1. Introduction
Connected and Autonomous Vehicles (CAVs) are rapidly becoming a reality, enabled by advances in computing, electronics, sensors, and communication. Enriched hardware and advanced sensors significantly improve the situational awareness of CAVs, while network, security, and performance improvements enable them to better interact with infrastructure and other road users [
1]. CAVs require large volumes of real-time data collected from various sensors [
2]. These sensors include Light Detection and Ranging (LiDAR), radar, cameras, and GPS [
3] that continuously collect data on the current conditions around the vehicle, obstacles on the road, traffic flow, and pedestrians who move around, which is crucial for correct decision-making, good navigation, and safety for all in the autonomous driving systems.
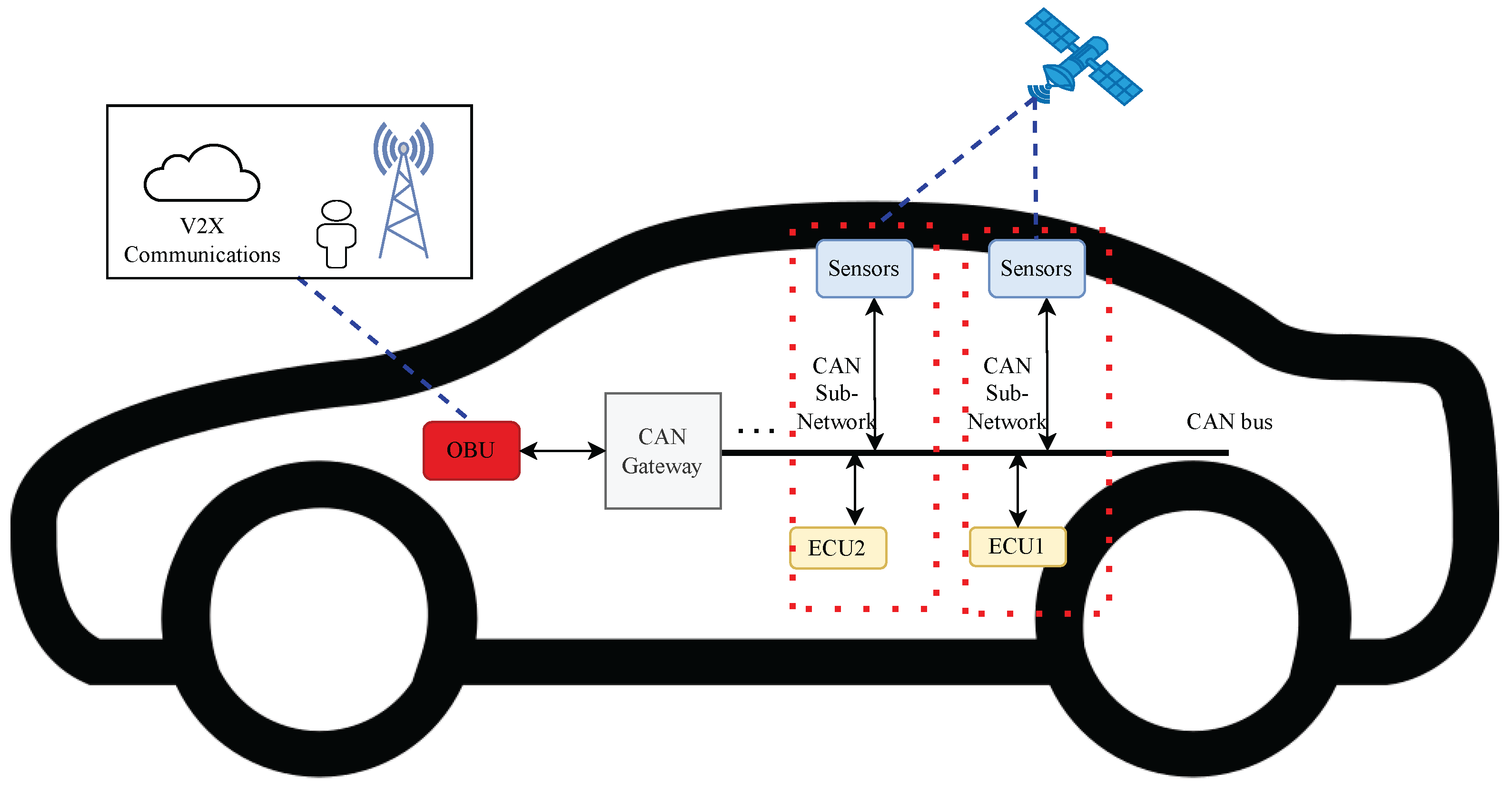
To develop autonomous driving, numerous electronic control units (ECUs) are required to control sensors and communication systems. CAN bus has been a backbone of IVNs for over three decades, enabling reliable broadcast communication among ECUs [
4] and between sensors and ECUs. Unlike traditional networks such as USB or Ethernet, CAN uses a different protocol to send large data blocks between nodes, with a maximum signaling rate of 1 Mbps [
5]. The CAN network consists of multiple subnetworks [
6] interconnected through a CAN Gateway. The CAN gateway filters and relays the CAN frames between the CAN bus and the 0n-Board Unit (OBU), which connects via a CAN-to-USB adapter [
7]. The CAN gateway sends frames of CAN (comprising sensor data) for vehicle speed, brakes status on/off, emergency brake lights status on/off, and hazard detection status [
7] in time intervals (i.e., every 50 ms). On the other hand, the OBU acts as an intermediate between IVNs and Vehicle to Everything (V2X).
Figure 1 describes the communication process between IVNs and V2X.
As the CAN messages are not encrypted, they significantly compromise the data confidentiality leading to various cyberattacks. In an IVN, the attacks can infiltrate both the CAN bus and the OBU, which poses a severe security risk. Attackers may intercept CAN messages, manipulate data exchanged between ECU and OBU, or inject malicious commands to disrupt vehicle operations. Furthermore, attackers may compromise the OBU and ECU to retrieve sensitive information such as private data that allows illegitimate access to communications within the CAN network [
8].
Deep learning models have been increasingly employed to address these security vulnerabilities. These models detect complex patterns and anomalies in network traffic, making them suitable detecting intrusions in CAN-based networks [
9]. The authors in [
10] describe an LSTM-based IVN-IDS to identify and mitigate attacks on the CAN bus. A custom dataset is created by collecting normal CAN traffic and injecting simulated attacks. Training and testing of this model achieved a high detection accuracy (
9.995%). A light BiLSTM-based anomaly detection with an attention mechanism proposed for efficient protection of IVS in CAN messages is proposed in [
11], leveraging correlations in CAN ID sequences to identify replay attacks, DoS attacks, and fuzzing attacks. With the increasing connectivity of modern vehicles, ensuring the security of IVN communication has become critical, as connected vehicles are now exposed to various attacks. To this end, we propose a deep learning-based approach for multiclass intrusion detection for in-vehicular CAN messages.
While the centralized deep learning LSTM and BiLSTM methods demonstrate excellent performance, deployment has critical practical constraints. Specifically, they require aggregation of all the training data within a central server, which is extremely problematic in terms of privacy, security, and data administration, especially for safety-critical use cases like V2X communication. In addition, in real-world contexts, central data aggregation is often impossible due to geographic dispersal, low connectivity, and constrained bandwidth.
In contrast to centralized deep learning approaches that require sharing raw data to a central server where significant privacy and latency risks are present. The proposed approach takes advantage of federated learning, making use of the V2X edge computing environment to improve privacy and real-time processing. FL enables decentralized training in multiple vehicles or edge devices without exposing raw CAN data. This approach provides the confidentiality of sensitive driving information and supports heterogeneous data sources across different vehicle types. FL’s compatibility with real-time low-latency edge computing makes it most suitable for safety-critical automotive applications. Furthermore, our model performs multiclass classification, identifying not only the presence of an attack but also the specific type of intrusion, such as Flood, Fuzzing, and Malfunction attacks. By learning from historical time-series data, our model is trained using CAN bus traffic patterns and learns to detect anomalies in different classes. To improve real-time detection and maintain data privacy, we integrate federated learning paradigm into a V2X edge computing framework. This setup enables edge entities such as OBUs, RSUs and edge servers, and the cloud to collaboratively train models without centralizing raw data and reducing the threats of data exposure. The edge computing layer offers low-latency intrusion detection through processing close to vehicles. On the other hand, federated learning allows vehicles to share model updates without transmitting sensitive CAN bus data to a central server. By suggesting this new deep learning-based architecture and combining it with FL, this paper offers a scalable, real-time, and privacy preserving solution to defend vehicular networks against cyber-attacks in an intelligent transportation system. Our contributions can be summarized as follows:
We propose adapted-BiLSTM (or, a-BiLSTM), an adapted BiLSTM architecture to identify intrusions in in-vehicular network CAN messages.
We present a federated learning-based intrusion detection system for in-vehicular network to tackle the issues related to privacy and facilitate V2X communication in a distributed manner.
We evaluate our proposal using three real-world datasets to demonstrate its ability to accurately identify attack types and adapt to each dataset characteristics. The evaluation results show how the a-BiLSTM model outperforms the baseline LSTM architecture in a federated learning system, demonstrating superior accuracy compared to other alternatives.
The remainder of the paper is structured as follows.
Section 2 consists of the necessary background and preliminaries to understand the proposed framework.
Section 3 describes our proposed FL-IVN-IDS framework.
Section 4 and
Section 5 present the experimental evaluation and the analysis of the results. Finally,
Section 6 concludes the paper with a summary of the contributions and perspective.
Author Contributions
Conceptualization, by M.G., N.-E.-H.Y. and S.B.; methodology, M.G., N.-E.-H.Y., A.B. and S.B.; software, M.G.; validation, N.-E.-H.Y., S.B. and A.B.; formal analysis, M.G., N.-E.-H.Y., S.B. and A.B.; investigation, M.G., N.-E.-H.Y., S.B. and A.B.; resources, M.G.; data curation, M.G.; writing—original draft preparation, M.G., N.-E.-H.Y., S.B. and A.B.; writing—review and editing, M.G., N.-E.-H.Y., S.B. and A.B.; visualization, N.-E.-H.Y. and M.G.; supervision, N.-E.-H.Y., S.B. and A.B.; project administration, M.G.; funding acquisition, M.G., N.-E.-H.Y., S.B. and A.B. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| CAN | Controller Area Network |
| ML | Machine Learning |
| DL | Deep Learning |
| IVN | In-Vehicle Network |
| IDS | Intrusion Detection System |
| CAV | Connected and Autonomous vehicle |
| ECU | Electrical Control Units |
| OBU | On-Board Unit |
| RSU | Road Side Unit |
| V2X | Vehicle-to-Everything |
| ReLU | Rectified Linear Unit |
| FL | Federated Learning |
| FL-IVN-IDS | FL-based BiLSTM with 5 epochs |
| LSTM | Long Short-Term Memory |
| BiLSTM | Bidirectional Long Short-Term Memory |
| ROC | Receiver Operating Characteristic |
| CPU | Central Processing Unit |
| GPU | Graphics Processing Unit |
| CM | Confusion Matrix |
References
- Yusuf, S.A.; Khan, A.; Souissi, R. Vehicle-to-everything (V2X) in the autonomous vehicles domain—A technical review of communication, sensor, and AI technologies for road user safety. Transp. Res. Interdiscip. Perspect. 2024, 23, 100980. [Google Scholar]
- Wang, B.; Li, W.; Khattak, Z.H. Anomaly Detection in Connected and Autonomous Vehicle Trajectories Using LSTM Autoencoder and Gaussian Mixture Model. Electronics 2024, 13, 1251. [Google Scholar] [CrossRef]
- Ayala, R.; Mohd, T.K. Sensors in autonomous vehicles: A survey. J. Auton. Veh. Syst. 2021, 1, 031003. [Google Scholar] [CrossRef]
- Palaniswamy, B.; Camtepe, S.; Foo, E.; Pieprzyk, J. An efficient authentication scheme for intra-vehicular controller area network. IEEE Trans. Inf. Forensics Secur. 2020, 15, 3107–3122. [Google Scholar] [CrossRef]
- Oladimeji, D.; Rasheed, A.; Varol, C.; Baza, M.; Alshahrani, H.; Baz, A. CANAttack: Assessing Vulnerabilities within Controller Area Network. Sensors 2023, 23, 8223. [Google Scholar] [CrossRef]
- Earth2 Digital. What is Vehicle CAN Bus ECU? Available online: https://www.earth2.digital/blog/what-is-vehicle-can-bus-ecu-evoque-adam-ali.html (accessed on 18 June 2024).
- Sedar, R.; Vázquez-Gallego, F.; Casellas, R.; Vilalta, R.; Muñoz, R.; Silva, R.; Alonso-Zarate, J. Standards-compliant multi-protocol on-board unit for the evaluation of connected and automated mobility services in multi-vendor environments. Sensors 2021, 21, 2090. [Google Scholar] [CrossRef]
- Yu, D.; Hsu, R.H.; Lee, J.; Lee, S. EC-SVC: Secure CAN bus in-vehicle communications with fine-grained access control based on edge computing. IEEE Trans. Inf. Forensics Secur. 2022, 17, 1388–1403. [Google Scholar] [CrossRef]
- Lampe, B.; Meng, W. A survey of deep learning-based intrusion detection in automotive applications. Expert Syst. Appl. 2023, 221, 119771. [Google Scholar] [CrossRef]
- Hossain, M.D.; Inoue, H.; Ochiai, H.; Fall, D.; Kadobayashi, Y. LSTM-based intrusion detection system for in-vehicle CAN bus communications. IEEE Access 2020, 8, 185489–185502. [Google Scholar] [CrossRef]
- Kan, X.; Zhou, Z.; Yao, L.; Zuo, Y. Research on Anomaly Detection in Vehicular CAN Based on Bi-LSTM. J. Cyber Secur. Mobil. 2023, 12, 629–652. [Google Scholar] [CrossRef]
- Buscemi, A.; Turcanu, I.; Castignani, G.; Panchenko, A.; Engel, T.; Shin, K.G. A survey on controller area network reverse engineering. IEEE Commun. Surv. Tutor. 2023, 25, 1445–1481. [Google Scholar] [CrossRef]
- Nazakat, I.; Khurshid, K. Intrusion detection system for in-vehicular communication. In Proceedings of the 2019 15th International Conference on Emerging Technologies (ICET), Islamabad, Pakistan, 2–3 December 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Bhatia, R.; Kumar, V.; Serag, K.; Celik, Z.B.; Payer, M.; Xu, D. Evading Voltage-Based Intrusion Detection on Automotive CAN. In Proceedings of the NDSS, Virtual Conference, 21–25 February 2021. [Google Scholar]
- Almehdhar, M.; Albaseer, A.; Khan, M.A.; Abdallah, M.; Menouar, H.; Al-Kuwari, S.; Al-Fuqaha, A. Deep learning in the fast lane: A survey on advanced intrusion detection systems for intelligent vehicle networks. IEEE Open J. Veh. Technol. 2024, 5, 869–906. [Google Scholar] [CrossRef]
- Nguyen, T.P.; Nam, H.; Kim, D. Transformer-based attention network for in-vehicle intrusion detection. IEEE Access 2023, 11, 55389–55403. [Google Scholar] [CrossRef]
- Ma, H.; Cao, J.; Mi, B.; Huang, D.; Liu, Y.; Li, S. A GRU-based lightweight system for CAN intrusion detection in real time. Secur. Commun. Netw. 2022, 2022, 5827056. [Google Scholar] [CrossRef]
- Sun, H.; Chen, M.; Weng, J.; Liu, Z.; Geng, G. Anomaly detection for in-vehicle network using CNN-LSTM with attention mechanism. IEEE Trans. Veh. Technol. 2021, 70, 10880–10893. [Google Scholar] [CrossRef]
- Al-Aql, N.; Al-Shammari, A. Hybrid RNN-LSTM networks for enhanced intrusion detection in vehicle CAN systems. J. Electr. Syst. 2024, 20, 3019–3031. [Google Scholar] [CrossRef]
- Althunayyan, M.; Javed, A.; Rana, O. A Survey of Learning-Based Intrusion Detection Systems for In-Vehicle Network. arXiv 2025, arXiv:2505.11551. [Google Scholar] [CrossRef]
- Al-Quayed, F.; Tariq, N.; Humayun, M.; Khan, F.A.; Khan, M.A.; Alnusairi, T.S. Securing the Road Ahead: A Survey on Internet of Vehicles Security Powered by a Conceptual Blockchain-Based Intrusion Detection System for Smart Cities. Trans. Emerg. Telecommun. Technol. 2025, 36, e70133. [Google Scholar] [CrossRef]
- Wang, K.; Sun, Z.; Wang, B.; Fan, Q.; Li, M.; Zhang, H. ATHENA: An In-vehicle CAN Intrusion Detection Framework Based on Physical Characteristics of Vehicle Systems. arXiv 2025, arXiv:2503.17067. [Google Scholar] [CrossRef]
- Liu, Y.; Xue, L.; Wang, S.; Luo, X.; Zhao, K.; Jing, P.; Ma, X.; Tang, Y.; Zhou, H. Vehicular Intrusion Detection System for Controller Area Network: A Comprehensive Survey and Evaluation. IEEE Trans. Intell. Transp. Syst. 2025, 26, 10979–11009. [Google Scholar] [CrossRef]
- Gesteira-Miñarro, R.; López, G.; Palacios, R. Revisiting Wireless Cyberattacks on Vehicles. Sensors 2025, 25, 2605. [Google Scholar] [CrossRef] [PubMed]
- Abdullah, M.F.A.; Yogarayan, S.; Razak, S.F.A.; Azman, A.; Amin, A.H.M.; Salleh, M. Edge computing for vehicle to everything: A short review. F1000Research 2023, 10, 1104. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.; Wu, B.; Shi, W. A comparison of communication mechanisms in vehicular edge computing. In 3rd USENIX Workshop on Hot Topics in Edge Computing (HotEdge 20); USENIX Association: Berkeley, CA, USA, 2020. [Google Scholar]
- Sharmin, S.; Mansor, H.; Abdul Kadir, A.F.; Aziz, N.A. Benchmarking frameworks and comparative studies of Controller Area Network (CAN) intrusion detection systems: A review. J. Comput. Secur. 2024; preprint. [Google Scholar] [CrossRef]
- Hossain, M.D.; Inoue, H.; Ochiai, H.; Fall, D.; Kadobayashi, Y. An effective in-vehicle CAN bus intrusion detection system using CNN deep learning approach. In Proceedings of the 2020 IEEE Global Communications Conference (GLOBECOM), Taipei, Taiwan, 7–11 December 2020. [Google Scholar] [CrossRef]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Wei, K.; Li, J.; Ma, C.; Ding, M.; Wei, S.; Wu, F.; Ranbaduge, T. Vertical federated learning: Challenges, methodologies and experiments. arXiv 2022, arXiv:2202.04309. [Google Scholar] [CrossRef]
- Huang, W.; Li, T.; Wang, D.; Du, S.; Zhang, J.; Huang, T. Fairness and accuracy in horizontal federated learning. Inf. Sci. 2022, 589, 170–185. [Google Scholar] [CrossRef]
- Boualouache, A.; Brik, B.; Rahal, R.; Ghamri-Doudane, Y.; Senouci, S.M. Federated Learning for Zero-Day Attack Detection in 5G and Beyond V2X Networks. arXiv 2024, arXiv:2407.03070. [Google Scholar] [CrossRef]
- Selamnia, A.; Brik, B.; Senouci, S.M.; Boualouache, A.; Hossain, S. Edge Computing-enabled Intrusion Detection for C-V2X Networks using Federated Learning. In Proceedings of the GLOBECOM 2022–2022 IEEE Global Communications Conference, Rio de Janeiro, Brazil, 4–8 December 2022. [Google Scholar] [CrossRef]
- Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. Toward Generating a New Intrusion Detection Dataset and Intrusion Traffic Characterization. In Proceedings of the 4th International Conference on Information Systems Security and Privacy (ICISSP), Madeira, Portugal, 22–24 January 2018. [Google Scholar]
- Yang, J.; Hu, J.; Yu, T. Federated AI-enabled in-vehicle network intrusion detection for Internet of Vehicles. Electronics 2022, 11, 3658. [Google Scholar] [CrossRef]
- Al-Smadi, B.S. DeBERTa-BiLSTM: A multi-label classification model of Arabic medical questions using pre-trained models and deep learning. Comput. Biol. Med. 2024, 170, 107921. [Google Scholar] [CrossRef]
- Desta, A.K.; Ohira, S.; Arai, I. ID sequence analysis for intrusion detection in the CAN bus using long, short-term memory networks. In Proceedings of the IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), Austin, TX, USA, 23–27 March 2020. [Google Scholar]
- Khan, W.; Minallah, N.; Sher, M.; Khan, M.A.; Rehman, A.U.; Al-Ansari, T.; Bermak, A. Advancing crop classification in smallholder agriculture: A multifaceted approach combining frequency-domain image coregistration, transformer-based parcel segmentation, and Bi-LSTM for crop classification. PLoS ONE 2024, 19, e0299350. [Google Scholar] [CrossRef]
- Natha, S.; Ahmed, F.; Siraj, M.; Lagari, M.; Altamimi, M.; Chandio, A.A. Deep BiLSTM Attention Model for Spatial and Temporal Anomaly Detection in Video Surveillance. Sensors 2025, 25, 251. [Google Scholar] [CrossRef]
- Yadav, D.P.; Rathor, S. Bone fracture detection and classification using deep learning approach. In Proceedings of the 2020 International Conference on Power Electronics & IoT Applications in Renewable Energy and its Control (PARC), Mathura, India, 28–29 February 2020. [Google Scholar] [CrossRef]
- Ho, Y.; Wookey, S. The real-world-weight cross-entropy loss function: Modeling the costs of mislabeling. IEEE Access 2019, 8, 4806–4813. [Google Scholar] [CrossRef]
- Wu, H. Intrusion Detection Model for Wireless Sensor Networks Based on FedAvg and XGBoost Algorithm. Int. J. Distrib. Sens. Netw. 2024, 2024, 5536615. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. Artif. Intell. Stat. 2019, 54, 1273–1282. [Google Scholar]
- In-Vehicle Network Intrusion Detection Dataset. Available online: https://ocslab.hksecurity.net/Datasets/datachallenge2019/car (accessed on 18 June 2024).
- Lv, Y.; Ding, H.; Wu, H.; Zhao, Y.; Zhang, L. FedRDS: Federated learning on non-iid data via regularization and data sharing. Appl. Sci. 2023, 13, 12962. [Google Scholar] [CrossRef]
- Tan, Q.; Wu, S.; Tao, Y. Privacy-enhanced federated learning for non-iid data. Mathematics 2023, 11, 4123. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, X.; Liu, Z.; Fu, F.; Jiao, Y.; Xu, F. A Network Intrusion Detection Model Based on BiLSTM with Multi-Head Attention Mechanism. Electronics 2023, 12, 4170. [Google Scholar] [CrossRef]
- Lemaitre, G.; Nogueira, F.; Aridas, C.K. Imbalanced-learn: A Python toolbox to tackle the curse of imbalanced datasets in machine learning. J. Mach. Learn. Res. 2017, 18, 559–563. [Google Scholar]
- Wang, K.; Zhang, A.; Sun, H.; Wang, B. Analysis of recent deep-learning-based intrusion detection methods for in-vehicle network. IEEE Trans. Intell. Transp. Syst. 2022, 24, 1843–1854. [Google Scholar] [CrossRef]
- Alalwany, E.; Mahgou, I. An Effective Ensemble Learning-Based Real-Time Intrusion Detection Scheme for an In-Vehicle Network. Electronics 2024, 13, 919. [Google Scholar] [CrossRef]
- Ji, H.; Wang, Y.; Qin, H.; Wang, Y. Comparative performance evaluation of intrusion detection methods for in-vehicle networks. IEEE Access 2018, 6, 37523–37532. [Google Scholar] [CrossRef]
- Flower Framework. Available online: https://flower.ai/docs/framework/tutorial-series-what-is-federated-learning.html (accessed on 1 August 2024).
Figure 1.
CAN communication in autonomous vehicles.
Figure 2.
CAN frame format.
Figure 3.
Reference architecture of FL-IVN-IDS.
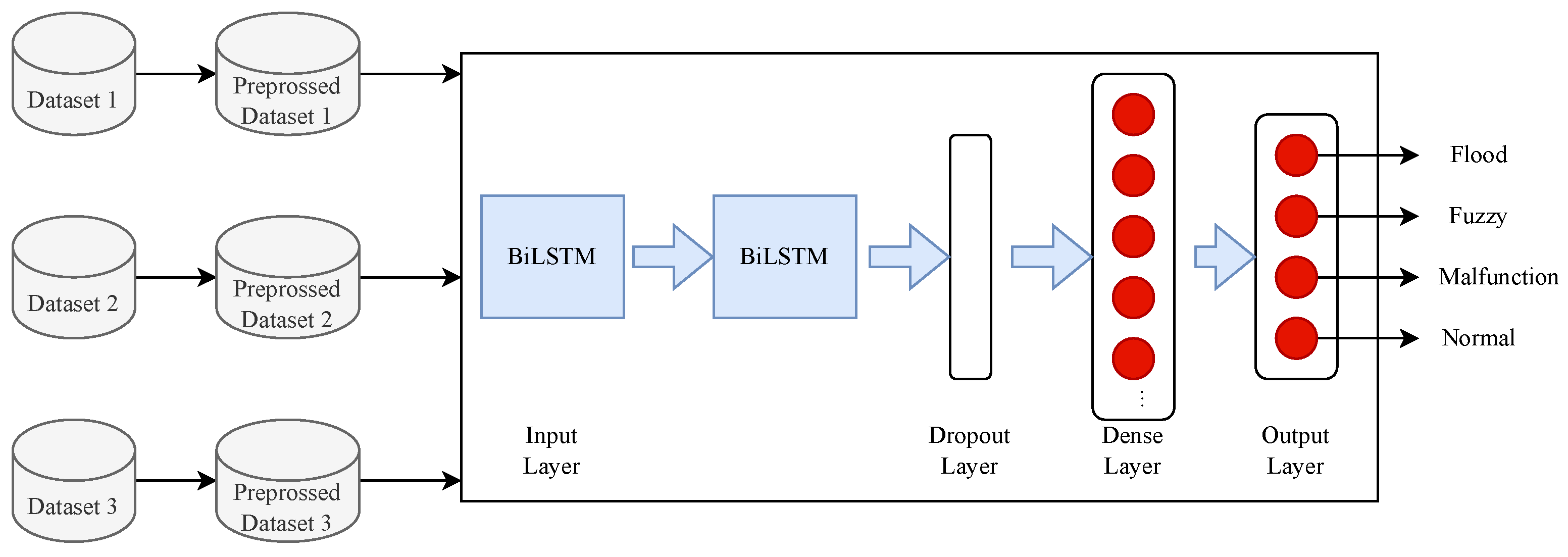
Figure 4.
Adapted-BiLSTM Architecture for IVN-IDS.
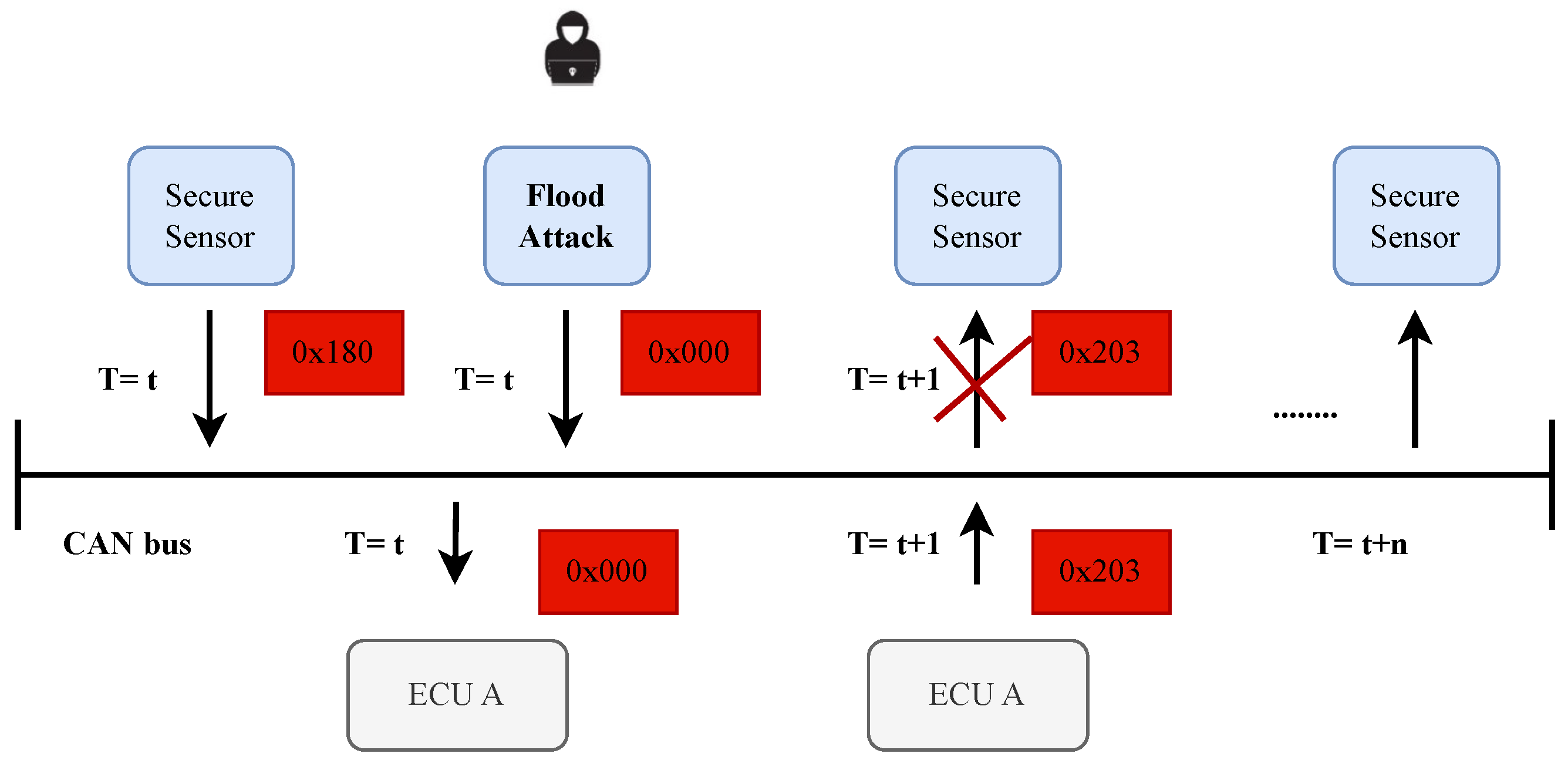
Figure 5.
Flood Attack Strategy.
Figure 6.
Fuzzy Attack Strategy.
Figure 7.
Malfunction Attack Strategy.
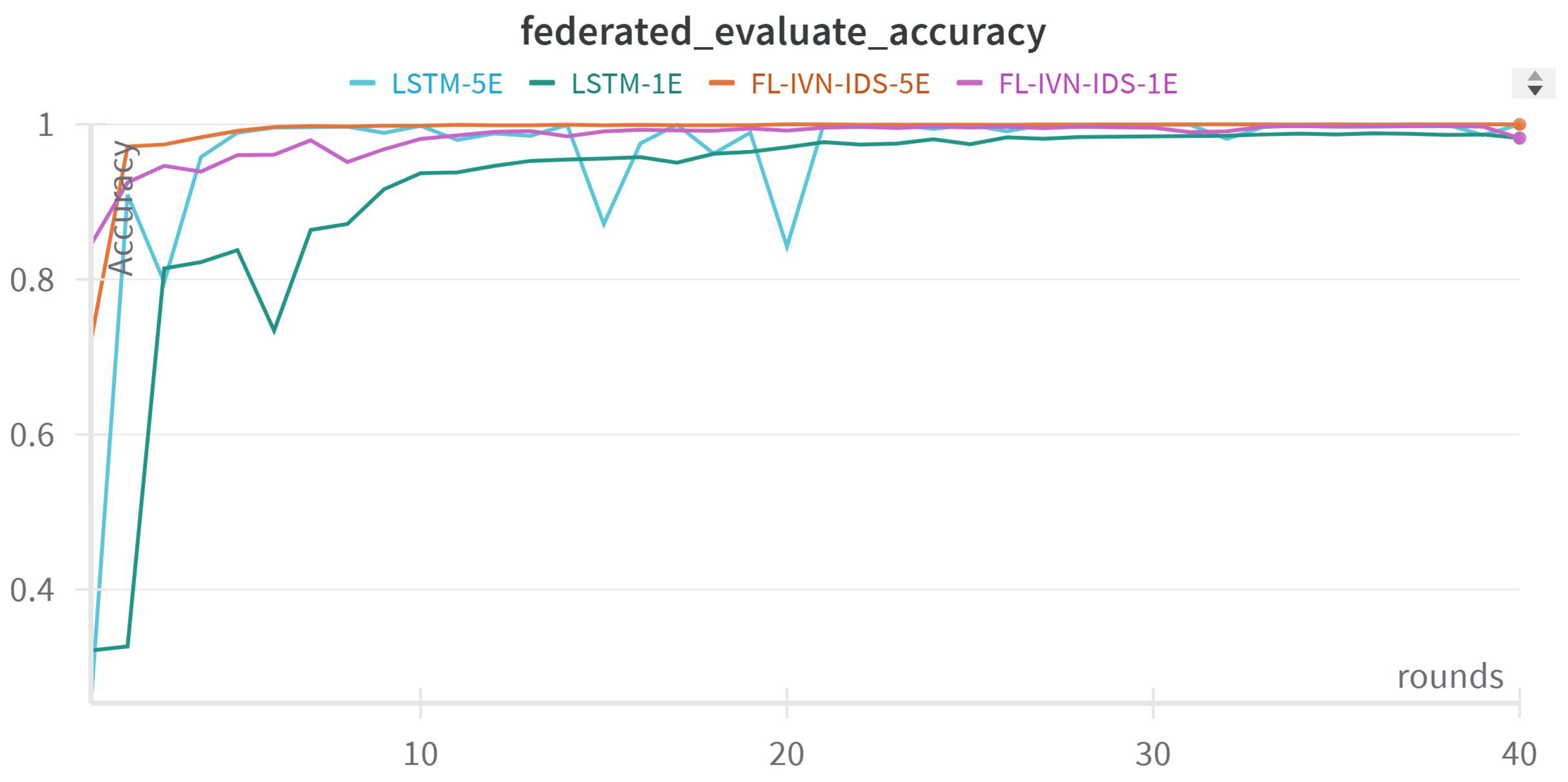
Figure 8.
Accuracy Training History of Distributed Learning for Per-Round Evaluation.
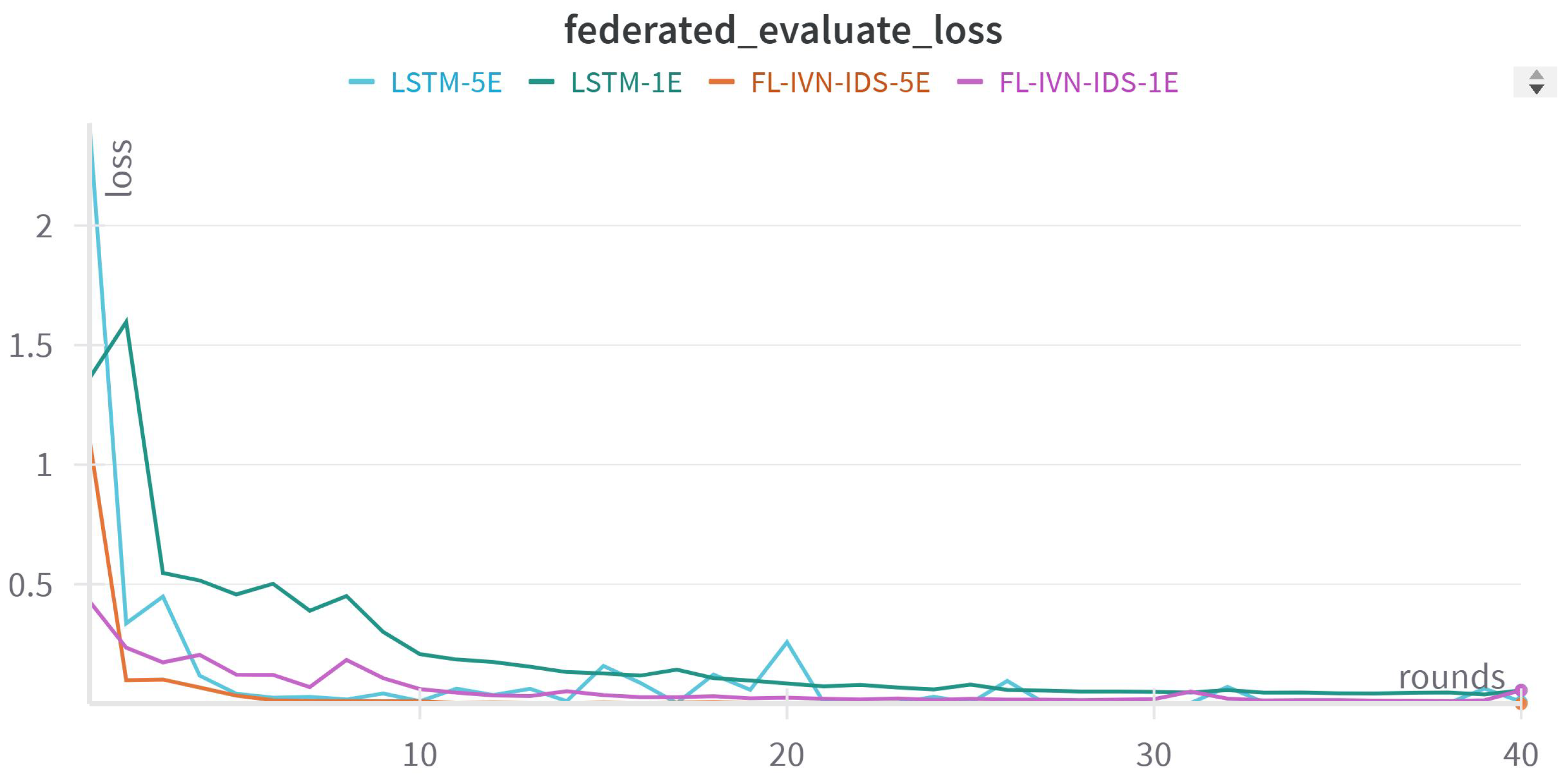
Figure 9.
Loss Training History of distributed learning for Per-Round Evaluation.
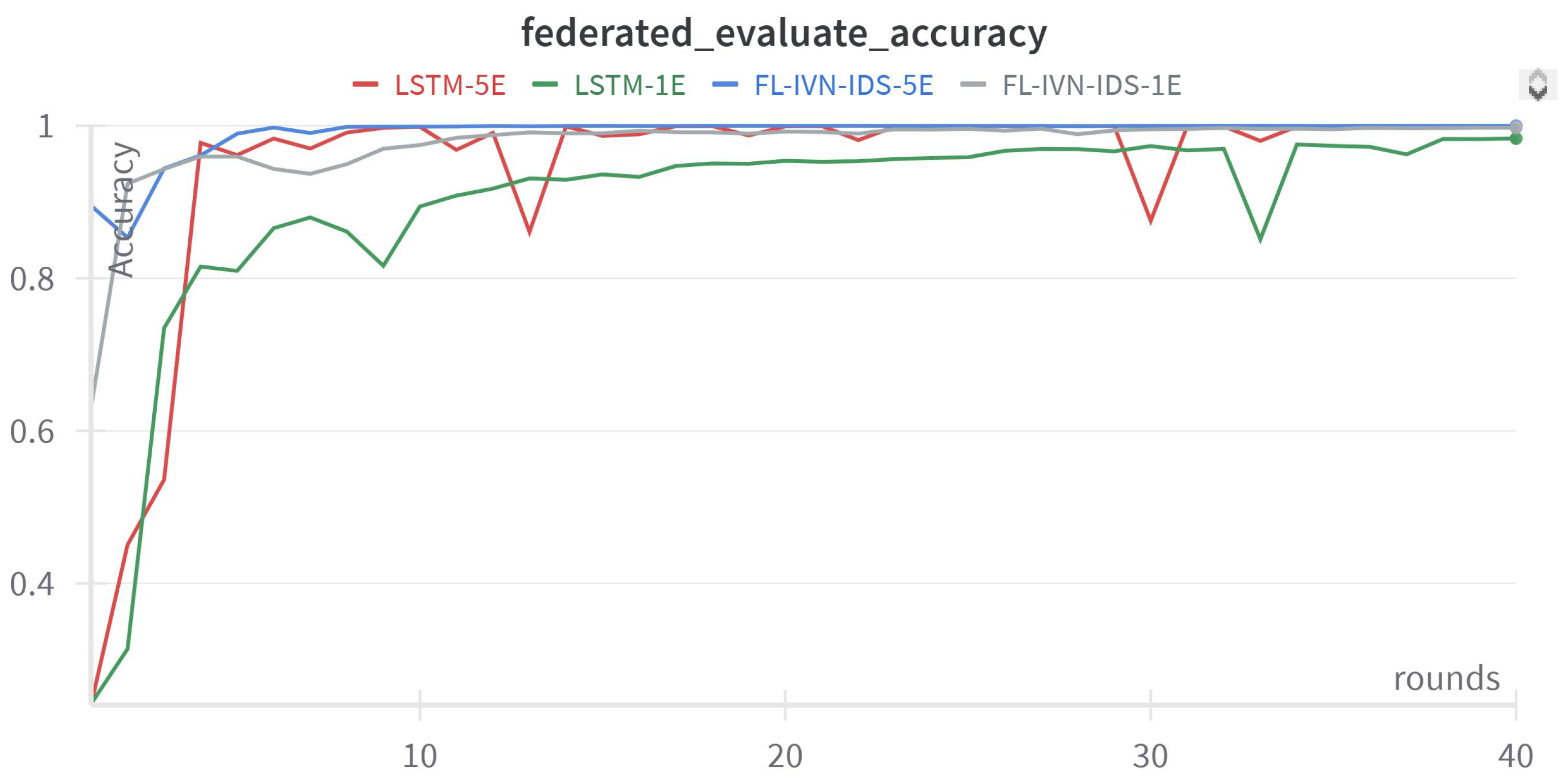
Figure 10.
Accuracy Training History of Distributed Learning for Final Global Model Evaluation.
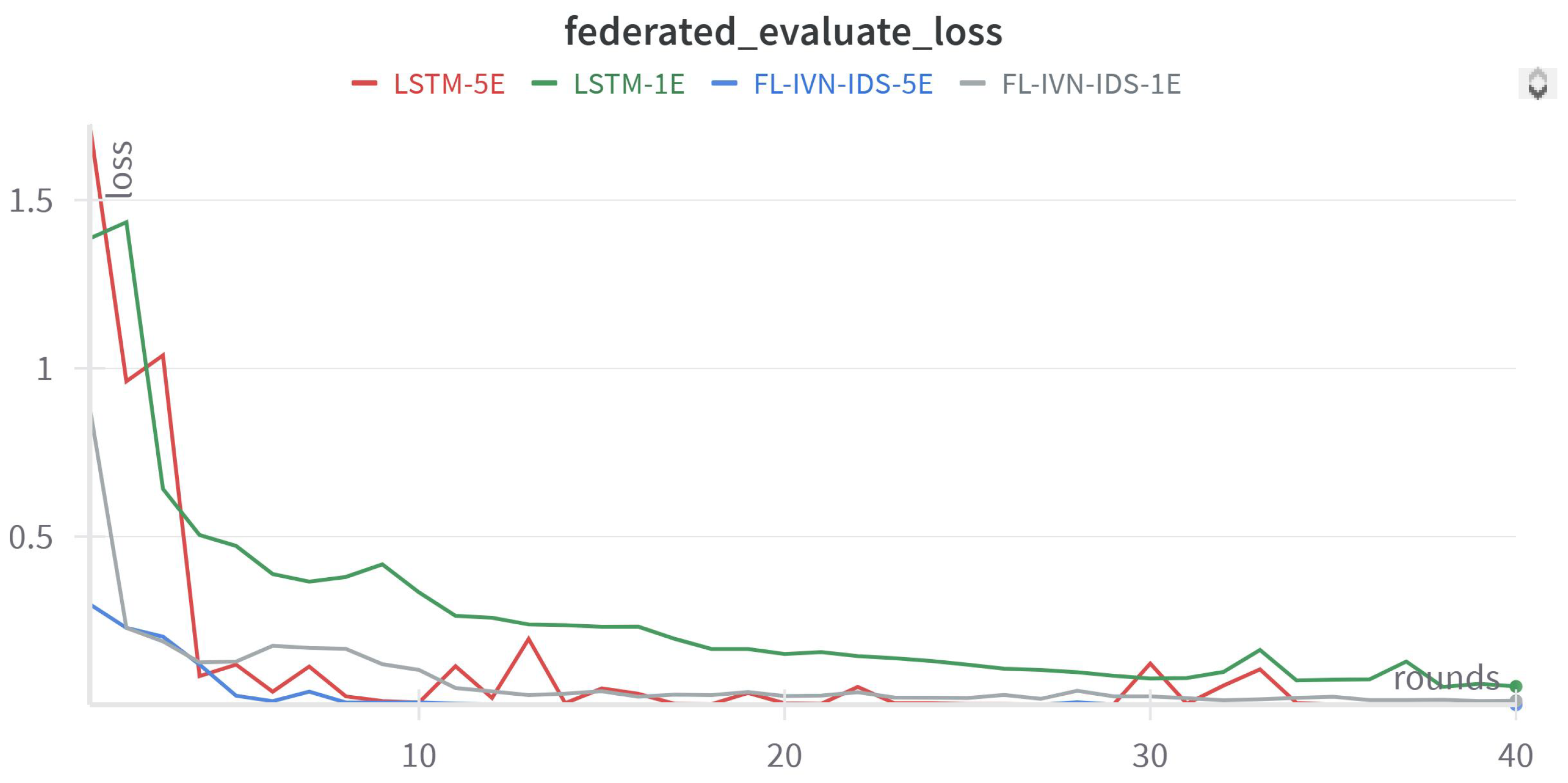
Figure 11.
Loss Training History of distributed learning for Final Global Model Evaluation.
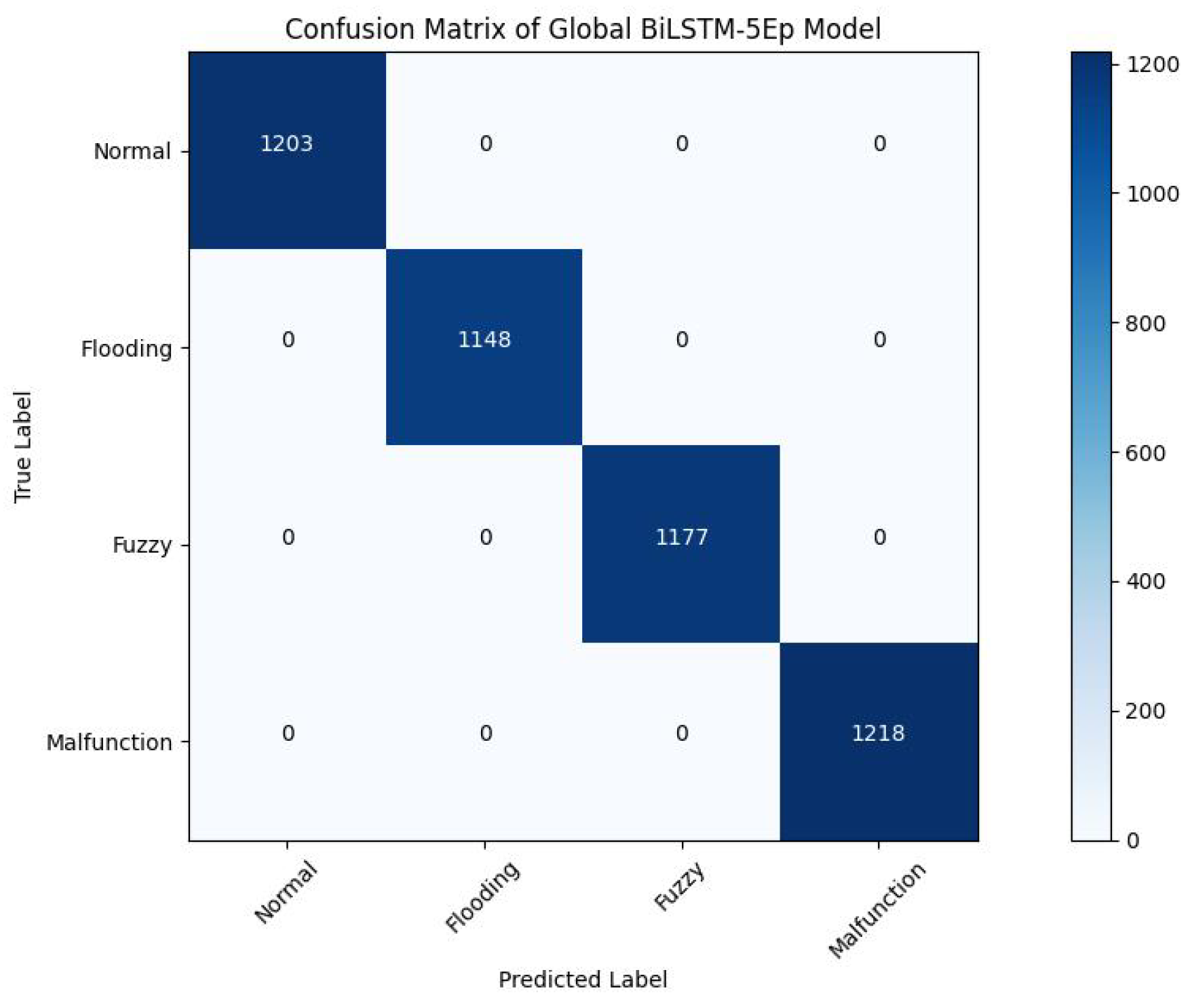
Figure 12.
Confusion Matrix of FL-IVN-IDS-5E Architecture.
Figure 13.
ROC of FL-IVN-IDS-5E Architecture.
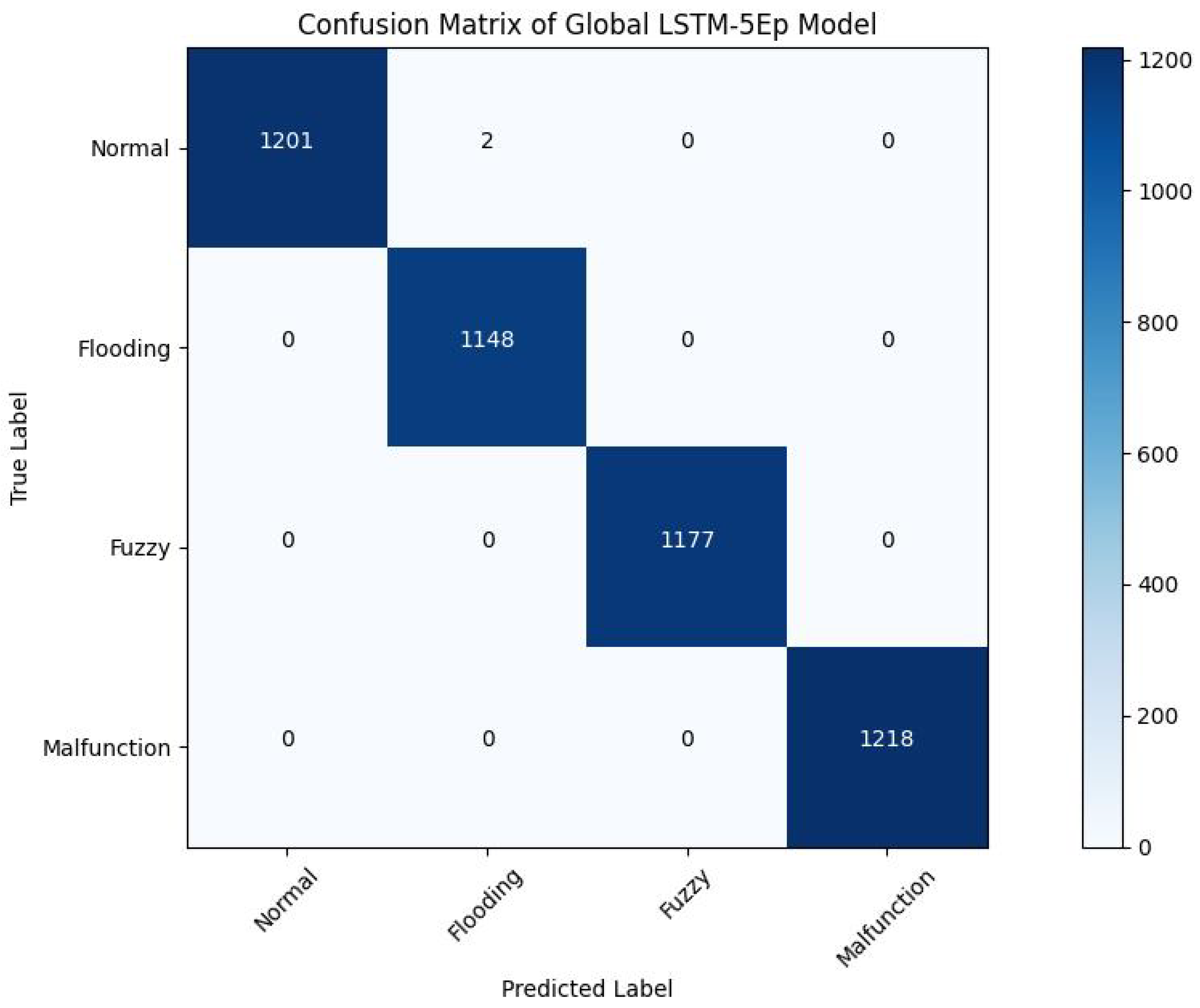
Figure 14.
Confusion Matrix of LSTM-5E Architecture.
Figure 15.
ROC of LSTM-5E Architecture.
Figure 16.
Accuracy Training History of Centralized Learning.
Figure 17.
Loss Training History of Centralized Learning.
Figure 18.
Traffic Network exchanges during the training period.
Figure 19.
Distribution of the per-round training time using the four approaches.
Table 1.
Summary of Notations.
| Symbol | Description |
|---|
| N | Number of clients in federated learning |
| E | Number of local training epochs per round |
| B | Batch size for local training |
| Global model weights at round t |
| Local model weights of client i at round t |
| H | Hellinger distance |
| G | Local label distribution |
| S | Reference balanced distribution |
| C | Local dataset of client i |
| instances of a specific attack type that were correctly predicted |
| instances of a particular attack type that were incorrectly predicted |
| instances of a specific attack type that were correctly identified |
| instances of a particular attack type that were missed |
Table 2.
Complete Simulation Parameters and Settings.
| Category | Parameter | Value/Description |
|---|
| General Setup | Number of Clients | 3 clients (each using a separate dataset) |
| Server Rounds | 40 |
| Fraction of Clients per Round | 1.0 (fit), 0.5 (evaluate) |
| Local Epochs per Round | {1, 5} |
| Batch Size | 64 |
| Model Architecture | Input Shape | (11, 1) |
| Layer 1 | Bidirectional LSTM with 64 units, return_sequences = True |
| Layer 2 | Bidirectional LSTM with 64 units |
| Dropout Layer | Dropout rate = 0.5 |
| Dense Layer | Dense layer with 128 units, ReLU activation |
| Output Layer | Dense layer with 4 units, Softmax activation |
| Loss Function | Categorical Crossentropy |
| Optimizer | Adam (learning rate = 0.001) |
| Metrics | Accuracy |
Table 3.
Class Distribution Before Oversampling.
| Dataset | Normal | Flooding | Fuzzy | Malfunction |
|---|
| Hyundai | 236,607 | 17,093 | 9095 | 8202 |
| Chevrolet | 154,960 | 14,999 | 3043 | 3995 |
| Kia | 334,542 | 16,072 | 21,613 | 4770 |
Table 4.
Class Distribution After Oversampling (SMOTE).
| Dataset | Normal | Flooding | Fuzzy | Malfunction |
|---|
| Hyundai | 189,297 | 189,297 | 189,297 | 189,297 |
| Chevrolet | 123,987 | 123,987 | 123,987 | 123,987 |
| Kia | 267,616 | 267,616 | 267,616 | 267,616 |
Table 5.
Number of Training and Testing Samples Per Round After Oversampling.
| Dataset | Training Samples (80%) | Testing Samples (20%) |
|---|
| Hyundai | 15,144 | 3786 |
| Chevrolet | 9918 | 2480 |
| Kia | 21,410 | 5352 |
Table 6.
Classification Report for FL-based LSTM-1E Model: Precision, Recall, F1-Score, and Support.
| Class | Precision | Recall | F1-Score | Support |
|---|
| Normal | 0.96 | 0.97 | 0.96 | 1203 |
| Flooding | 0.99 | 1.00 | 1.00 | 1148 |
| Fuzzy | 0.98 | 0.96 | 0.97 | 1177 |
| Malfunction | 0.99 | 1.00 | 1.00 | 1218 |
| Accuracy (FL-based LSTM-1E) | 0.9815 |
Table 7.
Classification Report for FL-IVN-IDS-1E Model: Precision, Recall, F1-Score, and Support.
| Class | Precision | Recall | F1-Score | Support |
|---|
| Normal | 1.00 | 0.99 | 0.99 | 1203 |
| Flooding | 1.00 | 1.00 | 1.00 | 1148 |
| Fuzzy | 1.00 | 1.00 | 1.00 | 1177 |
| Malfunction | 1.00 | 1.00 | 1.00 | 1218 |
| Accuracy (FL-IVN-IDS-1E) | 0.9973 |
Table 8.
Classification Report for LSTM-5E Model: Precision, Recall, F1-Score, and Support.
| Class | Precision | Recall | F1-Score | Support |
|---|
| Normal | 1.00 | 1.00 | 1.00 | 1203 |
| Flooding | 1.00 | 1.00 | 1.00 | 1148 |
| Fuzzy | 1.00 | 1.00 | 1.00 | 1177 |
| Malfunction | 1.00 | 1.00 | 1.00 | 1218 |
| Accuracy (LSTM-5E) | 0.9996 |
Table 9.
Classification Report for FL-IVN-IDS-5E Model: Precision, Recall, F1-Score, and Support.
| Class | Precision | Recall | F1-Score | Support |
|---|
| Normal | 1.00 | 1.00 | 1.00 | 1203 |
| Flooding | 1.00 | 1.00 | 1.00 | 1148 |
| Fuzzy | 1.00 | 1.00 | 1.00 | 1177 |
| Malfunction | 1.00 | 1.00 | 1.00 | 1218 |
| Accuracy (FL-IVN-IDS-5E) | 1.0000 |
Table 10.
Comparison of Model Performance in Testing Accuracy and Training Time- Global model.
| Model | Accuracy (%) | Time (s) |
|---|
| LSTM-1E | 98.15 | 5300.74 |
| LSTM-5E | 99.95 | 20,139.08 |
| FL-IVN-IDS-1E | 99.73 | 3822.06 |
| FL-IVN-IDS-5E | 100 | 12,001.79 |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}