
Automatic Processing Pipeline for Collecting and Annotating Air-Traffic Voice Communication Data †

 , , , , ,
, , , , ,
Abstract
:1. Introduction
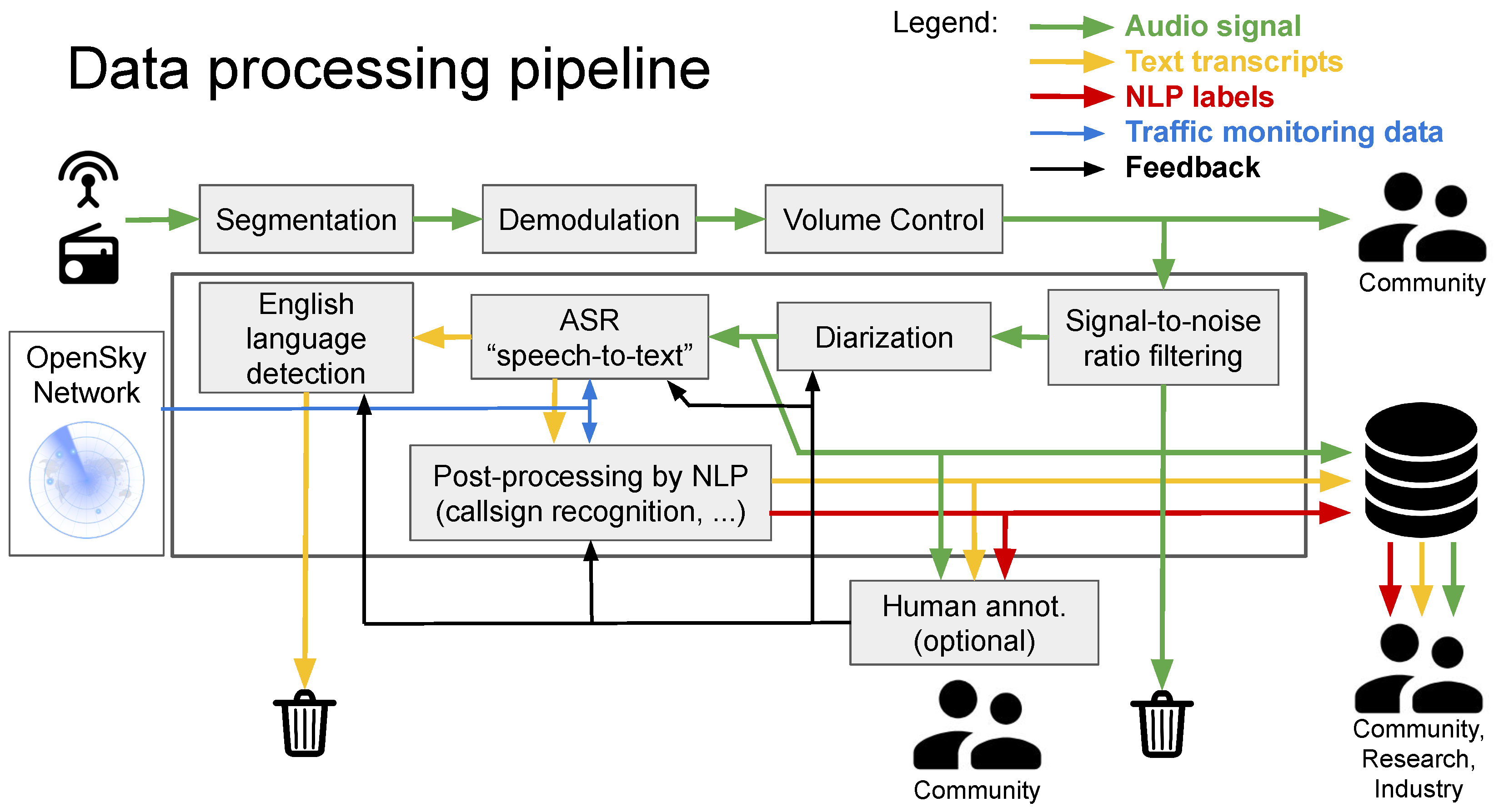
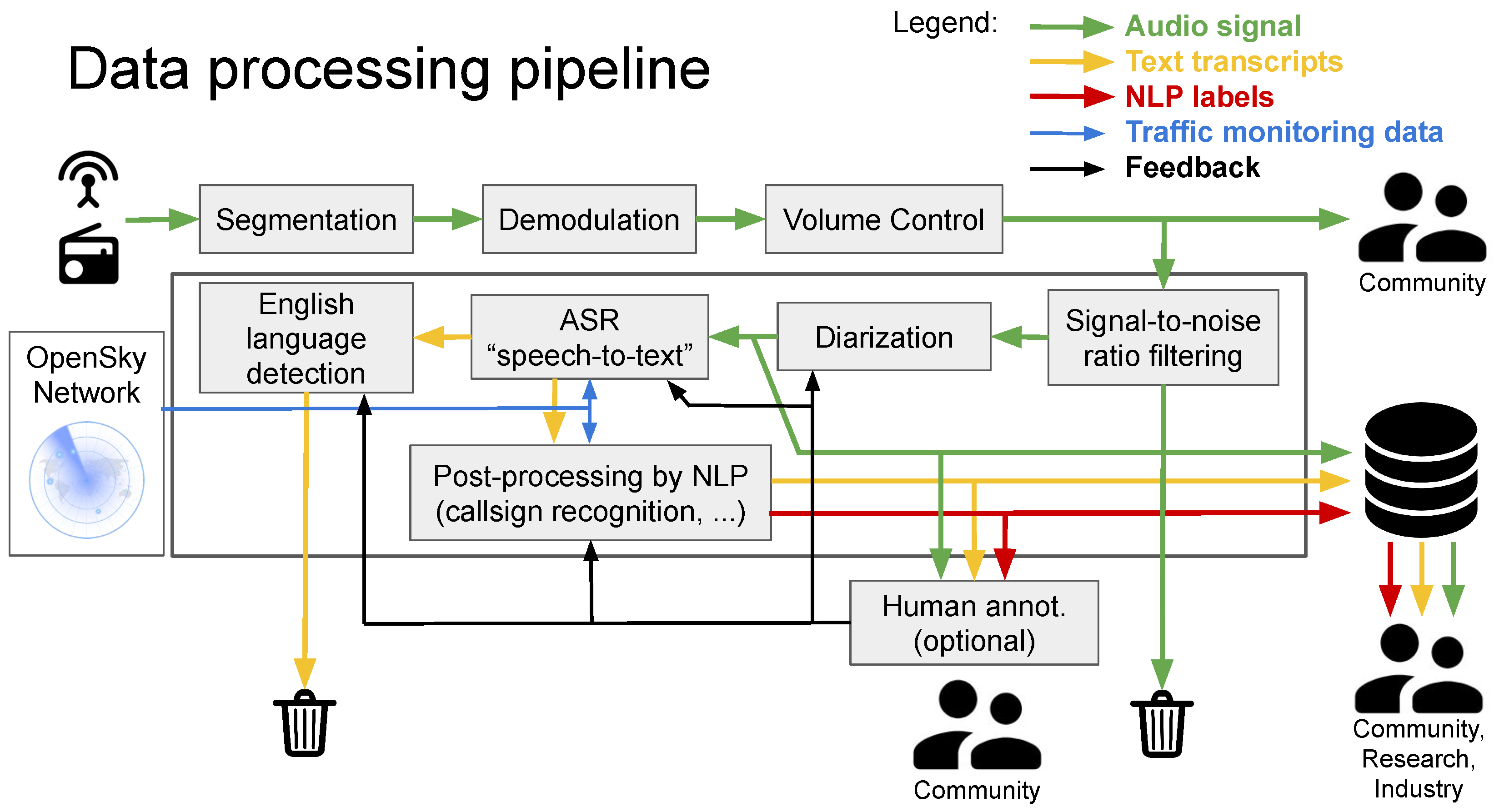
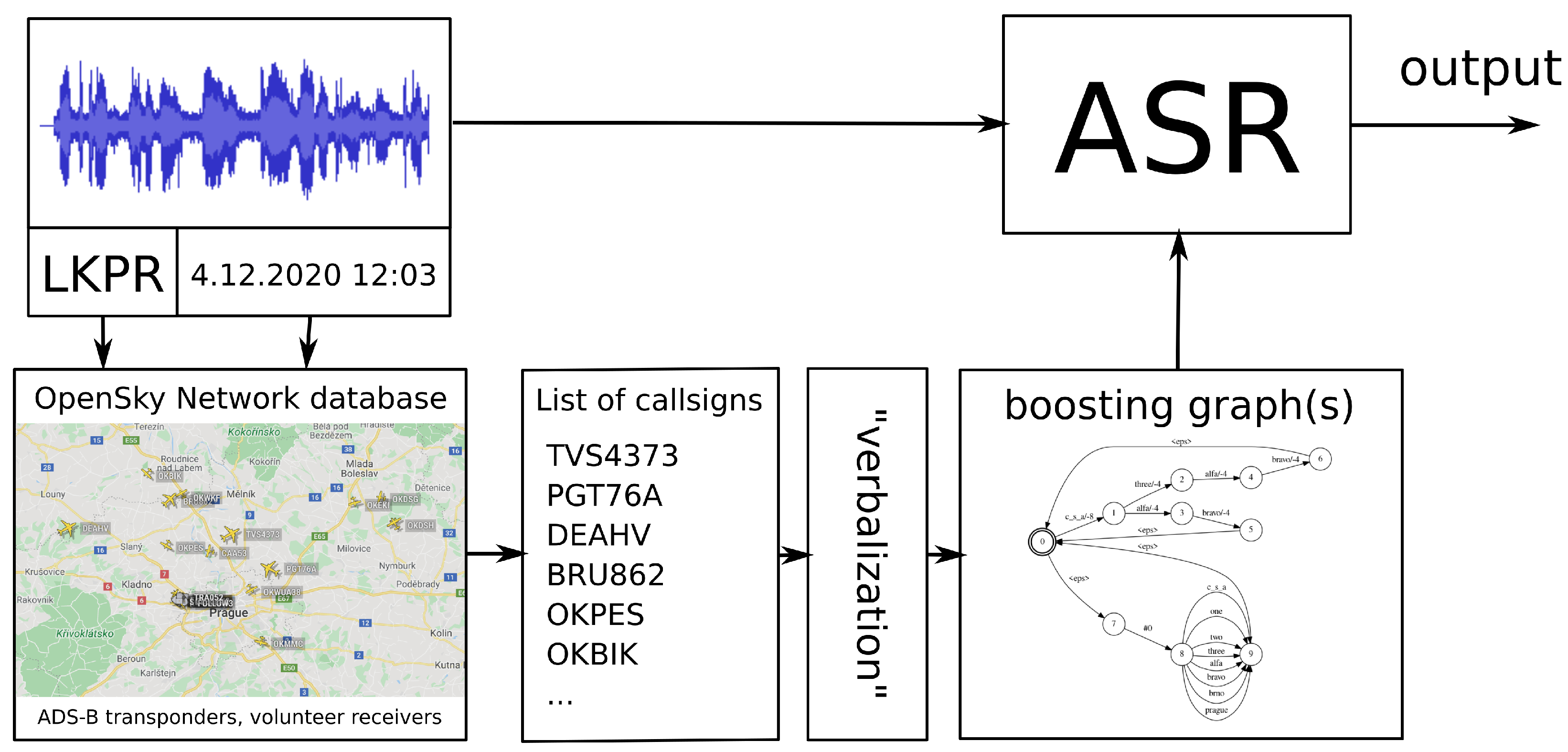
2. Data Pre-Processing and Diarization
3. Automatic Speech Recognition
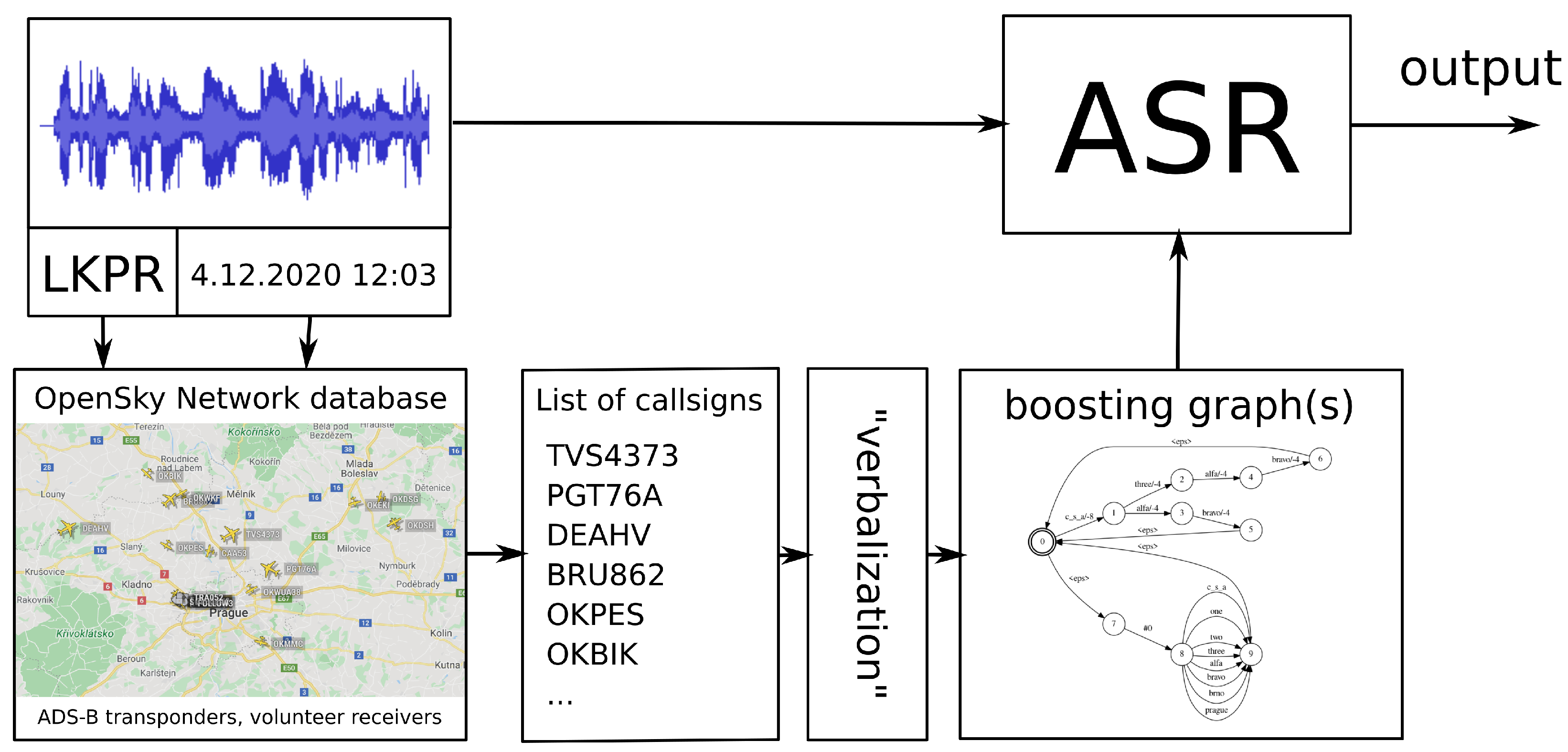
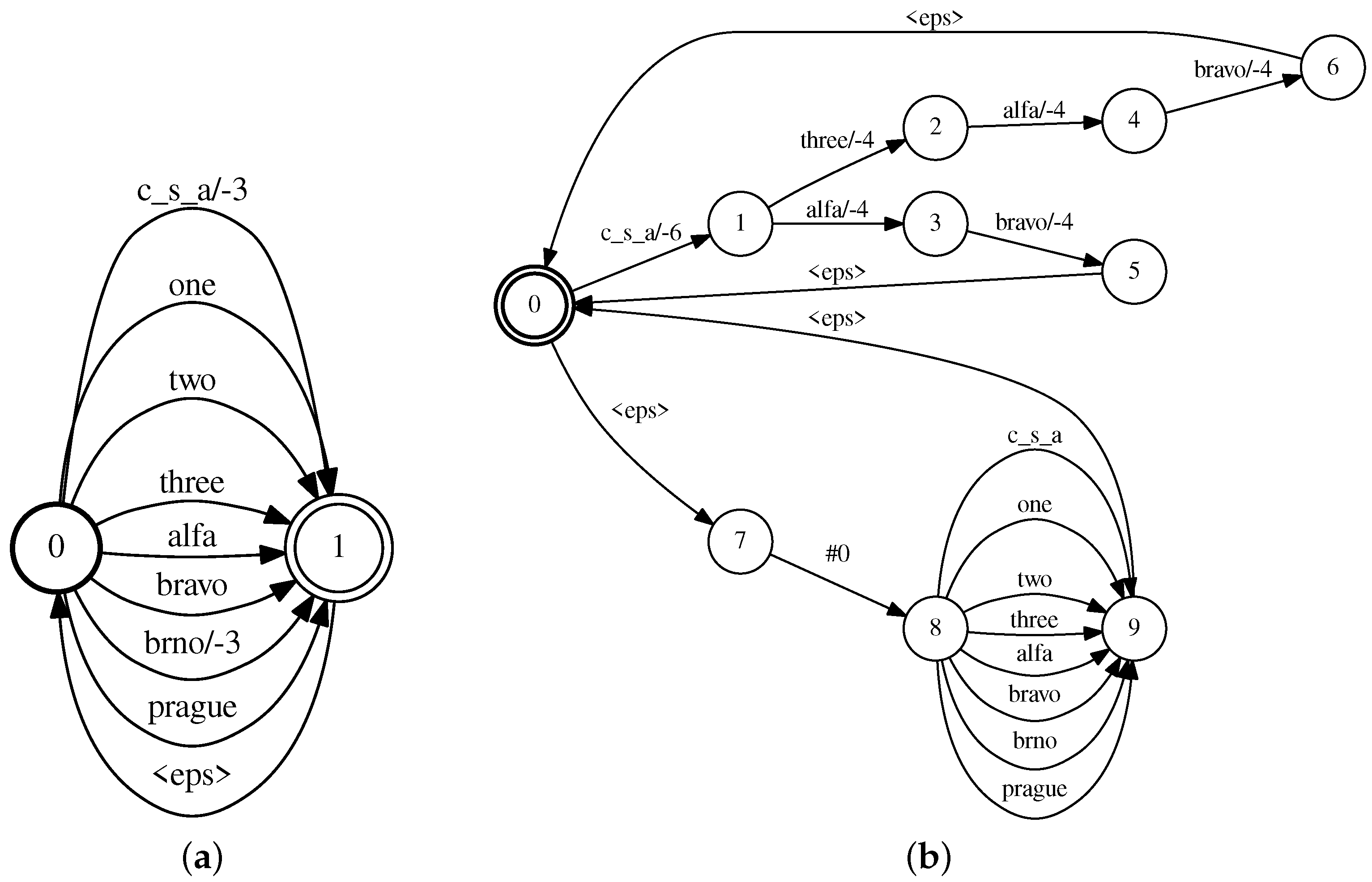
3.1. Call-Sign Boosting
3.2. Semi-Supervised Learning
4. English Language Detection
5. Post-Processing by NLP/NLU
- Call-sign recognition (i.e., locate the call-sign and convert it to code such as "DLH81J");
- ATCO—pilot classification (i.e., decide who is speaking in the entire utterance);
- ATC-Entity recognition (i.e., highlight the callsign, command and value in text).
5.1. Call-Sign Recognition
5.2. ATCO—Pilot Classification
5.3. ATC-Entity Recognition
- <COM> CLIMBING TO </COM> <VAL> FLIGHT LEVEL SEVEN ZERO </VAL>
- <CAL> OSCAR KILO TANGO UNIFORM ROMEO </CAL>
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Helmke, H.; Ohneiser, O.; Buxbaum, J.; Kern, C. Increasing ATM Efficiency with Assistant Based Speech Recognition. In Proceedings of the Twelfth USA/Europe Air Traffic Management Research and Development Seminar (ATM2017), Seattle, WA, USA, 26–30 June 2017; pp. 1–10. [Google Scholar]
- Plchot, O.; Matějka, P.; Novotný, O.; Cumani, S.; Lozano, A.D.; Slavíček, J.; Diez, M.S.; Grézl, F.; Glembek, O.; Kamsali, M.V.; et al. Analysis of BUT-PT Submission for NIST LRE 2017. In Proceedings of the Odyssey 2018 The Speaker and Language Recognition Workshop, Les Sables d’Olonne, France, 26–29 June 2018; pp. 47–53. [Google Scholar]
- Kim, C.; Stern, R.M. Robust signal-to-noise ratio estimation based on waveform amplitude distribution analysis. In Proceedings of the Interspeech 2008, Brisbane, Australia, 22–26 September 2008; pp. 2598–2601. [Google Scholar] [CrossRef]
- Landini, F.; Profant, J.; Diez, M.; Burget, L. Bayesian HMM clustering of x-vector sequences (VBx) in speaker diarization: Theory, implementation and analysis on standard tasks. Comput. Speech Lang. 2022, 71, 101254. [Google Scholar] [CrossRef]
- Mohri, M.; Pereira, F.; Riley, M. Weighted finite-state transducers in speech recognition. Comput. Speech Lang. 2002, 16, 69–88. [Google Scholar] [CrossRef] [Green Version]
- Zuluaga-Gomez, J.; Veselý, K.; Blatt, A.; Motlíček, P.; Klakow, D.; Tart, A.; Szőke, I.; Prasad, A.; Sarfjoo, S.; Kolčárek, P.; et al. Automatic call sign detection: Matching air surveillance data with air traffic spoken communications. Proceedings 2020, 59, 14. [Google Scholar] [CrossRef]
- Aeronautical Telecommunications, Annex 10, Volume II, 6th ed.; International Civil Aviation Organization (ICAO): Montreal, ON, Canada,, 2001.
- Kocour, M.; Veselý, K.; Blatt, A.; Gomez, J.Z.; Szöke, I.; Černocký, J.; Klakow, D.; Motlíček, P. Boosting of contextual information in ASR for air-traffic call-sign recognition. In Proceedings of the INTERSPEECH 2021 (ISCA), Brno, Czech Republic, 30 August–3 September 2021. [Google Scholar]
- Zuluaga-Gomez, J.; Motlícek, P.; Zhan, Q.; Veselý, K.; Braun, R. Automatic speech recognition benchmark for air-traffic communications. In Proceedings of the Interspeech 2020, 21st Annual Conference of the International Speech Communication Association (ISCA), Virtual Event, Shanghai, China, 25–29 October 2020; Meng, H., Xu, B., Zheng, T.F., Eds.; International Speech Communication Association: Shanghai, China, 2020; pp. 2297–2301. [Google Scholar]
- Olive, X. Traffic, a toolbox for processing and analysing air traffic data. J. Open Source Softw. 2019, 4, 1518. [Google Scholar] [CrossRef] [Green Version]
- Stolcke, A. SRILM—An extensible language modeling toolkit. In Proceedings of the ICSLP2002—INTERSPEECH 2002 (ISCA), Denver, CO, USA, 16–20 September 2002; Hansen, J.H.L., Pellom, B.L., Eds.; International Speech Communication Association: Denver, CO, USA, 2002. [Google Scholar]
- Povey, D.; Cheng, G.; Wang, Y.; Li, K.; Xu, H.; Yarmohammadi, M.; Khudanpur, S. Semi-orthogonal low-rank matrix factorization for Deep Neural Networks. In Proceedings of the INTERSPEECH 2018, Hyderabad, India, 2–6 September 2018; pp. 3743–3747. [Google Scholar] [CrossRef] [Green Version]
- Peddinti, V.; Chen, G.; Manohar, V.; Ko, T.; Povey, D.; Khudanpur, S. JHU ASpIRE system: Robust LVCSR with TDNNS, iVector adaptation and RNN-LMS. In Proceedings of the 2015 IEEE ASRU, Scottsdale, AZ, USA, 13–17 December 2015; pp. 539–546. [Google Scholar]
- Schäfer, M.; Strohmeier, M.; Lenders, V.; Martinovic, I.; Wilhelm, M. Bringing up OpenSky: A large-scale ADS-B sensor network for research. In Proceedings of the 13th IEEE/ACM International Symposium on Information Processing in Sensor Networks, Berlin, Germany, 15–17 April 2014; pp. 83–94. [Google Scholar]
- Sun, J.; Hoekstra, J.M. Integrating pyModeS and OpenSky historical database. In Proceedings of the 7th OpenSky Workshop, Zurich, Switzerland, 21–22 November 2019; Volume 67, pp. 63–72. [Google Scholar]
- Xu, H.; Povey, D.; Mangu, L.; Zhu, J. Minimum Bayes Risk decoding and system combination based on a recursion for edit distance. Comput. Speech Lang. 2011, 25, 802–828. [Google Scholar] [CrossRef]
- Zuluaga-Gomez, J.; Nigmatulina, I.; Prasad, A.; Motlicek, P.; Veselỳ, K.; Kocour, M.; Szöke, I. Contextual semi-supervised learning: An approach to leverage air-surveillance and untranscribed ATC data in ASR systems. In Proceedings of the Interspeech 2021, Brno, Czech Republic, 30 August–3 September 2021; pp. 3296–3300. [Google Scholar] [CrossRef]
- Szöke, I.; Kesiraju, S.; Novotný, O.; Kocour, M.; Veselý, K.; Černocký, J. Detecting English speech in the air traffic control voice communication. In Proceedings of the INTERSPEECH 2021 (ISCA), Brno, Czech Republic, 30 August–3 September 2021. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 38–45. [Google Scholar] [CrossRef]
- Zuluaga-Gomez, J.; Sarfjoo, S.S.; Prasad, A.; Nigmatulina, I.; Motlicek, P.; Ohneiser, O.; Helmke, H. BERTraffic: A robust BERT-based approach for speaker change detection and role identification of air-traffic communications. arXiv 2021, arXiv:2110.05781. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| LiveATC | ATCO | |||
|---|---|---|---|---|
| WER (%) | CA (%) | WER (%) | CA (%) | |
| no-boosting | 35.9 | 46.8 | 21.4 | 77.3 |
| HCLG-boosting | 35.4 | 50.0 | 21.4 | 81.3 |
| lattice-boosting | 31.8 | 70.2 | 20.1 | 84.6 |
| HCLG + lattice-boosting | 31.4 | 72.8 | 20.0 | 85.3 |
| Oracle (correct transcripts) | 0.0 | 89.6 | 0.0 | 92.0 |
| LiveATC | ATCO | ||||
|---|---|---|---|---|---|
| # | WER (%) | CA (%) | WER (%) | CA (%) | |
| 1 | seed-system | 35.9 | 46.8 | 21.4 | 77.3 |
| 2 | SSL + gradient weighting | 30.6 | 56.8 | 18.6 | 81.3 |
| 3 | (2) + lattice boosting | 27.2 | 73.0 | 17.6 | 85.3 |
| 4 | (2) + HCLG+lattice boosting | 26.8 | 75.8 | 17.6 | 86.0 |
| Oracle (correct transcripts) | 0.0 | 89.6 | 0.0 | 92.0 | |
| ASR | Train Data | Equal Error Rate | ||
|---|---|---|---|---|
| CZEN | FREN | GEEN | ||
| EN + CZ | CZEN | 0.0470 | 0.2397 | 0.3433 |
| EN + CZ | CZEN + FREN + GEEN | 0.0617 | 0.1338 | 0.2602 |
| Classification Accuracy | ||
|---|---|---|
| Model | ATCO | LiveATC |
| TF-IDF + LR | 77.8 | 76.6 |
| CNN (no pre-training) | 80.2 | 82.2 |
| BERT (pre-training + fine-tuning) | 91.0 | 87.0 |
| Entity | Callsign | Command | Value | Unknown Phraseology |
|---|---|---|---|---|
| LiveATC | 80 | 52 | 52 | 34 |
| ATCO | 89 | 77 | 68 | 57 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kocour, M.; Veselý, K.; Szöke, I.; Kesiraju, S.; Zuluaga-Gomez, J.; Blatt, A.; Prasad, A.; Nigmatulina, I.; Motlíček, P.; Klakow, D.; et al. Automatic Processing Pipeline for Collecting and Annotating Air-Traffic Voice Communication Data. Eng. Proc. 2021, 13, 8. https://doi.org/10.3390/engproc2021013008
Kocour M, Veselý K, Szöke I, Kesiraju S, Zuluaga-Gomez J, Blatt A, Prasad A, Nigmatulina I, Motlíček P, Klakow D, et al. Automatic Processing Pipeline for Collecting and Annotating Air-Traffic Voice Communication Data. Engineering Proceedings. 2021; 13(1):8. https://doi.org/10.3390/engproc2021013008
Chicago/Turabian StyleKocour, Martin, Karel Veselý, Igor Szöke, Santosh Kesiraju, Juan Zuluaga-Gomez, Alexander Blatt, Amrutha Prasad, Iuliia Nigmatulina, Petr Motlíček, Dietrich Klakow, and et al. 2021. "Automatic Processing Pipeline for Collecting and Annotating Air-Traffic Voice Communication Data" Engineering Proceedings 13, no. 1: 8. https://doi.org/10.3390/engproc2021013008
APA StyleKocour, M., Veselý, K., Szöke, I., Kesiraju, S., Zuluaga-Gomez, J., Blatt, A., Prasad, A., Nigmatulina, I., Motlíček, P., Klakow, D., Tart, A., Atassi, H., Kolčárek, P., Černocký, J., Cevenini, C., Choukri, K., Rigault, M., Landis, F., Sarfjoo, S., & Salamin, C. (2021). Automatic Processing Pipeline for Collecting and Annotating Air-Traffic Voice Communication Data. Engineering Proceedings, 13(1), 8. https://doi.org/10.3390/engproc2021013008