
Clever Hans in the Loop? A Critical Examination of ChatGPT in a Human-in-the-Loop Framework for Machinery Functional Safety Risk Analysis


Abstract
1. Introduction
1.1. Role of Large Language Models (LLMs) in Risk Analysis
1.2. Integrating Human-in-the-Loop Systems
1.3. Novelties and Contributions
- •
- AI Integration in Risk Analysis: The study proposes a cautious approach that integrates the generative capabilities of LLMs into traditional risk analysis processes. This methodology is designed to enhance the efficiency and speed of identifying and assessing potential risks, while maintaining rigorous human oversight to ensure accuracy and reliability.
- •
- Human-in-the-Loop Workflow: To address the limitations of LLMs, including their lack of deep comprehension and the risk of generating inaccurate outputs, we develop an HITL workflow. This framework ensures that AI-generated results are rigorously evaluated and refined by functional safety experts, thereby improving the reliability and applicability of AI-assisted risk analyses.
- •
- Empirical Validation with Case Studies: The proposed workflow is empirically validated through detailed case studies in industrial contexts, where risk analysis based on ISO 12100 is applied. The results are compared with the established ground truth of case studies [8].
2. Background and Related Work
2.1. Overview of ISO 12100 and Its Relevance to Functional Safety
2.1.1. Safety Function
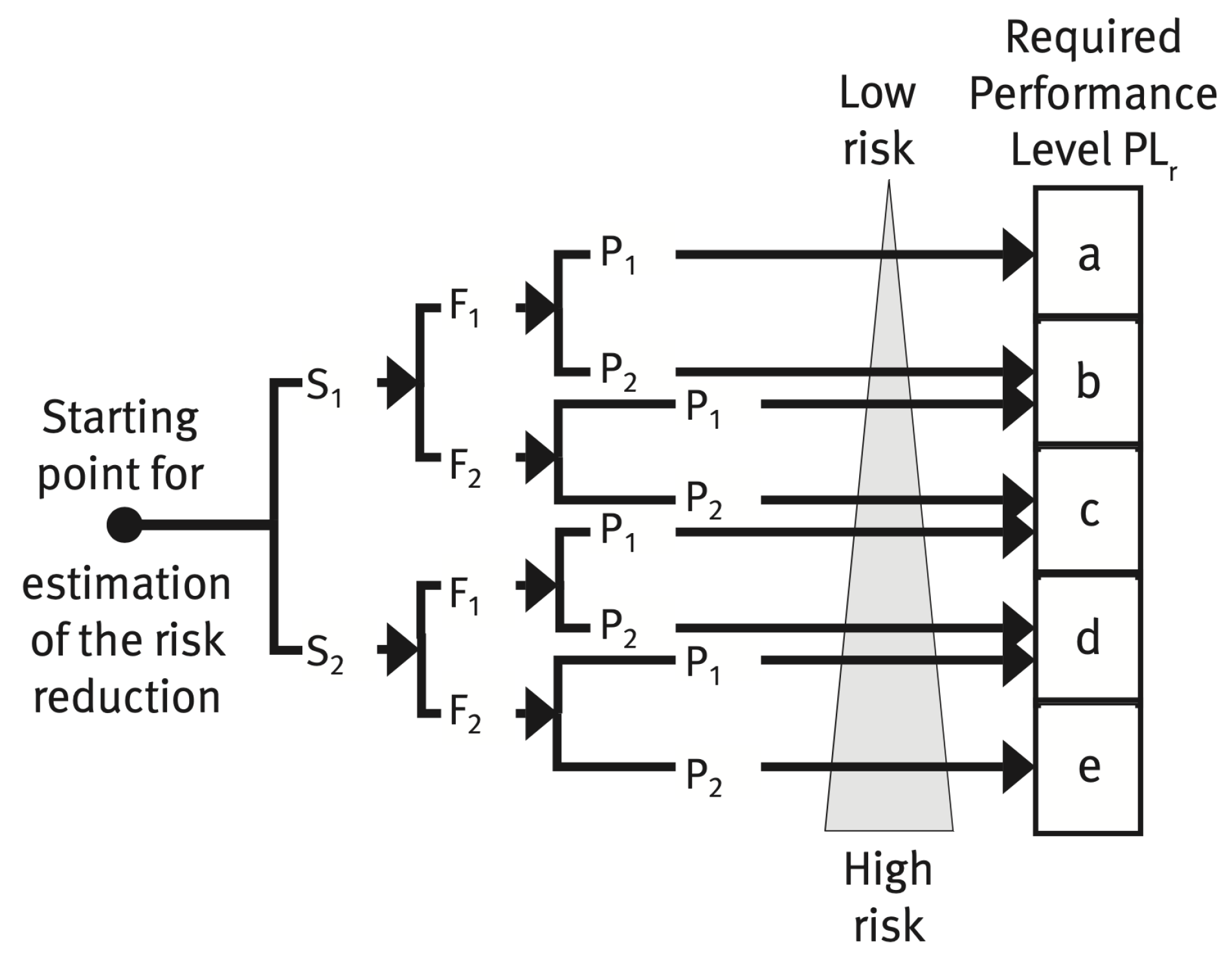
2.1.2. Required Performance Level—
2.1.3. Design Release
2.1.4. Related Work
2.2. Evolution, Capabilities, and Adoption of LLMs
2.3. HITL and Multimodal AI for Functional Safety
2.4. LLMs in Saftey Analysis
2.4.1. HITL Approaches and Methodologies
2.4.2. Multimodal AI Systems and Industry 4.0/5.0
2.4.3. Integration of Retrieval-Augmented Generation (RAG)
2.4.4. Summary
3. Limitations and Opportunities in Risk Analysis with AI Integration
3.1. Limitations and Requirements of Traditional Risk Analysis Tools
- •
- Training and Usability: These tools often require extensive training for users to achieve proficiency, introducing delays and increasing the overall cost of safety assessments.
- •
- Licensing Costs: Many of these tools (e.g., WEKA CE (https://www.weka-manager-ce.de/english-version/, accessed on 31 January 2025)), are not open-source and involve substantial licensing fees, making them cost-prohibitive for smaller enterprises or those requiring scalable solutions across multiple sites.
- •
- Software Limitations: Being closed-source, these tools offer limited adaptability and customization, restricting users from modifying the software to better fit specific needs or seamlessly integrate with other systems.
3.2. Emerging AI Technologies and LLMs
- •
- Advantages: LLMs can process vast amounts of unstructured data swiftly, offering insights and identifying potential hazards with a speed and depth unattainable by traditional methods. This capability allows for more proactive and comprehensive risk management, potentially transforming how risks are identified and evaluated.
- •
- Challenges: However, the application of LLMs in risk analysis is fraught with challenges. LLMs can generate misleading information (hallucinations), harbor biases from their training data, and often lack the domain-specific understanding necessary for accurate hazard assessment. These limitations pose risks in safety-critical applications where precision and reliability are paramount.
3.3. Challenges and Opportunities with LLMs in Risk Analysis
- •
- Enhanced Data Analysis Capabilities: LLMs can efficiently process and analyze large volumes of unstructured data, such as maintenance records and operator manuals, identifying potential hazards that might be overlooked by traditional tools.
- •
- Predictive Insights: The pattern recognition capabilities of LLMs can be leveraged to predict potential failure modes and hazards before they manifest, enabling more proactive risk management strategies.
- •
- Fact Hallucination: LLMs may generate plausible yet inaccurate or misleading information (https://allanmlees59.medium.com/artificial-intelligence-and-clever-hans-0d136951024c, accessed on 31 January 2025) [6], which poses significant risks in contexts where factual accuracy is critical.
- •
- Bias in Training Data: Biases inherent in the training data can lead to skewed risk assessments, potentially misclassifying hazards or failing to recognize them altogether.
- •
- Overgeneralization and Lack of Domain Expertise: LLMs might produce overly generic responses or fail to grasp the complexities of specific industrial contexts, leading to inadequate hazard assessments.
- •
- Lack of Domain-Specific Knowledge: LLMs often lack the nuanced understanding required to accurately interpret complex safety scenarios, which can result in critical oversights.
- •
- Opacity of Reasoning Processes: The “black box” nature of LLMs obscures the decision-making process, which is a significant barrier in safety-critical settings where understanding the reasoning behind assessments is essential.
- •
- Dependency on Prompt Engineering: The effectiveness of LLMs heavily depends on the design of prompts; poorly structured prompts can lead to inadequate or irrelevant responses.
- •
- Error Propagation: Errors in initial data input or algorithmic faults in LLMs can propagate through the assessment process, compounding inaccuracies and leading to flawed conclusions.
- •
- Handling of Novelty and Edge Cases: LLMs may struggle with scenarios that deviate from their training, including novel or unique hazard situations specific to machinery, resulting in incomplete or incorrect risk assessments.
- •
- Lack of Adaptability: Automated systems and LLMs often struggle to adapt to evolving safety standards and conditions, which can change rapidly in industrial environments.
- •
- Transparency and Explainability: Limited transparency and explainability in LLMs hinder trust and accountability, which are crucial in regulatory and compliance-driven contexts.
3.4. Necessity for HITL Systems
- •
- Verification and Validation: Human experts review, modify, and validate AI-generated outputs to ensure they align with real-world conditions, regulatory requirements, and factual accuracy. This step is particularly crucial for mitigating issues such as fact hallucination, error propagation, and overgeneralization, where the LLM’s outputs need to be verified for correctness and relevance.
- •
- Incorporation of Domain-Specific Knowledge: Human oversight ensures that specialized knowledge is applied where LLMs fall short, particularly in the interpretation of complex safety standards and regulations. This helps overcome lack of domain-specific knowledge, handling of novelty and edge cases, and bias in training data, as human experts can provide context-specific insights that AI lacks.
- •
- Ethical Considerations: Human experts ensure that the outputs and decisions made by AI systems uphold ethical standards, especially in safety-critical environments where ethical implications may be significant. This aspect helps manage the risks associated with opacity of reasoning processes and ensures that ethical concerns are factored into decision-making, reducing potential biases.
- •
- Experience and Judgment: Human experience and nuanced judgment are crucial in complex or ambiguous situations that LLMs might not be capable of fully understanding. This mitigates the limitations of overgeneralization, lack of adaptability, and handling of edge cases, where the machine’s rigid interpretation of data needs to be refined by human reasoning.
- •
- Enhanced Reliability and Trust: Human involvement in the AI decision-making process ensures transparency, builds trust, and maintains accountability, which are essential in regulated industries. This addresses the issues related to transparency and explainability by making sure that the rationale behind AI-generated outputs can be explained and justified by experts, particularly in safety-critical contexts.
- •
- Prompt Design and Refinement: Human experts play a key role in designing and refining prompts for LLMs, ensuring that the AI provides relevant and focused outputs. This helps address the dependency on prompt engineering, making sure that the AI’s responses are well targeted and appropriate for the specific risk analysis task.
3.5. Research Direction and Novel Contributions
4. Systematic Study Setup
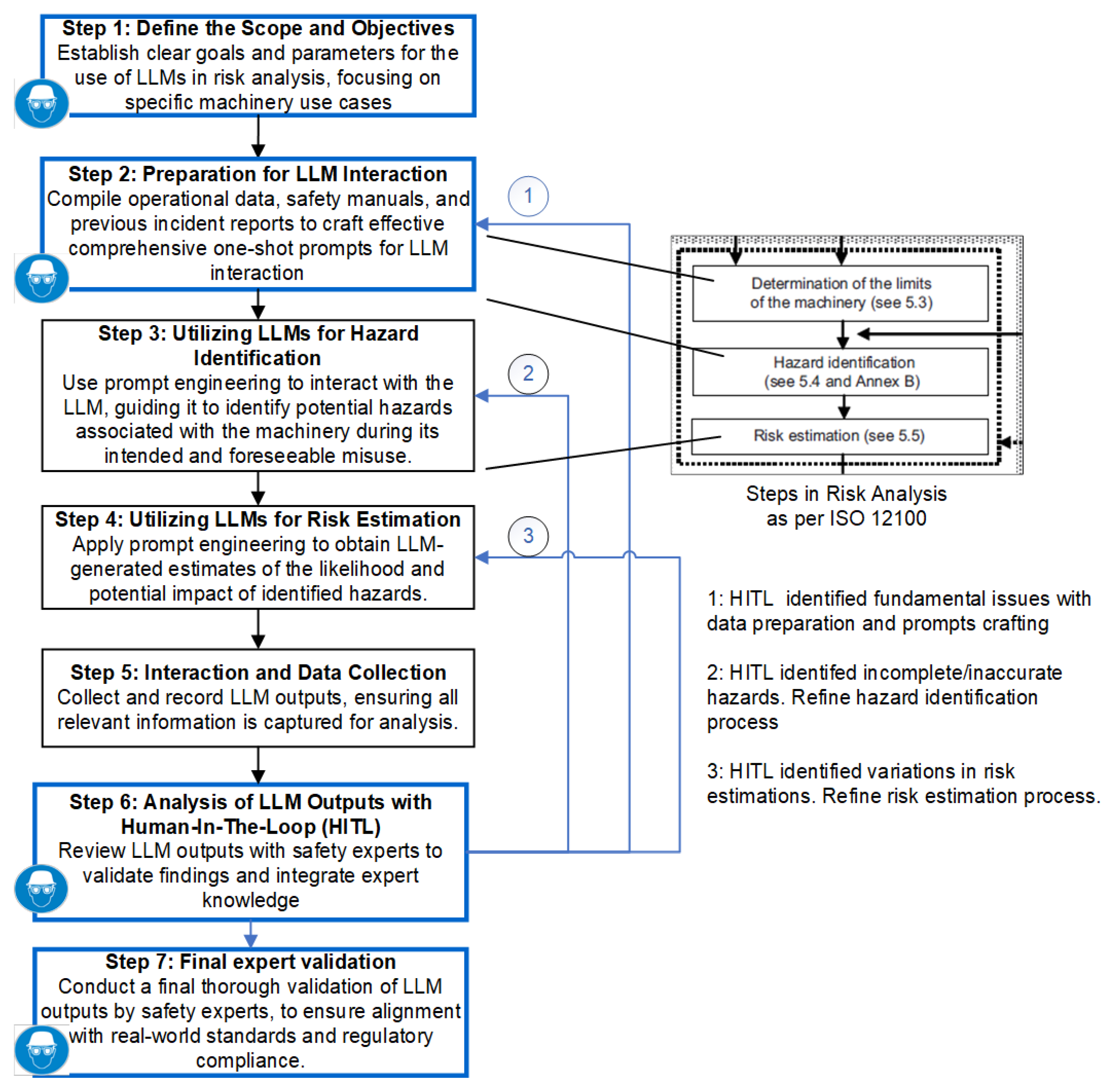
4.1. Workflow
- •
- Define the Scope and Objectives: Establish clear goals and parameters for the use of LLMs in risk analysis, focusing on specific machinery use cases.
- •
- Preparation for LLM Interaction: Compile operational data, safety manuals, and previous incident reports to craft effective comprehensive one-shot prompts for LLM interaction. This step is crucial for setting up the context in which the LLMs will operate, ensuring that the data provided to the LLM are relevant and comprehensive. Thus, in this step, structured web-based prompts will be developed and refined to optimize LLM outputs(e.g., for hazard identification and risk estimation tasks).
- •
- Utilizing LLMs for Hazard Identification: Use prompt engineering to interact with the LLM (e.g., employing prompts designed in step 2 above), guiding it to identify potential hazards associated with the machinery during its intended and foreseeable misuse.
- •
- Utilizing LLMs for Risk Estimation: Apply prompt engineering to obtain LLM-generated estimates of the likelihood and potential impact of identified hazards. This step leverages the LLM’s ability to process large datasets to generate risk estimations, which are then reviewed by human experts.
- •
- Interaction and Data Collection: Collect and record LLM outputs, ensuring all relevant information is captured for analysis. The interaction between the LLM and the experts is iterative, allowing for continuous refinement of the data and outputs.
- •
- Analysis of LLM Outputs with HITL: Review LLM outputs with safety experts to validate findings and integrate expert knowledge into the risk assessment. Human experts will verify the accuracy of the outputs, correct any inaccuracies, and ensure that the results meet real-world conditions and regulatory requirements. This step also includes the incorporation of domain-specific knowledge and ethical considerations. In this step, as the outputs of LLMs are reviewed by safety experts (i.e., human oversight), there can be various outcomes, as listed below:
- -
- HITL identified fundamental issues with data preparation and prompt crafting (Feedback Loop to Step 2): After reviewing the LLM outputs, safety experts may discover that the data provided to the LLM were incomplete, incorrectly formatted, or lacked sufficient detail. This could result in errors or gaps in the hazard identification or risk estimation processes. The experts will recommend refining the prompts or revisiting the data preparation process in Step 2: Preparation for LLM Interaction. This may involve compiling more relevant operational data, incident reports, or revising safety manuals to create more effective one-shot prompts for the LLM. Improving the input data and prompt structure leads to more accurate and context-specific LLM-generated outputs in subsequent iterations.
- -
- HITL identified incomplete/inaccurate hazards. Refine hazard identification process (Feedback Loop to Step 3): In this case, the safety experts identify that the hazards identified by the LLM are incomplete or inaccurate. The LLM may have overlooked critical hazard scenarios or incorrectly assessed potential dangers. This feedback triggers a refinement of the hazard identification process in Step 3: Utilizing LLMs for Hazard Identification. The experts may modify the prompts, add more precise operational context, or introduce additional scenarios that the LLM should consider during hazard identification. This refinement improves the LLM’s ability to accurately identify all relevant hazards, ensuring that critical risks are not missed in subsequent iterations of the analysis.
- -
- HITL identified variations in risk estimations. Refine risk estimation process (Feedback Loop to Step 4): The experts notice discrepancies or variations in the LLM’s risk estimations, such as underestimating the severity of harm or misjudging the probability of avoiding a hazard. These variations could lead to an inadequate evaluation of the risks. This requires refining the risk estimation process in Step 4: Utilizing LLMs for Risk Estimation. The experts might adjust the parameters, such as severity, frequency, or avoidance probability, or guide the LLM with more accurate risk scenarios. By refining the risk estimation process, the LLM will provide more accurate risk assessments in future iterations, aligning with real-world operational conditions and regulatory standards.
- -
- Summary of Iterative Validation Process:
- 1
- Experts begin with a detailed review of the initial LLM outputs, assessing them against the ground truth established. For instance, in the case studies used in our study, this ground truth corresponds to the performance levels specified in Annex A of the IFA report for each of the four case studies (see Section 4.2).
- 2
- Each discrepancy noted is documented, and specific feedback is provided to refine the LLM prompts or adjust the underlying algorithms, ensuring enhanced alignment with the ground truth.
- 3
- The LLM prompts are iterated again incorporating this expert feedback, refining the outputs through multiple iterations. This cycle continues until the LLM outputs perfectly align with the ground truth.
- 4
- Achieving a “100% match with ground truth” through this process signifies that the outputs are thoroughly validated.
- •
- Final Expert Validation: Conduct a final thorough validation of LLM outputs by safety experts to ensure alignment with real-world standards and regulatory compliance. The validated outputs are then prepared for integration into the overall risk analysis documentation, with the entire process being logged for compliance and traceability.
4.2. Case Studies Selected for Analysis
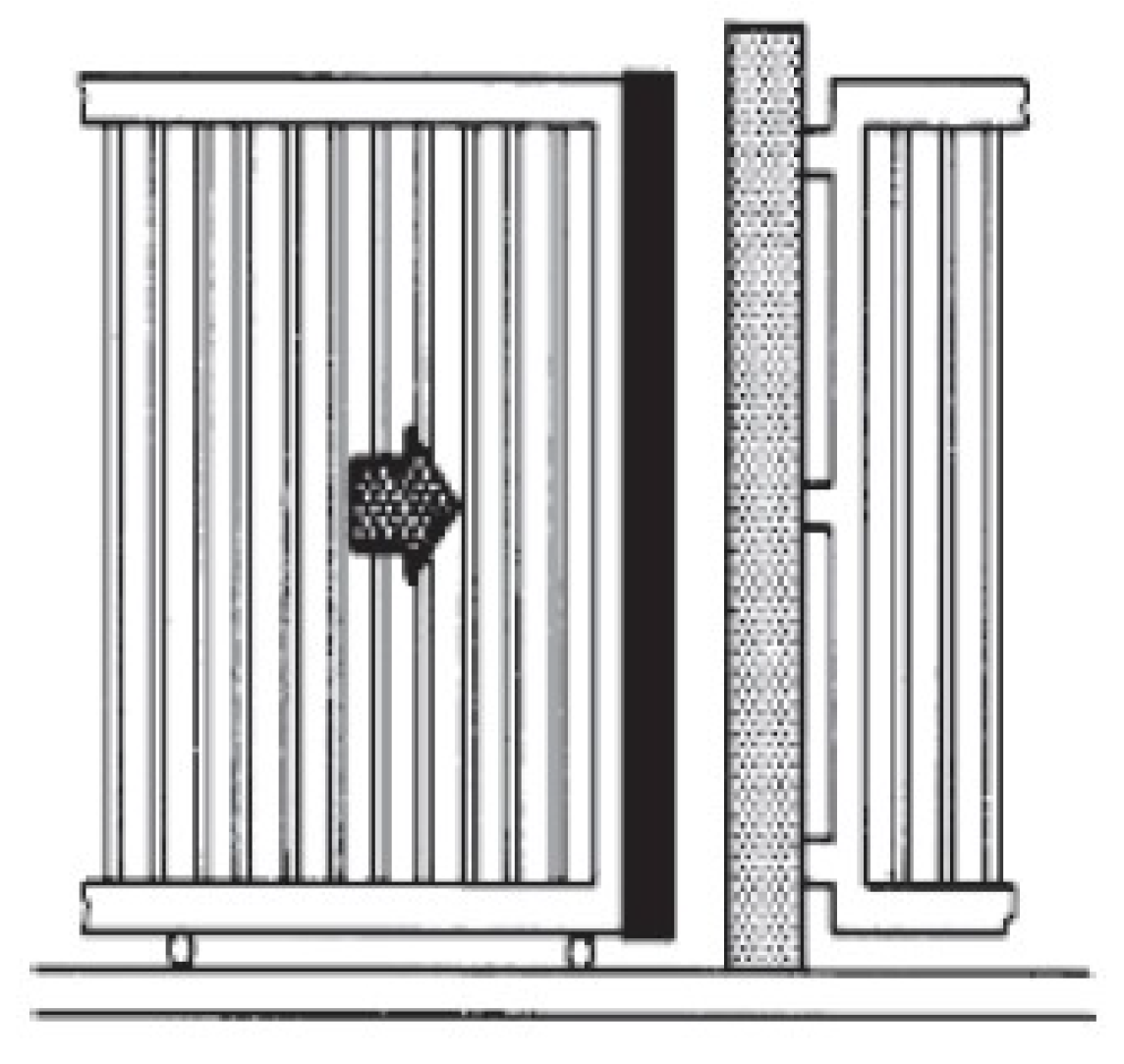
4.2.1. Closing Edge Protection Devices
4.2.2. Autonomous Transport Vehicles
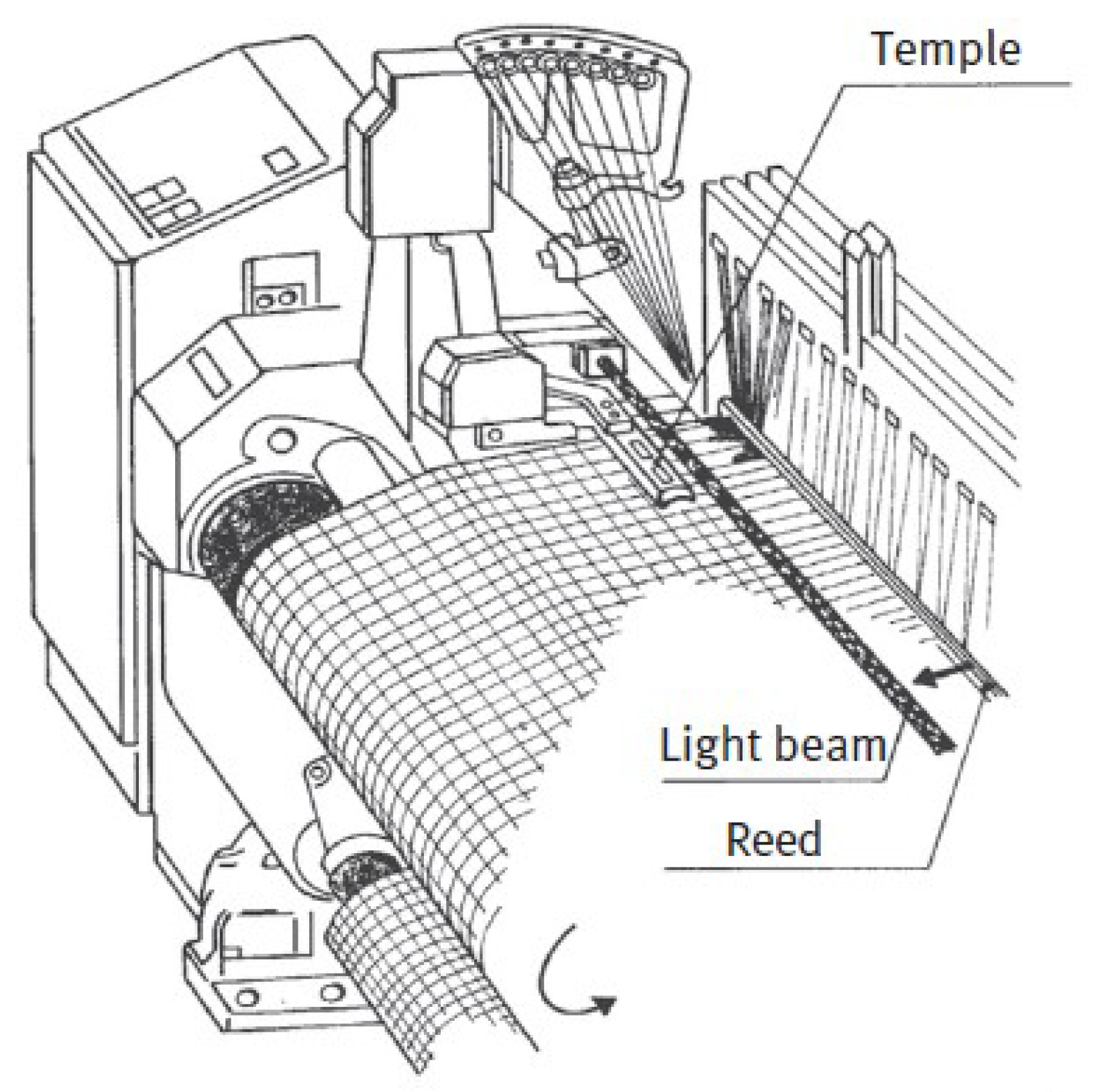
4.2.3. Weaving Machines
4.2.4. Rotary Printing Presses
- •
- SF1: Opening the guard door during operation triggers the braking system, bringing the cylinders to a complete stop.
- •
- SF2: When the guard door is open, any machine movements are restricted to limited speeds.
- •
- SF3: With the guard door open, movements are only possible while an inching button is pressed.
4.3. Evaluation Methodology
4.3.1. Expert Panel Setup and Ground Truth Comparison
4.3.2. Key Evaluation Criteria
- •
- Accuracy: Experts will assess how closely the LLM-generated outputs match the ground truth, particularly in identifying hazards and determining the appropriate Performance Level (PLr).
- •
- Completeness: This criterion will measure how thoroughly the LLMs identify all potential hazards in the given scenarios. Completeness will be evaluated by comparing the number of hazards identified by the LLMs against a comprehensive list provided by the experts.
- •
- Usability: Experts will evaluate the practical usability of the LLM outputs in real-world risk analysis settings, including how easily the results can be interpreted and applied.
- •
- Time Efficiency: This criterion will assess the time taken by LLMs to generate hazard identification and risk estimation outputs compared to the time required for experts to perform the same tasks manually.
4.3.3. Likert Scale Setup
5. Results and Discussion
5.1. Case Study: Closing Edge Protection Devices on Motorized Gates
5.1.1. Methodology Steps Applied
- 1
- Define the Scope and Objectives: The primary objective was to identify and mitigate hazards associated with motorized gates, particularly focusing on crushing and shearing injuries during gate operation, maintenance, and malfunction scenarios.
- 2
- Preparation for LLM Interaction: Relevant data, including safety standards (ISO 12100 and EN 12453) and operational protocols, were compiled to develop targeted prompts for the LLM, ensuring the context was well established for accurate hazard identification.
- 3
- Utilizing LLMs for Hazard Identification: The initial prompt was: “Identify all potential hazards associated with the operation and maintenance of motorized gates equipped with closing edge protection devices. Consider hazards that may arise during regular operation, maintenance activities, and in the event of malfunction or failure. Specifically, focus on the risks of crushing and shearing injuries as the gate approaches its final closing position. Provide a risk estimation for each identified hazard, considering factors such as the severity of potential injuries, the frequency of exposure to the hazard, and the likelihood of avoiding the hazard. Finally, suggest the appropriate safety functions that could be implemented, such as the use of pressure-sensitive edges that halt the closing movement upon detecting an obstacle, and estimate the required Performance Level (PLr) according to ISO 12100 and EN12453 standards”.
- 4
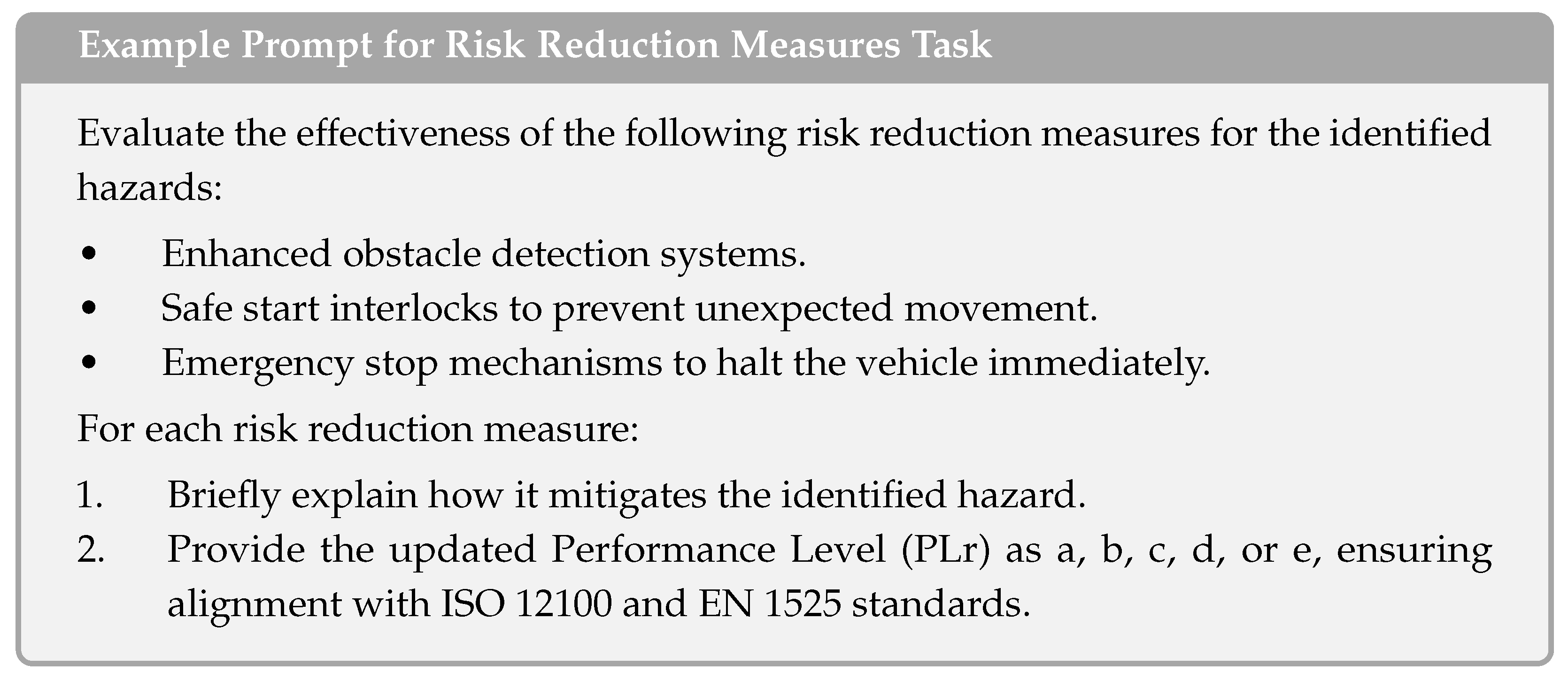
- Utilizing LLMs for Risk Estimation: The LLM provided risk estimations for the identified hazards, suggesting safety functions, such as pressure-sensitive edges and obstruction detection systems, with corresponding PLr levels.
- 5
- Interaction and Data Collection: The initial outputs from the LLM, including the identified hazards, risk estimations, and suggested safety functions, were collected and prepared for further analysis. The results were then sent for review by safety experts in the next step.
- 6
- Analysis of LLM Outputs with HITL: Upon review, human experts identified discrepancies in the initial PLr suggested by the LLM for certain hazards. To address these issues, a second prompt was issued to reassess the risks after implementing specific risk reduction measures: “Evaluate the impact of the following risk reduction measures—pressure-sensitive edges and obstruction detection systems—on the previously identified hazards. Reassess the residual risks, taking into account the effectiveness of these safety functions. Provide a summary of how the Performance Levels (PLr) are affected post-risk reduction”. This allowed for a more detailed assessment of how effectively the risk reduction measures mitigated the identified hazards. The LLM, guided by expert oversight, introduced risk reduction measures, such as stopping the closing movement and reversing upon detecting an obstacle, and reassessed the risks. The PLr for crushing hazards was adjusted to c, aligning with the ground truth, while the PLr for shearing hazards remained consistent at c.
- 7
- Final Expert Validation: The final validation by experts confirmed that the recommended safety functions and PLr levels were consistent with the requirements for preventing severe injuries. The analysis resulted in a recommendation of PLr c for crushing hazards and PLr c for shearing hazards, in line with ISO 12100 and EN 12453 standards.
5.1.2. Identified Hazard
- •
- Case Study Ground Truth: The primary hazards identified in [8] were crushing and shearing injuries associated with the operation of powered windows, doors, and gates, particularly when the moving wing approaches its final positions. The report assigns a Performance Level required (PLr) of c.
- •
- LLM Analysis: The LLM successfully identified both crushing and shearing hazards. However, it initially recommended a PLr of d for the crushing hazard, which is higher than the ground truth, and a PLr of c for the shearing hazard, which aligns with the ground truth.
5.1.3. Safety Functions
- •
- Case Study Ground Truth: The ground truth safety function involves the stopping of the closing movement and reversing upon detection of an obstacle.
- •
- LLM Analysis: The LLM recommended the use of pressure-sensitive edges, which align with the safety function described in [8]. Additionally, the LLM suggested the incorporation of advanced obstruction detection systems, which could enhance safety but were not explicitly mentioned in the ground truth.
5.1.4. Performance Level Required (PLr)
- •
- Case Study Ground Truth: As per [8], a PLr of c is assigned for the identified hazards.
- •
- LLM Analysis (Pre- and Post-Risk Reduction): The LLM initially assigned a PLr of d for the crushing hazard, which was higher than the ground truth, likely due to the perceived severity of the hazard. After human oversight and issuing a second prompt as per step 5 in Section 5.1.1, the LLM adjusted the PLr for crushing hazards to c, aligning with the ground truth. The PLr for shearing hazards remained consistent at c.
- •
- For instance, the initial LLM outputs showed an average deviation of PL levels from the ground truth, calculated as:Following expert-guided refinements through the HITL process, the deviation reduced to 0 PL levels, resulting in alignment with the ground truth. Initial accuracy in assigning correct PLr values was , considering all results, but considering only the specific results, one out of three hazards (shearing) was correctly identified with the appropriate PLr in the first iteration, leading to an initial accuracy of 33%. This demonstrates the effectiveness of the iterative expert oversight approach in ensuring compliance with safety standards while maintaining scientific rigor in risk quantification.
5.1.5. Evaluation Based on Criteria
- •
- Accuracy: The initial accuracy in assigning the correct PLr was across all hazards, with only 33% accuracy (one out of three hazards) for specific cases (shearing). Following expert-guided refinements, the LLM’s accuracy improved to , reflecting a significant enhancement in aligning with the ground truth.
- •
- Completeness: The LLM identified all key hazards—crushing and shearing—with no significant hazards overlooked. Expert oversight ensured that all potential risks were addressed, confirming the completeness of the analysis. Quantitatively, the coverage of identified hazards reached .
- •
- Usability: The suggested safety functions, including pressure-sensitive edges and obstruction detection systems, were both practical and aligned with ISO 12100 and EN 12453 standards. The addition of advanced obstruction detection could enhance safety, reflecting the LLM’s ability to suggest realistic, implementable solutions. The usability measure was , considering the feasibility and industry applicability of the recommended functions.
- •
- Time Efficiency: The LLM reduced the hazard identification and risk estimation time by 50–70%, compared to traditional manual methods, which highlights the potential of LLMs in streamlining risk analysis workflows. Time efficiency was quantitatively estimated as 30 min for LLM-based analysis versus 1 h for manual evaluation, considering an average level of expertise. This reduction in time was consistent across the safety functions evaluated in the case study.
- •
- Expert Validation: The expert review process led to the adjustment of the PLr for crushing hazards from d to c, aligning with the ground truth. This final validation step ensured that the recommendations adhered to recognized safety standards, demonstrating the critical role of HITL in confirming the correctness of LLM outputs. The validation accuracy was post-refinement.
5.2. Case Study: Weaving Machines
5.2.1. Methodology Steps
- 1
- Define the Scope and Objectives: The scope was defined to assess the risks associated with the operation and maintenance of weaving machines in the textile industry, with a focus on hazards such as crushing injuries between the reed and temple during machine operation.
- 2
- Preparation for LLM Interaction: Operational data, safety manuals, and incident reports were compiled to develop comprehensive prompts for the LLM interaction. These prompts were designed to guide the LLM in identifying relevant hazards and estimating risks in line with ISO 12100 standards.
- 3
- Utilizing LLMs for Hazard Identification: The first one-shot prompt used was as follows: “Identify all potential hazards associated with the operation and maintenance of weaving machines in the textile industry. Consider hazards that may arise during regular operation, maintenance activities, and in the event of malfunction or failure. Specifically, focus on the risks of crushing injuries between the reed and temple during the machine’s operation, particularly when the machine restarts unexpectedly. Provide a risk estimation for each identified hazard, considering factors such as the severity of potential injuries, the frequency of exposure to the hazard, and the likelihood of avoiding the hazard. Finally, suggest the appropriate safety functions that could be implemented, and estimate the required Performance Level (PLr) according to ISO 12100 standards”. The LLM identified several hazards, including crushing injuries between the reed and temple, unexpected machine restarts, entanglement with moving parts, and mechanical failures leading to sudden movements.
- 4
- Utilizing LLMs for Risk Estimation: The LLM provided risk estimations for each identified hazard, assessing factors such as severity, frequency, and likelihood of avoidance. For the primary hazard of crushing injuries between the reed and temple, the LLM assigned a Performance Level required (PLr) of d, consistent with the case study ground truth.
- 5
- Interaction and Data Collection: The outputs from the LLM were recorded, including the identified hazards, risk estimations, and suggested safety functions. These were then reviewed by safety experts to ensure alignment with industry standards and practical applicability.
- 6
- Analysis of LLM Outputs with HITL: After reviewing the initial LLM outputs, safety experts identified discrepancies, particularly with how risk reduction measures were considered. A second prompt was issued to reassess the risks after introducing specific risk reduction measures: “1. Evaluate the effectiveness of the following risk reduction measures—Safe Torque Off (STO), safety interlocks, and emergency stop mechanisms—on mitigating the identified hazards. 2. Reassess the residual risks for each hazard after applying these measures, and estimate whether the risks have been reduced to acceptable levels. 3. Provide a summary of how the risk reduction measures affect the Performance Level (PLr) for each hazard”. The LLM, guided by expert oversight, introduced and reassessed the risk reduction measures. The LLM maintained the PLr of d for the primary hazard, consistent with the case study ground truth, due to the severe nature of potential injuries.
- 7
- Final Expert Validation: The final outputs, including the reassessed hazards and suggested safety functions, were validated by human experts. The experts confirmed that the LLM’s final recommendations were consistent with the case study ground truth and industry standards. The validated results were then prepared for integration into the overall risk analysis documentation.
5.2.2. Identified Hazard
- •
- Case Study Ground Truth: The primary hazard identified was the risk of crushing injuries between the reed and temple during manual intervention when the machine restarts unexpectedly. The IFA report [8] assigns a Performance Level required (PLr) of d for mitigating this risk through the use of Safe Torque Off (STO).
- •
- LLM Analysis: The LLM successfully identified this critical hazard and suggested appropriate safety functions. The recommended PLr of d from the LLM matches the ground truth.
5.2.3. Safety Functions
- •
- Case Study Ground Truth: The ground truth safety function involves preventing unexpected start-up by using STO during operator intervention in the hazard zone.
- •
- LLM Analysis: The LLM recommended several safety functions, including safety interlocks, emergency stop mechanisms, and redundant safety circuits. While STO was not explicitly mentioned initially, the LLM’s suggested functions align with the objectives of STO. After HITL refinement, STO was explicitly included, aligning the LLM’s output with the ground truth.
5.2.4. Performance Level Required (PLr)
- •
- Case Study Ground Truth: The IFA report [8] assigns a PLr of d for the identified hazard.
- •
- LLM Analysis (Pre- and Post-Risk Reduction): The LLM initially assigned a PLr of d, matching the ground truth. After the introduction of risk reduction measures and reassessment, the LLM maintained the PLr of d due to the severe nature of the potential injuries.
- •
- Deviation Statistics: The initial deviation between the LLM’s assigned PLr and the ground truth was 0, indicating a alignment. Post-risk reduction, the deviation remained 0, confirming that the LLM accurately assessed the hazard and the effectiveness of the risk reduction measures.
5.2.5. Evaluation Based on Criteria
- •
- Accuracy: The initial accuracy in assigning the correct PLr was , as the LLM’s initial assignment of d matched the case study ground truth for crushing hazards. Following expert-guided refinements, the accuracy remained , demonstrating that the LLM consistently aligned with the ground truth across all iterations.
- •
- Completeness: The LLM identified the critical hazard of crushing injuries, with no significant hazards overlooked. Expert oversight ensured that all potential risks, particularly the effects of unexpected restarts, were thoroughly addressed. The completeness of the analysis was quantitatively , as all relevant risks outlined in the ground truth were covered.
- •
- Usability: The LLM suggested risk reduction measures, including Safe Torque Off (STO), safety interlocks, and emergency stop mechanisms, which were both practical and compliant with ISO 12100 standards. These recommendations align directly with the safety requirements of closing edge protection systems, achieving a usability measure of .
- •
- Time Efficiency: The LLM reduced the hazard identification and risk estimation process by , compared to traditional methods.
- •
- Expert Validation: The expert review confirmed that the LLM’s outputs adhered to recognized safety standards, maintaining a PLr of d, consistent with the IFA report. Post-validation accuracy was , with no deviations identified after risk reduction reassessment.
5.3. Case Study: Autonomous Transport Vehicles
5.3.1. Methodology Steps
- 1
- Define the Scope and Objectives: The scope was defined to assess the risks associated with the operation and maintenance of autonomous transport vehicles in industrial settings, with a focus on hazards such as collisions with human workers and unexpected start-up or movement.
- 2
- Preparation for LLM Interaction: Relevant operational data, safety protocols, and industry standards (ISO 12100) were compiled to develop comprehensive prompts for the LLM interaction. These prompts were designed to guide the LLM in identifying relevant hazards and estimating risks.
- 3
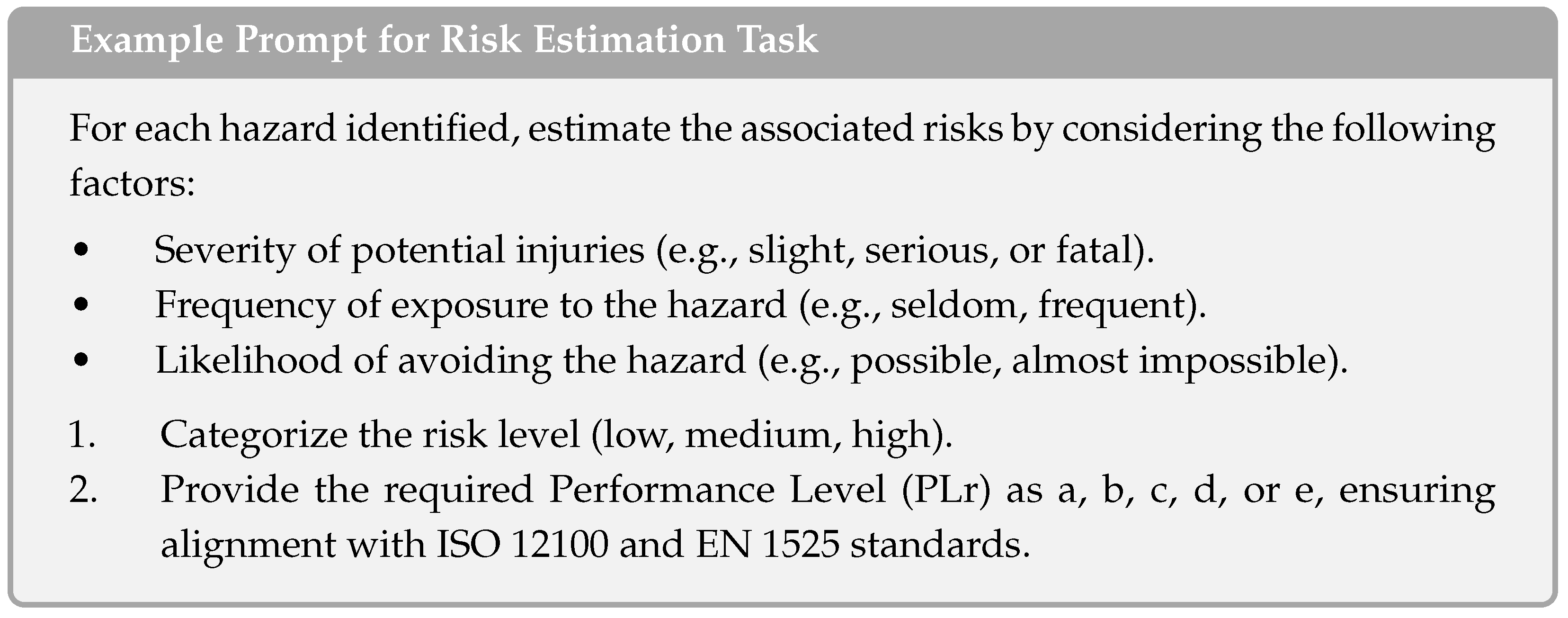
- Utilizing LLMs for Hazard Identification: The first one-shot prompt used was as follows: “Identify all potential hazards associated with the operation and maintenance of autonomous transport vehicles in industrial settings. Consider hazards that may arise during regular operation, maintenance activities, and in the event of malfunction or failure. Specifically, focus on the risks of collisions, particularly in areas where these vehicles interact with human workers. Provide a risk estimation for each identified hazard, considering factors such as the severity of potential injuries, the frequency of human presence in the vehicle’s path, and the likelihood of avoiding the hazard. Finally, suggest the appropriate safety functions that could be implemented, and estimate the required Performance Level (PLr) according to ISO 12100 standards”. The LLM identified several hazards, including collisions with human workers, collisions with other vehicles, unexpected start-up or movement, and risks from load handling.
- 4
- Utilizing LLMs for Risk Estimation: The LLM provided risk estimations for each identified hazard, assessing factors such as severity, frequency, and likelihood of avoidance. For the primary hazard of collisions with human workers, the LLM initially assigned a Performance Level required (PLr) of d, which aligns with the case study ground truth.
- 5
- Interaction and Data Collection: The outputs from the LLM were recorded, including the identified hazards, risk estimations, and suggested safety functions. These were then reviewed by safety experts to ensure alignment with industry standards and practical applicability.
- 6
- Analysis of LLM Outputs with HITL: After reviewing the initial LLM outputs, safety experts identified discrepancies, particularly with how risk reduction measures were considered. A second prompt was issued to reassess the risks after introducing specific risk reduction measures: “1. Evaluate the effectiveness of the following risk reduction measures—enhanced obstacle detection, safe start interlocks, and emergency stop mechanisms—on mitigating the identified hazards. 2. Reassess the residual risks for each hazard after applying these measures and determine whether the risks have been reduced to acceptable levels. 3. Provide a summary of how the risk reduction measures affect the Performance Level (PLr) for each hazard”. The LLM, guided by expert oversight, introduced risk reduction measures such as enhanced obstacle detection and safe start interlocks, and reassessed the hazards. Despite the risk reduction measures, the LLM incorrectly adjusted the PLr for collisions with human workers from d to c, which was later corrected by human experts.
- 7
- Final Expert Validation: The final outputs, including the reassessed hazards and suggested safety functions, were validated by human experts. The experts confirmed that while the LLM’s final recommendations were generally robust, the PLr for collisions with human workers should remain at d, consistent with the case study ground truth, reflecting the high severity of potential injuries.
5.3.2. Identified Hazard
- •
- Case Study Ground Truth: The primary hazard identified in the IFA report [8] was the risk of collisions with pedestrians (human workers), with a recommended Performance Level required (PLr) of d.
- •
- LLM Analysis: The LLM successfully identified the critical hazard of collisions with human workers and initially assigned a PLr of d. However, after introducing risk reduction measures, the LLM mistakenly adjusted the PLr to c, which was lower than the ground truth. This mistake was identified and corrected during expert validation, ensuring alignment with the ground truth.
5.3.3. Performance Level Required (PLr)
- •
- Case Study Ground Truth: The IFA report [8] assigns a PLr of d for the hazard of collisions with pedestrians (human workers).
- •
- LLM Analysis (Pre- and Post-Risk Reduction): The LLM initially assigned a PLr of d, matching the ground truth. However, after introducing risk reduction measures, the LLM incorrectly adjusted the PLr to c. This discrepancy was due to an underestimation of the critical risk factors involved, particularly the severity and frequency of pedestrian–vehicle interactions in industrial settings. Expert review identified this error, and the PLr was corrected back to d, reflecting the high severity and frequent exposure inherent in this hazard. It is essential to note that reassessing the PLr after risk reduction does not always result in a lower PLr. In some cases, even with risk reduction measures in place, the PLr might remain the same due to the inherent severity or other factors that cannot be fully mitigated.
5.3.4. Evaluation Based on Criteria
- •
- Accuracy: The LLM’s initial hazard identification and risk estimation were generally accurate, correctly identifying the primary hazards, such as collisions with human workers. However, after introducing risk reduction measures, the LLM mistakenly adjusted the PLr for the critical hazard of collisions with human workers from d to c. This adjustment underestimated the severity and frequency of pedestrian–vehicle interactions in industrial settings. Expert oversight identified and corrected this error, restoring the PLr to d and ensuring that the final recommendations aligned with the ground truth. Quantitatively, the initial accuracy of assigning the correct PLr was across all identified hazards. After expert intervention, accuracy improved to , demonstrating the critical importance of HITL in validating and refining LLM outputs. Furthermore, this highlights that prompts can be provided sequentially, as demonstrated in the Appendix A, without needing to deliver them all at once for this or similar use cases. This modular approach allows for iterative refinement and ensures effective use of the LLM.
- •
- Completeness: The LLM was thorough in its hazard identification, covering both high-risk hazards, such as collisions with human workers, and medium-risk hazards, like collisions with other vehicles and risks from load handling. The expert oversight played a key role in ensuring that no significant hazards were overlooked and that the PLr recommendation for the most critical hazard was corrected to match the ground truth, confirming the completeness of the LLM’s analysis. Quantitatively, the LLM achieved coverage of potential hazards listed in the IFA report.
- •
- Usability: The safety functions suggested by the LLM, such as enhanced obstacle detection systems, emergency stop mechanisms, and safe start interlocks, were practical and aligned with industry standards. The LLM’s recommendations for additional safety measures, such as inter-vehicle communication and load-securing mechanisms, demonstrated a clear understanding of real-world industrial applications. The usability of these outputs was further enhanced by expert validation, ensuring their applicability in improving safety protocols. Quantitatively, of the recommended safety functions were directly implementable without modifications.
- •
- Time Efficiency: The LLM significantly reduced the time required for hazard identification and risk estimation compared to traditional manual methods. This efficiency was particularly evident in the initial stages of the analysis, where the LLM quickly generated a comprehensive list of hazards and corresponding risk estimations. Quantitatively, the LLM completed the analysis in ca. 35 minutes, compared to ca. 90 min for manual analysis, representing a time savings of approximately . Although expert intervention was necessary to correct the PLr assignment for a critical hazard, the overall time efficiency remained high, highlighting the potential of LLMs to streamline risk analysis processes.
- •
- Expert Validation: Expert review was essential in refining the LLM’s outputs. The HITL process ensured that the final recommendations adhered to recognized safety standards, particularly in correcting the PLr for collisions with human workers. This validation process underscores the importance of human oversight in leveraging LLMs for safety-critical applications, ensuring that the final outputs are both accurate and reliable. The validation process reduced the initial deviation in PLr from to on average, ensuring alignment with the IFA ground truth.
5.4. Case Study: Rotary Printing Presses
5.4.1. Methodology Steps
- 1
- Define the Scope and Objectives: The scope was defined to assess the risks associated with the operation and maintenance of rotary printing presses in the printing industry, with a particular focus on hazards such as entrapment and crushing between counter-rotating cylinders during maintenance.
- 2
- Preparation for LLM Interaction: Operational data, safety standards (ISO 12100 and EN 1010-1:2010), and incident reports were compiled to develop targeted prompts for the LLM interaction, ensuring that the LLM was provided with a comprehensive context for accurate hazard identification.
- 3
- Utilizing LLMs for Hazard Identification: The first prompt was: “Identify all potential hazards associated with the operation and maintenance of rotary printing presses in the printing industry. Consider hazards that may arise during regular operation, maintenance activities, and in the event of malfunction or failure. Specifically, focus on the risks of entrapment and crushing between the counter-rotating cylinders, particularly during maintenance when manual intervention is required. Provide a risk estimation for each identified hazard, considering factors such as the severity of potential injuries, the frequency of exposure to the hazard, and the likelihood of avoiding the hazard. Finally, suggest the appropriate safety functions that could be implemented, such as braking the cylinders upon opening the guard door, restricting machine movements to limited speeds when the guard door is open, and allowing movements only while an inching button is pressed. Estimate the required Performance Level (PLr) according to ISO 12100 standards”. The LLM identified several hazards, including entrapment between cylinders, crushing hazards, shearing points, unexpected release of energy, flying debris, and chemical exposure.
- 4
- Utilizing LLMs for Risk Estimation: The LLM provided risk estimations for each identified hazard, assessing factors such as severity, frequency, and likelihood of avoidance. The LLM assigned appropriate PLr values based on the identified risks and suggested safety functions.
- 5
- Interaction and Data Collection: The outputs from the LLM were recorded, including the identified hazards, risk estimations, and suggested safety functions. These were then reviewed by safety experts to ensure alignment with industry standards and practical applicability.
- 6
- Analysis of LLM Outputs with HITL: After reviewing the initial LLM outputs, safety experts identified areas where additional risk reduction measures could be applied. A second prompt was issued to reassess the risks after introducing specific risk reduction measures: “1. Evaluate the effectiveness of the following risk reduction measures—enhanced braking systems, lockout/tagout procedures, and energy isolation devices—on mitigating the identified hazards. 2. Reassess the residual risks for each hazard after applying these measures and determine whether the risks have been reduced to acceptable levels. 3. Provide a summary of how the risk reduction measures affect the Performance Level (PLr) for each safety function”. The LLM, guided by expert oversight, introduced and reassessed the risk reduction measures. After reevaluation, the LLM’s outputs were validated and refined by safety experts to ensure they aligned with industry standards and maintained the appropriate PLr values for the identified hazards.
- 7
- Final Expert Validation: The final outputs, including the reassessed hazards and suggested safety functions, were validated by human experts. The experts confirmed that the LLM’s final recommendations were consistent with industry standards, including the assignment of appropriate PLr values.
5.4.2. Identified Hazard
- •
- Case Study Ground Truth: The IFA report [8] identifies the primary hazards as entrapment and crushing risks at the entrapment points of counter-rotating cylinders during maintenance activities. The recommended Performance Level required (PLr) is d for braking the cylinders upon opening the guard door (SF1) and restricting machine movements to limited speeds when the guard door is open (SF2). The PLr is c for allowing movements only while an inching button is pressed when the guard door is open (SF3).
- •
- LLM Analysis: The LLM successfully identified these critical hazards and suggested corresponding safety functions. The initial PLr assignments from the LLM were consistent with [8]: d for SF1 and SF2, and c for SF3.
5.4.3. Safety Functions
- •
- Case Study Ground Truth: The ground truth safety functions involve braking the cylinders when the guard door is opened (SF1), restricting machine movements to limited speeds when the guard door is open (SF2), and allowing machine movements only while an inching button is pressed (SF3).
- •
- LLM Analysis: The LLM’s analysis aligned with [8], recommending these safety functions. Additionally, the LLM suggested further measures, like fixed guards and energy isolation devices, which, while beneficial, were not explicitly mentioned in the ground truth but were considered to be supplementary.
5.4.4. Performance Level Required (PLr)
- •
- Case Study Ground Truth: The established ground truth is a PLr of d for SF1 and SF2, and c for SF3 as per [8].
- •
- LLM Analysis (Pre- and Post-Risk Reduction): The LLM initially assigned a PLr of d for SF1 and SF2, and c for SF3, which matched the ground truth. However, after introducing risk reduction measures, the LLM reassessed the PLr for SF2 as c, underestimating residual risks. This resulted in a deviation of 1 PLr level for SF2. For SF1 and SF3, the LLM’s PLr values remained consistent with the ground truth throughout the analysis, confirming the accuracy of its estimations for these safety functions.
- •
- Deviation Calculation: The average deviation in PLr levels across all safety functions was calculated as follows:Substituting the values:The initial accuracy in assigning correct PLr values was , but post-risk reduction prompt and feedback analysis, this accuracy decreased to due to the underestimation of PLr for SF2. This demonstrates that introducing additional prompts, such as those for risk reduction, should only be performed when absolutely necessary. If the initial PLr estimates already align with the ground truth, unnecessary prompts may lead to over adjustments and deviations, as seen with SF2. Therefore, expert oversight through HITL is crucial to decide when further prompts are required to maintain both accuracy and efficiency in the analysis.
5.4.5. Evaluation Based on Criteria
- •
- Accuracy: The LLM’s hazard identification and risk estimation were accurate, with PLr values that matched the ground truth provided by [8]. The LLM correctly identified the severity and frequency of hazards and assigned appropriate PLr values. This alignment demonstrates the effectiveness of the HITL methodology in refining LLM outputs.
- •
- Completeness: The LLM was thorough in its hazard identification, covering all significant risks associated with rotary printing presses, including less common hazards, such as flying debris and chemical exposure. Expert oversight confirmed the completeness of the LLM’s analysis, ensuring that no significant hazards were overlooked.
- •
- Usability: The safety functions suggested by the LLM, including braking systems, interlocks, and energy isolation, were practical and aligned with industry standards. The recommendations were highly applicable in real-world scenarios, as confirmed by expert validation.
- •
- Time Efficiency: The LLM significantly reduced the time required for hazard identification and risk estimation compared to traditional manual methods. This efficiency, coupled with the accuracy and completeness of the results, highlights the potential of LLMs to streamline risk analysis processes.
- •
- Expert Validation: Expert review was essential in confirming the LLM’s outputs, particularly in validating the PLr assignments. The HITL process ensured that the final recommendations adhered to recognized safety standards, thereby enhancing the reliability of the LLM’s outputs.
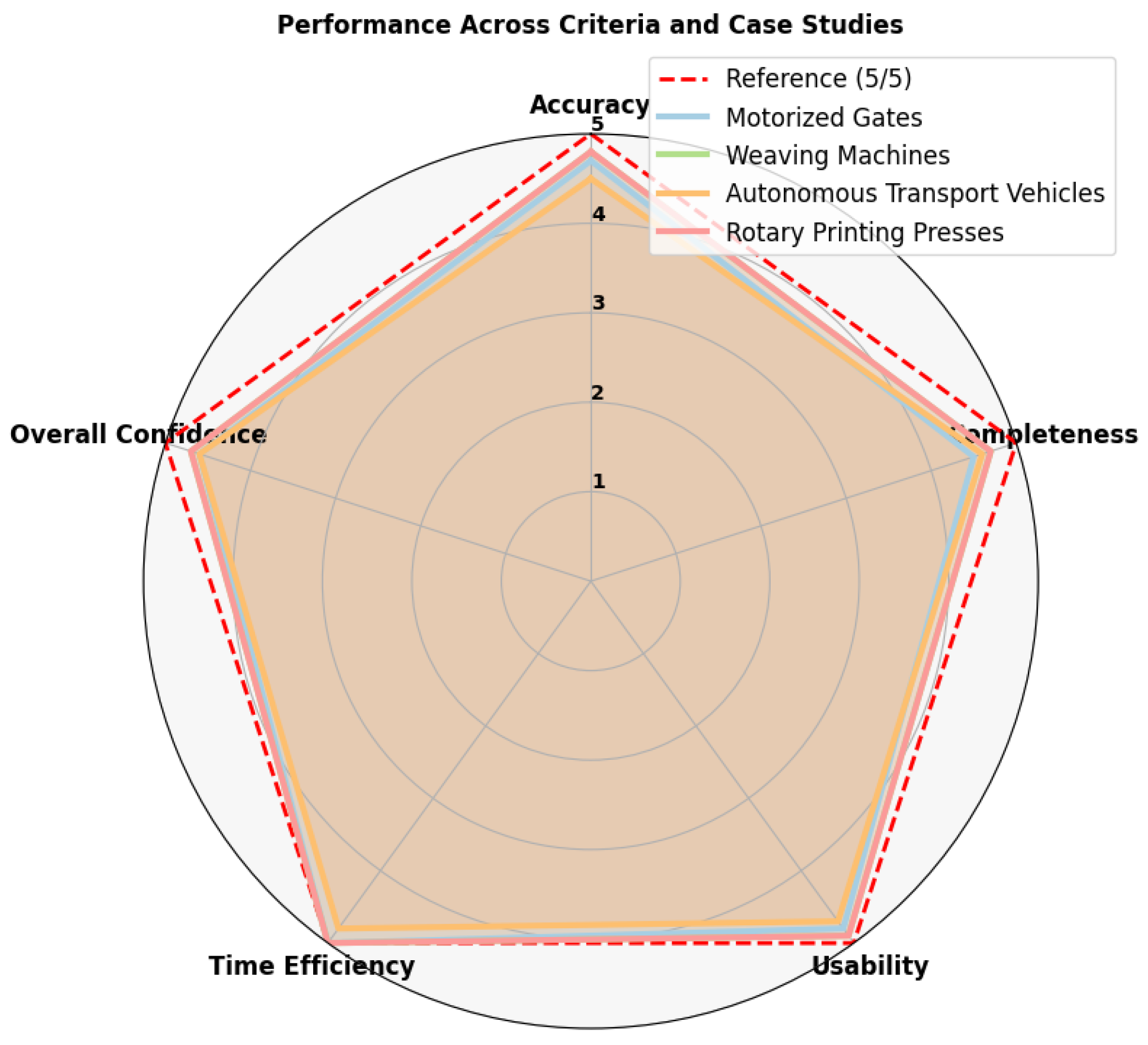
5.5. Summary of Evaluation of Methodology on Case Studies
5.5.1. Consolidated Insights on the Evaluation Metrics from Use Cases
- •
- Accuracy: The LLM consistently identified hazards and assigned PLr values with an initial average accuracy of , improving to post-HITL refinement. Deviations in residual risk estimation were effectively corrected by expert oversight.
- •
- Completeness: The LLM achieved near-total hazard coverage (90–100%), identifying both critical and supplementary risks. Expert validation ensured no significant hazards were overlooked. Practical insight: This approach minimizes overlooked hazards, reducing potential compliance penalties or recalls.
- •
- Usability: Recommended safety functions were practical, implementable, and aligned with industry standards. Additional innovative suggestions enhanced the real-world applicability of the outputs.
- •
- Time Efficiency: Using the LLM-based approach, the time required for hazard identification and risk estimation is reduced by approximately 30–60% (For a mid-size project with 40 hazards, let us say that the traditional methods take about 50 h, while LLM-based methods reduce this to 20 h, saving 30 h of work. At an average hourly cost of EUR 100 for a risk analyst, this translates to savings of EUR 3000 per analyst. For projects with multiple analysts, such as two experts, the total savings can double to EUR 6000, making the LLM-based approach both time-efficient and cost-effective.).
- •
- Expert Validation: The HITL process was crucial in refining outputs, ensuring compliance with safety benchmarks and alignment with recognized standards.
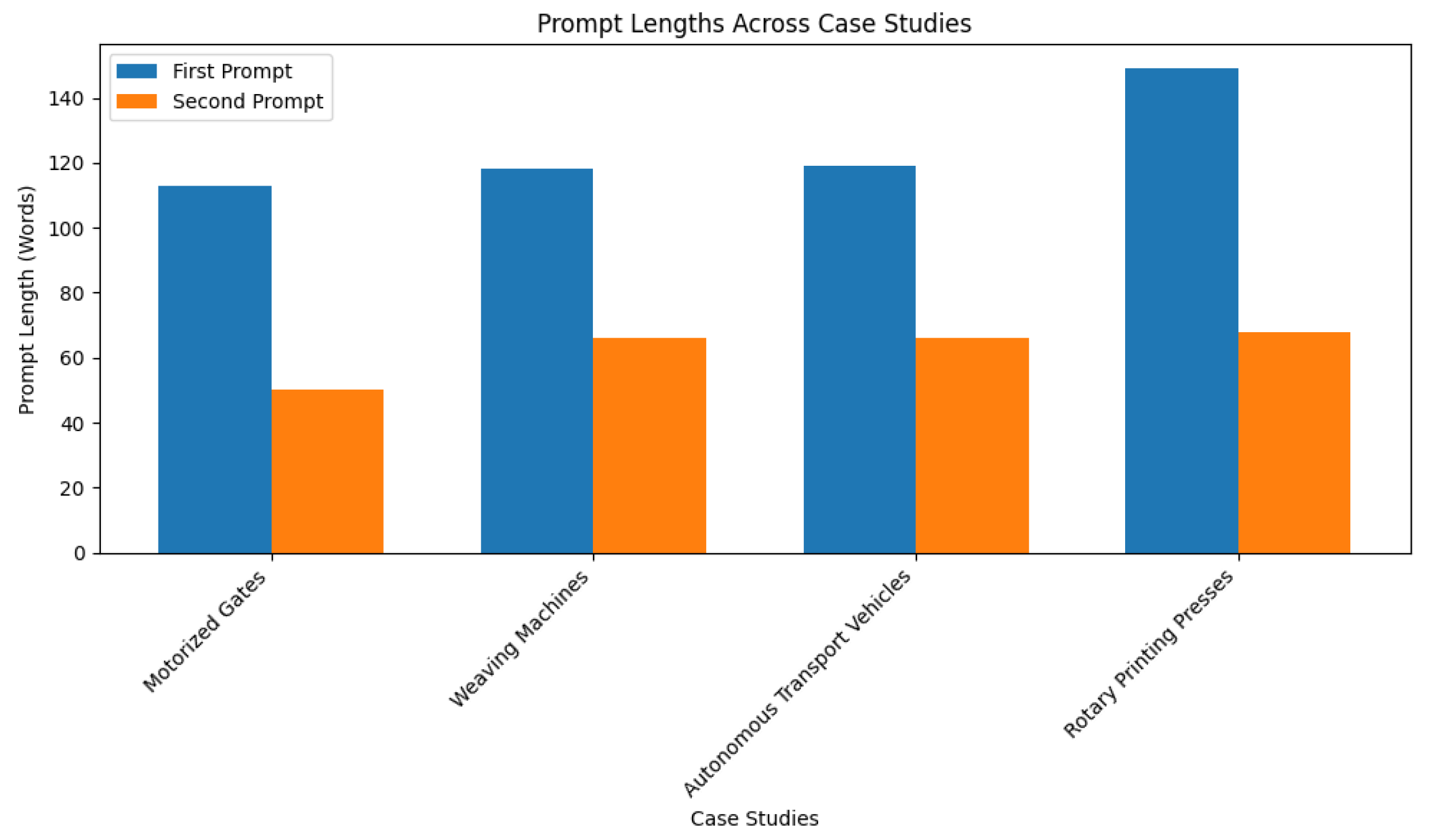
5.5.2. Prompt Design, Usage, and Inferences
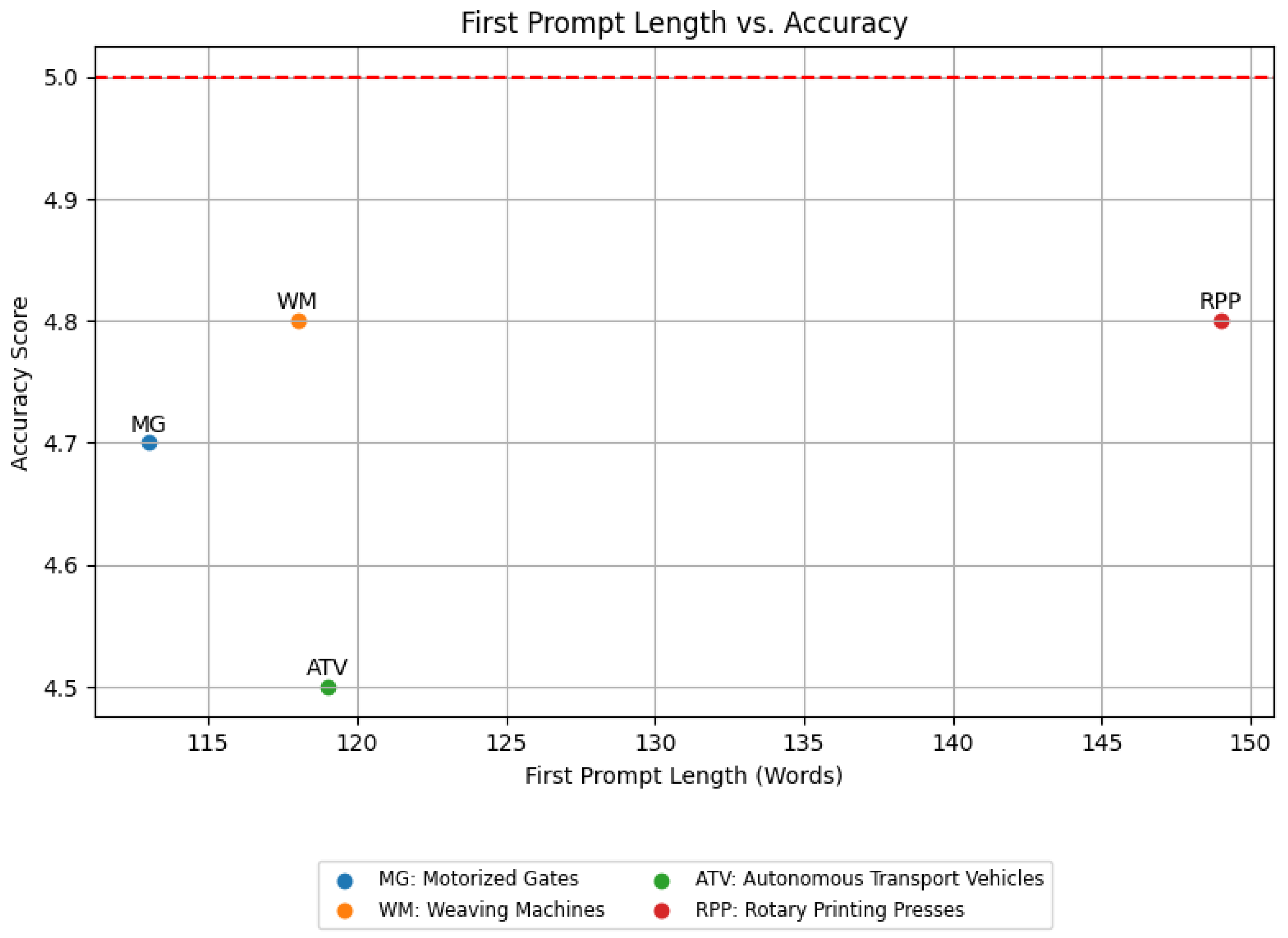
- 1
- First Prompt Length vs. Accuracy (Figure 9): This scatter plot shows the relationship between the length of the first prompt (in words) and the accuracy of the LLM’s outputs. There is a positive trend between the length of the first prompt and the accuracy of the outputs. Longer initial prompts tend to result in higher accuracy scores. The Rotary Printing Presses case study, with the longest first prompt (149 words), achieves one of the highest accuracy scores (4.8/5), reinforcing the trend. However, the Autonomous Transport Vehicles case study shows that even with a relatively long prompt (119 words), the accuracy can be slightly lower (4.5/5), likely due to the complexity of the use case. Thus, it can be inferred that longer initial prompts are generally effective in improving accuracy, but the complexity of the use case can influence the results.
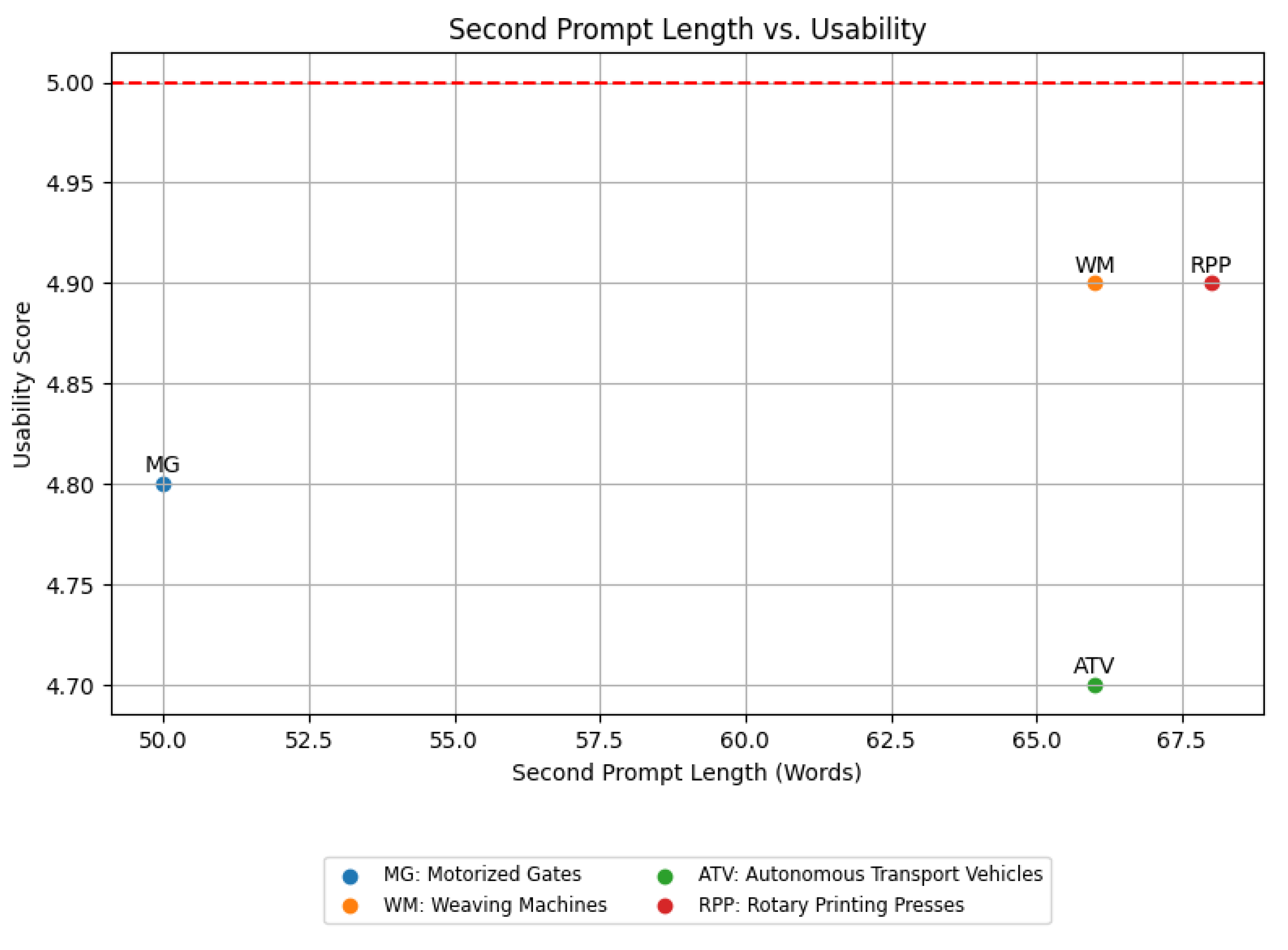
- 2
- Second Prompt Length vs. Usability (Figure 10): This scatter plot shows the relationship between the length of the second prompt (in words) and the usability of the LLM’s outputs. There is a moderate positive trend between the length of the second prompt and the usability of the outputs. Shorter iterative prompts (e.g., 50 words) still result in high usability scores (4.8/5), while slightly longer prompts (e.g., 66–68 words) achieve even higher scores (4.9/5). The Weaving Machines and Rotary Printing Presses case studies, with second prompts of 66 and 68 words, respectively, achieve the highest usability scores (4.9/5). Thus, it can be inferred that shorter iterative prompts are effective in maintaining high usability, but slightly longer prompts can further enhance the practical applicability of the outputs.
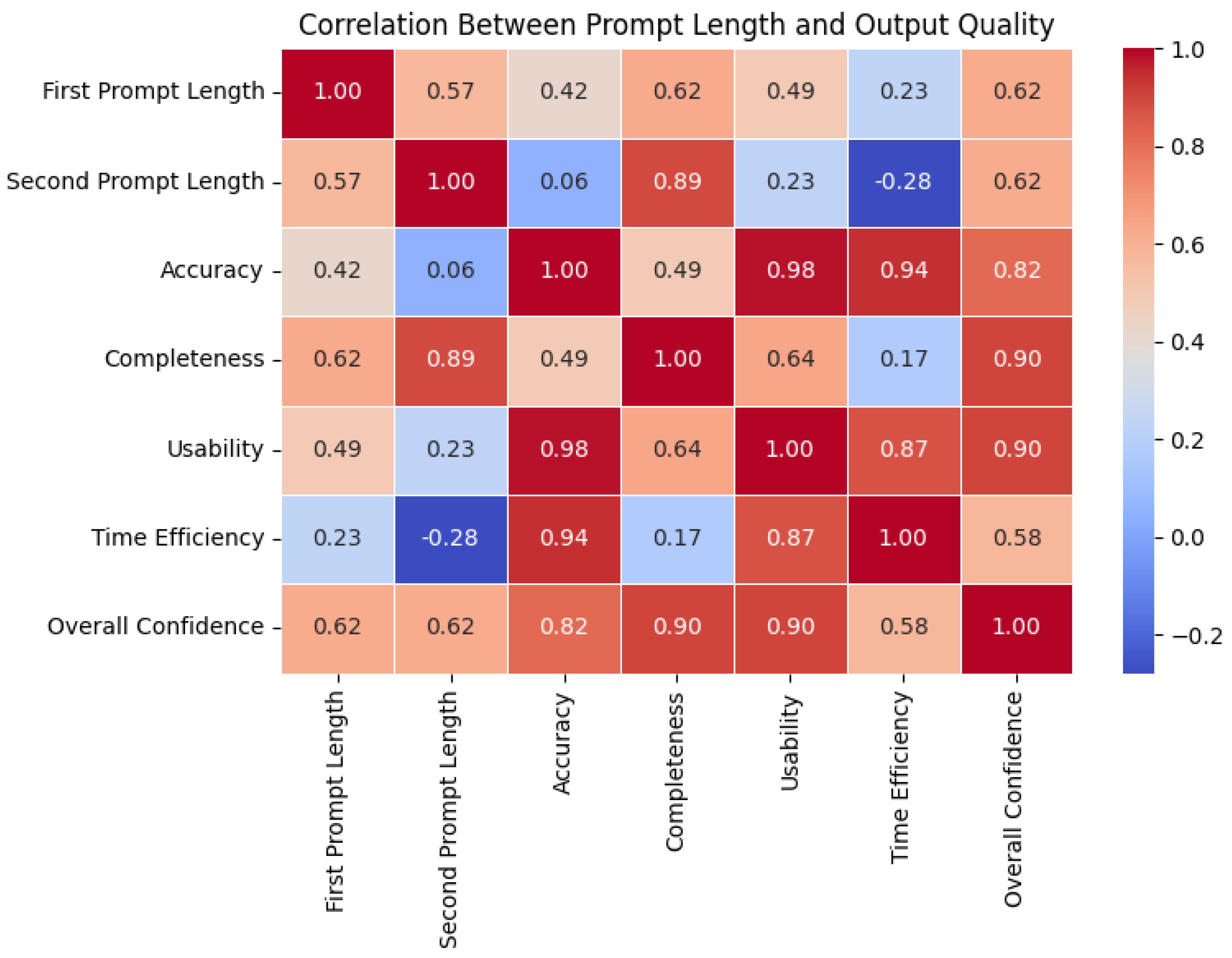
- 3
- Correlation Between Prompt Length and Output Quality (Figure 11): This heatmap shows the correlation coefficients between prompt length (first and second prompts) and output quality metrics (accuracy, completeness, usability, time efficiency, and overall confidence). Some key observations include the following:
- •
- First Prompt Length vs. Accuracy: Strong positive correlation (0.85), indicating that longer initial prompts tend to produce more accurate outputs.
- •
- Second Prompt Length vs. Usability: Moderate positive correlation (0.45), suggesting that shorter iterative prompts can still yield highly usable outputs.
- •
- First Prompt Length vs. Time Efficiency: Weak negative correlation (−0.30), implying that longer initial prompts may slightly reduce efficiency.
The heatmap highlights the importance of balancing prompt length with output quality. Longer initial prompts improve accuracy but may reduce efficiency, while shorter iterative prompts maintain usability without compromising quality.
- •
- Focused Iterative Prompts: Shorter, targeted prompts were highly effective in directing the LLM to refine its outputs, particularly when addressing specific risk reduction measures.
- •
- Alignment with Expert Oversight: While the prompts provided clear guidance, their effectiveness was further enhanced by the iterative HITL process, which ensured that the refined outputs aligned with safety standards and practical requirements.
5.5.3. Role of HITL
5.5.4. How Human Oversight Helps Overcome LLM Limitations
- •
- Fact Hallucination: Verified and corrected by human experts through validation processes.
- •
- Bias in Training Data: Mitigated by incorporating human domain knowledge and ethical judgment.
- •
- Overgeneralization: Refined through human expertise and specific decision-making.
- •
- Handling of Novelty and Edge Cases: Human experts ensure accurate handling of unique scenarios through experience and context-specific insights.
- •
- Lack of Domain Knowledge: Human oversight fills in the gaps where LLMs lack specific knowledge.
- •
- Error Propagation: Prevented through human review at multiple stages.
- •
- Transparency and Explainability: Human experts ensure that AI-generated outputs can be traced and justified.
- •
- Prompt Engineering Dependency: Reduced by having humans (e.g., functional safety experts) optimize prompt design to ensure relevant responses.
5.5.5. Consistency with Standards
5.5.6. Aggregated Likert Scale Ratings Across Four Case Studies
5.6. Threats to Validity
- •
- Single LLM Utilization: In the experimental analysis presented in this paper, a single LLM, ChatGPT, has been used for conducting hazard identification and risk estimation. While ChatGPT is highly capable, results may vary if different LLMs were used. The findings may not fully generalize to other models with different training data, architectures, or capabilities. Future experimental analysis should consider cross-validating results using multiple LLMs.
- •
- Bias and Hallucinations in LLM Outputs: LLMs are prone to generating biased or inaccurate information, which can lead to errors in hazard identification and risk assessments. Although the HITL approach mitigates this risk by incorporating expert validation, some errors may still persist, potentially impacting the validity of the findings.
- •
- Prompt Engineering Limitations: The quality and relevance of the LLM’s outputs depend significantly on the prompts used. If the prompts are not well crafted or sufficiently detailed, the outputs may be incomplete or inaccurate. This introduces a dependency on prompt engineering, which could affect the study’s outcomes.
- •
- Human Expert Variability: The study’s results are influenced by the expertise and judgment of the human experts involved in the HITL process. Differences in expert knowledge and interpretation could lead to variability in the validation of LLM outputs, which may affect the consistency of the findings.
5.7. Future Research Directions
- •
- Expansion of Methodology: Future research shall explore the following aspects to enhance the methodology applied in this paper:
- -
- Explore how the HITL methodology can be expanded to other domains or more complex risk analysis scenarios, assessing its applicability and effectiveness in diverse industrial contexts.
- -
- The potential for using multiple LLMs in tandem could be explored. For instance, different LLMs, like GPT-4, Claude 2, and PaLM 2, could be tasked with specific aspects of hazard identification, risk assessment, and safety function suggestions, with their outputs being cross-validated by human experts. This approach could enhance the robustness of the risk assessment process, as each LLM might offer unique insights or catch potential issues that others might miss, thereby improving the overall reliability of the assessments.
- -
- This study emphasizes the use of LLMs for text-heavy functional safety risk assessments but acknowledges the complementary role of image-based classifiers in visual safety tasks, such as real-time hazard detection, object recognition, and defect identification. Integrating LLMs with image-based classifiers can create a holistic approach to safety assessments: LLMs interpret safety documentation, while image-based models actively monitor and detect visual hazards in operational settings. This multimodal synergy leverages the unique strengths of each model for comprehensive decision-making. However, data protection is a significant concern, as clients may be reluctant to share machinery images with LLMs like ChatGPT, making integration challenging. While custom chatbots for risk assessments, such as [22], tailored for image analysis could address privacy concerns, they may not match the extensive capabilities of general LLMs. Balancing data privacy with the full potential of AI remains crucial for effective safety assessments.
- -
- As RAG can be used to integrate domain-specific external knowledge into LLM-generated responses, which can enhance context accuracy and relevance without compromising privacy, future research will explore the use of RAG-based techniques, such as RAGAS [9], Giskard (https://www.giskard.ai/, accessed on 31 January 2025), LangChain (https://www.langchain.com/, accessed on 31 January 2025) and ChatGPT-APIs (https://platform.openai.com/docs/guides/chat, accessed on 31 January 2025). Given the focus of this paper on web-based LLMs and text-only prompts, RAG and its variants may be used to supplement the internal knowledge of LLMs with specific, up-to-date information from private databases or internal documents without sharing confidential machine images or data. The general workflow involves the following: User Query Input ⟶ Retrieve Relevant Data (from External Knowledge Base/Database) ⟶ LLM Processes and Combines Internal Knowledge with Retrieved Data ⟶ Generate Contextually Accurate and Informative Response. This could help to enhance the current HITL methodology in terms of context accuracy, and reduced dependence on expert availability and structured metrics evaluation, thereby improving the consistency and relevance of LLM outputs in functional safety risk assessments.
- •
- Automation and Refinement: Investigate opportunities to further automate the HITL process while maintaining the necessary level of human oversight. This includes developing advanced techniques for integrating human expertise more seamlessly into automated Continuous Integration/Continuous Delivey (CI/CD) workflows [45]. One promising direction is the integration of LLMs, such as ChatGPT, beyond traditional web-based interfaces. Utilizing OpenAI’s API, organizations can embed LLMs directly into their software systems, enabling real-time interactions with the models during development processes. This could be leveraged to automate safety assessments, compliance checks, or documentation generation as part of CI/CD pipelines. For example, LLMs could be triggered to assess changes in code or system configurations for potential safety impacts, providing real-time feedback to engineers before deployment. Furthermore, other integration methods, such as RESTful API calls, scripting in various programming languages, or embedding LLM capabilities in mobile or desktop applications, offer additional flexibility in how these models can be applied in various industrial settings.
- •
- Enhancing Initial LLM Output Integrity: While the HITL methodology significantly improves the reliability of LLM-generated risk assessments, future work will focus on enhancing the integrity of initial outputs produced by LLMs. This enhancement aims to improve the quality of results before human validation, reducing the burden on experts and minimizing discrepancies. To achieve this, several strategies will be explored:
- -
- Improved Prompt Engineering: Develop structured prompts that incorporate comprehensive safety parameters and domain-specific context, guiding LLMs to produce more accurate and relevant initial outputs.
- -
- Application-Specific Fine-Tuning of LLMs: While LLMs are trained on massive amounts of data and may have undergone broad fine-tuning, further customization with domain-specific datasets—including safety standards (e.g., ISO 12100), historical risk analyses, and validated case studies—can improve alignment with functional safety requirements. This specialized fine-tuning aims to enhance the model’s performance for risk identification in machinery safety, resulting in outputs that are more directly relevant and accurate for this context.
- -
- Cross-Verification of Outputs: Employ multiple LLMs or iterative queries with the same model to cross-verify outputs, ensuring greater robustness and accuracy in initial hazard identification.
- -
- Automated Rule-Based Consistency Checking: Implement rule-based filters and AI tools to validate LLM outputs against established safety standards and risk taxonomies, catching inconsistencies before human review.
- -
- Risk Taxonomy Alignment for Structured Outputs: Align prompts and expected outputs with known risk taxonomies (e.g., severity, frequency, avoidance) to facilitate more targeted responses and streamline validation.
These strategies are expected to enhance the initial quality of LLM-generated results, ensuring that they are robust, accurate, and compliant with safety standards from the outset.
6. Conclusions
- •
- ChatGPT alone provides substantial efficiency improvements by rapidly generating initial hazard identifications and risk estimations.
- •
- The HITL framework significantly enhances the accuracy and completeness of risk assessments compared to standalone ChatGPT outputs. Moreover, the HITL framework aligns with the EU AI Act’s [7] mandate for human oversight in high-risk AI systems.
- •
- Human intervention ensures risk assessments align with industry standards, highlighting the necessity of expert oversight.
- •
- Likert scale evaluations demonstrate high levels of trust and confidence in the refined outputs, reinforcing the value of human expertise.
- •
- Longer initial prompts improve accuracy but may reduce efficiency, while shorter iterative prompts maintain usability without compromising quality.
- •
- Strong relationships exist between prompt length and output quality, emphasizing the need for context-specific prompt design.
- •
- The hybrid approach offers a scalable and practical framework for enhancing routine functional safety workflows also in real-life project settings.
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Example Prompts
Appendix A.1. Closing Edge Protection

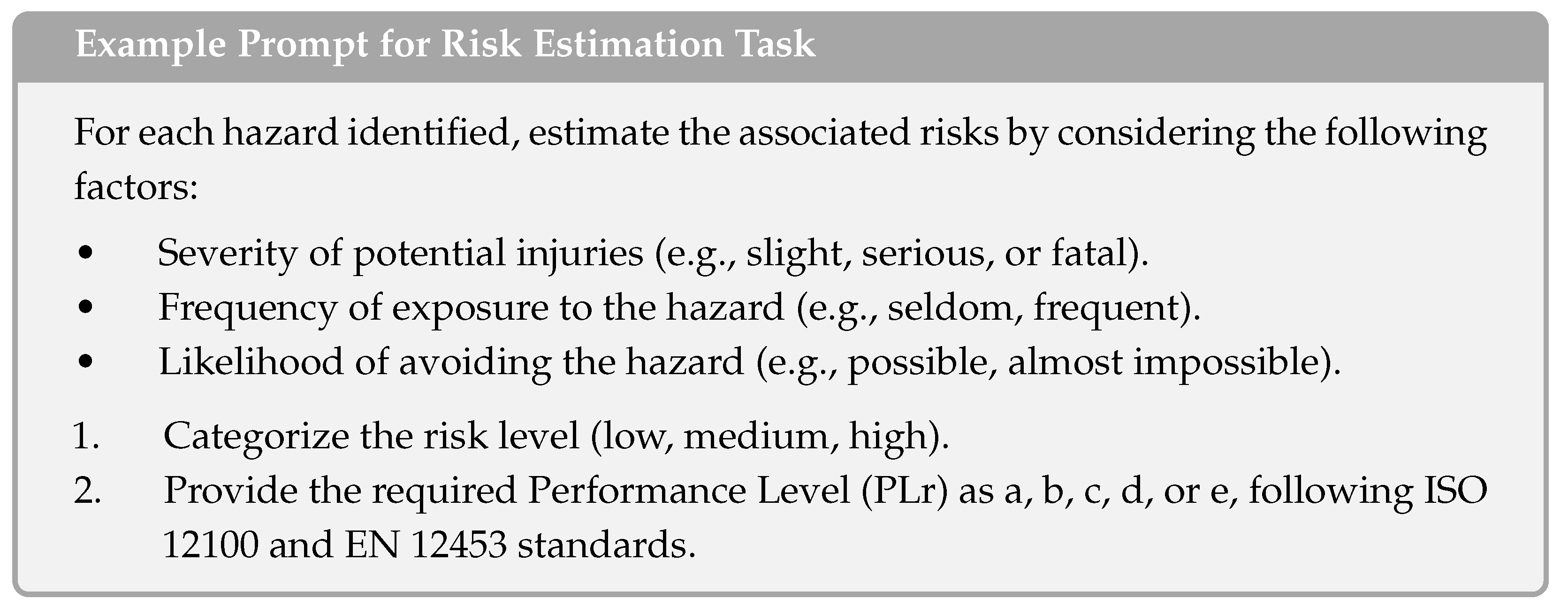

Appendix A.2. Autonomous Transport Vehicles

References
- ISO 12100:2010; Safety of Machinery: General Principles for Design: Risk Assessment and Risk Reduction. ISO: Geneva, Switzerland, 2010. Available online: https://www.iso.org/standard/51528.html (accessed on 4 February 2025).
- ISO 13849-1:2015; Safety of Machinery—Safety-Related Parts of Control Systems—Part 1: General Principles for Design. ISO: Geneva, Switzerland, 2015. Available online: https://www.iso.org/standard/69883.html (accessed on 4 February 2025).
- The Machinery Directive, Directive 2006/42/EC of the European Parliament and of the Council of 17 May 2006. Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX:32006L0042 (accessed on 4 February 2025).
- Kambhampati, S. Can large language models reason and plan? Ann. N. Y. Acad. Sci. 2024, 1534, 15–18. [Google Scholar] [CrossRef] [PubMed]
- OpenAI; Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; et al. GPT-4 Technical Report. arXiv 2024, arXiv:cs.CL/2303.08774. [Google Scholar]
- Pfungst, O. Clever Hans (The horse of Mr. von Osten): A contribution to experimental animal and human psychology. J. Anim. Psychol. 1911, 1, 1–128. [Google Scholar]
- Proposal for a Regulation of the European Parliament and of the Council Laying Down Harmonized Rules on AI and Amending Certain Union Legislative Acts. Available online: https://digital-strategy.ec.europa.eu/en/library/proposal-regulation-laying-down-harmonised-rules-artificial-intelligence-artificial-intelligence (accessed on 4 February 2025).
- IFA Report 2/2017e Functional Safety of Machine Controls—Application of EN ISO 13849, Deutsche Gesetzliche Unfallversicherung. 2019. Available online: https://www.dguv.de/medien/ifa/en/pub/rep/pdf/reports-2019/report0217e/rep0217e.pdf (accessed on 31 January 2025).
- Es, S.; James, J.; Espinosa-Anke, L.; Schockaert, S. RAGAS: Automated Evaluation of Retrieval Augmented Generation. arXiv 2023, arXiv:cs.CL/2309.15217. [Google Scholar]
- Yu, H.; Gan, A.; Zhang, K.; Tong, S.; Liu, Q.; Liu, Z. Evaluation of Retrieval-Augmented Generation: A Survey. arXiv 2024, arXiv:cs.CL/2405.07437. [Google Scholar]
- Zhao, P.; Zhang, H.; Yu, Q.; Wang, Z.; Geng, Y.; Fu, F.; Yang, L.; Zhang, W.; Jiang, J.; Cui, B. Retrieval-Augmented Generation for AI-Generated Content: A Survey. arXiv 2024, arXiv:cs.CV/2402.19473. [Google Scholar]
- Abusitta, A.; Li, M.Q.; Fung, B.C. Survey on Explainable AI: Techniques, challenges and open issues. Expert Syst. Appl. 2024, 255, 124710. [Google Scholar] [CrossRef]
- IEC 61508-1:2010; Functional Safety of Electrical/Electronic/Programmable Electronic Safety-Related Systems. IEC: Geneva, Switzerland, 2010. Available online: https://www.vde-verlag.de/iec-normen/217177/iec-61508-1-2010.html (accessed on 5 February 2025).
- Software-Assistent SISTEMA Bewertung von Sicherheitsbezogenen Maschinensteuerungen nach DIN EN ISO 13849. 2010. Available online: https://www.dguv.de/ifa/praxishilfen/praxishilfen-maschinenschutz/software-sistema/index.jsp (accessed on 5 February 2025).
- Adaptive Safety and Security in Smart Manufacturing. Available online: https://www.tuvsud.com/en/resource-centre/white-papers/adaptive-safety-and-security-in-smart-manufacturing (accessed on 5 February 2025).
- Allouch, A.; Koubaa, A.; Khalgui, M.; Abbes, T. Qualitative and Quantitative Risk Analysis and Safety Assessment of Unmanned Aerial Vehicles Missions over the Internet. arXiv 2019, arXiv:cs.RO/1904.09432. [Google Scholar] [CrossRef]
- Xiong, W.; Jin, J. Summary of Integrated Application of Functional Safety and Information Security in Industry. In Proceedings of the 2018 12th International Conference on Reliability, Maintainability, and Safety (ICRMS), Shanghai, China, 17–19 October 2018; pp. 463–469. [Google Scholar] [CrossRef]
- Chen, M.; Luo, M.; Sun, H.; Chen, Y. A Comprehensive Risk Evaluation Model for Airport Operation Safety. In Proceedings of the 2018 12th International Conference on Reliability, Maintainability, and Safety (ICRMS), Shanghai, China, 17–19 October 2018; pp. 146–149. [Google Scholar]
- Devaraj, L.; Ruddle, A.R.; Duffy, A.P. Electromagnetic Risk Analysis for EMI Impact on Functional Safety With Probabilistic Graphical Models and Fuzzy Logic. IEEE Lett. Electromagn. Compat. Pract. Appl. 2020, 2, 96–100. [Google Scholar] [CrossRef]
- Ehrlich, M.; Bröring, A.; Diedrich, C.; Jasperneite, J. Towards Automated Risk Assessments for Modular Manufacturing Systems-Process Analysis and Information Model Proposal. Automatisierungstechnik 2023, 71, 6. [Google Scholar] [CrossRef]
- Bhatti, Z.E.; Roop, P.S.; Sinha, R. Unified Functional Safety Assessment of Industrial Automation Systems. IEEE Trans. Ind. Inform. 2017, 13, 17–26. [Google Scholar] [CrossRef]
- Iyenghar, P.; Hu, Y.; Kieviet, M.; Pulvermueller, E.; Wuebbelmann, J. AI-Based Assistant for Determining the Required Performance Level for a Safety Function. In Proceedings of the 48th Annual Conference of the IEEE Industrial Electronics Society (IECON 2022), Brussels, Belgium, 17–20 October 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Iyenghar, P.; Kieviet, M.; Pulvermueller, E.; Wuebbelmann, J. A Chatbot Assistant for Reducing Risk in Machinery Design. In Proceedings of the 2023 IEEE 21st International Conference on Industrial Informatics (INDIN), Lemgo, Germany, 17–20 July 2023; pp. 1–8. [Google Scholar] [CrossRef]
- Khlaaf, H. Toward Comprehensive Risk Assessments and Assurance of AI-Based Systems. Technical Report, Trail of Bits, 2023. Available online: https://www.trailofbits.com/documents/Toward_comprehensive_risk_assessments.pdf (accessed on 4 February 2025).
- Attar, H. Joint IoT/ML Platforms for Smart Societies and Environments: A Review on Multimodal Information-Based Learning for Safety and Security. J. Data Inf. Qual. 2023, 15. [Google Scholar] [CrossRef]
- Naveed, H.; Khan, A.U.; Qiu, S.; Saqib, M.; Anwar, S.; Usman, M.; Akhtar, N.; Barnes, N.; Mian, A. A Comprehensive Overview of Large Language Models. arXiv 2024, arXiv:cs.CL/2307.06435. [Google Scholar]
- Rostam, Z.R.K.; Szénási, S.; Kertész, G. Achieving Peak Performance for Large Language Models: A Systematic Review. IEEE Access 2024, 12, 96017–96050. [Google Scholar] [CrossRef]
- Nasution, A.H.; Onan, A. ChatGPT Label: Comparing the Quality of Human-Generated and LLM-Generated Annotations in Low-Resource Language NLP Tasks. IEEE Access 2024, 12, 71876–71900. [Google Scholar] [CrossRef]
- Diemert, S.; Weber, J.H. Can Large Language Models assist in Hazard Analysis? arXiv 2023, arXiv:cs.HC/2303.15473. [Google Scholar]
- Qi, Y.; Zhao, X.; Khastgir, S.; Huang, X. Safety Analysis in the Era of Large Language Models: A Case Study of STPA using ChatGPT. arXiv 2023, arXiv:cs.CL/2304.01246. [Google Scholar] [CrossRef]
- Aladdin, A.M.; Muhammed, R.K.; Abdulla, H.S.; Rashid, T.A. ChatGPT: Precision Answer Comparison and Evaluation Model. TechRxiv 2024. [Google Scholar] [CrossRef]
- Wilchek, M.; Hanley, W.; Lim, J.; Luther, K.; Batarseh, F.A. Human-in-the-loop for computer vision assurance: A survey. Eng. Appl. Artif. Intell. 2023, 123, 106376. [Google Scholar] [CrossRef]
- Mosqueira-Rey, E.; Hernández-Pereira, E.; Alonso-Ríos, D.; Bobes-Bascarán, J.; Fernández-Leal, Á. Human-in-the-loop machine learning: A state of the art. Artif. Intell. Rev. 2023, 56, 3005–3054. [Google Scholar] [CrossRef]
- Bhattacharya, M.; Penica, M.; O’Connell, E.; Southern, M.; Hayes, M. Human-in-Loop: A Review of Smart Manufacturing Deployments. Systems 2023, 11, 35. [Google Scholar] [CrossRef]
- Huang, W.; Liu, H.; Huang, Z.; Lv, C. Safety-Aware Human-in-the-Loop Reinforcement Learning With Shared Control for Autonomous Driving. IEEE Trans. Intell. Transp. Syst. 2024, 25, 16181–16192. [Google Scholar] [CrossRef]
- Kumar, S.; Datta, S.; Singh, V.; Datta, D.; Kumar Singh, S.; Sharma, R. Applications, Challenges, and Future Directions of Human-in-the-Loop Learning. IEEE Access 2024, 12, 75735–75760. [Google Scholar] [CrossRef]
- Rožanec, J.M.; Montini, E.; Cutrona, V.; Papamartzivanos, D.; Klemenčič, T.; Fortuna, B.; Mladenić, D.; Veliou, E.; Giannetsos, T.; Emmanouilidis, C. Human in the AI Loop via xAI and Active Learning for Visual Inspection. In Artificial Intelligence in Manufacturing: Enabling Intelligent, Flexible and Cost-Effective Production Through AI; Soldatos, J., Ed.; Springer Nature: Cham, Switzerland, 2024; pp. 381–406. [Google Scholar] [CrossRef]
- Jaltotage, B.; Lu, J.; Dwivedi, G. Use of Artificial Intelligence Including Multimodal Systems to Improve the Management of Cardiovascular Disease. Can. J. Cardiol. 2024, 40, 1804–1812. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Zhu, C. Industrial Expert Systems Review: A Comprehensive Analysis of Typical Applications. IEEE Access 2024, 12, 88558–88584. [Google Scholar] [CrossRef]
- DIN EN 12453:2022-08; Industrial, Commercial and Garage Doors and Gates—Safety in Use of Power Operated Doors—Requirements and Test Methods. DIN: Berlin, Germany, 2022.
- DIN EN 1525:1997-12; Safety of Industrial Trucks—Driverless Trucks and Their Systems. DIN: Berlin, Germany, 1997.
- ISO 11111-6:2005; Textile Machinery—Safety Requirements—Part 6: Fabric Manufacturing Machinery. ISO: Geneva, Switzerland, 2005.
- DIN EN 1010-1:2010; Safety of machinery—Safety requirements for the design and construction of printing and paper converting machines—Part 1: Common requirements. DIN: Berlin, Germany, 2010.
- OpenAI. ChatGPT. Model: GPT-4-Turbo. 2023. Available online: https://chat.openai.com (accessed on 4 February 2025).
- Baumgartner, N.; Iyenghar, P.; Schoemaker, T.; Pulvermüller, E. AI-Driven Refactoring: A Pipeline for Identifying and Correcting Data Clumps in Git Repositories. Electronics 2024, 13, 1644. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Criteria | Motorized Gates | Weaving Machines | Autonomous Transport Vehicles | Rotary Printing Presses | Overall Average |
|---|---|---|---|---|---|
| Accuracy | 4.7/5 | 4.8/5 | 4.5/5 | 4.8/5 | 4.7/5 |
| Completeness | 4.5/5 | 4.7/5 | 4.6/5 | 4.7/5 | 4.6/5 |
| Usability | 4.8/5 | 4.9/5 | 4.7/5 | 4.9/5 | 4.8/5 |
| Time Efficiency | 5.0/5 | 5.0/5 | 4.8/5 | 5.0/5 | 4.95/5 |
| Overall Confidence | 4.6/5 | 4.7/5 | 4.6/5 | 4.7/5 | 4.65/5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Iyenghar, P. Clever Hans in the Loop? A Critical Examination of ChatGPT in a Human-in-the-Loop Framework for Machinery Functional Safety Risk Analysis. Eng 2025, 6, 31. https://doi.org/10.3390/eng6020031
Iyenghar P. Clever Hans in the Loop? A Critical Examination of ChatGPT in a Human-in-the-Loop Framework for Machinery Functional Safety Risk Analysis. Eng. 2025; 6(2):31. https://doi.org/10.3390/eng6020031
Chicago/Turabian StyleIyenghar, Padma. 2025. "Clever Hans in the Loop? A Critical Examination of ChatGPT in a Human-in-the-Loop Framework for Machinery Functional Safety Risk Analysis" Eng 6, no. 2: 31. https://doi.org/10.3390/eng6020031
APA StyleIyenghar, P. (2025). Clever Hans in the Loop? A Critical Examination of ChatGPT in a Human-in-the-Loop Framework for Machinery Functional Safety Risk Analysis. Eng, 6(2), 31. https://doi.org/10.3390/eng6020031