
Image-Based Analysis of Dense Particle Mixtures via Mask R-CNN



Abstract
1. Introduction
2. Data
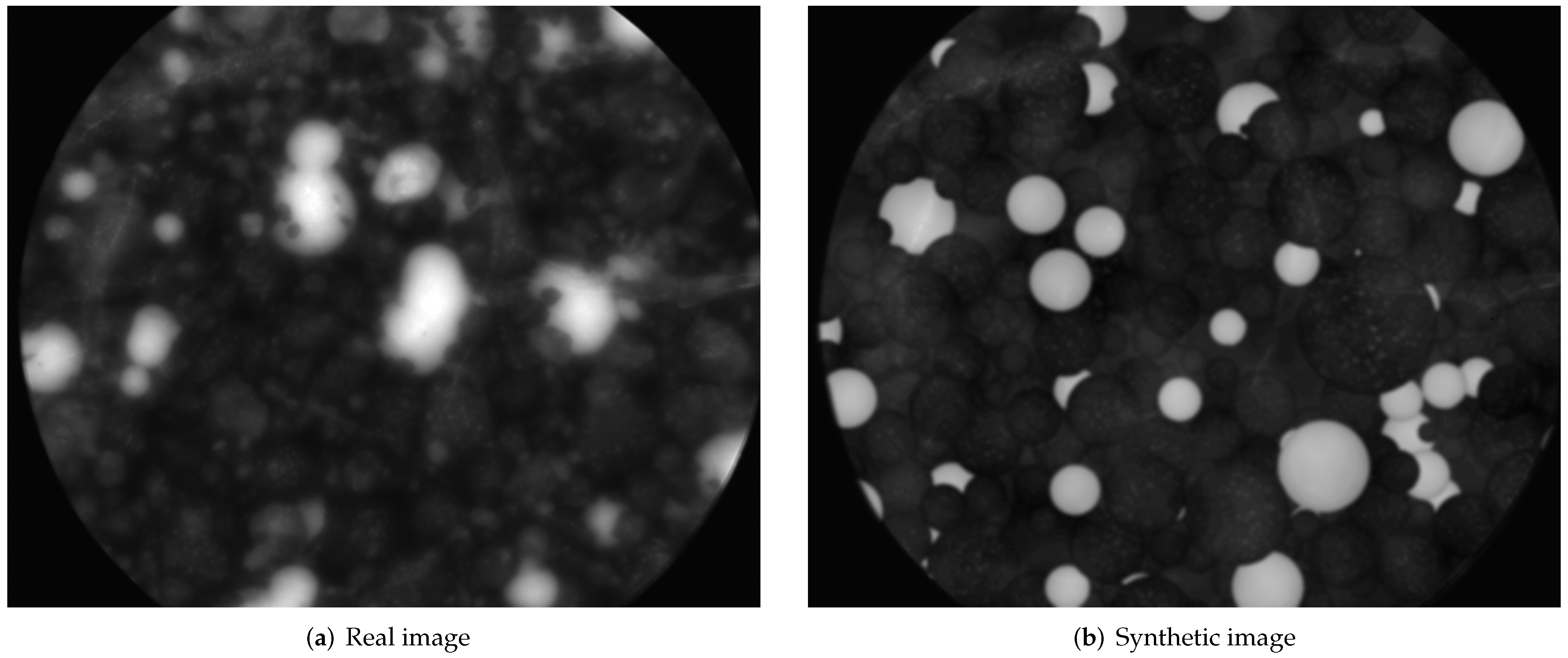
2.1. Training and Validation Data
2.2. Test Data
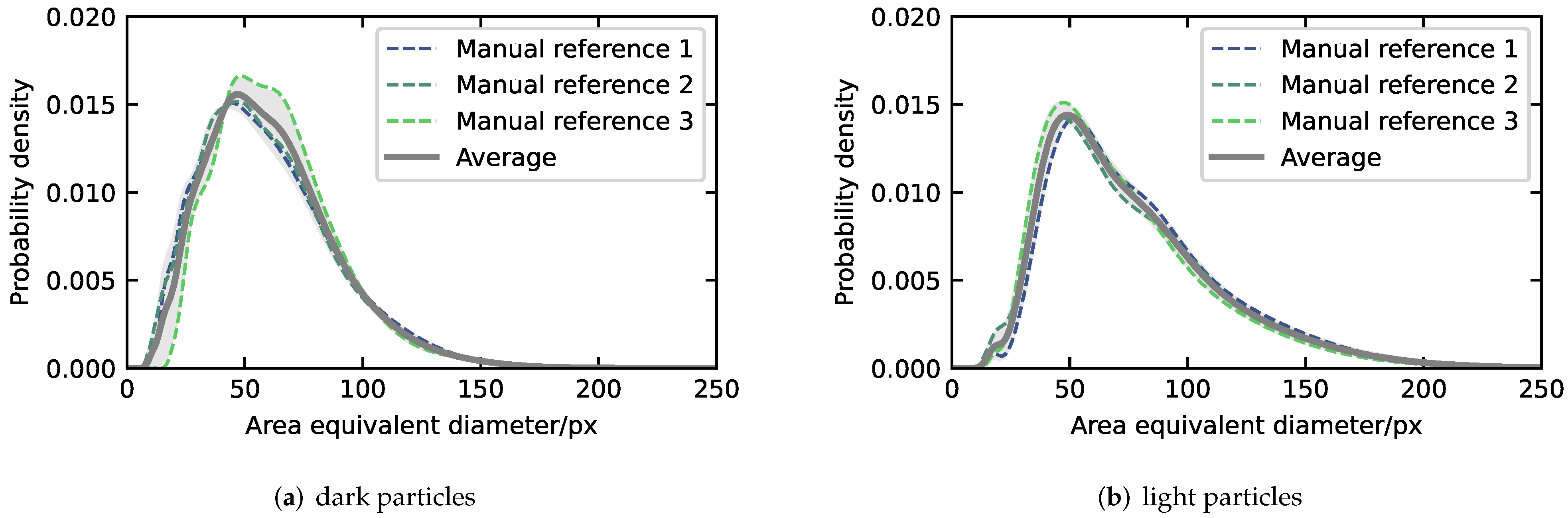
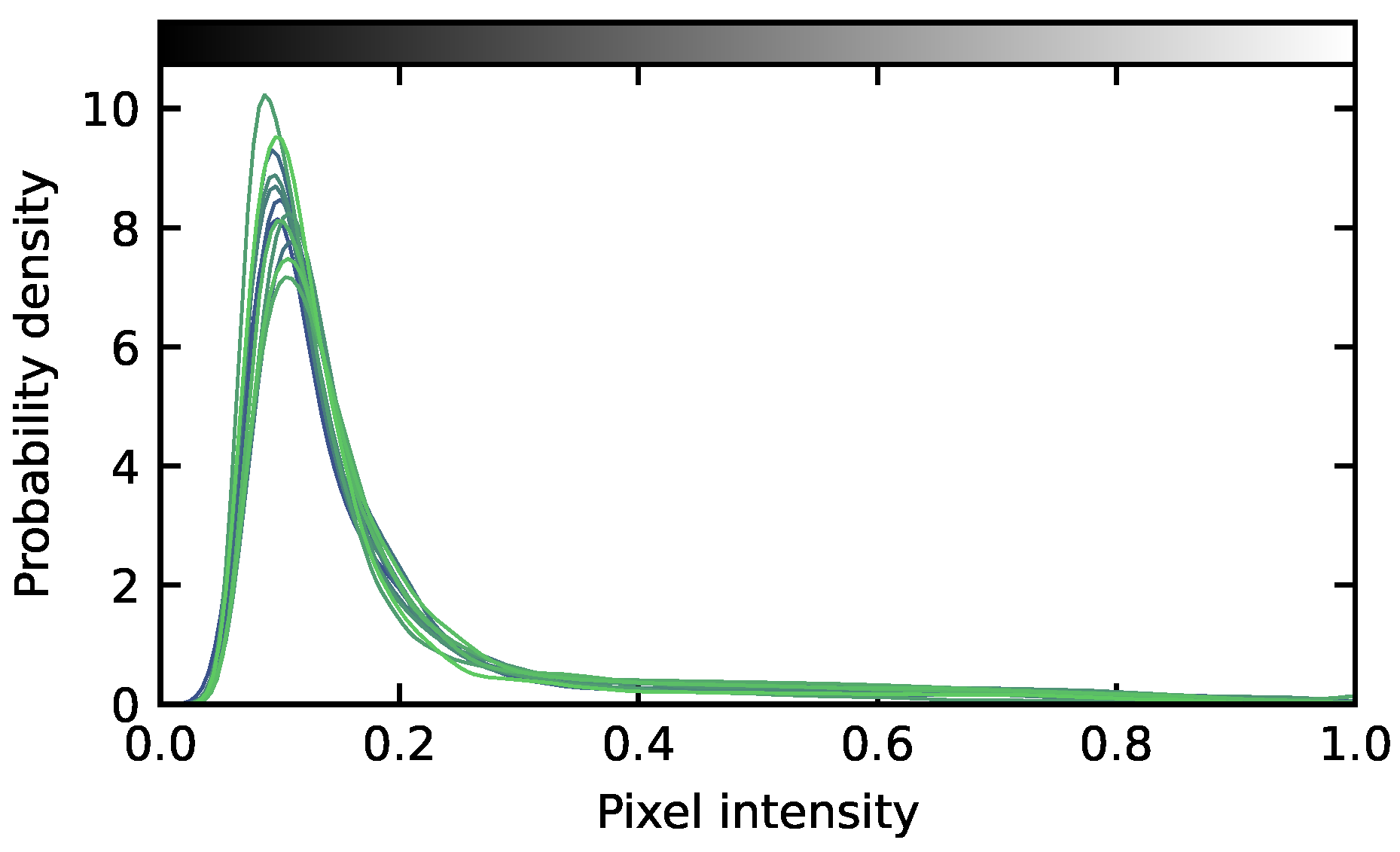
2.2.1. Average Particle Size Distribution
- Interpolation of the three resulting KDEs at 200 linearly spaced support values, between the minimum and maximum observed area equivalent diameters (see Figure 3a,b, dashed lines).
- Calculation of the means and standard deviations of the characteristic properties (geometric mean diameter dg and geometric standard deviation σg) of the reference PSDs (see Table 1).
2.2.2. Merged Annotations
Intersection over Union
3. Methods
3.1. Proposed Method
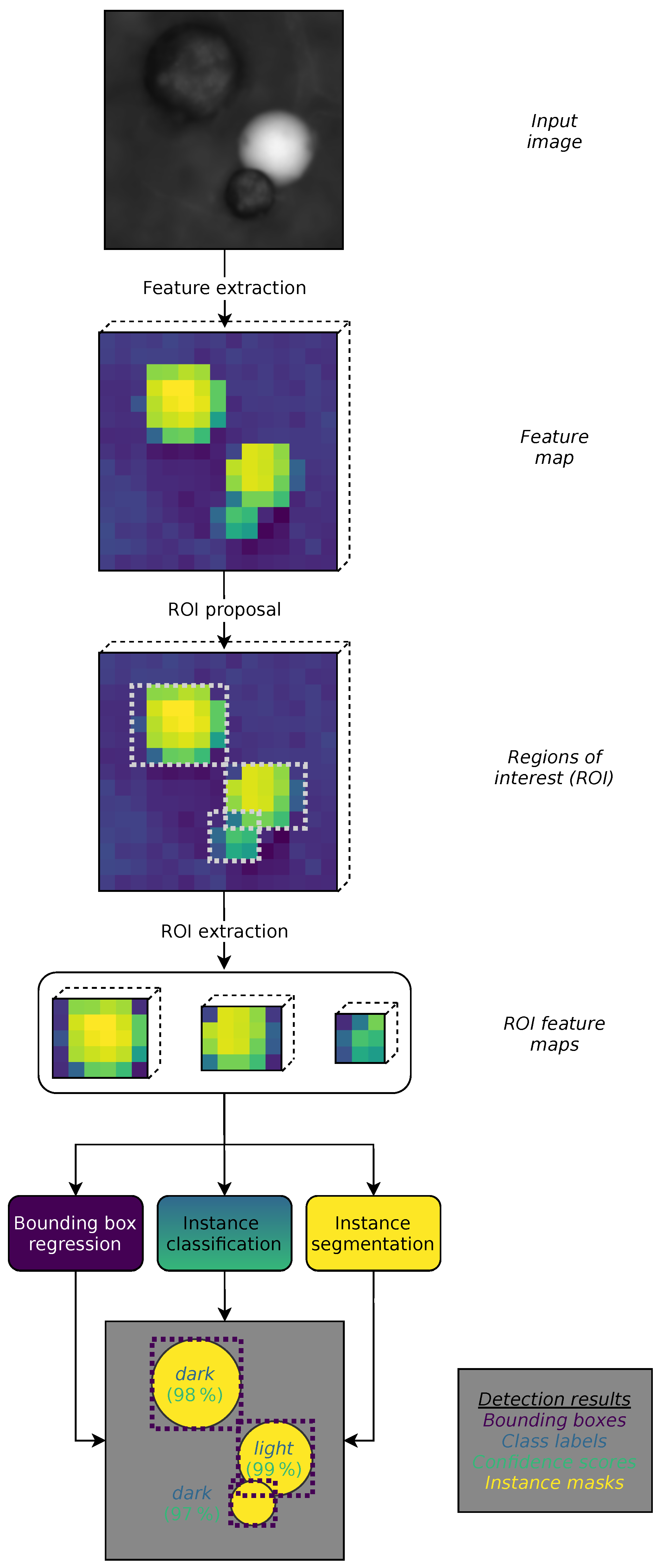
3.1.1. Mask R-CNN
Implementation Details
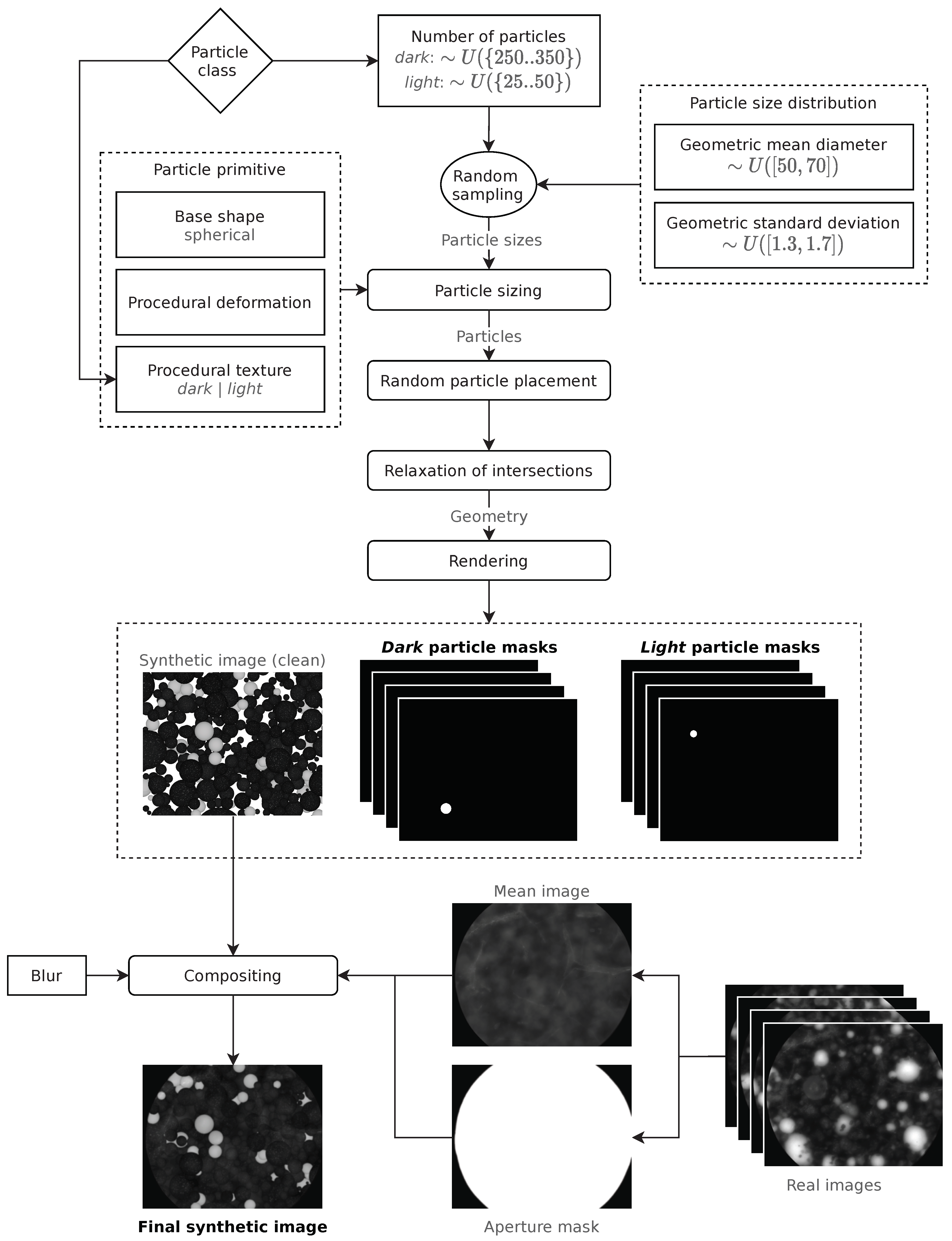
3.1.2. Image Synthesis
- A unique random PSD, represented by a geometric mean diameter dg (in pixels) and a geometric standard deviation σg, both picked from a wide uniform distribution U of plausible values:
- A number of particles N, which is picked from a uniform distribution U, with different boundaries for dark and light particles, since in the real images, there are many more dark than light particles:The boundaries were chosen based on the resulting similarity of the synthetic images to the real images used for the testing of the proposed method.
- A so-called particle primitive, which serves as prototype for the particles of the respective population. Each primitive features a certain base shape, a procedural (i.e., based on randomizable parameters) deformation and a procedural texture (this is where dark and light particles differ).
3.2. Benchmark Methods
3.2.1. Manual Analysis
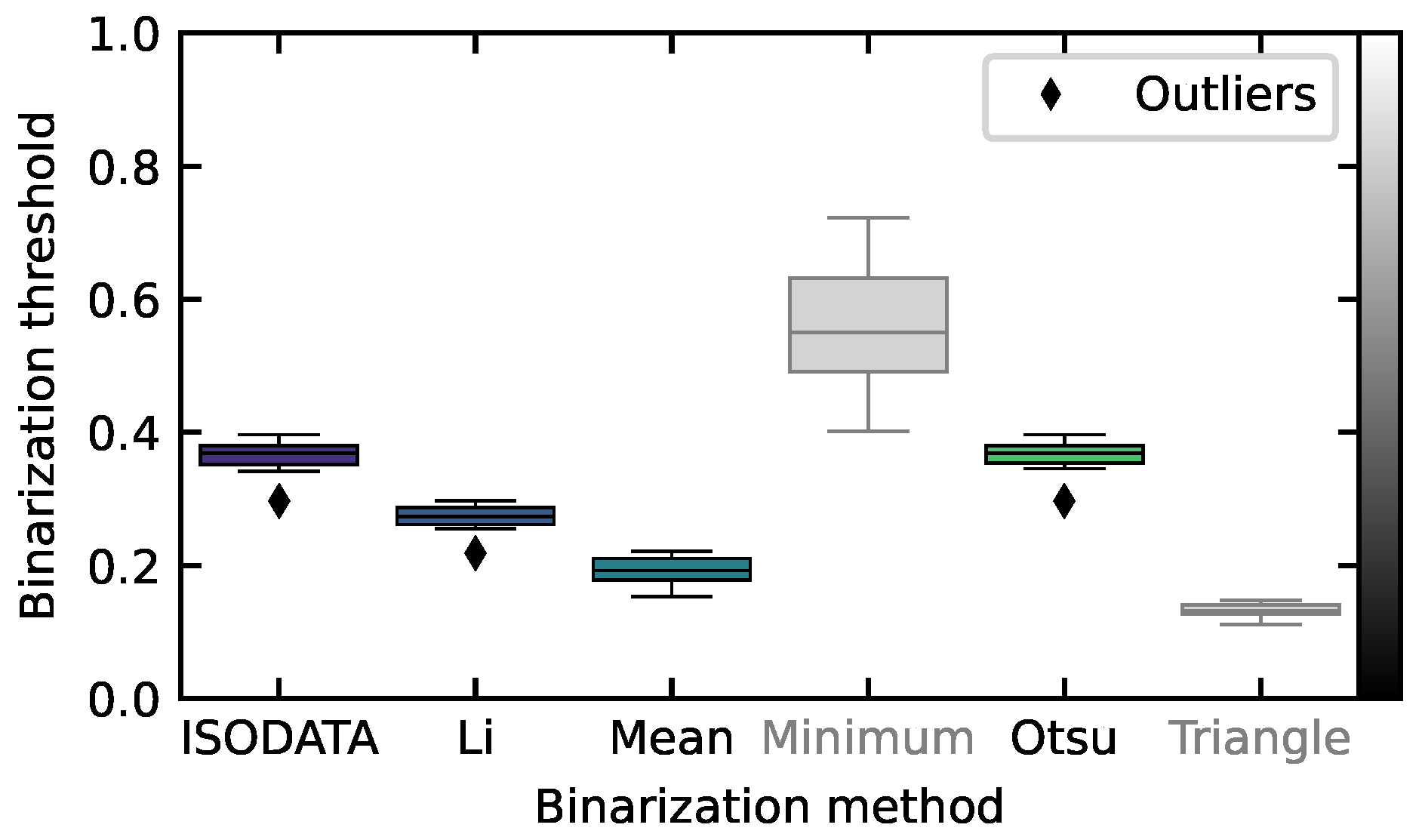
3.2.2. Hough Transform
Aperture Mask Extraction
Mean Thresholding with Mask
Histogram Equalization with Mask
Canny Edge Detection with Mask
Circle Hough Transform with Mask
4. Results
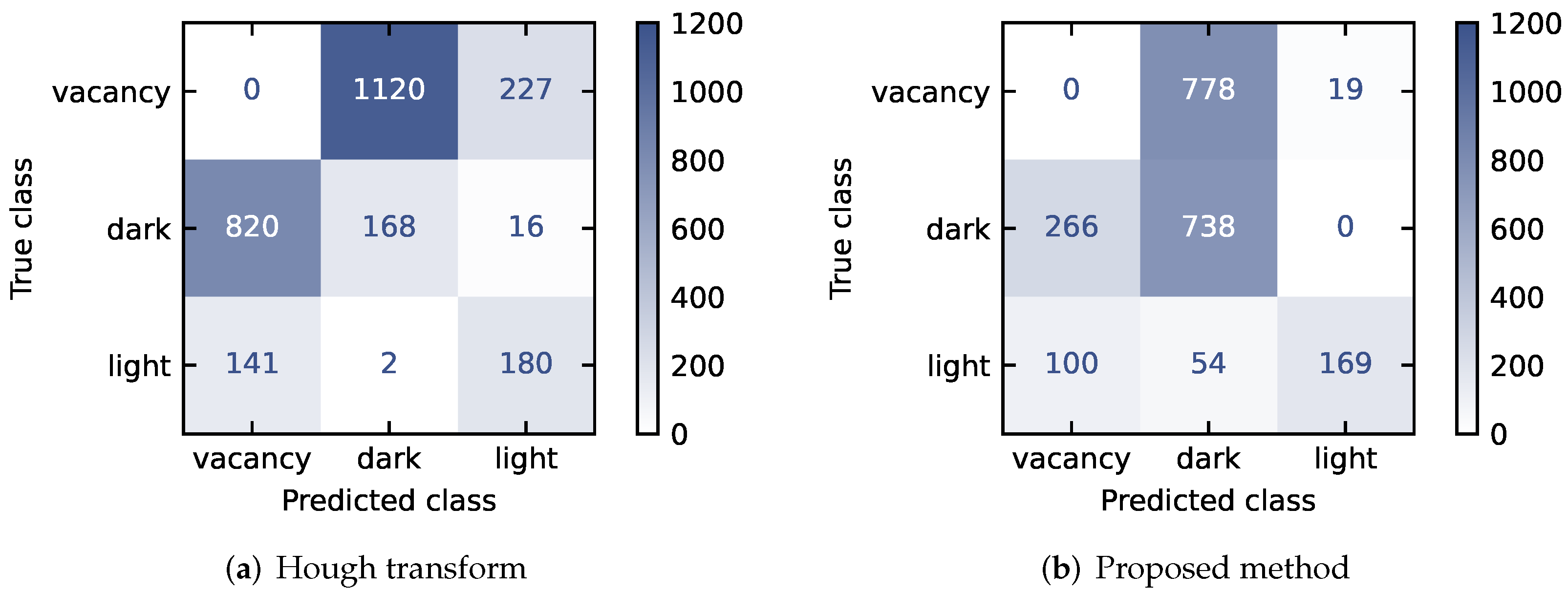
4.1. Detection Quality
Classification
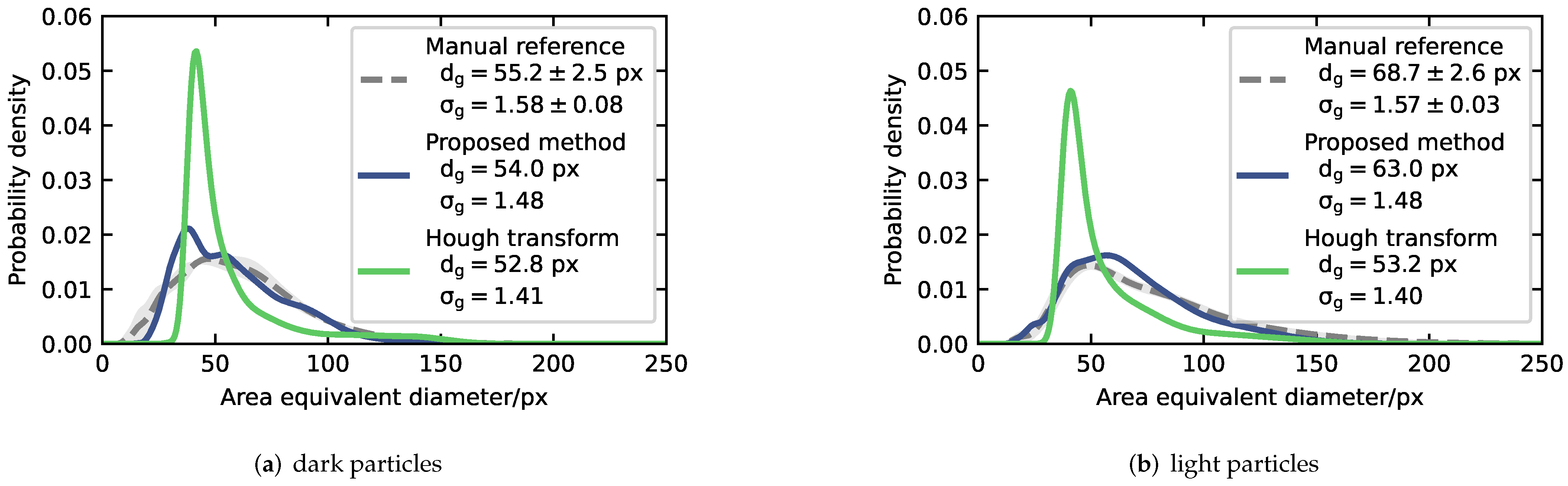
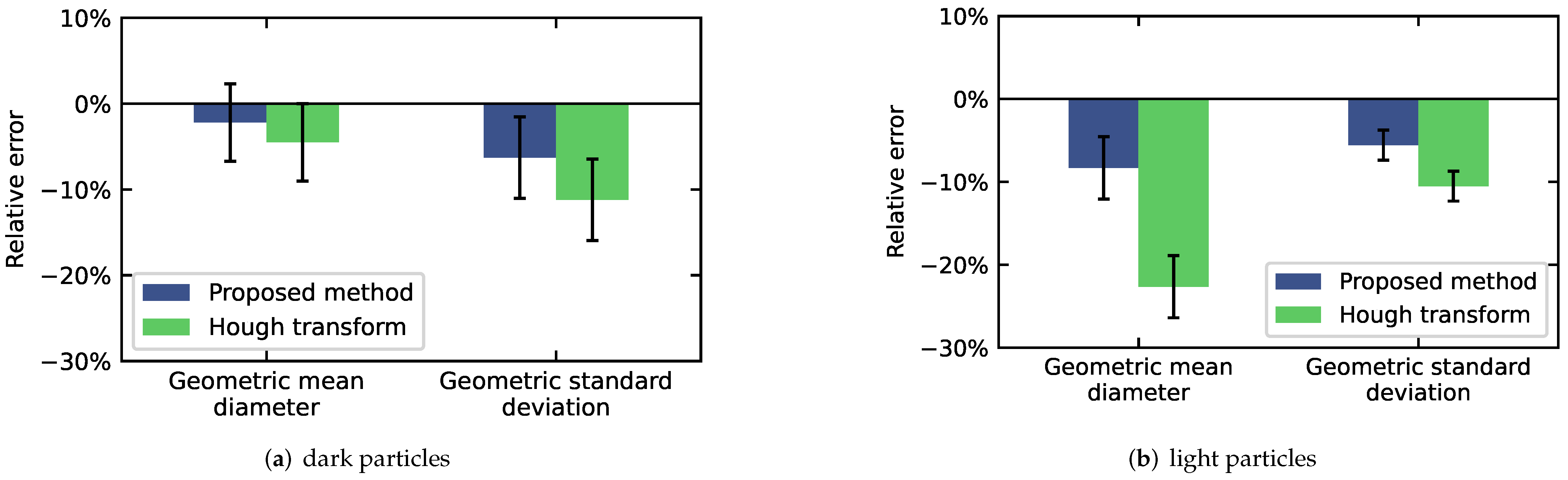
4.2. Particle Size Distribution Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Acronyms | |
| CNN | convolutional neural network |
| COCO | common objects in context |
| FCC | fluid catalytic cracking |
| GAN | generative adversarial network |
| HT | Hough transform |
| IoU | intersection over union |
| ISODATA | iterative self-organizing data analysis technique |
| KDE | kernel density estimation |
| Pascal | pattern analysis, statistical modeling and computational learning |
| PSD | particle size distribution |
| R-CNN | region-based convolutional neural network |
| RGB | red, green, blue |
| ROI | region of interest |
| VOC | visual object classes |
| Symbols | |
| ACC | (overall) accuracy |
| ACC | dark vs. light accuracy |
| ACC | object vs. vacancy accuracy |
| area equivalent diameter | |
| percentage error of the geometric mean diameter | |
| geometric mean diameter | |
| percentage error of the geometric standard deviation | |
| F | false prediction |
| false prediction of class p for an instance of class t | |
| prediction of class p for an instance of class t | |
| IoU | intersection over union |
| N | number of particles |
| p | predicted class |
| standard deviation | |
| geometric standard deviation | |
| T | true prediction |
| t | true class |
| true prediction of class t | |
| U | uniform distribution |
References
- Schulze, D. Pulver und Schüttgüter: Fließeigenschaften und Handhabung, 3., erg. Aufl. 2014 ed.; VDI-Buch, Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Kaye, B.H. Powder Mixing, 1st ed.; Powder Technology Series; Chapman & Hall: London, UK, 1997. [Google Scholar]
- Sadeghbeigi, R. Fluid Catalytic Cracking Handbook: Design, Operation, and Troubleshooting of FCC Facilities, 2nd ed.; Gulf: Houston, TX, USA, 2000. [Google Scholar]
- Musha, H.; Chandratilleke, G.R.; Chan, S.L.I.; Bridgwater, J.; Yu, A.B. Effects of Size and Density Differences on Mixing of Binary Mixtures of Particles. In Powders & Grains 2013, Proceedings of the 7th International Conference on Micromechanics of Granular Media, Sydney, Australia, 8–12 July 2013; AIP Publishing LLC: Melville, NY, USA, 2013; pp. 739–742. [Google Scholar] [CrossRef]
- Shenoy, P.; Viau, M.; Tammel, K.; Innings, F.; Fitzpatrick, J.; Ahrné, L. Effect of Powder Densities, Particle Size and Shape on Mixture Quality of Binary Food Powder Mixtures. Powder Technol. 2015, 272, 165–172. [Google Scholar] [CrossRef]
- Daumann, B.; Nirschl, H. Assessment of the Mixing Efficiency of Solid Mixtures by Means of Image Analysis. Powder Technol. 2008, 182, 415–423. [Google Scholar] [CrossRef][Green Version]
- Zuki, S.A.M.; Rahman, N.A.; Yassin, I.M. Particle Mixing Analysis Using Digital Image Processing Technique. J. Appl. Sci. 2014, 14, 1391–1396. [Google Scholar] [CrossRef]
- Realpe, A.; Velázquez, C. Image Processing and Analysis for Determination of Concentrations of Powder Mixtures. Powder Technol. 2003, 134, 193–200. [Google Scholar] [CrossRef]
- Šárka, E.; Bubník, Z. Using Image Analysis to Identify Acetylated Distarch Adipate in a Mixture. Starch 2009, 61, 457–462. [Google Scholar] [CrossRef]
- Frei, M.; Kruis, F.E. Image-Based Size Analysis of Agglomerated and Partially Sintered Particles via Convolutional Neural Networks. Powder Technol. 2020, 360, 324–336. [Google Scholar] [CrossRef]
- Frei, M.; Kruis, F.E. FibeR-CNN: Expanding Mask R-CNN to Improve Image-Based Fiber Analysis. Powder Technol. 2021, 377, 974–991. [Google Scholar] [CrossRef]
- Yang, D.; Wang, X.; Zhang, H.; Yin, Z.Y.; Su, D.; Xu, J. A Mask R-CNN Based Particle Identification for Quantitative Shape Evaluation of Granular Materials. Powder Technol. 2021, 392, 296–305. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Wu, Y.; Lin, M.; Rohani, S. Particle Characterization with On-Line Imaging and Neural Network Image Analysis. Chem. Eng. Res. Des. 2020, 157, 114–125. [Google Scholar] [CrossRef]
- SOPAT GmbH. SOPAT Pl Mesoscopic Probe; Sopat GmbH: Berlin, Germany, 2018. [Google Scholar]
- Scott, D.W. Multivariate Density Estimation: Theory, Practice, and Visualization, 2nd ed.; Wiley: Hoboken, NJ, USA, 2014. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- COCO Consortium. COCO—Common Objects in Context: Metrics. COCO Consortium, 2019. Available online: https://cocodataset.org/#home (accessed on 1 December 2021).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., D’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates Inc.: Red Hook, NY, USA, 2019. [Google Scholar]
- Falcon, W.; Borovec, J.; Wälchli, A.; Eggert, N.; Schock, J.; Jordan, J.; Skafte, N.; Bereznyuk, V.; Harris, E.; Murrell, T.; et al. PyTorchLightning/Pytorch-Lightning: 0.7.6 Release; Zenodo: Geneva, Switzerland, 2020. [Google Scholar] [CrossRef]
- Buslaev, A.; Parinov, A.; Khvedchenya, E.; Iglovikov, V.I.; Kalinin, A.A. Albumentations: Fast and Flexible Image Augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef]
- Yadan, O. Hydra—A Framework for Elegantly Configuring Complex Applications; Github: San Francisco, CA, USA, 2019. [Google Scholar]
- Biewald, L. Experiment Tracking with Weights and Biases; Weights and Biases: San Francisco, CA, USA, 2020. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems; Google LLC: Mountain View, CA, USA, 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition; Technical Report; arXiv (Cornell University): Ithaca, NY, USA, 2015. [Google Scholar]
- Smith, L.N. Cyclical Learning Rates for Training Neural Networks; Technical Report; arXiv (Cornell University): Ithaca, NY, USA, 2015. [Google Scholar]
- Blender Online Community. Blender—A 3D Modelling and Rendering Package; Blender Foundation: Amsterdam, The Netherlands, 2018. [Google Scholar]
- Van Rossum, G.; Drake, F.L. Python 3 Reference Manual; CreateSpace: Scotts Valley, CA, USA, 2009. [Google Scholar]
- The GIMP Development Team. GIMP (GNU Image Manipulation Program). The GIMP Development Team, 2021. Available online: https://www.gimp.org/ (accessed on 1 December 2021).
- Media Cybernetics, Inc. Media Cybernetics-Image-Pro Plus; Media Cybernetics, Inc.: Rockville, MD, USA, 2021. [Google Scholar]
- Media Cybernetics, Inc. Media Cybernetics-Image-Pro Plus-FAQs; Media Cybernetics, Inc.: Rockville, MD, USA, 2021. [Google Scholar]
- Schneider, C.A.; Rasband, W.S.; Eliceiri, K.W. NIH Image to ImageJ: 25 Years of Image Analysis. Nat. Methods 2012, 9, 671–675. [Google Scholar] [CrossRef]
- Russ, J.C. The Image Processing Handbook, 6th ed.; CRC Press: Boca Raton, FL, USA, 2011. [Google Scholar]
- Solem, J.E. Histogram Equalization with Python and NumPy. 2009. Available online: https://stackoverflow.com/questions/28518684/histogram-equalization-of-grayscale-images-with-numpy/28520445 (accessed on 1 December 2021).
- Canny, J. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. 1986, PAMI-8, 679–698. [Google Scholar] [CrossRef]
- Hough, P. Method and Means for Recognizing Complex Patterns. U.S. Patent 3,069,654, 18 December 1962. [Google Scholar]
- Van der Walt, S.; Schönberger, J.L.; Nunez-Iglesias, J.; Boulogne, F.; Warner, J.D.; Yager, N.; Gouillart, E.; Yu, T. Scikit-Image: Image Processing in Python. PeerJ 2014, 2. [Google Scholar] [CrossRef]
- Ridler, T.W.; Calvert, S. Picture Thresholding Using an Iterative Selection Method. IEEE Trans. Syst. Man Cybern. 1978, 8, 630–632. [Google Scholar] [CrossRef]
- Li, C.; Lee, C. Minimum Cross Entropy Thresholding. Pattern Recognit. 1993, 26, 617–625. [Google Scholar] [CrossRef]
- Prewitt, J.M.S.; Mendelsohn, M.L. The Analysis of Cell Images. Ann. N. Y. Acad. Sci. 1966, 128, 1035–1053. [Google Scholar] [CrossRef]
- Otsu, N. A Threshold Selection Method from Gray-Level Histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Zack, G.W.; Rogers, W.E.; Latt, S.A. Automatic Measurement of Sister Chromatid Exchange Frequency. J. Histochem. Cytochem. 1977, 25, 741–753. [Google Scholar] [CrossRef] [PubMed]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dark Particles | Light Particles | |||||
|---|---|---|---|---|---|---|
| dg | σg | N | dg | σg | N | |
| Manual reference 1 | px | 1.63 | 1525 | px | 1.54 | 325 |
| Manual reference 2 | px | 1.64 | 1106 | px | 1.61 | 335 |
| Manual reference 3 | px | 1.48 | 864 | px | 1.55 | 328 |
| Manual reference (avg.) | px | 1.58 ± 0.08 | – | px | 1.57 ± 0.03 | – |
| Hough Transform | Proposed Method | |
|---|---|---|
| accuracy | % | % |
| ACCobj.|vac. | % | % |
| ACCdark|light | % | % |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Frei, M.; Kruis, F.E. Image-Based Analysis of Dense Particle Mixtures via Mask R-CNN. Eng 2022, 3, 78-98. https://doi.org/10.3390/eng3010007
Frei M, Kruis FE. Image-Based Analysis of Dense Particle Mixtures via Mask R-CNN. Eng. 2022; 3(1):78-98. https://doi.org/10.3390/eng3010007
Chicago/Turabian StyleFrei, Max, and Frank Einar Kruis. 2022. "Image-Based Analysis of Dense Particle Mixtures via Mask R-CNN" Eng 3, no. 1: 78-98. https://doi.org/10.3390/eng3010007
APA StyleFrei, M., & Kruis, F. E. (2022). Image-Based Analysis of Dense Particle Mixtures via Mask R-CNN. Eng, 3(1), 78-98. https://doi.org/10.3390/eng3010007