1. Introduction
Process mining (PM) is an important approach suitable for designing processes based on machine learning (ML) decision-making engines. PM has been applied to improve industrial processes [
1,
2] and subsequently to design healthcare processes [
3,
4] regarding the cost optimization of healthcare services [
5], telemedicine [
6], and patient fall risk management [
7]. The application of PM is important for the design of organizational models based on workflows integrating ML algorithms and supporting decisions about human resource (HR) allocation or engagement [
6]. The ML-HR decision-making engine upgrades the PM model to a Process Mining Organization (PMO) model. A method suitable for representing and sketching processes is the Business Process Modeling and Notation (BPMN) approach [
8]. BPMN is an international standard [
9,
10], providing graphical elements to map processes. The BPMN is useful to design healthcare processes such as Diagnostic and Therapeutic Care Pathways (PDTAs). An example of a PDTA mapped by BPMN is illustrated in
Figure 1, representing the ‘AS IS’ care path of diabetics [
11]. As observed in
Figure 1, the Italian diabetic PDTA is exhaustive for the chronic pathology, but no details are provided for primary prevention highlighted by the green box (prevention task). The goal of the proposed paper is therefore precisely the optimization of the prevention task using telemedicine and ML facilities. Specifically, we have proposed a basic organizational model and technological facilities that can be used to implement a prevention PDTA with the goal of eliminating the risk of chronic degeneration, and, consequently, avoiding the execution of the whole PDTA process of chronic care, which requires high resource costs.
Figure 2 presents the sketch of a diagram summarizing the goal of the paper.
In Italy, high care costs are estimated for chronic diabetic patients; by analyzing the socio-economic impact of diabetes, it is noted that in only the Italian Puglia region, approximately 5% of the adult population aged 18–69 years is affected by diabetes [
12]; furthermore, the average annual cost per diabetic patient is EUR 2792 [
13], and for the Puglia region alone, there are an estimated 232,000 diabetic people (Source: Istat 2020), corresponding to a total annual cost for the region of EUR 647,744,000. Concerning the stroke cost, in Italy, there are 100 thousand new cases a year, corresponding to an estimated cost of EUR 16 billion for the whole National Healthcare Service (source: ‘Sanità 24’, 2018). These initial analyses highlight the importance of finding a solution capable of reducing, from a predictive perspective, the onset of chronic diseases in various possible forms.
The prevention of diabetes could also have implications in the prediction of the risk of stroke. In particular, cases of hypoglycemia or hyperglycemia represent stroke risks [
14,
15]. Other elements concerning risks which are correlated with strokes are hypertension [
16] and heart disease [
17]. These risk elements are analyzed in the paper.
Regarding prevention, telemedicine could improve healthcare organization by optimizing care processes [
6]. For this reason, the goal of the proposed work is to design a prevention process matching diabetes and stroke risks by highlighting ML data processing aspects in decision-making procedures and in organizational aspects.
The purpose of the study is to provide ML tools and process mapping methods to actuate the new PDTA to prevent chronic diseases. The PDTA prevention process is modeled in this paper through BPMN, thus suggesting an innovative workflow to follow the patient monitoring care patterns through telemedicine tools. Furthermore, telemedicine provides digital data useful for executing the preventive decision-making procedures.
The paper is structured as follows:
- -
In
Section 2, we provide information about the materials and methods, discussing the analyzed dataset and the ML data processing workflow.
- -
In
Section 3, we propose a PDTA BPMN workflow management prevention process and care service organization, including telemedicine monitoring tools to decrease the risks of diabetes and stroke.
- -
In
Section 3, we apply supervised and unsupervised ML algorithms, improving the initial decision making about possible risks and focusing the data analysis on stroke risk.
- -
In
Section 4 and in the appendices, we provide information about organizational aspects supported by telemedicine facilities and improved by other possible healthcare actors.
- -
In
Section 4 and in the appendices, we also discuss advantages, disadvantages, limitations, and perspectives of the proposed approaches and technologies.
3. Results
The first result is obtained by discussing the ML application with medical staff (general practitioners and specialists validating the methodology) and by evaluating the feasibility of deploying a telemedicine platform by adopting certified medical kits (standard CE: 93/42/CEE, 2017/745/UE, class 2a) for diabetes and stroke prevention.
The BPMN workflow of
Figure 5 is the result of the validated design, describing the platform monitoring patients during the prevention phase. The workflow examines the combined risk of patients to be affected by diabetes or to be injured by a stroke, thus defining a PDTA of prevention. The same workflow is also suitable for the prevention of the hypertension risk by adopting specific sensors, mainly measuring heart disease. The diagram in
Figure 5 is structured into three pools, indicating the processes of the three main actors involved in the system:
patient to be monitored for diabetes risk (pool named ‘Diabetes Prevention Process’);
patient to be monitored for stroke risk (pool named ‘Stroke Prevention Process’);
general practitioner deciding the medical kit to assign and analyze data to decide on possible exams or drug assignments after the detection of digital alerting conditions (alerting thresholds overcoming critical values of physiological parameters, or alerting predicted results).
The model is designed by considering real-time monitoring of the patient’s physiological parameters, and an automatic alerting condition enabling the decision of the general practitioner.
Data Result Interpretation and Decision-Making Processs Preventing Stroke Risk
The dataset [
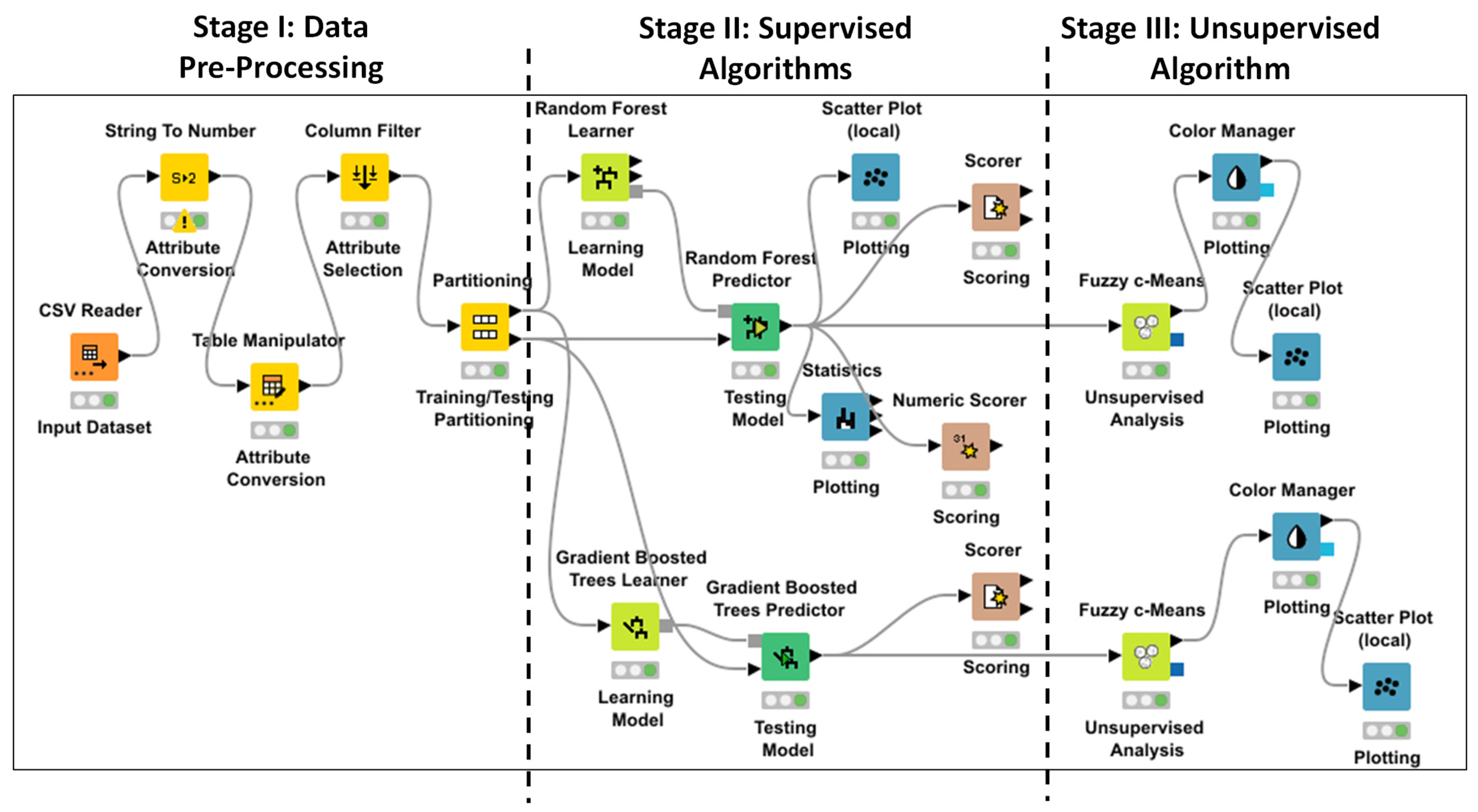
18] is processed by the two algorithms RF and GBT. In
Figure 6a,b, two screenshots are shown, indicating the stroke prediction of the same records by executing both the ML RF and GBT algorithms; the algorithms provide the same alerting condition with a weakly different confidence (0.7 in the case of RF and 0.776 for GBT). The algorithms provide similar prediction results and good performances (see performance parameters of
Table 1). In
Figure 7 can be seen the Receiver Operating Characteristic Curves (ROCs) of both the approaches, providing the values of the Area Under the ROC Curve (AUC) of
Table 1, furthermore confirming the high algorithm performance. A further estimated performance index indicated in
Table 1 is the F-measure (or F-score), measuring the predictive performance. The F-measure is typically adopted for statistical analysis of binary classification and information retrieval systems.
We observe that the results to pay attention to are those where the risk of stroke is predicted even though there has not been an alert condition in the past. In order to group the results, the RF and GBT outputs are clustered by the Fuzzy c-Means algorithm, highlighting in red the predicted risk cases of stroke (the red color indicates the cluster of the predicted stroke risk). By considering three clusters, it is observed that the predicted stroke cases do not appertain to the first cluster characterized by patients having an age lower than 40 years old (this allows for excluding the preventive monitoring of these patients). In
Figure 8, a comparison is presented of RF and GBT risk cases due to hyperglycemia and hypoglycemia status, by confirming the results expected in the literature [
14,
15]. The results of both algorithms present few differences.
In
Figure 9a,b, the RF and the GBT stroke risks are shown, matching patient age and patient work type, respectively. Also, in this case, both algorithms provide similar results by highlighting that private companies employees or managers are characterized by a high stroke risk. This result enhances the impact of the work about the stroke risk and could enable the formulation of new welfare policies in private work environments; according to the results, possible interventions could be applied regarding the optimization of working conditions, improving the quality of life, and consequently decreasing the health risk.
As expected in the literature, stroke risk happens when heart disease and hypertension cases are checked [
16,
17]. The results of
Figure 10 and
Figure 11 confirm these scientific expectations.
In addition, social conditions could also have an impact on the risk.
Figure 12 demonstrates that no married patients are characterized by a possible stroke risk; this can be explained by the fact that that unmarried workers overwork themselves (work hard) and are therefore subject to a greater risk of stroke.
4. Discussion: The Telemedicine Framework
The BPMN workflow of
Figure 5 is a basic process involving only the patient and the general practitioner actors. More actors could be involved by further optimizing the whole prevention process. The ML results discussed in
Section 3 are to be used for the decision of patients to enroll, for the assignment of the medical kit, and for the decisions of the general practitioner upon reading the alerting conditions (corresponding to the ‘Exclusive Event-Based’ symbols of
Figure 5). For example, concerning the diabetes risk, an important parameter to predict with ML is glycemic values. In
Table 2, a list of further actors is presented which could collaborate to prevent chronic cases or dangerous health status conditions. In
Appendix A, we detail the whole ecosystem involving actors, companies, and research units, improving the telemedicine system and describing the interconnections (action fluxes) between the actions required to perform a preventive PDTA. The realization of a telemedicine platform suitable for chronic prevention requires investment in technology having a high Key Performance Indicator (KPI) of technology readiness (see
Appendix B). The technology readiness KPI indicates the company’s capabilities in terms of technology development and organization management.
The advantages of the use of a telemedicine platform can be estimated by KPIs. For example, in
Table 3, we list and comment on some qualitative and quantitative KPIs associated with a telediabetology platform.
Table 4 indicates limitations and perspectives of telemedicine technology. The listed limits are common for all telemedicine platforms.
In
Appendix B, we discuss an example of the KPI technology readiness model structured by the Ishikawa diagram, typically adopted to model organizational aspects in healthcare [
30,
31] and production management processes [
32]. For the stroke telemonitoring platform, different KPIs should be considered, including neurological assessment, nutritional assessment, hyperthermia management, lipid management [
33], stroke education, and screening actions [
34]. Another approach useful for mapping processes is the Unified Modeling Language (UML) [
35,
36], used in
Appendix A, where we detail a complete framework of a telemedicine platform. In
Appendix C, we list some PMO aspects associated with actors listed in
Table 2, and possible advantages and disadvantages following the corrective actions.
The limitations about the adoption of the new PDTA based on ML data processing are mainly in the availability of enough clinical data to learn an ML model, and in the execution of new organizational models capable of ensuring the correct functioning of the PDTA. In this direction, future developments are in the design of new structured process workflows able to efficiently manage new human resources having new roles.
The results proposed in this paper regarding stroke analysis highlight that there are many aspects to consider for risk assessment decision processes in order to prevent dangerous cases. For example, the risk could be reduced over time, improving the social quality of life or optimizing the work conditions, as well as suggesting the inclusion of corrective actions or lifestyles, including the choice of a specific diet. The limitations mainly involve the deployment of an organizational model suitable for directing patients to the correct health path. The organizational model implies new human resources and a synergic collaboration between them by executing efficient processes. The future direction of the research is to integrate as much as possible into the PDTA the automatisms of AI decision making and the synergies between all the actors that serve to implement risk prevention.
Other alternative ML algorithms adopted in the literature for stroke classification or prediction are Artificial Neural Networks (ANNs) and Support Vector Machine (SVM) [
37,
38,
39,
40]. In
Table 5, we compare the performance of the ANN and SVM methods found in the literature with the FR and GBT algorithms applied in this work; the ANN and the SVM algorithms exhibit a performance lower or slightly lower than that of the FR and GBT algorithms.
Future works will apply the experimentation of the proposed PDTA of
Figure 5 and of the use of medical kits, which will be assigned to the hospitalization units characterized by many confirmed cases, as for the Italian district units represented in
Figure 13 and
Table 6 (Unit 1, Unit 6, and Unit 7).
The proposed framework will be able to integrate decision-making procedures suggested by research topics, such as the use of efficient dietary components [
41], sentiment analysis [
42] matching with the psychological profile of the patient, the metabolism balancing approach [
43], the improvement of psychological processes of consumer purchase decision making [
44], and the detailed analyses of etiological aspects [
45].







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}