Research on Pavement Crack Detection Based on Random Structure Forest and Density Clustering

Abstract
1. Introduction
2. Research Framework and Algorithms
2.1. Research Framework
2.2. Image Preprocessing
- (1)
- Perform morphological closure operations on the original image to remove road cracks. The brightness of cracks is relatively low. In order to avoid mistakenly dividing cracks into shadow areas and performing brightness compensation, it is necessary to filter out cracks in the road surface image before grading the shadow areas. The image after closed operation is shown in Figure 3.
- (2)
- Perform two-dimensional Gaussian filtering on the image to eliminate the influence of noise and road texture on shadow area division, as shown in Figure 4.
- (3)
- In order to maintain a roughly balanced number of pixels in each shadow area, it is required that the area of each shadow area is not less than 2% of the original image area. The shadow areas are divided into N levels based on brightness, with S lower brightness areas considered as shadow areas and the rest as non-shadow areas, as shown in Figure 5. The red line marked area in Figure 5 is the shaded area.
- (4)
- Use Formula (1) to compensate for the brightness of the pixels in the original image corresponding to each shadow area and obtain the road surface image after removing the shadows, as shown in Figure 6.
- (5)
- Choose to use a median filter with a window size of 3 × 3 to filter the road surface image after eliminating shadows, remove particle noise in the image, and enhance the contrast between cracks and background, as shown in Figure 7.
2.3. Building a Random Structure Forest
- (1)
- Obtain road crack images and corresponding crack segmentation masks. In order to overcome the impact of road surface shadows on the performance of crack detectors, a crack detector is constructed using road surface crack images and the corresponding crack segmentation masks after removing shadows. Using the image processing software Photoshop CS6(13.0.1.3), cracks in road crack images are manually annotated to obtain the crack segmentation mask of the road crack image. The value corresponding to crack pixels is 0, and the value corresponding to non-crack pixels is 1.
- (2)
- Extract channel features from road crack images. Feature extraction is an important factor affecting the performance of crack detectors. Multiple image channels are obtained by performing linear and nonlinear transformations on road crack images, and feature extraction is performed on each channel. This article converts road crack images into the LUV color space to obtain three color channel features. Gaussian difference filtering and Gabor filtering are applied to the crack images to obtain two channel features. The gradient size of the crack image is calculated from the horizontal and vertical directions to generate two channel features. The gradient histograms of the crack image are calculated in each of the eight directions to obtain eight channel features. By performing linear and nonlinear transformations on crack images, a total of 15 channel features were extracted. Figure 9b shows the channel characteristics of the crack image block in the LUV color space.
- (3)
- Using the sliding window method to extract crack image blocks, corresponding channel features, and crack segmentation masks. This section uses a sliding window of size 16 × 16 to extract channel features and structured labels corresponding to image blocks from 15 channel images and crack segmentation masks, where x is the feature matrix of size and y is the binarized image of size. When the central pixel of structured label y is a crack, it is considered a positive sample, and vice-versa, it is considered a negative sample. In order to facilitate the calculation of the information gain of the samples, it is necessary to vectorize the channel features x of the extracted image blocks, transforming the feature matrix of size into a feature vector of size. The sliding window method can be used to extract crack image blocks and the structured labels corresponding to crack image blocks from the image, as shown in Figure 9a,c.
- (4)
- Sample each decision tree to generate a training subset, and each decision tree is trained using a different set of samples. Using the bootstrap sampling method to generate multiple training subsets from the original training set, each with a size of approximately two-thirds of the original training set, results in a certain degree of repetition in the samples in the training subset.
- (5)
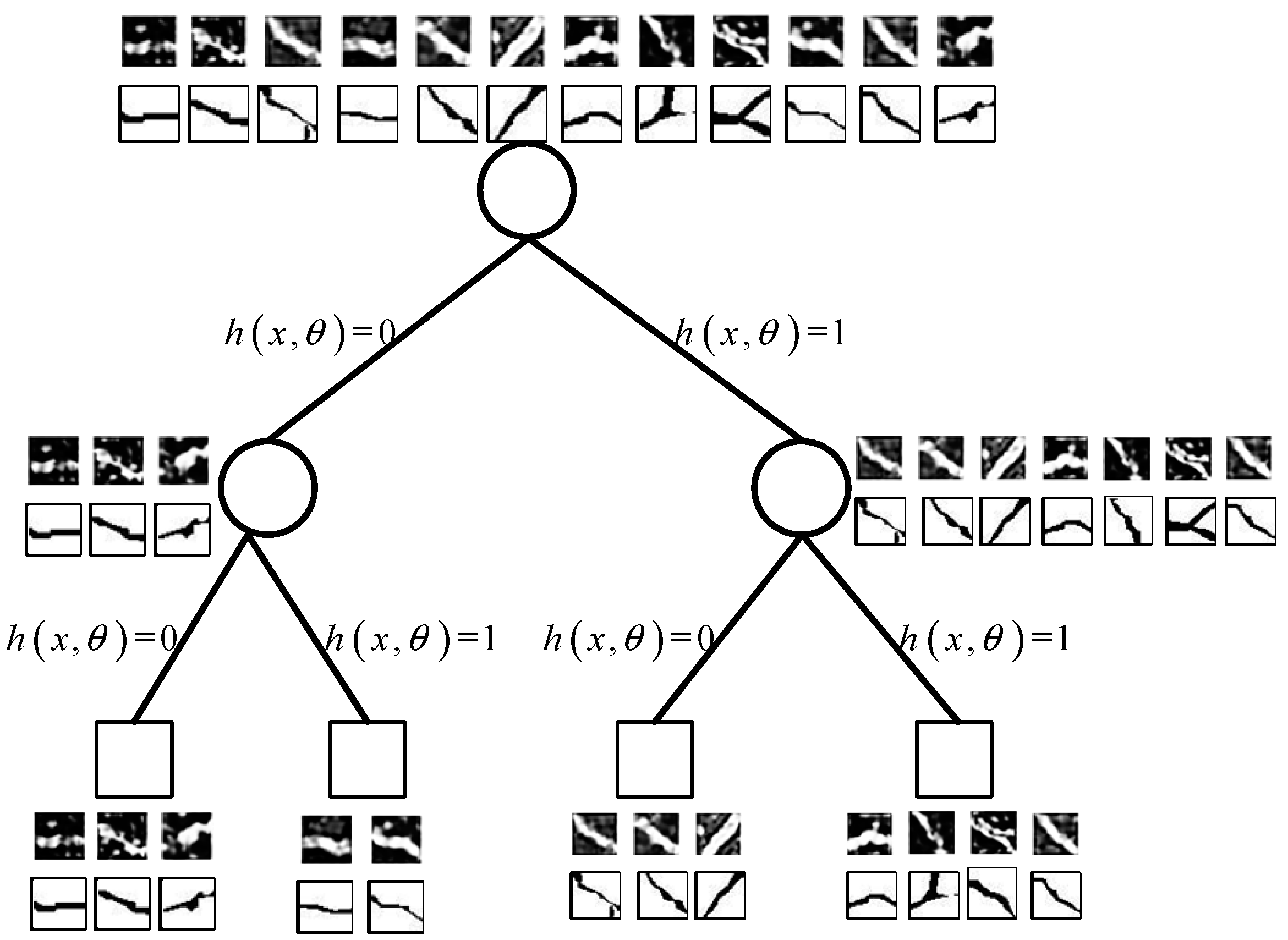
- Construct a random structured forest using the channel features and structured labels of image blocks. The training of decision trees involves constructing prediction results for decision tree nodes (represented by circles in Figure 10) and leaf nodes (represented by rectangles in Figure 10). Constructing a decision tree starts from the root node and initializes the root node first. Node splitting is the core step in constructing a decision tree, and it is through node splitting that a complete decision tree can be generated. Each node corresponds to a binary splitting function . If sample , x reaches the left subtree of that node, and vice-versa, if it reaches the right subtree of that node, the splitting of the decision tree node occurs, as shown in Figure 10. When splitting nodes, the decision tree’s nodes are determined based on the maximum depth of the tree, the minimum number of samples, and the information gain of the samples. If the node no longer splits, it will serve as a leaf node, where the most representative structured label on the node will be used as the predicted result for the leaf node. If the node continues to split, all partitions of each attribute in the random feature subset are sorted according to the information gain, and then the attribute with the highest information gain is selected as the splitting attribute. The samples on the node are divided into samples from the left subtree and samples from the right subtree, and the branching growth of the decision tree is achieved based on their division until the node no longer satisfies the node splitting rule. The last node of each branch is considered a leaf node. For each leaf node, a structured label with the smallest distance from other structured labels as the decision result for that leaf node is selected. The process of constructing a random structure forest is shown in Figure 11.
2.4. Road Crack Recognition Method Based on Density Clustering
- (1)
- Perform binarization on the crack probability map to obtain crack candidate points through threshold segmentation.
- (2)
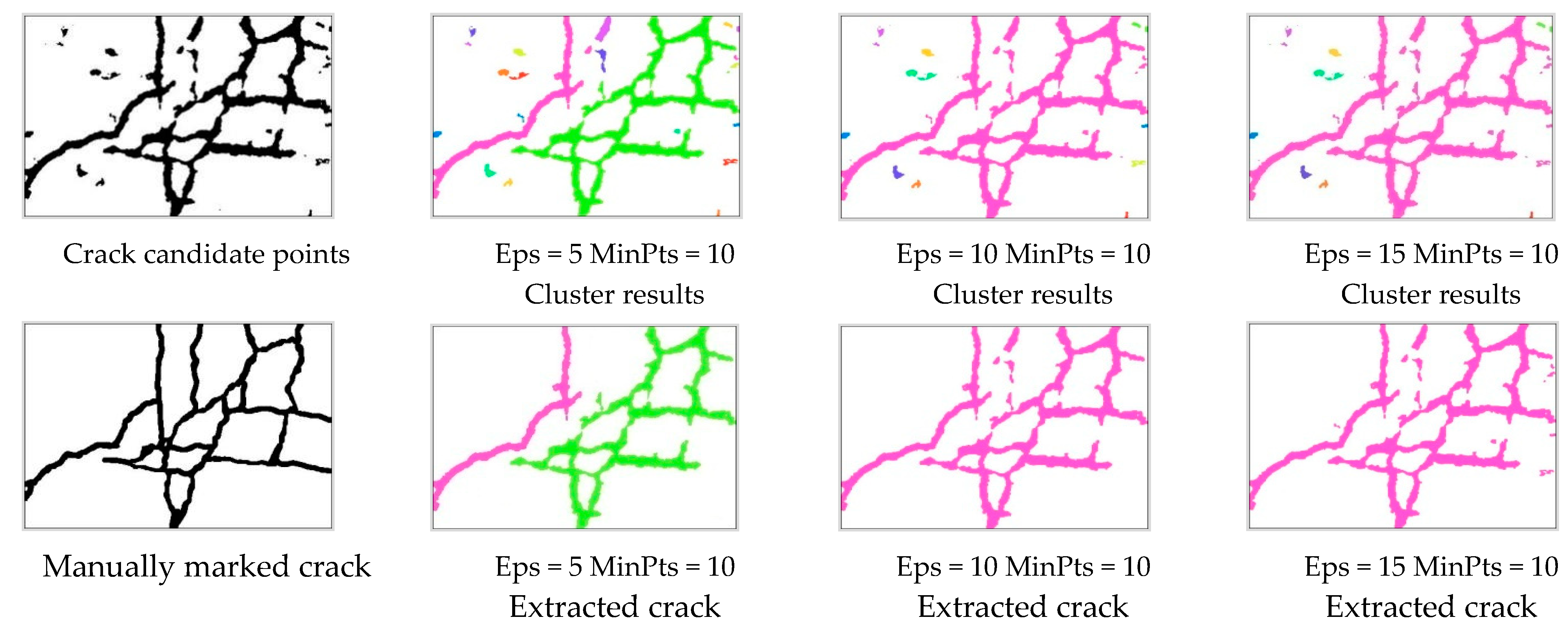
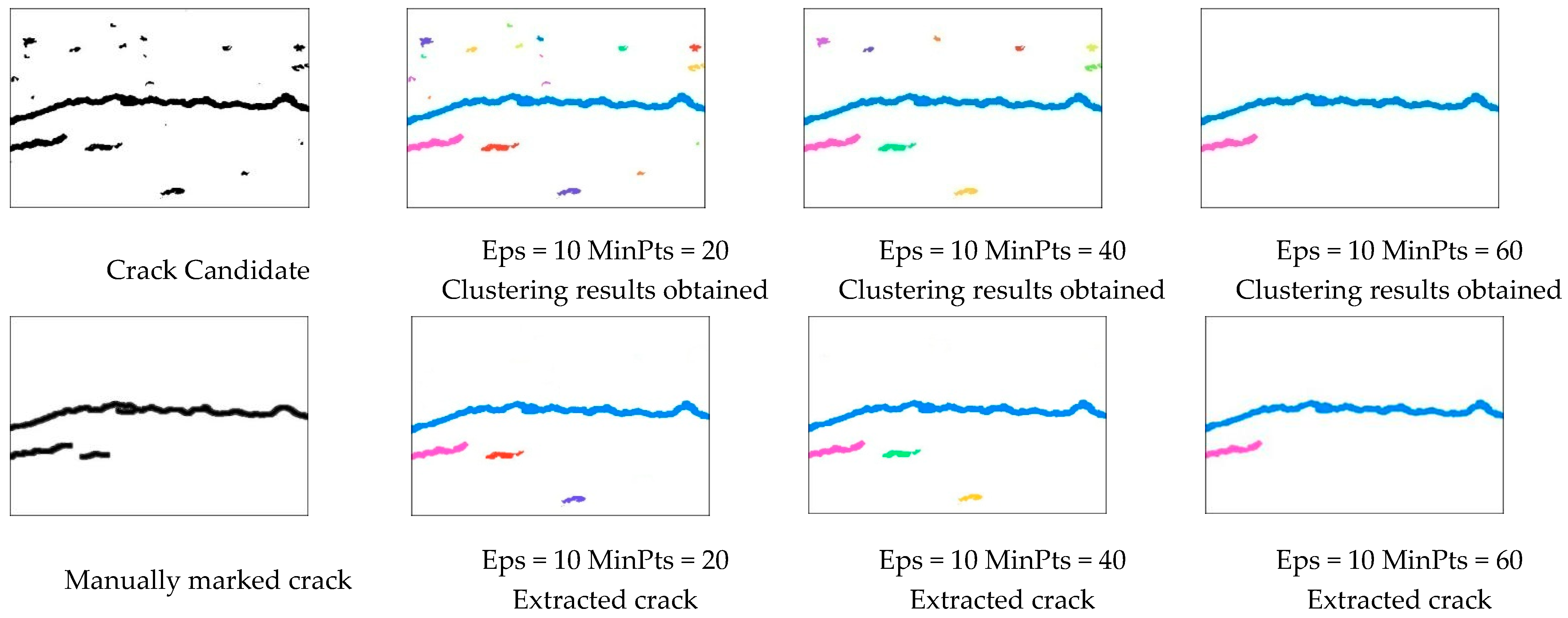
- Perform density clustering on crack candidate points. Take all crack candidate points as a dataset and use the DBSCAN algorithm to cluster the crack candidate points. Firstly, examine a core point in the set of crack candidate points and generate a new object cluster centered on this core point. All data points in the Eps neighborhood of the core point are added to this object cluster, and these data points will serve as the objects to be examined next (referred to as seed points). Continuously explore the Eps neighborhood of seed points, expanding clusters until all density-connected points in the candidate set are identified. Generate other clusters using this method. Crack candidate points that have not been assigned to any cluster are considered noise points. Usually, the density of noise points is smaller than that of crack points; so, the DBSCAN algorithm can automatically filter out noise points and retain crack points by utilizing the density difference of crack points.
- (3)
- Extract the geometric features of each object cluster. The geometric features that need to be extracted mainly include the total number of pixels in the object cluster, the coordinates of extreme points in eight directions, and the pixel ratio between the object cluster and its smallest convex polygon. The total number of pixels in the object cluster reflects the size of the cluster area. By using the coordinates of the extreme points of the object cluster in eight directions, the longest distance of the object cluster in the four directions can be calculated. The pixel ratio between the object cluster and its smallest convex polygon reflects the reliability of the object cluster.
- (4)
- Using geometric features to classify various object clusters and accurately extract surface cracks. Although the DBSCAN algorithm can automatically filter out more scattered crack candidate points, some more concentrated and block-shaped crack candidate points may still be incorrectly clustered into crack clusters. Firstly, the coordinates of the extreme points in 8 directions of each crack cluster are queried so as to calculate the ratio of the shortest distance to the longest distance of each cluster. Taking advantage of the linear characteristics of road cracks, clusters with a ratio of the shortest distance to the longest distance greater than a specified threshold are identified as noise, thereby filtering out the true cracks and improving recognition accuracy.
3. Test Results
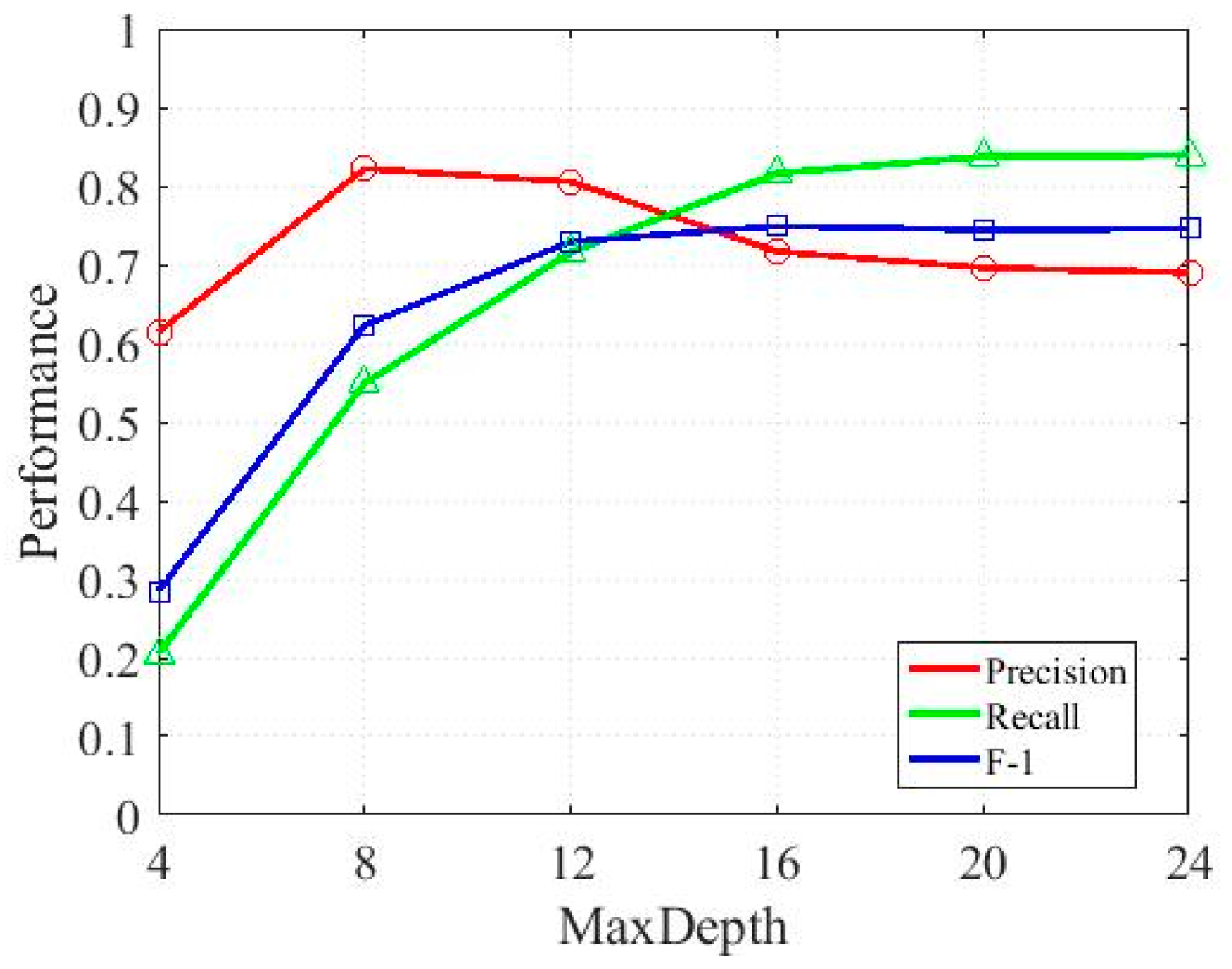
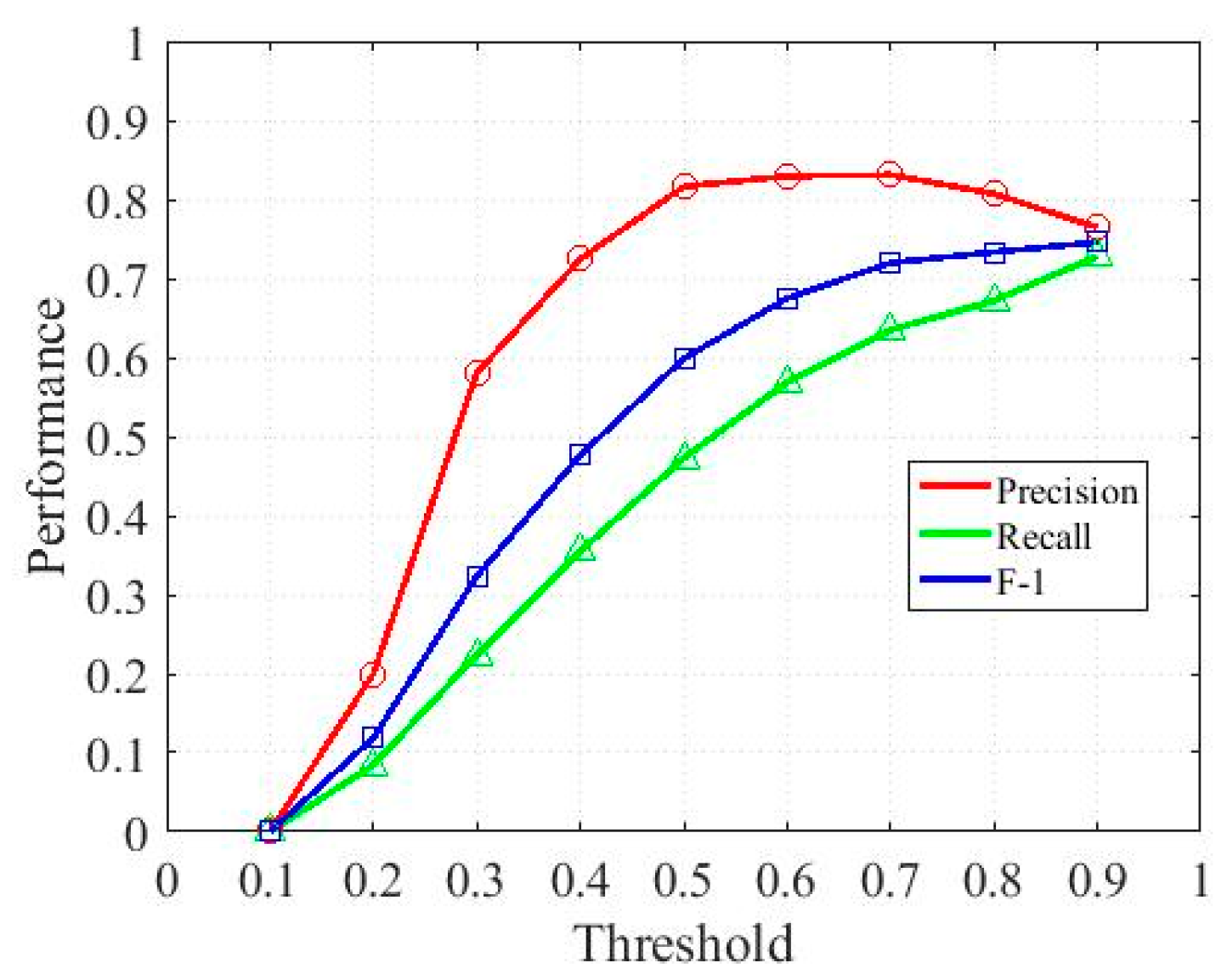
3.1. Impact of Key Parameters
3.2. Test Results of Test Set
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Munawar, H.S.; Hammad, A.W.; Haddad, A.; Soares, C.A.P.; Waller, S.T. Image-based crack detection methods: A review. Infrastructures 2021, 6, 115. [Google Scholar] [CrossRef]
- Amhaz, R.; Chambon, S.; Idier, J.; Baltazart, V. Automatic crack detection on two-dimensional pavement images: An algorithm based on minimal path selection. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2718–2729. [Google Scholar] [CrossRef]
- Walubita, L.F.; Faruk, A.N.; Zhang, J.; Hu, X. Characterizing the cracking and fracture properties of geosynthetic interlayer reinforced HMA samples using the Overlay Tester (OT). Constr. Build. Mater. 2015, 93, 695–702. [Google Scholar] [CrossRef]
- Oliveira, H.; Correia, P.L. Automatic road crack detection and characterization. IEEE Trans. Intell. Transp. Syst. 2012, 14, 155–168. [Google Scholar] [CrossRef]
- Walubita, L.F.; Mahmoud, E.; Lee, S.I.; Carrasco, G.; Komba, J.J.; Fuentes, L.; Nyamuhokya, T.P. Use of grid reinforcement in HMA overlays–A Texas field case study of highway US 59 in Atlanta District. Constr. Build. Mater. 2019, 213, 325–336. [Google Scholar] [CrossRef]
- Han, C.; Ma, T.; Ju, H.; Huang, X.; Zhang, Y. CrackW-Net: A novel pavement crack image segmentation convolutional neural network. IEEE Trans. Intell. Transp. Syst. 2021, 23, 22135–22144. [Google Scholar] [CrossRef]
- Chen, F.C.; Jahanshahi, M.R. NB-CNN: Deep Learning-based Crack Detection Using Convolutional Neural Network and Naïve Bayes Data Fusion. IEEE Trans. Ind. Electron. 2018, 65, 4392–4400. [Google Scholar] [CrossRef]
- Liao, Y.P.; Wang, W.X. Improved Graph MST-Based Image Segmentation with Non-Subsampled Contourlet Transform. Huanan Ligong Daxue Xuebao/J. South China Univ. Technol. Nat. Sci. 2017, 45, 143–152. [Google Scholar]
- Kahmann, S.L.; Rausch, V.; Plümer, J.; Müller, L.P.; Pieper, M.; Wegmann, K. The automized fracture edge detection and generation of three-dimensional fracture probability heat maps. Med. Eng. Phys. 2022, 110, 103913. [Google Scholar] [CrossRef]
- Xu, D.; Zhao, Y.; Jiang, Y.; Zhang, C.; Sun, B.; He, X. Using Improved Edge Detection Method to Detect Mining-Induced Ground Fissures Identified by Unmanned Aerial Vehicle Remote Sensing. Remote Sens. 2021, 13, 3652. [Google Scholar] [CrossRef]
- Xu, D.; Zhao, Y.; Jiang, Y.; Zhang, C.; Sun, B.; He, X. An image enhancement algorithm to improve road tunnel crack transfer detection. Constr. Build. Mater. 2022, 348, 128583. [Google Scholar]
- Liu, X.; Ai, Y.; Scherer, S. Robust image-based crack detection in concrete structure using multi-scale enhancement and visual features. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 2304–2308. [Google Scholar]
- Peng, C.; Yang, M.; Zheng, Q.; Zhang, J.; Wang, D.; Yan, R.; Wang, J.; Li, B. A triple-thresholds pavement crack detection method leveraging random structured forest. Constr. Build. Mater. 2020, 263, 120080. [Google Scholar] [CrossRef]
- Shen, L.; Wee Chua, T.; Leman, K. Shadow optimization from structured deep edge detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 2067–2074. [Google Scholar]
- Landabaso, J.L.; Pardàs, M.; Xu, L.Q. Shadow removal with morphological reconstruction. In Proceedings of the Jornades de Recerca en Automàtica, Barcelona, Spain, 4–6 July 2020. [Google Scholar]
- Gong, H.; Cosker, D. User-assisted image shadow removal. Image Vis. Comput. 2017, 62, 19–27. [Google Scholar] [CrossRef]
- Khan, S.H.; Bennamoun, M.; Sohel, F.; Togneri, R. Automatic shadow detection and removal from a single image. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 431–446. [Google Scholar] [CrossRef]
- Liu, S.; Chen, M.; Li, Z.; Liu, J.; He, M. A differential correction based shadow removal method for real-time monitoring. PLoS ONE 2023, 18, e0276284. [Google Scholar] [CrossRef]
- Wang, H.; Zou, H.; Zhang, D. Attentive Generative Adversarial Network with Dual Encoder-Decoder for Shadow Removal. Information 2022, 13, 377. [Google Scholar] [CrossRef]
- Jongwoo, H.; Dongsoo, K.; Minsoo, K. Assessing severity of road cracks using deep learning-based segmentation and Detection. J. Supercomput. 2022, 78, 17721–17735. [Google Scholar]
- Zhao, G.; Wang, T.; Ye, J. Anisotropic clustering on surfaces for crack extraction. Mach. Vis. Appl. 2015, 26, 675–688. [Google Scholar] [CrossRef]
- Zheng, Q.; Tian, X.; Yang, M.; Wu, Y.; Su, H. Pac-bayesian framework based droppath method for 2d discriminative convolutional network pruning. Multidimens. Syst. Signal Process. 2020, 31, 793–827. [Google Scholar] [CrossRef]
- Li, R.; Yu, J.; Li, F.; Yang, R.; Wang, Y.; Peng, Z. Automatic bridge crack detection using Unmanned aerial vehicle and Faster R-CNN. Constr. Build. Mater. 2023, 362, 129659. [Google Scholar] [CrossRef]
- Yan, B.F.; Xu, G.Y.; Luan, J.; Lin, D.; Deng, L. Pavement distress detection based on faster r-cnn and morphological operations. China J. Highw. Transp. 2021, 34, 181. [Google Scholar]
- Tran, T.S.; Tran, V.P.; Lee, H.J.; Flores, J.M.; Le, V.P. A two-step sequential automated crack detection and severity classification process for asphalt pavements. Int. J. Pavement Eng. 2022, 23, 2019–2033. [Google Scholar] [CrossRef]
- Liu, Z.; Yeoh, J.K.; Gu, X.; Dong, Q.; Chen, Y.; Wu, W.; Wang, L.; Wang, D. Automatic pixel-level detection of vertical cracks in asphalt pavement based on GPR investigation and improved mask R-CNN. Autom. Constr. 2023, 146, 104689. [Google Scholar] [CrossRef]
- Nguyen, N.H.T.; Perry, S.; Bone, D.; Le, H.T.; Nguyen, T.T. Two-stage convolutional neural network for road crack detection and segmentation. Expert Syst. Appl. 2021, 186, 115718. [Google Scholar] [CrossRef]
- Hou, Y.; Chen, Y.H.; Gu, X.Y.; Mao, Q.; Cao, D.D.; Wang, L.B.; Jing, P. Automatic Indentification of Pavament Objects and Cracks Using the Convolutional Auto-encoder. China J. HighW. Transp. 2020, 33, 288–303. [Google Scholar]
- Liu, P.; Yuan, J.; Chen, S. A road damage segmentation method for complex environment based on improved UNet. In Proceedings of the International Conference on Image and Graphics, Beijing China, 19–21 January 2023; Springer Nature: Cham, Switzerland, 2023; pp. 332–343. [Google Scholar]
- Sun, X.; Xie, Y.; Jiang, L.; Cao, Y.; Liu, B. DMA-Net: DeepLab with multi-scale attention for pavement crack segmentation. IEEE Trans. Intell. Transp. Syst. 2022, 23, 18392–18403. [Google Scholar] [CrossRef]
- Shi, Y.; Cui, L.; Qi, Z.; Meng, F.; Chen, Z. Automatic Road Crack Detection Using Random Structured Forests. IEEE Trans. Intell. Transp. Syst. 2016, 17, 3434–3445. [Google Scholar] [CrossRef]
- Nowozin, S.; Lampert, C.H. Structured Learning and Prediction in Computer Vision., Found. Trends® Comput. Graph 2010, 6, 185–365. [Google Scholar] [CrossRef]
- Kontschieder, P.; Bulò, S.R.; Bischof, H.; Pelillo, M. Structured class-labels in random forests for semantic image labelling. IEEE Int. Conf. Comput. Vis. ICCV 2011, 11, 6–13. [Google Scholar]
- Dollar, P.; Zitnick, C.L. Fast Edge Detection Using Structured Forests. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1558–1570. [Google Scholar] [CrossRef]
- Xu, Z.; Che, Y.; Min, H.; Wang, Z.; Zhao, X. Initial Classification Algorithm for Pavement Distress Images Using Features Fusion; Springer International Publishing AG: Cham, Switzerland, 2019; pp. 418–427. [Google Scholar]
- Zhang, D. Crack detection for bituminous pavements based on cluster and minimum spanning tree. Zhongshan Daxue Xuebao/Acta Sci. Natralium Univ. Sunyatseni. 2017, 56, 68–74. [Google Scholar]
- Dollár, P.; Zitnick, L.C. Structured Forests for Fast Edge Detection. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1841–1848. [Google Scholar]
- Kremers, B.J.; Citrin, J.; Ho, A.; van de Plassche, K.L. Two-step clustering for data reduction combining DBSCAN and k-means clustering. Contrib. Plasma Phys. 2023, 63, e202200177. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Precision | Recall | F-1 |
|---|---|---|---|
| CrackForest | 0.558 | 0.76 | 0.643 |
| UNet++ | 0.796 | 0.754 | 0.774 |
| Deeplabv3+ | 0.823 | 0.792 | 0.807 |
| Proposed method | 0.874 | 0.839 | 0.856 |
| Method | Precision | Recall | F-1 |
|---|---|---|---|
| CrackForest | 0.635 | 0.717 | 0.674 |
| UNet++ | 0.789 | 0.766 | 0.777 |
| Deeplabv3+ | 0.821 | 0.786 | 0.803 |
| Proposed method | 0.846 | 0.826 | 0.836 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Wang, X.; Li, J.; Liang, W.; Bi, C. Research on Pavement Crack Detection Based on Random Structure Forest and Density Clustering. Automation 2024, 5, 467-483. https://doi.org/10.3390/automation5040027
Wang X, Wang X, Li J, Liang W, Bi C. Research on Pavement Crack Detection Based on Random Structure Forest and Density Clustering. Automation. 2024; 5(4):467-483. https://doi.org/10.3390/automation5040027
Chicago/Turabian StyleWang, Xiaoyan, Xiyu Wang, Jie Li, Wenhui Liang, and Churan Bi. 2024. "Research on Pavement Crack Detection Based on Random Structure Forest and Density Clustering" Automation 5, no. 4: 467-483. https://doi.org/10.3390/automation5040027
APA StyleWang, X., Wang, X., Li, J., Liang, W., & Bi, C. (2024). Research on Pavement Crack Detection Based on Random Structure Forest and Density Clustering. Automation, 5(4), 467-483. https://doi.org/10.3390/automation5040027