1. Introduction
Agriculture is a crucial sector of the Indian economy and is considered the backbone of the country. Around 60% of India’s population is engaged in agriculture, and it contributes about 17–18% to the country’s Gross Domestic Product (GDP). With the increasing demand for organic and eco-friendly products in the global market, the Indian agriculture sector is expected to grow even further [
1]. As agriculture is the primary occupation for a significant proportion of the population, productivity gains are crucial for ensuring food security, reducing poverty, and achieving sustainable development. With a growing population and increasing demand for food, there is a pressing need to increase agricultural productivity to meet the rising demand. Improved productivity in agriculture can be achieved through the adoption of modern technologies like precision farming techniques and the use of fertilizers and pesticides. Precision agriculture, also known as precision farming, is an approach to farming that uses technology and data analytics to optimize crop production and resource management. It involves the use of sensors and other advanced technologies to collect and analyze data about soil conditions, crop growth, and other factors that affect agricultural productivity [
2,
3,
4,
5].
Kerala (a state in India) is renowned for its diverse cultivation practices, ranging from traditional crops to modern horticulture and floriculture. Various crops cultivated in Kerala include coconut, rubber, paddy, cardamom, tea, ginger, tapioca, coffee, cashew, etc. [
6]. These crops are important for both their cultural significance and economic value in Kerala and are widely used in the state’s cuisine and traditional medicine practices. To maximize productivity, it is necessary to know the right crop for the soil based on the soil properties and climatic conditions. Crop prediction is a subdomain of precision agriculture that involves using historical data and current soil conditions to forecast the yield of a specific crop. The process of crop prediction typically involves collecting and analyzing data on various factors. For crop prediction, we can make use of the IoT and machine learning [
7,
8].
The IoT involves using various sensors and IoT devices to collect data on factors such as soil moisture, temperature, and fertility, which can be analyzed to predict the suitable crop for the soil [
9,
10,
11]. The process typically involves deploying a network of sensors in the soil to gather data on soil conditions. For instance, soil moisture sensors can be used to determine the optimal amount of water required by the crops, while temperature sensors can help predict the growth rate of the plants. Humidity sensors can assist in detecting the humidity level, and NPK sensors can help us to understand how much of the fertility components are available for plant growth [
12]. By this data analysis, farmers could predict suitable crops for the land, resulting in better efficiency and improved crop productivity. The data collected are then transmitted to a central database, where they are processed and analyzed using machine learning algorithms to identify patterns and make predictions. Machine learning (ML) has transformed the landscape of data analysis and smart agriculture [
13,
14,
15,
16]. Agi-technology has recently emerged due to the advancements of machine learning and deep learning methods. This transformative technology empowers agricultural stakeholders with predictive insights and decision-making capabilities based on vast datasets, enhancing precision farming practices and sustainability efforts worldwide. In some aspects, successful farming is the result of different technologies that utilize relationships such as crop requirements, soil characteristics, climatic change, and so forth [
17]. Traditionally, farming methods have been used on a whole field or, at most, a section of one. Machine learning enhances decision-making in agriculture by enabling much higher precision and allowing farmers to handle plants and animals practically and individually [
18].
Understanding soil characteristics is essential for successful farming, as the nutrient content and other properties of the soil significantly influence crop growth and yield. Traditional soil testing methods, although accurate, are often time-consuming, labor-intensive, and not easily accessible for all farmers, particularly those in remote areas. These methods also require specialized equipment and expertise, which can be a barrier for small-scale or impoverished farmers. To address these challenges, integrating IoT technology with machine learning offers a promising solution. IoT-enabled soil sensors can provide real-time data on soil properties, such as nutrient levels, moisture, and pH, directly to farmers. By applying machine learning algorithms to these data, farmers can receive immediate and actionable insights into soil health and crop suitability. This innovative approach simplifies the soil testing process, making it more efficient and accessible, ultimately leading to better crop management and increased agricultural productivity.
The primary issue facing Indian farmers is that they frequently fail to select the appropriate crop for their soil. Precision agriculture has been used to alleviate this issue for farmers. Pudumalar et al. described a model that implemented precision agriculture (PA), using machine learning algorithms that work on small, open farms, which help farmers with the prediction of suitable crops [
19]. Rao et al. conducted a comparative study on three supervised machine learning models—KNN, decision tree, and random forest—to determine the most suitable crop for specific land areas, aiming to enhance crop efficiency for farmers [
5]. Their analysis revealed that the random forest classifier, using both entropy and the Gini criterion, achieved the highest accuracy at 99.3%. In contrast, the KNN demonstrated the lowest accuracy at 97%, while the decision tree classifier’s performance fell between the two, with the Gini criterion yielding a better accuracy (98.8%) than the entropy criterion. Samuel et al. used specific data analytic approaches to estimate the crop price analysis using already collected data [
20]. Agricultural datasets were used to find significant information using linear regression. To boost the accuracy rate of the price prediction, neural networks were built. To precisely assess the accuracy of each system used, the root mean square error was calculated for each technique. The most accurate system was then chosen. Rajakumaran et al. proposed a machine learning method named the multi-attribute weighted tree-based support vector machine (MAWT-SVM) for predicting crop yields. Initially, the dataset was gathered and normalized using the z-score normalization technique to handle noisy data [
8]. A principal component analysis was then used to extract the significant features. Furthermore, a genetic algorithm was applied to enhance the performance of the model by selecting the optimal features. The results indicate that the proposed method outperforms other approaches, achieving impressive performance metrics with an accuracy of 98.5%. Iniyan et al. explored crop yield predictions using various regression models, identifying the features of the engineering-based Long Short-Term Memory (LSTM) model as the most effective, achieving an accuracy of 86.3%, along with the lowest mean absolute error and root mean square error [
10]. Mobile equipment was developed by Patil et al. to detect soil nutrients in real time [
21]. This system recorded the soil nutrients and characteristics, including humidity, temperature, and pH data, and these can be accessed globally with valid cloud channel verification credentials. In the proposed framework, the soil analysis was conducted using a Soil Doctor Plus kit and an RGB color sensor. The soil samples were gathered from various farms near Pune city (India) to showcase the cloud-based, real-time soil analysis.
In this study focusing on agriculture in Kerala, the significance of agriculture as a vital economic sector cannot be overstated, contributing nearly half of the state’s total income. Over recent years, there has been a substantial expansion in the cultivation area, with an increase of approximately 100,000 hectares. The research focuses on a comparative analysis of various machine learning algorithms, leveraging essential soil fertility factors including potassium, phosphorus, nitrogen content, temperature, pH, moisture content, and electrical conductivity. The cultivation of tapioca, plantain, ginger, and coconut serves as the focal point for this study, presenting a rich dataset for training and assessing multiple classification algorithms crucial for crop prediction accuracy. Integrating advanced IoT technologies, the research utilizes a sophisticated real-time soil fertility analyzer to capture instant data on critical soil characteristics. This innovative system streamlines the data collection process and lays the foundation for developing a robust crop prediction model by employing the most appropriate algorithm for the dataset.
The objectives of this work include the following:
To investigate the impact of soil fertility factors, such as potassium, phosphorus, nitrogen content, temperature, pH, moisture content, and electrical conductivity, on crop yields and productivity.
To conduct a comparative analysis of various machine learning algorithms in predicting suitable crops for specific soil conditions.
To integrate IoT technologies, such as real-time soil fertility analyzers, to streamline the data collection and enhance the precision of crop prediction models.
To identify the most effective machine learning algorithm for predicting crop yields based on the dataset collected, focusing on the cultivation of tapioca, plantain, ginger, and coconut.
2. Materials and Methods
Nitrogen, potassium, and phosphorus are key components of soil fertilizer. Understanding the concentrations of these parameters in the soil can reveal whether the soil has an excess or deficiency of the nutrients necessary for plant growth. There are several ways to measure the amount of nutrients in soil, including employing spectrometers or optical sensors. However, the spectrum analysis method is not practical, and a disadvantage is that the results are only 60–70% accurate. Given the lack of available information, it is still unclear whether the spectrum analysis method is as accurate as more established wet chemistry techniques. Here, we developed a real-time soil monitoring portable system for the analysis of soil. Apart from nitrogen, phosphorous, and potassium, it also measures attributes like the temperature, pH, moisture content, and electrical conductivity of the soil.
2.1. Soil Sample Collection
Soil samples were collected to analyze characteristics such as potassium, phosphorus, nitrogen content, temperature, pH, moisture content, and electrical conductivity. It was necessary to follow a specific procedure to collect the samples. The procedure is described below:
Segment the field into distinct homogeneous sections based on visual assessment and the farmer’s knowledge.
Clear away any surface debris at the sampling location.
Use an auger to extract soil samples to a depth of 15 cm.
Collect between ten and fifteen samples from each section and deposit them into a tray/bucket. If an auger is not accessible, utilize a spade to carve a ‘V’-shaped trench to a depth of fifteen centimeters at the sampling location.
Extract thick slices of soil from the visible side of the ‘V’-shaped trench and put them into a clean container.
Mix the samples thoroughly and remove any foreign materials such as roots, gravel, and stones.
Reduce the total sample size to approximately 500 g to 1 kg by employing either quartering or compartmentalization techniques.
For quartering, divide the mixed sample into four equal parts. Discard two opposite quarters and remix the remaining two. Repeat this procedure until achieving the desired sample size.
For compartmentalization, spread the soil uniformly on a clean, hard surface and divide it into smaller sections by drawing lines across its length and width. Collect a pinch of soil from each section, repeating the procedure until achieving the desired sample size.
Place the final sample carefully into a clean bag made of cloth or polythene for further sample analysis.
The samples contained 100 instances, with the system measuring five attributes that define soil characteristics. The multiclass representation with four classes and five characteristics was the intended classification. The samples were collected from different wards surrounding Kulashekharapuram Panchayat, Kollam district, Kerala, India. Agriculture is an important sector of its economy. The region is known for its fertile land, favorable climate, and abundant rainfall, which make it suitable for cultivating a wide range of crops.
2.2. Hardware Details
2.2.1. JXCT 7-in-1 Soil Sensor
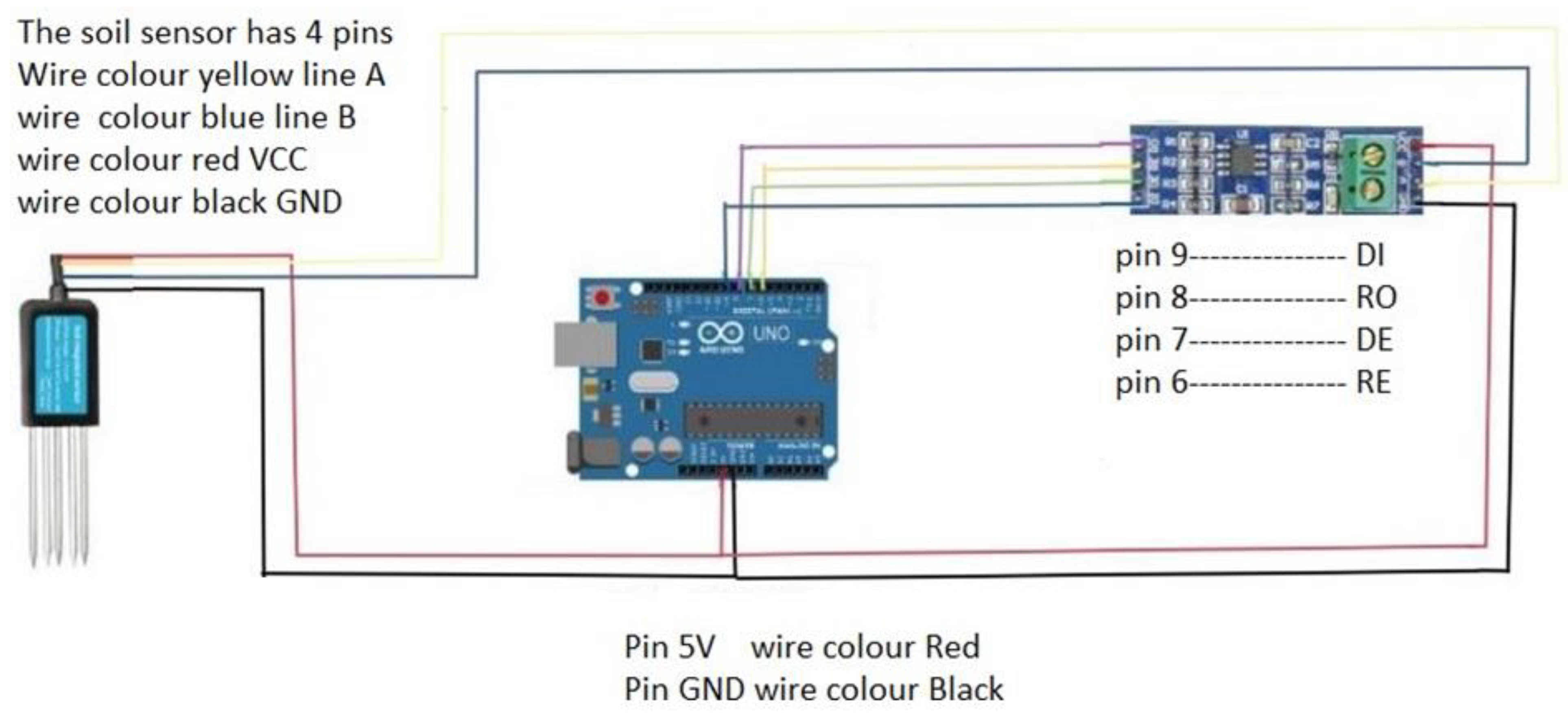
The JXCT 7-in-1 soil sensor (Weihai JXCT Electronic Technology, Shandong, China), which identifies the soil’s potassium, phosphorus, nitrogen content, temperature, pH, moisture content, and electrical conductivity, is shown in
Figure 1. It works with Modbus RS485 and benefits from a low cost, a quick response, high precision, and portability. It facilitates the systematic evaluation of the soil conditions by assisting in assessing the soil’s fertility. The sensor can be buried in the ground for a very long time. To ensure the long-term functionality of the probe component, it features a high-quality probe that is resistant to corrosion from salt and alkali, rust, and electrolysis. It is therefore appropriate for all types of soil, including alkaline, acidic, substrate, seedling beds, and coconut bran soil. This sensor’s advantages over more conventional detection techniques are its extremely quick measurements and highly precise data. It only needs its probe to be buried in the ground, and Arduino can be used to read the readings.
2.2.2. Interfacing Sensor with Arduino UNO
For this project, the Arduino Uno (Arduino, Boston, MA, USA) serves as the central controller interfacing with the JXCT 7-in-1 soil sensor. It manages the collection of the data regarding the soil characteristics, such as potassium, phosphorus, nitrogen content, temperature, pH, moisture content, and electrical conductivity. The Arduino Uno’s versatility and ease of programming enable the real-time monitoring and analysis of the soil parameters, supporting informed decision-making in agricultural practices. Its compact design and compatibility with various sensors make it an ideal choice for integrating into precision agriculture systems aimed at enhancing crop yields and soil health management.
Figure 2 illustrates the interfacing of the sensor with the Arduino UNO. The R0 and DI pins from the Modbus should be connected to D2 and D3 on the Arduino via SoftwareSerial. Additionally, DE and RE should be enabled by setting them to a high state, connecting the DE and RE pins to D7 and D8 on the Arduino, respectively. The NPK sensor features four wires: the red wire (VCC), requiring a 5V–24V power supply, which should be connected to the VCC on the Arduino; the black wire (GND), which should be connected to the Arduino’s GND; the blue wire (B pin), which should be connected to the B pin of the MAX485; and the yellow wire (A pin), which should be connected to the A pin of the MAX485.
2.3. Monitoring Soil Data on PC
The fertility analysis of the soil is displayed through the serial monitor of the Arduino IDE. The Arduino Uno, interfaced with the JXCT 7-in-1 soil sensor, collects real-time data on soil characteristics, including potassium, phosphorus, nitrogen content, temperature, pH, moisture content, and electrical conductivity.
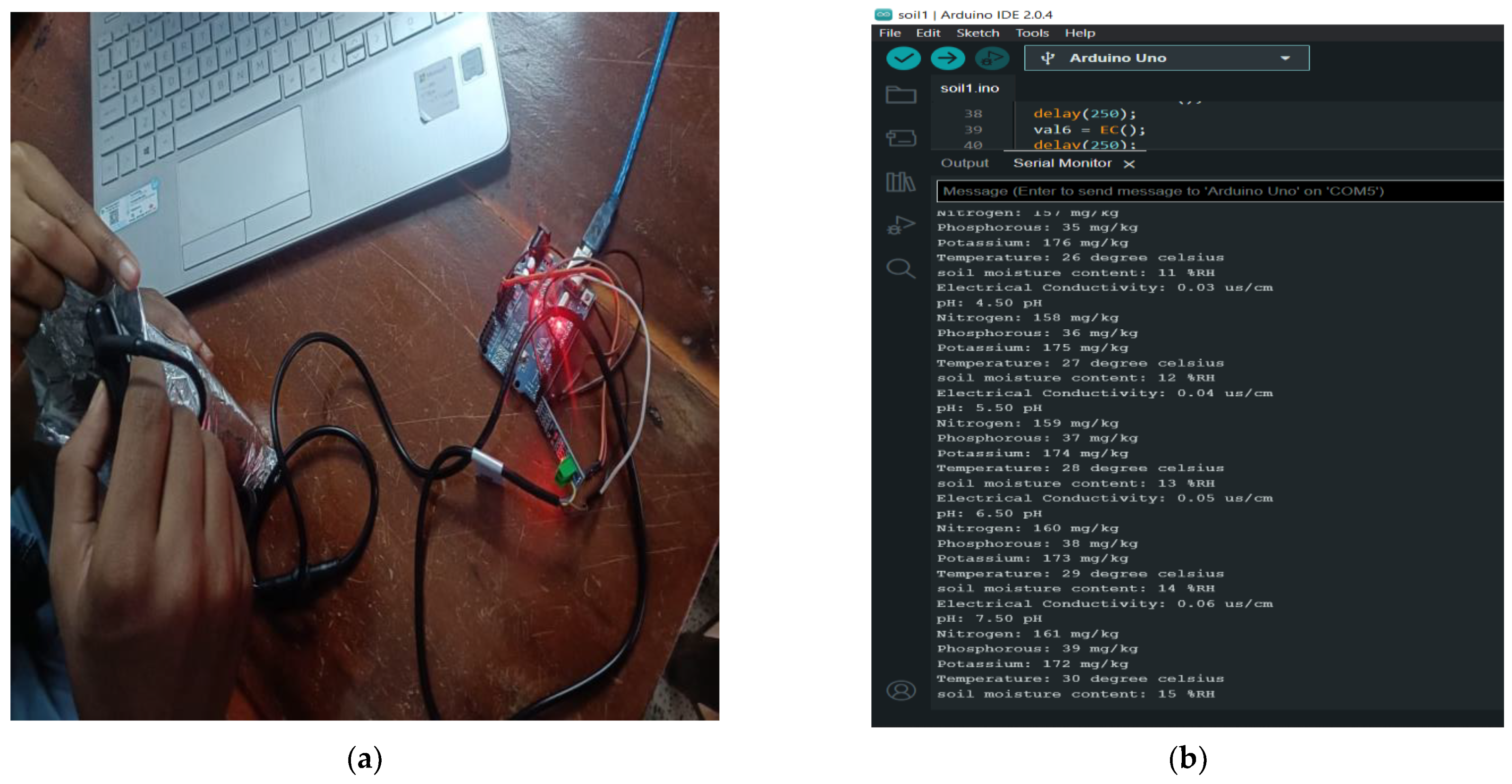
Figure 3 shows the setup for monitoring the soil data and how the data are collected from sensors and visualized in Arduino IDE. These data are transmitted to the Arduino IDE via SoftwareSerial, where they are processed and displayed for monitoring purposes. Farmers and researchers can observe the soil parameters in real time on their PCs, allowing for immediate analysis and decision-making regarding soil management practices. This setup enables the precise monitoring of soil conditions, facilitating adjustments in irrigation, fertilization, and crop management strategies to optimize agricultural productivity and sustainability.
2.4. Classification
Machine learning has the potential to revolutionize the agriculture industry by enabling farmers to make informed decisions based on real-time data. The machine learning classification was executed by Matlab R2020b programming. By analyzing the soil nutrient levels and other critical factors, machine learning algorithms can be trained to predict crop yields with remarkable accuracy [
22,
23,
24]. This technology assists farmers in planning their planting and harvesting schedules, optimizing the use of resources, and ultimately enhancing productivity and sustainability. Through the application of machine learning, agriculture can become more efficient, resilient, and capable of meeting the growing demands of a global population.
In our work, we utilized the k-nearest neighbor (KNN), Support Vector Machine (SVM), and neural network models, due to their extensive application and proven effectiveness in agricultural contexts. These machine learning models have been extensively used in agriculture to enhance decision-making processes, optimize resource use, and improve overall productivity [
25,
26,
27,
28]. By integrating these models into our system, we aimed to provide accurate and reliable predictions to support farmers in making informed decisions about crop cultivation.
The key soil characteristics, such as potassium, phosphorus, nitrogen, temperature, pH, moisture content, and electrical conductivity, measured by the sensors and processed by the Arduino were used as the features for classification.
2.4.1. KNN
K-nearest neighbors (KNN) is a simple and popular machine learning algorithm used for classification and regression tasks. In KNN, the output is determined based on the k-nearest data points to the input sample. For the classification, the class of the input sample is decided by the most frequently occurring class among its k-nearest neighbors [
29]. In the regression, the output value is calculated by averaging the output values of the k-nearest neighbors. KNN is a non-parametric algorithm, meaning it does not make any assumptions about the underlying data distribution. The algorithm is flexible, easy to implement, and suitable for small- to medium-sized datasets. The drawback is the computational cost and that it may not perform well on high-dimensional data. It is also sensitive to irrelevant features and outliers in the data. To address these issues, techniques such as feature selection and data normalization can be employed.
2.4.2. Support Vector Machines (SVMs)
Support Vector Machines (SVMs) are popular machine learning algorithms used for classification, regression, and outlier detection. In SVMs, the algorithm tries to find a hyperplane that separates the classes in the feature space with the largest margin possible. The hyperplane is defined as a decision boundary that separates the data into different classes [
30]. SVMs are particularly useful when the data have a clear separation between classes, but it can also be used for non-linear classification tasks by using kernel functions that transform the input space into a higher dimensional space. SVMs have several advantages over other machine learning algorithms, such as being less prone to overfitting, having a strong theoretical foundation, and being effective even in high-dimensional spaces. However, they can be computationally intensive, and the selection of relevant kernels and hyperparameters is a difficult task.
2.4.3. Neural Network
An artificial neural network (ANN) is an advanced subset of machine learning inspired by the structure and function of the human brain, consisting of interconnected nodes and neurons. Each neuron in an ANN receives inputs from other neurons, processes this information, and passes the output to neurons in subsequent layers iteratively until the final output is produced [
31]. ANNs can be trained through various techniques, including supervised, unsupervised, and reinforcement learning. During the training phase, the network finetunes its internal parameters, such as weights and biases, to enhance the accuracy of its classifications or predictions. In our work on IoT-enabled real-time crop prediction based on soil fertility analysis, ANNs are utilized to process and analyze the soil nutrient data, specifically the nitrogen, phosphorus, potassium, pH, and other relevant parameters collected by the sensors. This approach allows for accurate crop prediction, enabling farmers to make informed decisions about which crops to plant for the optimal yield. By leveraging ANNs, our system aims to provide precise and actionable insights, enhancing agricultural productivity and sustainability.
2.5. Performance Metrics
To evaluate the performance of our machine learning models, we utilized four key metrics: accuracy, precision, recall, and specificity. These metrics provide a comprehensive assessment of the model’s effectiveness in classifying data accurately.
Accuracy is the ratio of correctly predicted instances to the total instances and provides an overall measure of the model’s correctness. It is calculated as follows:
Precision is the ratio of true positive predictions to the total positive predictions made by the model. It measures the accuracy of positive predictions and is calculated as follows:
Recall, also known as sensitivity or the true positive rate, is the ratio of true positive predictions to the total actual positives. It indicates the model’s ability to correctly identify all positive instances and is calculated as follows:
Specificity is the ratio of true negative predictions to the total actual negatives. It measures the model’s ability to correctly identify negative instances and is calculated as follows:
These metrics collectively provide a detailed understanding of the model’s performance, highlighting its strengths and potential areas for improvement. By analyzing accuracy, precision, recall, and specificity, we can ensure that our model not only performs well overall but also maintains a balance between correctly identifying positive and negative instances.
3. Results
3.1. Validation of Collected Data in Different ML Models
The right attributes were chosen to discover the precise soil traits for projecting a suitable crop for more effective farming. Machine learning algorithms were used to determine which crop would be best for a specific area of land. Following that, the procedures were assessed using criteria including accuracy, precision, recall, and specificity.
To ensure the robustness and reliability of our machine learning models, we performed cross-validation using ten-fold, five-fold, and three-fold techniques. Cross-validation is a statistical method used to evaluate and improve the performance of a model by partitioning the data into subsets, training the model on some subsets, and validating it on the remaining ones. In a ten-fold cross-validation, the dataset is divided into ten equal parts; the model is trained on nine parts and tested on the remaining part, repeating this process ten times. Similarly, in a five-fold cross-validation, the data are split into five parts, and, in a three-fold cross-validation, they are divided into three parts, with the model trained and tested accordingly. This process helps in mitigating overfitting and provides a more accurate estimate of the model’s performance by averaging the results across all the folds. By employing multiple cross-validation techniques, we can confirm the consistency and stability of our model’s predictive power across different data partitions.
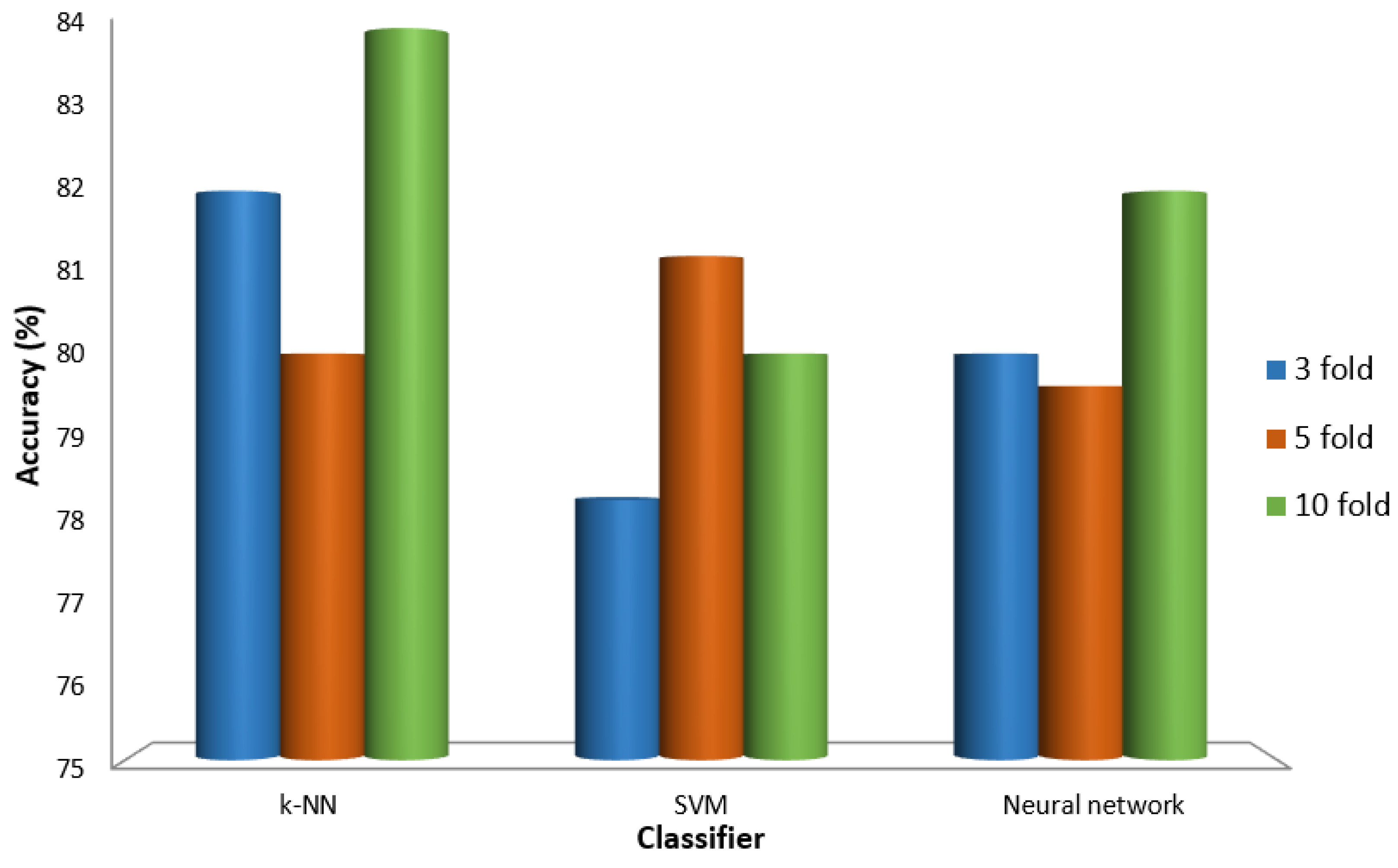
Figure 4 presents a performance evaluation of various machine learning algorithms, including KNN, SVMs, and neural networks, based on the soil characteristics such as pH, electrical conductivity (EC), nitrogen (N), phosphorus (P), and potassium (K) during cross-validation using MATLAB. The figure graphically represents the accuracy levels of the different models, comparing the dataset using the ten-fold, five-fold, and three-fold cross-validation techniques. This comprehensive analysis allows us to assess the consistency and effectiveness of each algorithm across different validation methods. From the results, we observed the comparative performance and accuracy trends of the models, providing valuable insights into their suitability for soil characteristic analysis and prediction.
The 10-fold cross-validation method yielded favorable results, demonstrating the robustness of our models.
Table 1 showcases the performance comparison for different crops using a k-fold cross-validation on the measured dataset. Among the various algorithms, KNN emerged as the best method, achieving a maximum accuracy of 84%, a precision of 85%, a recall of 88.8%, and a specificity of 92.4%. These metrics highlight KNN’s effectiveness in accurately classifying soil characteristics. Furthermore,
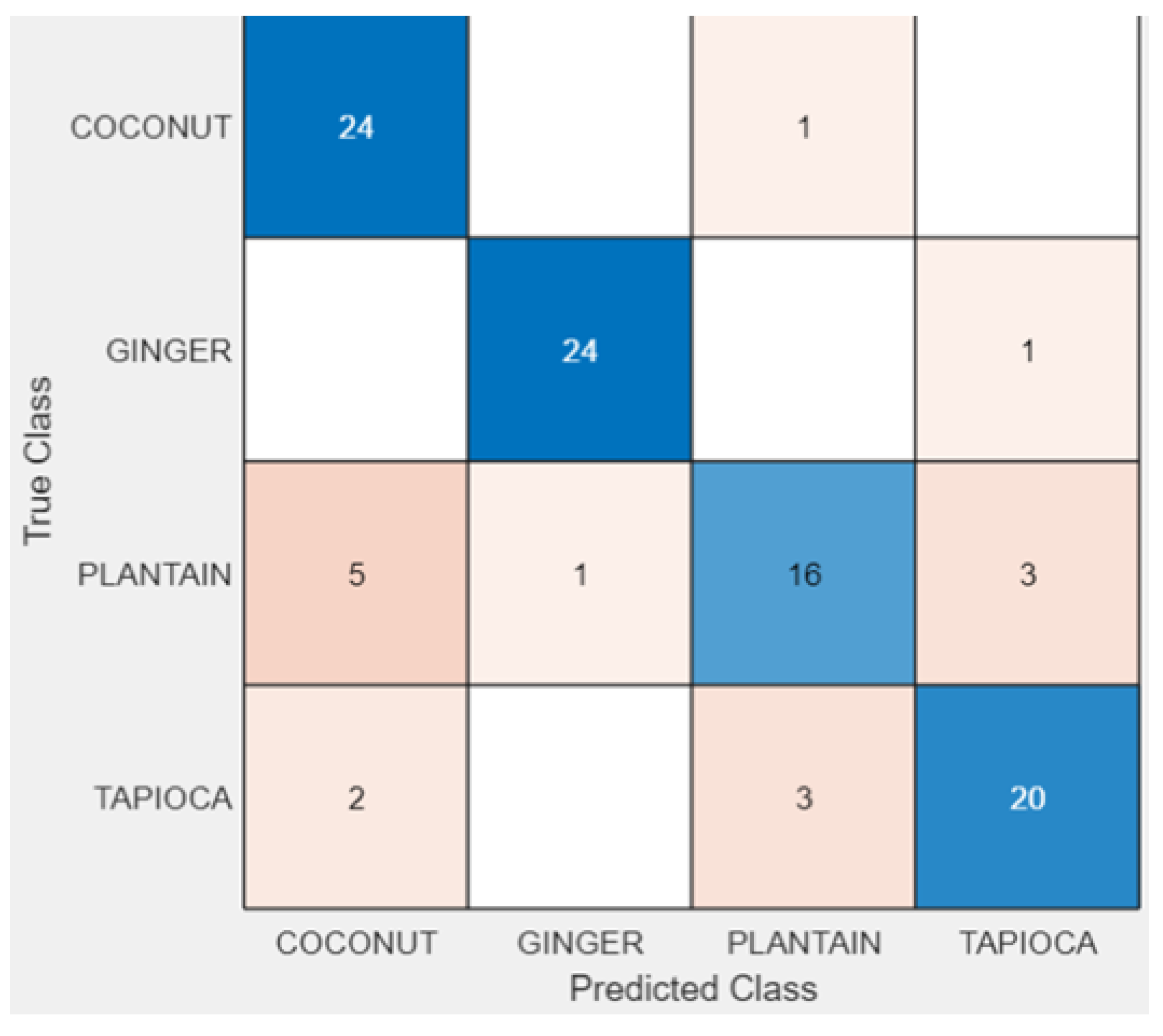
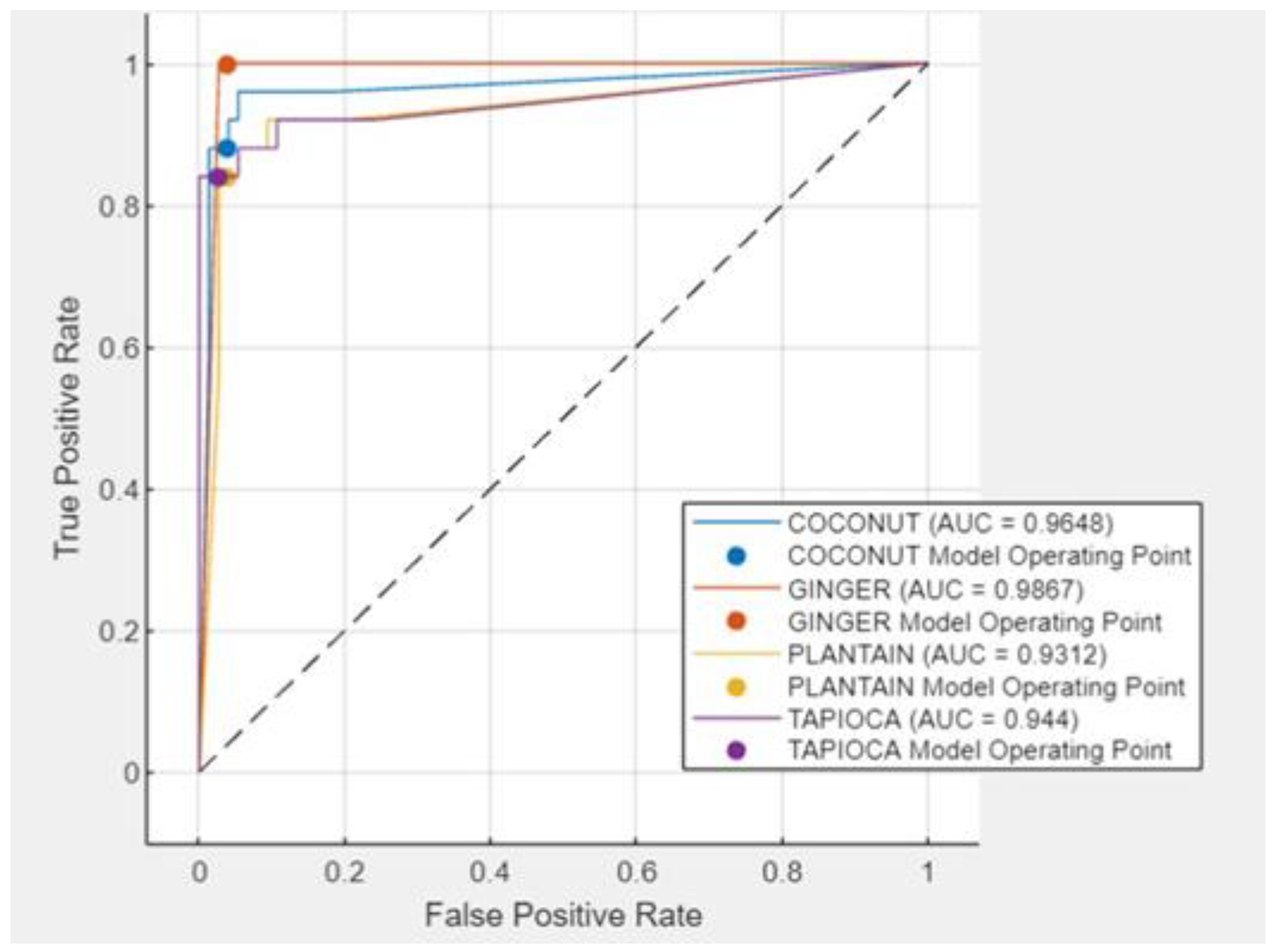
Figure 5 illustrates the confusion matrix for the KNN 10-fold model, providing a detailed view of its classification performance, while
Figure 6 displays the ROC curve, underscoring the model’s ability to distinguish between classes with high precision. This comprehensive analysis affirms KNN’s superior performance in our study.
In our work, KNN emerged as the most effective algorithm for crop prediction, demonstrating the highest accuracy among the models analyzed. The KNN algorithm utilizes ‘feature similarity’ to predict the values of new data points, assigning a value based on the resemblance to points in the training set. This characteristic makes KNN particularly adept at handling the variability and complexity of the soil data, where slight differences in features can significantly impact crop outcomes. By inputting new data points into the trained model, we leveraged KNN’s capability to deliver precise predictions, which was validated by its superior performance metrics. The model’s ability to accurately classify and predict based on the soil characteristics underscores its potential utility in practical agricultural applications, offering a reliable tool for farmers to make informed decisions about crop planting and management.
3.2. Comparative Analysis of Machine Learning Algorithms
In this study, we evaluated the performance of three machine learning algorithms— KNN, SVM, and neural networks—on crop prediction based on soil characteristics. Although KNN consistently demonstrated the best performance in terms of accuracy, precision, recall, and specificity, it is essential to discuss the comparative results of all the algorithms in detail, along with an analysis.
3.2.1. Support Vector Machines
SVMs are a powerful classifier that work well with high-dimensional data and are widely used for classification tasks. In our experiments, the SVM achieved a reasonable accuracy, with a maximum of 81.2% in the five-fold cross-validation. While the SVM demonstrated relatively strong precision (83.6% in 10-fold), its recall and specificity were slightly lower than the KNN. One reason for this could be that the SVM relies on defining a decision boundary between classes. Given the variability in the soil data, which often feature noisy and overlapping characteristics, the SVM might struggle to find an optimal boundary, leading to a slightly reduced performance compared to the KNN. Additionally, the SVM’s complexity and the need for parameter tuning, such as selecting an appropriate kernel, might have contributed to its lower accuracy.
3.2.2. Neural Networks
Neural networks are highly flexible models capable of capturing complex patterns in data, particularly when sufficient training data are available. However, in this study, the neural networks did not outperform the KNN, achieving a maximum accuracy of 82% in the 10-fold cross-validation. Neural networks are prone to overfitting, especially in cases where the dataset is small or when there are subtle variations in the data. The challenge of tuning the hyperparameters such as the learning rate, hidden layers, and regularization might also have limited the performance of the neural networks in this scenario. Although the neural networks achieved competitive precision (83.5%) and recall scores (84.4%), their complexity might have reduced their suitability for this particular application, where simpler models like the KNN could better capture the relationships in soil data.
3.2.3. K-Nearest Neighbors
The KNN algorithm consistently outperformed SVMs and neural networks across all validation techniques, achieving the highest accuracy of 84% in the 10-fold cross-validation. KNN’s strength lies in its simplicity and ability to leverage ‘feature similarity’ to make predictions. This makes it particularly effective for crop prediction, where slight variations in soil properties can lead to significant changes in crop outcomes. KNN’s non-parametric nature means it does not make assumptions about the underlying data distribution, making it highly adaptable to the complex and non-linear relationships found in the soil data. Moreover, KNN’s reliance on nearest neighbors allows it to capture local patterns in the data, which may explain its superior performance in this study.
While KNN exhibited a strong performance, it is not without limitations. KNN’s effectiveness can be influenced by the size of the dataset and the choice of the number of neighbors (k). A small dataset might result in noisy predictions, while large datasets can increase computation time. Additionally, KNN can be sensitive to the scaling of input features, and the performance might degrade if the features are not appropriately normalized. To improve KNN’s performance further, future work could explore the use of a weighted KNN, where closer neighbors are assigned higher weights, or the implementation of feature selection methods to reduce dimensionality and enhance prediction accuracy. In contrast, both SVMs and neural networks have the potential for improvement through more extensive hyperparameter tuning and larger datasets. For instance, optimizing the kernel function in SVMs or exploring different architectures in neural networks could lead to a better performance. Moreover, integrating ensemble techniques, such as combining KNN with SVMs or neural networks, might offer a more robust prediction system by leveraging the strengths of multiple algorithms.
4. Discussion
The results obtained from our study highlight the effectiveness and robustness of using machine learning algorithms for predicting suitable crops based on a soil fertility analysis. Our approach utilized three-fold, five-fold, and ten-fold cross-validation methods to ensure the reliability of the models and to avoid overfitting. The 10-fold cross-validation method yielded the most favorable results, indicating that this method effectively balances bias and variance, providing a more accurate assessment of the model’s performance. Among the various algorithms tested, the KNN algorithm consistently outperformed the others across all the validation methods. For the 10-fold cross-validation, KNN achieved a maximum accuracy, precision, recall, and specificity. These metrics indicate that KNN not only correctly identifies the majority of the suitable crops (high accuracy) but also minimizes false positives (high precision) and false negatives (high recall). The high specificity further demonstrates the algorithm’s capability to accurately exclude unsuitable crops. Although both the SVM and neural network models performed reasonably well, they fell short of the KNN model’s performance.
These findings are consistent with previous studies, such as the work of Rao et al., which demonstrated that random forest outperformed KNN and decision trees in crop prediction, though our study found KNN to be the most effective for our specific dataset and conditions [
5]. Similarly, Morales et al. found random forest to be highly effective in predicting crop yields using biophysical crop models, reinforcing the value of tree-based algorithms in agricultural applications [
32]. However, our focus on KNN aligns with Rajakumaran et al.’s emphasis on feature selection and model optimization to achieve a high accuracy in crop yield prediction [
8].
The findings from our study emphasize the practical application of KNN in precision agriculture, particularly for crop prediction based on soil fertility analysis. One of the key advantages of KNN is its simplicity and ease of interpretation, making it a viable option for real-time decision-making in small-scale farming environments. Unlike more complex models such as neural networks, which require extensive parameter tuning, the KNN model can be implemented with minimal adjustments, reducing computational overheads while still providing accurate predictions. This is especially beneficial for farmers and agricultural systems with limited access to advanced computational resources. Furthermore, the scalability of this approach suggests its potential to be applied across diverse agricultural landscapes, with future studies able to validate the model on larger datasets, encompassing a variety of soil types and regional conditions.
The high accuracy, precision, recall, and specificity achieved by the KNN model indicate its suitability for practical applications in agriculture. By using the robustness of the 10-fold cross-validation method, our model demonstrates that it can handle variations in soil data effectively, ensuring reliable predictions. This can significantly aid farmers in making informed decisions regarding crop selection, thereby enhancing agricultural productivity and resource efficiency. By accurately predicting the most suitable crops, farmers can optimize their planting strategies, reduce the use of unnecessary fertilizers, and improve overall crop productivity.
Despite its strengths, KNN has certain limitations, such as its sensitivity to the choice of the k-value and its memory-intensive nature when dealing with large datasets. Future work could explore automatic methods for optimizing the k-value or hybrid models that combine KNN with other machine learning algorithms to enhance performance. Additionally, integrating real-time environmental data, such as weather patterns or pest infestations, could further improve the model’s adaptability and predictive accuracy. Although KNN outperformed SVMs and neural networks in this study, advanced algorithms like ensemble learning techniques, such as bagging and boosting, may offer additional improvements in specific scenarios. Exploring these methods could lead to more robust and generalizable models for crop prediction, enhancing their utility across various agricultural contexts.
The integration of additional agro-climatic factors into the prediction models can further enhance the accuracy and reliability. Incorporating real-time weather data, pest and disease occurrences, and other environmental variables can provide a more comprehensive analysis for crop prediction. Employing advanced machine learning and deep learning algorithms, such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs), may yield an even better performance. The scalability of our approach can also be tested by expanding the dataset to include soil samples from diverse geographical locations and different crop types, helping the validation of the model for its robustness and generalizability across various agricultural settings. Our study demonstrates the feasibility and effectiveness of using IoT-enabled machine learning models for real-time crop prediction based on soil fertility analysis. The superior performance of the KNN algorithm, validated through rigorous cross-validation methods, offers a promising tool for enhancing agricultural decision-making and productivity. These results align with previous research and highlight the potential for integrating machine learning with IoT technologies to support sustainable agriculture.
One of the key limitations of this work is its reliance on a relatively small and region-specific dataset, which may limit the generalizability of the model to broader agricultural contexts. While KNN performed well for the selected soil fertility parameters and crop types in this study, its memory-intensive nature makes it less suitable for large-scale datasets, where computational efficiency could become an issue. Additionally, KNN’s performance is sensitive to the choice of the k-value, which may vary across different datasets and could lead to suboptimal predictions without careful tuning. The absence of agro-climatic factors such as temperature, rainfall, and pest activity in the prediction model also restricts its ability to account for the dynamic environmental conditions that significantly influence crop growth. The cross-validation mitigates overfitting, but further testing with more diverse datasets, including different soil types and climatic zones, is necessary to fully assess the robustness and scalability of the proposed approach.
5. Conclusions
Crop cultivation traditionally relied on farmers’ experience, but changes in soil fertility are now adversely impacting agricultural yields. Effective crop productivity is heavily influenced by soil fertility and environmental conditions. Forecasting the optimal crops to grow is essential in agriculture, with machine learning algorithms playing a crucial role in this predictive process. In our study, we developed a system using machine learning algorithms to predict suitable crops for specific lands. The soil fertility analysis considered factors such as pH, electrical conductivity, organic carbon, and elements like phosphorus, potassium, boron, sulfur, manganese, iron, zinc, and copper. The KNN model demonstrated a maximum accuracy of 84% in the measured dataset. Our sensor-based system also monitors key soil parameters including potassium, nitrogen, phosphorus, pH, electrical conductivity, temperature, and humidity.
Agriculture stands as a pivotal driver of national development, necessitating enhanced productivity within the sector. Soil and climate conditions significantly impact crop productivity, highlighting the importance of integrating both datasets to refine prediction models. Future endeavors should focus on developing more efficient models based on comprehensive agro-climatic factors. While our current study primarily considers soil conditions, future enhancements could involve expanding the analysis methods for real-time data acquisition. Moreover, optimizing data transmission using protocols such as TCP/IP or HTTP will further enhance the functionality and applicability of our system in practical agricultural settings. Incorporating real-time weather data, such as rainfall, temperature, humidity, and wind speed, into the prediction model could significantly improve the accuracy and reliability of the crop forecasts. Future research should explore integrating weather stations or IoT-based sensors with the existing system to capture real-time environmental conditions, which are critical for crop growth. Additionally, the inclusion of pest and disease occurrence data would allow for more comprehensive modeling, helping to predict potential threats to crop yields. Another promising direction is the use of advanced machine learning techniques, such as ensemble models or deep learning algorithms, which can better handle large and complex datasets. These enhancements could transform the current system into a more holistic, real-time decision support tool for farmers, helping them to make more informed decisions that optimize crop productivity and sustainability.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}