
Intelligent Handover Decision-Making for Vehicle-to-Everything (V2X) 5G Networks



Abstract
1. Introduction
- Develop a dual HO decision method for 5G V2X communications by integrating TOPSIS with a value-based RL algorithm in the form of Q-Learning to provide long-term network stability.
- Use the TOPSIS method integrated with stay time (ST) and connection context requirements to improve decision quality.
- The novelty of adjusting the TOPSIS weightage dynamically based on the updated Q-values and accumulated experiences can guarantee achieving better performance for the V2X UDN network.
2. Related Work
3. Intelligent Handover Decision for V2X (IHD-V2X)
- Decreased exploration space for Q-Learning: The IHD-V2X algorithm efficiently narrows down the search space for Q-Learning by pre-filtering and ranking the SCs using TOPSIS rather than considering every potential small cell. Q-Learning concentrates on the top-ranked possibilities that TOPSIS has found. Because it works with a more focused collection of superior choices, the Q-Learning process can converge more quickly and effectively because of this reduction in the search space.
- Enhanced performance and adaptability: High-quality SCs selection is made possible by the TOPSIS approach, which also incorporates Q-Learning for adaptive learning and handover strategy refinement, based on feedback and real-world network performance. With the help of this adaptive learning feature, the network may continuously improve the handover procedure in response to shifting circumstances, including traffic loads, user movement patterns, and signal conditions, thereby improving resilience and performance.
- Balancing long-term optimization and immediate quality: TOPSIS prioritizes instant quality using performance measurements to rank SCs. By drawing lessons from the past and refining future handover procedures to maximize cumulative rewards, Q-Learning presents a long-term view. Collectively, they guarantee that the network makes choices that promote long-term network stability and efficiency, in addition to optimizing the quality of handovers.
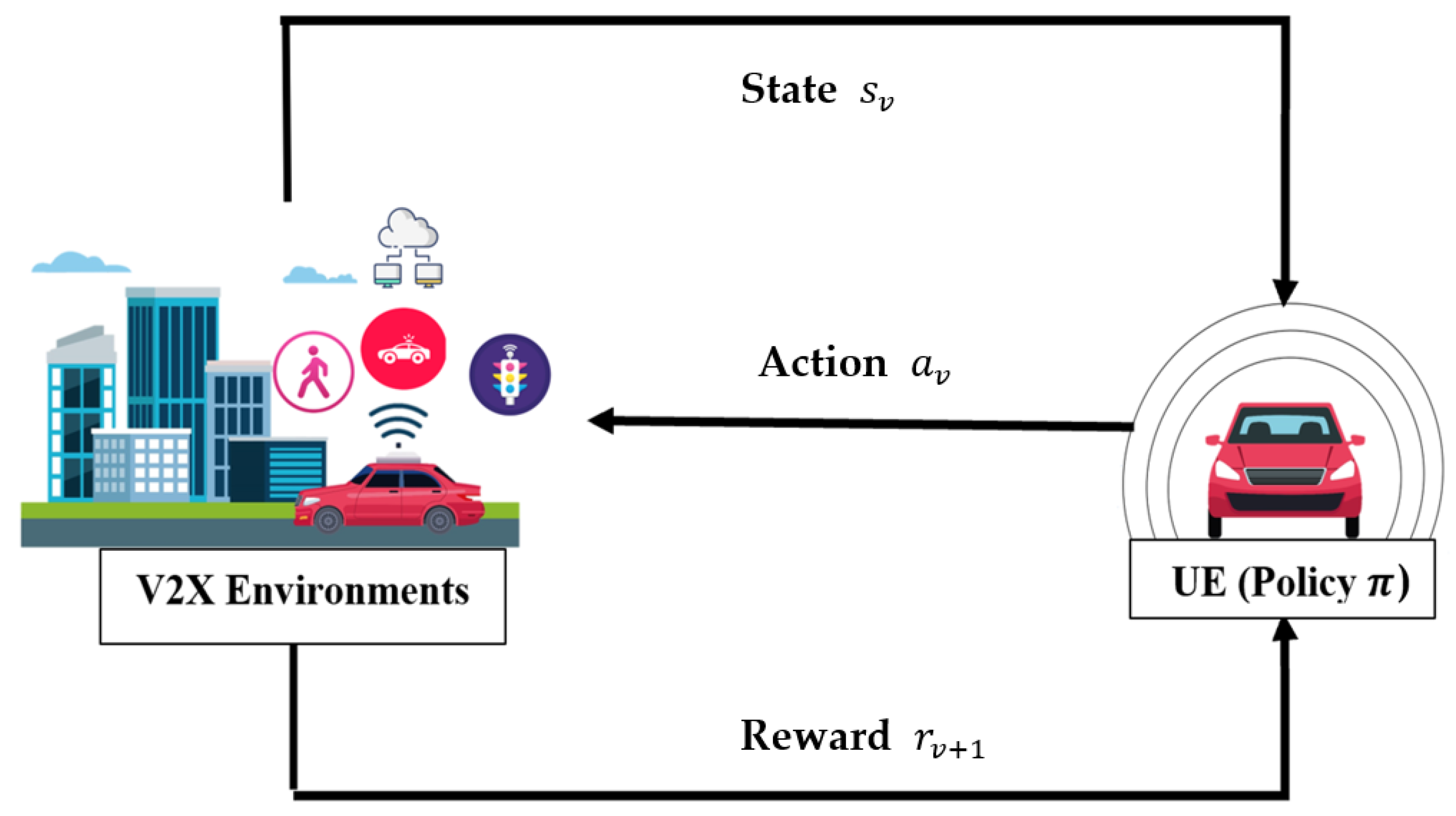
- Assistance in complex and dynamic environments: This method is especially well-suited for complex and dynamic environments such as 5G V2X networks, where quick decision-making and adaptive learning are essential, because it integrates TOPSIS and Q-Learning. TOPSIS guarantees sound decision-making in multi-criteria scenarios, whereas Q-Learning manages the dynamic nature of the environment by determining the best course of action under various circumstances. Figure 1 illustrates the key Q-Learning components, where a state is mapped to a sequence of actions while interacting with an environment to maximize rewards. The knowledge gained from the environment by the agent is represented by a Q-table (Q). It keeps track of the predicted utility, or Q-values, of performing particular tasks under particular conditions.
- ▪
- RSSI: It represents a traditional HO decision method that provides a measure of how good a received signal is to a UE.
- ▪
- SINR: It is a user-perceived metric that evaluates the ratio of signal level to noise level. A high SINR value represents good signal quality, while a value below 0 indicates more noise, which means low connection speed and a high probability of losing connection.
- ▪
- BER: It is one of the most used performance indicators in wireless networks. It is calculated by dividing the erroneous bits by the number of transmitted bits. It is used in decision-making in cognitive radio networks to determine channel quality. This parameter has been used to analyze the performance and achievable throughput of 5G uplink and downlink communications, and as a reference value for the vertical handover algorithm.
- ▪
- Data Transmission Rate: It represents the amount of data that is transmitted. Maintaining seamless and uninterrupted service is essential for upholding user satisfaction, and this is ensured by higher data rates. By choosing smaller cells with faster data rates, the network efficiency can be maximized by transferring data faster and freeing up resources for other users.
- ▪
- Packet loss: It represents the dropped packets when the data is transmitted over a network.
- ▪
- Delay: It is a crucial component of safety-related communications in V2X scenarios, as even a slight delay might have serious repercussions. It calculates the amount of time the data takes to transfer from source to destination.
- ▪
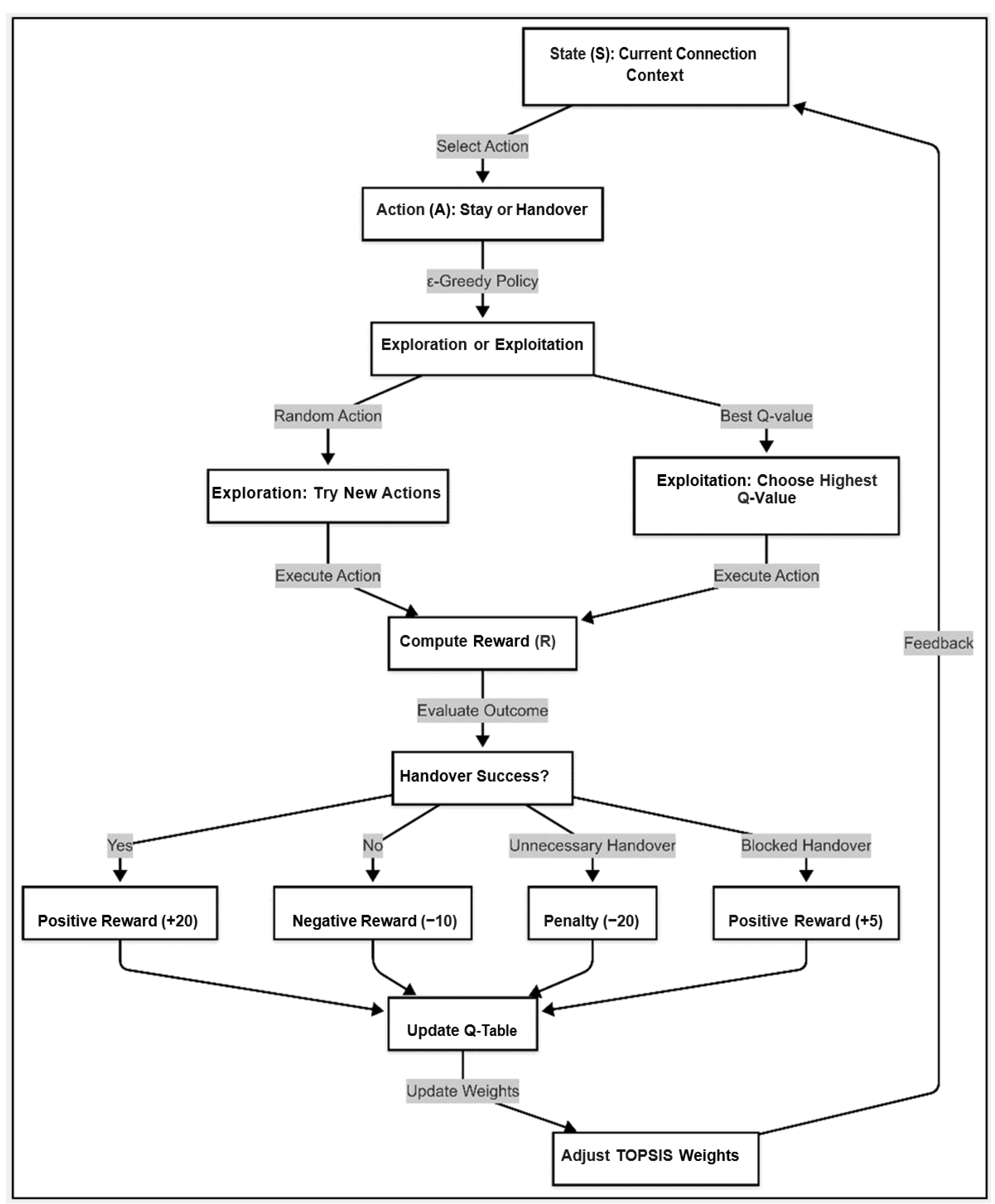
- The following discusses the flow of the algorithm.
- 1.
- Define the State (sv)
- 2.
- Select an Action (av)
- ○
- Stay: The UE remains connected to its current small cell.
- ○
- Handover: The UE switches to another small cell.
- ▪
- a0 represents stay at the current small cell.
- ▪
- az for z ≠ 0 represents the UE changing its connection to a better network.
- 3.
- Compute the Reward ()
- ○
- Successful HO () represents the positive rewards of better QoS: +20 points.
- ○
- Failed HO () represents the negative rewards of worse performance: −10 points.
- ○
- The ping-pong effect () represents the negative rewards of unnecessary handover: −20 points.
- ○
- Blocked HO () represents the positive rewards where the Stay decision is better: +5 points.
- ▪
- represents the penalties.
- ▪
- represents the adding points.
- ▪
- is the set of possible rewards.
- 4.
- Update the Q-values
- ▪
- represents the expected reward for action A in state S.
- ▪
- represents the learning rate (adjusts the influence of new information), given .
- ▪
- represents the discount factor (prioritizing immediate vs. future rewards), given .
- ▪
- represents the immediate reward for the chosen action.
- ▪
- represents the best future reward in the next state.
- 5.
- Adjust the TOPSIS weights
- ○
- If a high SINR consistently leads to successful handovers, increase the SINR weight.
- ○
- If a low delay is critical, increase the delay weight.
- ○
- If high packet loss leads to failures, reduce the weight on unreliable connections.
| Algorithm 1: IHD-V2X Algorithm | |
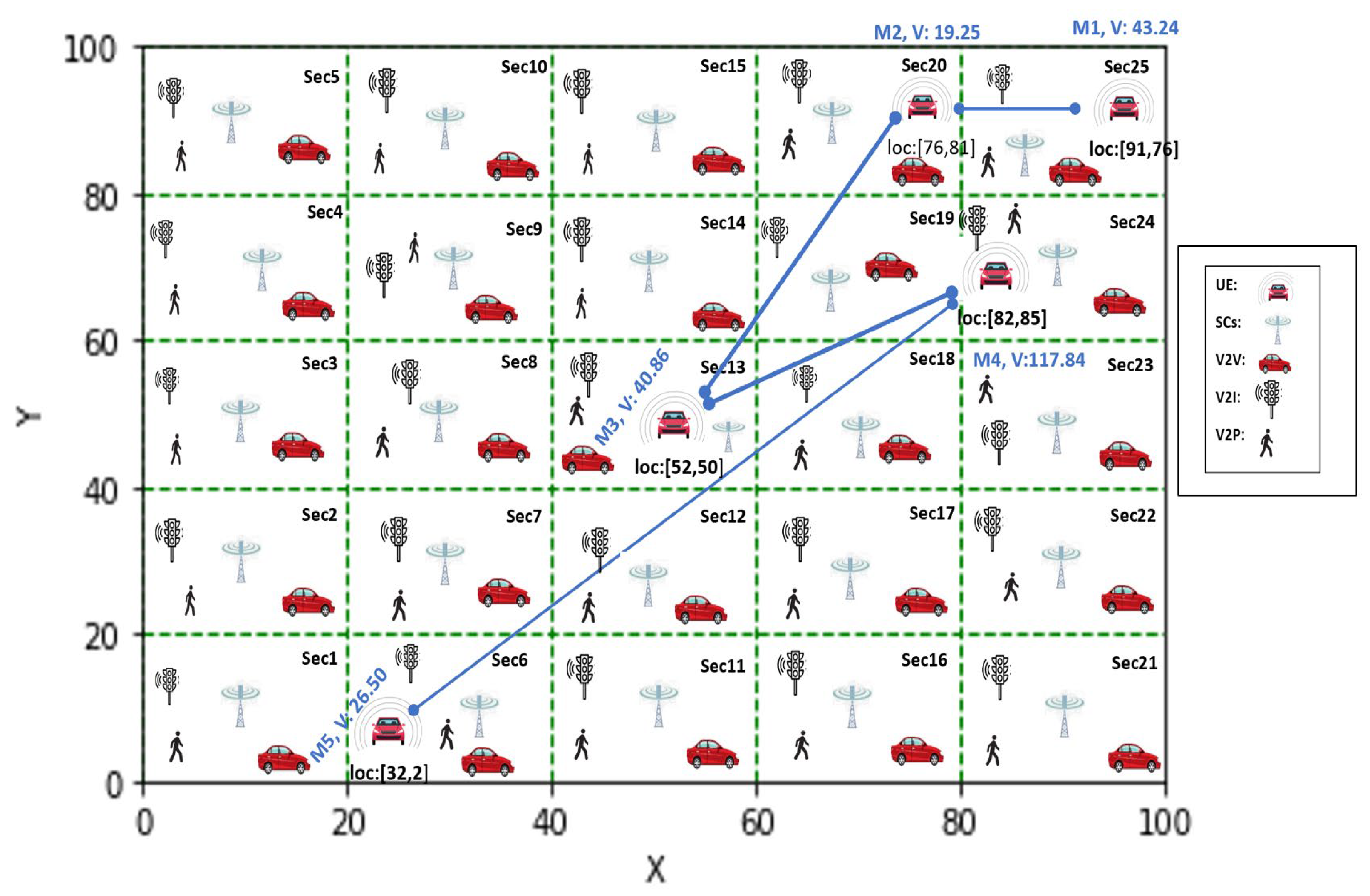
| 1 | Model the network grid |
| 2 | Identify UEs and plot their movements in the network grid sector |
| 3 | Inputs: |
| 4 | • User movement in Sector Secn |
| 5 | • Distance between each movement D |
| 6 | • UE velocity V |
| 7 | • List of SCs in UE Sector ID No (m, n) = [x/20],[y/20] ranked using TOPSIS |
| 8 | • Q-table initialized with zero values |
| 9 | • Q-Learning parameters: |
| 10 | ○ Learning rate α = 0.3 |
| 11 | ○ Discount factor = 0.7 |
| 12 | ○ Exploration rate ε = 1.0 |
| 13 | Outputs: |
| 14 | • Successful and unsuccessful handover attempts |
| 15 | • Small cell selection and stay time assignment |
| 16 | • Q-Learning adjusted weights |
| 17 | • Network performance metrics |
| 18 | while List of SCs [i] ≤ List of SCs[max] do |
| 19 | Extract and normalize parameters values N_ij = X_ij/sqrt(sum(X_ij2)) |
| 20 | Compute weighted normalized values W_ij = N_ij * W_j |
| 21 | Compute Ideal Positive and Negative Solutions (IPS, INS) |
| 22 | Compute Performance Index PI = D−/(D+ + D−) |
| 23 | Rank SCs Rn = arg max Pi(i) |
| 24 | Filter top n% SCs LSC = {Si/Si ∈ Sorted Rn ∧ Rn × C/100} |
| 25 | Compute ST Value for sector STV = D/V |
| 26 | Assign ST ST_SC = STV − (PI + R) |
| 27 | end while |
| 28 | for each UE movement |
| 29 | while Handover required = True do |
| 30 | Query SC Load |
| 31 | if SC Load < Max SC Load then |
| 32 | Choose Action (A): Stay or Handover using ε-Greedy strategy: (1) |
| 33 | ▪ Exploration: Select a random action with probability ε |
| 34 | ▪ Exploitation: Select the action with the highest Q(S,A) value |
| 35 | Compute Reward (R): (2) |
| 36 | ▪ Successful handover R = +20 |
| 37 | ▪ Failed handover R = −10 |
| 38 | ▪ Unnecessary handover (Ping-Pong) R = −20 |
| 39 | ▪ Blocked handover R = +5 |
| 40 | Update Q-table: |
| 41 | Adjust TOPSIS weights dynamically based on learned Q-values |
| 42 | if ST ≤ STV then |
| 43 | ▪ Assign current SC = SC |
| 44 | ▪ Increment SC Load by 1 |
| 45 | ▪ Decrement ST by 1 |
| 46 | else |
| 47 | ▪ Current SC = None |
| 48 | end while |
| 49 | end for |
4. Performance Evaluation
4.1. Simulation Settings
4.2. Performance Measures
4.2.1. HO KPIs
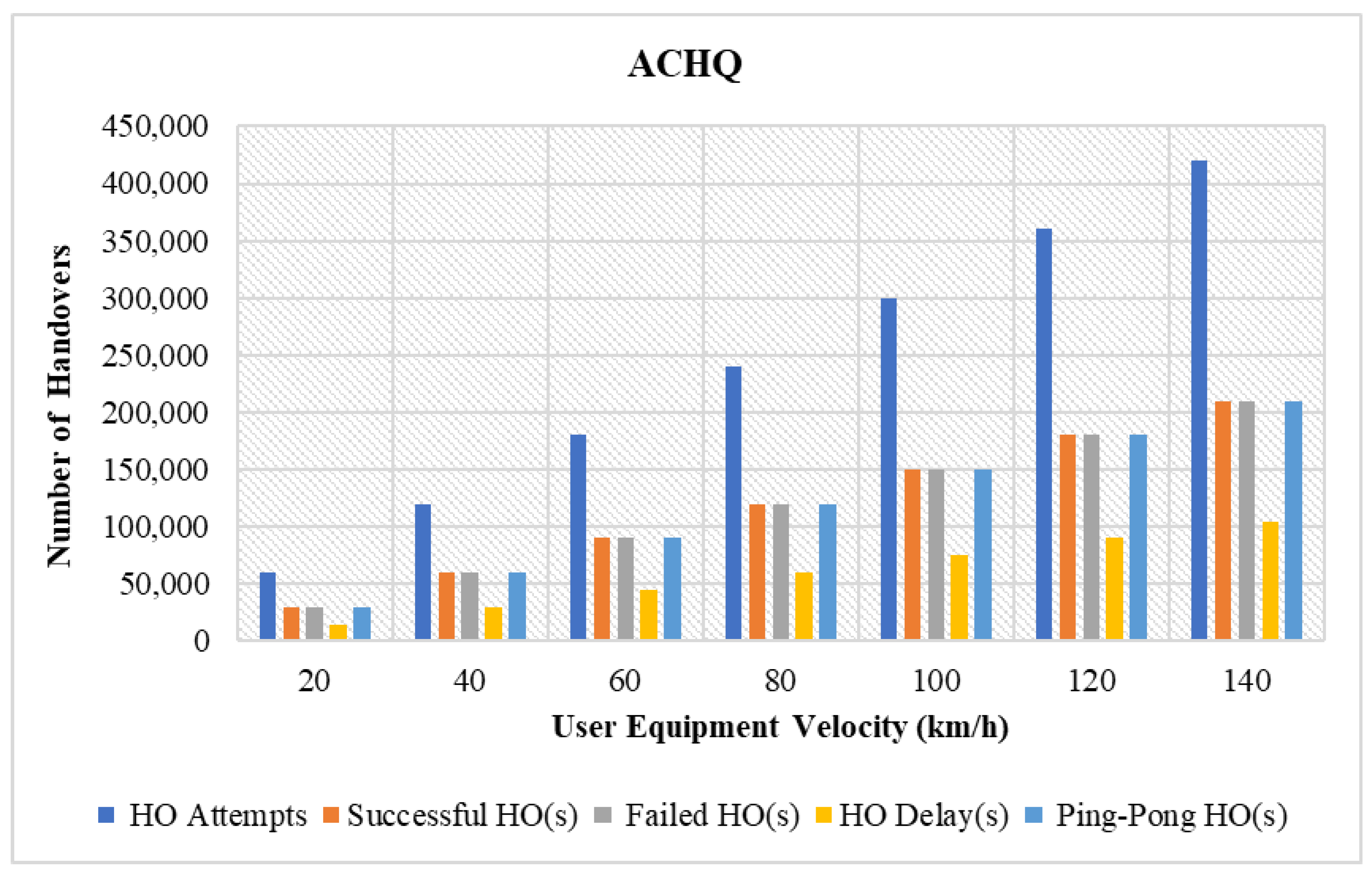
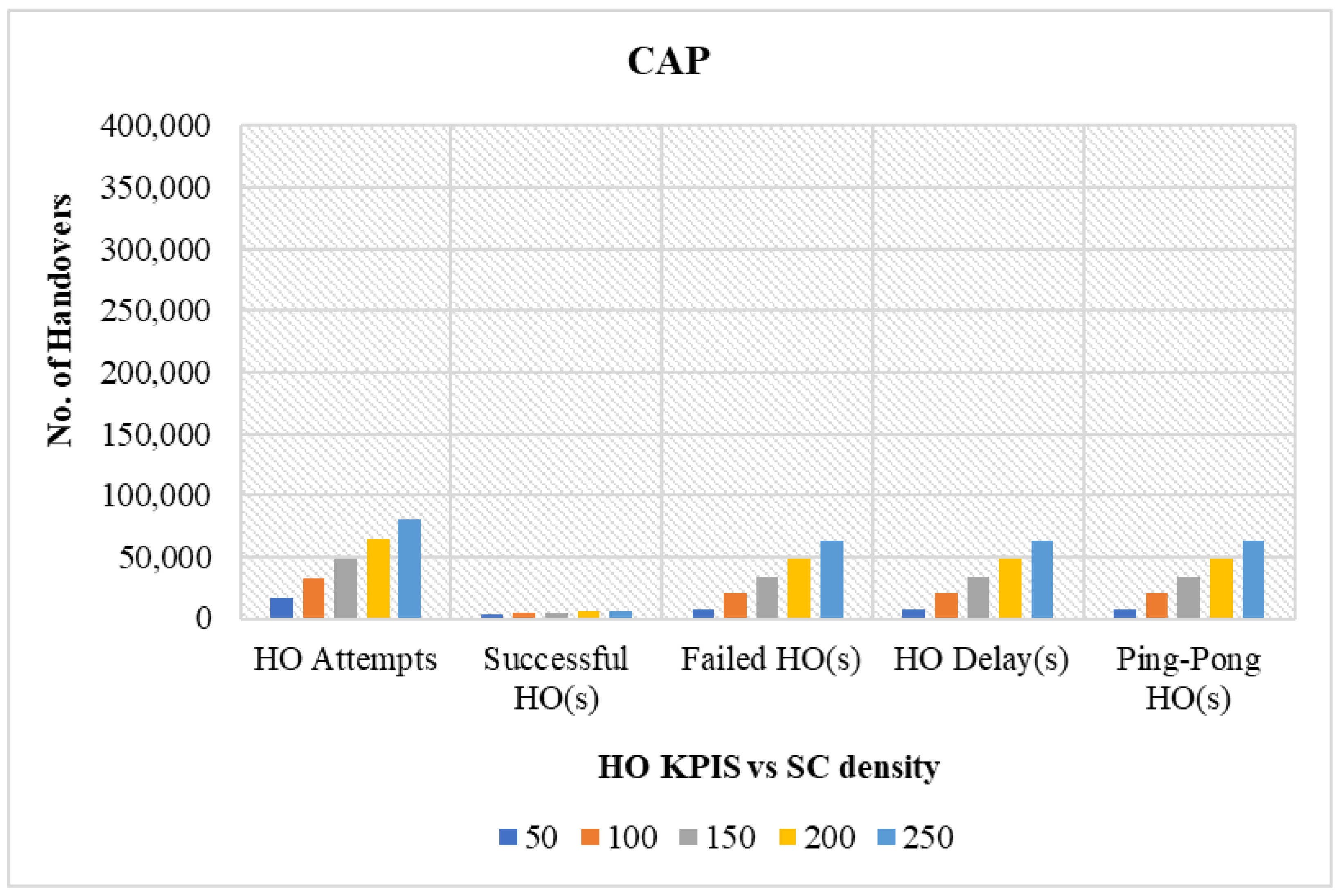
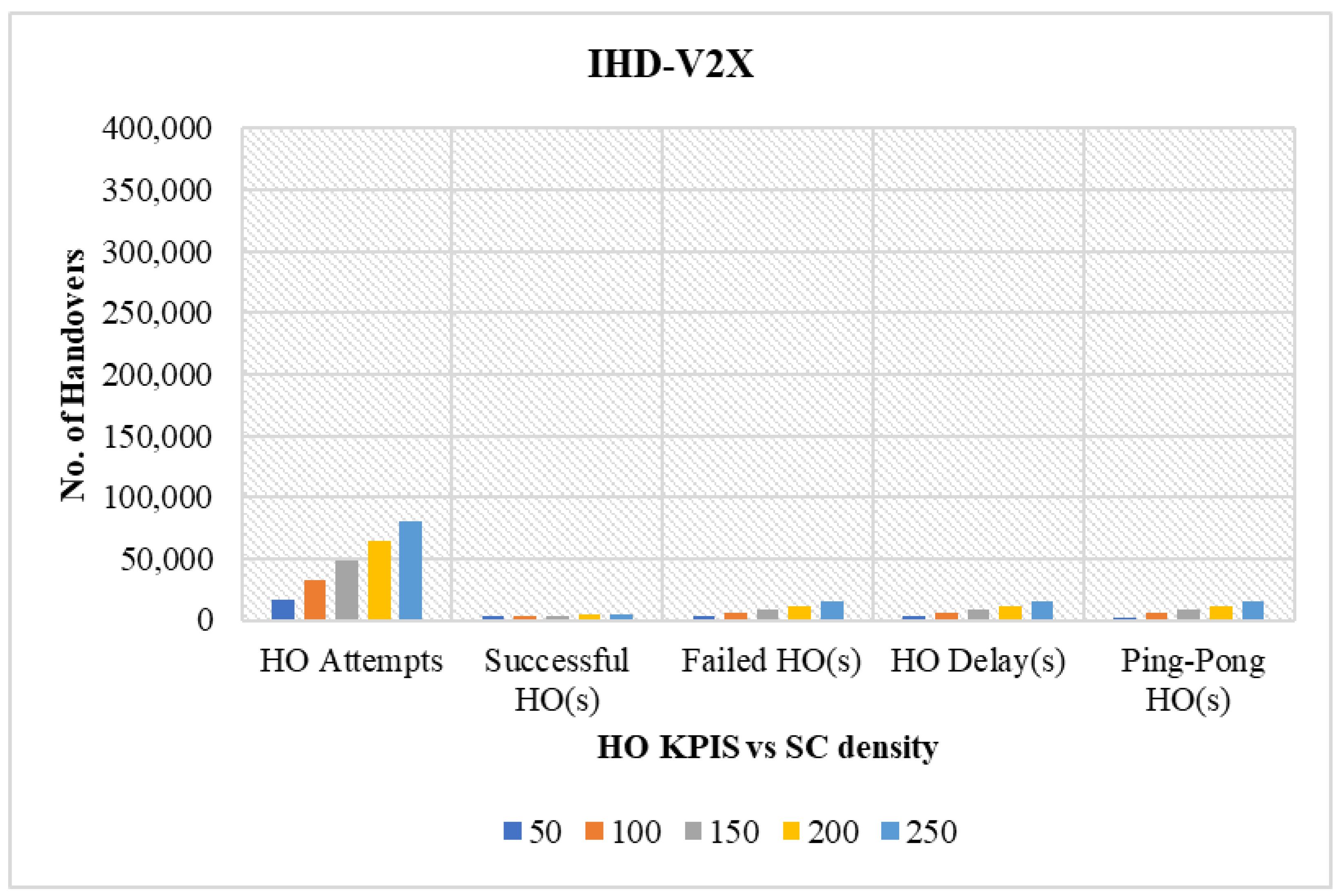
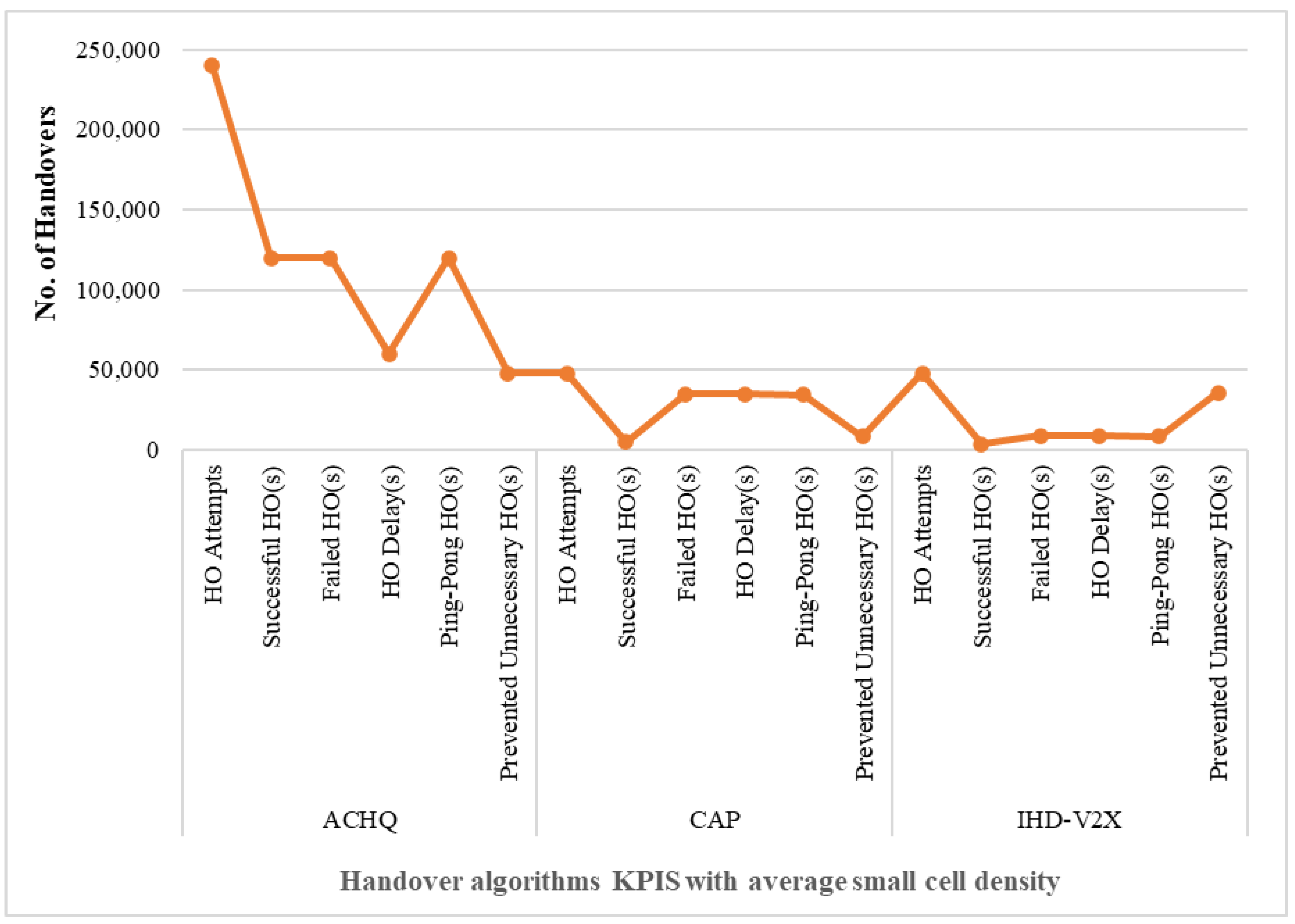
- HOs attempts: Refers to the total number of times the handover process is initiated to transfer the UE connection from the source cell to the target cell.
- Successful HOs: Occur when the UE seamlessly changes the connection between two cells. The handover success rate is obtained as the ratio of the number of successful handovers to the total number of HO attempts.
- Failed HOs: Occurs when the handover between two cells is unsuccessful owing to inefficient resources. Failed HOs are defined as the ratio of the number of failed handovers to the total number of HO attempts.
- Ping-pong HOs: Describes an unwanted situation where a UE rapidly transitions back and forth between SCs, causing unnecessary power consumption, inducing signal overhead, and inefficient resource utilization. Ping-pong HOs quantify the ratio of the number of occurrences of ping-pong HOs to the total number of handovers performed.
- Prevented unnecessary HOs: The unnecessary handover occurred as a consequence of the UE attempting to change its current connection, despite the fact that it is sufficient for communication.
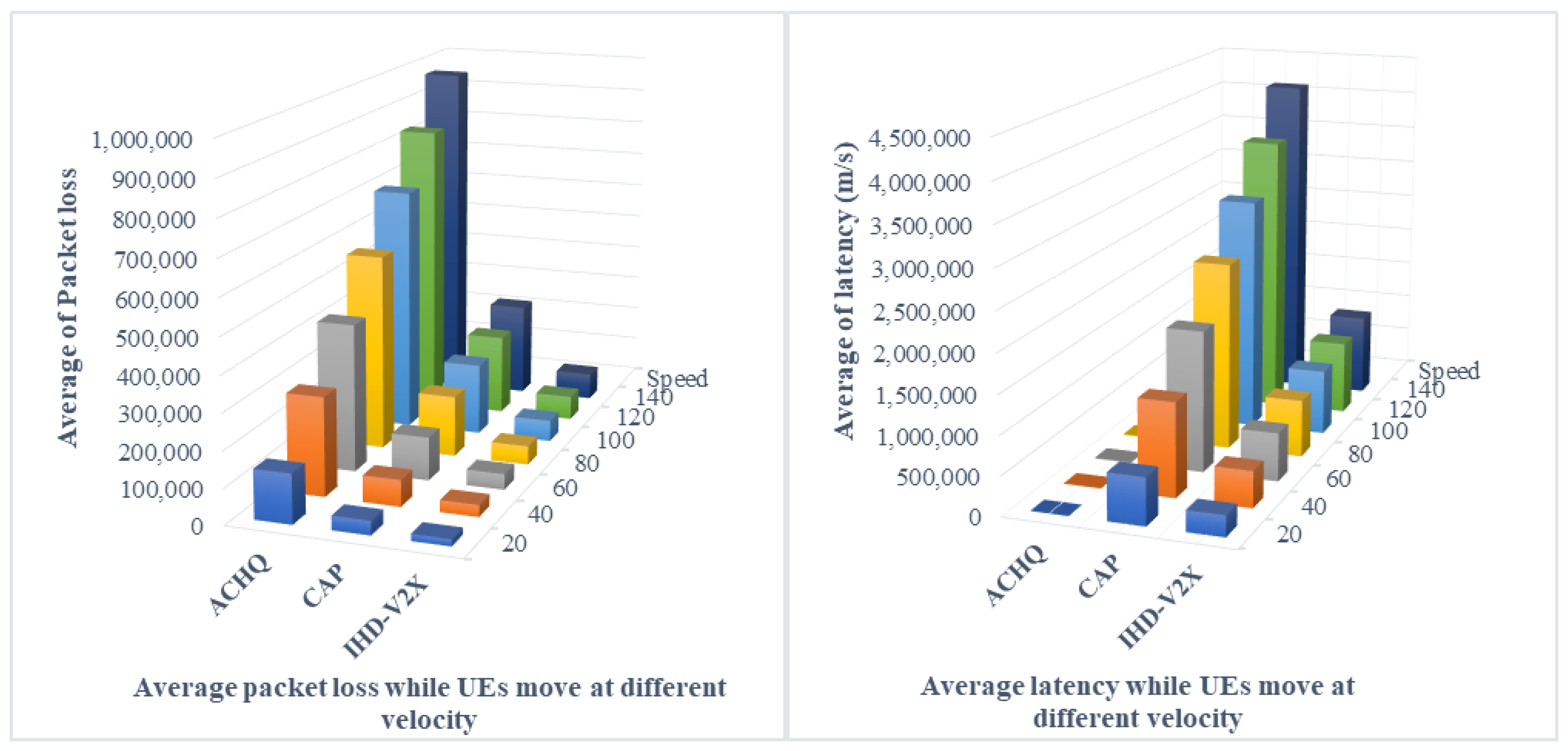
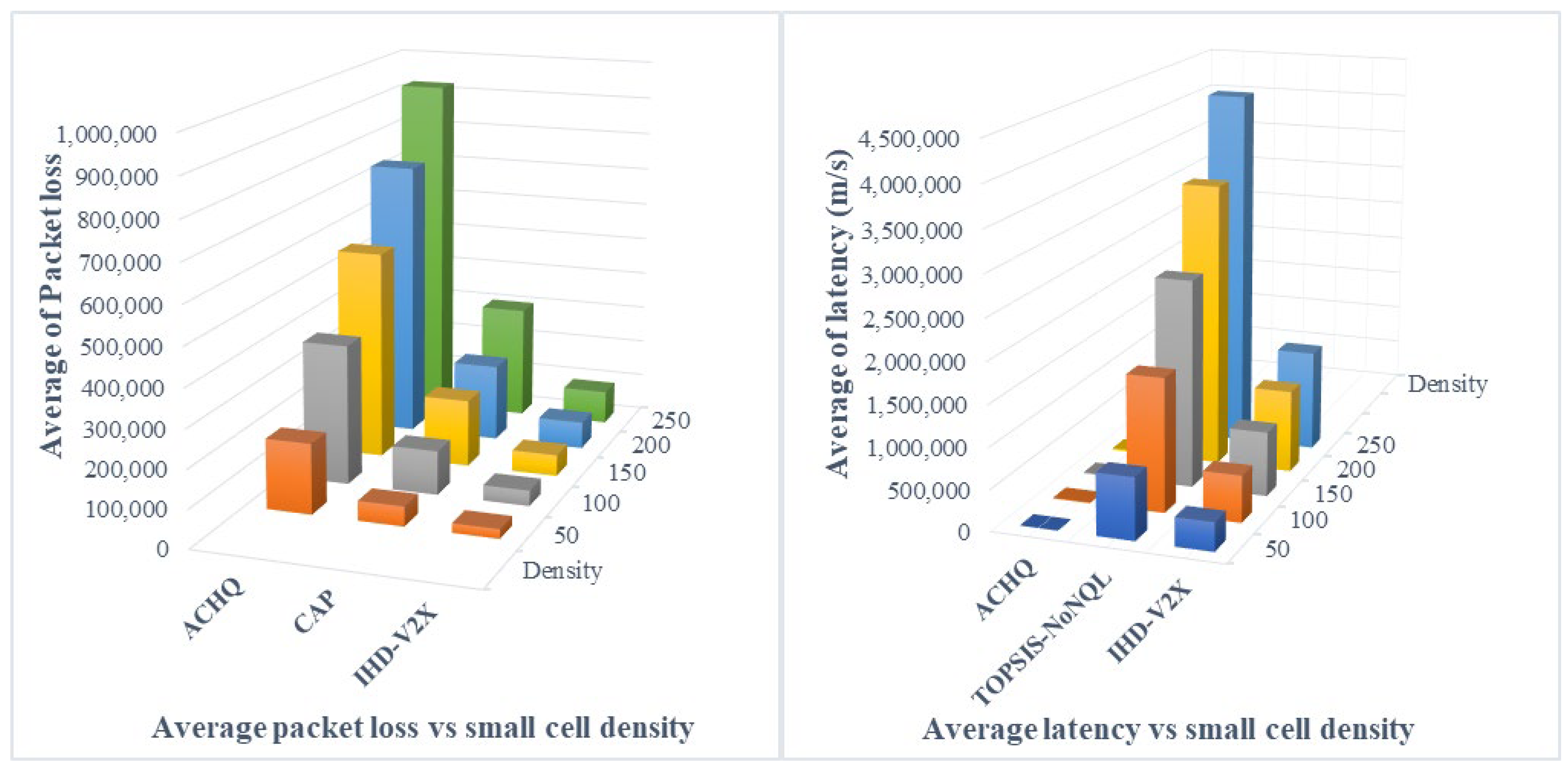
4.2.2. Packet Loss
- ▪
- the signal power.
- ▪
- the signal inference.
- ▪
- the signal noise.
4.2.3. Latency
- ▪
- represents the Queue delay(s) of 5 ms.
- ▪
- represents the Propagation delay(s) = distance/speed of light.
- ▪
- is the handover delay(s), radio resource control time+ path switch time+ procedure time.
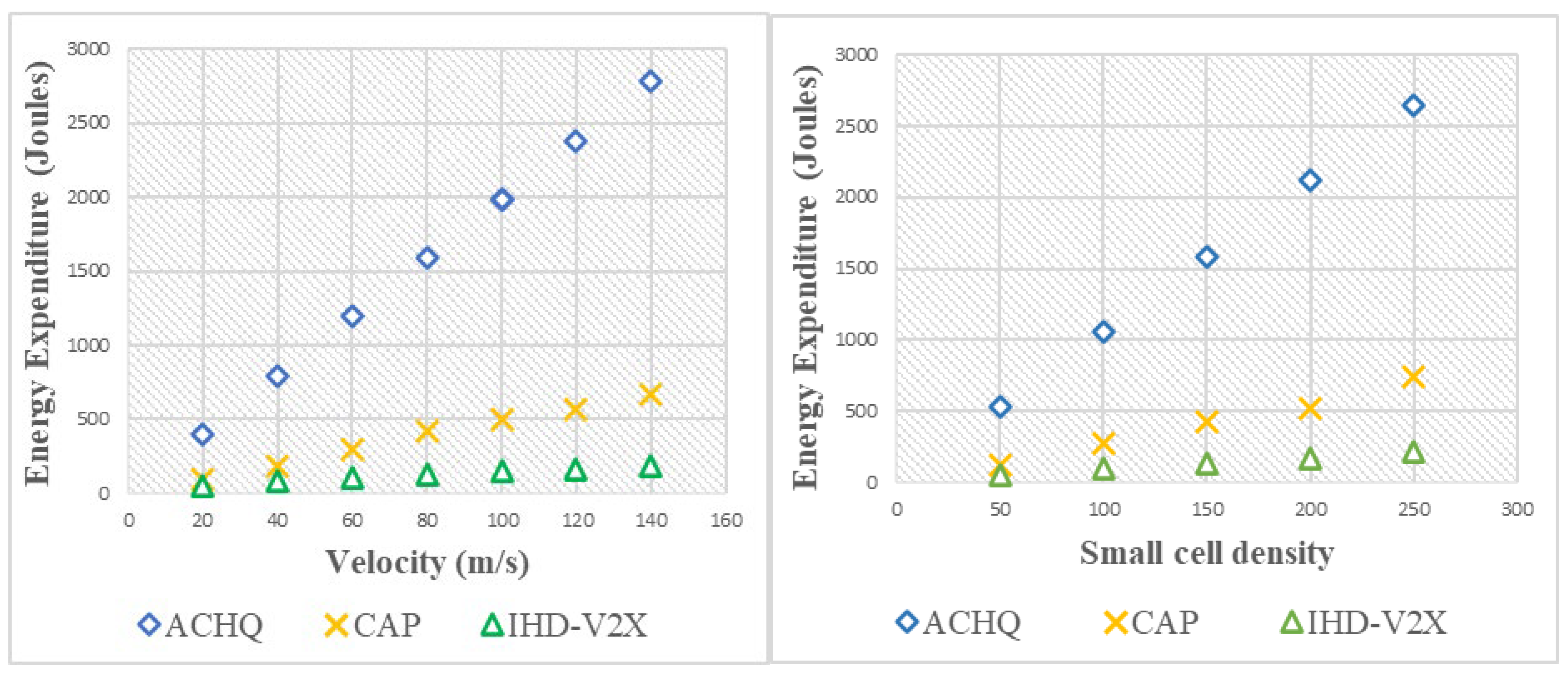
4.2.4. Energy Consumption
- ▪
- .
- ▪
- .
- ▪
- is the Transmit Power (W).
- ▪
- is the Time on Air (s).
- ▪
- represents the number of retransmissions.
4.3. Result Analysis
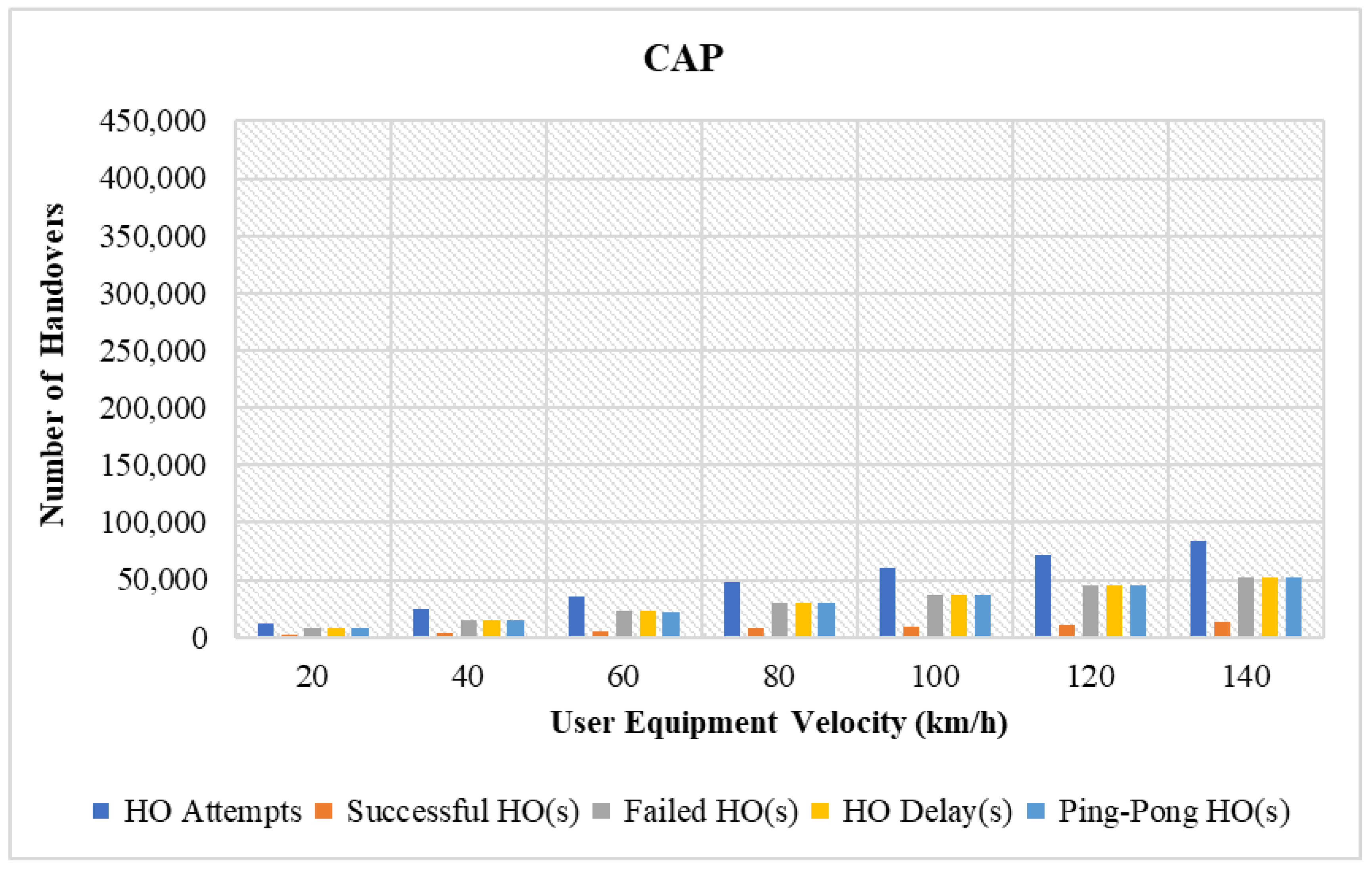
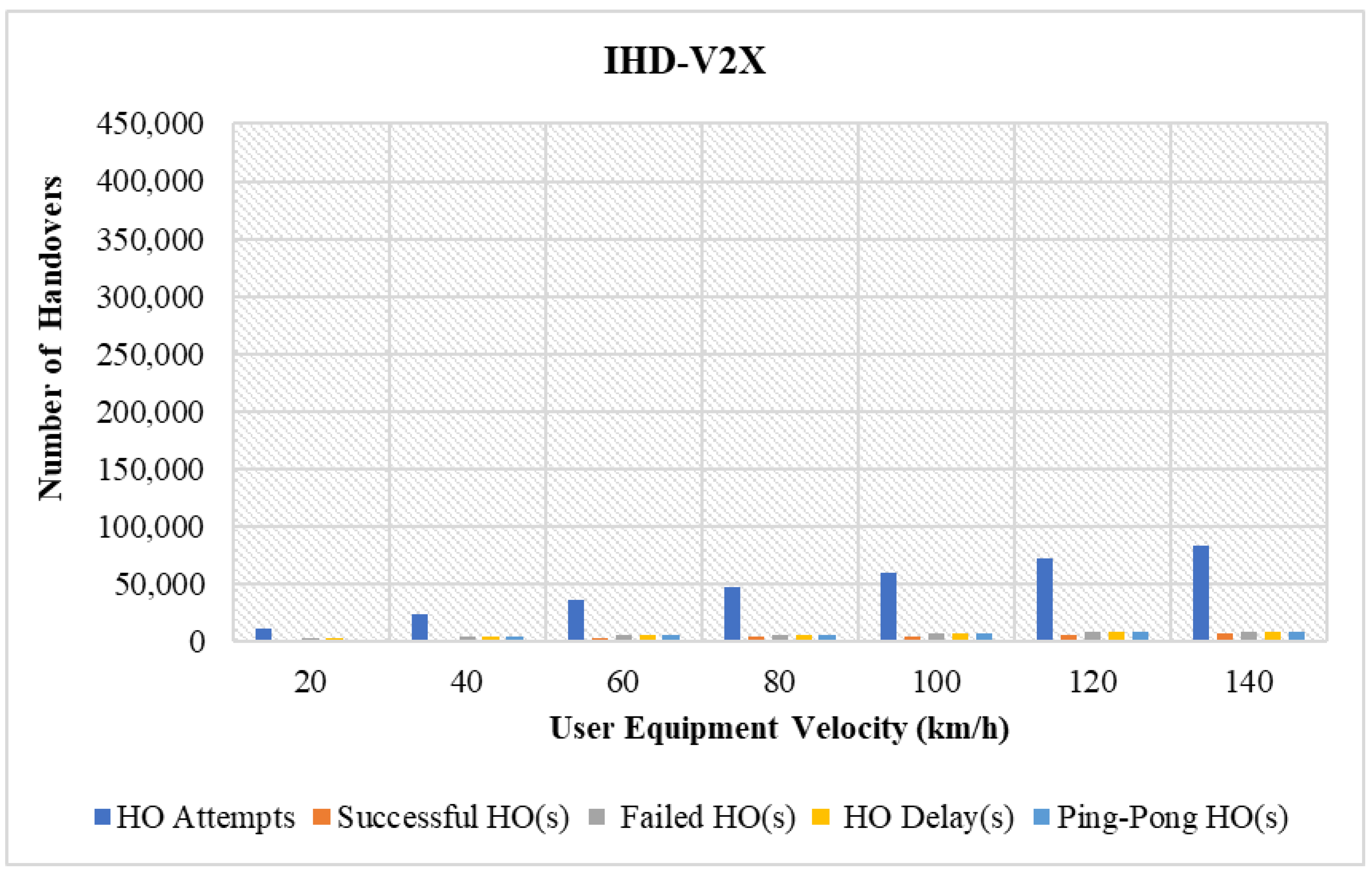
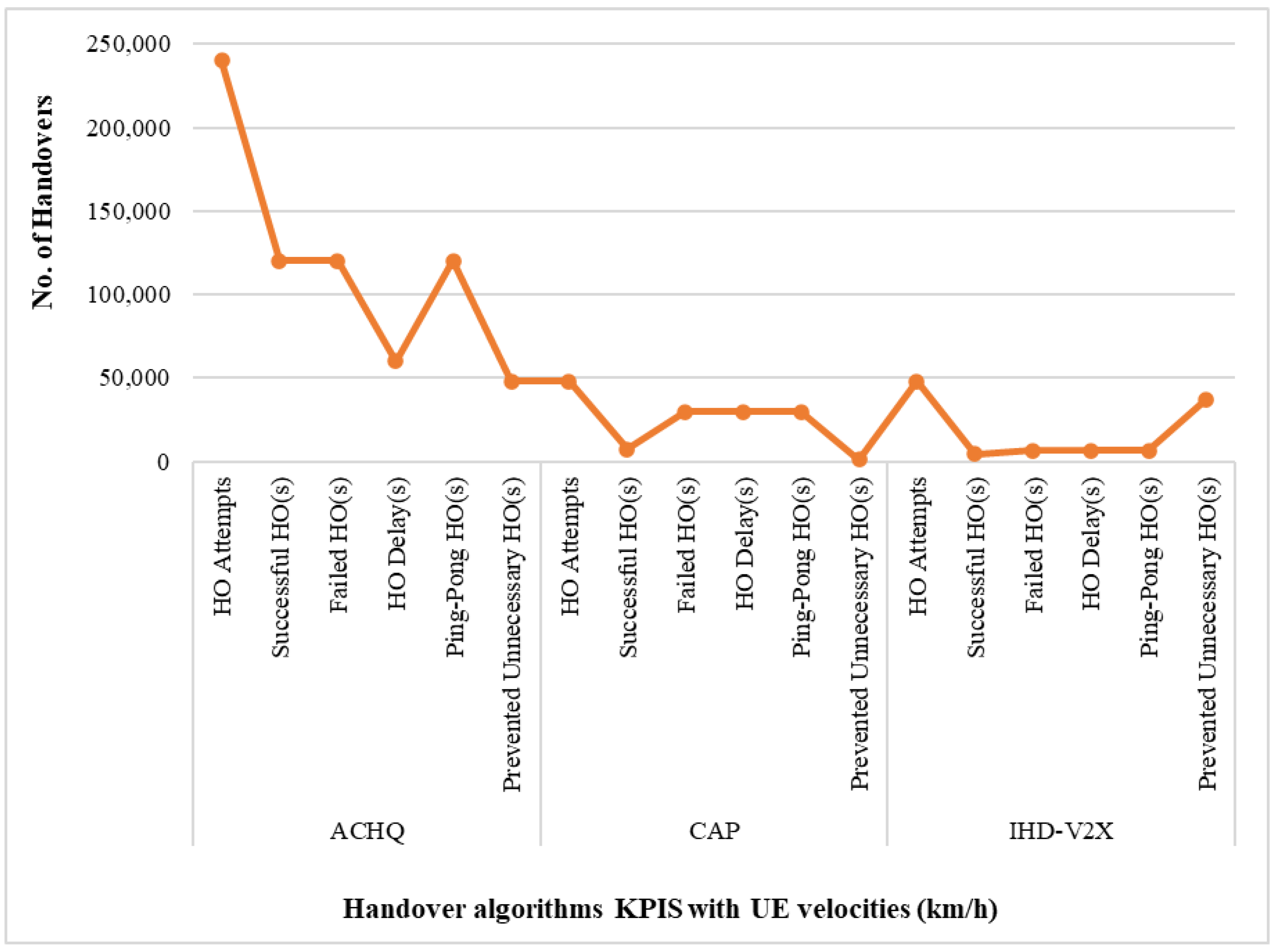
4.3.1. Performance Comparison in Terms of Varying UE Velocity
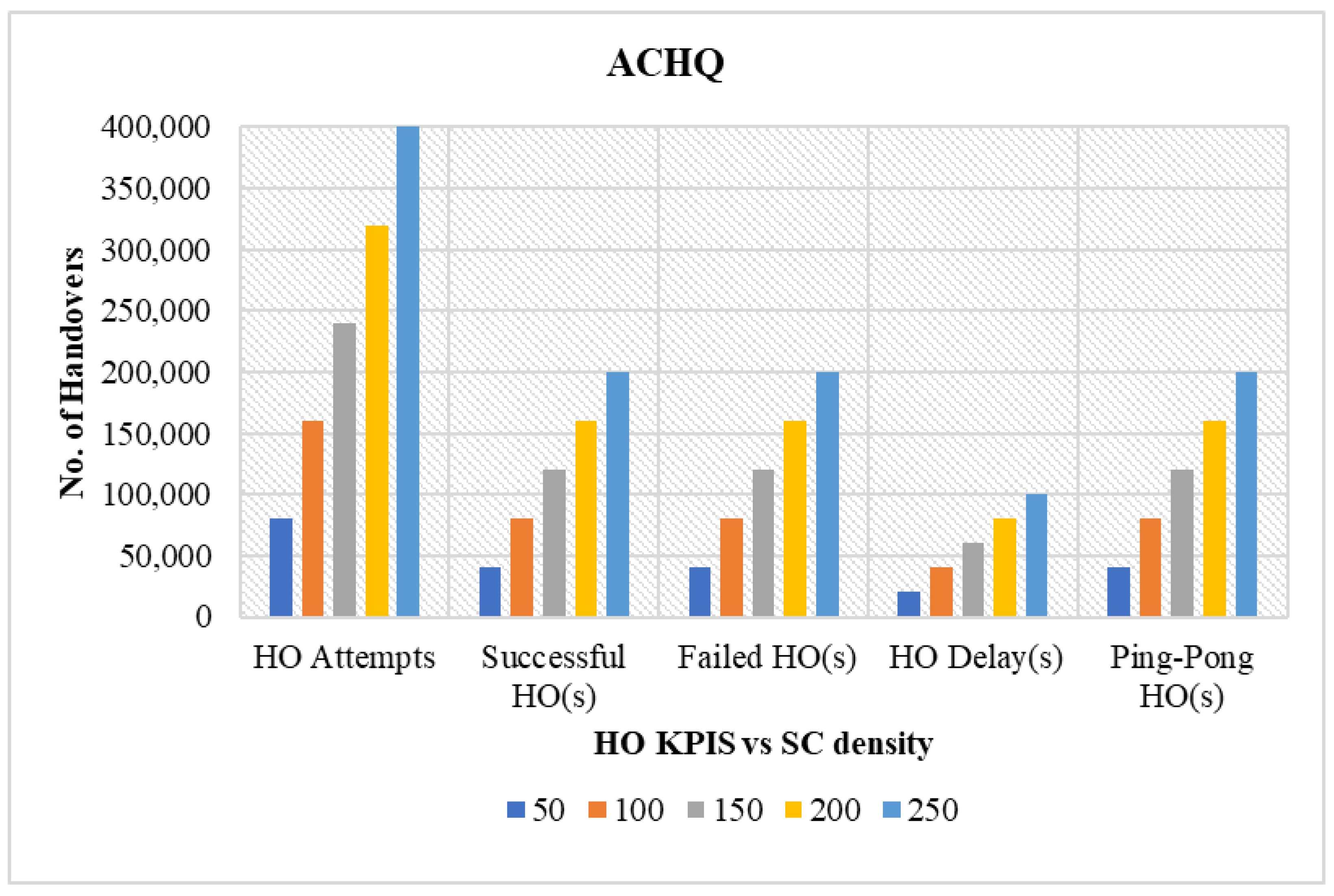
4.3.2. Performance Comparison in Terms of Varying Network Sector Density
4.3.3. Performance Comparison in Terms of Packet Losses and Latency Ratio
4.3.4. Performance Comparison in Terms of Energy Consumption
5. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| 5G | Fifth Generation |
| ACHO | Advanced Conditional Handover |
| BER | Bit Error Rate |
| BS | Base Station; |
| C-V2X | Cellular V2X; |
| CHO | Conditional Handover |
| CIO | Cell Individual Offset |
| FCC | Federal Communications Commission |
| D2D | Device-to-Device |
| DQN | Deep Q-Learning |
| DDQN | Double DQN |
| DSRC | Dedicated Short Range Communication |
| eMBB | Enhanced Mobile Broadband |
| E-URAN | Evolved Universal Terrestrial Radio Access Network |
| HOM | Handover Margin |
| HetNets | Heterogeneous Networks |
| HO | Handover |
| ITS | Intelligent Transportation System |
| KPIs | Key Performance Indicators |
| LSTM | Long Short-Term Memory |
| LTE | Long-Term Evolution |
| MCDM | Multiple Criteria Decision-Making |
| ML | Machine Learning |
| NG | New Generation |
| PER | Packet Error Rate |
| PI | Performance Index |
| Q-Learning | Quality Learning |
| QoS | Quality of Service |
| RAT | Radio Access Technology; |
| RL | Reinforcement Learning; |
| RSRQ | Reference Signal Received Quality |
| RSSI | Received Signal Strength Indicator; |
| SARSA | State–Action–Reward–State–Action |
| SINR | Signal-to-Interference-Noise Ratio |
| SCs | Small Cells |
| SL | Sidelink |
| SON | Self-Organizing Network |
| ST | Stay Yime |
| TTT | Time-To-Trigger |
| TOPSIS | Technique for Order Preference by Similarity to Ideal Solution |
| UDN | Ultra-Dense-Network |
| URLLC | Ultra-Reliable Low-Latency Communication |
| V2N | Vehicle-to-Network |
| UE | User Equipment |
| V2X | Vehicle-to-Everything |
References
- WHO Road Traffic Injuries. Available online: https://www.who.int/news-room/fact-sheets/detail/road-traffic-injuries (accessed on 26 January 2024).
- Technical Specification, Universal Mobile Telecommunications System (UMTS); LTE. Proximity-Services (PROSE) Management Objects, “ETSI TS 124 333 V12.5.0 (2017-04),” Etsi.org. [Online]. Available online: https://www.etsi.org/deliver/etsi_ts/124300_124399/124333/12.05.00_60/ts_124333v120500p.pdf (accessed on 13 February 2025).
- 5G Automotive Association (5GAA). 5GAA P-180106 (White Paper). 5GAA. 2019. Available online: https://5gaa.org/content/uploads/2019/07/5GAA_191906_WP_CV2X_UCs_v1-3-1.pdf (accessed on 6 October 2024).
- Andreev, S.; Petrov, V.; Dohler, M.; Yanikomeroglu, H. Future of Ultra-Dense Networks Beyond 5G: Harnessing Heterogeneous Moving Cells. IEEE Commun. Mag. 2019, 57, 86–92. [Google Scholar] [CrossRef]
- Si, Q.; Cheng, Z.; Lin, Y.; Huang, L.; Tang, Y. Network Selection in Heterogeneous Vehicular Network: A One-to-Many Matching Approach. In Proceedings of the 2020 IEEE 91st Vehicular Technology Conference (VTC2020-Spring), Antwerp, Belgium, 25–28 May 2020; IEEE: Antwerp, Belgium, 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Haghrah, A.; Abdollahi, M.P.; Azarhava, H.; Niya, J.M. A survey on the handover management in 5G-NR cellular networks: Aspects, approaches and challenges. EURASIP J. Wirel. Commun. Netw. 2023, 2023, 52. [Google Scholar] [CrossRef]
- Thakkar, M.K.; Agrawal, L.; Rangisetti, A.K.; Tamma, B.R. Reducing ping-pong handovers in LTE by using A1-based measurements. In Proceedings of the 2017 Twenty-third National Conference on Communications (NCC), Chennai, India, 2–4 March 2017; IEEE: Chennai, India, 2017; pp. 1–6. [Google Scholar]
- Shayea, I.; Dushi, P.; Banafaa, M.; Rashid, R.A.; Ali, S.; Sarijari, M.A.; Daradkeh, Y.I.; Mohamad, H. Handover Management for Drones in Future Mobile Networks—A Survey. Sensors 2022, 22, 6424. [Google Scholar] [CrossRef]
- 3GPP Tdoc R2-131233 Frequent Handovers and Signaling Load Aspects in Heterogeneous Networks 2013. Available online: https://www.3gpp.org/ftp/tsg_ran/WG2_RL2/TSGR2_81bis/Docs (accessed on 9 June 2024).
- 3GPP TS 22.185 Version 14.3.0 Release 14 LTE; Service Requirements for V2X Services 2017. Available online: https://www.etsi.org/deliver/etsi_ts/122100_122199/122185/14.03.00_60/ts_122185v140300p.pdf (accessed on 15 April 2023).
- Mollel, M.S.; Abubakar, A.I.; Ozturk, M.; Kaijage, S.F.; Kisangiri, M.; Hussain, S.; Imran, M.A.; Abbasi, Q.H. A Survey of Machine Learning Applications to Handover Management in 5G and Beyond. IEEE Access 2021, 9, 45770–45802. [Google Scholar] [CrossRef]
- Tashan, W.; Shayea, I.; Aldirmaz-Colak, S.; Aziz, O.A.; Alhammadi, A.; Daradkeh, Y.I. Advanced Mobility Robustness Optimization Models in Future Mobile Networks Based on Machine Learning Solutions. IEEE Access 2022, 10, 111134–111152. [Google Scholar] [CrossRef]
- tr_136932v130000p.pdf. Available online: https://www.etsi.org/deliver/etsi_tr/136900_136999/136932/13.00.00_60/tr_136932v130000p.pdf (accessed on 16 August 2024).
- Jain, A.; Tokekar, S. Application Based Vertical Handoff Decision in Heterogeneous Network. Procedia Comput. Sci. 2015, 57, 782–788. [Google Scholar] [CrossRef]
- Satapathy, P.; Mahapatro, J. An adaptive context-aware vertical handover decision algorithm for heterogeneous networks. Comput. Commun. 2023, 209, 188–202. [Google Scholar] [CrossRef]
- Jiang, D.; Huo, L.; Lv, Z.; Song, H.; Qin, W. A Joint Multi-Criteria Utility-Based Network Selection Approach for Vehicle-to-Infrastructure Networking. IEEE Trans. Intell. Transport. Syst. 2018, 19, 3305–3319. [Google Scholar] [CrossRef]
- Guo, X.; Omar, M.H.; Zaini, K.M.; Liang, G.; Lin, M.; Gan, Z. Multiattribute Access Selection Algorithm for Heterogeneous Wireless Networks Based on Fuzzy Network Attribute Values. IEEE Access 2022, 10, 74071–74081. [Google Scholar] [CrossRef]
- Kaur, R.; Mittal, S. Handoff parameter selection and weight assignment using fuzzy and non-fuzzy methods. In Proceedings of the 2021 2nd International Conference on Secure Cyber Computing and Communications (ICSCCC), Jalandhar, India, 21–23 May 2021; IEEE: Jalandhar, India, 2021; pp. 388–393. [Google Scholar] [CrossRef]
- Tan, K. Adaptive Vehicular Networking with Deep Learning. Ph.D. Thesis, University of Glasgow, Glasgow, UK, 2023. [Google Scholar]
- Ye, H.; Liang, L.; Li, G.Y.; Kim, J.; Lu, L.; Wu, M. Machine Learning for Vehicular Networks. arXiv 2018, arXiv:1712.07143. [Google Scholar] [CrossRef]
- Mekrache, A.; Bradai, A.; Moulay, E.; Dawaliby, S. Deep reinforcement learning techniques for vehicular networks: Recent advances and future trends towards 6G. Veh. Commun. 2022, 33, 100398. [Google Scholar] [CrossRef]
- Nguyen, M.-T.; Kwon, S. Machine Learning–Based Mobility Robustness Optimization Under Dynamic Cellular Networks. IEEE Access 2021, 9, 77830–77844. [Google Scholar] [CrossRef]
- Peng, M.; Liang, D.; Wei, Y.; Li, J.; Chen, H.-H. Self-Configuration and Self-Optimization in LTE-Advanced Heterogeneous Networks. IEEE Commun. Mag. 2013, 51, 36–45. [Google Scholar] [CrossRef]
- Tan, K.; Bremner, D.; Le Kernec, J.; Sambo, Y.; Zhang, L.; Imran, M.A. Intelligent Handover Algorithm for Vehicle-to-Network Communications With Double-Deep Q-Learning. IEEE Trans. Veh. Technol. 2022, 71, 7848–7862. [Google Scholar] [CrossRef]
- He, J.; Xiang, T.; Wang, Y.; Ruan, H.; Zhang, X. A Reinforcement Learning Handover Parameter Adaptation Method Based on LSTM-Aided Digital Twin for UDN. Sensors 2023, 23, 2191. [Google Scholar] [CrossRef]
- Ortiz, M.T.; Salient, O.; Camps-Mur, D.; Escrig, J.; Nasreddine, J.; Pérez-Romero, J. On the Application of Q-learning for Mobility Load Balancing in Realistic Vehicular Scenarios. In Proceedings of the 2023 IEEE 97th Vehicular Technology Conference (VTC2023-Spring), Florence, Italy, 20–23 June 2023; IEEE: Florence, Italy, 2023; pp. 1–7. [Google Scholar] [CrossRef]
- Karmakar, R.; Kaddoum, G.; Chattopadhyay, S. Mobility Management in 5G and Beyond: A Novel Smart Handover With Adaptive Time-to-Trigger and Hysteresis Margin. IEEE Trans. Mob. Comput. 2023, 22, 5995–6010. [Google Scholar] [CrossRef]
- Sundararaju, S.C.; Ramamoorthy, S.; Basavaraj, D.P.; Phanindhar, V. Advanced Conditional Handover in 5G and Beyond Using Q-Learning. In Proceedings of the 2024 IEEE Wireless Communications and Networking Conference (WCNC), Dubai, United Arab Emirates, 21–24 April 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Thillaigovindhan, S.K.; Roslee, M.; Mitani, S.M.I.; Osman, A.F.; Ali, F.Z. A Comprehensive Survey on Machine Learning Methods for Handover Optimization in 5G Networks. Electronics 2024, 13, 3223. [Google Scholar] [CrossRef]
- Al Harthi, F.R.A.; Touzene, A.; Alzidi, N.; Al Salti, F. Context-Aware Enhanced Application-Specific Handover in 5G V2X Networks. Electronics 2025, 14, 1382. [Google Scholar] [CrossRef]
- Tayyab, M.; Gelabert, X.; Jantti, R. A Survey on Handover Management: From LTE to NR. IEEE Access 2019, 7, 118907–118930. [Google Scholar] [CrossRef]
- Kassler, A.; Castro, M.; Dely, P. VoIP Packet Aggregation based on Link Quality Metric for Multihop Wireless Mesh Networks. Int. J. Comput. Sci. Eng. 2011, 3, 2323–2331. [Google Scholar]
- Signal Quality [LTE/5G ]—LTE and 5G Signal Quality Parameters, Zyxel Support Campus EMEA. 2019. Available online: https://support.zyxel.eu/hc/en-us/articles/360005188999-Signal-quality-LTE-5G-LTE-and-5G-signal-quality-parameters (accessed on 20 February 2025).
- Ullah, Y.; Roslee, M.B.; Mitani, S.M.; Khan, S.A.; Jusoh, M.H. A Survey on Handover and Mobility Management in 5G HetNets: Current State, Challenges, and Future Directions. Sensors 2023, 23, 5081. [Google Scholar] [CrossRef] [PubMed]
- BER vs. PER: What’s the Difference? Available online: https://www.test-and-measurement-world.com/measurements/general/ber-vs-per-understanding-bit-error-rate-and-packet-error-rate (accessed on 20 February 2025).
- Clancy, J.; Mullins, D.; Ward, E.; Denny, P.; Jones, E.; Glavin, M.; Deegan, B. Investigating the Effect of Handover on Latency in Early 5G NR Deployments for C-V2X Network Planning. IEEE Access 2023, 11, 129124–129143. [Google Scholar] [CrossRef]
- Coll-Perales, B.; Lucas-Estañ, M.C.; Shimizu, T.; Gozalvez, J.; Higuchi, T.; Avedisov, S.; Altintas, O.; Sepulcre, M. End-to-End V2X Latency Modeling and Analysis in 5G Networks. IEEE Trans. Veh. Technol. 2023, 72, 5094–5109. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DSRC (Dedicated Short Range Communication) | C-V2X (Cellular-V2X) |
|---|---|
| Released in 2010 and deployed in 2017. | Deployed for LTE direct C-V2X in 2016, and indirect-V2X in 2024. |
| Standardized by IEEE 802.11p and IEEE 802.11bd. | Defined by 3GPPP |
| Primarily operates in the 5.9GHz band | Can operate in the 5.9 GHz band and in operator operator-licensed band. |
| Supports Vehicle-to-Vehicle (V2V) and Vehicle-to-Infrastructure (V2I) communications. | Supports inter-vehicle (V2V), pedestrian (V2P, infrastructure (V2I), and network (V2N) communications. |
| Ref. | Algorithm | Rewarding | Network Type | Input Parameters | Optimized Parameters | HO Decision | Mobility Model | Performance KPIs | Result/ Performance | Key Contributions | Limitations |
|---|---|---|---|---|---|---|---|---|---|---|---|
| [22] IEEE 2021 | Distributed RL | Adjustment of TTT and CIO | 5G (Xn Interface) | RSRP | TTT and Hysteresis | Hybrid | Random WAY point | RLF and PP | Adopted twenty-four times faster and improved the user satisfaction rate by 417.7% more than the non-ML algorithm. | Proposed ML based on a mobility robustness optimization algorithm to minimize unnecessary handover. | The UDN paradigm is not considered, and infrequently updated centralized databases can lead to wrong decisions. |
| [24] IEEE 2022 | Double DQN (DDQN) | Maximize cumulated RSRP-based reward | LTE | RSRP | TTT and Hysteresis | Centralized | Google Maps Directions API | Packet loss (PL) | Offset the traditional network, by reducing packet loss by 25.72% per HO. | Designed an ML-Based HO algorithm for the V2N network using a real data set collected from the city of Glasgow (UK). | The execution agent is in the core network, adding signaling overhead to the network. |
| [25] Sensors 2023 | DQN integrated with LSTM | Coefficient between RFL and PP | UDN | RSRP | TTT and Hysteresis | Mobile terminal | NS | RLF and PP | Enhanced DQN with a digital twin outperforms the baseline DQN by achieving an effective handover rate of 2.7%. | Proposed an ML optimization method to predict handover parameters/thresholds based on the conditions of the environment. | Not involved in the HO decision, leading to inefficient information for critical dynamic use cases such as V2X. |
| [26] IEEE 2023 | Q-Learning | Load reward adjustment strategy | LTE | RARP | TTT and Hysteresis | Distributed (RAT) | Poisson distribution centered | Throughput and PLR | Reduction in the average of the overloaded time by 91.87% and the load is sufficiently distributed among cells. | Proposed a Q-Learning strategy that addresses the cell overload problem while serving the QoS needs. | Implemented only for two neighboring cells. Needs dynamic environmental factors (such as user mobility). |
| [27] IEEE 2023 | SARSA | RSRQ | 5G NR module | RSRP and speed | TTT and Hysteresis | Centralized | Constant speed | Throughput, RLF | Minimize HO failure between 6 and 10% and maintain a throughput of 80% of the total connections. | Designed an adaptive online learning-based handover mechanism (LIM2). | Load balancing is not considered. |
| [28] IEEE 2024 | Q-Learning | RSRP | 5G Networks | RSRP and speed | TTT and Hysteresis | Centralized | Uniform distribution | Handover rate | Reducing the HO rate by 40%. | Enhanced 5G mobility by giving the UE the ability to self-optimize handover decisions. | Load balancing is not considered. |
| IHD-V2X | Q-Learning Integrated with TOPSIS decision | Parameter weightage adjustment | 5G V2X | RSSI, SINR, Bits Error Rate (BER), date rate, delay, PL | Handover Decision | Distributed | Random way point | HO KPIs, PLR, latency and energy consumption | Minimizing HO issues and improving PLR, latency, and energy consumption. | Intelligence-based considering QoS requirements. | To experiment with the algorithm's effectiveness using real-time traffic. |
| RL Algorithm | Strengths | Weaknesses |
|---|---|---|
| Q-Learning | A model-free algorithm to identify the optimal policy. It is considered a trial-and-error-free algorithm. The epsilon-greedy policy is applied to balance between exploration and exploitation. |
|
| Deep Q-Learning | Combines the Artificial Neural Network (ANN) with Q-Learning and is suitable for making a decision in a complex environment. |
|
| Distributed Reinforcement Learning | The training process is accelerated due to the decoupling of the tasks of acting and learning. |
|
| State–Action–Reward–State–Action (SARSA) | Simplifying the implementation does not require modeling the environment. |
|
| Parameters | Value |
|---|---|
| Network area | 100 × 100 km2 |
| Network sectors | 25 sectors |
| Date Rate | 100–400 Mbps -Mid-Band 5G |
| Q-Learning parameters | Learning rate α = 0.1 Discount factor γ = 0.9 Exploration Rate = 0.9 |
| Network configuration | Queue delay(s) = 5 ms Radio resource control (RRC) time = 20 ms Path switch time = 0.03 ms RACH procedure time = 0.01 ms |
| Mov ID (M): 4 Sector ID No (Secn): 24 No. of SCs in Secn: 30 |
Maximum Load: 20 Velocity (V): 117.84 Context: Audio | ||||
| SC | PI | SC load | ST | status | Action |
| SC9 | 0.258674345 | 15 | 1 | Successful HOs | Necessary |
| SC3 | 0.296381396 | 8 | 0.9915143 | Unnecessary | |
| SC21 | 0.308723826 | 9 | 0.9830286 | Unnecessary | |
| SC23 | 0.309375018 | 16 | 0.9745429 | Unnecessary | |
| SC26 | 0.375878704 | 3 | 0.9660573 | Unnecessary | |
| SC1 | 0.4069305 | 5 | 0.9575716 | Unnecessary | |
| SC5 | 0.409621584 | 4 | 0.9490859 | Unnecessary | |
| SC16 | 0.418339327 | 6 | 0.9406003 | Unnecessary | |
| SC29 | 0.428719489 | 10 | 0.9321146 | Unnecessary | |
| SC19 | 0.435141813 | 5 | 0.9236289 | Unnecessary | |
| SC4 | 0.457167959 | 13 | 0.9151433 | Unnecessary | |
| SC14 | 0.521482773 | 18 | 0.9066576 | Unnecessary | |
| SC22 | 0.53638102 | 20 | 0.8981719 | Unnecessary | |
| SC11 | 0.55055526 | 4 | 0.8896862 | Unnecessary | |
| SC12 | 0.582608246 | 8 | 0.8812006 | Unnecessary | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al Harthi, F.R.A.; Touzene, A.; Alzidi, N.; Al Salti, F. Intelligent Handover Decision-Making for Vehicle-to-Everything (V2X) 5G Networks. Telecom 2025, 6, 47. https://doi.org/10.3390/telecom6030047
Al Harthi FRA, Touzene A, Alzidi N, Al Salti F. Intelligent Handover Decision-Making for Vehicle-to-Everything (V2X) 5G Networks. Telecom. 2025; 6(3):47. https://doi.org/10.3390/telecom6030047
Chicago/Turabian StyleAl Harthi, Faiza Rashid Ammar, Abderezak Touzene, Nasser Alzidi, and Faiza Al Salti. 2025. "Intelligent Handover Decision-Making for Vehicle-to-Everything (V2X) 5G Networks" Telecom 6, no. 3: 47. https://doi.org/10.3390/telecom6030047
APA StyleAl Harthi, F. R. A., Touzene, A., Alzidi, N., & Al Salti, F. (2025). Intelligent Handover Decision-Making for Vehicle-to-Everything (V2X) 5G Networks. Telecom, 6(3), 47. https://doi.org/10.3390/telecom6030047