Abstract
Background: Large Language Models (LLMs) such as ChatGPT, Claude, and Gemini are being increasingly adopted in medicine; however, their reliability in cardiology remains underexplored. Purpose of the study: To compare the performance of three general-purpose LLMs in response to cardiology-related clinical queries. Study design: Seventy clinical prompts stratified by diagnostic phase (pre or post) and user profile (patient or physician) were submitted to ChatGPT, Claude, and Gemini. Three expert cardiologists, who were blinded to the model’s identity, rated each response on scientific accuracy, completeness, clarity, and coherence using a 5-point Likert scale. Statistical analysis included Kruskal–Wallis tests, Dunn’s post hoc comparisons, Kendall’s W, weighted kappa, and sensitivity analyses. Results: ChatGPT outperformed both Claude and Gemini across all criteria (mean scores: 3.7–4.2 vs. 3.4–4.0 and 2.9–3.7, respectively; p < 0.001). The inter-rater agreement was substantial (Kendall’s W: 0.61–0.71). Pre-diagnostic and patient-framed prompts received higher scores than post-diagnostic and physician-framed ones. Results remained robust across sensitivity analyses. Conclusions: Among the evaluated LLMs, ChatGPT demonstrated superior performance in generating clinically relevant cardiology responses. However, none of the models achieved maximal ratings, and the performance varied by context. These findings highlight the need for domain-specific fine-tuning and human oversight to ensure a safe clinical deployment.
1. Introduction
The integration of artificial intelligence (AI) into healthcare is rapidly transforming the generation, communication, and consumption of clinical information. Among recent innovations, Large Language Models (LLMs) such as ChatGPT (OpenAI), Claude (Anthropic), and Gemini (Google DeepMind) have demonstrated impressive capabilities in producing coherent, contextually relevant medical narratives in response to natural language prompts. These tools are being explored for various applications, including patient education, clinical decision support, and administrative documentation [1,2].
Despite their promise, the reliability, clinical accuracy, and contextual appropriateness of LLM-generated medical content remain insufficiently validated, particularly in specialized domains.
This issue is particularly critical in cardiology and cardiac surgery, in which misinformation or ambiguity may contribute to misdiagnosis, inappropriate treatment, or adverse outcomes. Errors in cardiologic reasoning, even when subtle, can result in life-threatening [3,4] consequences, such as misclassification of acute coronary syndromes or inappropriate anticoagulant use. Cardiovascular diseases are among the leading global causes of mortality and morbidity and require nuanced, patient-specific guidance, highlighting the need for precision and trustworthiness in AI-generated content [5].
Furthermore, the deployment of LLMs in medical contexts raises important ethical and operational challenges, particularly regarding transparency, accountability, and the preservation of patient–clinician trust [6,7]. Ensuring that AI systems enhance, rather than replace, clinical reasoning and remain under human supervision is paramount. Several bioethical frameworks recommend a cautious, evidence-based integration of AI into healthcare settings to ensure patient safety and uphold standards of medical professionalism [8].
This study aimed to systematically evaluate the performance of three state-of-the-art conversational LLMs, ChatGPT, Claude, and Gemini, in the cardiology domain. A series of structured prompts was designed to simulate both pre-diagnostic (symptom interpretation) and post-diagnostic (treatment and management) inquiries from two user types: laypersons and general practitioners. The output of each model was assessed by expert cardiologists, who were blinded to the model identity, using a standardized rubric based on scientific accuracy, completeness, clarity, and internal consistency.
By quantifying the strengths and limitations of these models in a high-stakes specialty, this study provides empirical evidence for the responsible use of LLMs in clinical practice. It also offers a benchmark for future developments and regulatory considerations concerning the deployment of AI tools in medicine.
2. Methods
This study was a comparative observational investigation aimed at evaluating the performance of large language models (LLMs) in cardiology-related medical applications. The investigation methodology is based on four key aspects. First, it includes a comparative analysis of three prominent artificial intelligence platforms (ChatGPT, Claude, and Gemini). Furthermore, the study implemented a standardized framework incorporating 70 predetermined clinical inquiries with uniformly applied assessment criteria. Moreover, the investigation employed a double-blind evaluation protocol, wherein evaluators were unaware of the artificial intelligence source for each response. Lastly, the study utilizes a multi-rater methodology, engaging three cardiology specialists, each possessing a minimum of ten years of clinical expertise.
2.1. Artificial Intelligence Platforms
To simulate a realistic user experience, we accessed publicly available chatbot interfaces of three AI platforms without premium features: ChatGPT (GPT-4o, OpenAI, San Francisco, CA, USA), Claude (Claude 3.5 Sonnet, Anthropic, San Francisco, CA, USA), and Gemini (Gemini 1.5 Flash-002, Google DeepMind, Mountain View, CA, USA). The evaluation used the latest freely accessible model version between September and December 2024.
2.2. Prompt Formulation and Scenario Design
The research team constructed a set of 70 de novo prompts to achieve a broad coverage of the cardiology domain. Of the 70 predefined clinical questions, 40 were randomly assigned to simulate patient inquiries, and the remaining 30 were assigned to simulate physician inquiries. Efforts were made to emulate real-world clinical inquiries, as typically encountered by cardiologists in daily practice, by both patients and non-specialist colleagues. This approach aims to maximize the external validity of the evaluation framework.
Two diagnostic stages are presented.
- Pre-diagnostic: Presentation of symptoms with a request for diagnostic reasoning.
- Post-diagnostic: Established diagnosis with queries regarding treatment and disease management.
Each diagnostic category was further subdivided to reflect two types of users:
- Layperson (simulated patient);
- General practitioner (simulated physician requesting specialist input).
All prompts positioned the AI model as an “expert cardiologist” and explicitly instructed the system to respond to natural conversational language, excluding bullet points or lists, with a strict upper limit of 300 words. Preliminary testing revealed consistent violations of 300-word constraints. To mitigate this, prompts were revised using assertive lexical constraints—specifically, the insertion of the adverb ‘absolutely’—which improved compliance without compromising content quality. The representative prompt is structured as follows:
“I experience chest pain during exercise. Could this be angina? As an expert cardiologist, please explain the condition and how it is diagnosed in absolutely no more than 300 words. Could you please provide a detailed explanation in plain text without using lists or bullet points?”
All 70 predefined clinical questions, including their stratifications (patient or physician, pre- or post-diagnostic), are available in the Supplementary Table S1 (Table S1).
2.3. Evaluation Criteria and Rating Protocol
The AI-generated responses were anonymized and independently evaluated by three cardiologists who were blinded to the model source. The evaluations are based on four predefined dimensions:
- Scientific accuracy: Correctness of clinical information;
- Completeness: Inclusion of all relevant diagnostic or therapeutic elements;
- Clarity: Use of accessible language appropriate for the intended audience;
- Coherence: Internal coherence and logical flow of information.
Each criterion was rated using a 5-point Likert scale (1 = very poor, 5 = excellent), without intermediate values. The full scoring rubric, including operational definitions and rating descriptions for each level, is available in the Supplementary Materials (Supplementary File S1).
2.4. Pilot Study and Power Analysis
A pilot analysis involving 20 representative questions was conducted to estimate variability and determine the sample size. For each question, responses from all three AI models were scored by three cardiologists, and the mean score across the criteria was calculated.
To estimate intra-question variability, we computed the average standard deviation of the model scores for each question and obtained a pooled within-subject standard deviation of approximately σ ≈ 0.35. Given the scale granularity and judgment-based nature of scoring, a mean difference of 0.5 points between models was defined as the minimal clinically and methodologically relevant effect size.
This corresponds to an estimated Cohen’s f of 1.02 [9], which constitutes a very large effect. Under this assumption, the selected sample of 70 questions for detecting such differences yielded a statistical power >0.99 at α = 0.05, confirming the adequacy of the study design for its comparative objective [9,10].
2.5. Inter-Rater Reliability Analysis
To assess the agreement among evaluators, we employed two complementary statistics:
- Kendall’s W (coefficient of concordance) was computed separately for each evaluation criterion to assess the consistency of rankings across the three raters. The values ranged from 0 (no agreement) to 1 (perfect agreement). Values above 0.6 are generally interpreted as substantial agreement in medical studies (Table S2).
- Quadratic Weighted Kappa was used for pairwise comparisons between raters. This measure accounts for the ordinal nature of the ratings and penalizes larger disagreements more severely than smaller ones do. Interpretation thresholds were based on standard benchmarks: <0.20 (poor), 0.21–0.40 (fair), 0.41–0.60 (moderate), 0.61–0.80 (substantial), and >0.80 (almost perfect agreement).
These measures provide a comprehensive overview of scoring reliability while mitigating bias due to subjective interpretations.
2.6. Comparative Performance Analysis
We computed descriptive statistics (mean, standard deviation (SD), and interquartile range [IQR]) for each evaluation metric stratified by model and criterion. Score normality was assessed using the Shapiro-Wilk test. Given the significant deviations from normality (p < 0.05), we applied non-parametric methods for the inferential analysis [11].
To compare model performance across the four evaluation criteria (accuracy, completeness, clarity, and coherence), we used the non-parametric Kruskal–Wallis H test. If a significant difference was found, Dunn’s post hoc test was conducted to identify which model pairs differed. To control for the increased risk of type I error due to multiple pairwise comparisons, we applied the Bonferroni correction to all post hoc p-values (Table S3).
Additional comparisons were made using the Mann-Whitney U test to explore whether response quality varied across the following:
- Diagnostic stage (pre- vs. post-diagnostic);
- User profile (doctor vs. patient scenario).
In addition to p-values, effect sizes were calculated for each comparison using Cohen’s r (r = Z/√N), where Z is the standardized test statistic and N is the total number of observations. This provides a measure of the magnitude of the observed differences beyond statistical significance.
2.7. Sensitivity Analysis
To evaluate the robustness of between-model differences to potential reviewer bias, we conducted a leave-one-reviewer-out sensitivity analysis. For each iteration, one cardiologist’s ratings were excluded, and Kruskal–Wallis H tests were recomputed across the remaining two evaluators. This procedure was repeated for all three reviewers and for each of the four evaluation criteria. The preservation of statistical significance across these iterations supports the internal validity of the comparative results by demonstrating that no single reviewer disproportionately influenced the findings [12].
2.8. Statistical Tools and Implementation
All statistical analyses were performed using Python, version 3.12.4. The primary libraries employed included pandas, sci-kit-learn, statsmodels, SciPy, and matplotlib. All the analysis scripts, data, and dependencies are openly available in the project’s GitHub repository (https://github.com/micheledpierri/llm_cardiology_eval (accessed on 10 June 2025)).
3. Results
3.1. Inter-Rater Reliability
To assess the consistency of expert scoring, two complementary inter-rater reliability metrics were computed: Kendall’s W for overall concordance, and Quadratic Weighted Kappa for pairwise agreement.
Kendall’s W indicated substantial agreement among the three blinded cardiologists across all four evaluation criteria, ranging between 0.61 for coherence and 0.71 for completeness (Table 1). These values suggest a high degree of shared understanding in the ordinal ranking of the AI-generated responses.

Table 1.
Inter-rater reliability—weighted kappa per reviewer pair.
Pairwise inter-rater reliability was further assessed using Quadratic Weighted Kappa, which accounts for the ordinal nature of the rating scale and penalizes large discrepancies more heavily. Agreement levels varied across rater pairs and criteria: for accuracy, agreement ranged from moderate (Reviewer2 vs. Reviewer3: κ = 0.557) to substantial (Reviewer1 vs. Reviewer2: κ = 0.679); for completeness, the highest kappa was observed between Reviewer1 and Reviewer2; agreements for clarity and coherence followed similar patterns, with kappa values consistently in the moderate to substantial range (Table 1).
Together, these metrics support the reliability of the evaluation process and confirm that the scoring framework is consistently applied across expert raters.
Friedman-derived Kendall’s W values, computed as a robustness check, were lower in magnitude, but statistically significant for all criteria except clarity, confirming the presence of non-random agreement.
3.2. Descriptive Statistics and Score Distributions
A total of 210 AI-generated responses (70 clinical prompts × three models) were evaluated across four quality dimensions: scientific accuracy, completeness, clarity, and coherence. Each criterion was rated on a 5-point Likert scale (1 = very poor, 5 = excellent).
Descriptive analyses were conducted to examine the central tendencies and dispersion within each criterion by using the model. Figure 1 shows the distribution of the scores. The mean scores for accuracy, completeness, clarity, and coherence were highest for ChatGPT (ranging from 3.7 to 4.2), followed by Claude (3.4 to 4.0), and lowest for Gemini (2.9 to 3.7). Score variability was moderate across all models (standard deviation of ~0.9), with interquartile ranges indicating consistent performance distributions. The median values suggested that both ChatGPT and Claude often achieved ratings of 4, whereas Gemini scored lower (Table 2).
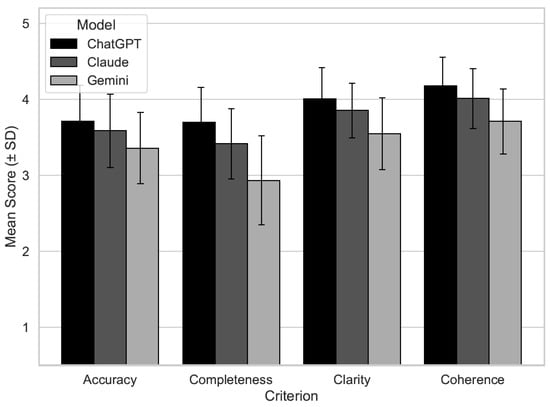
Figure 1.
Mean expert evaluation scores by AI model (ChatGPT, Claude, and Gemini) across four quality dimensions: scientific accuracy, completeness, clarity, and coherence. Scores represent the average ratings assigned by three blinded cardiologists using a 5-point Likert scale (1 = very poor, 5 = excellent). Error bars indicate standard deviation. Bars are shaded in grayscale to represent the three models (black = ChatGPT, dark gray = Claude, and light gray = Gemini).
Table 2.
Descriptive statistics by model and criterion.
To assess the underlying statistical assumptions, normality was evaluated using the Shapiro–Wilk test for each criterion within each model. None of the distributions conformed to normality (all p < 0.05), justifying the use of non-parametric statistical methods in the subsequent analyses.
3.3. Comparative Analysis Between AI Models
The Kruskal–Wallis H test was used to detect global differences among the three models across each rating dimension. Statistically significant differences were observed for all the four criteria (Supplementary Material).
Post hoc analyses using Dunn’s test with Bonferroni correction revealed statistically significant differences among the three AI models across all four evaluation criteria (Figure S1). For accuracy, ChatGPT significantly outperformed Gemini (p < 0.001), whereas the differences between ChatGPT and Claude (p = 0.512) and between Claude and Gemini (p = 0.018) were less pronounced. In terms of completeness, ChatGPT achieved significantly higher scores than both Claude (p = 0.019) and Gemini (p < 0.001), and Claude outperformed Gemini (p < 0.001). Regarding clarity, ChatGPT showed significantly better performance than Gemini (p < 0.001), but not Claude (p = 0.241); however, Claude still significantly outperformed Gemini (p = 0.002). A similar pattern was observed for coherence, with ChatGPT scoring significantly higher than Gemini (p < 0.001) and marginally better than Claude (p = 0.066); Claude also outperformed Gemini (p = 0.002). These findings reinforce the superior and more consistent performance of ChatGPT, particularly over Gemini, across all evaluated domains (Table 3).
Table 3.
Post hoc pairwise comparisons—Dunn’s test.
3.4. Subgroup Analysis by Diagnostic Phase and User Type
Mann–Whitney U tests were conducted to explore whether model performance varied by diagnostic phase (pre- vs. post-diagnostic) and user profile (simulated patient vs. physician).
Across all evaluated dimensions, except coherence, responses to pre-diagnostic prompts received significantly higher ratings than those to post-diagnostic scenarios (all p < 0.05), suggesting that AI models perform better when addressing questions with a defined clinical context (Table 4).
Table 4.
Subgroup analysis—diagnostic phase.
User profile comparisons revealed that prompts framed for simulated patients consistently received higher evaluation scores than those framed for general practitioners across all four criteria (Table 5).
Table 5.
Subgroup analysis—user profile comparison.
Effect sizes (Cohen’s r) were also computed to assess the magnitude of differences. Most values fell in the small-to-moderate range (r = 0.05–0.22), with the largest observed effect for clarity in the patient-versus-doctor comparison (r = 0.22). Full results are available in Supplementary Table S4 (Table S4).
3.5. Sensitivity Analysis
To test the robustness of our findings, we performed a leave-one-reviewer-out sensitivity analysis, recalculating the Kruskal–Wallis H test for each evaluation criterion while excluding each cardiologist (Table S5).
The results demonstrate that statistical significance was preserved across all criteria and exclusions, confirming the stability of between-model differences regardless of individual reviewer contributions. These results strengthen the internal validity of our primary findings by demonstrating that no single reviewer disproportionately influenced comparative outcomes.
4. Discussion
This study offers a systematic, blinded comparison of three advanced large language models (LLMs), ChatGPT, Claude, and Gemini, on structured, clinically relevant cardiology prompts. ChatGPT achieved the highest mean scores across all four evaluation criteria (scientific accuracy, completeness, clarity, and coherence), followed by Claude and Gemini. These differences were statistically significant (Kruskal–Wallis and Bonferroni-corrected post hoc analyses), with ChatGPT consistently outperforming Gemini (p < 0.001), while differences between ChatGPT and Claude were less pronounced and sometimes not significant. The magnitude of these differences (typically 0.3–0.5 points on a 5-point scale) was regarded by the expert raters as clinically meaningful, potentially impacting real-world model selection.
Several recent studies have highlighted the generally superior linguistic coherence and clinical plausibility of ChatGPT compared to other conversational AI systems. For instance, Yavuz and Kahraman (2024) [13] evaluated ChatGPT-4.0 in both pre- and post-diagnostic cardiology cases and reported moderate accuracy and utility, but they also noted clinically relevant omissions. Similarly, the AMSTELHEART-2 study (Harskamp & De Clercq, 2024) [14] assessed ChatGPT as a decision support tool for common cardiac conditions, highlighting its potential but warning against uncritical adoption in clinical settings. Kozaily et al. (2024) [15] reported notable variability in accuracy and internal consistency among multiple LLM platforms when answering heart failure–related queries, reinforcing the need for rigorous, head-to-head benchmarking across cardiovascular subdomains. Our study confirms these observations, showing that while general-purpose LLMs, such as ChatGPT, currently demonstrate the best performance, their outputs remain variable and sometimes incomplete from a specialist perspective.
Compared with these prior studies, our study adds greater methodological rigor and granularity. The use of expert-blinded, multi-evaluator scoring, stratified prompt design (by diagnostic phase and user type), and robust inter-rater reliability analysis provides a strong foundation for reliable benchmarking. Previous studies have often relied on single-expert reviews or have focused on case vignettes and layperson queries. In contrast, our protocol supports direct, statistically robust comparisons between competing models and better simulates real-world information needs in cardiology.
The subgroup analysis in our study revealed that pre-diagnostic, open-ended prompts and patient-style questions consistently received higher ratings across all models and criteria. While these differences were statistically significant, the corresponding effect sizes (Cohen’s r) were generally small to moderate, ranging from 0.05 to 0.22. This indicates that, although systematic, the observed differences were of limited magnitude, emphasizing the importance of evaluating both statistical and practical significance. This echoes prior observations that current LLMs, being tuned to general language tasks, handle everyday language and broad explanations better than focused, clinician-oriented prompts requiring specialist-level reasoning [16]. These findings underscore the necessity of domain-specific calibration, particularly for professional and clinical integration [17].
The performance gradient observed among the LLMs can be attributed to differences in architecture, training data, and alignment approaches. ChatGPT’s superior scores may reflect a more developed reinforcement-learning framework and broader exposure to medical texts, whereas Claude’s safety-oriented tuning appears to limit completeness, and Gemini’s lower performance may be due to less clinical optimization. These technical differences have been emphasized by recent comparative studies in both general QA [18] and medical diagnostic applications, further highlighting the impact of design and alignment on clinical utility.
Despite ChatGPT’s lead, it is important to note that no model achieved maximum scores in any domain, and all models exhibited moderate variability. This is consistent with the findings of Yavuz and Kahraman [13] and Kozaily et al. [15], who noted substantial room for improvement in LLM accuracy, consistency, and completeness when deployed in clinical tasks. These limitations support the view, also expressed by Harskamp & De Clercq [14], that LLMs may serve as adjuncts for basic health education or decision support, but cannot replace professional clinical reasoning and individualized patient management.
4.1. Clinical and Practical Implications
The clear differences in LLM performance have direct implications for clinical practice. ChatGPT’s higher clarity and coherence scores suggest a possible role in supporting the general information needs of patients and non-specialist practitioners, including health education, reassurance, and initial triage. However, variability and occasional inaccuracies preclude their use as substitutes for expert consultation. However, variability and occasional inaccuracies preclude their autonomous use for clinical decision-making [19]. While LLMs may assist with preliminary triage or explanatory tasks, their outputs must remain subject to expert validation. Our findings further reinforce the need for human oversight and a “human-in-the-loop” approach, with qualified clinicians reviewing the AI outputs before any clinical application. This is especially important given the evolving nature of the cardiovascular guidelines. As new evidence emerges, LLMs trained on older data risk provide outdated or suboptimal recommendations [17]. Periodic retraining and explicit versioning are essential to maintain alignment with current clinical standards and regulatory expectations.
4.2. Ethical and Regulatory Considerations in Clinical Deployment
The deployment of LLMs in cardiology raises significant ethical challenges due to the high clinical risks of misinformation or incomplete recommendations. Unlike traditional decision support tools, LLMs operate as probabilistic black boxes, lacking transparency and explainability [20]. This opacity hinders clinicians’ ability to verify AI-generated outputs, conflicting with ethical standards of informed consent and clinical accountability [21,22,23].
Furthermore, the training data behind these models is often undisclosed or untraceable. This creates concerns about outdated knowledge, missed guideline updates, and potential biases in source materials [24], which are particularly problematic in cardiology, where guidelines change frequently and contain important nuances [25].
Accountability remains an unresolved critical issue: when AI-assisted advice contributes to patient harm, responsibility becomes diffused among developers, vendors, and clinicians, complicating legal and ethical determinations [26]. Regulatory frameworks like the EU AI Act [27] and the FDA SaMD Action Plan [28] now stress the importance of version transparency, real-world performance monitoring, and human oversight safeguards.
To uphold ethical principles and clinical standards, LLMs should function as augmented intelligence systems, not autonomous agents, always subject to human oversight, validation, and ongoing auditing. Recent bioethical frameworks such as AI4People [8] and WHO guidance on AI in health [29] support this approach, advocating for trustworthy, interpretable, and patient-centered implementation strategies.
4.3. Methodological Strengths and Limitations
The key strengths of our study include its comparative, blinded design, use of real-world style prompts, multi-expert ratings with high inter-rater agreement (Kendall’s W 0.61–0.71; weighted kappa moderate to substantial), and formal power analysis. Statistical analyses were performed using robust non-parametric methods, and all codes, data, and scripts were openly available for reproducibility. Sensitivity analyses demonstrated that no single reviewer drove the observed between-model differences, further supporting the internal validity of the results.
However, several limitations must be acknowledged. The reported results are inherently version-specific, reflecting LLM capabilities during the evaluation period (September–December 2024). Since these systems undergo frequent updates, even minor architectural changes can cause significant performance shifts, limiting our findings’ long-term applicability. Furthermore, the training data cutoffs of the evaluated models vary and are not fully disclosed, potentially creating knowledge gaps regarding recent cardiology guidelines (ESC/ACC/AHA updates). This temporal lag may affect the accuracy and safety of AI-generated responses. For continued relevance, future research should implement dynamic re-benchmarking, regularly reassessing model performance using updated prompts and current clinical standards [30,31]. Prompts were simulated, not patient-generated, and all evaluations were single-turn, limiting the assessment of multistep reasoning or conversational depth. Despite good agreement, the subjective component of expert ratings may introduce interpretive variability. Supplementary files provide illustrative cases with discordant expert scores and cross-references to the ESC/ACC/AHA guidelines, addressing reviewer requests for examples and external validation. Additionally, only three LLMs were included; future work should expand to emerging and domain-adapted models (e.g., Perplexity AI, Mistral, and DeepSeek).
4.4. Future Directions
Future research should focus on developing and evaluating cardiology-specific LLMs trained on curated, guideline-driven, clinical datasets (ESC and ACC/AHA), annotated case records, and regularly updated medical literature. Fine-tuning general-purpose models with such corpora can improve the diagnostic precision and therapeutic completeness, thereby mitigating some of the current limitations [32,33]. Dynamic benchmarking protocols, including new and updated models, are required to keep pace with rapid advances in AI. Longitudinal study designs that simulate multistep clinical reasoning along real patient journeys are important for understanding LLM capabilities in complex care settings [34]. EHR integration, initially for non-decisional support such as documentation or patient education, may offer a practical path for clinical deployment [35]. Hybrid systems linking LLMs to structured medical ontologies (SNOMED CT, UMLS, and ICD-11) can further enhance accuracy and traceability [36].
As general-purpose LLMs evolve, innovative architectures address limitations in specialized fields like cardiology. Two promising approaches are Retrieval-Augmented Generation (RAG) and AI Agents for autonomous information gathering and decision support.
RAG integrates LLMs with real-time information retrieval systems, combining generative capabilities with dedicated databases for up-to-date, domain-specific content. Unlike models relying solely on training knowledge, RAG systems can access curated repositories at inference time, incorporating retrieved information into their responses. Studies show RAG frameworks improve factual accuracy and clinical relevance in medical settings. Ke et al. (2025) demonstrated that retrieval augmentation with GPT-4 achieved diagnostic accuracy matching or exceeding human clinicians in medical fitness assessments [37].
In cardiology, this approach bridges the gap between evolving guidelines and clinical decision support, enhancing trust and safety.
AI Agents are autonomous, LLM-powered systems that interact with external resources and execute multistep tasks [38]. Unlike traditional LLMs responding to static prompts, these systems access online resources, retrieve documents, cross-check information, and synthesize recommendations in real time. Tu et al. (2025) developed AMIE, an agent-based diagnostic LLM conducting dynamic dialogues, gathering clinical information through interactive questioning, and providing adaptive advice [39].
Zhou et al. (2024) created ZODIAC, a multi-agent system for cardiology that integrates subspecialty knowledge, ECG interpretation, and collaborative diagnostic reasoning validated by cardiologists [40].
These approaches represent a significant advancement toward LLMs that can autonomously interact with digital health infrastructures, supporting clinicians in managing complex patient cases. They are likely to shape the next generation of AI tools in cardiology, and rigorous evaluation will be essential to ensure their safe and effective clinical adoption.
Finally, deployment in healthcare requires transparent versioning, post-market surveillance, and the establishment of institutional AI governance boards for validation and ongoing monitoring, as advocated by leading bioethical and regulatory frameworks [41,42].
5. Conclusions
This systematic evaluation demonstrates that ChatGPT currently outperforms Claude and Gemini in addressing structured cardiology-related prompts, particularly in pre-diagnostic and patient-facing scenarios. Nonetheless, no model has achieved professional-level reliability, and substantial variability remains. These findings reinforce the need for domain-specific fine-tuning, rigorous human oversight, and continuous, transparent evaluation to ensure safe and effective use of LLMs in clinical practice. The open, reproducible benchmarking protocol established herein provides a foundation for ongoing assessments as both AI models and clinical standards evolve.
Supplementary Materials
The following supporting information can be downloaded at https://www.mdpi.com/article/10.3390/hearts6030019/s1, Table S1: File Excel “Supplementary_Table_S1.xlsl”, Table S2. inter-rater reliability—Kendall’s W per Criterion, Table S3. Kruskal-Wallis H test per criterion, Table S4. Effect sizes for group comparisons, Table S5. Sensitivity Analysis—Leave-One-Reviewer-Out, Figure S1: Dunn’s Post Hoc Comparisons (Bonferroni-corrected p-values). Supplementary File S1: “Evaluation Rubric Used by Reviewers” [43,44]. Supplementary File S2: “Examples_of_Discordant_Evaluations.docx”. Other supplementary material is available in the project’s GitHub repository (https://github.com/micheledpierri/llm_cardiology_eval (accessed on 10 June 2025)). References [43,44,45,46,47,48] are cited in the supplementary materials.
Author Contributions
Conceptualization: M.D.P.; Data curation: M.G., S.D. and M.D.E.; Investigation: M.G., S.D., M.D., I.C., C.C. and M.M.; Methodology: M.D.P.; Resources: M.D., I.C., C.C. and M.M.; Supervision: M.D.E. Writing—original draft: M.D.P.; Writing—review and editing: M.G., S.D. and M.D.E. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.
Institutional Review Board Statement
This study did not involve human subjects or patient data and was therefore exempt from IRB review.
Informed Consent Statement
Not applicable.
Data Availability Statement
All anonymized data, prompts, and evaluation scripts are available in the GitHub repository of the project: https://github.com/micheledpierri/llm_cardiology_eval (accessed on 10 June 2025).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Jeblick, K.; Schachtner, B.; Dexl, J.; Mittermeier, A.; Stüber, A.T.; Topalis, J.; Weber, T.; Wesp, P.; Sabel, B.O.; Ricke, J.; et al. ChatGPT makes medicine easy to swallow: An exploratory case study on simplified radiology reports. Eur. Radiol. 2024, 34, 2817–2825. [Google Scholar] [CrossRef] [PubMed]
- Kung, T.H.; Cheatham, M.; Medenilla, A.; Sillos, C.; De Leon, L.; Elepaño, C.; Madriaga, M.; Aggabao, R.; Diaz-Candido, G.; Maningo, J.; et al. Performance of ChatGPT on USMLE: Potential for AI-assisted medical education using large language models. PLoS Digit. Health 2023, 2, e0000198. [Google Scholar] [CrossRef] [PubMed]
- Gandhi, T.K.; Kachalia, A.; Thomas, E.J.; Puopolo, A.; Yoon, C.; Brennan, T.A.; Studdert, D.M. Missed and delayed diagnoses in the ambulatory setting: A study of closed malpractice claims. Ann. Intern. Med. 2006, 145, 488–496. [Google Scholar] [CrossRef] [PubMed]
- Pope, J.H.; Aufderheide, T.P.; Ruthazer, R.; Woolard, R.H.; Feldman, J.A.; Beshansky, J.R.; Griffith, J.L.; Selker, H.P. Missed diagnoses of acute cardiac ischemia in the emergency department. N. Engl. J. Med. 2000, 342, 1163–1170. [Google Scholar] [CrossRef] [PubMed]
- Huerta, N.; Rao, S.J.; Isath, A.; Wang, Z.; Glicksberg, B.S.; Krittanawong, C. The premise, promise, and perils of artificial intelligence in critical care cardiology. Prog. Cardiovasc. Dis. 2024, 86, 2–12. [Google Scholar] [CrossRef] [PubMed]
- Morley, J.; Machado, C.C.V.; Burr, C.; Cowls, J.; Joshi, I.; Taddeo, M.; Floridi, L. The ethics of AI in health care: A mapping review. Soc. Sci. Med. 2020, 260, 113172. [Google Scholar] [CrossRef] [PubMed]
- Amann, J.; Blasimme, A.; Vayena, E.; Frey, D.; Madai, V.I. Explainability for artificial intelligence in healthcare: A multidisciplinary perspective. BMC Med. Inform. Decis. Mak. 2020, 20, 310. [Google Scholar] [CrossRef] [PubMed]
- Floridi, L.; Cowls, J.; Beltrametti, M.; Chatila, R.; Chazerand, P.; Dignum, V.; Luetge, C.; Madelin, R.; Pagallo, U.; Rossi, F.; et al. AI4People—An ethical framework for a good AI society: Opportunities, risks, principles, and recommendations. Minds Mach. 2018, 28, 689–707. [Google Scholar] [CrossRef] [PubMed]
- Cohen, J. Statistical Power Analysis for the Behavioral Sciences, 2nd ed.; Lawrence Erlbaum Associates: Mahwah, NJ, USA, 1988. [Google Scholar]
- Lakens, D. Sample size justification. Collabra Psychol. 2022, 8, 33267. [Google Scholar] [CrossRef]
- Roldan-Vasquez, E. Nonparametric Statistical Methods for Ordinal Data Analysis. J. Stat. Methods 2024, 15, 123–145. [Google Scholar]
- McDonald, J.H. Handbook of Biological Statistics, 3rd ed.; Baltimore, M.D., Ed.; Sparky House Publishing: Baltimore, MD, USA, 2014; Available online: http://www.biostathandbook.com/ (accessed on 14 July 2025).
- Yavuz, Y.E.; Kahraman, F. Evaluation of the prediagnosis and management of ChatGPT-4.0 in clinical cases in cardiology. Future Cardiol. 2024, 20, 197–207. [Google Scholar] [CrossRef] [PubMed]
- Harskamp, R.E.; De Clercq, L. Performance of ChatGPT as an AI-assisted decision support tool in medicine: AMSTELHEART-2. Acta Cardiol. 2024, 79, 358–366. [Google Scholar] [CrossRef] [PubMed]
- Kozaily, E.; Geagea, M.; Akdogan, E.; Atkins, J.; Elshazly, M.; Guglin, M.; Tedford, R.J.; Wehbe, R.M. Accuracy and consistency of online large language model-based artificial intelligence chat platforms in answering patients’ questions about heart failure. Int. J. Cardiol. 2024, 408, 132115. [Google Scholar] [CrossRef] [PubMed]
- Shi, C.; Su, Y.; Yang, C.; Yang, Y.; Cai, D. Specialist or Generalist? Instruction Tuning for Specific NLP Tasks. arXiv 2023, arXiv:2310.15326. [Google Scholar]
- Kim, S. MedBioLM: Optimizing Medical and Biological QA with Fine-Tuned Large Language Models and Retrieval-Augmented Generation. arXiv 2025, arXiv:2502.03004. [Google Scholar]
- Rangapur, A.; Rangapur, A. The Battle of LLMs: A Comparative Study in Conversational QA Tasks. arXiv 2024, arXiv:2405.18344. [Google Scholar]
- Gallegos, I.O.; Rossi, R.A.; Barrow, J.; Research, A.; Kim, S.; Dernoncourt, F.; Yu, T.; Zhang, R.; Ahmed, N.K. Bias and Fairness in Large Language Models: A Survey. Comput. Linguist. 2024, 50, 1097–1179. [Google Scholar] [CrossRef]
- Heersmink, R.; de Rooij, B.; Clavel Vázquez, M.J.; Colombo, M. A phenomenology and epistemology of large language models: Transparency, trust, and trustworthiness. Ethics Inf. Technol. 2024, 26, 47. [Google Scholar] [CrossRef]
- Weiner, E.; Dankwa-Mullan, I.; Nelson, W.; Hassanpour, S. Ethical challenges and evolving strategies in the integration of artificial intelligence into clinical practice. PLoS Digit. Health 2024, 4, e0000810. [Google Scholar] [CrossRef] [PubMed]
- Pruski, M. AI-Enhanced Healthcare: Not a new Paradigm for Informed Consent. J. Bioeth. Inq. 2024, 21, 475–489. [Google Scholar] [CrossRef] [PubMed]
- Iserson, K.V. Informed consent for artificial intelligence in emergency medicine: A practical guide. Am. J. Emerg. Med. 2024, 76, 225–230. [Google Scholar] [CrossRef] [PubMed]
- Navigli, R.; Conia, S.; Ross, B. Biases in Large Language Models: Origins, Inventory, and Discussion. J. Data Inf. Qual. 2023, 15, 10. [Google Scholar] [CrossRef]
- Han, H.; Chao, H.; Guerra, A.; Sosa, A.; Christopoulos, G.; Christakopoulos, G.E.; Rangan, B.V.; Maragkoudakis, S.; Jneid, H.; Banerjee, S.; et al. Evolution of the American College of Cardiology/American Heart Association Clinical Guidelines. J. Am. Coll. Cardiol. 2015, 65, 2726–2734. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Mao, R.; Lin, Q.; Ruan, Y.; Lan, X.; Feng, M.; Cambria, E. A survey of large language models for healthcare: From data, technology, and applications to accountability and ethics. Inf. Fusion. 2025, 118, 102816. [Google Scholar] [CrossRef]
- European Commission. Artificial Intelligence Act—Final Version Adopted by the Council of the EU. 2024. Available online: https://data.consilium.europa.eu/doc/document/ST-5662-2024-INIT/en/pdf (accessed on 14 July 2025).
- US Food and Drug Administration. Artificial Intelligence/Machine Learning (AI/ML)-Based Software as a Medical Device (SaMD) Action Plan. 2021. Available online: https://www.fda.gov/media/145022/download (accessed on 14 July 2025).
- World Health Organization. Ethics and Governance of Artificial Intelligence for Health: WHO Guidance. 2021. Available online: https://www.who.int/publications/i/item/9789240029200 (accessed on 14 July 2025).
- Kanithi, P.K.; Christophe, C.; Pimentel, M.A.; Raha, T.; Saadi, N.; Javed, H.; Maslenkova, S.; Hayat, N.; Rajan, R.; Khan, S. MEDIC: Towards a Comprehensive Framework for Evaluating LLMs in Clinical Applications. arXiv 2024, arXiv:2409.07314. [Google Scholar]
- Budler, L.C.; Chen, H.; Chen, A.; Topaz, M.; Tam, W.; Bian, J.; Stiglic, G. A Brief Review on Benchmarking for Large Language Models Evaluation in Healthcare. WIREs Data Min. Knowl. Discov. 2025, 15, e70010. [Google Scholar] [CrossRef]
- Nazar, W.; Nazar, G.; Kamińska, A.; Danilowicz-Szymanowicz, L. How to Design, Create, and Evaluate an Instruction-Tuning Dataset for Large Language Model Training in Health Care: Tutorial From a Clinical Perspective. J. Med. Internet Res. 2025, 27, e58924. [Google Scholar] [CrossRef] [PubMed]
- Han, T.; Adams, L.C.; Papaioannou, J.M.; Grundmann, P.; Oberhauser, T.; Figueroa, A.; Löser, A.; Truhn, D.; Bressem, K.K. MedAlpaca—An Open-Source Collection of Medical Conversational AI Models and Training Data. arXiv 2025, arXiv:2304.08247. [Google Scholar]
- Sprague, Z.; Ye, X.; Bostrom, K.; Chaudhuri, S.; Durrett, G. MuSR: Testing the Limits of Chain-of-thought with Multistep Soft Reasoning. arXiv 2024, arXiv:2310.16049. [Google Scholar]
- Ahsan, H.; McInerney, D.J.; Kim, J.; Potter, C.; Young, G.; Amir, S.; Wallace, B.C. Retrieving Evidence from EHRs with LLMs: Possibilities and Challenges. arXiv 2024, arXiv:2309.04550. [Google Scholar]
- El-Sappagh, S.; Franda, F.; Ali, F.; Kwak, K.S. SNOMED CT standard ontology based on the ontology for general medical science. BMC Med. Inform. Decis. Mak. 2018, 18, 76. [Google Scholar] [CrossRef] [PubMed]
- Ke, Y.H.; Jin, L.; Elangovan, K.; Abdullah, H.R.; Liu, N.; Sia, A.T.H.; Soh, C.R.; Tung, J.Y.M.; Ong, J.C.L.; Kuo, C.-F.; et al. Retrieval augmented generation for 10 large language models and its generalizability in assessing medical fitness. NPJ Digit. Med. 2025, 8, 187. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Yi, H.; You, M.; Liu, W.Z.; Wang, L.; Li, H.; Zhang, X.; Guo, Y.; Fan, L.; Chen, G.; et al. Enhancing diagnostic capability with multi-agents conversational large language models. NPJ Digit. Med. 2025, 8, 159. [Google Scholar] [CrossRef] [PubMed]
- Tu, T.; Schaekermann, M.; Palepu, A.; Saab, K.; Freyberg, J.; Tanno, R.; Wang, A.; Li, B.; Amin, M.; Cheng, Y.; et al. Towards conversational diagnostic artificial intelligence. Nature 2025, 642, 442–450. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.; Zhang, P.; Song, M.; Zheng, A.; Lu, Y.; Liu, Z.; Chen, Y.; Xi, Z. Zodiac: A Cardiologist-Level LLM Framework for Multi-Agent Diagnostics. arXiv 2024, arXiv:2410.02026. Available online: http://arxiv.org/abs/2410.02026 (accessed on 15 July 2025).
- Lekadir, K.; Frangi, A.; Glocker, B.; Cintas, C.; Langlotz, C.; Weicken, E.; Porras, A.R.; Asselbergs, F.W.; Prior, F.; Collins, G.S.; et al. FUTURE-AI: International consensus guideline for trustworthy and deployable artificial intelligence in healthcare. BMJ 2024, 388, e081554. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.Y.; Boag, W.; Gulamali, F.; Hasan, A.; Hogg, H.D.J.; Lifson, M.; Mulligan, D.; Patel, M.; Raji, I.D.; Sehgal, A.; et al. Organizational Governance of Emerging Technologies: AI Adoption in Healthcare. In ACM International Conference Proceeding Series, Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency, Chicago IL USA, 12–15 June 2023; Association for Computing Machinery: New York, NY, USA, 2023; pp. 1396–1417. [Google Scholar]
- Hindricks, G.; Potpara, T.; Dagres, N.; Arbelo, E.; Bax, J.J.; Blomström-Lundqvist, C.; Boriani, G.; Castella, M.; Dan, G.A.; Dilaveris, P.E.; et al. 2020 ESC Guidelines for the diagnosis and management of atrial fibrillation developed in collaboration with the European Association for Cardio-Thoracic Surgery (EACTS): The Task Force for the diagnosis and management of atrial fibrillation of the European Society of Cardiology (ESC) Developed with the special contribution of the European Heart Rhythm Association (EHRA) of the ESC. Eur. Heart J. 2021, 42, 373–498. [Google Scholar] [CrossRef] [PubMed]
- Al-Khatib, S.M.; Stevenson, W.G.; Ackerman, M.J.; Bryant, W.J.; Callans, D.J.; Curtis, A.B.; Deal, B.J.; Dickfeld, T.; Field, M.E.; Fonarow, G.C.; et al. 2017 AHA/ACC/HRS Guideline for Management of Patients with Ventricular Arrhythmias and the Prevention of Sudden Cardiac Death. J. Am. Coll. Cardiol. 2018, 72, e91–e220. [Google Scholar] [CrossRef] [PubMed]
- National Institute for Health and Care Excellence. Chest Pain of Recent Onset: Assessment and Diagnosis (NICE Clinical Guideline CG95). 2016. Available online: https://www.nice.org.uk/guidance/cg95 (accessed on 14 July 2025).
- Writing Committee Members; Gulati, M.; Levy, P.D.; Mukherjee, D.; Amsterdam, E.; Bhatt, D.L.; Birtcher, K.K.; Blankstein, R.; Boyd, J.; Bullock-Palmer, R.P.; et al. 2021 AHA/ACC/ASE/CHEST/SAEM/SCCT/SCMR Guideline for the Evaluation and Diagnosis of Chest Pain: A Report of the American College of Cardiology/American Heart Association Joint Committee on Clinical Practice Guidelines. J. Am. Coll. Cardiol. 2021, 78, e187–e285. [Google Scholar] [CrossRef] [PubMed]
- Brugada, J.; Katritsis, D.G.; Arbelo, E.; Arribas, F.; Bax, J.J.; Blomström-Lundqvist, C.; Calkins, H.; Corrado, D.; Deftereos, S.G.; Diller, G.P.; et al. 2019 ESC Guidelines for the management of patients with supraventricular tachycardia (The Task Force for the management of patients with supraventricular tachycardia of the European Society of Cardiology in collaboration with AEPC). Eur. Heart J. 2019, 41, 655–720. [Google Scholar] [CrossRef] [PubMed]
- Page, R.L.; Joglar, J.A.; Caldwell, M.A.; Calkins, H.; Conti, J.B.; Deal, B.J.; Estes, N.A.M.; Field, M.E.; Goldberger, Z.D.; Hammill, S.C.; et al. 2015 ACC/AHA/HRS guideline for the management of adult patients with supraventricular tachycardia: A report of the American College of Cardiology/American Heart Association Task Force on Clinical Practice Guidelines and the Heart Rhythm Society. Circulation 2016, 133, e506–e574. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).