1. Introduction
Renewable energy has always piqued humanity’s interest. Given the problems of global warming and finite fossil fuel reserves, everyone is looking for a dependable and renewable energy source. Renewable energy has the potential to replace carbon-based fossil fuels as the primary energy source for future cities. Given recent rapid global urbanization, it is now more important than ever to incorporate clean renewable energy sources in order to reduce environmental damage while also ensuring reliable and sustainable population growth in the coming decades. As a result, there has been a massive increase in renewable energy installations in recent years, including solar, wind, and geothermal energy facilities. This is especially noticeable when using electricity instead of natural fuels. Solar energy, wind energy, and hydro energy are the primary sources of renewable energy. Solar energy plants have numerous advantages, including increased longevity, environmental friendliness, quiet operation, and cleanliness.
With solar energy being a major source of renewable energy, the market for PV (photovoltaic) plants, also known as solar plants, is rapidly expanding. PV plant expansion has reached 35% in the last decade. According to the data, new solar installations account for 55% of this new capacity, with Asia accounting for 70%. GCC desert-climate countries like the UAE and Saudi Arabia are major solar energy investors in the region. With an average daily sunshine of 10 h per day and a Global Horizontal Irradiance index (GHI) of 2.12 MWh/m2/year, such countries have the potential to generate massive amounts of solar power, which could eventually replace their current reliance on carbon-based fossil fuels. Nonetheless, the integration of solar energy sources into main grids remains relatively low. In the United Arab Emirates, for example, 22.5 MW of installed solar capacity amounts to only 0.49% of total capacity. Despite the GCC’s recent exponential growth in new solar installations, a 100% renewable energy grid remains a long-term goal. This is primarily because desert solar installations face challenges such as overheating and soiling. As a result, significant research efforts have been devoted to improving and optimizing the performance of solar modules in such environments.
Because of the advent of new technologies, there is currently a lot of interest in autonomous monitoring for PV systems. Aerial robots have been used to inspect utility-scale PV plants in recent years. Many efforts have been expended in order to create a dependable and cost-effective aerial monitoring system for maximum productivity in PV plant inspection. The high return on investment of solar panels, as well as the low production costs of PV panels, are important factors in this. The market for PV plants is exploding as a result of the proposal of using carbon credits to reduce carbon emissions and thus global warming, as well as increased government subsidies around the world.
As usage grows, so does the need for upkeep. Major issues in PV plants include inverter failure due to voltage differences and poor PV module performance. A variety of factors can influence PV module performance. Among them are PV panel build quality, environmental conditions, installation location, and height. Because PV panels are typically installed on roofs or farms, expert maintenance is required under extremely demanding working conditions. Weather fluctuations reflect the intermittent nature of weather conditions, which can propagate through main girds, causing power planning inconvenience at best and critical asset damage at worst. Furthermore, solar modules are frequently installed in remote and harsh environments, making them vulnerable to environmental damage such as overheating, surface scratching, and material decay. Such faults can cause serious issues such as module mismatch or open circuits, significantly reducing an installation’s power output. Furthermore, once a solar installation is connected to the grid, it is critical that the system is always aware of the installation’s status and output in order to ensure reliable power planning. PV maintenance is frequently associated with high costs and a lengthy process. Professional personnel are expected to need up to 8 h to inspect each megawatt of power generated by the panels. This is one of the most important factors influencing PV plant growth.
Many tasks, including farm maintenance, delivery of goods, and high-altitude maintenance, have benefited greatly from the use of drones and UAVs (Unmanned Aerial Vehicles). A lot of work has been carried out that proposes the use of UAVs and drones to automate, at least to some extent, the maintenance of PV plants. As a result, research teams are currently working on developing equipment that can automatically inspect and clean PV systems. UAVs can enable automatic evaluation and tracking at a lower cost, cover larger areas, and detect threats faster than the traditional method of PV plant maintenance, which involves trained personnel manually inspecting and cleaning the surface of PV plants. UAVs (Unmanned Aerial Vehicles) have recently been proposed for PV inspections. Over the last few decades, research has made significant advances in the development of Unmanned Aerial Vehicles (UAVs) for monitoring applications such as power transmission lines, gas and oil pipeline inspection, precision agriculture, and bridge inspection. Indeed, the ability of multirotor UAVs to hover and freely move in the air, as well as the ease with which they can be piloted and outfitted with various sensors, makes this technology very appealing in monitoring scenarios.
UAV cameras photograph the area of the photovoltaic system, which can then be identified using image analysis in a process known as border extraction. Based on the estimated boundary, the UAVs can use CPP to compute a path to cover the panels (Coverage Path Planning). It is not possible to fly precisely over all of the PV plants. The path planning algorithm requires the maximum and minimum dimensions of the PV plants in both the horizontal and vertical axes. Based on the shape of the panel and the surrounding environment, a few points are identified as pivot points in CPP. To connect the pivot points and thus cover the PV panels, tracks are calculated. Once the CPP is completed, a flight zone is assigned to a UAV equipped with a GPS receiver and an Inertial Measurement Unit (IMU). The drone can cover the entire panel area and detect and repair some defects depending on the equipment installed in the UAV. PV plants which are partially covered in dust, snow, or leaves, for example, could be cleaned. UAVs can also detect and repair cracks in PV plants’ surfaces automatically. More manual maintenance areas can be identified, and the necessary maintenance can be automatically scheduled.
To improve monitoring accuracy during diagnosis using machine learning algorithms, massive amounts of data from various PV systems are required for autonomous monitoring. The maintenance of PV plants is critical to the profitability of energy production, and the autonomous inspection of such systems is a promising technology, particularly for large utility-scale plants where manned techniques face significant time, cost, and performance constraints. Sensors mounted on an aerial robot can capture typical aerial imagery consisting of RGB and infrared (IR) images during PV plant inspection to systematically detect the borders of PV plants.
The goal of this work is to develop a dependable and simple technique for identifying PV plant boundaries and detecting panel defects in comparison to the currently available techniques for detecting PV plant boundaries. Previous studies are concerned with establishing boundaries using advanced image processing techniques. This necessitates the use of a variety of filters and edge detection techniques. Because deep learning on images is currently so popular, newer works rely heavily on large and complex neural network architectures. The goal of this work is to combine the two major methods by applying image processing techniques to the data and developing a lightweight neural network to detect the boundaries based on the processed images.
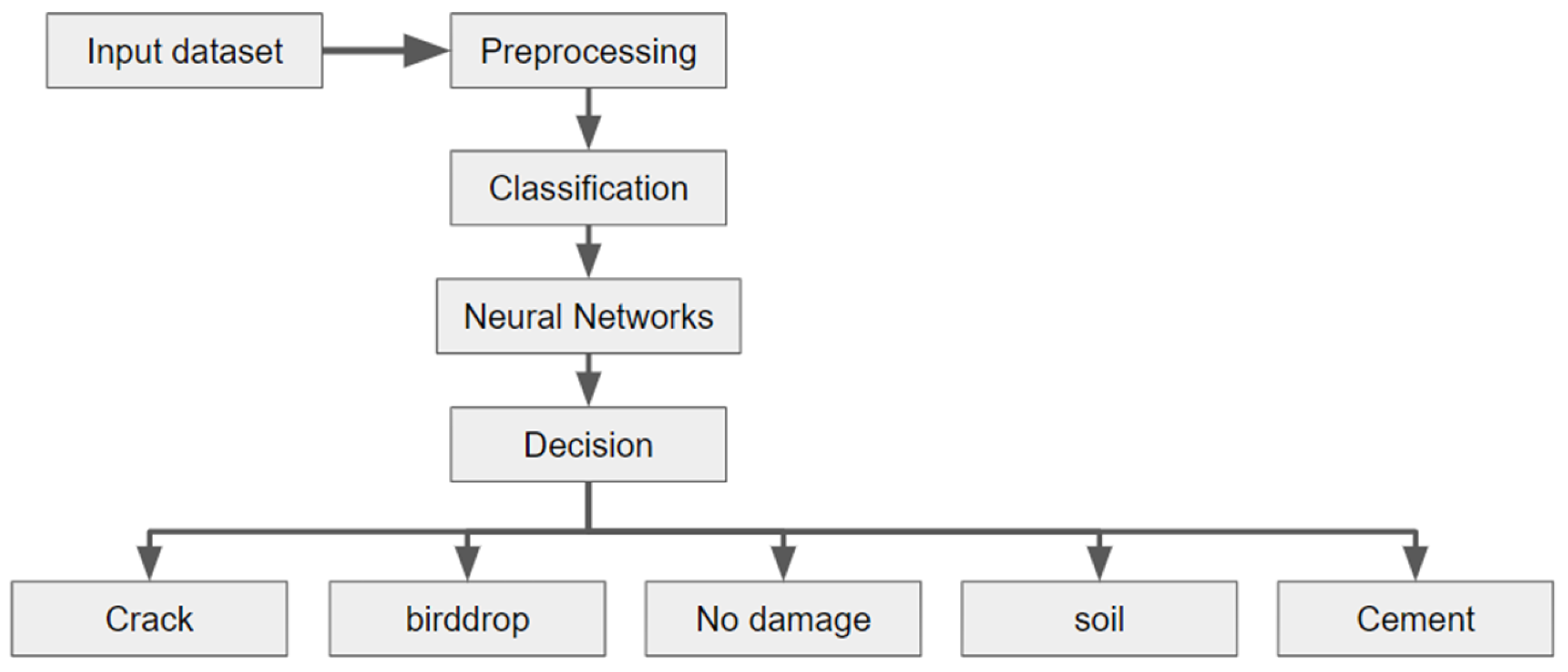
It is well understood that any type of damage to the solar panel surface affects the efficiency of a solar panel. When even the solar panel is damaged, the amount of power it generates reduces; the extent of this reduction depends on the nature of the damage. There are many kinds of damage that a solar panel can experience. For instance, due to weather conditions, solar panels may be covered with snow, soil, cement, etc. Bird droppings on solar panels can not only cover the panel, but also damage the surface of the solar panel by reacting with the panel materials. Cracks on solar panels are very common; they may occur due to impacts from falling objects such as stones or even ice. Thus, for the effective monitoring of solar panels, having a damage detection system is vital.
1.1. Literature Review
Andres Perez et al. [
1] proposed a deep learning-based model for boundary estimation. The major aim of their work was to predict a mask that semantically identified the PV panels in a given aerial image. They extensively discussed the various techniques used to solve this task of edge detection and showed how their implementation mostly overcame the drawbacks of the existing approaches. In terms of data, they worked on the “Amir” dataset. The input for their model was an RGB image captured by a UAV. The model predicted a set of ones and zeros equal to the dimensions of the input image. The high areas indicated the presence of a PV plant. Their model was able to achieve a mean IOU of around 90%, which is accurate enough. Yet, we find that there is scope for improvement here as well. In terms of the complexity of the model, they used a UNet implementation for this task. UNet is a state-of-the-art architecture for medical image semantic segmentation which has recently been widely used for other tasks as well. Sizkouhi et al. [
2] proposed an encoder–decoder architecture for the detection of faults in PV plants. Their work majorly focused on identifying bird droppings on panels and estimating the severity of bird droppings on the performance of PV modules. Their encoder–decoder architecture is very similar to that of UNet; indeed, they both use VGG as a backbone. Though their task also involved identifying PV plants, not much data were provided on their efficiency while doing so. But they claim that their model was able to achieve a pixel accuracy of around 93% when identifying bird dropping areas on the panels. Based on the area of the patch, i.e., the number of pixels predicted to be bird droppings, they predicted the severity of the effects of the blockage on the PV modules’ performance.
Ramirez, Isacc et al. [
3] proposed a novel condition monitoring system to accurately identify hot spots, i.e., possible fault areas, in PV panels. Their method achieved a testing accuracy of 93%. In their work, they used two ANNs for identifying the hot spots. They proposed an IOT platform approach that inputs the data from a thermal camera fitted on the UAV. The data from the UAV as well as the IoT platform equipped on the PV plants were used by two different neural networks to make predictions. Based on the output of the two models, they made predictions about the possible hot spots. Most of the approach is very similar to others in the literature, but the inclusion of the IoT platform gives some novelty to this approach. Shapsough et al. [
4] worked on using IoT and deep learning to create a low-cost edge-based anomaly detection system. This system can remotely sense any outliers in the PV module’s performance and generate respective alerts. They used soil conditioning sensors to constantly collect and monitor data and used deep learning techniques to identify fluctuations based on these data. Sizkouhi et al. [
5] created a framework called RoboPV. The major modules of this framework were boundary detection and CPP (Coverage Path Planning). As far as the task of boundary detection is concerned, they also used an encoder–decoder-based architecture for boundary identification. Overall, they claimed that the framework was able to execute inspections with over 93% accuracy. For CPP and the autonomous maneuvering of the UAV, they used the MAVLink protocol. Once the boundary was identified and the CPP was carried out, the UAV monitored regions while covering the panels. Any damage detected during this process was reported in the framework. In another work [
6], they explained the fully convolutional network (FCN) architecture used to predict the boundary of the PV panels. Similar to other works, they used a UNet-based model. The authors claimed that they obtained an overall accuracy of 96.99%. The inputs for the model were the RGB images captured by the UAV. My work also uses the same dataset.
The work of Zhen Xu et al. [
7] involved the usage of infrared thermography images. They claimed that their clustering-based model was able to achieve an average quality of 92%. They proposed a DBSCAN-based approach on the IRT (infrared thermography) data captured by UAVs. They collected over 1200 IRT images and claim that their model outperformed traditional edge detection techniques such as Sobel and Canny. Overall, though this approach is not as computationally expensive as neural networks, the usage of IR cameras and the cost incurred for its maintenance increases the overall cost of this approach. The work of Ying, Yuxiang et al. [
8] achieved an accuracy of 97.5% in locating faults on the surface of PV plants. This is a major improvement when compared with other nonprogressive locating methods. Their work involved capturing video footage from IR cameras equipped with a UAV. Based on the video footage, faults were located in each frame of the video, and the latter is converted to the overall coordinate system. They used the AKAZE algorithm to identify the anchor points and the Lucas–Kanade sparse optical flow algorithm for matching. Overall, this work is very innovative in terms of how they approach the problem. But when considering the practical implementation of such techniques in real-world scenarios, they still are unable to address the problem of cost-effectiveness and low maintenance. The work [
9] proposed an algorithm based on the IR data collected by a UAV to identify the number of PV panels as well as the state and condition of the panel array. This was accomplished through the use of IM (image mosaicing). They claimed that this technique produces very accurate depth assessments in PV plant inspections. Above a certain average elevation, aerial imagery typically does not provide a lot of spatial data to work with. In addition, GPS errors caused by position overlap are extremely difficult to correct. Such methods are ineffective in automation due to their error-prone nature. To address this problem, Marondo, Luca, and colleagues [
10] devised a novel method in which the UAV flies at a much lower altitude, capturing the details needed to detect boundaries and damage as well as identifying empty areas with no PV modules. They used their algorithm on UAVs, and the data show that the quality of detail captured by this technique improved. Visual inspection of the outputs can confirm this.
The study conducted by Mellit, Adel et al. [
11] and Fend, Cong [
12] provide critical insights into the various challenges faced in the maintenance of PV plants and how emerging technologies such as AI and IoT can address them. They also made recommendations on what challenges should be majorly dealt with by future works. They basically identified all possible implementations of AI and IoT in PV plant maintenance. This ranges from automatically correcting power fluctuation in inverters and identifying faults in PV panels to the automated grid maintenance of PV plants. With respect to our work, though they have concluded that a variety of techniques using various sources of inputs are carried out to automate boundary detection, mostly they are region-specific and are poorly performing in terms of cost-effectiveness and high maintenance. Though these approaches are novel, they are not able to effectively address the issues at hand. Though PV plants are very efficient at harvesting solar energy, the amount of land they occupy is very large. To solve this problem, a hybrid dual-use land method is proposed, where both land and water bodies are used. In this approach, agriculture is interwoven into PV plants. But the implementation of the dual-use hybrid model is very complicated, considering the number of factors involved in decision-making. Thus, Ghiassi, Manoochehr et al. [
13], in their works, proposed an ANN-based model to assist management in effective decision-making. Dimd et al. [
14] worked on using LSTMs to predict the output power generated by PV panels. This is very useful for automating the correction of power fluctuations caused at inverters. This also can be used to estimate the amount of power generated. Ramzi, Hadi et al. [
15] proposed an adaptive sliding control technique for maneuvering UAVs in their work. This work primarily focused on adjusting the UAV’s orientation and altitude while monitoring the PV panels. They claimed that this technique can prepare the UAV for inspection in 5.6 s with a 7.5% deviation from the track. They claim that neural networks played a significant role in improving response time and tracking accuracy.
The work of S. Prabhakaran et al. [
16] focused on a CNN-based approach to damage classification. Their proposed architecture used a series of convolution and normalization operations to extract spatial features from the RGB images of the solar panel provided as an input. The outputs of the feature extraction process were given as inputs to the FCN model which was trained to predict the class of damage based on the features given as input. Overall, they achieved an accuracy of around 98% when trained on a dataset of 5000 images. Selvaraj et al. [
17] focused on using thermal images of solar panels to identify any coverings on the solar panel. Their work included the identification of hot spots, which are regions where the thermal signatures are high, and using this hot spot information, they created a neural network to detect the damage, but they restricted their dataset to only include cover by snow, mud, and soil. Other damage types were not included.
In [
18], Pathak et al. worked on identifying hot spots on solar panels, and using this hot spot information, they classified the faults on the solar panels. Unlike other approaches, they used infrared imagery and overall they achieved an accuracy of 85% when identifying the hot spots. Deitsch et al. [
19] also worked on using infrared imagery to detect damage on solar panels, but the number of faults they identified was higher than in other works. Though their approach did not identify any coverings or depositions on the solar panel surface, they concentrated on identifying the cracks and material defects inside the solar panels. Espinosa et al. [
20], in their work, performed semantic segmentation on input images to identify the solar panels in an image and only used these data to classify the faults on solar panels. The major advantage of this approach over the other approaches is that the classification is performed solely based on the solar panel information, and other unwanted information such as the background is removed, thus leading to a much more accurate model. But in terms of results, their model performed poorly in terms of both
F1 score and other metrics. Greco et al. [
21] performed a boundary box-based segmentation on infrared images of solar panels. They used DarkNet-53 as a backbone for their model. In this approach, they obtained multiple outputs from the boundary box for different sizes, thus identifying different-sized hot spots on the solar panel infrared data.
The novelty of the proposed work is that the authors developed a deep learning model for the segmentation of solar power plants which efficiently processes images. The proposed work consumes less time and uses a low memory profile in terms of the number of parameters. Another novelty of the work is the classification of solar panel damage.
1.2. Research Gaps and Challenges
PV plants come in different shapes and sizes and are used everywhere currently. The maintenance and monitoring of such PV plants is tedious and resource-consuming, especially when required for large-scale PV plants that extend over hundreds of acres of land. For the maintenance of such plants, boundary detection for PV panels is needed to automatically deploy drone-based solutions to clean them. Also, we can use such boundary information to estimate the area covered by the plants and thereby the amount of power generated. Even minor improvements in performance or space could be very effective in large-scale systems. PV plants are the third largest source of electricity and the most widely used renewable source of power. PV monitoring can help in maintaining the large PV plants which are currently under proposal. The major challenges to developing cost-effective and low-resource algorithms for PV plants are listed below:
There is a need for large volumes of data to train deep learning models which are reliable.
PV plants are strategic for nations, and thus inaccurate aerial images of satellites are most often available.
There is a need for more open access to drone-captured videos and images using sensor information to obtain spatial positions.
The main objective of this work is to automate the process of area measurement for PV plants and implement a robust framework for boundary detection which can be integrated with other automation techniques for the maintenance of PV plants. The primary aim of this work is to combine image processing-based edge detection techniques with deep learning models to create a reliable and deployable system for detecting damage in solar panels in real time.
3. Experimental Results and Discussion
3.1. Performance Metrics
The metrics used for evaluating the performance of various models that we used for the task of damage classification were accuracy, precision, recall and
F1 score. Accuracy is the ratio between the number of predictions that are correctly made and the total number of predictions made. Precision and recall are metrics based on relevance. Precision can be defined as the fraction of true predictions as shown in Equation (4), which match with the ground truth out of all the predictions made. Since the task is classification into multiple classes, the definitions of
TP,
FP,
TN, and
FN are slightly different in terms of their calculations. The calculations are represented in terms of the confusion matrix.
where
TP (true positive) is the number of predictions where the actual class and predicted class match;
FP (false positive) is the number of predictions where the predicted class is not the same as the actual class, i.e., it is the sum of values of a corresponding column except for TP values;
FN (false negative) is the sum of the values of rows except for the
TP values; and
TN (true negative) is the sum of values of all columns and rows except for the values of the class that the values are being calculating for.
Using the above defined calculations, we can define recall as shown in Equation (5).
High precision and recall are good indications of an efficient model. Giving equal importance to both precision and recall, since in our case making correct predictions was equally valued with not making wrong predictions, we also used the
F1 score, shown in Equation (6), which is twice the harmonic mean between precision and recall, as another metric for evaluating the performance of the model.
Other than this, to evaluate the training performance of the model, we monitored the trends in the training loss, accuracy, and validation loss and looked at how the model performed on the validation dataset. The fit of the model was evaluated based on the performance shown while using the training dataset.
3.2. Classification Results
From
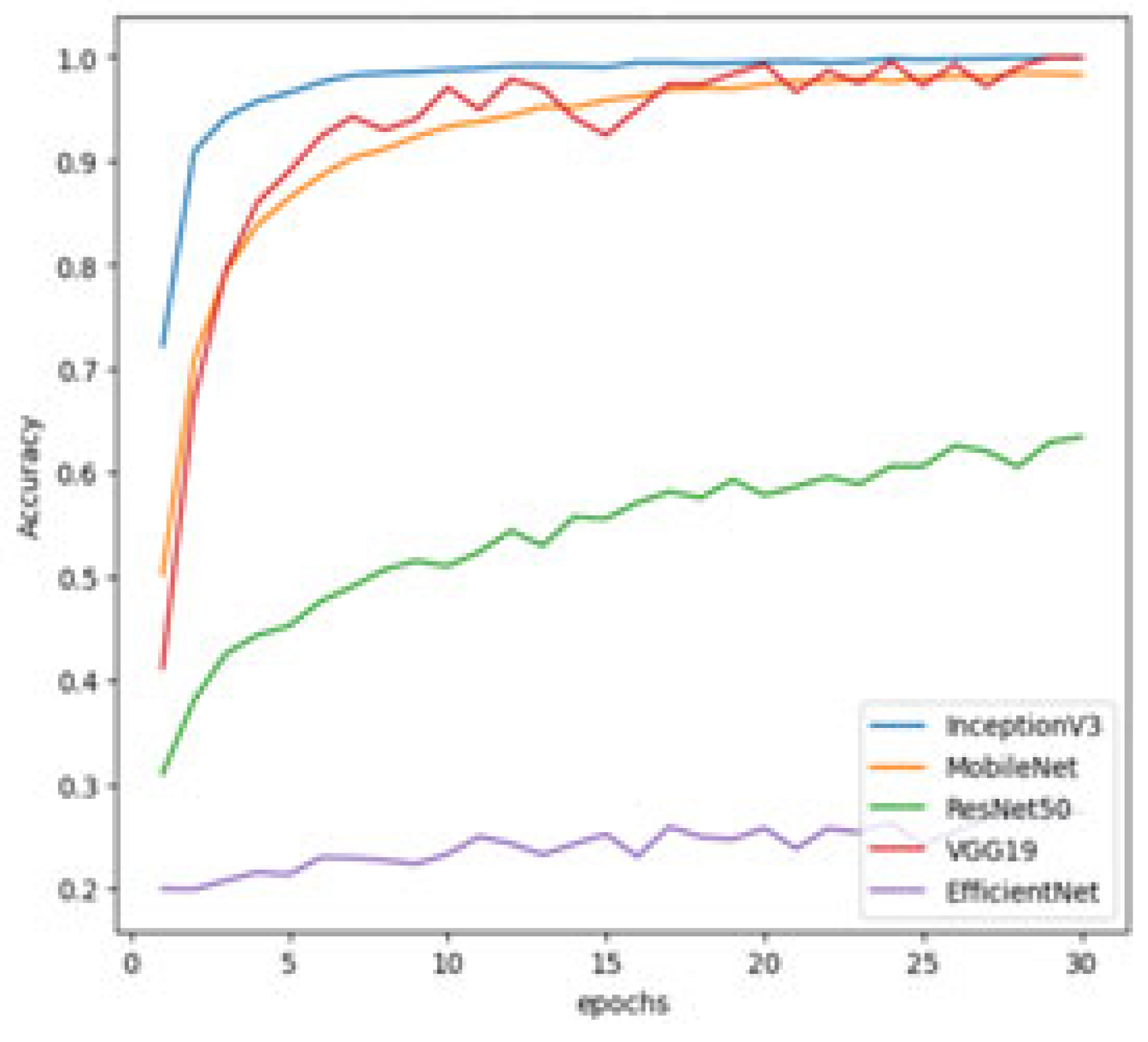
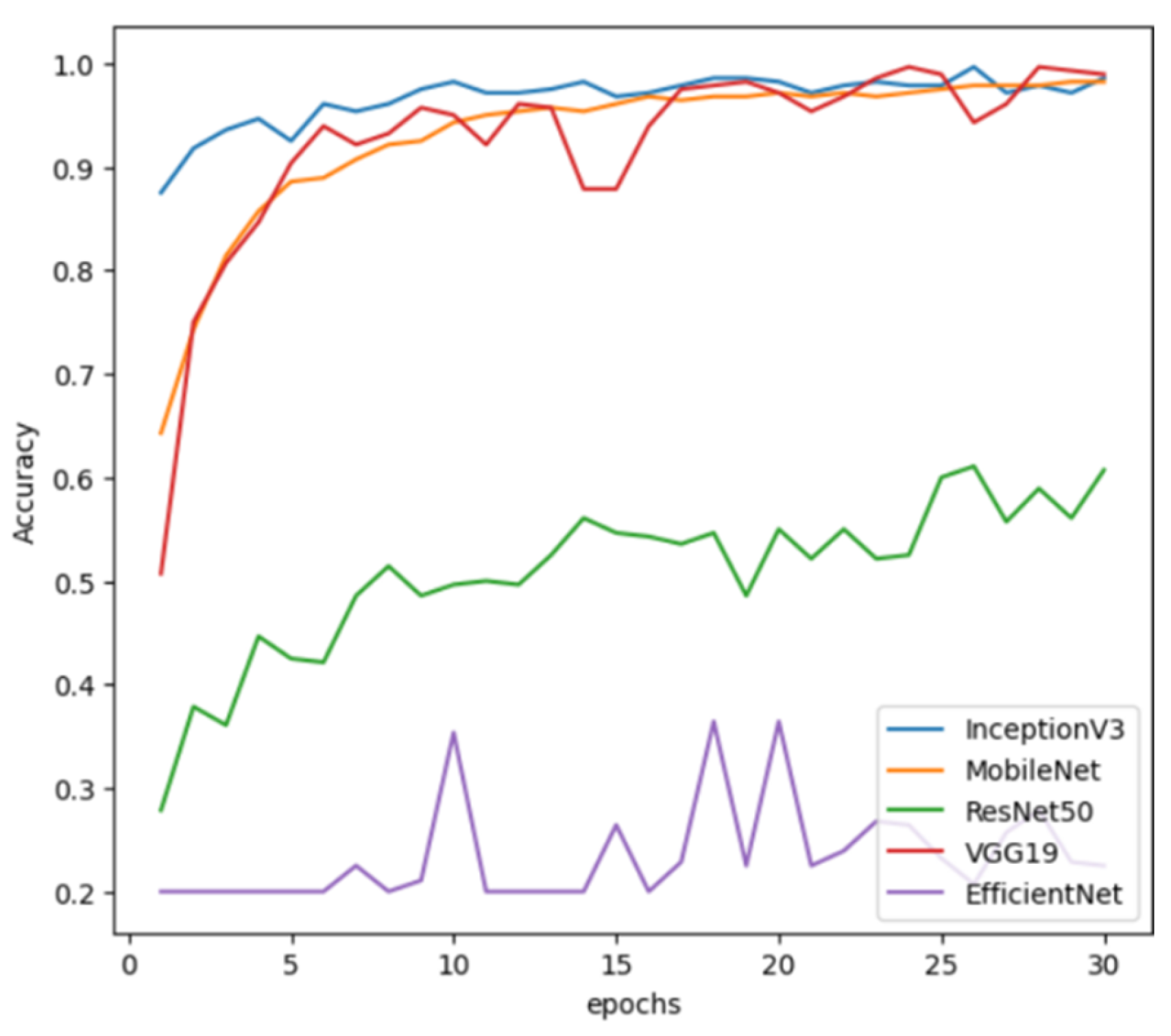
Figure 11, one can understand that in the first five epochs, the loss of the VGG19 model was very high in comparison with the other models, but by the end of 30 epochs, the losses of VGG19, InceptionV3, and MobileNet stabilized and reached close to zero, indicating that they reached the point of best fit for the given model. Even the training accuracies of the three models, as shown in
Figure 12, were high at the end of 30 epochs. But one can entirely rely on the training accuracy of the models to evaluate the models, and thus we also looked at the validation performance of the models. One trend that is observed is that the EfficientNet loss is almost the same in the entire process of training, with a slight improvement in terms of accuracy; this is an indication that the EfficientNet model was under-fitted for the given data.
From
Figure 13 and
Figure 14, we can observe similar trends in terms of the validation loss and accuracy of various models. For VGG19, InceptionV3, and MobileNet, we can observe that even with validation data, they performed very well in terms of accuracy. Based on the validation loss, which smoothly decreased to zero by the end of thirty epochs, we can say that all the three aforementioned models fitted very well on the training data and performed well on the validation data. Thus, no case of over-fitting was observed. Since there are no class imbalances in the dataset, we expect the precision and recall of the models to match with the
F1 score.
Since this is a task involving multiclass classification, in the calculations of precision, recall and
F1 scores, the metrics were calculated individually of each class and their mean is represented in
Table 3. VGG19 has the highest accuracy (98.6%) and
F1 score (99%), indicating that it performs the best overall among the five models. VGG19 also has the highest precision and recall, both at 99%. MobileNet and InceptionV3 also have high accuracy and
F1 scores, but are slightly less accurate than VGG19.
On the other hand, ResNet50 and EfficientNetB0 have significantly lower accuracy and F1 scores. ResNet50 has a precision of 65% and a recall of 64%, while EfficientNetB0 has a precision of 13% and a recall of 23%. These lower values indicate that these models are not performing as well as the other three models when correctly classifying the images in the test set. Overall, in comparison, the VGG19 model outperformed the other models with an overall accuracy of 98.6%. As expected, the EfficientNetB0 model performed poorly, with an accuracy of 23%. In terms of F1 score, the VGG19 model obtained a mean F1 score of 99%, not only outperforming the other models, but also outperforming models discussed in the literature. Thus, we created a highly accurate model for identifying the types of damage done to solar panels.
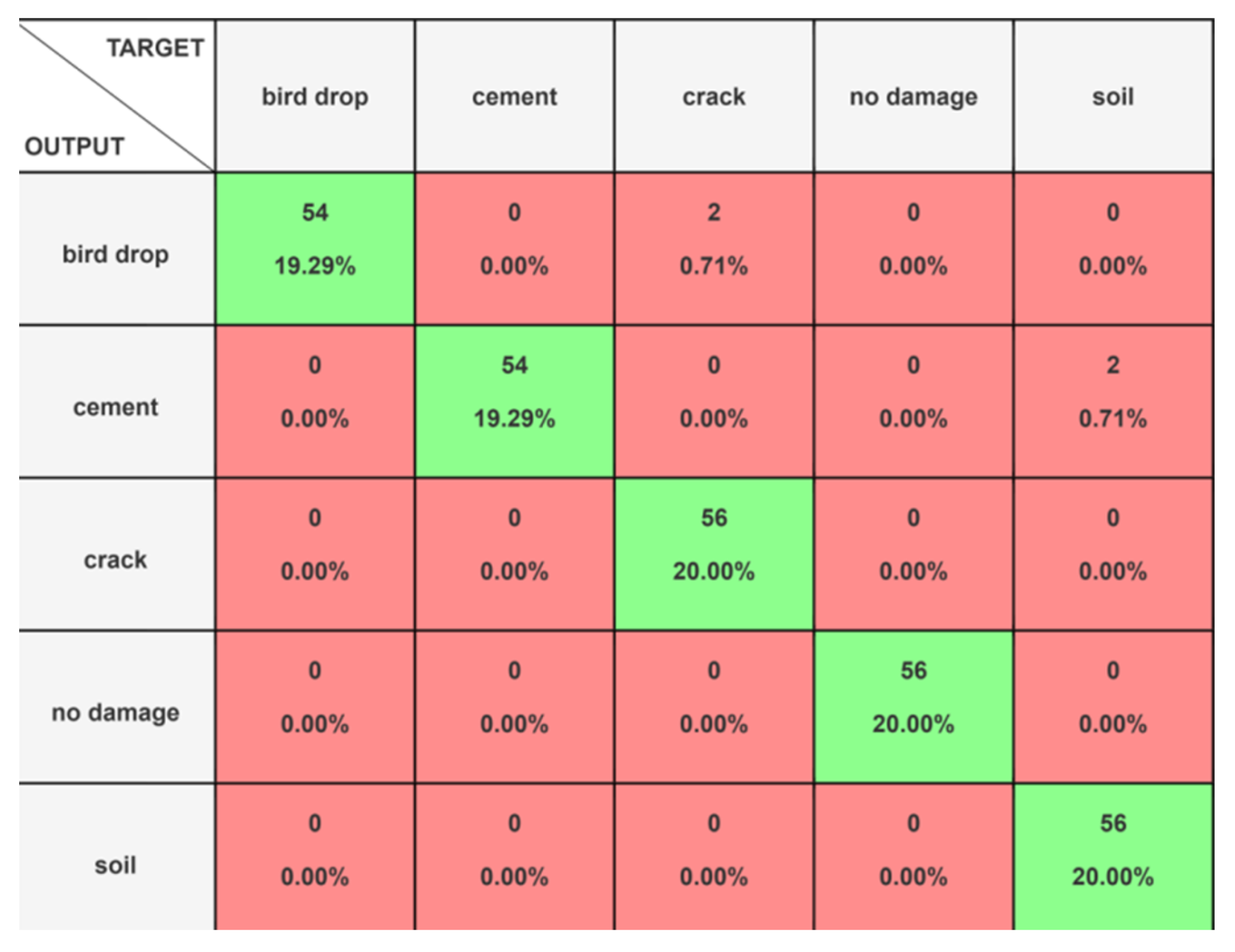
From
Figure 15, we can see that except for bird droppings and cement damage, for all the other classes in the testing data, there was no misclassification.
Figure 16 contains a few sample predictions made by the VGG19 model.
3.3. Segmentation Metrics
A higher mean IOU score in the context of picture segmentation suggests better segmentation accuracy because it measures the amount of overlap between the anticipated and actual masks. When measuring the efficacy of models that create segmentation masks, where the distinctions between object classes are not clearly defined, this metric is very helpful.
MeanIoU is the summation of IoU shown in Equation (7) for all images in the corresponding dataset. The performance of image segmentation models is frequently assessed using the Mean Intersection-over-Union (IOU) measure. IOU estimates the ratio of the intersection of the two masks to their union by measuring the overlap between the predicted segmentation mask and the ground truth mask for each pixel in the picture. The average of the IOU ratings for each pixel in the image is then used to determine the mean IOU.
It should be mentioned that mean IOU has limitations despite being a statistic that is frequently employed in picture segmentation studies. For instance, it does not consider the degree of segmentation error in each particular object class or the geographic distribution of defects inside the segmentation mask. To obtain a more thorough insight into model performance, researchers might also think about employing other indicators, like pixel accuracy.
Apart from mean IoU, we also used pixel accuracy and F1 score as metrics. F1 score is calculated individually for each image, which is divided into two classes: one is the background and other is the mask area. Neural networks are an excellent choice for a lot of image processing problems, but the major drawback they have is the consumption of resources and the high computational requirements needed to process the image and make a prediction. When creating models that may be deployed in real-world systems such as UAVs, automobiles, and CC cameras, a major concern is the amount of time they take to process the image, and thus we also added processing time as a metric for evaluating the model. Based on the use case requirements and resources at hand, corresponding implementations can be used. We defined processing time as the time taken in seconds from the moment the input is provided to the model to the moment the mask is generated by the model. In our experiments, we measured it in seconds.
3.4. Segmentation Results
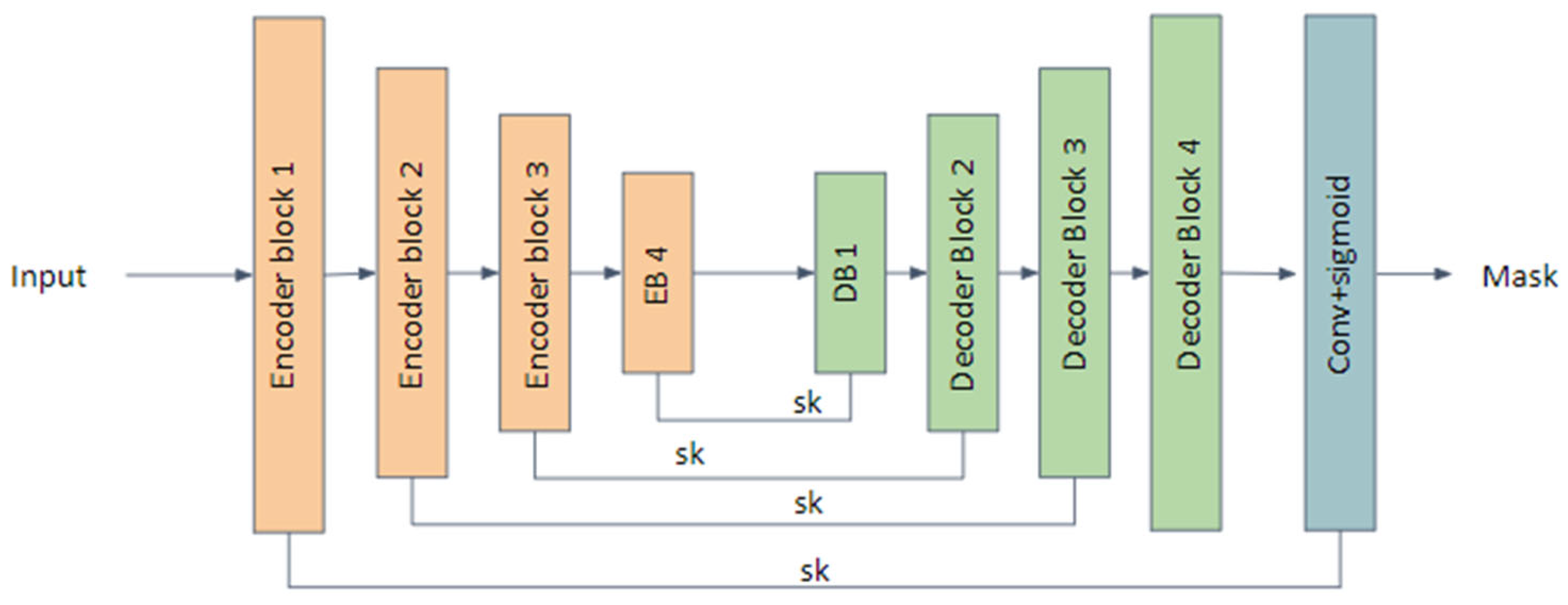
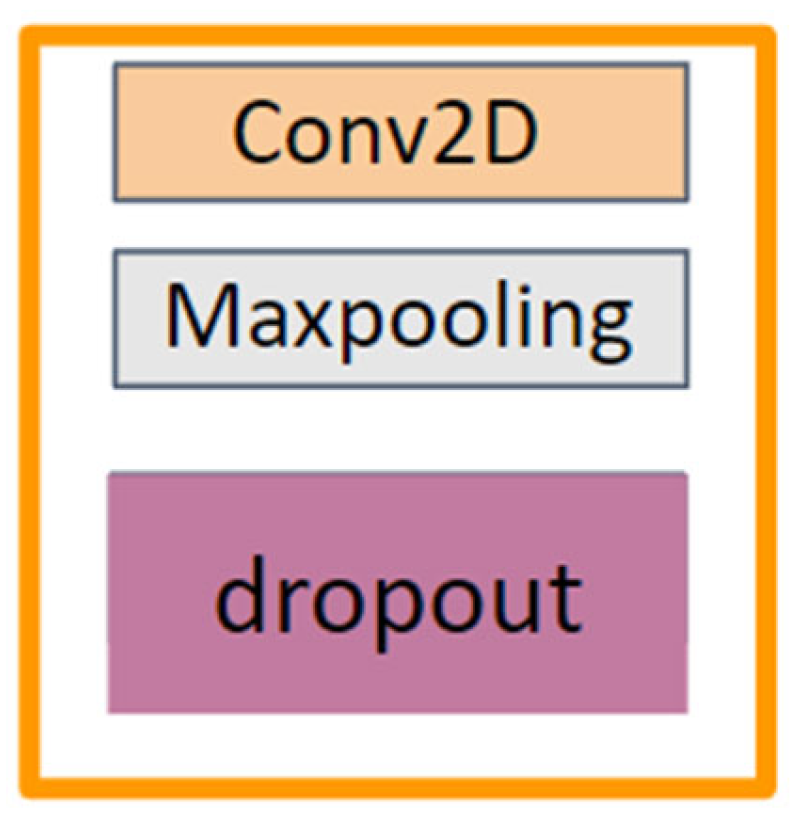
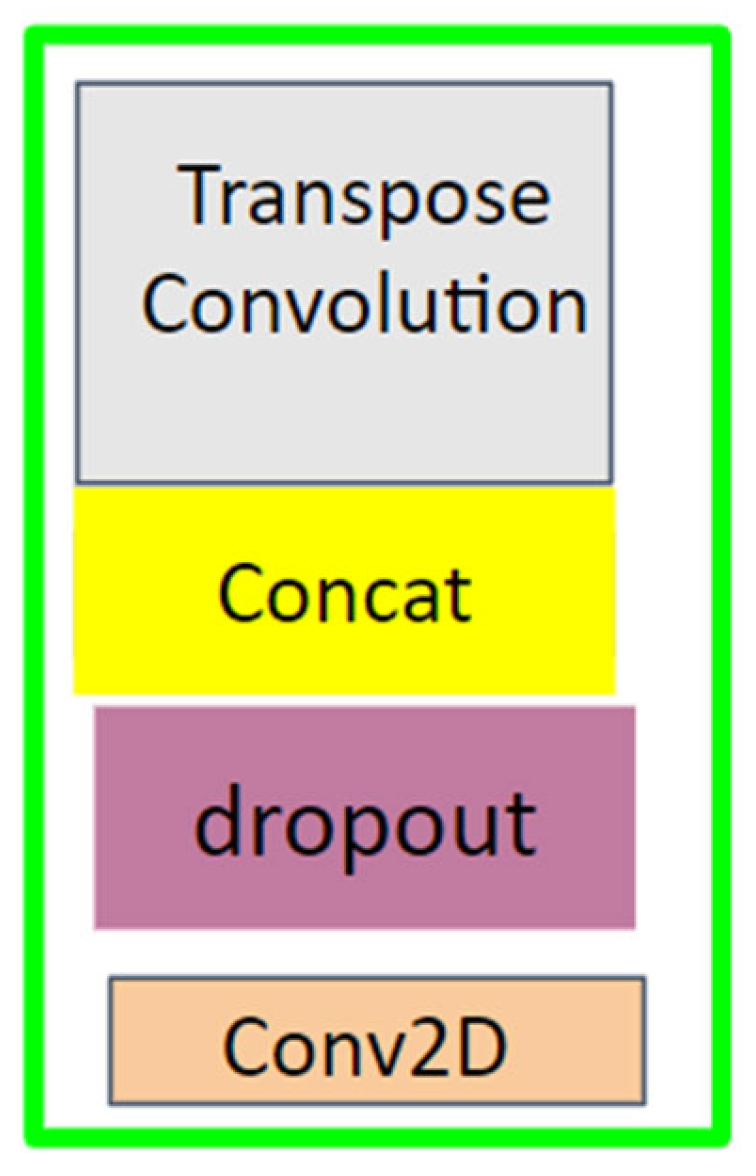
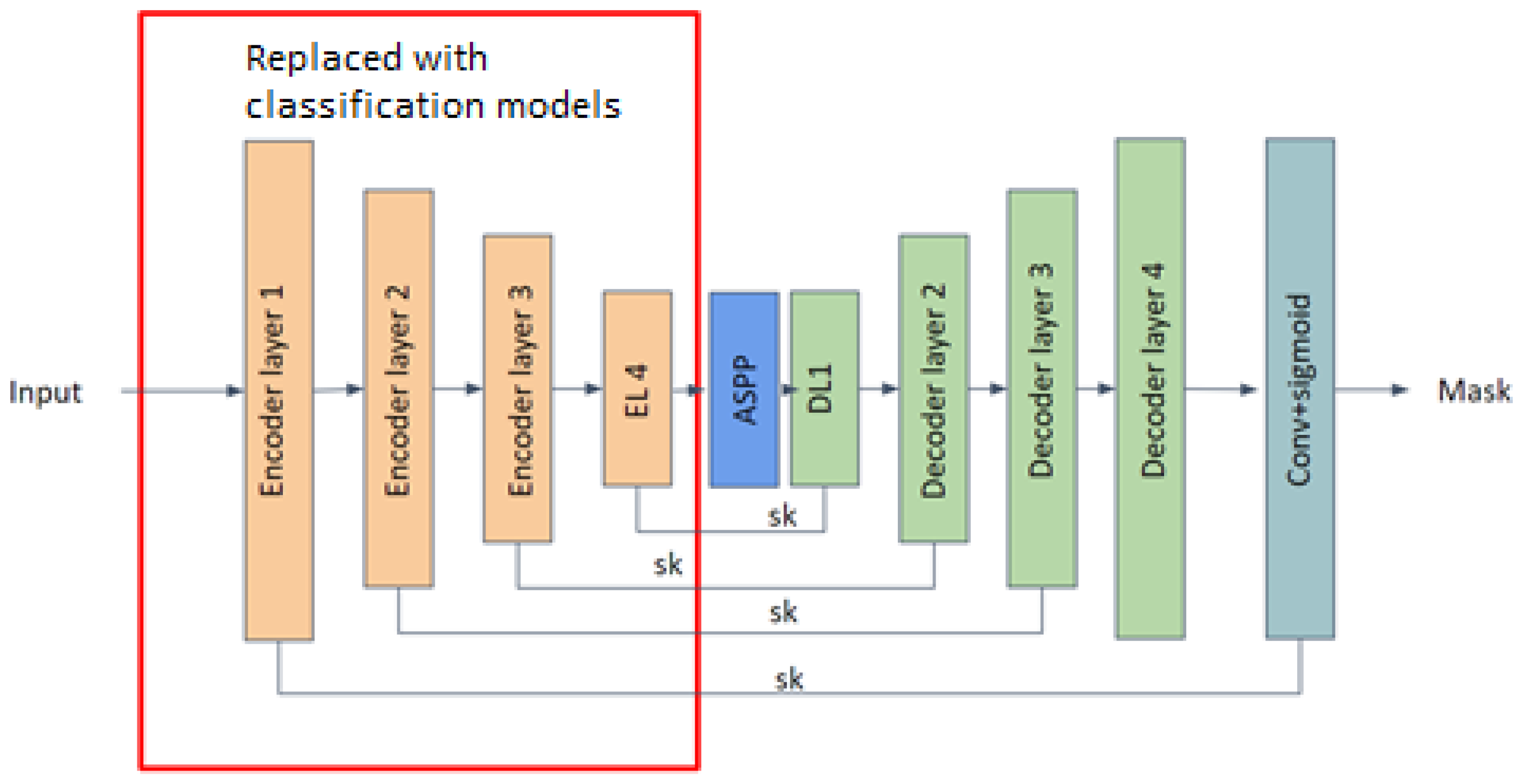
To compare our model’s performance, we also trained UNet and DoubleUNet [
34] along with our proposed model. UNet was used as a reference since we used a modified version of UNet. We used DoubleUNet because this model has outperformed UNet in medical segmentation and has also been used for segmentation in other domains, showing great efficiency on a large number of datasets.
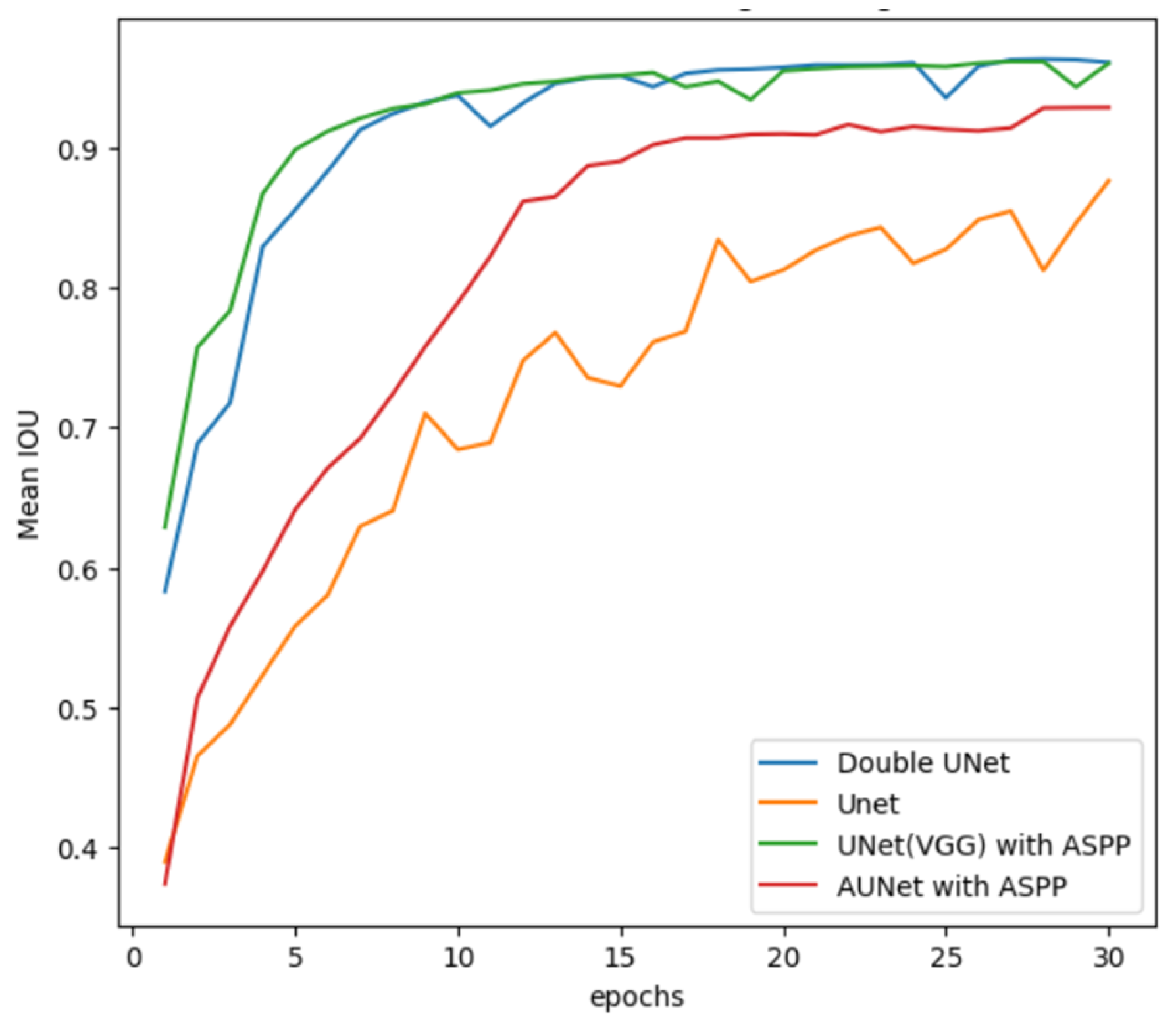
Figure 17 shows that in the 15 epochs, the training loss of the segmentation model was very high in comparison with the other models, but by the end of 30 epochs, the loss of all models approached zero, indicating that they reached the point of best fit for the given model. Even the training mean IoUs of the models were high at the end of 30 epochs. UNet had a lower training mean IoU in comparison with other models, and even its loss was a bit high in comparison with other models, but considering the smooth decrease in loss during the training we can say it attained its best fit. Though AUNet started with a low mean IoU, at the end of training, its mean IoU performance was close to the UNet (VGG) and DoubleUNet models.
Figure 18 depicts the training mean IoU plot of segmentation models.
In terms of validation loss, from
Figure 19, we can observe that among all the models, AUNet has the smoothest curve in terms of loss and mean IoU as shown in
Figure 20 based on validation data. Based on the performance of the models on the validation data, we expect the AUNet model with the VGG backbone to outperform other models. Also, though some models still reached the best fit given their limitations, none of them over-fitted nor under-fitted, which is a good indication. The comparison of the models used for segmentation is listed in
Table 4, where pixel accuracy, mean IoU,
F1 score, processing time and the number of parameters used are compared.
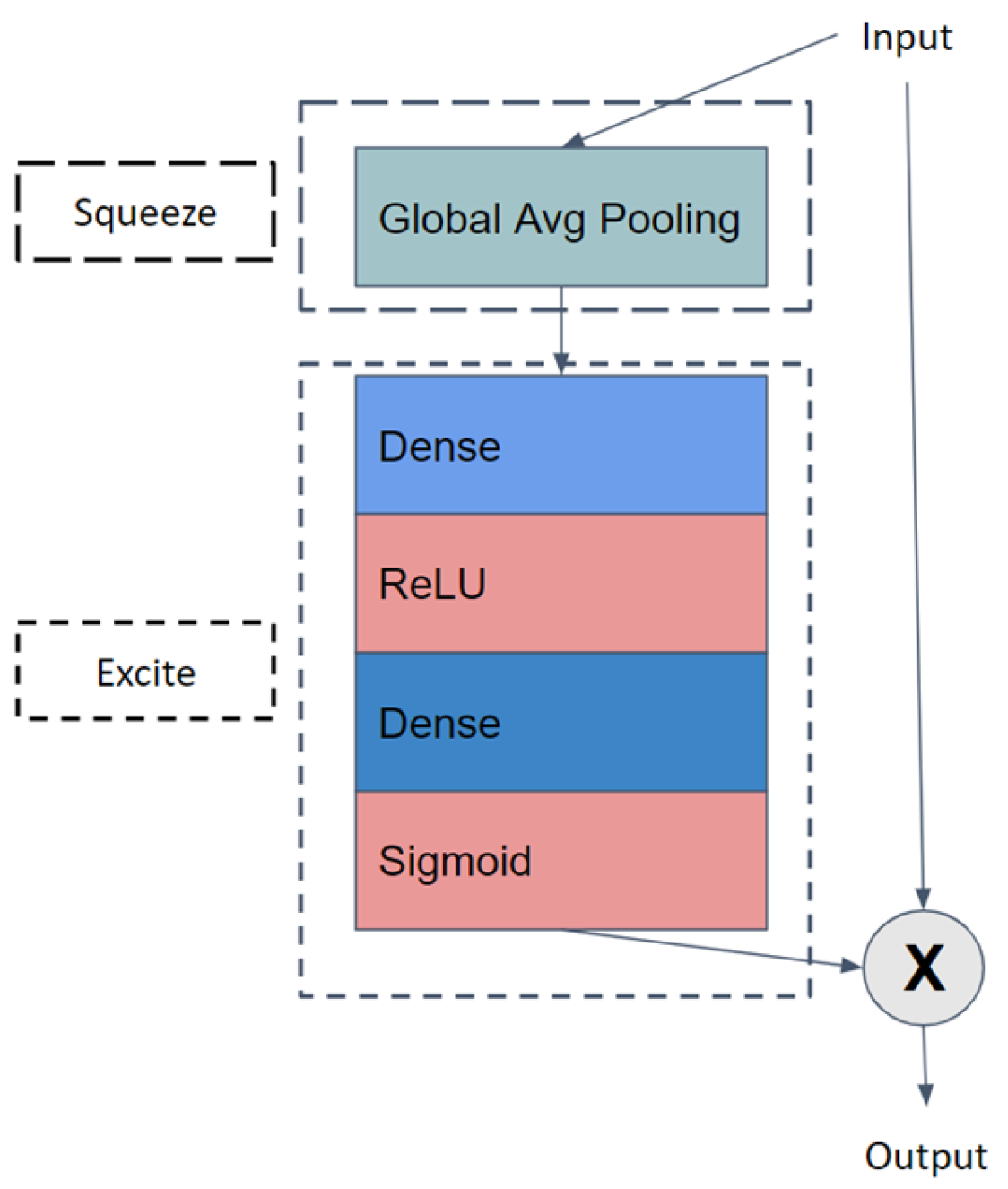
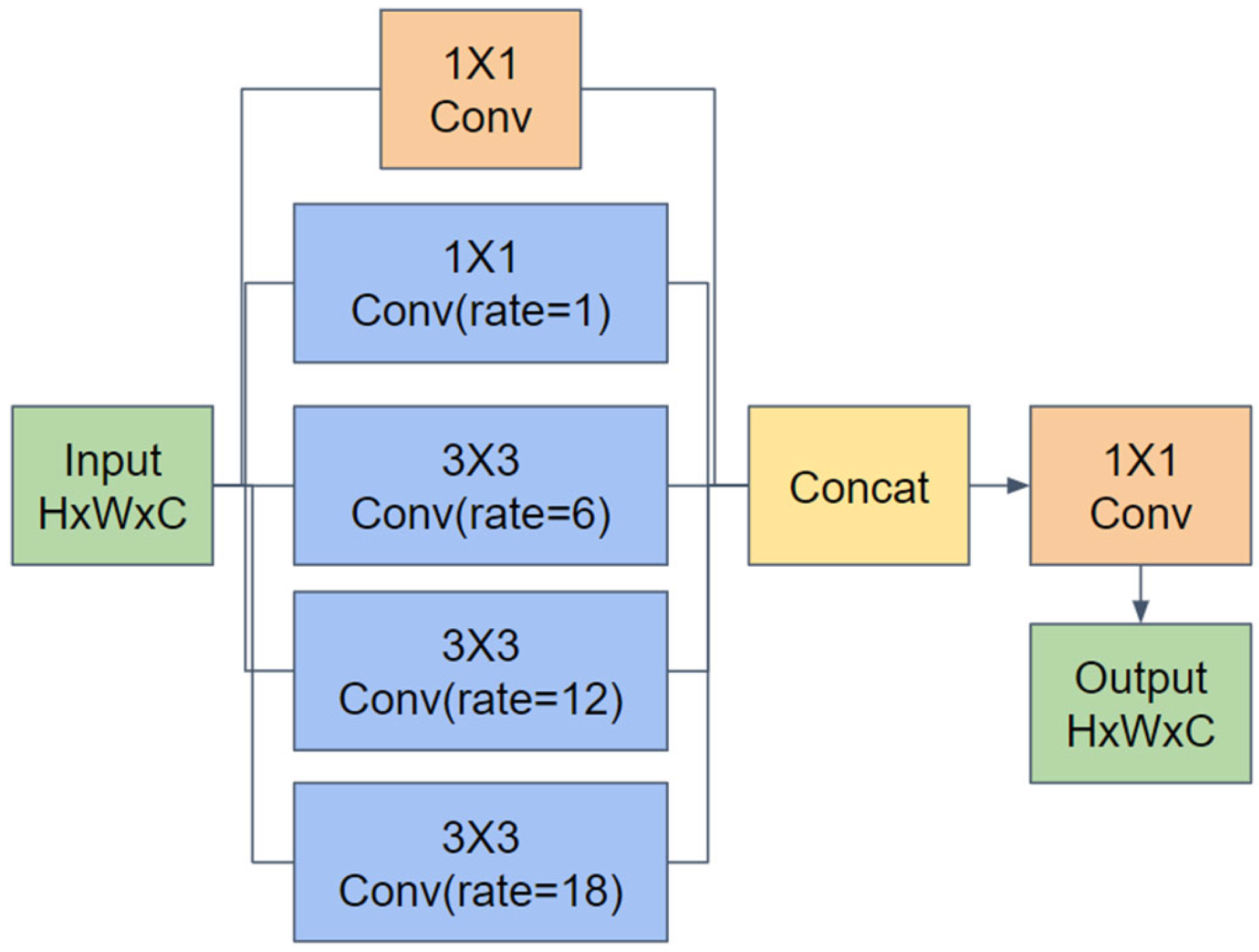
Due to the large number of parameters present in the segmentation models, the processing time the model takes for an image increases, and it requires more time and resources for training and maintenance. Our aim was to create a model with low processing time and with less parameters in comparison to the literature. By analyzing the results, we understand that in terms of overall performance, AdaptiveUNet showed better accuracy (98%) and mean IOU (95%). It was able to process an image in under one second with 23 times fewer parameters than the DoubleUNet or AUNet models with a VGG backbone.
Apart from the inclusion of the VGG model as a backbone, no major changes were made to the model, but since VGG is a 19-layer model with lots of parameters, its total parameter count reached that of DoubleUNet, a model with two UNet networks in it. If we compare the performance of AUNet with UNet, we increased the accuracy by three points and the Mean IoU score by three points. The processing time increased by only 0.1 s and the number of parameters increased by only 0.27 million. Thus, for large segmentation networks, we can say that the addition of an attention mechanism and ASPP module comes with a small cost in terms of the number of parameters, but also shows a gain in performance. If the use case requirements are high performance, then we can use the AUnet model with a VGG backbone. In comparison with DoubleUNet, it has a slightly better performance in terms of accuracy, Mean IoU, and F1 score and it has almost half the process time per image as that of DoubleUNet.
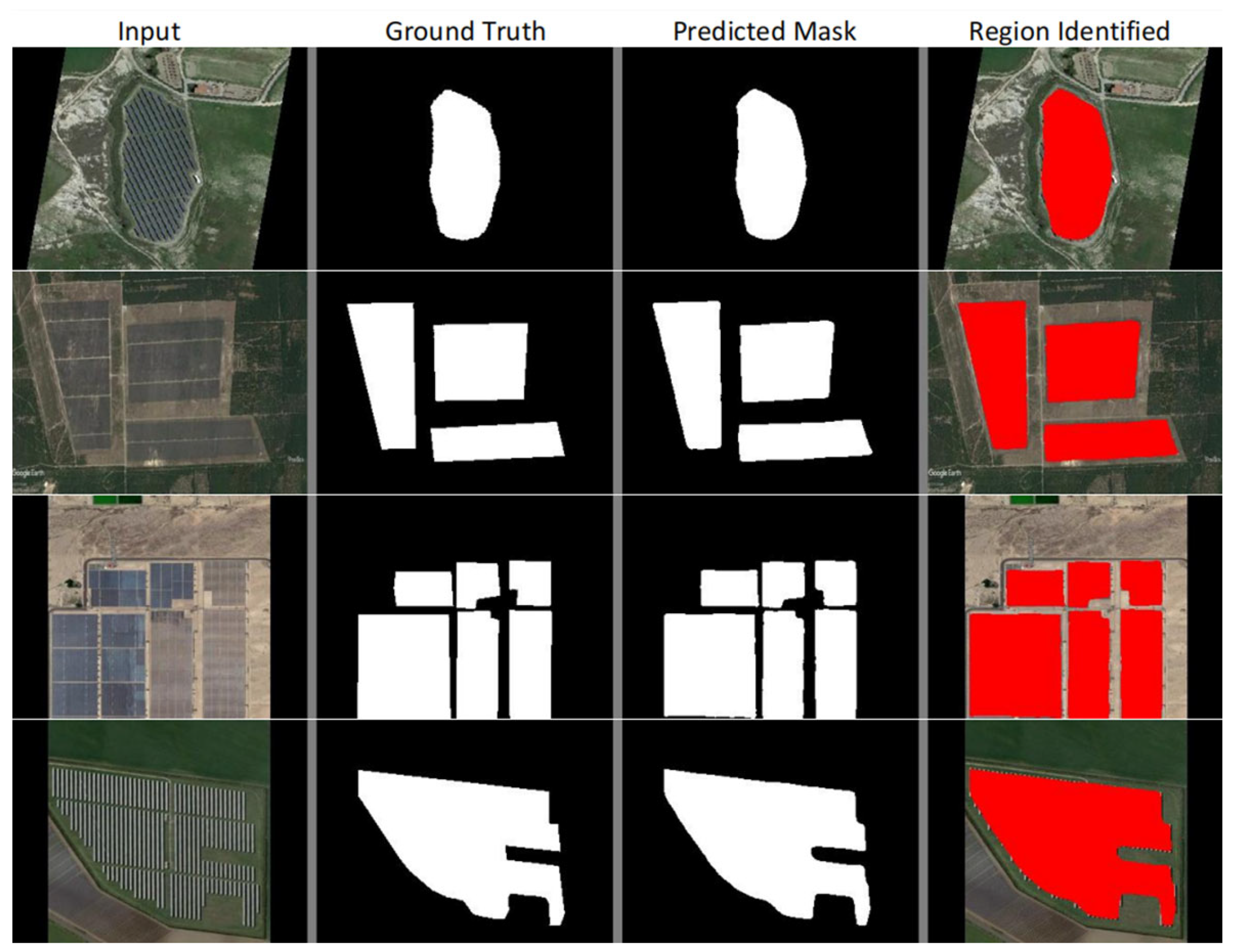
Figure 21 shows some predictions made by the AUNet model without the VGG backbone. The last column (Region Identified) was generated using the Predicted Mask. By superposing the Predicted Mask onto the original image and assigning it a red color, we obtained the last column. If we have the scale information of the aerial image, i.e., the proportion between the number of pixels and the length on the surface, we can compute the approximate area of each solar plant. The proportion information may be obtained by taking into consideration the height of the UAV or the camera specifications, or can be manually calculated.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}