1. Introduction
The integration of the Taylor method with neural networks in antenna array design signifies a sophisticated synergy between mathematical modeling and computational learning, yielding unprecedented levels of precision and adaptability. Unlike Chebyshev- or Fourier-based designs, Taylor excitation offers a balance between analytical simplicity and control over sidelobe levels, making it well suited to integration with learning-based optimization [
1].
At its core, the Taylor method, founded on mathematical principles, provides engineers with a robust framework for approximating complex functions through series expansions. Within the context of antenna arrays, this method enables the manipulation of radiation patterns by fine-tuning polynomial coefficients, affording precise control over crucial parameters like beamwidth, sidelobe levels, and null steering [
2,
3]. Complementing this mathematical prowess, neural networks harness their intrinsic learning capabilities to optimize these coefficients based on desired radiation patterns [
4,
5]. Through iterative training processes, neural networks iteratively adjust the Taylor-series coefficients to minimize discrepancies between predicted and desired radiation patterns, refining their understanding with each iteration. This collaborative optimization process enables antenna arrays to achieve remarkable levels of performance across a myriad of applications. For instance, in beamforming, this integrated approach facilitates the precise steering of radiation beams towards specific directions while mitigating interference from undesired sources, enhancing signal quality and coverage. Furthermore, it enables the customization of radiation patterns to suit diverse application requirements, such as minimizing sidelobes for radar systems or optimizing coverage patterns for wireless communication networks [
6,
7]. Unlike previous methods that treat analytical and machine learning techniques separately, this work introduces a hybrid synthesis framework where Taylor series-based excitation is used to guide and initialize a neural network model, resulting in enhanced optimization and interpretability. Additionally, in environments prone to interference, adaptive antenna arrays equipped with neural networks can dynamically adjust radiation patterns in real time to mitigate interference sources, ensuring robust performance even in challenging operating conditions. Overall, the integration of the Taylor method with neural networks empowers antenna arrays with unparalleled levels of performance, adaptability, and versatility, driving transformative advancements in wireless communication, radar systems, and beyond.
The applications of integrating the Taylor method with neural networks in antenna design are extensive and span various domains. Wireless communication and mobile networks: In cellular networks and wireless communication systems, optimizing antenna radiation patterns is crucial to maximizing coverage, capacity, and signal quality. Integrating the Taylor method with neural networks enables the dynamic adaptation of radiation patterns to varying channel conditions, ensuring optimal network performance [
8,
9]. Radars: In radar systems, the precision and reliability of radar data largely depend on the antenna’s ability to form directional beams and suppress unwanted echoes [
10,
11,
12]. The joint use of the Taylor method and neural networks optimizes radiation patterns for precise target detection and localization, even in noisy environments. Remote sensing and surveillance: In applications such as environmental monitoring, natural resource management, and traffic surveillance, antennas must detect and track objects accurately over large areas [
13,
14]. Integrating the Taylor method with neural networks enables the design of adaptive antennas capable of meeting the specific needs of each surveillance application. Smart antenna systems: Smart antenna systems, which use adaptive algorithms to optimize antenna performance based on channel conditions, greatly benefit from integrating the Taylor method with neural networks. These systems can dynamically adapt to changes in the RF environment, ensuring reliable connectivity and high-quality service delivery in various scenarios [
15,
16,
17]. The integration of the Taylor method with neural networks opens up new perspectives in antenna design, offering optimized performance and increased adaptability across a wide range of applications, from wireless communication networks to radar systems to environmental surveillance.
Table 1 compares different beamforming methods for antenna arrays, each with specific advantages and disadvantages. The Taylor method adjusts antenna phases using Taylor coefficients, offering easy implementation but requiring prior knowledge of the spatial signal distribution [
18]. The Dolph–Chebyshev method [
19] minimizes amplitude error through Chebyshev polynomials, achieving high sidelobe attenuation, though its complexity increases in certain antenna configurations. Particle swarm optimization (PSO) [
20] adjusts parameters by simulating the collective behavior of animals, ensuring quick convergence, but its effectiveness depends on the initial setup. Genetic algorithms (GAs) [
21] optimize parameters by simulating natural selection mechanisms, making them well suited to complex designs, although they require significant computation times. Therefore, the choice of method depends on performance goals and implementation constraints. This hybrid integration strategy provides a structured design pipeline that not only accelerates convergence but also enhances the physical interpretability of the learned model, distinguishing it from purely data-driven or purely analytical approaches.
2. Modern Radar and Phased Antenna Arrays
Phased-array radars use antenna arrays that can be electronically controlled to steer the radar beam without mechanical movement, enabling fast scanning and efficient target detection and tracking. The array factor (
) plays a crucial role in beamforming and is defined as the sum of contributions from each antenna element in the array, where each element is fed with a phase-adjusted signal [
22,
23]. For a linear array of
N elements spaced with
d, the array factor is given by the following:
where
is the wave number,
is the wavelength of the radar signal,
is the observation angle, and
is the phase shift applied to each antenna element. In the case of a linear phase shift with an angle,
, of the main beam direction, each element receives a phase,
, where
is the direction of the main beam. This allows the beam to be steered towards
without requiring the physical movement of the antennas [
24,
25].
The array factor is often expressed in a closed form as follows:
where
. By manipulating this equation, the array factor can also be expressed in a trigonometric form:
This formulation shows that the main beam is directed toward
, and the radiation pattern, including the main lobe width and side lobes, depends on the number of elements,
N, the element spacing,
d, and the phase shift,
. The angular resolution of the radar, which defines the ability to distinguish closely spaced targets, is determined by the width of the main lobe at −3 dB, calculated as follows:
Thus, increasing the number of elements in the array results in a narrower beam and better angular resolution, but it also requires optimal element spacing to avoid the formation of grating lobes. If the element spacing,
d, exceeds
, unwanted side lobes, or grating lobes, may appear, leading to detection errors. To mitigate these effects, windowing functions such as Taylor, Chebyshev, or Hamming windows are applied to reduce side lobes, optimizing radar performance without significantly increasing the main beam width [
26,
27]. Among these, Taylor-series expansion is favored in this work due to its analytical tractability and ability to produce physically interpretable excitation profiles with controlled sidelobe behavior. Unlike Chebyshev- or Fourier-based designs, Taylor excitation enables the smooth tapering of the amplitude distribution, which integrates naturally with neural network optimization and facilitates convergence. This balance between simplicity, control, and compatibility with data-driven tuning makes Taylor series a strong candidate for hybrid synthesis frameworks.
Phased-array radars enable electronic beam steering, where the beam can be directed in any direction by electronically adjusting the phase of each array element. This allows for faster scanning compared to traditional mechanical antenna radars, as well as real-time adaptability to track multiple targets simultaneously, which is essential for modern radar systems used in defense, airborne surveillance, weather radars, and autonomous vehicles. By adjusting the phases,
, of the array elements, the radar can track multiple targets, perform frequency hopping across different angles, and provide real-time information on the position and velocity of targets [
28].
Phased array radars are used in critical applications where speed and accuracy are essential [
29,
30,
31]. For example, in missile defense, phased array radars such as the AN/SPY-1 enable the real-time detection and tracking of missiles. Similarly, in airborne radar systems, AESA (active electronically scanned array) radars provide comprehensive surveillance of airspace, enabling precise flight path control and the better detection of stealth targets. In meteorology, these radars allow for the detailed monitoring of weather phenomena, such as storms and precipitation, with high spatial resolution and the ability to scan large areas quickly.
Phased-array radars offer advanced capabilities in electronic beam steering and multi-target detection, enabling them to be used in a wide range of complex applications. The precise control of the beam, enabled by the array factor, and the ability to adapt to dynamic tracking needs make phased array radars an essential technology in modern defense, airborne surveillance, and intelligent transportation systems.
Figure 1 illustrates the structure of a smart antenna, which consists of an array of antennas, including both analog and digital low noise amplifiers (LNAs), a high-power amplifier (HPA), a power amplifier (PA), an analog-to-digital Converter (ADC), a digital-to-analog converter (DAC), a local oscillator (LO) for baseband transmission (Tx) and reception (Rx), and the weights for antenna array synthesis. The antenna array synthesis involves adjusting the weights applied to each antenna element to optimize the overall radiation pattern and performance of the system for various communication or sensing applications, based on the architecture proposed by Prof. A. Manikas [
32].
3. The Taylor Method
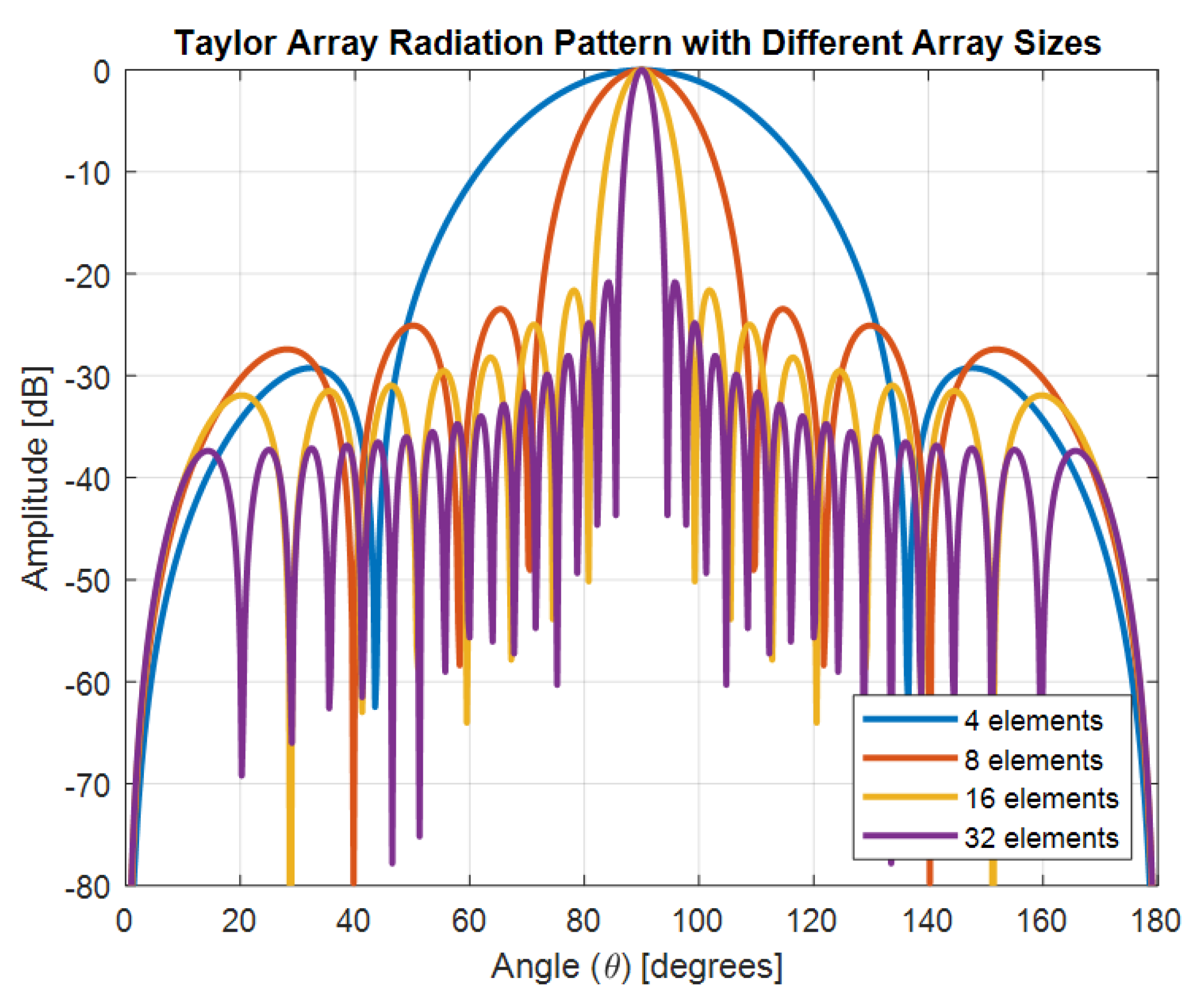
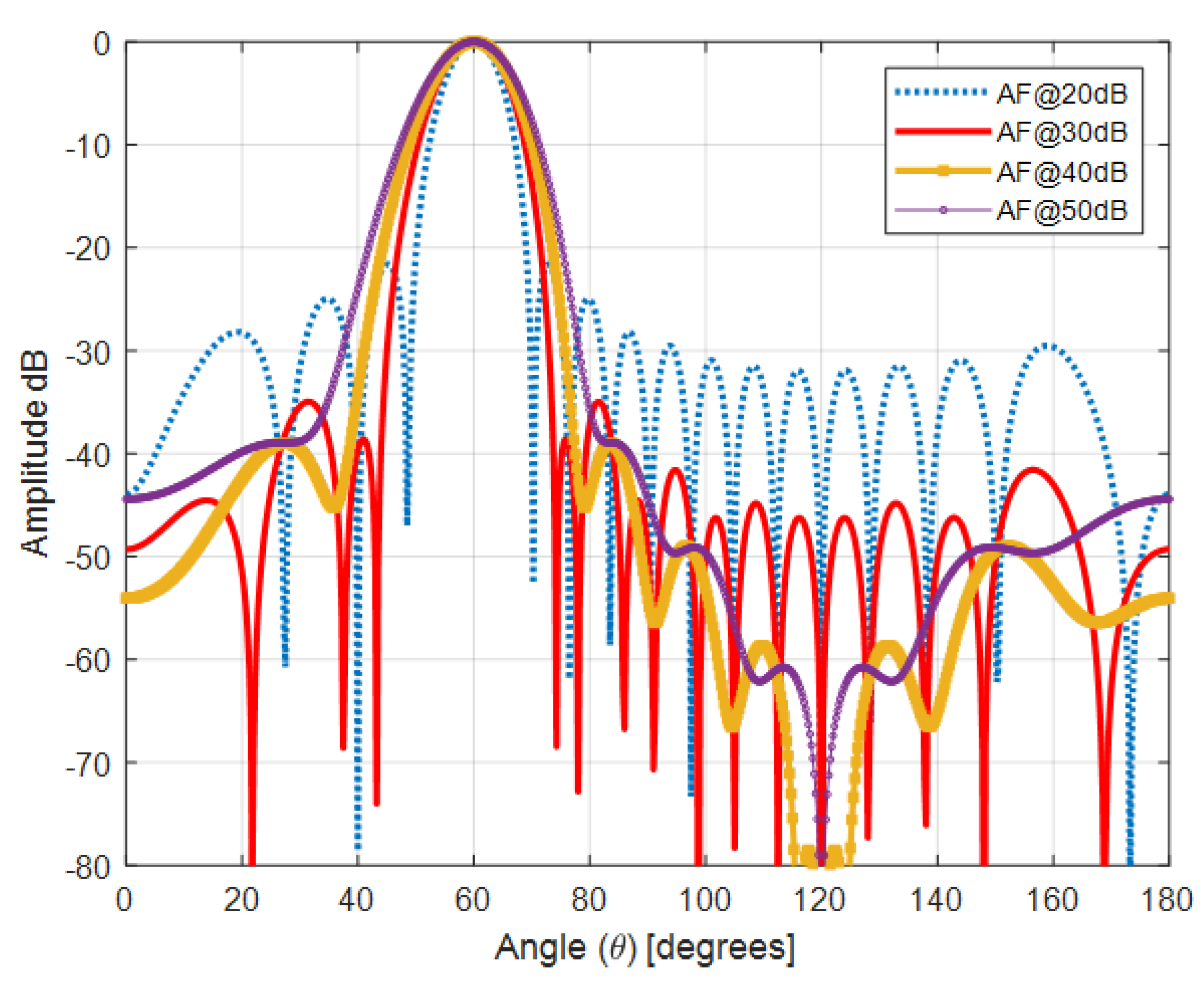
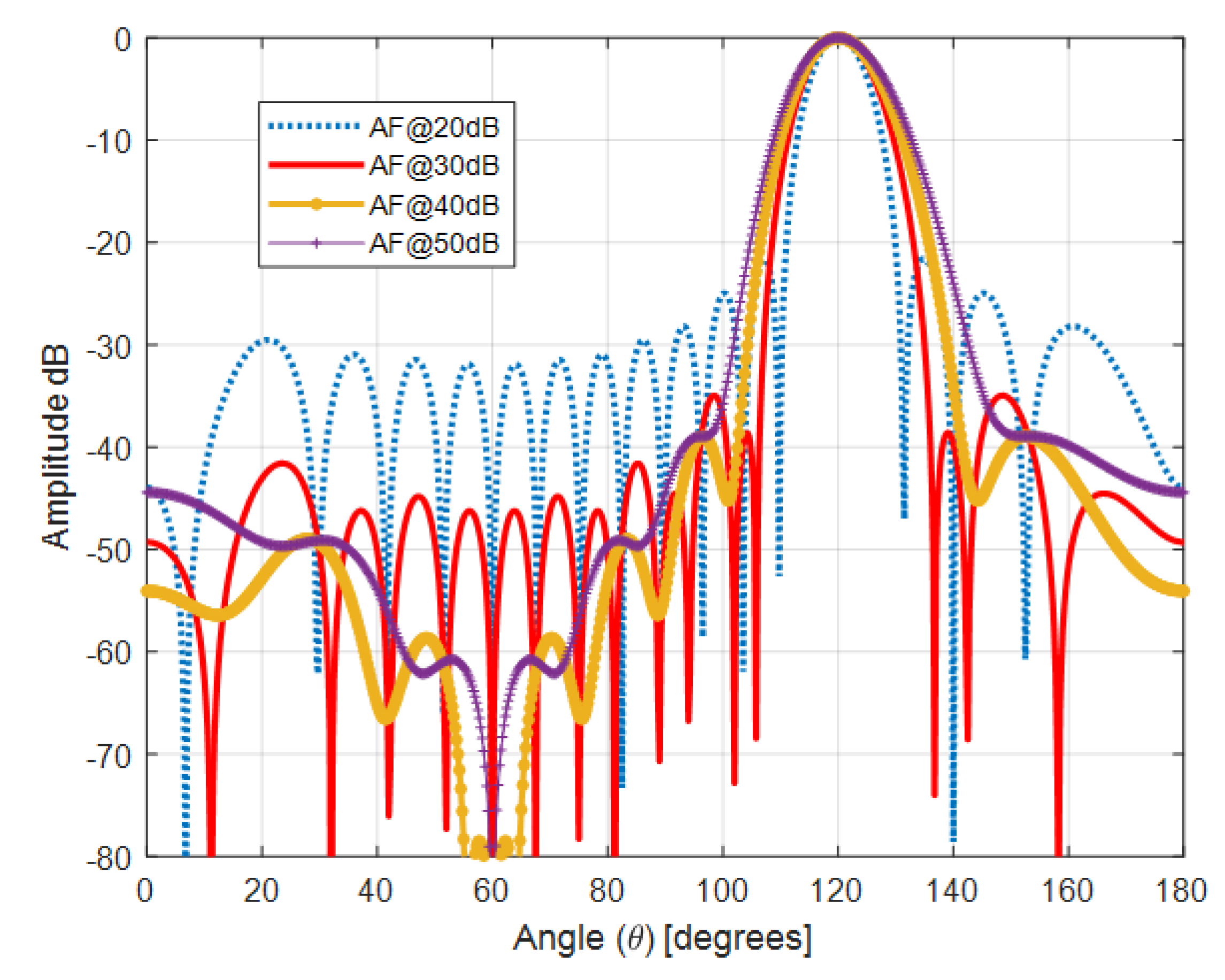
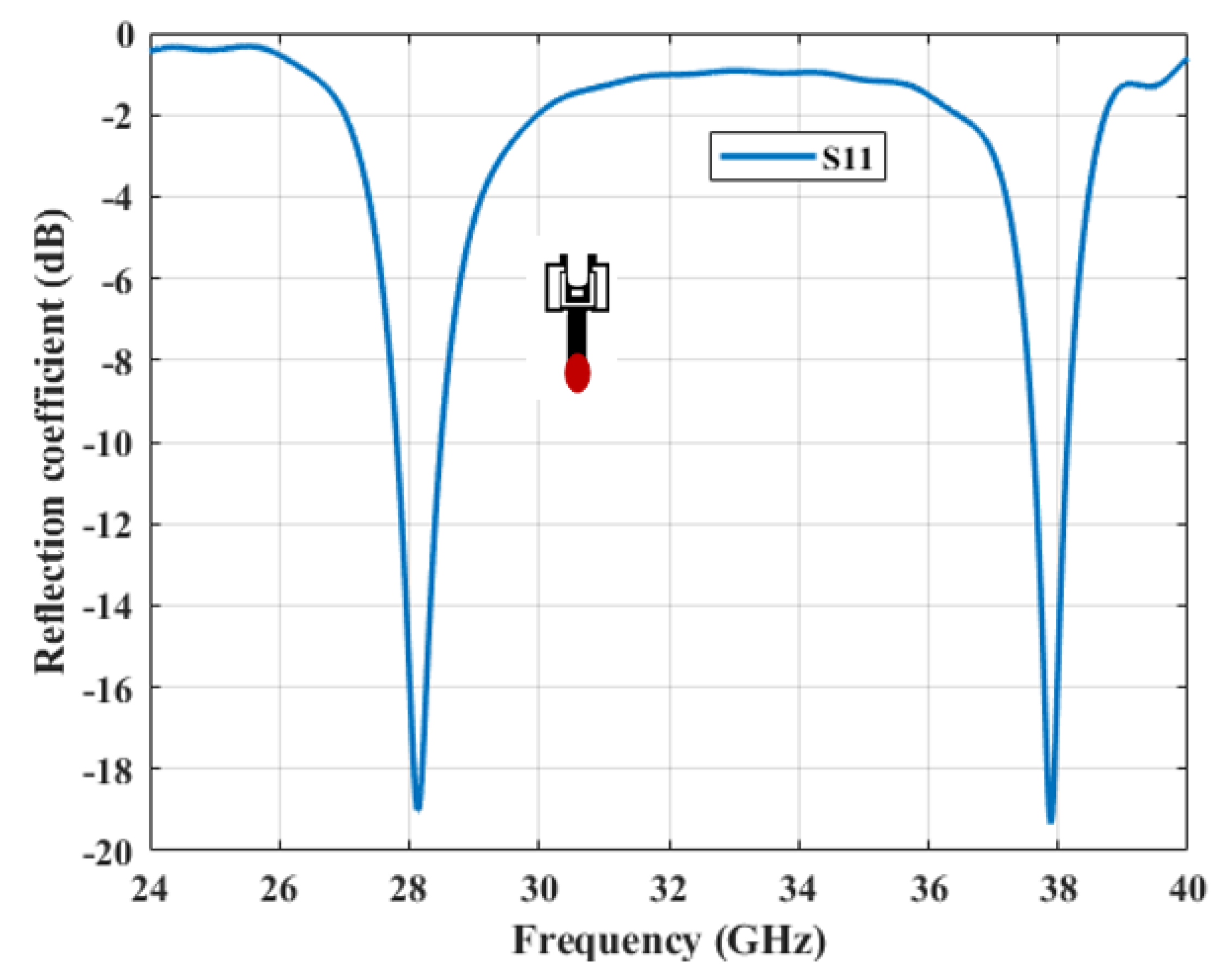
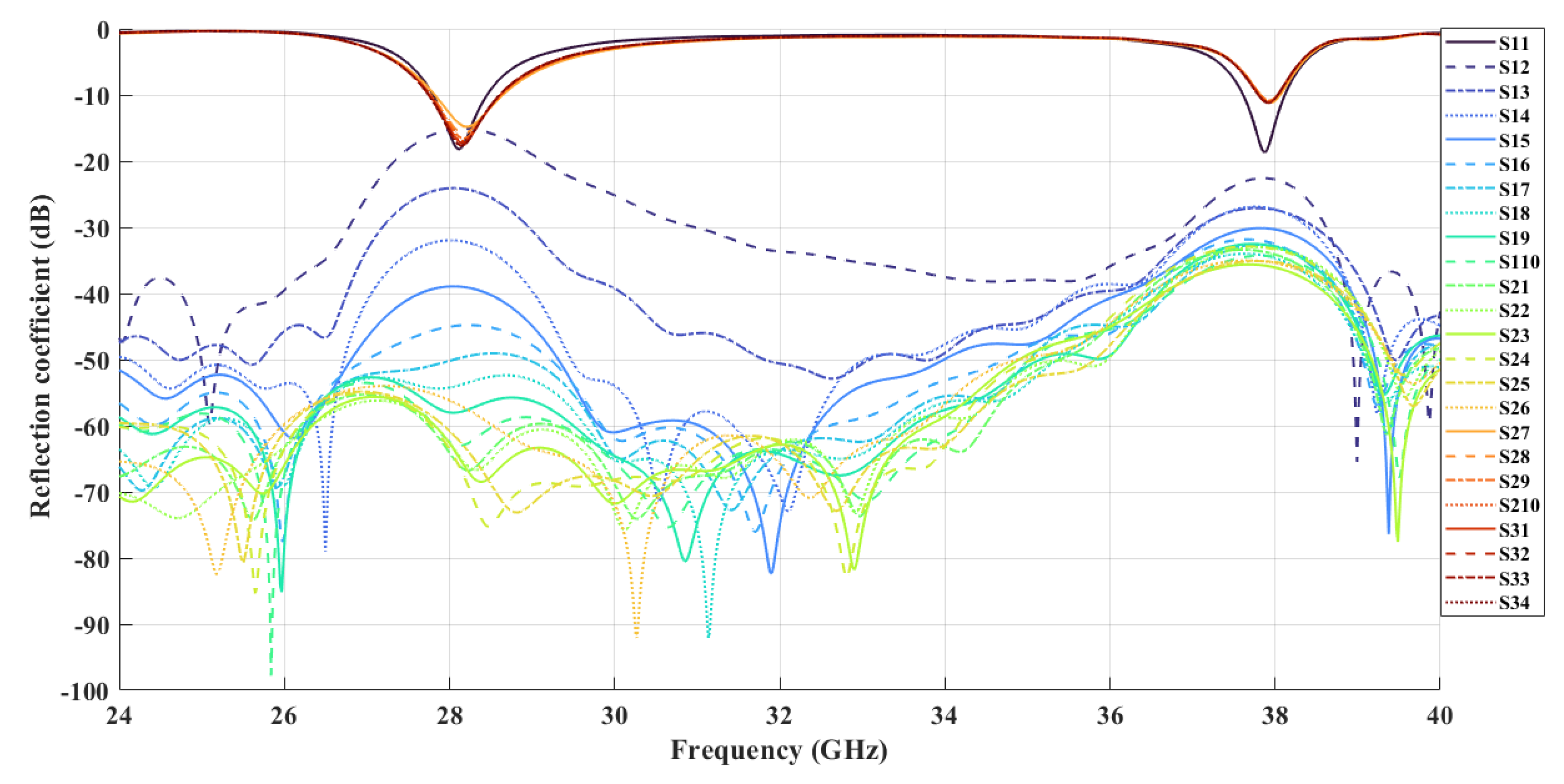
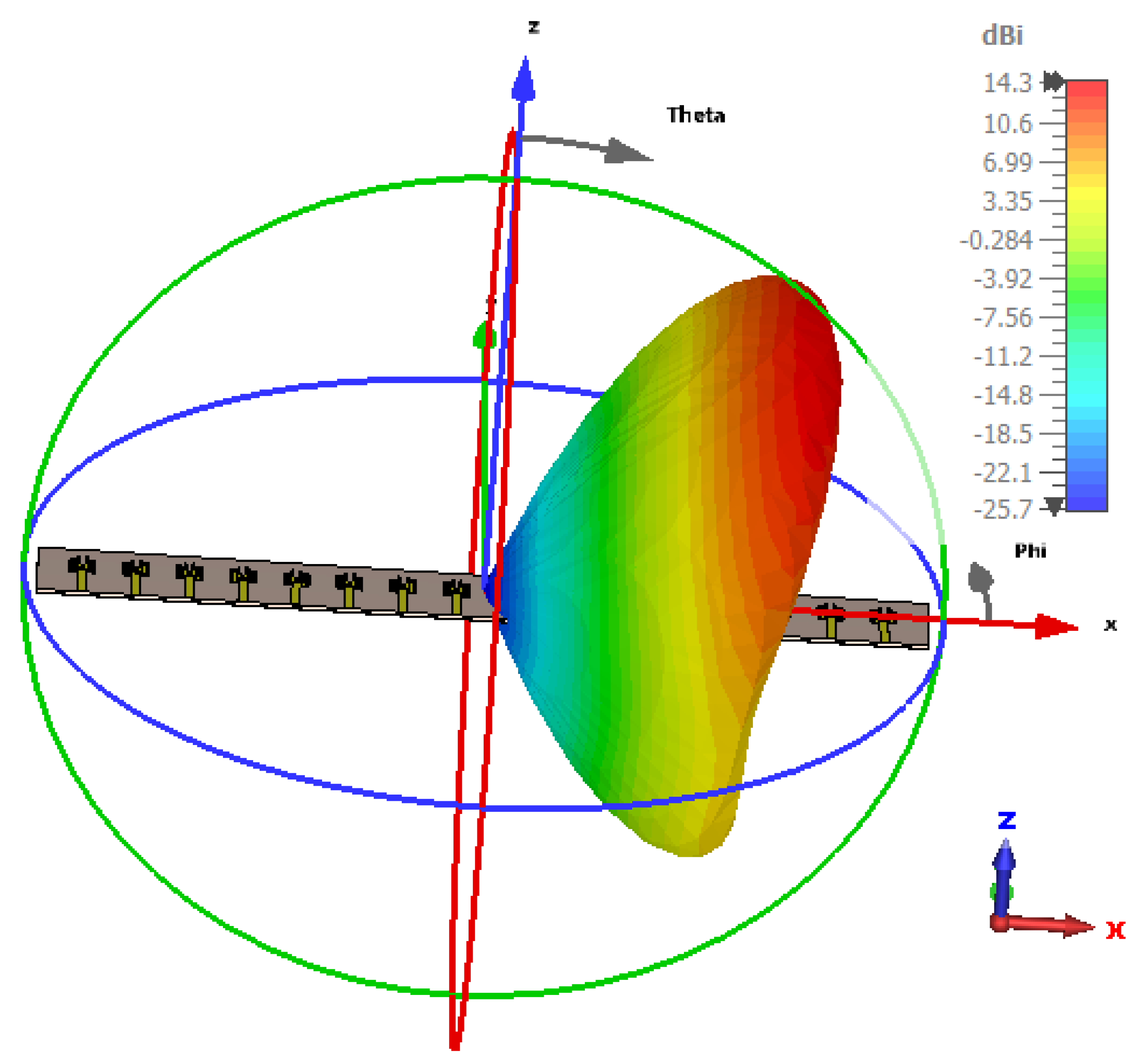
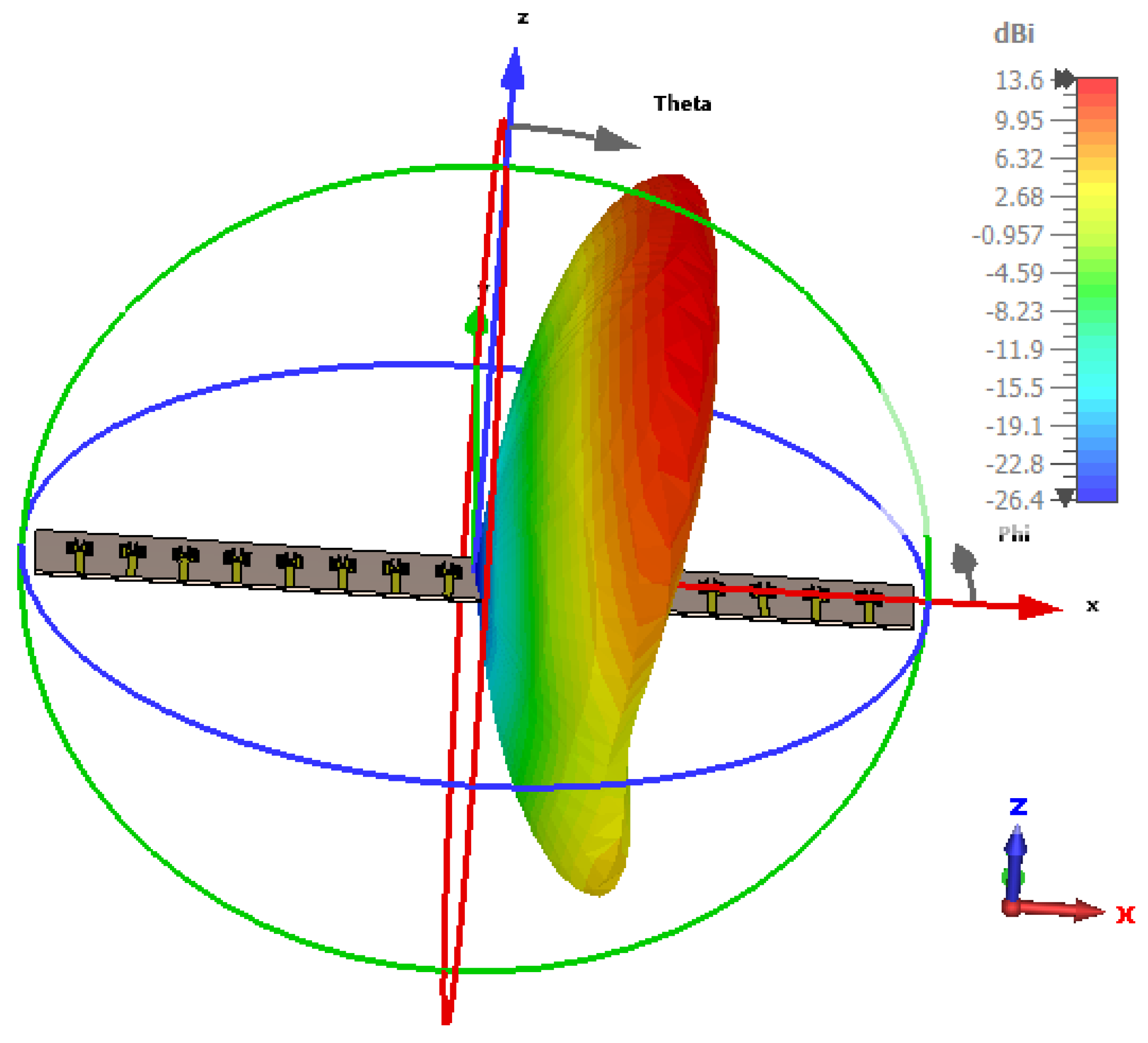
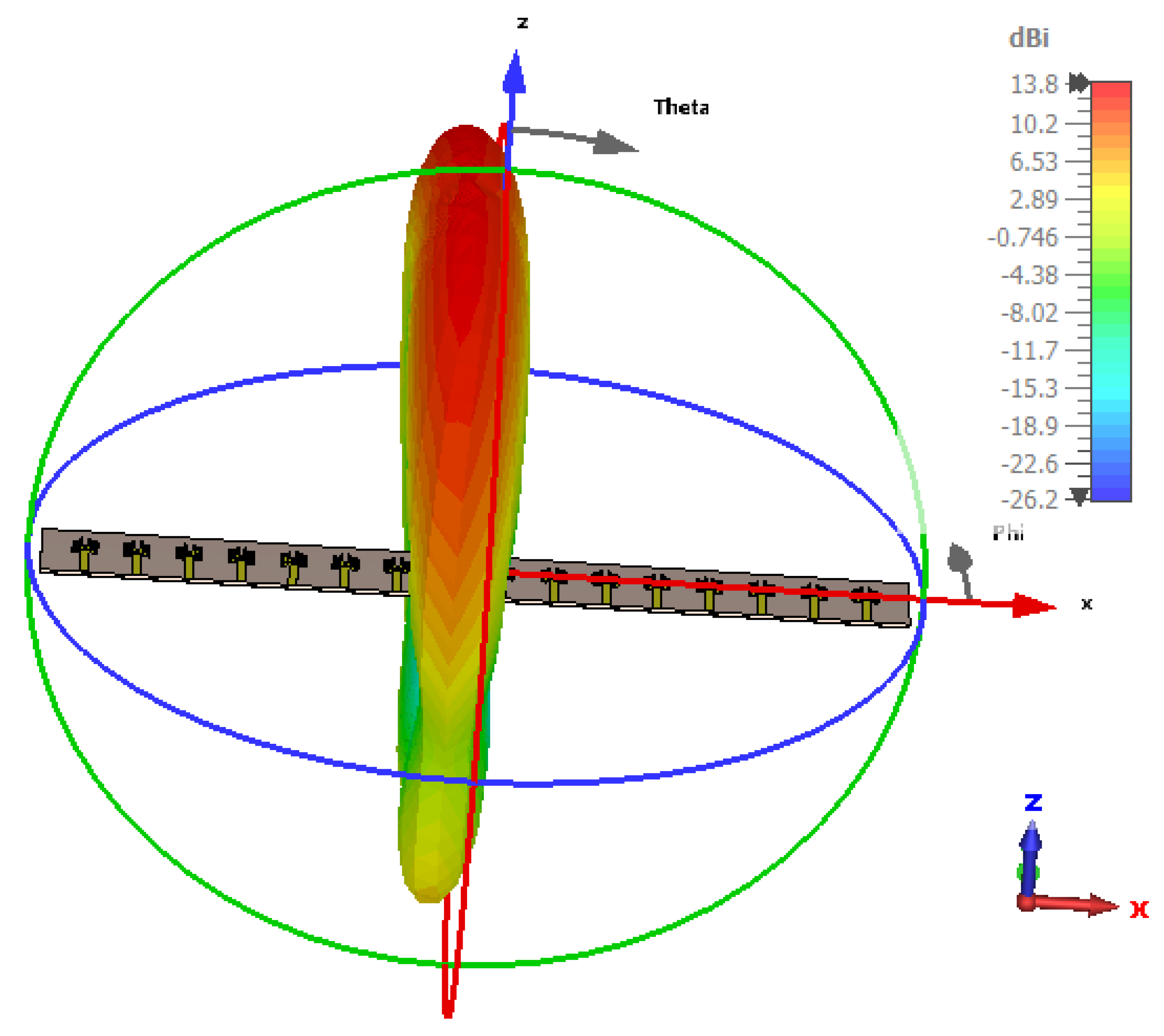
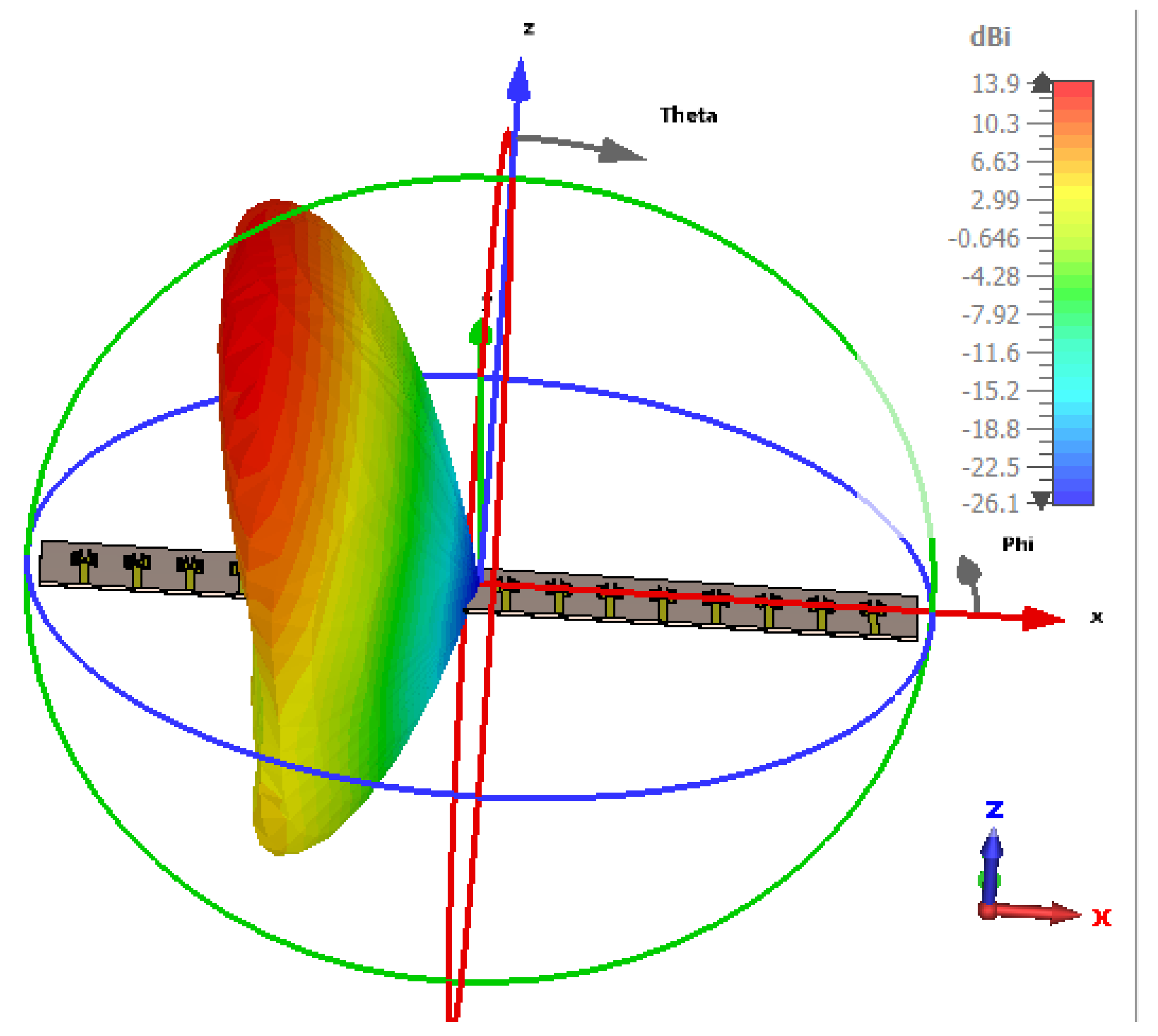
The simulated antenna consists of 16 identical microstrip patch elements arranged in a uniform linear array with
spacing. This structure serves as the physical basis for the optimization framework and simulation results presented in
Figure 2,
Figure 3,
Figure 4 and
Figure 5. The Taylor method is a classical technique used in antenna array design to control how energy is distributed across the radiation pattern. It enables designers to fine-tune parameters such as beamwidth and sidelobe level by adjusting excitation amplitudes across the array elements using a mathematical series expansion. When a precise expression of the electromagnetic field is not easily available, Taylor expansion allows engineers to locally approximate the field distribution and apply optimized amplitude weights to shape the desired beam [
25,
33,
34,
35].
Using spherical coordinates
, where
r represents the radial distance from the observation point,
represents the azimuthal angle, and
represents the elevation angle, the Taylor method can be extended to approximate the spatial distribution of the electromagnetic field as follows [
36,
37]:
In this expression, the following applies:
represents the spatial distribution of the electromagnetic field of the antenna array.
is the reference point around which the Taylor series is developed.
, , and are the partial derivatives of E with respect to r, , and respectively, evaluated at the reference point .
The Taylor method is utilized in antenna design to dictate the amplitude attenuation of elements within an antenna array, often characterized by a single parameter such as the main lobe width. This amplitude attenuation, when applied to the array elements, directly impacts the array factor, a mathematical function delineating each array element’s contribution to the overall radiation pattern formation. Thus, employing the Taylor method to ascertain the amplitude of array elements directly influences the array factor and subsequently the comprehensive radiation pattern of the antenna array [
38,
39,
40]. Through parameter adjustments in the Taylor method, like modifying the main lobe width, one can manipulate the amplitude of the array factor, enabling precise control and optimization of the antenna array’s radiation pattern to align with specific requirements. This Algorithm 1 outlines the steps to synthesize a Taylor–Kaiser antenna array. It starts by choosing the appropriate window and calculating coefficients based on the given specifications. Then, for each antenna element, it calculates the weight and position. If the performance is satisfactory, it finalizes the design; otherwise, it adjusts the parameters to improve performance.
| Algorithm 1 Synthesize Taylor–Kaiser antenna array. |
- 1:
function Synthesize Antenna(specs) - 2:
Step 0: Initialize Parameters - 3:
Define the number of elements N and the desired sidelobe level (SLL). - 4:
Set the beamwidth and aperture size according to specs. - 5:
Step 1: Select Window Function - 6:
Choose the appropriate window (Taylor or Kaiser) based on SLL and beamwidth. - 7:
Step 2: Calculate Array Coefficients - 8:
Compute the excitation coefficients for each element using the selected window. - 9:
Step 3: Compute Element Weights and Positions - 10:
for to N do - 11:
Calculate weight = WindowFunction(). - 12:
Calculate element position = , where d is the element spacing. - 13:
end for - 14:
Step 4: Evaluate Performance - 15:
Compute the radiation pattern and evaluate sidelobe levels, beamwidth, and directivity. - 16:
Step 5: Adjust and Finalize - 17:
if Performance is satisfactory then - 18:
Finalize the array design and export the parameters. - 19:
else - 20:
Adjust window parameters or element spacing and repeat from Step 2. - 21:
end if - 22:
end function
|
This Taylor series can be truncated after the first order if a linear approximation is sufficient for the spatial distribution of the electromagnetic field around the reference point.
The amplitude distribution for the Taylor one-parameter distribution is given by the following:
where the following applies:
is the amplitude weighting coefficient for the n-th element of the array.
is the zeroth-order Bessel function of the first kind.
is the design parameter that controls the characteristics of the radiation pattern.
is the normalized distance between array elements, where
- -
d is the spacing between elements;
- -
is the wavelength;
- -
is the angle of radiation.
The Bessel function of the first kind of order zero,
, is defined by the infinite series:
It satisfies the recurrence relation:
and its asymptotic behavior for large
x is approximated by
This function frequently appears in applications such as wave propagation in cylindrical waveguides, heat conduction in cylindrical coordinates, and vibration analysis in cylindrical structures.
5. Neural Networks for Synthesis and Optimization of Antenna Arrays
Artificial neural networks (ANNs) provide a flexible and powerful framework for improving antenna array design. These models are capable of learning complex, nonlinear relationships between the excitation parameters of antenna elements and the resulting radiation pattern. Once trained, ANNs can quickly predict optimal excitation weights to achieve desired performance metrics such as minimized sidelobe levels or enhanced beam directivity. This is particularly useful in adaptive antenna systems, where fast real-time adjustments are needed to respond to changing environments, such as in mobile communication, radar, or satellite applications. By training on large datasets, ANNs can optimize parameters such as directivity, sidelobe levels, and the overall adaptability of antenna arrays. This capability enables them to deliver superior results compared to traditional optimization techniques.
In particular, neural networks can significantly improve the performance of antenna arrays by reducing sidelobes, enhancing the main lobe, and optimizing array configurations to achieve specific radiation patterns. They are capable of managing multiple constraints simultaneously, such as power distribution, array size, and performance under various environmental conditions. This makes ANNs particularly useful in designing adaptive and reconfigurable antenna systems for advanced communication systems, radar, and smart antennas.
In comparison to conventional numerical methods like Taguchi, Sequential Quadratic Programming (SQP), Dolph–Chebyshev, and Particle Swarm Optimization (PSO), neural networks offer faster convergence and are more effective at dealing with the complexity of large parameter spaces. These traditional methods often require iterative processes that can be computationally expensive and time-consuming. However, ANNs, once trained, can generate solutions quickly and with high accuracy.
The dataset used in this context is based on numerical algorithms and synthesis techniques, including Taguchi, SQP, Dolph-Chebyshev, and PSO. These methods are well established in antenna array design for optimizing radiation patterns, but in this paper, the focus is specifically on the synthesis of antenna arrays using the Taylor method. The Taylor method allows for the generation of optimal phase distributions and array element positions, leading to highly efficient antenna designs. By integrating this method with the power of neural networks, this approach aims to further enhance the synthesis process and improve overall array performance.
To bridge the analytical synthesis and neural optimization components of our approach, a visual representation of the workflow is introduced below.
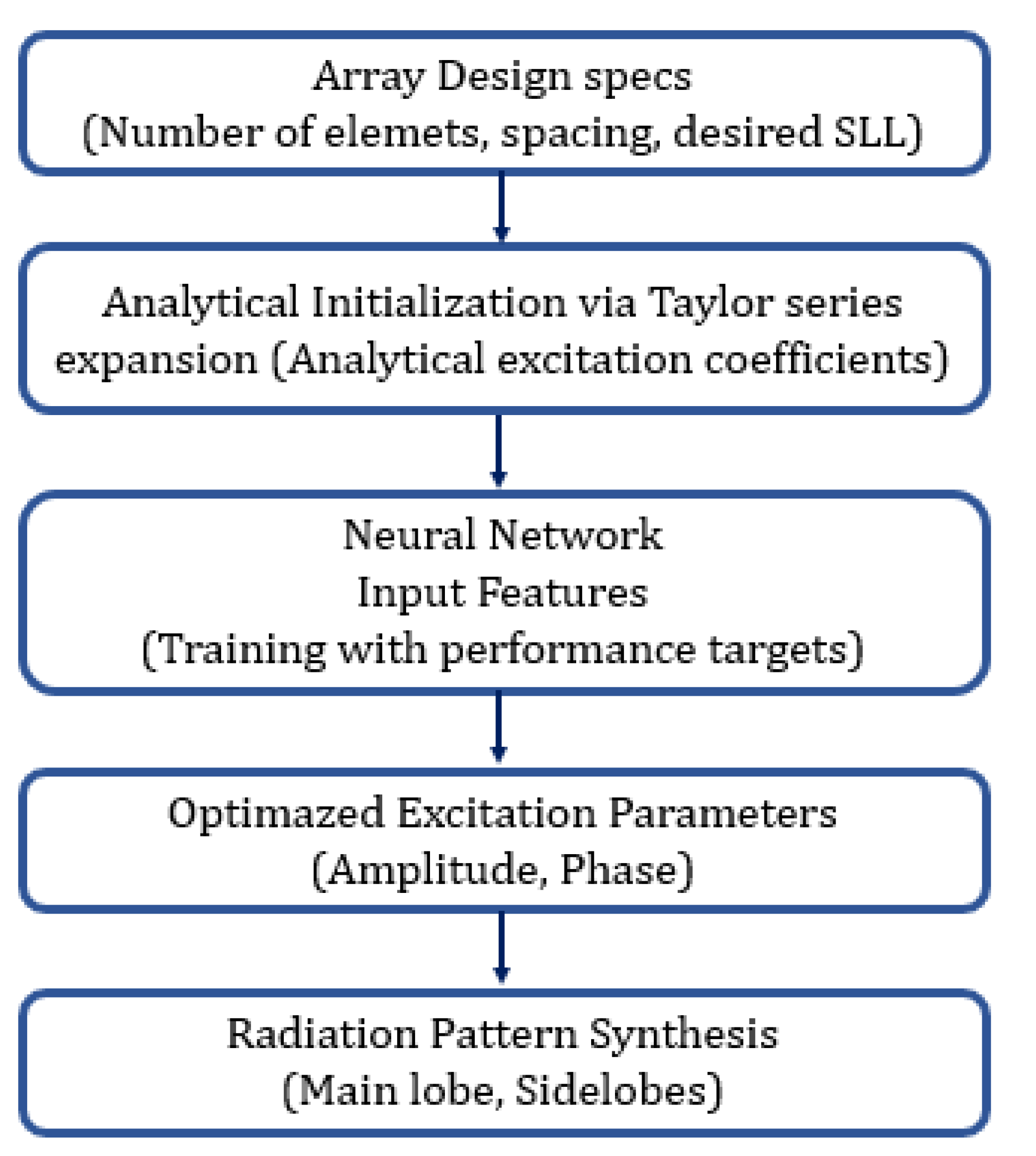
To facilitate a clearer understanding of the proposed hybrid approach,
Figure 27 presents a flowchart illustrating the interaction between the Taylor series expansion and the neural network. This schematic outlines the sequential process beginning with array design specifications, followed by the analytical initialization of excitation coefficients via the Taylor method. These coefficients are then used as input features for the neural network, which optimizes the excitation parameters based on predefined performance targets such as sidelobe level and beam direction. The result is an enhanced radiation pattern synthesis that integrates both analytical modeling and learning-based refinement. This visual representation helps clarify the modular structure of the framework and emphasizes the complementarity between deterministic and data-driven components.
5.1. Taylor–Neural Network Architectures
Taylor–Neural Network architectures combine the advantages of the Taylor method with the learning capabilities of neural networks to optimize antenna array designs. This hybrid approach allows for a more efficient synthesis of radiation patterns by leveraging the strengths of both techniques. Below is a detailed exploration of their interaction.
Figure 28 illustrates the architecture of the Taylor-neural network. This figure presents a schematic representation of how the Taylor series expansion is integrated with the neural network model. It likely shows the layers, nodes, and activation functions used within the network, as well as how the Taylor series is applied to enhance the network’s ability to model complex patterns or solve specific problems. This architecture may be used for applications such as pattern recognition, signal processing, or optimization tasks, where the combination of Taylor series and neural networks provides an efficient method for approximation and learning. The Taylor method is a widely used technique for antenna array synthesis, particularly in phased arrays, where it aims to control the radiation pattern by optimizing the phase distribution across the antenna elements. The method involves using Taylor series expansion to define the phase distribution
, which dictates the desired radiation pattern in a specific direction.
The phase distribution for a uniformly spaced linear array with
N elements and a desired radiation pattern can be expressed as follows:
where
is the angle of observation;
are the Taylor-series coefficients;
M is the order of the Taylor expansion;
is the central angle where the main lobe is located.
The Taylor method allows for controlling the main lobe width and sidelobe levels by adjusting the values of the coefficients . For instance, the coefficients can be adjusted to minimize sidelobes or create a specific shape for the main lobe, depending on the application.
Although the Taylor method is effective in many cases, it involves limitations, especially when dealing with complex antenna array designs that involve multiple constraints such as non-uniform spacing, irregular element distributions, or specific performance goals. These constraints make it difficult to achieve optimal results using the Taylor method alone.
Furthermore, the Taylor method does not account for nonlinearities in real-world systems or the interactions between different antenna elements, which could lead to suboptimal performance in practical applications.
Neural networks can address these limitations by learning complex, nonlinear relationships between the input parameters (such as element positions, excitation amplitudes, etc.) and the desired output (such as radiation patterns). By using a training dataset of antenna configurations and their corresponding radiation patterns, the neural network can learn the optimal configuration for the antenna array.
A feed-forward neural network for antenna array optimization can be formulated as follows:
where
y is the output (the optimized radiation pattern or phase distribution);
is the input vector containing parameters such as element positions, excitation amplitudes, and other design factors;
represents the weights of the network, and
b is the bias term.
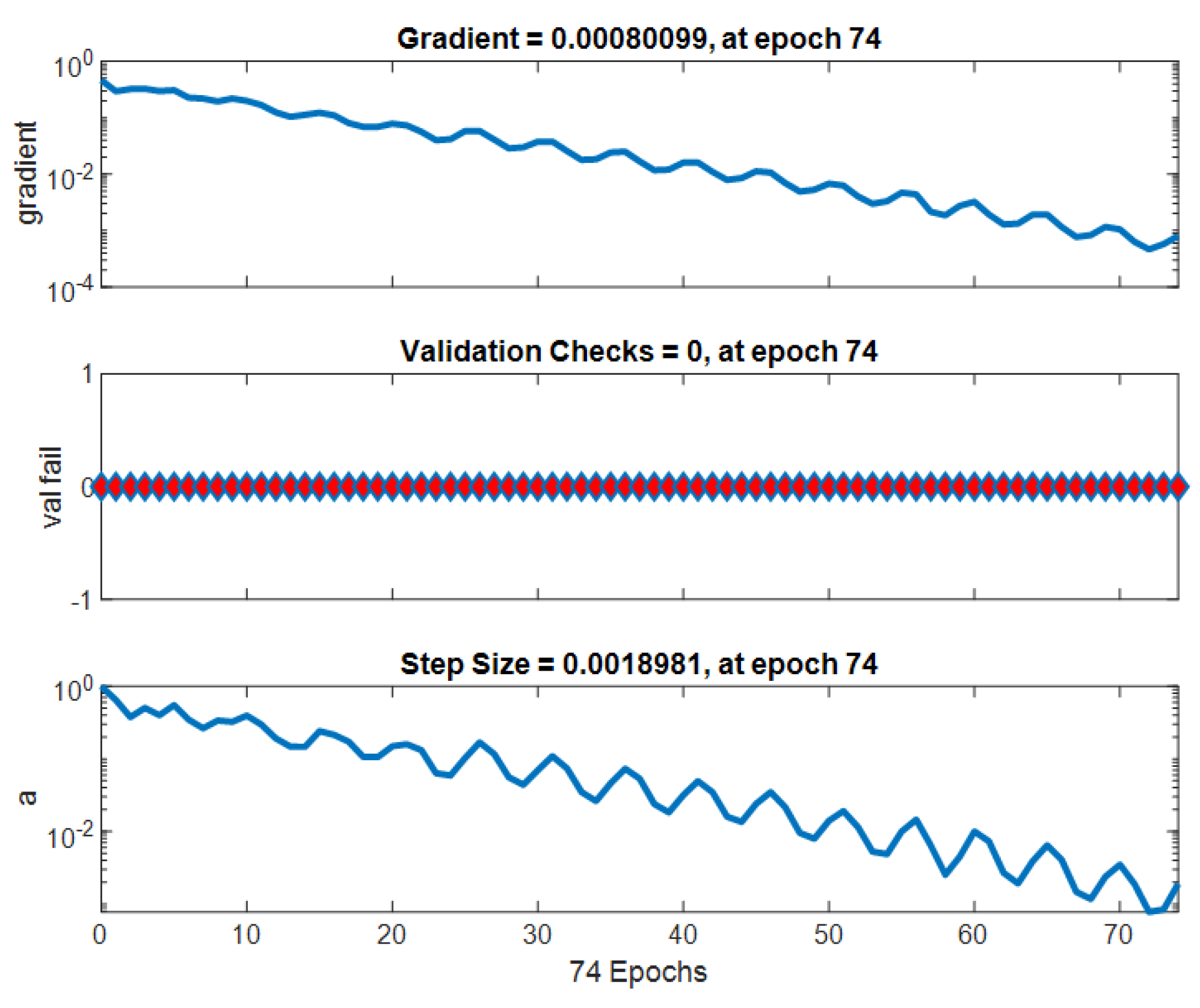
The network is trained to minimize a loss function that measures the difference between the desired radiation pattern and the output produced via the network. A feedforward, fully connected neural network was used, consisting of three hidden layers with 64, 32, and 16 neurons, respectively. ReLU activation was applied to all hidden layers, while the output layer used a linear activation function. The network inputs include initial Taylor-based excitation values and a steering angle, and the outputs correspond to optimized excitation weights. The model was trained using the Adam optimizer with a learning rate of and mean squared error loss. A dataset of 1000 samples was synthetically generated by varying array parameters and desired pattern characteristics. A validation set of 200 samples was used, and training was stopped after 74 epochs based on the convergence of validation loss.
In the hybrid Taylor–neural network architecture, the neural network is integrated with the phase distribution generated via the Taylor method. The Taylor method provides an initial phase distribution, , which is then refined and optimized by the neural network.
Let the phase distribution generated via the Taylor method be denoted as
, which serves as an input to the neural network:
The neural network adjusts the phase distribution by fine-tuning the excitation parameters or array configurations to achieve the desired radiation pattern while satisfying multiple constraints. This could include minimizing sidelobes, improving directivity, or optimizing element positions.
The training process involves optimizing the weights
and bias
b to minimize the loss function, typically defined as the squared error between the desired output
and the network’s output
:
where
N is the number of training samples.
5.2. Benefits of the Taylor-Neural Network Architecture
The integration of Taylor-series phase synthesis with neural network optimization offers a powerful solution to improve antenna array performance. This hybrid approach effectively reduces sidelobe levels, shapes the main beam, and enhances overall directivity. While the Taylor method provides a mathematically grounded initial phase distribution, it faces limitations in handling practical constraints such as irregular element spacing or varying antenna geometries. Neural networks complement this by learning from data and adapting to complex design conditions, including those affected by environmental factors or hardware imperfections. Compared to traditional methods like genetic algorithms (GAs) or particle swarm optimization (PSO), neural networks require less computational time once trained and can rapidly adjust excitation parameters to meet performance targets. Moreover, their ability to generalize allows them to be used across different array configurations, including MIMO antennas, radar systems, and satellite platforms, making the approach versatile and scalable.
The hybrid Taylor–neural network approach can be summarized as follows:
where
is the optimized phase distribution;
f represents the neural network optimization function;
and b are the weights and biases of the neural network;
are the Taylor-series coefficients for phase distribution.
The Taylor–neural network architecture provides a robust framework for optimizing antenna array designs, combining the mathematical precision of the Taylor method with the adaptability and learning power of neural networks. This hybrid approach enables efficient, high-performance antenna array synthesis capable of meeting the stringent demands of modern communication systems.
The Taylor method for antenna array synthesis is a well-established approach used to optimize the distribution of the array’s element amplitudes in order to achieve a desired radiation pattern, such as minimizing side lobes while maintaining the main lobe characteristics. This method involves solving an optimization problem to determine the appropriate excitation levels for each element in the array, ensuring that the synthesized radiation pattern meets specific requirements. The Taylor method is widely used for controlling side lobe levels in antenna arrays, providing a smooth, continuous pattern that reduces interference from unwanted directions.
When applying neural networks to this problem, the Taylor method can be combined with machine learning techniques to enhance the process of optimizing the antenna array design. In this context, neural networks can learn from a dataset that includes different configurations of antenna arrays and their corresponding radiation patterns. The neural network is trained to recognize the relationship between the array’s excitation parameters and the resulting radiation pattern, improving its ability to predict and optimize array designs. The dataset used for training typically contains both the array configurations (as input features) and their associated radiation patterns (as target outputs). Through this approach, the neural network can generalize and efficiently identify optimal solutions for antenna array synthesis, reducing the computational cost and time required compared to traditional methods.
In essence, by using the Taylor method as a dataset, neural networks can become an effective tool for synthesizing antenna arrays, automating the design process, and optimizing performance in terms of radiation pattern control and interference management.
Table 3 compares various neural network training algorithms and their performance characteristics. The Levenberg–Marquardt (LM) algorithm is known for its high convergence rate, making it efficient in reaching an optimal solution quickly. The BFGS Quasi-Newton (BFG) algorithm also offers fast convergence, while resilient backpropagation (RP) is robust to noise, performing well even with inconsistent data. Bayesian regularization (BR) is particularly effective for small datasets, preventing overfitting. The Scaled Conjugate Gradient (SCG) algorithm is memory-efficient, making it suitable for large-scale problems. Conjugate Gradient with Powell/Beale Restarts (CGB) offers balanced performance, providing a trade-off between speed and accuracy, while Fletcher–Powell Conjugate Gradient (CGF) ensures stable convergence. Polak–Ribiére Conjugate Gradient (CGP) excels with sparse data, handling many zero values efficiently. The One-Step Secant (OSS) algorithm is known for its fast convergence, while Variable Learning Rate Backpropagation (GDX) adapts its learning rate during training for improved performance. Basic gradient descent (GD) is simple and easy to implement but may not converge as efficiently, whereas gradient descent with momentum (GDM) accelerates convergence by incorporating momentum, helping avoid local minima. Each algorithm offers specific advantages, and the choice depends on factors like data size, speed, and memory constraints.
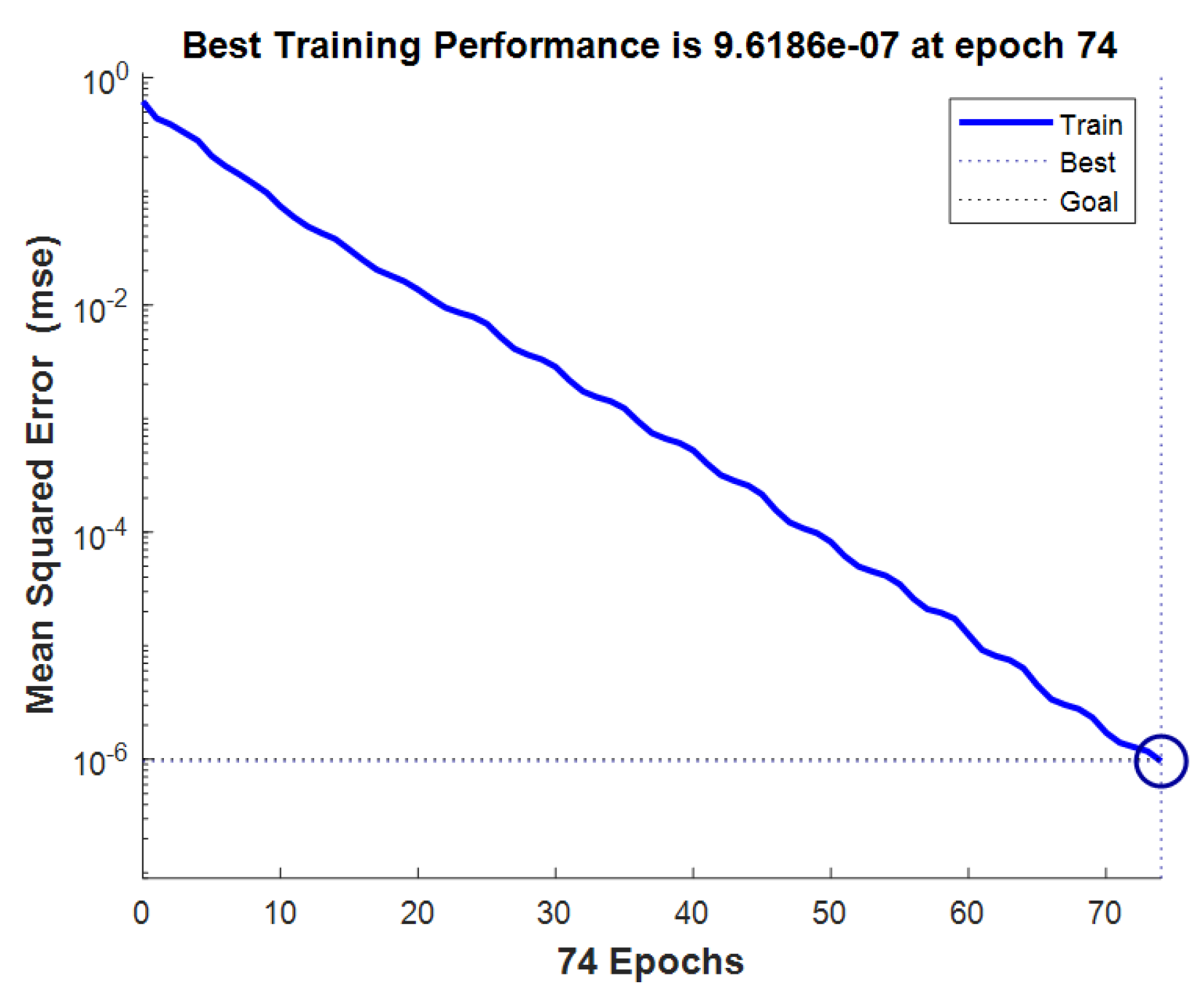
Figure 29 shows the progress of the Taylor neural network training at epoch 74. At this stage, the performance goal has been achieved, meaning the model has converged to an optimal solution according to the specified performance criteria. This suggests that the training process has effectively adjusted the model’s parameters to meet the desired objectives, with a significant reduction in error over the iterations. This figure could also represent the convergence curve, showing the decrease in the cost function or error during the training iterations.
Figure 30 illustrates the evolution of the mean squared error (MSE) for the Taylor neural network. MSE is a key indicator of model quality, measuring the difference between predicted values and actual values. A low MSE indicates good performance, as it shows that the model’s predictions are close to the expected results. This figure likely shows the progressive reduction in the MSE as the neural network learns and adjusts its parameters. A steadily decreasing MSE curve would suggest that the network is effectively converging to a solution with minimal prediction error.
Figure 31 presents the correlation coefficient (
R) achieved with the Taylor neural network, which is 0.99999. Such a high correlation coefficient indicates an extremely strong relationship between the predicted values and the actual values. In other words, the model’s predictions are almost identical to the expected results. This level of performance is exceptional and suggests that the model is very well fitted to the training data. A correlation of 0.99999 indicates that the model has learned with great accuracy, which is a strong indicator of the quality of the training and the model’s ability to generalize to new data.
The training process was stopped at epoch 74, where the network reached convergence with minimal loss variation and no further improvement in validation performance, ensuring both efficiency and generalization.
Compared to conventional synthesis approaches, the proposed Taylor–NN method offers a favorable balance between accuracy and computational cost. While methods like PSO and GA require iterative population-based optimization and may take several seconds to converge, the trained neural network provides near-instantaneous inference with high fidelity to the target pattern.
Table 4 summarizes these aspects across several popular techniques.
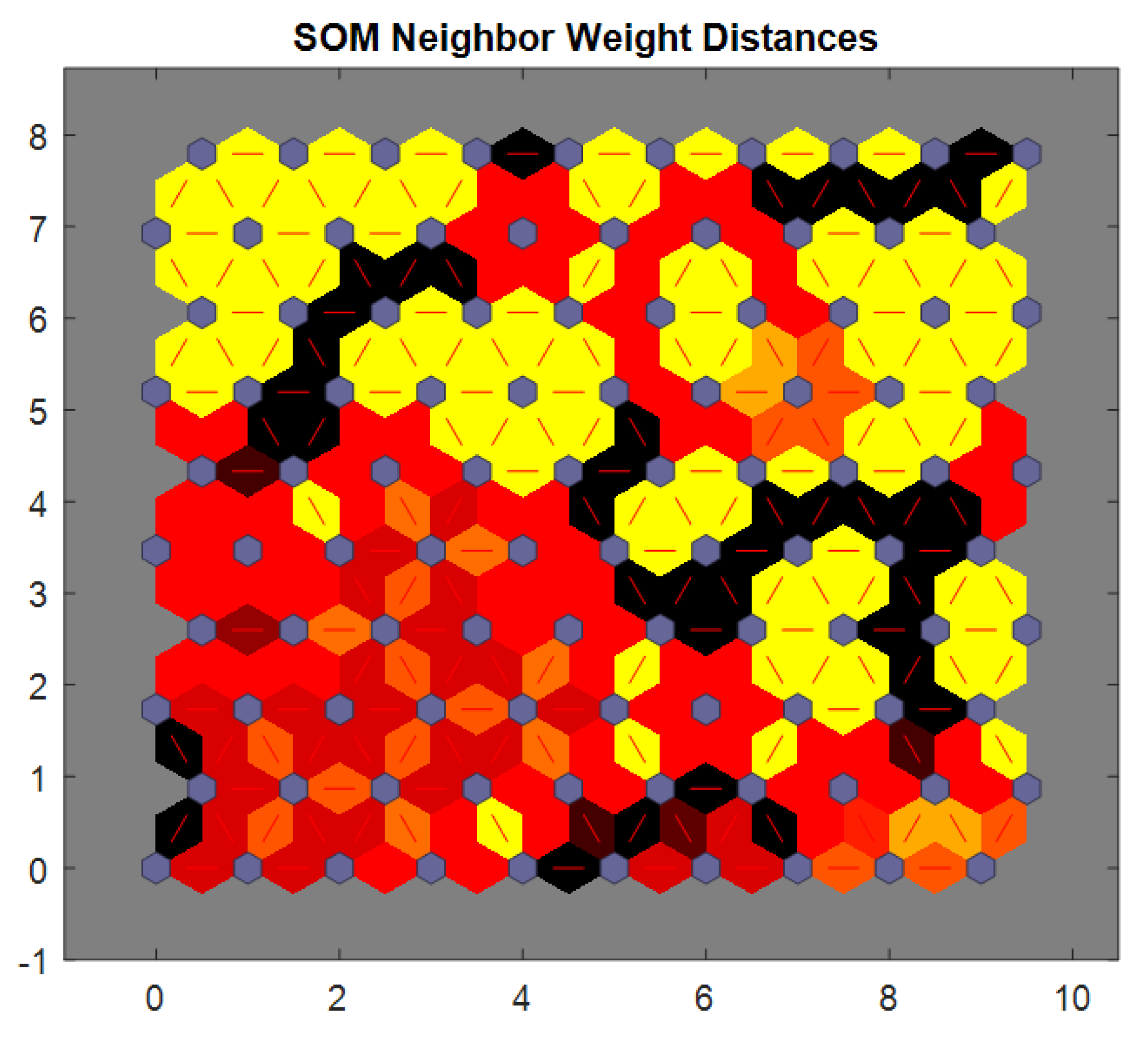
Figure 32 illustrates the SOM (self-organizing map) neighbor weight distances. The SOM is a type of unsupervised neural network used for clustering and dimensionality reduction. In this figure, the distances between the weight vectors of neighboring neurons in the SOM are represented. Each neuron in the SOM has an associated weight vector that represents the characteristics of the data points it maps to. The distances between these weight vectors indicate how similar or different the neurons are in terms of the data they represent. A smaller distance between two neurons suggests that the data points associated with those neurons are similar to each other, while a larger distance indicates greater dissimilarity. This figure likely shows a heatmap or a color-coded representation of the weight distances, where the colors represent the magnitude of the distances. A well-organized SOM would show smaller distances between neurons that are closer to each other on the map, indicating good clustering of similar data points. This figure is crucial for evaluating how the SOM algorithm has grouped the data and how well the structure of the dataset has been captured.
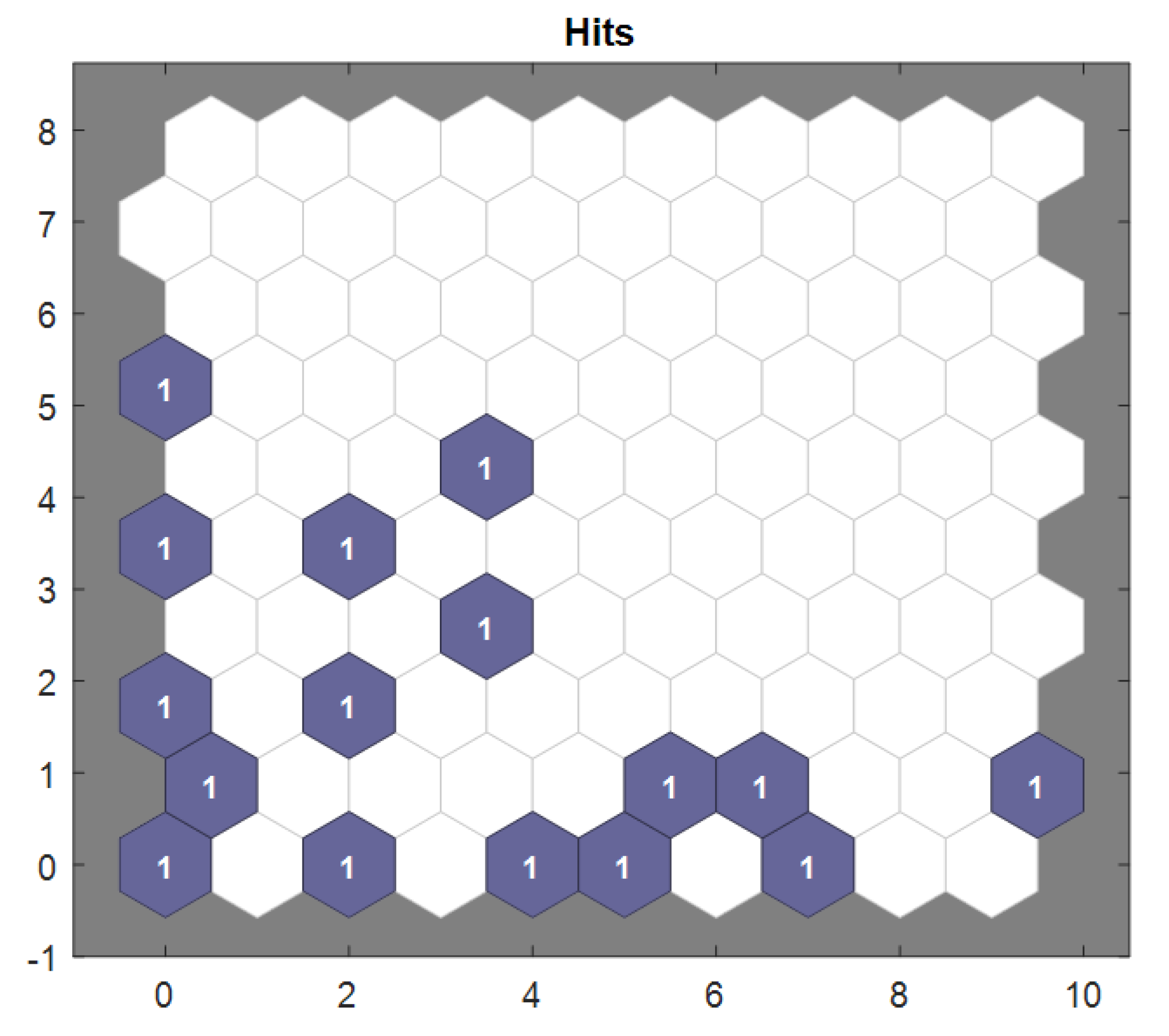
Figure 33 presents the sample hits for the Taylor method dataset. Sample hits refer to the number of data points that have been mapped to each individual neuron in the SOM. In this context, the figure shows a visualization of how frequently each neuron has been activated via the input samples. A high number of hits for a particular neuron indicates that the neuron has been frequently activated via similar data points, suggesting that the neuron represents a dense region or cluster of the dataset. Conversely, a neuron with fewer hits may represent a region in the dataset that is sparsely populated or less representative of the overall data distribution. This figure helps assess the distribution of data across the SOM grid, with areas of the map that have a high number of hits corresponding to well-represented regions of the data. The distribution of hits across the map also reveals how well the SOM has managed to generalize the data into different regions, providing insights into the quality of the clustering. A uniform distribution of hits would indicate a balanced representation of the dataset, whereas a skewed distribution could suggest that some regions of the data are underrepresented or overrepresented in the map. Please refer to the
Appendix A for detailed data.
In addition to the benefits discussed above, scalability and future application domains must also be considered. While the current study validates the proposed framework on a 16-element linear array operating at mmWave frequencies (28.14 GHz and 37.88 GHz), the architecture is designed to be scalable and adaptable to more complex configurations, including arrays with 64 elements or more. At such scales, mutual coupling, nonlinear interactions, and hardware-induced uncertainties become more pronounced. These effects can be addressed in future work by incorporating domain-specific mitigation strategies—such as inter-element spacing adjustments, electromagnetic decoupling techniques, or the use of engineered metasurfaces—into the neural network’s training dataset. Furthermore, we aim to extend the applicability of this approach to THz-band antenna arrays, where fabrication tolerances, material dispersion, and surface-wave effects require more intricate modeling. By retraining the network with simulation or measurement-based data that reflect these challenges, the proposed method has the potential to remain robust across a wide range of real-world deployment scenarios.
Beyond scalability, we also recognize that the current focus on uniform linear arrays may limit the generalization of the method to more complex array geometries. Many practical applications involve non-linear configurations, such as conformal, sparse, or irregular arrays—especially in aerospace, vehicular, and satellite systems. While the linear assumption facilitates analytical modeling and initial validation, the proposed Taylor–neural network framework is not intrinsically constrained by geometry. Future developments will extend the approach by incorporating geometric position encodings and training on synthetic datasets representing diverse topologies. These adaptations will enable the model to handle non-uniform or platform-integrated arrays with varying curvature and element spacing. We have explicitly outlined this limitation in the revised manuscript and defined it as a key direction for future research.



 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}