




Machine Learning Based Recommendation System for Web-Search Learning

 ,
,  , , ,
, , ,
Abstract
1. Introduction
- Setting the learning objectives and goals.
- Locating and searching for the information through search engines and accessing the required information in the desired forms such as text, image, and video.
- Resources or information evaluation from the online resources accessed.
- Information processing and knowledge integration with other online resources.
- Synthesis and knowledge representation after the learning phase.
- To analyze the usage of these formats, some of the learner’s characteristics, such as the page or link navigations, learner eye movements, and language markup of traversed resources, are recorded during the simulation.
- To record the search time for the specific format. The proposed model automatically analyzes the learners’ interests while searching online and analyzes the origin of the acquired and the information learned online. This research performs text content mapping and video content.
- To analyze the efficiency of the eye tracker and to measure the characteristics of the learners—pupil dilation, visual blinking, eye movements, gazing point, visual attention of engaging and ignoring.
2. Literature Review
3. Materials and Methods
3.1. Novelty of the Proposed Model
- Evaluate and analyze the learner’s knowledge acquisition through the core operations, obtaining better measures using cluster-based recommendations.
- Store the complete track of online resources that are visited.
- Define the mapping between the information that has been newly learned to resources processing, using sensors.
- Store the sequence of words that the learners had learned online.
- Apply the video transcripts to keep track of the words visited through online videos.
- Analyze the overlapping between the traversed words and the recalled data.
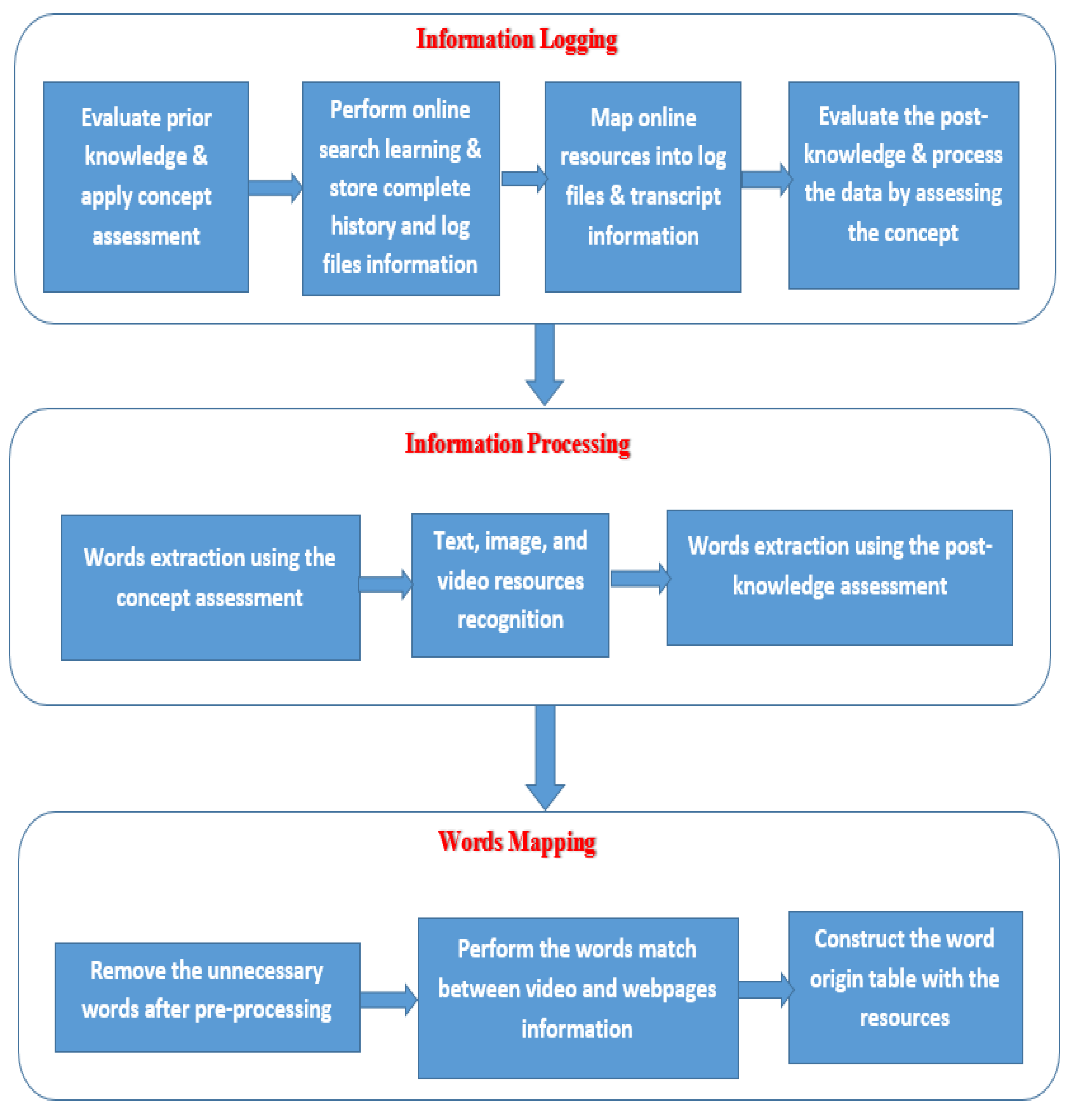
3.2. Architecture of the Proposed Model
| Algorithm 1: Proposed Model—Resources Processing |
| 1: Data or information logging 1.1 Evaluate prior knowledge. 1.2 Perform online search learning. 1.3 Map online resources into log files and transcript information. 1.4 Evaluate the post-knowledge. 2: Processing the data or information. 2.1 Extract the words using the concept assessment. 2.2 Use the software to recognize the text, image, and video resources. 2.3 Extract the words using the post-knowledge assessment. 3: Define the mapping operation. 3.1 Remove the unnecessary words after preprocessing. 3.2 Perform the word match between video and webpages information. 3.3 Construct the word origin table with the resources. |
3.3. Datasets and Learners’ Information
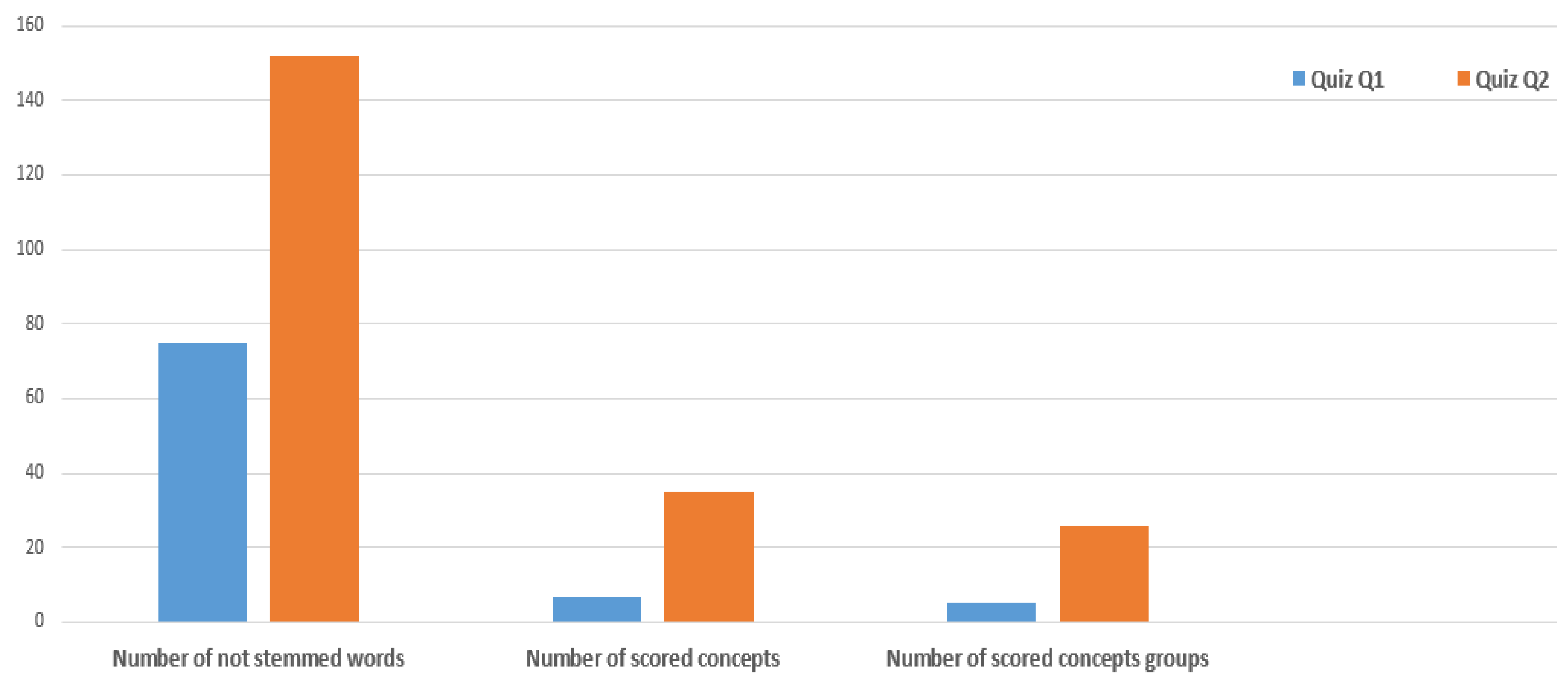
3.4. Learner’s Task and Information Processing
3.5. Mapping Operation
3.6. New Recommendation Model
| Algorithm 2: New clustered intelligent CF |
| Inputs: learner dataset, learner x, S, 1: Input the learner’s rating information from the learner’s dataset and items. 2: Split the knowledge requirements of the learners from the datasets. 3: Evaluate linear cluster operation to find out the knowledge requirements for every partition and bring better requirements from the table. 4: Apply every learner y available in the learner dataset with y ≠ x in every cluster partition: 5: Evaluate using items separation for the learners x and y. 6: Calculate r using (1) 7: Sort the learners reversely based on Equation (1). 8: Separate elements from List and update S. 9: Update the learner’s similar requirements in every partition. 10: Calculate such that j using (2) 11: Sort from Equation (2) in every partition, find the overall prediction rating for all items not rated. 12: Update the list from all partitions and select a better choice from the database evaluation. 13: Separate entries and update L. |
4. Results and Discussion
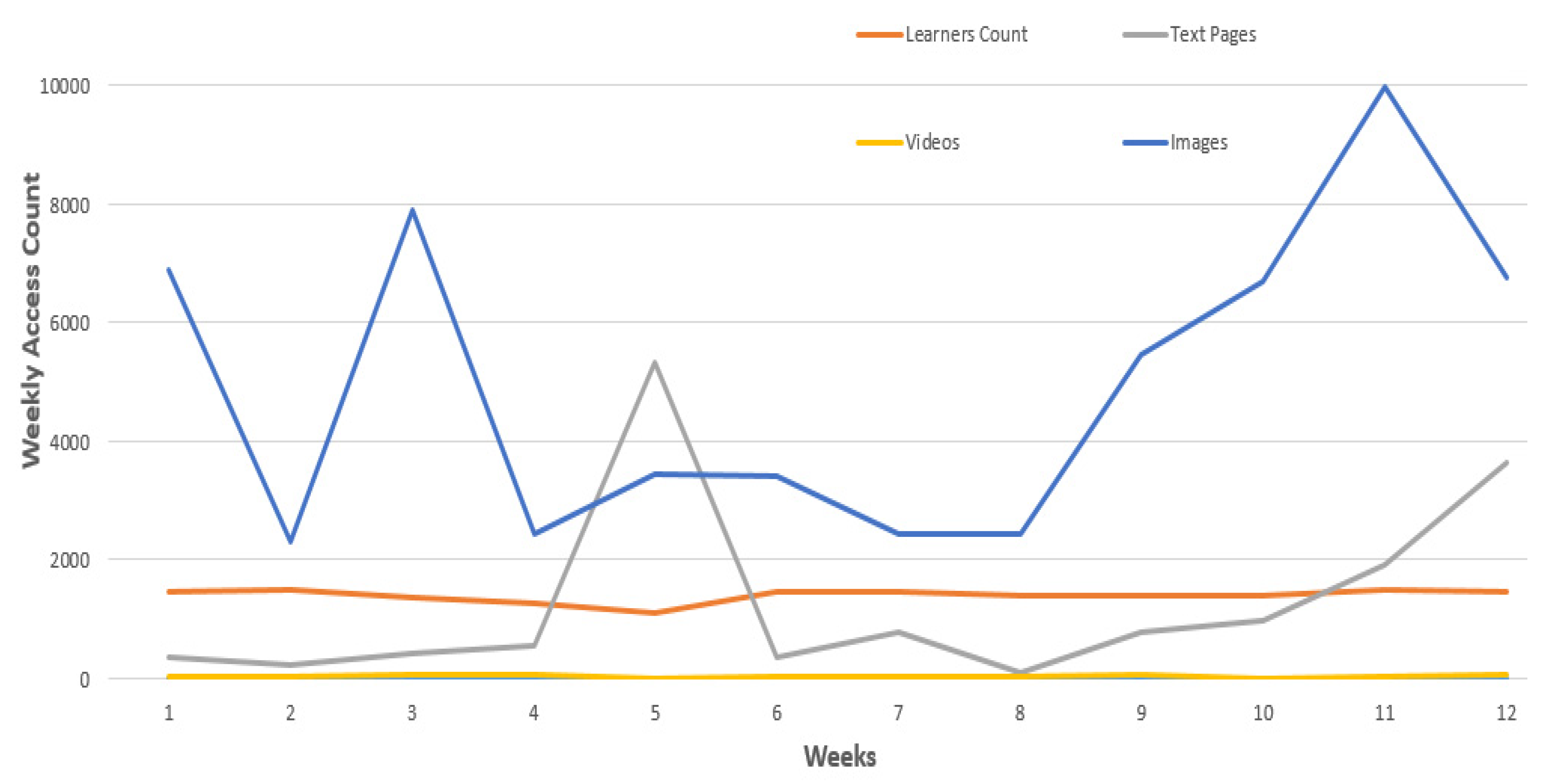
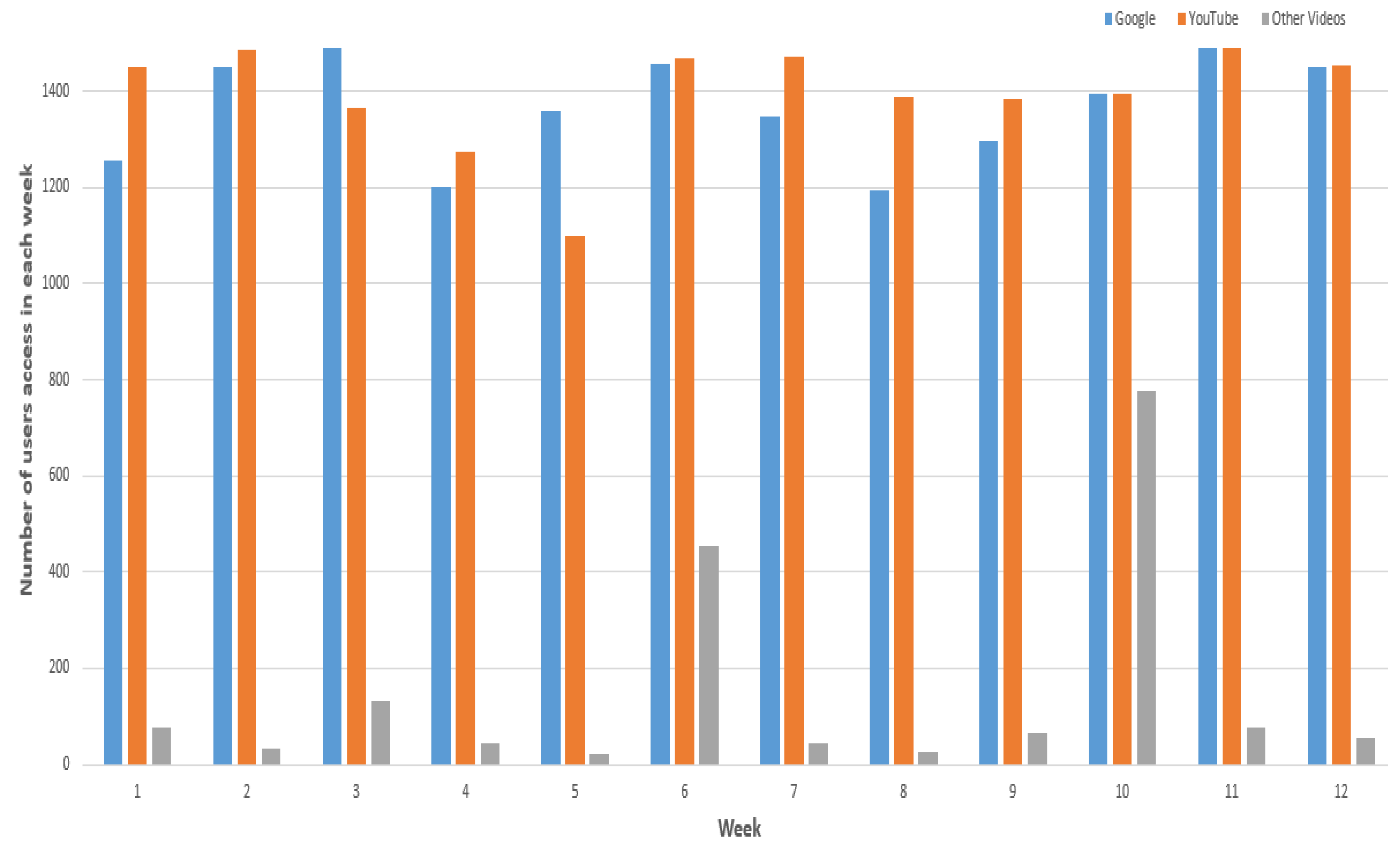
4.1. Access to Online Resources
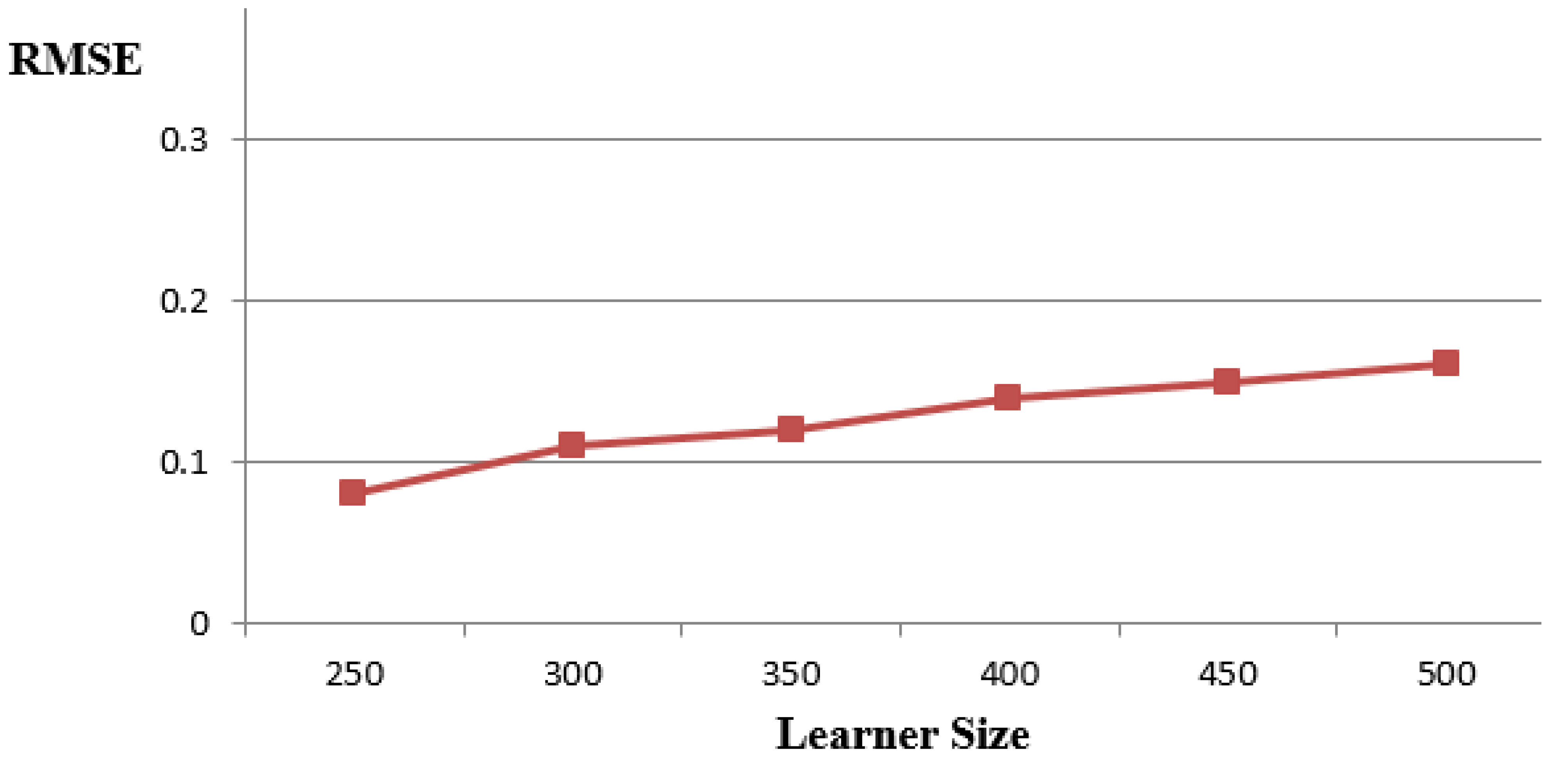
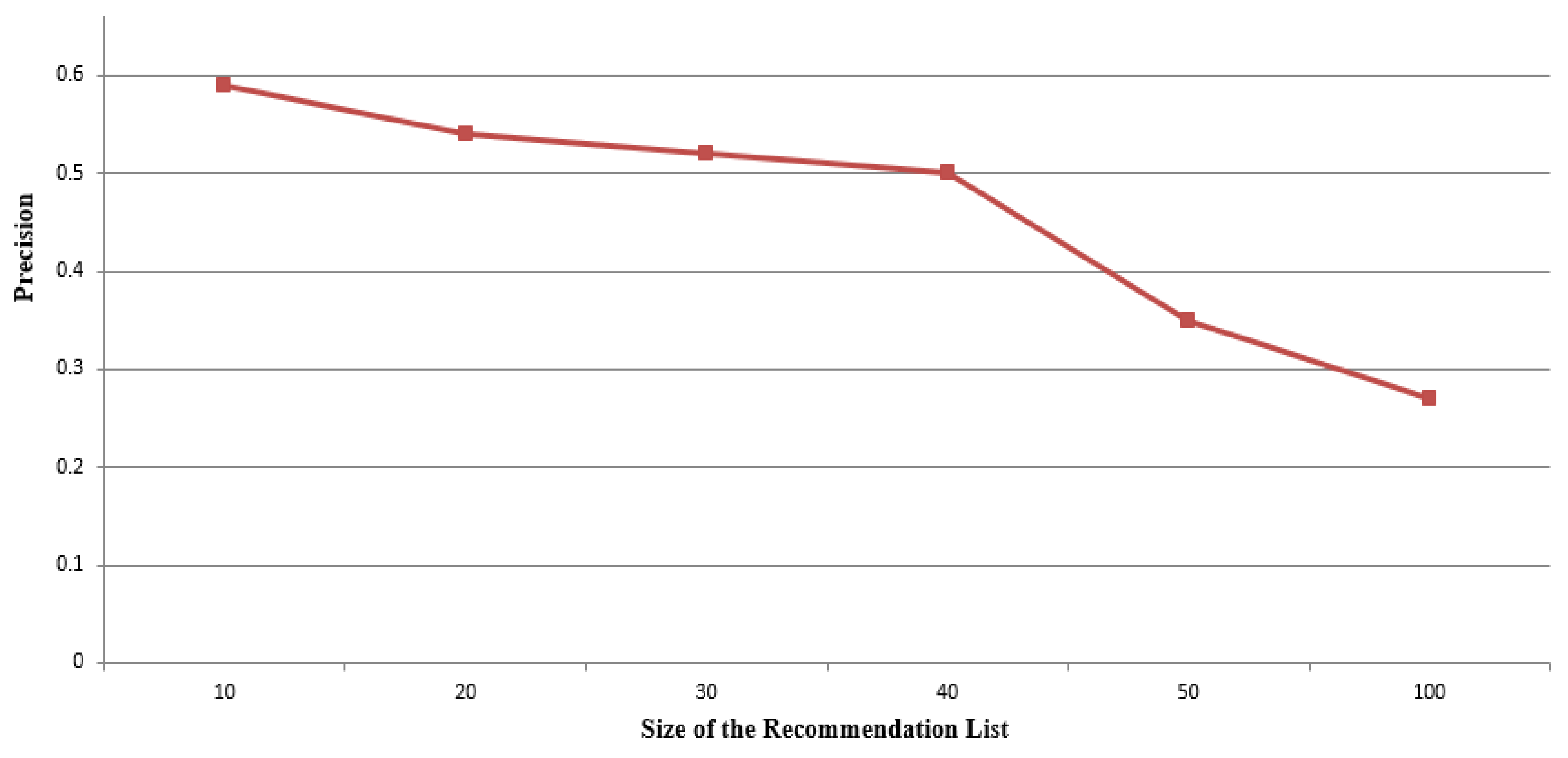
4.2. Recommender Model Analysis
4.3. Eye Tracker Efficiency Analysis
- The technology implemented in the eye tracker software measures the learners’ characteristics—pupil dilation, visual blinking, eye movements, gazing point, and visual attention of engaging and ignoring.
- The accuracy of the eye tracker is less than 0.5° in the controlled environments, with the actual gaze point offset frequently by at least 1°. The gazing point is sampled at different rates.
- The standard frame rate lies (60 Hz, 500 Hz) images per second. The frame rate of the web camera lies (5 Hz, 30 Hz).
- The learner’s performance in answering the questions is also analyzed. The repetition of gazing in choosing some options is a wavering characteristic of the learners when they are confused about choosing the option. The system predicted that 12% of the learners had the wavering characteristic, in which 7% of the learners failed to choose the correct option, and 5% chose the right option.
- The learner’s knowledge acquisition is evaluated as 88% ground truth responses and 12% underperformance.
- The learner’s engagement and findability characteristics in solving quizzes are analyzed as follows: 84% of the quick response learners, 16% of the learners are gazed or uninterested.
- The average response times of the simulation are observed as follows: choosing correct options (selectivity) 2.5 min, and choosing incorrect options lies 3 to 5 min. Sensitivity: 87% of the learners sensed the suitable options, 8% showed inattentional blindness, and 5% of the learners with had wavering gaze characteristics.
- The proposed model’s overall expected eye tracking or eye movement percentage in web-search learning is 88%.
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Brand-Gruwel, S.; Kammerer, Y.; van Meeuwen, L.; van Gog, T. Source evaluation of domain experts and novices during Web search. J. Comput. Assist. Learn. 2017, 33, 234–251. [Google Scholar] [CrossRef]
- Brand-Gruwel, S.; Wopereis, I.; Vermetten, Y. Information problem solving by experts and novices: Analysis of a complex cognitive skill. Comput. Hum. Behav. 2005, 21, 487–508. [Google Scholar] [CrossRef]
- Brand-Gruwel, S.; Wopereis, I.; Walraven, A. A descriptive model of information problem solving while using internet. Comput. Educ. 2009, 53, 1207–1217. [Google Scholar] [CrossRef]
- Feierabend, S.; Rathgeb, T.; Kheredmand, H.; Glöckler, S. JIM-Studie 2020: Jugend, Information, Medien: Basisuntersuchung zum Medienumgang 12- bis 19-Jähriger in Deutschland [JIM-Study 2020: Youth, Information, Media: Basic Study on Media Use by 12- to 19-Year-Olds in Germany]. Medienpädagogischer Forschungsverbund Südwest. 2020. Available online: https://www.mpfs.de/fileadmin/files/Studien/JIM/2020/JIM-Studie-2020_Web_final.pdf (accessed on 1 December 2022).
- Koch, W.; Beisch, N. Ergebnisse der ARD/ZDF-Onlinestudie 2020: Erneut Starke Zuwächse bei Onlinevideo [Results of the ARD/ZDF Online Study 2020: Again Large Growth in Online Video]. Media Perspektiven, 9/2020, 482–500. Available online: https://www.ardwerbung.de/fileadmin/user_upload/media-perspektiven/pdf/2020/0920_Koch_Beisch_Korr_30-11-20.pdf (accessed on 1 December 2022).
- Singh, P.; Ahuja, S.; Jaitly, V.; Jain, S. A framework to alleviate common problems from recommender system: A case study for technical course recommendation. J. Discret. Math. Sci. Cryptogr. 2020, 23, 451–460. [Google Scholar] [CrossRef]
- Gupta, R.D.; Madhukar, M. Operational Challenges in Online Self-Learning Education Adoption. In Proceedings of the 2021 6th International Conference on Signal Processing, Computing and Control (ISPCC), Solan, India, 7–9 October 2021; pp. 51–55. [Google Scholar] [CrossRef]
- Fan, H.; Du, W.; Dahou, A.; Ewees, A.; Yousri, D.; Elaziz, M.; Elsheikh, A.; Abualigah, L.; Al-Qaness, M. Social Media Toxicity Classification Using Deep Learning: Real-World Application UK Brexit. Electronics 2021, 10, 1332. [Google Scholar] [CrossRef]
- Khoshaim, A.B.; Moustafa, E.B.; Bafakeeh, O.T.; Elsheikh, A.H. An Optimized Multilayer Perceptrons Model Using Grey Wolf Optimizer to Predict Mechanical and Microstructural Properties of Friction Stir Processed Aluminum Alloy Reinforced by Nanoparticles. Coatings 2021, 11, 1476. [Google Scholar] [CrossRef]
- Delgado, P.; Anmarkrud, Ø.; Avila, V.; Altamura, L.; Chireac, S.M.; Pérez, A.; Salmerón, L. Learning from text and video blogs: Comprehension effects on secondary school students. Educ. Inf. Technol. 2021, 27, 5249–5275. [Google Scholar] [CrossRef]
- Gerjets, P.; Kammerer, Y.; Werner, B. Measuring spontaneous and instructed evaluation processes during web search: Integrating concurrent thinking-aloud protocols and eye-tracking data. Learn. Instr. 2011, 21, 220–231. [Google Scholar] [CrossRef]
- Gerjets, P.; Scheiter, K.; Opfermann, M.; Hesse, F.W.; Eysink, T.H. Learning with hypermedia: The influence of representational formats and different levels of learner control on performance and learning behavior. Comput. Hum. Behav. 2009, 25, 360–370. [Google Scholar] [CrossRef]
- List, A. Strategies for comprehending and integrating texts and videos. Learn. Instr. 2018, 57, 34–46. [Google Scholar] [CrossRef]
- List, A.; Ballenger, E.E. Comprehension across mediums: The case of text and video. J. Comput. High. Educ. 2019, 31, 514–535. [Google Scholar] [CrossRef]
- Tarchi, C.; Zaccoletti, S.; Mason, L. Learning from Text, Video, or Subtitles: A Comparative Analysis. Comput. Educ. 2020, 160, 104034. [Google Scholar] [CrossRef]
- Câmara, A.; Roy, N.; Maxwell, D.; Hauff, C. Searching to Learn with Instructional Scaffolding. In Proceedings of the 2021 Conference on Human Information Interaction and Retrieval, Canberra, Australia, 14’19 March 2021; Scholer, F., Thomas, P., Elsweiler, D., Joho, H., Kando, N., Smith, C., Eds.; ACM: New York, NY, USA, 2021; pp. 209–218. [Google Scholar] [CrossRef]
- Kalyani, R.; Gadiraju, U. Understanding user search behavior across varying cognitive levels. In Proceedings of the 30th ACM Conference on Hypertext and Social Media, New York, NY, USA, 17–20 September 2019; ACM: New York, NY, USA, 2019; pp. 123–132. [Google Scholar] [CrossRef]
- Kammerer, Y.; Brand-Gruwel, S.; Jarodzka, H. The Future of Learning by Searching the Web: Mobile, Social, and Multimodal. Front. Learn. Res. 2018, 6, 81–91. [Google Scholar] [CrossRef]
- Knight, S.; Rienties, B.; Littleton, K.; Mitsui, M.; Tempelaar, D.; Shah, C. The relationship of (perceived) epistemic cognition to interaction with resources on the internet. Comput. Hum. Behav. 2017, 73, 507–518. [Google Scholar] [CrossRef]
- Liu, J.; Cole, M.J.; Liu, C.; Bierig, R.; Gwizdka, J.; Belkin, N.J.; Zhang, J.; Zhang, X. Search behaviors in different task types. In Proceedings of the ACM International Conference on Digital Libraries, New York, NY, USA, 21–25 June 2010; Hunter, J., Lagoze, C., Giles, L., Li, Y.-F., Gwizdka, J., Belkin, N.J., Eds.; ACM: New York, NY, USA; pp. 69–78. [Google Scholar] [CrossRef]
- Marenzi, I.; Zerr, S. Multiliteracies and Active Learning in CLIL—The Development of LearnWeb2.0. IEEE Trans. Learn. Technol. 2012, 5, 336–348. [Google Scholar] [CrossRef]
- Roy, N.; Moraes, F.; Hauff, C. Exploring users’ learning gains within search sessions. In Proceedings of the 2020 Conference on Human Information Interaction and Retrieval; ACM: New York, NY, USA, March, 2020; pp. 432–436. [Google Scholar] [CrossRef]
- Tibau, M.; Siqueira, S.W.; Nunes, B.P.; Bortoluzzi, M.; Marenzi, I.; Kemkes, P. Investigating Users’ Decision-Making Process While Searching Online and Their Shortcuts towards Understanding, Proceedings of the 2018 International Conference on Web-Based Learning; Hancke, G., Spaniol, M., Osathanunkul, K., Unankard, S., Klamma, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; pp. 54–64. [Google Scholar] [CrossRef]
- Yu, R.; Gadiraju, U.; Holtz, P.; Rokicki, M.; Kemkes, P.; Dietze, S. Predicting user knowledge gain in informational search sessions. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval; ACM: New York, NY, USA, June, 2018; pp. 75–84. [Google Scholar] [CrossRef]
- Muhasin, H.J.; Jabar, M.A.; Abdullah, S.; Kasim, S. Managing Sensitive Data in Cloud Computing For Effective Information Systems’ Decisions. Acta Inform. Malays. 2017, 1, 1–2. [Google Scholar] [CrossRef]
- Zlatkin-Troitschanskaia, O.; Hartig, J.; Goldhammer, F.; Krstev, J. Students’ online information use and learning progress in higher education—A critical literature review. Stud. High. Educ. 2021, 46, 1996–2021. [Google Scholar] [CrossRef]
- Whitelock-Wainwright, A.; Laan, N.; Wen, D.; Gašević, D. Exploring student information problem solving behaviour using fine-grained concept map and search tool data. Comput. Educ. 2019, 145, 103731. [Google Scholar] [CrossRef]
- Salmerón, L.; Sampietro, A.; Delgado, P. Using Internet videos to learn about controversies: Evaluation and integration of multiple and multimodal documents by primary school students. Comput. Educ. 2020, 148, 103796. [Google Scholar] [CrossRef]
- Sverdlyka, Z.; Klynina, T.; Fedushko, S.; Bratus, I. Youtube Web-Projects: Path from Entertainment Web Content to Online Educational Tools. In Developments in Information & Knowledge Management for Business Applications; Studies in Systems, Decision and Control; Kryvinska, N., Greguš, M., Eds.; Springer: Cham, Switzerland, 2022; Volume 421, pp. 491–512. [Google Scholar] [CrossRef]
- Kathuria, M.; Nagpal, C.K.; Duhan, N. Journey of Web Search Engines: Milestones, Challenges & Innovations. Int. J. Inf. Technol. Comput. Sci. 2016, 8, 47–58. [Google Scholar] [CrossRef]
- Ahuja, S.; Kaur, P.; Panda, S.N. Identification of Influencing Factors for Enhancing Online Learning Usage Model: Evidence from an Indian University. Int. J. Educ. Manag. Eng. 2019, 9, 15–24. [Google Scholar] [CrossRef]
- Strzelecki, A. Eye-Tracking Studies of Web Search Engines: A Systematic Literature Review. Information 2020, 11, 300. [Google Scholar] [CrossRef]
- Ullal, M.S.; Nayak, P.M.; Dais, R.T.; Spulbar, C.; Birau, R. Investigating the Nexus Between Artificial Intelligence and Machine Learning Technologies in the Case of Indian Services Industry. Business: Theory Pract. 2022, 23, 323–333. [Google Scholar] [CrossRef]
- Bhaskaran, S.; Marappan, R.; Santhi, B. Design and Comparative Analysis of New Personalized Recommender Algorithms with Specific Features for Large Scale Datasets. Mathematics 2020, 8, 1106. [Google Scholar] [CrossRef]
- Bhaskaran, S.; Marappan, R.; Santhi, B. Design and Analysis of a Cluster-Based Intelligent Hybrid Recommendation System for E-Learning Applications. Mathematics 2021, 9, 197. [Google Scholar] [CrossRef]
- Bhaskaran, S.; Marappan, R. Design and analysis of an efficient machine learning based hybrid recommendation system with enhanced density-based spatial clustering for digital e-learning applications. Complex Intell. Syst. 2021, 1, 1–17. [Google Scholar] [CrossRef]
- Marappan, R.; Bhaskaran, S. Analysis of Recent Trends in E-Learning Personalization Techniques. Educ. Rev. USA 2022, 6, 167–170. [Google Scholar] [CrossRef]
- Marappan, R.; Bhaskaran, S. Analysis of Collaborative, Content & Session Based and Multi-Criteria Recommendation Systems. Educ. Rev. USA 2022, 6, 387–390. [Google Scholar] [CrossRef]
- Marappan, R.; Sethumadhavan, G. Solution to Graph Coloring Using Genetic and Tabu Search Procedures. Arab. J. Sci. Eng. 2017, 43, 525–542. [Google Scholar] [CrossRef]
- Marappan, R.; Sethumadhavan, G. Complexity Analysis and Stochastic Convergence of Some Well-known Evolutionary Operators for Solving Graph Coloring Problem. Mathematics 2020, 8, 303. [Google Scholar] [CrossRef]
- Marappan, R.; Sethumadhavan, G. Solving Graph Coloring Problem Using Divide and Conquer-Based Turbulent Particle Swarm Optimization. Arab. J. Sci. Eng. 2021, 47, 9695–9712. [Google Scholar] [CrossRef]
- Sethumadhavan, G.; Marappan, R. A genetic algorithm for graph coloring using single parent conflict gene crossover and mutation with conflict gene removal procedure. In Proceedings of the 2013 IEEE International Conference on Computational Intelligence and Computing Research, Enathi, India, 26–28 December 2013; pp. 1–6. [Google Scholar] [CrossRef]
- Marappan, R.; Sethumadhavan, G. A New Genetic Algorithm for Graph Coloring. In Proceedings of the 2013 Fifth International Conference on Computational Intelligence, Modelling and Simulation, Seoul, Republic of Korea, 24–25 September 2013; pp. 49–54. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subjects | Learner Size |
|---|---|
| Social Science | 25% |
| English | 10% |
| Mathematics | 15% |
| Management | 20% |
| Computer Science | 30% |
| Subjects | |
|---|---|
| Social Science | μ: 1.78, σ: 1.89 |
| English | μ: 1.12, σ: 1.95 |
| Mathematics | μ: 1.65, σ: 1.76 |
| Management | μ: 1.34, σ: 1.65 |
| Computer Science | μ: 1.92, σ: 1.98 |
| Concept Groups | Quiz Q1 | Quiz Q2 |
|---|---|---|
| CG1 | 56% | 92% |
| CG2 | 52% | 93% |
| CG3 | 65% | 98% |
| CG4 | 72% | 85% |
| CG5 | 25% | 56% |
| CG6 | 36% | 67% |
| CG7 | 61% | 82% |
| CG8 | 12% | 56% |
| CG9 | 25% | 78% |
| CG10 | 32% | 75% |
| CG11 | 41% | 61% |
| CG12 | 47% | 68% |
| Concept Groups | Text | Videos | Overlapping Text or Video | Overall |
|---|---|---|---|---|
| CG1 | 15 | 13 | 8 | 18 |
| CG2 | 7 | 7 | 5 | 12 |
| CG3 | 8 | 8 | 5 | 10 |
| CG4 | 9 | 8 | 4 | 10 |
| CG5 | 12 | 11 | 3 | 12 |
| CG6 | 15 | 14 | 4 | 16 |
| CG7 | 10 | 9 | 3 | 12 |
| CG8 | 12 | 12 | 3 | 12 |
| CG9 | 15 | 14 | 3 | 16 |
| CG10 | 18 | 17 | 4 | 20 |
| CG11 | 20 | 20 | 3 | 25 |
| CG12 | 15 | 15 | 5 | 20 |
| Strategies | Ranking Score | Recall | Precision |
|---|---|---|---|
| CF | 0.592 | 0.253 | 0.023 |
| MDHS | 0.185 | 0.284 | 0.084 |
| UPOD | 0.163 | 0.338 | 0.092 |
| Proposed Method | 0.076 | 0.352 | 0.093 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
M. R. M., V.; Rodriguez, C.; Navarro Depaz, C.; Concha, U.R.; Pandey, B.; S. Kharat, R.; Marappan, R. Machine Learning Based Recommendation System for Web-Search Learning. Telecom 2023, 4, 118-134. https://doi.org/10.3390/telecom4010008
M. R. M. V, Rodriguez C, Navarro Depaz C, Concha UR, Pandey B, S. Kharat R, Marappan R. Machine Learning Based Recommendation System for Web-Search Learning. Telecom. 2023; 4(1):118-134. https://doi.org/10.3390/telecom4010008
Chicago/Turabian StyleM. R. M., Veeramanickam, Ciro Rodriguez, Carlos Navarro Depaz, Ulises Roman Concha, Bishwajeet Pandey, Reena S. Kharat, and Raja Marappan. 2023. "Machine Learning Based Recommendation System for Web-Search Learning" Telecom 4, no. 1: 118-134. https://doi.org/10.3390/telecom4010008
APA StyleM. R. M., V., Rodriguez, C., Navarro Depaz, C., Concha, U. R., Pandey, B., S. Kharat, R., & Marappan, R. (2023). Machine Learning Based Recommendation System for Web-Search Learning. Telecom, 4(1), 118-134. https://doi.org/10.3390/telecom4010008