1. Introduction
In the area of petroleum engineering, production forecasting, generally referring to oil production forecasting, is an important stage [
1], reflected in the optimization of production plans, reduction of recovery cycles, resource management, investment decisions, environmental sustainability, and the improvement of oilfield economic benefits. Commonly used forecasting methods include numerical simulation, physical modeling [
2], decline curve analysis (DCA) methods [
3], and machine learning. These methods have continuously emerged and improved over the history of reservoir development, and the reasons for their advancement include both accuracy and the requirement for rapid on-site deployment. Specifically, numerical simulation relies on reservoir simulation software, taking into account geological characteristics such as permeability and porosity of the oilfield, as well as fluid dynamics and other physical processes, for forecasting. However, reservoir simulation software incurs high computational costs, making it difficult to achieve fast and accurate decision-making. When it comes to physical modeling, the complexity, diversity, and heterogeneity of reservoirs make it difficult to establish a comprehensive physical model. Even worse, the limited understanding of underground structures also makes it more difficult to rely solely on physical models for forecasting. From a practical perspective, DCA methods based on mathematical statistics can provide engineers with quick assistance in on-site production forecasting, although the accuracy of these methods depends on engineers’ knowledge in determining key parameters. Therefore, with the current level of knowledge, other more flexible methods, such as machine learning or artificial intelligence combined with classical methods, may be more effective in coping with these uncertainties and improving the accuracy of subsurface structure prediction.
Neural networks, a branch of machine learning, have a wide range of applications in forecasting, performing well in performance testing of various machine learning methods including multivariate linear regression, artificial neural networks, gradient boost trees, adaptive boosting, and support vector regression [
4,
5]. Traditional methods such as autoregressive integral moving average (ARIMA) [
6,
7], random walk (RW) [
8], generalized autoregressive conditional heteroskedasticity (GARCH) [
9,
10], and vector autoregression (VAR) [
11] are effective in forecasting linearly correlated variables. Time series data in reality often exhibit nonlinear long sequence characteristics and are prone to unstable fixed points due to environmental interference and human recording errors. In this regard, ARIMA and VAR may exhibit low prediction accuracy due to strict requirements for data stability, RW may be difficult to achieve long-term prediction due to strong randomness, and GARCH may have inaccurate estimation of non-negative constraint model parameters that are easily violated. Overall, traditional methods lack the ability to capture complex dynamic relationship problems, manifested as insufficient accuracy and low efficiency. The limitations of traditional methods have given rise to numerous nonlinear artificial intelligence and deep learning methods that can be applied to time series forecasting tasks. For instance, artificial neural networks (ANNs) [
12], support vector machines [
13], and back propagation neural networks (BPNNs) are nonlinear methods and models that can be employed to address the inherent nonlinearity of time series [
14].
Since production forecasting is not only related to the sequence at the current time but also to previous data, the information carried by earlier data will be lost if only the data at the most recent point in time is used. This type of time series forecasting problem gave rise to recurrent neural networks (RNN) [
15]. In contrast to traditional ANNs, some of the connections between hidden units are refactored, which enables the neural structure to retain the memory of the most recent state, rendering it particularly well suited for the task of time series forecasting [
16,
17]. However, RNN suffers from gradient explosion and gradient vanishing, so an improved model based on RNN, called long short-term memory (LSTM), is proposed [
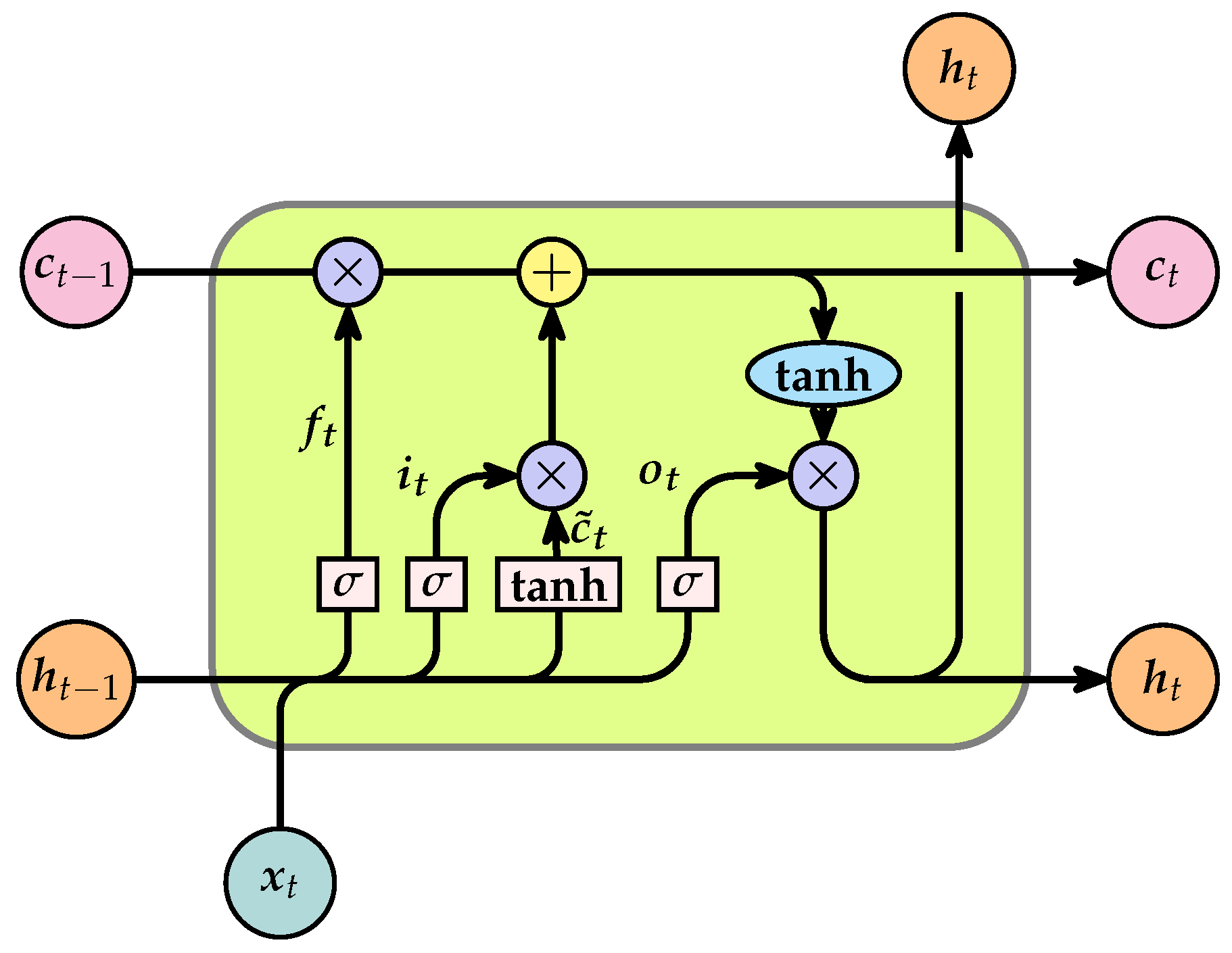
18,
19]. LSTM introduces a gating mechanism that can be viewed as a simulation of human memory. This mechanism allows the network to memorize useful information and discard useless information, thereby emulating the selective retention observed in human memory [
20]. LSTM can be used to extract the data’s long- and short-term dependencies for the purpose of sequence forecasting.
In order to further improve the prediction effect of the model, it is necessary to optimize the hyperparameters in the neural network model. The optimization of hyperparameters represents a pivotal stage in the enhancement of the model’s performance. This study focuses on the optimization of hyperparameters within the network’s loss function, with the objective of optimizing the model’s generalization ability and overall performance. The more common hyperparameter optimization methods include stochastic optimization [
21], gradient-based optimization [
22], genetic algorithm optimization [
23], particle swarm optimization [
24], etc. The particle swarm optimization (PSO) algorithm [
25] is a heuristic optimization algorithm that can achieve global optimization with fewer parameters. It is more widely used because of its excellent performance in terms of simplicity and ease of implementation, strong global search capability, parallelism, adaptability, and no gradient requirement. However, it also has the limitations of precocious convergence and sensitive parameter selection. In order to overcome the shortcomings of the algorithm, scholars have improved the particle swarm algorithm in several aspects, such as convergence improvement, parameter adaptation, mixing, and fusion. The canonical PSO algorithm tends to fall into local optimum due to lack of diversity, improper parameter selection, complexity of the search space, etc. Consequently, an improved PSO algorithm based on individual difference evolution [
26] adopts an enhanced restart strategy to regenerate the corresponding particles, thereby enhancing population diversity. The multi-population particle swarm optimization algorithm [
27] adopts various swarm strategies that are considered to have the potential to improve population diversity. Besides, the algorithm cooperates with the dynamic subpopulation number strategy, subpopulation recombination strategy, and purposeful detection strategy. The stretching technique in PSO can also improve the performance of the algorithm [
28]. Subsequently, the pyramid particle swarm optimization (PPSO) algorithm [
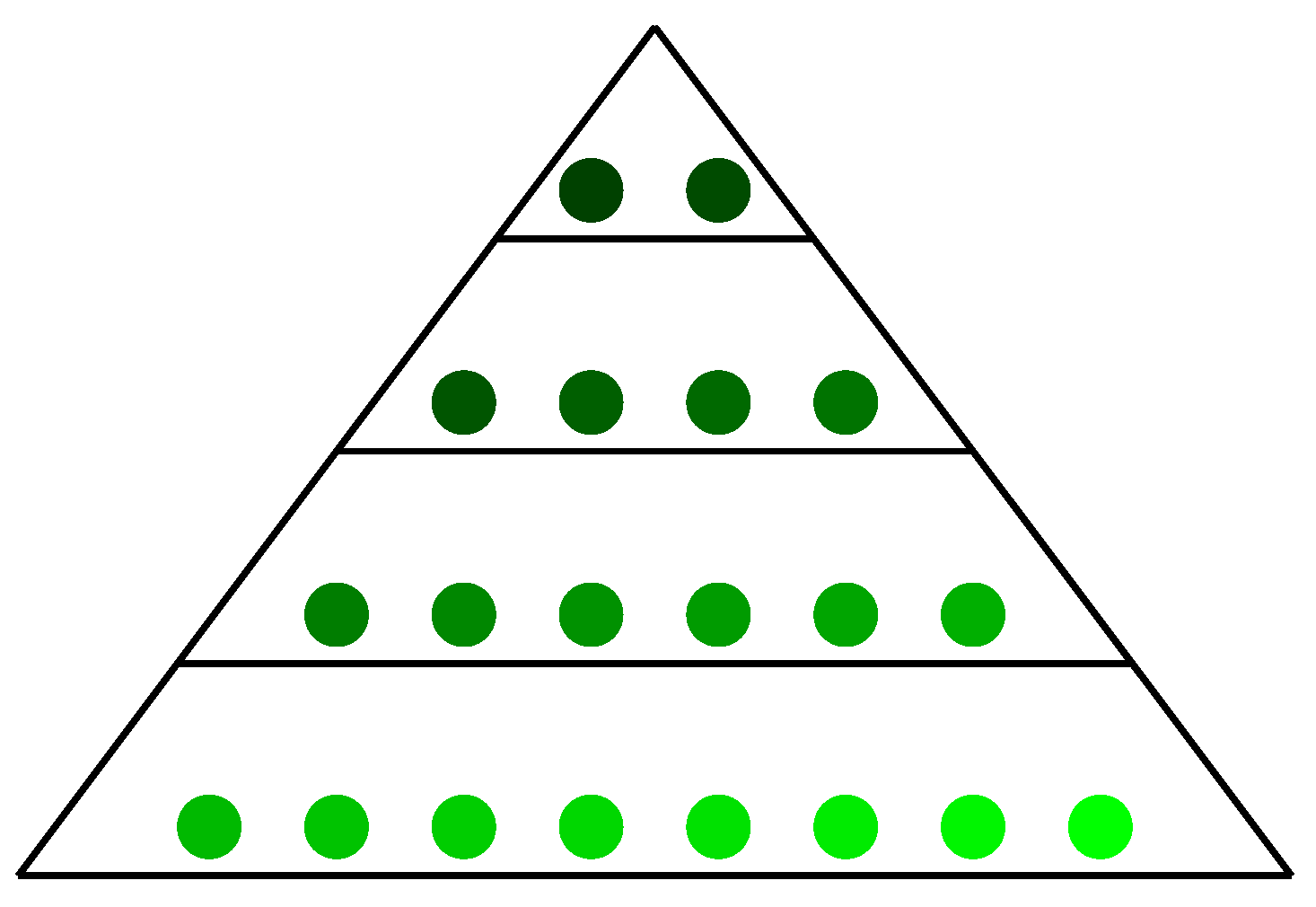
29] incorporating the pyramid concept combines novel competitive and cooperative strategies. A chaotic map has been introduced into the whale optimization algorithm [
30], increasing the diversity of the population and accelerating the convergence of the algorithm.
While machine learning algorithms have achieved considerable success, they remain imperfect, such as in their lack of interpretability. Lack of interpretability refers to the difficulty for humans to intuitively understand or explain the decision-making process and internal mechanisms of neural networks using simple logic. In engineering fields such as reservoir development, lack of interpretability typically refers to models that are only based on data modeling without fully considering expert knowledge and physical constraints, which may lead to low modeling efficiency [
31]. To solve the problem of poor interpretability of neural network models, a joint learning model that incorporates both physical information and neural networks has been developed. This approach makes use of the structural information inherent to physical equations, as well as the learning capabilities of neural networks, with the aim of enhancing the accuracy, generalization capacity, and interpretability of the model. The neural network framework based on physical information has a wide range of applications in power system applications [
32], solving partial differential equations [
33,
34], fluid dynamics [
35], turbulence prediction [
36] and other areas. Numerical experiments have shown that the joint learning model of physical information and neural networks has better predictability, reliability, and generalization ability. However, for oilfield production forecasting, the current model faces some challenges in practical applications. The physical constraints used in the models require real-time access to data on saturation or pressure changes, which is not easy to obtain in practical oilfield applications.
It is worthwhile to highlight several aspects of the contributions developed by this study.
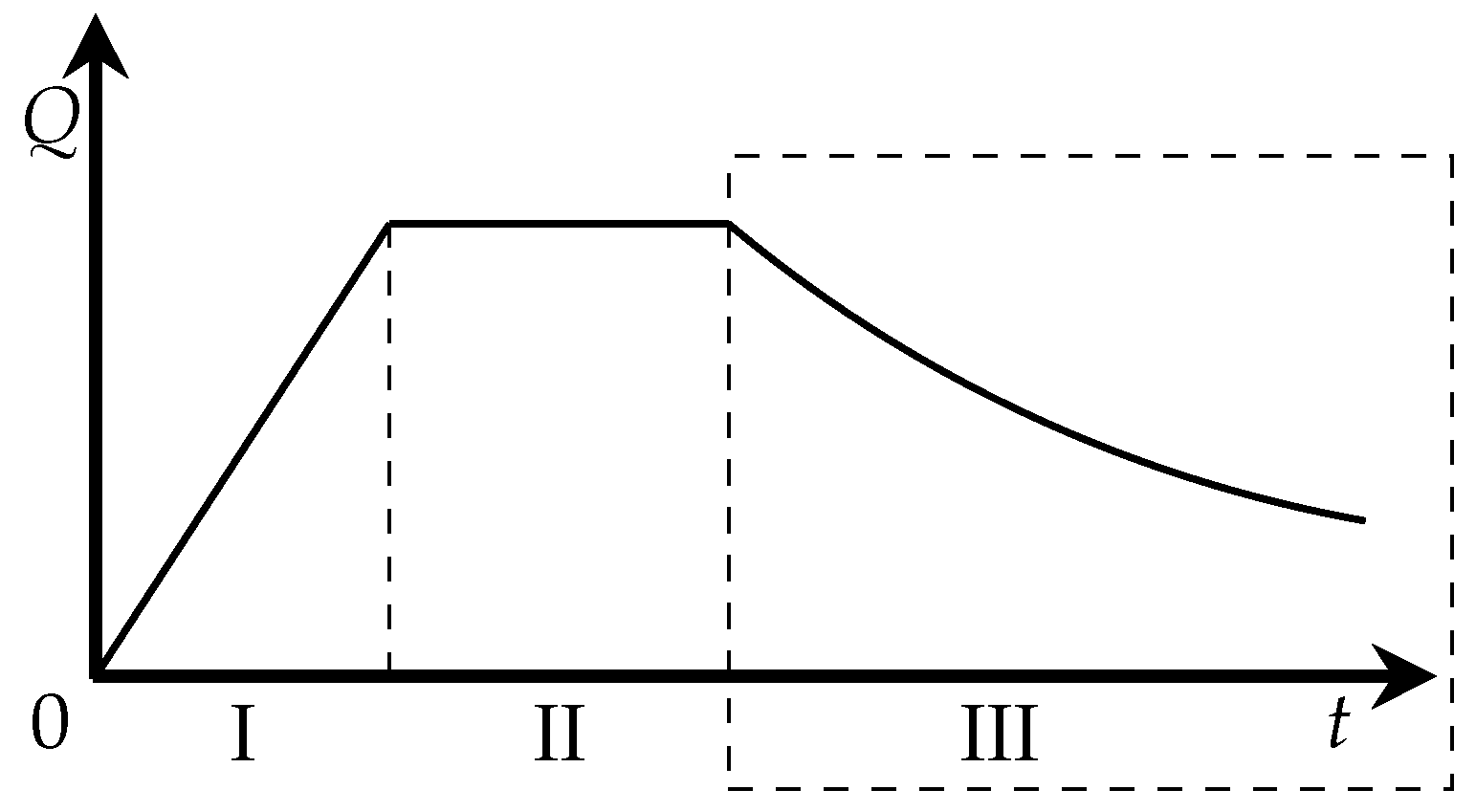
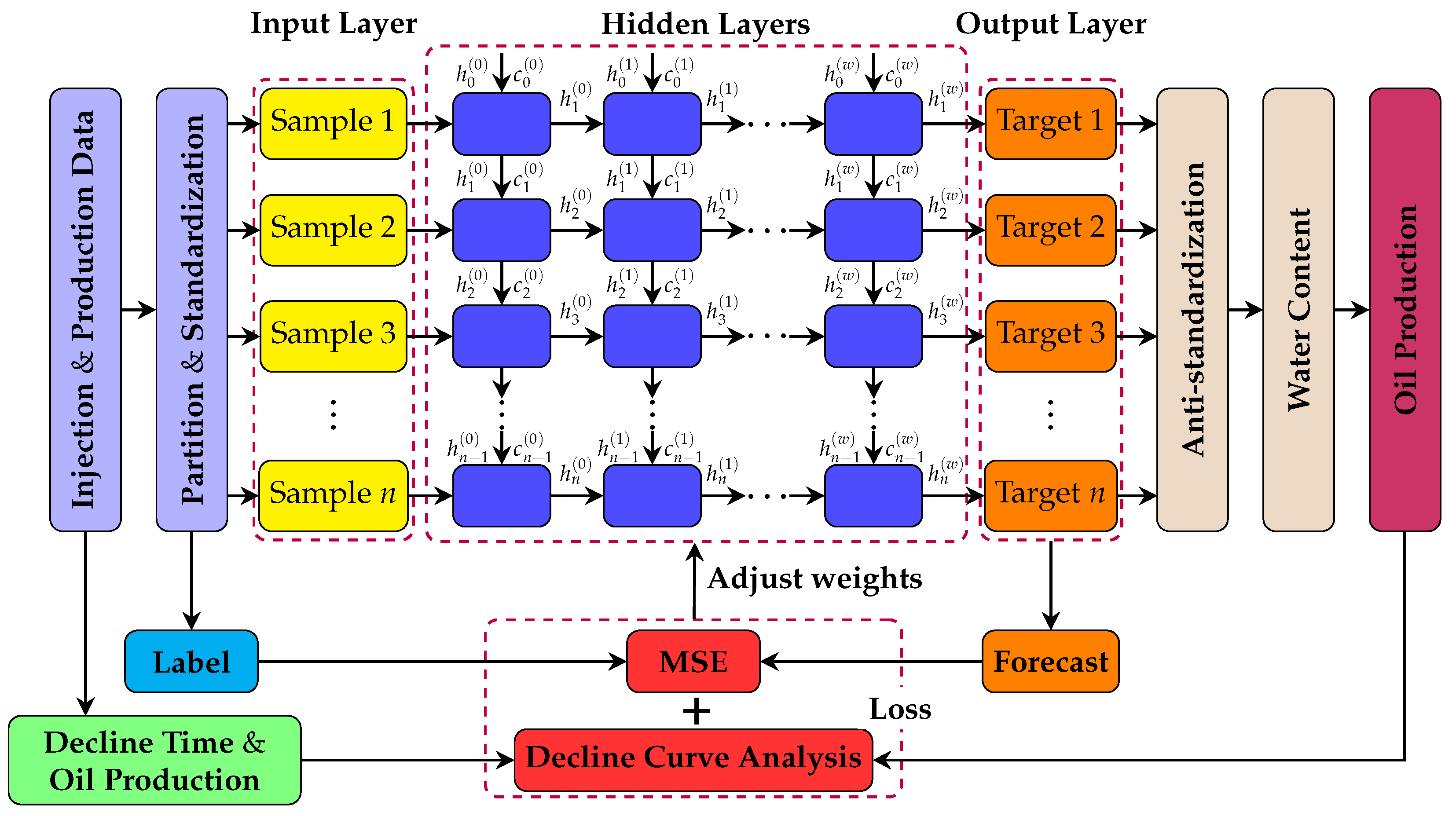
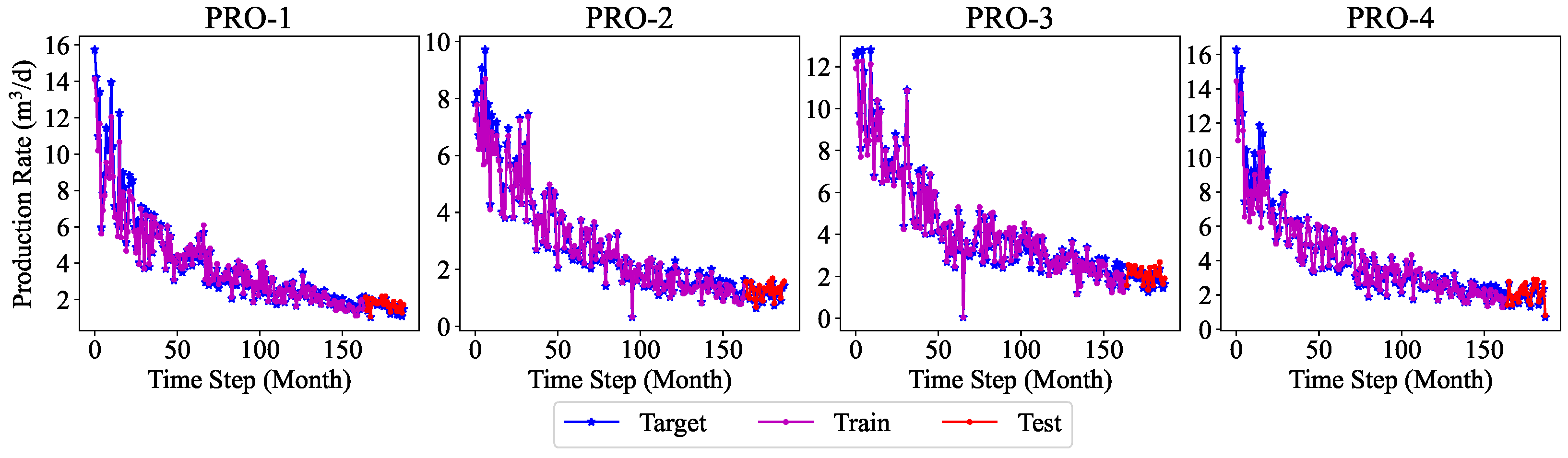
A machine-learning multi-well production forecasting model embedded with the production development pattern is proposed. Specifically, this study aims to provide a more comprehensive and dynamic analysis method to improve the development efficiency of water-driven oilfields by introducing the production decline pattern as a physical constraint of the neural network. In addition, compared with the single-well production forecasting model, the multi-well model is more general and more adaptable to the oilfield.
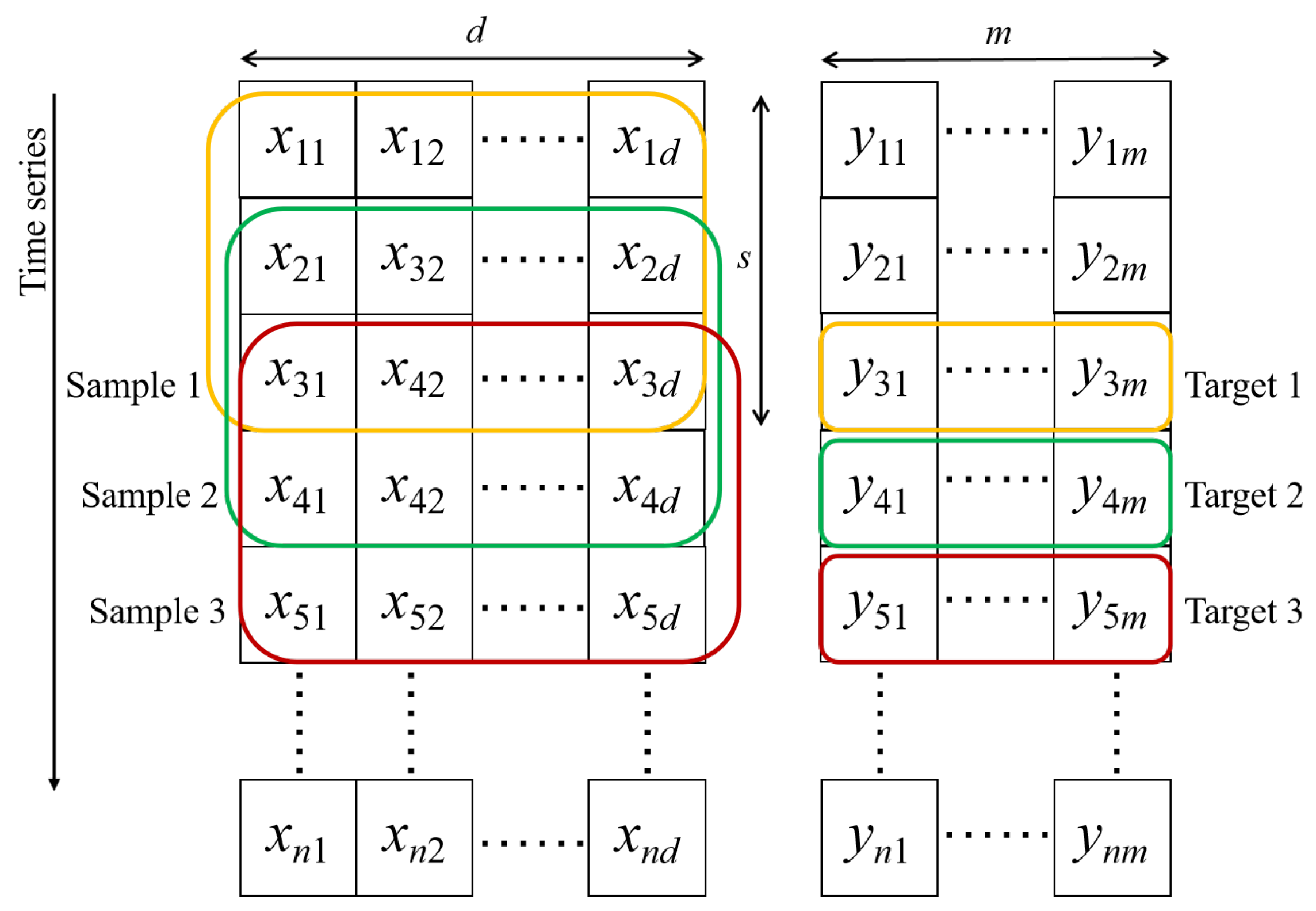
The model is constructed entirely on the basis of real-time acquisition of dynamic oilfield development data by monitoring and recording key parameters during actual operations and production. This universal approach ensures the practicality of the model, as it directly reflects the real situation of oilfield development.
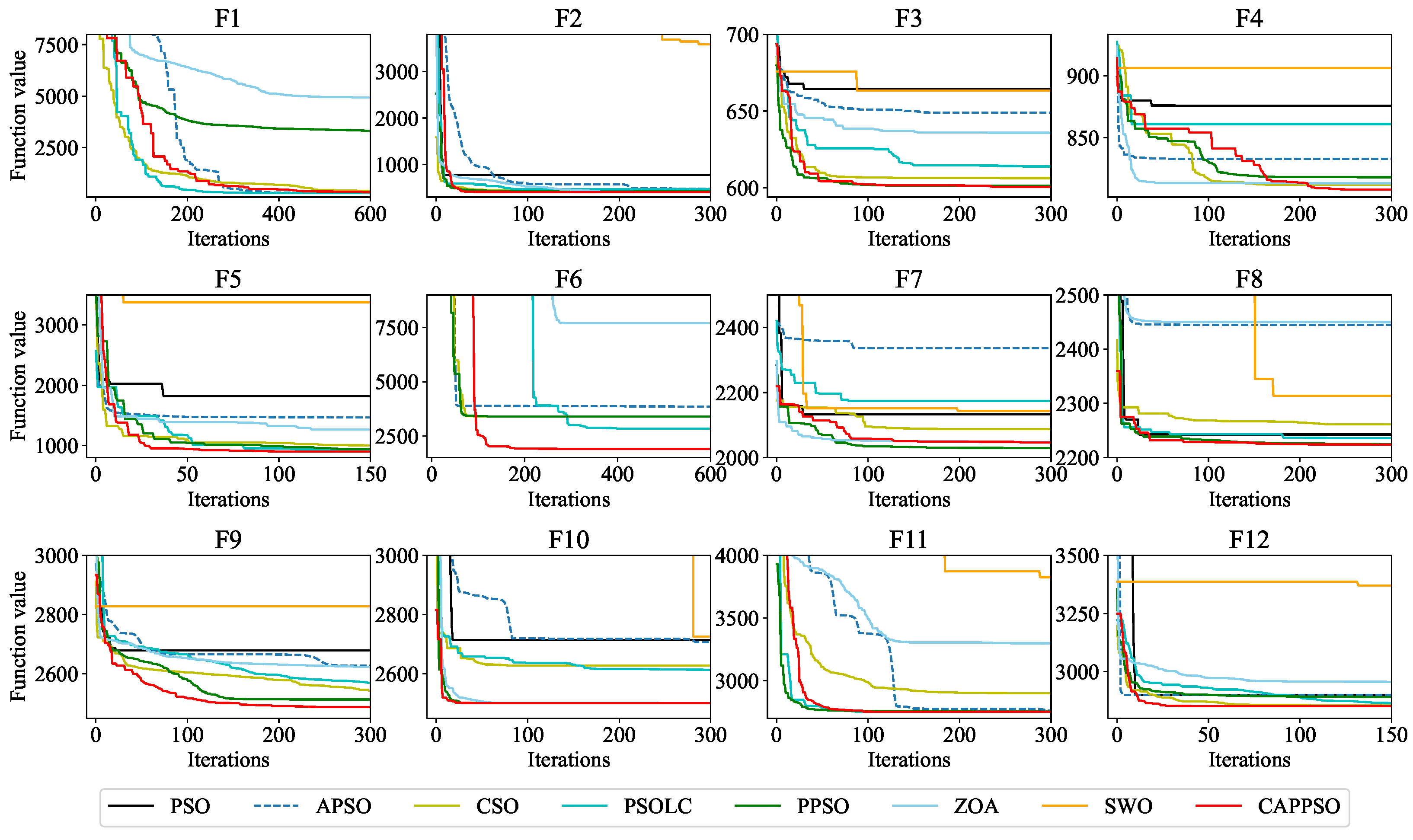
An improved PSO algorithm is proposed to optimize the hyperparameters in the loss function of the neural network to find the optimal setting instead of expert knowledge, thereby enhancing the performance of the model. During the optimization process, particles are updated by PSO with pyramid topology. The learning factor is adaptive, a particle iteration stagnation value strategy is introduced to ensure population diversity, and a chaotic map is used to initialize the initial population.
4. Conclusions
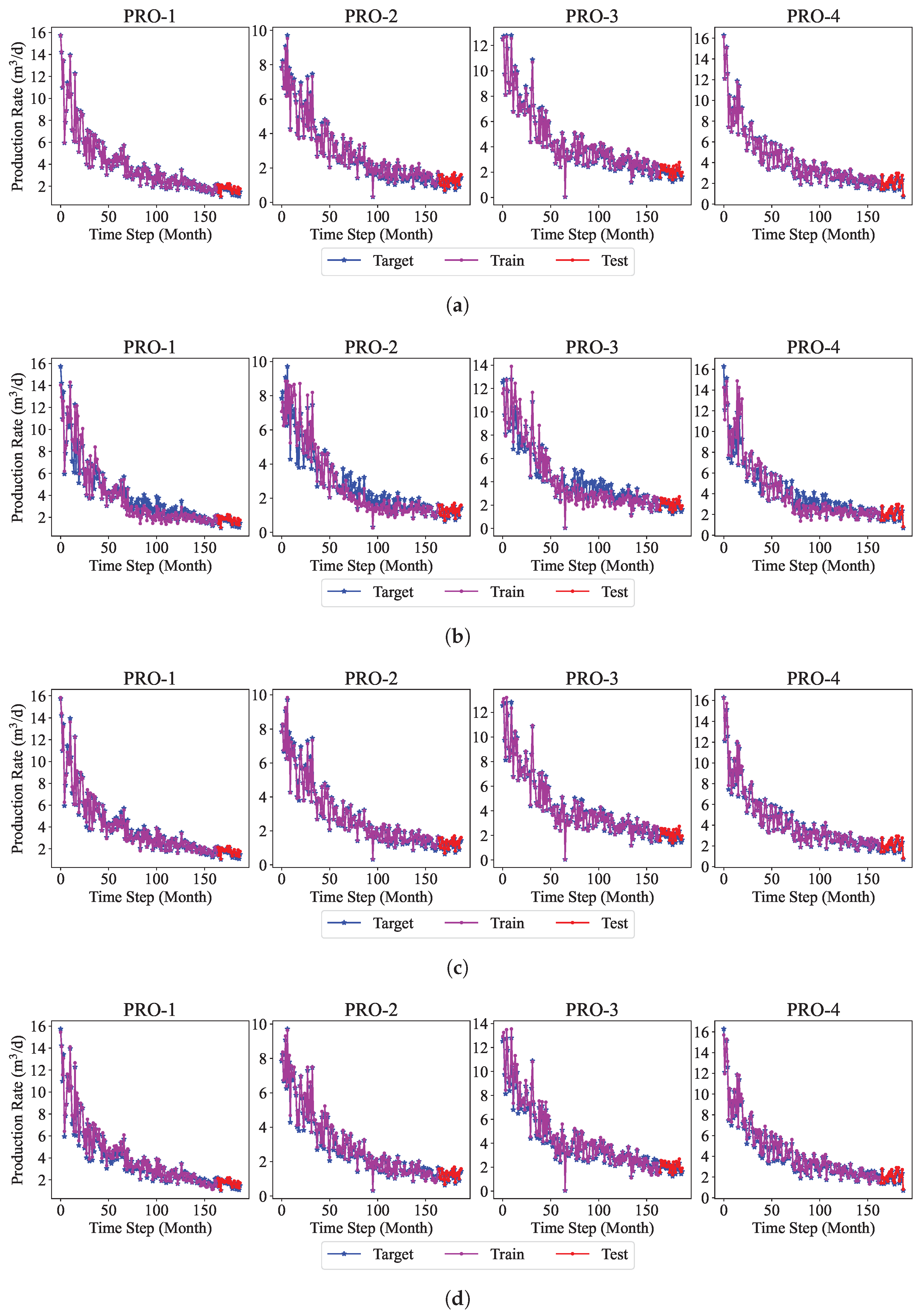
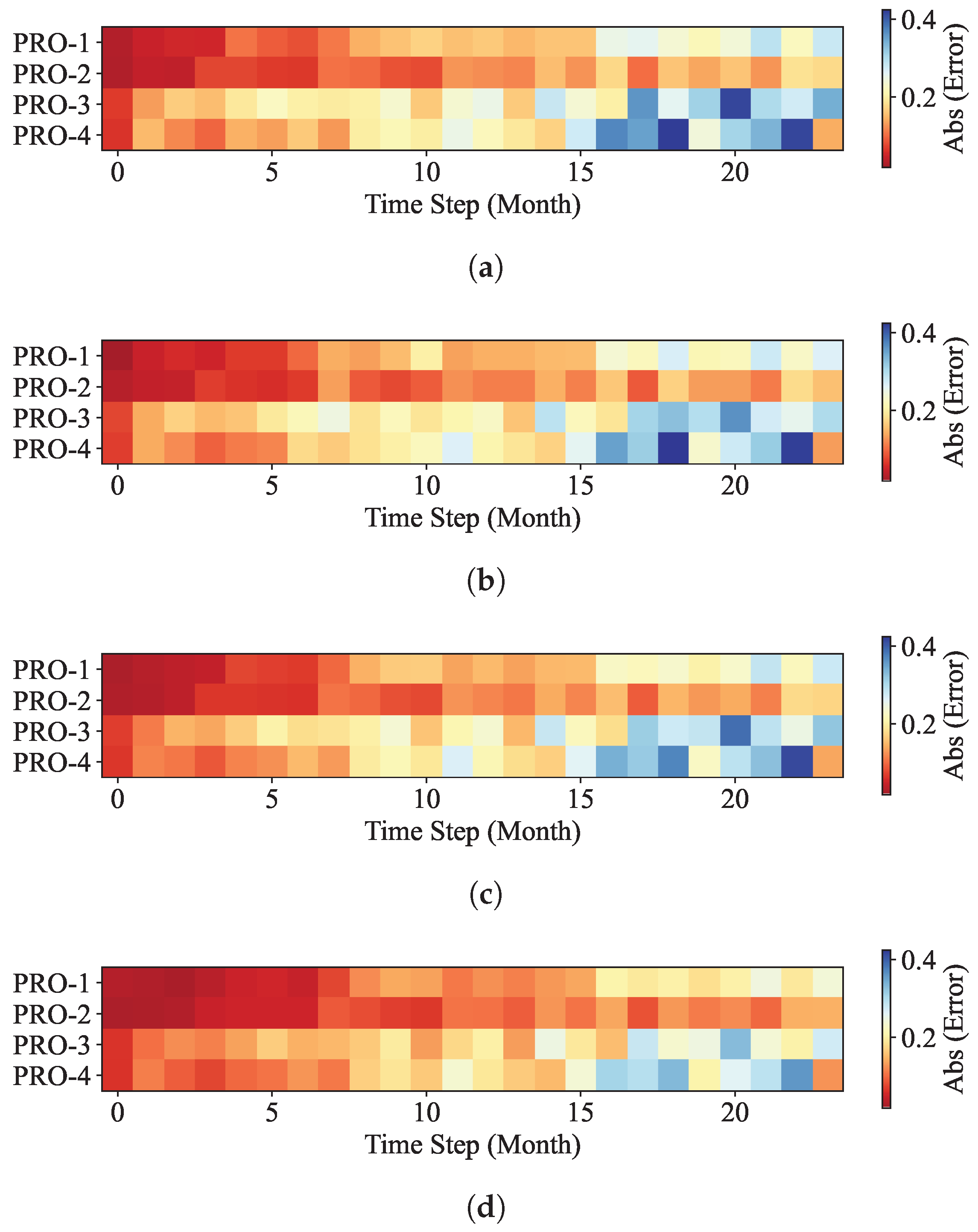
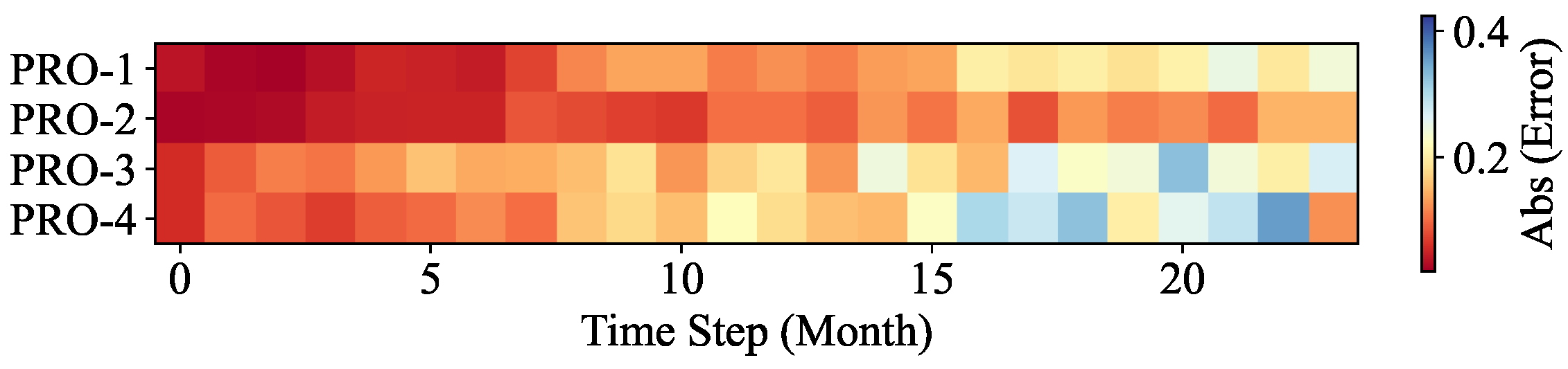
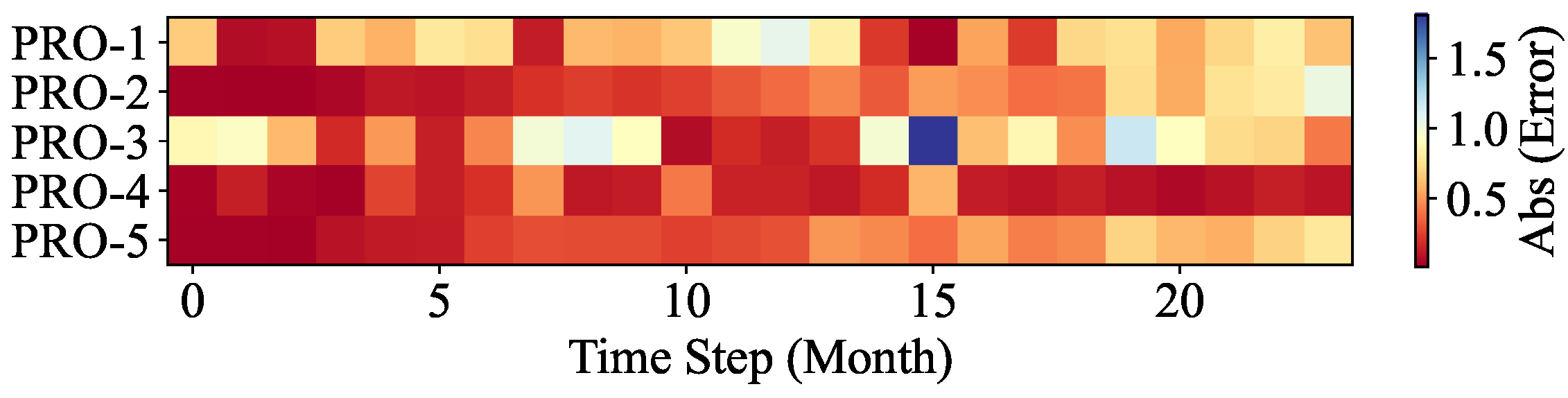
In this work, a machine learning model for multi-well production forecasting is implemented. This model incorporates physical information by introducing DCA, making it closely aligned with production practice. An improved PSO algorithm, CAPPSO, is proposed to adjust the importance proportions of each module derived from DCA within the loss function, thereby further improving the performance of the model. All the data required for model training can be obtained at the development site, making it practical. From the experimental results, the proposed model, i.e., LSTM-DCA and LSTM-DCA-CAPPSO, fits the experimental data better than the traditional BPNN, CNN, and LSTM models, leading the better performance in oil production forecasting. Furthermore, compared with traditional empirical parameters, a better combination of coefficients for DCA is found by CAPPSO, which reflects its engineering application value. The experimental results conducted on different reservoir types to validate the model’s generalization performance further demonstrate its high adaptability.
In the future, we plan to further improve the model so that it will have the same high forecasting capability in more types of oilfields by incorporating more physical mechanisms and dynamic adjustment strategies.



 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}