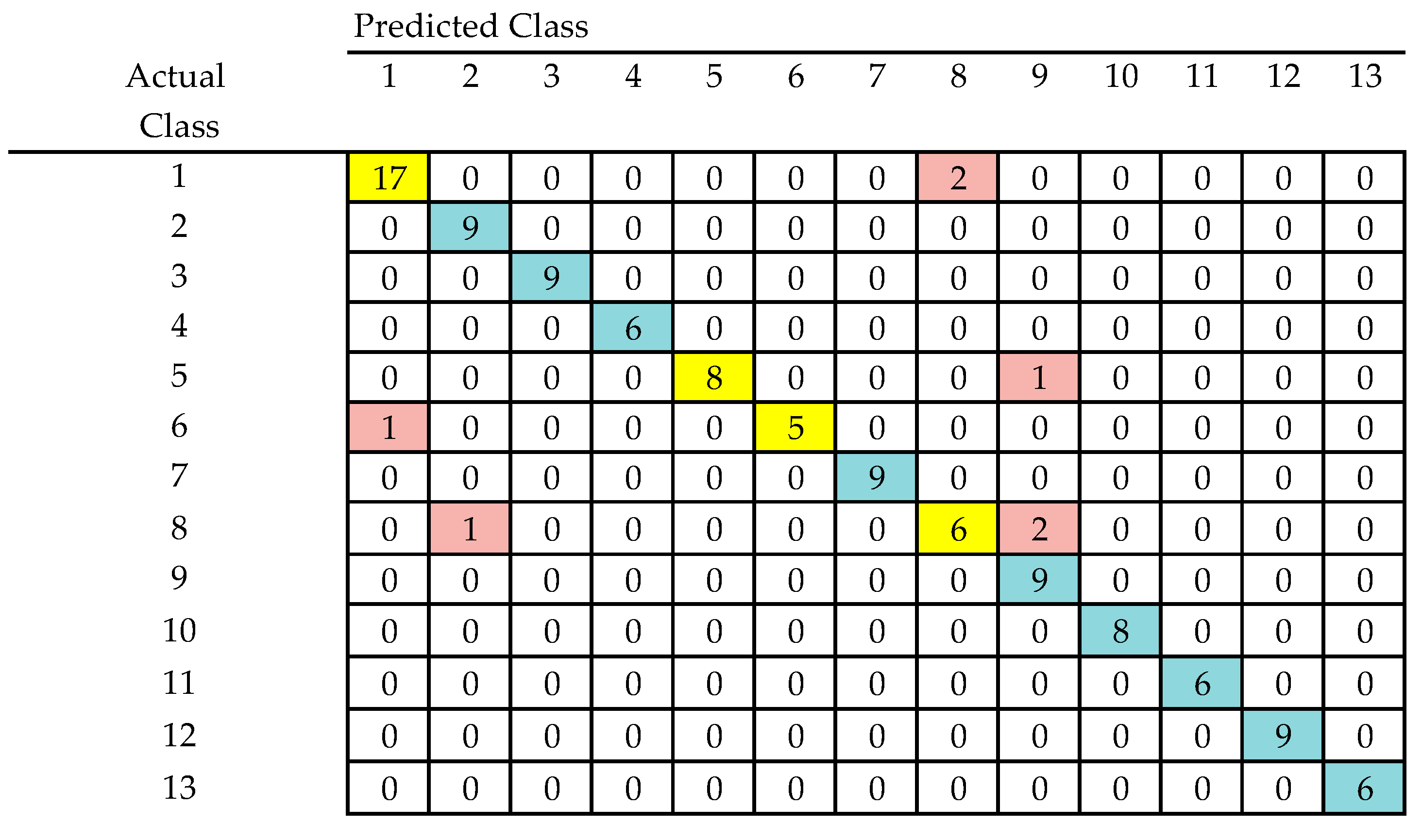
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Podrażka, M.; Baczynska, E.; Kundys, M.; Jeleń, P.S.; Nery, E.W. Electronic tongue—A tool for all tastes? Biosensors 2017, 8, 3. [Google Scholar] [CrossRef] [PubMed]
- Valle, M. Bioinspired sensor systems. Sensors 2011, 11, 10180–10186. [Google Scholar] [CrossRef] [PubMed]
- Leon-Medina, J.X.; Anaya, M.; Pozo, F.; Tibaduiza, D. Nonlinear Feature Extraction Through Manifold Learning in an Electronic Tongue Classification Task. Sensors 2020, 20, 4834. [Google Scholar] [CrossRef] [PubMed]
- Leon-Medina, J.X.; Cardenas-Flechas, L.J.; Tibaduiza, D.A. A data-driven methodology for the classification of different liquids in artificial taste recognition applica-tions with a pulse voltammetric electronic tongue. Int. J. Distrib. Sens. Networks 2019, 15. [Google Scholar] [CrossRef]
- Chandrashekar, G.; Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, X.; Huang, G.-B.; Liu, T.; Tan, X. Taste recognition in e-tongue using local discriminant preservation projection. IEEE Trans. Cybern. 2018, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blon-del, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Kumar, M.; Kumar Rath, N.; Swain, A.; Kumar Rath, S. Feature Selection and Classification of Microarray Data using MapReduce based ANOVA and K-Nearest Neighbor. Procedia Comput. Sci. 2015, 54, 301–310. [Google Scholar] [CrossRef]
- Ding, H.; Feng, P.-M.; Chen, W.; Lin, H. Identification of bacteriophage virionproteins by the anova feature selection and analysis. Mol. Biosyst. 2014, 10, 2229–2235. [Google Scholar] [CrossRef] [PubMed]
- Chen, Q.; Meng, Z.; Liu, X.; Jin, Q.; Su, R. Decision variants for the automatic determination of optimal feature subset in rf-rfe. Genes 2018, 9, 301. [Google Scholar] [CrossRef] [PubMed]
- Duan, K.-B.; Rajapakse, J.; Wang, H.; Azuaje, F. Multiple svm-rfe for gene selection in cancer classification with expression data. IEEE Trans. Nanobioscience 2005, 4, 228–234. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classifier | Threshold Selection from Model | Accuracy |
|---|---|---|
| Multilayer perceptron (MLPC) (adjusted) | 0.4 | 0.9032 |
| 0.6 | 0.9032 | |
| Multilayer perceptron (MLPC) | 0.2 | 0.9028 |
| Classifier | Threshold Selection from Model | Threshold Variance | Features | Accuracy |
|---|---|---|---|---|
| Multilayer perceptron(adjusted) | 0.5 | 0.0001 | 5200 | 0.9285 |
| 0.4 | 0.0001 | 5200 | 0.9285 | |
| 0.3 | 0.0001 | 5200 | 0.9123 |
| Classifier | Threshold Variance | Features | Accuracy |
|---|---|---|---|
| Multilayer perceptron(adjusted) | 0 | 6200 | 0.9032 |
| 0 | 5200 | 0.9028 | |
| 0 | 4800 | 0.8937 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Villamil-Cubillos, L.F.; Leon-Medina, J.X.; Anaya, M.; Tibaduiza, D.A. Evaluation of Feature Selection Techniques in a Multifrequency Large Amplitude Pulse Voltammetric Electronic Tongue. Eng. Proc. 2020, 2, 62. https://doi.org/10.3390/ecsa-7-08242
Villamil-Cubillos LF, Leon-Medina JX, Anaya M, Tibaduiza DA. Evaluation of Feature Selection Techniques in a Multifrequency Large Amplitude Pulse Voltammetric Electronic Tongue. Engineering Proceedings. 2020; 2(1):62. https://doi.org/10.3390/ecsa-7-08242
Chicago/Turabian StyleVillamil-Cubillos, Luis F., Jersson X. Leon-Medina, Maribel Anaya, and Diego A. Tibaduiza. 2020. "Evaluation of Feature Selection Techniques in a Multifrequency Large Amplitude Pulse Voltammetric Electronic Tongue" Engineering Proceedings 2, no. 1: 62. https://doi.org/10.3390/ecsa-7-08242
APA StyleVillamil-Cubillos, L. F., Leon-Medina, J. X., Anaya, M., & Tibaduiza, D. A. (2020). Evaluation of Feature Selection Techniques in a Multifrequency Large Amplitude Pulse Voltammetric Electronic Tongue. Engineering Proceedings, 2(1), 62. https://doi.org/10.3390/ecsa-7-08242