
Diagnostic Performance of Artificial Intelligence in Rib Fracture Detection: Systematic Review and Meta-Analysis


Abstract
1. Introduction
1.1. Rationale
1.2. Objectives
2. Materials and Methods
2.1. Protocol and Registration
2.2. Eligibility Criteria
2.3. Information Sources
2.4. Search
2.5. Study Selection
2.6. Data Collection Process
2.7. Data Items
2.8. Risk of Bias in Individual Studies
2.9. Summary Measures
2.10. Synthesis of Results
2.11. Risk of Bias across Studies
2.12. Additional Analyses
3. Results
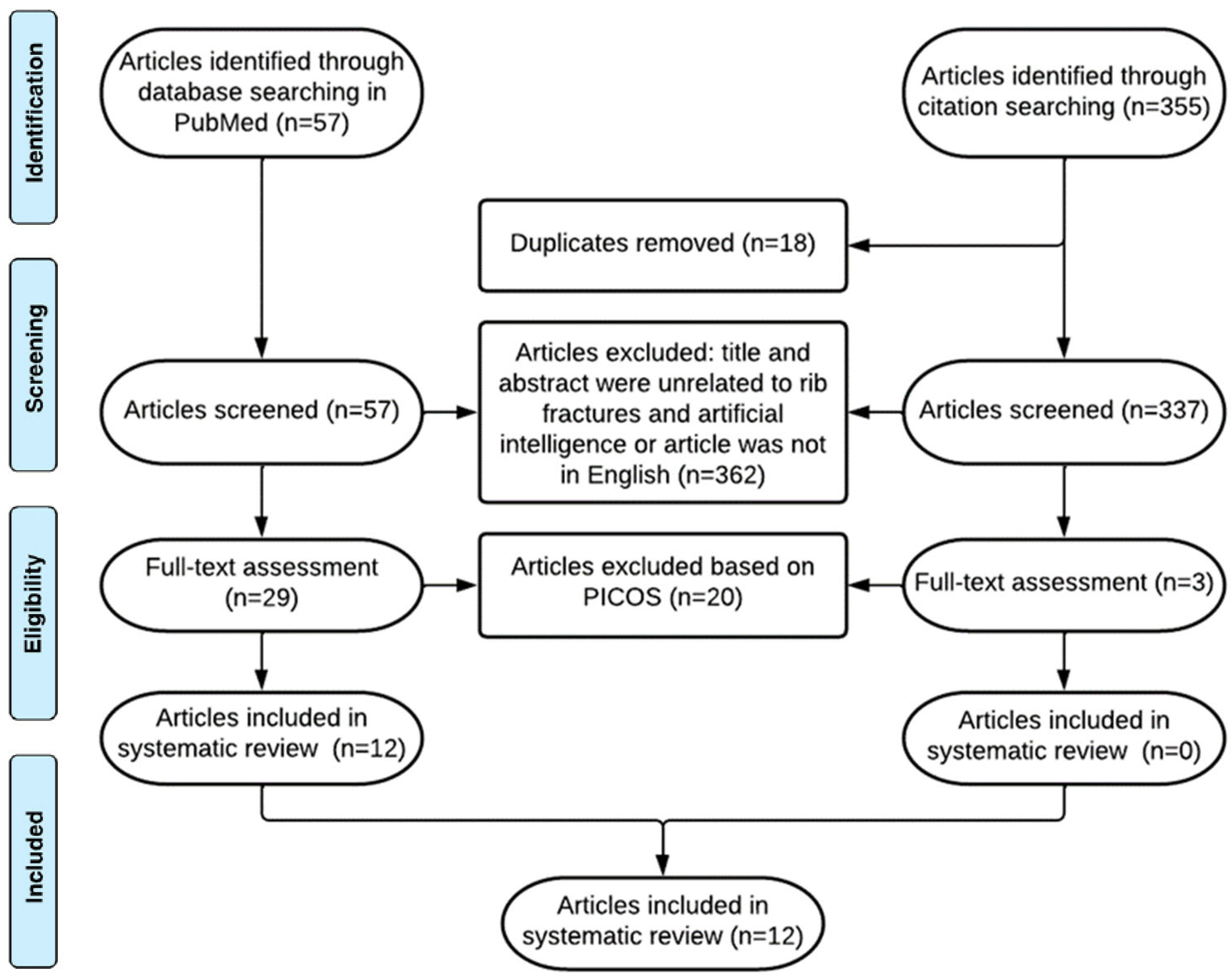
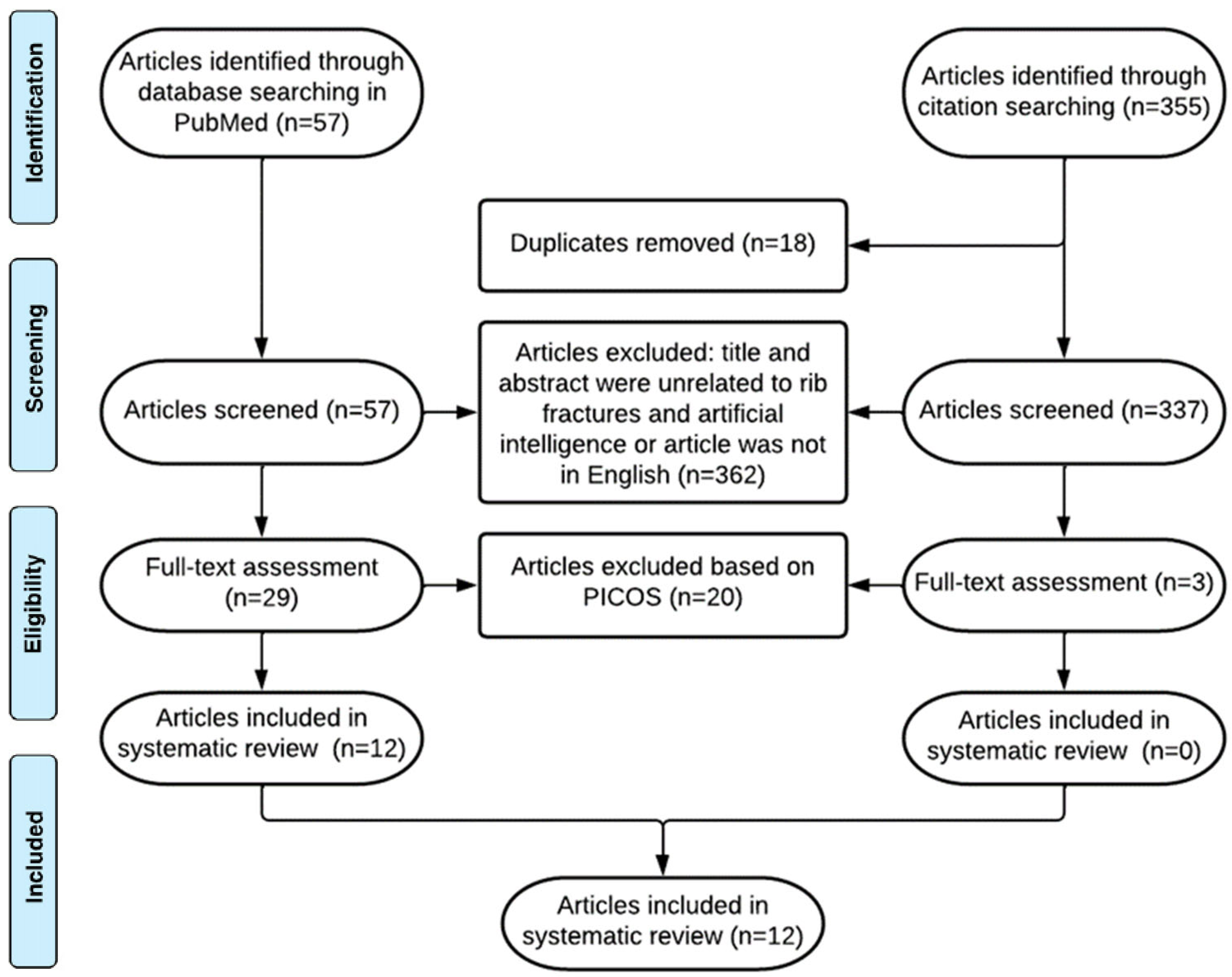
3.1. Study Selection
3.2. Study Characteristics
3.3. Risk of Bias within Studies: Quality Assessment
3.4. Results of Individual Studies
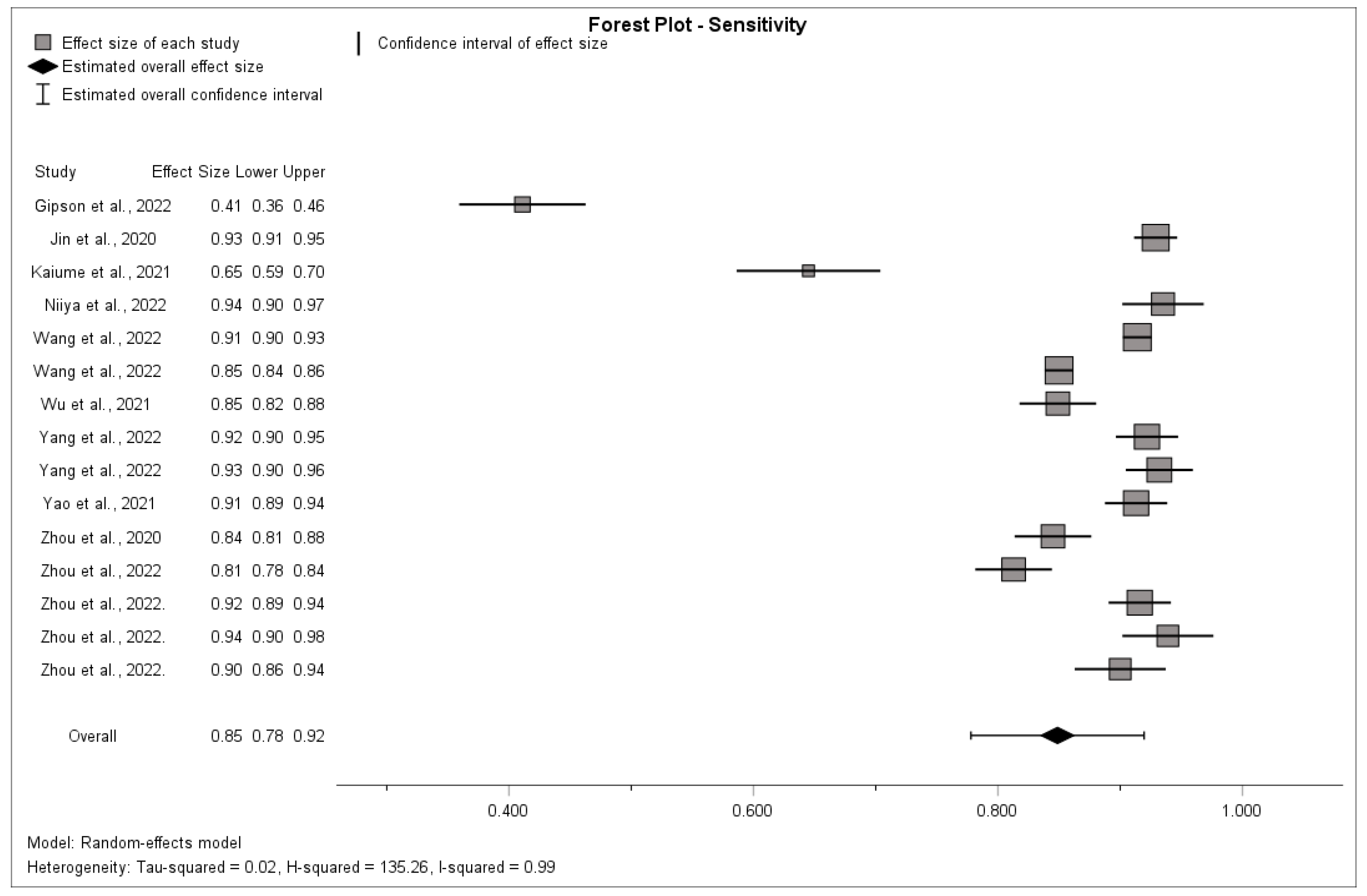
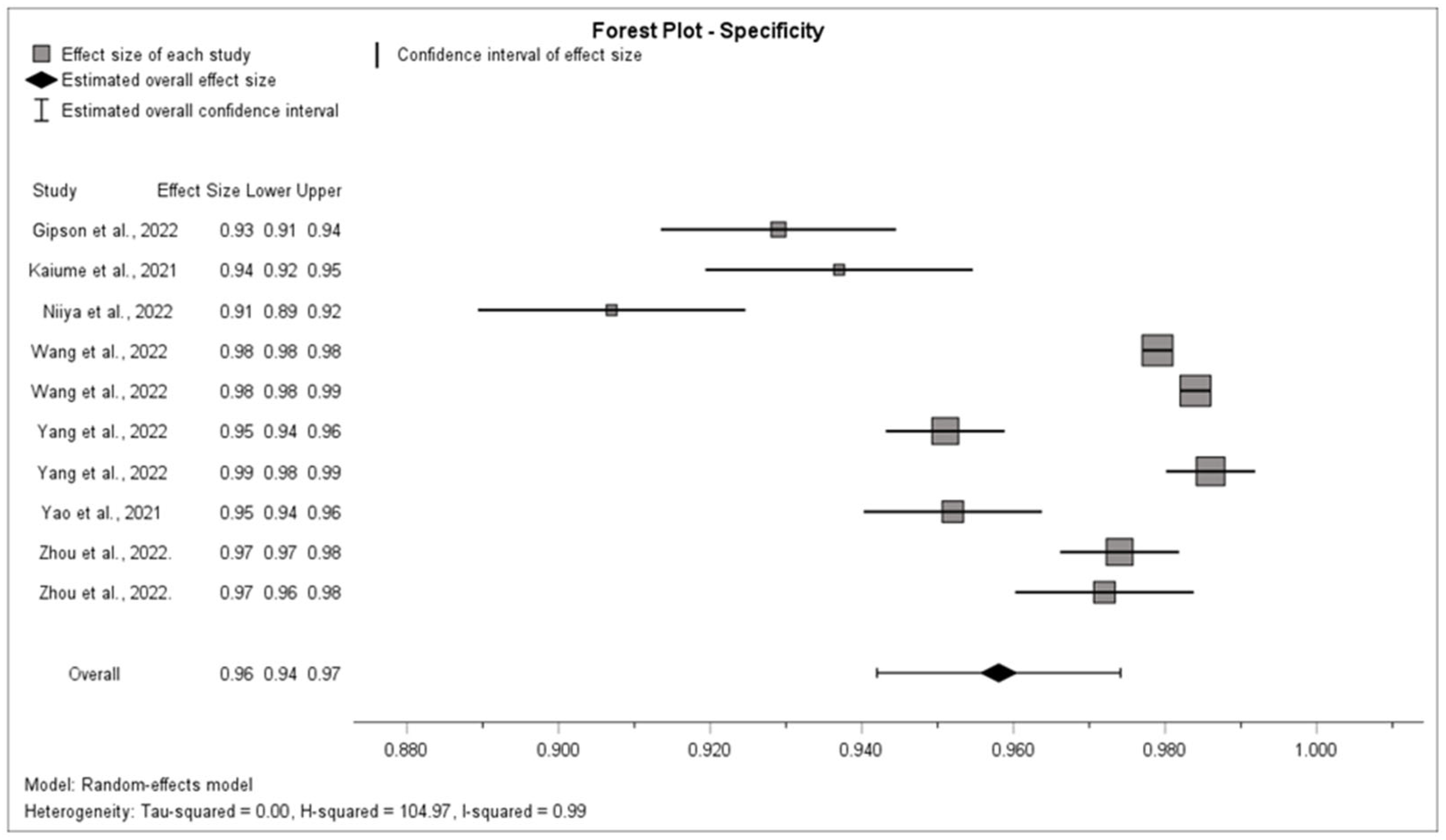
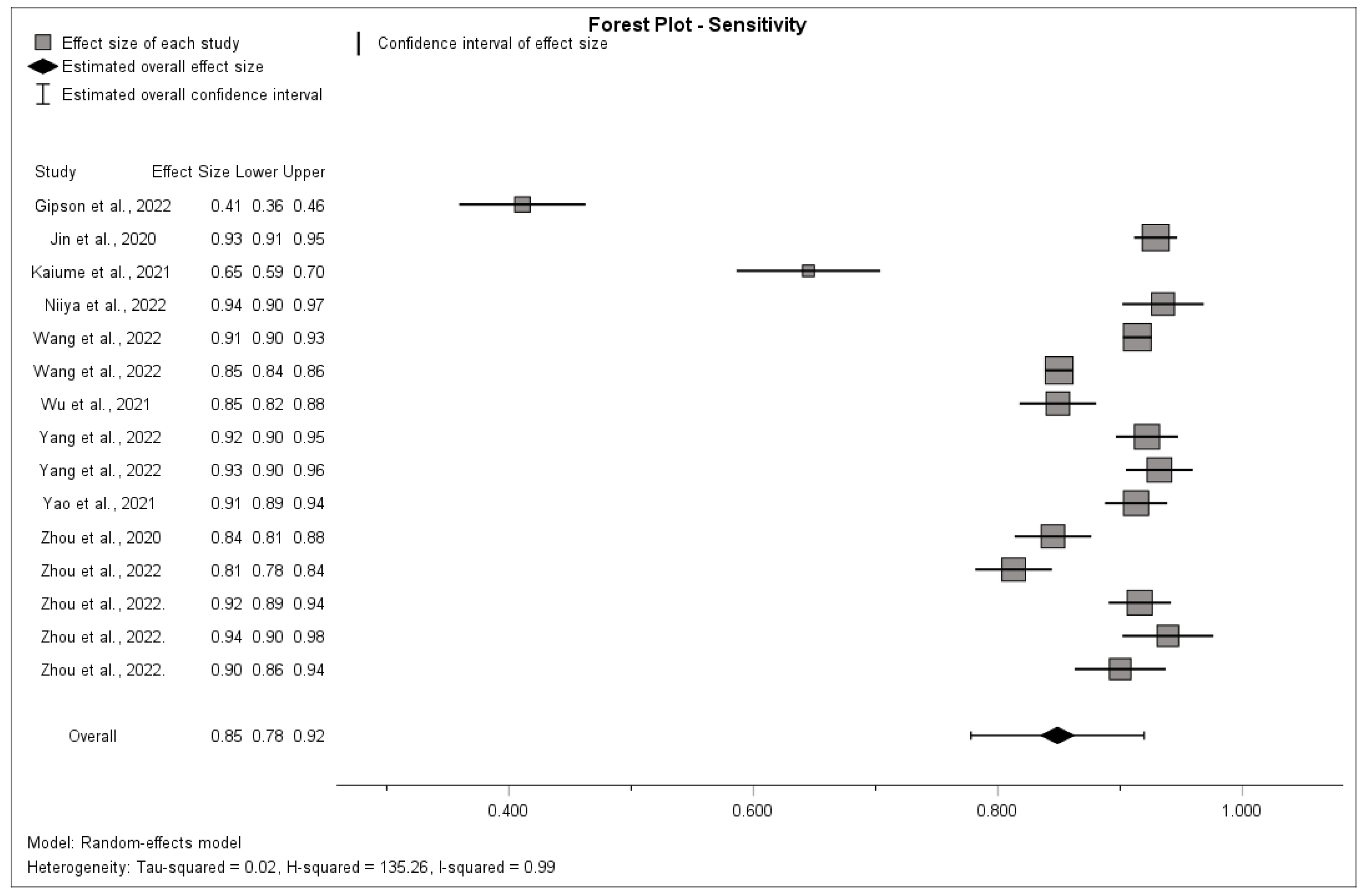
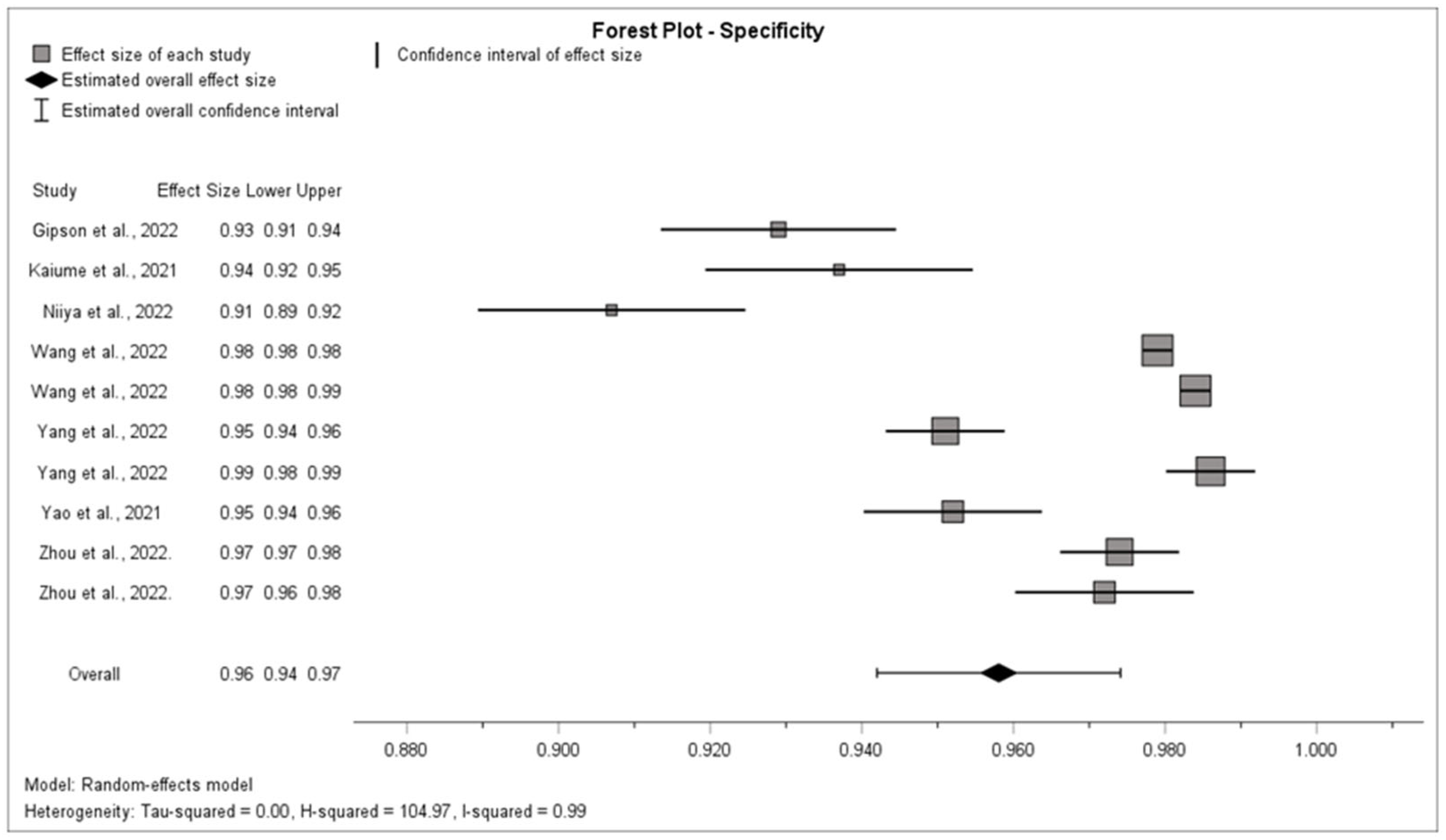
3.5. Synthesis of Results
3.6. Risk of Bias across Studies
3.6.1. Assessment of the Risk of Publication Bias
3.6.2. Assessment of the Risk of Within-Study Selective Reporting
3.7. Additional Analysis
4. Discussion
4.1. Summary of Evidence
4.2. Limitations
4.2.1. Outcome Level
4.2.2. Study and Review Level
5. Conclusions
5.1. Implications for Practice
5.2. Implications for Research
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial intelligence |
| CT | Computer tomography |
| I² | I-square statistic |
| NPV | Negative predictive value |
| PPV | Positive predictive value |
| RCT | Randomized controlled trials |
References
- Ziegler, D.W.; Agarwal, N.N. The morbidity and mortality of rib fractures. J. Trauma 1994, 37, 975–979. [Google Scholar] [CrossRef] [PubMed]
- Marasco, S.; Lee, G.; Summerhayes, R.; Fitzgerald, M.; Bailey, M. Quality of life after major trauma with multiple rib fractures. Injury 2015, 46, 61–65. [Google Scholar] [CrossRef]
- Bulger, E.M.; Arneson, M.A.; Mock, C.N.; Jurkovich, G.J. Rib fractures in the elderly. J. Trauma 2000, 48, 1040–1047. [Google Scholar] [CrossRef] [PubMed]
- Chrysou, K.; Halat, G.; Hoksch, B.; Schmid, R.A.; Kocher, G.J. Lessons from a large trauma center: Impact of blunt chest trauma in polytrauma patients-still a relevant problem? Scand. J. Trauma Resusc. Emerg. Med. 2017, 25, 42. [Google Scholar] [CrossRef] [PubMed]
- Kasotakis, G.; Hasenboehler, E.A.; Streib, E.W.; Patel, N.; Patel, M.B.; Alarcon, L.; Bosarge, P.L.; Love, J.; Haut, E.R.; Como, J.J. Operative fixation of rib fractures after blunt trauma: A practice management guideline from the Eastern Association for the Surgery of Trauma. J. Trauma Acute Care Surg. 2017, 82, 618–626. [Google Scholar] [CrossRef] [PubMed]
- Omert, L.; Yeaney, W.W.; Protetch, J. Efficacy of thoracic computerized tomography in blunt chest trauma. Am. Surg. 2001, 67, 660–664. [Google Scholar] [CrossRef] [PubMed]
- Park, S.H.; Song, H.H.; Han, J.H.; Park, J.M.; Lee, E.J.; Park, S.M.; Kang, K.J.; Lee, J.H.; Hwang, S.S.; Rho, S.C. Effect of noise on the detection of rib fractures by residents. Investig. Radiol. 1994, 29, 54–58. [Google Scholar] [CrossRef]
- Sokolovskaya, E.; Shinde, T.; Ruchman, R.B.; Kwak, A.J.; Lu, S.; Shariff, Y.K.; Wiggins, E.F.; Talangbayan, L. The Effect of Faster Reporting Speed for Imaging Studies on the Number of Misses and Interpretation Errors: A Pilot Study. J. Am. Coll. Radiol. 2015, 12, 683–688. [Google Scholar] [CrossRef]
- Weikert, T.; Winkel, D.J.; Bremerich, J.; Stieltjes, B.; Parmar, V.; Sauter, A.W.; Sommer, G. Automated detection of pulmonary embolism in CT pulmonary angiograms using an AI-powered algorithm. Eur. Radiol. 2020, 30, 6545–6553. [Google Scholar] [CrossRef]
- Nagel, S.; Sinha, D.; Day, D.; Reith, W.; Chapot, R.; Papanagiotou, P.; Warburton, E.A.; Guyler, P.; Tysoe, S.; Fassbender, K.; et al. e-ASPECTS software is non-inferior to neuroradiologists in applying the ASPECT score to computed tomography scans of acute ischemic stroke patients. Int. J. Stroke 2017, 12, 615–622. [Google Scholar] [CrossRef]
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef]
- Gulshan, V.; Peng, L.; Coram, M.; Stumpe, M.C.; Wu, D.; Narayanaswamy, A.; Venugopalan, S.; Widner, K.; Madams, T.; Cuadros, J.; et al. Development and Validation of a Deep Learning Algorithm for Detection of Diabetic Retinopathy in Retinal Fundus Photographs. JAMA 2016, 316, 2402–2410. [Google Scholar] [CrossRef] [PubMed]
- Blum, A.; Gillet, R.; Urbaneja, A.; Gondim Teixeira, P. Automatic detection of rib fractures: Are we there yet? EBioMedicine 2021, 63, 103158. [Google Scholar] [CrossRef] [PubMed]
- Liberati, A.; Altman, D.G.; Tetzlaff, J.; Mulrow, C.; Gotzsche, P.C.; Ioannidis, J.P.A.; Clarke, M.; Devereaux, P.J.; Kleijnen, J.; Moher, D. The PRISMA statement for reporting systematic reviews and meta-analyses of studies that evaluate health care interventions: Explanation and elaboration. PLoS Med. 2009, 6, e1000100. [Google Scholar] [CrossRef] [PubMed]
- Whiting, P.F.; Rutjes, A.W.S.; Westwood, M.E.; Mallett, S.; Deeks, J.J.; Reitsma, J.B.; Leeflang, M.M.G.; Sterne, J.A.C.; Bossuyt, P.M.M. QUADAS-2 Group QUADAS-2: A revised tool for the quality assessment of diagnostic accuracy studies. Ann. Intern. Med. 2011, 155, 529–536. [Google Scholar] [CrossRef] [PubMed]
- Sterne, J.A.C.; Sutton, A.J.; Ioannidis, J.P.A.; Terrin, N.; Jones, D.R.; Lau, J.; Carpenter, J.; Rucker, G.; Harbord, R.M.; Schmid, C.H.; et al. Recommendations for examining and interpreting funnel plot asymmetry in meta-analyses of randomised controlled trials. BMJ 2011, 343, d4002. [Google Scholar] [CrossRef]
- Zhou, Q.; Tang, W.; Wang, J.; Hu, Z.; Xia, Z.; Zhang, R.; Fan, X.; Yong, W.; Yin, X.; Zhang, B.; et al. Automatic detection and classification of rib fractures based on patients’ CT images and clinical information via convolutional neural network. Eur. Radiol. 2021, 31, 3815–3825. [Google Scholar] [CrossRef]
- Zhou, Z.; Fu, Z.; Jia, J.; Lv, J. Rib Fracture Detection with Dual-Attention Enhanced U-Net. Comput. Math. Methods Med. 2022, 2022, 8945423. [Google Scholar] [CrossRef]
- Zhou, Q.; Hu, Z.; Tang, W.; Xia, Z.; Wang, J.; Zhang, R.; Li, X.; Chen, C.; Zhang, B.; Lu, L.; et al. Precise anatomical localization and classification of rib fractures on CT using a convolutional neural network. Clin. Imaging 2022, 81, 24–32. [Google Scholar] [CrossRef]
- Zhou, Q.Q.; Wang, J.; Tang, W.; Hu, Z.C.; Xia, Z.Y.; Li, X.S.; Zhang, R.; Yin, X.; Zhang, B.; Zhang, H. Automatic Detection and Classification of Rib Fractures on Thoracic CT Using Convolutional Neural Network: Accuracy and Feasibility. Korean J. Radiol. 2020, 21, 869–879. [Google Scholar] [CrossRef]
- Yang, C.; Wang, J.; Xu, J.; Huang, C.; Liu, F.; Sun, W.; Hong, R.; Zhang, L.; Ma, D.; Li, Z.; et al. Development and assessment of deep learning system for the location and classification of rib fractures via computed tomography. Eur. J. Radiol. 2022, 154, 110434. [Google Scholar] [CrossRef] [PubMed]
- Yao, L.; Guan, X.; Song, X.; Tan, Y.; Wang, C.; Jin, C.; Chen, M.; Wang, H.; Zhang, M. Rib fracture detection system based on deep learning. Sci. Rep. 2021, 11, 23513–23517. [Google Scholar] [CrossRef] [PubMed]
- Wu, M.; Chai, Z.; Qian, G.; Lin, H.; Wang, Q.; Wang, L.; Chen, H. Development and Evaluation of a Deep Learning Algorithm for Rib Segmentation and Fracture Detection from Multicenter Chest CT Images. Radiol. Artif. Intell. 2021, 3, e200248. [Google Scholar] [CrossRef]
- Wang, S.; Wu, D.; Ye, L.; Chen, Z.; Zhan, Y.; Li, Y. Assessment of automatic rib fracture detection on chest CT using a deep learning algorithm. Eur. Radiol. 2022, 33, 1824–1834. [Google Scholar] [CrossRef] [PubMed]
- Niiya, A.; Murakami, K.; Kobayashi, R.; Sekimoto, A.; Saeki, M.; Toyofuku, K.; Kato, M.; Shinjo, H.; Ito, Y.; Takei, M.; et al. Development of an artificial intelligence-assisted computed tomography diagnosis technology for rib fracture and evaluation of its clinical usefulness. Sci. Rep. 2022, 12, 8363–8365. [Google Scholar] [CrossRef]
- Kaiume, M.; Suzuki, S.; Yasaka, K.; Sugawara, H.; Shen, Y.; Katada, Y.; Ishikawa, T.; Fukui, R.; Abe, O. Rib fracture detection in computed tomography images using deep convolutional neural networks. Medicine 2021, 100, e26024. [Google Scholar] [CrossRef] [PubMed]
- Jin, L.; Yang, J.; Kuang, K.; Ni, B.; Gao, Y.; Sun, Y.; Gao, P.; Ma, W.; Tan, M.; Kang, H.; et al. Deep-learning-assisted detection and segmentation of rib fractures from CT scans: Development and validation of FracNet. EBioMedicine 2020, 62, 103106. [Google Scholar] [CrossRef]
- Gipson, J.; Tang, V.; Seah, J.; Kavnoudias, H.; Zia, A.; Lee, R.; Mitra, B.; Clements, W. Diagnostic accuracy of a commercially available deep-learning algorithm in supine chest radiographs following trauma. Br. J. Radiol. 2022, 95, 20210979. [Google Scholar] [CrossRef]
- Yang, S.; Yin, B.; Cao, W.; Feng, C.; Fan, G.; He, S. Diagnostic accuracy of deep learning in orthopaedic fractures: A systematic review and meta-analysis. Clin. Radiol. 2020, 75, 713.e17–713.e28. [Google Scholar] [CrossRef]
- Kuo, R.Y.L.; Harrison, C.; Curran, T.; Jones, B.; Freethy, A.; Cussons, D.; Stewart, M.; Collins, G.S.; Furniss, D. Artificial Intelligence in Fracture Detection: A Systematic Review and Meta-Analysis. Radiology 2022, 304, 50–62. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
| Criteria | Description |
|---|---|
| P: Population of interest | CT scans or thoracic X-rays of patients that were analyzed for the presence of rib fractures by at least 2 radiologists, which was stated as the reference standard. |
| I: Intervention | Diagnostic detection by an artificial intelligence tool on its own |
| C: Comparison | All comparisons |
| O: Outcome | Number of true positives, true negatives, false positives and false negatives and/or the sensitivity and specificity |
| S: Study type | Diagnostic case–control studies, diagnostic cohort studies and diagnostic RCTs |
| Author, Year | Number of Patients or CT Scans in Dataset 1 | Imaging Modality | Reference Standard | Comparisons | Relevant Outcomes | Type of Study | Quality |
|---|---|---|---|---|---|---|---|
| Gipson et al., 2022 [28] | 1400 | CT | Contemporaneous CT reports | Comparison with reference standard and performance of radiologists using the AI tool | Sensitivity, specificity, TP, FN, FP and TN | Retrospective diagnostic cohort study | High |
| Jin et al., 2020 [27] | 120 | CT | Five radiologists with 3 to 20 years of experience | Comparison with different AI tools | Sensitivity | Retrospective diagnostic cohort study | High |
| Kaiume et al., 2021 [26] | 39 | CT | Two radiologists with 26 and 6 years of image interpretation experience | Diagnostic performance rib fractures of two intern doctors | Sensitivity | Retrospective diagnostic cohort study | High |
| Niiya et al., 2022 [25] | 56 | CT | Two radiologists with 6 and 9 years of experience | Comparison with a reference standard | Sensitivity | Retrospective diagnostic case–control study | High |
| Wang et al., 2022 [24] | 1613 | CT | Two radiologists with at least 9 years of experience, and in case of inconclusion they made consensus with a senior radiologist with at least 20 years of experience | Comparison with six attending radiologists | Sensitivity and specificity | Retrospective diagnostic case–control study | High |
| Wu et al., 2021 [23] | 105 | CT | Three radiologists with 6, 10 and 14 years of experience and one senior radiologist with 18 years of experience | Comparison radiologists who used AI to diagnose | Sensitivity | Retrospective diagnostic case–control study | High |
| Yang et al., 2022 [21] | 120 | CT | Two experienced musculoskeletal radiologists with at least 10 years of experience and a third radiologist was invited to participate if there was a discussion | Comparison with the diagnosis of three radiologists, with 5, 7 and 21 years of experience; those radiologists were not the same as the radiologists who determined the reference standard | Sensitivity, TP, FP, TN and FN | Retrospective diagnostic cohort study | High |
| Yao et al., 2021 [22] | 100 | CT | Three experienced radiologists (over 10 years experience) and checking by two senior radiologists (over 15 years experience) | Comparison of the performance between AI, radiologist and radiologic–AI collaboration | Sensitivity | Retrospective diagnostic cohort study | High |
| Zhou et al., 2020 [20] | 30 | CT | Two experienced musculoskeletal radiologists with 8 and 9 years of experience and two senior radiologists with 20 and 14 years of experience; if the conclusion was inconsistent, one thoracic surgeon was invited to participate in the discussion | Comparison with the performance of five attending radiologists with 6–8 years of experience; there was no overlap between those radiologists and the radiologists who determined the reference standard | Sensitivity and FP | Multicenter retrospective diagnostic case–control study | High |
| Zhou et al., 2021 [17] | 260 | CT | Two experienced musculoskeletal radiologists with 8 and 9 years of experience, two senior radiologists with 20 and 14 years of experience and one thoracic surgeon in case of inconclusion | Five radiologists with 6 to 8 years of experience with no overlap with the radiologists who determined the reference standard | Sensitivity and specificity | Multicenter retrospective diagnostic cohort study | High |
| Zhou et al., 2022 [18] | 164 | CT | Two musculoskeletal radiologists withfive years of experience and one senior musculoskeletal radiologist with more than ten years of experience | Comparison with different AI tools | Sensitivity | Retrospective diagnostic cohort study | Intermediate |
| Zhou et al., 2022. [19] | Internal dataset: 90External dataset: 38 | CT | Two experienced musculoskeletal radiologists (9 and 10 years of experience), two senior radiologists (21 and 15 years of experience) and, in case of doubt, one thoracic surgeon | Comparison with the diagnosis of five radiologists with 7–9 years of CT diagnosis experience which were different from the radiologists who determined the reference standard | Sensitivity, TP, FN and FP | Multicenter retrospective diagnostic cohort study | Intermediate |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
van den Broek, M.C.L.; Buijs, J.H.; Schmitz, L.F.M.; Wijffels, M.M.E. Diagnostic Performance of Artificial Intelligence in Rib Fracture Detection: Systematic Review and Meta-Analysis. Surgeries 2024, 5, 24-36. https://doi.org/10.3390/surgeries5010005
van den Broek MCL, Buijs JH, Schmitz LFM, Wijffels MME. Diagnostic Performance of Artificial Intelligence in Rib Fracture Detection: Systematic Review and Meta-Analysis. Surgeries. 2024; 5(1):24-36. https://doi.org/10.3390/surgeries5010005
Chicago/Turabian Stylevan den Broek, Marnix C. L., Jorn H. Buijs, Liselotte F. M. Schmitz, and Mathieu M. E. Wijffels. 2024. "Diagnostic Performance of Artificial Intelligence in Rib Fracture Detection: Systematic Review and Meta-Analysis" Surgeries 5, no. 1: 24-36. https://doi.org/10.3390/surgeries5010005
APA Stylevan den Broek, M. C. L., Buijs, J. H., Schmitz, L. F. M., & Wijffels, M. M. E. (2024). Diagnostic Performance of Artificial Intelligence in Rib Fracture Detection: Systematic Review and Meta-Analysis. Surgeries, 5(1), 24-36. https://doi.org/10.3390/surgeries5010005