
Modelling Software Architecture for Visual Simultaneous Localization and Mapping




Abstract
:1. Introduction
2. Overview of Approaches in VSLAM
2.1. Front-End Modules for VSLAM
2.1.1. Feature-Based
2.1.2. Direct
2.1.3. Hybrid Approaches
2.1.4. Other Common Modules
3. Back-End Modules of VSLAM
4. Software Model for VSLAM Architecture
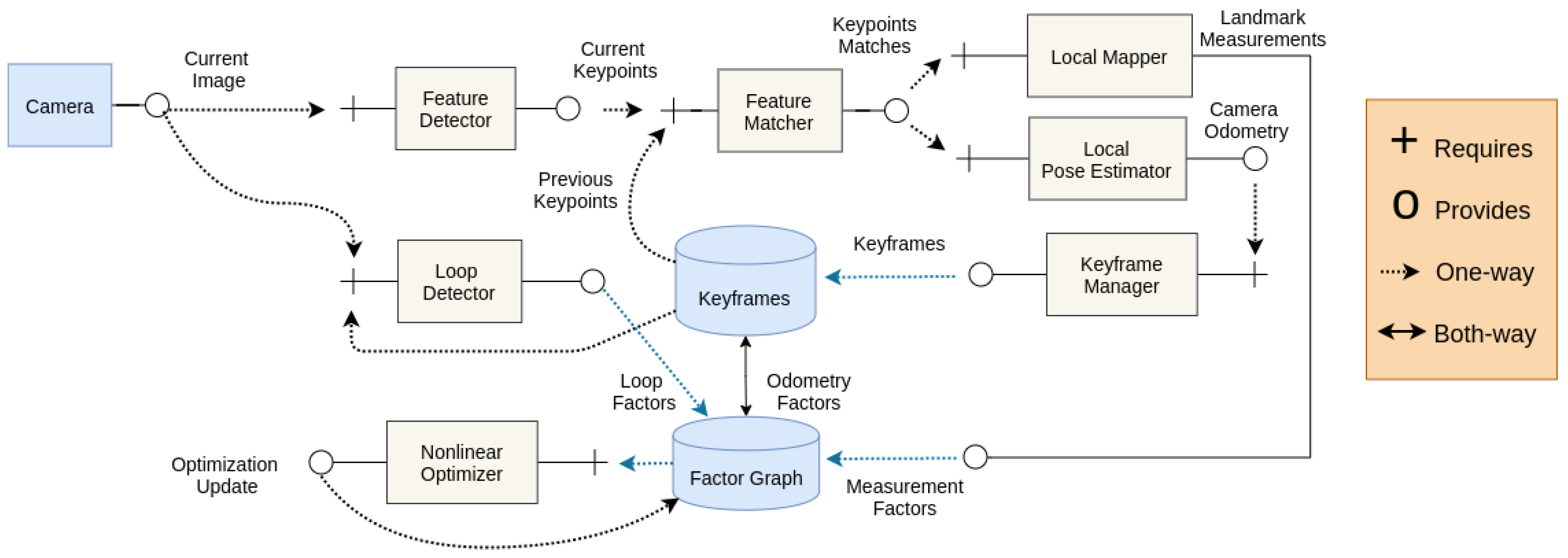
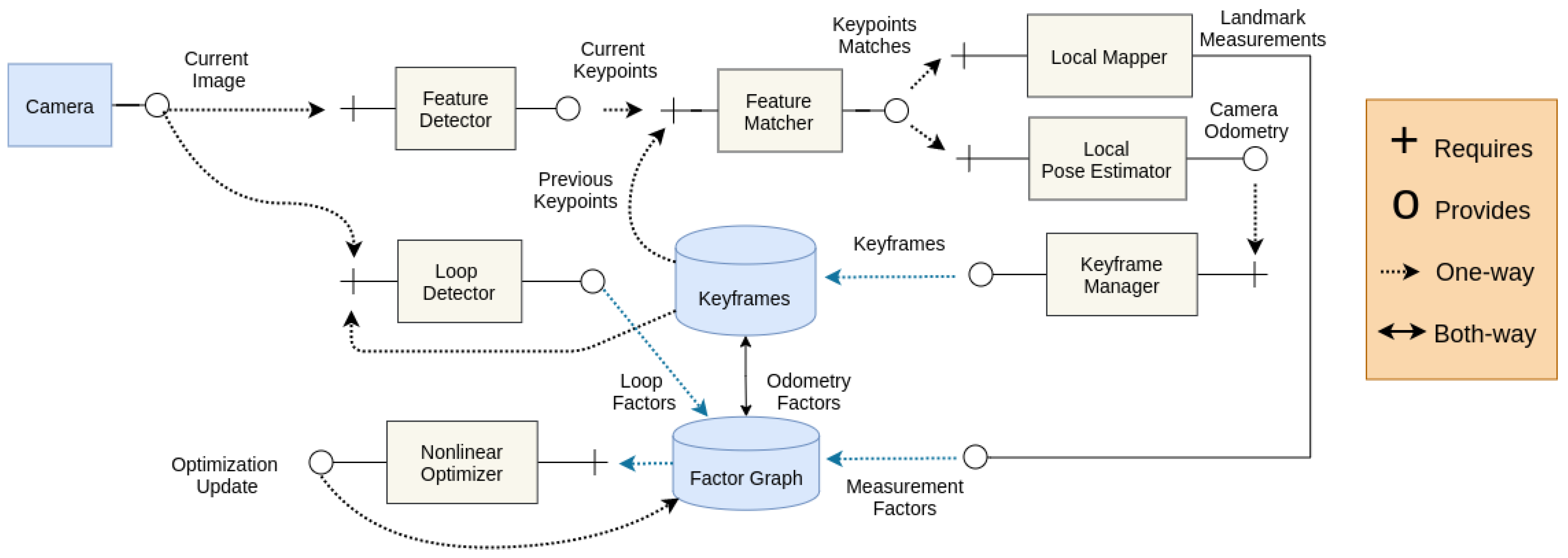
4.1. Architecture
- Feature detector: requires an image frame and descriptor type and provides image coordinates of the detected feature points and feature descriptors;
- Feature matcher: requires feature coordinates and descriptors from two images and provides feature point correspondences between two images;
- Local mapper: requires keypoint correspondences and camera intrinsics, and provides local 3D map points;
- Local pose estimator: requires feature point correspondences from two images and provides a transform between camera image and last keyframe;
- Keyframe manager: requires a new image frame and its feature points, and provides a keyframe decision and keyframe update;
- Loop detector: requires a last keyframe and a new image frame and provides a loop closure constraint for a factor graph;
- Nonlinear optimizer: requires a factor graph of measurement, motion, and loop constraints and provides an optimized graph based on maximum a posteriori inferencing; and
- Analyzer (for benchmarking purposes): requires the camera pose and 3D map points and provides accuracy measurements tested against benchmarking datasets.
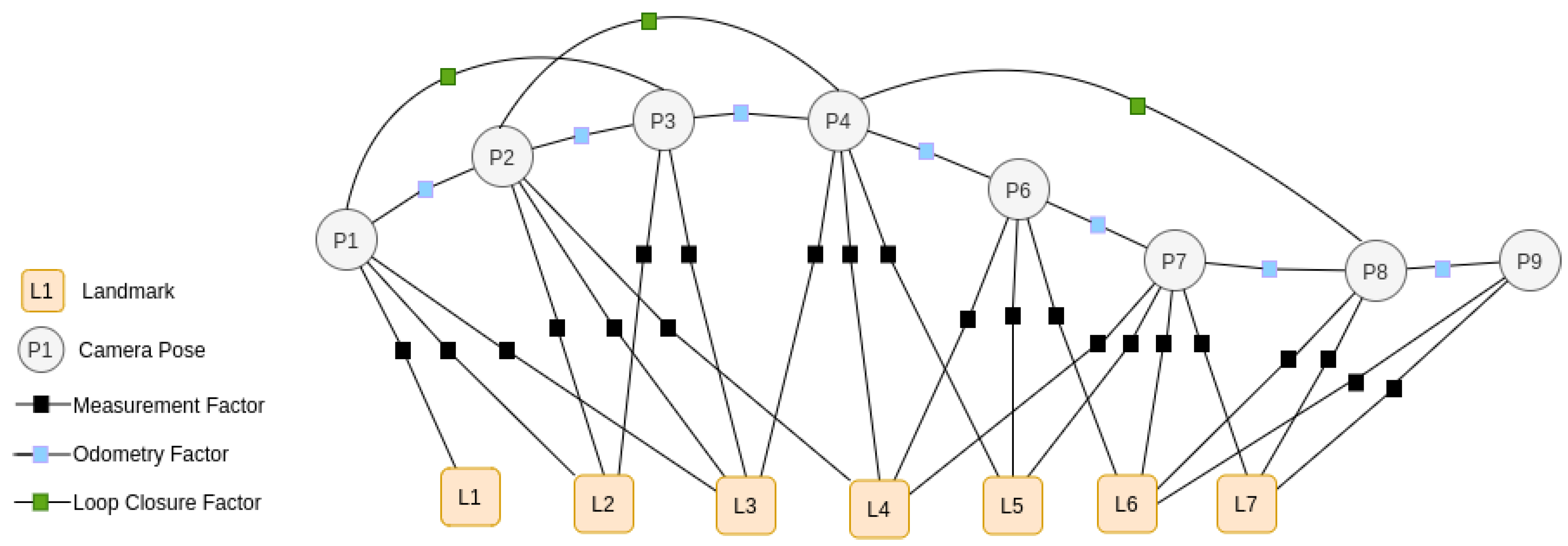
- Keyframe list: stores the keyframes collected by the keyframe manager based on the keyframe generation and culling conditions and continuously optimized by the factor-graph nonlinear optimizer component
- Factor graph: stores a graph of all the constraints from odometry; landmark measurements; loop closures; and other sensors such as Inertial Measurement Unit (IMU) factors, kinematics factors, etc.
4.2. Data Flow
4.3. Additional Modules
5. Algorithms, Tools, and Libraries
6. Benchmarking and Datasets
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pascoe, G.; Maddern, W.; Tanner, M.; Piniés, P.; Newman, P. NID-SLAM: Robust Monocular SLAM Using Normalised Information Distance. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1446–1455. [Google Scholar] [CrossRef]
- Davison, A.J.; Reid, I.D.; Molton, N.D.; Stasse, O. MonoSLAM: Real-Time Single Camera SLAM. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1052–1067. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Taketomi, T.; Uchiyama, H.; Ikeda, S. Visual SLAM algorithms: A survey from 2010 to 2016. IPSJ Trans. Comput. Vis. Appl. 2017, 9, 16. [Google Scholar] [CrossRef]
- Cadena, C.; Carlone, L.; Carrillo, H.; Latif, Y.; Scaramuzza, D.; Neira, J.; Reid, I.; Leonard, J.J. Past, Present, and Future of Simultaneous Localization and Mapping: Toward the Robust-Perception Age. IEEE Trans. Robot. 2016, 32, 1309–1332. [Google Scholar] [CrossRef] [Green Version]
- Mur-Artal, R.; Montiel, J.M.M.; Tardós, J.D. ORB-SLAM: A Versatile and Accurate Monocular SLAM System. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef] [Green Version]
- Engel, J.; Schöps, T.; Cremers, D. LSD-SLAM: Large-scale direct monocular SLAM. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 834–849. [Google Scholar]
- Newcombe, R.A.; Lovegrove, S.J.; Davison, A.J. DTAM: Dense tracking and mapping in real-time. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2320–2327. [Google Scholar] [CrossRef] [Green Version]
- Gomez-Ojeda, R.; Moreno, F.; Zuñiga-Noël, D.; Scaramuzza, D.; Gonzalez-Jimenez, J. PL-SLAM: A Stereo SLAM System Through the Combination of Points and Line Segments. IEEE Trans. Robot. 2019, 35, 734–746. [Google Scholar] [CrossRef] [Green Version]
- Brugali, D.; Scandurra, P. Component-based robotic engineering (Part I) [Tutorial]. IEEE Robot. Autom. Mag. 2009, 16, 84–96. [Google Scholar] [CrossRef]
- Fraundorfer, F.; Scaramuzza, D. Visual odometry: Part ii: Matching, robustness, optimization, and applications. IEEE Robot. Autom. Mag. 2012, 19, 78–90. [Google Scholar] [CrossRef] [Green Version]
- Cremers, D. Direct methods for 3D reconstruction and visual SLAM. In Proceedings of the 2017 Fifteenth IAPR International Conference on Machine Vision Applications (MVA), Nagoya, Japan, 8–12 May 2017; pp. 34–38. [Google Scholar] [CrossRef]
- Irani, M.; Anandan, P. About Direct Methods. In Proceedings of the International Workshop on Vision Algorithms: Theory and Practice, Corfu, Greece, 21–22 September 2000. [Google Scholar]
- Mur-Artal, R.; Tardós, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef] [Green Version]
- Klein, G.; Murray, D. Parallel Tracking and Mapping for Small AR Workspaces. In Proceedings of the 6th IEEE and ACM International Symposium on Mixed and Augmented Reality, Nara, Japan, 13–16 November 2007; pp. 225–234. [Google Scholar] [CrossRef]
- Nister, D. An efficient solution to the five-point relative pose problem. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 756–770. [Google Scholar] [CrossRef] [PubMed]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision, 2nd ed.; Cambridge University Press: New York, NY, USA, 2003. [Google Scholar]
- Forster, C.; Zhang, Z.; Gassner, M.; Werlberger, M.; Scaramuzza, D. SVO: Semidirect Visual Odometry for Monocular and Multicamera Systems. IEEE Trans. Robot. 2017, 33, 249–265. [Google Scholar] [CrossRef] [Green Version]
- Herrera, C.D.; Kim, K.; Kannala, J.; Pulli, K.; Heikkilä, J. DT-SLAM: Deferred Triangulation for Robust SLAM. In Proceedings of the 2014 2nd International Conference on 3D Vision, Tokyo, Japan, 8–11 December 2014; Volume 1, pp. 609–616. [Google Scholar] [CrossRef]
- Pumarola, A.; Vakhitov, A.; Agudo, A.; Sanfeliu, A.; Moreno-Noguer, F. PL-SLAM: Real-time monocular visual SLAM with points and lines. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 4503–4508. [Google Scholar] [CrossRef] [Green Version]
- Harris, C.G.; Pike, J. 3D positional integration from image sequences. Image Vis. Comput. 1988, 6, 87–90. [Google Scholar] [CrossRef] [Green Version]
- Jianbo, S. Good features to track. In Proceedings of the 1994 IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 21–23 June 1994; pp. 593–600. [Google Scholar] [CrossRef]
- Moravec, H.P. Obstacle Avoidance And Navigation in the Real World by a Seeing Robot Rover; Technical Report; Stanford University: Stanford, CA, USA, 1980. [Google Scholar]
- Fan, H.; Ling, H. Parallel Tracking and Verifying: A Framework for Real-Time and High Accuracy Visual Tracking. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5487–5495. [Google Scholar] [CrossRef] [Green Version]
- Rosten, E.; Drummond, T. Machine learning for high-speed corner detection. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2006; pp. 430–443. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Van Gool, L. Surf: Speeded up robust features. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2006; pp. 404–417. [Google Scholar]
- Agrawal, M.; Konolige, K.; Blas, M.R. Censure: Center surround extremas for realtime feature detection and matching. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2008; pp. 102–115. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar] [CrossRef]
- Mei, C.; Malis, E. Fast central catadioptric line extraction, estimation, tracking and structure from motion. In Proceedings of the 2006 IEEE/RSJ International Conference on Intelligent Robots and Systems, Beijing, China, 9–15 October 2006; pp. 4774–4779. [Google Scholar] [CrossRef]
- Solà, J.; Vidal-Calleja, T.; Devy, M. Undelayed initialization of line segments in monocular SLAM. In Proceedings of the 2009 IEEE/RSJ International Conference on Intelligent Robots and Systems, St. Louis, MO, USA, 10–15 October 2009; pp. 1553–1558. [Google Scholar] [CrossRef] [Green Version]
- Hofer, M.; Maurer, M.; Bischof, H. Efficient 3D Scene Abstraction Using Line Segments. Comput. Vis. Image Underst. 2017, 157, 167–178. [Google Scholar] [CrossRef]
- Zhang, L.; Koch, R. Hand-Held Monocular SLAM Based on Line Segments. In Proceedings of the 2011 Irish Machine Vision and Image Processing Conference, Dublin, Ireland, 7–9 September 2011; pp. 7–14. [Google Scholar] [CrossRef]
- Briales, J.; Gonzalez-Jimenez, J. A Minimal Closed-form Solution for the Perspective Three Orthogonal Angles (P3oA) Problem: Application To Visual Odometry. J. Math. Imaging Vis. 2016, 55, 266–283. [Google Scholar] [CrossRef]
- Özuysal, M.; Lepetit, V.; Fleuret, F.; Fua, P. Feature harvesting for tracking-by-detection. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2006; pp. 592–605. [Google Scholar]
- Pritchett, P.; Zisserman, A. Wide baseline stereo matching. In Proceedings of the Sixth International Conference on Computer Vision (IEEE Cat. No. 98CH36271), Bombay, India, 4–7 January 1998; pp. 754–760. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Vakhitov, A.; Funke, J.; Moreno-Noguer, F. Accurate and linear time pose estimation from points and lines. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 583–599. [Google Scholar]
- Lucas, B.D.; Kanade, T. An Iterative Image Registration Technique with an Application to Stereo Vision. In Proceedings of the 7th International Joint Conference on Artificial Intelligence-Volume 2; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1981; pp. 674–679. [Google Scholar]
- Baker, S.; Matthews, I. Lucas-kanade 20 years on: A unifying framework. Int. J. Comput. Vis. 2004, 56, 221–255. [Google Scholar] [CrossRef]
- Forster, C.; Pizzoli, M.; Scaramuzza, D. SVO: Fast semi-direct monocular visual odometry. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 15–22. [Google Scholar] [CrossRef] [Green Version]
- Engel, J.; Sturm, J.; Cremers, D. Semi-dense Visual Odometry for a Monocular Camera. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1449–1456. [Google Scholar] [CrossRef] [Green Version]
- Younes, G.; Asmar, D.; Shammas, E.; Zelek, J. Keyframe-based Monocular SLAM. Robot. Auton. Syst. 2017, 98, 67–88. [Google Scholar] [CrossRef] [Green Version]
- Strasdat, H.; Montiel, J.; Davison, A.J. Scale drift-aware large scale monocular SLAM. Robot. Sci. Syst. VI 2010, 2, 7. [Google Scholar]
- Mei, C.; Sibley, G.; Newman, P. Closing loops without places. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010; pp. 3738–3744. [Google Scholar] [CrossRef]
- Strasdat, H.; Davison, A.J.; Montiel, J.M.M.; Konolige, K. Double window optimisation for constant time visual SLAM. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2352–2359. [Google Scholar] [CrossRef] [Green Version]
- Williams, B.; Klein, G.; Reid, I. Real-Time SLAM Relocalisation. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar] [CrossRef]
- Gálvez-López, D.; Tardos, J.D. Bags of binary words for fast place recognition in image sequences. IEEE Trans. Robot. 2012, 28, 1188–1197. [Google Scholar] [CrossRef]
- Lowry, S.; Sünderhauf, N.; Newman, P.; Leonard, J.J.; Cox, D.; Corke, P.; Milford, M.J. Visual Place Recognition: A Survey. IEEE Trans. Robot. 2016, 32, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Nilsback, M.; Zisserman, A. A Visual Vocabulary for Flower Classification. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 1447–1454. [Google Scholar] [CrossRef]
- Angeli, A.; Filliat, D.; Doncieux, S.; Meyer, J. Fast and Incremental Method for Loop-Closure Detection Using Bags of Visual Words. IEEE Trans. Robot. 2008, 24, 1027–1037. [Google Scholar] [CrossRef] [Green Version]
- Kümmerle, R.; Grisetti, G.; Strasdat, H.; Konolige, K.; Burgard, W. g2o: A general framework for graph optimization. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 3607–3613. [Google Scholar]
- Mikolajczyk, K.; Tuytelaars, T.; Schmid, C.; Zisserman, A.; Matas, J.; Schaffalitzky, F.; Kadir, T.; Van Gool, L. A comparison of affine region detectors. Int. J. Comput. Vis. 2005, 65, 43–72. [Google Scholar] [CrossRef] [Green Version]
- Jogan, M.; Leonardis, A. Robust localization using panoramic view-based recognition. In Proceedings of the 15th International Conference on Pattern Recognition, ICPR-2000, Barcelona, Spain, 3–7 September 2000; Volume 4, pp. 136–139. [Google Scholar]
- Ulrich, I.; Nourbakhsh, I. Appearance-based place recognition for topological localization. In Proceedings of the 2000 ICRA, Millennium Conference, IEEE International Conference on Robotics and Automation, Symposia Proceedings (Cat. No.00CH37065), San Francisco, CA, USA, 24–28 April 2000; Volume 2, pp. 1023–1029. [Google Scholar] [CrossRef] [Green Version]
- Agarwal, S.; Mierle, K. Ceres Solver. Available online: http://ceres-solver.org (accessed on 21 March 2021).
- Kaess, M.; Ranganathan, A.; Dellaert, F. iSAM: Incremental Smoothing and Mapping. IEEE Trans. Robot. 2008, 24, 1365–1378. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are We Ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; IEEE Computer Society: Washington, DC, USA, 2012; pp. 3354–3361. [Google Scholar]
- Engel, J.; Koltun, V.; Cremers, D. Direct Sparse Odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 611–625. [Google Scholar] [CrossRef] [PubMed]
- Gao, X.; Wang, R.; Demmel, N.; Cremers, D. LDSO: Direct Sparse Odometry with Loop Closure. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 2198–2204. [Google Scholar] [CrossRef] [Green Version]
- Zhu, J. Image Gradient-based Joint Direct Visual Odometry for Stereo Camera. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence (IJCAI-17), Melbourne, Australia, 19–25 August 2017; pp. 4558–4564. [Google Scholar]
- Engel, J.; Stückler, J.; Cremers, D. Large-scale direct SLAM with stereo cameras. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 1935–1942. [Google Scholar] [CrossRef]
- Wang, R.; Schwörer, M.; Cremers, D. Stereo DSO: Large-Scale Direct Sparse Visual Odometry with Stereo Cameras. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3923–3931. [Google Scholar] [CrossRef] [Green Version]
- Burri, M.; Nikolic, J.; Gohl, P.; Schneider, T.; Rehder, J.; Omari, S.; Achtelik, M.W.; Siegwart, R. The EuRoC micro aerial vehicle datasets. Int. J. Robot. Res. 2016, 35, 1157–1163. [Google Scholar] [CrossRef]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 573–580. [Google Scholar] [CrossRef] [Green Version]
- Gomez-Ojeda, R.; Briales, J.; Gonzalez-Jimenez, J. PL-SVO: Semi-direct Monocular Visual Odometry by combining points and line segments. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 4211–4216. [Google Scholar] [CrossRef]
- Handa, A.; Whelan, T.; McDonald, J.; Davison, A.J. A benchmark for RGB-D visual odometry, 3D reconstruction and SLAM. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 1524–1531. [Google Scholar] [CrossRef] [Green Version]
- Smith, M.; Baldwin, I.; Churchill, W.; Paul, R.; Newman, P. The new college vision and laser data set. Int. J. Robot. Res. 2009, 28, 595–599. [Google Scholar] [CrossRef] [Green Version]
- Mei, C.; Sibley, G.; Cummins, M.; Newman, P.; Reid, I. RSLAM: A system for large-scale mapping in constant-time using stereo. Int. J. Comput. Vis. 2011, 94, 198–214. [Google Scholar] [CrossRef] [Green Version]
- Maddern, W.; Pascoe, G.; Linegar, C.; Newman, P. 1 Year, 1000km: The Oxford RobotCar Dataset. Int. J. Robot. Res. 2017, 36, 3–15. [Google Scholar] [CrossRef]
- Tamura, H.; Kato, H. Proposal of international voluntary activities on establishing benchmark test schemes for AR/MR geometric registration and tracking methods. In Proceedings of the 2009 8th IEEE International Symposium on Mixed and Augmented Reality, Orlando, FL, USA, 19–22 October 2009; pp. 233–236. [Google Scholar]
- Bodin, B.; Wagstaff, H.; Saeedi, S.; Nardi, L.; Vespa, E.; Mayer, J.; Nisbet, A.; Luján, M.; Furber, S.; Davison, A.; et al. SLAMBench2: Multi-Objective Head-to-Head Benchmarking for Visual SLAM. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018. [Google Scholar]
- Martull, S.; Peris, M.; Fukui, K. Realistic CG stereo image dataset with ground truth disparity maps. In Proceedings of the ICPR Workshop TrakMark2012, Tsukuba, Japan, 11–15 November 2012; Volume 111, pp. 117–118. [Google Scholar]

{kind=link}
{kind=link}
| ATE/RMSE | T_abs | T_rel | |||||||
|---|---|---|---|---|---|---|---|---|---|
| (ATE/RMSE) | ORB-SLAM | Mono DSO | LDSO | ORB-SLAM2 | St. LSD | GDVO | Stereo DSO | ORB-SLAM2 | St LSD-VO |
| Seq 00 | 5.33 | 126.7 | 9.322 | 1.3 | 1 | 4.9 | 0.84 | 0.83 | 1.09 |
| Seq 01 | - | 165.03 | 11.68 | 10.4 | 9 | 5.2 | 1.43 | 1.38 | 2.13 |
| Seq 02 | 21.28 | 138.7 | 31.98 | 5.7 | 2.6 | 6.1 | 0.78 | 0.81 | 1.09 |
| Seq 03 | 1.51 | 4.77 | 2.85 | 0.6 | 1.2 | 0.3 | 0.92 | 0.71 | 1.16 |
| Seq 04 | 1.62 | 1.08 | 1.22 | 0.2 | 0.2 | 0.2 | 0.65 | 0.45 | 0.42 |
| Seq 05 | 4.85 | 49.85 | 5.1 | 0.8 | 1.5 | 1.8 | 0.68 | 0.64 | 0.9 |
| Seq 06 | 12.34 | 113.57 | 13.55 | 0.8 | 1.3 | 1.5 | 0.67 | 0.82 | 1.28 |
| Seq 07 | 2.26 | 27.99 | 2.96 | 0.5 | 0.5 | 0.8 | 0.83 | 0.78 | 1.25 |
| Seq 08 | 46.48 | 120.17 | 129.02 | 3.6 | 3.9 | 2.4 | 0.98 | 1.07 | 1.24 |
| Seq 09 | 6.62 | 74.29 | 21.64 | 3.2 | 5.6 | 2.2 | 0.98 | 0.82 | 1.22 |
| Seq 10 | 8.68 | 16.32 | 17.36 | 1 | 1.5 | 1.1 | 0.49 | 0.58 | 0.75 |
| Trans (RMSE) | T_abs | T_rel | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Seq. | St ORB-SLAM2 | St LSD-SLAM | St SVO | MonoVO ORB-SLAM | Mono DSO | MonoVO LSD | P-SLAM | L-SLAM | PL-SLAM |
| V1_01 | 0.035 | 0.066 | 0.04 | 0.04 | 0.12 | 1.24 | 0.0583 | 0.0464 | 0.0423 |
| V1_02 | 0.02 | 0.074 | 0.04 | - | 0.11 | 1.11 | 0.0608 | - | 0.0459 |
| V1_03 | 0.048 | 0.089 | 0.07 | - | 0.93 | - | 0.1008 | - | 0.689 |
| V2_01 | 0.037 | - | 0.05 | 0.02 | 0.04 | - | 0.0784 | 0.0974 | 0.0609 |
| V2_02 | 0.035 | - | 0.09 | 0.07 | 0.13 | - | 0.0767 | - | 0.0565 |
| V2_03 | - | - | 0.79 | - | 1.16 | - | 0.1511 | - | 0.1261 |
| MH_01 | 0.035 | - | 0.04 | 0.03 | 0.05 | 0.18 | 0.0811 | 0.0588 | 0.0416 |
| MH_02 | 0.018 | - | 0.05 | 0.02 | 0.05 | 0.56 | 0.1041 | 0.0566 | 0.0522 |
| MH_03 | 0.028 | - | 0.06 | 0.02 | 0.18 | 2.69 | 0.0588 | 0.0371 | 0.0399 |
| MH_04 | 0.119 | - | 0.17 | 0.2 | 0.24 | 2.13 | - | 0.109 | 0.0641 |
| MH_05 | 0.06 | - | 0.12 | 0.19 | 0.11 | 0.85 | 0.1208 | 0.0811 | 0.0697 |
| AKfT (RMSE) | LSD-SLAM | PL-SLAM | ORB-SLAM | PTAM |
|---|---|---|---|---|
| f1_xyz | 9 | 1.46 | 1.38 | 1.15 |
| f2_xyz | 2.15 | 1.49 | 0.54 | 0.2 |
| floor | 38.07 | 9.42 | 8.71 | - |
| kidnap | - | 60.11 | 4.99 | 2.63 |
| office | 38.53 | 5.33 | 4.05 | - |
| NstrTexFar | 18.31 | 37.6 | - | 34.74 |
| NstrTexNear | 7.54 | 1.58 | 2.88 | 2.74 |
| StrTexFar | 7.95 | 1.25 | 0.98 | 0.93 |
| StrTexNear | - | 7.47 | 1.5451 | 1.04 |
| deskPerson | 31.73 | 6.34 | 5.95 | - |
| sitHalfsph | 7.73 | 9.03 | 0.08 | 0.83 |
| WalkXyz | 5.87 | 9.05 | 1.48 | - |
| WalkXyz | 12.44 | - | 1.64 | - |
| WalkHalfsph | - | - | 2.09 | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mishra, B.; Griffin, R.; Sevil, H.E. Modelling Software Architecture for Visual Simultaneous Localization and Mapping. Automation 2021, 2, 48-61. https://doi.org/10.3390/automation2020003
Mishra B, Griffin R, Sevil HE. Modelling Software Architecture for Visual Simultaneous Localization and Mapping. Automation. 2021; 2(2):48-61. https://doi.org/10.3390/automation2020003
Chicago/Turabian StyleMishra, Bhavyansh, Robert Griffin, and Hakki Erhan Sevil. 2021. "Modelling Software Architecture for Visual Simultaneous Localization and Mapping" Automation 2, no. 2: 48-61. https://doi.org/10.3390/automation2020003
APA StyleMishra, B., Griffin, R., & Sevil, H. E. (2021). Modelling Software Architecture for Visual Simultaneous Localization and Mapping. Automation, 2(2), 48-61. https://doi.org/10.3390/automation2020003