
Classifier Module of Types of Movements Based on Signal Processing and Deep Learning Techniques †




Abstract
:1. Introduction
2. Materials and Methods
2.1. Datasets
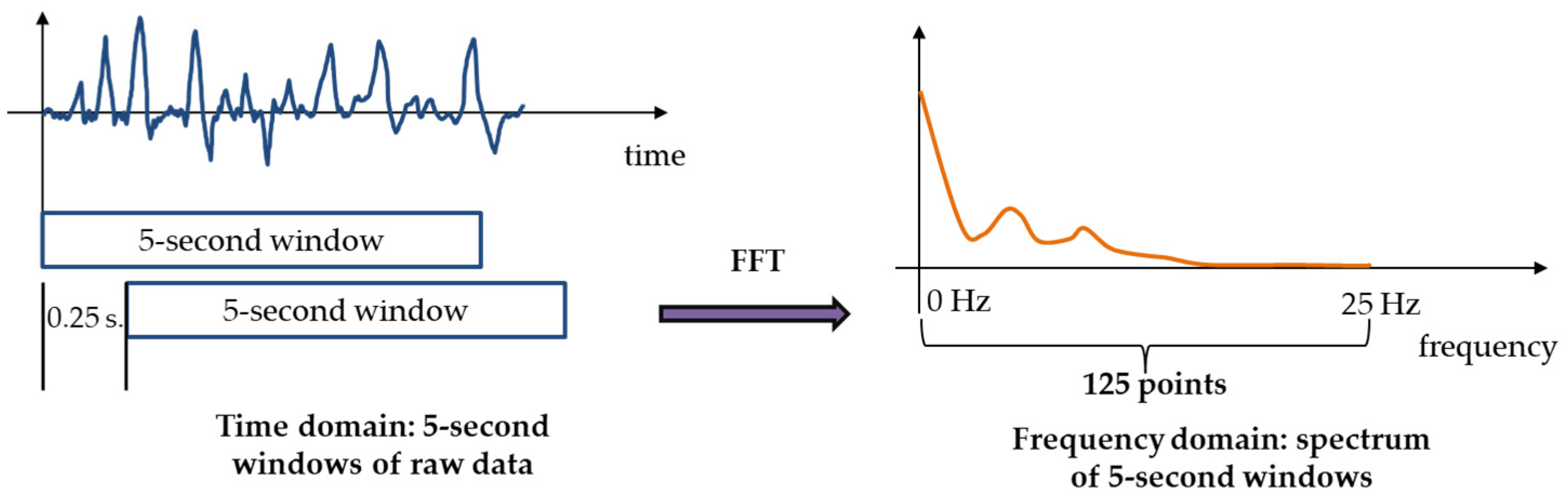
2.2. Signal Processing
2.3. Deep Learning
2.4. Cross-Validation
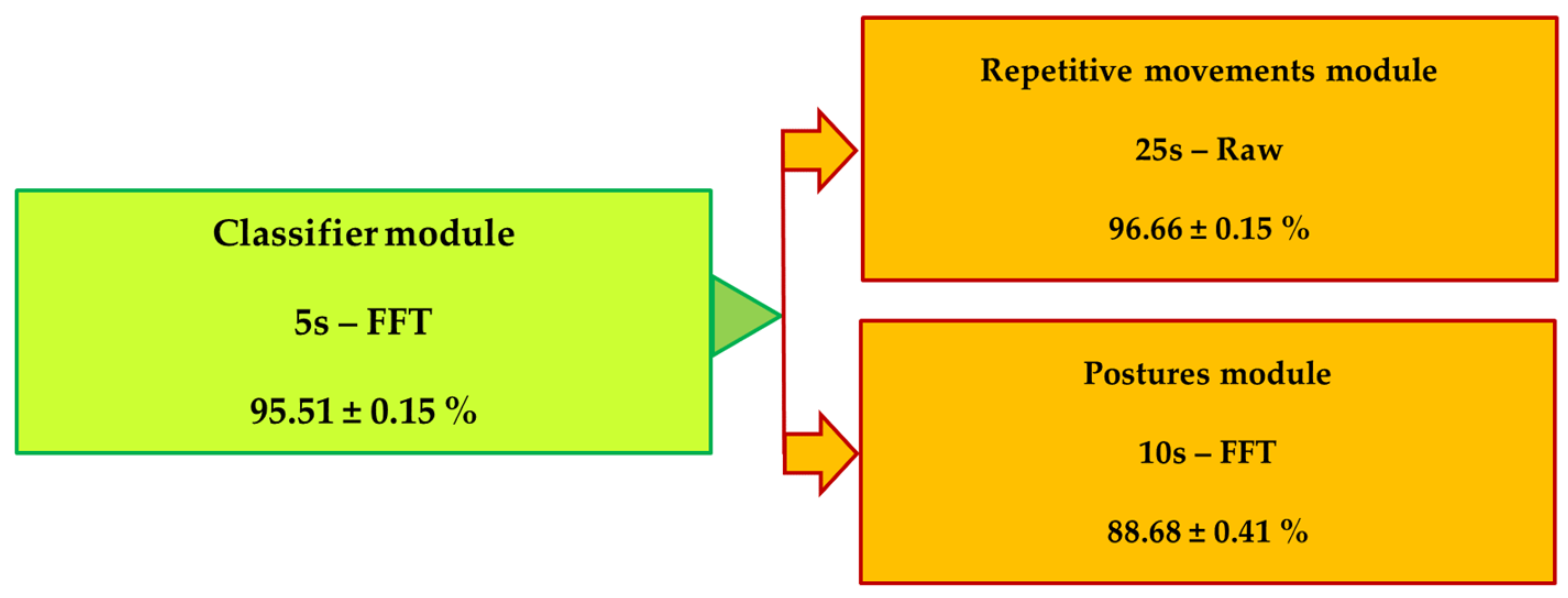
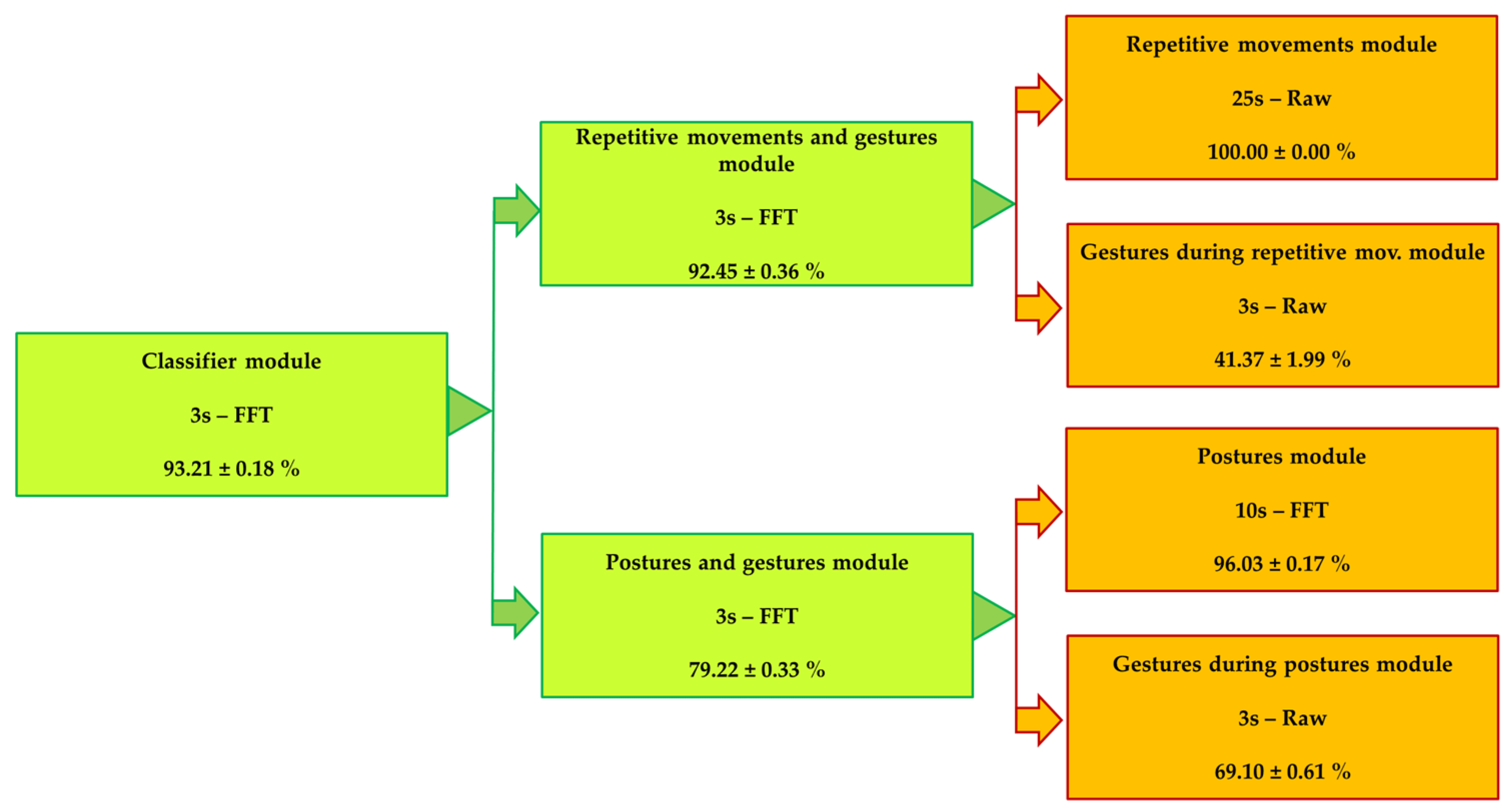
3. Results
4. Discussion and Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep learning for sensor-based activity recognition: A survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef] [Green Version]
- Slim, S.O.; Atia, A.; Elfattah, M.; Mostafa, M.-S. Survey on Human Activity Recognition based on Acceleration Data. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 84–98. [Google Scholar] [CrossRef]
- Gil-Martín, M.; San-Segundo, R.; Fernández-Martínez, F.; Ferreiros-López, J. Improving physical activity recognition using a new deep learning architecture and post-processing techniques. Eng. Appl. Artif. Intell. 2020, 92, 103679. [Google Scholar] [CrossRef]
- Gil-Martín, M.; San-Segundo, R.; Fernández-Martínez, F.; de Córdoba, R. Human activity recognition adapted to the type of movement. Comput. Electr. Eng. 2020, 88, 106822. [Google Scholar] [CrossRef]
- Gil-Martín, M.; San-Segundo, R.; Fernández-Martínez, F.; Ferreiros-López, J. Time Analysis in Human Activity Recognition. Neural Process. Lett. 2021, 53, 4507–4525. [Google Scholar] [CrossRef]
- Gil-Martin, M.; San-Segundo, R.; Lutfi, S.L.; Coucheiro-Limeres, A. Estimating gravity component from accelerometers. IEEE Instrum. Meas. Mag. 2019, 22, 48–53. [Google Scholar] [CrossRef]
- Gil-Martín, M.; San-Segundo, R.; de Córdoba, R.; Pardo, J.M. Robust Biometrics from Motion Wearable Sensors Using a D-vector Approach. Neural Process. Lett. 2020, 52, 2109–2125. [Google Scholar] [CrossRef]
- Gil-Martín, M.; Montero, J.M.; San-Segundo, R. Parkinson’s Disease Detection from Drawing Movements Using Convolutional Neural Networks. Electronics 2019, 8, 907. [Google Scholar] [CrossRef] [Green Version]
- Reiss, A.; Stricker, D. Introducing a New Benchmarked Dataset for Activity Monitoring. In Proceedings of the 2012 16th International Symposium on Wearable Computers, Newcastle upon Tyne, UK, 18–22 June 2012; pp. 108–109. [Google Scholar] [CrossRef]
- Chavarriaga, R.; Sagha, H.; Calatroni, A.; Digumarti, S.T.; Tröster, G.; Millan, J.D.R.; Roggen, D. The Opportunity challenge: A benchmark database for on-body sensor-based activity recognition. Pattern Recognit. Lett. 2013, 34, 2033–2042. [Google Scholar] [CrossRef] [Green Version]
- Weiss, N.A. Introductory Statistics; Pearson: London, UK, 2017. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experiment | Test Accuracy (%) | |
|---|---|---|
| PAMAP2 | OPPORTUNITY | |
| Direct system | 85.26 ± 0.25 | 67.33 ± 0.33 |
| System with classifier | 90.09 ± 0.35 | 68.45 ± 0.66 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gil-Martín, M.; López-Iniesta, J.; San-Segundo, R. Classifier Module of Types of Movements Based on Signal Processing and Deep Learning Techniques. Eng. Proc. 2021, 10, 14. https://doi.org/10.3390/ecsa-8-11316
Gil-Martín M, López-Iniesta J, San-Segundo R. Classifier Module of Types of Movements Based on Signal Processing and Deep Learning Techniques. Engineering Proceedings. 2021; 10(1):14. https://doi.org/10.3390/ecsa-8-11316
Chicago/Turabian StyleGil-Martín, Manuel, Javier López-Iniesta, and Rubén San-Segundo. 2021. "Classifier Module of Types of Movements Based on Signal Processing and Deep Learning Techniques" Engineering Proceedings 10, no. 1: 14. https://doi.org/10.3390/ecsa-8-11316
APA StyleGil-Martín, M., López-Iniesta, J., & San-Segundo, R. (2021). Classifier Module of Types of Movements Based on Signal Processing and Deep Learning Techniques. Engineering Proceedings, 10(1), 14. https://doi.org/10.3390/ecsa-8-11316